
Cassandra London - C* Spark Connector
65
©2013 DataStax Confidential. Do not distribute without consent. @chbatey Christopher Batey C* Spark Connector
-
Upload
christopher-batey -
Category
Software
-
view
87 -
download
1
Transcript of Cassandra London - C* Spark Connector

©2013 DataStax Confidential. Do not distribute without consent.
@chbateyChristopher Batey
C* Spark Connector

@chbatey
Cassandra London Needs you• We are always looking for Cassandra speakers to share
their experience and have created a Speakers Program full of benefits! If you are interested please contact us for details. Talk to Ale

@chbatey
Overview• Reading data from C* into Spark• Writing data to C*: effective batching

@chbatey
C* Table -> RDD

Spark RDDs Represent a Large
Amount of Data Partitioned into Chunks
RDD
1 2 3
4 5 6
7 8 9Node 2
Node 1 Node 3
Node 4

Node 2
Node 1
Spark RDDs Represent a Large
Amount of Data Partitioned into Chunks
RDD
2
346
7 8 9
Node 3
Node 4
1 5

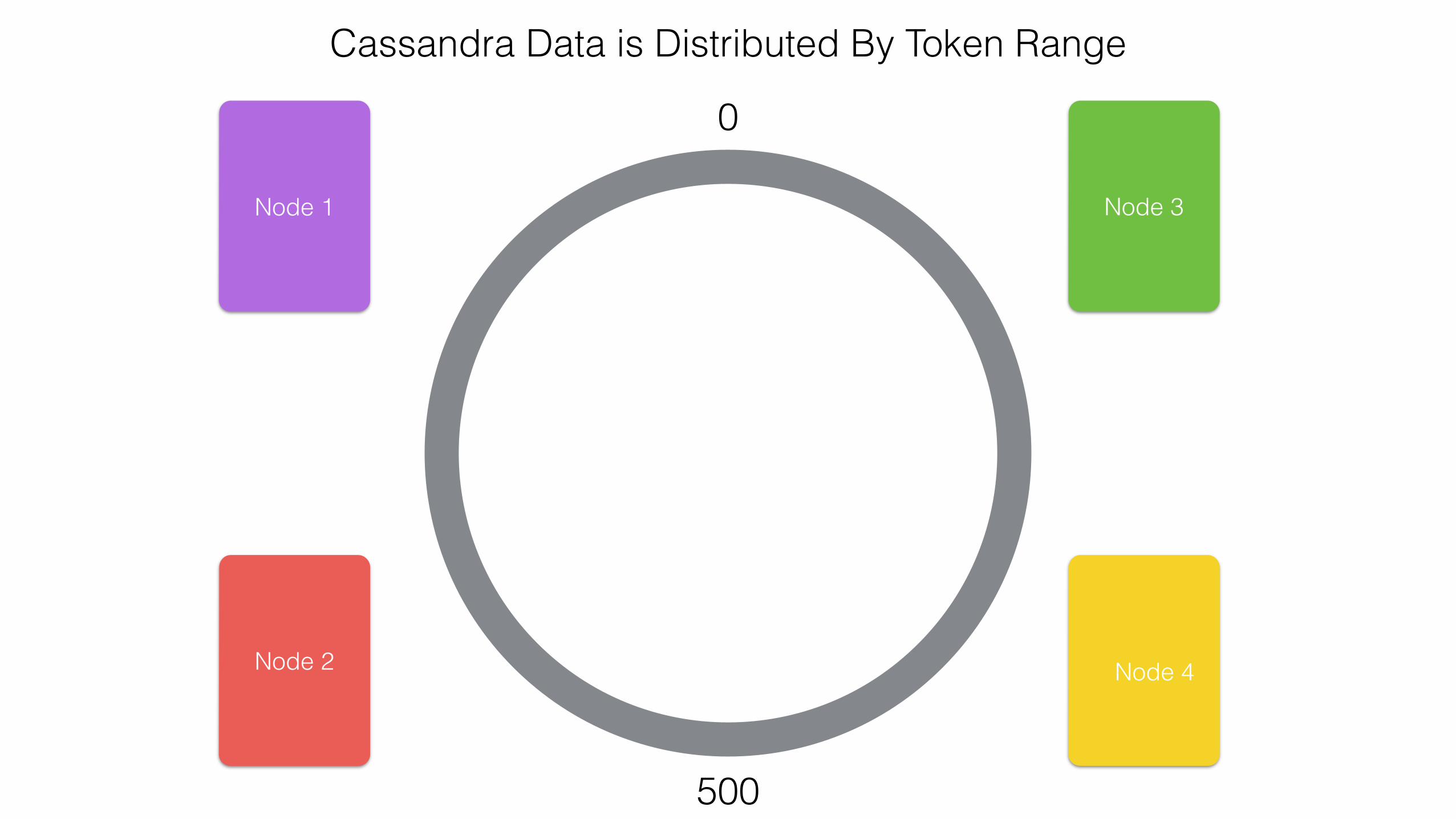
Cassandra Data is Distributed By Token Range

