
Superscalar Processors J. Nelson Amaral. Scalar to Superscalar Scalar Processor: one instruction...
66
Superscalar Processors J. Nelson Amaral
-
Upload
tavion-hollaway -
Category
Documents
-
view
238 -
download
0
Transcript of Superscalar Processors J. Nelson Amaral. Scalar to Superscalar Scalar Processor: one instruction...

Superscalar Processors
J. Nelson Amaral

Scalar to Superscalar
• Scalar Processor: one instruction pass through each pipeline stage in each cycle
• Superscalar Processor: multiple instructions at each pipeline stage in each cycle–Wider pipeline
• Superpipelined Processor: Decompose stages into smaller stages → More Stages– Deeper pipeline
Baer p. 75

Superscalar
• Front end (IF and ID)– Must fetch and decode multiple instructions per
cycle• m-way superscalar: brings (ideally) m instructions per
cycle into the pipeline
• Back end (EX, Mem and WB) – Must execute and write back several instructions
per cycle
Baer p. 75

Superscalar
• In-order (or static)– Instructions leave front-end in program order
• Out-of-order (or dynamic)– instructions leave front-end, and execute, in a
different order than the program order– WB is called commit stage• must ensure that the program semantics is followed• more complex design
Baer p. 76
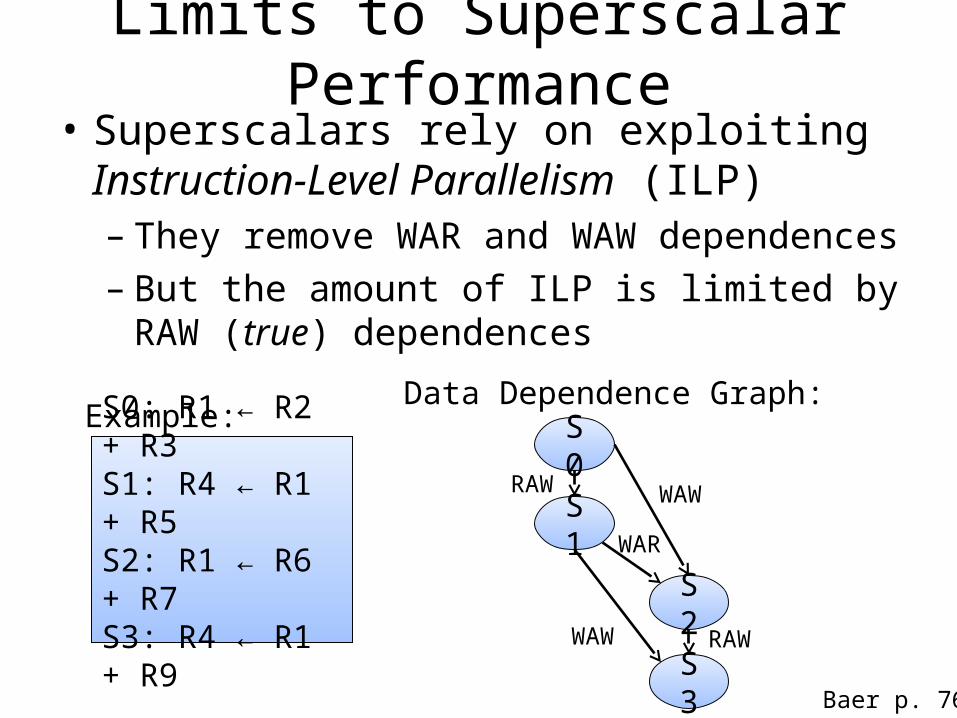
Limits to Superscalar Performance• Superscalars rely on exploiting Instruction-
Level Parallelism (ILP)– They remove WAR and WAW dependences– But the amount of ILP is limited by RAW (true)
dependences
Baer p. 76
S0: R1 ← R2 + R3S1: R4 ← R1 + R5S2: R1 ← R6 + R7S3: R4 ← R1 + R9
Example:Data Dependence Graph:
S0
S1
S2
S3
RAW WAW
RAW
WAR
WAW

Limits to Superscalar Performance• Superscalars rely on exploiting Instruction-
Level Parallelism (ILP)– They remove WAR and WAW dependences– But the amount of ILP is limited by RAW (true)
dependences
Baer p. 76
S0: R1 ← R2 + R3S1: R4 ← R1 + R5S2: R1 ← R6 + R7S3: R4 ← R1 + R9
Example:Data Dependence Graph:
S0
S1RAW WAW
S2
S3RAW
WAR
WAWRBRA
RA

Limits to Superscalar Performance
• Complexity of logic to remove dependencies– Designers predicted 8-way and 16-way
superscalars– We have 6-way superscalars and m is not likely to
grow
Baer p. 76
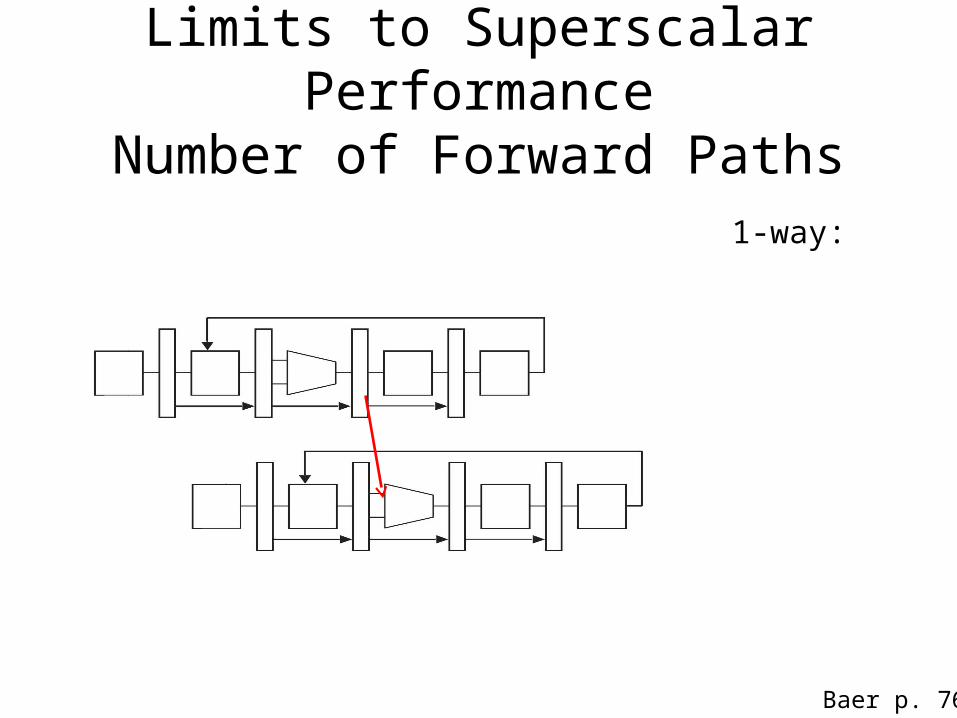
Limits to Superscalar PerformanceNumber of Forward Paths
1-way:
Baer p. 76
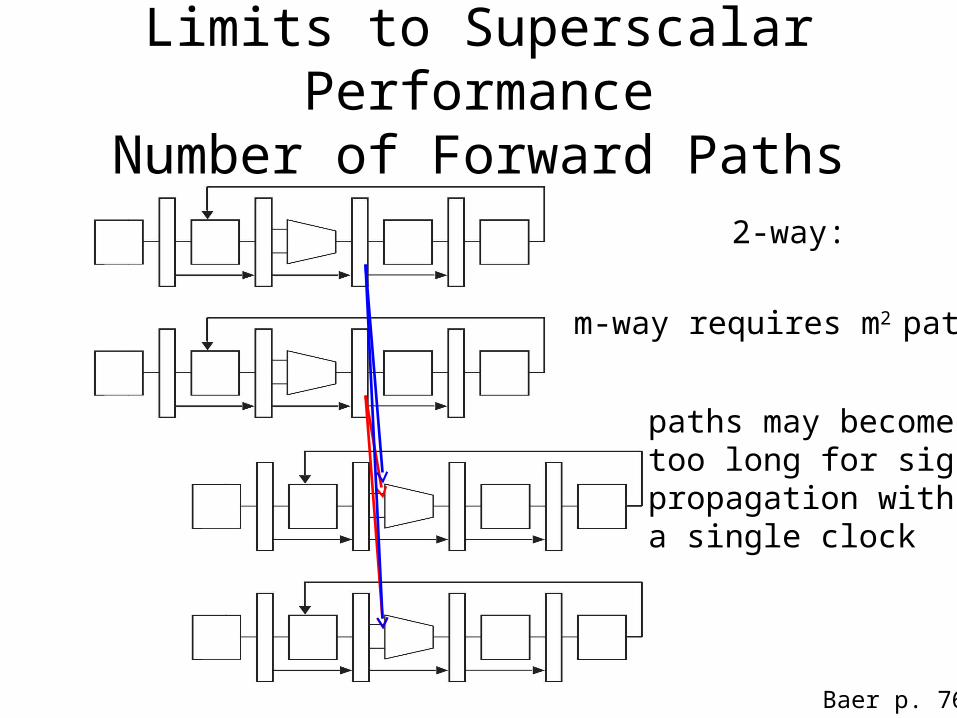
Limits to Superscalar PerformanceNumber of Forward Paths
2-way:
m-way requires m2 paths
paths may becometoo long for signalpropagation withina single clock
Baer p. 76

Limits to Clock Cycle Reduction
• Power dissipation increases with frequency• Read and Writing to pipeline registers in every
cycle.– Time to access pipeline register imposes a bound
on the duration of a pipeline stage
Baer p. 76

Limits on Pipeline Length• Speculative actions (pe. branch prediction) are
resolved later in a longer pipeline– Recovery from misspeculation is delayed
Branch Misspred.Penalty: 10 cycles
Branch Misspred.Penalty: 20 cycles
31-stage pipeline
14-stage pipeline
Baer p. 76

Why the Multicore Revolution?
Power Dissipation: Linear growth with clock frequency
- Cannot make single cores faster
Moore’s Law: Number of transistors ina chip continues the exponential growth
- What to do with extra logic?
Design Complexity: Extracting more performancefrom single core requires extreme design complexity.
- What to do with extra logic?Baer p. 77

Speed Demons X Brainiacs
Pentium IIIOut-of-Order Superscalar1999DEC Alpha
In-Order Superscalar1994
Baer p. 77
register renaming
reorder buffer
reservation stations

