
Teradata Parallel Transporter User Guide - …dbmanagement.info/Books/MIX/2445_TeraData.pdfTeradata...
190
Teradata Parallel Transporter User Guide Release 12.0 B035-2445-067A July 2007
-
Upload
duongnguyet -
Category
Documents
-
view
240 -
download
3
Transcript of Teradata Parallel Transporter User Guide - …dbmanagement.info/Books/MIX/2445_TeraData.pdfTeradata...

Teradata Parallel TransporterUser Guide
Release 12.0B035-2445-067A
July 2007

The product or products described in this book are licensed products of Teradata Corporation or its affiliates.
Teradata, BYNET, DBC/1012, DecisionCast, DecisionFlow, DecisionPoint, Eye logo design, InfoWise, Meta Warehouse, MyCommerce, SeeChain, SeeCommerce, SeeRisk, Teradata Decision Experts, Teradata Source Experts, WebAnalyst, and You’ve Never Seen Your Business Like This Before are trademarks or registered trademarks of Teradata Corporation or its affiliates.
Adaptec and SCSISelect are trademarks or registered trademarks of Adaptec, Inc.
AMD Opteron and Opteron are trademarks of Advanced Micro Devices, Inc.
BakBone and NetVault are trademarks or registered trademarks of BakBone Software, Inc.
EMC, PowerPath, SRDF, and Symmetrix are registered trademarks of EMC Corporation.
GoldenGate is a trademark of GoldenGate Software, Inc.
Hewlett-Packard and HP are registered trademarks of Hewlett-Packard Company.
Intel, Pentium, and XEON are registered trademarks of Intel Corporation.
IBM, CICS, DB2, MVS, RACF, Tivoli, and VM are registered trademarks of International Business Machines Corporation.
Linux is a registered trademark of Linus Torvalds.
LSI and Engenio are registered trademarks of LSI Corporation.
Microsoft, Active Directory, Windows, Windows NT, and Windows Server are registered trademarks of Microsoft Corporation in the United States and other countries.
Novell and SUSE are registered trademarks of Novell, Inc., in the United States and other countries.
QLogic and SANbox trademarks or registered trademarks of QLogic Corporation.
SAS and SAS/C are trademarks or registered trademarks of SAS Institute Inc.
SPARC is a registered trademarks of SPARC International, Inc.
Sun Microsystems, Solaris, Sun, and Sun Java are trademarks or registered trademarks of Sun Microsystems, Inc., in the United States and other countries.
Symantec, NetBackup, and VERITAS are trademarks or registered trademarks of Symantec Corporation or its affiliates in the United States and other countries.
Unicode is a collective membership mark and a service mark of Unicode, Inc.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Other product and company names mentioned herein may be the trademarks of their respective owners.
THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN “AS-IS” BASIS, WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NON-INFRINGEMENT. SOME JURISDICTIONS DO NOT ALLOW THE EXCLUSION OF IMPLIED WARRANTIES, SO THE ABOVE EXCLUSION MAY NOT APPLY TO YOU. IN NO EVENT WILL TERADATA CORPORATION BE LIABLE FOR ANY INDIRECT, DIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, INCLUDING LOST PROFITS OR LOST SAVINGS, EVEN IF EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
The information contained in this document may contain references or cross-references to features, functions, products, or services that are not announced or available in your country. Such references do not imply that Teradata Corporation intends to announce such features, functions, products, or services in your country. Please consult your local Teradata Corporation representative for those features, functions, products, or services available in your country.
Information contained in this document may contain technical inaccuracies or typographical errors. Information may be changed or updated without notice. Teradata Corporation may also make improvements or changes in the products or services described in this information at any time without notice.
To maintain the quality of our products and services, we would like your comments on the accuracy, clarity, organization, and value of this document. Please e-mail: [email protected]
Any comments or materials (collectively referred to as “Feedback”) sent to Teradata Corporation will be deemed non-confidential. Teradata Corporation will have no obligation of any kind with respect to Feedback and will be free to use, reproduce, disclose, exhibit, display, transform, create derivative works of, and distribute the Feedback and derivative works thereof without limitation on a royalty-free basis. Further, Teradata Corporation will be free to use any ideas, concepts, know-how, or techniques contained in such Feedback for any purpose whatsoever, including developing, manufacturing, or marketing products or services incorporating Feedback.
Copyright © 2005-2007 by Teradata Corporation. All Rights Reserved.

Preface
Purpose
This book provides information about Teradata Parallel Transporter (Teradata PT), which is a Teradata® Tools and Utilities product. Teradata Tools and Utilities is a group of client products designed to work with the Teradata Database.
Teradata PT provides high-performance extraction, transformation, and loading operations on the Teradata Database. This book provides information about how to use Teradata PT to extract, load, and update data.
Audience
This book is intended for use by:
• System and application programmers
• System administrators
• Data administrators
• Relational database developers
• System operators
• Other database specialists using Teradata PT
Supported Releases
This book applies to the following releases:
• Teradata Database 12.0
• Teradata Tools and Utilities 12.00.00
• Teradata Parallel Transporter 12.00.00
For the most current information about platform support for this release, do the following:
1 Go to www.info.teradata.com.
2 Navigate to General Search > Publication Product ID.
3 Enter 3119.
4 Open the version of Teradata Tools and Utilities xx.xx.xx Supported and Certified Versions that corresponds with this release.
5 In the spreadsheet, locate this product and the platform in question.
Teradata Warehouse Builder User Guide 3

PrefacePrerequisites
Prerequisites
The following prerequisite knowledge is required for this product:
• Computer technology and terminology
• Relational database management systems
• SQL and Teradata SQL
• Basic concepts and facilities of the Teradata Database and the NCR server
• Connectivity software, such as ODBC or CLI
• Teradata utilities that load and retrieve data
Changes to This Book
The following changes were made to this book in support of the current release. Changes since the last publication are marked with change bars. For a complete list of changes to the product, see the Teradata Tools and Utilities Release Definition associated with this release.
Some new functions and features for the current release of Teradata PT might not be documented in this manual. New Teradata PT features and functions are also documented in the other manuals listed in “Additional Information” on page 6.
4 Teradata Warehouse Builder User Guide

PrefaceChanges to This Book
Date/Release Description
July 2007Teradata Tools and Utilities 12.0
• Product version levels have been updated.
• The Large Decimal feature can be accessed through the Export operator’s MaxDecimalDigits attribute. See “Using the Large Decimal Teradata Database Feature” on page 58.
• The IgnoreMaxDecimalDigits attribute has been introduced to work with the MaxDecimalDigits attribute. See “Using the Large Decimal Teradata Database Feature” on page 58 and Figure 7 on page 59.
• The -e option for the tbuild command allows job scripts encoded in UTF-16. See “UTF-16 Support” on page 41.
• For viewing logs in UTF-16 format, use the -e option with the tlogview command. See “Viewing Logs in UTF-16 Format” on page 43.
• For directing log output on MVS, use the -S option with the tbuild command. See “Directing Log Output” on page 44.
• The Multiple Parallelism section has been removed.
• DATE and TIME data types are now directly supported. The Note referring to conversion information in the Teradata Parallel Transporter Reference has been deleted.
• Use the tbuild command’s -n option for job continuation when a job step returns a nonzero exit code. See “Exit and Termination Codes” on page 165.
• When a job step returns an exit code of four (a warning code) the job will continue and not terminate, regardless of the use of the tbuild command’s -n option. See “Exit and Termination Codes” on page 165.
• Information on the DataConnector operator’s EscapeTextDelimiter optional attribute has been added. See “Input File Formats” on page 51.
• Three new topics have been added to the Advanced Topics chapter. Review these new sections: “INCLUDE Statement” on page 111, “Query Banding Considerations” on page 130, and “Using LONG VARCHAR with Unicode Character Sets” on page 131.
• The User-Defined Column Data Types section has been moved from the Job Startup and Cleanup chapter to the Advanced Topics chapter.
• Chapter 9: “Wizard Help” has been enlarged, covering more tasks and adding detail on options.
• “Delimited Data Issues” on page 168 has been added to the Troubleshooting chapter.
Teradata Warehouse Builder User Guide 5

PrefaceAdditional Information
Additional Information
Additional information that supports this product and the Teradata Tools and Utilities is available at the following web sites.
In the table, mmyx represents the publication date of a manual, where mm is the month, y is the last digit of the year, and x is an internal publication code. Match the mmyx of a related publication to the date on the cover of this book. This ensures that the publication selected supports the same release.
November 2006Teradata Tools and Utilities 8.2
• Added procedures for using the new twbcmd command to manage active jobs.
• Added procedures for switching between multiple versions of Teradata PT.
• Added Exporting, Loading, and Updating chapters.
• Added Scripting Basics, Advanced Scripting, and Using the Wizard chapters.
• Added introductory information that relates Teradata PT to the standalone Teradata utilities.
• Added the -p option for obtaining a list of private logs.
March 2006 Teradata Tools and Utilities 8.1
• First release.
• Product name change from Teradata Warehouse Builder to Teradata Parallel Transporter.
Date/Release Description
Type of Information Description Source
Release overview
Late information
Use the Release Definition for the following information:
• Overview of all the products in the release
• Information received too late to be included in the manuals
• Operating systems and Teradata Database versions that are certified to work with each product
• Version numbers of each product and the documentation for each product
• Information about available training and support center
1 Go to http://www.info.teradata.com/.
2 In the left pane, click General Search.3 In the Publication Product ID box, type 2029.
4 Click Search.
5 Select the appropriate Release Definition from the search results.
6 Teradata Warehouse Builder User Guide

PrefaceAdditional Information
Additional product information
Use the Teradata Information Products Publishing Library site to view or download specific manuals that supply related or additional information to this manual.
1 Go to http://www.info.teradata.com/.
2 In the left pane, click Teradata Data Warehousing.
3 Do one of the following:
• For a list of Teradata Tools and Utilities documents, click Teradata Tools and Utilities and then select a release or a specific title.
• Select a link to any of the data warehousing publications categories listed.
Specific books related to Teradata PT are as follows:
• Teradata Tools and Utilities Access Module Programmer GuideB035-2424-mmyx
• Teradata Tools and Utilities Access Module ReferenceB035-2425-mmyx
• Teradata Parallel Transporter Operator Programmer GuideB035-2435-mmyx
• Teradata Parallel Transporter ReferenceB035-2436-mmyx
• International Character Set SupportB035-1125-mmyx
• Teradata Tools and Utilities Installation Guide for Microsoft WindowsB035-2407-mmyx
• Teradata Tools and Utilities Installation Guide for UNIX and LinuxB035-2459-mmyx
• Teradata Tools and Utilities Installation Guide for IBM z/OSB035-2458-mmyx
• Teradata Parallel Transporter Application Programming Interface Programmer GuideB035-2516-mmyx
CD-ROM images Access a link to a downloadable CD-ROM image of all customer documentation for this release. Customers are authorized to create CD-ROMs for their use from this image
1 Go to http://www.info.teradata.com/.
2 Select the General Search check box.
3 In the Title or Keyword box, type CD-ROM.
4 Click Search.
Ordering information for manuals
Use the Teradata Information Products Publishing Library site to order printed versions of manuals.
1 Go to http://www.info.teradata.com/.
2 Select the How to Order check box under Print & CD Publications.
3 Follow the ordering instructions.
Type of Information Description Source
Teradata Warehouse Builder User Guide 7

PrefaceAdditional Information
General information about Teradata
The Teradata home page provides links to numerous sources of information about Teradata. Links include:
• Executive reports, case studies of customer experiences with Teradata, and thought leadership
• Technical information, solutions, and expert advice
• Press releases, mentions and media resources
1 Go to Teradata.com.
2 Select a link.
Type of Information Description Source
8 Teradata Warehouse Builder User Guide

Table of Contents
Preface. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
Audience . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
Supported Releases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
Prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
Changes to This Book. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
Additional Information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6
Chapter 1: Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
High-Level Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Major Features. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Differences from Teradata Standalone Utilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Parallel Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Pipeline Parallelism . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Data Parallelism . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Basic Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Key Features. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Compatibilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
Operator Basics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Producer Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Consumer Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
INMOD and OUTMOD Adapter Operators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Filter Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Standalone Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Access Modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Operator Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Limitations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Teradata Warehouse Builder User Guide 9

Table of Contents
Chapter 2: Job Basics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .35
Creating Job Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .35
Running Job Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38
Privileges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .39
UTF-16 Support . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
Usage Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
Security. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
Public and Private Logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
Public Logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .42
Private Logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .42
Viewing Logs in UTF-16 Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .43
Directing Log Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .44
Chapter 3: Extracting Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
Extracting with the Export Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
Checkpoint and Restart . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .46
Export Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .46
About This Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .46
Export Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
Limiting Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .50
Extracting with the DataConnector Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .50
Input File Formats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
Directory Scan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
DataConnector Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .52
DataConnector Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .52
Extracting with the SQL Selector Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .52
Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .53
Restrictions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .53
SQL Selector Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .53
SQL Selector Job Example. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .53
Combining Data Sources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .55
UNION ALL Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .55
Using the Large Decimal Teradata Database Feature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .58
10 Teradata Warehouse Builder User Guide

Table of Contents
Chapter 4: Loading Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Loading with the Load Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Space Requirements. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Load Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
About This Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Load Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Options with Load Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Loading with the SQL Inserter Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
SQL Inserter Advantage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
SQL Inserter Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
SQL Inserter Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Chapter 5: Updating Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Deciding Between Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Updating with the Update Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
Update Function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
Supported Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
Update Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
About This Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Options with Update Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Update Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
Delete Task Option . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Using Delete Task. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
Why Choose the Delete Task Option? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Delete Task Option - Example 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
Delete Task Option - Example 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Updating with the Stream Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Stream Operator Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Options with Stream Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
Stream Job Example. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
Teradata Warehouse Builder User Guide 11

Table of Contents
Chapter 6: Job Startup and Cleanup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .101
Job Steps. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .101
Defining Job Steps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .101
Starting a Job Step Mid-Script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .102
Setting Up with the DDL Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .102
Checkpoint Restartability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .102
SQL Statements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .103
DDL Operator Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .104
Chapter 7: Advanced Topics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .107
Job Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .107
Defining Job Variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .108
Example Script With Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .109
Sharing Variables Between Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .110
INCLUDE Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .111
Data Conversions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .112
User-Defined Column Data Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .113
Processing UDFs and UDTs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .113
Multiple Targets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .114
Scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .114
Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .114
Notify Exit Routines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .115
Export Operator Events. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .116
Load Operator Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .119
Update Operator Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .121
Stream Operator Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .124
Managing Active Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .128
Using External Commands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .128
Command Descriptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .130
Query Banding Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .130
Using LONG VARCHAR with Unicode Character Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
Switching Versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
12 Teradata Warehouse Builder User Guide

Table of Contents
Chapter 8: Operational Metadata(Performance Data) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Availability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Obtaining Metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Data Schemas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
Performance and Statistical Metadata - TWB_STATUS . . . . . . . . . . . . . . . . . . . . . . . . . 134
Job Operator Source and Target Metadata - TWB_SRCTGT . . . . . . . . . . . . . . . . . . . . . 134
Exporting (Loading) Metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Chapter 9: Wizard Help. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Wizard Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
Main Window . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
Create a New Script. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
Step 1 - Name the Job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
Step 2 - Select a Source and Select Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
Step 3 - Select a Destination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
Step 4 - Run the Job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
Stop, Restart, Delete, Edit Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
View Job Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
Job Status . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
Log Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
Menus and Toolbars . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
Chapter 10: Troubleshooting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
Exit and Termination Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
Debugging Teradata PT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
Choosing the Number of Instances for the Operators in a Job . . . . . . . . . . . . . . . . . . . . 167
Shared Memory Usage Based on Instances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
Job Failure. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
Delimited Data Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
Teradata Warehouse Builder User Guide 13

Table of Contents
Appendix A: Script Samples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .169
Example 1: Load and Export Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .169
Example 2: Export and DataConnector Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .172
Example 3: Load and DataConnector Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .174
Glossary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .179
Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .183
14 Teradata Warehouse Builder User Guide

List of Figures
Figure 1: Contrast of Traditional Utilities to Teradata PT . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Figure 2: Teradata PT Pipeline Parallelism. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Figure 3: Teradata PT Data Parallelism. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Figure 4: Job Flow Using a FastLoad INMOD Adapter Operator . . . . . . . . . . . . . . . . . . . . . . 29
Figure 5: Job Flow Using an INMOD Adapter Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Figure 6: Job Flow Using an OUTMOD Adapter Operator . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Figure 7: How the Teradata Database Large Decimal Feature Affects Job Continuation . . . 59
Teradata Warehouse Builder User Guide 15

List of Figures
16 Teradata Warehouse Builder User Guide

List of Tables
Table 1: Comparison of Teradata PT Operators to Standalone Utilities . . . . . . . . . . . . . . . . . 21
Table 2: Comparison of Job Scripting. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Table 3: Operator Summary. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Table 4: SELECT Requests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Table 5: Operator Comparison - Update Versus Stream . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Table 6: Export Operator Notify Event Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Table 7: Export Operator Events That Create Notifications. . . . . . . . . . . . . . . . . . . . . . . . . . 118
Table 8: Load Operator Notify Event Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Table 9: Load Operator Events That Create Notifications . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
Table 10: Update Operator Notify Event Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
Table 11: Update Operator Events That Create Notifications . . . . . . . . . . . . . . . . . . . . . . . . 123
Table 12: Stream Operator Notify Event Codes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
Table 13: Stream Operator Events that Create Notifications . . . . . . . . . . . . . . . . . . . . . . . . . 127
Table 14: Menu Items . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
Table 15: Toolbar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
Teradata Warehouse Builder User Guide 17

List of Tables
18 Teradata Warehouse Builder User Guide

CHAPTER 1
Introduction
The following section provides an overview of the Teradata Parallel Transporter (Teradata PT) product. Topics include the following:
• High-Level Description
• Major Features
• Differences from Teradata Standalone Utilities
• Architecture
• Basic Processing
• Key Features
• Compatibilities
• Operator Basics
• Limitations
For a more detailed description of functions and processes, see the Teradata Parallel Transporter Reference.
High-Level Description
Teradata PT is an object-oriented client application suite that provides parallel extract and load capabilities that can be extended with third-party products or customizations. Teradata PT combines a parallel execution structure, process-specific operators, an application programming interface (API), a graphical user interface (GUI), and a log viewing service that work together to execute multiple instances of data extraction, transformations, and loading functions in a scalable, high-speed, parallel processing environment:
• Teradata PT combines and expands on the functionality of the traditional Teradata extract/load utilities (FastLoad, MultiLoad, FastExport, and TPump, also known as standalone utilities) into a single product through the use of a single scripting language.
• Jobs are run using operators, which are discrete object-oriented modules that perform specific extract and load processes.
• Teradata PT can be invoked with scripts or with the Teradata PT API, which allows third-party applications to directly execute Teradata PT operators.
• A GUI-based Teradata PT Wizard is available to generate simple scripts.
Teradata Warehouse Builder User Guide 19

Chapter 1: IntroductionMajor Features
Major Features
Following are the key features of Teradata PT:
• SQL-like Job Script Language - Unlike the traditional Teradata standalone utilities that each use their own script language, Teradata PT uses a single script language to specify export, transform, and load (ETL) operations. This language is a combination of SQL and a syntactically similar proprietary language, sometimes referred to as Teradata SQL.
• Multi-Step Loading - A single script can contain multiple job steps, each performing a separate load or unload function. This ability dramatically increases the potential for creating complex jobs with a single script. Teradata PT can simultaneously load data from multiple and dissimilar sources in a single job, and execute multiple instances of most operators. It can export, transform, and load data to multiple targets in a single job. It can perform inline filtering and transformations.
• Increased Throughput - In addition to allowing multi-session capabilities of the Teradata standalone utilities, Teradata PT permits multiple instances of operators to access multiple sources and multiple targets in a single job. Teradata PT also automatically distributes input and output data into data streams that can be shared with multiple operator instances. The result is increased throughput capacity and performance.
• Checkpoints and Restarts - In addition to manual (or client) restarts, Teradata PT can automatically resume jobs from the last checkpoint if a job fails.
• Direct API - The Teradata PT API allows developers to create a direct program-to-program calling structure that interfaces with the load and unload protocols of the Teradata standalone utilities. Using the C or C++ languages with the API, developers can create third-party tools that can load and unload Teradata tables without scripts. For more information, see the Teradata Parallel Transporter Application Programming Interface Programmer Guide.
• Reduce File Storage - For intermediary steps that require temporary storage, Teradata PT stores data in buffers, called data streams, eliminating the need to write temporary data to flat files. This capability permits large amounts of data to be transferred from sources to targets without file size limits imposed by system resources or operating system.
• Teradata PT Wizard - For help in creating, managing, and running simple Teradata PT scripts, use the Teradata PT Wizard. The Wizard steps through the process of specifying source data, destination data, and operators. Generated scripts from the Wizard can be copied into other scripts. Scripts in the Wizard can be immediately run or saved for later use. For more information, see Chapter 9: “Wizard Help.”
• Reusability - Operators are reusable components that can be combined in many ways to address a wide variety of extract, transform, and load (ETL) operations. For example, producer operators and consumer operators can work together as long as the output and input schema of inter-connected operators match.
20 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionDifferences from Teradata Standalone Utilities
Differences from Teradata Standalone Utilities
Teradata PT replaces the former Teradata Warehouse Builder product with extended capabilities and features, while maintaining the underlying architecture. Rather than referring to the use of utilities, Teradata PT refers to operators. For example, instead of running FastLoad, the Load operator is used; instead of running MultiLoad, the Update operator is used.
Table 1 compares Teradata PT operators with the Teradata standalone utilities. For a complete list of Teradata PT operators, see “Operator Basics” on page 29.
Table 1: Comparison of Teradata PT Operators to Standalone Utilities
OperatorStandalone Equivalent Purpose
DataConnector operator Data Connector (PIOM)
Read data from and write data to flat files
DataConnector operator with WebSphere MQ© Access Module
same with Data Connector (PIOM)
Read data from IBM WebSphere MQ
DataConnector operator with Named Pipes Access Module
same with Data Connector (PIOM)
Read data from a named pipe
DDL operator BTEQ Execute DDL, DCL, and self-contained DML SQL statements
Export operator FastExport High-volume export of data from Teradata Database
FastExport OUTMOD Adapter operator
FastExport OUTMOD Routine
Preprocess exported data with a FastExport OUTMOD routine before writing the data to a file
FastLoad INMOD Adapter operator
FastLoad INMOD Routine
Read and preprocess data from a FastLoad INMOD data source
Load operator FastLoad High-volume load of an empty table
MultiLoad INMOD Adapter operator
MultiLoad INMOD Routine
Read and preprocess data from a MultiLoad INMOD data source
ODBC operator OLE DB Access Module
Export data from any non-Teradata database that has an ODBC driver
OS Command operator Client host operating system
Execute host operating system commands
SQL Inserter operator BTEQ Insert data into a Teradata table using SQL protocol
SQL Selector operator BTEQ Select data from a Teradata table using SQL protocol
Teradata Warehouse Builder User Guide 21

Chapter 1: IntroductionDifferences from Teradata Standalone Utilities
Teradata PT also differs from the Teradata standalone utilities in the way that scripts are written and in syntax used in scripts. Table 2 explains the differences, and indicates a suggested order for creating job scripts in Teradata PT.
Stream operator TPump Continuous loading of Teradata tables using SQL protocol
Update operator MultiLoad Update, insert, and delete rows
Table 2: Comparison of Job Scripting
Step Description In Standalone Utilities In Teradata PT
1. Input file name
The name of the source file that contains the data to be loaded, such as a file on UNIX, Windows, or mainframe
Parameter in a script Attribute in an operator definition
2. Input file format
Describe the format of the data in the input file, such as “the first field is an Integer, followed by a Char (10)”
.Layout in MultiLoad and TPump
.Define in FastLoad
DEFINE SCHEMA statement
3. Define Load protocol
What protocol to use to load a Teradata Database
Run completely different standalone utilities (FastLoad, MultiLoad, TPump, etc.)
Run one job script that specifies an operator for each process.
4. Add SQL statements
The SQL statement sent to the Teradata Database, such as “Insert only with FastLoad, INS/UPD/DEL with MultiLoad.”
INSERT, UPDATE, DELETE
INSERT, UPDATE, DELETE, MERGE INTO
5. Map input files to columns
Map the fields from an input file to the columns in the table to be loaded
Various syntax SCHEMAs, SELECT list
6. Do simple transformations
Optional, simple data transformations on the fields read from the input file before being loaded into a Teradata Database
NULLIF, CONCATENATION, etc.
SELECT with expressions, including CASE and derived columns
Table 1: Comparison of Teradata PT Operators to Standalone Utilities (continued)
OperatorStandalone Equivalent Purpose
22 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionArchitecture
Architecture
Teradata PT offers an architecture that provides flexible and scalable linkages that can obtain data from multiple and dissimilar data sources for loading data into a Teradata Database. It is an efficient mechanism for high-speed extraction and loading of large data volumes using a wide array of loading techniques from bulk loading to loading from data streams.
Teradata PT offers data extraction from multiple sources, namely from Teradata Databases, flat files, access modules (Named Pipes or IBM WebSphere® MQ), and ODBC-compliant sources, relying on custom operators and partner products for additional data extraction and transformation functions.
The Teradata PT product contains various components designed to build a data warehouse, including a parallel architecture and a variety of special-purpose operators that perform specific extract and load processes. Data transformation can also be accomplished during extract and load processing. The architecture offers an open environment with a set of APIs that allow custom integration of third-party or user-written transformation operators.
Teradata PT provides the ability to extract, transform, and load data in parallel, thereby reducing the cost of building and maintaining the data warehouse. Use Teradata PT to efficiently manage system resources by specifying the number of instances needed for each extract, load, update, or optional transformation operator, thus leveraging the full power of a load server.
Parallel Environment
Although the traditional Teradata utilities (FastLoad, FastExport, and MultiLoad) also offer load and extract functionality, those utilities are limited to a serial environment. As shown in Figure 1, the parallel environment of Teradata PT offers much more functionality.
Teradata Warehouse Builder User Guide 23

Chapter 1: IntroductionArchitecture
Figure 1: Contrast of Traditional Utilities to Teradata PT
Teradata PT functionality uses a key software component called a data stream that acts as a pipeline between operators. With data streams, data basically flows from one operator to another. Teradata PT supports the following types of environments:
• Pipeline Parallelism
• Data Parallelism
Pipeline Parallelism
Pipeline parallelism is achieved by connecting operator instances through data streams during a single job. Figure 2 shows an export (or “read”) operator on the left that extracts data from a data source and writes it to the data stream. A filter operator extracts data from the data stream, processes it, then writes it to another data stream. Finally, a load (or “write”) operator starts writing data to a target as soon as data is available from the data stream. All three operators, each running its own process, can operate independently and concurrently.
Data sources and destinations for Teradata PT jobs can include:
• Databases (both relational and non-relational) or database servers
• Data storage devices, such as tapes or DVD readers
• File objects, such as images, pictures, voice, and text
Teradata Database
Load Utility
InMods orAccess Modules
Source1
Source2
Source3
Traditional Teradata Utilities
Teradata Database
User TransformOperator
Consumer (Load)Operator
Consumer (Load)Operator
User TransformOperator
User TransformOperator
Data Stream
Data Stream
Producer (Read)Operator
Producer (Read)Operator
Producer (Read)Operator
Source3
Source2
Source1
Teradata Parallel Transporter 2445C023
24 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionArchitecture
Figure 2: Teradata PT Pipeline Parallelism
Data Parallelism
Larger quantities of data can be processed by partitioning a source data into a number of separate sets, with each partition being handled by a separate instance of an operator, as shown in Figure 3.
DataStream
DataStream
queuesfilesrelational databasesnon-relationalsources TERADATA
Data ConnectorExportODBCSQL Selector
Producer operators"read" data
INMOD AdapterWHERE FilterAPPLY FilterUser-defined
Filter operators
LoadUpdateStreamSQL Inserter
Consumer operators"write" data
2445C024
Teradata Warehouse Builder User Guide 25

Chapter 1: IntroductionBasic Processing
Figure 3: Teradata PT Data Parallelism
Basic Processing
Teradata PT can load data into and export data from any accessible database object in the Teradata Database or other data store using Teradata PT operators in conjunction with special-purpose operators or access modules.
Multiple targets are possible in a single job. A data target or destination for a Teradata PT job can be any of the following:
• Databases (both relational and non-relational) or database servers
• Data storage devices
• File objects, texts, comma separated values (CSV) and so on
Note: Full tape support is not available for any function in Teradata PT for network-attached client systems. To import or export data using a tape, a custom access module must be written to interface with the tape device. See Teradata Tools and Utilities Access Module Programmer Guide for information about how to write a custom access module.
Between the data source and destination, Teradata PT jobs can perform the following types of processing:
• Retrieve, store, and transport specific data objects via parallel data streams
• Merge or split multiple parallel data streams
• Duplicate data streams for loading multiple targets
Operator
TERADATA
LoadUpdateStreamSQL Inserter
"Write" operators
Source Operator
Source Operator
SourceOperator
Data ConnectorExportODBCSQL Selector
"Read" operators
Data Stream Operator
Operator
2445A025
26 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionKey Features
• Filter, condition, and cleanse data
Teradata PT provides a simple, declarative SQL-like scripting language to specify the following:
• Load, update, and export processing
• Data sources and destinations
• Transformations and filtering
• Parallel instances of operators
• DML transactions (SQL INSERT, UPDATE, DELETE, MERGE INTO, or UPSERT) in a near real-time mode to a table (or tables) while queries are being performed.
When job scripts are submitted, Teradata PT does the following:
• Analyzes the statements in the job script.
• Initializes its internal components.
• Creates, optimizes, and executes a parallel plan for completing the job by:
• Creating instances of the required operator objects
• Creating a network of data streams that interconnect the operator instances
• Coordinating the execution of the operators
• Coordinates checkpoint and restart processing; automatically restarts the job when the Teradata Database signals restart.
• Terminates the processing environments.
Key Features
Teradata PT features include:
• Access Heterogeneous Load - Teradata PT can simultaneously load data from multiple and dissimilar sources, that may have different physical characteristics, in a single job. It can execute multiple instances of an operator to run multiple and concurrent updates and loads to the same table, and export, transform, and load a table in a single job. Additionally, it can perform in-line filtering and transformation of data and load or export derived values.
• Improved Performance through Parallelism and Scalability - Teradata PT runs multiple instances of the extract and load functions to maximize use of the CPUs. In addition, Teradata PT automatically and efficiently distributes data into data streams that are shared with multiple instances of the operators to scale up the data parallelism, thus speeding up the entire data load process. Data streaming eliminates the need for intermediate storage—data is streamed through the process without being written to disk. User-written or third-party transformations can occur during this parallel extract and load process.
• Checkpoints and Restarts - Teradata PT can automatically resume load jobs from the last checkpoint if the job aborts.
Teradata Warehouse Builder User Guide 27

Chapter 1: IntroductionCompatibilities
• Extensible - Teradata PT provides a set of open APIs that allow integration with third-party or custom transformation applications.
• Multiplatform Support - Teradata PT supports UNIX MP-RAS, IBM MVS, Windows, Linux, Solaris SPARC, AIX, and HP-UX platforms.
• Teradata PT API (Application Programming Interface) Support - Teradata PT supports Teradata PT API, which is a library of application programming interfaces that can be used in third-party applications to extract and load data to and from Teradata systems. Teradata PT API provides direct application access to the Teradata Database through proprietary Teradata Load and Export protocols such as Teradata FastLoad, Teradata FastExport, and Teradata MultiLoad. For more information, see the Teradata Parallel Transporter Application Programming Interface Programmer Guide.
Compatibilities
For information about supported platforms, see Chapter 1 in the Teradata Parallel Transporter Reference.
Scripts written for the former Teradata Warehouse Builder will work with Teradata PT without modification, but Teradata Warehouse Builder scripts cannot take advantage of new Teradata PT features. It is recommended that all new scripts be written using the Teradata PT scripting language.
Scripts written for Teradata standalone utilities (MultiLoad, FastLoad, and FastExport) are incompatible with Teradata PT. It is highly recommended that existing standalone utility scripts be reworked using Teradata PT scripting language. Contact Professional Services for help.
ETL vendor products can be used in conjunction with Teradata PT to either generate scripts for loading operations or to make API calls:
• Extract, Transform, and Load (ETL) vendors add value by performing data extractions and transformations prior to loading the Teradata Database. Teradata PT provides the ability to condition, condense, and filter data from multiple sources through the Teradata PT SELECT statement.
• Extract, Load, and Transform (ELT) vendors also add value by performing data extractions and loading, but leave all the complex SQL processing of data to occur inside the Teradata Database itself. Like ETL vendors, ELT vendors can condition, condense, and filter data from multiple sources into files that can be input into Teradata PT.
• The Teradata PT API provides additional advantages for third-party ETL/ELT vendors. For more information, see the Teradata Parallel Transporter Application Programming Interface Programmer Guide.
28 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionOperator Basics
Operator Basics
Operators are the data extracting, loading, transforming, and unloading components (or modules) of Teradata PT that are invoked through job scripts. Most operators receive data from or send data to a data stream.
Producer Operators
Producer (or read) operators send data to a data stream. Use a producer operator to do the following:
• Write data from one or more Teradata Databases or other external data source to the data stream.
• Make data available to other operators.
Producer operators are summarized in Table 3 on page 32. For more detail, see the Teradata Parallel Transporter Reference.
Consumer Operators
Consumer (or write) operators “consume” data from a data stream. Use a consumer operator to do the following:
• Read data from a data stream and load it into one or more Teradata tables or other data targets.
• Receive data from other operators.
• Write data to external disk files and access modules. ‘
Consumer operators are summarized in Table 3 on page 32. For more detail, see the Teradata Parallel Transporter Reference.
INMOD and OUTMOD Adapter Operators
INMOD Routines
Input modification (INMOD) routines are user-written programs that can pre-process data before it is sent to the Load or Update operator, and subsequently to the Teradata Database. An INMOD routine cannot be directly invoked by the operators; rather, existing routines are invoked by the FastLoad INMOD Adapter operator or the MultiLoad INMOD Adapter operator, both of which can act as a producer operator to pass data to the Load and Update operators. Figure 4 shows a sample job flow using the FastLoad INMOD Adapter Operator.
Figure 4: Job Flow Using a FastLoad INMOD Adapter Operator
Figure 5 shows a sample job flow using the INMOD Adapter Operator.
TeradataDatabase
LoadOperator
FastLoadINMODAdapterOperator
SourceData
2445A031
Teradata Warehouse Builder User Guide 29

Chapter 1: IntroductionOperator Basics
Figure 5: Job Flow Using an INMOD Adapter Operator
For more information, see “FastLoad INMOD Adapter Operator” or “MultiLoad INMOD Adapter Operator” in the Teradata Parallel Transporter Reference.
OUTMOD Routines
Output modification (OUTMOD) routines are user-written programs that process extracted data prior to delivering the data to its final destination. An OUTMOD routine cannot be directly invoked by the Export operator; rather, OUTMOD routines are invoked by the Teradata PT FastExport OUTMOD Adapter operator, which acts as a consumer operator to read data from the Export operator. Figure 6 shows a sample flow.
Figure 6: Job Flow Using an OUTMOD Adapter Operator
For more information, see “FastExport OUTMOD Adapter Operator” in the Teradata Parallel Transporter Reference.
Filter Operators
Filter operators are unique in that they can both consume data from an input data stream and produce data for an output data stream. In this unique position, filter operators prevent the output of any data row that contains column values that fail to satisfy filter conditions.
Although Teradata PT does not include any specific filter operators, the following filter operations can be accomplished using Teradata PT:
• Teradata PT job scripts can invoke user-written filter operators that are coded in the C or C++ programming languages. For more information about creating customized operators, see the Teradata Parallel Transporter Operator Programmer Guide.
• Teradata PT supports several filtering capabilities, specifically the WHERE clause and CASE DML expressions in APPLY statements, which can handle most filtering operations. Leveraging these existing capabilities might eliminate the need to create customized filter operators.
Functioning between producer and consumer operators, filter operators can also perform the following functions:
• Validating data
• Cleansing data
• Condensing data
TeradataDatabase
UpdateOperator
MultiLoadINMODAdapterOperator
SourceData
2445A032
TeradataDatabase
ExportOperator
FastExportOutmodAdapterOperator
OutputData
2445A030
30 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionOperator Basics
• Transforming data
Filter operators are summarized in Table 3 on page 32.
Standalone Operators
A standalone operator performs specialty processes that do not involve sending data to or receiving data from a data stream. In other words, standalone operators solely use input data from job scripts as their source.
Standalone operators can perform the following functions:
• Execute DDL and other self-contained SQL statements
• Execute host operating system commands
• Execute a DELETE task on the Teradata Database
Standalone operators are summarized in Table 3 on page 32.
Access Modules
Access modules are software modules that enable access to various data stores, such as CD-R, CD-RW, tape, and other subsystems (for example, IBM WebSphere MQ). The function of access modules is to provide Teradata PT with transparent, uniform access to various data sources.
Access modules are used with the DataConnector operator to read from different types of external data storage devices. The following access modules, which only read (import) data, are supported:
• Teradata Named Pipes Access Module allows the use of Teradata PT to load data into a Teradata Database from a UNIX named pipe, which is a type of data buffer that some operating systems allow applications to use for data storage. For more information, see the Teradata Tools and Utilities Access Module Programmer Guide and the Teradata Tools and Utilities Access Module Reference.
• Teradata WebSphere MQ Access Module allows the use of Teradata PT to load data fro a message queue using IBM WebSphere MQ message queuing middleware. For more information, see the Teradata Tools and Utilities Access Module Programmer Guide and the Teradata Tools and Utilities Access Module Reference
• Custom Access Modules can be created for use with the DataConnector operator to access specific systems. For more information, see the Teradata Parallel Transporter Operator Programmer Guide.
Operator Summary
Table 3 summarizes the function, type, and purpose of the operators supplied by Teradata PT. For more information about operators, see the Teradata Parallel Transporter Reference.
Teradata Warehouse Builder User Guide 31

