
Superscalar Processor Design - ERNET
72
Superscalar Processor Design Superscalar Architecture Virendra Singh Computer Design and Test Lab. Indian Institute of Science Bangalore [email protected] Advance Computer Architecture
Transcript of Superscalar Processor Design - ERNET

Superscalar Processor Design
Superscalar ArchitectureVirendra Singh
Computer Design and Test Lab.Indian Institute of Science
Advance Computer Architecture

2
Superscalar Pipelines
IF
ID
RD
ALU
MEM
WB
Advance Computer Architecture

3
Superscalar PipelinesDynamic Pipelines
1. Alleviate the limitations of pipelined implementation
2. Use diversified pipelines
3. Temporal machine parallelism
Advance Computer Architecture
4
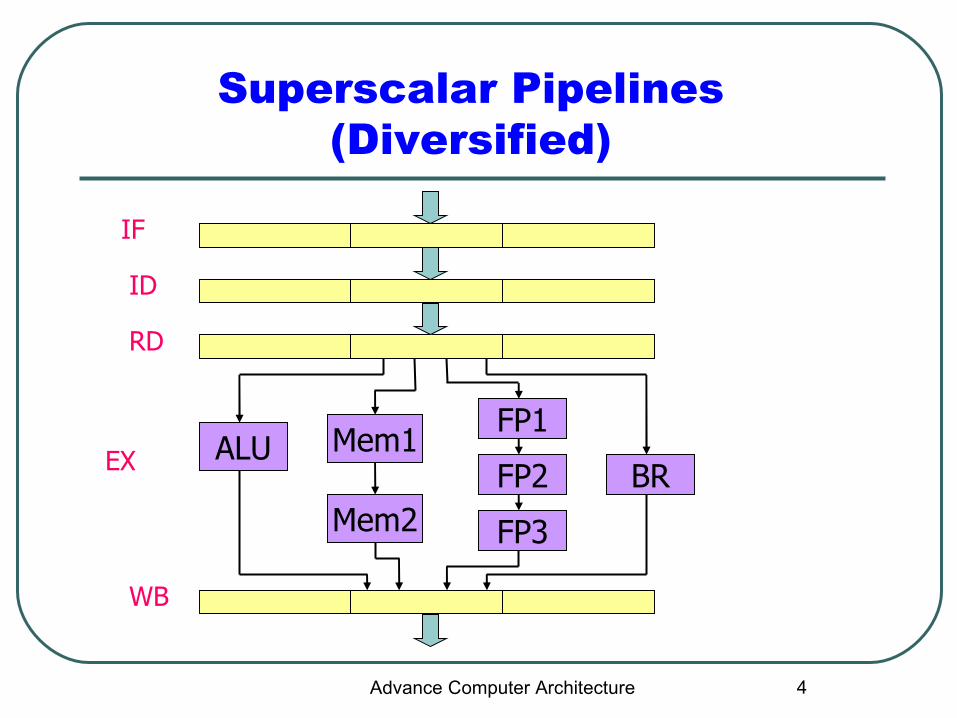
Superscalar Pipelines (Diversified)
IF
ID
RD
WB
ALU Mem1
Mem2
FP1
FP2
FP3
BREX
Advance Computer Architecture

5
Superscalar Pipelines (Diversified)
Diversified Pipelines
Each pipeline can be customized for particular instruction type
Each instruction type incurs only necessary latency
Certainly less expensive than identical copies
If all inter-instruction dependencies are resolved then there is no stall after instruction issue
Require special consideration
Number and Mix of functional unitsAdvance Computer Architecture

6
Superscalar Pipelines (Dynamic Pipelines)
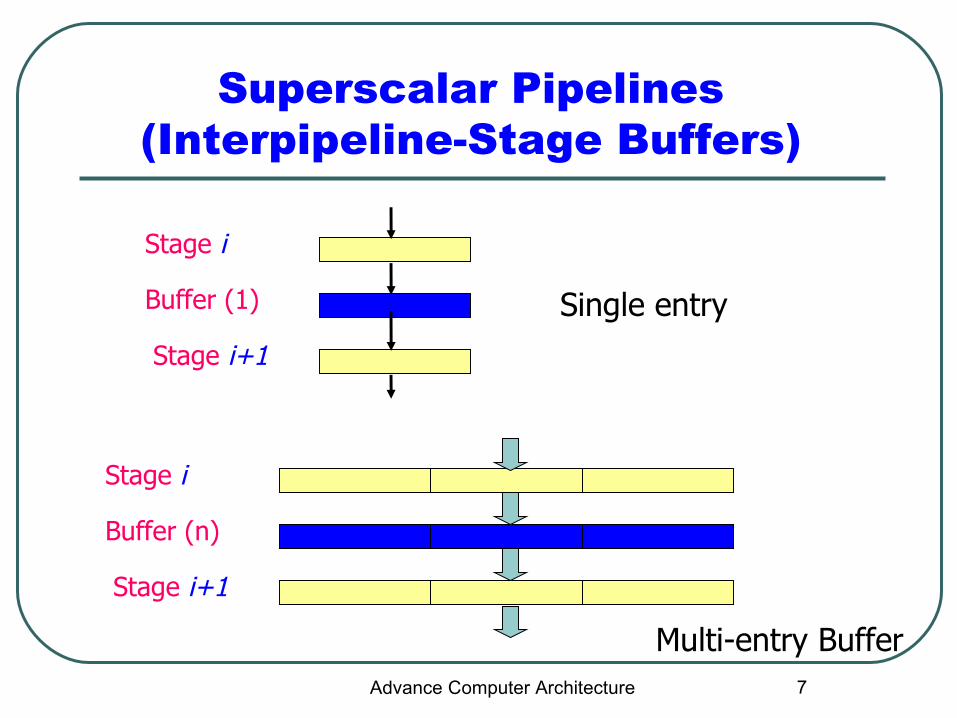
Dynamic Pipelines
Buffers are needed
Multi-entry buffers
Every entry is hardwired to one read port and one write port
Complex multi-entry buffers
Minimize stalls
Advance Computer Architecture
7
Superscalar Pipelines (Interpipeline-Stage Buffers)
Stage i
Buffer (n)
Stage i+1
Stage i
Buffer (1)
Stage i+1
Single entry
Multi-entry BufferAdvance Computer Architecture

8
Superscalar Pipelines (Interpipeline-Stage Buffers)
Stage i
Buffer (>= n)
Stage i+1
In-order
Out-of-order
Trailing instructions are allowed to bypass stalled instruction
Out-of-order execution
Advance Computer Architecture

