
Munich March 2015 - Cassandra + Spark Overview
39
@chbatey Christopher Batey Technical Evangelist for Apache Cassandra Cassandra Spark Integration
-
Upload
christopher-batey -
Category
Software
-
view
171 -
download
1
Transcript of Munich March 2015 - Cassandra + Spark Overview

@chbatey
Christopher BateyTechnical Evangelist for Apache Cassandra
Cassandra Spark Integration

@chbatey
Who am I? What is DataStax?• Technical Evangelist for Apache Cassandra• Cassandra related questions: @chbatey• DataStax- Enterprise ready version of Cassandra- Spark integration- Solr integration- OpsCenter- Majority of Cassandra drivers

@chbatey
Agenda•Cassandra overview• Spark overview• Spark Cassandra connector•Cassandra Spark examples

@chbatey
Cassandra
@chbatey
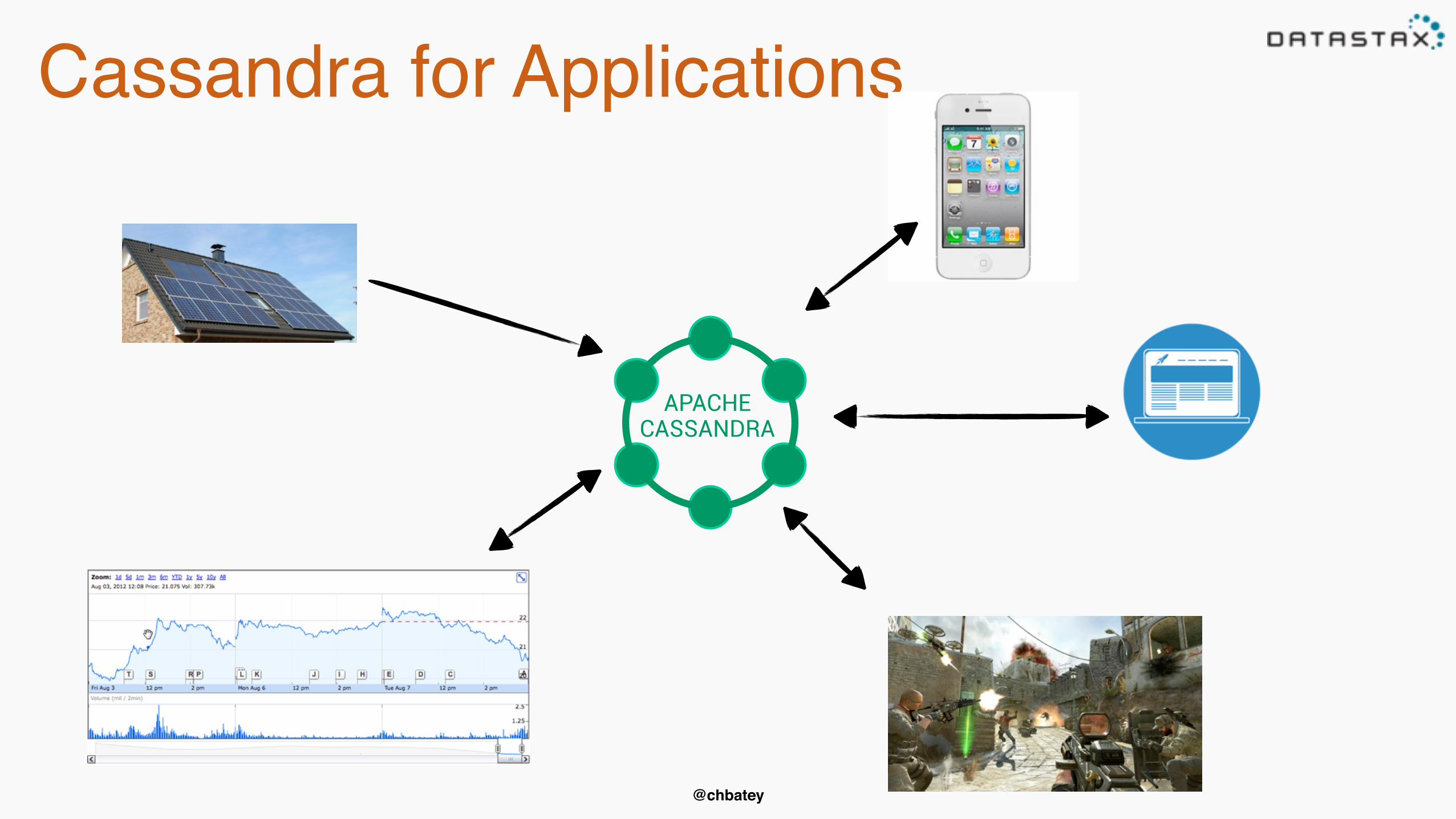
Cassandra for Applications
APACHE
CASSANDRA

@chbatey
Common use cases•Ordered data such as time series-Event stores-Financial transactions-Sensor data e.g IoT

