
Intro to py spark (and cassandra)
31
INTRO TO PYSPARK Jon Haddad, Technical Evangelist, DataStax @rustyrazorblade
-
Upload
jon-haddad -
Category
Technology
-
view
458 -
download
2
Transcript of Intro to py spark (and cassandra)

INTRO TO PYSPARKJon Haddad, Technical Evangelist, DataStax
@rustyrazorblade

WHAT TOOLS ARE YOU ALREADYUSING FOR DATA ANALYSIS?
NumPy / SciPyPandasiPython Notebooksscikit-learnhdf5pybrain

WHAT'S THE PROBLEM?GREAT TOOLS
BUT NOT BUILT FOR BIG DATA SETS
And not real time...

LIMITED TO 1 MACHINEWhat if we have a lot of data?
What if we use Cassandra?
We need distributed computing

Use when we have more data what fits on a single machine
WHAT IS SPARK?Fast and general purpose cluster computing system

LANGUAGESScalaJavaR (version >= 1.4)Python

WHAT CAN I DO WITH IT?Read and write data in bulk to and from CassandraBatch processingStream processingMachine LearningDistributed SQL

Operate on entire dataset (or at least a big chunk of it)
BATCH PROCESSING

RDDResilliant Distributed Dataset (it's a big list)Use functional concepts like map, filter, reduceCaveat: Will always pay penalty going from JVM <> Python

DATA MIGRATIONS

USERSname favorite_food
jon bacon
luke pie
patrick pizza
rachel pizza

SET UP OUR KEYSPACEcreate KEYSPACE demo WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
use demo ;

CREATE OUR DEMO USER TABLEcreate TABLE user ( name text PRIMARY KEY, favorite_food text );
insert into user (name, favorite_food) values ('jon', 'bacon');insert into user (name, favorite_food) values ('luke', 'pie');insert into user (name, favorite_food) values ('patrick', 'pizza');insert into user (name, favorite_food) values ('rachel', 'pizza');
create table favorite_foods ( food text, name text, primary key (food, name));

MAPPING FOODS TO USERSfrom pyspark_cassandra import CassandraSparkContext, Rowfrom pyspark import SparkContext, SparkConf
conf = SparkConf() \ .setAppName("User Food Migration") \ .setMaster("spark://127.0.0.1:7077") \ .set("spark.cassandra.connection.host", "127.0.0.1")
sc = CassandraSparkContext(conf=conf)
users = sc.cassandraTable("demo", "user")favorite_foods = users.map(lambda x: {"food":x['favorite_food'], "name":x['name']} )favorite_foods.saveToCassandra("demo", "favorite_foods")

MIGRATION RESULTScqlsh:demo> select * from favorite_foods ;
food | name-------+--------- pizza | patrick pizza | rachel pie | luke bacon | jon
(4 rows)cqlsh:demo> select * from favorite_foods where food = 'pizza';
food | name-------+--------- pizza | patrick pizza | rachel

AGGREGATIONSu = sc.cassandraTable("demo", "user")
u.map(lambda x: (x['favorite_food'], 1)).\ reduceByKey(lambda x, y: x + y).collect()
[(u'bacon', 1), (u'pie', 1), (u'pizza', 2)]

RDDS ARE COOLAnd very powerful
But kind of annoying

DATAFRAMESFrom R languageAvailable in Python via PandasDataFrames allow for optimized filters, sorting, groupingWith Spark, all the data stays in the JVMWith Cassandra it's still expensive due to JVM <> PythonBut it can be fixed

DATAFRAMES EXAMPLEfrom pyspark_cassandra import CassandraSparkContext, Rowfrom pyspark import SparkContext, SparkConffrom pyspark.sql import SQLContext # needed for toDF()
users = sc.cassandraTable("demo", "user").toDF()
food_count = users.select("favorite_food").\ groupBy("favorite_food").count()
food_count.collect()
[Row(favorite_food=u'bacon', count=1), Row(favorite_food=u'pizza', count=2), Row(favorite_food=u'pie', count=1)]