9
Superscalar ArchitectureInstruction issue and machine parallelismIn-order issue with in-order completionIn-Order issue with Out-of-Order
completionOut-of-Order issue withOut-of-Order
Completion
Advance Computer Architecture
10
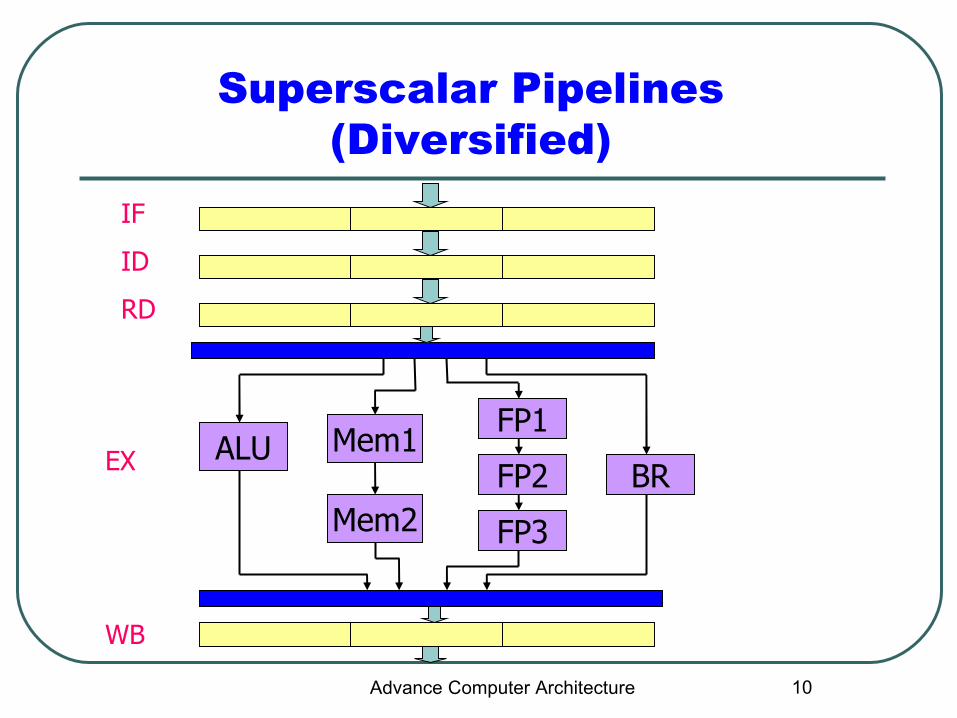
Superscalar Pipelines (Diversified)
IF
ID
RD
WB
ALU Mem1
Mem2
FP1
FP2
FP3
BREX
Advance Computer Architecture
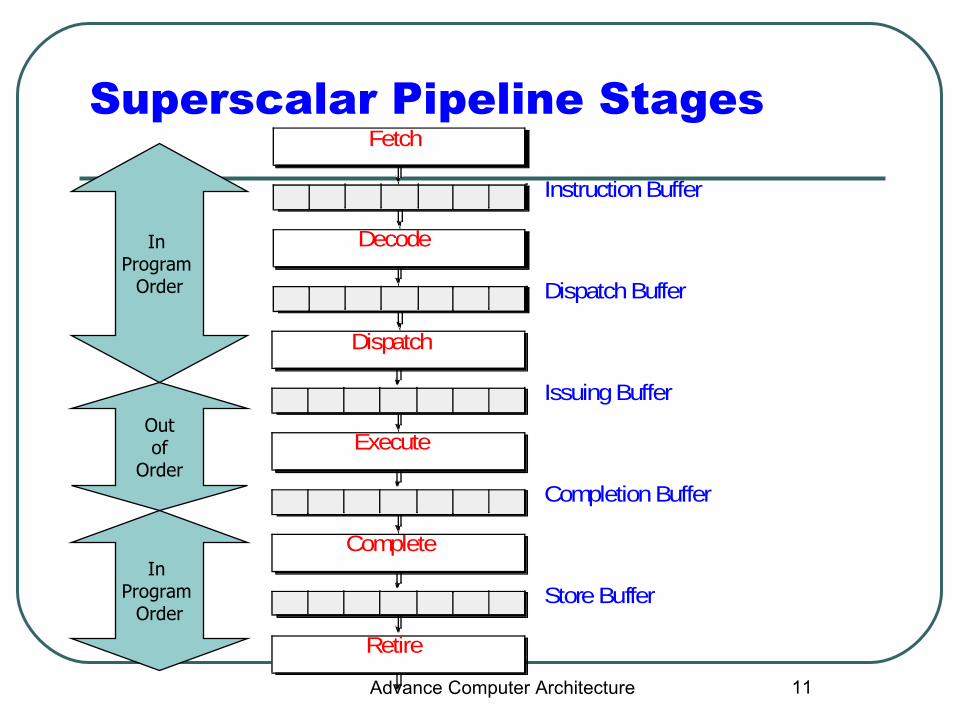
Superscalar Pipeline Stages
Instruction Buffer
Fetch
Dispatch Buffer
Decode
Issuing Buffer
Dispatch
Completion Buffer
Execute
Store Buffer
Complete
Retire
In Program
Order
In Program
Order
Outof
Order
11Advance Computer Architecture
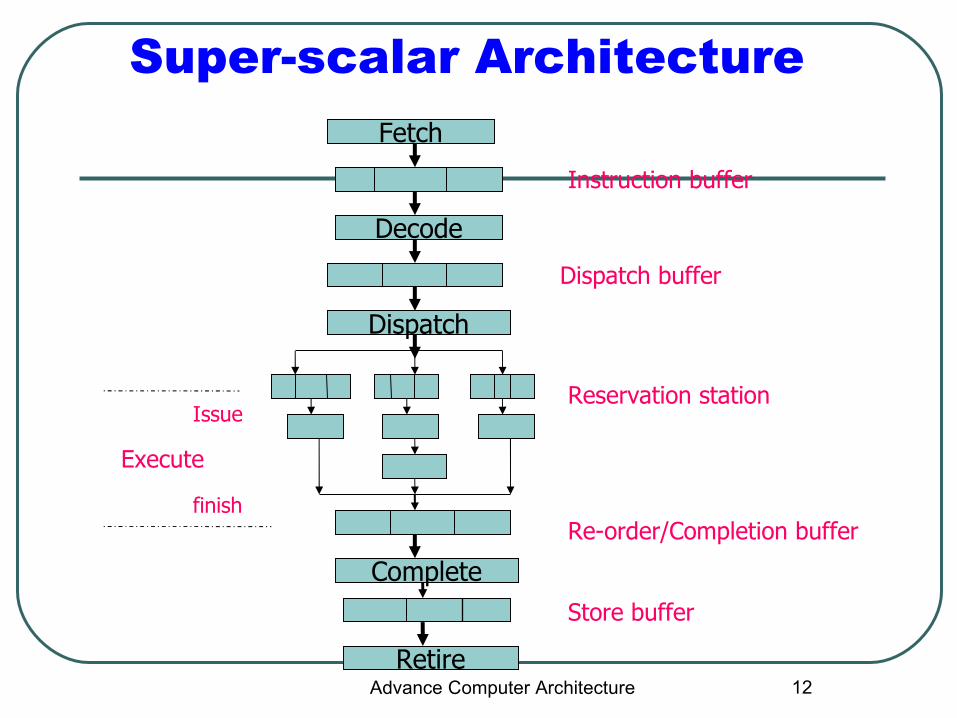
12
Super-scalar Architecture
Instruction buffer
Dispatch buffer
Reservation station
Re-order/Completion buffer
Store buffer
Fetch
Decode
Dispatch
Complete
Retire
Execute
finish
Issue
Advance Computer Architecture

Limitations of Scalar PipelinesScalar upper bound on throughput
• IPC <= 1 or CPI >= 1• Solution: wide (superscalar) pipeline
Inefficient unified pipeline• Long latency for each instruction• Solution: diversified, specialized pipelines
Rigid pipeline stall policy• One stalled instruction stalls all newer
instructions• Solution: Out-of-order execution, distributed
execution pipelines
13Advance Computer Architecture
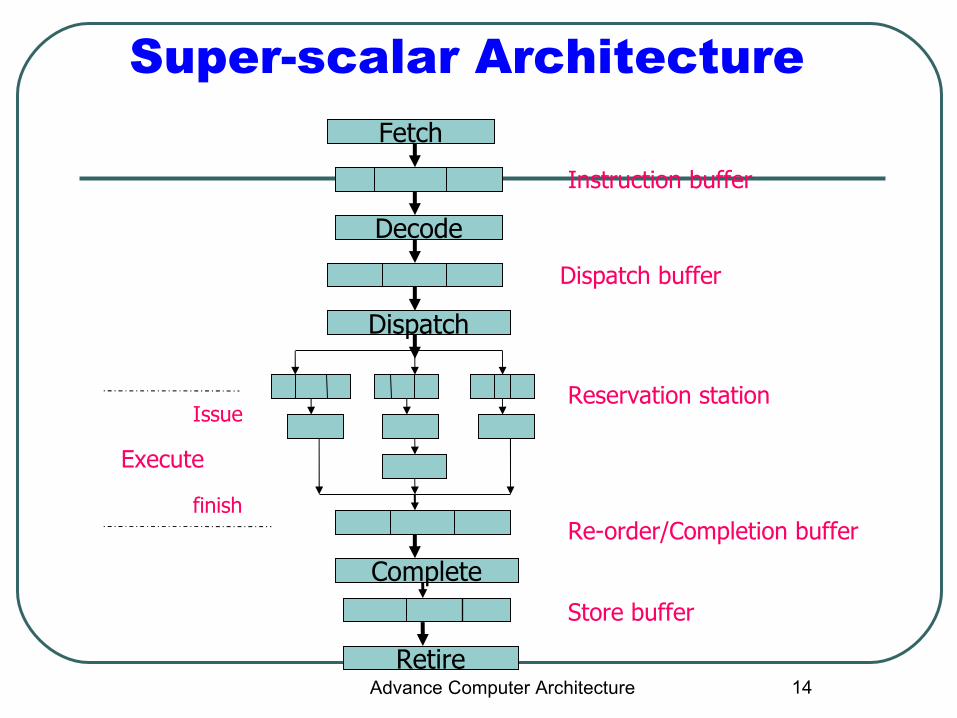
14
Super-scalar Architecture
Instruction buffer
Dispatch buffer
Reservation station
Re-order/Completion buffer
Store buffer
Fetch
Decode
Dispatch
Complete
Retire
Execute
finish
Issue
Advance Computer Architecture
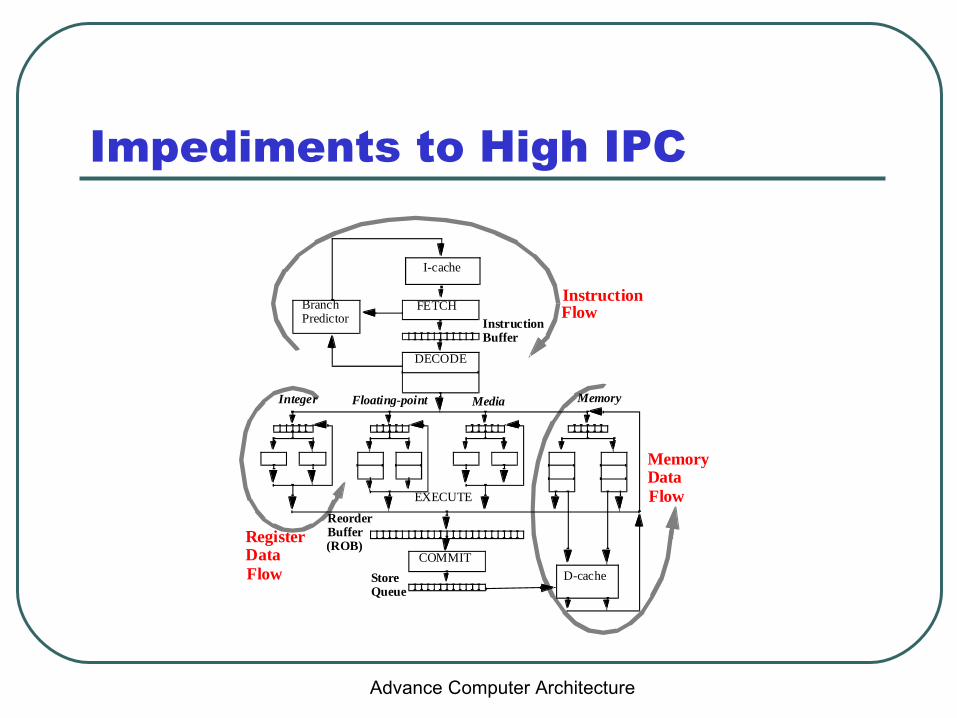
Impediments to High IPC
I-cache
FETCH
DECODE
COMMIT
D-cache
BranchPredictor Instruction
Buffer
StoreQueue
ReorderBuffer
Integer Floating-point Media Memory
Instruction
RegisterData
MemoryData
Flow
EXECUTE
(ROB)
Flow
Flow
Advance Computer Architecture

Superscalar Pipeline Design
Instruction Fetching IssuesInstruction Decoding IssuesInstruction Dispatching IssuesInstruction Execution IssuesInstruction Completion & Retiring
Issues
Advance Computer Architecture

Instruction Flow
Challenges:• Branches: control
dependences• Branch target misalignment• Instruction cache misses
Solutions• Code alignment (static
vs.dynamic)• Prediction/speculation
Instruction Memory
PC
3 instructions fetched
Objective: Fetch multiple instructions per cycle
Advance Computer Architecture

18
Instruction Fetch
Fetch s instructions from I-cache
I-Cache must be wide enough that each row of the I-Cache array can store s instructions and that an entire row can be accessed
Fetch width = Row width
Assume access latency is 1 cycle
Advance Computer Architecture