Out-of-Order and Memory Hierarchy
• Question: Does out-of-order execution help hide memory latencies?
• Short answer: No. – Latencies of 100 cycles or more are too long and fill
up all internal queues and stall pipelines– Latencies around 100 cycles are too short to justify
context switching.
• Solution: hardware for several contexts to enable fast context switching → multithreading
Baer p. 78
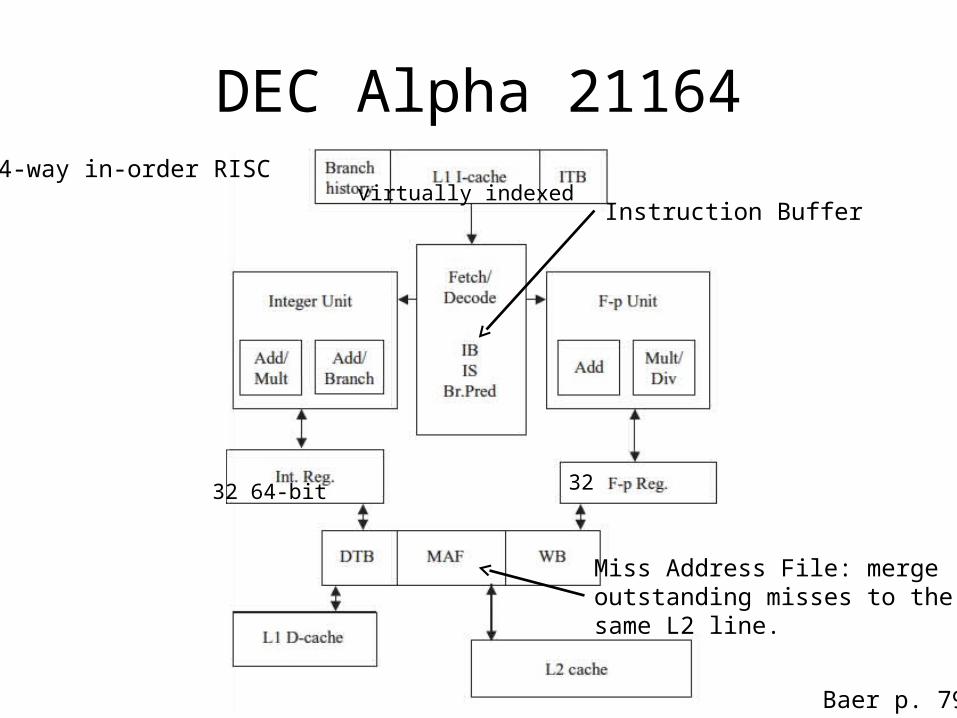
DEC Alpha 211644-way in-order RISC
32 64-bit 32
Miss Address File: mergeoutstanding misses to thesame L2 line.
Instruction Buffervirtually indexed
Baer p. 79
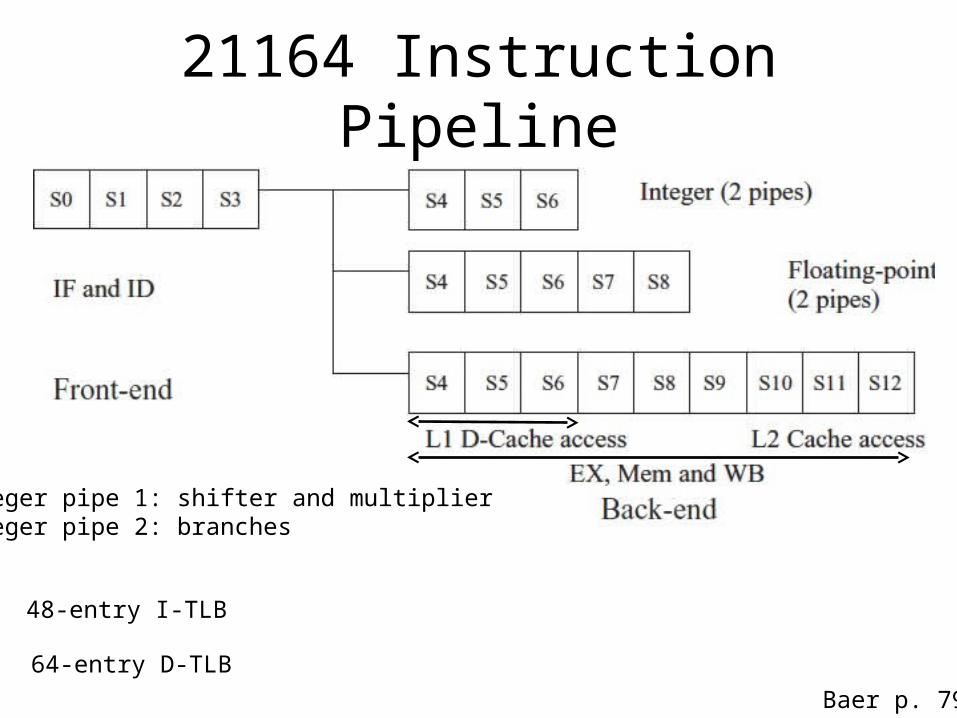
21164 Instruction Pipeline
Integer pipe 1: shifter and multiplierInteger pipe 2: branches
48-entry I-TLB
64-entry D-TLBBaer p. 79
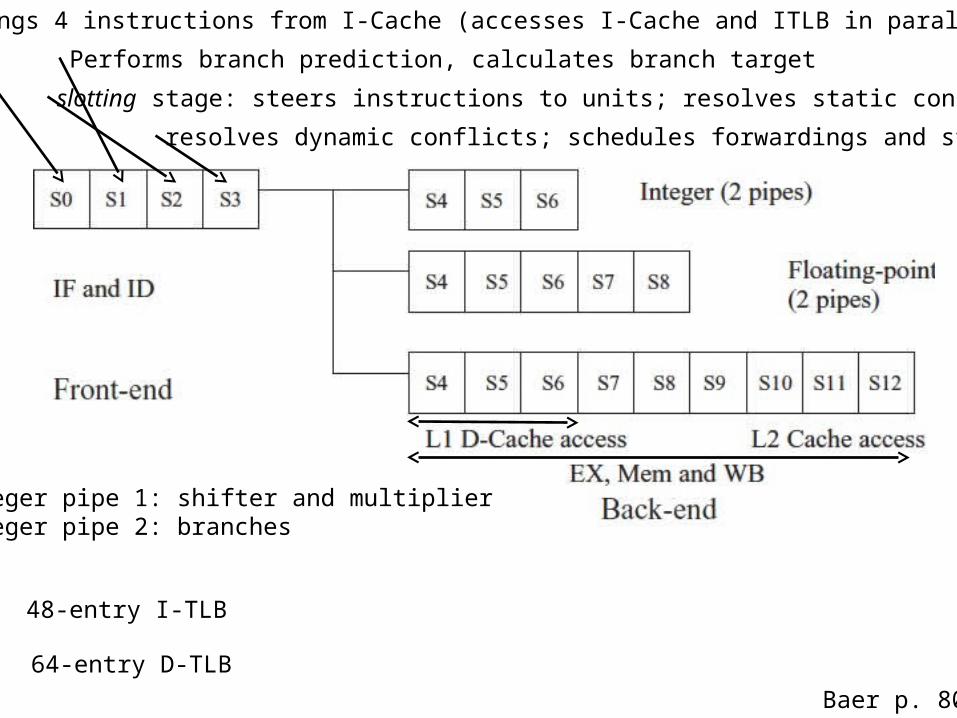
Integer pipe 1: shifter and multiplierInteger pipe 2: branches
48-entry I-TLB
64-entry D-TLB
Brings 4 instructions from I-Cache (accesses I-Cache and ITLB in parallel)
Performs branch prediction, calculates branch target
slotting stage: steers instructions to units; resolves static conflicts
resolves dynamic conflicts; schedules forwardings and stallings
Baer p. 80

