
Spark, ou comment traiter des données à la vitesse de l'éclair
37
Alexis Seigneurin @aseigneurin @ippontech 1 / 37
-
Upload
alexis-seigneurin -
Category
Data & Analytics
-
view
603 -
download
0
Transcript of Spark, ou comment traiter des données à la vitesse de l'éclair

Alexis Seigneurin
@aseigneurin @ippontech
1 / 37

SparkTraitement large volumes de données
Traitement distribué (commodity hardware)
Ecrit en Scala, binding Java
2 / 37

Histoire2009 : AMPLab de l'Université de Berkeley
Juin 2013 : "Top-level project" de la fondation
Apache
Mai 2014 : version 1.0.0
Actuellement : version 1.1.0
3 / 37

Use casesAnalyse de logs
Traitement de fichiers texte
Analytics
Recherche distribuée (Google, avant)
Détection de fraude
Recommendation (articles, produits...)
4 / 37

Proximité avec HadoopMêmes use cases
Même modèle de
développement : MapReduce
Intégration dans l'écosystème
5 / 37

Plus simple qu'HadoopAPI plus simple à prendre en main
Modèle MapReduce "relâché"
Spark Shell : traitement interactif
6 / 37

Plus rapide qu'HadoopSpark officially sets a new record in large-scalesorting (5 novembre 2014)
Tri de 100 To de données
Hadoop MR : 72 minutes avec 2100 noeuds
(50400 cores)
Spark : 23 minutes avec 206 noeuds (6592
cores)
7 / 37

Ecosystème SparkSpark
Spark Shell
Spark Streaming
Spark SQL
MLlib
GraphX
8 / 37

IntégrationYarn, Zookeeper, Mesos
HDFS
Cassandra
Elasticsearch
MongoDB
9 / 37

Fonctionnement de Spark
10 / 37

RDDResilient Distributed Dataset
Abstraction, collection traitée en parallèle
Tolérant à la panne
Manipulation de tuples :
Clé - Valeur
Tuples indépendants les uns des autres
11 / 37

Sources :Fichier sur HDFS
Fichier local
Collection en mémoire
S3
Base NoSQL
...
Ou une implémentation custom de InputFormat
12 / 37

TransformationsManipule un RDD, retourne un autre RDDLazy !
Exemples :map() : une valeur → une valeurmapToPair() : une valeur → un tuplefilter() : filtre les valeurs/tuplesgroupByKey() : regroupe la valeurs par clésreduceByKey() : aggrège les valeurs par clésjoin(), cogroup()... : jointure entre deux RDD
13 / 37

Actions finalesNe retournent pas un RDDExemples :
count() : compte les valeurs/tuplessaveAsHadoopFile() : sauve les résultats auformat Hadoopforeach() : exécute une fonction sur chaquevaleur/tuplecollect() : récupère les valeurs dans une liste(List< T >)
14 / 37