I-Cache Organization
Ro
w D
ec
od
er
•••
CacheLine
•••
TAG
TAG
Address
1 cache line = 1 physical row
•••Cache
Line•••
TAG
TAG
Address
1 cache line = 2 physical rows
TAG
TAGR
ow
De
co
der
Advance Computer Architecture

20
Instruction Fetch
Impediments:
1. Instruction misalignment
• Solutions
• Static – Compiler
• Needs information about the I-Cache org, indexing, row size
• Dynamic
1. Presence of control flow change
Advance Computer Architecture

Fetch Alignment
Advance Computer Architecture

22
Instruction Fetch 2 – way set associative I-Cache with a line size of 16
instructions (64 bytes)
Each row of the I-Cache stores 4 associative sets (two per set) of instructions
Each line of I-cache spans four physical rows
Physical I-cache array is actually composed of 4 independent sub-arrays
One instruction can be accessed form one array
Advance Computer Architecture

23
Instruction Fetch
A1 B1A5 B5A9 B9
A2 B2A6 B6A10 B10
A3 B3A7 B7A11 B11
A0 B0A4 B4A8 B8
TT T
IFAR
OddDirectory
set
OddDirectory
set
Instruction Buffer Network
Advance Computer Architecture
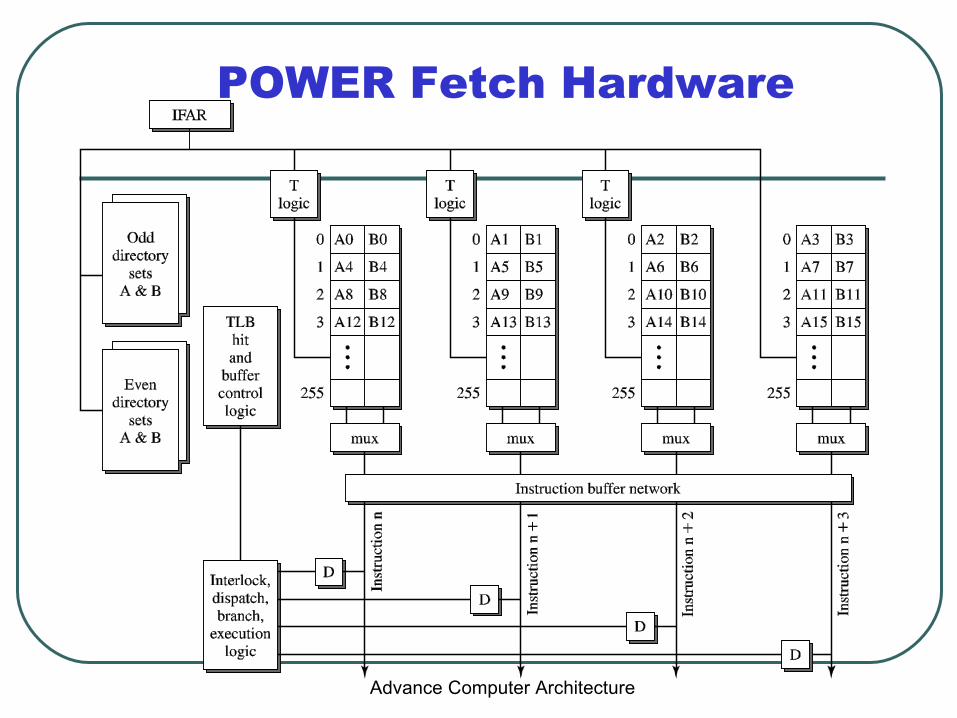
POWER Fetch Hardware
Advance Computer Architecture

Issues in Decoding
Primary Tasks• Identify individual instructions (!)• Determine instruction types• Determine dependences between
instructions
Two important factors• Instruction set architecture• Pipeline width
Advance Computer Architecture

26
Decode Stage
Decodes instruction types
Detect inter-instruction dependencies
Complexity
ISA
Fetch width
Large number of comparators
Multi-ported RF
Advance Computer Architecture
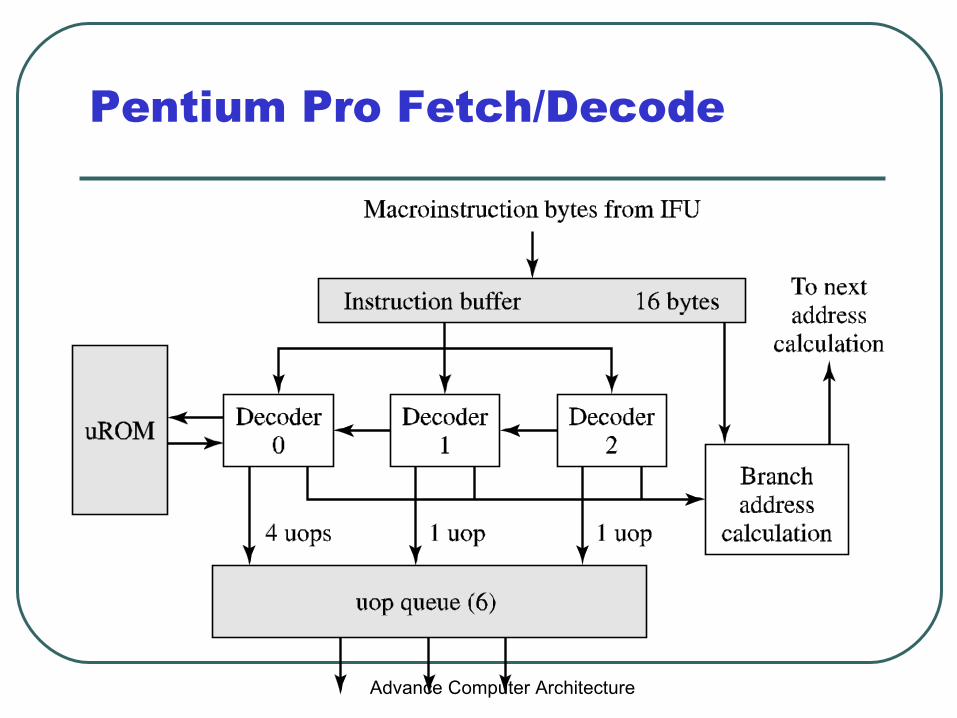
Pentium Pro Fetch/Decode
Advance Computer Architecture

Instruction Dispatch and Issue
Parallel pipeline• Centralized instruction fetch• Centralized instruction decode
Diversified pipeline• Distributed instruction execution
Advance Computer Architecture
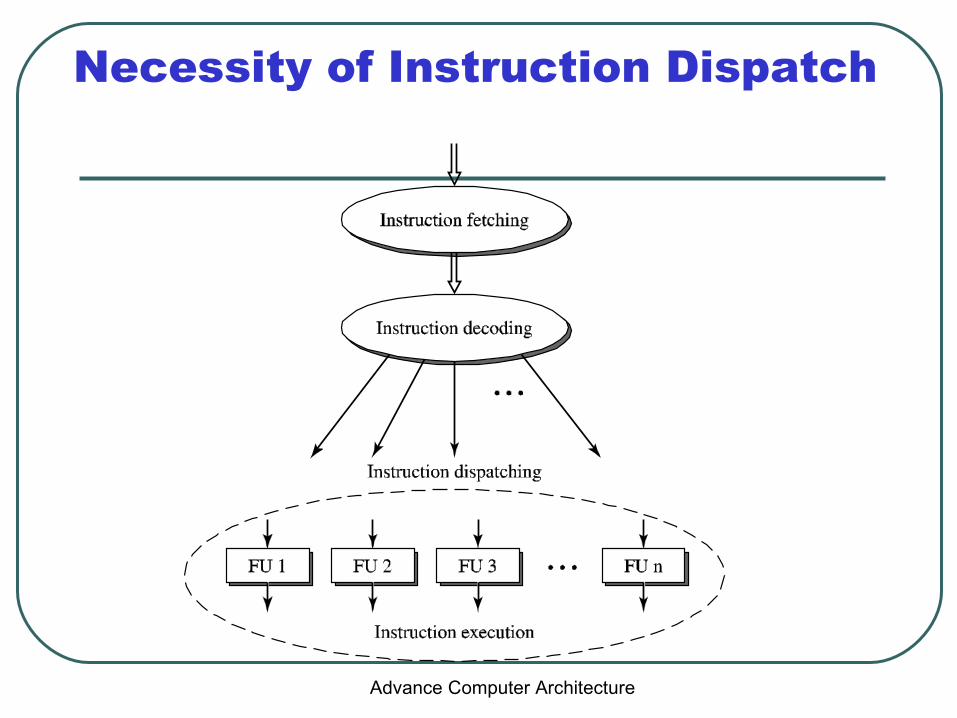
Necessity of Instruction Dispatch
Advance Computer Architecture
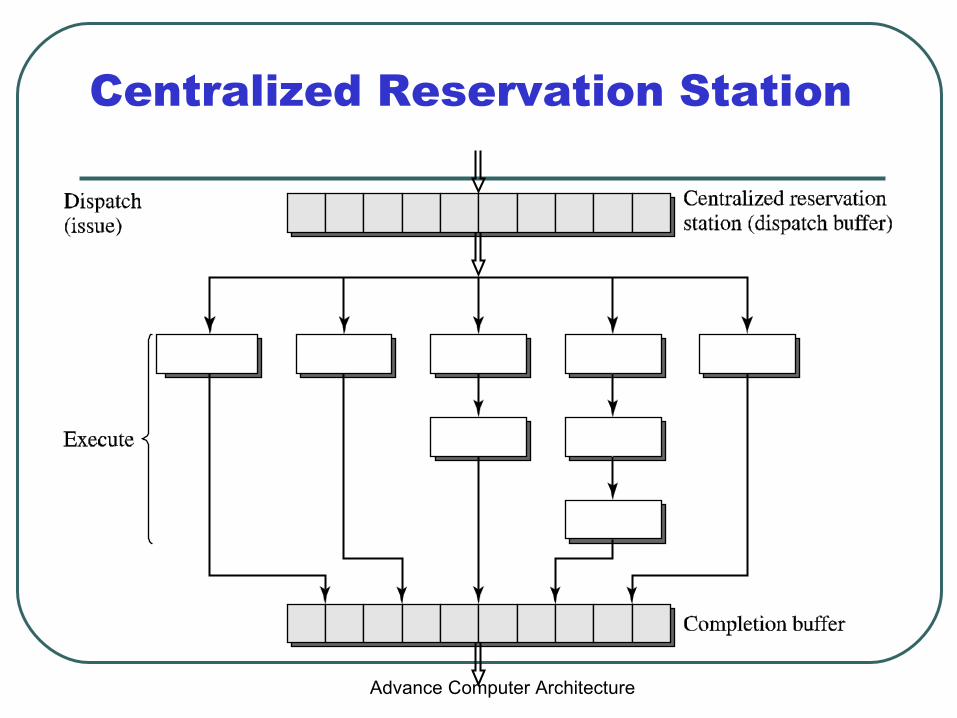
Centralized Reservation Station
Advance Computer Architecture