Examplei1: R1 ← R2 + R3 # Use integer pipeline 1i2: R4 ← R1 – R5 # Use integer pipeline 2i3: R7 ← R8 – R9 # Requires an integer pipelinei4: F0 ← F2 + F4 # Floating point addi5:i6:i7:i8:i9:i10:i11:i12:
Assume no structural or data hazardfor these instructions.
Baer p. 81
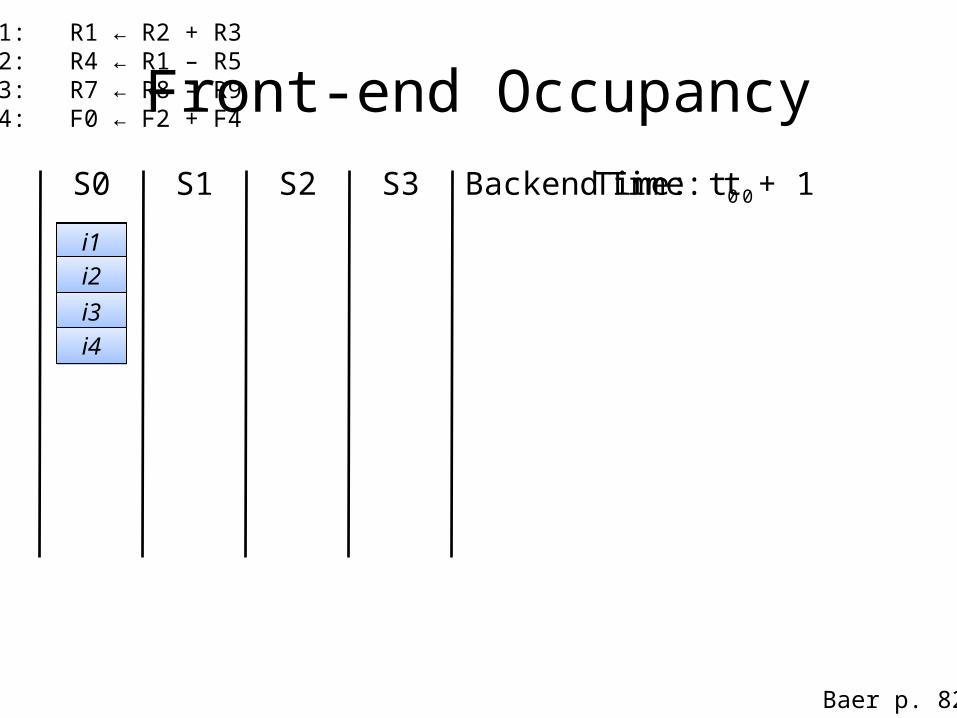
Front-end OccupancyS0 S1 S2 S3
i5i5i6i6
i7i7i8i8
Time: t0
i1i2i3i4
Time: t0 + 1Backend
i1: R1 ← R2 + R3i2: R4 ← R1 – R5i3: R7 ← R8 – R9i4: F0 ← F2 + F4
Baer p. 82
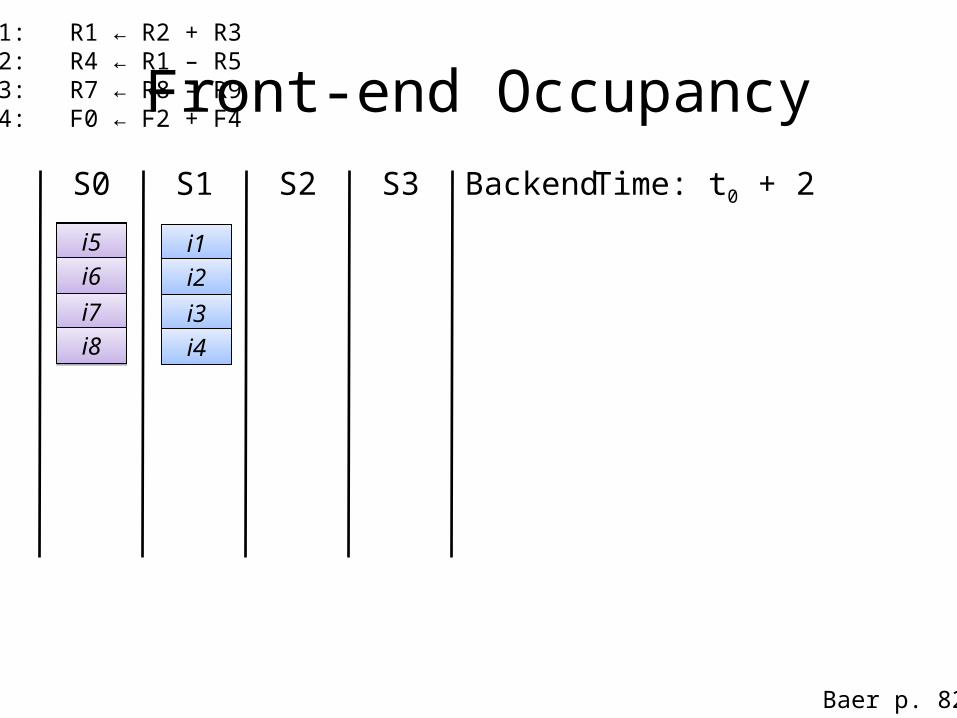
Front-end OccupancyS0 S1 S2 S3
i9i9i10i10
i11i11i12i12
Time: t0 + 1
i1i2i3i4
i5i5i6i6
i7i7i8i8
Time: t0 + 2Backend
i1: R1 ← R2 + R3i2: R4 ← R1 – R5i3: R7 ← R8 – R9i4: F0 ← F2 + F4
Baer p. 82
Time: t0 + 2
Front-end OccupancyS0 S1 S2 S3
i11i12
i3i4
i9i10
i1i2
i5i6i7i8
Time: t0 + 3Backend
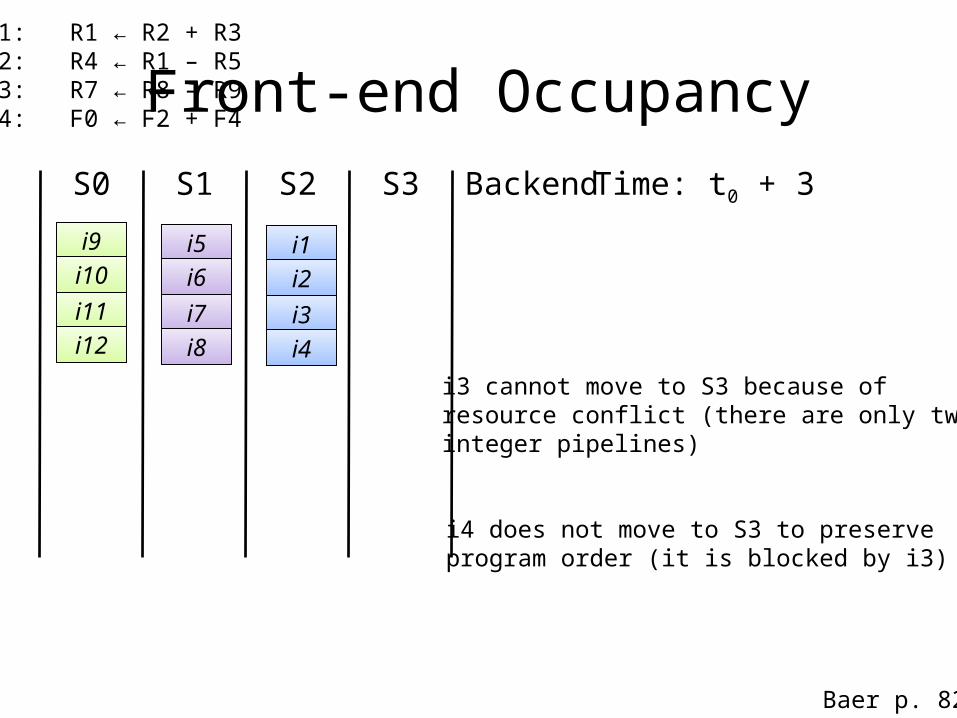
i3 cannot move to S3 because ofresource conflict (there are only twointeger pipelines)
i4 does not move to S3 to preserveprogram order (it is blocked by i3)
i1: R1 ← R2 + R3i2: R4 ← R1 – R5i3: R7 ← R8 – R9i4: F0 ← F2 + F4
Baer p. 82
Time: t0 + 3
Front-end OccupancyS0 S1 S2 S3
i11i12
i3i4
i9i10
i1i2
i5i6i7i8
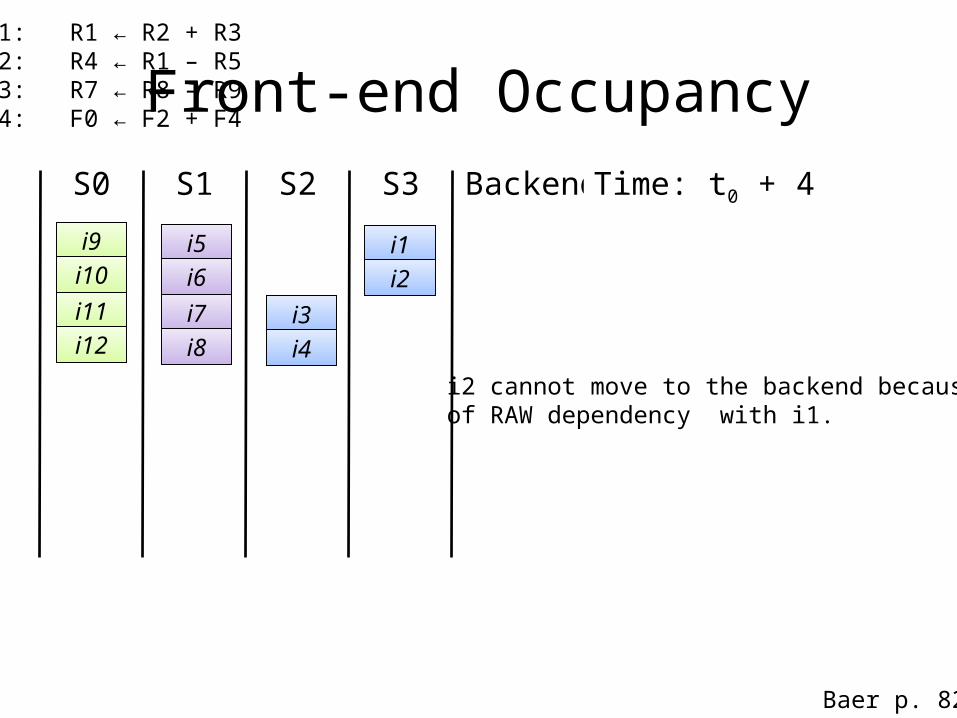
Backend Time: t0 + 4
i2 cannot move to the backend because ofof RAW dependency with i1.
i1: R1 ← R2 + R3i2: R4 ← R1 – R5i3: R7 ← R8 – R9i4: F0 ← F2 + F4
Baer p. 82
i15i15i16i16
i13i13i14i14
Time: t0 + 4
Front-end OccupancyS0 S1 S2 S3
i3i4
i11i11i12i12
i9i9i10i10 i2
i5i5i6i6
i7i7i8i8
Backend
i1
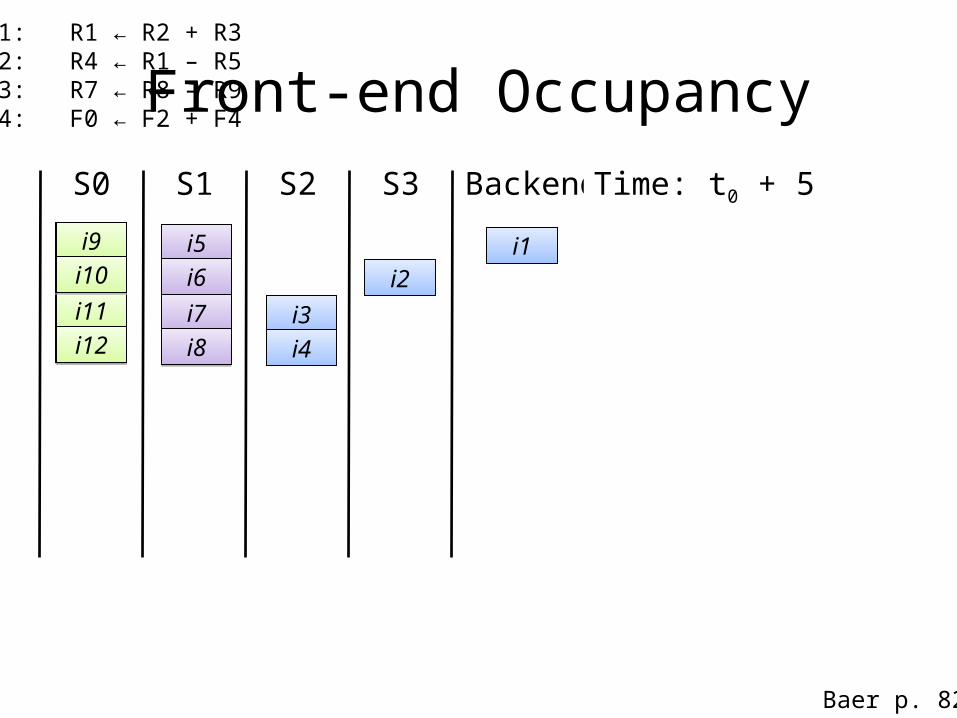
Time: t0 + 5
i1: R1 ← R2 + R3i2: R4 ← R1 – R5i3: R7 ← R8 – R9i4: F0 ← F2 + F4
Baer p. 82
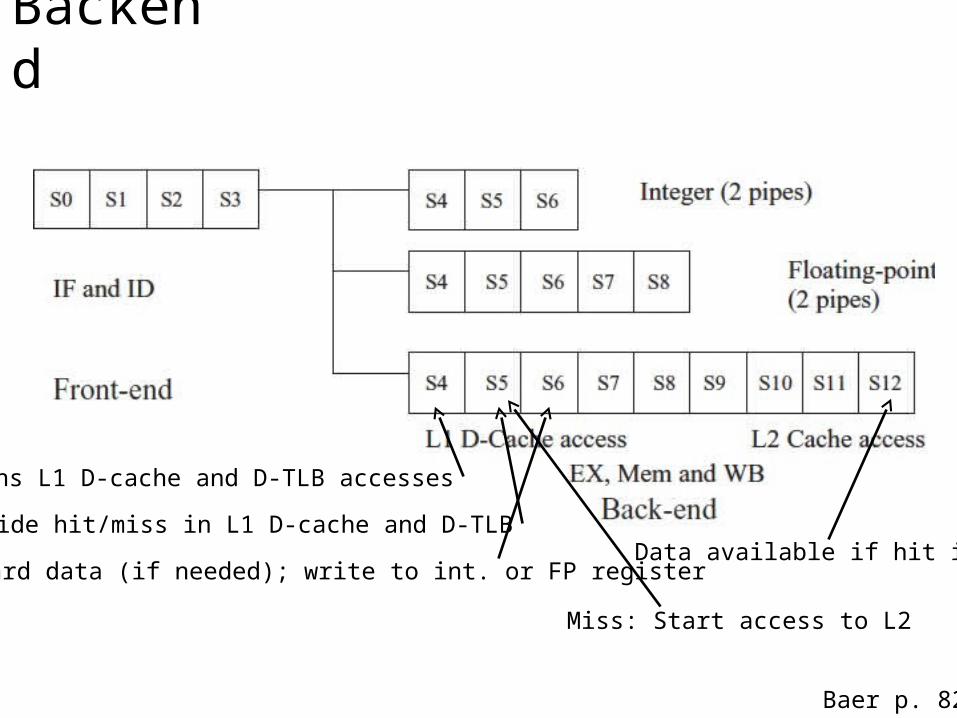
Backend
Begins L1 D-cache and D-TLB accesses
Decide hit/miss in L1 D-cache and D-TLB
Hit: Forward data (if needed); write to int. or FP register
Miss: Start access to L2
Data available if hit in L2
Baer p. 82
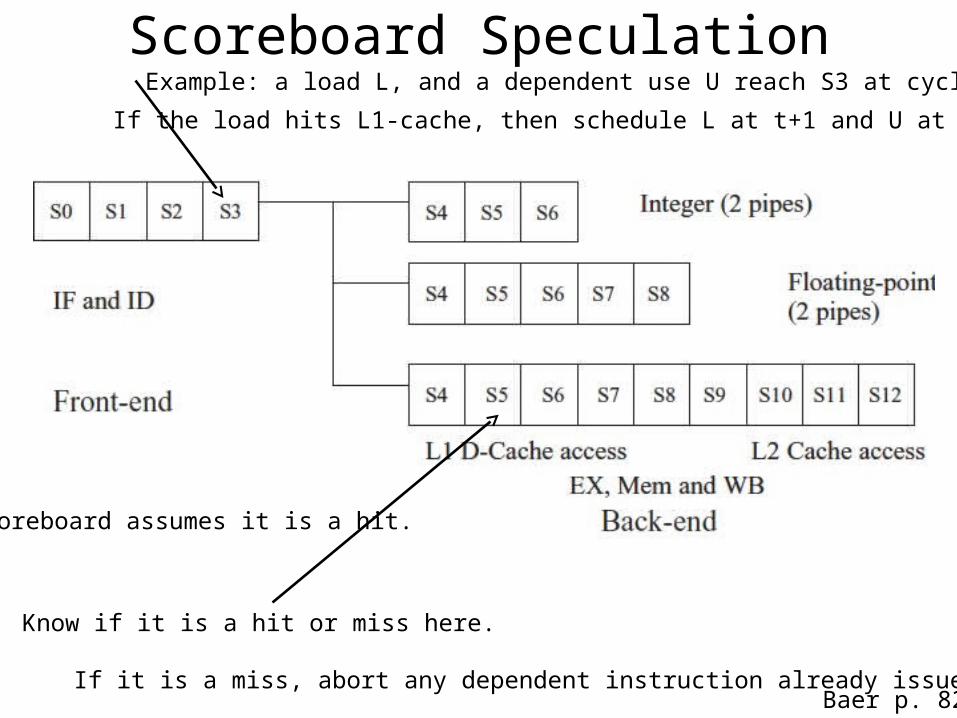
Scoreboard SpeculationExample: a load L, and a dependent use U reach S3 at cycle t
If the load hits L1-cache, then schedule L at t+1 and U at t+3.
Scoreboard assumes it is a hit.
Know if it is a hit or miss here.
If it is a miss, abort any dependent instruction already issued.Baer p. 82

