
Cassandra and Spark
57
Cassandra and Spark: Love at First Sight Nick Bailey @nickmbailey
-
Upload
nickmbailey -
Category
Software
-
view
1.267 -
download
0
Transcript of Cassandra and Spark

Cassandra and Spark: Love at First Sight Nick Bailey @nickmbailey

What’s a “DataStax”?
• DataStax Enterprise • Production Certification • Spark, Solr, Hadoop integration
• Monitoring and Dev Tooling • OpsCenter • DevCenter
• Cassandra Drivers • Java, Python, C#, C++, Ruby, …
2

What’s a “@nickmbailey”
• Joined DataStax (formerly Riptano) in 2010 • OpsCenter Architect • Austin Cassandra Users Meetup Organizer
3

Cassandra Summit!
• Santa Clara, September 22 - 24, 2015 • http://cassandrasummit-datastax.com/ • Free! (Priority passes available)
4

1 Cassandra
2 Spark
3 Cassandra and Spark
4 Demo

Cassandra
6

7

Cassandra
• A Linearly Scaling and Fault Tolerant Distributed Database !
• Fully Distributed – Data spread over many nodes – All nodes participate in a cluster – All nodes are equal – No SPOF (shared nothing)
8
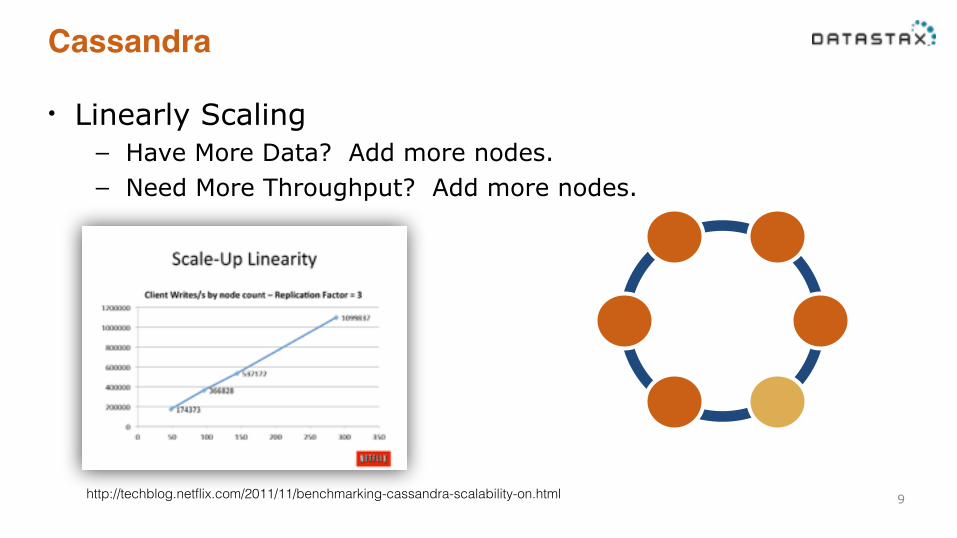
Cassandra
• Linearly Scaling – Have More Data? Add more nodes. – Need More Throughput? Add more nodes.
9http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability-on.html

Cassandra
• Fault Tolerant – Nodes Down != Database Down – Datacenter Down != Database Down
10
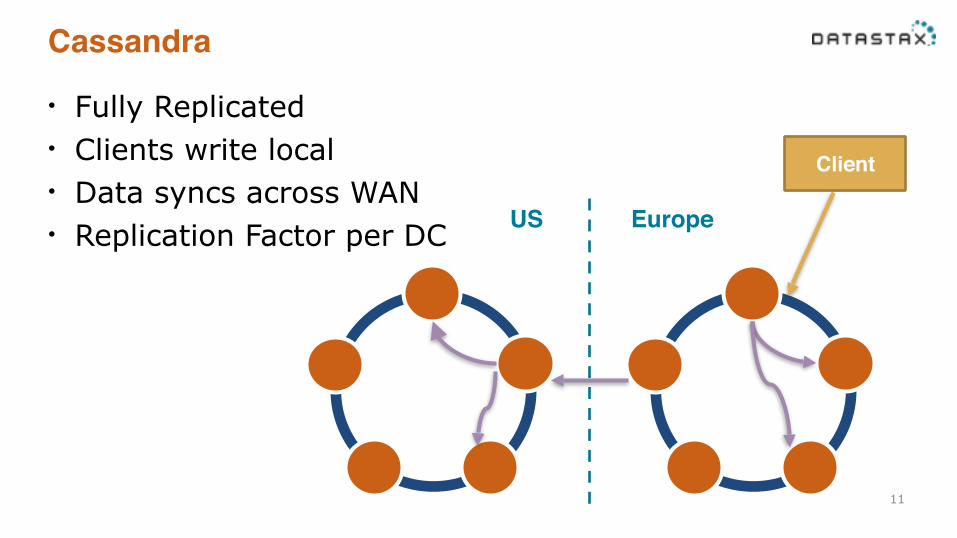
Cassandra
• Fully Replicated • Clients write local • Data syncs across WAN • Replication Factor per DC
11
US Europe
Client