@chbatey
Common use cases•Ordered data such as time series-Event stores-Financial transactions-Sensor data e.g IoT•Non functional requirements:-Linear scalability-High throughout durable writes-Multi datacenter including active-active-Analytics without ETL
@chbatey
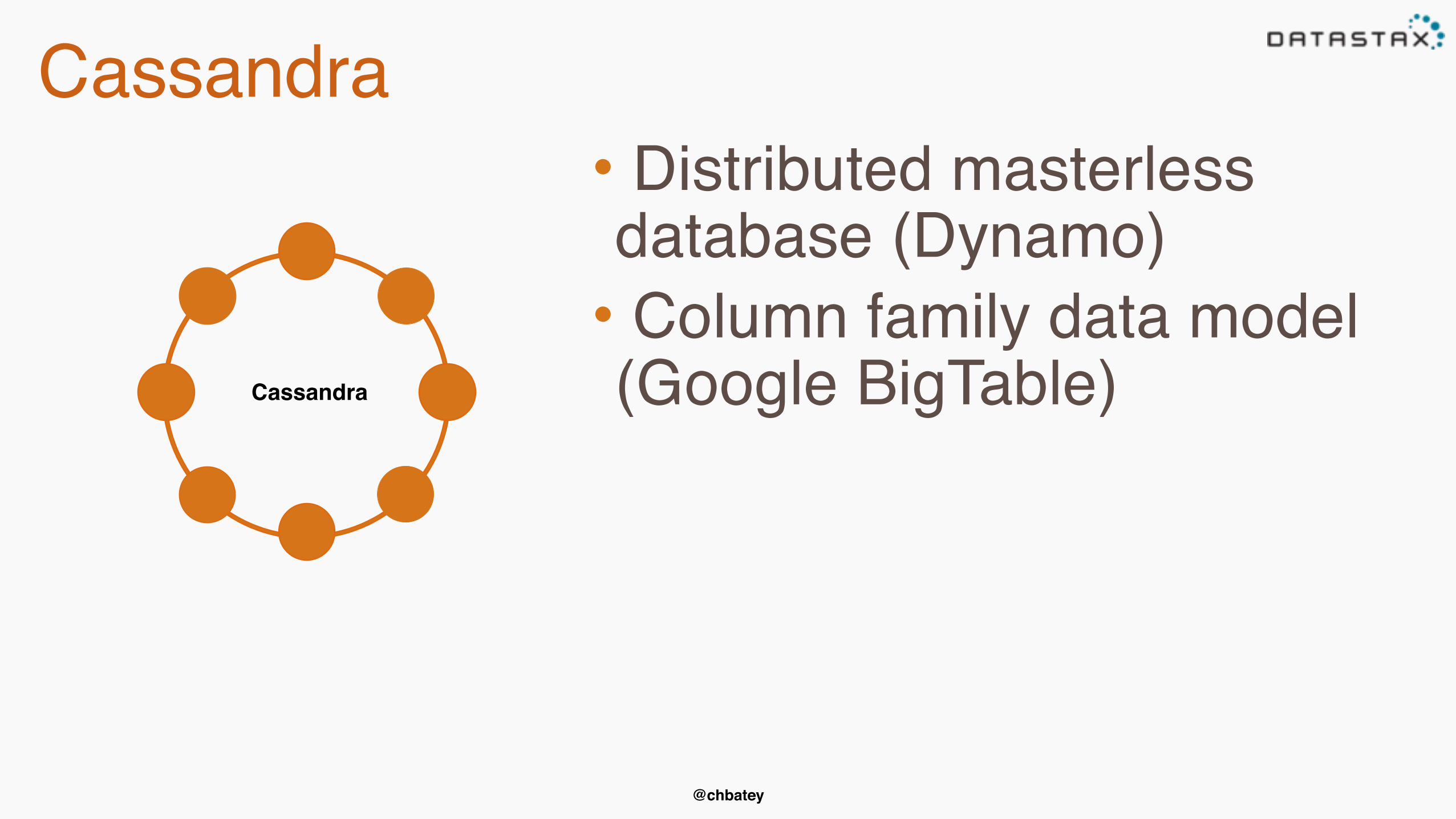
Cassandra
Cassandra
• Distributed masterless database (Dynamo)• Column family data model (Google BigTable)
@chbatey
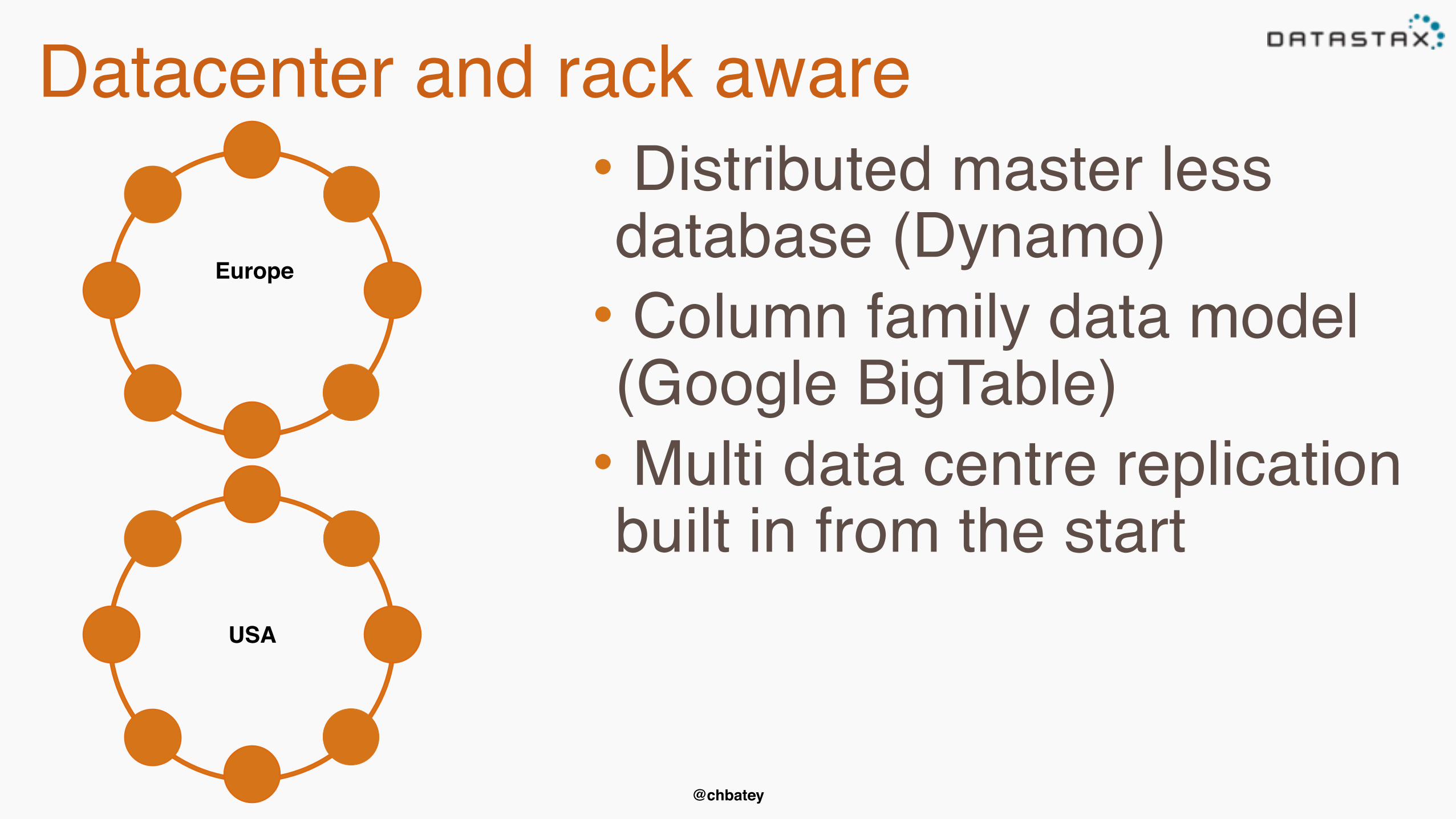
Datacenter and rack aware
Europe
• Distributed master less database (Dynamo)• Column family data model (Google BigTable)• Multi data centre replication built in from the start
USA
@chbatey
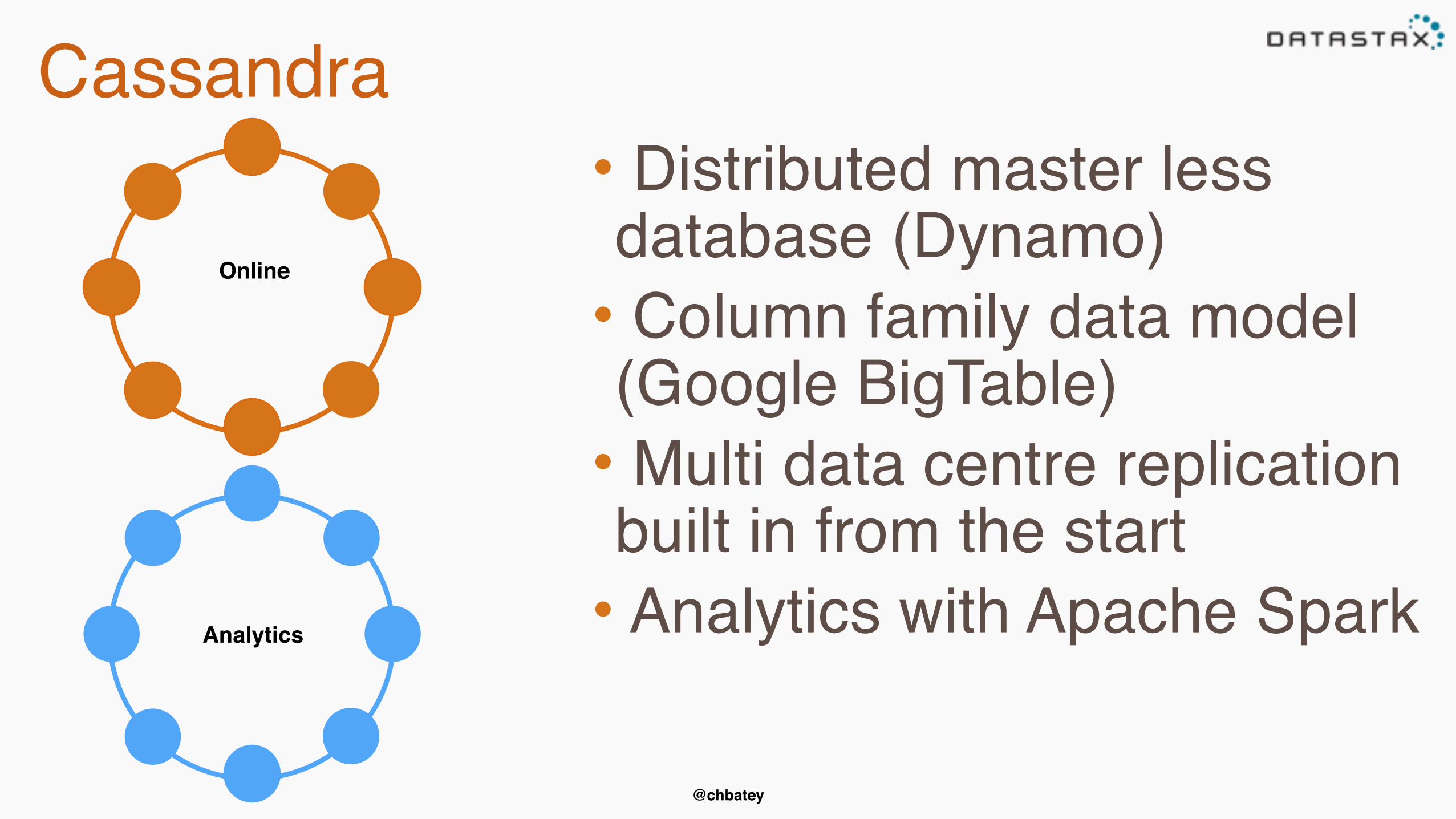
Cassandra
Online
• Distributed master less database (Dynamo)• Column family data model (Google BigTable)• Multi data centre replication built in from the start• Analytics with Apache SparkAnalytics