Can Compiler Help Performance?(Example)
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
Assume that all instructions are in issuing slot (state S2)at time t.
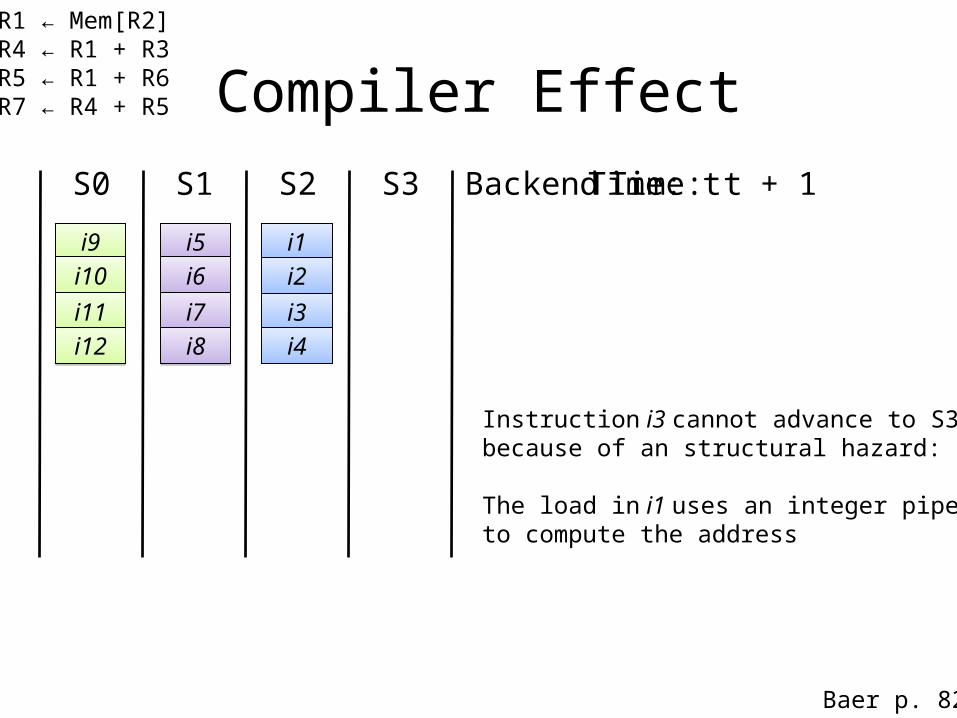
Compiler EffectS0 S1 S2 S3 Time: t
i1i2i3i4
Time: t + 1Backend
Baer p. 82
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i5i5i6i6
i7i7i8i8
Instruction i3 cannot advance to S3because of an structural hazard:
The load in i1 uses an integer pipeto compute the address
i9i9i10i10
i11i11i12i12

Time: t + 1
Compiler EffectS0 S1 S2 S3
i1i2
i3i4
Backend
Baer p. 82
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i5i5i6i6
i7i7i8i8
Time: t + 2
i2 cannot advance because ofthe RAW dependency with i1
Time: t + 3
at t+3 the load continues executionin the back end (2-cycle latency)
i9i9i10i10
i11i11i12i12
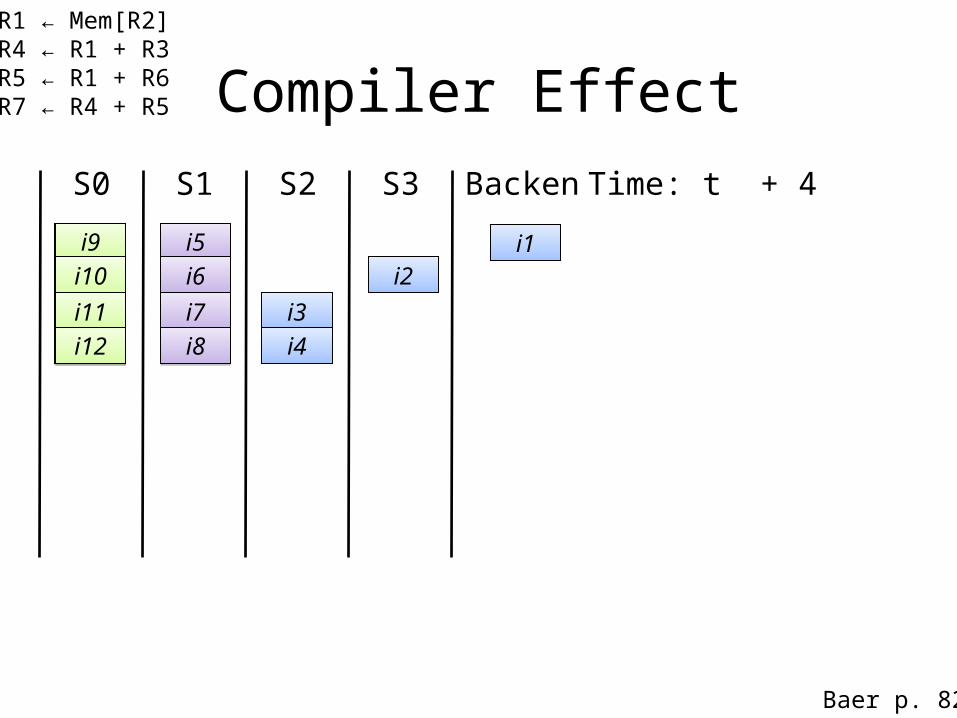
i13i13i14i14
i15i15i16i16
Time: t + 3
Compiler EffectS0 S1 S2 S3
i1
Backend
Baer p. 82
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
Time: t + 4
i2i3i4
i5i5i6i6
i7i7i8i8
i9i9i10i10
i11i11i12i12

