
Revisiting the quantitative phylogeny of the Uralic languages · Revisiting the quantitative...
38
Revisiting the quantitative phylogeny of the Uralic languages Kaj Syrjänen , Terhi Honkola, Jadranka Rota, Unni-Päivä Leino, Outi Vesakoski Contextualizing historical lexicology, 15.5.2017, University of Helsinki Map: Geographical Database of the Uralic languages by BEDLAN & J. Ylikoski
Transcript of Revisiting the quantitative phylogeny of the Uralic languages · Revisiting the quantitative...

Revisiting the quantitative phylogeny of the Uralic languages
Kaj Syrjänen,Terhi Honkola, Jadranka Rota,
Unni-Päivä Leino, Outi Vesakoski
Contextualizing historical lexicology,15.5.2017, University of Helsinki
Map: Geographical Database of the Uralic
languages by BEDLAN & J. Ylikoski

Chang et al. 2015
Grollemund et al. 2015
Background
Syrjänen et al. 2013
Bouckaert et al. 2012

Mathematical model
A
B
C
Background PhylogenyPARAMETERS

Mathematical model
Topology
Branch lenght
Background
Other parameters
Syrjänen et al. 2013
Basic rules of sequence evolution
PARAMETERS PhylogenyLanguage phylogeny

• Genetic data is used in biology to make phylogenies
• Not all genetic material is similar
- Heterogenous rate of change
-e.g. coding regions (genes) vs. non-coding regions
→ Should not be analysed together
Introduction
CC Attribution 4.0 License, http://cnx.org/contents/[email protected]:xiQtvh_M@3/Structure-and-Function-of Cell#OSC_Microbio_10_04_noncodDNA

Parameter set 1 Parameter set 2
• Phylogenetic partitioning is the solution
- Takes into account heterogenous patterns of evolution
- Different parameters for different parts of the genome
- Common in biological phylogenetic analyses!
Introduction
CC Attribution 4.0 License, http://cnx.org/contents/[email protected]:xiQtvh_M@3/Structure-and-Function-of Cell#OSC_Microbio_10_04_noncodDNA
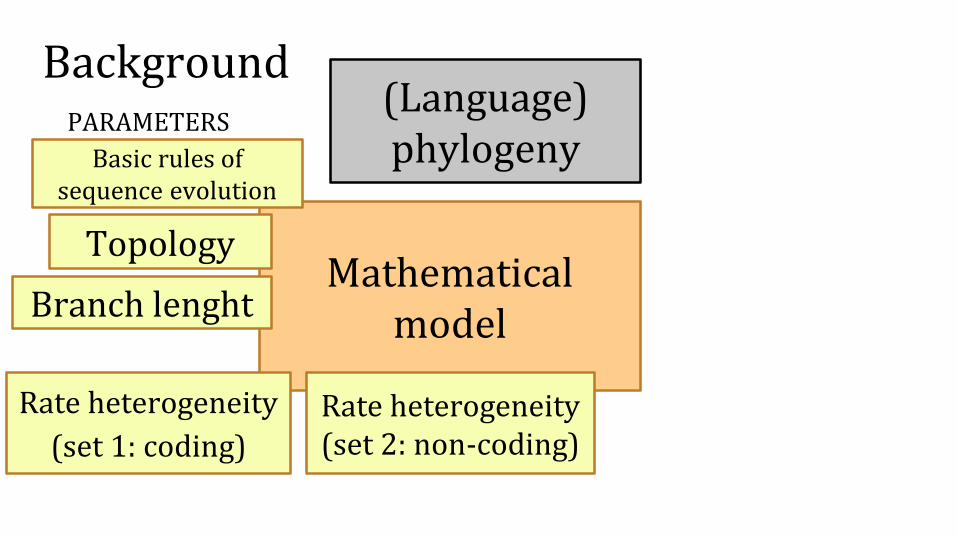
Mathematical model
Topology
Branch lenght
Background
Basic rules of sequence evolution
PARAMETERS(Language) phylogeny
Rate heterogeneity
(set 1: coding)
Rate heterogeneity (set 2: non-coding)

• Partitioning vs. no partitioning
• May produce trees which differ in (Kainer & Lanfear
2015)
- Branch support
- Topology
- Branch length
→ In other words, almost anything
Introduction

• Language data is used to make quantitative phylogenies
• Bayesian model-based methods
• Parsimony methods
• Distance based methods
- Glottochronology
• Not all linguistic material is similar
- Heterogenous rate of change
Introduction

Introduction
2) from one meaning to next
= e.g. parts of speech change at varying
rates
1) from one language to next
= Languages change at varying rates
Pagel et al. 2007
Solved in Bayesian analyses by using
evolutionary models
• Two notable points of linguistic variation:
- Rate of lexical replacement varies

