
One Giant Leap for Risk Mitigation - RBCS, Inc · One Giant Leap for Risk Mitigation ... In...
6
24 BETTER SOFTWARE APRIL 2007 www.StickyMinds.com By Rex Black & Barton Layne Four Small Steps for Testers One Giant Leap for Risk Mitigation GETTY IMAGES
-
Upload
phungthien -
Category
Documents
-
view
223 -
download
0
Transcript of One Giant Leap for Risk Mitigation - RBCS, Inc · One Giant Leap for Risk Mitigation ... In...

24 BETTER SOFTWARE APRIL 2007 www.StickyMinds.com
By Rex Black & Barton Layne
Four Small Steps for TestersOne Giant Leap for Risk Mitigation
GETTY IM
AGES

www.StickyMinds.com APRIL 2007 BETTER SOFTWARE 25
It doesn’t have to be this way. Nasty end-of-project performance surprises areavoidable. If you’ve suffered through oneor two of these projects and are looking toavoid them in the future, this case studywill provide a roadmap.
The Case StudyThis case study involves the testingof Internet appliances—simple de-
vices that allow a user to send and receiveemail, view simple email attachments, andsurf the Web. It is not a complex, general-purpose computer, but rather a simple boxproject.
On this project, in addition to testingthe clients—the appliances themselves—we also needed to test the servers. A keyquality risk for the servers was that theymight not be able to handle the 25,000 to40,000 appliances they would have to sup-port.
The project was planned to last aboutsix months. Rather than waiting to seewhat happened during system test, we cre-ated a comprehensive performancestrategy that included the following steps:
11.. Static performance tests of proposeddesigns
22.. Static performance analysis (simula-tion) of proposed designs
33.. Unit performance tests during actualimplementation of the system
44.. System performance tests of the im-plemented system
Most organizations skip steps 1through 3 and begin 4 just before systeminstallation. That’s often the beginning of asad story (see the StickyNotes for one suchstory). In this case, we went through eachstep. Since we were responsible for systemtesting, we’ll focus on the process fromthat perspective.
1: STATIC PERFORMANCE TESTINGBecause performance was a key is-
sue, the server system architect’s designwork on the server farm included amodel of system behavior under variousload levels. This model was a spread-sheet estimating resource utilizationlevel based on a number of Internet ap-pliances running in the field. Theestimated resource utilization includedCPU, memory, network bandwidth, etc.
After creation, this model underwentpeer review by members of the test teamand other developers and managers. Wemade adjustments to the model until wewere relatively confident we had a solidstarting design.
2: STATIC PERFORMANCE ANALYSISBased on the spreadsheet model, the
server system architect worked withconsultants to create a dynamic simula-tion. These consultants had diverseskills in network and internetwork ar-chitecture, programming, and systemadministration. The simulation wasfine-tuned in an iterative process untilthe architects had sufficient confidencein their predictions. Purchasing hard-ware and configuring the server farmalso were iterative processes. Once con-fident in a model’s prediction of theneed for a certain element, we wouldpurchase it.
3: UNIT PERFORMANCE TESTINGThe system consisted of ten servers
providing five key capabilities: e-com-merce hosting, email repository, IMAPmail, various user-related databases,and software and operating system up-dates. Load balancing split each key capability’s work across two servers.
Each of these five capabilities under-
Recently, we worked on a high-risk, high-visibility systemwhere performance testing (“Let’s just make sure it handles the load”) was the last item on the agenda. As luckwould have it, the system didn’t handle the load, and verylong days and nights ensued. Delivery was late, several serious disasters were narrowly averted, and largecosts were incurred.

application that could simulate thou-sands of clients, each by a networksocket talking to an update server. Thesimulated clients would request updates,creating load on the update servers. Asan update server received new events ordata needed by the client, it would placethose in a queue to be delivered at thenext update. The update servers couldchange flow control dynamically basedon bottlenecks (hung packets or toomany devices requesting updates atonce), which also needed to be tested.
Mail: The clients sent and receivedemail via the mail servers, which fol-lowed the IMAP standard. We needed to
simulate client email traffic, including at-tachments of various types. Emails variedin size due to message text and attach-ments. Some emails would go to multiplerecipients, some to only one.
Web: When an appliance was sent to acustomer, the server farm had to be toldto whom it belonged, what servers wouldreceive connections from the client, etc.This process was handled by provision-ing software on the Web servers. TheWeb servers also provided content filter-ing and Internet access. We simulated realistic levels of activity in these areas.
Database: Information about each ap-pliance was stored in database servers.
