
Research In the Post-Genomics Era
45
Research In the Post-Genomics Era Martina McGloughlin, Biotechnology Program and Life Sciences Informatics Program UC Davis
-
Upload
samson-trujillo -
Category
Documents
-
view
53 -
download
3
description
Research In the Post-Genomics Era. Martina McGloughlin, Biotechnology Program and Life Sciences Informatics Program UC Davis. UC Davis Biotechnology Program UC Systemwide Life Sciences Informatics Program. - PowerPoint PPT Presentation
Transcript of Research In the Post-Genomics Era

Research In the Post-Genomics
EraMartina McGloughlin,
Biotechnology Program and Life Sciences Informatics Program
UC Davis

2
“Biology in the 21st century will increasingly become an information science”
Leroy Hood, Jan 11, 1999
“Any cell has in it a billion years of experimentation by its ancestors”
Max Delbruck, 1949
“Biology in the 21st century will increasingly become an information science”
Leroy Hood, Jan 11, 1999
“Any cell has in it a billion years of experimentation by its ancestors”
Max Delbruck, 1949
UC Davis Biotechnology Program
UC Systemwide Life Sciences Informatics Program
UC Davis Biotechnology Program
UC Systemwide Life Sciences Informatics Program

3
The massive interest and commitment of resources in both the public and private sectors flows from the generally-held perception that genomics will be the single most fruitful approach to the acquisition of new information in basic and applied biology in the next several decades.
If genomics were only to be a tool for the basic biologist, the benefits of this approach would be staggering, yielding new insights into fundamental processes such as cell division, differentiation, transformation, the development and reproduction of organisms and the diversity of populations.
The rewards in applied biology, however, have clearly attracted the private sector and public interest. These include the promise of facile new approaches for drug discovery, new understanding of metabolic processes and new approaches to determining qualitative and quantitative traits in plants and animals for breeding and genetic engineering.
The massive interest and commitment of resources in both the public and private sectors flows from the generally-held perception that genomics will be the single most fruitful approach to the acquisition of new information in basic and applied biology in the next several decades.
If genomics were only to be a tool for the basic biologist, the benefits of this approach would be staggering, yielding new insights into fundamental processes such as cell division, differentiation, transformation, the development and reproduction of organisms and the diversity of populations.
The rewards in applied biology, however, have clearly attracted the private sector and public interest. These include the promise of facile new approaches for drug discovery, new understanding of metabolic processes and new approaches to determining qualitative and quantitative traits in plants and animals for breeding and genetic engineering.
GenomicsGenomics

4
Typed in 10-pitch font, one human sequence would stretch for more than 5,000 miles. Digitally formatted, it could be stored on one CD-ROM. Biologically encoded, it fits easily within a single cell.
One Human Sequence

5
Organism #of genes % genes with Comp. date inferred function for genome
sequencing
E. Coli 4,288 60 1997
Yeast 6,600 40 1996
C. Elegans 19,000 40 1998
Drosophila 12,000-14,000 25 1999
Arabidopsis 25,000 40 2000
Mouse 26,000-40,000 10-20 2002
Human 26,383-39,114 10-20 2001
Organism #of genes % genes with Comp. date inferred function for genome
sequencing
E. Coli 4,288 60 1997
Yeast 6,600 40 1996
C. Elegans 19,000 40 1998
Drosophila 12,000-14,000 25 1999
Arabidopsis 25,000 40 2000
Mouse 26,000-40,000 10-20 2002
Human 26,383-39,114 10-20 2001

6
Paradigm Shift in Biology
The new paradigm, now emerging, is that all the ‘genes’ will be known (in the sense of being resident in databases available electronically), and that the starting point of a biological investigation will be theoretical. An individual scientist will begin with a theoretical conjecture, only then turning to experiment to follow or test that hypothesis.
The new paradigm, now emerging, is that all the ‘genes’ will be known (in the sense of being resident in databases available electronically), and that the starting point of a biological investigation will be theoretical. An individual scientist will begin with a theoretical conjecture, only then turning to experiment to follow or test that hypothesis.
Walter Gilbert. 1991. Towards a paradigm shift in biology. Nature, 349:99.Walter Gilbert. 1991. Towards a paradigm shift in biology. Nature, 349:99.

7
Paradigm Shift in Biology
To use [the] flood of knowledge, which will pour across the computer networks of the world, biologists not only must become computer literate, but also change their approach to the problem of understanding life.
To use [the] flood of knowledge, which will pour across the computer networks of the world, biologists not only must become computer literate, but also change their approach to the problem of understanding life.
Walter Gilbert. 1991. Towards a paradigm shift in biology. Nature, 349:99.
Walter Gilbert. 1991. Towards a paradigm shift in biology. Nature, 349:99.

8
What’s Really Next
The post-genome era in biological research will take for granted ready access to huge amounts of genomic data.
The challenge will be understanding those data and using the understanding to solve real-world problems...

9
Fundamental Dogma
DNA
RNA
Proteins
Circuits
Phenotypes
Populations
GenBankEMBLDDBJ
MapDatabases
SwissPROTPIR
PDB
Gene Expression?
Clinical Data ?
Regulatory Pathways?Metabolism?
Biodiversity?
Neuroanatomy?
Development ?
Molecular Epidemiology?
Comparative Genomics?
the post-genomic era will need many more to collect, manage, and publish the coming flood of new findings.
the post-genomic era will need many more to collect, manage, and publish the coming flood of new findings.
Although a few databases already exist to distribute molecular information,
Although a few databases already exist to distribute molecular information,
If this extension covers functional genomics, then “functional genomics” is equivalent to biology.
If this extension covers functional genomics, then “functional genomics” is equivalent to biology.

10
There are Problems with the HGP . ..
• The actual sequence data makes up only 16% of the content; the other 84% is annotated.
• The is leads to a number of issues:
– How to structure databases for mining
– How to establish control vocabularies to establish integrity of searches
– What new algorithms are needed to facilitate processing and correlating the petabytes (1015 bytes) of information
– How can protein function be extracted for the purposes of diagnostics, drug discovery and therapeutics

Bioinformatics - Two ViewsUSERS
• of Information
• of Tools
• of Instrumentation
• In-Silico Modeling
INTERPRETERS
• of Information
DEVELOPERS*
• of Information
• of Tools
• of Instrumentation
• of Architecture/Storage
• Algorithms
• Modeling Strategies
• Visualization
Per Pete Smietana, VP Lumicyte
*
*These people are in highest demand