Distributed Reservation Station
Advance Computer Architecture

32
Instruction Dispatching Diversified pipeline
Different type instructions executed by different FU in different pipelines
Distributed control
Operands are fetched from RF
Operands may not be available
Reservation station
Centralized
DistributedAdvance Computer Architecture

Issues in Instruction Execution
Current trends• More parallelism bypassing very
challenging• Deeper pipelines• More diversity
Functional unit types• Integer• Floating point• Load/store most difficult to make parallel• Branch• Specialized units (media)
• Very wide datapaths (256 bits/register or more)Advance Computer Architecture

Bypass Networks
O(n2) interconnect from/to FU inputs and outputs
Associative tag-match to find operandsSolutions (hurt IPC, help cycle time)
• Use RF only (IBM Power4) with no bypass network
• Decompose into clusters (Alpha 21264)
34Advance Computer Architecture
35
Instruction Dispatching
Advance Computer Architecture
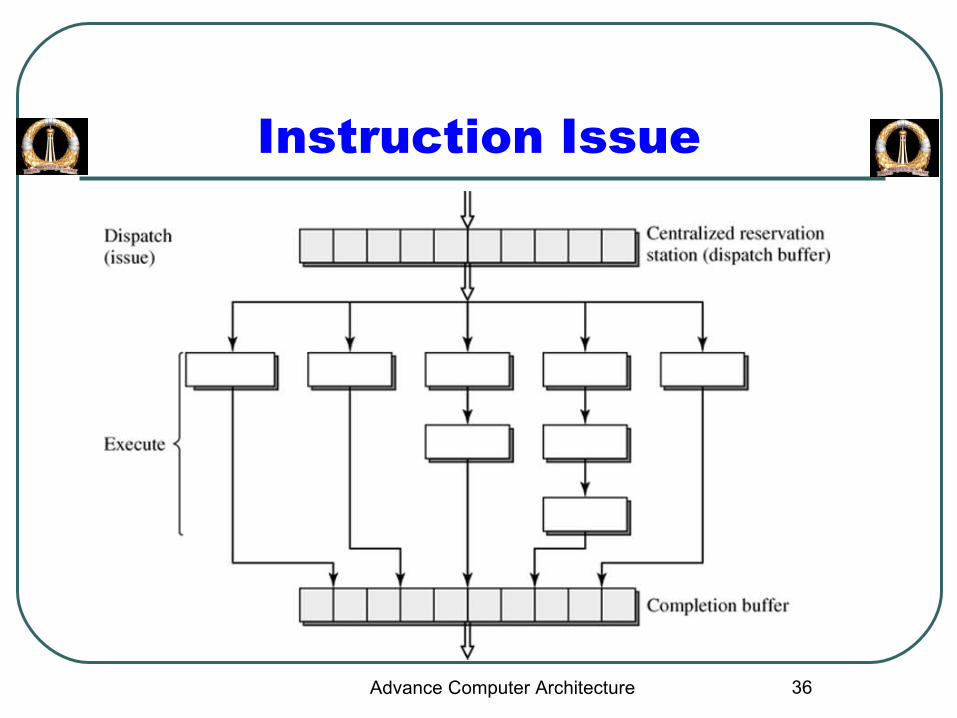
36
Instruction Issue
Advance Computer Architecture
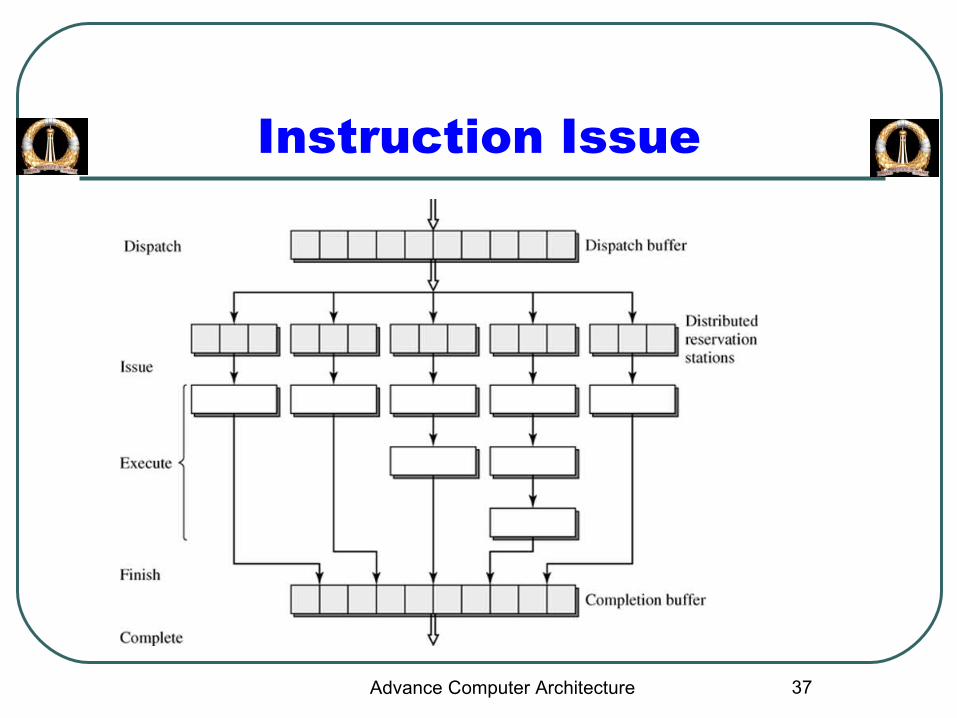
37
Instruction Issue
Advance Computer Architecture

Issues in Completion/Retirement
Out-of-order execution• ALU instructions• Load/store instructions
In-order completion/retirement• Precise exceptions• Memory coherence and consistency
Solutions• Reorder buffer• Store buffer• Load queue snooping (later)
Advance Computer Architecture

39
Super-scalar Architecture
Instruction buffer
Dispatch buffer
Reservation station
Re-order/Completion buffer
Store buffer
Fetch
Decode
Dispatch
Complete
Retire
Execute
finish
Issue
Advance Computer Architecture

Program Control Flow
• Implicit Sequential Control Flow– Static Program Representation
• Control Flow Graph (CFG)• Nodes = basic blocks• Edges = Control flow transfers
– Physical Program Layout• Mapping of CFG to linear program memory• Implied sequential control flow
– Dynamic Program Execution• Traversal of the CFG nodes and edges (e.g. loops)• Traversal dictated by branch conditions
– Dynamic Control Flow• Deviates from sequential control flow• Disrupts sequential fetching• Can stall IF stage and reduce I-fetch bandwidth
Advance Computer Architecture
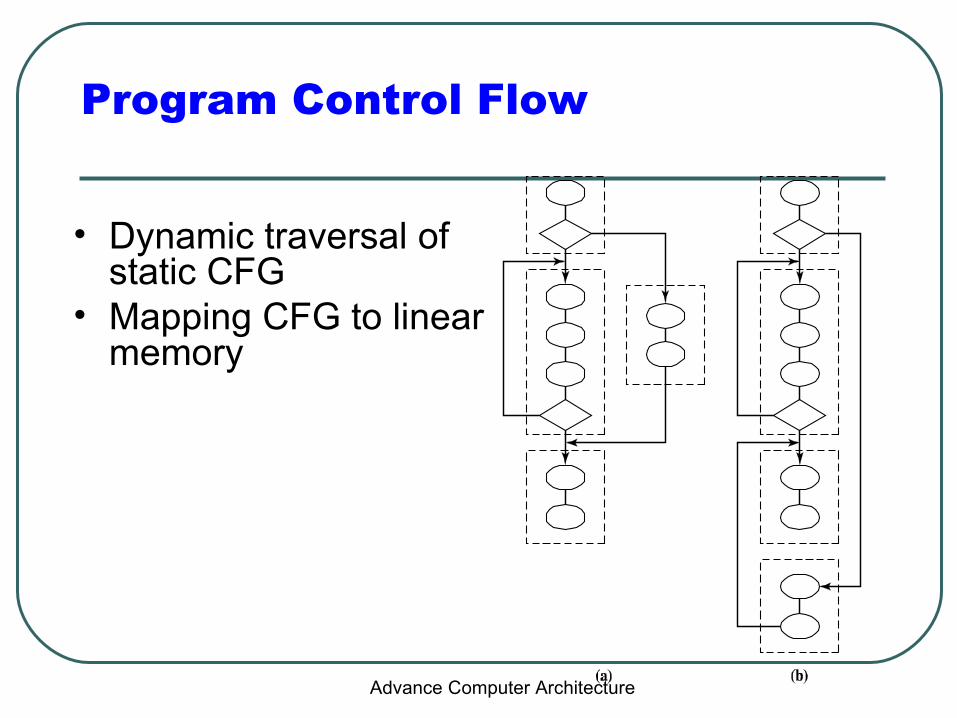
Program Control Flow
• Dynamic traversal of static CFG
• Mapping CFG to linear memory
Advance Computer Architecture
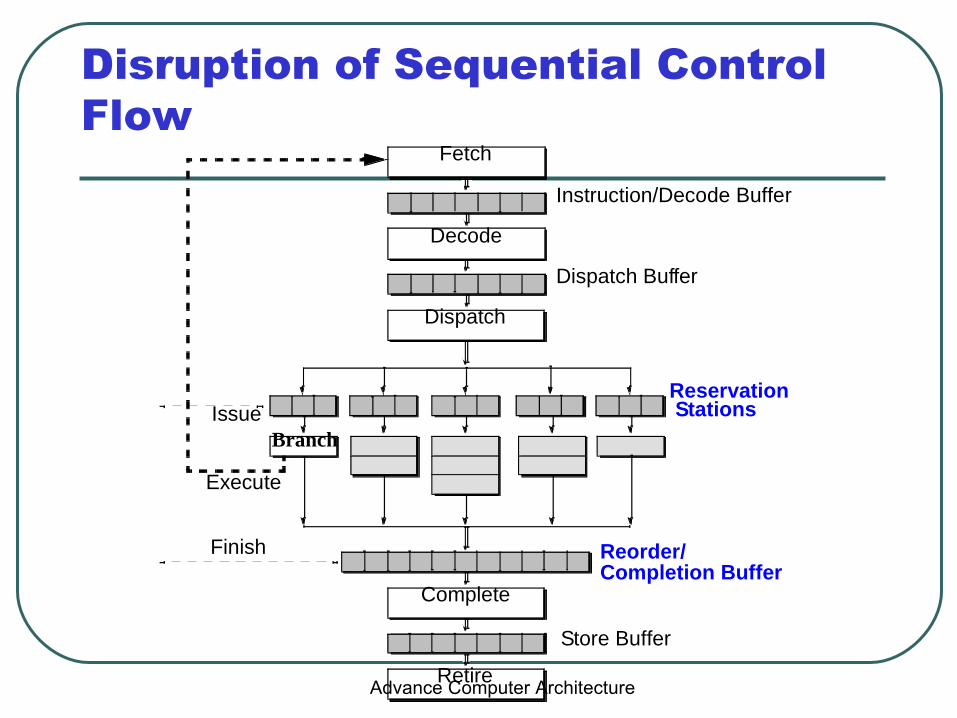
Disruption of Sequential Control Flow
Instruction/Decode Buffer
Fetch
Dispatch Buffer
Decode
Reservation
Dispatch
Reorder/
Store Buffer
Complete
Retire
StationsIssue
Execute
FinishCompletion Buffer
Branch
Advance Computer Architecture