Exemple
15 / 37

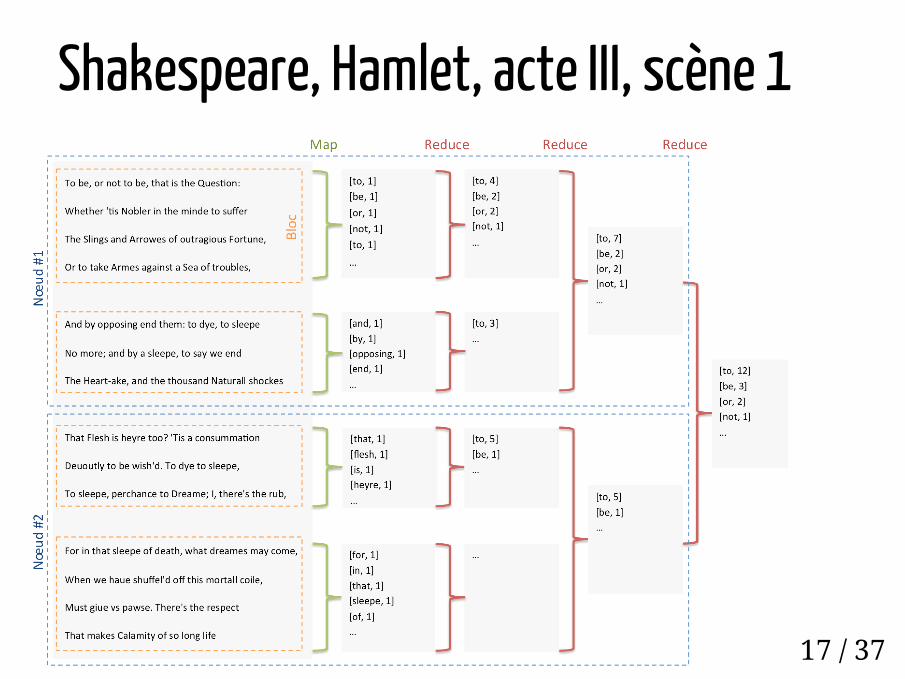
Word countDécoupage des fichiers par fragments de 128Mo (framework)Découpage des fragments par lignes(framework)Découpage des lignes en mots (map)Comptage des mots (reduce)
Sur chaque noeudPuis sur un noeud pour le résultat final
16 / 37
Shakespeare, Hamlet, acte III, scène 1
17 / 37
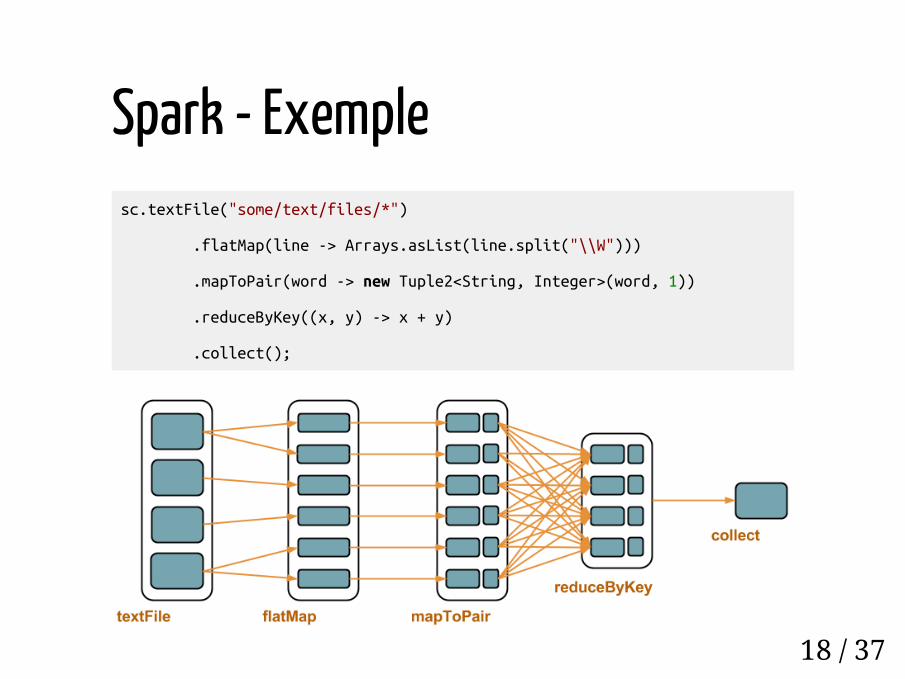
Spark - Exemplesc.textFile("some/text/files/*")
.flatMap(line -> Arrays.asList(line.split("\\W")))
.mapToPair(word -> new Tuple2<String, Integer>(word, 1))
.reduceByKey((x, y) -> x + y)
.collect();
18 / 37

Démo
Spark Shell
19 / 37

Démo de Spark Shell$ spark-shell
> var lines = sc.textFile(".../data/arbresalignementparis2010.csv")> lines.count()> var trees = lines.filter(s => !s.startsWith("geom"))> var treesSplit = trees.map(line => line.split(";"))> var heights = treesSplit.map(fields => fields(3).toFloat)> heights = heights.filter(h => h > 0)> heights.sum() / heights.count()
20 / 37

Spark en Cluster
21 / 37

TopologieUn master / des workers
(+ un master en standby)
Communication bidirectionnelle
On soumet une application
22 / 37

Spark en ClusterPlusieurs options
YARNMesosStandalone
Workers démarrés individuellementWorkers démarrés par le master
23 / 37

Stockage & traitementsMapReduce
Spark (API)Traitement parallèleTolérant à la panne
Stockage
HDFS, base NoSQL...Stockage distribuéTolérant à la panne
24 / 37

