
Percon XtraDB Cluster in a nutshell
128
Percona XtraDB Cluster in a nutshell Hands-on tutorial Liz van Dijk Kenny Gryp Frédéric Descamps 3 Nov 2014
-
Upload
frederic-descamps -
Category
Presentations & Public Speaking
-
view
171 -
download
0
Transcript of Percon XtraDB Cluster in a nutshell

Percona XtraDB Cluster in a nutshell
Hands-on tutorial
Liz van DijkKenny GrypFrédéric Descamps3 Nov 2014

Percona XtraDB Cluster in a nutshell
Hands-on tutorial
Liz van DijkKenny GrypFrédéric Descamps3 Nov 2014

Who are we ?
• Frédéric Descamps• @lefred• Senior Architect• devops believer• Percona Consultant since
2011• Managing MySQL since
3.23 (as far as I remember)• http://about.me/lefred
• Kenny Gryp• @gryp• Principal Architect• Kali Dal expert• Kheer master• Naan believer• Paratha Consultant
since 2012
• Liz van Dijk• @lizztheblizz•

Agenda
PXC and galera replication concepts
Migrating a master/slave setup
State transfer
Config / schema changes
Application interaction
Advanced Topics
4

Percona
• We are the oldest and largest independent MySQL Support, Consulting, Remote DBA, Training, and Software Development company with a global, 24x7 staff of nearly 100 serving more than 2,000 customers in 50+ countries since 2006 !
• Our contributions to the MySQL community include open source server and tools software, books, and original research published on the Percona's Blog
5

Get more after the tutorial
Synchronous Revelation, Alexey Yurchenko, 9:40am - 10:05am
Moving a MySQL infrastructure with 130K QPS to Galera, Walther Heck, 2:10pm – 3.00pm @ Cromwell 1&2
Galera Cluster New Features, Seppo Jaakola, 3:10pm – 4:00pm @ Cromwell 3&4
15 Tips to Boost your Galera Cluster, lefred, 5:30pm – 6:20pm @ Cromwell 1&2

Concepts
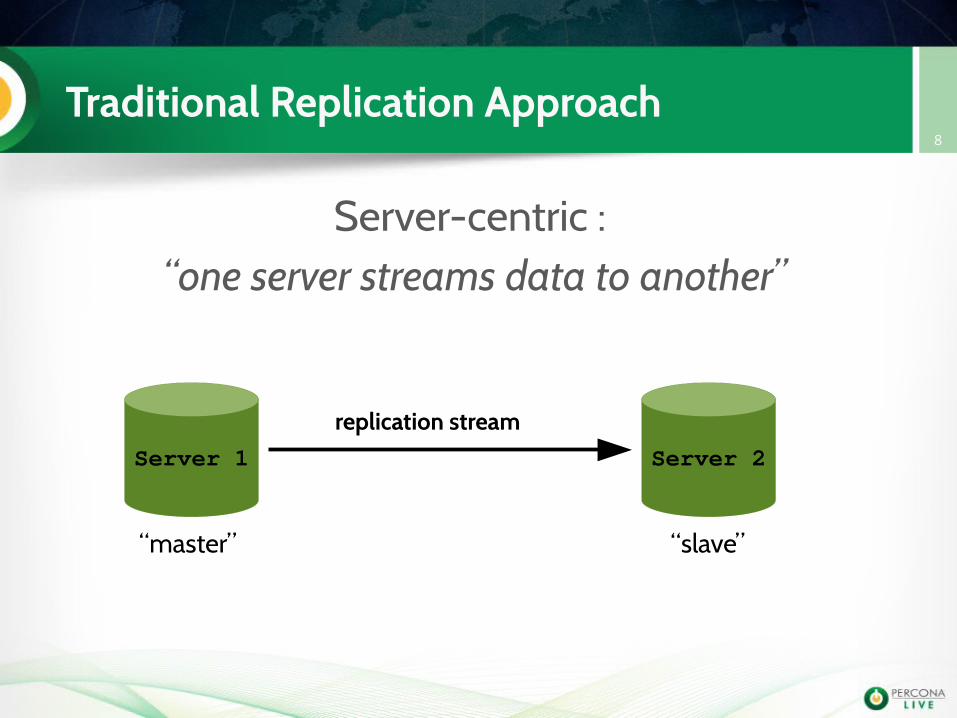
Traditional Replication Approach
Server-centric : “one server streams data to another”
8
Server 1 Server 2
replication stream
“master” “slave”

This can lead to cool topologies !9
1
2
3
4
5
6
7 8 910
1213
14
15
16 17
18
19
11
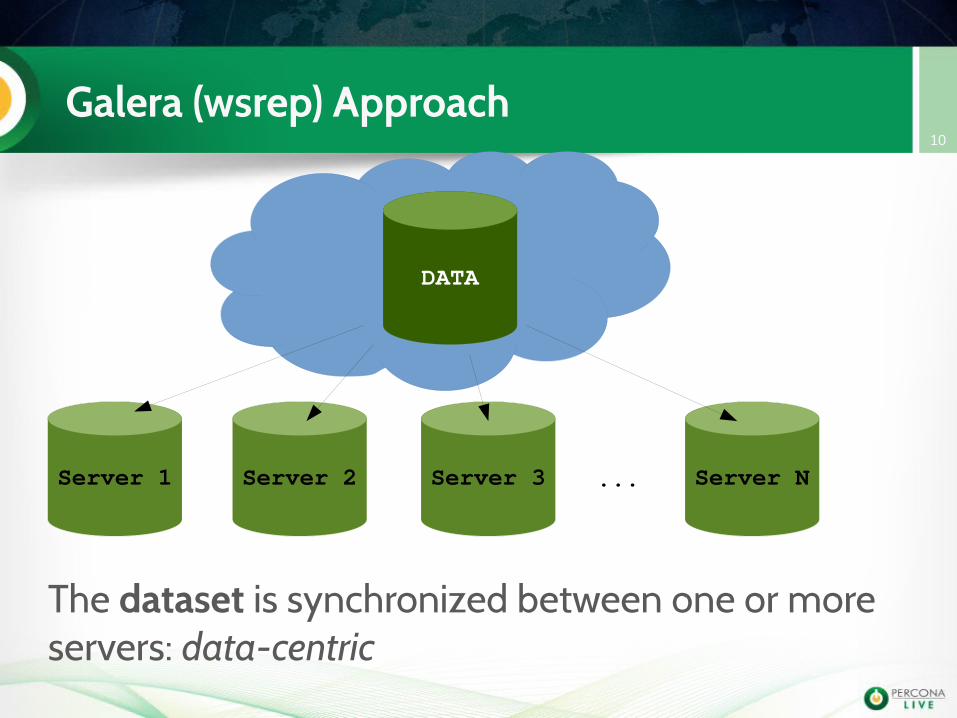
Galera (wsrep) Approach10
DATA
Server 1 Server 2 Server 3 Server N...
The dataset is synchronized between one or more servers: data-centric
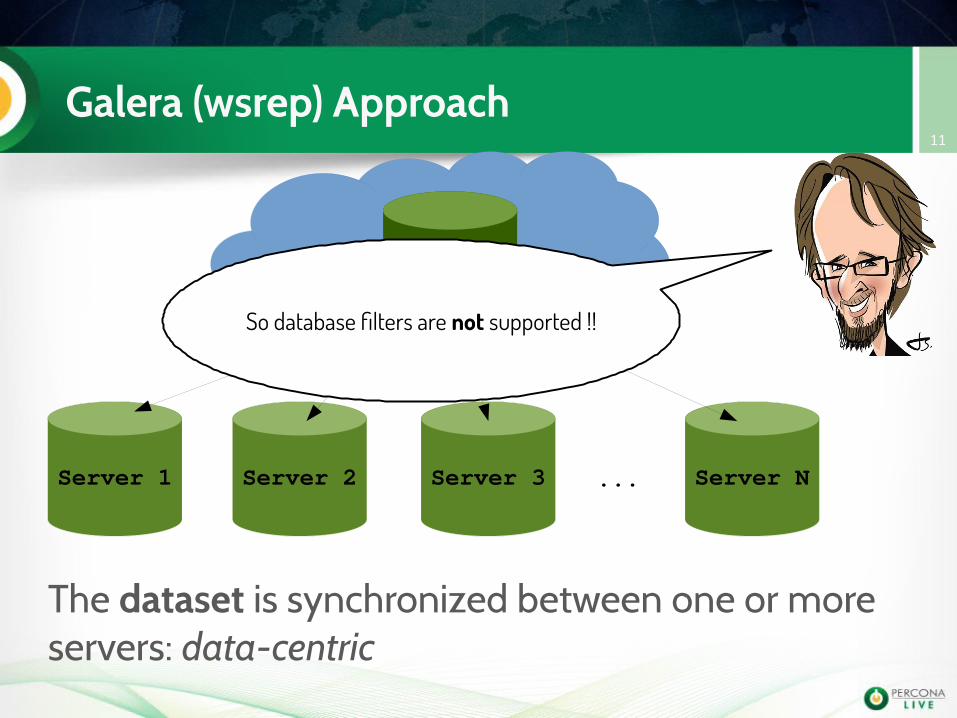
Galera (wsrep) Approach11
DATA
Server 1 Server 2 Server 3 Server N...
The dataset is synchronized between one or more servers: data-centric
So database filters are not supported !!

Multi-Master Replication
• You can write to any node in your cluster• Don't worry about eventual out-of-sync
12
writes
writeswrites
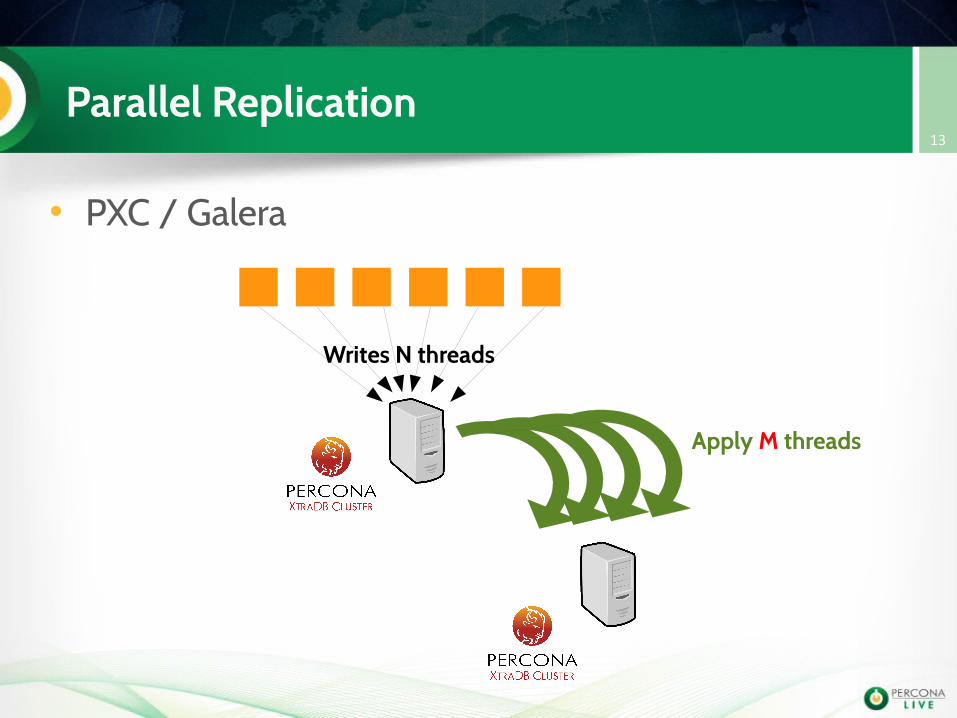
Parallel Replication
• PXC / Galera
13
Writes N threads
Apply M threads

Understanding Galera
14The cluster can be seen as a meeting !

PXC (Galera cluster) is a meeting15
bfb912e5-f560-11e2-0800-1eefab05e57d
PXC (Galera cluster) is a meeting16
bfb912e5-f560-11e2-0800-1eefab05e57d
PXC (Galera cluster) is a meeting17
bfb912e5-f560-11e2-0800-1eefab05e57d

PXC (Galera cluster) is a meeting18
bfb912e5-f560-11e2-0800-1eefab05e57d
PXC (Galera cluster) is a meeting19
bfb912e5-f560-11e2-0800-1eefab05e57d
PXC (Galera cluster) is a meeting20
bfb912e5-f560-11e2-0800-1eefab05e57d

PXC (Galera cluster) is a meeting21
bfb912e5-f560-11e2-0800-1eefab05e57d

PXC (Galera cluster) is a meeting22
bfb912e5-f560-11e2-0800-1eefab05e57d
Only one node remaining but as all theothers left gracefully, we still have a meeting !

PXC (Galera cluster) is a meeting23

PXC (Galera cluster) is a meeting24
???
PXC (Galera cluster) is a meeting25
4fd8824d-ad5b-11e2-0800-73d6929be5cf
New meeting !

Ready ? Handso
n!

Lab 1: prepare the VM's Handso
n!
Copy all .zip files from USB stick to your machine
Uncompress them and double click on each *.vbox files (ex: PLUK 2k14 node1 (32bit).box)
Start all virtual machines (app, node1, node2 and node3)
Install putty if you are using Windows

Lab 1: test connectivity Handso
n!
Try to connect to all VM's from a terminal or putty
ssh p 2221 [email protected] to node1
ssh p 2222 [email protected] to node2
ssh p 2223 [email protected] to node3
ssh p 2224 [email protected] to app
root password is “vagrant” !

Lab 1: everybody OK ? Handso
n!