Branch Prediction
• Target address generation → Target Speculation– Access register:
• PC, General purpose register, Link register
– Perform calculation: • +/- offset, autoincrement, autodecrement
• Condition resolution → Condition speculation– Access register:
• Condition code register, General purpose register
– Perform calculation:• Comparison of data register(s)
Advance Computer Architecture
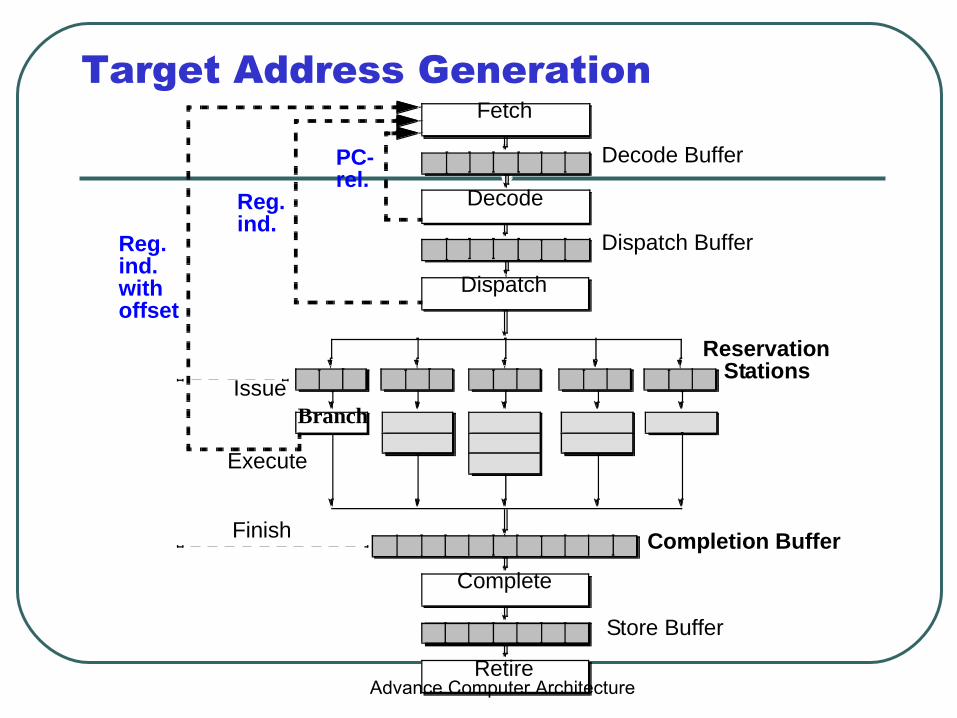
Target Address Generation
Decode Buffer
Fetch
Dispatch Buffer
Decode
Reservation
Dispatch
Store Buffer
Complete
Retire
StationsIssue
Execute
Finish Completion Buffer
Branch
PC-rel.
Reg.ind.
Reg.ind.withoffset
Advance Computer Architecture
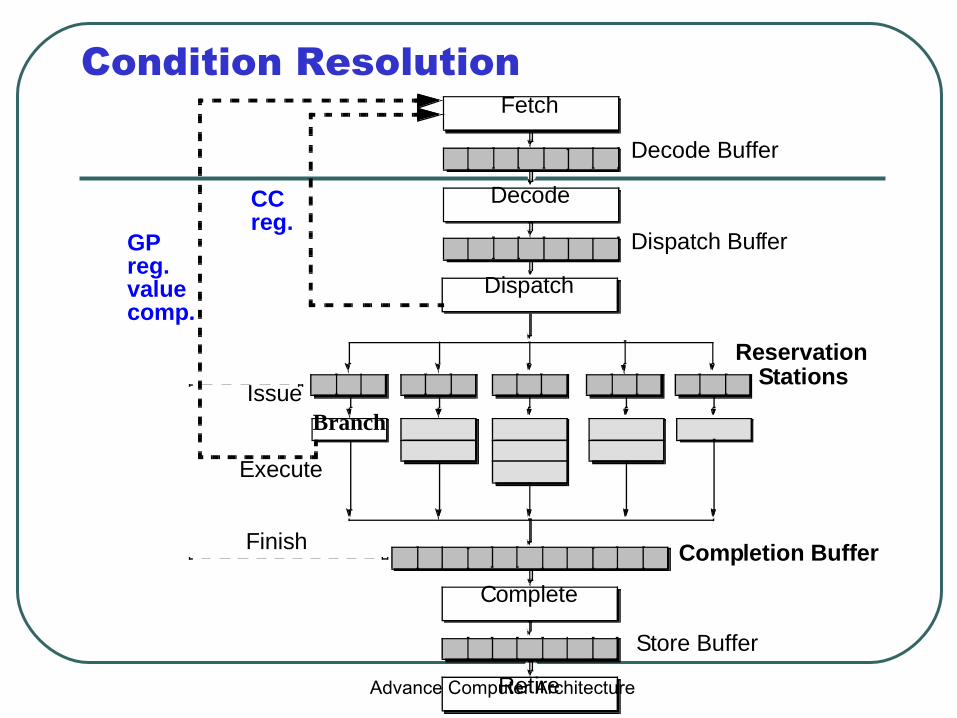
Condition Resolution
Decode Buffer
Fetch
Dispatch Buffer
Decode
Reservation
Dispatch
Store Buffer
Complete
Retire
StationsIssue
Execute
Finish Completion Buffer
Branch
CCreg.
GPreg.valuecomp.
Advance Computer Architecture
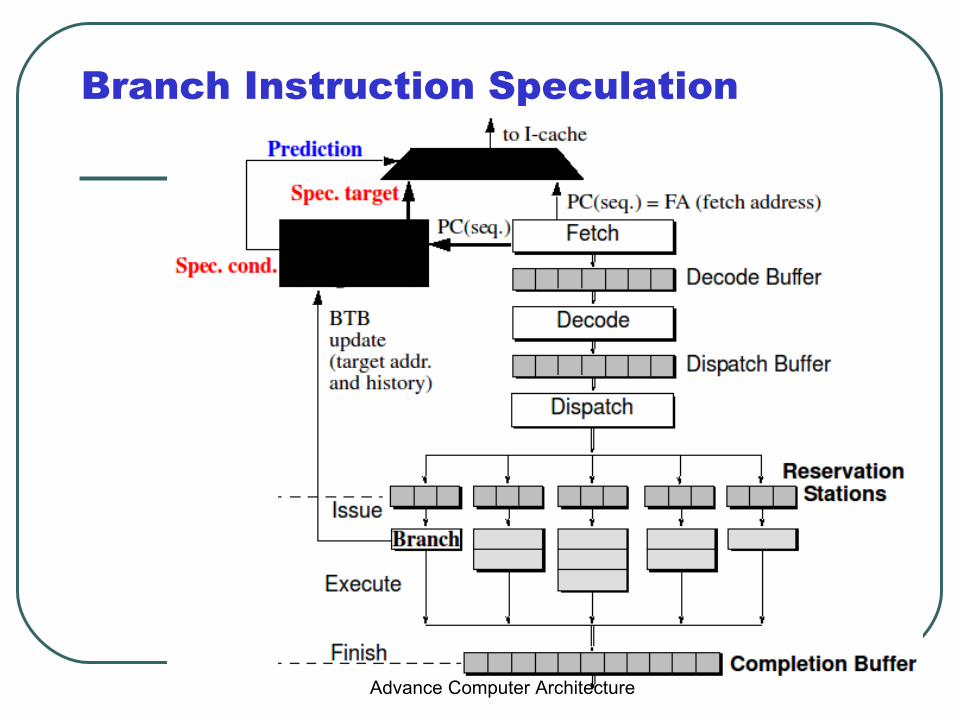
Branch Instruction Speculation
Advance Computer Architecture

Branch/Jump Target Prediction
• Branch Target Buffer: small cache in fetch stage– Previously executed branches, address, taken history, target(s)
• Fetch stage compares current FA against BTB– If match, use prediction– If predict taken, use BTB target
• When branch executes, BTB is updated• Optimization:
– Size of BTB: increases hit rate– Prediction algorithm: increase accuracy of prediction
Branch inst. Information Branch targetaddress for predict. address (most recent)
0x0348 0101 (NTNT) 0x0612
Advance Computer Architecture