26 BETTER SOFTWARE APRIL 2007 www.StickyMinds.com
went unit testing. A unit was defined as adistinct service provided as part of thecapability. To carry out this unit testing,the development staff used some inter-nally developed tools to which we addedsome enhancements. These tools exer-cised critical and complex componentssuch as update and mail.
4: SYSTEM PERFORMANCE TESTINGThe approach on this project was
unique, as static performance testing,static performance analysis, and unitperformance testing are not commonlydone. Typically, teams start with thisstep, but much of our system-testingachievement was enabled and supportedby this up-front work.
In parallel to the system developmentand unit performance testing, weplanned and prepared for system testingof the servers, including performancetesting. As a specialized testing type dur-ing the system test phase, performancetesting had its own test plan, for whichwe specified the following main objec-tives:
• Create real, user-like operationsagainst the production infrastruc-ture.
• Test our load test tools.• Provide quick feedback about per-
formance problems well before theend of the project.
• Validate our usage profile and re-sults against the static analysissimulation.
• Meet and exceed load volumespresent under anticipated releaseconditions.
• Force system and component fail-ures to test the SNMP safety net,and verify that SNMP alerts will betriggered if any hardware failureoccurs.
• Allow us to iterate tests expedi-tiously and efficiently as performancebugs are found and fixed.
In the performance test plan, we de-scribed the particular system features wewere to performance test—update, mail,Web, and database.
Update: Update servers updated theclient. Using the developer’s unit test har-ness, we built a load generating FIGURE 1: SYSTEM TEST ENVIRONMENT

This involved various database activi-ties—inserts, updates, and deletes—whichwe simulated by using SQL scripts to car-ry out these activities directly on thedatabase servers.
We created a usage scenario or profileand identified our assumptions (see theStickyNotes). We started discussing thisplan with developers in the early draftstage. Once we tuned the profiles basedon developers’ feedback, we met withmanagement and tuned some more. Wecorrected assumptions and tracked addi-tions supporting changes to the profile.
Part of our plan included specifyingand validating the test environment. Theenvironment used for performance test-ing is shown in figure 1. Note that weshow a pair of each server type—twophysical servers running identical appli-cations. Load balancing devices (notshown in the figure) balance the load between servers.
Since this testing occurred prior to thefirst product release, we were able to usethe production server farm as the test environment. This relieved us from whatis often a major challenge of performancetesting—testing in a “production-like”environment rather than the actual one.As shown in figure 1, we had both clienttesting appliances and beta testing appli-ances accessing the servers. In some cases,we would run other functional and non-functional tests while the performancetests were executing so that we could geta subjective impression from the testerson what the users’ experience would bewhen working with the clients while theservers were under load.
Preparing SystemPerformance TestsTo run our performance tests, we
needed load generators and probes. Forthe probes to monitor server perform-ance, we used top and vmstat. However,commercial load generation tools werenot available for most of the tasks. Toavoid enormous expenses and delays associated with creating these test tools,we tried to reuse or adapt other toolswherever possible.
Update: We discovered the developershad created a unit test tool for updatetesting. As luck would have it, the tool
www.StickyMinds.com APRIL 2007 BETTER SOFTWARE 27
was created using TCL, a scripting lan-guage we had used on a previous project.We obtained the code, but it needed to bemodified for our purposes. The lead developer was intrigued by our approachand plan. Instead of merely handing offthe tool to us, he spent a number of daysmodifying it for us. His modificationsmade it easier to maintain and addedmany of the features we needed such aslogging, standardized variables, somecommand line options, and an easiermechanism for multithreading. He evenexplained the added code to our teamand reviewed our documentation. Wespent another couple of days addingfunctionality and documenting further.
We were able to spawn many in-stances of the tool as simulated clients ona Linux server. These simulated clientswould connect to the update servers un-der test and force updates to occur. Wetested the tool by running different loadscenarios with various run durations.
Mail: Things went less smoothly inour quest for load generators for the mailserver. In theory, a load testing tool exist-ed and was to be provided by the vendorwho delivered the base IMAP mail serversoftware. In practice, that didn’t happen,and, as Murphy’s Law dictates, the factthat it wouldn’t happen only becameclear at the last possible minute.
We cobbled together an email loadgenerator package. It consisted of someTCL scripts that one developer had usedfor unit testing of the mail server, alongwith an IMAP client called clm that runson a QNX server and can retrieve mailfrom the IMAP mail server. We devel-oped a load script to drive the UNIXsendmail client using TCL.