@chbatey
Scalability & Performance• Scalability- No single point of failure- No special nodes that become the bottle neck- Work/data can be re-distributed• Operational Performance i.e single digit ms- Single node for query- Single disk seek per query
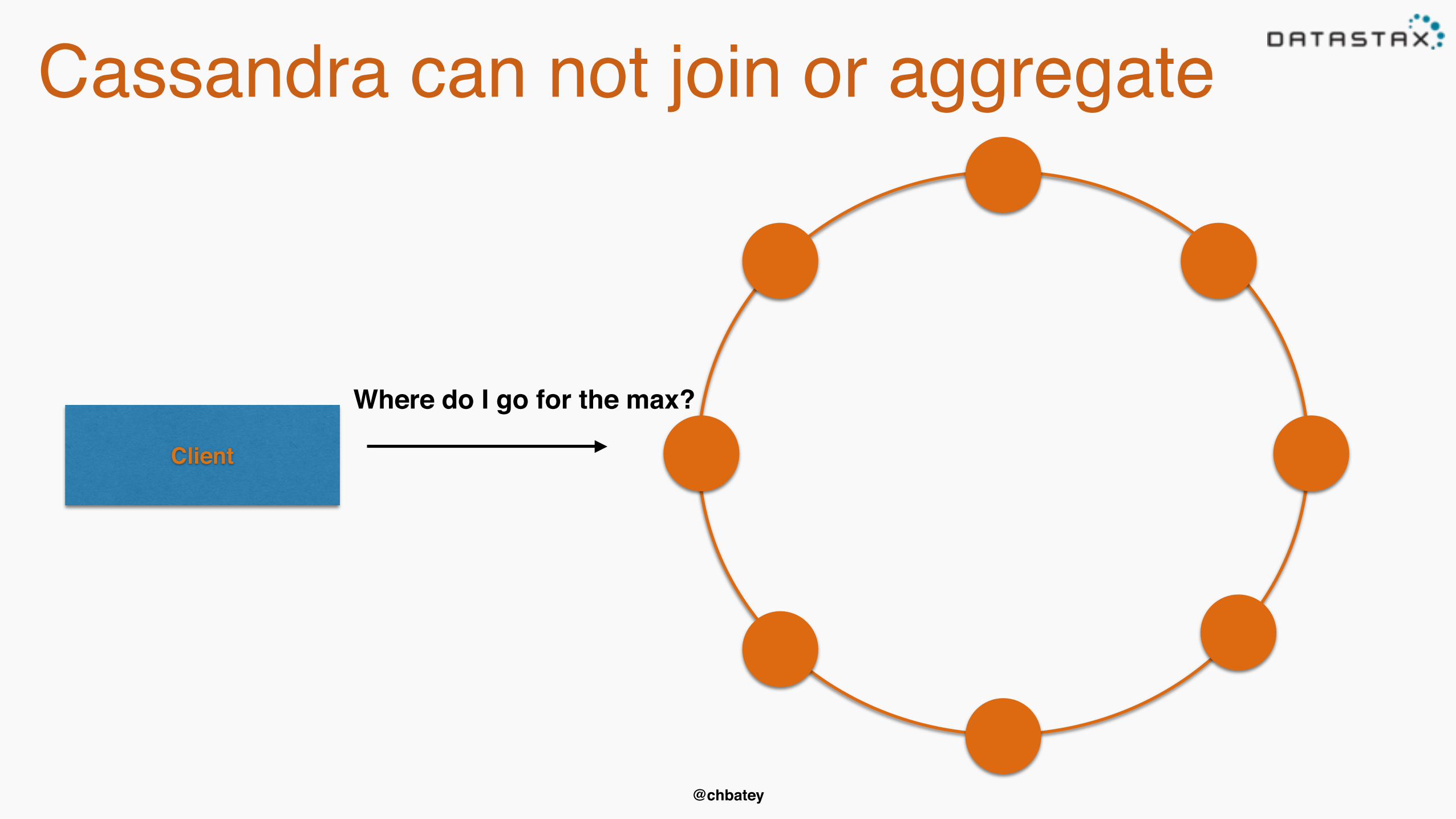
@chbatey
Cassandra can not join or aggregate
Client
Where do I go for the max?

@chbatey
But but…• Sometimes you don’t need a answers in milliseconds• Data models done wrong - how do I fix it?• New requirements for old data?• Ad-hoc operational queries• Reports and Analytics- Managers always want counts / maxs