Branch Prediction: Condition Speculation
1. Biased Not Taken– Hardware prediction– Does not affect ISA– Not effective for loops
1. Software Prediction– Extra bit in each branch instruction
• Set to 0 for not taken• Set to 1 for taken
– Bit set by compiler or user; can use profiling– Static prediction, same behavior every time
1. Prediction based on branch offset– Positive offset: predict not taken– Negative offset: predict taken
1. Prediction based on dynamic history
Advance Computer Architecture

UCB Study [Lee and Smith, 1984]• Benchmarks used
– 26 programs (IBM 370, DEC PDP-11, CDC 6400)– 6 workloads (4 IBM, 1 DEC, 1 CDC)– Used trace-driven simulation
• Branch types– Unconditional: always taken or always not taken– Subroutine call: always taken– Loop control: usually taken– Decision: either way, if-then-else– Computed goto: always taken, with changing target– Supervisor call: always taken– Execute: always taken (IBM 370)
IBM1 IBM2 IBM3 IBM4 DEC CDC Avg
T 0.640 0.657 0.704 0.540 0.738 0.778 0.676
NT 0.360 0.343 0.296 0.460 0.262 0.222 0.324
IBM1: compilerIBM2: cobol (business
app)IBM3: scientific
IBM4: supervisor (OS)
Advance Computer Architecture
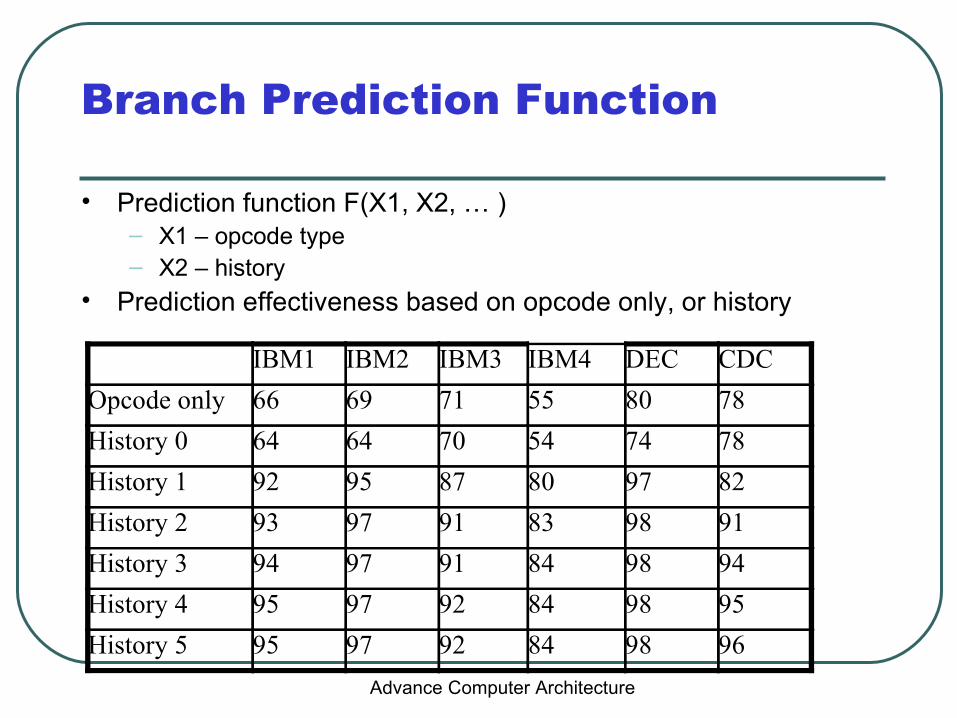
Branch Prediction Function
• Prediction function F(X1, X2, … )– X1 – opcode type– X2 – history
• Prediction effectiveness based on opcode only, or history
IBM1 IBM2 IBM3 IBM4 DEC CDC
Opcode only 66 69 71 55 80 78
History 0 64 64 70 54 74 78
History 1 92 95 87 80 97 82
History 2 93 97 91 83 98 91
History 3 94 97 91 84 98 94
History 4 95 97 92 84 98 95
History 5 95 97 92 84 98 96
Advance Computer Architecture
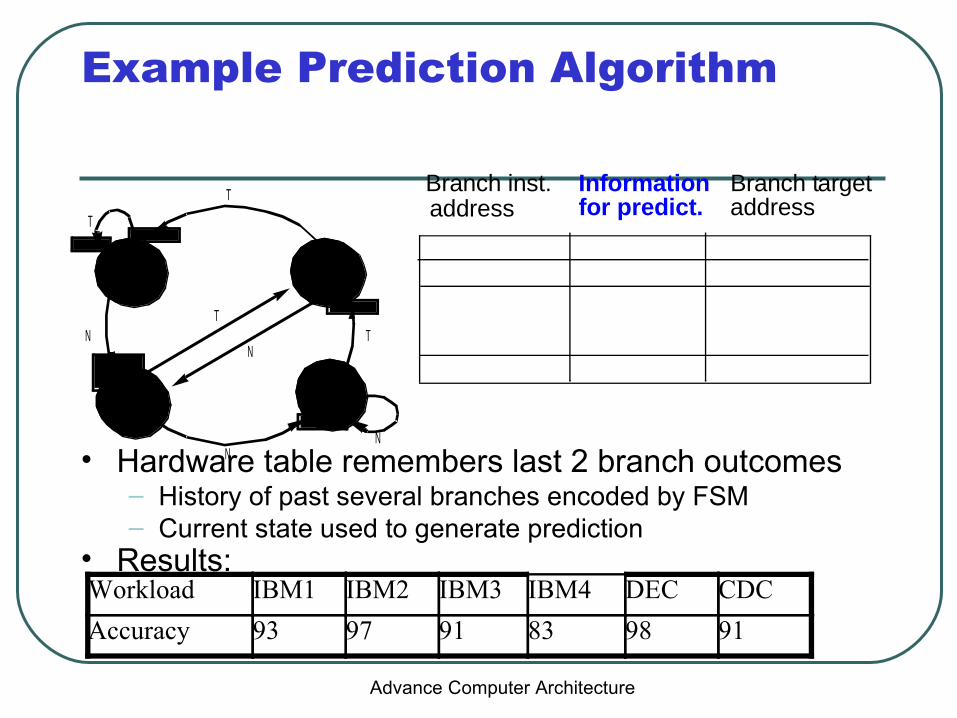
Example Prediction Algorithm
• Hardware table remembers last 2 branch outcomes– History of past several branches encoded by FSM– Current state used to generate prediction
• Results:
T TT
N
T
N TT
T NT
T NT
N NN
N
T
T
N
T
N
T TT
Branch inst. Information Branch targetaddress for predict. address
Workload IBM1 IBM2 IBM3 IBM4 DEC CDC
Accuracy 93 97 91 83 98 91
Advance Computer Architecture

Other Prediction Algorithms
• Combining prediction accuracy with BTB hit rate (86.5% for 128 sets of 4 entries each), branch prediction can provide the net prediction accuracy of approximately 80%. This implies a 5-20% performance enhancement.
N
TN
N
T
T NT
n ?
T
t
T
N
N
T
T NT
t ?
T
T N
n ?
tt ?
NN
nn
Advance Computer Architecture