Cassandra Data is Distributed By Token Range
0
500
999
Cassandra Data is Distributed By Token Range
0
500
Node 1
Node 2
Node 3
Node 4

Cassandra Data is Distributed By Token Range
0
500
Node 1
Node 2
Node 3
Node 4
Without vnodes

Cassandra Data is Distributed By Token Range
0
500
Node 1
Node 2
Node 3
Node 4
With vnodes

@chbatey
Goals• Spark partitions made up of token ranges on the same
node• Tasks to be executed on workers co-located with that
node• Same(ish) amount of data in each Spark partition
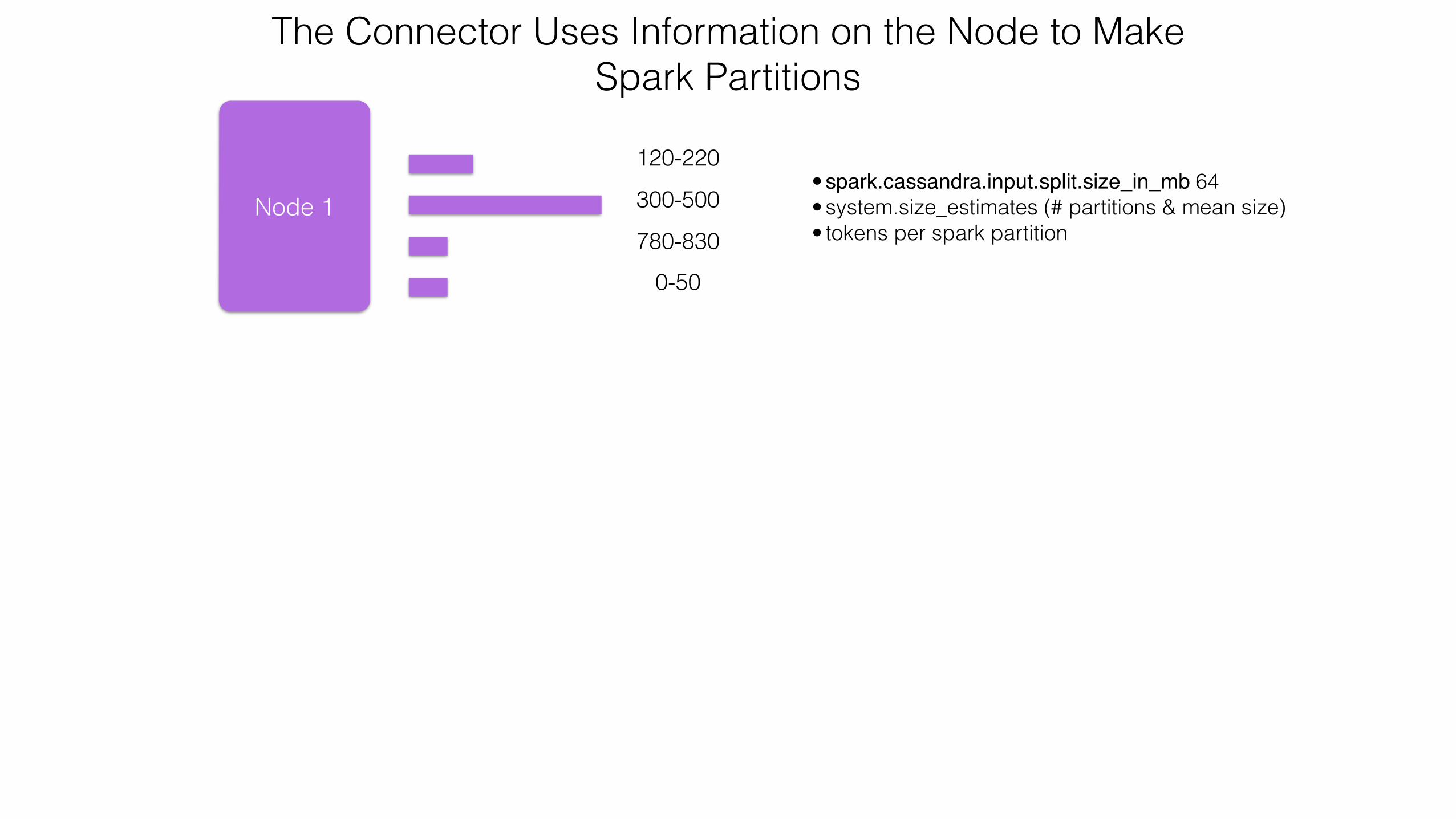
Node 1
120-220
300-500
780-830
0-50
• spark.cassandra.input.split.size_in_mb 64 • system.size_estimates (# partitions & mean size) • tokens per spark partition
The Connector Uses Information on the Node to Make Spark Partitions
Node 1
120-220
300-500
0-50
The Connector Uses Information on the Node to Make Spark Partitions
1
780-830