12
Typical BioinformaticsMulti-Disciplinary Training
•Scientists – Biology, Molecular Genetics, Clinical
Biochemistry, Protein Structure Chemistry
•Mathematicians – Statistics, Algorithms, Image processing
•Computer Scientists– Database, User Interface/Visualizations,
Networking (Internets/Intranets), Instrument Control
Typical BioinformaticsMulti-Disciplinary Training
•Scientists – Biology, Molecular Genetics, Clinical
Biochemistry, Protein Structure Chemistry
•Mathematicians – Statistics, Algorithms, Image processing
•Computer Scientists– Database, User Interface/Visualizations,
Networking (Internets/Intranets), Instrument Control

13
Typical BioinformaticsMulti-Disciplinary Functions
•Scientists– Experimental Design & Interpretation– Laboratory Protocols & Standards/Controls
•Mathematicians– Analysis & Correlation of Data– Validation methodologies
•Computer Scientists– Information Storage / Control Vocabulary– Data Mining
Typical BioinformaticsMulti-Disciplinary Functions
•Scientists– Experimental Design & Interpretation– Laboratory Protocols & Standards/Controls
•Mathematicians– Analysis & Correlation of Data– Validation methodologies
•Computer Scientists– Information Storage / Control Vocabulary– Data Mining
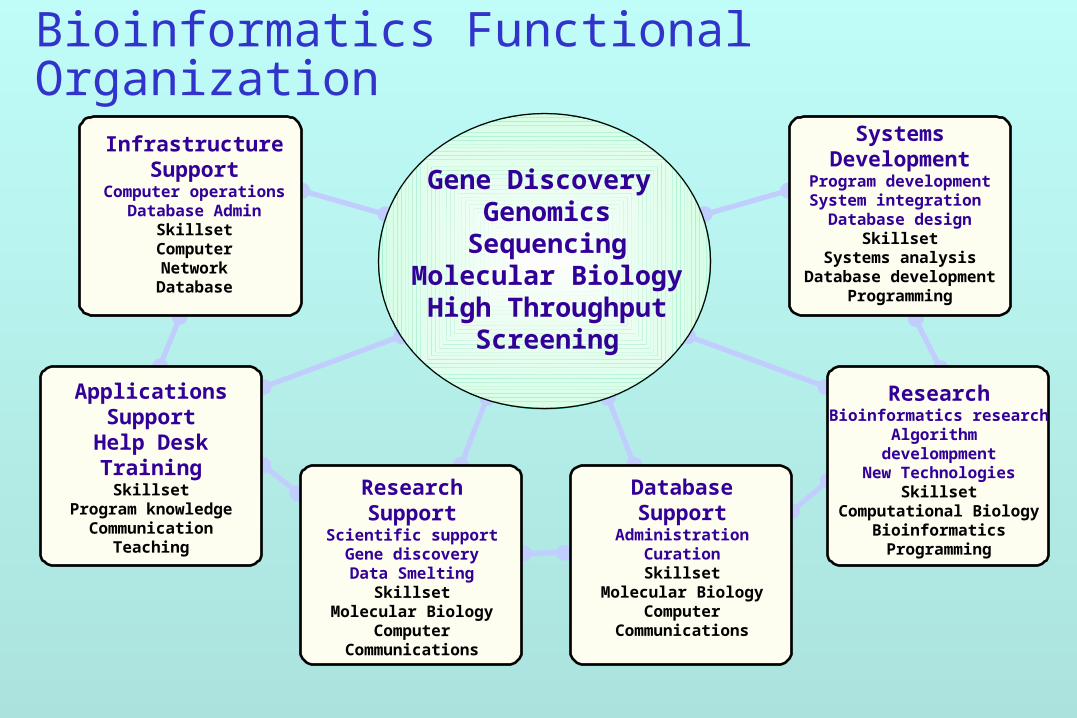
Bioinformatics Functional Organization
InfrastructureSupport
Computer operationsDatabase Admin
SkillsetComputerNetworkDatabase
ApplicationsSupport
Help DeskTraining
SkillsetProgram knowledge
CommunicationTeaching
ResearchSupport
Scientific supportGene discoveryData Smelting
SkillsetMolecular Biology
ComputerCommunications
ResearchBioinformatics research
Algorithm develompment
New TechnologiesSkillset
Computational BiologyBioinformaticsProgramming
SystemsDevelopment
Program developmentSystem integration
Database designSkillset
Systems analysisDatabase development
Programming
Gene Discovery Genomics
SequencingMolecular BiologyHigh Throughput
Screening
DatabaseSupport
AdministrationCurationSkillset
Molecular BiologyComputer
Communications

15
TGT AAT AGT TAT ATT TTCATT ATA AAT TGT GTT TGT AGA CAT CAT AAA TTT AAAACA TGG CTT TTT AAC CTGATA AAT CCT ACG AAT ATTTGT AAT AGT TAT GTT ATTGCA GTA AGT ACC GTT TGT ATT ATA AAT TGT GTT CTG
TGT AAT AGT TAT ATT TTCATT ATA AAT TGT GTT TGT AGA CAT CAT AAA TTT AAAACA TGG CTT TTT AAC CTGATA AAT CCT ACG AAT ATTTGT AAT AGT TAT GTT ATTGCA GTA AGT ACC GTT TGT ATT ATA AAT TGT GTT CTG
Which genes are turned off then on ? Courtesy of Dr. Young Moo Lee

16
0
200,000,000
400,000,000
600,000,000
800,000,000
1,000,000,000
1,200,000,000
1,400,000,000
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105
GenBank Release Numbers
9493929190898887 95 96 97
Growth in GenBank is exponential. Recently more data were added in ten weeks than were added in the first ten years of the project.
Growth in GenBank is exponential. Recently more data were added in ten weeks than were added in the first ten years of the project.
Base Pairs in GenBank

17
Rhetorical Question
Which is likely to be more complex:
• identifying, documenting, and tracking the whereabouts of all parcels in transit in the US at one time
• identifying, documenting, and analyzing the structure and function of all individual genes in all economically significant organisms; then analyzing all significant gene-gene and gene-environment interactions in those organisms and their environments
Which is likely to be more complex:
• identifying, documenting, and tracking the whereabouts of all parcels in transit in the US at one time
• identifying, documenting, and analyzing the structure and function of all individual genes in all economically significant organisms; then analyzing all significant gene-gene and gene-environment interactions in those organisms and their environments