@chbatey
Apache Spark• 10x faster on disk,100x faster in memory than Hadoop
MR• Works out of the box on EMR• Fault Tolerant Distributed Datasets• Batch, iterative and streaming analysis• In Memory Storage and Disk • Integrates with Most File and Storage Options
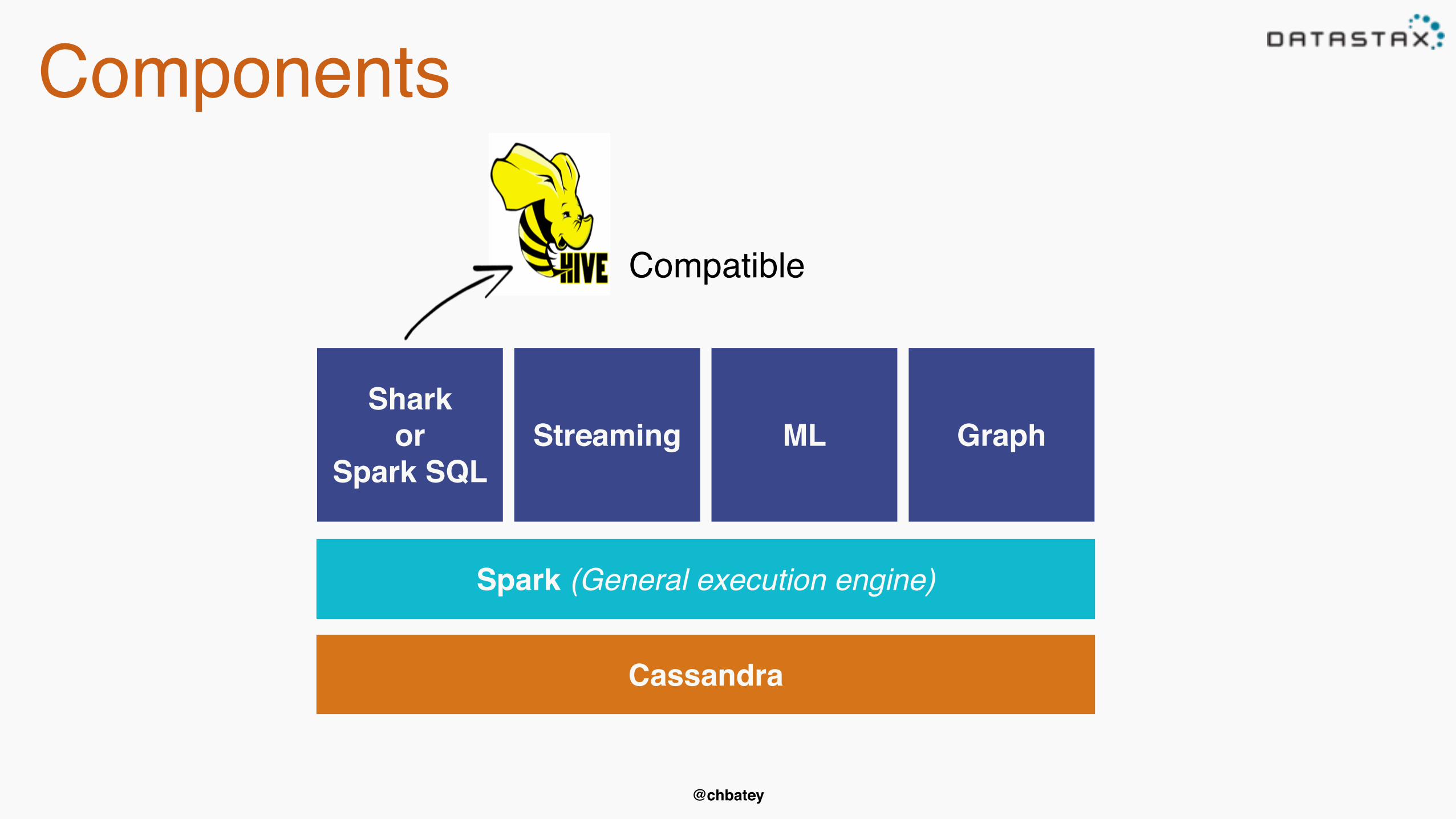
@chbatey
Components
Sharkor
Spark SQLStreaming ML
Spark (General execution engine)
Graph
Cassandra
Compatible
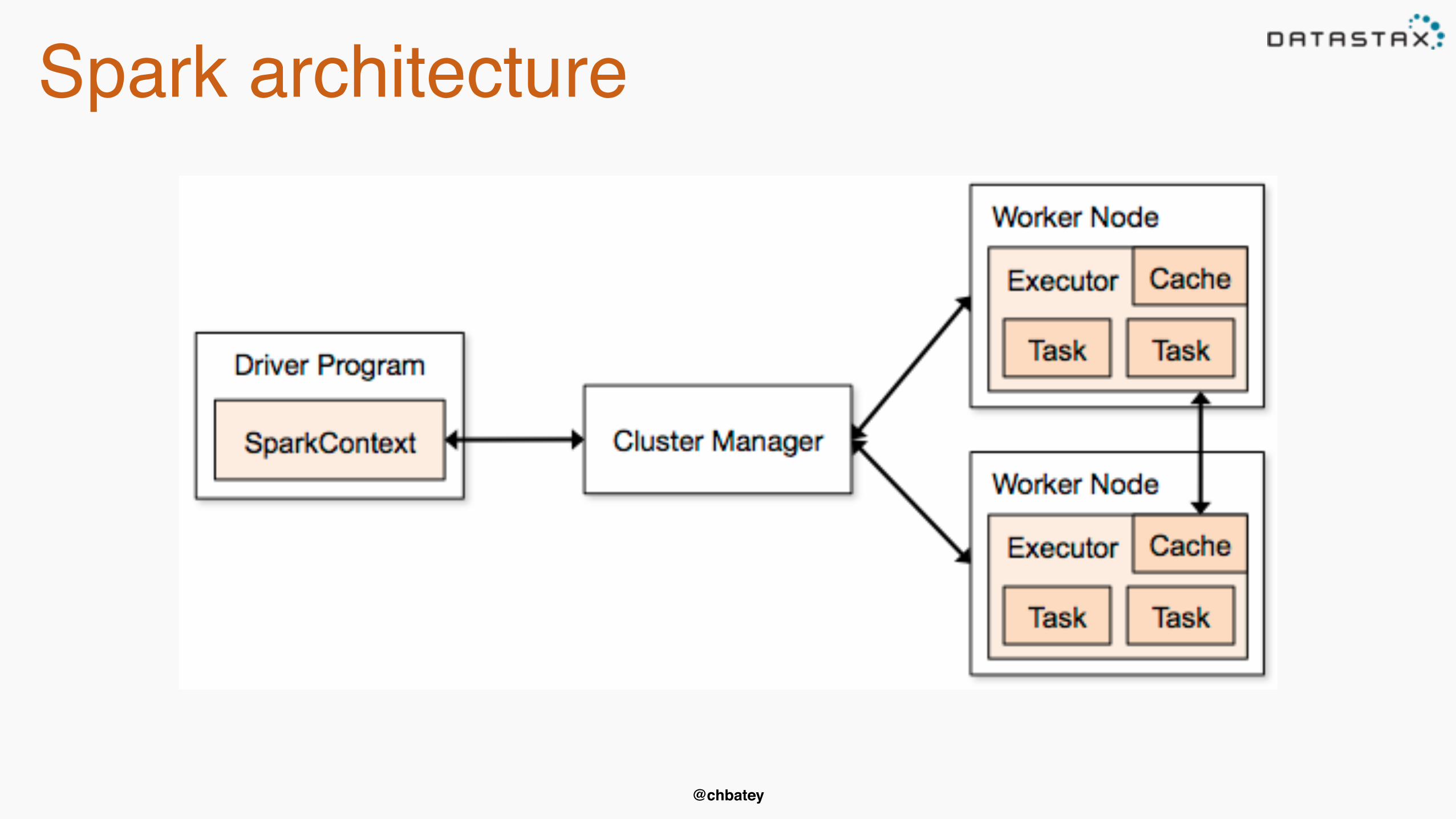
@chbatey
Spark architecture

@chbatey
org.apache.spark.rdd.RDD• Resilient Distributed Dataset (RDD)• Created through transformations on data (map,filter..) or other RDDs • Immutable• Partitioned• Reusable

@chbatey
RDD Operations• Transformations - Similar to Scala collections API• Produce new RDDs • filter, flatmap, map, distinct, groupBy, union, zip, reduceByKey, subtract
• Actions• Require materialization of the records to generate a value• collect: Array[T], count, fold, reduce..

@chbatey
Word count
val file: RDD[String] = sc.textFile("hdfs://...")
val counts: RDD[(String, Int)] = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")
@chbatey
Spark shell
@chbatey
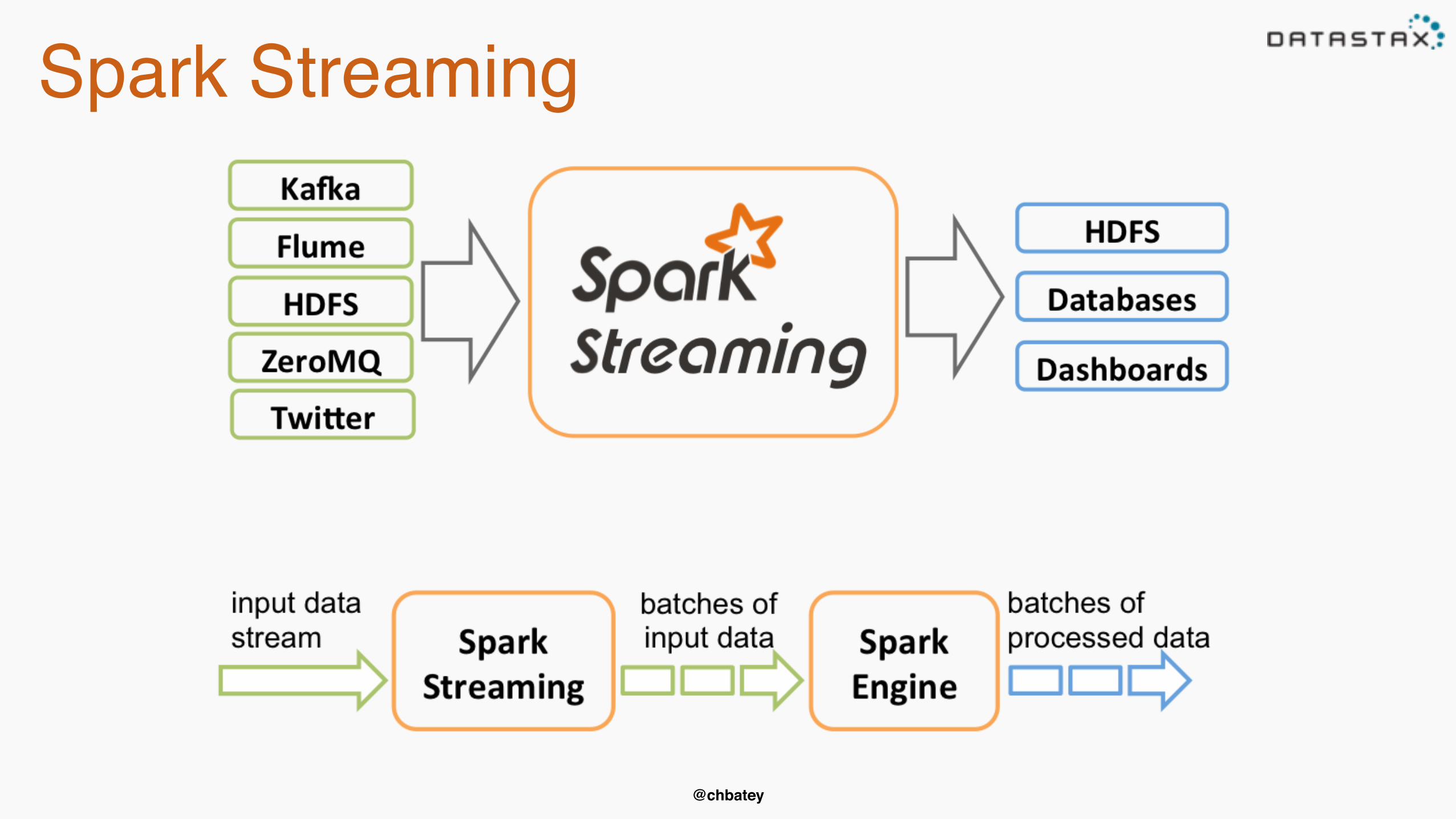
Spark Streaming