SPARKSQLRegister dataframes as tablesJOIN, GROUP BY

SPARKSQL IN ACTIONsql = SQLContext(sc)users = sc.cassandraTable("demo", "user").toDF()users.registerTempTable("users")sql.sql("""select favorite_food, count(favorite_food) from users group by favorite_food """).collect()
[Row(favorite_food=u'bacon', c1=1), Row(favorite_food=u'pizza', c1=2), Row(favorite_food=u'pie', c1=1)]

STREAMINGOperate on batch windowsEach batch is a small RDD
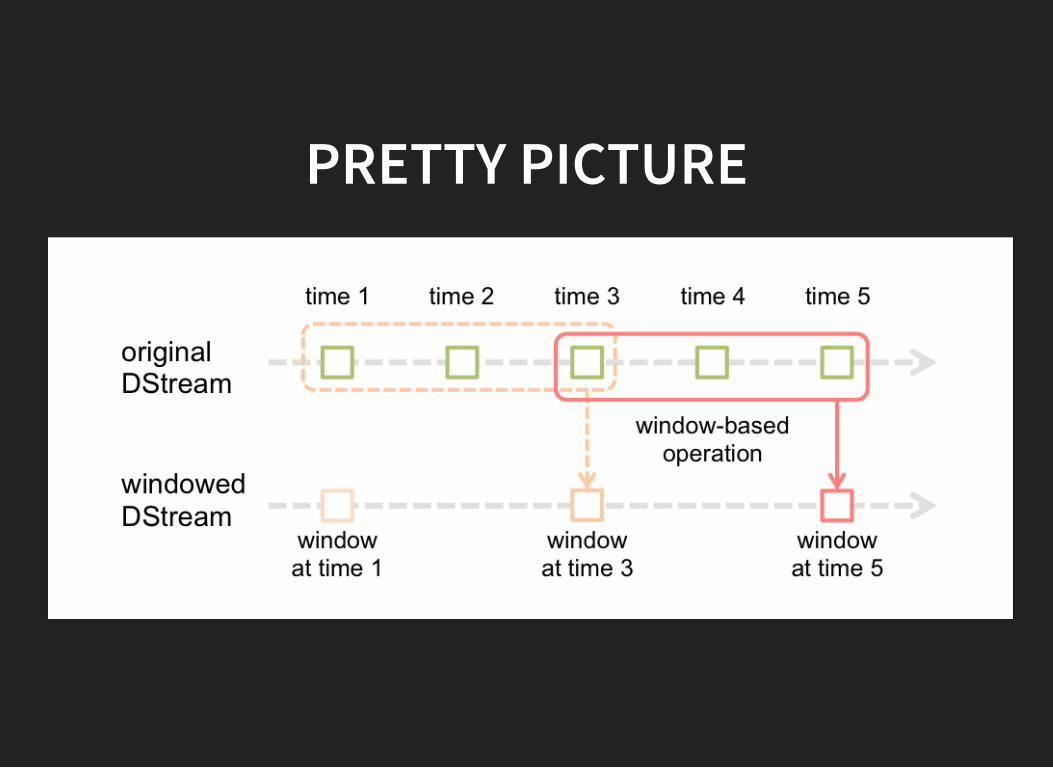
PRETTY PICTURE

STREAMINGfrom pyspark.streaming import StreamingContextfrom pyspark.streaming.kafka import KafkaUtils
stream = StreamingContext(sc, 1) # 1 second window
kafka_stream = KafkaUtils.createStream(stream, \ "localhost:2181", \ "raw-event-streaming-consumer", {"pageviews":1})
# manipulate kafka_stream as an RDD
stream.start()stream.awaitTermination()

MACHINE LEARNINGSupervised learningUnsupervised learning

SUPERVISED LEARNINGWhen we know the inputs and outputsExample: Real estate pricesTake existing knowledge about houses and pricesBuild a model to predict the future

UNSUPERVISED LEARNINGWhen we don't know the outputPopular usage: discover groups


INTERACTIVE IPYTHON NOTEBOOKSIterate quicklyVisualize your data


GET STARTED!Open Source:
Download CassandraDownload SparkCassandra PySpark Repo:https://github.com/TargetHolding/pyspark-cassandra
Integrated solution
Download DataStax Enterprise


