18
Business Factoids
United Parcel Service:
• uses two redundant 3 Terabyte (yes, 3000 GB) databases to track all packages in transit.
• has 4,000 full-time employees dedicated to IT
• spends one billion dollars per year on IT
• has an income of 1.1 billion dollars, against revenues of 22.4 billion dollars
United Parcel Service:
• uses two redundant 3 Terabyte (yes, 3000 GB) databases to track all packages in transit.
• has 4,000 full-time employees dedicated to IT
• spends one billion dollars per year on IT
• has an income of 1.1 billion dollars, against revenues of 22.4 billion dollars
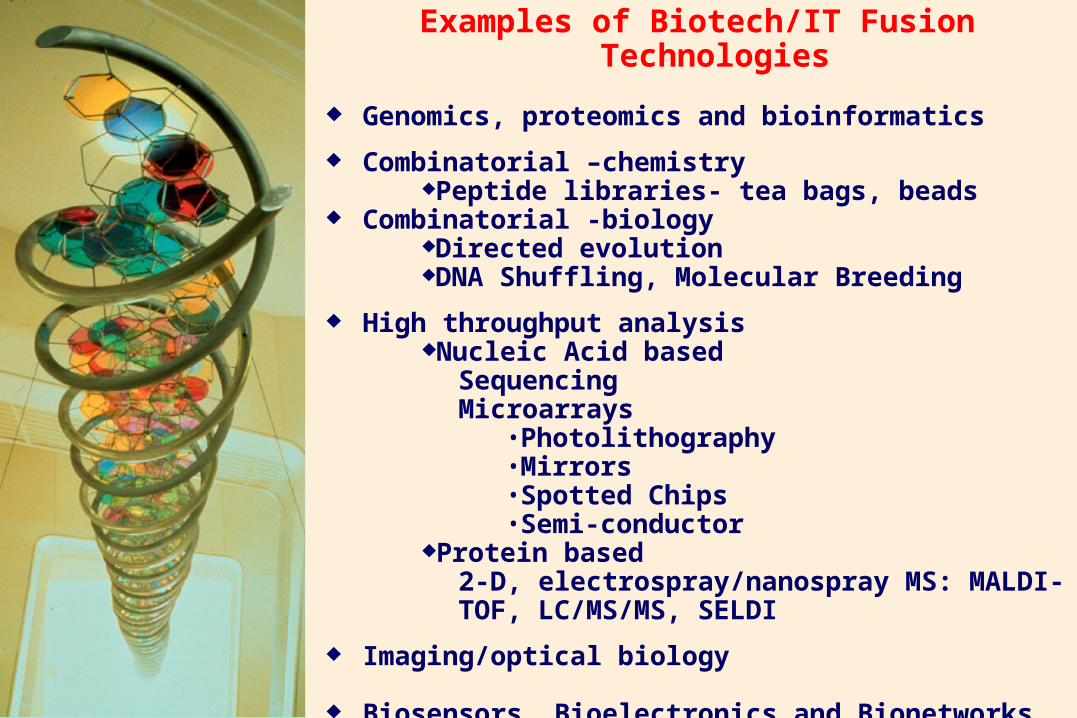
19
Examples of Biotech/IT Fusion Technologies
Genomics, proteomics and bioinformatics
Combinatorial –chemistryPeptide libraries- tea bags, beads
Combinatorial -biologyDirected evolutionDNA Shuffling, Molecular Breeding
High throughput analysis Nucleic Acid based
SequencingMicroarrays
•Photolithography•Mirrors•Spotted Chips•Semi-conductor
Protein based2-D, electrospray/nanospray MS: MALDI-TOF, LC/MS/MS, SELDI
Imaging/optical biology
Biosensors, Bioelectronics and Bionetworks (Nanotechnology)
Examples of Biotech/IT Fusion Technologies
Genomics, proteomics and bioinformatics
Combinatorial –chemistryPeptide libraries- tea bags, beads
Combinatorial -biologyDirected evolutionDNA Shuffling, Molecular Breeding
High throughput analysis Nucleic Acid based
SequencingMicroarrays
•Photolithography•Mirrors•Spotted Chips•Semi-conductor
Protein based2-D, electrospray/nanospray MS: MALDI-TOF, LC/MS/MS, SELDI
Imaging/optical biology
Biosensors, Bioelectronics and Bionetworks (Nanotechnology)

20
Genomics, Proteomics and Bioinformatics Genomics is operationally defined as investigations into the
structure and function of very large numbers of genes undertaken in a simultaneous fashion.
Structural genomics includes the genetic mapping, physical mapping and sequencing of entire genomes.
Comparative genomics means information gained in one organism can have application in other even distantly related organisms. This enables the application of information gained from facile model systems to agricultural and medical problems. The nature and significance of differences between genomes also provides a powerful tool for determining the relationship between genotype and phenotype through comparative genomics and morphological and physiological studies.
Functional genomics Phenotype is logically the subject of functional genomics. Genome sequencing for most organisms of interest will be complete within the near future, ushering in the so called "post-genome era." Walter Gilbert directly speculated on the nature of biology in the "post-genome era": "The new paradigm, now emerging, is that all genes will be known (in the sense of being resident in databases available electronically), and that the starting point of a biological investigation will be theoretical.“
Genomics, Proteomics and Bioinformatics Genomics is operationally defined as investigations into the
structure and function of very large numbers of genes undertaken in a simultaneous fashion.
Structural genomics includes the genetic mapping, physical mapping and sequencing of entire genomes.
Comparative genomics means information gained in one organism can have application in other even distantly related organisms. This enables the application of information gained from facile model systems to agricultural and medical problems. The nature and significance of differences between genomes also provides a powerful tool for determining the relationship between genotype and phenotype through comparative genomics and morphological and physiological studies.
Functional genomics Phenotype is logically the subject of functional genomics. Genome sequencing for most organisms of interest will be complete within the near future, ushering in the so called "post-genome era." Walter Gilbert directly speculated on the nature of biology in the "post-genome era": "The new paradigm, now emerging, is that all genes will be known (in the sense of being resident in databases available electronically), and that the starting point of a biological investigation will be theoretical.“

21
Genomics, Proteomics and Bioinformatics
Proteomics At the molecular level, phenotype includes all temporal and spatial aspects of gene expression as well as related aspects of the expression, structure, function and spatial localization of proteins. The Proteome is the set of all expressed proteins for a given organism.
The next hierarchical level of phenotype considers how the proteome within and among cells cooperates to produce the biochemistry and physiology of individual cells and organisms. “Physiomics" is a descriptor for this approach. “Phenomics" The final hierarchical levels of phenotype include anatomy and function for cells and whole organisms.
Bioinformatics: Computational or algorithmic approaches to the production of information from large amounts of biological data, include prediction of protein structure, dynamic modeling of complex physiological systems or the statistical treatment of quantitative traits in populations in order to determine the genetic basis for these traits.
Unquestionably, bioinformatics will be an essential component of all research activities utilizing structural and functional genomics approaches
Genomics, Proteomics and Bioinformatics
Proteomics At the molecular level, phenotype includes all temporal and spatial aspects of gene expression as well as related aspects of the expression, structure, function and spatial localization of proteins. The Proteome is the set of all expressed proteins for a given organism.
The next hierarchical level of phenotype considers how the proteome within and among cells cooperates to produce the biochemistry and physiology of individual cells and organisms. “Physiomics" is a descriptor for this approach. “Phenomics" The final hierarchical levels of phenotype include anatomy and function for cells and whole organisms.
Bioinformatics: Computational or algorithmic approaches to the production of information from large amounts of biological data, include prediction of protein structure, dynamic modeling of complex physiological systems or the statistical treatment of quantitative traits in populations in order to determine the genetic basis for these traits.
Unquestionably, bioinformatics will be an essential component of all research activities utilizing structural and functional genomics approaches