Colocation données & traitementTraiter la donnée là où elle se trouve
Eviter les network I/Os
25 / 37

Colocation données & traitement
26 / 37

Démo
Spark en Cluster
27 / 37

Démo$ $SPARK_HOME/sbin/start-master.sh
$ $SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://MBP-de-Alexis:7077 --cores 2 --memory 2G
$ mvn clean package$ $SPARK_HOME/bin/spark-submit --master spark://MBP-de-Alexis:7077 --class com.seigneurin.spark.WikipediaMapReduceByKey --deploy-mode cluster target/pres-spark-0.0.1-SNAPSHOT.jar
28 / 37

Spark Streaming
29 / 37

Micro-batchesDécoupe un flux continu en batches
API identique
≠ Apache Storm
30 / 37
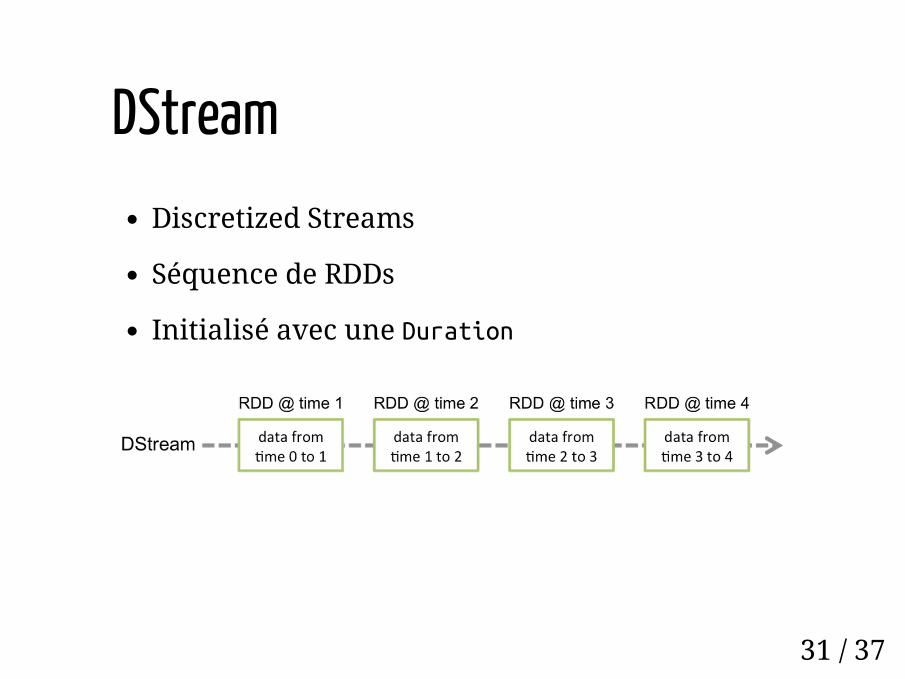
DStreamDiscretized Streams
Séquence de RDDs
Initialisé avec une Duration
31 / 37

Window operationsFenêtre glissante
Réutilise des données d'autres fenêtres
Initialisé avec window length et slide interval
32 / 37

SourcesSocketKafkaFlumeHDFSMQ (ZeroMQ...)Twitter...Ou une implémentation custom de Receiver
33 / 37

Démo
Spark Streaming
34 / 37

Démo de Spark StreamingConsommation de Tweets #Android
Twitter4J
Détection de la langue du Tweet
Language Detection
Indexation dans ElasticSearch
Analyse dans Kibana 4
35 / 37

DémoLancer ElasticSearch
$ curl -X DELETE localhost:9200$ curl -X PUT localhost:9200/spark/_mapping/tweets '{ "tweets": { "properties": { "user": {"type": "string","index": "not_analyzed"}, "text": {"type": "string"}, "createdAt": {"type": "date","format": "date_time"}, "language": {"type": "string","index": "not_analyzed"} } }}'
Lancer Kibanahttp://localhost:5601
Lancer le traitement
36 / 37

@aseigneurin - @ippontech
aseigneurin.github.io - blog.ippon.fr
37 / 37




![Equipe Bases de Données [Bases de Données / Databases]](https://static.fdocuments.us/doc/165x107/61ec2bcb6c24f366634bb8c5/equipe-bases-de-donnes-bases-de-donnes-databases.jpg)