Chapter 1: IntroductionOperator Basics
Note: Avoid using the keywords TYPE CONSUMER, TYPE PRODUCER, TYPE FILTER, OR TYPE STANDALONE in any operator definition.
Table 3: Operator Summary
Teradata PT Operator Needed TYPE Definition Action
Standalone Equivalent
DataConnector operator as a consumer
TYPE DATACONNECTOR CONSUMER
Write flat files Data Connector
DataConnector operator as a producer
TYPE DATACONNECTOR PRODUCER
Read flat files Data Connector
DDL operator TYPE DDL Execute various DDL, DML, and DCL statements
DDL statements in utility scripts
Export operator TYPE EXPORT Read bulk data from a Teradata Database FastExport
FastLoad INMOD Adapter
TYPE FASTLOAD INMOD Process data prior to writing to a data stream
FastLoad INMOD
FastExport OUTMOD Adapter operator
TYPE FASTEXPORT OUTMOD
Process data after an export FastExport OUTMOD
Load operator TYPE LOAD Load empty tables FastLoad
MultiLoad INMOD Adapter operator
TYPE MULTILOAD INMOD
Process data prior to updates MultiLoad INMOD
MultiLoad INMOD Adapter operator
TYPE MULTILOAD INMOD FILTER
Filter and clean input data MultiLoad INMOD
ODBC operator TYPE ODBC Export data from ODBC-compliant data sources
OLE DB Access Module
OS Command operator TYPE OS COMMAND Execute OS commands in a job OS FastLoad command
SQL Inserter operator TYPE INSERTER Insert data using SQL protocol BTEQ
SQL Selector operator TYPE SELECTOR Export data using SQL protocol BTEQ
Stream operator TYPE STREAM Perform continuous updates, deletes, and inserts into multiple tables
TPump
Update operator TYPE UPDATE Perform bulk updates, deletes, and inserts MultiLoad
Update operator as a standalone
TYPE UPDATEDeleteTask attribute
Delete rows from a single table with a DELETE Task
MultiLoad DELETE
32 Teradata Warehouse Builder User Guide

Chapter 1: IntroductionLimitations
Limitations
The following limitations apply to Teradata PT:
• The INSERT statement that permits the wildcard feature in APPLY clauses is available only with the Load operator; it is not available with the Stream or Update operators. For more information, see the “LOAD” topic in the Teradata Parallel Transporter Reference.
• Many, but not all, of the features of the standalone utilities Support Environment are supported in Teradata PT. For lists of supported features, see the “Load,” “Export,” “Update,” and “Stream” topics in the Teradata Parallel Transporter Reference.
• Scripts written for the standalone utilities are not portable to the Teradata PT environment.
Teradata Warehouse Builder User Guide 33

Chapter 1: IntroductionLimitations
34 Teradata Warehouse Builder User Guide

CHAPTER 2
Job Basics
This chapter describes the basics of creating and running simple load and unload Teradata PT scripts. Sample scripts are included.
The topics include:
• Creating Job Scripts
• Running Job Scripts
• Privileges
• UTF-16 Support
• Security
• Public and Private Logs
For MVS systems, Directing Log Output explains how to direct log output using the tbuild command’s -S option.
Creating Job Scripts
For examples of the job scripts created by the following procedure, see Appendix A: “Script Samples.”
Also, Chapter 9: “Wizard Help,” details using the Teradata PT Wizard, a GUI for creating simple job scripts.
To create a simple job script
This procedure does not cover creating scripts that involve filter operators.
1 (Optional) Create a job header comment.
Use a job header to record useful information about the job, such as the purpose of the job, date of creation, and special instructions. Job headers are processed like comments in a programming language; contents are not processed so they do not affect job execution.
2 Define the job.
The job definition defines the overall job, and packages together all of the following DEFINE and APPLY statements.
DEFINE JOB <job name>DESCRIPTION '<job description>'(
Teradata Parallel Transporter User Guide 35

Chapter 2: Job BasicsCreating Job Scripts
Notice that:
• The job name is a name given to the job.
• The optional job description is a short description of the job.
• The left parenthesis after the DEFINE JOB statement must be closed by a right parenthesis and semicolon at the end of the job script.
3 Define one or more job schemas.
DEFINE SCHEMA <schema name>DESCRIPTION '<schema description>'(
<column definitions>);
Notice that:
• The schema name is the name by which the schema is referenced throughout a job script.
• The optional schema description text is a short description of the schema.
• The column definitions describe the data columns to be represented by the schema, including data type attributes and the physical order of columns in a data source or a data target. Note that column names are case-insensitive and if a column name is a keyword, a compilation error will be returned.
• All data processed by a job must be defined, directly or indirectly, by a schema. See Teradata Parallel Transporter Reference for more information about schemas.
In Teradata PT, data is defined in terms of schemas that define the columns in a table or data source. Schemas are used to identify the data structure.
Producers have an output schema (to define what the source data looks like in the data stream). Consumers have an input schema (to define what it will read from the data stream).
The Teradata PT schema definition is similar to the DEFINE command in Teradata FastLoad or the LAYOUT command (.Layout) in Teradata MultiLoad.
The schema definition specifies the column name, length, and data type. Any other restrictions, such as NOT NULL or CHARACTER SET LATIN, that are defined in SQL are not specified in a schema definition.
A given schema definition can describe multiple data objects. Multiple schema can be defined in a single script.
4 Use a DEFINE OPERATOR statement to define each specific operator that the job will use.
An operator definition defines the specific operator to be used in a job.
DEFINE OPERATOR <operator name>DESCRIPTION '<operator description>'TYPE <operator type>DEFINE SCHEMA <schema name>ATTRIBUTES(INTEGER ErrorLimit,MaxSessions=3,MinSessions=2,VARCHAR TraceLevel,
36 Teradata Parallel Transporter User Guide

Chapter 2: Job BasicsCreating Job Scripts
VARCHAR WildCardInsert = ‘Yes’);
Notice that:
• The operator name is the name by which the job’s processing step(s) reference the operator.
• The operator description is a place for a short description of the operator.
• The operator type identifies the specific operator being defined. For a list of operators, see “Operator Summary” on page 31.
Operator choice is based on the characteristics of the target tables and on the specifics of the operations to be performed. A job can also employ other standalone operators to perform setup and cleanup operations. For more information about operators, see “Operator Basics” on page 29.
• The schema name is the name of a previously defined schema that describes the data columns to be processed by the operator.
An asterisk (*) can be coded instead of a schema name for a consumer operator to indicate that the operator will use the schema of the producer operator that put the data on the data stream.
SCHEMA *
• A declaration for each operator attribute that is assigned values in the script must be included in the operator definition. Normally the keywords VARCHAR and INTEGER are required in an attribute declaration to identify whether the attribute’s values are character strings or numbers. These keywords are optional if the attribute declaration specifies a default value which implicitly identifies its value data type: if the value is a number, then the INTEGER data type is assumed; otherwise, the value must be enclosed in single quote characters and the VARCHAR data type is assumed.
The Attribute Quick Reference table in the Teradata Parallel Transporter Reference lists all of the required and optional attributes for each of the Teradata PT operators.
5 Define job steps.
Job steps are units of execution in a Teradata PT job. Each job step contains an APPLY statement that specifies the combination of operators that will perform a specific operation, usually the movement of data from one or more sources to one or more targets.
Using job steps is optional, but when used they can execute multiple operational statements in a single Teradata PT job. Job steps are executed in the order in which they appear within the DEFINE JOB statement. See Teradata Parallel Transporter Reference for specific information on job steps.
For job steps that use standalone operators:
STEP <job step name>(
APPLY<SQL statements> or <operating system commands>TO OPERATOR (<operator name>);
);
For job steps that do not use standalone operators:
STEP <job step name>(
Teradata Parallel Transporter User Guide 37

Chapter 2: Job BasicsRunning Job Scripts
APPLY<SQL statements>TO OPERATOR (<operator name>)SELECT <column specification>FROM OPERATOR (<operator name>)WHERE <row selection conditions>;
);
Notice that:
• Job step name is the name of the job step that is unique within a job.
• The host-system commands to be executed by the OS Command operator are operating system commands.
• SQL statement(s) to be sent to the Teradata Database for execution by the operator referenced in the APPLY statement are SQL statements.
• Operator name is the name of a previously-defined job operator.
• Column specification is an asterisk (*), meaning all columns in the source rows or list of desired columns.
• Row selection conditions are filter conditions on the column values of source rows, that limit the rows to be processed to only those that satisfy the conditions.
• The WHERE clause is optional.
6 Save the job script to a <script name> file in the directory from which Teradata PT jobs are run.
For more information on job scripts, see the Teradata Parallel Transporter Reference. For procedures to run scripts based on operating system, see “Running Job Scripts” on page 38.
Running Job Scripts
Teradata PT scripts can be created and edited in any editor program, such as Windows Notepad or the UNIX vi editor. To run Teradata PT scripts, use one of the following procedures.
To run a job on UNIX
1 Use UNIX VI or some other editor to create/edit a script.
Scripts can be copied from the manuals or from the Sample directory that is installed in the same directory as Teradata PT. The defaults are:
• Linux - /opt/teradata/client/tbuild/<version>/sample/etl
• All other UNIX platforms - /usr/tbuild/<version>/sample/etl
2 Save the file to your UNIX directory.
Note: Remember that UNIX is case-sensitive.
3 Type the following at the UNIX command prompt to run the script, where filename is the name assigned to the script:
38 Teradata Parallel Transporter User Guide

Chapter 2: Job BasicsPrivileges
tbuild -f <file name>
To run a job on Windows
1 Use Windows Notepad or some other editor to create/edit a script.
Scripts can be copied from the manuals or from the Sample directory that is installed in the same directory as Teradata PT, the default being C:\Program Files\NCR\Teradata Parallel Transporter\<version>\sample\etl.
2 Click Start > Programs > Accessories > Command Prompt. 3 Type the following to run the script, where file name is the name assigned to the script:
tbuild -f <file name>
To run a job on z/OS (MVS)
Teradata PT job scripts that run on z/OS are normally member files in a z/OS library dataset (PDS/E) that contains Job Control Language (JCL). A job script is executed when its member JCL file is submitted to z/OS for batch execution.
1 On a z/OS system, log on to the Time Sharing Option (TSO).
2 At the Master Application menu, type P, then press Enter to execute the Program Development Facility (PDF, also known as ISPF).
3 At the ISPF Primary Option menu, type 2 (Edit), then press Enter to execute the TSO Editor.
4 In the Project, Group, and Type boxes, type the name of your Teradata PT JCL library.
5 In the Member box, type the name of the member file you want to execute, then press Enter.
6 At the command line (to the right of Command ===>), type SUBMIT, then press Enter to submit this JCL member file for batch execution.
7 To view job output, navigate to the PDF option S.O.8 Enter S before the name of the job (from the first line of the member job JCL), then press
Enter.
For JCL samples that can execute a Teradata PT job script, see Appendix C: “JCL Examples” in the Teradata Parallel Transporter Reference.
Privileges
Generally, the user requires the appropriate access rights for the actions that they will be executing. The following list cites necessary privileges so the logged-on user can run scripts:
• Load operator:
• SELECT and INSERT privileges on the Load target table.
Teradata Parallel Transporter User Guide 39

Chapter 2: Job BasicsPrivileges
• SELECT and INSERT privileges on the error tables, and DROP privileges on the database that contains the error tables.
• SELECT, INSERT, and DELETE privileges on the restart log table, and DROP privileges on the database that contains the restart log table.
• DDL operator:
• REPLCONTROL privilege to set the ReplicationOverride attribute.
• SQL Inserter:
• REPLCONTROL privilege to set the ReplicationOverride attribute.
• Stream operator:
• SELECT, INSERT, UPDATE, and DELETE privileges on the Stream target tables
• SELECT and INSERT privileges on the error tables, and CREATE and DROP privileges on the database that contains the error tables.
• SELECT, INSERT, and DELETE privileges on the restart log table, and CREATE and DROP privileges on the database that contains the restart log table.
• REPLCONTROL privilege to set the ReplicationOverride attribute.
The Stream operator does not have any special protections on the database objects it creates. Therefore, administrators and users must establish the following access rights on the databases used by the Stream operator:
• CREATE TABLE access rights on the database where the restart log table is placed.
• CREATE TABLE access rights on the database where the error table is placed.
• CREATE/DROP MACRO access rights on the database where macros are placed.
• EXECUTE MACRO access rights on the database where the macros are placed.
Macros slightly complicate access rights. The remaining access rights necessary to run the Stream operator have two scenarios.
• When a Stream operator macro is placed in the same database as the table that it affects, the required access rights are INSERT/UPDATE/DELETE on the table affected by the DML executed.
• When a Stream operator macro is placed in a different database from the table it affects, the required access rights for the database where the macro is placed are INSERT/UPDATE/DELETE WITH GRANT OPTION in the table affected by the DML executed. You must also have EXECUTE MACRO rights on the database where the macro is placed.
To change a table, you must have the corresponding INSERT, UPDATE, or DELETE privileges for that table.
• Update operator:
• SELECT and INSERT privileges on the Update target table
• SELECT and INSERT privileges on the error tables, and DROP privileges on the database that contains the error tables.
• SELECT, INSERT, and DELETE privileges on the restart log table, and DROP privileges on the database that contains the restart log table.
• REPLCONTROL privilege to set the ReplicationOverride attribute.
40 Teradata Parallel Transporter User Guide

Chapter 2: Job BasicsUTF-16 Support
UTF-16 Support
Note: The UTF-16 session character set can only be specified on network-attached platforms.
The USING CHARACTER SET <characterSet> statement in the Teradata PT job script is used to define the session character set. However, when submitting a job script that is encoded in UTF-16, specify the -e command line option for the tbuild command.
tbuild -f <file name> [-v jobVariablesFile] -e <characterSet>
Note that UTF16 is the only supported value of the -e option and is case-insensitive.
-e UTF16
indicates to Teradata PT that the job script is encoded in UTF-16. The file endianness is determined by the Byte Order Mark (BOM) at the beginning of the file.
Usage Notes
Consider the following when working with varying session character sets:
• When using UTF16 character set in TPT scripts, the value of n in VARCHAR(n) and CHAR(n) in the SCHEMA definition must be an even and positive number.
• LONG VARCHAR and LONG VARGRAPHIC are no longer supported as column types. LONG VARCHAR now corresponds to VARCHAR(64000). See “Using LONG VARCHAR with Unicode Character Sets” on page 131 for a discussion on how Teradata PT will handle this column type.
To view log files in UTF-16 format, see “Viewing Logs in UTF-16 Format” on page 43.
Security
To use the single sign-on feature on Windows systems, a user name and password are not required in a job script to log on to a Teradata Database. Logon information is automatically authenticated by network security when first logging on to a computer. For systems that use logon encryption, single sign-on cannot be used.
For more information regarding security, see Chapter 2 in the Teradata Parallel Transporter Reference.
Public and Private Logs
Public and private logs are helpful for analyzing jobs.
Teradata Parallel Transporter User Guide 41

Chapter 2: Job BasicsPublic and Private Logs
Public Logs
All log information associated with a Teradata PT job is automatically generated and stored in a file called a public log. The log contains the following information about what actually takes place in the execution of a job:
• Job Elapsed Time
• Job CPU Time
• Return Codes
• Checkpoints Taken
• Restarts Attempted
• Teradata PT Version Number
• Number Of Sessions
• Blocksize Used
• Number Of Blocks Created
Since multiple operators can be running in a single job, they all write asynchronously to the same public log, with information about a particular operator interspersed with other operators. This is where private logs can be helpful. For more information, see “Private Logs” on page 42.
Locating a Public Log
To locate the public log, locate the log directory by executing one of the following commands:
• UNIX
cd $TWB_ROOT/logs
• Windows
chdir %TWB_ROOT%\logs
• Linux
cd $TWB_ROOT/logs
Note: In the public log directory, job logs are filed according to the job name specified in a script, unless the job name is unspecified. In this case, logs are named according to the user ID that is logged on, then concatenated, such as <userid>-1.out, <userid>-2.out, and so on.
Reading a Public Log
To read public logs, execute the following command:
tlogview -l <userid>-1.out
Private Logs
When requested, a private log extracts from the public log information associated with a specific operator, which can isolate specific operator information from other operators in a job. These logs are easier to read and review.
Private logs must be explicitly requested with an assigned name using the PrivateLogName attribute of the designated operator.
42 Teradata Parallel Transporter User Guide

Chapter 2: Job BasicsPublic and Private Logs
Reading a Private Log
Private logs are kept in the same file as public logs. To read a private log for an operator, type the following command:
tlogview -j <job name> -v <output format> -f <log file name>
where:
• The –j option identifies the Teradata PT job that produced the log files.
• The –v option specifies the log data files to be displayed, including the order and any field separators.
• The –f option specifies one or more log files to be viewed.
The following format options can also be used:
• Use %M to show the message text from the log records.
• Use %T to show task names in output.
• Use %D to show date in output.
For example:
tlogview -j JM800903-4 -v "%M" -f ' * ' -g
where:
• The –j option get logs associated with job JM800903-4.
• The –v %M option specifies that only the message text field from the log records is displayed.
• The –f ' * ' option indicates that all private logs are to be extracted.
• The -g option sorts output so the private logs are segregated. This option must be used with <log file name> set to “*”. Using “ -f ' * ' “ without the -g option would interleave all the log records from different private logs.
It is also possible to obtain a list of the names of all the private logs in a target job log by typing the following command:
tlogview -j <job name> -p
Viewing Logs in UTF-16 Format
Note: The UTF-16 session character set can only be specified on network-attached platforms.
Both private and public logs can be viewed in UTF-16 format. Use the -e option with UTF16 as its value in the tlogview command line to display the log in UTF-16 characters. For example:
tlogview -l <userid>-1.out -e utf16
This tlogview command displays a public log specified by <userid>-1.out in UTF-16 format. Note that UTF16 is the only supported value of the -e option and is case-insensitive.
Teradata Parallel Transporter User Guide 43

Chapter 2: Job BasicsPublic and Private Logs
Directing Log Output
For directing both private and public log output on MVS systems, use the tbuild command’s -S option. Specify one of three parameters:
• To specify a dsname, where dsname is the target dataset name for the logfile:
-S <dsname>
Note: A fully qualified dsname can be specified by enclosing the dsname in single quote marks.
• The DD statement directs the log output to a dataset, where ddname is the name for the log file:
-S DD:<ddname>
• To specify a SYSOUT class, where class is the SYSOUT class for the log file:
-S <class>
44 Teradata Parallel Transporter User Guide

CHAPTER 3
Extracting Data
Teradata PT provides multiple operators for extracting data from internal or external data sources.
• Extracting with the Export Operator
• Extracting with the DataConnector Operator
• Extracting with the SQL Selector Operator
Consider the following special topics:
• Combining Data Sources
• Using the Large Decimal Teradata Database Feature
Extracting with the Export Operator
The Export operator is a producer operator that simulates Teradata FastExport protocol to extract large amounts of data at high speeds from Teradata tables using block transfers over multiple sessions. The data that is produced can be loaded as follows using other Teradata PT operators:
• Write data to other Teradata tables
• Write data to a different database system
• Write data to a flat file
• Write data to a device using the DataConnector operator
• Pass data to an access module or a custom-created access module
The following topics focus on using the Export operator to export data that can be used by the Load, Update, or Stream operators, or by the SQL Inserter operator, an option that bypasses the need for creating physical files.
Performance
The exporting ability of the Export operator is designed to outperform the SQL Selector operator (similar to BTEQ Export) in the transfer of large amounts of data from Teradata tables. This is because, among other factors, the Export operator is multi-sessioned and able to run in multiple parallel instances, performing block exports versus the SQL Selector operator’s single-session and one-row-at-a-time exports.
Teradata Warehouse Builder User Guide 45

Chapter 3: Extracting DataExtracting with the Export Operator
Export functions in Teradata PT do not actually make the Teradata Database perform faster. Rather, Teradata PT allows a greater use of multiple parsing engines and AMPs, in addition to using multiple sessions.
Checkpoint and Restart
The Export operator behaves differently from other Teradata PT operators in that it does not support a user-defined restart log table. Instead, it takes a checkpoint only when all data is sent to the data stream. If a restart occurs, the operator either must send all of the data or none of the data depending on whether the checkpoint has taken place.
Caution: If a checkpoint interval is specified on the tbuild command line, the checkpoints incurred between the start of data loading and the end of data loading are ignored by the Export operator.
Export Operator Definition
Following is an example of a Export operator definition. Most of the attributes can be defaulted. Comments about a few key attributes (shown bold) are included. More information follows the definition.
DEFINE OPERATOR EXPORTDESCRIPTION 'EXPORT OPERATOR'TYPE EXPORTSCHEMA PRODUCT_SOURCE_SCHEMAATTRIBUTES(INTEGER BlockSize,INTEGER TenacityHours, /*Hours before new Export job logon attempt*/INTEGER TenacitySleep, /*Minutes of pause before retrying a logon */INTEGER MaxSessions, /*Max. number of sessions required for Export*/INTEGER MinSessions, /*Min. number of sessions required for Export*/VARCHAR PrivateLogName, /*Captures log information for this operator only*/VARCHAR TraceLevel,VARCHAR DateForm,VARCHAR TdpId, /*Tdpid of the system the sessions will be logged onto*/VARCHAR UserName, /*User name used by the sessions*/VARCHAR UserPassword, /*Password used by the sessions*/VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR AccountId,VARCHAR WorkingDatabase,VARCHAR SelectStmt /*SELECT statement(s) used to generate export data*/);
For more detail about Export attributes, see “Export Operator” in the Teradata Parallel Transporter Reference.
About This Definition
Consider the following when using the Export operator.
46 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataExtracting with the Export Operator
Session Limits
When running the Export operator, the actual session limit is determined by the first limiting factor that is encountered.
For other general notes, see “Session Limits” on page 62. For detailed information about sessions and instances, see “Coding Job Scripts” in the Teradata Parallel Transporter Reference.
Limits to Export Jobs
The Export operator requires one designated Teradata Database load job; however, the number of concurrent loader tasks is also configurable in the Teradata Database environment using the same MaxLoadTasks field control used by FastLoad, FastExport, and MultiLoad. For example, one FastLoad job equates to one Teradata PT Load job in the count for MaxLoadTasks. For more information, see the “DBS Control Utilities” section of Utilities-Volume 1.
SELECT Requirements
The Export operator uses Teradata SQL SELECT statements to perform data selection from Teradata Database tables. Multiple parallel instances of the Export operator and multiple sessions within each instance can improve the performance of an export. A SELECT request within an Export script can have multiple SELECT statements, and multiple SELECT statements can still be considered as a single request. A SELECT statements can be optionally preceded by a LOCKING modifier.
One or many SELECT statements can drive the Export operator, with some restrictions. Export SELECT requests cannot:
• Specify a USING modifier.
• Access non-data tables, such as SELECT DATE or SELECT USER.
• Be satisfied by one or two AMPs, such as SELECT statement which accesses rows based on the primary index or unique secondary index of a table.
• Contain character large object (CLOB) or binary large object (BLOB) data types.
Use the following syntax to create SELECT requests for an Export operator job.
Table 4: SELECT Requests
Type of SELECT Request Result
Contains multiple SELECT statements
The Teradata Database might execute the requests in parallel, but response are still returned in the order of the requests, for the first statement first, then for the second, and so on.
If the structure of response rows differs, an error results and the job terminates.
Teradata Warehouse Builder User Guide 47

Chapter 3: Extracting DataExtracting with the Export Operator
Export Job Example
Following is an example of a script that uses the Export operator. The job will export 1,000 rows from a table and write them to a flat file. To do this, the DataConnector operator must be defined to handle the output file. Also, the schema definition must state the layout of the table and the file to be written. In this case, both layout are the same, so only a single schema definition is needed.
Details of the script are explained in the callouts and following the script.
DEFINE JOB Export_to_FileDESCRIPTION 'Export 1000 account rows from the Accounts table.'(
DEFINE SCHEMA Account_Schema(
Account_Number INTEGER, Number INTEGER, Street CHARACTER(25), City CHARACTER(20), State CHARACTER(2), Zip_Code INTEGER, Balance_Forward DECIMAL(10, 2), Balance_Current DECIMAL(10, 2) );
Uses a LOCKING modifier
The specified lock remains in effect during the execution of all statements within the request that contains the modifier. The Teradata Database does the following:
• Implements all resource locks for the entire request before executing any of the statements in the request.
• Maintains the locks until all of the response data for the request is moved to spool tables.
Following is a valid SELECT request using the LOCKING modifier:
LOCKING TABLE MYTABLE FOR ACCESS SELECT COL1, COL2 FROM MYTABLE;
Note that the LOCKING modifier can precede the SELECT statement.
Uses an ORDER BY clause
Specify one Export instance.
Following is a valid ORDER BY clause:
SELECT COL1, COL2 FROM MYTABLE ORDER BY COL1;
Table 4: SELECT Requests (continued)
Type of SELECT Request Result
DEFINE JOB• Name of the job is Export_to_File.• A brief description in included.
DEFINE SCHEMA• Name of schema is Account_Schema.• Defines the layout of the Accounts table.• Also defines the layout of output file.• Both operators use this schema.
48 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataExtracting with the Export Operator
DEFINE OPERATOR Data_ConnectorTYPE DATACONNECTOR CONSUMER
SCHEMA Account_SchemaATTRIBUTES
(VARCHAR FileName = 'Export_1000',VARCHAR Format = 'FORMATTED', VARCHAR OpenMode = 'Write', VARCHAR IndicatorMode);
DEFINE OPERATOR Export_Accounts TYPE EXPORT
SCHEMA Account_Schema ATTRIBUTES ( VARCHAR UserName = 'xxxxxx', VARCHAR UserPassword = 'xxxxxx',
VARCHAR TdpId = 'xxxxxx', VARCHAR SelectStmt = 'SELECT Account_Number,
Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current FROM Accounts
SAMPLE 1000;' ); APPLY TO OPERATOR ( Data_Connector[1] )
SELECT Account_Number, Number, Street,City, State, Zip_Code,
Balance_Forward, Balance_Current
FROM OPERATOR( Export_Accounts[1] ););
Notice the following about this job:
• The job has a single job step that is unnamed; it begins with the APPLY statement.
• Export does not provide an attribute for limiting the number of returned rows so the SAMPLE clause limits the number to 1000.
DEFINE OPERATOR Data_Connector • Name of this operator is Data_Connector.• DataConnector is used as a consumer type operator because
it consumes data from the data stream.• It references the Account_Schema to be used for the output
file layout.• Attributes include output file name, its format, and indicator
mode.• The file will be written to the directory where the script is
executed. • Both operators use this schema.• Data is exported to a data stream in INDICATOR mode, which
adds indicator bits on the front end of each record to indicate the presence of nulls in certain field positions.
DEFINE OPERATOR Export_Accounts• Name of the next operator is Export_Accounts.• Operator is indicated in the TYPE clause.• References Account_Schema for the table layout.• Attributes include userid, password, and tdpid (system) to
be logged onto.• SELECT statement, which produces the data, is included. • The less laborious technique for writing SELECT
statements is to use SELECT * instead of naming columns, as in this example.
APPLY Statement (TO Operator)• APPLY is like an SQL INSERT/SELECT.• Identifies the output operation.• The TO operator is DataConnector because the
output is a flat file.• SELECT statement defines the exact columns to be
produced relative to the schema definition.• If all input columns are to be selected, then code
SELECT * .• A single instance [1] of the operator is requested.
APPLY Statement (FROM Operator)• Identifies the input operation.• Name of the operator is Export_Accounts. It is producing the
data stream.• A single instance [1] of the operator is requested.
Teradata Warehouse Builder User Guide 49

Chapter 3: Extracting DataExtracting with the DataConnector Operator
• Only those attributes with values (other than the defaults) need to be included in the DEFINE statements.
• Attributes can be assigned values in the operator definition or in the APPLY statement; definitions in the APPLY statement override the definition statement.
For more information about the DataConnector operator, see “Extracting with the DataConnector Operator” on page 50.
To run this script
1 Copy and paste “Export Job Example” on page 48 to a file named Export_1000.txt.
2 Change the “xxxxxx” attributes to a valid username, password, and the Tdpid of the system being used.
3 Type the following at the command prompt:
tbuild -f Export_1000.txt
The FileName attribute of the Data Connector operator is preset to Export_1000. If no other value is specified, the file is written to the directory from which the script is executed.
Limiting Output
No specific attribute exists that can limit the number of rows that are exported; however, you can use one of the following:
• The WHERE clause can limit the number of rows that are exported by specifying conditions that must be met.
• The SAMPLE function is an SQL function that can limit the number of random rows returned. For more information, see the SQL Reference: Data Manipulation Statements.
For more detail about export attributes, see “Export Operator” in theTeradata Parallel Transporter Reference.
Extracting with the DataConnector Operator
The DataConnector operator can function as a file reader to read from flat files, or as a file writer to write to a flat file. As a reader, it is considered a producer operator (one that produces a data stream); as a writer, it is considered a consumer operator (one that consumes a data stream). It can also be used in conjunction with an access module to read from, or write to specialized devices and queues.
Parallel processing can be accomplished by specifying multiple instances of the operator.
When defining this operator, the following three values are minimally required:
• TYPE - Specify the operator as DATACONNECTOR PRODUCER.
• Filename - The name of the file to be accessed, consistent with the conventions of the operating system.
50 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataExtracting with the DataConnector Operator
• Format - The logical record format of the file being read.
Other attributes might also be available. For more information about DataConnector attributes, see “DataConnector Operator” in the Teradata Parallel Transporter Reference.
Input File Formats
Several file formats can be processed by the DataConnector operator. Specify file format with the Format attribute.
• Format = 'Binary' - Each record contains a two-byte integer data length (n) followed by n bytes of data.
• Format = 'Text' - Each record is entirely character data, an arbitrary number of bytes followed by one of the following end-of-record markers:
• A single-byte line feed (X'0A') on UNIX platforms
• A double-byte carriage-return/line-feed pair (X'0D0A') on Windows platforms
• Format = 'Delimited' - Each record is in variable-length text record format, but they contain fields (columns) separated by a delimiter character, as defined with the TextDelimiter attribute, which has the following limitations:
• It can only be a sequence of characters.
• It cannot be any character that appears in the data.
• It cannot be a control character other than a tab.
With this file format, all of the data types in the DEFINE SCHEMA must be VARCHARs. And, if not provided, the TextDelimiter attribute defaults to the pipe character ( | ).
Note: There is no default escape character when using delimited data. Use the DataConnector operator’s EscapeTextDelimiter optional attribute to define the escape character.
• Format = 'Formatted' - Each record is in a format traditionally known as FastLoad or Teradata format, which is a two-byte integer (n) followed by n bytes of data, followed by an end-of-record marker (X'0A' or X'0D0A).
• Format = 'Unformatted' - The data does not conform to any predefined format. Instead, the data is entirely described by the columns in the schema definition of the DataConnector operator.
Directory Scan
The DataConnector producer operator has a special feature, called Directory Scan, which allows multiple files in the same directory to be used as input. Specify a directory name in the DirectoryPath attribute, and then specify a wildcard character ( * ) for the FileName attribute to read all files from the directory. No limits exist to the number of files that can be used as input while appearing as a single source to Teradata PT. Multiple instances of the operator can be specified to handle multiple files.
Teradata Warehouse Builder User Guide 51

Chapter 3: Extracting DataExtracting with the SQL Selector Operator
DataConnector Operator Definition
Following is an example of a DataConnector operator definition as a producer. Most of the attributes can be defaulted. Comments about a few key attributes (shown bold) are included.
DEFINE OPERATOR DATACONDESCRIPTION 'DataConnector'TYPE DATACONNECTOR PRODUCER SCHEMA PRODUCT_SOURCE_SCHEMAATTRIBUTES(VARCHAR PrivateLogName,VARCHAR AccessModuleName,VARCHAR AccessModuleInitStr,VARCHAR FileName = 'File1', /*Name of the file read from or written to*/VARCHAR OpenMode = 'Read', /*How to open the file: read, write, or write-append*/VARCHAR Format = 'Text', /*Teradata file formats used (binary, delimited, formatted, unformatted or text)*/VARCHAR TextDelimiter,VARCHAR IndicatorMode = 'N', /*Whether indicator bytes are used in the operation*/INTEGER RowsPerInstance,INTEGER VigilWaitTime,VARCHAR VigilStartTime,VARCHAR VigilStopTime,VARCHAR VigilNoticeFileName,VARCHAR TraceLevel = 'none');
DataConnector Job Example
For an example of how the DataConnector operator is used as a consumer operator, see “Export Job Example” on page 48.
Extracting with the SQL Selector Operator
The SQL Selector operator is a producer operator (meaning that it produces a data stream) that submits a single Teradata SQL SELECT statement to a Teradata Database to retrieve data from a table. This function is similar to the Export operator. The main differences between the two operators is seen in their performance and feature sets. The Export operator allows multiple sessions and multiple instances to extract data from the Teradata Database while the SQL Selector operator only allows one session and one instance to extract rows from the Teradata Database. Another difference is that the Selector operator has features not found in the Export operator such as field mode processing. Generally, when exporting a small number of rows, the SQL Selector operator usually performs better. When exporting a large number of rows, it is usually better to use the Export operator.
The SQL Selector operator support of a single session and a single instance is similar to a BTEQ Export operation.
52 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataExtracting with the SQL Selector Operator
Advantages
One advantage of the SQL Selector operator is its Report Mode. (This mode is known as Field Mode in the BTEQ environment). All data retrieved in this mode is converted to character strings. The SQL Selector operator is also the better choice when retrieving data from a Teradata Database when the desired output format is VARTEXT (delimited) or TEXT format.
Another advantage of the SQL Selector operator is that it does not require an active load job. Instead, standard SQL protocol is used on the single session. If it is difficult to acquire DBS resources for running concurrent tasks, the SQL Selector operator is a logical choice rather than the Export operator.
Restrictions
The following restrictions exist when using the SQL Selector operator:
• The WITH and WITH BY clauses are not permitted.
• Multi-statement requests consisting of multiple SELECT statements are not permitted.
• The USING modifier is not permitted.
SQL Selector Operator Definition
Following is an example of an SQL Selector operator definition. Most of the attributes can be defaulted. Comments about a few key attributes (shown bold) are included.
DEFINE OPERATOR SQL_SELECTORDESCRIPTION 'SQL OPERATOR'TYPE SELECTORSCHEMA PRODUCT_SOURCE_SCHEMAATTRIBUTES(VARCHAR TraceLevel,VARCHAR PrivateLogName,VARCHAR DateForm,VARCHAR UserName = 'MyUser',VARCHAR UserPassword = 'MyPassword',VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR TdpId = 'MyDatabase',VARCHAR AccountID,VARCHAR ReportModeOn = 'Y', /*Indicator Mode is the default. 'Y' implies Report Mode is used or 'N' implies Indicator Mode is used. Record Mode is not supported.*/VARCHAR SelectStmt = 'SELECT * FROM source_tbl;' /*Generates the export data. Note that only a single SELECT statement is permitted.*/);
SQL Selector Job Example
Following is a script that uses the SQL Selector operator. This script does exactly the same thing as the “Export Job Example” on page 48, that is, it exports 1000 rows from a table called Accounts into a flat file. Differences in this script are highlighted in bold text.
DEFINE JOB Select_AccountsDESCRIPTION 'Select 1000 account rows from the Accounts table.'
Teradata Warehouse Builder User Guide 53

Chapter 3: Extracting DataExtracting with the SQL Selector Operator
( DEFINE SCHEMA Account_Schema ( Account_Number INTEGER, Number INTEGER, Street CHARACTER(25), City CHARACTER(20), State CHARACTER(2), Zip_Code INTEGER, Balance_Forward DECIMAL(10, 2), Balance_Current DECIMAL(10, 2) );DEFINE OPERATOR Data_Connector
TYPE DATACONNECTOR CONSUMERSCHEMA Account_SchemaATTRIBUTES
(VARCHAR FileName = 'Select_1000',VARCHAR Format = 'FORMATTED', VARCHAR OpenMode = 'Write', VARCHAR IndicatorMode = 'N'
);DEFINE OPERATOR Select_Accounts
TYPE SELECTOR SCHEMA Account_Schema ATTRIBUTES (
VARCHAR UserName = 'xxxxxxx', VARCHAR UserPassword = 'xxxxxx',
VARCHAR TdpId = 'xxxxxxx', VARCHAR SelectStmt = 'SELECT Account_Number, Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current FROM Accounts
SAMPLE 1000;' );APPLY TO OPERATOR ( Data_Connector[1] ) SELECT Account_Number, Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current FROM OPERATOR( Select_Accounts[1] ););
Notice that this operator involves only a single instance and a single session. This script will typically run slower than the Export operator script.
54 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataCombining Data Sources
To run this script
1 Copy and paste the script verbatim from “SQL Selector Job Example” on page 53 to a file named Select1000.txt.
2 Change the “xxxxxx” attributes to a valid username, password, and the Tdpid of the system being used.
3 Type the following at the command prompt:
tbuild -f Select1000.txt
Combining Data Sources
The UNION ALL operation allows data from different sources to be combined into a single data stream that is then applied to one or more data targets. The UNION ALL operation reduces the need to manually merge data sources as inputs to a load operation.
For example, assume that three separate inputs need to be loaded into a target table: one of the inputs comes from a flat file using the Data Connector operator, one comes from a table extraction using the Export operator, and the third comes from a non-Teradata database using the ODBC operator. Assuming that all three of these inputs share the same schema definition, they can be UNIONed together into a single data stream as input to an APPLY statement.
Acquiring source data is typically an I/O bound process, particularly when data is acquired sequentially, one file at a time. With UNION ALL, all operators involved in an operation are working in parallel. The result is that the time to acquire source data is shorter than the time needed to acquire the same data serially, as with a standalone utility.
Use UNION ALL with the SELECT portion of an APPLY statement, as shown in the following example.
UNION ALL Example
Following is an example of a script that uses UNION ALL. The script combines two Teradata data sources (data exported from existing tables Customer1 and Customer2 by the Export operator) into a single input data stream that is loaded into the Customer table by the Load operator:
DEFINE JOB LOAD_CUST_TBL_FROM_TWO_DATA_STREAMSDESCRIPTION 'Load Customer Table From Two Data Streams'(DEFINE SCHEMA CUSTOMER_SCHEMADESCRIPTION 'CUSTOMER SCHEMA'(
Cust_Num INTEGER,Last_name CHAR(30),First_name CHAR(20),Soc_Sec_No INTEGER
);
DEFINE OPERATOR DDL_OPERATOR
Teradata Warehouse Builder User Guide 55