Web: We recorded scripts for theWebLOAD tool based on feedback fromthe business users. These scripts repre-sented scenarios most likely to occur inproduction. To be more consistent withour TCL scripting, we utilized the com-mand line option for this tool. Thisallowed us to use a master script to kickoff the entire suite of tests. We discoveredthe impact of our tests was not adverselyaffecting the Web servers. Managementinformed us that the risk of slow Webpage rendering was at the bottom of ourpriority list. We continued to run these
scripts but did not provide detailedanalysis of the results.
Database: For the database servers,we wrote SQL scripts that were designedto enter data directly into the database.To enter data through the user interfacewould have required at least twenty dif-ferent screens. Since we had to periodicallyreset the data, it made sense to use scriptsinterfacing directly with the database. Wediscussed these details with the develop-ers and the business team. All agreed thatusing TCL to execute SQL would meetour database objectives and could realis-tically simulate the real world, eventhough such scripts might seem quite ar-tificial.
These scripts replicated the followingfunctionality:
• Address book entries—the additionand deletion of address book entries for a particular user or users
• Customer entry/provisioning—thecreation of a new customer and theaddition and deletion of a primaryuser on a device
• Secondary user provisioning—theaddition and deletion of secondaryusers on a device
We also created some useful utilityscripts to accomplish specific tasks:
• Setup—Populate the database withthe appropriate number of records.
• Insert—Insert entries into eachtable.
• Update—Change one or more col-umn values by giving a specifiedsearch value.
• Delete—Delete all or any entryfrom the table.
• Select—Perform the same querieswith known results to verifychanges occurred; list the channelentries for a given customer andcategory; or list the ZIP Code, city,and state for a given customer.
We used TCL to launch these scriptsfrom a master script.
PUTTING IT TOGETHER WITH THE MASTER SCRIPT
The profile called for testing each areaof functionality—first individually andthen in conjunction with other areas. To
28 BETTER SOFTWARE APRIL 2007 www.StickyMinds.com
Performing the Testsand PerfectingSystem Performance
As system testing started, we wentinto a tight loop of running the systemperformance tests, identifying perform-ance problems, getting those problemsfixed, and testing the fixes. We foundsome interesting bugs:
• Attempting to send corrupted filesconfused the update process intobelieving it was never done.
• Excessively large log files causedperformance problems.
• SNMP agents failed silently whenhardware was disabled or stoppedunexpectedly.
• Memory leaks resulted in perform-ance degradation.
• The Oracle database was config-ured improperly.
• Hardware was not hot-swappableas required.
• Throughput was very low on criti-cal processes.
• Load balancing did not work prop-erly.
• Proxy/filtering bugs caused slowInternet access.
Some of these bugs could be consid-
ered “test escapes” from unit testing, butmany were the kind that would be diffi-cult to find except in a properlyconfigured, production-like environmentsubjected to realistic, properly run, pro-duction-like test cases.
We encountered problems in two ma-jor functional areas: update and mail.
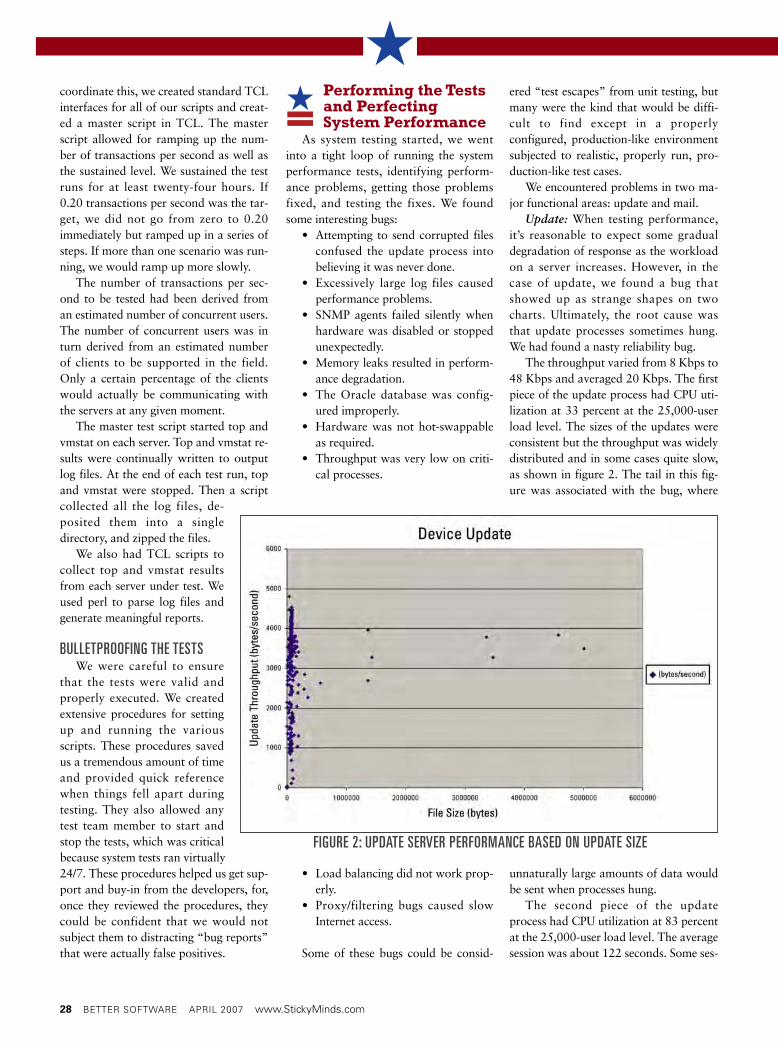
Update: When testing performance,it’s reasonable to expect some gradualdegradation of response as the workloadon a server increases. However, in thecase of update, we found a bug thatshowed up as strange shapes on twocharts. Ultimately, the root cause wasthat update processes sometimes hung.We had found a nasty reliability bug.