Medical Bioinformatics: What is it?
Laboratory/Clinical Laboratory/Clinical ExperimentsExperiments
Biological Biological InterpretationInterpretation
InformaticsInformatics
•Hi-throughput Screening Data Hi-throughput Screening Data •genotype sequencinggenotype sequencing• functional assaysfunctional assays•DNA libraryDNA library
•Patient Clinical DataPatient Clinical Data•cancer phenotypecancer phenotype•outcomes, treatments, ageoutcomes, treatments, age
•Patient SamplesPatient Samples•TissuesTissues•TumorsTumors
•Model SystemsModel Systems•RatsRats•cultured tissuescultured tissues
•Published LiteraturePublished Literature•Scientific/Medical ExpertsScientific/Medical Experts
•Sample/Experiment TrackingSample/Experiment Tracking•Data Processing, Quality ControlData Processing, Quality Control•Statistical AnalysesStatistical Analyses
•Sequence Matching/AnnotationSequence Matching/Annotation•Functional SignificanceFunctional Significance
•User Access to ResultsUser Access to Results
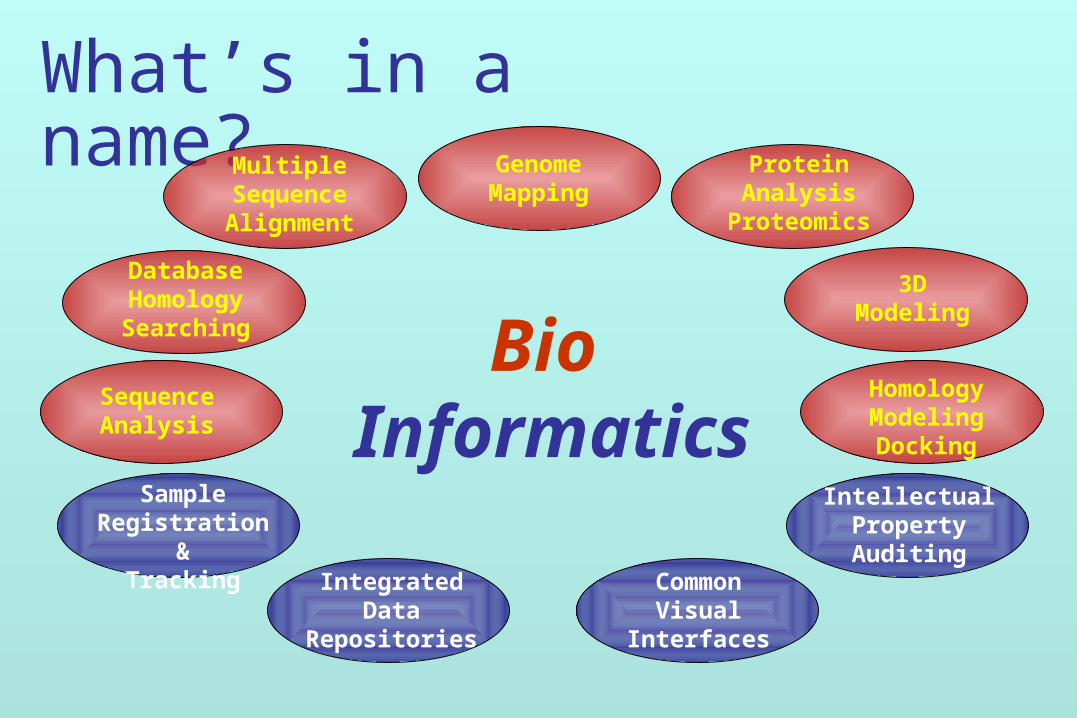
What’s in a name?
SequenceAnalysis
DatabaseHomologySearching
MultipleSequence
Alignment
HomologyModelingDocking
ProteinAnalysis
Proteomics
3DModeling
SampleRegistration &
TrackingIntegrated
DataRepositories
CommonVisual
Interfaces
IntellectualPropertyAuditing
Bio Informatics
GenomeMapping
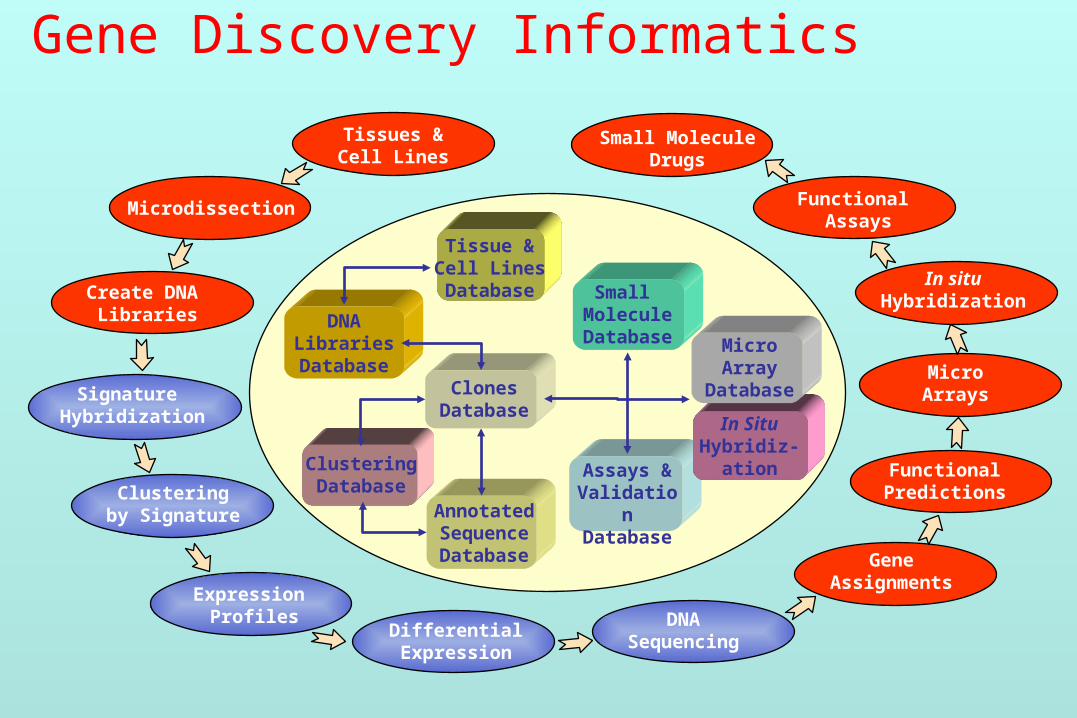
Gene Discovery Informatics
Microdissection
Create DNA Libraries
Signature Hybridization
Clusteringby Signature
Expression Profiles
DifferentialExpression
DNASequencing
GeneAssignments
FunctionalPredictions
MicroArrays
Functional Assays
Small MoleculeDrugs
Tissues &Cell Lines
In situHybridization
ClonesDatabase
DNALibrariesDatabase
AnnotatedSequenceDatabase
Assays &ValidationDatabase
ClusteringDatabase
Tissue &Cell LinesDatabase Small
MoleculeDatabase Micro
ArrayDatabase
In SituHybridiz-
ation
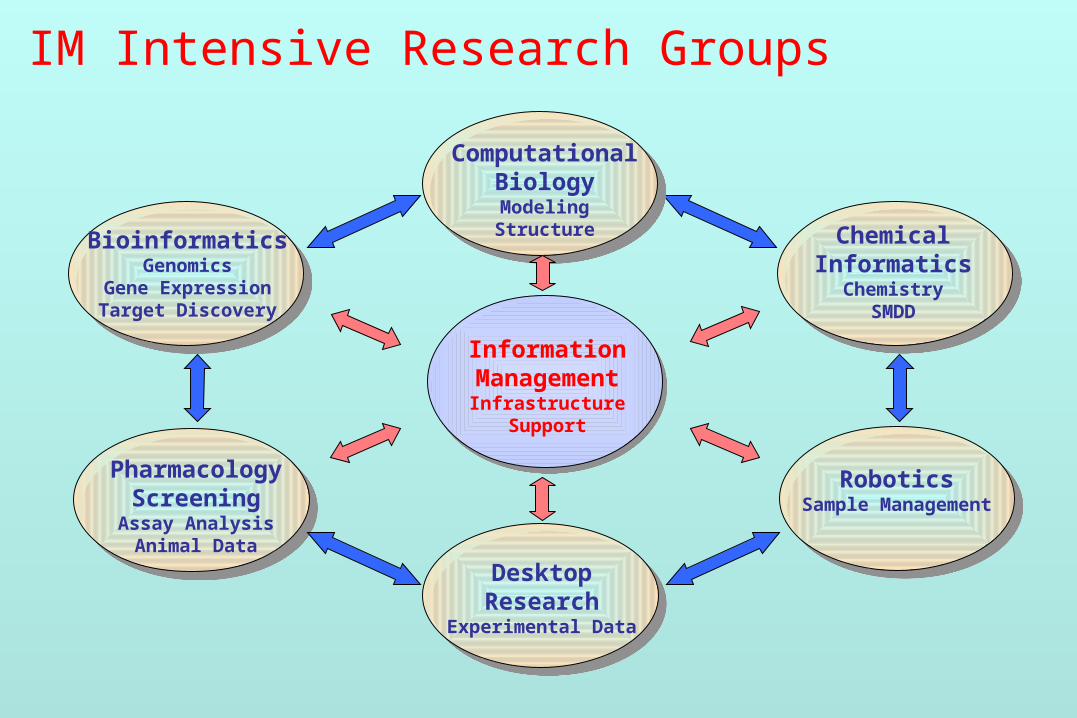
IM Intensive Research Groups
PharmacologyScreening
Assay AnalysisAnimal Data
RoboticsSample Management
ChemicalInformatics
ChemistrySMDD
BioinformaticsGenomics
Gene ExpressionTarget Discovery
ComputationalBiologyModelingStructure
DesktopResearch
Experimental Data
InformationManagement
InfrastructureSupport