Time: t + 4
Compiler EffectS0 S1 S2 S3 Backend
Baer p. 82
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i2i3i4
i5i5i6i6
i7i7i8i8
i4 cannot advance because ofthe RAW dependency with i3
Time: t + 5
i9i9i10i10
i11i11i12i12
i13i13i14i14
i15i15i16i16
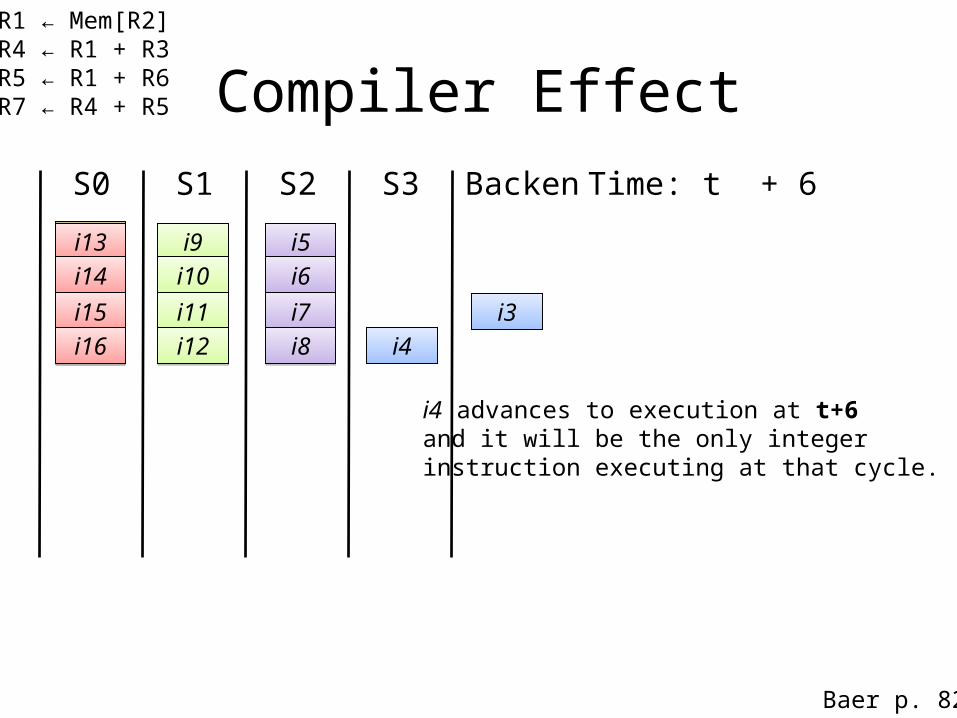
i17i17
i18i18i19i19
i20i20
Time: t + 5
Compiler EffectS0 S1 S2 S3 Backend
Baer p. 82
i1: R1 ← Mem[R2] i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i3
i4 advances to execution at t+6and it will be the only integerinstruction executing at that cycle.
Time: t + 6
i4
i5i5i6i6
i7i7i8i8
i9i9i10i10
i11i11i12i12
i13i13i14i14
i15i15i16i16

After Compiler Optimization
S0 S1 S2 S3 Time: t
i1i1’i2i3
Time: t + 1Backend
Baer p. 82
i1: R1 ← Mem[R2]i1’: integer nop i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i4i5i5
i6i6i7i7
Two integer Instructions advanceto S3.
i8i9i9
i10i10i11i11

i13i13
i14i14i15i15
i12i12 i1i1’
i2i3
i4i5i5
i6i6i7i7
i8i9i9
i10i10i11i11
Time: t + 1S0 S1 S2 S3 Backend
Baer p. 82
Time: t + 2
After Compiler Optimization
i1: R1 ← Mem[R2]i1’: integer nop i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5

Time: t + 2S0 S1 S2 S3 Backend
Baer p. 82
i1i1’
i2i3
i4i5i5
i6i6i7i7
i8i9i9
i10i10i11i11
Time: t + 3
Load in i1 still needs two cyclesto execute.
Time: t + 4
After Compiler Optimization
i1: R1 ← Mem[R2]i1’: integer nop i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i13i13
i14i14i15i15
i12i12

i17i17
i18i18i19i19
i16i16
Time: t + 4S0 S1 S2 S3 Backend
Baer p. 82
i1
i2 and i3 can advance to backendtogether. There is no depencencybetween them.
Time: t + 5
After Compiler Optimization
i1: R1 ← Mem[R2]i1’: integer nop i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i2i3
i4i5i5
i6i6i7i7
i8i9i9
i10i10i11i11
i13i13
i14i14i15i15
i12i12

Time: t + 4S0 S1 S2 S3 Backend
Baer p. 82
i2i3
i4i5i5
i6i6i7i7
i8i9i9
i10i10i11i11
i13i13
i14i14i15i15
i4 still advances to backend at t+6!
Time: t + 5
After Compiler Optimization
i1: R1 ← Mem[R2]i1’: integer nop i2: R4 ← R1 + R3i3: R5 ← R1 + R6 i4: R7 ← R4 + R5
i12i12
i17i17
i18i18i19i19
i16i16
but now i5 could advance along with i4
* Textbook says that i4 would advance to backend at t+5.
Time: t + 6

Scoreboarding
“Scoreboarding allows instructions to executeout of order when there are sufficient resourcesand no data dependences.”
John L. Hennessy and David A. PattersonComputer Architecture: A Quantitative ApproachThird Edition, p. A-69.