@chbatey
Cassandra + Spark

@chbatey
Spark Cassandra Connector• Loads data from Cassandra to Spark• Writes data from Spark to Cassandra• Implicit Type Conversions and Object Mapping• Implemented in Scala (offers a Java API)• Open Source • Exposes Cassandra Tables as Spark RDDs + Spark
DStreams
@chbatey
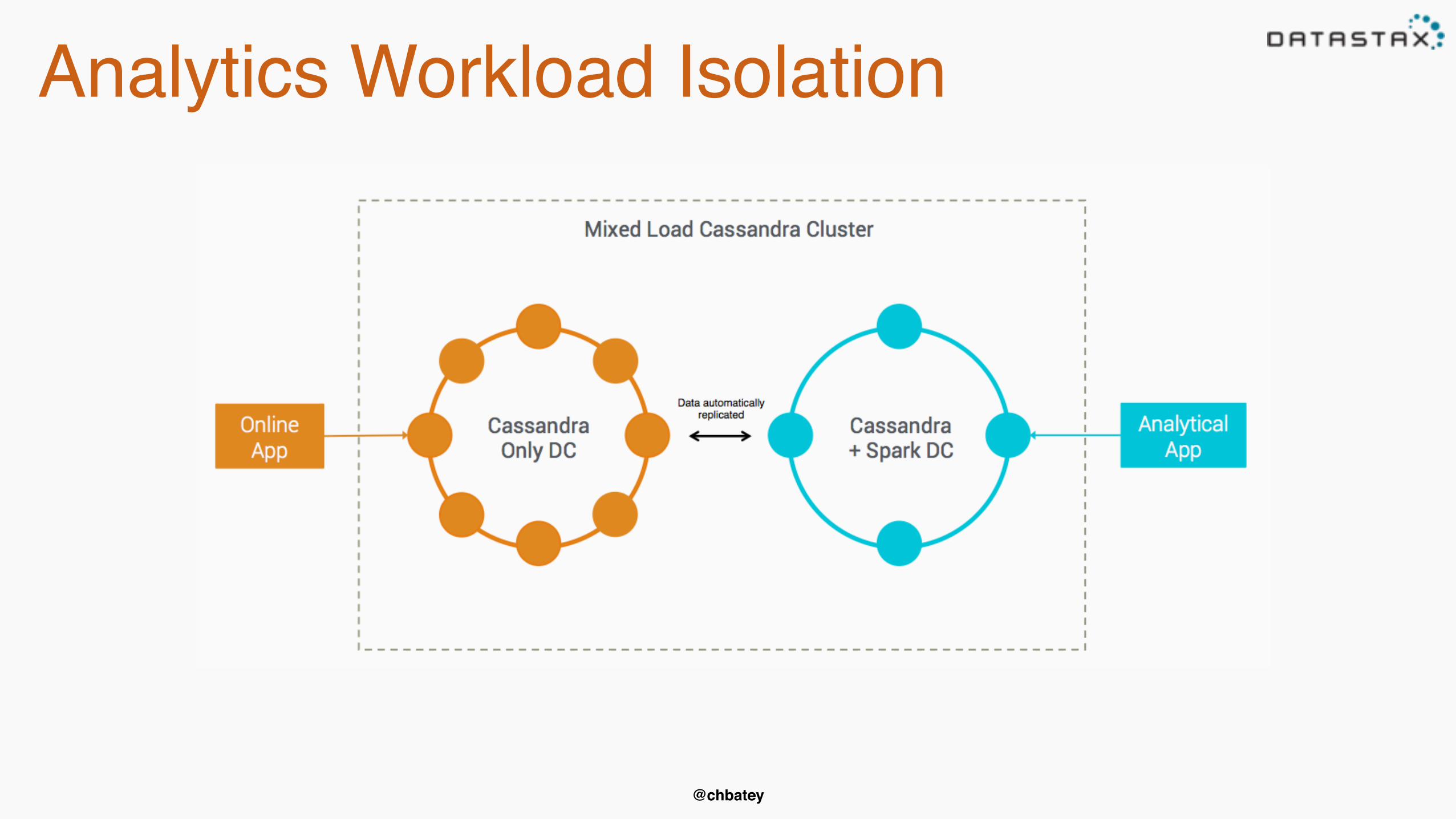
Analytics Workload Isolation
@chbatey
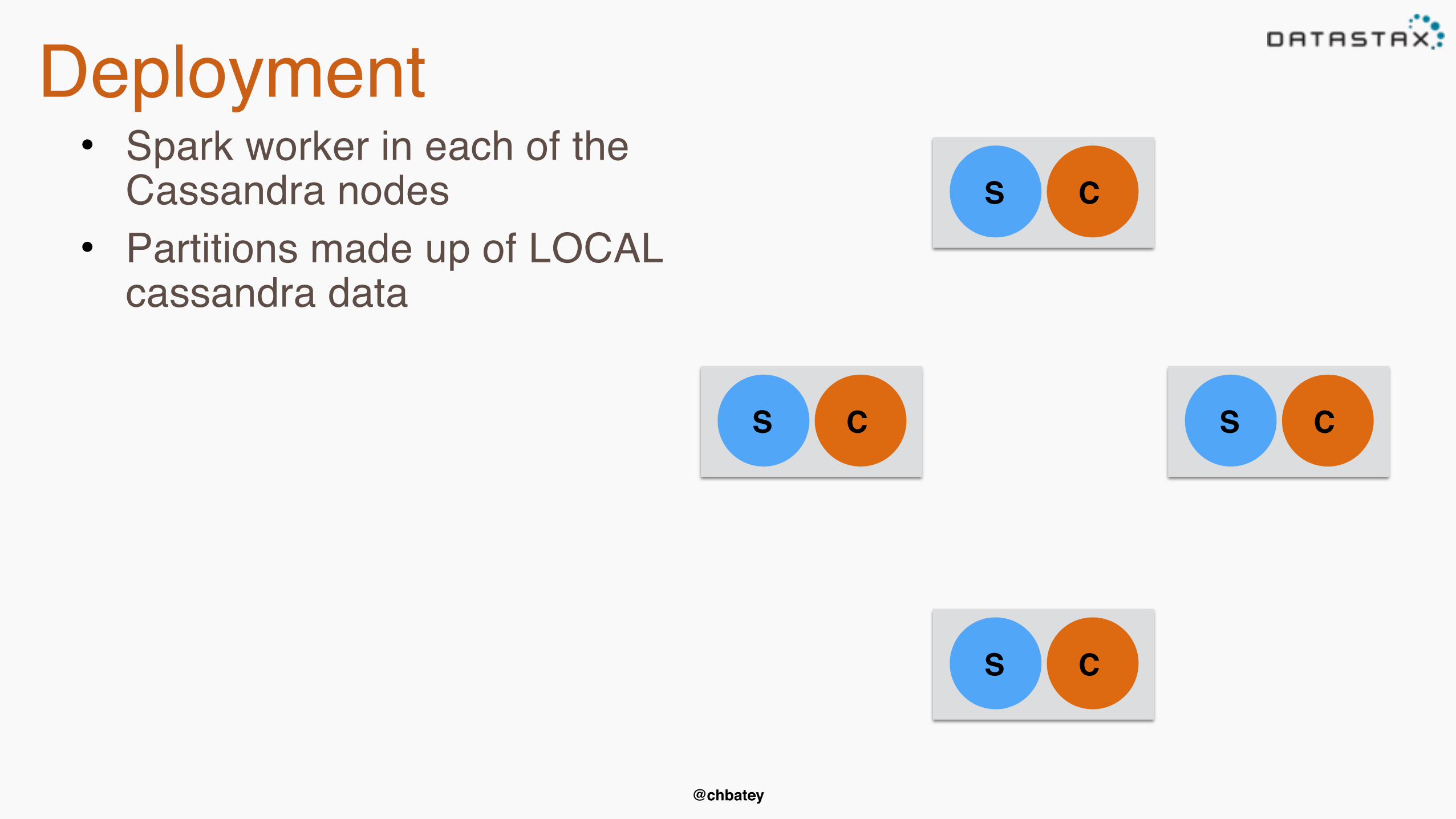
Deployment• Spark worker in each of the
Cassandra nodes• Partitions made up of LOCAL
cassandra data
S C
S C
S C
S C

