
Analytics with Cassandra, Spark & MLLib - Cassandra Essentials Day
Upload
datastax-academyCategory
view
1.054download
0
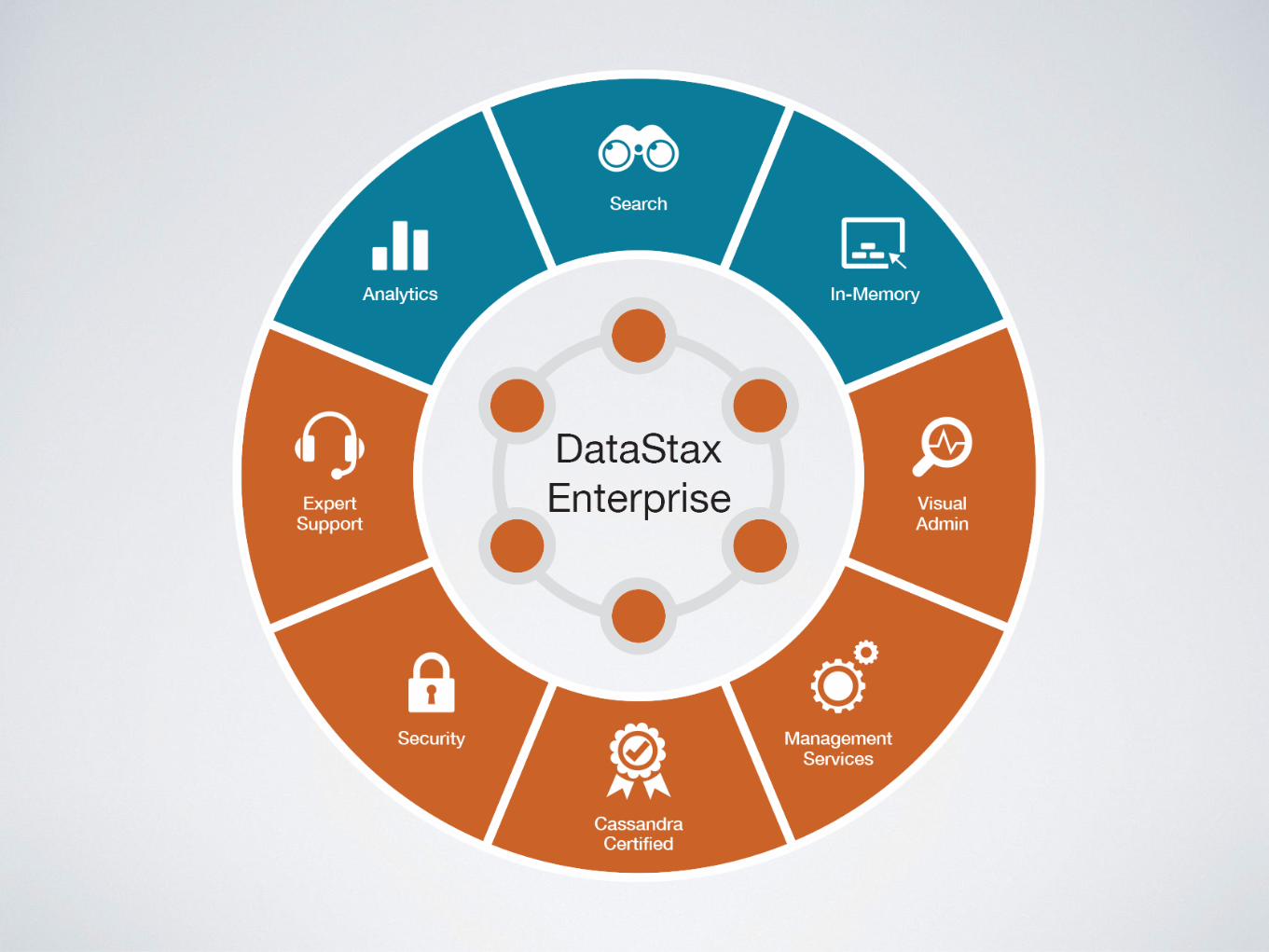
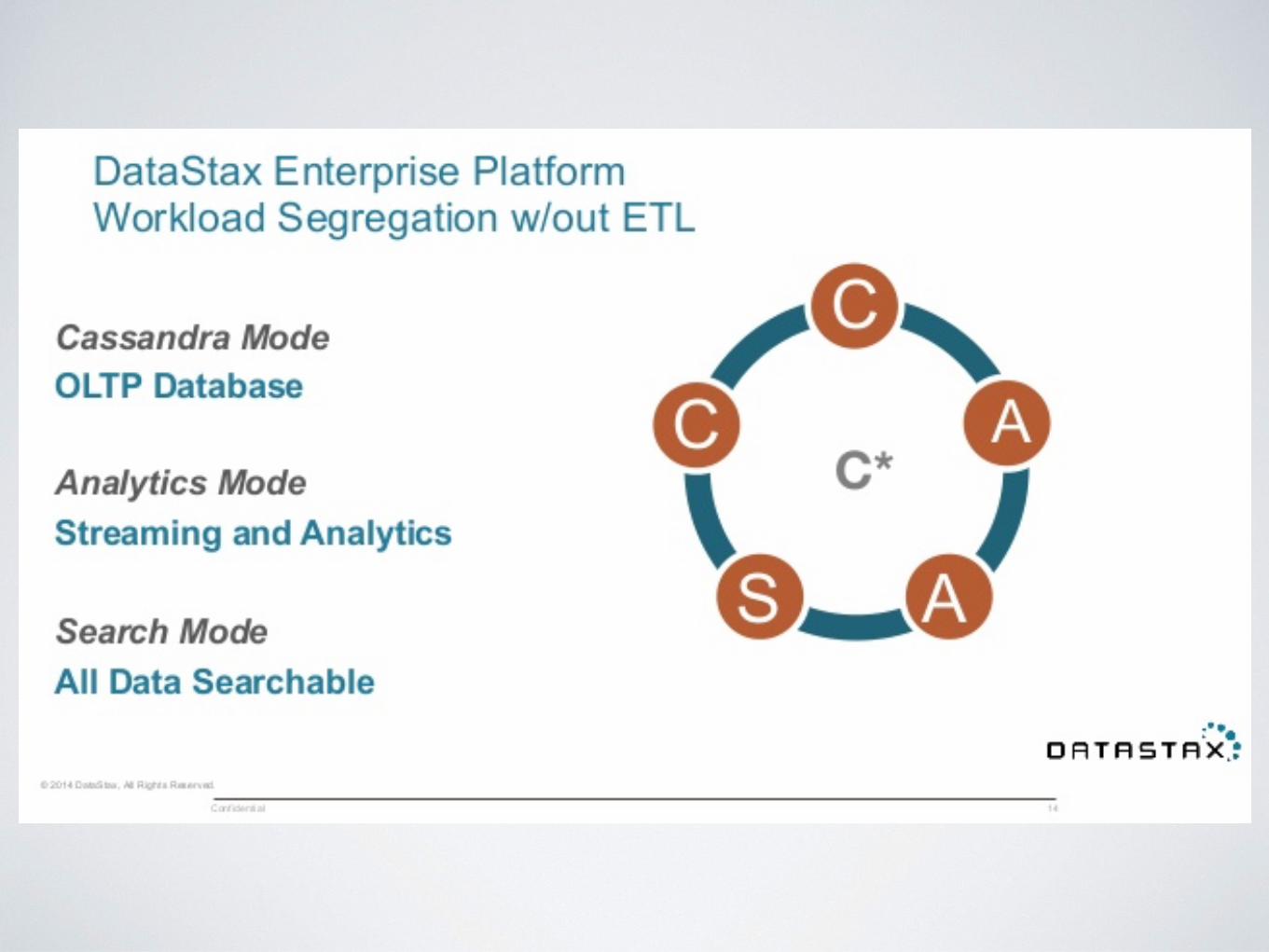
CASSANDRA DATA MAINTENANCE WITH SPARK
Operate on your Data

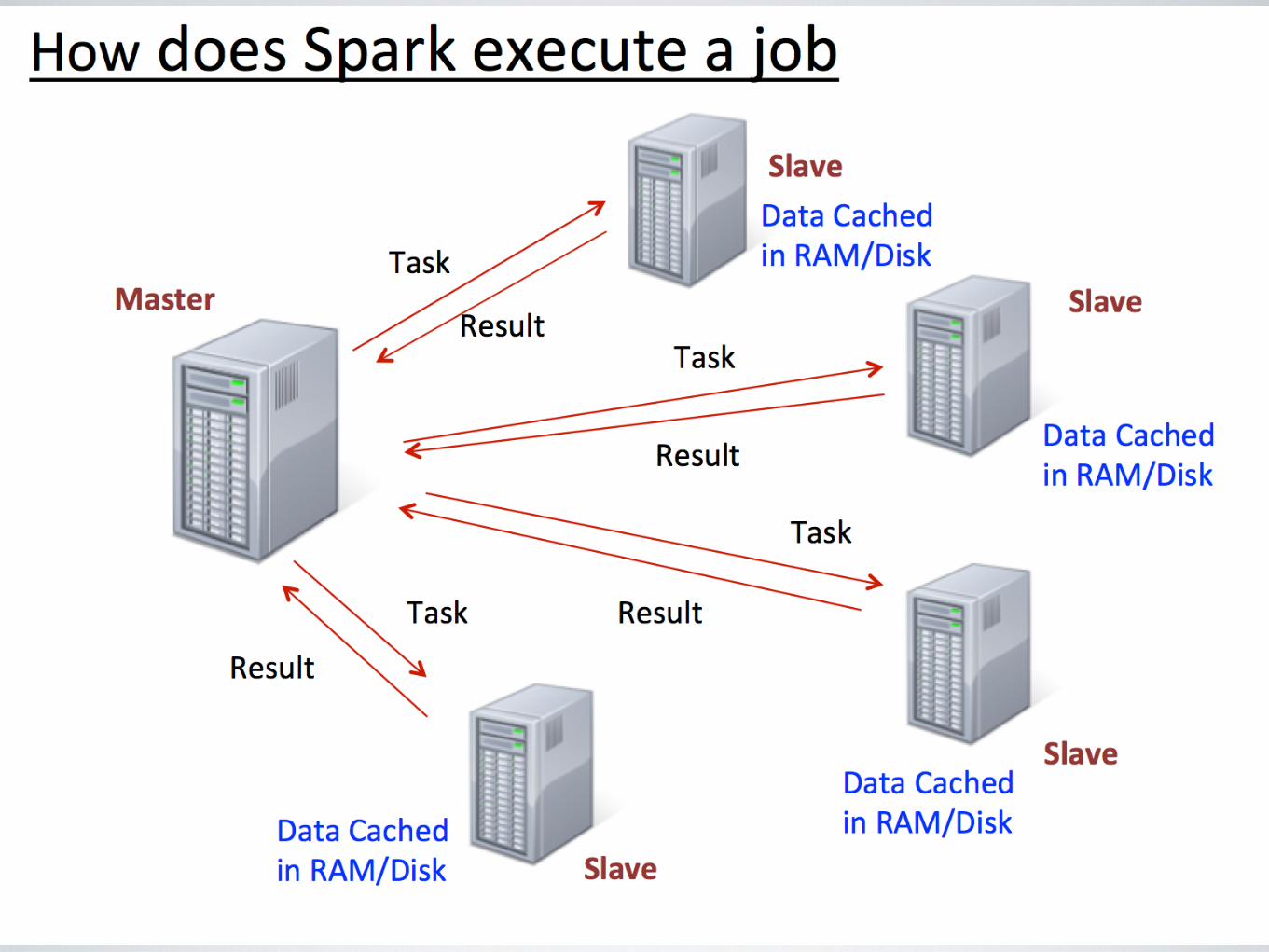