Chapter 3: Extracting DataCombining Data Sources
DESCRIPTION 'Teradata PT DDL OPERATOR'TYPE DDLATTRIBUTES(
VARCHAR PrivateLogName = 'Cust_DDL_Log',VARCHAR TdpId = @Tdpid,VARCHAR UserName = @Userid,VARCHAR UserPassword = @Pwd,VARCHAR AccountID,VARCHAR ErrorList = '3807'
);
DEFINE OPERATOR EXPORT_OPERATORDESCRIPTION 'EXPORT OPERATOR'TYPE EXPORTSCHEMA CUSTOMER_SCHEMAATTRIBUTES(
VARCHAR PrivateLogName,VARCHAR TdpId = @Tdpid,VARCHAR UserName = @Userid,VARCHAR UserPassword = @Pwd,VARCHAR AccountId,VARCHAR SelectStmt
);
DEFINE OPERATOR LOAD_OPERATORDESCRIPTION 'Teradata PT LOAD OPERATOR'TYPE LOADSCHEMA *ATTRIBUTES(
VARCHAR TargetTable = 'CUSTOMER',VARCHAR TdpId = @Tdpid,VARCHAR UserName = @Userid,VARCHAR UserPassword = @Pwd,VARCHAR AccountId,VARCHAR LogTable = 'Two_Streams_log'
);
STEP A_Setup_Tables(APPLY
('DROP TABLE Customer;'),('CREATE SET TABLE Customer ( Customer_Number INTEGER NOT NULL, Last_Name CHAR(30) , First_Name CHAR(20) , Social_Security INTEGER)UNIQUE PRIMARY INDEX ( Customer_Number );')
TO OPERATOR (DDL_OPERATOR ););
STEP B_Load_Data_From_Two_Streams(APPLY
56 Teradata Warehouse Builder User Guide

Chapter 3: Extracting DataCombining Data Sources
('INSERT INTO CUSTOMER (:CUST_NUM, :LAST_NAME, :FIRST_NAME, :SOC_SEC_NO);')TO OPERATOR (LOAD_OPERATOR [1] )
SELECT * FROM OPERATOR(EXPORT_OPERATOR [1]ATTR(SelectStmt = 'SELECT Customer_Number ,Last_Name ,First_Name ,Social_security FROM Customer1 WHERE Customer_Number LT 6001;'))
UNION ALLSELECT * FROM OPERATOR(EXPORT_OPERATOR [1]ATTR(SelectStmt = 'SELECT Customer_Number ,Last_Name ,First_Name ,Social_Security FROM Customer2 WHERE Customer_Number BETWEEN 6001 AND 9000; '));););
Notice the following about this script:
• Load combines two inputs into a single data stream.
• Physical flat files are not needed to hold the exported rows.
• The data streams are created using the Export operator.
• The DataConnector operator is not necessary because there are no external files.
• The job consists of two steps, and therefore, two APPLY statements:
• Use DDL operator to DROP and CREATE the Customer table.
• Use the UNION ALL syntax to combine two exported outputs into a single input data stream that is loaded into the Customer table by the Load operator.
• The job will run quickly due to the absence of physical file reads and writes.
To run this script
1 Copy the above script into a new file in the directory from which Teradata PT is executed, and save with a unique file name, such as union_all2.txt.
2 Make sure that a global job variables file exists (defined by the GlobalAttributeFile attribute) that contains the valid userid, password, and the Tdpid of the system being used for all operators.
Teradata Warehouse Builder User Guide 57

Chapter 3: Extracting DataUsing the Large Decimal Teradata Database Feature
3 Type the following at the command prompt:
tbuild -f union_all2.txt -v GlobalAttributeFile
Using the Large Decimal Teradata Database Feature
The Teradata PT Export operator optional attribute MaxDecimalDigits allows Teradata PT to use the Large Decimal functionality of the Teradata Database. But what if MaxDecimalDigits is set and the Teradata Database or the CLIv2 does not support this feature? Using the IgnoreMaxDecimalDigits attribute allows the Teradata PT job to continue. This attribute is available to the Export and SQL Selector operators.
Figure 7 depicts the logic flow used to determine if the Teradata PT job will continue. The main decision points are:
• Is MaxDecimalDigits a valid value? Then 18 <= MaxDecimalDigits <= 38. If the value does not fall in this range, a warning message is issued and the job will continue.
• Next, if the IgnoreMaxDecimalDigits attribute is set, continue to determine if the Teradata Database and CLI versions support the Large Decimal feature.
The job will terminate with an Exit code of eight and an error message if IgnoreMaxDecimalDigits has not been set and either the Teradata Database and CLI levels do not support the Large Decimal feature.
If the Teradata Database and CLI versions do not support the Large Decimal feature and the IgnoreMaxDecimalDigits attribute is set, continue the job.
The Export and SQL Selector operators should not terminate the job when the Large Decimal feature in not supported because the maximum returned decimal digits is 18 which is in the valid range.
• If the versions are supported and the MaxDecimalDigits attribute is not a valid value, display a message and continue the job with a Exit code of four.
• If either the Teradata Database or CLI version do not support the Large Decimal feature, and MaxDecimalDigits is a valid value but the IgnoreMaxDecimalDigits attribute is not set, display a message and continue the job with an Exit code of 4.
For complete information on the MaxDecimalDigits and IgnoreMaxDecimalDigits attributes, see the Teradata Parallel Transporter Reference.
58 Teradata Warehouse Builder User Guide
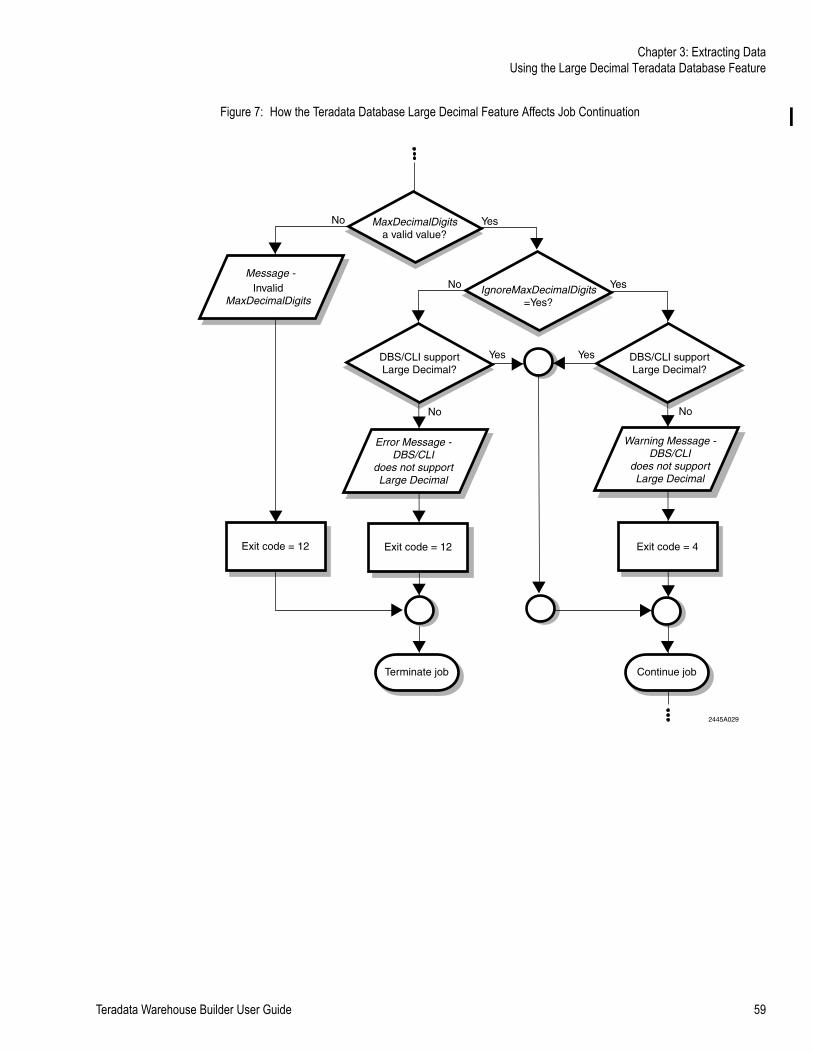
Chapter 3: Extracting DataUsing the Large Decimal Teradata Database Feature
Figure 7: How the Teradata Database Large Decimal Feature Affects Job Continuation
2445A029
No
Yes
MaxDecimalDigitsa valid value?
Yes
InvalidMaxDecimalDigits
Message -
DBS/CLI supportLarge Decimal?
IgnoreMaxDecimalDigits=Yes?
DBS/CLI supportLarge Decimal?
Error Message -DBS/CLI
does not supportLarge Decimal
Warning Message -DBS/CLI
does not supportLarge Decimal
Exit code = 12
Terminate job Continue job
Exit code = 4
YesNo
Yes
No No
Exit code = 12
Teradata Warehouse Builder User Guide 59

Chapter 3: Extracting DataUsing the Large Decimal Teradata Database Feature
60 Teradata Warehouse Builder User Guide

CHAPTER 4
Loading Data
Teradata PT provides multiple operators for loading data from internal or external data sources.
• Loading with the Load Operator
• Loading with the SQL Inserter Operator
Loading with the Load Operator
The Load operator is a consumer operator that, like the Teradata FastLoad utility, can load large numbers of rows at a high speed into a single, empty Teradata table. This operator is typically used for initial loading of Teradata tables as it inserts the data it consumes from data streams into individual rows of a target table. Multiple parallel instances of the Load operator can improve performance because all instances are concurrently loaded. Inserting is the only operation supported by this operator.
The data sources for the Load operator can be a Teradata Database, flat files, queues, ODBC sources, access modules, or a named pipe. A target table on a Teradata Database must already exist before a Load job is run, and the table must be empty, with no defined secondary or join indexes.
Space Requirements
Always estimate the final size of the Load target table to ensure that the destination on a Teradata Database has enough space to accommodate a Load operator job.
If the system that owns a Load target table, log table, or error tables runs out of space, Teradata Database returns an error message, then the Load operator job terminates. Additional space must be allocated to the database before the job can be restarted.
Load Operator Definition
Following is an example of a Load operator definition. Most attributes can be defaulted. Comments about a few key attributes (shown bold) are included.
DEFINE OPERATOR LOADOPDESCRIPTION 'Teradata PT LOAD OPERATOR'TYPE LOADSCHEMA INPUT_SCHEMAATTRIBUTES(
Teradata Warehouse Builder User Guide 61

Chapter 4: Loading DataLoading with the Load Operator
INTEGER ErrorLimit, /*Max. errors allowed in error tables before terminating the job.*/INTEGER BufferSize,INTEGER TenacityHours,INTEGER TenacitySleep,INTEGER MaxSessions,INTEGER MinSessions,VARCHAR TraceLevel,VARCHAR LogTable, /*Required attribute. Name of restart log table.*/VARCHAR TargetTable, /*Table to be loaded.*/VARCHAR ErrorTable1, /*Captures data errors as described above.*/VARCHAR ErrorTable2, /*Captures unique primary index violations.*/VARCHAR TdpId,VARCHAR UserName,VARCHAR UserPassword,VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR AccountId,VARCHAR PrivateLogName,VARCHAR WorkingDatabase,VARCHAR PauseAcq, /* 'Y' pauses the load operation prior to application phase.*/VARCHAR NotifyExit,VARCHAR DateForm,VARCHAR NotifyExitIsDll,VARCHAR NotifyLevel,VARCHAR WildcardInsert /*'Y' builds the INSERT statement from the target table definition, similar to a HELP TABLE statement in a FastLoad script. Use when input file schema exactly matches table schema. Permits the INSERT portion of the APPLY statement to simply specify INSERT INTO tablename, which reduce the amount of user coding.*/);
About This Definition
Session Limits
A Teradata Database consideration, a minimum and a maximum number of sessions (the session limits) can be specified for the Load operator. Both can also be specified for the Export and Update operators.
Consider the following usage notes which apply to all three types of operators.
• The maximum sessions connected can never exceed the number of available AMPs in the system, even if a larger number is specified.
• The default is one session per available AMP.
• For the MinSessions attribute, the minimum specification is one AMP.
• The MaxSessions attribute can be set to a number smaller than the number of AMPs on the database server if fewer sessions are suitable for the job.
• Network protocol software might also impose limits on network-attached systems.
• Platform limits for maximum sessions per application differ:
• On channel-attached MVS client system, use the TDP SET MAXSESSIONS command to specify a platform limit.
62 Teradata Warehouse Builder User Guide

Chapter 4: Loading DataLoading with the Load Operator
• On network-attached UNIX, Linux, and Windows client systems, this value is defined in the CLI file, clispb.dat, under the max_num_sess variable.
• On channel-attached MVS client systems, this value is defined in the HSHSPB parameter under the IBCSMAX setting.
The max_num_sess value in the clispb.dat file (or HSHSPB) specifies the total number of sessions allowed to be connected by a single application at one time. However, the Export, Load, and Update operators connect SQL sessions in addition to the specialized data loading sessions (these sessions have a restriction of one per AMP). The max_num_sess pertains to all sessions connected, both SQL and data loading.
Limits to Load Jobs
The Load operator requires one designated Teradata Database active job; however, the number of concurrent load tasks is also configurable in the Teradata Database environment using the same MaxLoadTasks field control used by FastLoad, FastExport, and MultiLoad. For example, one FastLoad job equates to one Teradata PT Load job in the count for MaxLoadTasks. For more information, see the “DBS Control Utilities” section of Utilities - Volume 1.
Caution: Simultaneously running many Teradata PT jobs might impact other running Teradata Database processes and applications.
Load Phases
Load operations have two phases:
• Acquisition Phase - Data from the input stream is transmitted to the AMPs. The AMPs 'acquire' the data, so to speak. The acquisition phase is not complete until all data sources are exhausted and all data rows are on the appropriate AMPs. The data is not yet sorted or blocked, and therefore, is not yet accessible.
• Application Phase - Data is sorted, blocked, and put into its final format. All activity in this phase is AMP-local. Data is accessible after the completion of this phase.
Staged Loading
Staged loading is the ability to pause an active load operation until additional data is available.
If a single table needs to be filled with the contents of three files, for example, usually all three files are streamed to look like a single source to Teradata PT. But if one of the files will not exist until the next day, it is possible to load in stages. In other words, Teradata PT can load the first two files, pause the Load operation, and then load the third file when it is available.
Staged loading is set by the attribute PauseAcq = 'Y', which prevents the Load operator from proceeding to the application phase. Each stage of the load operation is accomplished with a separate job script: one for the acquisition phase, and one for the application phase.
For example, to accomplish the scenario with three files (one of which is unavailable until the next day), run Job1 on Day 1 using the two existing files as input to the load, with the PauseAcq = 'Y' setting.
Teradata Warehouse Builder User Guide 63

Chapter 4: Loading DataLoading with the Load Operator
When this stage of the job is finished, the target table is paused and becomes inaccessible to users. Attempts to access the target table (or the error tables) return the following error message:
Operation Not Allowed <tablename> is being loaded
On Day 2, restart the paused job by running Job2 using the third, newly available file as input. For this stage, set PauseAcq = 'N'. When this stage of the job finishes, the table is fully loaded and ready for access.
Caution: A paused table, though inaccessible, can be dropped.
Restart Log Table
A restart log table, which contains restart information written during job runs, is required for any execution of the Load operator. Specify a restart log table in scripts with the LogTable attribute.
Restarts (as discussed in “Staged Loading” on page 63) are common during staged loading operations. When additional data is available after a job is paused, the job is restarted by submitting a second script that specifies the additional data. The Load operator recognizes the job as a restart, reads the restart log to determine the status of the job, then loads the additional file.
Restarts can also occur following any unexpected error on a database. For example, if a table runs out of available space during a load operation, the job terminates, the table is paused, and a checkpoint is recorded in the restart log. Pausing the job in this way allows you to manually increase the available space, if needed, then restart the job because the load operation can restart a job from the last checkpoint in the restart log.
Checkpoint and Restart
The Load operator takes checkpoints at the beginning and end of the acquisition phase. More granular checkpoints during the acquisition phase can be specified using the command line option -z when running Teradata PT using the tbuild command. The -z option specifies checkpoint intervals in terms of seconds.
The following command string is an example of the -z option:
tbuild -f <file name> -z 30
In this command string, the -f option indicates the script that is input to tbuild, and the -z option indicates that a checkpoint will be taken every 30 seconds.
The DEFINE JOB statement can also be used to specify a checkpoint value. For more information, see “DEFINE JOB” in the Teradata Parallel Transporter Reference.
Checkpointing during the application phase is managed internally by the Teradata Database, and therefore is not user-controlled.
Error Tables
Load operations create two error tables, called data errors and duplication errors, that capture errors during job runs. Jobs can use the default names of the error tables, or names can be user-specified as an attribute of the Load operator. Consider the following:
64 Teradata Warehouse Builder User Guide

Chapter 4: Loading DataLoading with the Load Operator
• If a job generates no errors, the error tables is empty. They are automatically dropped at the end of the job.
• If errors are generated, error tables are retained at the end of a job.
• To rerun jobs from the beginning, either delete the associated error tables or rename them, otherwise an error message results, stating that the error tables already exist.
• Conversely, to restart a Load job, an error table must already exist. In other words, do not delete error tables to restart a load job.
• To reuse names specified for error tables, use the DROP TABLE statement in the BTEQ utility or the DDL operator to remove the tables from the Teradata Database.
Errors are captured in ErrorTable1 and ErrorTable2, which separate information as follows:
• Error Table 1 contains most of the errors relating to data and the data environment. The following types of errors are captured:
• Constraint violations - Records that violate a range or value constraint defined for specific columns of a table.
• Unavailable AMP - Records to be written to a non-fallback table about an offline AMP.
• Data conversion errors - Records that fail to convert to a specified data type.
• Error Table 2 contains all of the rows that have violations of the unique primary index. This error table is not used when the target table has a non-unique primary index.
Duplicate Rows
Duplicate rows, which are exact duplicates of existing table rows, are never inserted, even if the target table is defined as a multiset table, which usually permits duplicate rows. Therefore, duplicate row violations are not captured in either error table. Instead, they are counted and reported in the status log at the end of a job.
If a table has a unique primary index, a duplicate row situation takes precedence over a duplicate primary index error, meaning that the offending row is counted and reported, but it is not captured in Error Table 2.
Error Limits
While loading large amounts of data, it is possible that a single data error might be repeated for each input record. Because an error can often be corrected long before errors are generated for all of the records in a job run, consider using the ErrorLimit attribute to specify a limit to the number of errors that can be tolerated before a job is terminated.
This limit, which is specified with the ErrorLimit attribute, represents the combined total of errors written to the two error tables per instance of the Load operator, not to all instances combined. Therefore, if an error limit is set to 1,000, a single load instance must detect that 1,000 rows are inserted into the error tables before the job is terminated.
The error limit can also be reached at checkpoint time; see the examples below.
Teradata Warehouse Builder User Guide 65

Chapter 4: Loading DataLoading with the Load Operator
Error Limit Examples
To illustrate how Teradata PT determines if the number of errors has reached the Error Limit, consider these examples if there are two instances running and the Error Limit has been set to 1000.
• If either instance by itself reaches 1000, it will terminate the job by returning a fatal error.
• If instance #1 processes 500 error rows and instance #2 processes 500 error rows but does not reach a checkpoint. The job will continue processing.
• If instance #1 processes 500 error rows and instance #2 processes 500 error rows but does reach a checkpoint. The total number of error rows for all instances combined is determined at checkpoint time and at the end of the Acquisition Phase. If the total of all instances exceeds the error limit at that time, the job will terminate with an error.
Load Job Example
Following is an example of a script that uses the Load operator to load 1,000 rows to a table called Accounts. It assumes that the “Export Job Example” on page 48 has been run, resulting in an exported flat file that is used here as input. As in the Export example, a DataConnector operator needs to be defined, but this time it reads the input file as a producer operator. The Schema definition must also state the layout of the table and of the file to be read. In this case, both layouts are the same, so only a single schema definition is needed.
66 Teradata Warehouse Builder User Guide

Chapter 4: Loading DataLoading with the Load Operator
DEFINE JOB Fload_From_Exported_fileDESCRIPTION 'Load 1000 rows to empty Accounts table' (
DEFINE OPERATOR Load_Operator TYPE LOAD
SCHEMA *ATTRIBUTES(VARCHAR UserName, VARCHAR UserPassword, VARCHAR LogTable, VARCHAR TargetTable, VARCHAR ErrorTable1,
VARCHAR ErrorTable2, VARCHAR PauseAcq,
VARCHAR PrivateLogName, VARCHAR TdpId );DEFINE SCHEMA Account_Schema (
account_number INTEGER,number INTEGER,street CHARACTER(25),city CHARACTER(20),state CHARACTER(2),zip_code INTEGER,
balance_forward DECIMAL(10, 2),balance_current DECIMAL(10, 2));
DEFINE OPERATOR Data_ConnectorTYPE DATACONNECTOR PRODUCER
SCHEMA Account_Schema ATTRIBUTES ( VARCHAR FileName, VARCHAR Format, VARCHAR OpenMode, VARCHAR DirectoryPath,
VARCHAR IndicatorMode );
APPLY ( 'INSERT INTO accounts (Account_Number,Number,Street,City,State,Zip_Code ,Balance_Forward,Balance_Current)
VALUES (:account_number,:number,:street,:city,:state,:zip_code ,:balance_forward,:balance_current);' ) TO OPERATOR
DEFINE JOB• Name of the job is Fload_From_Exported _file.
DEFINE OPERATOR Load_Operator• Name of the first operator is
Load_Operator.• The SCHEMA * syntax means the schema
syntax is deferred. See “Deferred Schemas,” next page.
• Attributes are specified but not valued; they are valued in the APPLY statement.
DEFINE SCHEMA• Name of schema is Account_Schema.• It defines the layout of the Accounts table
and input file.• Both defined operators use this schema.
DEFINE OPERATOR Data_Connector• This is the DataConnector as a producer
because it produces data for the Load operator.
• It references Account_Schema as the input file layout.
• Attributes include file name, its format, and indicator mode.
• Attributes are valued in the APPLY statement.
APPLY Statement(TO OPERATOR) • This APPLY statement is like an SQL
INSERT/SELECT.• The TO operator is the Load operator,
and the output is going to a table.• A single instance [1] of the operator is
requested.
Teradata Warehouse Builder User Guide 67

Chapter 4: Loading DataLoading with the Load Operator
(Load_Operator[1]
ATTRIBUTES(
UserName = 'xxxxx', UserPassword = 'xxxxxx', LogTable = 'accounts_log',
TargetTable = 'Accounts', TdpId = 'xxxxxx'
))
SELECT account_number, number, street, city, state, zip_code, balance_forward, balance_current
FROM OPERATOR(Data_Connector[1]
ATTRIBUTES(
FileName = 'Export_1000', Format = 'FORMATTED', OpenMode = 'Read', IndicatorMode = 'Y'
) ); );
Notice the following about this script:
• The job has a single job step that is unnamed. It begins with the APPLY statement.
• All attributes are explicitly valued in the APPLY statement rather than in the DEFINE sections.
• Only attributes that are valued (as opposed to defaulted) need to be included in the DEFINE statements.
• The script includes a deferred schema. For more information, see “Deferred Schemas (SCHEMA *)” on page 68.
Options with Load Operations
Consider the following options for Load operations.
Deferred Schemas (SCHEMA *)
Instead of explicitly naming a schema in an operator definition, it is often appropriate to defer a schema until a certain phase of a job is ready to execute in order to prevent a job from terminating. Deferrals only work with consumer operators, such as a Load operation. Use the following syntax:
SCHEMA *
APPLY Statement(FROM OPERATOR)
• The FROM OPERATOR clause of the APPLY statement is the input portion.
• The FROM operator is the DataConnector operator, which produces the input stream.
• The explicit SELECT statement precisely defines the elements to be produced relative to the schema definition.
• A single instance [1] of the operator is requested.
68 Teradata Warehouse Builder User Guide

Chapter 4: Loading DataLoading with the SQL Inserter Operator
Consumer operators (like Load) use the schema as input, meaning that the schema definition specifies what input data is read (or consumed). It is possible that a filter operator might alter a schema during a job. It is also possible that data input changes during the course of a job.
For example, if a given data stream contains eight fields of data although the SELECT portion of an APPLY statement states that it will read only six of the loaded fields, the schema definition can be deferred until that phase of the job is ready to execute. Without the deferred schema, the job would compare the data stream against the SELECT portion, then declare a mismatch, resulting in an error.
Therefore, it is generally advised that deferred schemas always included in the definitions of consumer operators. An explicit schema definition is advised only it a schema definition will not change, such as when consumed data and loaded data are identical.
For an example of a deferred schema in a load script, see “Load Job Example” on page 66.
Loading with the SQL Inserter Operator
The SQL Inserter operator is a consumer operator that accepts data from other operators, and then inserts the data into a specified table on a Teradata Database. It is similar in function to a BTEQ Import operation.
This operator uses a single SQL session to insert data records into a target table on a Teradata Database. The target table can either be populated or unpopulated. The operator immediately terminates if a duplicate data row is inserted.
Usually the SQL Inserter operator is not used for massive data loading because it is slower than the other load operators. Because the operator uses only one session, and because it does not support multiple instances, it does not take advantage of Teradata PT parallel processing.
To protect data integrity, the SQL Inserter operator treats the entire loading job as a single explicit transaction. Any error during an insert operation causes the SQL Inserter operator to back out all rows of data inserted up to that point.
SQL Inserter Advantage
To load large amounts of data, it is usually better to use the Load operator, but for smaller load jobs, the SQL Inserter might perform better that most load jobs because it does not need to set up multiple sessions to run.
One other advantage is that the SQL Inserter operator does not require an active load job. It simply uses standard SQL protocol on a single session. If it is difficult to acquire DBS resources for running concurrent tasks, the SQL Inserter operator has advantages over the Load operator.
A disadvantage is that the SQL Inserter operator is not restartable.
Teradata Warehouse Builder User Guide 69

Chapter 4: Loading DataLoading with the SQL Inserter Operator
SQL Inserter Operator Definition
Following is an example of a SQL Inserter operator definition. Most attributes can be defaulted.
DEFINE OPERATOR SQL_INSERTERDESCRIPTION 'Teradata PT SQL Inserter Operator'TYPE INSERTERSCHEMA *ATTRIBUTES(
VARCHAR TraceLevel,VARCHAR PrivateLogName,VARCHAR Tdpid = 'MyDatabase',VARCHAR UserName = 'MyUser',VARCHAR UserPassword = 'MyPassword',VARCHAR AccountId,VARCHAR DateForm,VARCHAR PrivateLogName,VARCHAR DataEncryption,VARCHAR LogonMech,VARCHAR LogonMechData
);
SQL Inserter Job Example
Following is an example script that uses the SQL Inserter operator. This script does exactly the same thing as the “Load Job Example” on page 66, that is, it loads 1000 rows from a flat file into the Accounts table.
DEFINE JOB INSERT_1000_ROWS DESCRIPTION 'INSERTER Operator to load 1000 rows to empty Accounts table' (DEFINE OPERATOR INSERT_OPERATOR TYPE INSERTER
SCHEMA *ATTRIBUTES(VARCHAR UserName,
VARCHAR UserPassword, VARCHAR PrivateLogName, VARCHAR TdpId,
VARCHAR TraceLevel );
DEFINE SCHEMA ACCOUNT_SCHEMA ( account_number INTEGER, number INTEGER, street CHARACTER(25), city CHARACTER(20), state CHARACTER(2), zip_code INTEGER, balance_forward DECIMAL(10, 2), balance_current DECIMAL(10, 2) );
70 Teradata Warehouse Builder User Guide

Chapter 4: Loading DataLoading with the SQL Inserter Operator
DEFINE OPERATOR DATA_CONNECTOR TYPE DATACONNECTOR PRODUCER
SCHEMA ACCOUNT_SCHEMA ATTRIBUTES
( VARCHAR FileName,
VARCHAR Format, VARCHAR OpenMode, VARCHAR DirectoryPath, VARCHAR IndicatorMode );APPLY
('INSERT INTO Accounts (Account_Number,Number,Street,City,State
,Zip_Code,Balance_Forward,Balance_Current) VALUES (:account_number,:number,:street,:city,:state,:zip_code ,:balance_forward,:balance_current);'
) TO OPERATOR (
INSERT_OPERATOR[1]
ATTRIBUTES(UserName = 'xxxxxx',
UserPassword = 'xxxxxx', TdpId = 'xxxxxx'
) ) SELECT account_number, number, street, city, state, zip_code, balance_forward, balance_current
FROM OPERATOR ( DATA_CONNECTOR[1] ATTRIBUTES (
FileName = 'EXPORT_1000', Format = 'FORMATTED', OpenMode = 'Read', IndicatorMode = 'Y' ) ););
Notice the following about this script:
• Data Connector operator is needed to read the input file.
• This job will most likely run slower than the Load job due to the single session nature of the operation.
Teradata Warehouse Builder User Guide 71

Chapter 4: Loading DataLoading with the SQL Inserter Operator
To run this script
1 Copy and paste “SQL Inserter Job Example” on page 70 verbatim to a file named SQL_Inserter.txt.
2 Change the “xxxxxx” attributes to a valid username, password, and the Tdpid of the system being used.
3 Create a flat file named as input.
4 Create an Accounts table.
5 Enter the following at the command prompt:
tbuild -f SQL_Inserter.txt
72 Teradata Warehouse Builder User Guide

CHAPTER 5
Updating Data
Teradata PT provides multiple operators for updating data from internal or external data sources.
• Deciding Between Operators
• Updating with the Update Operator
• Delete Task Option
• Updating with the Stream Operator
Deciding Between Operators
Both the Update and Stream operators are consumer operators that can perform inserts, updates, deletes, and upserts into target tables. Deciding between these operators involves many trade-offs and considerations. It is recommended that the Teradata Professional Services organization be contacted for specific guidance. The items in this table are simply considerations.
Table 5: Operator Comparison - Update Versus Stream
Update Operator Stream Operator
Volume Performs high-volume updates against a large number of rows.
Works better for low-volume batch maintenance.
Performance Performance improves as the volume of updates increases.
Performance improved with multi-statement requests.
Lock Granularity Bulk updates at block level. Must lock all tables, which prevents access until complete.
Rows are not available until the load job is complete.
Does not fully lock target tables during updates. Instead, uses standard SQL locking protocols to individually lock rows as updates are applied, which permits concurrent read and write access to target tables by other users.
Rows are immediately available for access once the transaction is complete.
Number of Tables No more than 5. Up to 127.
Teradata Warehouse Builder User Guide 73
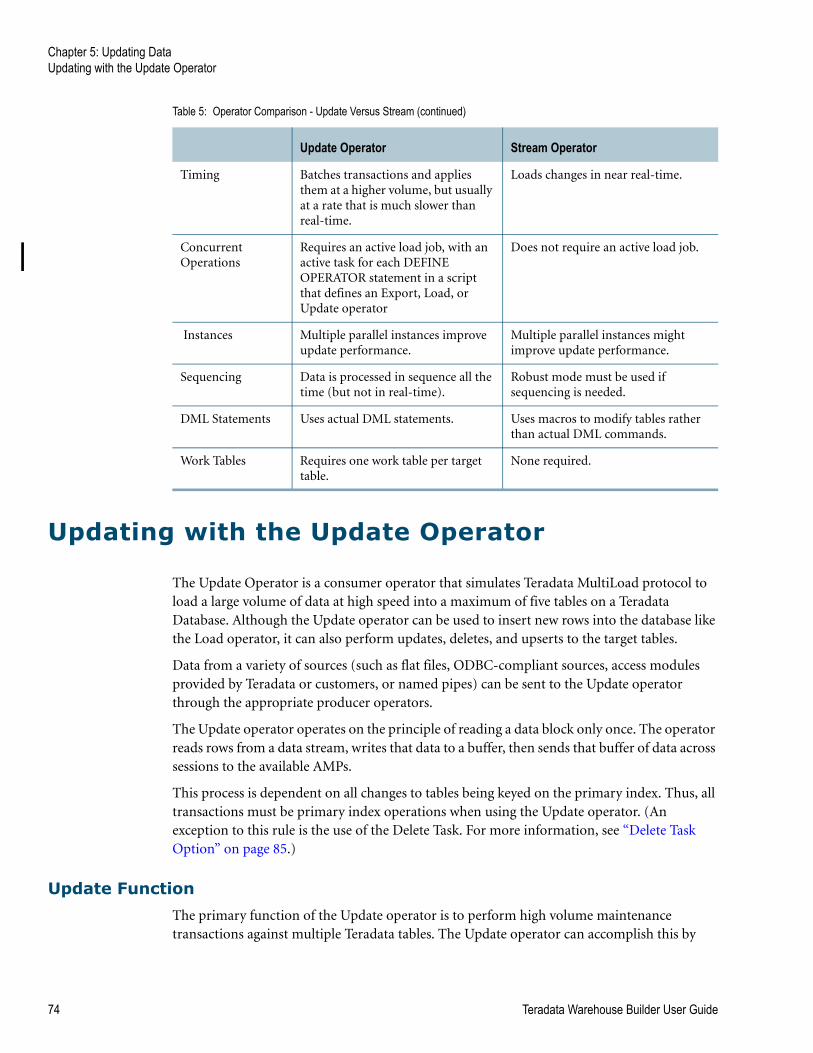
Chapter 5: Updating DataUpdating with the Update Operator
Updating with the Update Operator
The Update Operator is a consumer operator that simulates Teradata MultiLoad protocol to load a large volume of data at high speed into a maximum of five tables on a Teradata Database. Although the Update operator can be used to insert new rows into the database like the Load operator, it can also perform updates, deletes, and upserts to the target tables.
Data from a variety of sources (such as flat files, ODBC-compliant sources, access modules provided by Teradata or customers, or named pipes) can be sent to the Update operator through the appropriate producer operators.
The Update operator operates on the principle of reading a data block only once. The operator reads rows from a data stream, writes that data to a buffer, then sends that buffer of data across sessions to the available AMPs.
This process is dependent on all changes to tables being keyed on the primary index. Thus, all transactions must be primary index operations when using the Update operator. (An exception to this rule is the use of the Delete Task. For more information, see “Delete Task Option” on page 85.)
Update Function
The primary function of the Update operator is to perform high volume maintenance transactions against multiple Teradata tables. The Update operator can accomplish this by
Timing Batches transactions and applies them at a higher volume, but usually at a rate that is much slower than real-time.
Loads changes in near real-time.
ConcurrentOperations
Requires an active load job, with an active task for each DEFINE OPERATOR statement in a script that defines an Export, Load, or Update operator
Does not require an active load job.
Instances Multiple parallel instances improve update performance.
Multiple parallel instances might improve update performance.
Sequencing Data is processed in sequence all the time (but not in real-time).
Robust mode must be used if sequencing is needed.
DML Statements Uses actual DML statements. Uses macros to modify tables rather than actual DML commands.
Work Tables Requires one work table per target table.
None required.
Table 5: Operator Comparison - Update Versus Stream (continued)
Update Operator Stream Operator
74 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Update Operator
using multiple sessions to perform inserts, updates, deletes, and upserts involving up to five Teradata tables in a single pass. The Update operator cannot perform SELECT operations.
Additionally, the Update operator does the following:
• Loads large volumes of data into a Teradata Database.
• Accepts specialized processed input data from an INMOD Adapter operator.
• Takes advantage of available sessions and multiple instances.
• Supports error limits.
• Uses two error tables and a single work table per target table.
Supported Operations
The Update operator supports the standard DML operations of INSERT, UPDATE, and DELETE. It also supports upsert processing, a convention of batch processing systems where a row is updated if it exists, but is inserted if it does not exist.
The Update operator also supports a Delete Task option that permits the high-speed deletion of table rows based on a non-index value. For more information, see “Delete Task Option” on page 85.
Update Operator Definition
Following is an example of an Update operator definition. Most of the attributes can be defaulted, except for:
• UserName
• UserPassword
• TargetTable
• LogTable
Comments about a few key attributes (shown bold) are included. Additional discussion of some attributes follow this definition:
DEFINE OPERATOR UPDATE_OPERATORDESCRIPTION 'Teradata PT UPDATE OPERATOR'TYPE UPDATESCHEMA *ATTRIBUTES(INTEGER ErrorLimit = 1, /*Max. errors allowed in error tables before terminating the job.*/VARCHAR PauseAcq,VARCHAR TdpId = 'Tdpid',VARCHAR UserName = 'Userid',VARCHAR UserPassword = 'Password',VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR AccountID,VARCHAR ARRAY TargetTable = ['TEST1','TEST2'], /*Target table to be loaded. ARRAY is required only when targeting multiple tables. */VARCHAR ARRAY ErrorTable1 = ['TEST1_ET','TEST2_ET'], /*One per each target table. Captures data errors.*/
Teradata Warehouse Builder User Guide 75