IBM Study [Nair, 1992]• Branch processing on the IBM RS/6000
– Separate branch functional unit– Five different branch types
• b: unconditional branch• bl: branch and link (subroutine calls)• bc: conditional branch• bcr: conditional branch using link register (returns)• bcc: conditional branch using count register
– Overlap of branch instructions with other instructions
• Zero cycle branches
– Two causes for branch stalls• Unresolved conditions• Branches downstream too close to unresolved branches
Advance Computer Architecture
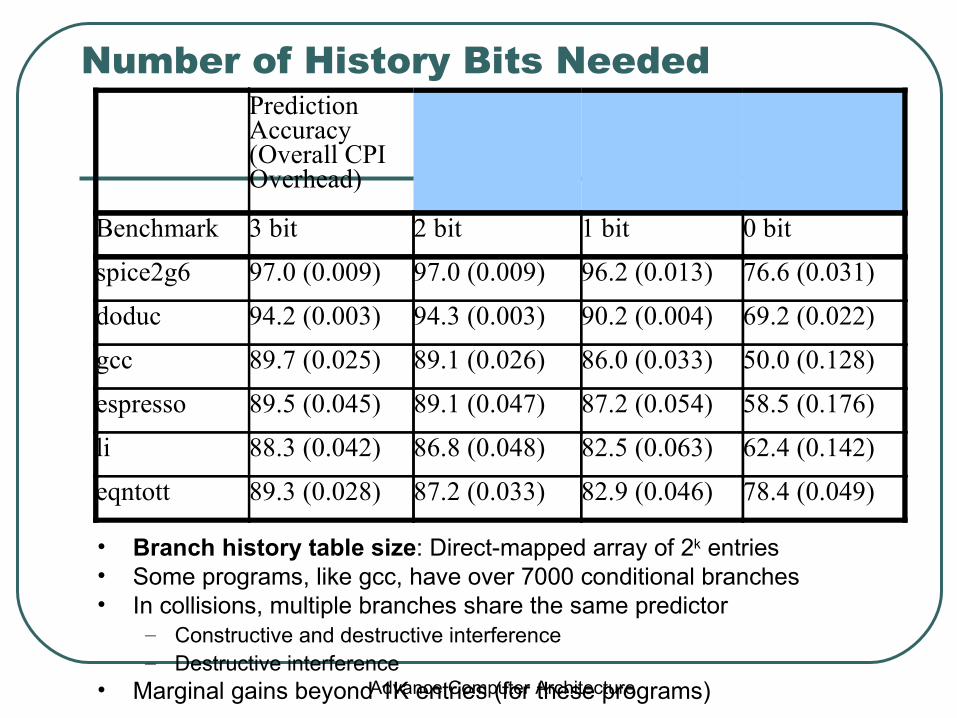
Number of History Bits Needed
• Branch history table size: Direct-mapped array of 2k entries• Some programs, like gcc, have over 7000 conditional branches• In collisions, multiple branches share the same predictor
– Constructive and destructive interference– Destructive interference
• Marginal gains beyond 1K entries (for these programs)
Prediction Accuracy (Overall CPI Overhead)
Benchmark 3 bit 2 bit 1 bit 0 bit
spice2g6 97.0 (0.009) 97.0 (0.009) 96.2 (0.013) 76.6 (0.031)
doduc 94.2 (0.003) 94.3 (0.003) 90.2 (0.004) 69.2 (0.022)
gcc 89.7 (0.025) 89.1 (0.026) 86.0 (0.033) 50.0 (0.128)
espresso 89.5 (0.045) 89.1 (0.047) 87.2 (0.054) 58.5 (0.176)
li 88.3 (0.042) 86.8 (0.048) 82.5 (0.063) 62.4 (0.142)
eqntott 89.3 (0.028) 87.2 (0.033) 82.9 (0.046) 78.4 (0.049)
Advance Computer Architecture
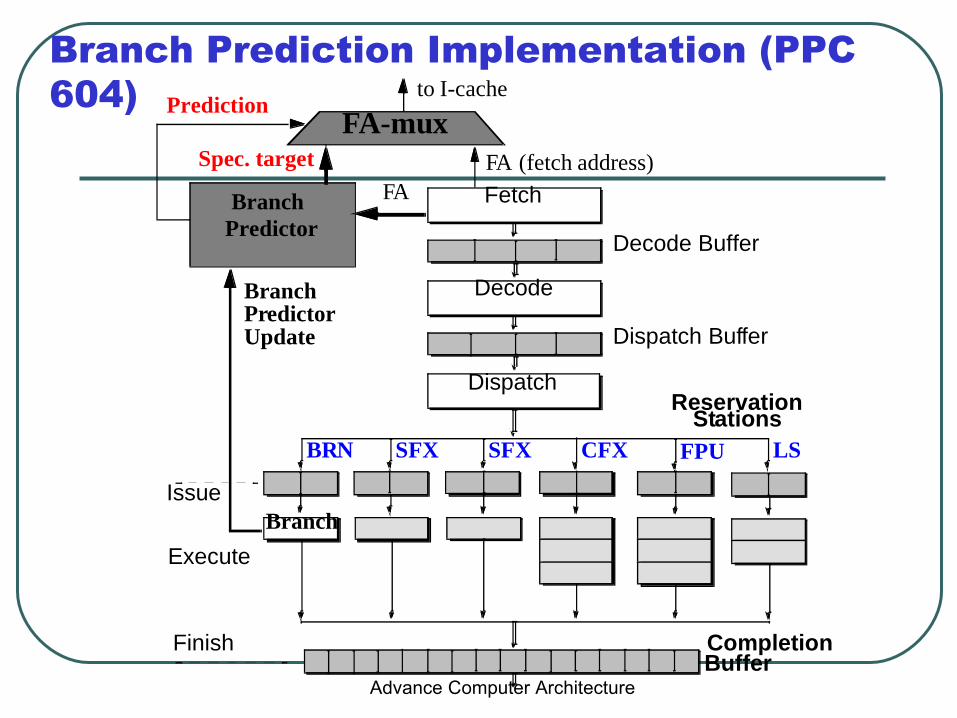
Branch Prediction Implementation (PPC 604)
Decode Buffer
Fetch
Dispatch Buffer
Decode
ReservationDispatch
Stations
Issue
Execute
Finish Completion
Branch
to I-cache
FA (fetch address)FABranch
Predictor
Spec. target
Prediction FA-mux
SFX SFX CFX FPU LSBRN
Buffer
BranchPredictorUpdate
Advance Computer Architecture
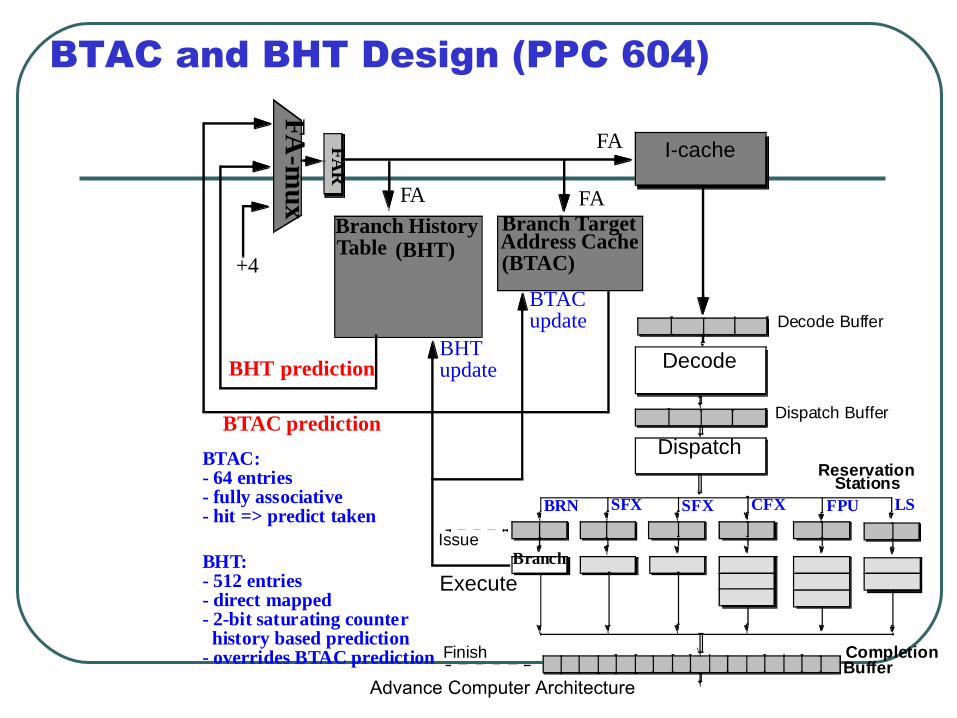
BTAC and BHT Design (PPC 604)
Decode Buffer
Dispatch Buffer
Decode
ReservationDispatch
Stations
Issue
Execute
Finish Completion
Branch
FA
Branch TargetAddress Cache
FA-m
ux
Branch HistoryTable (BHT)
BTAC
BHT
SFX SFX CFX FPU LSBRN
Buffer
(BTAC)
I-cache
update
update
FA FA
FAR
+4
BTAC prediction
BHT prediction
BTAC:- 64 entries- fully associative- hit => predict taken
BHT:- 512 entries- direct mapped- 2-bit saturating counter history based prediction- overrides BTAC prediction
Advance Computer Architecture

BTAC and BHT Design (PPC 604)
Advance Computer Architecture

Advanced Branch Prediction• Control Flow Speculation
– Branch Speculation– Mis-speculation Recovery
• Branch Direction Prediction– Static Prediction– Dynamic Prediction– Hybrid Prediction
• Branch Target Prediction• High-bandwidth Fetch• High-Frequency Fetch
Advance Computer Architecture

Dynamic Branch Prediction• Main advantages:
– Learn branch behavior autonomously• No compiler analysis, heuristics, or profiling
– Adapt to changing branch behavior• Program phase changes branch behavior
• First proposed in 1979-1980– US Patent #4,370,711, Branch predictor using
random access memory, James. E. Smith
• Continually refined since then
Advance Computer Architecture
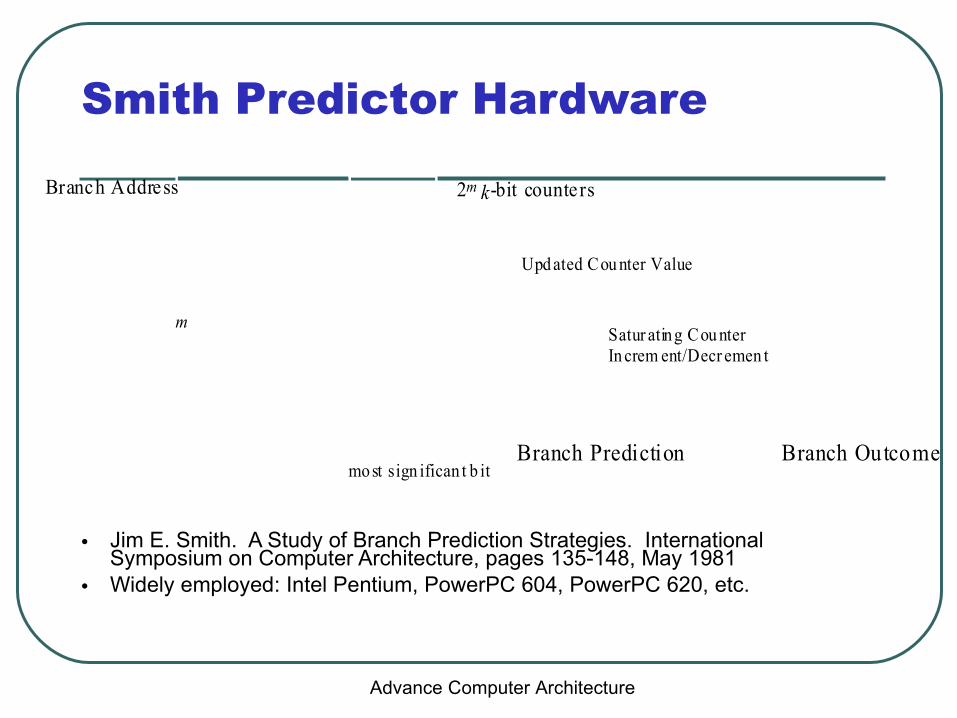
Smith Predictor Hardware
• Jim E. Smith. A Study of Branch Prediction Strategies. International Symposium on Computer Architecture, pages 135-148, May 1981
• Widely employed: Intel Pentium, PowerPC 604, PowerPC 620, etc.
Branch Address
Branch Prediction
m
2m k-bit counters
mo st sign ifican t b it
Satur ating Cou nterIn crem ent/Decr emen t
Branch Outcome
Upd ated Cou nter Value
Advance Computer Architecture