Another scoreboarding

Scoreboarding
• Thornton Algorithm (Scoreboarding): CDC 6600 (1964):– A single unit (the scoreboard) monitors the
progress of the execution of instructions and the status of all registers.
• Tomasulo’s Algorithm: IBM 360/91 (1967)– Reservation stations buffer operands and results.
A Common Data Bus (CDB) distributes results directly to functional units
Some of this material is from Prof. Vojin G. Oklobzija’s tutorial at ISSCC’97. Baer p. 81
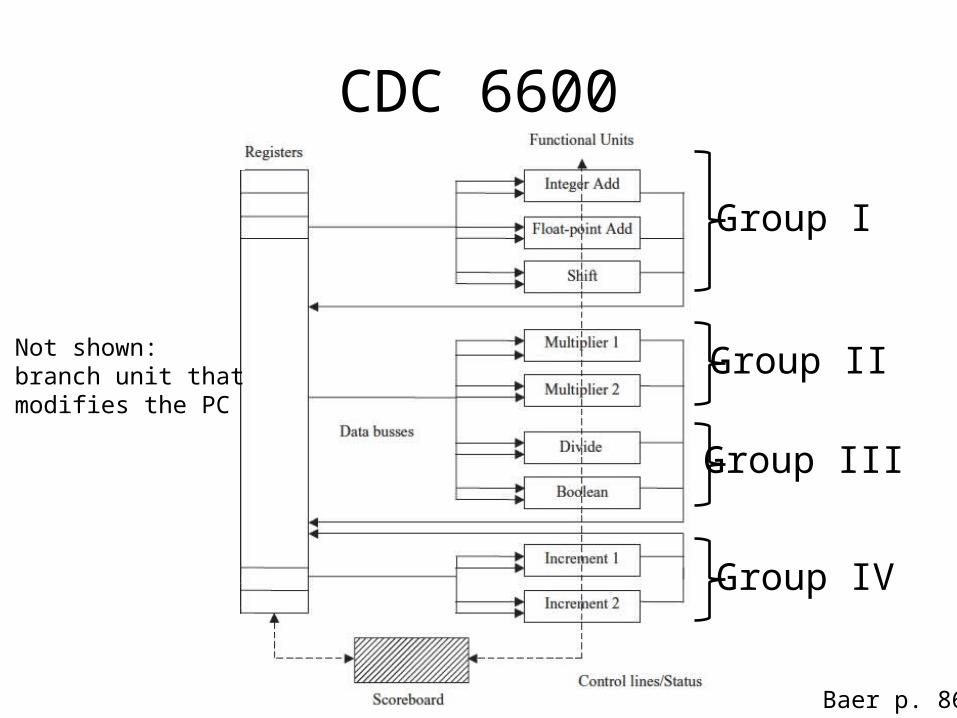
CDC 6600
Group I
Group II
Group III
Group IV
Baer p. 86
Not shown:branch unit that modifies the PC
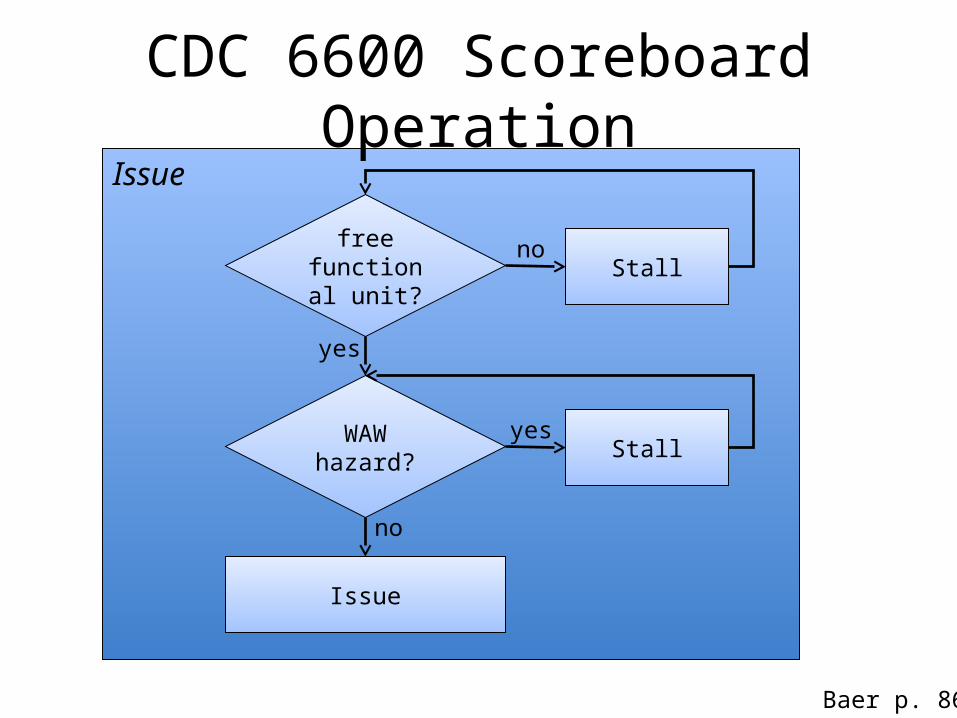
CDC 6600 Scoreboard Operation
free functional
unit?
WAW hazard?
yes
Issue
no
Stallyes
Stallno
Issue
Baer p. 86
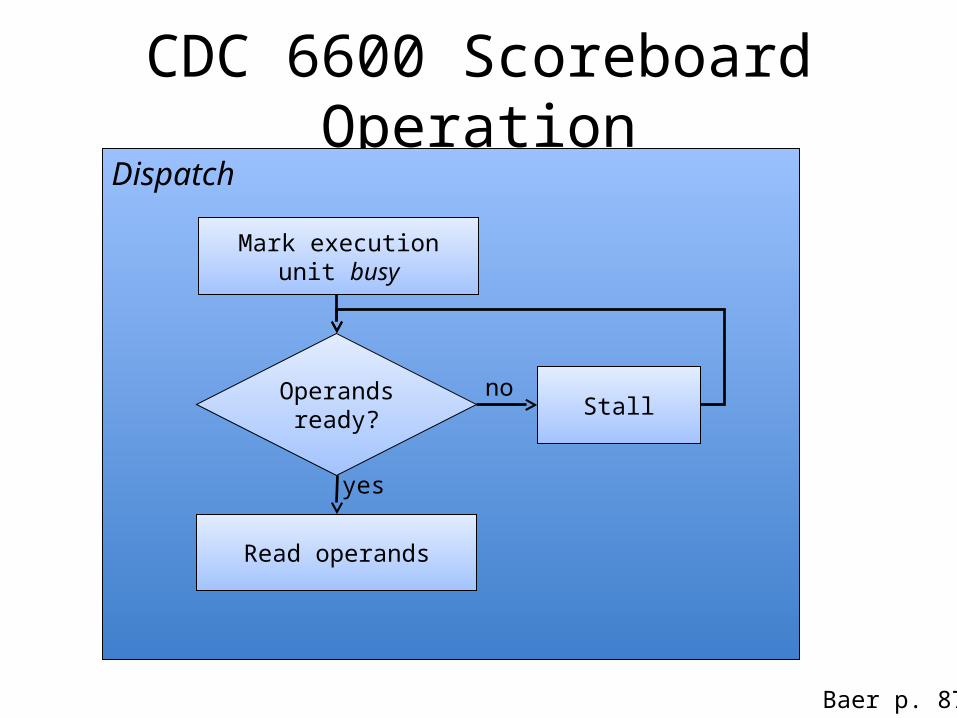
CDC 6600 Scoreboard OperationDispatch
Mark execution unit busy
Operands ready? Stall
no
yes
Read operands
Baer p. 87
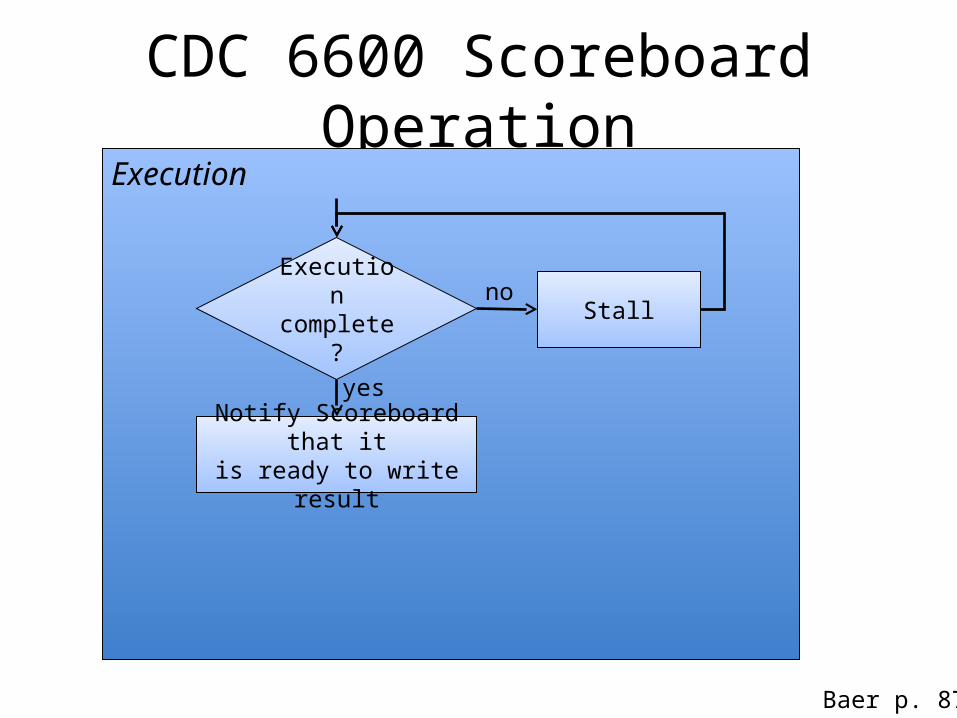
CDC 6600 Scoreboard OperationExecution
Execution complete? Stall
no
yes
Notify Scoreboard that itis ready to write result
Baer p. 87
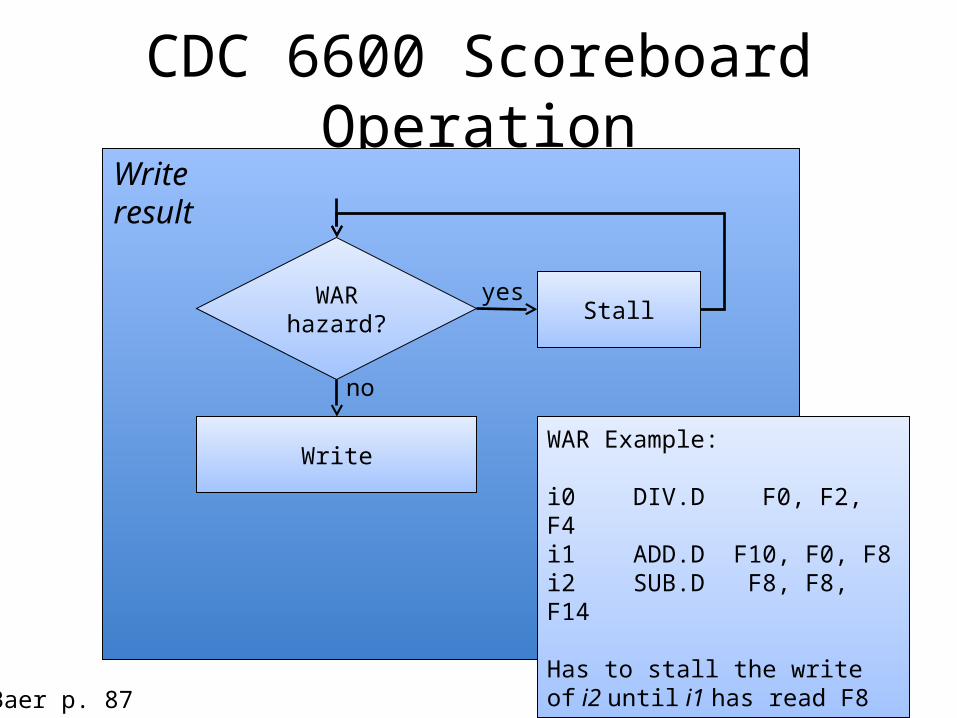
CDC 6600 Scoreboard OperationWriteresult
WAR hazard? Stall
yes
no
Write WAR Example:
i0 DIV.D F0, F2, F4i1 ADD.D F10, F0, F8i2 SUB.D F8, F8, F14
Has to stall the write of i2 until i1 has read F8
Baer p. 87

Scoreboarding Example
i1: R4 ← R0 * R2 # Uses multiplier 1
i2: R6 ← R4 * R8 # Uses multiplier 2
i3: R8 ← R2 + R12 # Uses Adder
i4: R4 ← R14 + R16 # Uses Adder
Baer p. 88
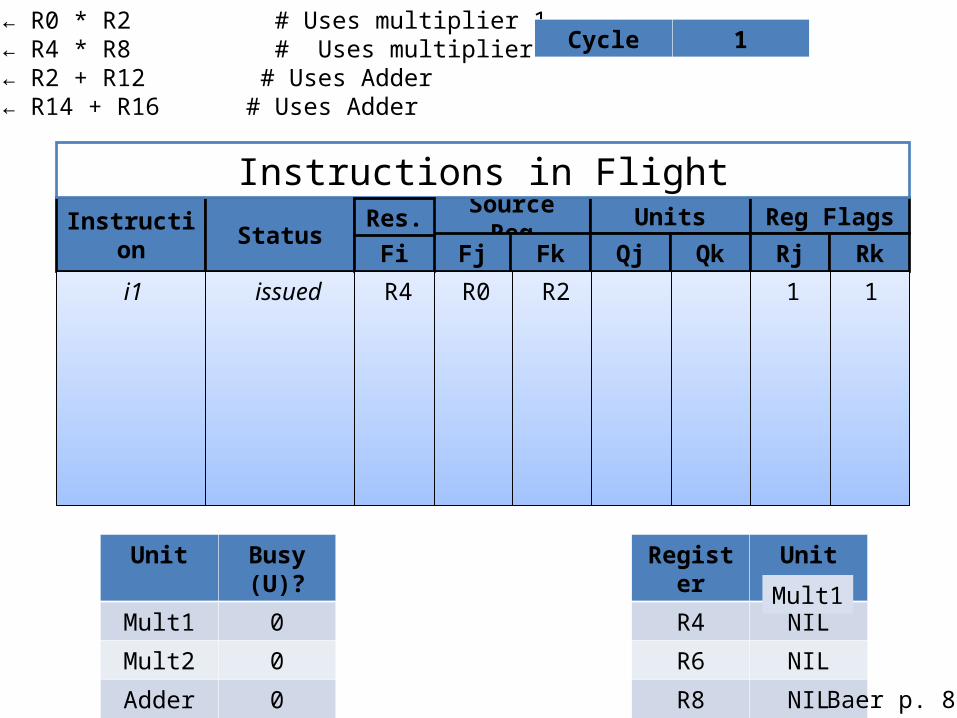
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 1
Unit Busy (U)?
Mult1 0
Mult2 0
Adder 0
Register Unit
R4 NIL
R6 NIL
R8 NIL
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 issued R4 R0 R2 1 1
Baer p. 88
Mult1
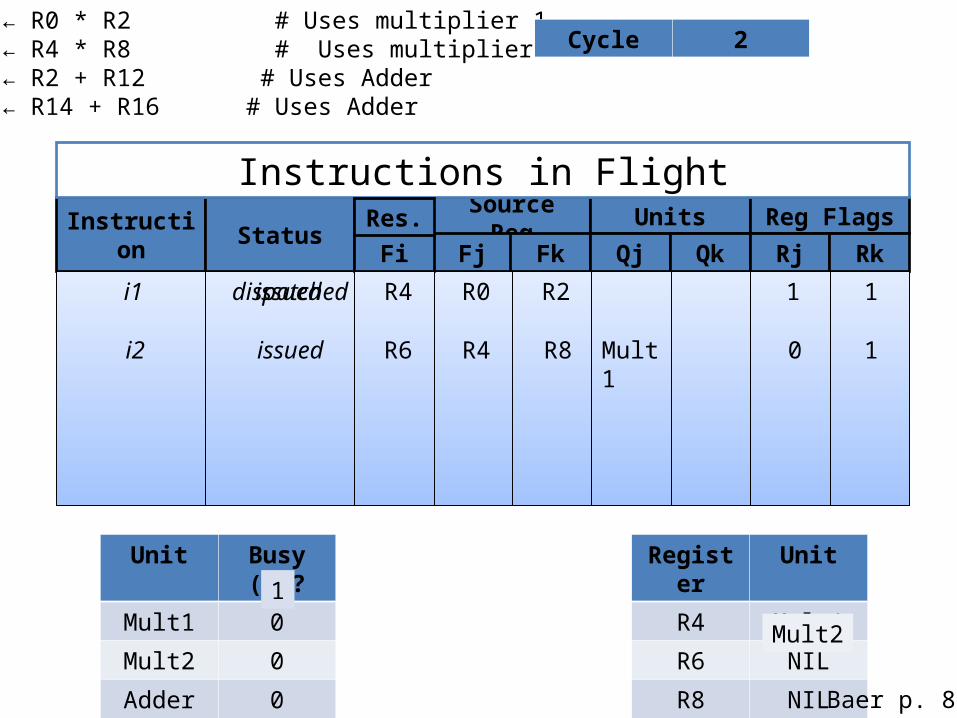
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 2
Unit Busy (U)?
Mult1 0
Mult2 0
Adder 0
Register Unit
R4 Mult1
R6 NIL
R8 NIL
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 dispatched R4 R0 R2
i2
issued
issued R6 R4 R8 Mult1
1 1
0 1
Baer p. 88
1
Mult2
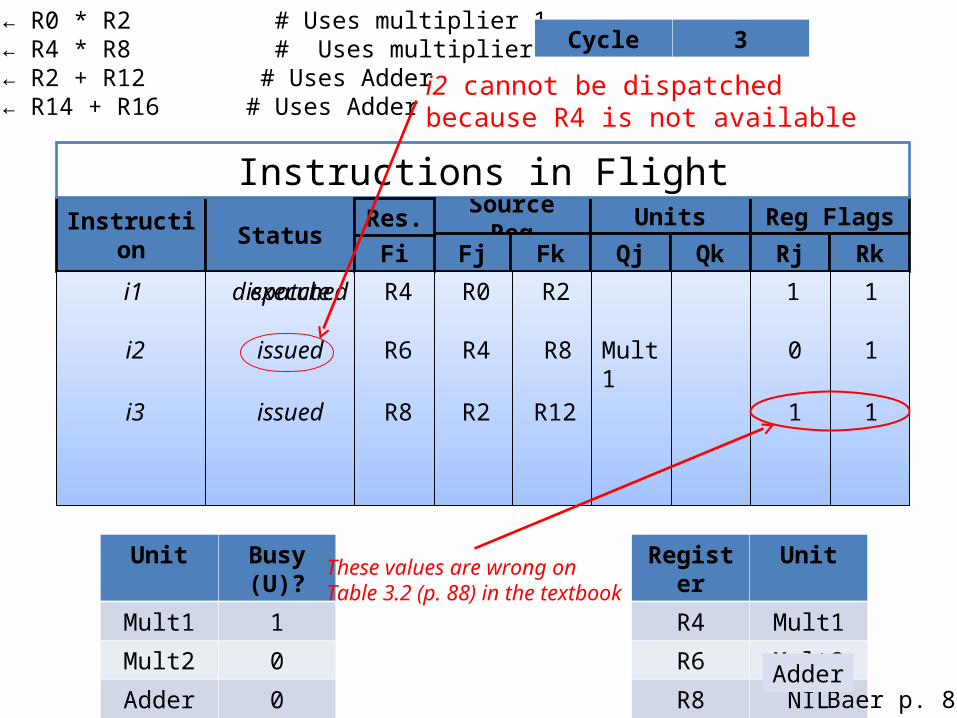
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 3
Unit Busy (U)?
Mult1 1
Mult2 0
Adder 0
Register Unit
R4 Mult1
R6 Mult2
R8 NIL
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 dispatched R4 R0 R2
i2 issued R6 R4 R8 Mult1
1 1
0 1
execute
i3 issued R8 R2 R12 1 1
i2 cannot be dispatchedbecause R4 is not available
Baer p. 88Adder
These values are wrong onTable 3.2 (p. 88) in the textbook