Cancer Gene Discovery Knowledgebase
User'sWeb Browser
DNA SequenceDNA SequenceProprietary
Relational DatabaseHomology searchesFunctional Profiles
Cancer TissueInventoryPatient DataPathologyTissue Info
Functional/ValidationMicroarrays
In situ HybridizationFunctional validation
Anti-sense RNAKnockouts
Cancer Differential Expression Data
Tissue cDNA librariesGene Expression Patterns
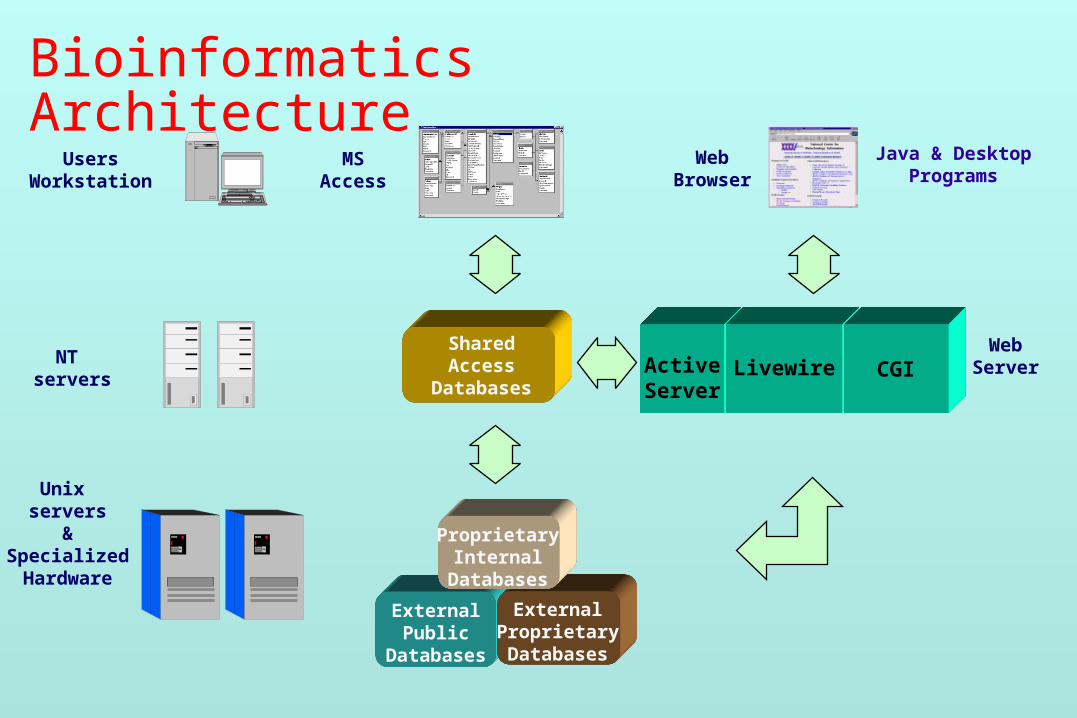
ExternalPublic
Databases
Bioinformatics Architecture
ExternalProprietaryDatabases
Unix servers
&SpecializedHardware
UsersWorkstation
Java & DesktopPrograms
WebBrowser
ActiveServer
Livewire CGINT
servers
ProprietaryInternal
Databases
WebServer
SharedAccess
Databases
MSAccess