1
Node 1
120-220
300-500
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830

2
1
Node 1 300-500
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830

2
1
Node 1 300-500
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830

2
1
Node 1
300-400
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830400-500

21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830400-500

21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830400-500
3
21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830
3
400-500

21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830
3

4
21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830
3

4
21
Node 1
0-50
The Connector Uses Information on the Node to Make Spark Partitions
780-830
3

421
Node 1
The Connector Uses Information on the Node to Make Spark Partitions
3

@chbatey
Key classes• CassandraTableScanRDD, CassandraRDD- getPreferredLocations• CassandraTableRowReaderProvider- DataSizeEstimates - goes to C* • CassandraPartitioner- Gets ring information from the driver• CassandraPartition- endpoints- tokenRanges

4
spark.cassandra.input.fetch.size_in_rows 50
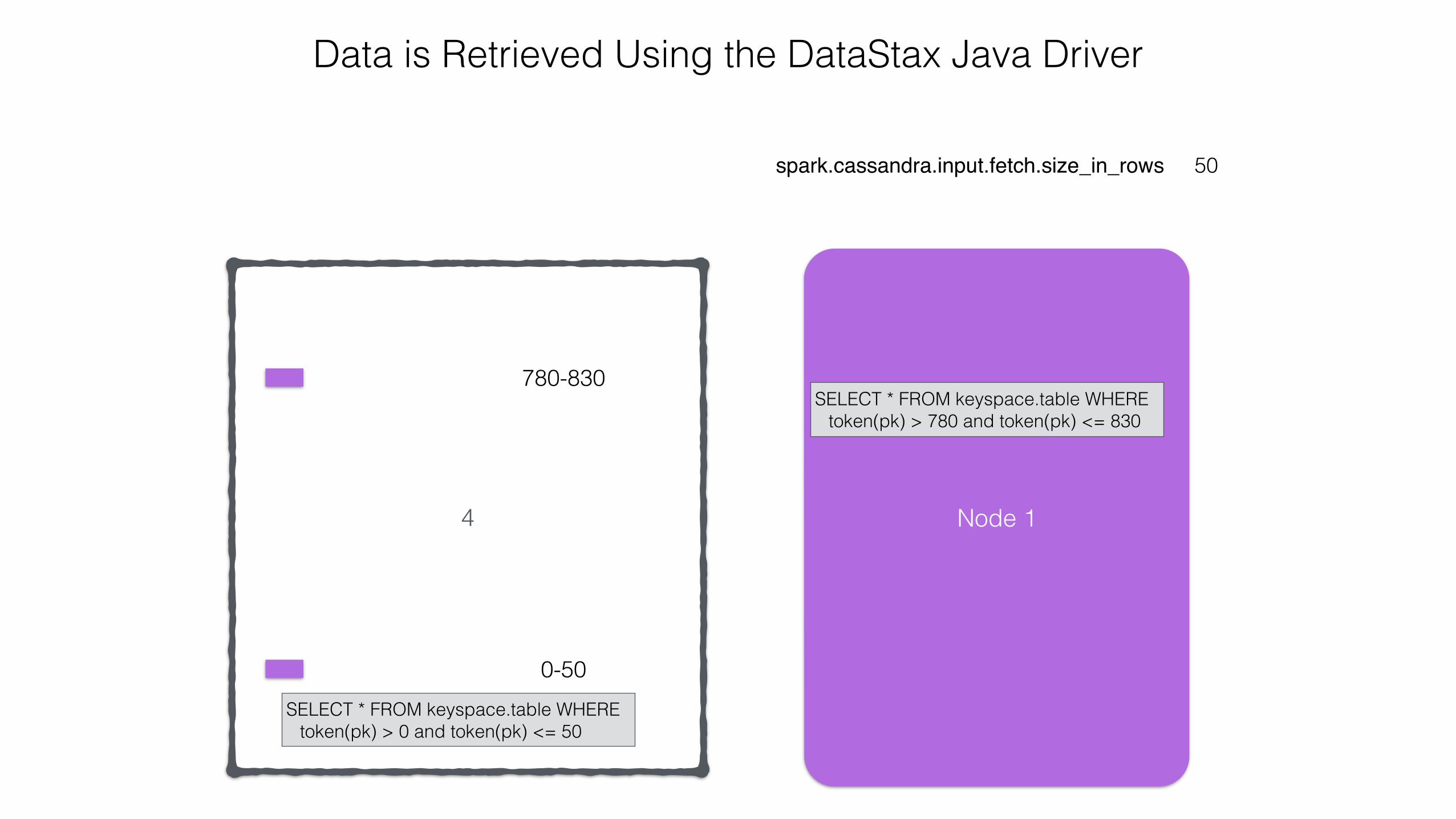
Data is Retrieved Using the DataStax Java Driver
0-50780-830
Node 1