Chapter 5: Updating DataUpdating with the Update Operator
VARCHAR ARRAY ErrorTable2 = ['TEST1_UV','TEST2_UV'], /*One per each target table. Captures unique primary index violations.*/VARCHAR ARRAY WorkTable = ['TEST1_WT','TEST2_WT'], /*One per each target table. Used in acquisition phase.*/VARCHAR LogTable = 'My_log', /*Required attribute to specify the name of restart log table.*/VARCHAR PrivateLogName = 'Private_Log', /*A status log kept for this operator only.*/VARCHAR WorkingDatabase,VARCHAR NotifyMethod,VARCHAR NotifyLevel);
About This Definition
Consider the following when running the Update operator.
Limits to Update Jobs
The Update operator requires one active load job. In addition, an active task is needed and counted towards the maximum number of active load tasks permitted only when an operator is running, not for each DEFINE OPERATOR statement in a script that defines an Export, Load, or Update operator. A script may have many operators defined and only use one of them. The number of active load tasks is configurable in the Teradata environment.
In an APPLY-SELECT statement, there is one active task for each operator that is specified. An active task is counted for the database to which the operator has connected.
For example, an Export operator is connected to DBS “A,” sending data to the Load operator connected to DBS “B.” There is an active load job counted for DBS “A” and one on DBS “B.” Similarly, there could be one Export operator defined in a script, but actually two instances are active because there are two SELECT statements (connected with a UNION ALL) in the APPLY-SELECT statement.
So the number of active tasks does not necessarily relate to how many DEFINE OPERATOR statements that are in a script. The number of active tasks can be determined by how many operators are specified in the APPLY-SELECT statement.
In most Teradata systems, a maximum of 15 active load tasks is permitted; however, the number of concurrent load tasks can be dynamically allocated and may exceed 15, depending on the version of the Teradata Database being used. Consult the Teradata Parallel Transporter Reference for more information.
Sessions
For other general notes, see “Session Limits” on page 62. For detailed information about sessions and instances, see “Coding Job Scripts” in the Teradata Parallel Transporter Reference.
Error Tables
Update operations create two error tables for each target table. These error tables are similar to those used for the Load operator, but the Update error tables are typically named with the following suffixes to distinguish them. Consider the following:
76 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Update Operator
• Names for error tables can be defaulted or they can be explicitly named using the VARCHAR ARRAY ErrorTable attribute.
• If a job generates no errors, the error tables will be empty. They are automatically dropped at the end of the job.
• If errors are generated, the tables are retained at the end of the job so error conditions can be analyzed.
• To rerun a job from the beginning, either delete the error tables, or rename them, otherwise an error message results, stating that error tables already exist.
• Conversely, if you restart a job (not from the beginning), an error tables must already exist. In other words, do not delete error tables to restart an update job.
Errors are separated into two tables, as follows:
• Error Table (ET) contains most of the errors relating to data and the data environment.
The following types of errors are captured:
• Constraint violations records that violate a range constraint defined for the table.
• Unavailable AMP records that are written to a non-fallback table on an offline AMP.
• Data conversion errors records that fail to convert to a specified data type.
By default, this error table is assigned a name using the convention:
Target_Tablename_ET
• Uniqueness Violations (UV) contains all of the rows that have violations of a unique primary index.
By default, this error table is assigned a name using the following convention:
Target_Tablename_UV
Work Tables
Update operations create one work table for each target table, using the following naming convention:
Target_TableName_WT
As with the error tables, these default names can be overridden. Use the VARCHAR ARRAY WorkTable attribute.
Error Capture
When running insert, update, delete, or upsert requests, errors can occur due to missing or duplicate rows. When errors occur, the request is rolled back and the error is normally reported. Use the APPLY statement to specify how to handle this type of error:
• MARK means the error is to be captured and recorded.
• IGNORE means the error is not to be recorded.
Specify whether errors are marked or ignored with the following in mind:
• DUPLICATE INSERT ROWS means an attempt to insert a duplicate row.
• DUPLICATE UPDATE ROWS means an update will result in a duplicate row.
• MISSING DELETE ROWS means an attempt to delete a row that is missing.
Teradata Warehouse Builder User Guide 77

Chapter 5: Updating DataUpdating with the Update Operator
• MISSING UPDATE ROWS means an attempt to update a row that is missing.
Duplicate Rows
Duplicate rows are exact duplicates of existing table rows. Control how duplicate rows are handled by the APPLY statement specification:
• MARK DUPLICATE INSERT ROWS means duplicate row inserts are captured in ErrorTable2. (This setting is the default.)
• IGNORE DUPLICATE INSERT ROWS means duplicate inserted rows are not captured.
Upserts
Upsert operations update rows if they already exist in a table, and insert new rows they do not already exist. Specified an upsert operation in an APPLY statement using the expression:
INSERT FOR MISSING UPDATE ROWS;
An upsert operation fails only if both the update and the insert fail.
Also, the following specification is usually included for upsert operations in anticipation of missing rows:
IGNORE MISSING UPDATE ROWS
Error Limits
The Update operator provides the same capability as the Load operator for setting a limit on the number of errors captured before a job is terminated. When updating large amounts of data, it is not uncommon to encounter a data error that occurs repeatedly on each input record. Because an error can often be corrected long before errors are generated for all of the records in a job run, consider using the ErrorLimit attribute to specify a limit to the number of errors that can be tolerated before a job is terminated.
Note that the ET table contains errors in rows detected during the acquisition phase (the loading of data). These are commonly data conversion errors. The second table is the UV table and contains rows that are detected to be in error during the application phase of the job. These errors are commonly “uniqueness violation” errors (hence the name UV).
The ErrorLimit specification applies to each instance of the Update operator, not to all instances combined. For example, if the limit is set to 1,000, a single instance must detect that 1,000 rows were inserted into error tables to terminate the job.
This limit is specified with the ErrorLimit attribute. Errors are counted only during the Acquisition Phase, so the number of error rows being placed in the ET table are counted towards the number set in the ErrorLimit attribute. This applies to each instance of the Update operator, not to all instances combined. Therefore, if an error limit is set to 1,000, a single load instance must detect that 1,000 rows are inserted into the error tables before the job is terminated.
The error limit can also be reached at checkpoint time; see the examples below.
78 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Update Operator
Error Limit Examples
To illustrate how Teradata PT determines if the number of errors has reached the Error Limit, consider these examples if there are two instances running and the Error Limit has been set to 1000.
• If either instance by itself reaches 1000, it will terminate the job by returning a fatal error.
• If instance #1 processes 500 error rows and instance #2 processes 500 error rows but does not reach a checkpoint. The job will continue processing.
• If instance #1 processes 500 error rows and instance #2 processes 500 error rows but does reach a checkpoint. The total number of error rows for all instances combined is determined at checkpoint time and at the end of the Acquisition Phase. If the total of all instances exceeds the error limit at that time, the job will terminate with an error.
Update Phases
Update operations have two phases:
• Acquisition Phase - Data from the input stream is transmitted to the AMPs, and access locks are placed on the target tables, limiting table access to read-only. The acquisition phase is complete when all data rows are on the appropriate AMPs where their changes will be applied.
Records are sorted according to the hash value of the primary index value. This sorting order becomes the sequence in which they are applied to a target table. Sorted records are placed in temporary work tables that require permanent space for the duration of the job.
One work table per target table is created by the Teradata Database. Because the acquisition phase involves writing only to work tables, target tables are left available for user access.
• Application Phase - Sorted input records are applied to data blocks of target tables using the appropriate DML commands (insert, update, delete). Each target block is read once into memory, and all changes are applied at that time. The access lock on target tables is upgraded to a write lock, so tables are not available for user access until the phase is complete. At the end of this phase, the work tables are dropped during a subsequent clean-up phase.
Checkpoint and Restart
The Update operator cannot be rolled back. Once changes are applied to target tables in the application phase, a job can only move forward. Since a target table cannot be returned to its original state, it is advisable to archive tables prior to running Update operations against them.
To restart a job from the beginning (and bypass the restart log table) do the following:
1 Drop the restart log table.
2 Drop the error and work tables.
3 Drop the checkpoint files.
To discontinue an Update operation and drop the target tables, do the following:
Teradata Warehouse Builder User Guide 79

Chapter 5: Updating DataUpdating with the Update Operator
1 Drop the restart log table.
2 Drop the error and work tables.
3 Drop the target tables.
The Update operator takes a checkpoint at the beginning and the end of the acquisition phase. More granular checkpoints during the acquisition phase can be specified using the -z option of the tbuild command, which specifies checkpoint intervals in terms of seconds. For example:
tbuild -f <file name> -z 30
In this example, the -f option specifies the name of the script that is input to tbuild, and the -z option indicates that a checkpoint is taken every 30 seconds.
For more information about checkpoints and restarts, see “Checkpoint Restartability” in the Teradata Parallel Transporter Reference.
Options with Update Operations
Consider the following options for Update operations.
VARCHAR ARRAY Tables
Target, error, and work table names can be specified in terms of VARCHAR ARRAY types if specifying more than one table, using the following syntax:
VARCHAR ARRAY TargetTable = ['table1', 'table2', ..., 'tableN']
You cannot specify more error or work tables than there are target tables defined, but you may specify fewer. If fewer error/work table names are defined than target tables, the Update operator creates a name for the error/work table:
• The first error table is ttnameN_ET
• The second error table is ttnameN_UV
• The work table is ttnameN_WT, where ttnameN is the name of the corresponding target table
Note: Target table names are truncated to 27 characters before the suffixes "_ET", "_UV", or "_WT" are appended.
For example, if the following is specified when no other error/work table specifications exist,
VARCHAR ARRAY TargetTable = ['targtable1', 'targtable2', 'thirdtable']
the Update operator creates the following error tables and work tables:
targtable1_ETtargtable1_UVtargtable1_WTtargtable2_ETtargtable2_UVtargtable2_WTthirdtable_ETthirdtable_UVthirdtable_WT
Note that each set of two error tables and one work table belong to a particular target table; the naming convention preserves the uniqueness of the associated target table.
80 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Update Operator
If you specify the following, the Update operator creates the necessary missing table names:
VARCHAR ARRAY TargetTable = ['ttname1','ttname2','ttname3']VARCHAR ARRAY ErrorTable1 = ['error_1']VARCHAR ARRAY ErrorTable2 = ['error_2']VARCHAR ARRAY WorkTable = ['work_1','work_2']
If you specify more error table names or work table names than there are target table names, the Update operator issues an error message and terminates the job.
If only one table is used, the ARRAY syntax is not needed. For example, with only one target table, you can use the following VARCHAR syntax:
VARCHAR TargetTable = 'ttname'
However, the ARRAY syntax still works for just one table.
Update Job Example
The following example includes callouts that explain each section of the script. The script transfers data to three tables using Export, DataConnector, and SQL Selector operators as producers and two instances of the Update operator.
Teradata Warehouse Builder User Guide 81

Chapter 5: Updating DataUpdating with the Update Operator
DEFINE JOB PRODUCT_SOURCE_LOADDESCRIPTION 'LOAD PRODUCT DEFINITION TABLE'(
DEFINE OPERATOR UPDATE_OPERATOR() DESCRIPTION 'Teradata PT UPDATE OPERATOR' TYPE UPDATE SCHEMA * ATTRIBUTES (
VARCHARTdpId = @TdpId,
VARCHARUserName = Userid,
VARCHAR UserPassword = Pwd,
VARCHAR AccountID,VARCHAR ARRAY TargetTable=['upd_006','upd_006a','upd_006b'], VARCHAR ARRAY ErrorTable,VARCHAR ARRAY WorkTable,VARCHAR LogTable = 'Three_Tables_Log',VARCHAR PrivateLogName = 'UPD_006',VARCHAR WorkingDatabase,
VARCHAR AmpCheck ); DEFINE SCHEMA PRODUCT_SOURCE_SCHEMA DESCRIPTION 'PRODUCT INFORMATION SCHEMA' ( Associate_Id integer, Associate_Name
char(25), Salary float, DOJ intdate, Designation varchar(25), Loan_Amount decimal(5,2), Martial_Status char(1),
No_Of_Dependents byteint );
DEFINE JOB• Job name is
PRODUCT_SOURCE_LOAD.• A brief description in included.
DEFINE OPERATOR • Name of this operator is UPDATE_OPERATOR.• TYPE identifies this operator as the Update operator.• All target tables are specified in the VARCHAR
ARRAY target table.• Restart log (required) is named Three_Tables_Log.• Private log is requested and named UPD_006.
DEFINE SCHEMA• Name of schema is
Product_Source_Schema.• Defines the layout of the row/record.• All operators use this single schema
by referencing it.
82 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Update Operator
DEFINE OPERATOR FILE_READER () DESCRIPTION 'DataConnector READER' TYPE DATACONNECTOR PRODUCER SCHEMA PRODUCT_SOURCE_SCHEMA ATTRIBUTES ( VARCHAR PrivateLogName = 'UPD_006a',
VARCHAR DirectoryPath = @DirectoryPath,
VARCHAR FileName = 'UPDDT2', VARCHAR IndicatorMode, VARCHAR OpenMode = 'Read', VARCHAR Format = 'Formatted' );
DEFINE OPERATOR EXPORT_OPERATOR () DESCRIPTION 'EXPORT OPERATOR' TYPE EXPORT
SCHEMA PRODUCT_SOURCE_SCHEMA ATTRIBUTES ( VARCHAR PrivateLogName = 'UPD_006b', INTEGER Blocksize = 64260,
INTEGER TenacityHours = 1, INTEGER TenacitySleep = 1, INTEGER MaxSessions = 4, INTEGER MinSessions = 1, VARCHAR TdpId = @TdpId, VARCHAR DateForm = 'INTEGERDATE', VARCHAR UserName = @Userid, VARCHAR UserPassword = @Pwd, VARCHAR AccountID,
VARCHAR WorkingDatabase, VARCHAR SelectStmt = 'sel *
from upd_source1 where Associate_Id > 5 and Associate_Id < 11;'
);DEFINE OPERATOR SQL_SELECTOR ()
DESCRIPTION 'SQL OPERATOR' TYPE SELECTOR SCHEMA PRODUCT_SOURCE_SCHEMA ATTRIBUTES ( VARCHAR UserName = @Username, VARCHAR PrivateLogName = 'UPD_006c', VARCHAR UserPassword = @Pwd, VARCHAR TdpId = @TdpId, VARCHAR AccountID = '', VARCHAR SelectStmt = 'select *
from upd_source1 where Associate_Id > 0 and Associate_Id < 6;'
L
DEFINE OPERATOR• The name of this operator is
File_Reader. • TYPE identifies the DataConnector
operator used as a producer.• The schema Product_Source_Schema
is referenced.• The DataConnector reads data from a
file named UPDDT2 using a value for the directory path that is defined in a job variables file.
• The Format attribute (required) reflects the format of the row being read.
DEFINE OPERATOR• The name of this operator is
EXPORT_OPERATOR.• TYPE identifies the Export operator as
a producer operator. • The schema Product_Source_Schema
is referenced.
DEFINE OPERATOR• The name of this operator is
SQL_SELECTOR.• TYPE identifies the SQL Selector operator
as a producer. • The schema Product_Source_Schema is
referenced.
Teradata Warehouse Builder User Guide 83

Chapter 5: Updating DataUpdating with the Update Operator
);
APPLYCASE
WHEN (Associate_Id > 0 and Associate_Id < 5) THEN 'INSERT INTO upd_006 ( :Associate_Id,
:Associate_Name,:Salary,:DOJ,:Designation,:Loan_Amount,:Martial_Status,:No_Of_Dependents + 20
); ' IGNORE DUPLICATE INSERT ROWS
WHEN (Associate_Id > 4 and Associate_Id < 9) THEN 'INSERT INTO upd_006a ( :Associate_Id, :Associate_Name, :Salary, :DOJ, :Designation, :Loan_Amount, :Martial_Status, :No_Of_Dependents + 20 ); ' IGNORE DUPLICATE INSERT ROWS WHEN (Associate_Id > 8 and Associate_Id < 13) THEN 'INSERT INTO upd_006b( :Associate_Id, :Associate_Name, :Salary, :DOJ, :Designation, :Loan_Amount, :Martial_Status, :No_Of_Dependents+20 ); ' IGNORE DUPLICATE INSERT ROWSEND
APPLY Statement • The CASE DML expressions test the value
of column Associate ID in each input row to determine what table to update (upd_006, upd_006a, or upd_006b).
• The IGNORE DUPLICATE INSERT ROWS discards duplicate inserted rows instead of capturing them in the error table.
84 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataDelete Task Option
TO OPERATOR (UPDATE_OPERATOR () [2])SELECT * FROM OPERATOR (
FILE_READER()) UNION ALL
SELECT * FROM OPERATOR (EXPORT_OPERATOR () ) UNION ALL
SELECT * FROM OPERATOR (SQL_SELECTOR () ););
Notice the following about this Update script:
• One APPLY statement is used because this script involves a single job step.
• The APPLY statement consists of multiple APPLY specifications (or clauses, or operations), separated by commas, that specify groups of DML statements that can be applied to up to five target tables.
• Each APPLY specification specifies a single logical data target regardless of the number of tables referenced in its DML, and represents a separate consumer of the common input data stream that is shared by all specified targets.
• The private log will provide status information about the Update operator only.
To run this script
This script assumes the existence of source table upd_source1 and source file UPDDT2, as well as target tables upd_006, upd_006a, and upd_006b. The script specifies that each input row is inserted into only one of the target tables based on the value of the input row column Associate_Id. The script also assumes that the global job variables file contains the directory path to the UPPDT2 file.
1 Copy and paste “Update Job Example” on page 81 verbatim into a file named Update_3_Tables.txt.
2 Make sure that a global job variables file exists (defined by the GlobalAttributeFile attribute) that contains the valid userid, password, and the Tdpid of the system being used for all operators.
3 Type the following at the command prompt:
tbuild -f Update_3_Tables.txt -v GlobalAtributeFile
Delete Task Option
The Delete Task option is unique to the Update operator, and it deletes rows more quickly than using a single DELETE SQL statement. When the DeleteTask attribute is set to 'Y', rows
APPLY Statement (TO OP-ERATOR)
• The TO OPERATOR portion identifies what operator is used. In this case, it’s the Update operator.
• The SELECT portion represents the source data applied to the target tables.
• Two [2] instances of the Update operator are requested.
• UNION ALL is used to combine three exports from the DataConnector, Export and SQL Selector operators into a single source data stream.
Teradata Warehouse Builder User Guide 85

Chapter 5: Updating DataDelete Task Option
are deleted from a single table based on values other than a unique primary index (UPI) equality condition. A Delete Task option uses a single session and a single instance.
The Delete Task option is a good choice when a large percentage of rows in a table need to be deleted, such as deleting all rows with a transaction date prior to a specified date.
The Delete Task option operates very similarly to the standard DELETE statement in the Update operator, with the following differences:
• Deleting based on non-index columns is normal for the Delete Task option.
• Deleting based on a primary index, although possible, has certain limitations:
• An equality test of a UPI value is not permitted.
• An inequality test of a UPI value is permitted.
• An equality test of a NUPI value is permitted.
• A single DELETE statement is used in the APPLY statement.
• The Delete Task option does not include an acquisition phase because there are no varying input records to apply.
• The application phase reads each target block and deletes qualifying rows.
• Altered blocks are written back to disk.
When the Delete Task option is specified, the Update operator functions as a standalone operator, that is, not as the usual consumer operator that reads from a source data stream. The exception is when the Delete Task is invoked by an APPLY statement that includes a WHERE clause, and the source data stream contains only a single row. In this case, the Update operator with the Delete Task option still functions as a consumer operator.
The following rules apply to a Delete Task operation regardless of whether it functions as a standalone or consumer operator:
• Only one session is connected.
• Only one instance is specified.
• Only one DML group is specified.
• Only one DML statement in the DML group is specified.
• Only a single DELETE statement is used.
• Only one target table is specified.
• The first error table is not used and is ignored.
• Only one data record is provided if using a WHERE clause.
Using Delete Task
Using the Delete Task option of the Update operator can run as either a consumer operator or as a standalone operator, depending on the construction of the APPLY statement:
• As a standalone operator that does not attempt to retrieve a row from the data stream:
APPLY<SQL DELETE statement>
• As a consumer operator that attempts to read a row from the data stream:
86 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataDelete Task Option
APPLY<SQL DELETE statement>
SELECT FROM …
Specify a single DELETE statement in the APPLY statement:
APPLY(
'DELETE FROM TABLE xyz;') ;
In this case, the Update operator runs as a standalone operator. (The Update operator is a consumer operator and there is no producer operator, so there is no SELECT statement).
You can also specify a DELETE statement in which information in the DELETE requires some data. In this case, the APPLY needs a SELECT statement:
APPLY(
'DELETE FROM TABLE xyz WHERE Field1 = :Field1;')SELECT * FROM OPERATOR (FILE_READER [1] . . .;
In this case, the Update operator is running as a consumer operator and it requires exactly one row of data. That row of data is passed to the Teradata Database, which extracts the data from the column as specified in the WHERE clause.
Another example, similar to the first one, is where the Update operator runs as a standalone operator but the DELETE statement has a WHERE clause:
APPLY(
'DELETE FROM TABLE xyz WHERE Field1 = ''abc'';') ;
In this case, there is a WHERE clause, but the information in the WHERE clause does not require data from a producer operator.
Note: When the Update operator runs as a standalone operator, no schema is necessary. That is, you do not need to define a schema using the DEFINE SCHEMA statement. This is because no data is needed from a producer operator for the job.
Why Choose the Delete Task Option?
A simple SQL DELETE statement can usually accomplish the same result as the Delete Task option, but the Delete Task option is usually preferred because it requires fewer system resources, and therefore generally performs better than an SQL DELETE.
• The Delete Task option does not use the Transient Journal so it uses less disk space, requires less I/O, and runs faster.
• The Delete Task option aborts without rollback as opposed to the SQL DELETE, which uses the Transient Journal to roll back all changes. The Delete Task option only moves forward.
Teradata Warehouse Builder User Guide 87

Chapter 5: Updating DataDelete Task Option
Delete Task Option - Example 1
Following is an example of a job that uses the Delete Task option to delete rows from a table named Customer, where customer_number is less than the hard-coded job script value of 100000:
DEFINE JOB DELETE_TASK DESCRIPTION 'Hard-coded DELETE FROM CUSTOMER TABLE' ( DEFINE OPERATOR UPDATE_OPERATOR DESCRIPTION 'Teradata PT UPDATE OPERATOR' TYPE UPDATE SCHEMA * ATTRIBUTES ( VARCHAR TargetTable = 'Customer', VARCHAR TdpId = @Tdpid, VARCHAR UserName = @Userid, VARCHAR UserPassword = @Pwd, VARCHAR AccountId, VARCHAR LogTable = 'DeleteTask_log', VARCHAR DeleteTask = 'Y' );
APPLY ( 'DELETE FROM CUSTOMER WHERE CUSTOMER_NUMBER LT 100000;' )
TO OPERATOR( UPDATE_OPERATOR [1] ););
Notice the following about this script:
• Setting the attribute DeleteTask to 'Y' makes this execution of the Update operator a Delete Task.
• The example uses the hard-coded value of 100000 in the deletion criterion.
For increased flexibility, this value could be specified as a job variable, such as:
'DELETE FROM CUSTOMER WHERE CUSTOMER_NUMBER LT ' || @Custno || ';'
The value for the variable in this expression can come from a job variable file, or it can come from the command line:
tbuild -f <job file name> -u "Custno = '100000'"
• The script still requires the SCHEMA * clause even though the Update operator is functioning as a standalone operator.
• The APPLY statement must specify a single SQL DELETE statement.
• The LogTable attribute is always required for the Update operator.
For additional information about using variables, see “Job Variables” on page 107.
88 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataDelete Task Option
To run this script
This procedure assumes that an existing Customer table contains a numeric column named Customer_Number:
1 Copy the above script into a new file in the directory from which Teradata PT is executed, and save with a unique file name, such as del_task.txt.
2 Make sure that a global job variables file exists (defined by the GlobalAttributeFile attribute) that contains the valid userid, password, and the Tdpid of the database system that contains the Customer table.
3 Type the following at the command prompt:
tbuild -f del_task.txt -v GlobalAtributeFile
Delete Task Option - Example 2
The following example accomplishes the same purpose as the previous Delete Task example, but with a slightly different technique. Rather than hard-coding values in the deletion criterion, the value in this example is supplied from an external file by the DataConnector operator and a data stream. The SQL host variable (:CustNo) represents the value in the DELETE statement.
In this case, the Update operator, used as a Delete Task, is a consumer operator because it receives input from a data stream. Differences between this approach and the first example are shown in bold text.
DEFINE JOB DELETE_TASK_PARAMDESCRIPTION 'External File DELETE FROM CUSTOMER TABLE'(DEFINE SCHEMA CUST_NUM_SCHEMADESCRIPTION 'CUSTOMER NUMBER SCHEMA'(Cust_Num INTEGER);
DEFINE OPERATOR UPDATE_OPERATOR DESCRIPTION 'Teradata PT UPDATE OPERATOR' TYPE UPDATE
SCHEMA CUST_NUM_SCHEMA ATTRIBUTES ( VARCHAR TargetTable = 'Customer', VARCHAR TdpId = @Tdpid, VARCHAR UserName = @Userid, VARCHAR UserPassword = @Pwd, VARCHAR AccountId, VARCHAR LogTable = 'DeleteTask_log', VARCHAR DeleteTask = 'Y' );
DEFINE OPERATOR DATA_PRODUCERDESCRIPTION 'DATA CONNECTOR OPERATOR'TYPE DATACONNECTOR PRODUCERSCHEMA CUST_NUM_SCHEMA
Teradata Warehouse Builder User Guide 89

Chapter 5: Updating DataUpdating with the Stream Operator
ATTRIBUTES(
VARCHAR OpenMode = 'Read',VARCHAR Format = 'Formatted',VARCHAR IndicatorMode,VARCHAR FileName = 'Single_Row_File');APPLY ( 'DELETE FROM CUSTOMER WHERE CUSTOMER_NUMBER LT :CustNo')
TO OPERATOR (UPDATE_OPERATOR [1])
SELECT * FROM OPERATOR (DATA_PRODUCER[1]);
);
Notice the following in this script:
• When using this approach, the DataConnector operator write a single row to the data stream so its input file contains a single record.
• A schema must be defined in order for the input value to be read.
• An SQL host variable (:CustNo) is used in the DELETE statement.
• The colon ( : ) symbol prefixed to CustNo specifies to the Teradata Database that the value comes from a source external to the SQL DELETE statement.
To run this script
This script assumes that an existing Customer table contains a numeric column named Customer_Number:
1 Copy the above script into a new file in the directory from which Teradata PT is executed, and save with a unique file name, such as del_task2.txt.
2 Make sure that a global job variables file exists (defined by the GlobalAttributeFile attribute) that contains the valid userid, password, and the Tdpid of the database system that contains the Customer table.
3 Type the following at the command prompt:
tbuild -f del_task2.txt
Updating with the Stream Operator
The Stream Operator is a consumer operator that simulates the Teradata TPump utility to perform inserts, updates, deletes, and upserts in a near real-time mode to one or more tables. The major advantage of the Stream operator is that it can do these operations during periods of heavy table access by other users.
Unlike the Load, Update and Export operators, the Stream operator does not use its own protocol to access Teradata. Instead, it uses Teradata SQL protocol.
90 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Stream Operator
Like the other Teradata PT operators, the Stream operator can use multiple sessions and multiple operator instances to process data from several data sources concurrently.
Performance
To provide optimal performance, the Stream operator packs individual DML statements into a larger multi-statement request based on the rate specified by the Pack attribute. This type of processing requires less overhead than multiple individual requests.
The Stream operator submits these multi-statement requests using macros which it creates to hold the requests. The macros are then executed instead of running each individual DML statement.
The macros are automatically removed after the job is complete. The use of macros in place of lengthy requests helps to minimize both network and parsing overhead.
Limitations
The Stream operator has the following limitations.
• SELECT is not allowed.
• Exponential and aggregate operators are not allowed.
• Arithmetic functions (for example, square roots) are not supported.
• When using dates before 1900 or after 1999, a four-digit year must be used.
Stream Operator Definition
Following is a Stream operator definition. Most of the attributes can be defaulted. A few key attributes are formatted in bold, and discussed as comments following the definition:
Teradata Warehouse Builder User Guide 91

Chapter 5: Updating DataUpdating with the Stream Operator
DEFINE OPERATOR STREAM_LOAD_OPERATORDESCRIPTION 'STREAM OPERATOR FOR Teradata PT’TYPE STREAMSCHEMA *
ATTRIBUTES(
VARCHAR AccountID,INTEGER Buffers,INTEGER ErrorLimit,VARCHAR ErrorTable,/* The default name is TargetTableName_ET */VARCHAR LogTable,INTEGER MaxSessions,INTEGER MinSessions,INTEGER Pack,/* Specifies the number of statements to pack into a
multi-statement request*/INTEGER PackMaximum,VARCHAR Robust,VARCHAR MacroDatabase,VARCHAR PrivateLogName,VARCHAR TdpId,INTEGER TenacityHours,INTEGER TenacitySleep,VARCHAR TraceLevel = 'NONE',VARCHAR UserName,VARCHAR UserPassword,VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR WorkingDatabase,VARCHAR NotifyMethod,VARCHAR NotifyLevel);
About This Definition
Consider the following when running the Stream operator.
Pack Rate
The Pack attribute specifies the number of statements in a multi-statement request. Specifying a Pack rate improves network/channel efficiency by reducing the number of sends and receives between Teradata PT and the Teradata Database. A maximum of 600 statements can be specified.
Trial and error might be required to determine the best Pack rate for a Stream job. As the Pack rate is increased, the throughput improvement is usually great at first, then falls off. In other words, going from a Pack rate of 1 to 2 could provide huge performance gains, and going from 2 to 4 could be just as beneficial, but moving from 8 to 16 might cause a performance drop.
If the PackMaximum attribute is set to 'Yes', the Stream operator determines the maximum pack for the job, and then reports it.
Two factors to consider are:
• The maximum Pack factor based on Stream operator restrictions
• The optimal Pack factor for a particular job
92 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Stream Operator
These two factors might not be equal. The maximum rate lets you know the upper limit, but performance might improve at a smaller rate. For this reason, it is recommended that PACKMAXIMUM not be used for production jobs until you determine the optimal Pack factor.
Error-Free Data
It is more important to have error-free data when using the Stream operator than with other Teradata PT operators. If data contains errors, a large Pack factor can slow performance because of the way Stream handles errors.
For instance, if several hundred statements are packed, when an error occurs, the entire request is rolled back. The Stream operator then removes the error-producing statement(s) and then reissues the entire request. Such a process can be costly from a performance standpoint.
Checkpointing
Checkpoint options control how often a row is written to the checkpoint file for the purposes of restarting a job. Unless otherwise specified, a checkpoint is taken at the start of and at the end of the input data. Since this process does not provide granular restartability in the case of longer running jobs, checkpoint intervals can be user-specified in terms of minutes or seconds.
• Seconds - Use the command line option -z. For example, the following command indicates that a checkpoint will be taken every 30 seconds:
tbuild -f <script file name> -z 30
• Minutes or seconds - Specify as part of a DEFINE JOB statement. For example:
DEFINE JOB test_jobSET CHECKPOINT INTERVAL 30 SECONDS
or
SET CHECKPOINT INTERVAL 10 MINUTES
Sessions
Both a minimum and a maximum number of sessions can be used by the Stream operator. The minimum specification is one. The default is one session for each operator instance. The number of sessions is evenly distributed among the number of operator instances. If 20 sessions are requested and four instances of the operator are invoked, then each instance will receive five of the sessions.
Checkpointing and Robust Mode
For more robust restartability, use robust mode, which causes every DML operation to be checkpointed and ensures on restart that no operation is applied more than once. The robust mode requires more writes to a restart log, which might impact performance more, however, using robust mode ensures that a restart avoids reprocessing rows that a normal interval checkpoint might necessitate.
Robust is the default mode for all Stream operator jobs. The Robust attribute turns the mode on or off. If uncertain whether to use robust restart logic, it is always safe to set the Robust parameter to 'Yes'.
Teradata Warehouse Builder User Guide 93

Chapter 5: Updating DataUpdating with the Stream Operator
• Non-Robust Mode - Setting the attribute to “no” tells the Stream operator to use simple restart logic rather than robust logic.
VARCHAR Robust = 'No' (or 'N')
In a non-robust mode, restarts begin where the last checkpoint occurs in a job. Because some additional processing will most likely take place after the checkpoint is written, the requests that occur after the checkpoint are resubmitted by the Stream operator as part of the restart process. For deletes, inserts and upserts, this does not usually cause a problem or harm the database; however, re-running statements generates more rows in the error table because the operator will be attempting to insert rows that already exist and to delete rows that do not exist.
Re-attempting updates can also be a problem if update calculation, for example, is based on existing data in the row, such as adding 10% to an amount. Doing the update calculation a second time add an additional 10% to the amount, thus compromising data integrity. In this type of update, it is best to use robust mode to ensure that no DML operation is applied more than once.
The non-robust (or simple restart) method does not involve the extra overhead that comes with the additional inserts to the restart log table that are needed for robust logic, so overall processing should be notably faster.
• Robust Mode - Setting the attribute to “yes” tells the Stream operator to use robust restart logic.
VARCHAR Robust = 'Yes' (or 'Y')
Robust mode causes a row to be written to the log table each time a buffer successfully completes its updates. Mini-checkpoints are written for each successfully processed row. These mini-checkpoints are deleted from the log when a checkpoint is taken, and are used at restart to identify the rows that have been successfully processed, which permits them to be bypassed at restart. In robust mode, each row is processed only once. The larger the Pack factor, the less overhead is involved in this activity.
Choosing the Robust mode is particularly useful to avoid problems with data integrity and unacceptable performance. Robust mode is recommended in the following situations to avoid having an adverse affect on restarts:
• INSERTs into multi-set tables - Robust mode prevents the insertion of duplicate rows, which could insert the same row a second time.
• UPDATEs based on calculations - Robust mode prevents the duplicate application of calculations.
• Large Pack factors - Robust mode does not involve the application and rejection of duplicate rows after restarts, which is a time-consuming process of logging errors to the error table.
• Time-stamped data - Robust mode prevents the possibility of stamping identical rows with different time stamps, resulting in duplicate rows.
If rows are reapplied in non-robust mode, each reapplied row is marked with a time stamp that is different from the original row even though all of the other data is identical. To Teradata, these reapplied rows are different rows with the same primary index value, so they are inserted even though they are duplicates.
94 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Stream Operator
MACRO DATABASE
The Stream operator uses macros to modify tables rather than actual DML statements. Before beginning a load, the operator creates macros to represent the DML statements. The macros are then iteratively executed in place of the DML statements. The Stream operator also removes the macros after all rows are loaded.
These actions are accomplished through the use of CREATE/DROP MACRO SQL statements.
Use the MacroDatabase attribute to specify the database that contains the macros created by the Stream operator. If not specified, the database used is the database that contains the Restart Log table.
Options with Stream Operations
Consider the following options for Stream operations.
SERIALIZE Option
The Serialize option only applies to the Stream operator. Use the Serialize option when correct sequencing of transactions is required. For example, when a job contains a transaction that inserts a row to open a new account, and another transaction updates the balance for the account, then the sequencing of the transactions is critical.
Using the Serialize option in APPLY statements, the Stream operator ensures that operations for a given row occur in the order they are received from the input stream.
To use this option, associate a sequencing key (usually the primary index) with the target table. Each input data row is hashed based on the key to determine the session assigned to process each input row. This allows all rows with the same key to be processed in sequence by the same session, which is especially important if rows are distributed among many sessions.
When using the Serialize option, only one instance of the Stream operator is allowed. Specifying more than one instance causes the Stream operator to terminate with an error.
SERIALIZE OFF
When the Serialize option is set to OFF, transactions are processed in the order they are encountered, then they are placed in the first available buffer. Buffers are sent to parsing engine (PE) sessions and PEs process the data independently of other PEs. In other words, transactions might occur in any order.
If the Serialize option is not specified, the default is OFF unless the job contains an upsert operation, which causes Serialize to switch the default to ON.
SERIALIZE ON
If the Serialize option is set to ON, operations on a row occur serially in the order submitted.
The sequencing key of SERIALIZE ON is specified as one or more column names occurring in the input data SCHEMA definition. These SCHEMA columns are collectively referred to as the key. Usually the key is the primary index of the table being updated, but it can be a different column or set of columns. For example:
Teradata Warehouse Builder User Guide 95

Chapter 5: Updating DataUpdating with the Stream Operator
APPLY ('UPDATE emp SET dept_name = :dept_name
WHERE empno = :empno;')SERIALIZE ON (empno)
TO TARGET_TABLE[1]
This APPLY statement guarantees that all data rows with the same key (empno) are applied to the database in the same order received they are received from the producer operator. In this case, the column empno is the primary index of the Emp table.
Note that SERIALIZE ON is local to a specific DML statement. In the following example, a group DML is specified, but only the first statement uses the Serialize option:
APPLY('UPDATE emp SET dept_num = :dept_num
WHERE empno = :empno; ')SERIALIZE ON (empno)
('UPDATE dept SET dept_name = :dept_nameWHERE deptno = :deptno; ')
TO TARGET_TABLE[1]
Following are some of the advantages to using the Serialize option, and might improve performance:
• SERIALIZE ON can eliminate the lock delays or potential deadlocks caused by primary index collisions coming from multiple sessions.
• SERIALIZE ON can also reduce deadlocks when rows with non-unique primary index values are processed.
Latency Interval
Latency is the interval value, expressed in seconds, between the flushing of stale buffers. Latency interval is an option that is exclusively used by the Stream operator.
In normal operations (without latency), the Stream operator reads data from the data stream until its buffer is full, then it writes all buffered rows to the Teradata Database. The data is written to the Teradata Database only when the buffer is full or when a checkpoint is taken. However, a latency interval (for example, set to 5400 seconds) causes the following:
• The Stream operator reads data from the data stream, and empties its buffer, writing the contents to the Teradata Database every 90 minutes (5400 seconds) regardless of whether it is full.
• If the buffer fills up within the time period (in this case, 90 minutes), it writes to the Teradata Database as it would during normal operation.
To set the latency interval, use the following syntax:
tbuild -l <LatencyInterval> -f <file name>
The value used for the latency interval must be a non-zero unsigned integer. The guiding factor is how stale you are willing to allow data to be.
For example, to run a continual load script with a latency interval of two hours, enter:
tbuild -l 7200 -f continualload
96 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Stream Operator
Stream Job Example
Following is an example of a job that uses the Stream operator. The example assumes that an existing target table named Accounts contains 100 rows, and that values in its Account_Number column range from 20024101 to 20024200. The example also assumes that an existing source table named Au.Accounts contains 200 rows, only half of which contain Account_Number values in this same range.
The script results in 200 upserts against Accounts, updates of the Balance_Current column of the existing 100 rows to $0.99, and 100 newly inserted rows when the Account_Number values fell outside the range.
Teradata Warehouse Builder User Guide 97

Chapter 5: Updating DataUpdating with the Stream Operator
DEFINE JOB Export_Upsert_StreamDESCRIPTION 'EXPORT 200 transactions then input to the Stream operator'
(DEFINE SCHEMA Accounts_Schema(Account_Number INTEGER,Number INTEGER,Street CHARACTER(25),City CHARACTER(20),State CHARACTER(2),Zip_Code
INTEGER, Balance_Forward DECIMAL(10, 2),
Balance_Current DECIMAL(10, 2) );
DEFINE OPERATOR Stream_OperatorDESCRIPTION 'Teradata PT STREAM OPERATOR'TYPE STREAMSCHEMA *ATTRIBUTES(
VARCHAR TdpId = @Tdpid,VARCHAR UserName =
@Userid,VARCHAR UserPassword =
@Pwd,VARCHAR AccountId,VARCHAR LogTable,INTEGER Pack = 40,VARCHAR PrivateLogName
);
DEFINE OPERATOR Export_OperatorTYPE EXPORTSCHEMA Accounts_SchemaATTRIBUTES(
VARCHAR UserName = @Userid,VARCHAR UserPassword = @Pwd,VARCHAR TdpId = @Tdpid,
VARCHAR SelectStmt, INTEGER BlockSize, INTEGER MaxSessions, INTEGER MinSessions, INTEGER TenacityHours, INTEGER TenacitySleep, VARCHAR AccountID, VARCHAR DateForm, VARCHAR NotifyExit, VARCHAR NotifyExitIsDLL,
DEFINE JOB• Job name is Export_Upsert_Stream.• A brief description in included.
DEFINE SCHEMA• Name of schema is Accounts_Schema.• Defines the layout of the data row.• All operators use this single schema by
referencing it.
L
DEFINE OPERATOR• The name of this operator is
Stream_Operator. • TYPE identifies the Stream operator is
used.• All target tables are specified in the
VARCHAR ARRAY.• Restart log (required) is defined later in the
script.• Private log is requested and defaulted. • The Pack factor combines a maximum of 40
statements. • Job variables for the Tdpid, userid, and
password are read from a global job variables file.
L
DEFINE OPERATOR• The name of this operator is
Export_Operator as a producer. • TYPE identifies the Export operator.• The Accounts_Schema is referenced.
98 Teradata Warehouse Builder User Guide