Lab 1: YES !! Handso
n!
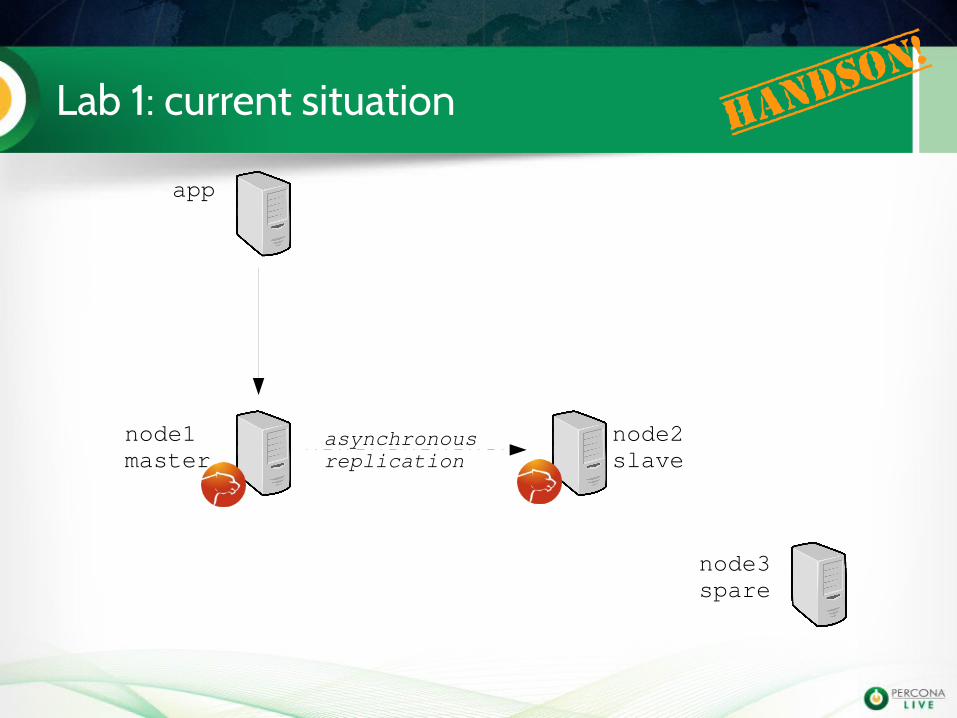
Lab 1: current situation Handso
n!
app
node1master
node2slave
node3spare
asynchronousreplication
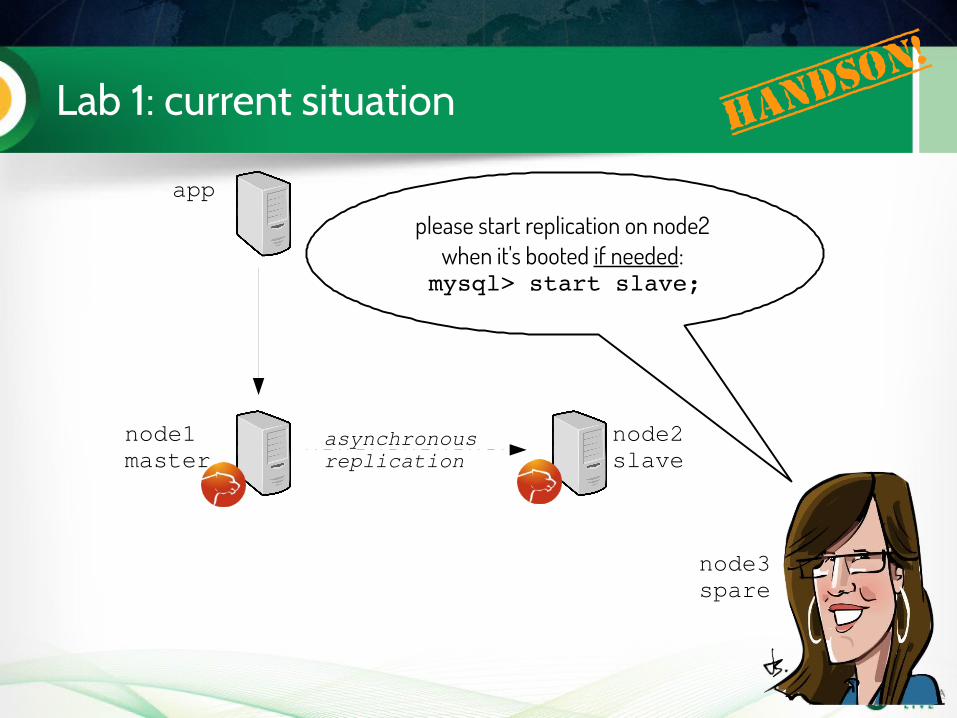
Lab 1: current situation Handso
n!
app
node1master
node2slave
node3spare
asynchronousreplication
please start replication on node2 when it's booted if needed: mysql> start slave;
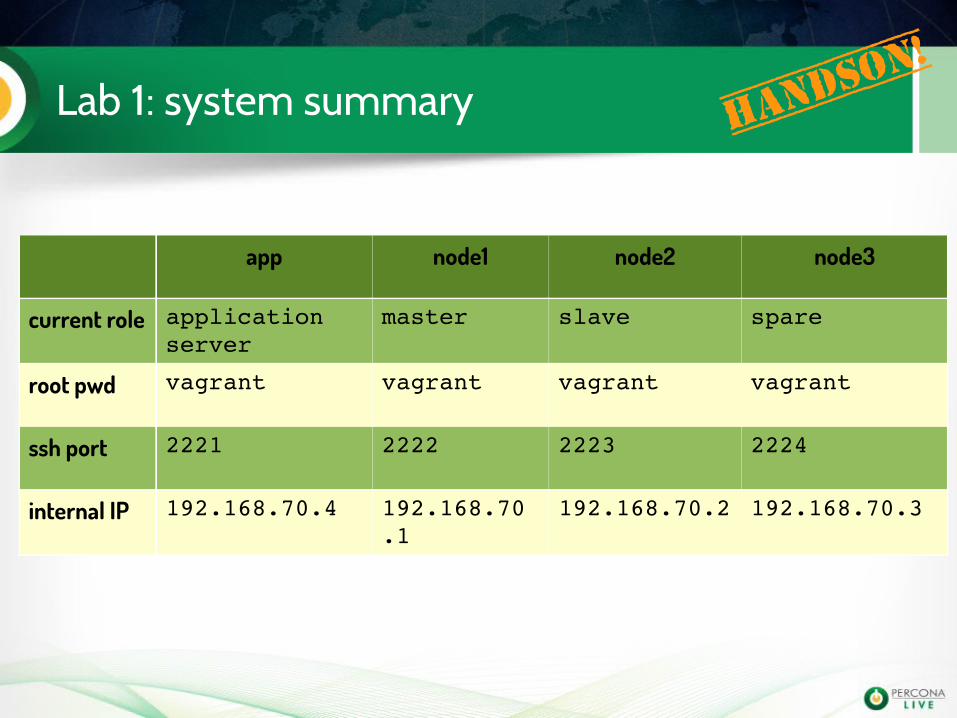
Lab 1: system summary Handso
n!
app node1 node2 node3
current role application server
master slave spare
root pwd vagrant vagrant vagrant vagrant
ssh port 2221 2222 2223 2224
internal IP 192.168.70.4 192.168.70.1
192.168.70.2 192.168.70.3

Is PXC Good for me?

(Virtual) Synchronous Replication
• Different from asynchronous MySQL replication:
– Writesets (tx) are replicated to all available nodes on commit (and en-queued on each)
– Writesets are individually “certified” on every node, determinsitically.
– Queued writesets are applied on those nodes independently and asynchronously
– Flow Control avoids too much “lag”.
35

Limitations
Supports only InnoDB tables– MyISAM support is very basic and will stay in alpha.
Different locking: optimistic locking
The weakest node limits the write performance
For write intensive applications there could be datasize limit per node
All tables should have a Primary Key !

Limitations
Supports only InnoDB tables– MyISAM support is very basic and will stay in alpha.
Different locking: optimistic locking
The weakest node limits the write performance
For write intensive applications there could be datasize limit per node
All tables should have a Primary Key !
wsrep_certify_nonPK=1can now deal with non PK, but it's still notrecommended to use tables without PK !

Limitations (2)
Large transactions are not recommended if you write on all nodes simultaneously
If your application has a data hotspot then PXC may not be right for you.
By default a writeset can contain maximum 128k rows and limited to 1G

Limitations (2)
Large transactions are not recommended if you write on all nodes simultaneously
If your application has a data hotspot then PXC may not be right for you.
By default a writeset can contain maximum 128k rows and limited to 1GThis is defined by wsrep_max_ws_rows and
wsrep_max_ws_size
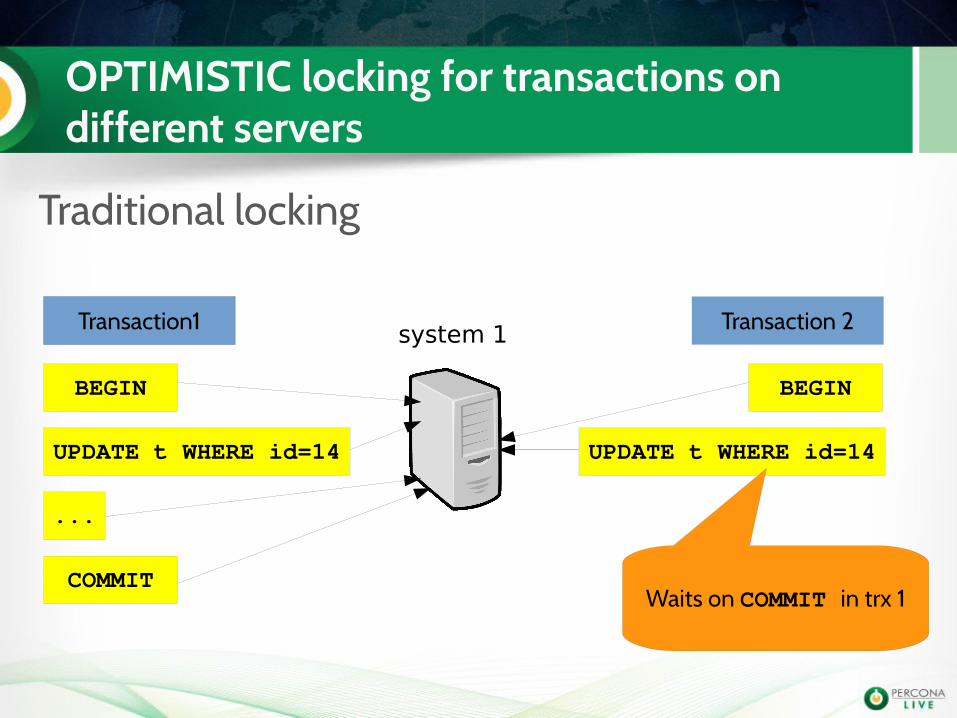
OPTIMISTIC locking for transactions on different servers
Traditional locking
system 1Transaction 1 Transaction 2
BEGIN
Transaction1
BEGIN
UPDATE t WHERE id=14 UPDATE t WHERE id=14
...
COMMITWaits on COMMIT in trx 1
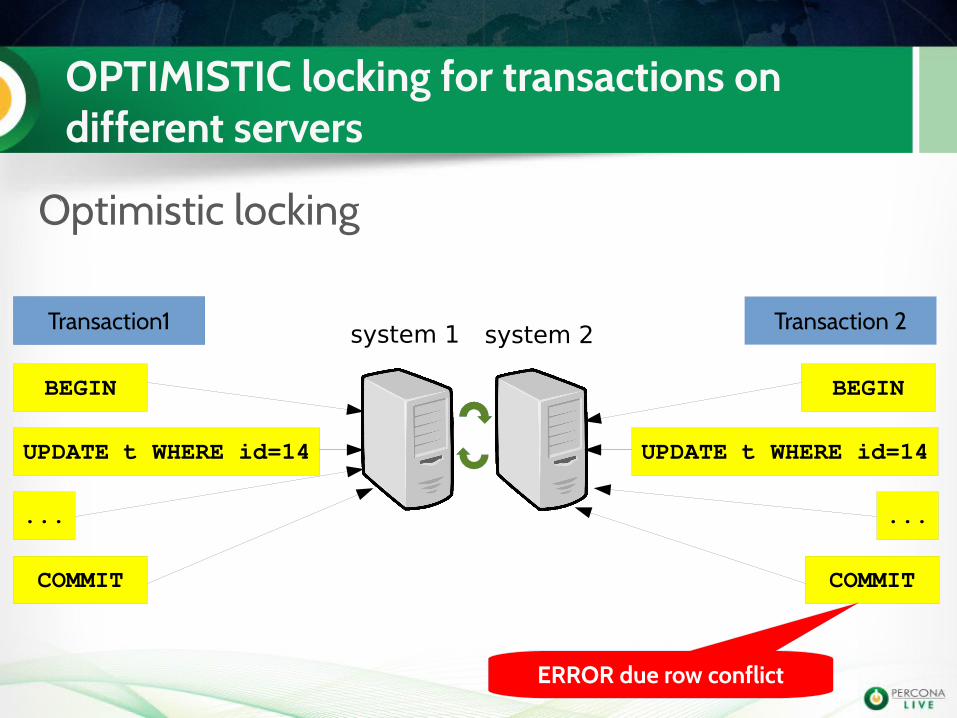
OPTIMISTIC locking for transactions on different servers
Optimistic locking
system 1Transaction 1 Transaction 2
BEGIN
Transaction1
BEGIN
UPDATE t WHERE id=14 UPDATE t WHERE id=14
...
COMMIT
system 2
...
COMMIT
ERROR due row conflict

OPTIMISTIC locking for transactions on different servers
Optimistic locking
system 1Transaction 1 Transaction 2
BEGIN
Transaction1
BEGIN
UPDATE t WHERE id=14 UPDATE t WHERE id=14
...
COMMIT
system 2
...
COMMIT
ERROR due row conflict
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction

Summary
Make sure you have no long running transactions– They can stall replication
Make sure you have no data hot spots– They are not locks waits, but rollbacks if coming from
different nodes