Challenges in High Throughput Biotechnology R&D Volume of Data is Growing Rapidly Technology is Evolving Rapidly
Instrumentation, Informatics
Biological Definitions are Constantly Updated New Interactions and Functions Discovered Daily
New Genes Sometimes Homologous to Known Genes ->re-evaluate old data
Full Value is Realized by Integrating Multiple High-Throughput Platforms Sequencing, Functional Screens, Small Molecule Activity
Up-Front Design of Data and Quality Control Databases is Crucial to Success High Data Quality is Essential Financially Impossible to Repeat Experiments Requires Informatics Specialist who Understands Laboratory Techniques

Recent Informatics Job DescriptionDUTIES: The role of this position is to provide scientific bioinformatics support for gene
discovery research utilizing DNA microarray technology at Chiron. The successful candidate will participate in research projects within a bioinformatics team that will provide analysis and data management resources necessary to optimize research activities. REQUIREMENTS: A BS/MS in molecular biology, biochemistry and/or a field related to bioinformatics. A minimum of 1 year of biotechnology research experience working with projects and scientists in the field and 1 year experience utilizing data analysis tools in biotechnology research, specifically in the field of microarrays. Proficiency with bioinformatics programs and algorithms including both unix and desktop systems. Proficiency in data analysis programs such as Excel and statistical analysis packages used in the analysis of microarray data. Proficiency in SQL and working with relational database systems. Strong communication and teaching skills for working with colleagues and project researchers.
Scientist II, Research Microarrays
DUTIES; Develop and apply data analysis methods for interpreting high-throughput microarray experiments. Disseminate research results in presentations and writing. Should be flexible and work well in a team environment.
REQUIREMENTS: Ph.D. in Physical Sciences, Computing Sciences or Statistics. Previous experience analyzing large data sets, modeling laboratory experiments, developing quantitative assessments of data reliability, and associated computer programming tasks.
Title: Information Specialist

30
Slide 30
Funding UC-Industryresearch collaborations in
•bioinformatics•food and agricultural informatics
•environmental informatics•medical informatics
•computational aspects of imaging & modeling
LSI Research ProposalsJanuary 26, 2001
May 22, 2001October 2, 2001
Opportunity AwardsYear round
Learn more about it…http://lsi.ucdavis.edu

31
“The two technologies that will shape the next century are biotechnology and information technology”
Bill Gates
“The two technologies that will have the greatest impact on each other in the new millennium are biotechnology and information technology”
Martina McGloughlin
“The two technologies that will shape the next century are biotechnology and information technology”
Bill Gates
“The two technologies that will have the greatest impact on each other in the new millennium are biotechnology and information technology”
Martina McGloughlin
32
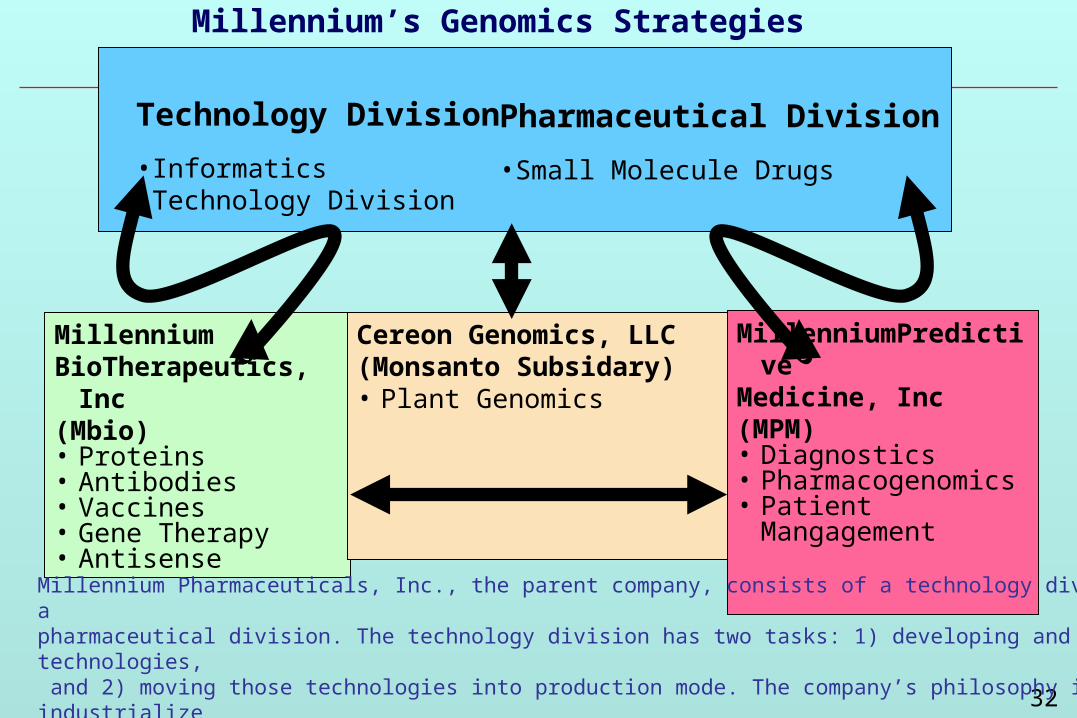
Technology Division
•Informatics•Technology Division
Pharmaceutical Division
•Small Molecule Drugs
MillenniumBioTherapeutics, Inc(Mbio)• Proteins• Antibodies• Vaccines• Gene Therapy• Antisense
Cereon Genomics, LLC(Monsanto Subsidary)• Plant Genomics
MillenniumPredictive Medicine, Inc(MPM)• Diagnostics• Pharmacogenomics• Patient Mangagement
Millennium’s Genomics Strategies
Millennium Pharmaceuticals, Inc., the parent company, consists of a technology division and a pharmaceutical division. The technology division has two tasks: 1) developing and acquiring technologies, and 2) moving those technologies into production mode. The company’s philosophy is to industrialize discovery and development, moving as many discovery and development operations as possible into a production mode.
33