@chbatey
Example Time
@chbatey
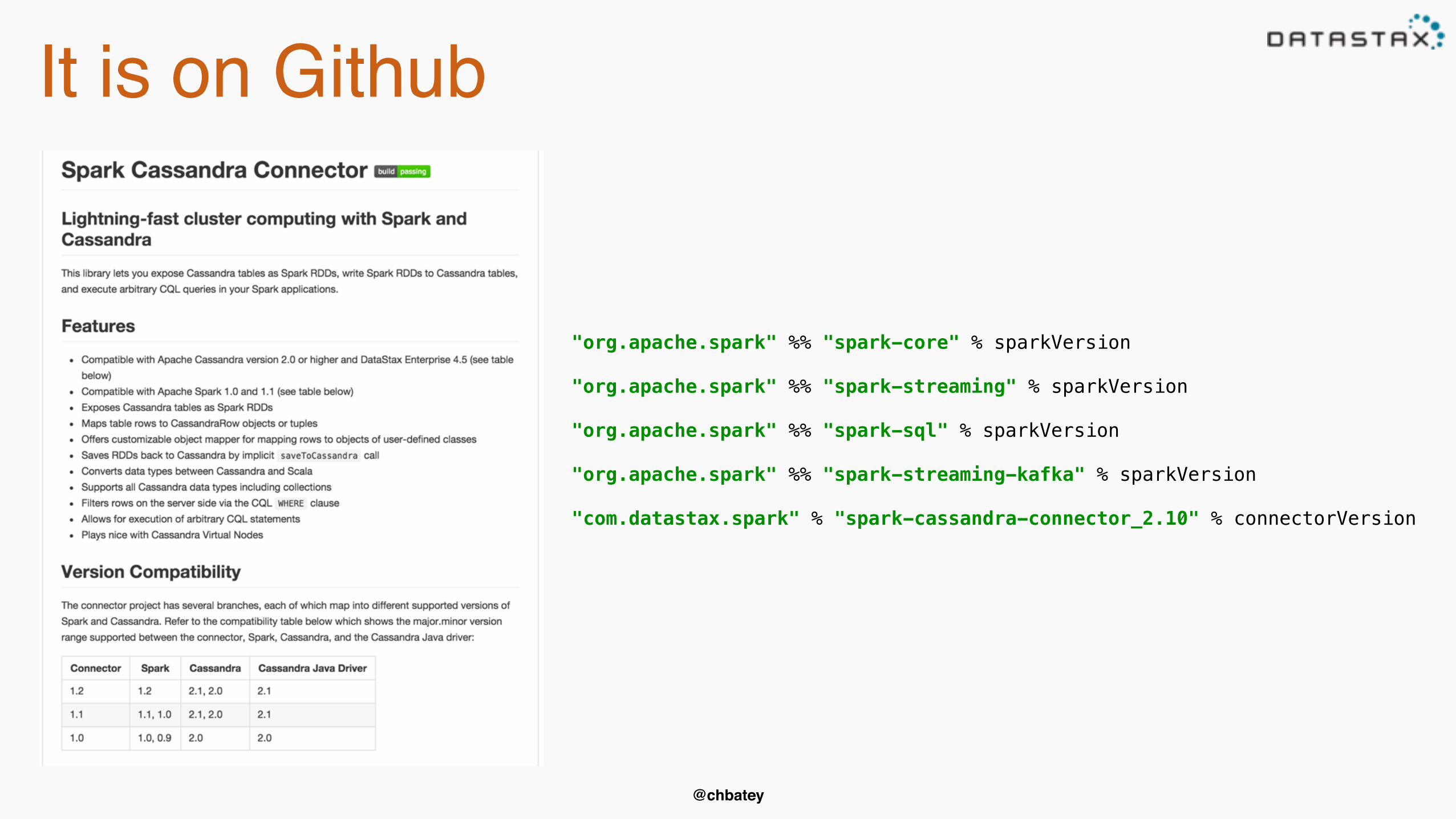
It is on Github
"org.apache.spark" %% "spark-core" % sparkVersion"org.apache.spark" %% "spark-streaming" % sparkVersion"org.apache.spark" %% "spark-sql" % sparkVersion"org.apache.spark" %% "spark-streaming-kafka" % sparkVersion"com.datastax.spark" % "spark-cassandra-connector_2.10" % connectorVersion
@chbatey
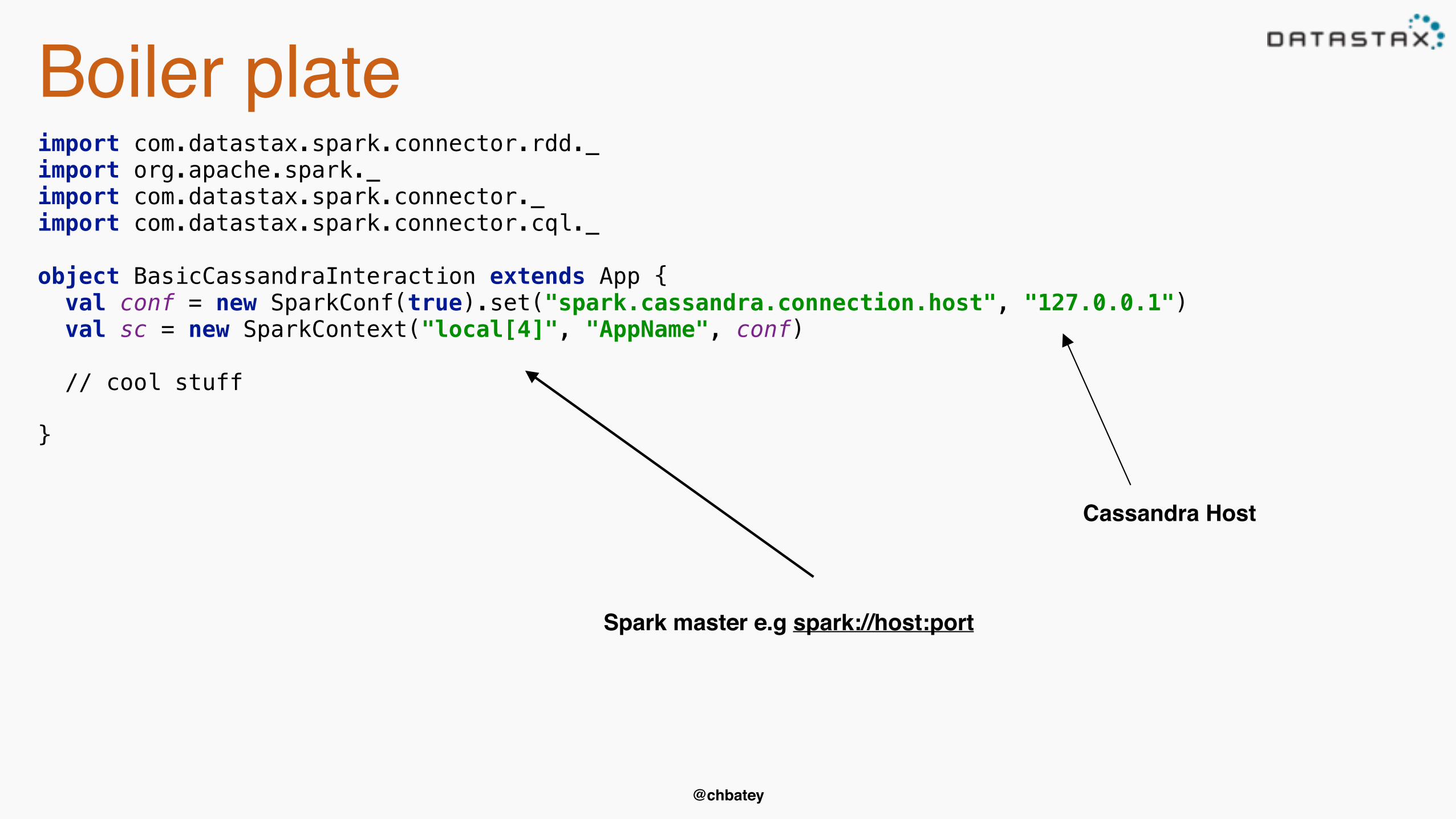
Boiler plateimport com.datastax.spark.connector.rdd._import org.apache.spark._import com.datastax.spark.connector._import com.datastax.spark.connector.cql._object BasicCassandraInteraction extends App { val conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1") val sc = new SparkContext("local[4]", "AppName", conf)
// cool stuff}
Cassandra Host
Spark master e.g spark://host:port