Migrating a master/slave setup
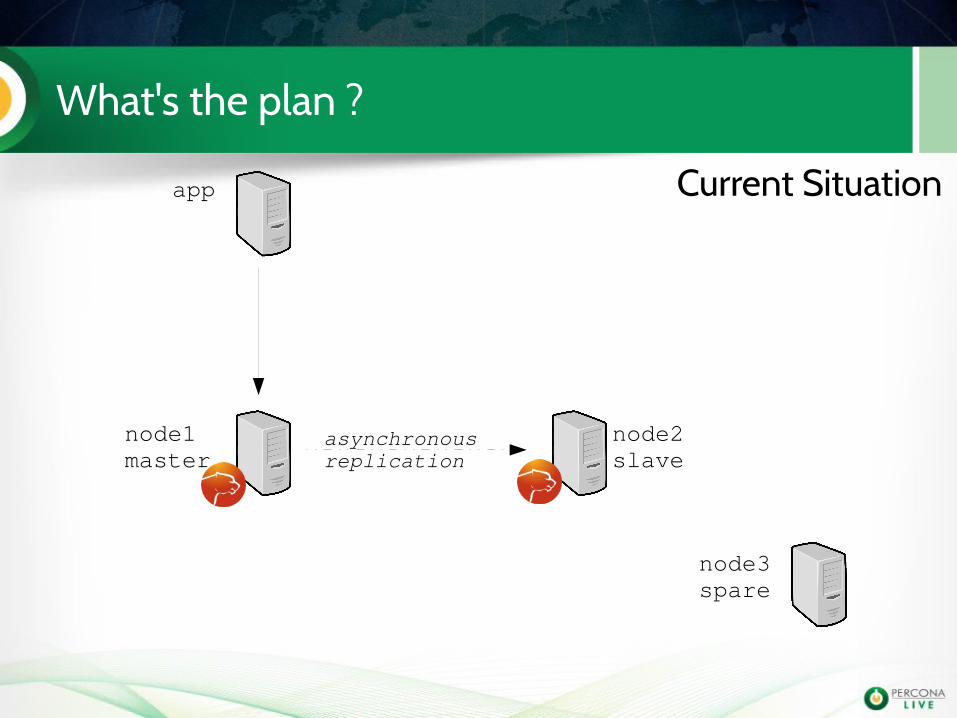
What's the plan ?
app
node1master
node2slave
node3spare
asynchronousreplication
Current Situation
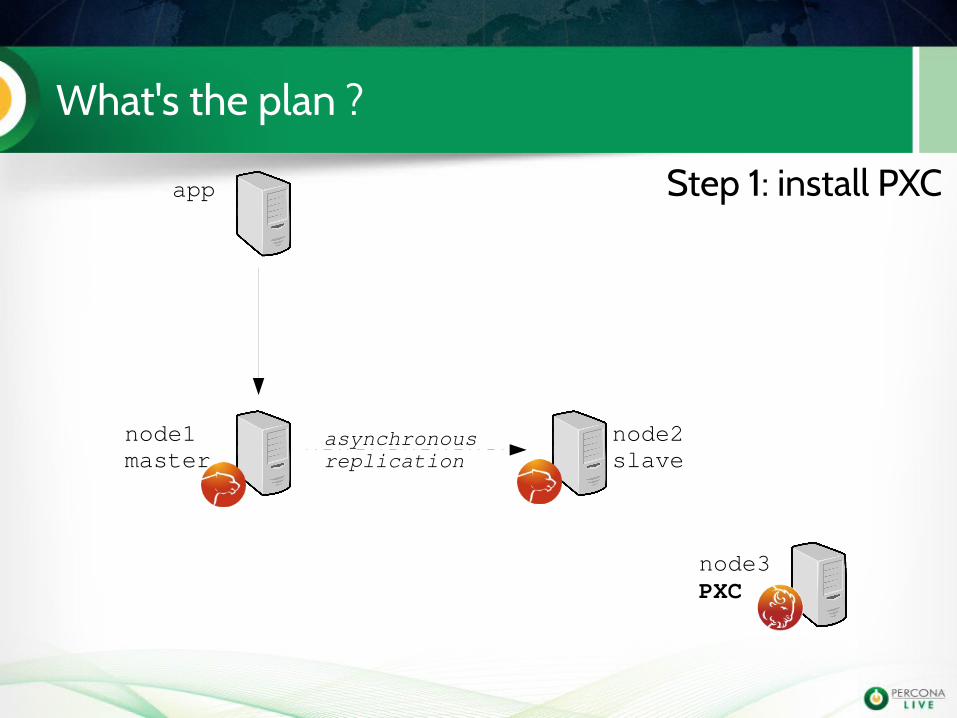
What's the plan ?
app
node1master
node2slave
node3PXC
asynchronousreplication
Step 1: install PXC
What's the plan ?
app
node1master
node2slave
node3PXCslave
asynchronousreplication
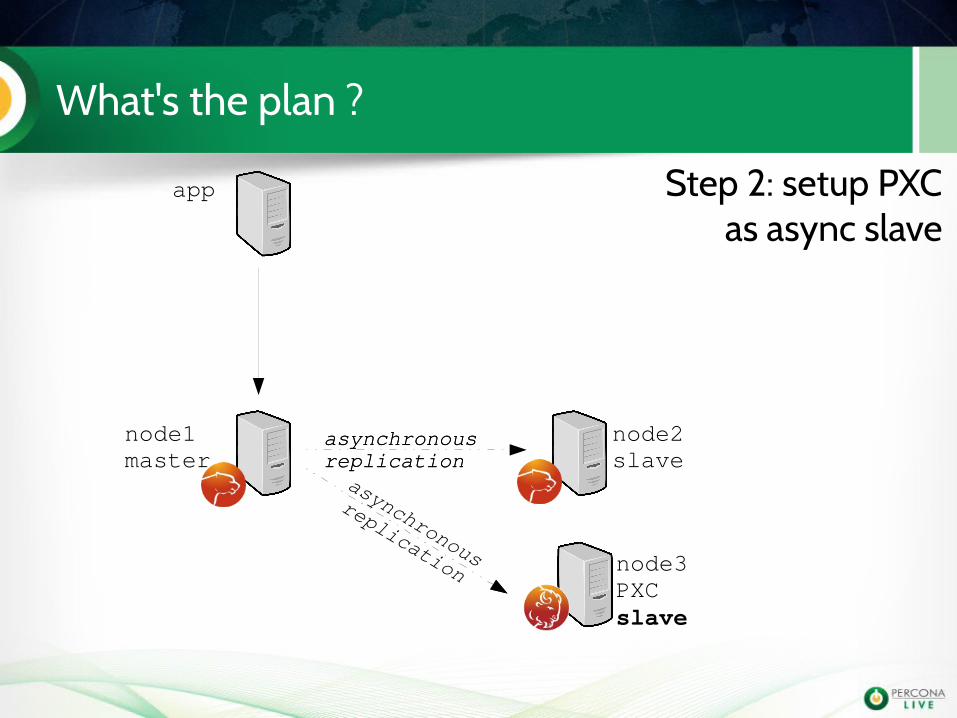
Step 2: setup PXC as async slave
asynchronousreplicationasynchronous
replication
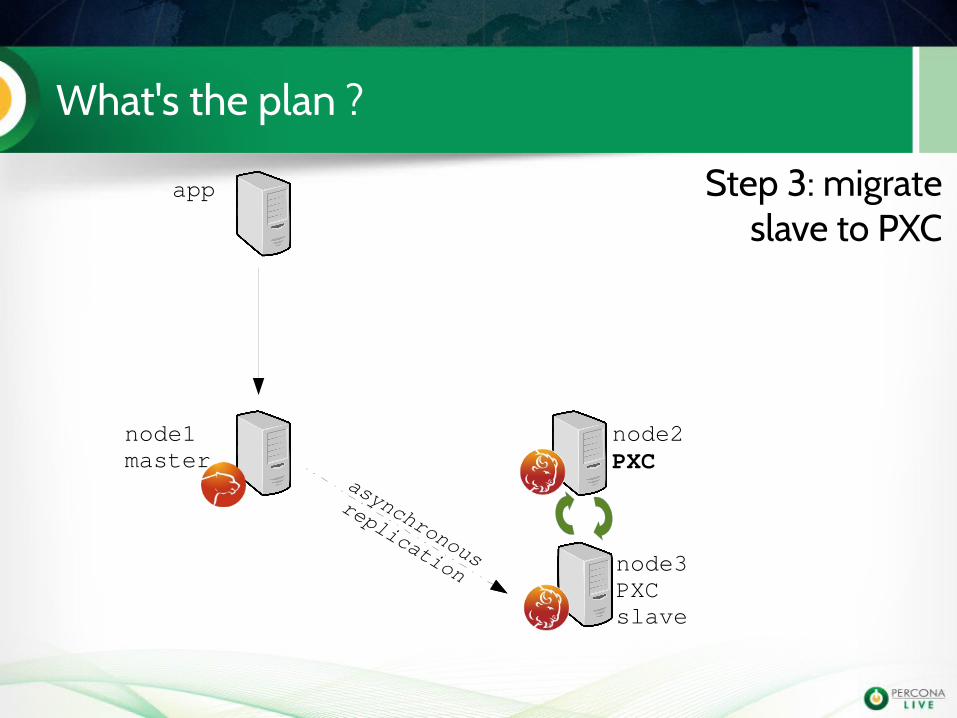
What's the plan ?
app
node1master
node2PXC
node3PXCslave
Step 3: migrate slave to PXC
asynchronous
replication
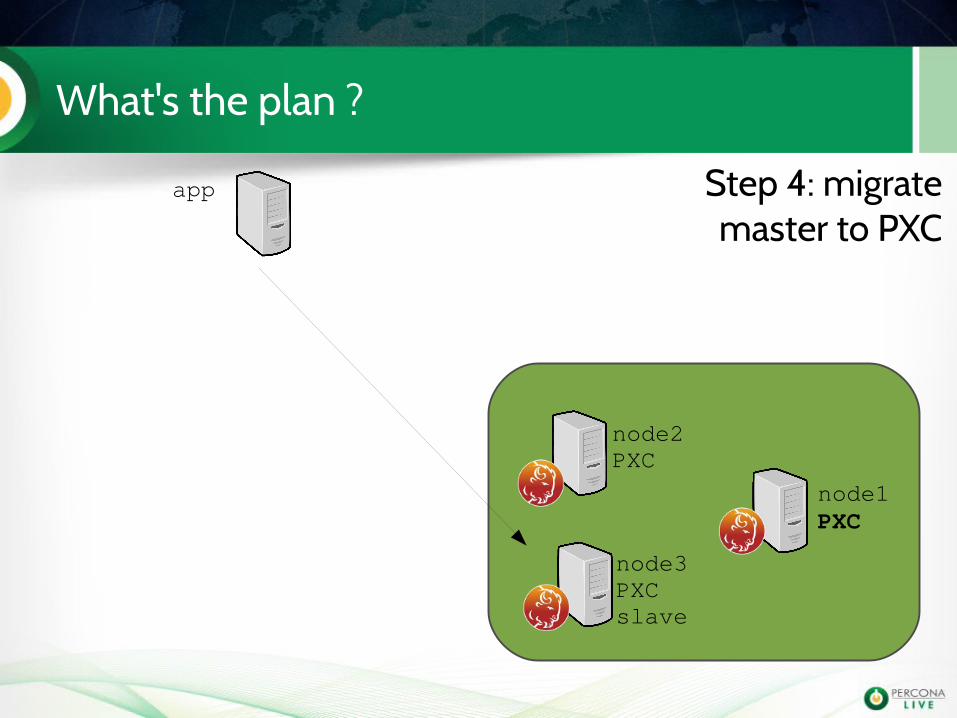
What's the plan ?
app
node1PXC
node2PXC
node3PXCslave
Step 4: migrate master to PXC

Lab 2: Install PXC on node3
Install PerconaXtraDBClusterserver56
Edit my.cnf to have the mandatory PXC settings
node3PXC
Handso
n!
[mysqld]binlog_format=ROWwsrep_provider=/usr/lib/libgalera_smm.so wsrep_cluster_address=gcomm://192.168.70.3wsrep_node_address=192.168.70.3wsrep_cluster_name=Pluk2k13wsrep_node_name=node3 innodb_autoinc_lock_mode=2

Step 2: setup that single node cluster as asynchronous slave
We need to verify if the configuration is ready for that
Make a slave
Bootstrap our single node Percona XtraDB Cluster
Start replication.... we use 5.6 with GTID!
Disable selinux on all boxes !– setenforce 0

Lab 2: let's make a slave ! Handso
n!
We need to take a backup (while production is running)
We need to restore the backup
We need to add requested grants
We need to configure our PXC node to use GTID
We need to see a bit longer and prepare that new slave to spread all the replicated events to the future cluster nodes
Lab 2: It's time for some extra work ! Handso
n!
It's always better to have a specific user to use with xtrabackup (we will use it later for SST too)
Even if you use the default datadir in MySQL, it's mandatory to add it in my.cnf
node1 mysql> GRANT reload, lock tables, replication client ON *.* TO 'sst'@'localhost' IDENTIFIED BY 'sst';
datadir=/var/lib/mysl
[xtrabackup]user=sstpassword=sst

Lab 2: backup and restore Handso
n!
node3# /etc/init.d/mysql stopnode3# cd /var/lib/mysql; rm rf *node3# nc l 9999 | tar xvmfi
node1# innobackupex stream=tar /tmp | nc 192.168.70.3 9999
node3# innobackupex applylog .node3# chown R mysql. /var/lib/mysql
node1 mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.70.3' IDENTIFIED BY 'pluk';

Lab 2: backup and restore Handso
n!
node3# /etc/init.d/mysql stopnode3# cd /var/lib/mysql; rm rf *node3# nc l 9999 | tar xvmfi
node1# innobackupex stream=tar /tmp | nc 192.168.70.3 9999
node3# innobackupex applylog .node3# chown R mysql. /var/lib/mysql
node1 mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.70.3' IDENTIFIED BY 'pluk';
we need to know the last GTID purged, check in/var/lib/mysql/xtrabackup_binlog_info

Lab 2: configuration for replication Handso
n!
[mysqld]binlog_format=ROWlog_slave_updates
wsrep_provider=/usr/lib/libgalera_smm.so wsrep_cluster_address=gcomm://192.168.70.3wsrep_node_address=192.168.70.3wsrep_cluster_name=Pluk2k13wsrep_node_name=node3wsrep_slave_threads=2wsrep_sst_method=xtrabackupv2wsrep_sst_auth=sst:sstinnodb_autoinc_lock_mode=2innodb_file_per_table
gtid_mode=onenforce_gtid_consistencyskip_slave_startserverid=3log_bin=mysqlbin
datadir=/var/lib/mysql
[xtrabackup]user=sstpassword=sst
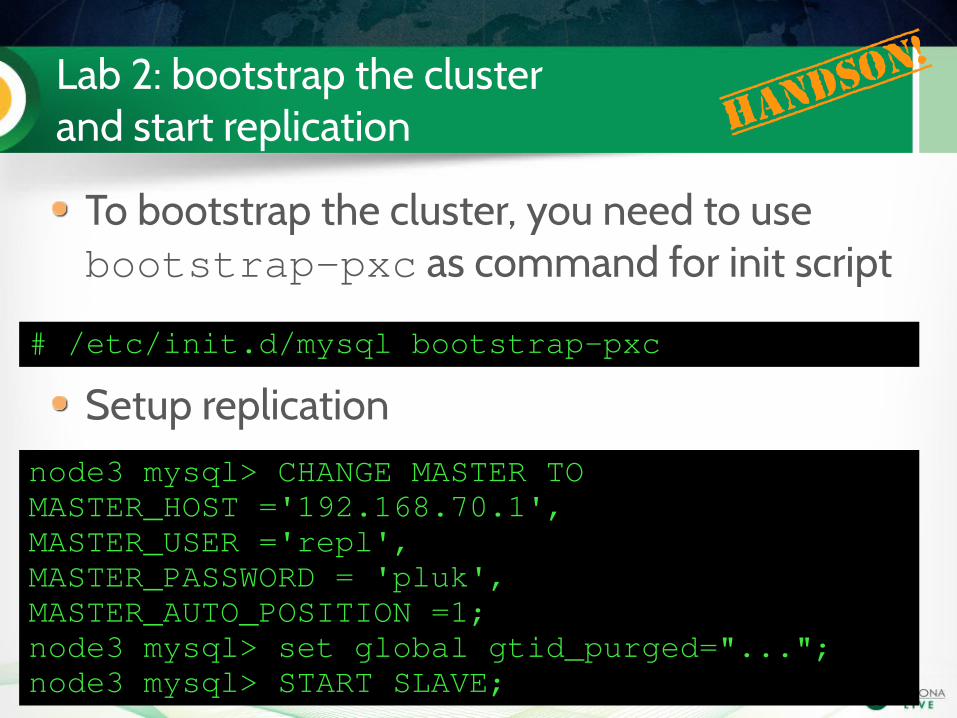
Lab 2: bootstrap the cluster and start replication Han
dson!
# /etc/init.d/mysql bootstrappxc
To bootstrap the cluster, you need to use bootstrappxc as command for init script
Setup replicationnode3 mysql> CHANGE MASTER TO MASTER_HOST ='192.168.70.1',MASTER_USER ='repl',MASTER_PASSWORD = 'pluk',MASTER_AUTO_POSITION =1;node3 mysql> set global gtid_purged="...";node3 mysql> START SLAVE;

Lab 2: bootstrap the cluster and start replication Han
dson!
# /etc/init.d/mysql bootstrappxc
To bootstrap the cluster, you need to use bootstrappxc as command for init script
Setup replicationnode3 mysql> CHANGE MASTER TO MASTER_HOST ='192.168.70.1',MASTER_USER ='repl',MASTER_PASSWORD = 'pluk',MASTER_AUTO_POSITION =1;node3 mysql> set global gtid_purged="...";node3 mysql> START SLAVE;
Did you disable selinux ??setenforce 0

Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both PXC nodes
node2PXC
node3PXCslave
Handso
n!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3wsrep_node_address=192.168.70.2wsrep_node_name=node2[...]
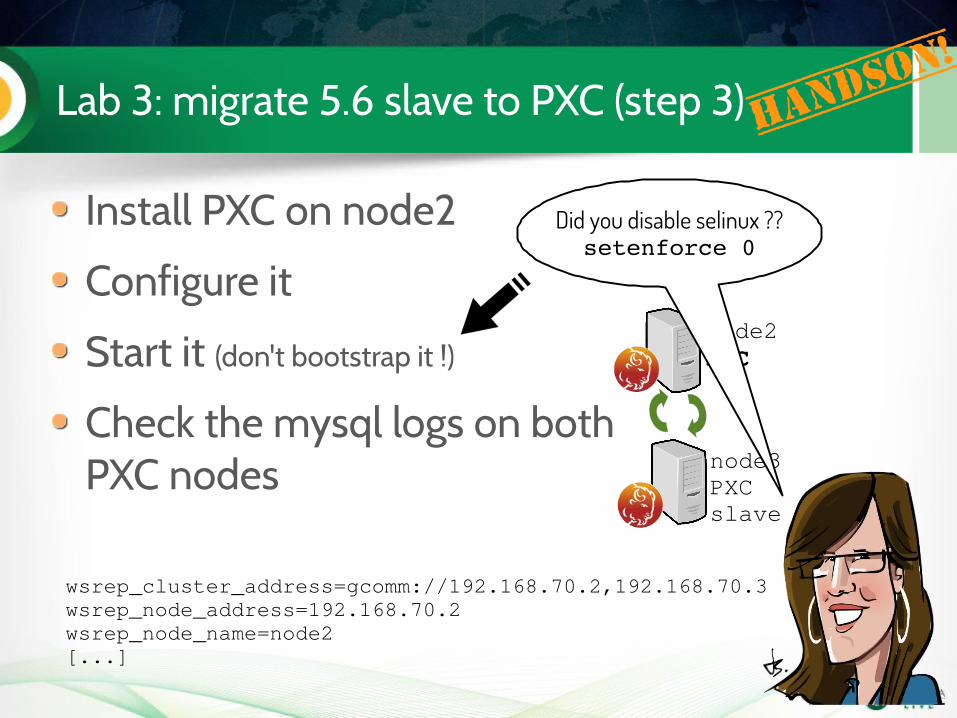
Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both PXC nodes
node2PXC
node3PXCslave
Handso
n!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3wsrep_node_address=192.168.70.2wsrep_node_name=node2[...]
Did you disable selinux ??setenforce 0

Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both PXC nodes
node2PXC
node3PXCslave
Handso
n!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3wsrep_node_address=192.168.70.2wsrep_node_name=node2[...]
on node3 (the donor) tail the file innobackup.backup.log in datadiron node 2 (the joiner) as soon as created check the file innobackup.prepare.log

Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both PXC nodes
node2PXC
node3PXCslave
Handso
n!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3wsrep_node_address=192.168.70.2wsrep_node_name=node2[...]
we can check on one of the nodes if the clusteris indeed running with two nodes:
mysql> show global status like 'wsrep_cluster_size';+++| Variable_name | Value |+++| wsrep_cluster_size | 2 |+++
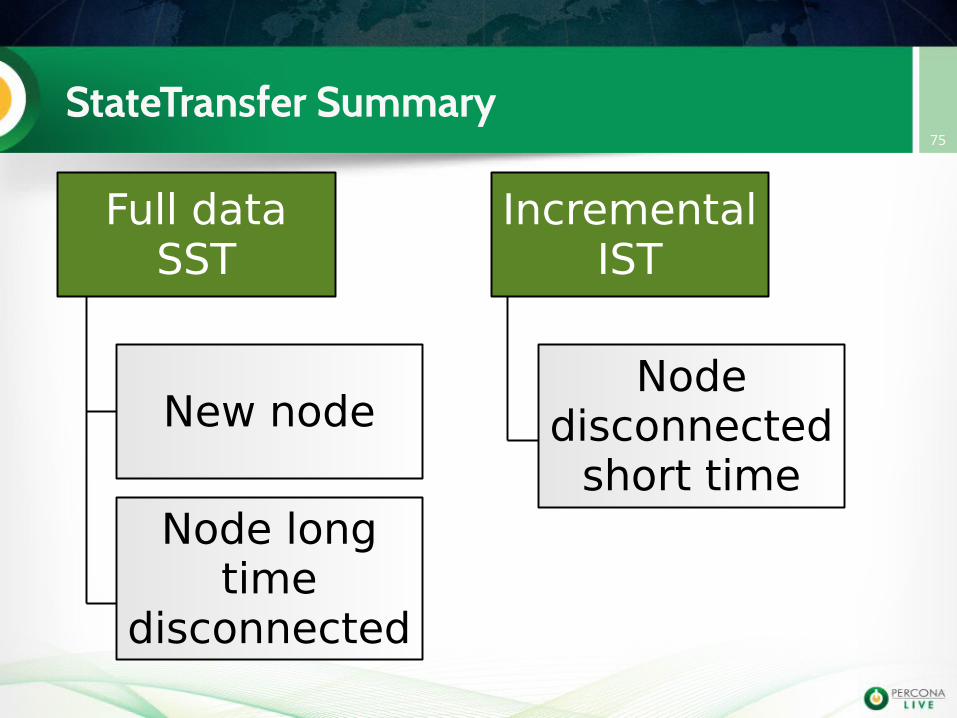
StateTransfer Summary75
Full dataSST
IncrementalIST
New node
Node longtime
disconnected
Nodedisconnected
short time
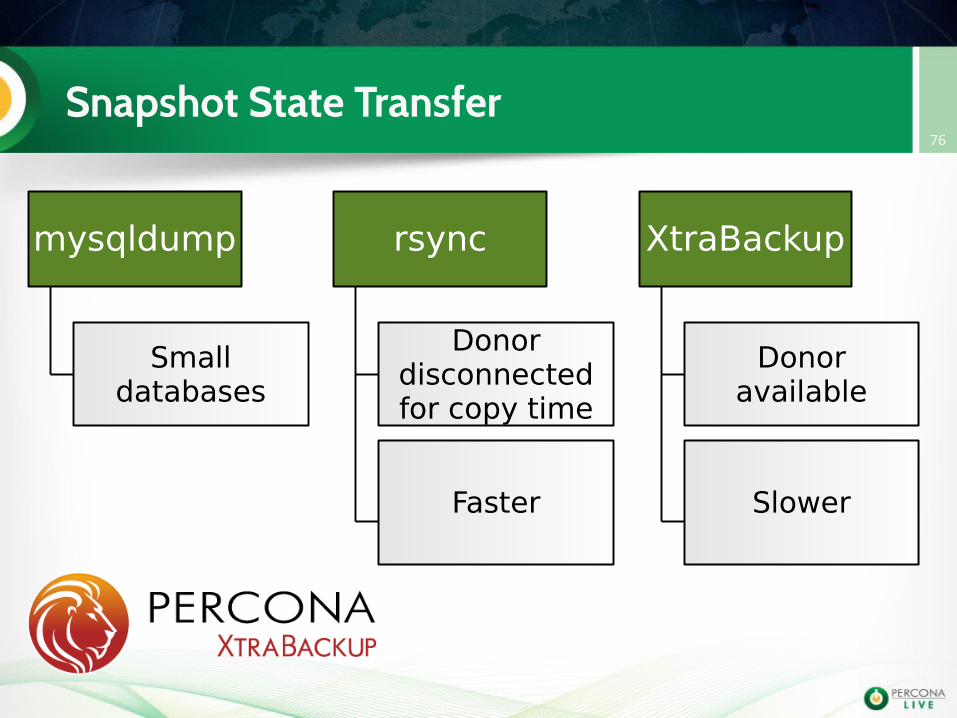
Snapshot State Transfer76
mysqldump
Smalldatabases
rsync
Donordisconnectedfor copy time
Faster
XtraBackup
Donoravailable
Slower
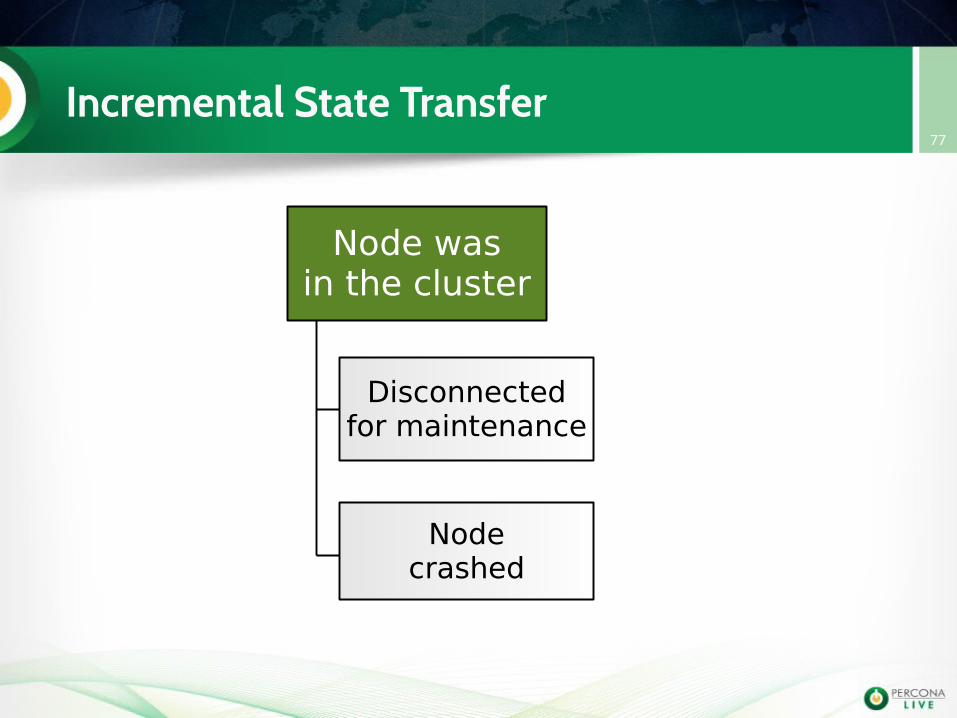
Incremental State Transfer77
Node wasin the cluster
Disconnectedfor maintenance
Nodecrashed
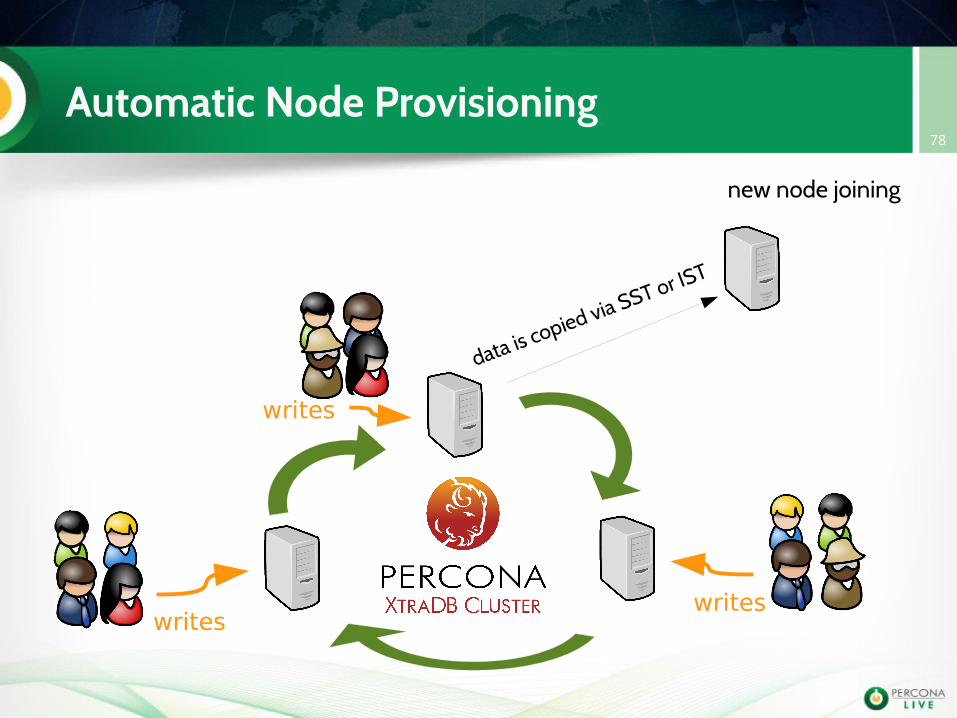
Automatic Node Provisioning78
writes
writeswrites
new node joining
data is copied via SST or IST
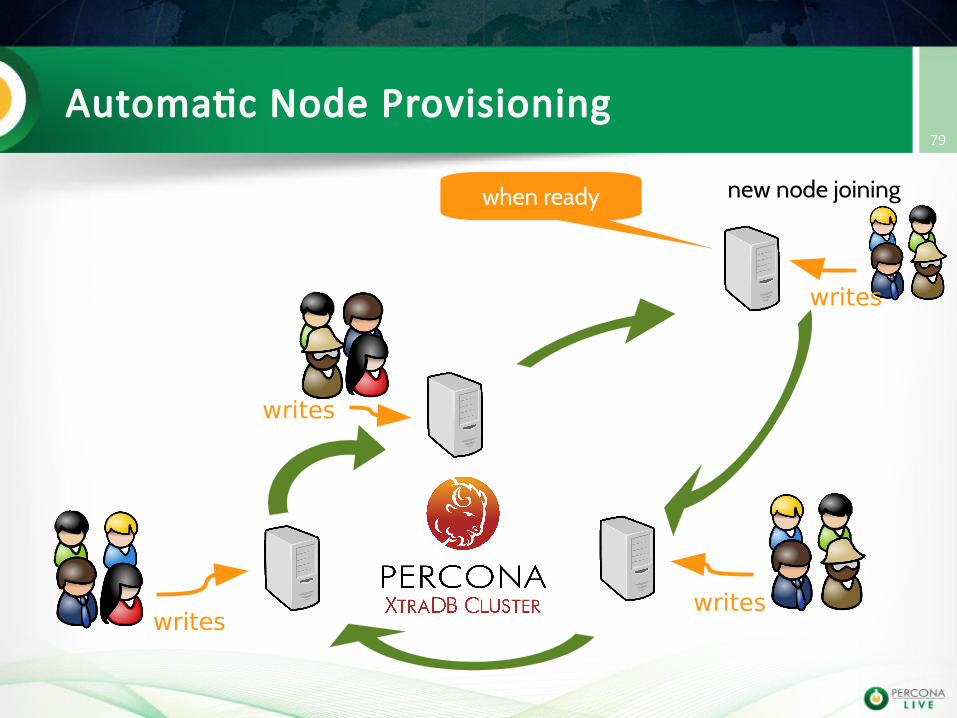
Automatic Node Provisioning79
writes
writeswrites
new node joiningwhen ready
writes

What's new in SST

XtraBackup as SST
XtraBackup as SST now supports xbstream format. This allows:– Xtrabackup in parallel
– Compression
– Compact format
– Encryption

Lab 4: Xtrabackup & xbstreamas SST (step 4)
Migrate the master to PXC
Configure SST to use Xtrabackup with 2 threads and compression
[mysqld]wsrep_sst_method=xtrabackupv2wsrep_sst_auth=sst:sst
[xtrabackup]compressparallel=2compressthreads=2
[sst]streamfmt=xbstream
Handso
n!
qpress needs to be installed on all nodes
don't forget to stop & reset async slave