Chapter 5: Updating DataUpdating with the Stream Operator
VARCHAR NotifyLevel, VARCHAR NotifyMethod, VARCHAR NotifyString, VARCHAR PrivateLogName, VARCHAR TraceLevel, VARCHAR WorkingDatabase);
STEP APPLY_UPSERT(
APPLY('UPDATE ACCOUNTS SET BALANCE_CURRENT = :BALANCE_CURRENT
WHERE Account_Number = :account_number ;',
'INSERT INTO accounts (Account_Number,Number,Street,City,State,Zip_Code,Balance_Forward,Balance_Current)
VALUES (:account_number,:number,:street,:city,:state,:zip_code,:balance_forward,:balance_current);')
INSERT FOR MISSING UPDATE ROWS
IGNORE MISSING UPDATE ROWS
TO OPERATOR (Stream_Operator[1]
ATTRIBUTES (LogTable =
'Accounts_tables_log', PrivateLogName = 'StreamLog.log'))
SELECT Account_Number, Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current
FROM OPERATOR (Export_Operator[1] ATTRIBUTES
(SelectStmt = 'SELECT Account_Number, Number, Street, City, State, Zip_Code, Balance_Forward, 0.99 (DECIMAL (10,2))
FROM AU.AccountsWHERE Account_Number LT 20024101;SELECT Account_Number, Number,
Street, City, State, Zip_Code, Balance_Forward, Balance_Current
FROM AU.AccountsWHERE Account_Number BETWEEN 20024101 AND 20024200;')
); ); );
STEP APPLY_UPSERT• The name of this job step is APPLY_UPSERT. • Job steps can have only one APPLY statement. • Although an APPLY statement can contain multiple
APPLY specifications (clause, or operation), this job step uses a single APPLY specification.
INSERT FOR MISSING UPDATEROWSIGNORE MISSING UPDATE ROWS• Both UPDATE and INSERT are be
specified for an upsert operation. • The upsert operation requires the
INSERT FOR MISSING UPDATE ROWS syntax.
Multi-Statement Export• A multi-statement Export
(FROM clause) is used to create the source data stream.
Teradata Warehouse Builder User Guide 99

Chapter 5: Updating DataUpdating with the Stream Operator
Notice the following about this script:
• The job uses a single step, named APPLY_UPSERT.
• The resulting Accounts table has 200 rows, 100 of which are new rows and 100 of which have their current balance updated to $0.99.
• The script upserts against a 100-row table, which results in a new 200-row table.
• The bold line that begins “INSERT FOR MISSING...” is the upsert logic that tells the Stream operator to insert into Accounts the rows with Account_Number values that are outside the defined range rather than inserting them into an error table.
To run this script
1 Copy the above script into a new file in the directory from which Teradata PT is executed, and save with a unique file name, such as upsert_100.txt.
2 Make sure that a global job variables file exists (defined by the GlobalAttributeFile attribute) that contains the valid userid, password, and the Tdpid of the system.
3 Type the following at the command prompt:
tbuild -f upsert_100.txt
100 Teradata Warehouse Builder User Guide

CHAPTER 6
Job Startup and Cleanup
Use this chapter to create and modify database objects before running jobs in Teradata PT and to set up job steps.
• Job Steps
• Setting Up with the DDL Operator
Job Steps
Job steps are units of execution of a Teradata PT job. Each job step contains a single APPLY (operational) statement that specifies an operation to be performed, usually the movement of data from a source to a target. Initial job steps can perform setup operations, by submitting SQL DDL, or executing host system commands, and final steps can similarly perform any required cleanup operations.
A job must have at least one job step, although jobs with only one step do not need to use the STEP syntax.
Defining Job Steps
Teradata PT allows you to use job steps to execute multiple operational statements in a single Teradata PT job. Job steps are executed in the order in which they appear within the DEFINE JOB statement.
For example, the first job step could execute a DDL operator to create a target table. The second step could execute a Load operator to load the target table. Following is an example of how to implement multiple job steps:
DEFINE JOB multi-step(
DEFINE SCHEMA...;DEFINE SCHEMA...;
DEFINE OPERATOR...;DEFINE OPERATOR...;
STEP first_step( APPLY...; /* DDL step */);
STEP second_step(
Teradata Warehouse Builder User Guide 101

Chapter 6: Job Startup and CleanupSetting Up with the DDL Operator
APPLY...; /* DML step */);
STEP third_step( APPLY...; /* DDL step */);
);
Starting a Job Step Mid-Script
Jobs can be executed at a specified job step by using the tbuild command option, -s. The option -s allows you to execute a job starting at a specified step, identified either by the step name, as specified in the job STEP syntax, or by the implicit step number, such as 1, 2, 3, and so on.
The job execution then begins at the specified job step, skipping over the job steps that come before it in the job. For other information on the tbuild command syntax -s, see the “tbuild” topic in the Teradata Parallel Transporter Reference.
Following are samples of the -s tbuild syntax element:
• To start a job at the job step named “BuildStep”:
tbuild -s BuildStep -f DailyLoad
• To start a job at its third job step:
tbuild -s 3 -f MonthlyExport
Note: To avoid jumping steps that could invalidate the sequence of operations as defined in the checkpoint file,Teradata PT automatically removes the checkpoint files before executing the -s option.
Setting Up with the DDL Operator
The DDL Operator allows the use of DDL SQL statements in a Teradata PT script to perform any setup activities, such as creation, alteration, and modification of database objects (tables or views), that might formerly be accomplished by an external utility, such as BTEQ.
As a standalone operator, the DDL operator does not send data to or retrieve data from a data stream. All data values used by the SQL commands must be hard-coded into the submitted SQL statements. The SQL statements are submitted to Teradata PT as part of an APPLY statement as seen in “DDL Operator Example” on page 104.
Checkpoint Restartability
The DDL operator restarts at the beginning of the group of SQL statements whose execution is interrupted by an abnormal termination. If the interrupted group has only one SQL statement, the DDL operator restarts at that statement.
Because SQL statements are sent to Teradata Database by group in the order in which they are specified in the Teradata PT APPLY statement, the DDL operator can take a checkpoint after each group is executed. A group can contain one or more SQL statements. A checkpoint, in
102 Teradata Warehouse Builder User Guide

Chapter 6: Job Startup and CleanupSetting Up with the DDL Operator
the case of the DDL operator, marks the last group of DDL/DML SQL statements to execute successfully.
If the last request was successful prior a restart, the operator can resume at the next request in line. If the last request failed prior to a restart, then the operator resumes at the failed request.
SQL Statements
Use a single SQL statement per group to execute each statement in its own transaction. Group several SQL statements together to perform a desired logical database task and still take advantages of the automatic roll-back feature on the Teradata Database in case of any statement failures or any errors occurring during the transaction.
When multiple SQL statements are specified in a DML group in an APPLY statement, that group must only contain one DDL statement, and that DDL statement must be the last statement in the group.
Therefore, given that the information in parentheses, below, represents a group, the validity of the statements can be determined as follows:
• Group 1: (DDL) is valid.
• Group 2: (DDL, DDL) is invalid because only one DDL statement is allowed.
• Group 3: (DML, DML, DDL) is valid.
• Group 4: (DML, DML, DML) is valid, even though the group contains no DDL statement.
• Group 5: (DML, DDL, DML) is invalid because the DDL statement is not the last statement in the group.
If a script contains unsupported or invalid statements, the job terminates so the script can be fixed before continuing.
SQL Statements
The DDL operator supports the following:
• ALTER / CREATE / DROP REPLICATION GROUP
• ALTER TABLE
• COMMENT
• CREATE / DROP AUTHORIZATION
• CREATE TABLE / VIEW / MACRO / DATABASE / INDEX
• DATABASE
• DELETE / DROP / MODIFY DATABASE
• DROP TABLE / VIEW / MACRO / INDEX
• RENAME TABLE/VIEW/MACRO
• REPLACE MACRO/VIEW
• SET SESSION (SS) COLLATION
Supporting UDFs
The DDL operator supports the following for user-defined functions (UDFs):
Teradata Warehouse Builder User Guide 103

Chapter 6: Job Startup and CleanupSetting Up with the DDL Operator
• CREATE/REPLACE UDF (from source components stored on the Teradata Database host).
• ALTER/DROP/RENAME UDF
Note: Error diagnostic messages and warnings that are caused by building UDFs (from executing a CREATE/REPLACE UDF SQL statement) are returned from the Teradata Database to the DDL operator, which writes them to the log file specified in the DDL operator definition.
Supporting UDTs
The DDL operator supports the following for user-defined tables (UDTs):
• CREATE / ALTER / DROP the following:
• METHOD
• TYPE
• CREATE / REPLACE / DROP the following:
• CAST
• ORDERING
• TRANSFORM
DCL Statements
The DDL operator supports the following data control language (DCL) statement:
• GIVE
• GRANT
• REVOKE
DML Statements
The DDL operator supports the following data manipulation language (DML) statements:
• DELETE (DEL)
• INSERT (INS)
• UPDATE (UPD)
Note: These statements can be used as long as the syntax does not rely on any data. All values must be hard coded within the DML statement.
Non-Supported SQL Statements
Because standalone operators do not send data to or retrieve data from data streams, the DDL operator does not support the USING clause with the INSERT, UPDATE, and DELETE DML SQL statements. These statements are not DDL SQL statements, but they are supported by the DDL operator to provide functionality equivalent to the standalone utilities.
DDL Operator Example
Following is an example of the DDL operator in a script that drops, creates, and populates a table called Test_tbl:
104 Teradata Warehouse Builder User Guide

Chapter 6: Job Startup and CleanupSetting Up with the DDL Operator
DEFINE JOB TEST_LOADDESCRIPTION 'SET UP TABLES FOR Teradata PT JOB'(DEFINE OPERATOR DDL_OPERATORDESCRIPTION 'Teradata PT DDL OPERATOR Sample'TYPE DDLATTRIBUTES(
VARCHAR TdpId = 'MyDatabase',VARCHAR UserName = 'MyUser',VARCHAR UserPassword = 'MyPassword',VARCHAR LogonMech,VARCHAR LogonMechData,VARCHAR AccountID,VARCHAR PrivateLogName = 'ddllog',VARCHAR ErrorList = '3807'
);APPLY('DROP TABLE Test_tbl;'),('CREATE TABLE Test_tbl, FALLBACK (col1 INTEGER, col2 CHAR(4));'),('INSERT INTO Test_tbl VALUE (1,''Paul'');','INSERT INTO Test_tbl VALUE (2,''Dave'');' )TO OPERATOR (DDL_OPERATOR );)
Notice the following about the DDL definition:
• It is critical that two single quotes be used around the values for col2. Because the INSERT statement is already enclosed in quotes, one quote acts as an escape character.
• The specified UserName must have permissions to perform all operations in the script.
• The DROP and CREATE TABLE statements are submitted sequentially as individual statements.
• The two INSERT statements are submitted as a group because they are parenthesized, meaning that they are submitted as a multi-statement request.
• The ErrorList attribute identifies specific error conditions to ignore. In this case, 3807 is a “Table Not Found” condition.
• A DROP TABLE failure due to a missing table will not stop the job as long as the correct error code is specified in the ErrorList attribute.
• The DDL operator is frequently used to drop error tables and restart logs as the first job step.
Teradata Warehouse Builder User Guide 105

Chapter 6: Job Startup and CleanupSetting Up with the DDL Operator
106 Teradata Warehouse Builder User Guide

CHAPTER 7
Advanced Topics
This chapter describes some of the optional, advanced features of Teradata PT. Topics include:
• Job Variables
• INCLUDE Statement
• Data Conversions
• User-Defined Column Data Types
• Multiple Targets
• Notify Exit Routines
• Managing Active Jobs
• Query Banding Considerations
• Using LONG VARCHAR with Unicode Character Sets
• Switching Versions
Job Variables
Job variables (formerly known as job attributes) allow you to code various text segments in job scripts as variables. Job variables allow you to assign values at script execution time, rather than coding them as constants with fixed values in every script. Variables are then replaced at compilation time.
Consider the following when using job variables:
• Job variables in scripts must begin with the @ symbol as an identifier; the assigned values (in a separate file) do not need the @ symbol.
• Job variables are most commonly used to substitute operator attributes, although job variables can be used anywhere in a script.
• Job variables must never occur within quoted strings.
• When scripts are run, values for job variables can be supplied directly on the command line by using the tbuild command -u option, or values can be supplied indirectly from a file by using the tbuild command -v option. The latter option is likely to be more useful because it allows multiple jobs to share a common set of variable values.
• Some Unix vi editors drop the @ symbol when text is pasted. If this occurs, either manually replace the symbol before running the script, or paste and edit the script into Notepad, then transfer it using FTP.
Teradata Warehouse Builder User Guide 107

Chapter 7: Advanced TopicsJob Variables
Defining Job Variables
Job variables are used in scripts according to a certain prioritization:
• Global job variables file - The lowest priority for defining values for job variables is defining them inside the global job variables file. The global job variables file is read by every Teradata PT job. Place common, system-wide job variables in this file, then specify the path of the global job variables in the Teradata PT configuration file using the GlobalAttributeFile parameter.
• Script - The second lowest priority for defining values for job variables is defining them inside the Teradata PT script using the SET directive, which must be placed before the DEFINE JOB statement as follows:
SET TdpId='tddbms60';
• Local job variables file - The second highest priority for defining values for job variables is defining them inside a local job variables file. A local job variables file contains the values for job variables and is specified on the command line with the -v option as follows:
tbuild -f weekly_update.tbr -v local.jobvars
Note: On MVS, specify a local job variables file through the DDNAME of ATTRFILE.
• Command line - The highest priority for defining values for job variables is defining them on the command line using the -u option as follows:
tbuild -f weekly_update.tbr -u "UserName = 'user', UserPassword = 'pass' "
Values of job variables that are defined on the command line override all other job variable definitions.
Using the SET Directive
Default values for job variables can also be defined inside the Teradata PT job script using the SET directive, which must be placed before the DEFINE JOB statement as follows:
SET TdpId='tddbms60';
Example
The following examples illustrate possible uses of job variables.
In the first example, the values of @ConsumerOperator and @ProducerOperator can either be defined in the script using the SET directive, in a job variables file, or at the command line.
APPLY'INSERT INTO TABLE xyz (:col1, :col2);'TO OPERATOR ( @ConsumerOperator [1] )SELECT * FROM OPERATOR ( @ProducerOperator[2] );
The next example uses a job variable in a quoted string. This is a way of supplying job variables for DML and DDL statements:
'INSERT INTO TABLE ' || @TargTable || ' (:col1, :col2, . . ., :coln);'
108 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsJob Variables
Example Script With Variables
The following example assumes that an existing script, named script1, is stored in the directory from which Teradata PT is executed, and that the script contains the following four job variables:
@TdpId@UserName@UserPassword@WorkingDatabase
Based on the following example, suppose that a file of variable assignments named jobvars, contains the following variable assignments:
TdpId= 'solaris8',UserName = 'production3',UserPassword = 'sysadmin02',WorkingDatabase = 'PRODW'
Given these suppositions, the following tbuild command will then run the following script and substitute the assigned values for the job variables.
tbuild -f script1 -v jobvars
The script with job variables:
DEFINE JOB PRODUCT_SOURCE_LOADDESCRIPTION 'LOAD PRODUCT DEFINITION TABLE'(
DEFINE OPERATOR UPDATE_OPERATOR () DESCRIPTION 'TERADATA UPDATE OPERATOR UTILITY' TYPE UPDATE INPUT SCHEMA *
ATTRIBUTES ( INTEGER ErrorLimit = 1, INTEGER BufferSize = 64, INTEGER TenacityHours = 1, INTEGER TenacitySleep = 4, INTEGER MaxSessions = 8, INTEGER MinSessions = 1, VARCHAR TargetTable = 'flin_013', VARCHAR PrivateLogName = 'flin_013.fldlog', VARCHAR TdpId = @TdpId, VARCHAR UserName = @UserName, VARCHAR UserPassword = @UserPassword, VARCHAR AccountID, VARCHAR LogTable = 'flin_013_log', VARCHAR ErrorTable1 = 'flin_013_e1', VARCHAR ErrorTable2 = 'flin_013_e2', VARCHAR WorkingDatabase = @WorkingDatabase );
DEFINE SCHEMA PRODUCT_SOURCE_SCHEMA DESCRIPTION 'PRODUCT INFORMATION SCHEMA' ( field1 INT, field2 CHAR(4), field3 CHAR(10), field4 CHAR(10)
Teradata Warehouse Builder User Guide 109

Chapter 7: Advanced TopicsJob Variables
);
DEFINE OPERATOR FILE_READER () DESCRIPTION 'FILE READER' TYPE PRODUCER OUTPUT SCHEMA PRODUCT_SOURCE_SCHEMA EXTERNAL NAME 'libflimop' ATTRIBUTES ( VARCHAR InmodName = './flin_013_3m.so', VARCHAR PrivateLogName = 'flin_013.inmlog', VARCHAR IndicatorMode );
APPLY CASEWHEN (field1<100000000) THEN 'insert into flin_013 values (:field1, :field2, :field3,
:field4);'END
TO OPERATOR ( UPDATE_OPERATOR() )
SELECT * FROM OPERATOR ( FILE_READER() ) ;);
Sharing Variables Between Jobs
The job variables feature provides support for user logon values and any other variables whose values can be shared across multiple Teradata PT jobs. Job variables can be used anywhere in the script except between quoted strings.
Note: Job variables cannot be used between quoted strings unless they are concatenated. Job variables, however, can represent entire quoted strings. For example, to insert the literal term “@item” into a column, use a string such as the following: 'Insert this @item into a column'. However, to use @item as a job variable, use a string such as the following: 'Insert this'|| @item || 'into a column'
The job variables feature also allows you to parameterize and defer operator attribute values for later specification. When submitting a job, specify the necessary job variable values as in the following example:
DEFINE JOB CREATE_SOURCE_EMP_TABLE(
DEFINE OPERATOR DDL_OPERATORDESCRIPTION 'Teradata Parallel Transporter DDL Operator'TYPE DDLATTRIBUTES(
VARCHAR UserName = @MyUserName,VARCHAR UserPassword = @MyPassword
);
APPLY('DROP TABLE SOURCE_EMP_TABLE;'),('CREATE TABLE SOURCE_EMP_TABLE(EMP_ID INTEGER, EMP_NAME
CHAR(10));'),
110 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsINCLUDE Statement
('INSERT INTO SOURCE_EMP_TABLE(1,''JOHN'');'),('INSERT INTO SOURCE_EMP_TABLE(2,''PETER'');')
TO OPERATOR (DDL_OPERATOR()););
In this example, the DDL operator issues four DML statements that create a table called SOURCE_EMP_TABLE and then populate that table with two rows. The UserName and UserPassword operator attributes are job variables.
See Teradata Parallel Transporter Reference for more information about job variables.
INCLUDE Statement
The INCLUDE statement allows parts of job scripts, previously stored in files, to be included into the body of a job script. This feature permits greater reuse of generic definitions, such as operators or schemas across multiple scripts.
This example, for instance, defines a schema in a text file named account_schema.
DEFINE SCHEMA(Account_Number INTEGER,
Number INTEGER,Street CHARACTER(25),City CHARACTER(20),
State CHARACTER(2), Zip_Code INTEGER, Balance_Forward DECIMAL(10, 2), Balance_Current DECIMAL(10, 2));
Based on the example, above, include the following definition in the job script to reference the account.schema file:
DEFINE JOB CustomerUpdate(
INCLUDE '/home/et1/account_schema';
DEFINE OPERATOR......);
The INCLUDE statement allows the use of symbols (such as @) in included files or anything that normally occurs in an object definition. Multiple object definitions in a single INCLUDE file are also permitted.
Note: Teradata PT does not support nested INCLUDE statements. That is, a file that is referenced in the INCLUDE statement cannot itself have an INCLUDE statement.
Teradata Warehouse Builder User Guide 111

Chapter 7: Advanced TopicsData Conversions
Data Conversions
Teradata PT’s ability to convert data is limited to assigning a data type to a null value or changing data from a null value. For example:
CAST (NULL AS INTEGER)
Using the CAST clause, you can convert to an alternate data type prior to loading data into a table. The following APPLY statement demonstrates this option.
APPLY('INSERT INTO CUSTOMER (:CUST_NUM, :LAST_NAME, :FIRST_NAME, :SOC_SEC_NO);')TO OPERATOR (LOAD_OPERATOR [1] )
SELECT * FROM OPERATOR(EXPORT_OPERATOR [1]...
Here, the use of SELECT * implies data is accepted as is from the Export operator; however, the data can also be converted. If data is needed in a different table, create the following APPLY statement:
APPLY('INSERT INTO CUSTOMER (:CUST_NUM, :LAST_NAME, :FIRST_NAME, :SOC_SEC_NO);')TO OPERATOR (LOAD_OPERATOR [1] )SELECT
CAST (NULL AS CHAR(10)) AS CUST_NUM,LAST NAME, FIRST NAME, CASE
WHEN (SOC_SEC_NO = '000000000')THEN NULLELSE SOC_SEC_NO
END AS SOC_SEC_NO,FROM OPERATOR(EXPORT_OPERATOR [1]...
Notice that:
• This example assumes that the loading is into a different schema.
• The first field is a permitted data conversion.
• The target Social Security number is assigned the NULL value if the source Social Security number is a string of all zero characters.
• This use of the CASE statement is comparable to the NULLIF function of the FastLoad utility.
• The functionality provided by the CASE expression is available to all Teradata PT operators because expressions are allowed in the APPLY statement.
112 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsUser-Defined Column Data Types
User-Defined Column Data Types
It is possible to customize column data types into composites of intrinsic (pre-defined or native) Teradata data types. However, Teradata PT does not support these user-defined types (UDTs) in layout or schema definitions. Therefore, to import or export data between a client and Teradata server using the DDL operator, you must represent UDTs as a set of the intrinsic Teradata data types that make up the UDT.
For example, assume the following composites at the database level.
CREATE TYPE FULLNAME (FirstName VARCHAR (32),MiddleInitial CHAR (1),LastName VARCHAR (32)
);
CREATE TABLE PERSON (Age BYTEINT,Name FULLNAME,Gender BYTEINT
);
Given these composites, the following must be specified (using only intrinsic Teradata data types) to load Teradata PT:
DEFINE SCHEMA PERSON(
Age BYTEINT,FirstName VARCHAR (32),MiddleName CHAR (1),LastName VARCHAR (32),Gender BYTEINT
);
Processing UDFs and UDTs
A single DDL script can create, alter, replace, or drop any user-defined function (UDF) or UDT on a Teradata server so you can avoid using BTEQ. However, in order for the DDL operator to handle UDFs and UDTs, the C/C++ source file of the specified function or method must be located on a Teradata Database rather than on a client.
Also, when running a Teradata Database on a Windows server, you must manually create a folder for UDFs as follows:
D:\Program Files\NCR\Tdat\tdconfig\Teradata\tdbs_udf\usr\
Failure to create this folder results in errors when running DDL statements. For a list of supported SQL statements for the DDL operator, see “SQL Statements” on page 103.
Teradata Warehouse Builder User Guide 113

Chapter 7: Advanced TopicsMultiple Targets
Multiple Targets
Using multiple APPLY specifications (clauses or operations within an APPLY statement), it is possible to extract data and simultaneously load it into as many as 32 targets in a single job step. This read-once-apply-to-many approach allows source data to be loaded into multiple targets, ensuring that each target receives identical data. By using multiple APPLY specifications, multiple updates and loads can now be accomplished with fewer system resources compared to creating separate job steps for each load or update, thereby redundantly extracting data from a data source.
Scenarios
The following scenarios are examples of situations that benefit from using multiple targets.
• Simultaneous loading of multiple warehouse targets - Multiple warehouse targets can be loaded with a single input data source by using multiple APPLY statements, and the loading of each target can be done in a parallel, scalable manner by using multiple operator instances. The benefit of this method is that if a failure occurs, all load operations terminate, then restart in an orderly, coordinated manner.
The use of multiple APPLY statements and multiple operator instances allows input data to be read and processed once, which minimizes I/O and system resource usage. In addition to homogeneous loading, multiple kinds of consumer operators can also be used simultaneously. For example, warehouse A can be loaded using the Update operator while warehouse B is loaded using the Stream operator, and so on.
This method also allows the use of the APPLY CASE statement so data that is applied to each of the targets can be filtered with different CASE statements.
• Simultaneous loading and archiving - Maintaining archives that accurately reflect loaded data can be problematic when data is transformed between source and target, with only the transformed data being written to the target. Redundant extractions and redundant transformations are time-consuming and difficult. With the ability of Teradata PT to load to multiple data targets, transformed data can simply be loaded into both the primary target and an archive in a single job step.
Procedure
Use this procedure to implement multiple data targets in an APPLY statement in the executable section of a script (after the DEFINE statements).
To send data to multiple targets
In all of the following syntax examples, <DML spec x> represents the DML statements to be applied to data target x. For more information, see “APPLY” in the Teradata Parallel Transporter Reference.
To send data to multiple targets, do the following:
114 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsNotify Exit Routines
1 Define an APPLY specification for the first target, specifying its consumer operator:
APPLY <DML spec> TO OPERATOR <consumer_operator>
2 Repeat Step 1 for a maximum of 32 targets, separating each APPLY specification by a comma. Omit the comma after the last one.
3 Define one or more sources with any combination of the following:
• Use a SELECT statement for each reference to a producer operator or database object.
• Use a UNION ALL statement to combine multiple SELECT statements.
Use the following syntax to define multiple sources:
SELECT <column_list> FROM <producer_operator1>UNION ALLSELECT <column_list> FROM <producer_operator2>UNION ALLSELECT <column_list> FROM <producer_operator3>
For more information about the required and optional attributes for the APPLY specification, see the Teradata Parallel Transporter Reference.
For more information about the UNION ALL option, see “Combining Data Sources” on page 55
Example
The following examples compare a single APPLY specification to multiple APPLY specifications. The examples use the syntax discussed in the previous procedure:
• Single APPLY target:
APPLY ('INSERT INTO EMP_TARGET1 (:EMP_ID, :EMP_LNAME, :EMP_FNAME, :EMP_DEP);') TO OPERATOR (LOAD_OPERATOR_1)
SELECT * FROM OPERATOR (EXPORT_OPERATOR_1);
• Two APPLY targets:
APPLY ( 'UPDATE table1 SET C2 = :col2 WHERE C1 = :col1;', 'INSERTINTO table2 ( :col1, :col2, …)' ) TO OPERATOR ( UPDATE_OPERATOR () [2]ATTR(…..))
,APPLY ( 'INSERT INTO table3 ( :col1, :col2, …)' ) TO OPERATOR (LOAD_OPERATOR () [3] ATTR(….))SELECT * FROM OPERATOR (EXPORT_OPERATOR_1);
Notify Exit Routines
The Load, Export, Update, and Stream operators support notify exit routines. A notify exit routine specifies a predefined action to be performed whenever certain significant events occur during a job, for example, whether a load job succeeds or fails, how many records are loaded, what the return code is for the failed job, and so on. Only the main instance sends a notify event.
Teradata Warehouse Builder User Guide 115

Chapter 7: Advanced TopicsNotify Exit Routines
Jobs accumulate operational information about specific events that occur. If the NotifyMethod attribute specifies the Exit method, when the specific events occur the operator calls the named notify exit routine and passes the following to it:
• An event code to identify the event
• Specific information about the event
Export Operator Events
The Export operator supports notify exit routines. A notify exit routine specifies a predefined action to be performed whenever certain significant events occur during a job, for example, whether a job succeeds or fails, how many records are exported, what the return code is for the failed job, and so on. Only the main instance sends a notify event.
The Export operator job accumulates operational information about specific events that occur during a job. If the Export operator job script includes the NotifyMethod attribute with the Exit method specification, then when the specific events occur, the Export operator calls the named notify exit routine and passes to it:
• An event code to identify the event
• Specific information about the event
Table 6 lists the event codes and describes the data that the Export operator passes to the notify exit routine for each event. The information in this table is also sent to the system log.
Note: Ensure that notify exit routines ignore invalid or undefined event codes, and that they do not cause the operator to terminate abnormally.
Table 6: Export Operator Notify Event Codes
EventEvent Code Event Description and Data Passed to the Notify Exit Routine
Initialize 0 Signifies successful processing of the notify feature:
• Version ID length—4-byte unsigned integer
• Version ID string—32-character (maximum) array
• Operator ID—4-byte unsigned integer
• Operator name length—4-byte unsigned integer
• Operator name string—32-character (maximum) array
• User name length—4-byte unsigned integer
• User name string—64-character (maximum) array
• Optional string length—4-byte unsigned integer
• Optional string—80-character (maximum) array
• Operator handle—4-byte unsigned integer
Teradata Database Restart
9 Signifies that the Export operator received a crash message from the Teradata Database or from the CLIv2:
• No data accompanies the Teradata Database restart event code
116 Teradata Warehouse Builder User Guide
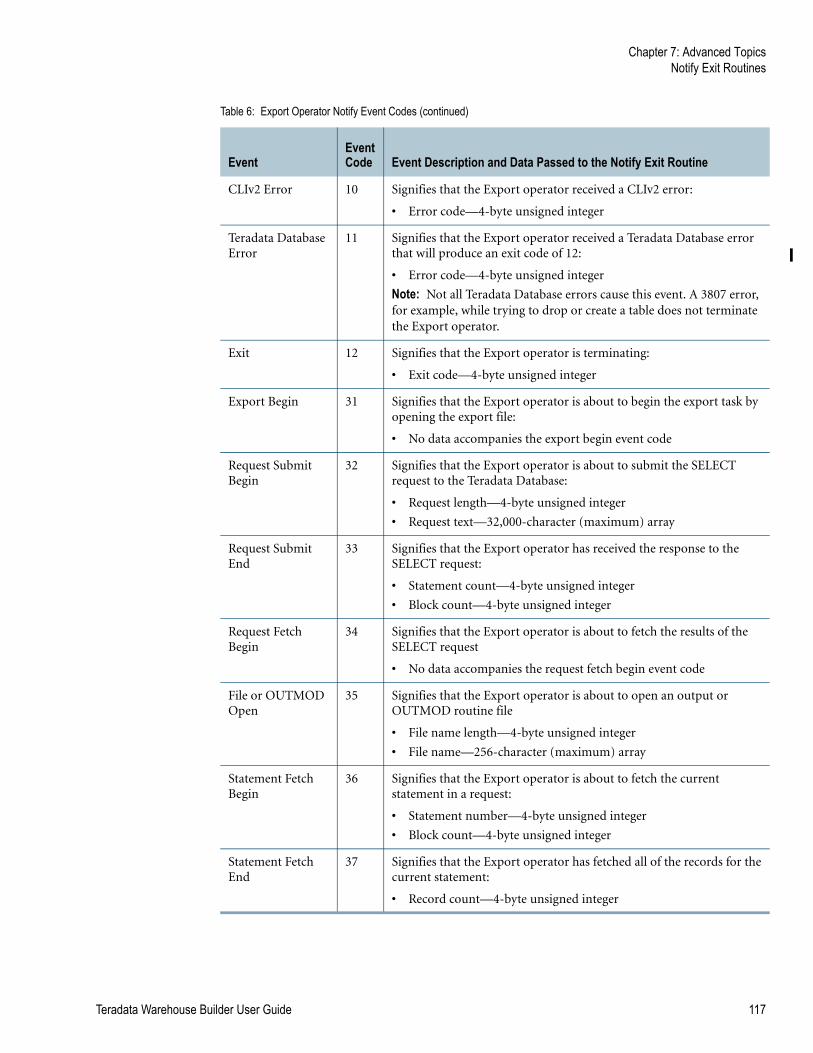
Chapter 7: Advanced TopicsNotify Exit Routines
CLIv2 Error 10 Signifies that the Export operator received a CLIv2 error:
• Error code—4-byte unsigned integer
Teradata Database Error
11 Signifies that the Export operator received a Teradata Database error that will produce an exit code of 12:
• Error code—4-byte unsigned integer
Note: Not all Teradata Database errors cause this event. A 3807 error, for example, while trying to drop or create a table does not terminate the Export operator.
Exit 12 Signifies that the Export operator is terminating:
• Exit code—4-byte unsigned integer
Export Begin 31 Signifies that the Export operator is about to begin the export task by opening the export file:
• No data accompanies the export begin event code
Request Submit Begin
32 Signifies that the Export operator is about to submit the SELECT request to the Teradata Database:
• Request length—4-byte unsigned integer
• Request text—32,000-character (maximum) array
Request Submit End
33 Signifies that the Export operator has received the response to the SELECT request:
• Statement count—4-byte unsigned integer
• Block count—4-byte unsigned integer
Request Fetch Begin
34 Signifies that the Export operator is about to fetch the results of the SELECT request
• No data accompanies the request fetch begin event code
File or OUTMOD Open
35 Signifies that the Export operator is about to open an output or OUTMOD routine file
• File name length—4-byte unsigned integer
• File name—256-character (maximum) array
Statement Fetch Begin
36 Signifies that the Export operator is about to fetch the current statement in a request:
• Statement number—4-byte unsigned integer
• Block count—4-byte unsigned integer
Statement Fetch End
37 Signifies that the Export operator has fetched all of the records for the current statement:
• Record count—4-byte unsigned integer
Table 6: Export Operator Notify Event Codes (continued)
EventEvent Code Event Description and Data Passed to the Notify Exit Routine
Teradata Warehouse Builder User Guide 117