WHAT IS SPARK?A large-scale data processing framework

STEP 1:Make Fake Data
(unless you have a million records to spare)
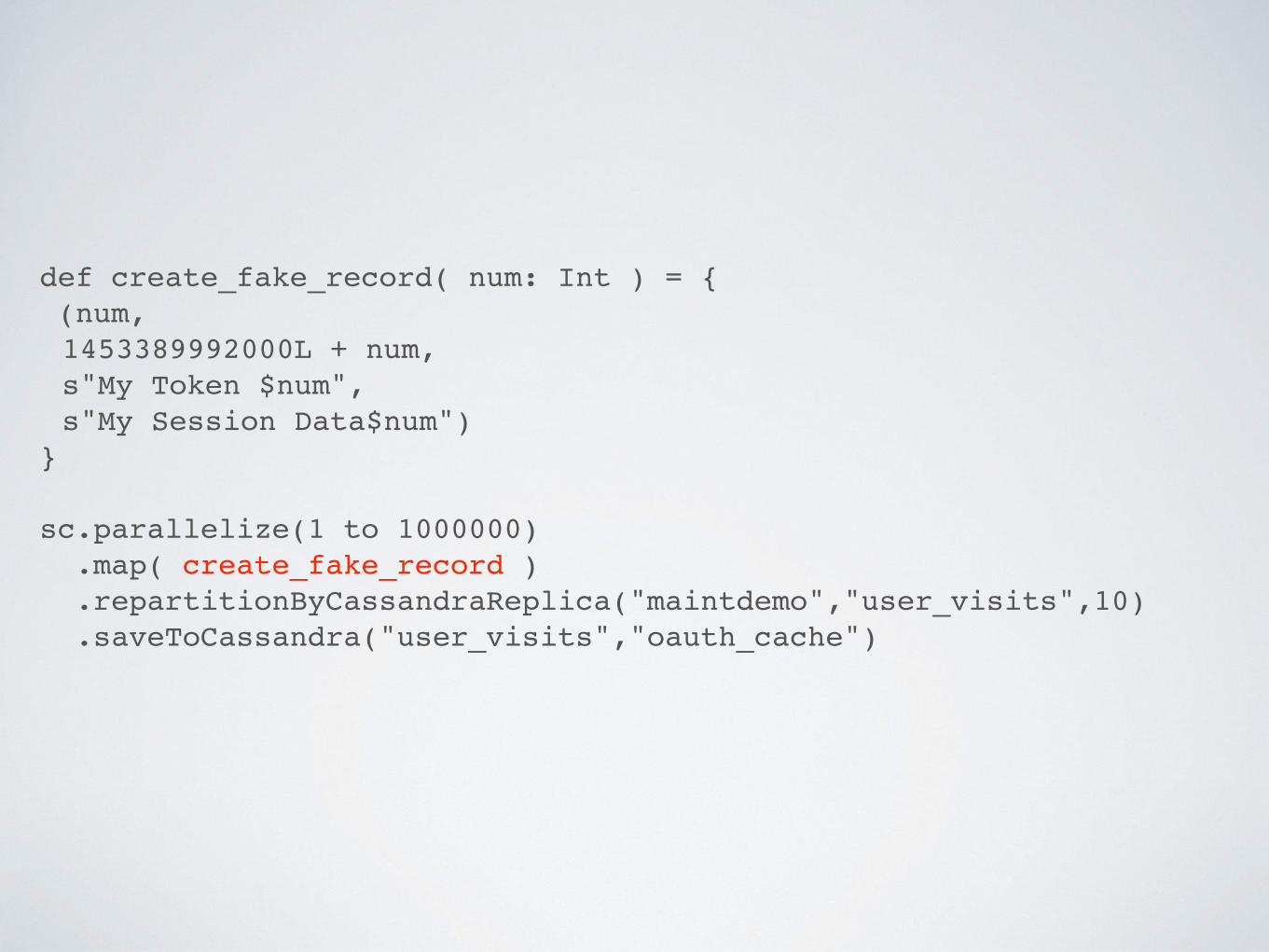
def create_fake_record( num: Int ) = { (num, 1453389992000L + num, s"My Token $num", s"My Session Data$num")
}
sc.parallelize(1 to 1000000) .map( create_fake_record ) .repartitionByCassandraReplica("maintdemo","user_visits",10) .saveToCassandra("user_visits","oauth_cache")

THREE BASIC PATTERNS
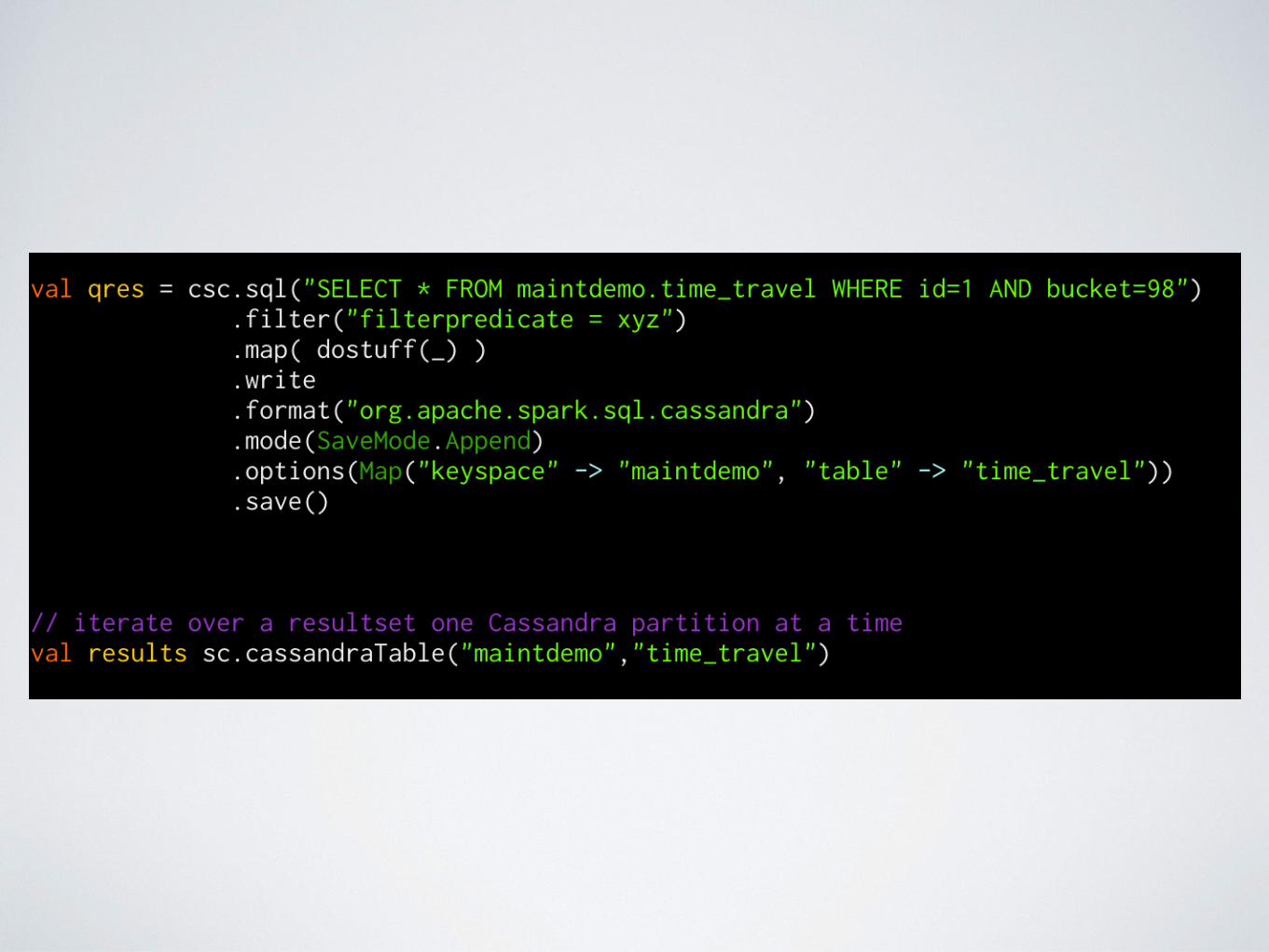
• Read - Transform - Write (1:1) - .map()
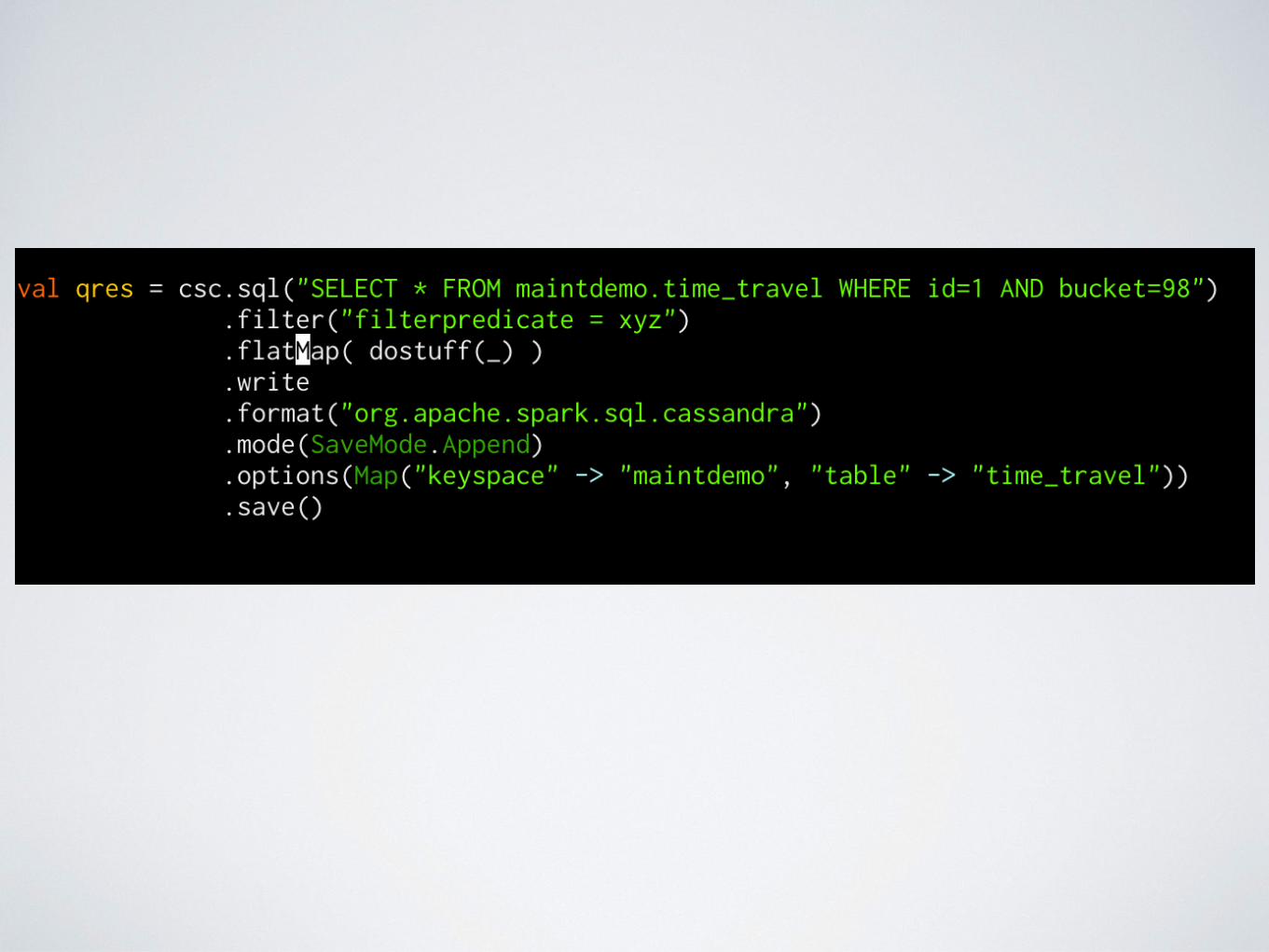
• Read - Transform - Write (1:m) - .flatMap()
• Read - Filter - Delete (m:1) - it’s complicated