Cassandra and the CAP Theorem
• The CAP Theorem limits what distributed systems can do !
• Consistency • Availability • Partition Tolerance !
• Limits? “Pick 2 out of 3”
12

Cassandra: Distributed Architecture
13

Two knobs control Cassandra fault tolerance
• Replication Factor (server side) – How many copies of the data should exist?
14
Client
B AD
C AB
A CD
D BC
Write A
RF=3

Two knobs control Cassandra fault tolerance
• Consistency Level (client side) – How many replicas do we need to hear from before we
acknowledge?
15
Client
B AD
C AB
A CD
D BC
Write A
CL=QUORUM
Client
B AD
C AB
A CD
D BC
Write A
CL=ONE

Consistency Levels
• Applies to both Reads and Writes (i.e. is set on each query) !
• ONE – one replica from any DC • LOCAL_ONE – one replica from local DC • QUORUM – 51% of replicas from any DC • LOCAL_QUORUM – 51% of replicas from local DC • ALL – all replicas • TWO
16
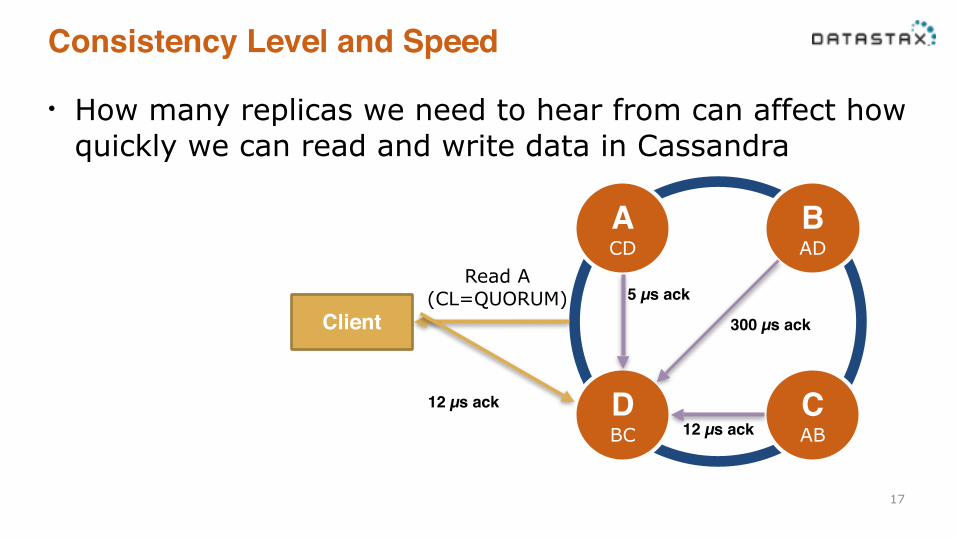
Consistency Level and Speed
• How many replicas we need to hear from can affect how quickly we can read and write data in Cassandra
17
Client
B AD
C AB
A CD
D BC
5 µs ack
300 µs ack
12 µs ack12 µs ack
Read A (CL=QUORUM)

Consistency Level and Availability
• Consistency Level choice affects availability • For example, QUORUM can tolerate one replica being
down and still be available (in RF=3)
18
Client
B AD
C AB
A CD
D BC
A=2
A=2
A=2
Read A (CL=QUORUM)

Writes in the cluster
• Fully distributed, no SPOF • Node that receives a request is the Coordinator for
request • Any node can act as Coordinator
19
Client
B AD
C AB
A CD
D BC
Write A (CL=ONE)
Coordinator Node