Using a load balancer

PXC with a Load balancer
• PXC can be integrate with a load balancer and service can be checked using clustercheck or pyclustercheck
• The load balancer can be a dedicated one• or integrated on each application servers
84
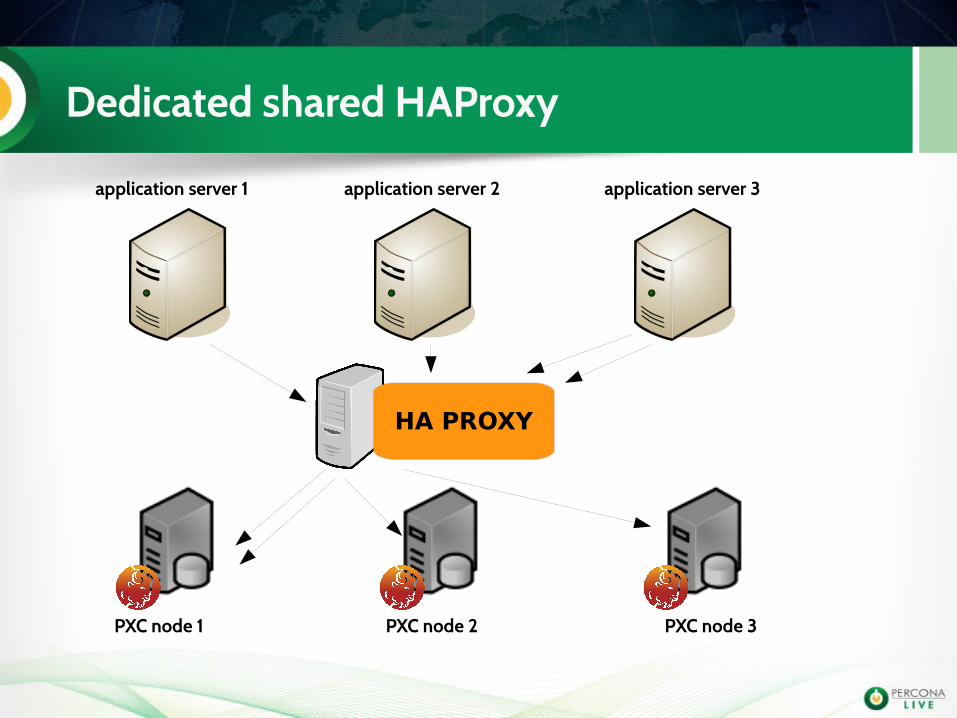
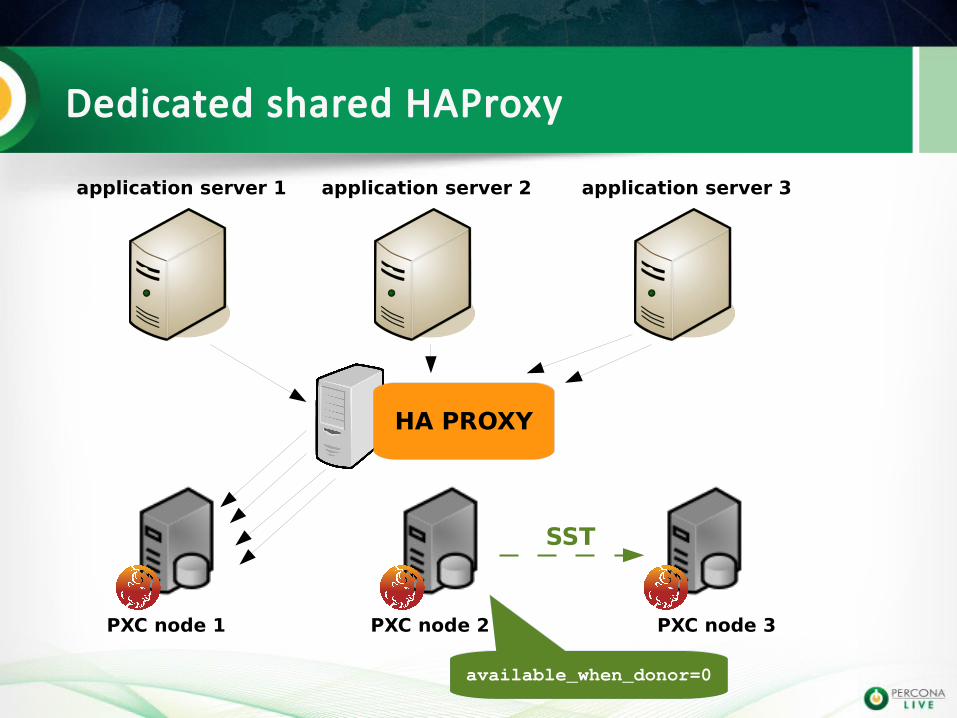
Dedicated shared HAProxy
application server 1 application server 2 application server 3
PXC node 1 PXC node 2 PXC node 3
HA PROXY

Dedicated shared HAProxy
application server 1 application server 2 application server 3
PXC node 1 PXC node 2 PXC node 3
HA PROXY
Dedicated shared HAProxy
application server 1 application server 2 application server 3
PXC node 1 PXC node 2 PXC node 3
HA PROXY
SST
available_when_donor=0
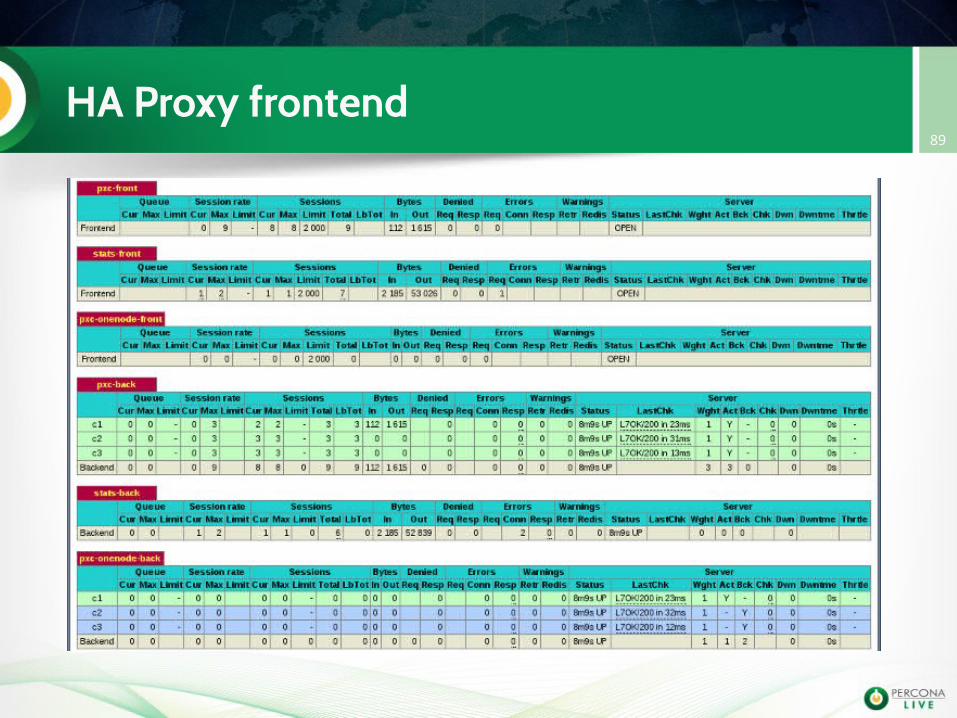
HA Proxy frontend89

Lab 5: PXC and Load Balancer Handso
n!
Intsall xinetd and configure mysqchk on all nodes
Test that it works using curl
Install HA Proxy (haproxy.i686) on app and start it
Connect on port 3306 several times on app, what do you see?
Connect on port 3307 several times, what do you see ?
Modify runapp.sh to point to 192.168.70.4, run it...
Check the HA proxy frontend (http://127.0.0.1:8081/haproxy/stats)
Stop xinetd on the node getting the writes, what do you see ?
haproxy's configuration file is /etc/haproxy/haproxy.cfg

Rolling out changes
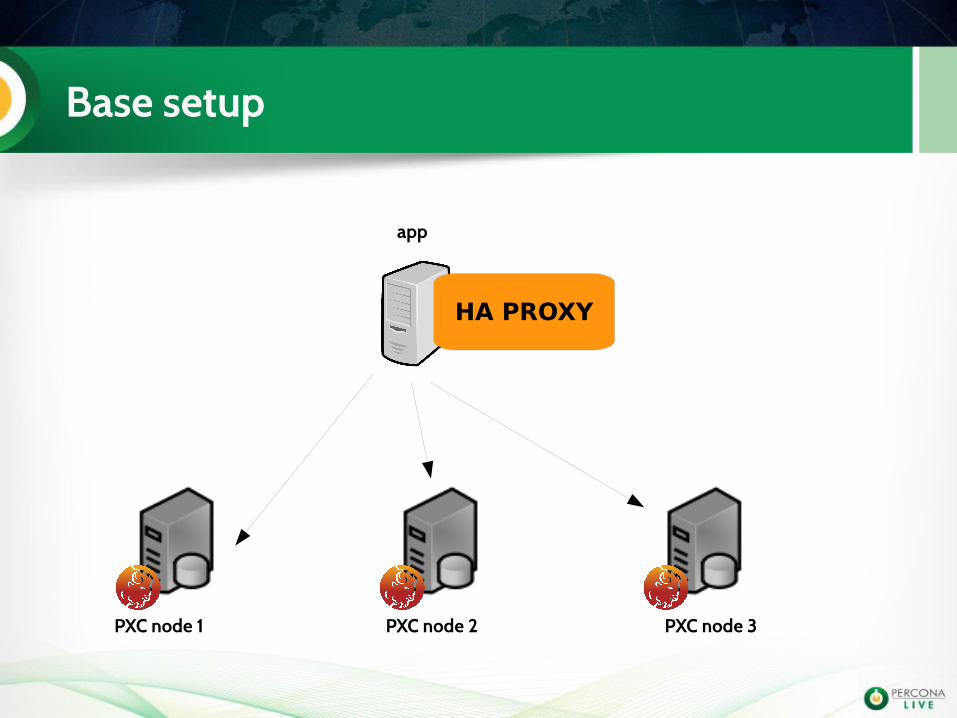
Base setup
app
PXC node 1 PXC node 2 PXC node 3
HA PROXY
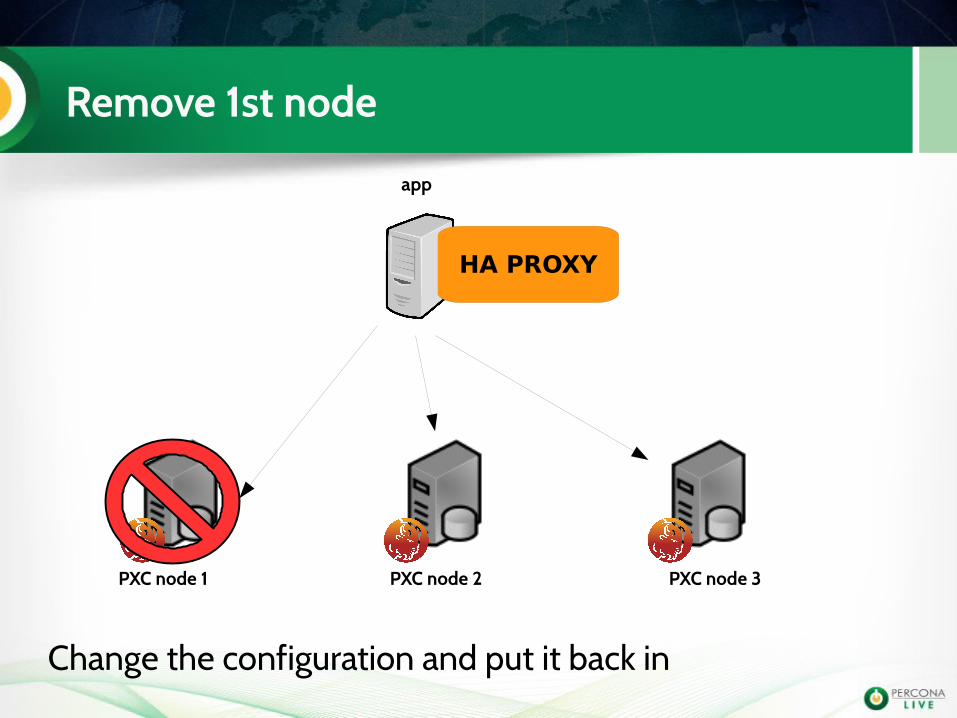
Remove 1st node
app
PXC node 1 PXC node 2 PXC node 3
HA PROXY
Change the configuration and put it back in
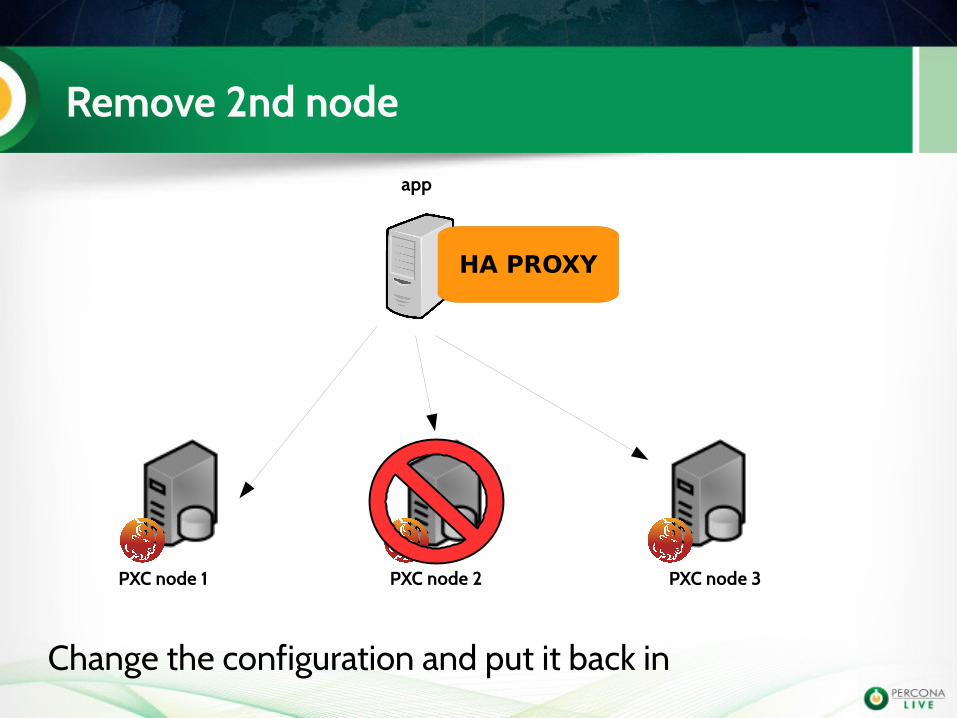
Remove 2nd node
app
PXC node 1 PXC node 2 PXC node 3
HA PROXY
Change the configuration and put it back in
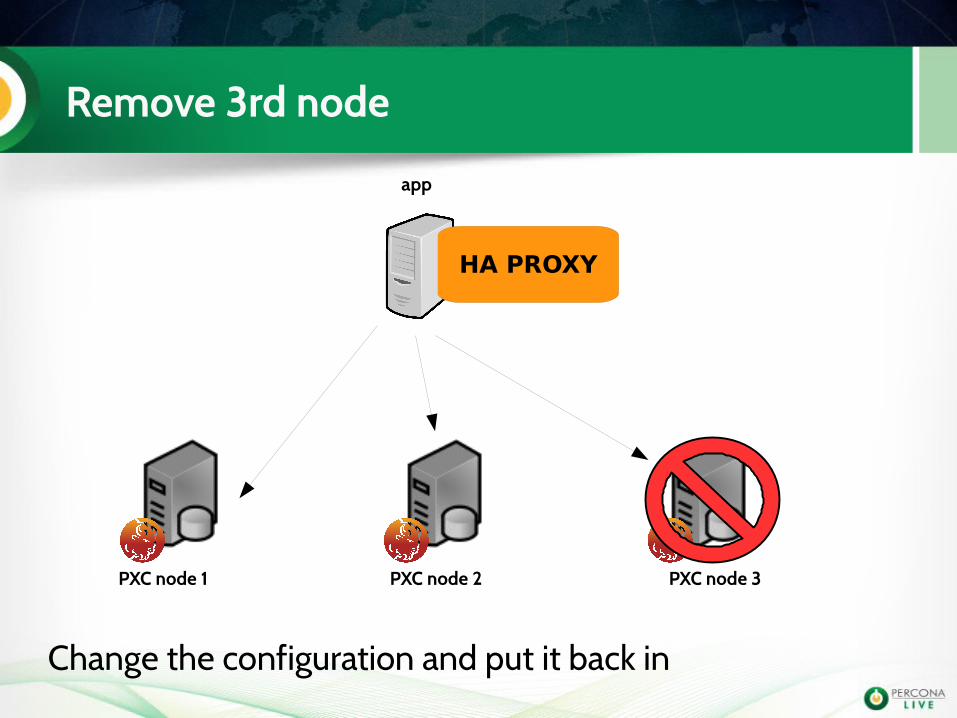
Remove 3rd node
app
PXC node 1 PXC node 2 PXC node 3
HA PROXY
Change the configuration and put it back in