Introduction
1) from one language to next
= Languages change at varying rates
• Two notable points of linguistic variation:
- Rate of lexical replacement varies
2) from one meaning to next
= e.g. parts of speech change at varying
rates
a) Solved by allowing rate variation
along gamma distribution
b) Another option could be data
partitioning

Introduction2) from one meaning to next
a) Rate variation along gamma distribution
Used in language phylogenies by e.g.
- Grollemund et al. 2015
- Chang et al. 2015
- Bouckaert et al. 2012
b) Data partitioning
- manual vs. algorithmic
-e.g. with TIGER algorithm
Not used earlier to make language
phylogenies
By Gamma_distribution_pdf.png: MarkSweep and Cburnettderivative work: Autopilot (talk) -Gamma_distribution_pdf.png, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=10734916

Test data partitioning of lexical data to see if this
can solve the rate heterogeneity problem
1. Test TIGER as an algorithmic partitioning method
2. Assess different approaches
- manual partitioning (e.g. basic vs less basic)
- algorithmic partitioning (TIGER)
- unpartitioned, with rate variation along gamma distribution
3. Compare Uralic phylogenies made with different approaches
Aims

Materials • Lexical data of 26 Uralic languages
• Three basic meaning lists
- Swadesh 100, Swadesh 200, Leipzig-Jakarta
226 meanings in total
• One ”less-basic” meaning list
- WOLD401-500
• Basic + ”less basic” = in total 313 meanings

• Algorithmic partitioning schemes using TIGER (Cummings & McInerey 2011)
• TIGER = Tree Independent Generation of Evolutionary Rates
• Calculates stability values (TIGER rates) from aligned phylogenetic data
• TIGER rates are relative measurements ranging between 0 and 1, with 1 being stable
• Can also produce partitioning schemes for phylogenetic analysis tools based on TIGER rates
Clicker training a Tiger In Odensee ZooPhoto by OV
Method: TIGER

Detailed explanation for mathematically oriented readers: Cummings & McInerey 2011
2. calculate pairwise
partition agreement (pa)
scores set partitions
between all the aligned
characters
1. identify set partitions
(=identical characters on
each column)
3. calculate TIGER rate
as the averaged partition
agreement score of a
character to all the other
characters
2. pa(A,B)1. set partitions
Method: How TIGER rates are calculated

Option 1: Binary Option 2: Multistate
• Same input as used in phylogenetic analysis
tools
• Each column gets its own TIGER rate
meanings get broken up
• Produces meaning-specific TIGER rates
• Needs additional conversion steps
high-stabilitymid-stabilitylow-stabilityhigh-stabilitymid-stabilitylow-stability
Method: Coding language data for TIGER input

Option 1: Binary Option 2: Multistate
• Same input as used in phylogenetic analysis
tools
• Each column gets its own TIGER rate
meanings get broken up
• Produces meaning-specific TIGER rates
• Needs additional conversion steps
• The better option
high-stabilitymid-stabilitylow-stabilityhigh-stabilitymid-stabilitylow-stability
Method: Coding language data for TIGER input

jkl
0.56 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1.0
TIGER rate (stability)
Nu
mb
er o
f m
ean
ings
eye 1.0
I 1.0
name 1.0
two 1.0
we 1.0
fish 0.99
not 0.985
roast 0.575
dust 0.574
throw 0.573
rope 0.572
squeeze 0.571
shut 0.57
soon 0.569
Distribution of TIGER rates

Results 1. Sanity check for lexical TIGER rates
TIGER rates vs basic and less basic
vocabulary
TIGER rate vs rate of lexical replacement
(Pagel et al. 2007)

Results 1. Sanity check for lexical TIGER rates
TIGER rates vs basic and less basic
vocabulary
TIGER rate vs rate of lexical replacement
(Pagel et al. 2007)
Log(TIGER rate)0.45 0.50 0.55 0.60 0.65 0.70
2.0
1.5
1.0
0.5
Spearman: -0.71
Kendall: -0.52
p-value < 2.2e-16
with both
Log(r
ate
of
lexic
al re
pla
cem
ent)

Results 1. Sanity check for lexical TIGER rates
TIGER rates vs basic and less basic
vocabulary
TIGER rate vs rate of lexical replacement
(Pagel et al. 2007)
TIGER rate
0.6 0.7 0.8 0.9 1.0
15
10
5
0
Less basic vocabulary
Basic vocabulary
Fre
quency
Log(TIGER rate)0.45 0.50 0.55 0.60 0.65 0.70
2.0
1.5
1.0
0.5
Spearman: -0.71
Kendall: -0.52
p-value < 2.2e-16
with both
Log(r
ate
of
lexic
al re
pla
cem
ent)

jkl
0.56 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1.0
Tiger rates
Partitioning based on TIGER ratesN
um
ber
of
mea
nin
gs