i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 4
Unit Busy (U)?
Mult1 1
Mult2 0
Adder 0
Register Unit
R4 Mult1
R6 Mult2
R8 Adder
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 R4 R0 R2
i2 issued R6 R4 R8 Mult1
1 1
0 1
execute
i3 issued R8 R2 R12 1 1
i4 cannot issue: (i) Adder is busy; AND (ii) WAW dependency on i1
dispatched
Baer p. 881
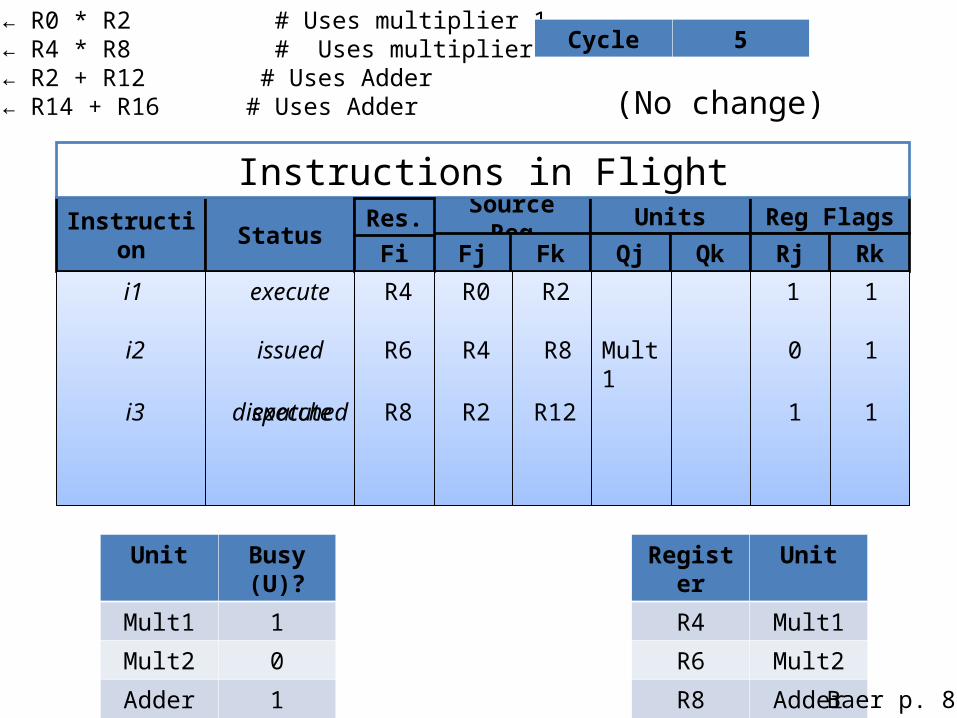
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 5
Unit Busy (U)?
Mult1 1
Mult2 0
Adder 1
Register Unit
R4 Mult1
R6 Mult2
R8 Adder
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 R4 R0 R2
i2 issued R6 R4 R8 Mult1
1 1
0 1
execute
R8 R2 R12 1 1dispatchedi3 execute
Baer p. 88
(No change)
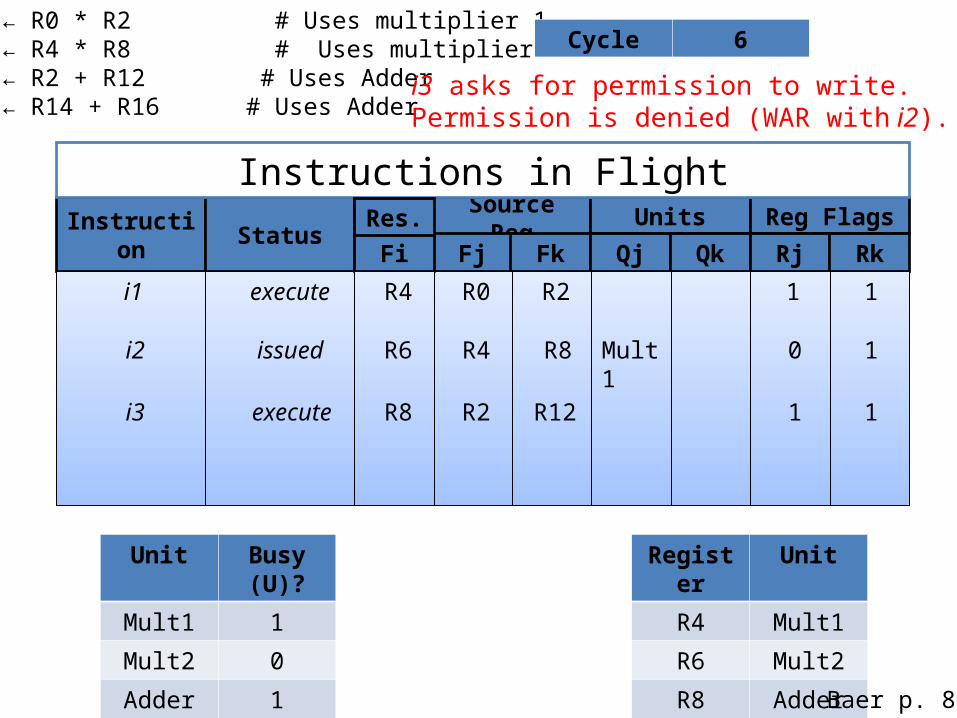
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 6
Unit Busy (U)?
Mult1 1
Mult2 0
Adder 1
Register Unit
R4 Mult1
R6 Mult2
R8 Adder
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 R4 R0 R2
i2 issued R6 R4 R8 Mult1
1 1
0 1
execute
R8 R2 R12 1 1i3 execute
i3 asks for permission to write.Permission is denied (WAR with i2).
Baer p. 88
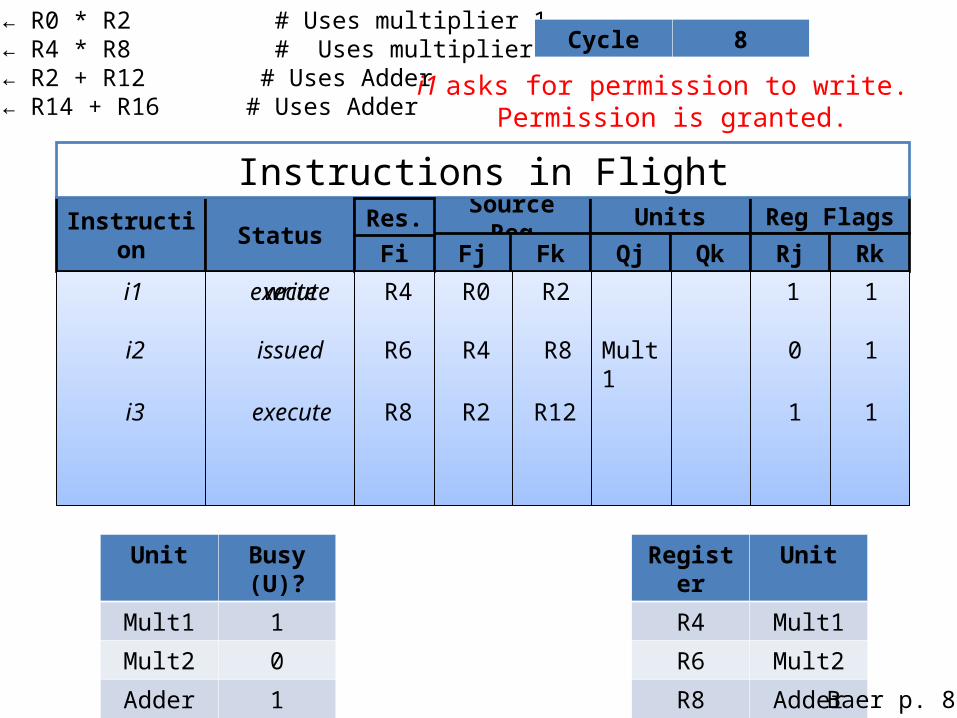
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 8
Unit Busy (U)?
Mult1 1
Mult2 0
Adder 1
Register Unit
R4 Mult1
R6 Mult2
R8 Adder
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i1 R4 R0 R2
i2 issued R6 R4 R8 Mult1
1 1
0 1
execute
R8 R2 R12 1 1i3 execute
i1 asks for permission to write. Permission is granted.
write
Baer p. 88
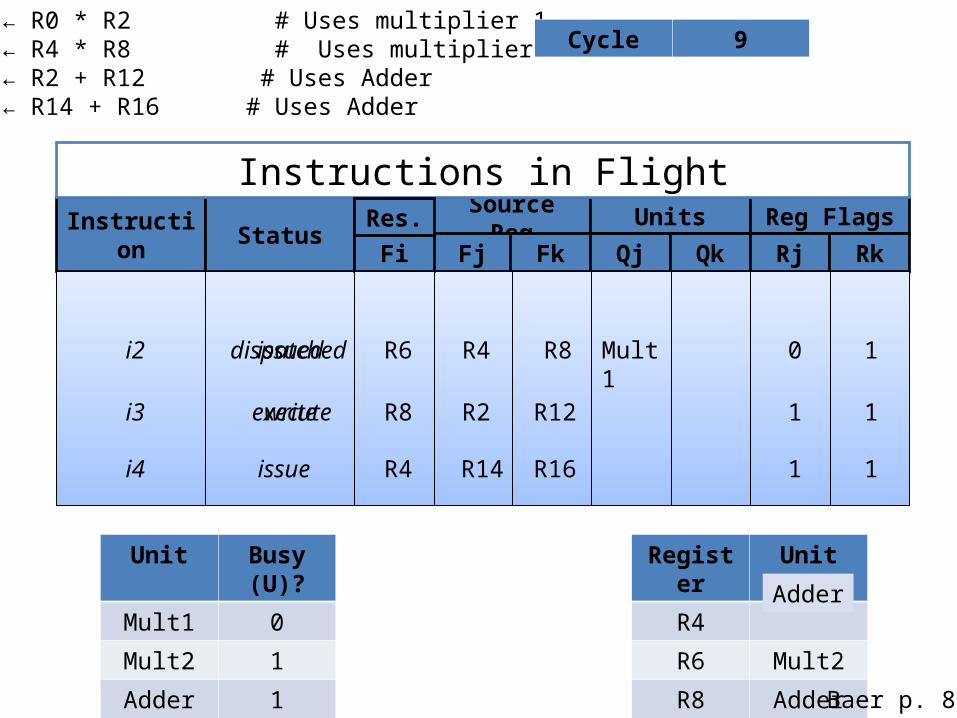
i1: R4 ← R0 * R2 # Uses multiplier 1i2: R6 ← R4 * R8 # Uses multiplier 2i3: R8 ← R2 + R12 # Uses Adderi4: R4 ← R14 + R16 # Uses Adder
Cycle 9
Unit Busy (U)?
Mult1 0
Mult2 1
Adder 1
Register Unit
R4
R6 Mult2
R8 Adder
Source Reg Units Reg FlagsInstruction Status
Fj Fk Qj Qk Rj Rk
Instructions in Flight
FiRes.
i2 issued R6 R4 R8 Mult1 0 1
R8 R2 R12 1 1i3 execute
dispatched
write
i4 issue R4 R14 R16 1 1
Baer p. 88
Adder