Lab 6: Configuration changes Handso
n!
Set wsrep_slave_threads=4 on all nodes without bringing down the whole cluster.
Make sure that the backend is down in haproxy.
Hint:# service xinetd stop… do the change ...# service xinetd start

Schema changes: pt-online-shema-change
Does the work in chunks
Everything is done in small transactions, which counts as a good workload
It can't modify tables with triggers
It's slower than 5.6 online DDL

Schema changes: 5.6's ALTER
It can be lockless, but it will be a large transcation which has to replicate
Most likely it will cause a stall because of that.
If the change is RBR compatible, it can be done on a node by node basis.
if the transaction is not too large, with 5.6 always try an alter statementwith lock=NONE and if it fails, then
use ptosc

Schema changes: RSU (rolling schema upgrade)
PXC's built-in solution
Puts the node into desync node during the alter.
ALTER the nodes one by one
Set using wsrep_OSU_method

Finer control for advanced users
Since PXC 5.5.33-23.7.6 you can manage your DDL (data definition language) you can proceed as follow:
mysql> SET GLOBAL wsrep_desync=ON;mysql> SET wsrep_on=OFF;... DDL (optimize, add index, rebuild, etc.) ...mysql> SET wsrep_on=ON;mysql> SET GLOBAL wsrep_desync=OFF
This is tricky and risky, try to avoid ;-)

Finer control for advanced users
Since PXC 5.5.33-23.7.6 you can manage your DDL (data definition language) you can proceed as follow:
mysql> SET GLOBAL wsrep_desync=ON; mysql> SET wsrep_on=OFF; ... DDL (optimize, add index, rebuild, etc.) ...mysql> SET wsrep_on=ON;mysql> SET GLOBAL wsrep_desync=OFF
this allows the node to fall
behind the cluster

Finer control for advanced users
Since PXC 5.5.33-23.7.6 you can manage your DDL (data definition language) you can proceed as follow:
mysql> SET GLOBAL wsrep_desync=ON; mysql> SET wsrep_on=OFF; ... DDL (optimize, add index, rebuild, etc.) ...mysql> SET wsrep_on=ON;mysql> SET GLOBAL wsrep_desync=OFF
this disables replication for the given session

myq_gadgets
During the rest of the day we will use myq_status to monitor our cluster
Command line utility part of myq_gadgets
Written by Jay Janssen - https://github.com/jayjanssen/myq_gadgets

Lab 7: Schema changes Handso
n!
Do the following schema change.– With regular ALTER
– With pt-online-schema-change
– With RSU
– With 5.6's online ALTER
ALTER TABLE sbtest.sbtest1 ADD COLUMN d VARCHAR(5);ALTER TABLE sbtest.sbtest1 DROP COLUMN d;
make sure sysbenchis running and
don't forget to examinemyq_status

Let's break things

PXC manages Quorum
If a node does not see more than 50% of the total amount of nodes: reads/writes are not accepted.
Split brain is prevented
This requires at least 3 nodes to be effective
a node can be an arbitrator (garbd), joining the communication, but not having any MySQL running
Can be disabled (but be warned!)
You can cheat and play with node weight
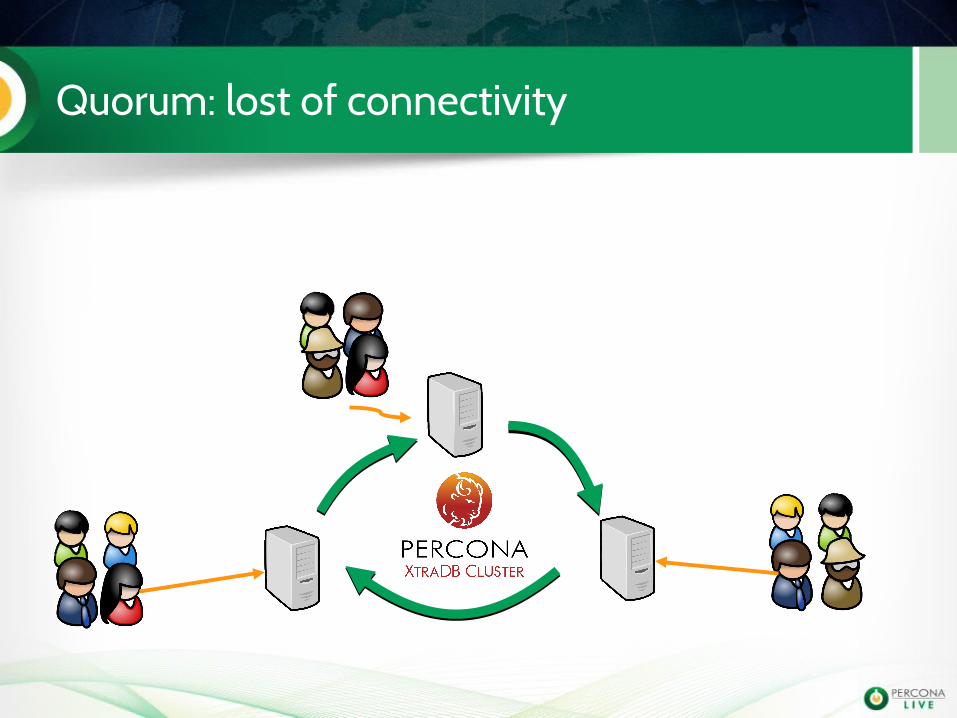
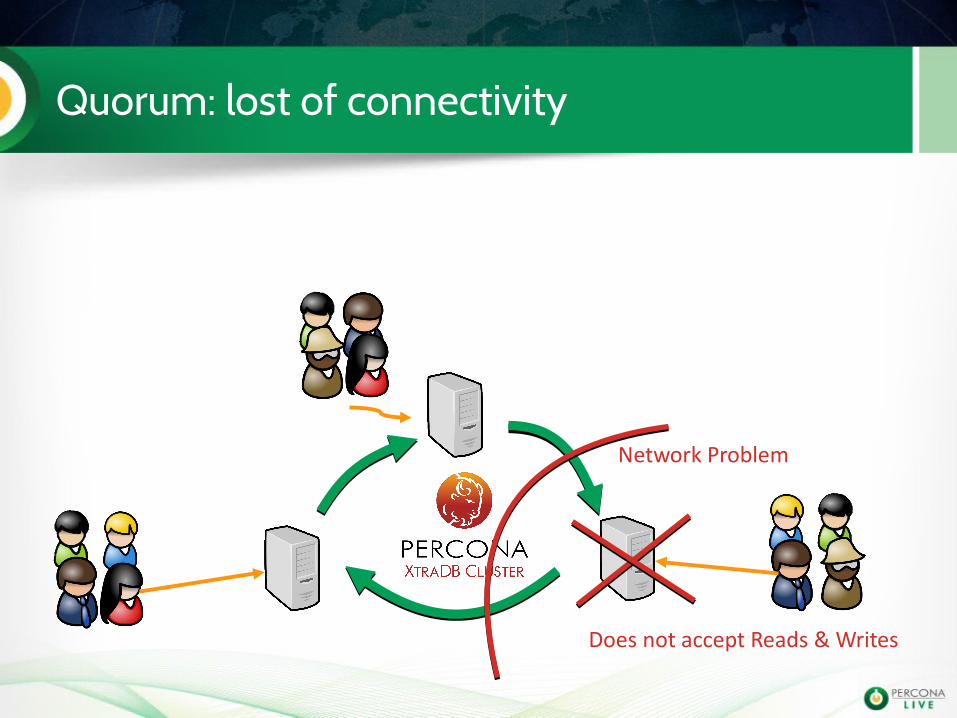
Quorum: lost of connectivity
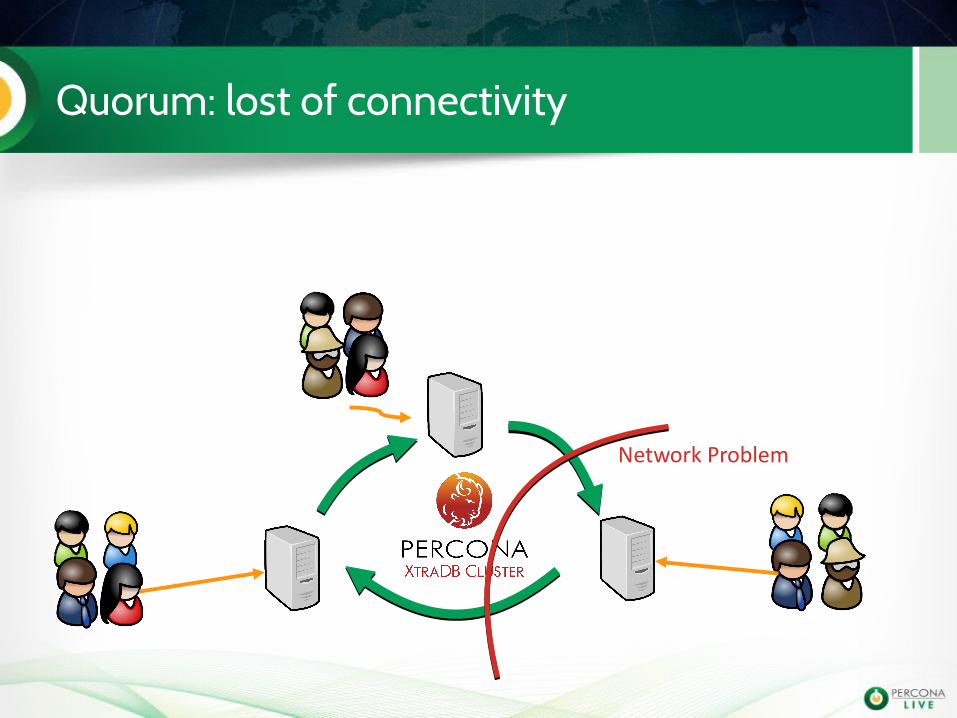
Quorum: lost of connectivity
Network Problem
Quorum: lost of connectivity
Network Problem
Does not accept Reads & Writes
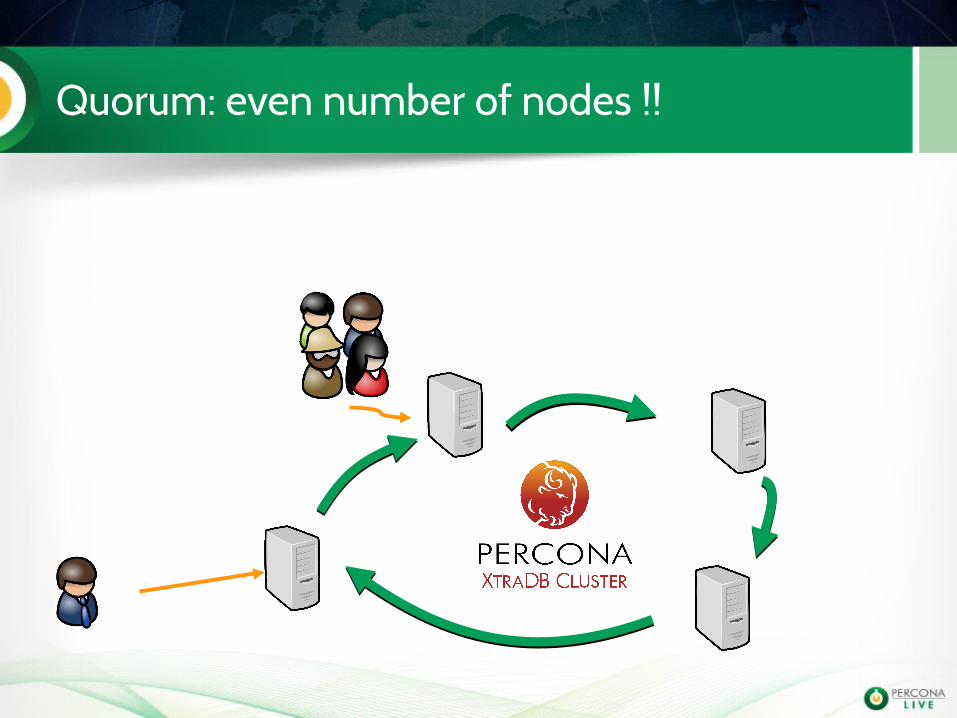
Quorum: even number of nodes !!
Quorum: even number of nodes !!
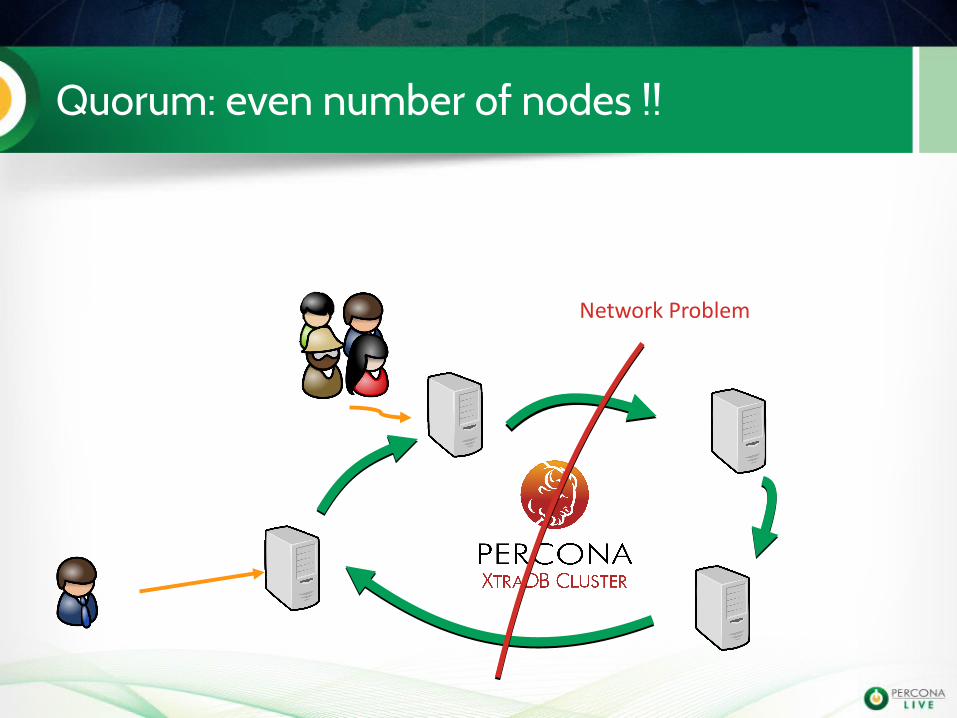
Network Problem
Quorum: even number of nodes !!
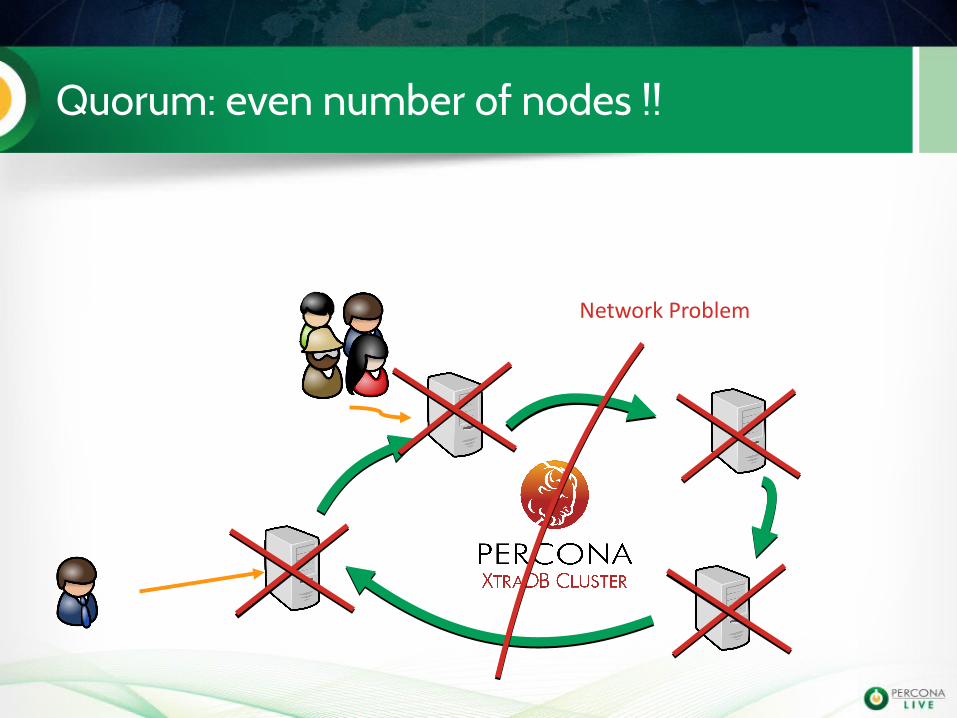
Network Problem
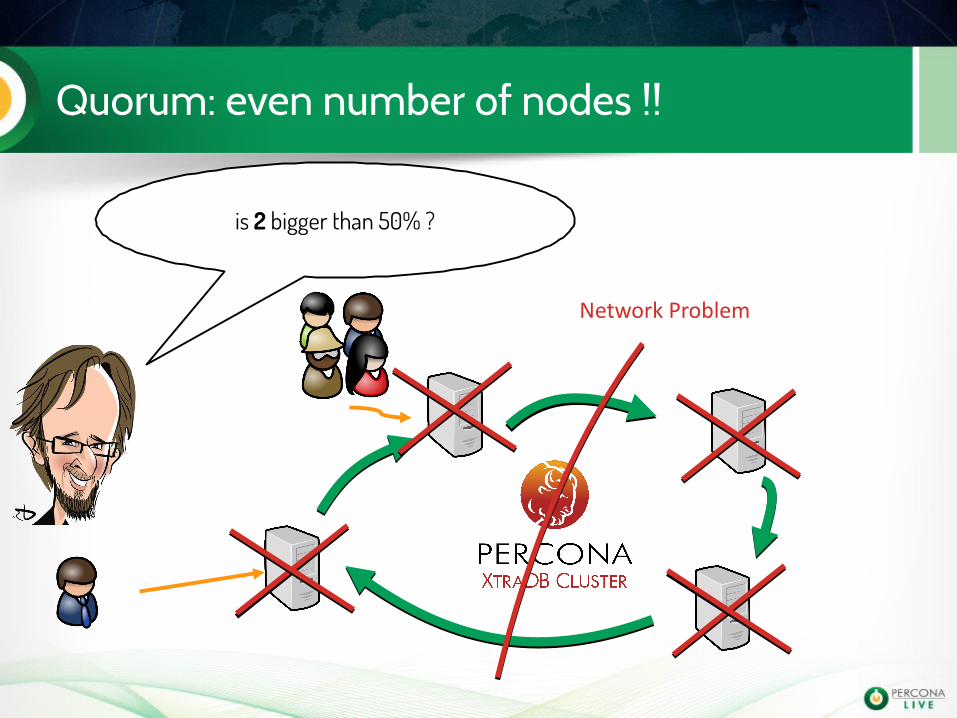
Quorum: even number of nodes !!
Network Problem
is 2 bigger than 50% ?