Two-level Branch Prediction
• BHR adds global branch history– Provides more context– Can differentiate multiple instances of the same static branch– Can correlate behavior across multiple static branches
BHR0110
PC = 01011010010101
010110
000000000001000010000011
010100010101010110010111
111110111111
PHT
1 0
1 Branch Prediction
Advance Computer Architecture
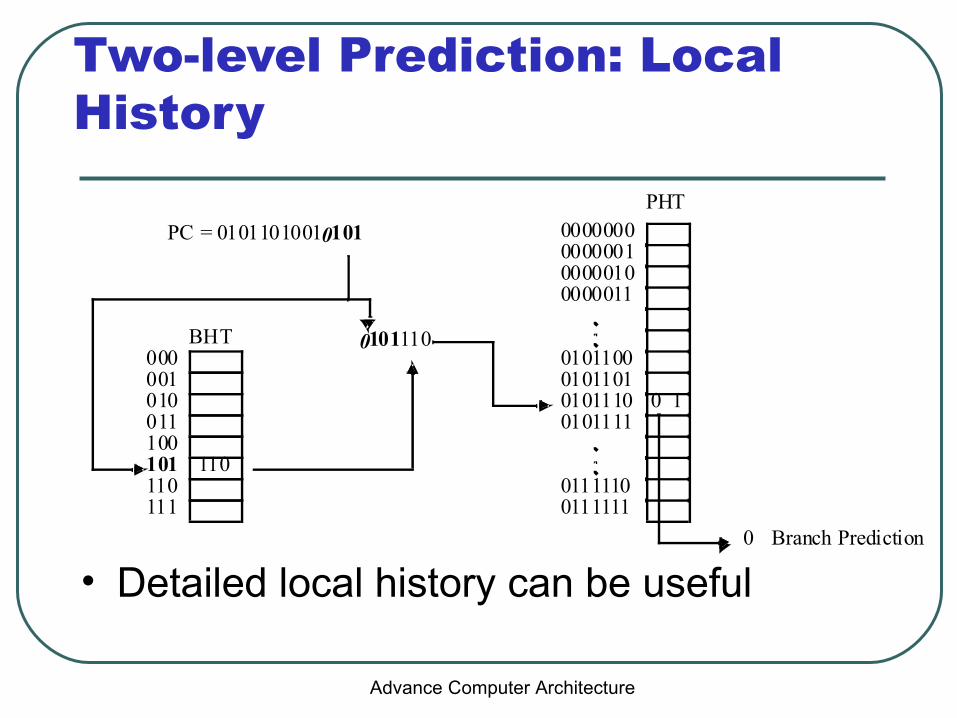
Two-level Prediction: Local History
• Detailed local history can be useful
110
PC = 01011010010101
0101110
0000000000000100000100000011
0101100010110101011100101111
01111100111111
PHT
0 1
0 Branch Prediction
000001010011100101110111
BHT
Advance Computer Architecture

Local History Predictor Example• Loop closing
branches– Must identify
last instance• Local history
dedicates PHT entry to each instance– ‘0111’ entry
predicts not taken
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
11
11
11
00
11101110111011101110PHTLoop closing branch’s history
Advance Computer Architecture

Two-level Taxonomy• Based on indices for branch history and
pattern history– BHR: {G,P,S}: {Global, Per-address, Set}– PHT: {g,p,s}: {Global, Per-address, Set}– 9 combinations: GAg, GAp, GAs, PAg, PAp,
PAs, SAg, SAp and SAs• Tse-Yu Yeh and Yale N. Patt. Two-Level
Adaptive Branch Prediction. International Symposium on Microarchitecture, pages 51-61, November 1991.
Advance Computer Architecture

Index Sharing in Two-level Predictors
• Use XOR function to achieve better utilization of PHT• Scott McFarling. Combining Branch Predictors. TN-36,
Digital Equipment Corporation Western Research Laboratory, June 1993.
• Used in e.g. IBM Power 4, Alpha 21264
1101
0110
GAp
BHR
PC
1001
1001
1010
BHR
PC
1001
gshare
BHR
PC
1101
0110
1011XOR
BHR
PC
1001
1010
0011XOR
0000000100100011010001010110011110001001101010111100110111101111
0000000100100011010001010110011110001001101010111100110111101111
Advance Computer Architecture

Branch Speculation
• Leading Speculation– Typically done during the Fetch stage– Based on potential branch instruction(s) in the current fetch
group• Trailing Confirmation
– Typically done during the Branch Execute stage– Based on the next Branch instruction to finish execution
NT T NT T NT TNT T
NT T NT T
NT T (TAG 1)
(TAG 2)
(TAG 3)
Advance Computer Architecture

Branch Speculation
Leading Speculation1. Tag speculative instructions2. Advance branch and following instructions3. Buffer addresses of speculated branch
instructions Trailing Confirmation
1. When branch resolves, remove/deallocate speculation tag
2. Permit completion of branch and following instructions
Advance Computer Architecture
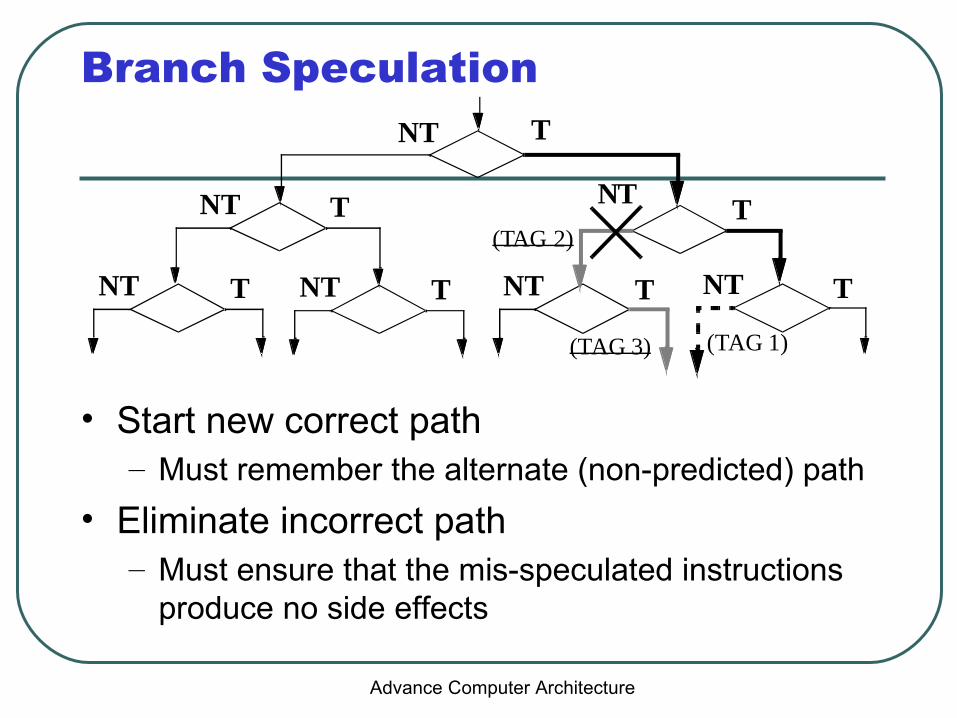
Branch Speculation
• Start new correct path– Must remember the alternate (non-predicted) path
• Eliminate incorrect path– Must ensure that the mis-speculated instructions
produce no side effects
NT T NT T NT TNT T
NT T NT T
NT T
(TAG 2)
(TAG 3) (TAG 1)
Advance Computer Architecture

Mis-speculation Recovery
Start new correct path1. Update PC with computed branch target (if predicted NT)
2. Update PC with sequential instruction address (if predicted T)
3. Can begin speculation again at next branch
Eliminate incorrect path1. Use tag(s) to deallocate ROB entries occupied by
speculative instructions
2. Invalidate all instructions in the decode and dispatch buffers, as well as those in reservation stations
Advance Computer Architecture

Tracking Instructions
• Assign branch tags– Allocated in circular order
– Instruction carries this tag throughout processor
• Track instruction groups– Instructions managed in groups, max. one
branch per group– ROB structured as groups
• Leads to some inefficiency
• Simpler tracking of speculative instructions
Advance Computer Architecture
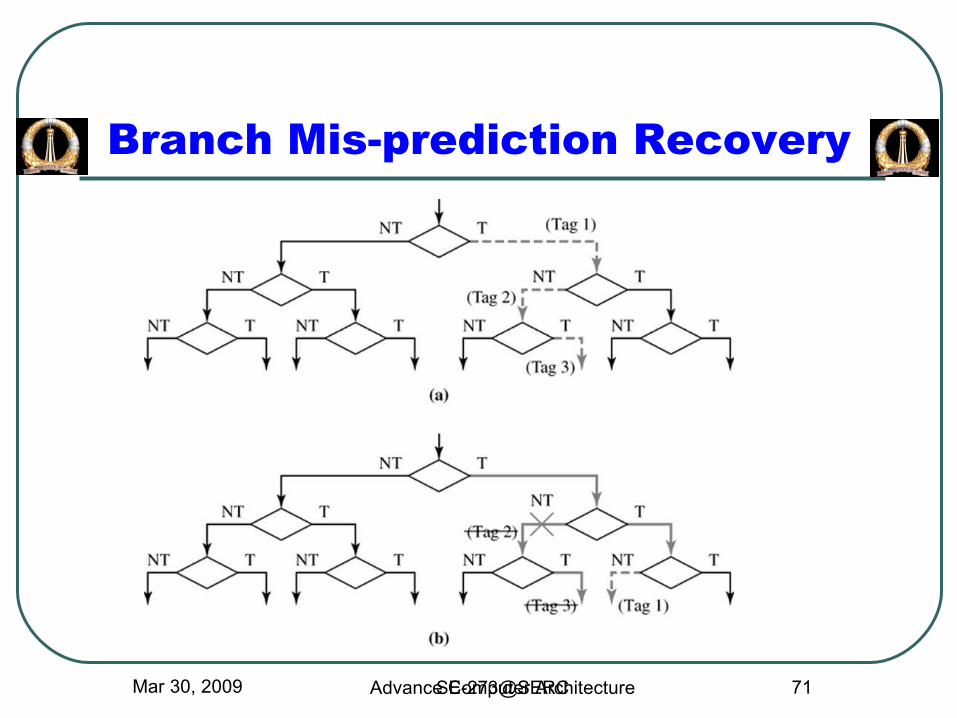
Mar 30, 2009 SE-273@SERC 71
Branch Mis-prediction Recovery
Advance Computer Architecture

72
Thank You
Advance Computer Architecture



![Visualizing Application Behavior on Superscalar Processors · MMIX [8] processor model. While our current focus is on the study of processor pipelines, this system could be extended](https://static.fdocuments.us/doc/165x107/5e7659003f038068f170395b/visualizing-application-behavior-on-superscalar-processors-mmix-8-processor-model.jpg)