DELETES ARE TRICKY

DELETES ARE TRICKY
• Keep tombstones in mind
• Select the records you want to delete, then loop over those and issue deletes through the driver
• OR select the records you want to keep, rewrite them, then delete the partitions they lived in… IN THE PAST…
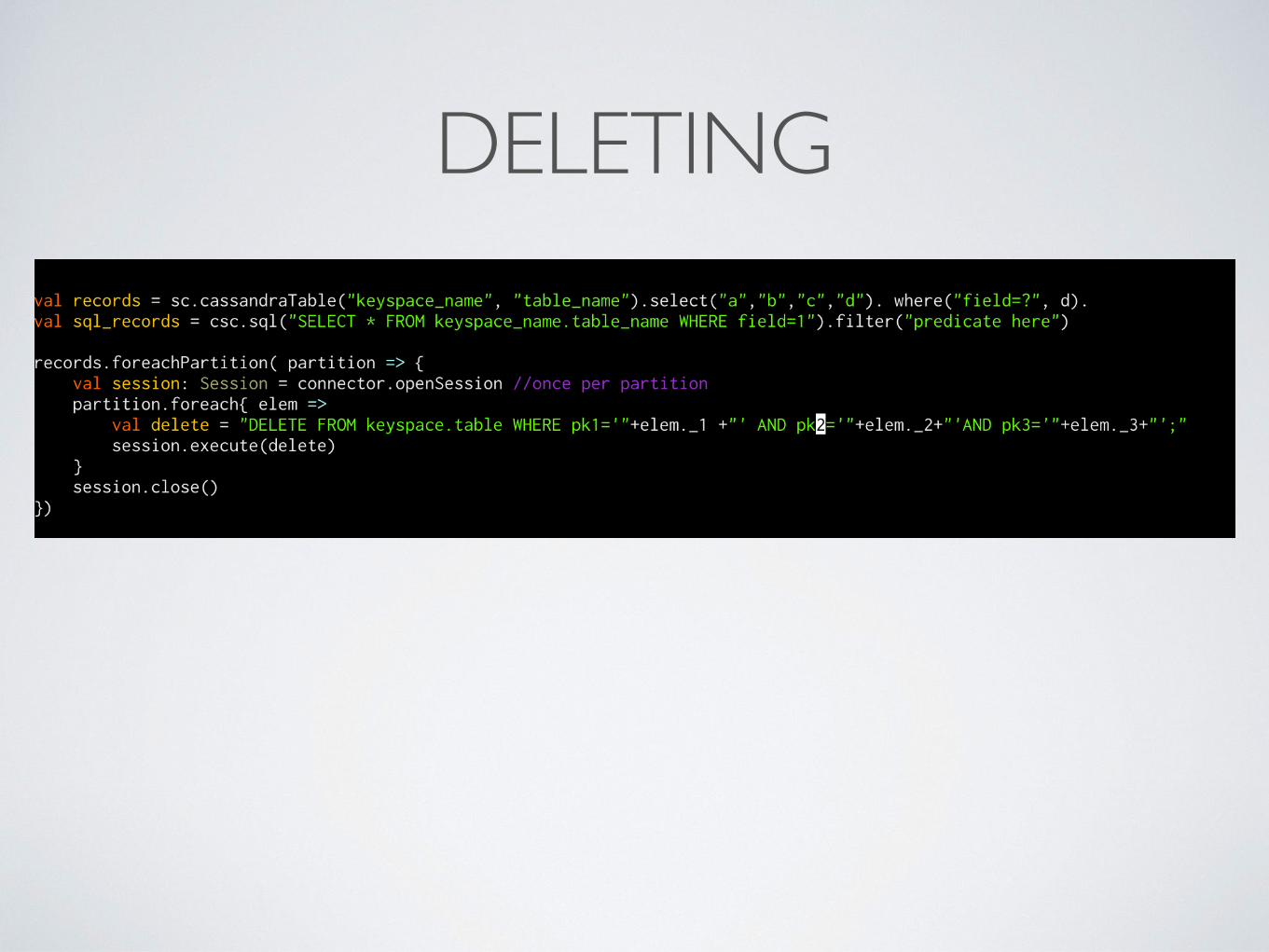
DELETING

PREDICATE PUSHDOWN
• Use Cassandra-level filtering at every opportunity
• With DSE, benefit from predicate pushdown to solr_query

GOTCHAS
• Null fields
• Writing jobs which aren’t or can’t be distributed.

TIPS & TRICKS
• .spanBy( partition key ) - work on one Cassandra partition at a time
• .repartitionByCassandraReplica()
• tune spark.cassandra.output.throughput_mb_per_sec to throttle writes

USE CASE : CACHE MAINTENANCE

USE CASE : TRIM USER HISTORY
• Cassandra Data Model: PRIMARY KEY( userid, last_access )
• Keep last X records
• .spanBy( partitionKey ) flatMap filtering Seq

USE CASE: PUBLISH DATA• Cassandra Data Model: publish_date field
• filter by date, map to new RDD matching destination, saveToCassandra()

USE CASE: MULTITENANT BACKUP AND RECOVERY
• Cassandra Data Model: PRIMARY KEY((tenant_id, other_partition_key), other_cluster, …)
• Backup: filter for tenant_id and .foreach() write to external location.
• Recovery: read backup and upsert


