@chbatey
Word Count + Save to Cassandra
val textFile: RDD[String] = sc.textFile("Spark-Readme.md") val words: RDD[String] = textFile.flatMap(line => line.split("\\s+")) val wordAndCount: RDD[(String, Int)] = words.map((_, 1)) val wordCounts: RDD[(String, Int)] = wordAndCount.reduceByKey(_ + _)println(wordCounts.first())wordCounts.saveToCassandra("test", "words", SomeColumns("word", "count"))

@chbatey
Denormalised tableCREATE TABLE IF NOT EXISTS customer_events( customer_id text, time timestamp, id uuid,
event_type text, store_name text, store_type text, store_location text, staff_name text, staff_title text, PRIMARY KEY ((customer_id), time, id))

@chbatey
Store it twiceCREATE TABLE IF NOT EXISTS customer_events(customer_id text, time timestamp, id uuid, event_type text, store_name text, store_type text, store_location text, staff_name text, staff_title text, PRIMARY KEY ((customer_id), time, id))
CREATE TABLE IF NOT EXISTS customer_events_by_staff( customer_id text, time timestamp, id uuid, event_type text, store_name text, store_type text, store_location text, staff_name text, staff_title text, PRIMARY KEY ((staff_name), time, id))

@chbatey
My reaction a year ago
@chbatey
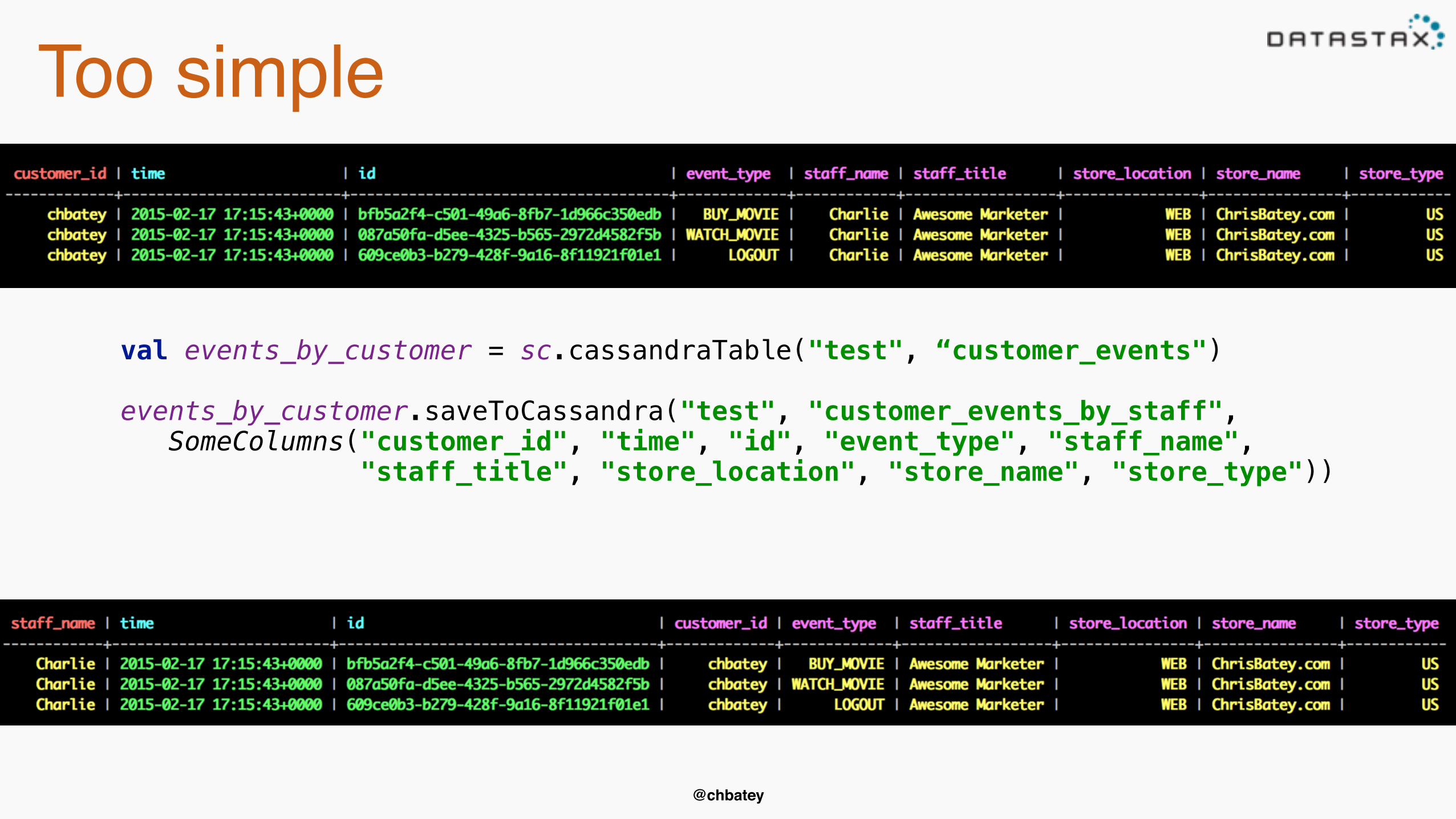
Too simple
val events_by_customer = sc.cassandraTable("test", “customer_events") events_by_customer.saveToCassandra("test", "customer_events_by_staff", SomeColumns("customer_id", "time", "id", "event_type", "staff_name", "staff_title", "store_location", "store_name", "store_type"))