Reads in the cluster
• Same as writes in the cluster, reads are coordinated • Any node can be the Coordinator Node
20
Client
B AD
C AB
A CD
D BC
Read A (CL=QUORUM)
Coordinator Node
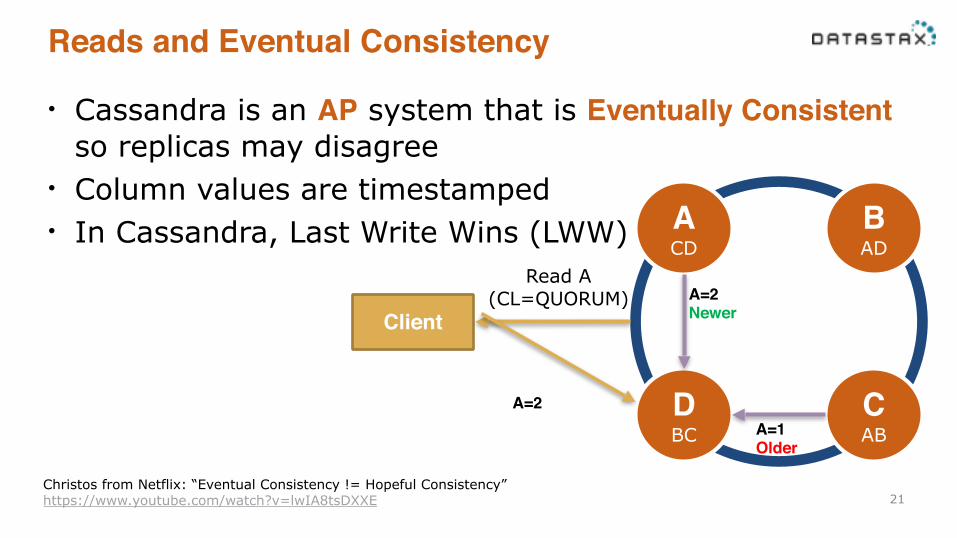
Reads and Eventual Consistency
• Cassandra is an AP system that is Eventually Consistent so replicas may disagree
• Column values are timestamped • In Cassandra, Last Write Wins (LWW)
21
Client
B AD
C AB
A CD
D BC
A=2!Newer
A=1!Older
A=2
Read A (CL=QUORUM)
Christos from Netflix: “Eventual Consistency != Hopeful Consistency” https://www.youtube.com/watch?v=lwIA8tsDXXE
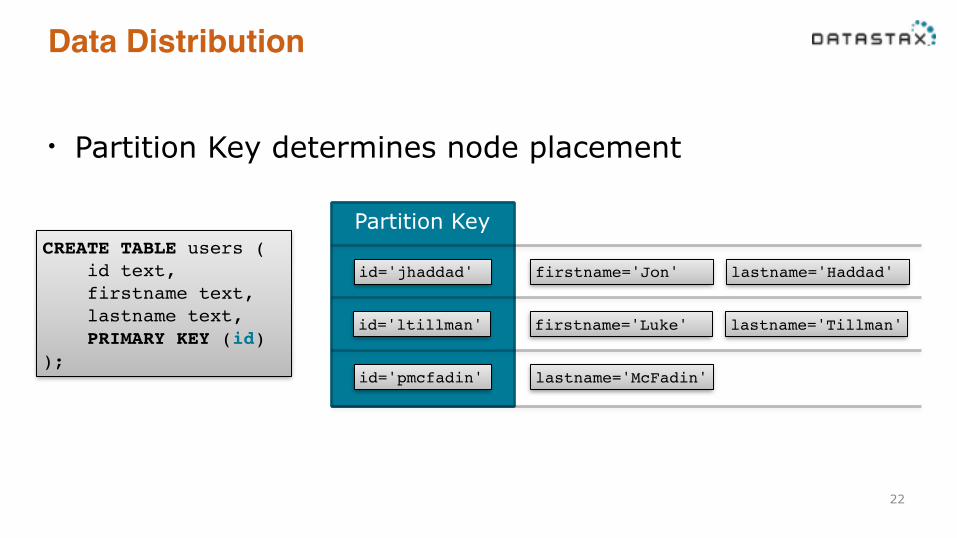
Data Distribution
• Partition Key determines node placement
22
Partition Key
id='pmcfadin' lastname='McFadin'
id='jhaddad' firstname='Jon' lastname='Haddad'
id='ltillman' firstname='Luke' lastname='Tillman'
CREATE TABLE users (! id text,! firstname text,! lastname text,! PRIMARY KEY (id)!);