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows50 CQL Rows50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows50 CQL Rows50 CQL Rows

4
spark.cassandra.input.fetch.size_in_rows 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 780 and token(pk) <= 830
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 50
50 CQL Rows50 CQL Rows50 CQL Rows 50 CQL Rows

4
spark.cassandra.input.page.row.size 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 5050 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows
50 CQL Rows

4
spark.cassandra.input.page.row.size 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 5050 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows
50 CQL Rows
50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows

4
spark.cassandra.input.page.row.size 50
Data is Retrieved Using the DataStax Java Driver
0-50
780-830
Node 1
SELECT * FROM keyspace.table WHERE token(pk) > 0 and token(pk) <= 5050 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows
50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows50 CQL Rows

@chbatey
Paging

@chbatey
Other bits and bobs• LocalNodeFirstLoadBalancingPolicy

@chbatey
Then we’re into Spark land• Spark partitions are made up of C* partitions that exist
on the same node• C* connector tells Spark which workers to use via
information from the C* driver

@chbatey
RDD -> C* Table

Node 2
Node 1
RDD
2
346
7 8 9
Node 3
Node 4
1 5
The Spark Cassandra Connector saveToCassandra
method can be called on almost all RDDs
rdd.saveToCassandra("Keyspace","Table")
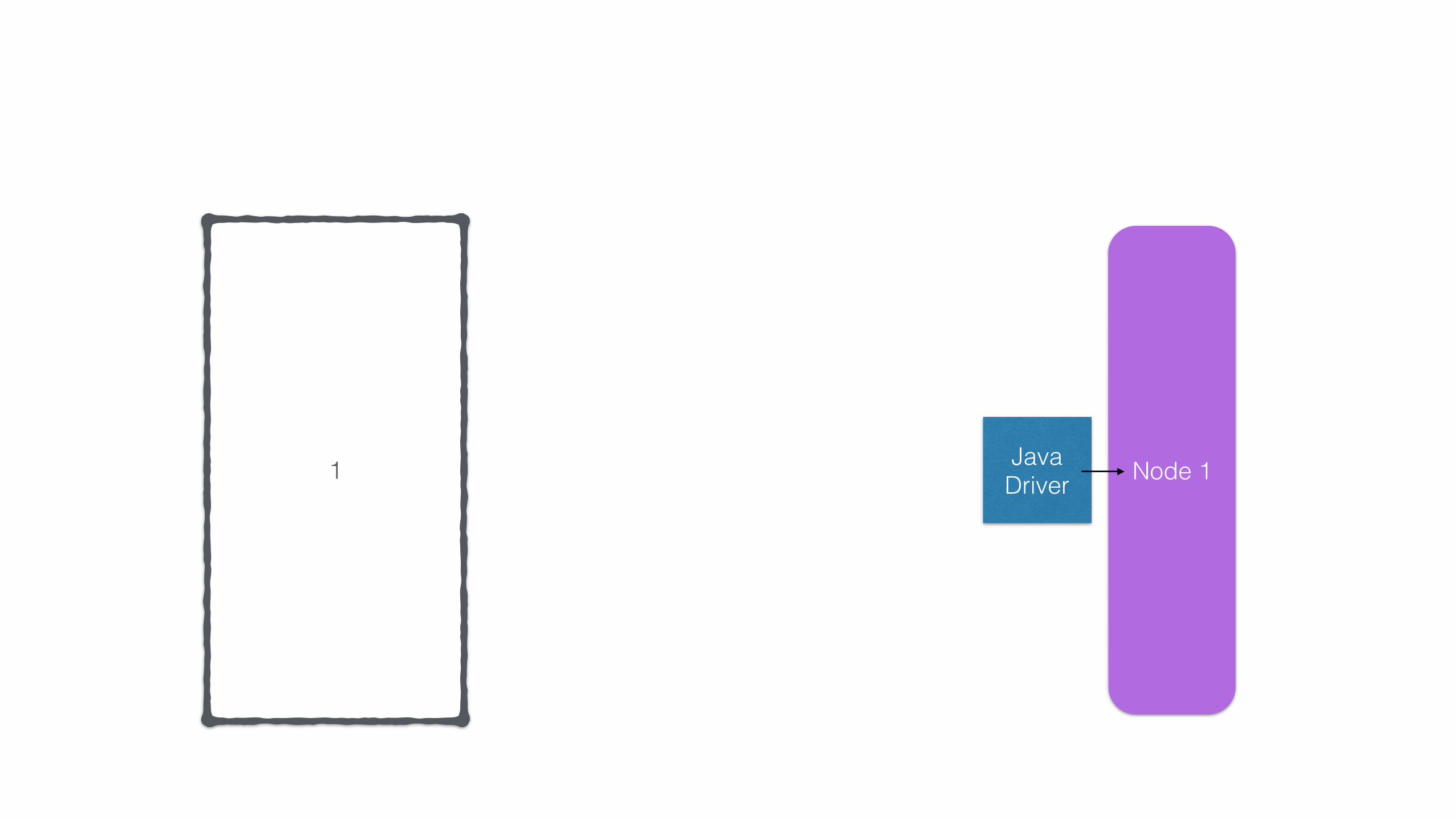
Node 11 Java Driver

Node 11 Java Driver
1,1,1
1,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
3,9,1