@chbatey
Aggregations with Spark SQLPartition Key Clustering Columns

@chbatey
Now now…val cc = new CassandraSQLContext(sc) cc.setKeyspace("test")
val rdd: SchemaRDD = cc.sql("SELECT store_name, event_type, count(store_name) from customer_events GROUP BY store_name, event_type")
rdd.collect().foreach(println)
[SportsApp,WATCH_STREAM,1][SportsApp,LOGOUT,1][SportsApp,LOGIN,1][ChrisBatey.com,WATCH_MOVIE,1][ChrisBatey.com,LOGOUT,1][ChrisBatey.com,BUY_MOVIE,1][SportsApp,WATCH_MOVIE,2]
@chbatey
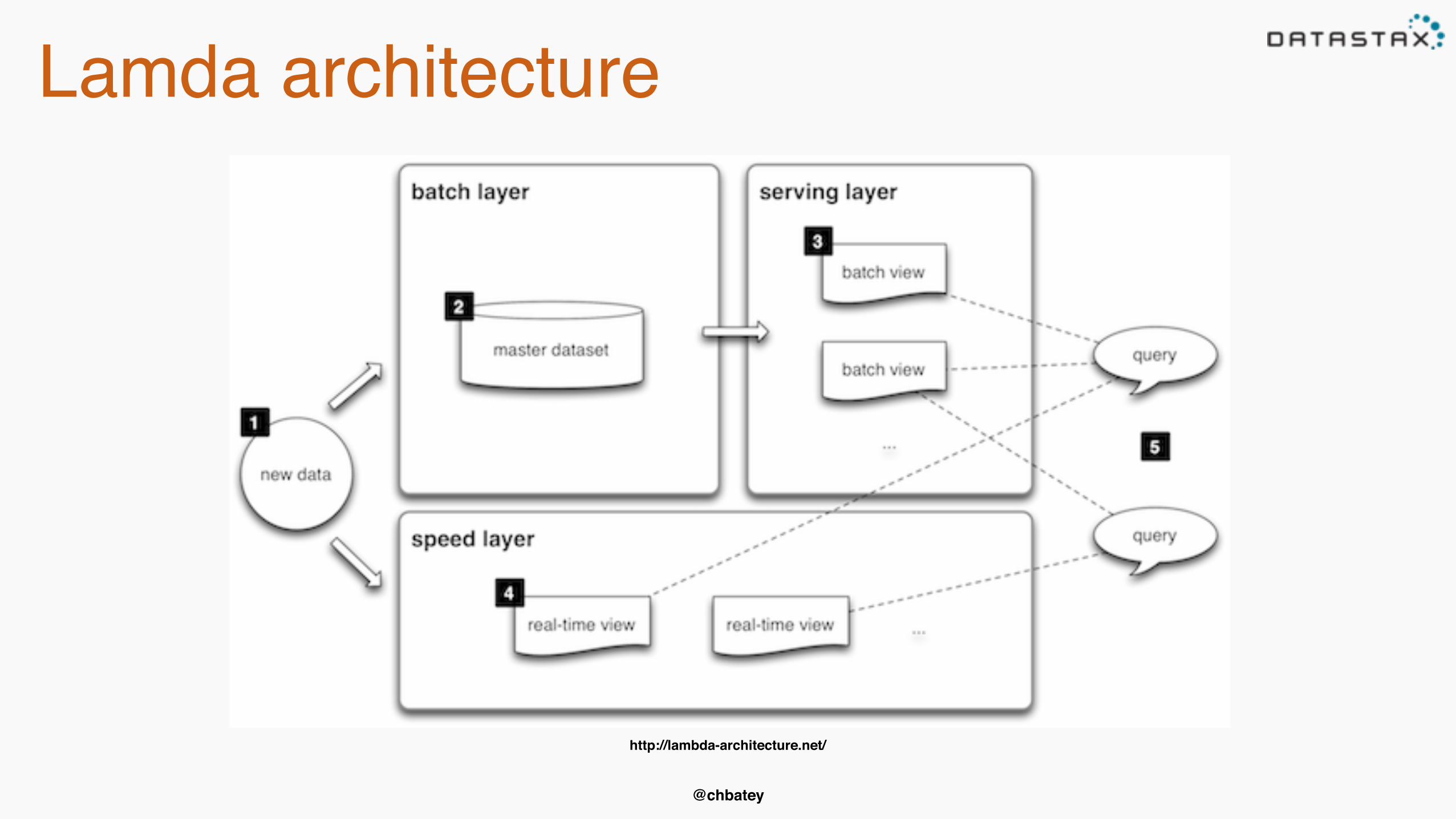
Lamda architecture
http://lambda-architecture.net/
@chbatey
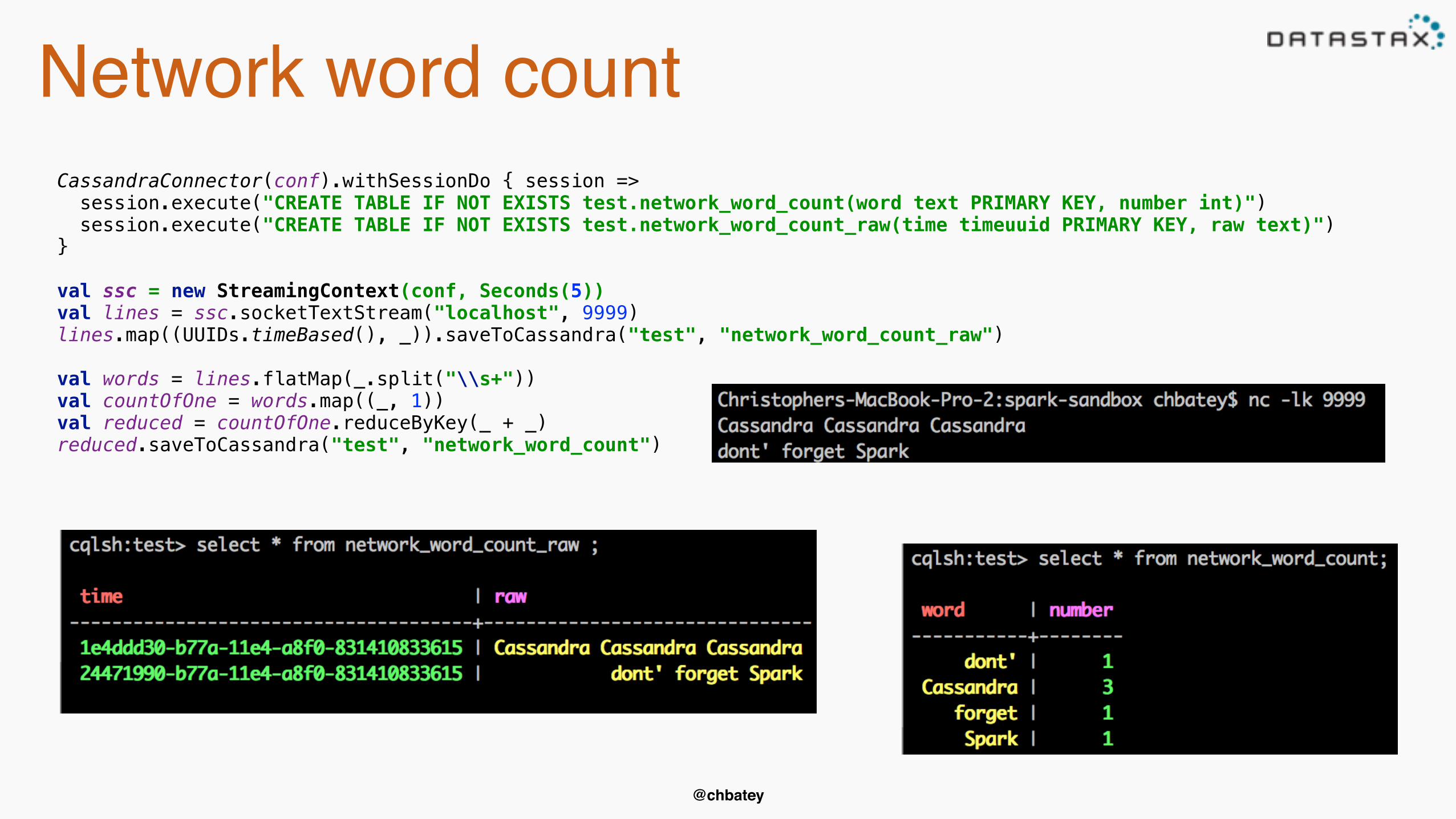
Network word countCassandraConnector(conf).withSessionDo { session => session.execute("CREATE TABLE IF NOT EXISTS test.network_word_count(word text PRIMARY KEY, number int)") session.execute("CREATE TABLE IF NOT EXISTS test.network_word_count_raw(time timeuuid PRIMARY KEY, raw text)") } val ssc = new StreamingContext(conf, Seconds(5))val lines = ssc.socketTextStream("localhost", 9999) lines.map((UUIDs.timeBased(), _)).saveToCassandra("test", "network_word_count_raw") val words = lines.flatMap(_.split("\\s+")) val countOfOne = words.map((_, 1)) val reduced = countOfOne.reduceByKey(_ + _)reduced.saveToCassandra("test", "network_word_count")

@chbatey
Summary• Cassandra is an operational database• Spark gives us the flexibility to do slower things- Schema migrations- Ad-hoc queries- Report generation• Spark streaming + Cassandra allow us to build online
analytical platforms

@chbatey
Thanks for listening• Follow me on twitter @chbatey• Cassandra + Fault tolerance posts a plenty: • http://christopher-batey.blogspot.co.uk/• Github for all examples: • https://github.com/chbatey/spark-sandbox• Cassandra resources: http://planetcassandra.org/• In London in April? http://www.eventbrite.com/e/cassandra-
day-london-2015-april-22nd-2015-tickets-15053026006?aff=CommunityLanding


