This is to avoid split-brain !!
Network Problem
no it's NOT !!FIGHT !!

Cheat with nodes weight for quorum
You can define the weight of a node to affect the quorum calculation using the galera parameter pc.weight (default is 1)

Lab 8: Breaking things Handso
n!
Start sysbench through the load balancer.
Stop 1 node gracefully.
Stop 2 nodes gracefully.
Start all nodes.
Crash 1 node.
Crash an other node.
Hint: # service mysql stop# echo c > /proc/sysrqtrigger

Asynchronous replication from PXC
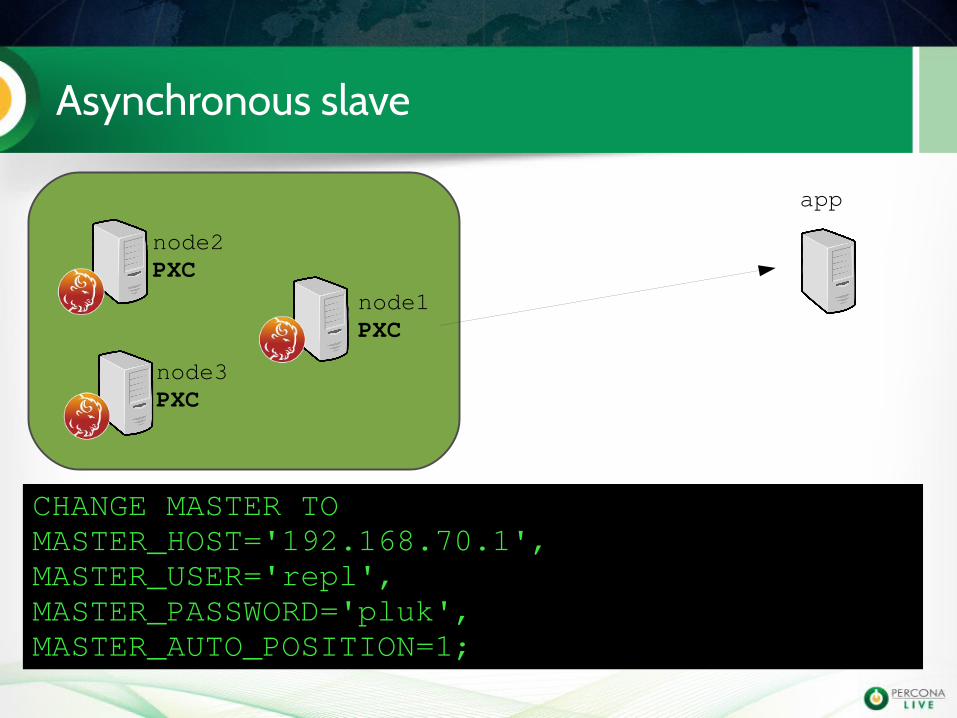
Asynchronous slave
app
node1PXC
node2PXC
node3PXC
CHANGE MASTER TOMASTER_HOST='192.168.70.1',MASTER_USER='repl',MASTER_PASSWORD='pluk',MASTER_AUTO_POSITION=1;

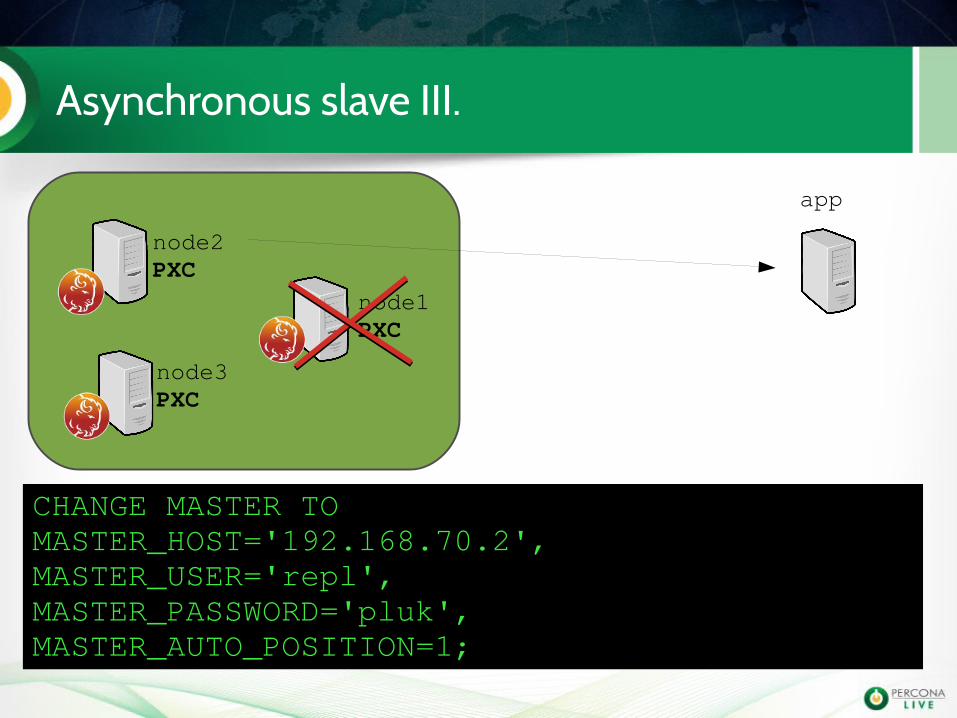
Asynchronous slave II.
app
node1PXC
node2PXC
node3PXC
If the node crashes, the async slave won't getthe updates.
Asynchronous slave III.
app
node1PXC
node2PXC
node3PXC
CHANGE MASTER TOMASTER_HOST='192.168.70.2',MASTER_USER='repl',MASTER_PASSWORD='pluk',MASTER_AUTO_POSITION=1;
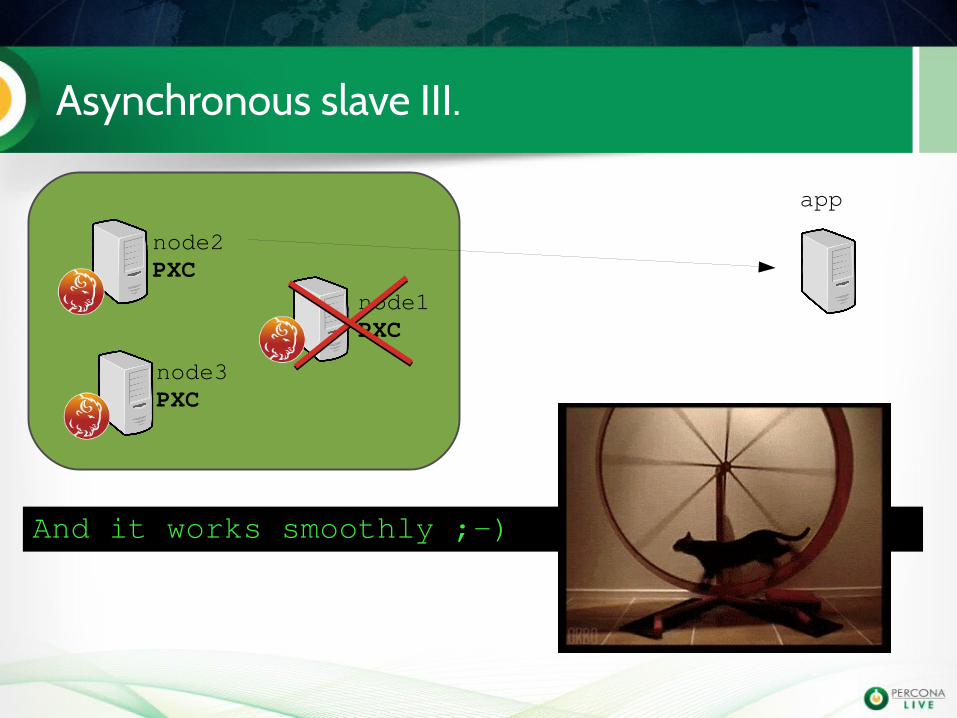
Asynchronous slave III.
app
node1PXC
node2PXC
node3PXC
And it works smoothly ;)

Lab 9: Asynchronous replication Handso
n!
Prepare the cluster for this lab
– nothing to do as we use xtrabackup >= 2.1.7 ;-)
Make sure some sysbench workload is running through some haproxy
before xtrabackup 2.1.7, rsync was the only
sst method supporting the copy of binary logs

Lab 9: Asynchronous replication Handso
n!
Install Percona Server 5.6 on app and make it a slave
Set the port to 3310 (because haproxy)
Crash node 1
Reposition replication to node 2 or 3
CHANGE MASTER TOMASTER_HOST='192.168.70.2',MASTER_USER='repl',MASTER_PASSWORD='pluk',MASTER_AUTO_POSITION=1;
# echo c > /proc/sysrqtrigger

WAN replication

WAN replication
MySQL
MySQL
MySQL
Works fine
Use higher timeouts and send windows
No impact on reads
No impact within a transaction
Increase commit latency

WAN replication - latencies
MySQL
MySQL
MySQL
Beware of latencies
Within EUROPE EC2– INSERT INTO table: 0.005100 sec
EUROPE <-> JAPAN EC2– INSERT INTO table: 0.275642 sec

WAN replication with MySQL asynchronous replication
MySQL
MySQL
MySQL
You can mix both replications
Good option on slow WAN link
Requires more nodes
If binlog position is lost, full cluster must be reprovisioned
MySQL
MySQL
MySQL
MySQL
MySQL MySQL