Register Renaming, Reorder Buffer, and Reservation Stations
• Difference between in-order X out-of-order execution:– When instructions leave the front end?• In-order: WAR and WAW prevent dispatch• Out-of-order: register renaming avoids WAR and WAW
• How are instructions processed in the back-end?
• Instructions can wait in reservation stations because of RAW dependencies or structural hazards• A reorder buffer imposes program order commitment
Baer p. 89

Register Renaming (example)
i1: R1 ← R2/R3 # Takes a long time
i2: R4 ← R1 + R5
i3: R5 ← R6 + R7
i4: R1 ← R8 + R9
In-order: Only i1 issues. Others are blocked by RAW dependency.
Out-of-order: i3 and i4 can issueand finish execution while i1 executes
The registers that appearin the program are logicalor architectural registers.
At the last stage of thefront end all registers aremapped to physical registers.
Baer p. 89

Renaming Process
Renaming Stage:
Ri ←Rj op Rk Ra ← Rb op Rc
Rb = Rename(Rj);Rc = Rename(Rk);Ra = freelist(first);Rename(Ri) = freelist(first);first ←next(first)
Baer p. 90

Register Renaming (example)
i1: R1 ← R2/R3
i2: R4 ← R1 + R5
i3: R5 ← R6 + R7
i4: R1 ← R8 + R9
Ri Rename(Ri)
R1 R1R2 R2R3 R3R4 R4R5 R5R6 R6R7 R7R8 R8R9 R9
Freelist = {R32, R33, R34, R35, R36, …}
R32R32
R32
R33
R33
R34
R34
R35
R35i4 will finish execution before i1. Can we allow itto write the result to R1 before i1?
How about i3, can it write into R5 beforei1 and i2 complete?
If i1 generates an exception, what will be the value of R5 in the exception state?
Baer p. 90

Reorder Buffer
• Even though we allow out-of-order execution, we require in-order-completion.
• A reorder buffer (ROB) ensures that the results produced by instructions are committed to the logical register in order.
Baer p. 91

Reorder Buffer (cont.)
• Each entry in the ROB has the following fields:– flag: has the instruction completed?– value: value computed by the instruction– result register name: logical register– instruction type: arithmetic/load/store/branch/…
• Each instruction that has its destination register renamed is entered in the ROB
Baer p. 91
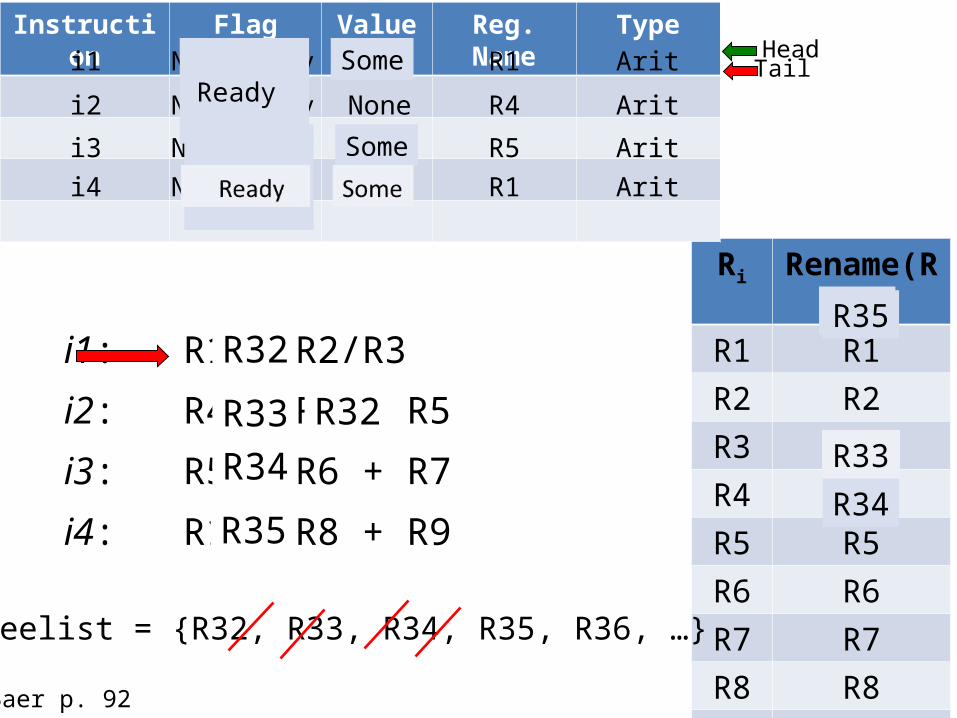
i1: R1 ← R2/R3
i2: R4 ← R1 + R5
i3: R5 ← R6 + R7
i4: R1 ← R8 + R9
Ri Rename(Ri)
R1 R1R2 R2R3 R3R4 R4R5 R5R6 R6R7 R7R8 R8R9 R9
Freelist = {R32, R33, R34, R35, R36, …}
R32R32
R32R33
R33
R34R34
R35
R35
Instruction Flag Value Reg. Name Typei1 Not Ready None R1 Arit Head
Tail
i2 Not Ready None R4 Arit
i3 Not Ready None R5 Ariti4 Not Ready None R1 Arit
Ready Some
Ready Some
Baer p. 92

But….
• Where do instructions wait before being executed?
• How an instruction knows that it is ready to be executed?
Baer p. 93

Reservation Stations
• After register renaming, the front-end dispatches the instruction to a reservation station.
• Reservation stations can:– be grouped into a centralized queue called an
instruction window.– be associated with functional units according to
the opcode.
Baer p. 93

Reservation Stations (cont.)
• Each entry in the Reservation Station must contain:– Operation to be performed– Source operands (either value or physical name of
the register) – a flag indicates which one– physical name of the result register– ROB entry where the result will be stored.
Baer p. 93

Scheduling
• Scheduling: Selection of which instruction should execute next in a given execution unit– oldest instruction;– critical instruction;
Baer p. 93

Ready Bit
• A ready bit is associated with each physical register.
• When an instruction that uses a physical register Ri is dispatched:– if Ri is ready, pass Ri value to the reservation
station and set flag to true (ready)– if Ri is not ready, pass the name of Ri to the
reservation station and set flag to false (not ready)– When both flags are true, the instruction is ready
to be issued.
Baer p. 93

Ready Bit (cont.)
• Upon completion, an instruction broadcasts the name and content of its result physical register to all reservation stations (RS).– Each RS that needs it, will grab the content and
update its flags.
Baer p. 93


