Data Distribution• The Partition Key is hashed using a consistent hashing
function (Murmur 3) and the output is used to place the data on a node !!!!!!
• The data is also replicated to RF-1 other nodes
23
Partition Keyid='ltillman' firstname='Luke' lastname='Tillman'
Murmur3id: ltillman Murmur3: A
B AD
C AB
A CD
D BC
RF=3

Cassandra Query Language (CQL)
24

Data Structures
• Keyspace is like RDBMS Database or Schema !
• Like RDBMS, Cassandra uses Tables to store data !
• Partitions can have multiple rows
25
Keyspace
Tables
Partitions
Rows

Schema Definition (DDL)
• Easy to define tables for storing data • First part of Primary Key is the Partition Key
CREATE TABLE videos (! videoid uuid,! userid uuid,! name text,! description text,! tags set<text>,! added_date timestamp,! PRIMARY KEY (videoid)!);
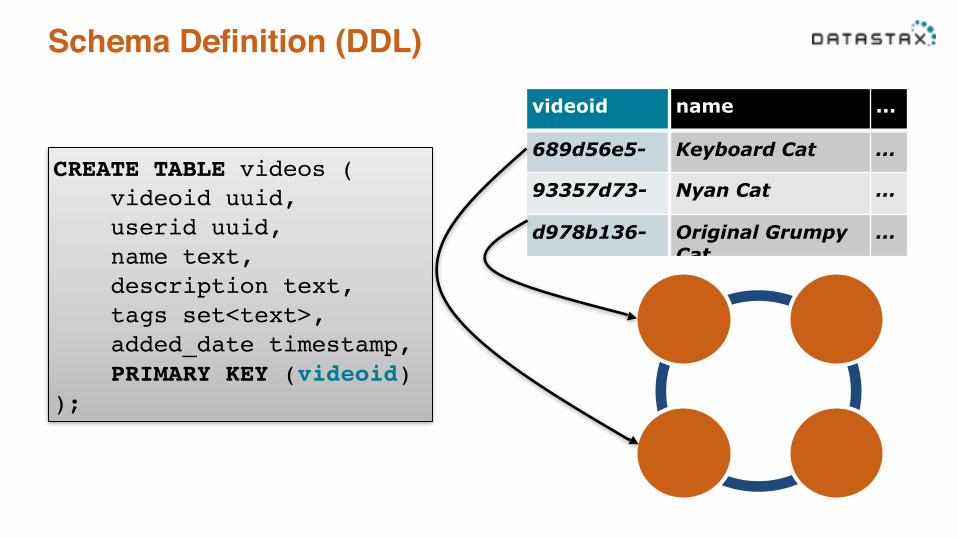
Schema Definition (DDL)
CREATE TABLE videos (! videoid uuid,! userid uuid,! name text,! description text,! tags set<text>,! added_date timestamp,! PRIMARY KEY (videoid)!);
name ...
Keyboard Cat ...
Nyan Cat ...
Original Grumpy Cat
...
videoid
689d56e5- …93357d73- …d978b136- …

Clustering Columns
• Second part of Primary Key is Clustering Columns!!!!!!!
• Clustering columns affect ordering of data (on disk) • Multiple rows per partition
28
CREATE TABLE comments_by_video (! videoid uuid,! commentid timeuuid,! userid uuid,! comment text,! PRIMARY KEY (videoid, commentid)!) WITH CLUSTERING ORDER BY (commentid DESC);