Chapter 7: Advanced TopicsNotify Exit Routines
Table 7 lists events that create notifications.
Request Fetch End 38 Signifies that the Export operator has fetched all of the records for the current request:
• Records exported—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
Export End 39 Signifies that the Export operator has completed the export operation and displayed the number of exported records:
• Records exported—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
Table 7: Export Operator Events That Create Notifications
Event
Notification Level
SignifiesLow Medium High
Initialize Yes Yes Yes Successful processing of the notify option
Teradata Database Restart
No Yes Yes A crash error from the Teradata Database or the CLIv2
CLIv2 Error Yes Yes Yes A CLIv2 error was encountered
Teradata Database Error
Yes Yes Yes A Teradata Database error was encountered that terminates the Export operator
Exit Yes Yes Yes The Export operator is terminating
Export Begin No Yes Yes Opening the export file
Request Submit Begin No Yes Yes Submitting the SELECT request
Request Submit End No Yes Yes Received SELECT request response
Request Fetch Begin No Yes Yes Fetching SELECT request results
File or OUTMOD Open
No No Yes Opening output file or OUTMOD
Statement Fetch Begin No No Yes Fetching current statement
Statement Fetch End No No Yes Last record fetched for current statement
Request Fetch End No Yes Yes Last record fetched for current request
Export End No Yes Yes Export task completed
Table 6: Export Operator Notify Event Codes (continued)
EventEvent Code Event Description and Data Passed to the Notify Exit Routine
118 Teradata Warehouse Builder User Guide
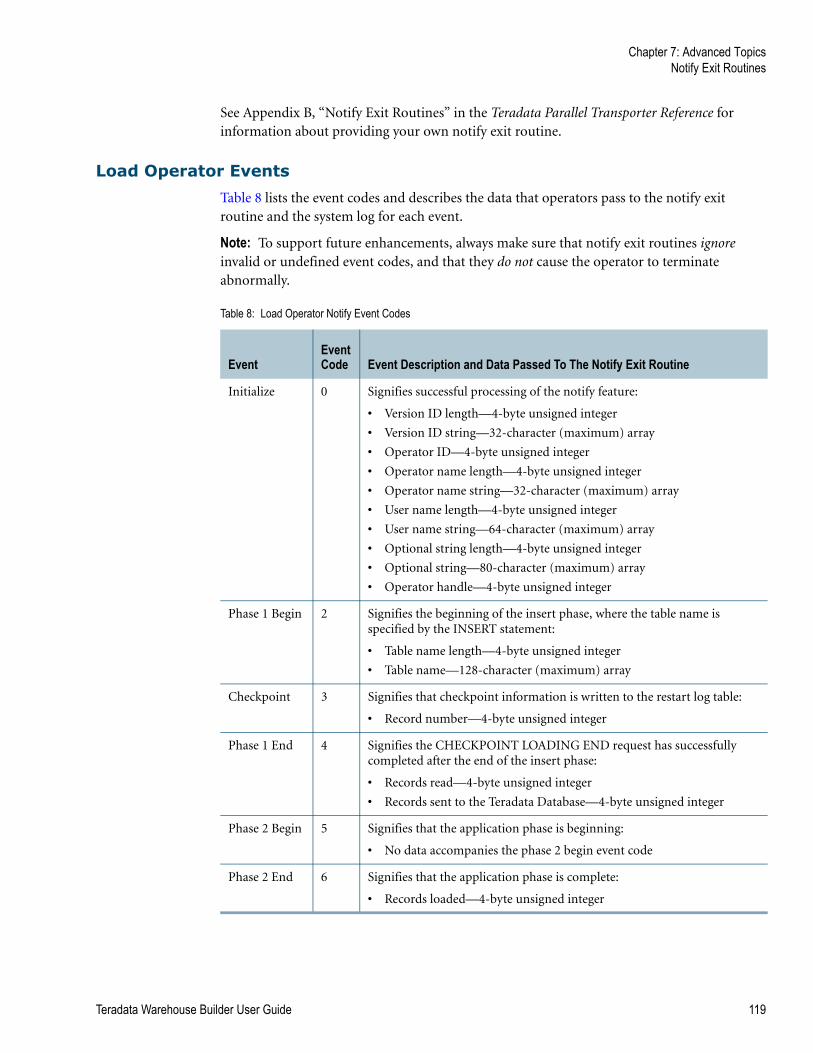
Chapter 7: Advanced TopicsNotify Exit Routines
See Appendix B, “Notify Exit Routines” in the Teradata Parallel Transporter Reference for information about providing your own notify exit routine.
Load Operator Events
Table 8 lists the event codes and describes the data that operators pass to the notify exit routine and the system log for each event.
Note: To support future enhancements, always make sure that notify exit routines ignore invalid or undefined event codes, and that they do not cause the operator to terminate abnormally.
Table 8: Load Operator Notify Event Codes
EventEvent Code Event Description and Data Passed To The Notify Exit Routine
Initialize 0 Signifies successful processing of the notify feature:
• Version ID length—4-byte unsigned integer
• Version ID string—32-character (maximum) array
• Operator ID—4-byte unsigned integer
• Operator name length—4-byte unsigned integer
• Operator name string—32-character (maximum) array
• User name length—4-byte unsigned integer
• User name string—64-character (maximum) array
• Optional string length—4-byte unsigned integer
• Optional string—80-character (maximum) array
• Operator handle—4-byte unsigned integer
Phase 1 Begin 2 Signifies the beginning of the insert phase, where the table name is specified by the INSERT statement:
• Table name length—4-byte unsigned integer
• Table name—128-character (maximum) array
Checkpoint 3 Signifies that checkpoint information is written to the restart log table:
• Record number—4-byte unsigned integer
Phase 1 End 4 Signifies the CHECKPOINT LOADING END request has successfully completed after the end of the insert phase:
• Records read—4-byte unsigned integer
• Records sent to the Teradata Database—4-byte unsigned integer
Phase 2 Begin 5 Signifies that the application phase is beginning:
• No data accompanies the phase 2 begin event code
Phase 2 End 6 Signifies that the application phase is complete:
• Records loaded—4-byte unsigned integer
Teradata Warehouse Builder User Guide 119
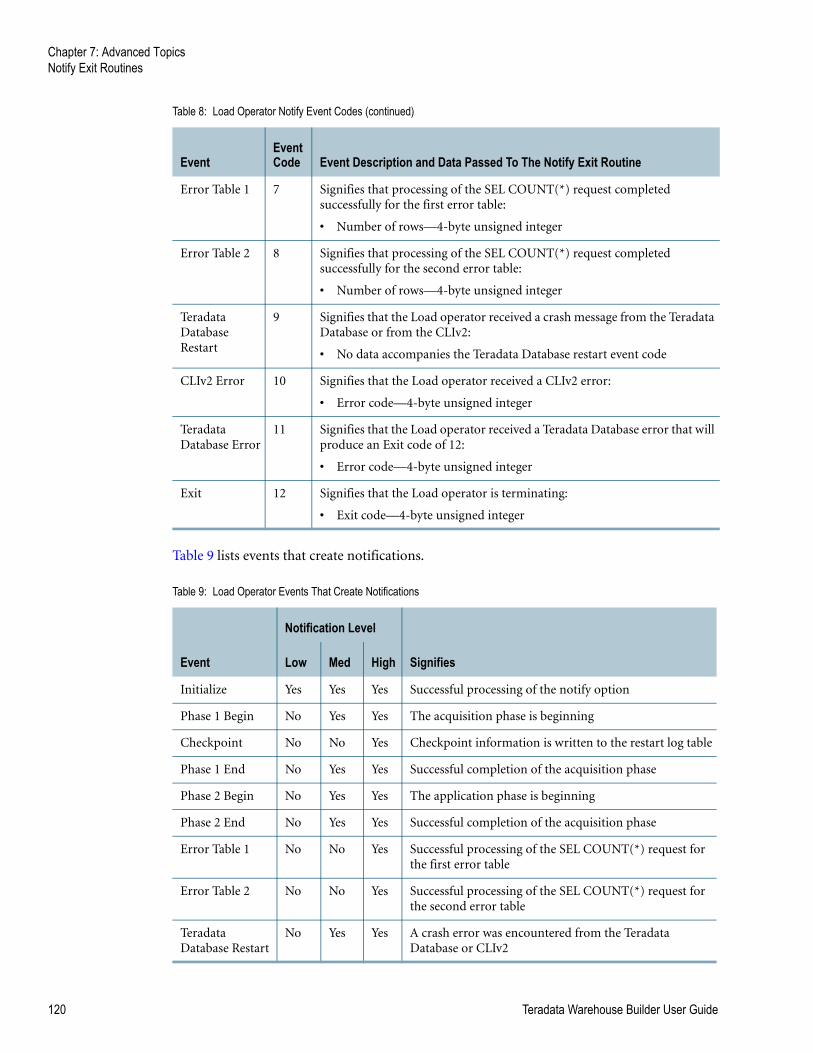
Chapter 7: Advanced TopicsNotify Exit Routines
Table 9 lists events that create notifications.
Error Table 1 7 Signifies that processing of the SEL COUNT(*) request completed successfully for the first error table:
• Number of rows—4-byte unsigned integer
Error Table 2 8 Signifies that processing of the SEL COUNT(*) request completed successfully for the second error table:
• Number of rows—4-byte unsigned integer
Teradata Database Restart
9 Signifies that the Load operator received a crash message from the Teradata Database or from the CLIv2:
• No data accompanies the Teradata Database restart event code
CLIv2 Error 10 Signifies that the Load operator received a CLIv2 error:
• Error code—4-byte unsigned integer
Teradata Database Error
11 Signifies that the Load operator received a Teradata Database error that will produce an Exit code of 12:
• Error code—4-byte unsigned integer
Exit 12 Signifies that the Load operator is terminating:
• Exit code—4-byte unsigned integer
Table 9: Load Operator Events That Create Notifications
Event
Notification Level
SignifiesLow Med High
Initialize Yes Yes Yes Successful processing of the notify option
Phase 1 Begin No Yes Yes The acquisition phase is beginning
Checkpoint No No Yes Checkpoint information is written to the restart log table
Phase 1 End No Yes Yes Successful completion of the acquisition phase
Phase 2 Begin No Yes Yes The application phase is beginning
Phase 2 End No Yes Yes Successful completion of the acquisition phase
Error Table 1 No No Yes Successful processing of the SEL COUNT(*) request for the first error table
Error Table 2 No No Yes Successful processing of the SEL COUNT(*) request for the second error table
Teradata Database Restart
No Yes Yes A crash error was encountered from the Teradata Database or CLIv2
Table 8: Load Operator Notify Event Codes (continued)
EventEvent Code Event Description and Data Passed To The Notify Exit Routine
120 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsNotify Exit Routines
See Appendix B, “Notify Exit Routines” in the Teradata Parallel Transporter Reference for information about providing your own notify exit routine.
Update Operator Events
Table 10 lists the event codes and describes the data that the Update operator passes to the notify exit routine for each event. The information in this table is also sent to the system log.
Note: To support future enhancements, always make sure that your notify exit routines ignore invalid or undefined event codes, and that they do not cause the operator to terminate abnormally.
CLIv2 Error Yes Yes Yes A CLIv2 error was encountered
Teradata Database Error
Yes Yes Yes A Teradata Database error was encountered that will terminate the load operation
Exit Yes Yes Yes The Load operator is terminating
Table 9: Load Operator Events That Create Notifications (continued)
Event
Notification Level
SignifiesLow Med High
Table 10: Update Operator Notify Event Codes
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
Initialize 0 Signifies successful processing of the notify feature:
• Version ID length—4-byte unsigned integer
• Version ID string—32-character (maximum) array
• Operator ID—4-byte unsigned integer
• Operator name length—4-byte unsigned integer
• Operator name string—32-character (maximum) array
• User name length—4-byte unsigned integer
• User name string—64-character (maximum) array
• Optional string length—4-byte unsigned integer
• Optional string—80-character (maximum) array
• Operator handle—4-byte unsigned integer
Phase 1 Begin 2 Signifies the beginning of the insert phase, where table name is specified by the INSERT statement:
• Table name length—4-byte unsigned integer
• Table name—128-character (maximum) array
• Table number—4-byte unsigned integer
Checkpoint 3 Signifies that checkpoint information is written to the restart log table:
• Record number—4-byte unsigned integer
Teradata Warehouse Builder User Guide 121

Chapter 7: Advanced TopicsNotify Exit Routines
Phase 1 End 4 Signifies the CHECKPOINT LOADING END request has successfully completed after the end of the acquisition phase:
• Records read—4-byte unsigned integer
• Records skipped—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
• Records sent to the Teradata Database—4-byte unsigned integer
Phase 2 Begin 5 Signifies that the application phase is beginning:
• No data accompanies the phase 2 begin event code
Phase 2 End 6 Signifies that the application phase is complete. For each table in the request:
• Records inserted—4-byte unsigned integer
• Records updated—4-byte unsigned integer
• Records deleted—4-byte unsigned integer
• Table number—4-byte unsigned integer
Error Table 1 7 Signifies that processing of the SEL COUNT(*) request completed successfully for the first error table.
• Number of rows—4-byte unsigned integer
• Table number—4-byte unsigned integer
Error Table 2 8 Signifies that processing of the SEL COUNT(*) request completed successfully for the second error table.
• Number of rows—4-byte unsigned integer
• Table number—4-byte unsigned integer
Teradata Database Restart
9 Signifies that the Update operator received a crash message from the Teradata Database or from the CLIv2:
• No data accompanies the Teradata Database restart event code
CLIv2 Error 10 Signifies that the Update operator received a CLIv2 error:
• Error code—4-byte unsigned integer
Teradata Database Error
11 Signifies that the Update operator received a Teradata Database error that will produce an Exit code of 12:
• Error code—4-byte unsigned integer
Note: Not all Teradata Database errors cause this event. A 3807 error, for example, while trying to drop or create a table does not terminate the Update operator.
Exit 12 Signifies that the Update operator is terminating:
• Exit code—4-byte unsigned integer
Table 10: Update Operator Notify Event Codes (continued)
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
122 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsNotify Exit Routines
The following table lists events that create notifications. Some events create notifications only for import tasks, some only for delete tasks, and some for both.
AMPs Down 21 Signifies that the Teradata Database has one or more down AMPs, just prior to the acquisition phase:
• No data accompanies the AMPs down event code
Import Begin 22 Signifies that the first record is about to be read for each import task:
• Import number—4-byte unsigned integer
Import End 23 Signifies that the last record is read for each import task. The returned data is the record statistics for the import task:
• Records read—4-byte unsigned integer
• Records skipped—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
• Records sent to the Teradata Database—4-byte unsigned integer
• Import number—4-byte unsigned integer
Delete Init 24 Signifies successful processing of a DELETE statement:
• No data accompanies the init. event code.
Delete Begin 25 Signifies that a DELETE statement is about to be sent to the Teradata Database:
• Table name length—4-byte unsigned integer
• Table name—128-character (maximum) array
• Table number—4-byte unsigned integer
Delete End 26 Signifies successful processing of a delete task:
• Records deleted—4-byte unsigned integer
• Table number—4-byte unsigned integer
Delete Exit 27 Signifies the end of a delete task:
• Exit code—4-byte unsigned integer
Table 11: Update Operator Events That Create Notifications
EventImport Task
Delete Task
Notification Level
SignifiesLow Med High
Initialize x Yes Yes Yes Successful processing of the notify option
Phase 1 Begin x No Yes Yes The acquisition phase is beginning
Checkpoint x No No Yes Checkpoint information is written to the restart log table
Table 10: Update Operator Notify Event Codes (continued)
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
Teradata Warehouse Builder User Guide 123

Chapter 7: Advanced TopicsNotify Exit Routines
See Appendix B: “Notify Exit Routines” in the Teradata Parallel Transporter Reference for information about providing your own notify exit routine.
Stream Operator Events
Table 12 lists the event codes and describes the data that the Stream operator passes to the notify exit routine or the system log.
Phase 1 End x No Yes Yes Successful completion of the acquisition phase
Phase 2 Begin x x No Yes Yes The application phase is beginning
Phase 2 End x No Yes Yes Successful completion of the application phase
Error Table 1 x No No Yes Successful processing of the SEL COUNT(*) request for the first error table
Error Table 2 x x No No Yes Successful processing of the SEL COUNT(*) request for the second error table
Teradata Database Restart
x x No Yes Yes A crash error was encountered from the Teradata Database or CLIv2 that will terminate the load operation
CLIv2 Error x x Yes Yes Yes A CLIv2 error was encountered
Teradata Database Error
x x Yes Yes Yes A Teradata Database error was encountered that will terminate the load operation
Exit x Yes Yes Yes The Update operator is terminating
AMPs Down x x No No Yes Down AMPs on the Teradata Database
Import Begin x No No Yes First record about to be read
Import End x No No Yes Last record is read
Delete Init x Yes Yes Yes The delete task is about to begin
Delete Begin x No Yes Yes DELETE statement about to be sent to the Teradata Database
Delete End x No Yes Yes Successful delete task processing
Delete Exit x Yes Yes Yes End of delete task
Table 11: Update Operator Events That Create Notifications (continued)
EventImport Task
Delete Task
Notification Level
SignifiesLow Med High
124 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsNotify Exit Routines
Note: To support future enhancements, always make sure that your notify exit routines ignore invalid or undefined event codes, and that they do not cause the operator to terminate abnormally.
Table 12: Stream Operator Notify Event Codes
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
Initialize 0 Signifies successful processing of the notify option:
• Version ID length—4-byte unsigned integer
• Version ID string—32-character (maximum) array
• Operator ID—4-byte unsigned integer
• Operator name length—4-byte unsigned integer
• Operator name string—32-character (maximum) array
• User Name length—4-byte unsigned integer
• User Name string—64-character (maximum) array
• Optional string length—4-byte unsigned integer
• Optional string—80-character (maximum) array
• Operator handle—4-byte unsigned integer
Checkpoint Begin
2 Signifies that the Stream operator is about to perform a checkpoint operation
Record number—4-byte unsigned integer
Import Begin 3 Signifies that the first record is about to be read for each import task:
• Import number—4-byte unsigned integer
Import End 4 Signifies that the last record is read for each import task. The returned data is the record statistics for the import task:
• Import number—4-byte unsigned integer
• Records read—4-byte unsigned integer
• Records skipped—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
• Records sent to the Teradata Database—4-byte unsigned integer
• Data Errors—4-byte unsigned integer.
Error Table 5 Signifies that processing of the SEL COUNT(*) request completed successfully for the error table:
• Table Name—128-byte character (maximum) array.
• Number of Rows—4-byte unsigned integer.
Teradata Database Restart
6 Signifies that the Stream operator received a crash message from the Teradata Database or from the CLIv2:
• No data accompanies the Teradata Database restart event code
CLIv2 Error 7 Signifies that the Stream operator received a CLIv2 error:
• Error code—4-byte unsigned integer
Teradata Warehouse Builder User Guide 125
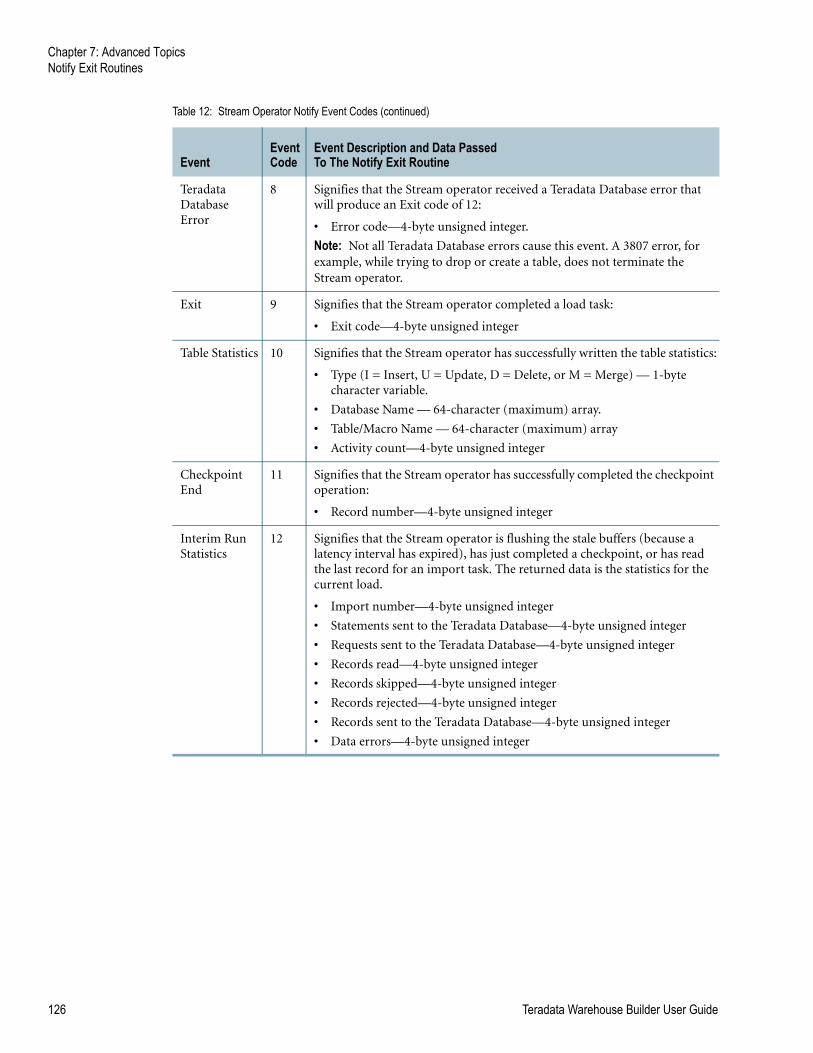
Chapter 7: Advanced TopicsNotify Exit Routines
Teradata Database Error
8 Signifies that the Stream operator received a Teradata Database error that will produce an Exit code of 12:
• Error code—4-byte unsigned integer.
Note: Not all Teradata Database errors cause this event. A 3807 error, for example, while trying to drop or create a table, does not terminate the Stream operator.
Exit 9 Signifies that the Stream operator completed a load task:
• Exit code—4-byte unsigned integer
Table Statistics 10 Signifies that the Stream operator has successfully written the table statistics:
• Type (I = Insert, U = Update, D = Delete, or M = Merge) — 1-byte character variable.
• Database Name — 64-character (maximum) array.
• Table/Macro Name — 64-character (maximum) array
• Activity count—4-byte unsigned integer
Checkpoint End
11 Signifies that the Stream operator has successfully completed the checkpoint operation:
• Record number—4-byte unsigned integer
Interim Run Statistics
12 Signifies that the Stream operator is flushing the stale buffers (because a latency interval has expired), has just completed a checkpoint, or has read the last record for an import task. The returned data is the statistics for the current load.
• Import number—4-byte unsigned integer
• Statements sent to the Teradata Database—4-byte unsigned integer
• Requests sent to the Teradata Database—4-byte unsigned integer
• Records read—4-byte unsigned integer
• Records skipped—4-byte unsigned integer
• Records rejected—4-byte unsigned integer
• Records sent to the Teradata Database—4-byte unsigned integer
• Data errors—4-byte unsigned integer
Table 12: Stream Operator Notify Event Codes (continued)
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
126 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsNotify Exit Routines
Table 13 lists events that create notifications.
DML Error 13 Signifies that the Stream operator received a Teradata Database error that was caused by DML and will introduce an error-row insert to the error table.
• Import number - 4-byte unsigned integer
• Error code - 4-byte unsigned integer
• Error message - 256-character (maximum) array
• Record number - 4-byte unsigned integer
• Data Input number - 1-byte unsigned char
• DML number - 1-byte unsigned char
• Statement number - 1-byte unsigned char
• Record data - 6,004-character (maximum) array
• Record data length - 4-byte unsigned integer
• Feedback - a pointer to 4-byte unsigned integer
"Feedback" always points to integer 0 when it is passed to the notify exit routine. You may change the value of this integer to 1 to instruct the Stream operator not to log the error to the error table. In this case, the Stream operator will not log the error, but will continue other regular processes on this error.
Table 13: Stream Operator Events that Create Notifications
Event
Notification Level
SignifiesLow Medium High Ultra
Initialize Yes Yes Yes Yes Successful processing of the notify option)
Checkpoint Begin No No Yes Yes Stream operator started a checkpoint
Import Begin No No Yes Yes Stream operator is about to start reading records
Import End No No Yes Yes Last record is read
Error Table No No Yes Yes Successful processing of the SEL COUNT(*) request for the error table
Teradata Database Restart No Yes Yes Yes Stream operator received a crash error from Teradata or CLI
CLIv2 Error Yes Yes Yes Yes A CLIv2 error was encountered
Teradata Database Error Yes Yes Yes Yes A crash error was encountered from the Teradata Database or CLIV2 that will terminate the load operation
Table 12: Stream Operator Notify Event Codes (continued)
EventEvent Code
Event Description and Data PassedTo The Notify Exit Routine
Teradata Warehouse Builder User Guide 127

Chapter 7: Advanced TopicsManaging Active Jobs
See Appendix B: “Notify Exit Routines” in the Teradata Parallel Transporter Reference for information about providing your own notify exit routine.
Managing Active Jobs
Teradata PT allows you to monitor and dynamically modify the behavior of jobs using external commands, which can be used to synchronize jobs, suspend and resume jobs, and balance jobs between resources and tables that are in use or locked. The methods for managing active jobs vary slightly depending on the platform.
Using External Commands
Use the following procedures to manage active jobs.
To take a checkpoint
An active job can be directed to a job at runtime using the external command interface. Upon receiving the checkpoint request, each of operator instance immediately takes a checkpoint rather than waiting for the checkpoint interval to expire. After the checkpoint completes, the job continues to process data.
Use the following procedure to take a checkpoint.
Exit Yes Yes Yes Yes Stream operator is terminating
Table Statistics No Yes Yes Yes Stream operator has successfully written the table statistics
Checkpoint End No No Yes Yes Stream operator successfully completed a checkpoint
Interim Run Statistics No No No Yes Stream operator is about to flush the stale buffers (because a latency internal has expired), or Stream operator successfully completed a checkpoint, or an Import is just successfully completed
DML Error No No Yes Yes Stream operator is about to log a DML error to the error table
Table 13: Stream Operator Events that Create Notifications (continued)
Event
Notification Level
SignifiesLow Medium High Ultra
128 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsManaging Active Jobs
1 Do one of the following, where jobname is the name of the target Teradata PT job (determined by using the twbstat command):
• MVS - External commands are sent to Teradata PT jobs using the console MODIFY command:
F <job name>,APPL=job checkpoint
• All other platforms:
twbcmd <job name> job checkpoint
2 The job immediately creates a checkpoint.
To take a checkpoint upon termination
When the twbkill command is used to terminate a job, it does not automatically take a checkpoint, which means that restarting a terminated job reprocesses everything done after the last checkpoint. This can cause errors, such as the reinsertion of rows. To avoid the problems caused by reprocessing, use the following procedure, which creates a checkpoint prior to termination.
Use the following procedure to create a checkpoint prior to termination.
1 Do one of the following, where jobname is the name of the target Teradata PT job (determined by using the twbstat command):
• MVS - External commands are sent to Teradata PT jobs using the console MODIFY command:
F <job name>,APPL=job job terminate
• All other platforms:
twbcmd <job name> job terminate
2 The job creates a checkpoint, then immediately terminates. Checkpoint files are retained, and the job is restartable.
To pause and resume a job
Sometimes resources are tied up, tables are locked, or jobs get out of sync. In another instance, a Data Connector job might “wake up” to find that no data is coming in. External commands allow you to avoid terminating jobs under these conditions. Use the following procedure to temporarily suspend the flow of data to control job timing and system resources.
1 Do one of the following to pause a job, where jobname is the name of the target Teradata PT job (determined by using the twbstat command):
• MVS:
F <job name>,APPL=job pause
• All other platforms:
Teradata Warehouse Builder User Guide 129

Chapter 7: Advanced TopicsQuery Banding Considerations
twbcmd <job name> job pause
2 To resume the job, do one of the following:
• MVS:
F <job name>,APPL=job resume
• All other platforms:
twbcmd <job name> job resume
To log and view the status of active jobs
Use the following procedure to determine the status of all active jobs:
1 Do one of the following, where jobname is the name of the target Teradata PT job (determined by using the twbstat command):
• MVS:
F <job name>,APPL=job status
• All other platforms:
twbcmd <job name> job status
2 The following happens:
• All active operators write a status record to the TWB_STATUS log.
• The console displays the current count for rows sent and received.
Command Descriptions
For command syntax, see “Utility Commands” in the Teradata Parallel Transporter Reference.
Query Banding Considerations
Available through the Load, Update, Stream, Export, SQL Selector, SQL Inserter and DDL operators, use the QueryBandSessInfo attribute to set the query banding feature of the Teradata Database. See the Teradata Parallel Transporter Reference for more details on default values and setting the Query Band for the duration of a job session.
There are two interaction items to consider for systems that are using Teradata Dynamic Workload Manager (Teradata DWM) and Teradata PT:
• Teradata Dynamic Workload Manager classifies the first utility-specific command in for a Teradata PT operator. Classification is based on query bands if the QueryBandSessInfo attribute contains a value.
• When the QueryBandSessInfo attribute contains a value, the system sets a flag in the session context so that all subsequent operator commands are not classified. This ensures that all work for the operator runs at the same priority and workload definition.
130 Teradata Warehouse Builder User Guide

Chapter 7: Advanced TopicsUsing LONG VARCHAR with Unicode Character Sets
• When the Delay option is specified, the TENACITY/TenacityHours and SLEEP/TenacitySleep attributes become ineffective for that job because Teradata DWM will automatically delay a logon until it is eligible to run.
Using LONG VARCHAR with Unicode Character Sets
Teradata supports a column type of LONG VARCHAR. When dealing with single-byte character sets (both client side session character set and server side storage character set) a LONG VARCHAR is interpreted as VARCHAR(64000).
When processing the script and coming across a column of type LONG VARCHAR, Teradata PT interprets this column type as VARCHAR(64000). Since the column type is passed on to the operators, some jobs may not run properly.
Problems may arise when the server side storage character set is Unicode or when the LONG VARCHAR column type is used in a schema definition. This is because the combination of the client side session character set and the server storage character set can cause the LONG VARCHAR specification in a DML USING clause to mean something other than VARCHAR(64000).
In summary:
• The use of LONG VARCHAR in a schema object definition is not recommended.
• Do not use LONG VARCHAR with Unicode character sets. Instead, specify VARCHAR(64000).
Switching Versions
Multiple versions of Teradata Warehouse Builder (Teradata WB) and Teradata PT can be installed. To switch between them, or between multiple versions of Teradata PT, refer to the instructions in these publications:
• Teradata Tools and Utilities Installation Guide for Microsoft Windows, B035-2407-mmyx.
• Teradata Tools and Utilities Installation Guide for UNIX and Linux, B035-2459-mmyx.
• Teradata Tools and Utilities Installation Guide for IBM z/OS, B035-2458-mmyx.
Teradata Warehouse Builder User Guide 131

Chapter 7: Advanced TopicsSwitching Versions
132 Teradata Warehouse Builder User Guide

CHAPTER 8
Operational Metadata(Performance Data)
Operational metadata provides detailed metrics describing performance, statistical, and source and target data usage within Teradata PT jobs. This information is accessible by querying Teradata PT logs that contain the operational metadata.
This chapter contains the following topics:
• Availability
• Obtaining Metadata
• Data Schemas
• Exporting (Loading) Metadata
Availability
Performance and statistical metadata are stored in the Teradata PT private log called TWB_STATUS. This metadata provides information, such as the time the job started, CPU and elapsed time usage, as well as the number of records/rows read (produced) or written (consumed) while the job runs.
Job operator source and target metadata are stored in the Teradata PT private log called TWB_SRCTGT. This metadata provides detailed information on the data accessed by Teradata PT operators, such as external data files processed, access module types, as well as actual Teradata PT tables populated while the job runs.
Obtaining Metadata
Obtain job performance and statistical metadata with the tlogview, as follows:
tlogview -l <user log file name> -f TWB_STATUS > <output file name>
where <user log file name> is the Teradata PT log file name, typically ending with an .out extension, and <output file name> is the user-supplied name of the file to receive the output from the command.
Obtain job operator source and target metadata with the tlogview command, as follows:
tlogview -l <user log file name> -f TWB_SRCTGT > <output file name>
Teradata Warehouse Builder User Guide 133

Chapter 8: Operational Metadata (Performance Data)Data Schemas
where <user log file name> is the Teradata PT log file name, typically ending with an .out extension and <output file name> is the user-supplied name of the file to receive the output from the command.
Data Schemas
Two data schemas exist for operational metadata, as follows.
Performance and Statistical Metadata - TWB_STATUS
The data schema for the TWB_STATUS’ private log can be mapped to the following CREATE TABLE DDL statement:
create table Job_Status_Tbl (
Step_Name varchar(21),Task_Name varchar(21),Status_Message varchar(21),Operator_Name varchar(21),Instance_Count varchar(5),Instance_Number varchar(5),Status varchar(21),Start_Time varchar(9),Elapsed_Time varchar(11),CPU_Time varchar(11),Block_Size varchar(11),Buffer_Count varchar(11),Input_Rows varchar(17),Output_Rows varchar(17),Checkpoint_Interval varchar(6),Latency_Interval varchar(6),End_of_Data varchar(2),Multi_Phase varchar(1)
);
Job Operator Source and Target Metadata - TWB_SRCTGT
The data schema for the TWB_SRCTGT private log can be mapped to the following CREATE TABLE DDL statement:
create Job_SrcTgt_Tbl (
Step_Name varchar(21),Task_Name varchar(21),Operator_Name varchar(21),SrcTgt_Type varchar(21),SrcTgt_System varchar(21),SrcTgt_Path varchar(41),SrcTgt_Name varchar(80)
);
134 Teradata Warehouse Builder User Guide

Chapter 8: Operational Metadata (Performance Data)Exporting (Loading) Metadata
Exporting (Loading) Metadata
Using the data schema described in “Obtaining Metadata” on page 133, you can access operational metadata from log files. To export (or load) that data from a log file to a Teradata table for SQL access, use the scripts supplied in the Samples directory that is installed with Teradata PT. Look for the Samples directory in the same directory where Teradata PT is installed. The script samples include instructions.
• To export performance and statistical metadata, use the script named twb_status.txt.
• To load operator source and target metadata, use the script named twb_targets.txt.
SQL examples for extracting operational metadata from Teradata tables are also stored in the Teradata PT Samples directory as follows:
• sql1.txt demonstrates how to extract job performance and statistical metadata.
• sql2.txt demonstrates how to extract job operator source and target metadata.
Each of the SQL files also provides examples for using an SQL join to extract combined metadata results from the operational metadata tables.
Teradata Warehouse Builder User Guide 135

Chapter 8: Operational Metadata (Performance Data)Exporting (Loading) Metadata
136 Teradata Warehouse Builder User Guide

CHAPTER 9
Wizard Help
The Teradata Parallel Transporter (Teradata PT) Wizard is a GUI-based Windows application that can simplify the process of defining, modifying, and running simple load and export jobs that move data from a single source to a single destination. In other words, the Wizard creates Teradata PT job scripts, but it offers limited Teradata PT functionality.
Topics include:
• Overview
• Wizard Limitations
• Main Window
• Create a New Script
• Stop, Restart, Delete, Edit Jobs
• View Job Output
• Menus and Toolbars
Overview
The basic workflow of the Wizard automatically creates the elements of a simple Teradata PT script. Following is a typical workflow, although variations to this flow often occur:
1 Type a job name and description.
2 Choose the data source.
3 Choose the data destination.
4 Map the source to a destination.
5 Select the type of processing, such as a simple insert or upsert, versus using the Load, Update, or Stream operators.
Note: Depending on the data source, the Wizard uses the DataConnector, Export, or ODBC operators to extract data.
6 Generate job components.
7 Run the job.
The resulting script can be rerun, edited, or copied into another script.
When scripts are run, the following output is produced and displayed in various tabs on the main window:
• Click the Job Output tab to view a short synopsis of the job run.
Teradata Warehouse Builder User Guide 137

Chapter 9: Wizard HelpWizard Limitations
• Click the Job Details tab to see a detailed table listing job instances. This table also shows the status of the running job and will be updated dynamically as the job progresses.
• Under the Job Script tab, the entire script is shown. Note that each line has a line number contained in a comment.
Wizard Limitations
The Wizard has the following limitations:
• Only a single job step can be created.
• Only selects, inserts, and upserts can be performed.
• The Update and Stream operators can only operate against a single table, and they only perform inserts and upserts (not updates or deletes). To perform updates and deletes, scripts must be manually altered.
• A maximum of 450 columns can be defined in the source table or source record.
• The Wizard only supports the OCI driver type 2 of the Oracle JDBC driver.
Main Window
The window of Teradata PT Wizard consists of two panes.
138 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpMain Window
The left pane displays a directory structure (or job tree) with a node root named Job. Clicking on the Job root will display a list of previous jobs, along with a description in the right pane. Clicking on a job name in the left pane displays the job summary.
As the session progresses and jobs are run, a history of job instances will build in the job tree in the left pane.
The right pane displays the name, description, and status of all jobs (or job nodes) that have been run.
Use the main window to run, delete, and modify jobs as follows:
• Click a job object in the job tree to see a description of the job, including the source and destination for the job, in the right pane.
Teradata Warehouse Builder User Guide 139
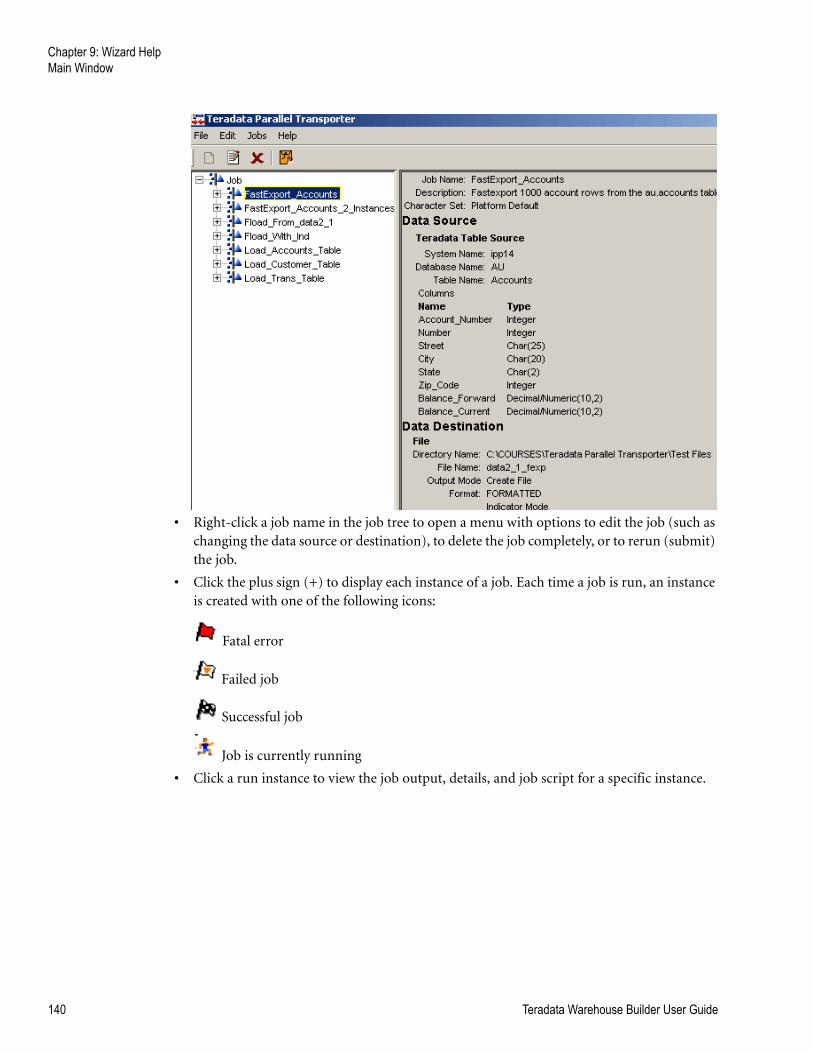
Chapter 9: Wizard HelpMain Window
• Right-click a job name in the job tree to open a menu with options to edit the job (such as changing the data source or destination), to delete the job completely, or to rerun (submit) the job.
• Click the plus sign (+) to display each instance of a job. Each time a job is run, an instance is created with one of the following icons:
Fatal error
Failed job
Successful job
Job is currently running
• Click a run instance to view the job output, details, and job script for a specific instance.
140 Teradata Warehouse Builder User Guide
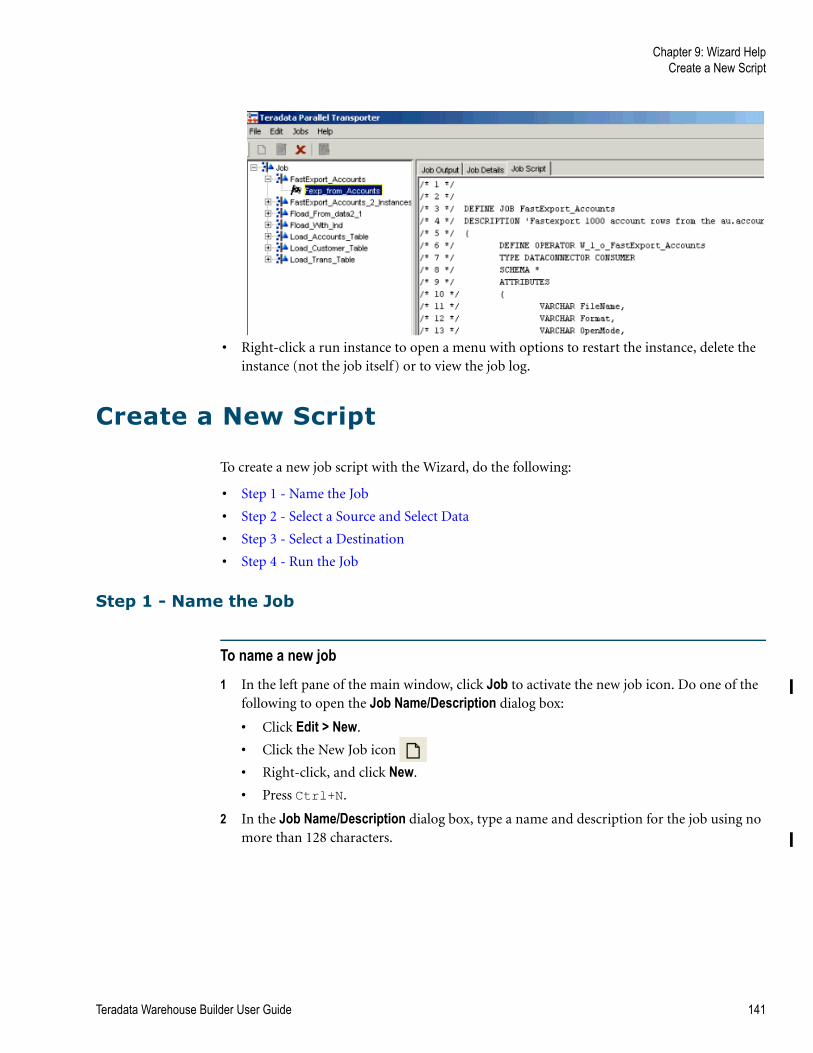
Chapter 9: Wizard HelpCreate a New Script
• Right-click a run instance to open a menu with options to restart the instance, delete the instance (not the job itself) or to view the job log.
Create a New Script
To create a new job script with the Wizard, do the following:
• Step 1 - Name the Job
• Step 2 - Select a Source and Select Data
• Step 3 - Select a Destination
• Step 4 - Run the Job
Step 1 - Name the Job
To name a new job
1 In the left pane of the main window, click Job to activate the new job icon. Do one of the following to open the Job Name/Description dialog box:
• Click Edit > New.
• Click the New Job icon
• Right-click, and click New.
• Press Ctrl+N.
2 In the Job Name/Description dialog box, type a name and description for the job using no more than 128 characters.
Teradata Warehouse Builder User Guide 141