34
Expression Technologies
There are currently four commonly used approaches to high throughput, comprehensive analysis of relative transcript expression levels. The enumeration of expressed sequence tags (ESTs), Serial Analysis of Gene Expression (SAGE), Differential Display Approaches, Array-based hybridization
The enumeration of expressed sequence tags (ESTs) from
representative cDNA libraries. A method of approximating the relative representation of the gene transcript within the starting cell population.
GeneTrace Systems, HHMI, IMAGE Consortium, Incyte, The Institute for Genomic Research
Serial Analysis of Gene Expression.The enumeration of serially concatenated 9-11 base tags from specially prepared cDNA libraries. The frequency of particular transcripts within the starting cell population is reflected by the number of times the associated sequence tag is encountered within the sequence pop
Genzyme Molecular Oncology, Johns Hopkins University
Expression Technologies
There are currently four commonly used approaches to high throughput, comprehensive analysis of relative transcript expression levels. The enumeration of expressed sequence tags (ESTs), Serial Analysis of Gene Expression (SAGE), Differential Display Approaches, Array-based hybridization
The enumeration of expressed sequence tags (ESTs) from
representative cDNA libraries. A method of approximating the relative representation of the gene transcript within the starting cell population.
GeneTrace Systems, HHMI, IMAGE Consortium, Incyte, The Institute for Genomic Research
Serial Analysis of Gene Expression.The enumeration of serially concatenated 9-11 base tags from specially prepared cDNA libraries. The frequency of particular transcripts within the starting cell population is reflected by the number of times the associated sequence tag is encountered within the sequence pop
Genzyme Molecular Oncology, Johns Hopkins University

35
Expression Technologies Differential Display Approaches Fragments defined by specific
sequence delimiters can be used as unique identifiers of genes, when coupled with information about fragment length or fragment location within the expressed gene. The relative representation of an expressed gene within a cell can then be estimated based on the relative representation of the fragment associated with that gene within the pool of all possible fragments. A number of different approaches have been developed to exploit this hypothesis for comprehensive expression analysis.
Curagen Corporation - Quantitative Expression Analysis (QEA)
Digital Gene Technologies, Inc. - Total Gene expression Analysis (TOGA)
Display Systems Biotech - Restriction Fragment Differential Display-PCR (RFDD-PCR)
Genaissance GeneLogic - Restriction Enzyme Analysis of Differentially-
expressed Sequences (READS)
Expression Technologies Differential Display Approaches Fragments defined by specific
sequence delimiters can be used as unique identifiers of genes, when coupled with information about fragment length or fragment location within the expressed gene. The relative representation of an expressed gene within a cell can then be estimated based on the relative representation of the fragment associated with that gene within the pool of all possible fragments. A number of different approaches have been developed to exploit this hypothesis for comprehensive expression analysis.
Curagen Corporation - Quantitative Expression Analysis (QEA)
Digital Gene Technologies, Inc. - Total Gene expression Analysis (TOGA)
Display Systems Biotech - Restriction Fragment Differential Display-PCR (RFDD-PCR)
Genaissance GeneLogic - Restriction Enzyme Analysis of Differentially-
expressed Sequences (READS)

36
Expression Technologies
Array-based hybridizationBased on the exquisite specificity of nucleotide interactions oligonucleotides or cDNA can be used to selectively identify or capture DNA or RNA of specific sequence composition. The primary approaches include array- based technologies that can identify specific expressed gene products on high density formats, including filters, microscope slides, or microchips, and solution-based technologies relying on spectroscopic analyses, such as mass spectrometry.
Affymetrix, Axon Instruments, Inc, BioDiscovery Inc. BioRobotics, Cartesian Technologies, Clontech General Scanning Inc., GeneMachines, Genetic MicroSystems Inc. ,GeneTrace Systems, Genome Systems, Genometrix, Genomic Solution, Hyseq, Inc. Hyseq/ Applied Biosystems Division of Perkin Elmer Incyte, Intelligent Automation Systems/Intelligent Bio-Instruments, Molecular Dynamics, NHGRI Laboratory of Cancer Genetics, NEN Life Science Products Protogene, Radius BioSciences, Research Genetics, Inc. Stanford University, Dr. Pat Brown, Synteni, TeleChem International, Rosetta Inpharmatics (LeeHood)

37
Expression Technologies- Proteomics Most processes manifest themselves at the level of protein
activity, but until recently, high throughput analysis of proteins was not possible. Several technologies now makes it feasible to perform mass screening of proteins
2- D Gel Electrophoresis- LifeProt Protein Expression Database provides a bioinformatics platform for investigating 2D gel images sequence data/annotation. (Incyte, Oxford Bioscience)Immobiline, ImageMaster software Amersham/ Pharmacia/Molecular Dynamics, BioRad
LC-MS/MS, MALDI-TOF mass spectrometer offers fast and reliable protein identification for high throughput proteomic studies. MD, Perkin Elmer
PerSeptive Biosystems, PE Biosystems venture, integrates robotics, mass spec, data searching technologies into 1 system for HT ID proteins, peptides
SELDI (Surface-Enhanced Laser Desorption/ Ionization) ProteinChip technology rapid separation, detection and analysis of proteins at the femtomole level directly from biological samples- Ciphergen
Variants on yeast two-hybrid system, which is widely used for analyzing protein–protein interactions in vivo
Phage Display
Expression Technologies- Proteomics Most processes manifest themselves at the level of protein
activity, but until recently, high throughput analysis of proteins was not possible. Several technologies now makes it feasible to perform mass screening of proteins
2- D Gel Electrophoresis- LifeProt Protein Expression Database provides a bioinformatics platform for investigating 2D gel images sequence data/annotation. (Incyte, Oxford Bioscience)Immobiline, ImageMaster software Amersham/ Pharmacia/Molecular Dynamics, BioRad
LC-MS/MS, MALDI-TOF mass spectrometer offers fast and reliable protein identification for high throughput proteomic studies. MD, Perkin Elmer
PerSeptive Biosystems, PE Biosystems venture, integrates robotics, mass spec, data searching technologies into 1 system for HT ID proteins, peptides
SELDI (Surface-Enhanced Laser Desorption/ Ionization) ProteinChip technology rapid separation, detection and analysis of proteins at the femtomole level directly from biological samples- Ciphergen
Variants on yeast two-hybrid system, which is widely used for analyzing protein–protein interactions in vivo
Phage Display