Clustering Columns
29
commentid ...
8982d56e5… ...
93822df62… ...
22dt62f69… ...
8319af913...
videoid
689d56e5- …689d56e5- …689d56e5- …93357d73- …
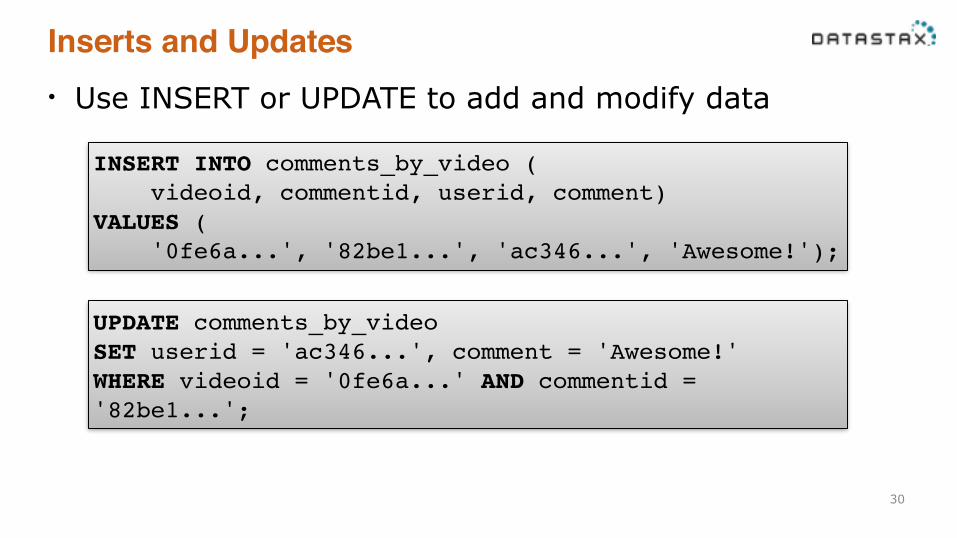
Inserts and Updates• Use INSERT or UPDATE to add and modify data
30
INSERT INTO comments_by_video (! videoid, commentid, userid, comment)!VALUES (! '0fe6a...', '82be1...', 'ac346...', 'Awesome!');
UPDATE comments_by_video!SET userid = 'ac346...', comment = 'Awesome!'!WHERE videoid = '0fe6a...' AND commentid = '82be1...';
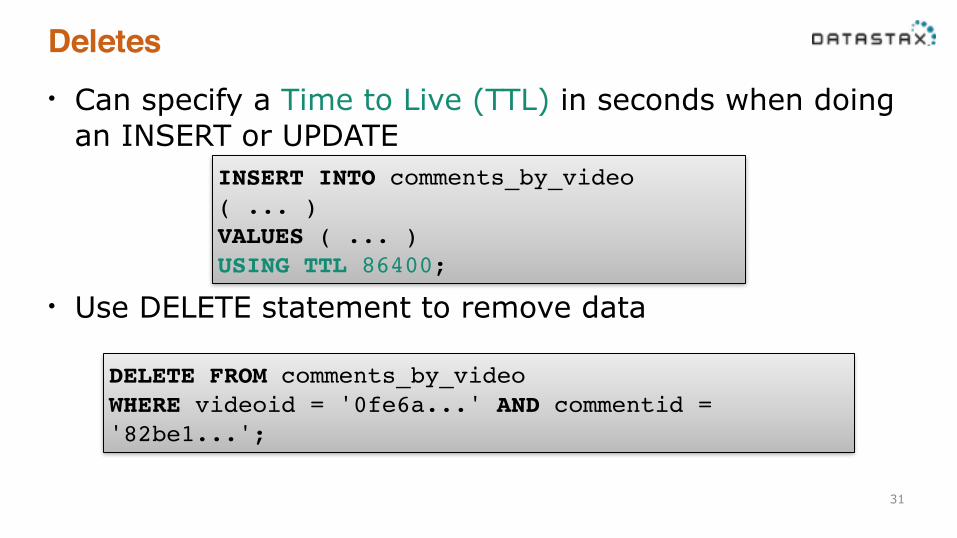
Deletes• Can specify a Time to Live (TTL) in seconds when doing
an INSERT or UPDATE !!!
• Use DELETE statement to remove data
31
INSERT INTO comments_by_video ( ... )!VALUES ( ... )!USING TTL 86400;
DELETE FROM comments_by_video!WHERE videoid = '0fe6a...' AND commentid = '82be1...';

Querying
• Use SELECT to get data from your tables !!!!
• Always include Partition Key and optionally Clustering Columns!
• Can use ORDER BY and LIMIT !
• Use range queries (for example, by date) to slice partitions32
SELECT * FROM comments_by_video !WHERE videoid = 'a67cd...'!LIMIT 10;

Cassandra Data Modeling
• Hmmm, looks like SQL, I know that…
33

Cassandra Data Modeling
• Hmmm, looks like SQL, I know that…
34

Cassandra Data Modeling
• Requires a different mindset than RDBMS modeling
• Know your data and your queries up front
• Queries drive a lot of the modeling decisions (i.e. “table per query” pattern)
• Denormalize/Duplicate data at write time to do as few queries as possible come read time
• Remember, disk is cheap and writes in Cassandra are FAST
35