Node 11 Java Driver
1,1,1
1,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
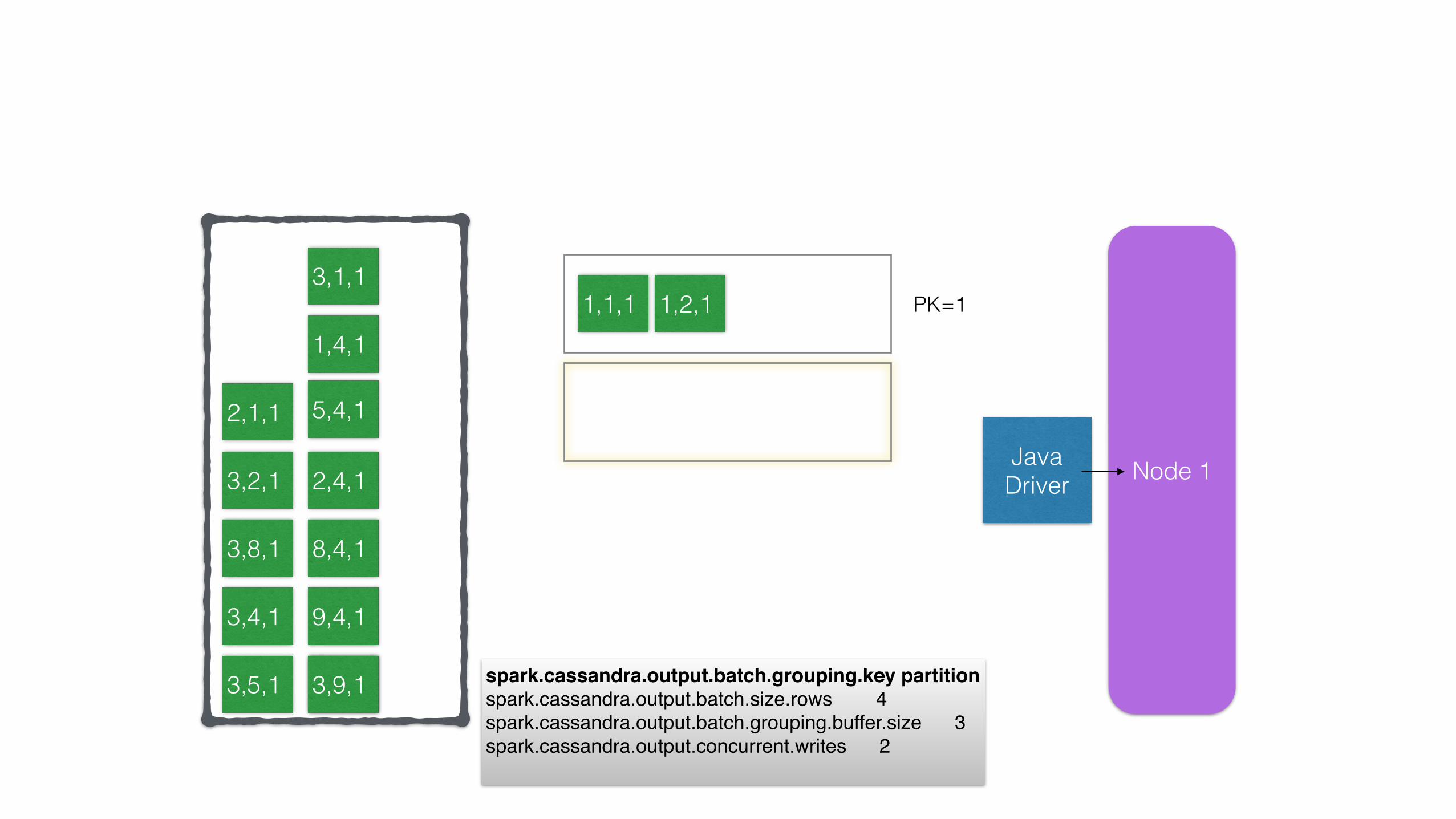
11,4, spark.cassandra.output.batch.grouping.key partitionspark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1

Node 11 Java Driver
1,1,11,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partitionspark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1
Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4,
spark.cassandra.output.batch.grouping.key partitionspark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partitionspark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1
PK=2

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,8,1
3,2,1
3,4,1
3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partitionspark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1
PK=2

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,8,13,2,1 3,4,1 3,5,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1
PK=2
PK=3

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4,3,9,1
3,1,1
spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
PK=1
PK=2

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4,3,9,1 spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
PK=1
PK=2
PK=3