38
Some of the 25 new genomics faculty will belong to the UC
Davis Genome Center, the first new product of the Genomics
Initiative. ($20m set aside for faculty) Designed to establish the campus as an international leader in
functional and comparative genomics, the center will include
scientists specializing in gene studies from a multitude of
disciplines, including human and animal medicine,
engineering, agriculture, mathematics and the biological and
physical sciences. The Genome Center will also include a revitalized
pharmacology and toxicology department in the School of
Medicine and a group of bioinformatics faculty members who
will provide the computational biology and informatics
research needed to analyze the enormous amounts of data
generated by the genomics research.
Some of the 25 new genomics faculty will belong to the UC
Davis Genome Center, the first new product of the Genomics
Initiative. ($20m set aside for faculty) Designed to establish the campus as an international leader in
functional and comparative genomics, the center will include
scientists specializing in gene studies from a multitude of
disciplines, including human and animal medicine,
engineering, agriculture, mathematics and the biological and
physical sciences. The Genome Center will also include a revitalized
pharmacology and toxicology department in the School of
Medicine and a group of bioinformatics faculty members who
will provide the computational biology and informatics
research needed to analyze the enormous amounts of data
generated by the genomics research.
Genomics CenterGenomics Center

39
Proteomics Companies Location Business Approach Collaborators
Ciphergen Biosystems Inc. Palo Alto, CA Protein arrays N/A Genomic Solutions Inc. Ann Arbor, MI Automated 2-D gel/
MS platform N/A Hybrigenics SA Paris, France Protein-protein interaction Pasteur Institute
mapping and databases Small Molecule Therapeutics Inc.;
Large Scale Biology Corp. Rockville, MD Biological assay Biosource and Vacaville, CA Technologies Inc.
(parent) Oxford GlycoSciences plc Oxford, England Biological assay; Incyte Pharma
Protein databases Pfizer IncLumicyte CA Protein Arrays . Proteome Inc. Beverly, MA Protein databases N/A Proteome Systems Ltd. Sydney, Australia Biological assay; Dow AgroSciences
Protein databasesMyriad Genetics Inc. Salt Lake City Protein datbases
Utah Biological assays CuraGen Corp Biogen, Genentech
COR Therapeutics, Glaxo Wellcome, Roche, Pioneer Hi-Bred/ Dupont

40
AffymtrixAgilent Alpha Gene Alpha Innotech Amersham Pharmacia Biotech Axon Instruments Bio DiscoveryBio Roboti c sBiospace Mesure s Cartesian Technologies CellomicsCiphergenClinical Micro SensorsCLONTECHCuraGenDisplay Systems BiotechDouble TwistGeneData GeneFocusGeneMachinesGenetic Micro Systems GenometrixGenomic Solutions GSI Lumonics
Imaging Research
Iris BioTechnologies Incyte Pharmaceutical s LION AgLumicyteMicronicsNanogen NEN Life Science Pro d u c t s PHASE 1 Molecular Toxicology Phoretix International Proteome Protogene Laboratories R&D Systems Radius Biosciences Research Genetics ScanalyticslSigma - Genosys Silicon Genetics TeleChem InternationalUniversal Imaging V&P Scientific Virtek Vysis
Companies dependant on Informatics

41
IP Challenges June 5, 1995--Human Genome Sciences applies for a patent on a gene
that produces a "receptor" protein that is later called CCR5. HGS has no idea that CCR5 is an HIV receptor.
December 1995--U.S. researcher Robert Gallo, the co-discoverer of HIV, and colleagues find three chemicals that inhibit the AIDS virus. Don’t how the chemicals work.
February 1996--Edward Berger at the NIH discovers that Gallo's inhibitors work in late-stage AIDS by blocking a receptor on the surface of T-cells.
June 1996--In a period of just 10 days, five groups of scientists publish papers saying CCR5 is the receptor for virtually all strains of HIV.
January 2000--Schering-Plough researchers tell a San Francisco AIDS conference they have discovered new inhibitors. Merck researchers are known to have made similar discoveries.
Feb. 15, 2000--The U.S. Patent and Trademark Office grants HGS a patent on the gene that makes CCR5 and on techniques for producing CCR5 artificially. The decision sends HGS stock flying and dismays researchers.
HGS: identified in whole or in part 95% of the 100,000 or so human genes. 100 human gene patents 7,500 pending.

42
The Shape of the Wave
– 1999» JGI releases 150 Mbases draft » Celera releases the sequence of Drosophila (140 Mb)» Public “draft” effort reaches halfway point (1,500 Mb)» 20 more Microbial genomes completed (80 Mb but 60,000 genes)» First release of Celera “shotgun” (9,000 Mb)
– 2000» Public “draft” completed (1,500 Mb)» Mouse “draft” begins (500 Mb - comparisons with human)» Two more Celera shotgun releases ( 18,000 Mb)» 40 more Microbial genomes sequenced (160 Mb -120,000 genes)

43
Projected Base Pairs
110
1001,000
10,000100,000
1,000,00010,000,000
100,000,0001,000,000,000
10,000,000,000100,000,000,000
1,000,000,000,00010,000,000,000,000
100,000,000,000,000
90 95 0 5 10 15 20 25
Year
500,00050,0005,000
Projected size of the sequence database, indicated as the number of base pairs per individual medical record in the US.The amount of digital data
necessary to store 1014 bases of DNA is only a fraction of the data necessary to describe the world’s microbial biodiversity at one square meter resolution...
The amount of digital data necessary to store 1014 bases of DNA is only a fraction of the data necessary to describe the world’s microbial biodiversity at one square meter resolution...

44
How much information is there in the World?
• Library of Congress: – 3 Petabytes (3,000 TB)
» 6 billion book pages (1 PB)
» 13 million photographs (13TB)
» maps, movies, audio tapes
• Cinema
• Images– 520 Petabytes (520,000TB)
» 52 billion photographs / year / 10KB
• Broadcasting
• Sound
• Telephony
• Library of Congress: – 3 Petabytes (3,000 TB)
» 6 billion book pages (1 PB)
» 13 million photographs (13TB)
» maps, movies, audio tapes
• Cinema
• Images– 520 Petabytes (520,000TB)
» 52 billion photographs / year / 10KB
• Broadcasting
• Sound
• Telephony
Michael Lesk, Bellcore 1997

45
Business ComparisonsCompany Revenues IT Budget Pct
Bristol-Myers Squibb 15,065,000,000 440,000,000 2.92 %
Pfizer 11,306,000,000 300,000,000 2.65 %
Pacific Gas & Electric 10,000,000,000 250,000,000 2.50 %
K-Mart 31,437,000,000 130,000,000 0.41 %
Wal-Mart 104,859,000,000 550,000,000 0.52 %
Sprint 14,235,000,000 873,000,000 6.13 %
MCI 18,500,000,000 1,000,000,000 5.41 %
United Parcel 22,400,000,000 1,000,000,000 4.46 %
AMR Corporation 17,753,000,000 1,368,000,000 7.71 %
IBM 75,947,000,000 4,400,000,000 5.79 %
Microsoft 11,360,000,000 510,000,000 4.49 %
Chase-Manhattan 16,431,000,000 1,800,000,000 10.95 %
Nation’s Bank 17,509,000,000 1,130,000,000 6.45 %


