The throughput varied from 8 Kbps to48 Kbps and averaged 20 Kbps. The firstpiece of the update process had CPU uti-lization at 33 percent at the 25,000-userload level. The sizes of the updates wereconsistent but the throughput was widelydistributed and in some cases quite slow,as shown in figure 2. The tail in this fig-ure was associated with the bug, where
unnaturally large amounts of data wouldbe sent when processes hung.
The second piece of the updateprocess had CPU utilization at 83 percentat the 25,000-user load level. The averagesession was about 122 seconds. Some ses-
coordinate this, we created standard TCLinterfaces for all of our scripts and creat-ed a master script in TCL. The masterscript allowed for ramping up the num-ber of transactions per second as well asthe sustained level. We sustained the testruns for at least twenty-four hours. If0.20 transactions per second was the tar-get, we did not go from zero to 0.20immediately but ramped up in a series ofsteps. If more than one scenario was run-ning, we would ramp up more slowly.
The number of transactions per sec-ond to be tested had been derived froman estimated number of concurrent users.The number of concurrent users was inturn derived from an estimated numberof clients to be supported in the field.Only a certain percentage of the clientswould actually be communicating withthe servers at any given moment.
The master test script started top andvmstat on each server. Top and vmstat re-sults were continually written to outputlog files. At the end of each test run, topand vmstat were stopped. Then a scriptcollected all the log files, de-posited them into a singledirectory, and zipped the files.
We also had TCL scripts tocollect top and vmstat resultsfrom each server under test. Weused perl to parse log files andgenerate meaningful reports.
BULLETPROOFING THE TESTSWe were careful to ensure
that the tests were valid andproperly executed. We createdextensive procedures for settingup and running the variousscripts. These procedures savedus a tremendous amount of timeand provided quick referencewhen things fell apart duringtesting. They also allowed anytest team member to start andstop the tests, which was criticalbecause system tests ran virtually24/7. These procedures helped us get sup-port and buy-in from the developers, for,once they reviewed the procedures, theycould be confident that we would notsubject them to distracting “bug reports”that were actually false positives.
FIGURE 2: UPDATE SERVER PERFORMANCE BASED ON UPDATE SIZE
the late 1980s, are quarter-century veter-ans of software engineering and testing.Rex’s focus is test management whileBarton’s is test automation. Rex is presi-dent of RBCS, a leading internationaltest consultancy based in Texas, and Bar-ton is a senior associate. Rex and Bartonhave worked together on various engage-ments entailing a variety of hardwareand software products. Combining theirexpertise has provided clients with valu-able test results focused on their specificneeds. Rex and Barton’s can-do attitudefor the client has solved problems, evenat 30,000 feet (though that would be awhole ‘nother article).
StickyNotes
For more on the following topics, go towww.StickyMinds.com/bettersoftware.
� A sad project story� Usage profile
• A holistic, front-loaded, preventivestrategy was used to mitigate per-formance risks, starting with statictesting and analysis, continuingthrough unit testing, and conclud-ing with system testing.
• The organization provided helpand support critical to the successof this complex testing effort.
• The organization responded quick-ly and resolved defects efficiently.
• The actual production infrastruc-ture was used for performancetesting.
• The test team collaborated with de-velopers who already had unit testtools, and we were able to reusethese tools for our own testing.
• Developers were excited aboutwhat we were doing and wentabove and beyond the call of dutyto improve their tools for our spe-cific purpose.