Node 11 Java Driver
1,1,1 1,2,1
2,1,1
3,1,1
1,4,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=1
PK=2
PK=3
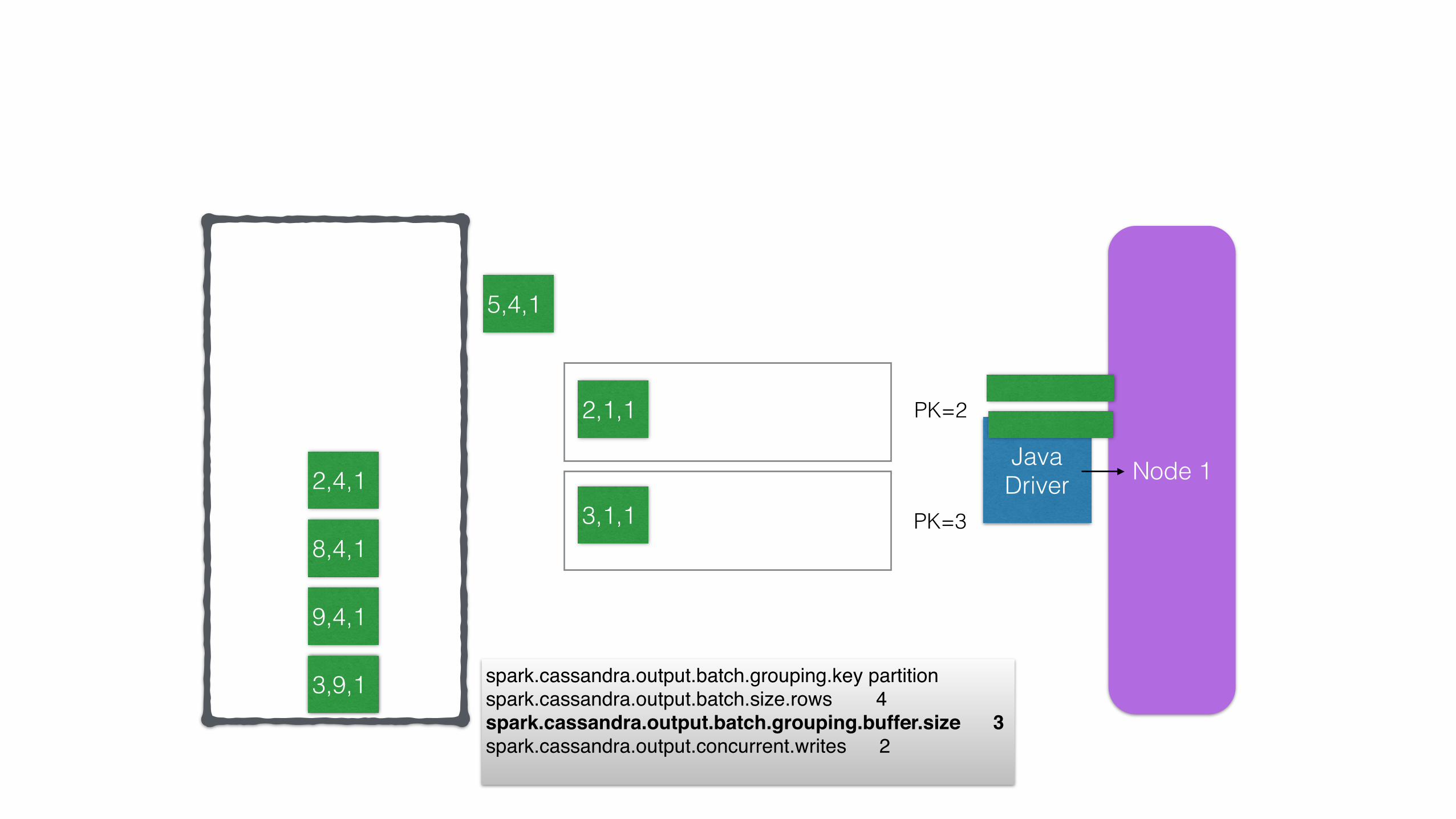
Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=2
PK=3

Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=2
PK=3
PK=5

Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,1
8,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,1
PK=2
PK=3
PK=5

Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,18,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,13,9,1
PK=2
PK=3
PK=5

Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,18,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,9,13,9,1
Write Acknowledged PK=2
PK=3
PK=5

Node 11 Java Driver
2,1,1
3,1,1
5,4,1
2,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
8,4,1
3,9,1
PK=2
PK=3
PK=5

Node 11 Java Driver
3,1,1
5,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
8,4,1
3,9,1
PK=3
PK=5

Node 11 Java Driver
3,1,1
5,4,1
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
8,4,1
3,9,1
PK=8
PK=3
PK=5

Node 11 Java Driver
9,4,1
11,4, spark.cassandra.output.batch.grouping.key partition spark.cassandra.output.batch.size.rows 4spark.cassandra.output.batch.grouping.buffer.size 3spark.cassandra.output.concurrent.writes 2
3,1,1
5,4,1
8,4,1
3,9,1
PK=8
PK=3
PK=5
@chbatey
Summary• Reading - data locality is key• Joining - repartition by C*• Writing - batching by C* partition is key


