Other Data Modeling Concepts
• Lightweight Transactions
• JSON
• User Defined Types
• User Defined Functions
36

Spark
37

Spark
• Distributed Computing Framework • Similar to the Hadoop map reduce engine
• Databricks • Company by the creators of Spark
38

Spark Stack
39
Shark!or
Spark SQLStreaming ML
Spark (General execution engine)
Graph
Cassandra

General Purpose API
40
map reduce

General Purpose API
41
map reduce sample
filter count take
groupby fold first
sort reduceByKey partitionBy
union cogroup mapWith
join cross save
… … …
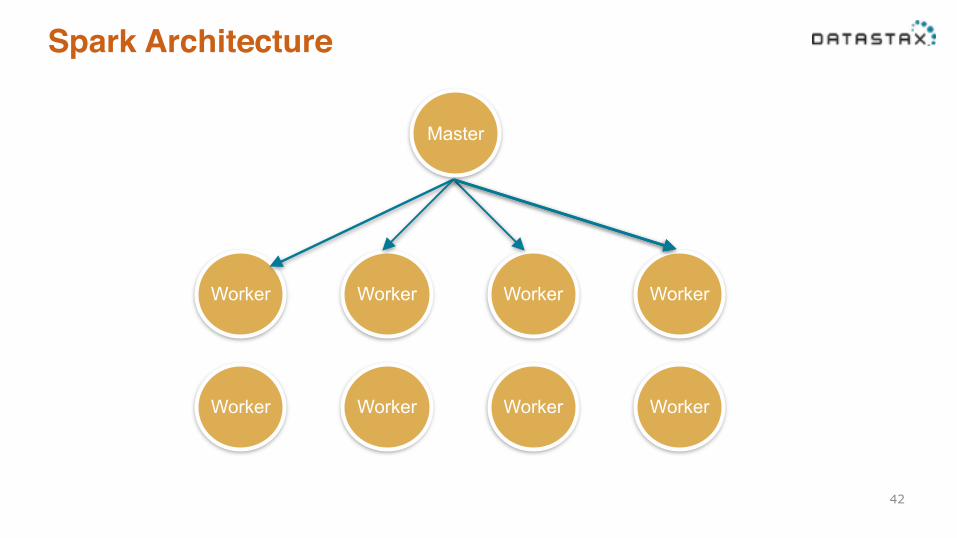
Spark Architecture
42
Worker
Master
Worker
Worker
Worker
Worker
Worker
Worker
Worker

Spark: General Concepts
43

RDD
• Resilient Distributed Dataset • Basically, a collection of elements to work on • Building block for Spark
44

Operation Types
• Transformations • Lazily computed
• Actions • Force computation
45
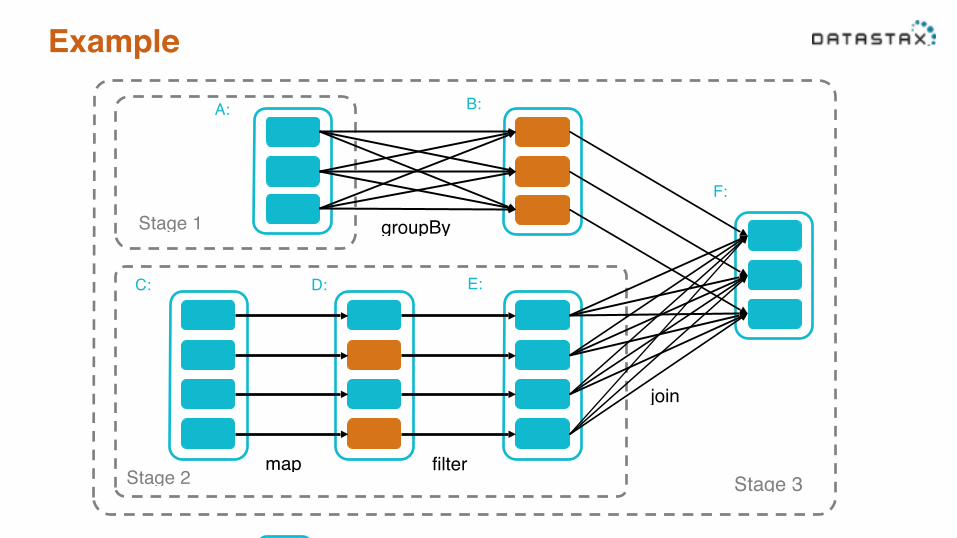
Example
join
filter
groupBy
Stage 3
Stage 1
Stage 2
A: B:
C: D: E:
F:
map