Chapter 9: Wizard HelpCreate a New Script
The job name must start with a letter (upper or lower case) followed by a zero or more letters, and may contain digits (0-9). An underscore is also valid. If the text turns red during typing, the name does not meet these requirements This informational message appears when the Next button is clicked:
Note: When a job name is changed, Teradata PT Wizard creates a new job script with the new job name. The script with the old job name still exists.
The job description can remain blank, it is not required. But like the job name, it appears in three places:
• The description is displayed in the second column next to the job name when the Job root is clicked in the left pane
• As the second line in the job summary
• In the Description statement in the job script
The job name and description can be changed when the job is edited.
3 (Optional) Click Character Set to change the language. Teradata PT allows all character sets as long as they are supported and defined for the Teradata Database. The default is the character set of the active platform; however, scripts and log output are always in English only.
The default character sets for all Teradata PT jobs are:
• ASCII for network-attached client systems
• EBCDIC for channel-attached client systems
For more information, the Teradata Parallel Transporter Reference discuses extended character sets and the International Character Set Support publications list supported character sets for each version of the Teradata Database.
4 Click Next to open the Job Source dialog box.
142 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
5 Continue with Step 2 - Select a Source and Select Data.
Step 2 - Select a Source and Select Data
Use one of the following procedures, depending on the data source for the job.
• Teradata Table as a Data Source
• File as a Data Source
• Oracle Table as a Data Source
• ODBC-Compliant Database as a Data Source
Logging onto a Data Source
When using a Teradata table, an Oracle table or an ODBC-compliant database as a data source, a Logon dialog box will appear to prompt for name, User ID and Password. The Logon dialog box will appear when creating a new script or editing an existing script. Optionally, logon information can be included in the Wizard scripts. After supplying this information, the Wizard will attempt to log on. When connected, the Wizard will continue. If the connection can not be made, informational messages will appear.
When running existing scripts, if the logon information has not been included in a script that has been submitted to run, information can be entered in the JobAttributes panel in the Run dialog box, as shown under step 4 on page 157.
Teradata Table as a Data Source
Use the Teradata Table option from the Job Source dialog box to log onto your Teradata system, then select a specific table as a data source for a job. The Teradata Logon dialog box appears, optionally allowing the User ID and Password to be included in the Wizard job.
Teradata Warehouse Builder User Guide 143

Chapter 9: Wizard HelpCreate a New Script
To export data from a Teradata table
1 From the Source Type list in the Job Source dialog box, select Teradata Table.
2 In the Teradata Logon dialog box, type the host name, user ID, and password to log on to your Teradata system.
3 (Optional) Select the check boxes to include your user ID and password in the generated scripts. The default is to enter placeholders.
4 Click OK.
The Job Source dialog box displays the directory structure of the Teradata system you logged onto.
5 In the left pane, select a database and a table to be the data source for the job.
Caution: Do not select tables that contain character large object (CLOB) or binary large object (BLOB) data types.
6 In the right pane, select up to 450 columns to include in the source schema, or click Select All or Select None. (Press Ctrl+click to select multiple columns.)
If a column name from a source table is a Teradata PT reserved word, the Teradata PT Wizard will append the phrase “_#” (where # is a numeric) so that the name will differ from the keyword and the submitted script will not get a parsing syntax error. For example, if the keyword DESCRIPTION is used as a column name the name will be
144 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
changed to DESCRIPTION_1. Teradata PT keeps an internal counter for generating the appended number.
For the complete list of Teradata PT reserved words see Appendix D of the Teradata Parallel Transporter Reference.
Note: The values under TPT Type are names of the data types associated with the columns according to Teradata PT; the values under DBS Type are the data types from the source database. When Teradata PT gets a column name from a source table, it looks at the definition schema of the table to deduce an accurate data type. Sometimes, these types can be recorded incorrectly or as a “?” when the Wizard cannot properly determine the data type. This often occurs when reading user-defined data types (UDTs).
To change or correct a Teradata PT data type, click Edit Type (or right-click), and select the correct data type from the shortcut menu. Also enter the length, precision, and scale if applicable. The precision and scale data types are only available when Decimal/Numeric is selected.
7 Click Next to open the Job Destination dialog box.
8 Continue with Step 3 - Select a Destination.
File as a Data Source
Use the File option from the Job Source dialog box to browse for a flat file to use as the data source for a job.
To export data from a flat file
1 From the Source Type list in the Job Source dialog box, select File.
2 Do one of the following:
• In Directory Name and File Name, type the path and name of the file to be used as the data source for the job.
• Click Select to browse for the source file.
Teradata Warehouse Builder User Guide 145

Chapter 9: Wizard HelpCreate a New Script
3 In Format, select either Binary, Delimited, Formatted, Text, or Unformatted as the format associated with the file.
For more information, see “Input File Formats” on page 51.
If specifying Delimited format, type the delimiter used in the file into the Delimiter box. With this file format, all of the data types in the DEFINE SCHEMA must be VARCHARs. Non-VARCHAR data types will result in an error when a job script is submitted to run. And, if not provided, the TextDelimiter attribute defaults to the pipe character ( | ).
4 (Optional) Select Indicator Mode to include indicator bytes at the beginning of each record. (Unavailable for delimited data.)
Note: If the file name contains a wildcard character (*), two additional input boxes are available. Type the number of minutes for a job to wait for additional data in the Vigil Elapsed Time box, and type the number of seconds to wait before Teradata PT checks for new data in Vigil Wait Time box.
5 Click Next to open the Define Columns dialog box.
146 Teradata Warehouse Builder User Guide
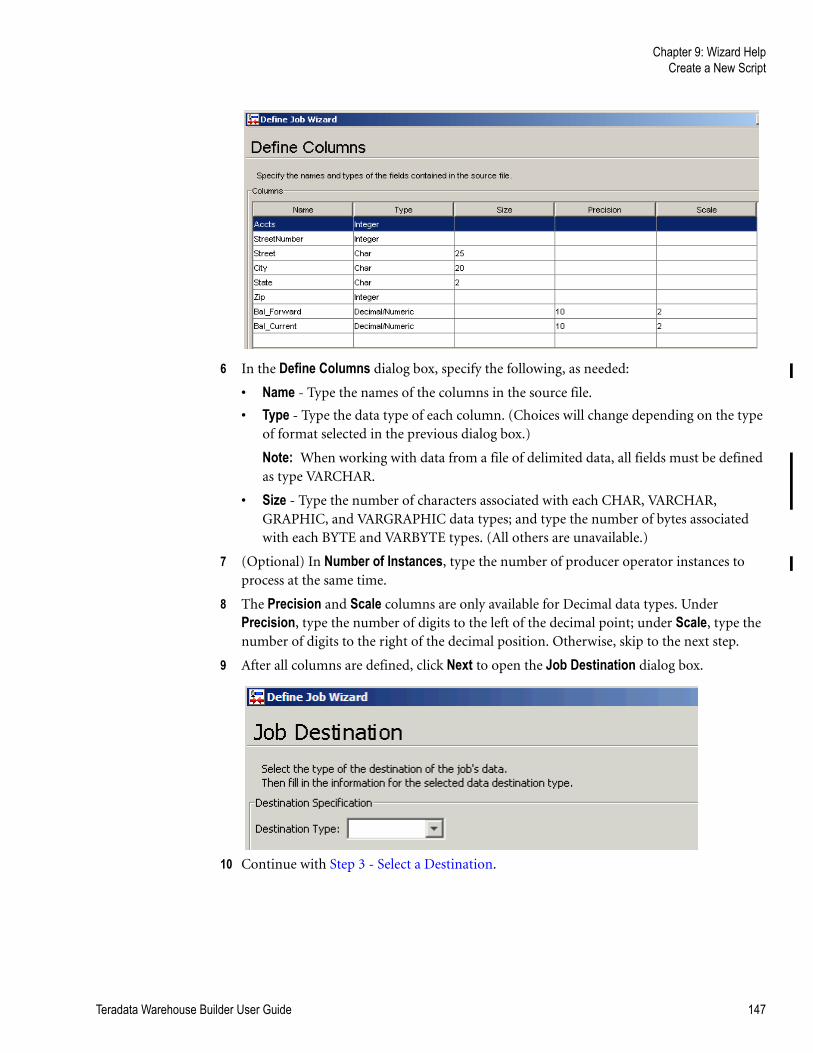
Chapter 9: Wizard HelpCreate a New Script
6 In the Define Columns dialog box, specify the following, as needed:
• Name - Type the names of the columns in the source file.
• Type - Type the data type of each column. (Choices will change depending on the type of format selected in the previous dialog box.)
Note: When working with data from a file of delimited data, all fields must be defined as type VARCHAR.
• Size - Type the number of characters associated with each CHAR, VARCHAR, GRAPHIC, and VARGRAPHIC data types; and type the number of bytes associated with each BYTE and VARBYTE types. (All others are unavailable.)
7 (Optional) In Number of Instances, type the number of producer operator instances to process at the same time.
8 The Precision and Scale columns are only available for Decimal data types. Under Precision, type the number of digits to the left of the decimal point; under Scale, type the number of digits to the right of the decimal position. Otherwise, skip to the next step.
9 After all columns are defined, click Next to open the Job Destination dialog box.
10 Continue with Step 3 - Select a Destination.
Teradata Warehouse Builder User Guide 147

Chapter 9: Wizard HelpCreate a New Script
Oracle Table as a Data Source
Use the Oracle Table option from the Job Source dialog box to log onto an Oracle server and select a specific table as a data source. The Oracle Logon dialog appears, optionally allowing the User ID and Password to be included in the Wizard job.
To export data from an Oracle table
1 From the Source Type list in the Job Source dialog box, click Oracle Table.
2 At the log on prompt, type the TSN name (a net service name that is defined in a TNSNAMES.ORA file or in the Oracle directory server, depending on how the Oracle net service is configured on the Oracle client and server), user ID, and the password needed to build the Oracle JDBC connection.
Caution: The value you enter into the TSN Service Name box at logon is the value that the Wizard uses for the DSNname attribute in all scripts; however, systems are often configured with different values for the TSN Service Name and DSN name. If this is the case, you must manually edit the value of the DSNname attribute in scripts to match the TSN Service Name before submitting a job script that involves an Oracle server.
3 (Optional) Select the check boxes to include your user ID and password in the generated scripts. The default is to enter placeholders.
4 Click OK.
The Job Source dialog box displays the directory structure of the active Oracle server.
5 From the directory tree in the left pane, select a database and table that are the source of data for the job.
Caution: Do not select tables that contain character large object (CLOB) or binary large object (BLOB) data types.
6 In the right pane, select up to 450 columns to be included in the source schema, or click Select All or Select None.
Note: The values under TPT Type are names of the data types associated with the columns according to Teradata PT; the values under DBS Type are the data types from the source database. When Teradata PT gets a column name from a source table, it looks at the definition schema of the table to deduce an accurate data type. Sometimes, these types can
148 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
be recorded incorrectly or as a “?” when the Wizard cannot properly determine the data type. This often occurs when reading user-defined data types (UDTs).
To change or correct a Teradata PT data type, click Edit Type (or right-click), and select the correct data type from the shortcut menu. You can also enter the length, precision, and scale if it is applicable, but the precision and scale data types only appear when Decimal/Numeric is selected.
7 Click Next to open the Job Destination dialog box.
8 Continue with Step 3 - Select a Destination.
ODBC-Compliant Database as a Data Source
Use the ODBC DSN option from the Job Source dialog box to log onto an ODBC-compliant database, then select a specific table as a data source for a job. The ODBC Logon dialog box appears, optionally allowing the User ID and Password to be included in the Wizard job.
To export data from an ODBC-compliant source
1 From the Source Type list in the Job Source dialog box, select ODBC DSN.
2 In the ODBC Logon dialog box, type the host name, user ID, and password to log on.
3 (Optional) Select the check boxes to include your user ID and password in the generated scripts. The default is to enter placeholders.
4 Click OK.
The Job Source dialog box displays the database and table hierarchy of the ODBC-compliant data source you logged onto.
Teradata Warehouse Builder User Guide 149

Chapter 9: Wizard HelpCreate a New Script
5 In the left pane, select a database and a table as the data source for the job.
Caution: Do not select tables that contain character large object (CLOB) or binary large object (BLOB) data types.
6 In the right pane, select up to 450 columns to be included in the source schema, or click Select All or Select None. (Press Ctrl+click to select multiple columns.)
Note: The values under TPT Type are names of the data types associated with the columns according to Teradata PT; the values under DBS Type are the data types from the source database. When Teradata PT gets a column name from a source table, it looks at the definition schema of the table to deduce an accurate data type. Sometimes, these types can be recorded incorrectly or as a “?” when the Wizard cannot properly determine the data type. This often occurs when reading user-defined data types (UDTs).
To change or correct a Teradata PT data type, click Edit Type (or right-click), and select the correct data type from the shortcut menu. You can also enter the length, precision, and scale if it is applicable, but the precision and scale data types are only available when Decimal/Numeric is selected.
7 Click Next to open the Job Destination dialog box.
150 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
8 Continue with Step 3 - Select a Destination.
Step 3 - Select a Destination
Regardless of whether the source for a job is a Teradata Database, a flat file, an ODBC-compliant source, or an Oracle database, the Wizard limits the load option in the Job Destination dialog box to the following:
• File as a Target
• Teradata Table as a Target
File as a Target
Use the File option in the Job Destination dialog box to export data to a flat file by using the following procedure.
To load data to a file
1 In Destination Type of the Job Destination dialog box, select File.
Teradata Warehouse Builder User Guide 151

Chapter 9: Wizard HelpCreate a New Script
2 Do one of the following:
• In Directory Name, type the directory that contains the destination file, then, in File Name, type the name of the destination file.
• Click Select to browse for the destination file. If the desired file does not exist, type in the file name and press Enter. When the job script runs, the file will be created or appended, based on the option button choice made in the Job Destination dialog box’s Output Mode.
3 In the Output Mode group box, do one of the following:
• Click Create File to export to an empty flat file.
• Click Append File to add exported data to a file that already contains data.
4 In Format, select either Binary, Delimited, Formatted, Text, or Unformatted as the format associated with the destination file.
Note: If the destination file is delimited, type the delimiter used in the file into the Delimiter box.
When exporting delimited data, only VARCHAR columns can be exported from the source tables. If non-VARCHAR columns are needed, these steps must be done:
a Convert these columns to VARCHAR.
b Edit the values under the Teradata PT Type setting to VARCHAR for these columns. Do this by clicking Edit Type which is detailed in step 6 of the File as a Data Source procedure.
c If needed, manually modify the SELECT statement in the attribute “SelectStmt” to cast non-VARCHAR columns to VARCHAR after generating the Wizard script.
5 (Optional) Select Indicator Mode to include indicator bytes at the beginning of each record. (Unavailable for delimited data.)
6 Click Next to open the Finish Job dialog box.
7 Continue with Step 4 - Run the Job.
Teradata Table as a Target
Use the Teradata Table option from the Job Destination dialog box to log onto your Teradata system, and to select a specific table as the destination for a job by using the following procedure.
152 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
To load data to a Teradata table
1 In Destination Type of the Job Destination dialog box, select Teradata Table.
2 In the Teradata Logon dialog box, type the host name, user ID, and password to log onto the target Teradata system.
3 (Optional) Select the check boxes to include your user ID and password in the generated scripts. The default is to enter placeholders.
4 Click OK to close the log on prompt and return to the Job Destination dialog box. For more information, see “Logging onto a Data Source” on page 143.
The directory structure and columns of the Teradata system are displayed. (The values are not editable.)
5 (Optional) In Number of Instances, type a number to designate the number of consumer operator instances to process at the same time.
6 Click Next to open the Operator Type Selection dialog box.
Teradata Warehouse Builder User Guide 153

Chapter 9: Wizard HelpCreate a New Script
7 Select one of the following options depending on what Teradata PT operator or operation is to be used for the job. For more information about operators, see the Teradata Parallel Transporter Reference.
• Load Operator - Use this option only if the destination table is empty; the job fails if it is not empty. This option transfers data much faster than the Update or Stream operators.
• Update Operator - Use this option to update an existing table regardless of whether it contains data. Selecting this option requires an additional selection of an insert or upsert operation.
• Stream Operator - Use this option to update a destination table from a source that generates constant data. Selecting this option requires an additional selection of an insert or upsert operation.
• Insert Operation - Use this option to copy data from the source to the destination.
• Upsert Operation - Selecting this option opens the Update Row Specification dialog box.
154 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
Use this option to select the destination columns that will get updated with data values from the source. Only the data values in the destination table that match the data values in the source are updated. When data does not match, a new row is created.
Note: At least one column must be selected, and at least one column must remain cleared.
8 Click Next to open the Map Source to Destination dialog box.
9 Click in each row of the Source column to open drop-down list for each row, and select a data value to map each source value to the specific destination column.
Note: Source columns can be left as Column Not Mapped as long as at least one column in the table is mapped.
10 Click Next to open the Finish Job dialog box.
Teradata Warehouse Builder User Guide 155

Chapter 9: Wizard HelpCreate a New Script
11 Continue with Step 4 - Run the Job.
Step 4 - Run the Job
The Finish Job dialog box displays a summary of the job.
To run a job
1 Decide to do one of the following:
• To run a new job, skip to step 4.
• To run a previously created job, continue with step 2.
• To save the job without running it (so you can run the script later), or to store the script (so you can copy it into another script), continue with step 2.
2 Review the job summary for accuracy, and do one of the following:
• To correct mistakes, click Back to return to the appropriate dialog box and make corrections.
• To store the job to be run or edited later, clear the Run Job Now option, and click Finish.
• To run the job now, select Run Job Now, then click Finish.
3 If you opted to run the job in Step 2, the Run Job dialog box opened. Otherwise, open the Run Job dialog box for a stored job now by right-clicking the job name in the job tree of the main Wizard window, and click Submit.
156 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpCreate a New Script
4 In Job Name, type the name of the job.
5 (Optional) In Checkpoint Interval, type the number of seconds between checkpoint intervals.
6 (Optional) In Retry Limit, type a positive number; the default value is 100. This option specifies how many times Teradata PT will automatically retry a job step after a restart. The Retry Limit option corresponds to the tbuild command’s -R option.
7 (Optional) In Latency Interval, type the number of seconds until the Wizard flushes stale buffers.
Note: Currently, the Latency Interval option is available only for the Stream operator. For more information, see the Teradata Parallel Transporter Reference.
8 (Optional) Select Enable Trace to enable the trace mechanisms.
9 If Job Attributes is available, type the name and password for the source table and the destination table. (This pane is available only if you did not select the two options to include the user ID and password in the generated script during log on. For information about these options, see “Teradata Table as a Target” on page 152 and “Oracle Table as a Data Source” on page 148.)
10 (Optional) View and edit the script before running it. Note that any changes made to the script will not be saved by the Wizard for the next use of the script. The changes will only apply for the current run when the OK button is clicked.
11 When you are ready to run the job, click OK.
While the job is running, the running icon is displayed. When the job is complete, status can be viewed in the Job Status dialog box. For more information, see “View Job Output” on page 160.
Teradata Warehouse Builder User Guide 157

Chapter 9: Wizard HelpStop, Restart, Delete, Edit Jobs
Stop, Restart, Delete, Edit Jobs
Use the follow procedures to manage active jobs and jobs that have already been created in Teradata PT.
To stop a running job
1 At any point during the running of a job, select the run instance in the main window.
2 Do one of the following:
• Click Jobs > Kill Job.
• Click , which only available during job processing.
• Press Ctrl+K.
To restart a job
1 From the main window, select a run instance in the job tree.
2 Do one of the following:
• Click Jobs > Restart Job.
• Click .
• Right-click the job instance, then click Restart Job.
• Press Crtl+R.
The job begins from the point at which the job was stopped. Also see “To stop a running job” on page 158.
To delete a job
This procedure completely removes a job and all its instances from the Wizard.
1 From the main window, select a job name in the job tree.
2 Do one of the following:
• Click Edit > Delete.
• Click .
• Right-click the job instance, then click Delete.
• Press Ctrl+Shift+D.
158 Teradata Warehouse Builder User Guide
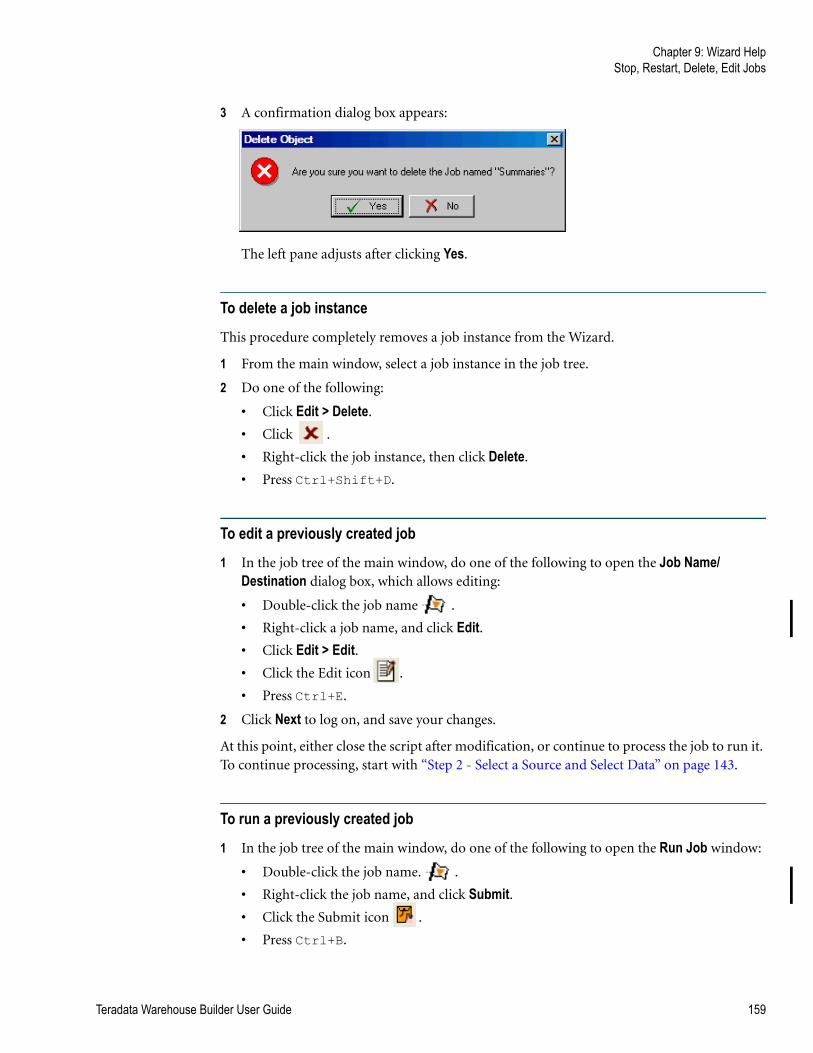
Chapter 9: Wizard HelpStop, Restart, Delete, Edit Jobs
3 A confirmation dialog box appears:
The left pane adjusts after clicking Yes.
To delete a job instance
This procedure completely removes a job instance from the Wizard.
1 From the main window, select a job instance in the job tree.
2 Do one of the following:
• Click Edit > Delete.
• Click .
• Right-click the job instance, then click Delete.
• Press Ctrl+Shift+D.
To edit a previously created job
1 In the job tree of the main window, do one of the following to open the Job Name/Destination dialog box, which allows editing:
• Double-click the job name .
• Right-click a job name, and click Edit.• Click Edit > Edit.• Click the Edit icon .
• Press Ctrl+E.
2 Click Next to log on, and save your changes.
At this point, either close the script after modification, or continue to process the job to run it. To continue processing, start with “Step 2 - Select a Source and Select Data” on page 143.
To run a previously created job
1 In the job tree of the main window, do one of the following to open the Run Job window:
• Double-click the job name. .
• Right-click the job name, and click Submit.• Click the Submit icon .
• Press Ctrl+B.
Teradata Warehouse Builder User Guide 159
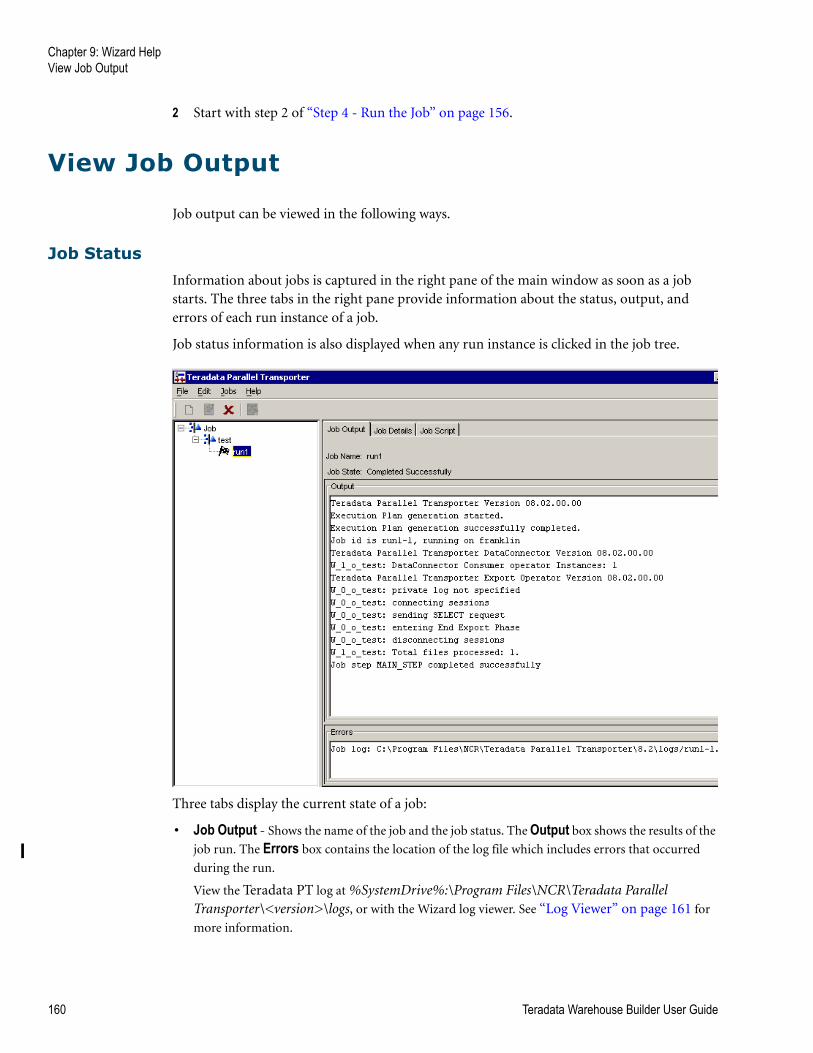
Chapter 9: Wizard HelpView Job Output
2 Start with step 2 of “Step 4 - Run the Job” on page 156.
View Job Output
Job output can be viewed in the following ways.
Job Status
Information about jobs is captured in the right pane of the main window as soon as a job starts. The three tabs in the right pane provide information about the status, output, and errors of each run instance of a job.
Job status information is also displayed when any run instance is clicked in the job tree.
Three tabs display the current state of a job:
• Job Output - Shows the name of the job and the job status. The Output box shows the results of the
job run. The Errors box contains the location of the log file which includes errors that occurred
during the run.
View the Teradata PT log at %SystemDrive%:\Program Files\NCR\Teradata Parallel Transporter\<version>\logs, or with the Wizard log viewer. See “Log Viewer” on page 161 for
more information.
160 Teradata Warehouse Builder User Guide
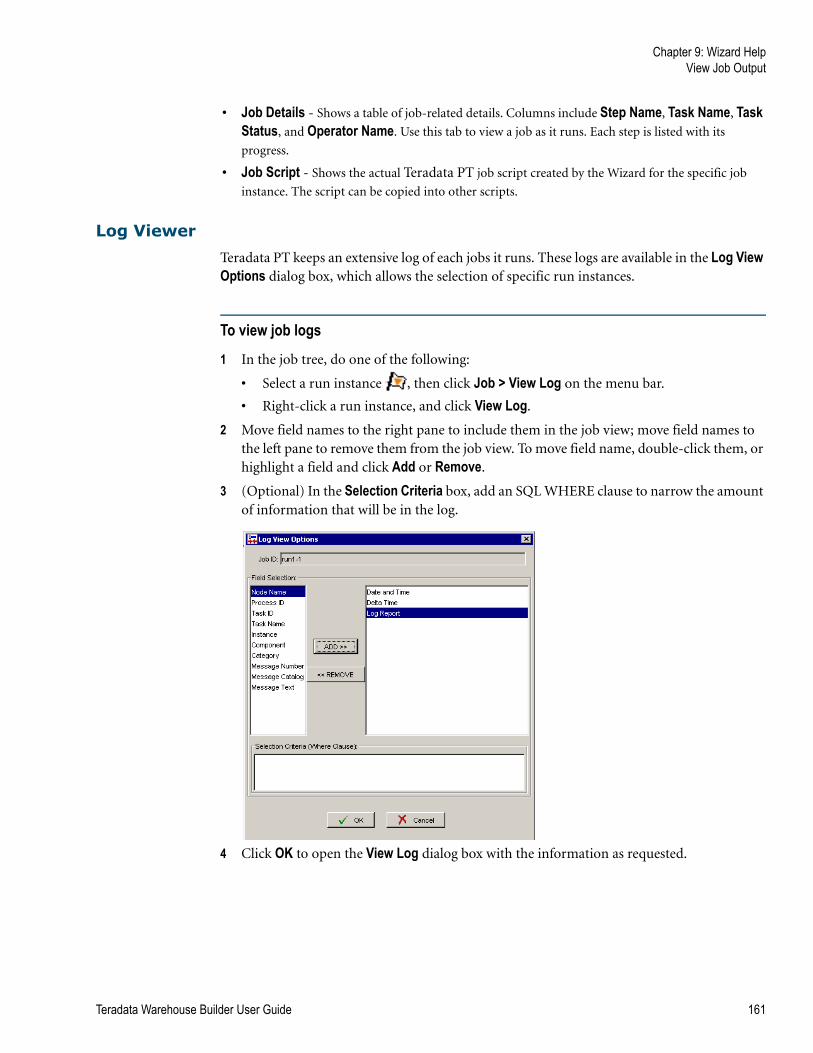
Chapter 9: Wizard HelpView Job Output
• Job Details - Shows a table of job-related details. Columns include Step Name, Task Name, Task Status, and Operator Name. Use this tab to view a job as it runs. Each step is listed with its
progress.
• Job Script - Shows the actual Teradata PT job script created by the Wizard for the specific job
instance. The script can be copied into other scripts.
Log Viewer
Teradata PT keeps an extensive log of each jobs it runs. These logs are available in the Log View Options dialog box, which allows the selection of specific run instances.
To view job logs
1 In the job tree, do one of the following:
• Select a run instance , then click Job > View Log on the menu bar.
• Right-click a run instance, and click View Log.
2 Move field names to the right pane to include them in the job view; move field names to the left pane to remove them from the job view. To move field name, double-click them, or highlight a field and click Add or Remove.
3 (Optional) In the Selection Criteria box, add an SQL WHERE clause to narrow the amount of information that will be in the log.
4 Click OK to open the View Log dialog box with the information as requested.
Teradata Warehouse Builder User Guide 161

Chapter 9: Wizard HelpMenus and Toolbars
Menus and Toolbars
The Teradata PT Wizard uses the following menu items. Many of these functions are also available by right-clicking icons in the main window and the job tree.
Many of the following toolbar functions are also available by right-clicking a job instance in the job tree.
Table 14: Menu Items
Menu Menu choice Description
File Exit Closes the wizard.
Edit New Creates a new job. See “Step 1 - Name the Job” on page 141.
Edit Allows editing of the attributes of an existing job. See “To edit a previously created job” on page 159.
Delete Deletes a job from the job tree, or deletes run instances from a specific job icon.
Refresh Refreshes the wizard screen.
Jobs Submit Submits a selected job.
Kill Job Stops the currently running job.
Restart Job Restarts a run instance.
View Log Opens the View Log Options dialog box.
Help Teradata Parallel Transporter Help
Opens the online help.
About Displays the active version of the Teradata PT Wizard.
Table 15: Toolbar
Buttons Name Function
New Job Creates a new job. See “Create a New Script” on page 141.
Edit Item Edits an existing job. See “To edit a previously created job” on page 159.
Delete Deletes jobs or run instances from the Wizard. See “To delete a job” on page 158.
Kill Job Stops an active job. See “To stop a running job” on page 158.
162 Teradata Warehouse Builder User Guide

Chapter 9: Wizard HelpMenus and Toolbars
Submit Job
Submits a job to be run. See “Step 4 - Run the Job” on page 156.
Restart Job Restarts a job. See “To restart a job” on page 158.
View Log Opens the View Log dialog box. See “Log Viewer” on page 161.
Table 15: Toolbar (continued)
Buttons Name Function
Teradata Warehouse Builder User Guide 163

Chapter 9: Wizard HelpMenus and Toolbars
164 Teradata Warehouse Builder User Guide

CHAPTER 10
Troubleshooting
This chapter discusses debugging Teradata PT and usage tips. The following sections are included:
• Exit and Termination Codes
• Debugging Teradata PT
• Choosing the Number of Instances for the Operators in a Job
• Shared Memory Usage Based on Instances
For more information about installation troubleshooting, see the Teradata Tools and Utilities Installation Guide for IBM z/OS, B035- 2458-mmyx, and the Teradata Tools and Utilities Installation Guide for UNIX and Linux, B035-2459-mmyx.
Exit and Termination Codes
Since every job step is a unit of execution, Teradata PT returns an exit code for every job step and when a job completes, a termination code is provided. These codes are helpful in the debugging process. An integer value, the following codes are possible:
• 0 = Normal completion. The job or job step completed successfully and according to the specified plan.
• 4 = Warning. A warning condition occurred, for example, because a job deviated from the specified plan but still completed successfully. A warning may indicate the deviation from the plan, such as the number of sessions specified were not actually used, or a part of the job did not run. Warning conditions do not terminate the job.
• 8 = User error. A user error, such as a syntax error in the job script, terminated the job.
• 12 = Severe error. A fatal error terminated the job. A fatal error is any error other than a user error.
A job step exit code of eight or higher will cause the job to terminate. But what about jobs in which processing is done as a series of independent job steps? To specify that the job should continue when a nonzero exit code is returned, specify the -n command line option with the tbuild command.
tbuild -n -f <job file name>
Where <job file name> is the name of a file containing the job script that is to be run to completion regardless of errors.
Teradata Warehouse Builder User Guide 165

Chapter 10: TroubleshootingDebugging Teradata PT
Note: Teradata PT jobs running with the -n option cannot be restarted. Since the -n option allows jobs to continue with failed steps, different treatment of the checkpoint files is needed.
Debugging Teradata PT
Use the following debugging techniques to solve Teradata PT problems.
• Learn and Understand the Teradata PT Architecture
• Know which components of Teradata PT run during each phase of job execution.
• Learn the commands of the Logger Services.
• Look at Console Messages
• Are there any error messages?
• Any premature termination?
• Look at the Public Log
• Use the command:
tlogview -j <jobID>
• What component or operator was in control at the time of failure?
• Look at the Private Log if an Operator Fails
• Use the command:
“tlogview -j <jobID> -f <log file name>”
• Are there any error messages?
• Run Trace Level
• Run the operators in your Teradata PT job in trace mode using the TraceLevel attribute.
TraceLevel = ‘all’
• Run your Teradata PT job in trace mode (recommended as a last resort)
• tbuild -t -f <job file>
• Provide truss output (UNIX only) from the Teradata PT problem component if any of the following errors occurs:
• IPC Initialization Error (Inter-Process Communication problem)
• Failed to create Coordinator task
• Unexpected hanging
• Use the following steps to get the truss output of the problem component:
a ps -ef | grep tbuild (if Coordinator, or Executor).
b Find the processid for the problem component.
c truss -f -o /tmp/trussout -p <processid>.
• Check the values of system resources such as shared memory, processes, semaphores, vmemory, and so on.
For example, on Solaris SPARC platform, use the following commands to get the values:
166 Teradata Warehouse Builder User Guide