If most projects with significant per-formance-related quality risks followedthe approach used on this project, manynear and outright disasters related tolate-discovered performance problemscould be avoided—and everyone couldcount on getting more sleep. {end}
Both Rex Black and Barton Layne, whohave worked together on and off since
www.StickyMinds.com APRIL 2007 BETTER SOFTWARE 29
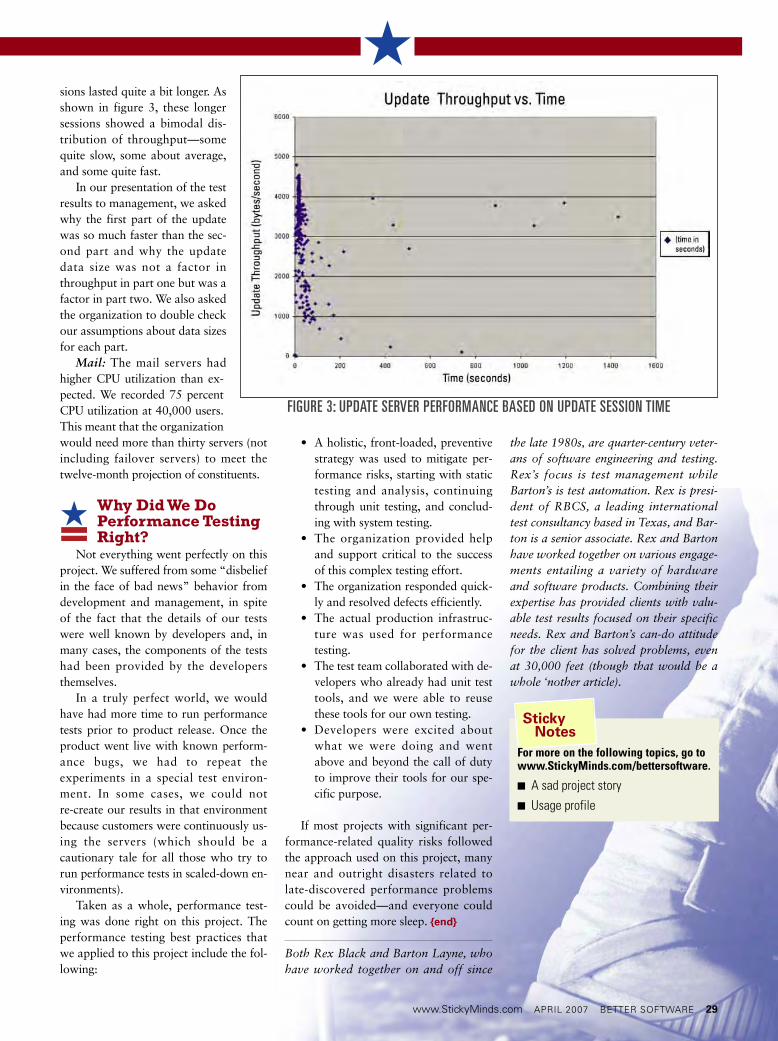
sions lasted quite a bit longer. Asshown in figure 3, these longersessions showed a bimodal dis-tribution of throughput—somequite slow, some about average,and some quite fast.
In our presentation of the testresults to management, we askedwhy the first part of the updatewas so much faster than the sec-ond part and why the updatedata size was not a factor inthroughput in part one but was afactor in part two. We also askedthe organization to double checkour assumptions about data sizesfor each part.
Mail: The mail servers hadhigher CPU utilization than ex-pected. We recorded 75 percentCPU utilization at 40,000 users.This meant that the organizationwould need more than thirty servers (notincluding failover servers) to meet thetwelve-month projection of constituents.
Why Did We DoPerformance TestingRight?
Not everything went perfectly on thisproject. We suffered from some “disbeliefin the face of bad news” behavior fromdevelopment and management, in spiteof the fact that the details of our testswere well known by developers and, inmany cases, the components of the testshad been provided by the developersthemselves.
In a truly perfect world, we wouldhave had more time to run performancetests prior to product release. Once theproduct went live with known perform-ance bugs, we had to repeat theexperiments in a special test environ-ment. In some cases, we could notre-create our results in that environmentbecause customers were continuously us-ing the servers (which should be acautionary tale for all those who try torun performance tests in scaled-down en-vironments).
Taken as a whole, performance test-ing was done right on this project. Theperformance testing best practices thatwe applied to this project include the fol-lowing:
FIGURE 3: UPDATE SERVER PERFORMANCE BASED ON UPDATE SESSION TIME


