Results 2. Which partition to use? (226 meanings)
Partitioning scheme Bayes Factor
unpartitioned -13124,21 -
semantic category (5) -13079,11 45,10
word lists (2) -13087,28 36,93
by meaning (226)
tiger-2-partitions -12933,21 191,00
tiger-4-partitions -12752,75 371,46
tiger-6-partitions -12705,79 418,42
tiger-8-partitions -12685,81 438,40
tiger-10-partitions -12680,27 443,94
gamma, 4 categories -12689,32 434,89
gamma, 10 categories
A
1) MrBayes analysis for different partitioning schemes
Manual partitions
Algorithmic partitions
Gamma model

Results 2. Which partition to use? (226 meanings)
1) MrBayes analysis for different partitioning schemes
2) Marginal likelihood estimatesused to calculate model support (Bayes Factors) for a given partitioning as opposed to an unpartitioned analysis
Partitioning schemeMarginal
Likelihood
unpartitioned -13124.21
semantic category (5) -13079.11
word lists (2) -13087.28
by meaning (226) -12689.32
tiger-2-partitions -12933.21
tiger-4-partitions -12752.75
tiger-6-partitions -12705.79
tiger-8-partitions -12685.81
tiger-10-partitions -12680.27
gamma, 4 categories -12920.03
gamma, 10 categories -12919.64

Results 2. Which partition to use? (226 meanings)
1) MrBayes analysis for different partitioning schemes
2) Marginal likelihood estimatesused to calculate model support (Bayes Factors) for a given partitioning as opposed to an unpartitioned analysis
Partitioning schemeMarginal
Likelihood
Bayes
Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57

Results 3. Uralic family tree with partitioned data
Multistate TIGER partitioning: 10 partitions, 226 meanings
Partitioning schemeMarginal
LikelihoodBayes Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57

Results 3. Uralic family tree with partitioned data
Wordlist-based partitioning: LJ and non-LJ; 226 meanings
Partitioning schemeMarginal
LikelihoodBayes Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57

Results 3. Uralic family tree with gamma model
10 gamma categories, 226 meanings
Partitioning schemeMarginal
LikelihoodBayes Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57

Results 3. Uralic family tree without partitioning
226 meanings
Partitioning schemeMarginal
LikelihoodBayes Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57

Results 3. Uralic family tree with partitioned data
“Incorrect” TIGER partitioning: 4 partitions, 226 meanings
Partitioning schemeMarginal
LikelihoodBayes Factor
unpartitioned -13124.21 -
semantic category (5) -13079.11 45,10
word lists (2) -13087.28 36,93
by meaning (226) -12689.32 434,89
tiger-2-partitions -12933.21 191,00
tiger-4-partitions -12752.75 371,46
tiger-6-partitions -12705.79 418,42
tiger-8-partitions -12685.81 438,40
tiger-10-partitions -12680.27 443,94
gamma, 4 categories -12920.03 204,18
gamma, 10 categories -12919.64 204,57
*tiger-4-partitions (binary) -13033.91 90,30

Discussion 1: Sanity of TIGER rates
• Rates generally seem to make sense, and work with
partitioning
• Similarly usable metric as e.g. WOLD’s stability metrics or
rate of lexical replacement (Pagel et al. 2007)?
• Needs further validation across language families / with
different data

• Partitioning/gamma distribution always improved model support
Bayes Factors Phylogeny
Manual partitions 3. 2.
Algorithmic partitions 1. 1.
Gamma model 2. 1.
Discussion 2: Assessing the approaches

Bayes Factors Phylogeny
Manual partitions 3. / 2. (2.)
Algorithmic partitions 1. (1. /3.)
Gamma model 2. (1./2. )
Large differences in BF Small differences in phylogenies
Discussion 2: Assessing the approaches
• Partitioning/gamma distribution always improved model support

• In algorithmic partitioning higher number of partitions is
better than low
• BUT careful of:
• Overparametrization (too small partitions)
• How the data is divided (meanings intact or not)
• Gamma distribution
• Works reasonably well
• Potential problem: meanings not kept intact
Discussion 2: Assessing the approaches

• Minor differences
(with this data)
• Big picture in
earlier results
did not change
• How about other
language families?
Discussion 3: Partitioned data and Uralic family

Mathematical models
Take home message
Language phylogeny Develop continuously
Great example of how linguists and model developerscan improve the
models whenworking together
Technical developmentis gradual!
Are flexible
1896 Telephone (Sweden). (Wikipedia)
120 years…

Thank you!
Acknowledgmentskielievoluutio.uta.fi


