Chapter 10: TroubleshootingDebugging Teradata PT
• /usr/sbin/sysdef -i | grep SHMMAX
• /usr/sbin/sysdef -i | grep SHMSEG
• /usr/sbin/sysdef -i | grep SEMMNI
• /usr/sbin/sysdef -i | grep SEMMNS
• ulimit -a
Choosing the Number of Instances for the Operators in a Job
Another issue that often arises while using Teradata PT is deciding the number of instances for the operators in a job. The following section provides some tips to help you decide.
• The best way to understand how the number of instances affects job performance is to measure where bottlenecks occur on the load. Teradata PT can scale to eliminate data I/O and load-process CPU bottlenecks.
• Try using only one to four instances for any given operator.
• Don't create more instances than needed, more instances consume system resources.
• Start with one instance and work up to more as needed.
• Read the Teradata PT log file, which displays statistics showing how much data was processed by each instance. Reduce the number of instances if you see under-used instances of any operators.
Shared Memory Usage Based on Instances
Use the following formula to decide the shared memory usage based in instance:
Let n and m be the number of instances of the producer and consumer operators, respectively.
Note: Data from producers are multiplexed into consumers through data streams. In other words, the number of data streams to be used per job would be n * m.
Let q be the maximum queue depth (in terms of 64K buffers) of a data stream. (In Teradata PT TTU 7.0, two appears to be the most efficient number of buffers)
Examples
Note the following examples assume each of the data streams between producers and consumers is full during execution (for example, q= 2 buffers):
Shared memory used by 2 producers and 2 consumers:
(((2 * 2)data streams) * 64K * q) = 512K
Shared memory used by 4 producers and 4 consumers:
(((4 * 4)data streams) * 64K * q) = 2048K
Shared memory used by 24 producers and 1 consumer:
(((24 * 1)data streams) * 64K * q) = 3072K
Note: The maximum shared memory available for a job is 10M.
Teradata Warehouse Builder User Guide 167

Chapter 10: TroubleshootingDebugging Teradata PT
Job Failure
Error message: Cannot get current job step from the Checkpoint file.
This type of job termination occurs when a restarted job uses a checkpoint file that is either out-of-date or that was created by another job.
Solution:
• If the checkpoint file is out-of-date, manually delete the file from the TWB_ROOT/Checkpoint directory.
• If the checkpoint file was created by another job, this means that the job does not have a unique job name. Specify a unique job name in the tbuild command using the jobname parameter so Teradata PT can create a unique checkpoint file for the job.
To avoid this problem, only submit jobs with unique, specified job names.
For more information about checkpoint restarting, see “Teradata PT Features” in the Teradata Parallel Transporter Reference.
Delimited Data Issues
When using the DataConnector operator to extract delimited data, errors may occur if the escape character is not defined. Since there is no default escape character, use the DataConnector operator’s EscapeTextDelimiter optional attribute to define the escape character.
If not provided, the TextDelimiter attribute defaults to the pipe character ( | ). See “Input File Formats” on page 51 for more information.
168 Teradata Warehouse Builder User Guide

APPENDIX A
Script Samples
This chapter provides script examples that can be copied into Notepad or a UNIX editor to be used by Teradata PT. Headers contain specific comments about using each script. Find additional scripts in the Sample directory in your local Teradata PT directory.
• Example 1: Load and Export Operators
• Example 2: Export and DataConnector Operators
• Example 3: Load and DataConnector Operators
Example 1: Load and Export Operators
The following script uses the Load and Export operators, a STEPS statement to set a progression, and the DDL operator to create an empty table.
/**************************************************************//* *//* Copyright (c) 2000-2007, NCR Corporation. *//* All Rights Reserved. *//* *//* Script Name: GT11.txt *//* Description: This Teradata Parallel Transporter sample *//* script exports 10 rows from a Teradata table *//* and loads the 10 rows into a different, empty *//* Teradata table. *//* *//**************************************************************//* Explanation: *//* *//* This script uses two job steps. *//* *//* The first job step called "setup" uses the DDL Operator to *//* setup the source and target tables. *//* *//* The second job step called "load_data" uses the Export *//* Operator to export the rows from a Teradata source table *//* and uses the Load Operator to load the rows into an empty *//* Teradata target table. *//* *//* This script shows how to use the following Teradata PT *//* features: *//* * Unconditional job steps. *//* * Export rows from a Teradata table and load the rows into *//* a different, empty Teradata table without landing the *//* rows to a data file. *//* */
Teradata Warehouse Builder User Guide 169

Appendix A: Script SamplesExample 1: Load and Export Operators
/**************************************************************//* Here are the required customizations before running this *//* script: *//* *//* 1. Need to modify the value for the following attributes *//* in the DDL Operator definition below: *//* *//* TdpId, UserName, UserPassword *//* *//* 2. Need to modify the value for the following attributes *//* in the Load Operator definition below: *//* *//* TdpId, UserName, UserPassword *//* *//* 3. Need to modify the value for the following attributes *//* in the Export Operator definition below: *//* *//* TdpId, UserName, UserPassword *//* *//* TdpId is the name of the Teradata Database system. *//* UserName is the user name on the Teradata Database system. *//* UserPassword is the password associated with the UserName. *//* *//**************************************************************//* Execution: *//* *//* Here is the command to execute this script: *//* tbuild -f GT11.txt *//* *//**************************************************************/
DEFINE JOB BACKUP_EMPLOYEE_TABLEDESCRIPTION 'BACKUP SAMPLE EMPLOYEE TABLE'( DEFINE SCHEMA EMPLOYEE_SCHEMA DESCRIPTION 'SAMPLE EMPLOYEE SCHEMA' ( EMP_ID INTEGER, EMP_NAME CHAR(10) );
DEFINE OPERATOR DDL_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DDL OPERATOR' TYPE DDL ATTRIBUTES ( VARCHAR PrivateLogName = 'GT11_ddloper_log', VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountID, VARCHAR ErrorList = '3807' );
DEFINE OPERATOR LOAD_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER LOAD OPERATOR' TYPE LOAD SCHEMA EMPLOYEE_SCHEMA
170 Teradata Warehouse Builder User Guide

Appendix A: Script SamplesExample 1: Load and Export Operators
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT11_loadoper_privatelog', INTEGER MaxSessions = 32, INTEGER MinSessions = 1, VARCHAR TargetTable = 'TARGET_EMP_TABLE', VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountId, VARCHAR ErrorTable1 = 'GT11_LOADOPER_ERRTABLE1', VARCHAR ErrorTable2 = 'GT11_LOADOPER_ERRTABLE2', VARCHAR LogTable = 'GT11_LOADOPER_LOGTABLE' );
DEFINE OPERATOR EXPORT_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER EXPORT OPERATOR' TYPE EXPORT SCHEMA EMPLOYEE_SCHEMA ATTRIBUTES ( VARCHAR PrivateLogName = 'GT11_exportoper_privatelog', INTEGER MaxSessions = 32, INTEGER MinSessions = 1, VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountId, VARCHAR SelectStmt = 'SELECT * FROM SOURCE_EMP_TABLE;' );
STEP setup ( APPLY ('DROP TABLE SOURCE_EMP_TABLE;'), ('DROP TABLE TARGET_EMP_TABLE;'), ('DROP TABLE GT11_LOADOPER_ERRTABLE1;'), ('DROP TABLE GT11_LOADOPER_ERRTABLE2;'), ('DROP TABLE GT11_LOADOPER_LOGTABLE;'), ('CREATE TABLE SOURCE_EMP_TABLE(EMP_ID INTEGER,
EMP_NAME CHAR(10));'), ('CREATE TABLE TARGET_EMP_TABLE(EMP_ID INTEGER,
EMP_NAME CHAR(10));'), ('INSERT INTO SOURCE_EMP_TABLE(1,''JOHN'');'), ('INSERT INTO SOURCE_EMP_TABLE(2,''PETER'');'), ('INSERT INTO SOURCE_EMP_TABLE(3,''FRANK'');'), ('INSERT INTO SOURCE_EMP_TABLE(4,''MARY'');'), ('INSERT INTO SOURCE_EMP_TABLE(5,''ELLEN'');'), ('INSERT INTO SOURCE_EMP_TABLE(6,''MICHAEL'');'), ('INSERT INTO SOURCE_EMP_TABLE(7,''SAM'');'), ('INSERT INTO SOURCE_EMP_TABLE(8,''JONATHAN'');'), ('INSERT INTO SOURCE_EMP_TABLE(9,''MICHELLE'');'), ('INSERT INTO SOURCE_EMP_TABLE(10,''ALICE'');') TO OPERATOR (DDL_OPERATOR ); );
STEP load_data ( APPLY
Teradata Warehouse Builder User Guide 171

Appendix A: Script SamplesExample 2: Export and DataConnector Operators
('INSERT INTO TARGET_EMP_TABLE (:EMP_ID, :EMP_NAME);') TO OPERATOR (LOAD_OPERATOR [1] )
SELECT * FROM OPERATOR (EXPORT_OPERATOR [1] ); ););
Example 2: Export and DataConnector Operators
/**************************************************************//* *//* Copyright (c) 2000-2007, NCR Corporation. *//* All Rights Reserved. *//* *//* Script Name: GT44.txt *//* Description: This Teradata Parallel Transporter sample *//* script exports 10 rows from a Teradata table *//* to a file. *//* *//**************************************************************//* Explanation: *//* *//* This script uses two job steps. *//* *//* The first job step called "setup" uses the DDL Operator to *//* setup the source table. *//* *//* The second job step called "export_to_file" uses the *//* Export Operator to export the rows from a Teradata table *//* and uses the Data Connector Operator to write the rows to *//* a file. *//* *//* This script shows how to use the following Teradata PT *//* features: *//* * Unconditional job steps. *//* * Export rows from a Teradata table and write the rows to *//* a file. *//* *//**************************************************************//* Here are the required customizations before running this *//* script: *//* *//* 1. Need to modify the value for the following attributes *//* in the below DDL Operator definition: *//* *//* TdpId, UserName, UserPassword *//* *//* 2. Need to modify the value for the following attributes *//* in the below Export Operator definition: *//* *//* TdpId, UserName, UserPassword *//* *//* TdpId is the name of the Teradata Database system. *//* UserName is the user name on the Teradata Database system. */
172 Teradata Warehouse Builder User Guide

Appendix A: Script SamplesExample 2: Export and DataConnector Operators
/* UserPassword is the password associated with the UserName. *//* *//**************************************************************//* Execution: *//* *//* Here is the command to execute this script: *//* tbuild -f GT44.txt *//* *//**************************************************************/
DEFINE JOB EXPORT_EMPLOYEE_TABLE_TO_FILEDESCRIPTION 'EXPORT SAMPLE EMPLOYEE TABLE TO A FILE'( DEFINE SCHEMA EMPLOYEE_SCHEMA DESCRIPTION 'SAMPLE EMPLOYEE SCHEMA' ( EMP_ID INTEGER, EMP_NAME CHAR(10) );
DEFINE OPERATOR DDL_O7PERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DDL OPERATOR' TYPE DDL ATTRIBUTES ( VARCHAR PrivateLogName = 'GT44_ddloper_log', VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountID, VARCHAR ErrorList = '3807' );
DEFINE OPERATOR FILE_WRITER DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DATA CONNECTOR OPERATOR' TYPE DATACONNECTOR CONSUMER SCHEMA EMPLOYEE_SCHEMA ATTRIBUTES ( VARCHAR PrivateLogName = 'GT44_dataconnoper_privatelog', VARCHAR FileName = 'GT44_employee.dat', VARCHAR IndicatorMode = 'N', VARCHAR OpenMode = 'Write', VARCHAR Format = 'Unformatted' );DEFINE OPERATOR EXPORT_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER EXPORT OPERATOR' TYPE EXPORT SCHEMA EMPLOYEE_SCHEMA ATTRIBUTES ( VARCHAR PrivateLogName = 'GT44_exportoper_privatelog', INTEGER MaxSessions = 32, INTEGER MinSessions = 1, VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountId, VARCHAR SelectStmt = 'SELECT * FROM SOURCE_EMP_TABLE;'
Teradata Warehouse Builder User Guide 173

Appendix A: Script SamplesExample 3: Load and DataConnector Operators
);
STEP setup ( APPLY ('DROP TABLE SOURCE_EMP_TABLE;'), ('CREATE TABLE SOURCE_EMP_TABLE(EMP_ID INTEGER,
EMP_NAME CHAR(10));'), ('INSERT INTO SOURCE_EMP_TABLE(1,''JOHN'');'), ('INSERT INTO SOURCE_EMP_TABLE(2,''PETER'');'), ('INSERT INTO SOURCE_EMP_TABLE(3,''FRANK'');'), ('INSERT INTO SOURCE_EMP_TABLE(4,''MARY'');'), ('INSERT INTO SOURCE_EMP_TABLE(5,''ELLEN'');'), ('INSERT INTO SOURCE_EMP_TABLE(6,''MICHAEL'');'), ('INSERT INTO SOURCE_EMP_TABLE(7,''SAM'');'), ('INSERT INTO SOURCE_EMP_TABLE(8,''JONATHAN'');'), ('INSERT INTO SOURCE_EMP_TABLE(9,''MICHELLE'');'), ('INSERT INTO SOURCE_EMP_TABLE(10,''ALICE'');') TO OPERATOR (DDL_OPERATOR ); );
STEP export_to_file ( APPLY TO OPERATOR ( FILE_WRITER ) SELECT * FROM OPERATOR ( EXPORT_OPERATOR [1] ); ););
Example 3: Load and DataConnector Operators
/**************************************************************//* *//* Copyright (c) 2000-2007, NCR Corporation. *//* All Rights Reserved. *//* *//* Script Name: GT62.txt *//* Description: This Teradata Parallel Transporter sample *//* script loads 10 records from a file into an *//* empty Teradata table. *//* *//**************************************************************//* Explanation: *//* *//* This script uses three job steps. *//* *//* The first job step called "setup_tables" uses the DDL *//* Operator to setup the source and target tables. *//* *//* The second job step called "export_to_file" uses the *//* Export Operator to export the rows from a Teradata table *//* and uses the Data Connector Operator to write the rows to *//* a file. *//* *//* The third job step called "load_data_from_file" uses the *//* Data Connector Operator to read records from a file and *//* uses the Load Operator to load the records into an empty */
174 Teradata Warehouse Builder User Guide

Appendix A: Script SamplesExample 3: Load and DataConnector Operators
/* Teradata table. *//* *//* This script shows how to use the following Teradata PT *//* features: *//* * Unconditional job steps. *//* * Export rows from a Teradata table and write the rows to *//* a file. *//* * Read records from a file and load the records into an *//* empty Teradata table. *//* *//**************************************************************//* Here are the required customizations before running this *//* script: *//* *//* 1. Need to modify the value for the following attributes *//* in the below DDL Operator definition: *//* *//* TdpId, UserName, UserPassword *//* *//* 2. Need to modify the value for the following attributes *//* in the below Export Operator definition: *//* *//* TdpId, UserName, UserPassword *//* *//* 3. Need to modify the value for the following attributes *//* in the below Load Operator definition: *//* *//* TdpId, UserName, UserPassword *//* *//* TdpId is the name of the Teradata Database system. *//* UserName is the user name on the Teradata Database system. *//* UserPassword is the password associated with the UserName. *//* *//**************************************************************//* Execution: *//* *//* Here is the command to execute this script: *//* tbuild -f GT62.txt *//* *//**************************************************************/
DEFINE JOB LOAD_EMPLOYEE_TABLE_FROM_FILEDESCRIPTION 'LOAD SAMPLE EMPLOYEE TABLE FROM A FILE'( DEFINE SCHEMA EMPLOYEE_SCHEMA DESCRIPTION 'SAMPLE EMPLOYEE SCHEMA' ( EMP_ID INTEGER, EMP_NAME CHAR(10) );
DEFINE OPERATOR DDL_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DDL OPERATOR' TYPE DDL
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT62_ddloper_log', VARCHAR TdpId = 'MyTdp',
Teradata Warehouse Builder User Guide 175

Appendix A: Script SamplesExample 3: Load and DataConnector Operators
VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountID, VARCHAR ErrorList = '3807' );
DEFINE OPERATOR FILE_WRITER DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DATA CONNECTOR OPERATOR' TYPE DATACONNECTOR CONSUMER SCHEMA EMPLOYEE_SCHEMA
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT62_dataconnoper_writer_privatelog', VARCHAR FileName = 'GT62_employee.dat', VARCHAR IndicatorMode = 'N', VARCHAR OpenMode = 'Write', VARCHAR Format = 'Formatted' );
DEFINE OPERATOR EXPORT_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER EXPORT OPERATOR' TYPE EXPORT SCHEMA EMPLOYEE_SCHEMA
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT62_exportoper_privatelog', INTEGER MaxSessions = 32, INTEGER MinSessions = 1, VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountId, VARCHAR SelectStmt = 'SELECT * FROM SOURCE_EMP_TABLE;' );
DEFINE OPERATOR LOAD_OPERATOR DESCRIPTION 'TERADATA PARALLEL TRANSPORTER LOAD OPERATOR' TYPE LOAD SCHEMA EMPLOYEE_SCHEMA
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT62_loadoper_privatelog', INTEGER MaxSessions = 32, INTEGER MinSessions = 1, VARCHAR TargetTable = 'TARGET_EMP_TABLE', VARCHAR TdpId = 'MyTdp', VARCHAR UserName = 'MyUser', VARCHAR UserPassword = 'MyPassword', VARCHAR AccountId, VARCHAR ErrorTable1 = 'GT62_LOADOPER_ERRTABLE1', VARCHAR ErrorTable2 = 'GT62_LOADOPER_ERRTABLE2', VARCHAR LogTable = 'GT62_LOADOPER_LOGTABLE' );
DEFINE OPERATOR FILE_READER DESCRIPTION 'TERADATA PARALLEL TRANSPORTER DATA CONNECTOR OPERATOR' TYPE DATACONNECTOR PRODUCER SCHEMA EMPLOYEE_SCHEMA
176 Teradata Warehouse Builder User Guide

Appendix A: Script SamplesExample 3: Load and DataConnector Operators
ATTRIBUTES ( VARCHAR PrivateLogName = 'GT62_dataconnoper_reader_privatelog', VARCHAR FileName = 'GT62_employee.dat', VARCHAR IndicatorMode = 'N', VARCHAR OpenMode = 'Read', VARCHAR Format = 'Formatted' );
STEP setup_tables ( APPLY ('DROP TABLE SOURCE_EMP_TABLE;'), ('DROP TABLE TARGET_EMP_TABLE;'), ('DROP TABLE GT62_LOADOPER_ERRTABLE1;'), ('DROP TABLE GT62_LOADOPER_ERRTABLE2;'), ('DROP TABLE GT62_LOADOPER_LOGTABLE;'), ('CREATE TABLE SOURCE_EMP_TABLE(EMP_ID INTEGER,
EMP_NAME CHAR(10));'), ('CREATE TABLE TARGET_EMP_TABLE(EMP_ID INTEGER,
EMP_NAME CHAR(10));'), ('INSERT INTO SOURCE_EMP_TABLE(1,''JOHN'');'), ('INSERT INTO SOURCE_EMP_TABLE(2,''PETER'');'), ('INSERT INTO SOURCE_EMP_TABLE(3,''FRANK'');'), ('INSERT INTO SOURCE_EMP_TABLE(4,''MARY'');'), ('INSERT INTO SOURCE_EMP_TABLE(5,''ELLEN'');'), ('INSERT INTO SOURCE_EMP_TABLE(6,''MICHAEL'');'), ('INSERT INTO SOURCE_EMP_TABLE(7,''SAM'');'), ('INSERT INTO SOURCE_EMP_TABLE(8,''JONATHAN'');'), ('INSERT INTO SOURCE_EMP_TABLE(9,''MICHELLE'');'), ('INSERT INTO SOURCE_EMP_TABLE(10,''ALICE'');') TO OPERATOR (DDL_OPERATOR ); );
STEP setup_export_to_file ( APPLY TO OPERATOR ( FILE_WRITER [1] ) SELECT * FROM OPERATOR ( EXPORT_OPERATOR [1] ); );
STEP load_data_from_file ( APPLY ('INSERT INTO TARGET_EMP_TABLE (:EMP_ID, :EMP_NAME);') TO OPERATOR ( LOAD_OPERATOR [1] )
SELECT * FROM OPERATOR ( FILE_READER [1] ); ););
Teradata Warehouse Builder User Guide 177

Appendix A: Script SamplesExample 3: Load and DataConnector Operators
178 Teradata Warehouse Builder User Guide

Glossary
A
administrator A special user responsible for allocating resources to a community of users.
access rights See privilege.
C
call-level interface (CLI) A programming interface designed to support SQL access to databases from shrink-wrapped application programs. SQL/CLI provides and international standard implementation-independent CLI to access SQL databases. Client-server tools can easily access database through dynamic link libraries. It supports and encourages a rich set of client-server tools.
column In the relational model of Teradata SQL, databases consist of one or more tables. In turn, each table consists of fields, organized into one or more columns by zero or more rows. All of the fields of a given column share the same attributes.
cost This is the outlay of database resources used by a given query.
D
data definition language (DDL) In Teradata SQL, the statements and facilities that manipulate database structures (such as CREATE, MODIFY, DROP, GRANT, REVOKE, and GIVE) and the dictionary information kept about those structures. In the typical, pre-relational data management system, data definition and data manipulation facilities are separated, and the data definition facilities are less flexible and more difficult to use than in a relational system.
data manipulation language (DML) In Teradata SQL, the statements and facilities that manipulate or change the information content of the database. These statements include INSERT, UPDATE, and DELETE.
database A related set of tables that share a common space allocation and owner. A collection of objects that provide a logical grouping for information. The objects include, tables, views, macros, triggers, and stored procedures.
DBA Acronym for Database Administrator.
E
endianness The byte ordering convention of data that is represented with multiple bytes. Big-endian is an order in which the “big end” (most significant value in the sequence) is stored first (at the lowest storage address). Little-endian is an order in which the “little end”
Teradata Warehouse Builder User Guide 179

Glossary
(least significant value in the sequence) is stored first. For example, in a big-endian computer, the number one is indicated as 0x00 0x01. In a little-endian computer, the number one is indicated as 0x01 0x00.
export This refers to extracting or transferring system information from the tables and views of a given source and saving it so it can be manipulated or pulled into another system.
F
field The basic unit of information stored in the Teradata Database. A field is either null, or has a single numeric or string value.
L
log A record of events. A file that records events. Many programs produce log files. Often you will look at a log file to determine what is happening when problems occur. Log files have the extension “.log”.
N
name A word supplied by the user that refers to an object, such as a column, database, macro, table, user, or view.
null The absence of any value for a field.
O
object In object-oriented programming, a unique instance of a data structure defined according to the template provided by its class. Each object has its own values for the variables belonging to its class and can respond to the messages, or methods, defined by its class.
object definition This is the details of the structure and instances of the objects used by a given query. Object definitions are used to create the tables, views, and macros, triggers, join indexes, and stored procedures in a database.
Open Database Connectivity (ODBC) Under ODBC, drivers are used to connect applications with databases. The ODBC driver processes ODBC calls from an application, but passes SQL requests to the Teradata Database for processing.
operator Is a term in Teradata PT used to describe a piece of software used to control loading and unloading data. There are different operators that perform different types of functions.
P
parameter A variable name in a macro for which an argument value is substituted when the macro is executed.
privilege In Teradata SQL, a user’s right to perform the Teradata SQL statements granted to him against a table, database, user, macro, or view. Also known as access right.
180 Teradata Warehouse Builder User Guide

Glossary
Q
query A Teradata SQL statement, such as a SELECT statement.
R
request In host software, a message sent from an application program to the Teradata Database.
result The information returned to the user to satisfy a request made of the Teradata Database.
row The fields that represent one entry under each column in a table. The row is the smallest unit of information operated on by data manipulation statements.
S
session In client software, a logical connection between an application program on a host and the Teradata Database. It permits the application program to send one request to and receive one response from the Teradata Database at a time.
SQL See structured query language (SQL).
statement A request for processing by the Teradata Database that consists of a keyword verb, optional phrases, and operands. It is processed as a single entity.
statistics These are the details of the processes used to collect, analyze, and transform the database objects used by a given query.
structured query language (SQL) A standardized query language for requesting information from a database. SQL consists of a set of facilities for defining, manipulating, and controlling data in a relational database.
T
table A two-dimensional structure made up of one or more columns with zero or more rows that consist of fields of related information. See also database.
Teradata Parallel Transporter (Teradata PT) Teradata PT is a load and unload utility that extracts, transforms, and loads data from one or more sources into one or more targets with parallel streams of data.
trigger One or more Teradata SQL statements associated with a table and executed when specified conditions are met.
U
user A database associated with a person who uses the Teradata Database. The database stores the person’s private information and accesses other Teradata Databases.
Teradata Warehouse Builder User Guide 181

Glossary
V
view An alternate way of organizing and presenting information in the Teradata Database. A view, like a table, has rows and columns. However, the rows and columns of a view are not directly stored by the Teradata Database. They are derived from the rows and columns of tables (or other views) whenever the view is referenced.
W
Wizard The Teradata PT Wizard. A GUI-based product that builds and runs simple load and unload job scripts.
182 Teradata Warehouse Builder User Guide

Index
Symbols@ symbol, in variables, 107
Aaccess modules
overview, 31access rights. See privilegesacquisition phase
load jobs 63relation to error limits 78update jobs 79
API, overview, 20application phase
load jobs 63relation to error limits 78update jobs 79
APPLY specifications, 114architecture, overview, 23ARRAY tables, 80
Bbasics
operator overview, 29processing overview, 26
binary file formatspecifying for DataConnector operator 51
binary files, format of, 51BLOBs
Wizard limitations, 144, 148, 150BOM (Byte Order Mark) 41BTEQ
comparison to Teradata PT, 21use with UDFs, 113use with UDTs, 113
buffers, 96
CCAST clause, 112, 152CD-ROM images, 7character sets
changing in Wizard, 142USING CHARACTER SET, tbuild command 41UTF-16 support 41
checkpointingcreating in active jobs, 129
DDL operator, 102Export operator, 46Load jobs, 64SQL Inserter operator, 69Stream operator, 93Update jobs, 79Wizard setting, 157
CLOBsWizard limitations, 144, 148, 150
columnsas keys for Serialization 95data types 41, 51defined 179defining in schemas 36defining in Wizard, 146Delete Task option 86LONG VARCHAR data types 131mapping to input files 22related to error table records 65user defined data types 113Wizard limits 138
combining data sources, 55comparisons
Delete Task vs. SQL DELETE, 87scripting, 22Teradata PT scripting vs. standalone utilities, 22Update vs. Stream, 73with standalone utilities, 21
compatibilities, 28completion codes, 165consumer operators, overview, 29CREATE TABLE, performance data, 134creating
job variables, 107scripts in the Wizard, 141scripts, 35
custom access module, overview, 31customized data types, 113
DData Connector (PIOM)
comparison to Teradata PT, 21data conversions, 112data source
combining, 55files, 145
Teradata Warehouse Builder User Guide 183

Index
flat files, 50ODBC-compliant, 149Oracle tables, 148selection in Wizard, 143Teradata tables, 143
data streamrelationship to operators, 29
data typesin source files, 147selection in Wizard, 145, 148, 150user-defined, 113
database objectssetting up with DDL operator, 102
DataConnector operatordefinition, 52input file formats 51job example with Export operator, 48overview, 50sample job script, 172, 174troubleshooting delimited data 168TYPE for consumer operator, 32TYPE for producer operator, 32
DataConnector operator (PIOM)input file formats 51
DCL statements, 104DDL operator
checkpoint restartability, 102example, 104feature support, 103setting up with, 102SQL statements, 103supported DCL statements, 104supported DML statements, 104
DDL statementsTYPE definition for, 32
deferred schemas, 68Define Columns dialog box, 146defining columns
in Wizard, 146DELETE privilege, 40Delete Task
description, 85job example, 88TYPE definition for, 32
deletingTYPE definition for, 32Wizard jobs, 158
deleting dataDelete Task, 85
delimited file formatspecifying for DataConnector operator 51troubleshooting 168
description, high-level, 19Directory Scan feature, 51
DML statementsin DDL operator jobs, 104in Stream jobs, 95
DROP privilege, 40DSN name, changing, 148duplicate rows, 65, 77
Eediting Wizard jobs, 158ELT vendors, 28encryption
Load operator, 41error limits
Load operator, 65error tables
Load operator, 64Update operator, 76, 80
errorslimits of, 78Update jobs, 77
ETL vendors, 28event codes
Export operator, 116Load operator, 115–121Stream operator, 124Update operator, 121
events for notificationExport operator, 118Update operator, 123
exit codes 165Export operator
checkpoint/restart, 46definition, 46extracting data with, 45job example, 48limits, 47notify exit events, 118notify exit feature, 116notify exit routines, 119performance vs. SQL Selector, 45relationship to outmod routines, 30sample job script, 169, 172SELECT request restrictions, 47SELECT requests, 47SELECT statements, 47
exportingfrom flat files with Wizard, 145from ODBC-compliant source with Wizard, 149from Oracle database with Wizard, 148TYPE definition for, 32
exporting SQLTYPE definition for, 32
external commands, 128
184 Teradata Warehouse Builder User Guide

Index
extracting dataDataConnector operator, 50overview, 45with SQL Selector operator, 52
F-f option 43FastExport, comparison to Teradata PT, 21FastLoad, comparison to Teradata PT, 21features
comparison with standalone utilities, 21main list, 20, 27
file storage, overview, 20files, as data sources, 145filter operators, overview, 30Finish Job dialog box 155, 156flat files
extracting with DataConnector operator, 50input formats, 51
formatted files, format of, 51
IIgnoreMaxDecimalDigits attribute 58INCLUDE statement 111indicator bytes
Wizard setting 146, 152inmod routines
loading data, 29TYPE definition for, 32
INMODsTYPE definition for, 32
INSERT privilege, 40inserting SQL
TYPE definition for, 32inserts
in Wizard, 154TYPE definition for, 32
instancesspecifying in Wizard, 147
interrupting jobs, 128
J-j option 43job attributes. See job variablesJob Destination dialog box 151, 153Job Name/Description dialog box 141job script
annotated Export example, 48annotated Load example, 66annotated Stream example, 97annotated Update example, 81creating, 35
Delete Task example, 88running on UNIX, 38running on Windows, 39running on z/OS (MVS), 39SQL Inserter example, 70status codes 165
Job Source dialog box 144, 149job status
active jobs, 128in Wizard, 161
job stepsdefining, 101overview, 20sample, 101SQL DDL, 101starting mid-script, 102tbuild -n option 165tbuild -s option, 102
job treeicon descriptions, 139, 140
job variablescreating, 107example script, 109
job variables, 108, 110jobs
checking status of, 130creating checkpoints, 129creating in Wizard, 141deleting, 158editing, 158naming in Wizard, 141pausing and resuming, 129restarting, 158running in Wizard, 156stopping, 158terminating with checkpoint, 129
Kkey features, 27
L-l option, 42language
changing in Wizard, 142Large Decimal DBS feature 58latency interval
defined, 96in tbuild command, 96Wizard setting, 157
limitationsBLOB and CLOB use, 144, 148, 150of Teradata PT, 33of Wizard, 138
Teradata Warehouse Builder User Guide 185

Index
Load operatorcheckpoints, 64definition, 61duplicate rows, 65error limits, 65error tables, 64limits on slot usage, 63load phases, 63notify exit feature, 115–121options, 68privileges, 40restart log table, 64sample job script, 169, 174session limits, 62space requirements, 61specifying in Wizard 154staged loading, 63
loadingto files, 151to Teradata tables, 152TYPE definition for, 32
loading datainmod routines, 29job example, 66session limits 62space requirements, 61SQL Inserter operator, 69with the Load operator, 61
lock granularitydeciding between operators, 73
LOCKING modifier, Export operator, 48Log View dialog box, 161logon encryption, 41logs
directing output (MVS) 44private, 42public, 41tlogview command 43viewing in UTF-16 format 43
LONG VARCHAR column typewith Unicode character sets 131
MMACRO SQL, 95MacroDatabase attribute, 95macros, 95main dialog box in Wizard, 138managing jobs, 128Map Source to Destination dialog box, 155mapping sources, 155MaxDecimalDigits attribute 58MaxSessions attribute
session limits 62
menus in Wizard, 162metadata
exporting from job logs, 135exporting, 135loading, 135SQL examples, 135
metadata, 133MinSessions attribute
session limits 62missing rows, 77modes
Stream operator, 93MulitLoad, comparison to Teradata PT, 22multiple targets, 114
NNamed Pipes Access Module, overview, 31non-robust mode, 93notify exit event codes
Export operator, 116Stream operator, 124Update operator, 121, 123
notify exit featureExport operator, 116Load operator, 115–121
null value, 112
Oobject attributes
overriding with job variables, 108objects
setting up with DDL operator, 102ODBC
TYPE definition for, 32ODBC DSN connectivity, 149ODBC-compliant data sources, 149OLE DB Access Module, comparison to Teradata PT, 21operating system commands, comparison to Teradata PT, 21operational metadata
availability, 133data schemas, 134
OPERATOR statementTYPE summary, 31
operatorscomparison with standalone utilities, 21summary, 31
Oracle tables, as data source, 148ORDER BY clause
Export operator, 48OS commands
TYPE definition for, 32outmod routines
TYPE definition for, 32
186 Teradata Warehouse Builder User Guide

Index
with Export operator, 30output
viewing in Wizard, 160overview, 19overview, of Wizard 137
P-p option 43pack rate, 92parallelism
data instances, 25overview, 23pipeline, 24
pausing jobs, 129performance
deciding between operators, 73operational metadata, 133overview, 20performance data, 135Stream operator, 91
precisionspecifying in Wizard, 147
privileges, 40processing basics, 26producer operators, overview, 29
QQuery Banding
considerations 130Delay option 131QueryBandSessInfo attribute 130
Rreplication privileges, 40restart log table
checkpoint information, 121event codes, 123Load jobs, 64
restartsDDL operator, 102Export operator, 46SQL Inserter operator, 69Wizard jobs, 158
resuming jobs, 129retry limit, Wizard setting 157return codes, 165robust mode, 93rows
capture of errors, 77Run Job dialog box, 156running a job, 156
S-S option 44-s option 102sample Teradata PT job scripts
using Export and DataConnector operators, 172using Load and DataConnector operators, 174using Load and Export operators, 169
scalespecifying in Wizard, 147
SCHEMA *, 68schemas
deferred, 68script language, description, 20scripting
comparison with standalone utilities, 22compatibility with old scripts, 28compatibility with standalone scripts, 28overview, 22using the INCLUDE statement 111with the Wizard, 141
security, 41SELECT privilege, 40SELECT requests
Export operator, 47restrictions, Export operator, 47
SELECT statementsExport operator, 47multiple for Export operator, 47
selecting a data source, Wizard, 143Serialize option, 95session limits
specifying MinSessions and MaxSession attributes, 62Update operator, 76
SET directive, 108set up
database objects, 102single sign-on, 41SLEEP/TenacitySleep
using with QueryBandSessInfo attribute 131sources
data for Wizard, 143flat files, 145Teradata tables, 143
space requirements, Load operator, 61SQL DELETE, comparison to Delete Task, 87SQL Inserter operator
advantages, 69checkpoint restartability, 69definition, 70job example, 70loading data with, 69
SQL Selector operatordefinition, 53
Teradata Warehouse Builder User Guide 187

Index
job example, 53overview, 52restrictions, 53
SQL statementsDDL operator, 103not supported, 104supporting UDTs, 104
staged loading, 63standalone operators, overview, 31standalone utilities, feature comparison, 21statistical data, 133status
active jobs, 130public and private logs, 41viewing in Wizard, 160
stopping Wizard jobs, 158Stream jobs
example, 97options, 95
Stream operatordeciding whether to use, 73definition, 91in Wizard, 154limitations, 91pack rate, 92Serialize option, 95sessions, 93updating with, 90
symbol substitution. See job variables
Ttables
create/drop/populate with DDL operator, 104specifying more than one, 80Update vs. Stream operator, 73
targetloading to files, 151Teradata tables, 152
tbuild command 43-e option 41-f option 43-n option 165required syntax, 38running a job script, 38-S option 44-s option 102starting mid-script, 102-v option 43
TENACITY/TenacityHoursusing with QueryBandSessInfo attribute 131
Teradata tablesas data sources, 143as targets, 152
Teradata Warehouse Builderformer name, 21script compatibility, 28
terminating jobs, 129termination return codes, 165text files
format of 51specifying for DataConnector operator 51
timing, deciding between operators, 74tlogview command 42
as part of the troubleshooting process 166-e option 43obtaining metadata 133options 42viewing logs in UTF-16 format 43
toolbar, in Wizard, 162TPump, comparison to Teradata PT, 22TSN Service Name, connecting Oracle, 148TWB_Root
locating public logs, 42reading private logs, 43
TWB_srctgtjob operator metadata, 134
TWB_statusperformance and statistical metadata, 134
TYPE DATACONNECTOR CONSUMER, 32TYPE DATACONNECTOR PRODUCER, 32TYPE DDL, 32TYPE EXPORT, 32TYPE FASTEXPORT OUTMOD, 32TYPE FASTLOAD INMOD, 32TYPE INSERTER, 32TYPE LOAD, 32TYPE MULTILOAD INMOD FILTER, 32TYPE MULTILOAD INMOD, 32TYPE ODBC, 32TYPE OS COMMAND, 32TYPE SELECTOR, 32TYPE STREAM, 32TYPE UPDATE, 32TYPE, summary of definitions, 31
UUDF
avoiding BTEQ, 113impact of, 113operator support, 103setting up source files, 113
UDTavoiding BTEQ, 113impact in Wizard, 145impact of, 113setting up source files, 113
188 Teradata Warehouse Builder User Guide

Index
statements for, 104unformatted files, format of, 51Union All, 55Update operator
deciding whether to use, 73definition, 75Delete Task option, 85error tables, 76limitations, 76notify exit events, 123overview, 74session use, 76specifying in Wizard, 154VARCHAR ARRAY tables, 80work tables, 77
updatesTYPE definition for, 32
updating datacheckpointing, 93comparison of operators, 73Delete Task option, 85deleting, 85example with Stream operator, 97examples with Delete Task, 88job example with Update operator, 81options, 80, 95phases of, 79Serialize option, 95sessions with Stream operator, 93Stream operator, 90Update operator, 74
upsertsdefining, 78in Wizard, 154
user ID, Load privileges, 40user-defined data types, 113user-defined functions. See UDFuser-defined tables. See UDTUTF-16 support
usage notes 41USING CHARACTER SET statement 41using with LONG VARCHAR column type 131viewing logs in UTF-16 format 43
V-v option 43VARCHAR ARRAY tables, 80variables
for multiple jobs, 110in quoted strings, 110SET directive, 108using, 108
versions
switching between, 28, 131Teradata WB and Teradata PT, 28TWB and TPT, 131
viewing job status, in Wizard, 161Vigil, in Wizard, 146volume, deciding between operators, 73
WWebSphere MQ Access Module
comparison to Teradata PT, 21overview, 31
Wizardchanging character set 142overview 20running job scripts 157
work tablesUpdate operator use, 77
Teradata Warehouse Builder User Guide 189

Index
190 Teradata Warehouse Builder User Guide


