Cassandra and Spark
47

Cassandra and Spark: The Why
• Easy analytics on your data • Easy transformation of your data
48

Cassandra and Spark: The Why
• Simple Deployment
49
Worker
Master
Worker
Worker Worker
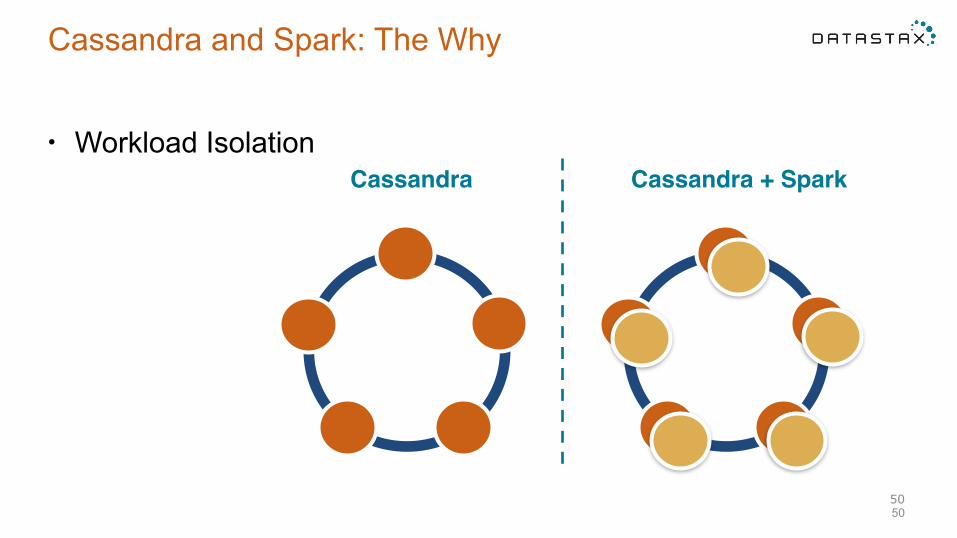
Cassandra and Spark: The Why
• Workload Isolation
5050
Cassandra Cassandra + Spark

Cassandra and Spark: The How
• Cassandra Spark Driver • https://github.com/datastax/spark-cassandra-connector
• Compatible With • Spark 0.9+ • Cassandra 2.0+ • DataStax Enterprise 4.5+
51

Cassandra and Spark: The How
• Cassandra tables exposed as RDDS • Read/write from/to Cassandra • Automatic type conversion
52

Code
53

54
// Import Cassandra-specific functions on SparkContext and RDD objects!import com.datastax.driver.spark._!!!// Spark connection options!val conf = new SparkConf(true)!! ! .setMaster("spark://192.168.123.10:7077")!! ! .setAppName("cassandra-demo")! .set(“cassandra.connection.host", "192.168.123.10") // initial contact! .set("cassandra.username", "cassandra")! .set("cassandra.password", "cassandra") !!val sc = new SparkContext(conf)
Connecting

55
AccessingCREATE TABLE test.words (word text PRIMARY KEY, count int);!!INSERT INTO test.words (word, count) VALUES ('bar', 30);!INSERT INTO test.words (word, count) VALUES ('foo', 20);
// Use table as RDD!val rdd = sc.cassandraTable("test", "words")!// rdd: CassandraRDD[CassandraRow] = CassandraRDD[0]!!rdd.toArray.foreach(println)!// CassandraRow[word: bar, count: 30]!// CassandraRow[word: foo, count: 20]!!rdd.columnNames // Stream(word, count) !rdd.size // 2!!val firstRow = rdd.first // firstRow: CassandraRow = CassandraRow[word: bar, count: 30]!firstRow.getInt("count") // Int = 30

56
Saving
val newRdd = sc.parallelize(Seq(("cat", 40), ("fox", 50)))!// newRdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2]!!newRdd.saveToCassandra("test", "words", Seq("word", "count"))
SELECT * FROM test.words;!! word | count!------+-------! bar | 30! foo | 20! cat | 40! fox | 50!!(4 rows)

Questions?
57


