Better WAN Replication with Galera 3.0
Galera 3.0's replication mode is optimized for high latency networks
Uses cluster segments
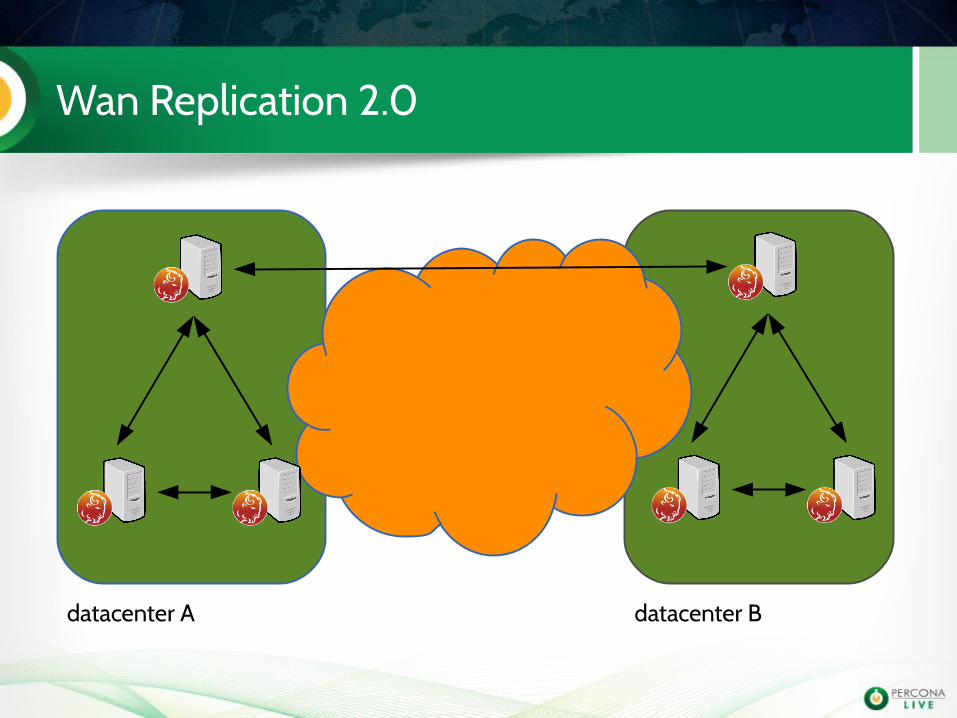
Wan Replication 2.0
datacenter A datacenter B
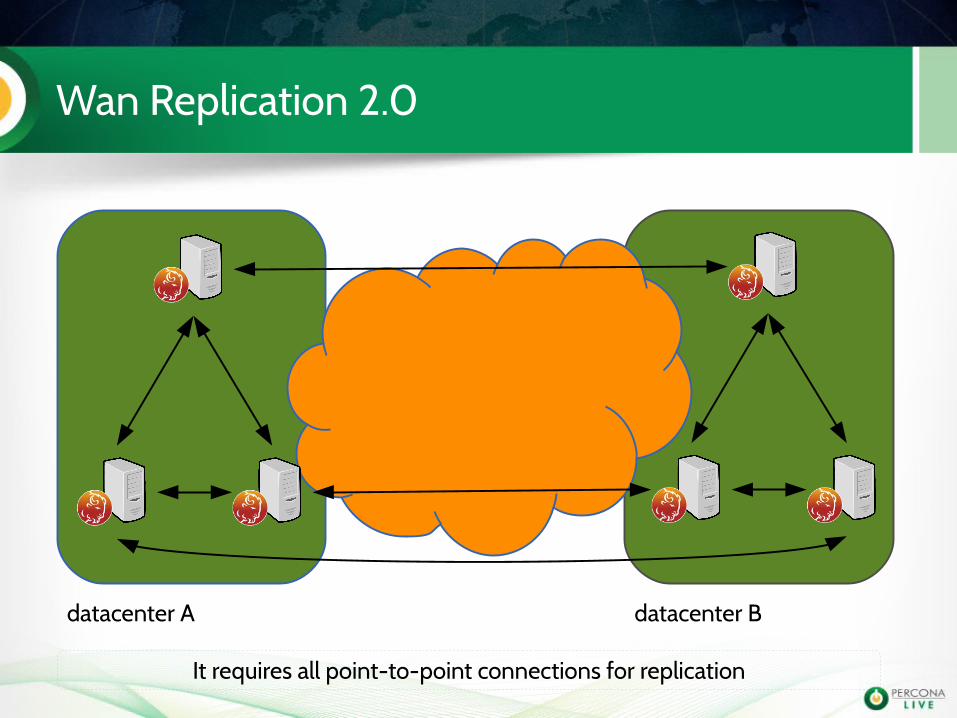
Wan Replication 2.0
datacenter A datacenter B
It requires all point-to-point connections for replication
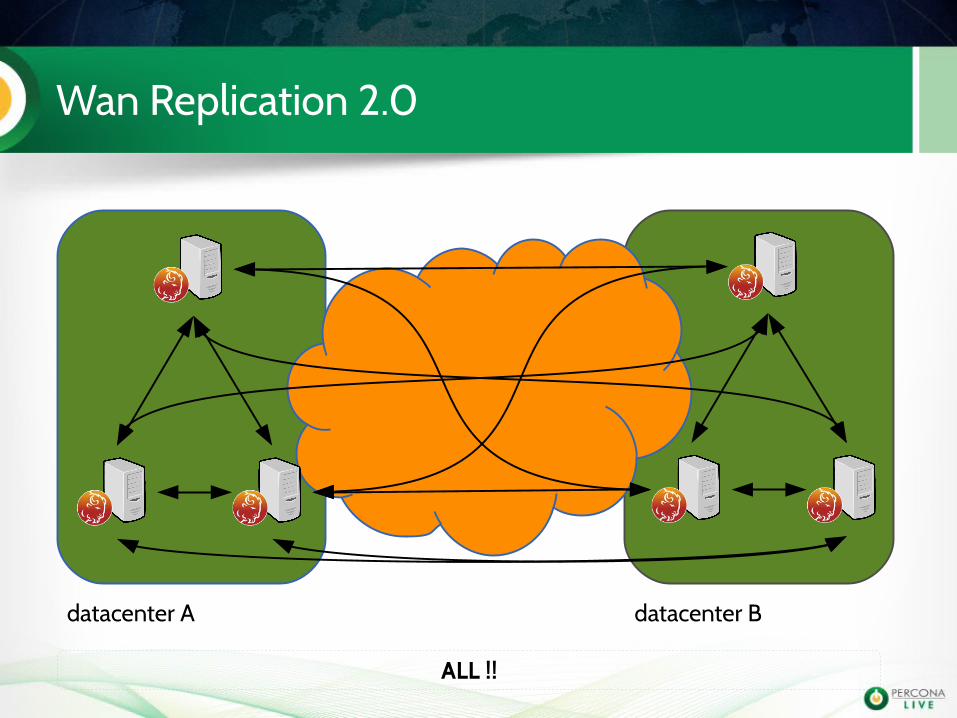
Wan Replication 2.0
datacenter A datacenter B
ALL !!
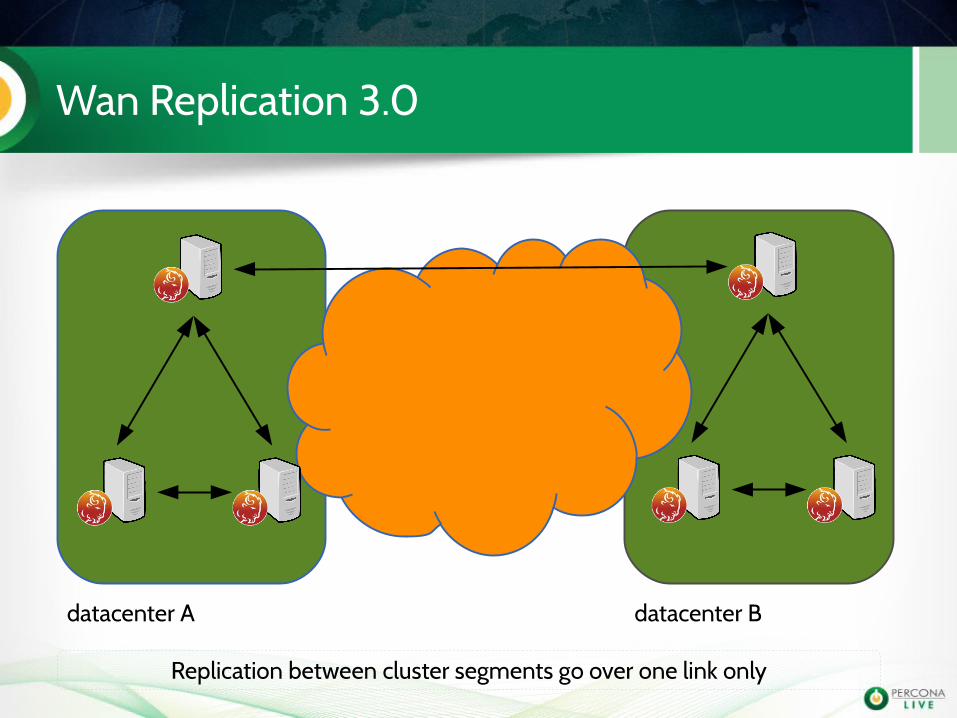
Wan Replication 3.0
datacenter A datacenter B
Replication between cluster segments go over one link only
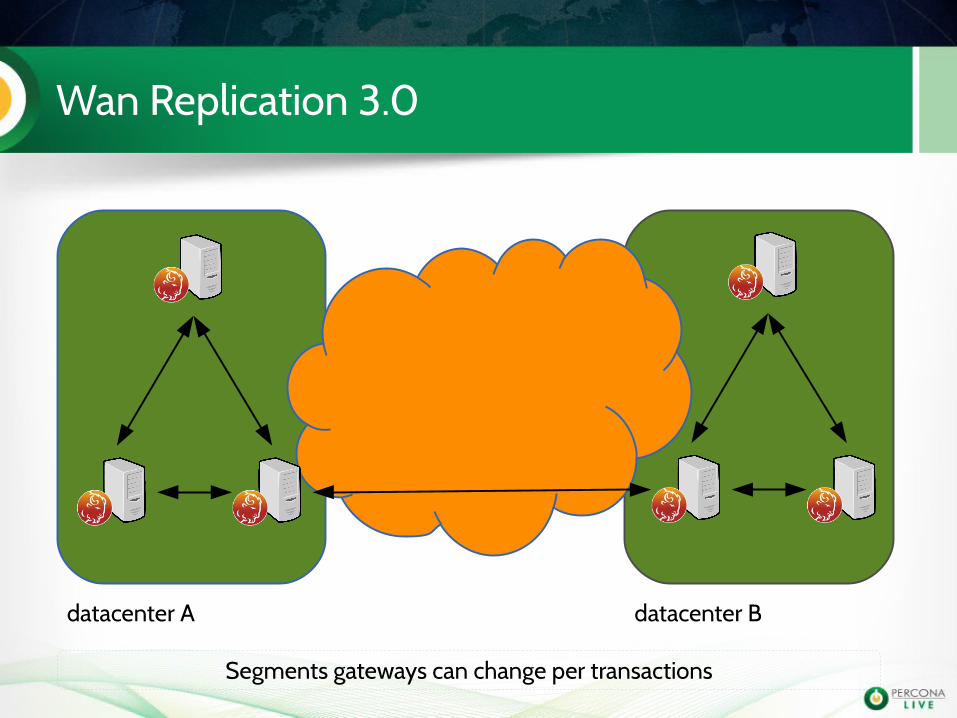
Wan Replication 3.0
datacenter A datacenter B
Segments gateways can change per transactions
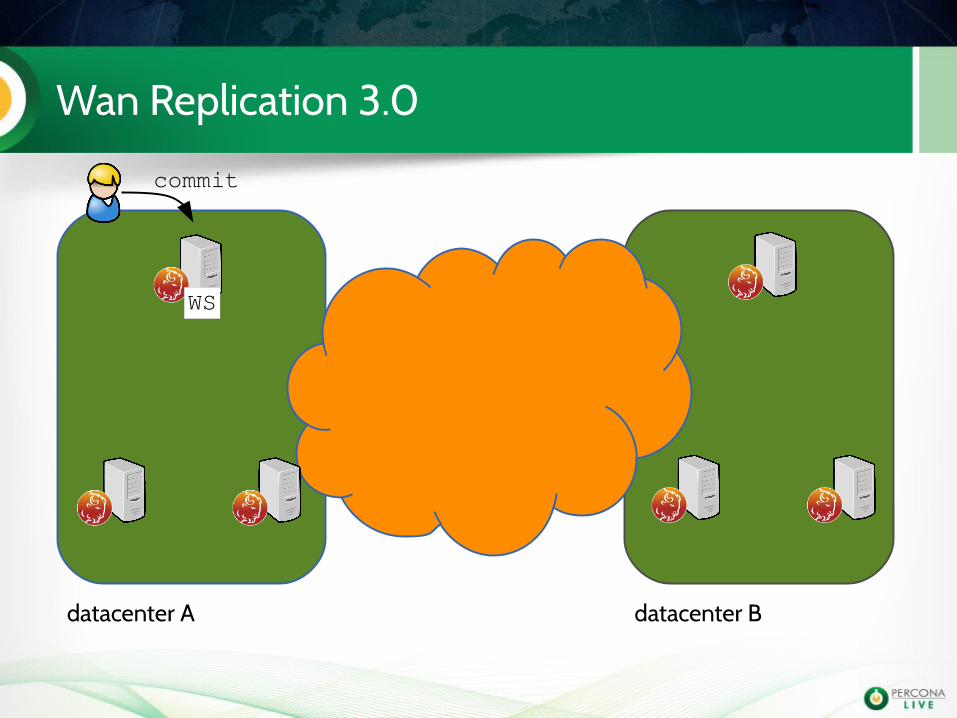
Wan Replication 3.0
datacenter A datacenter B
commit
WS
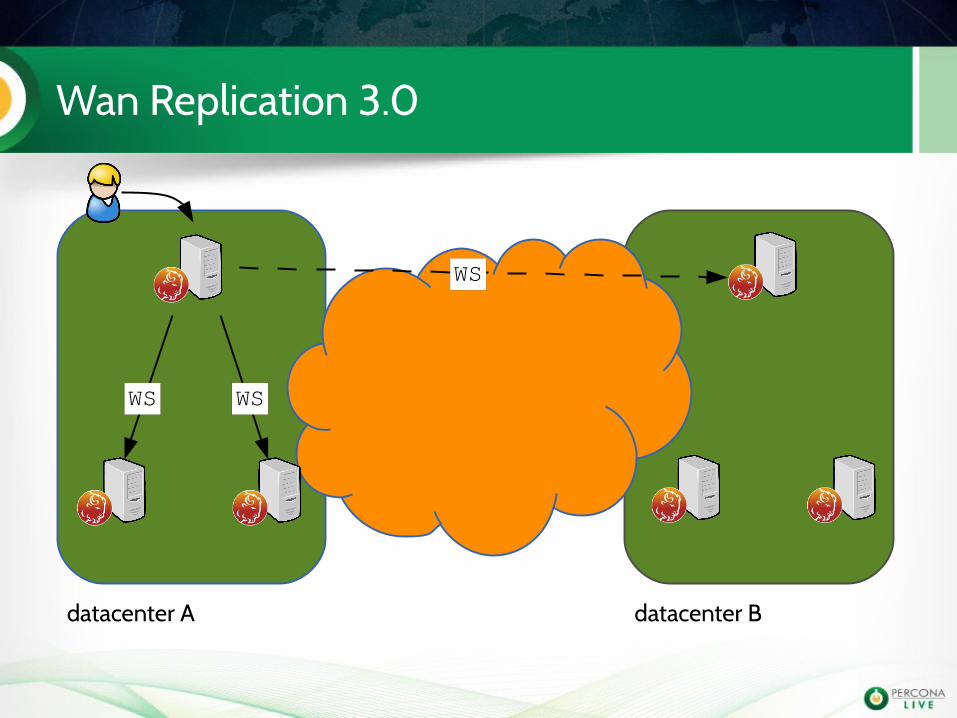
Wan Replication 3.0
datacenter A datacenter B
WSWS
WS
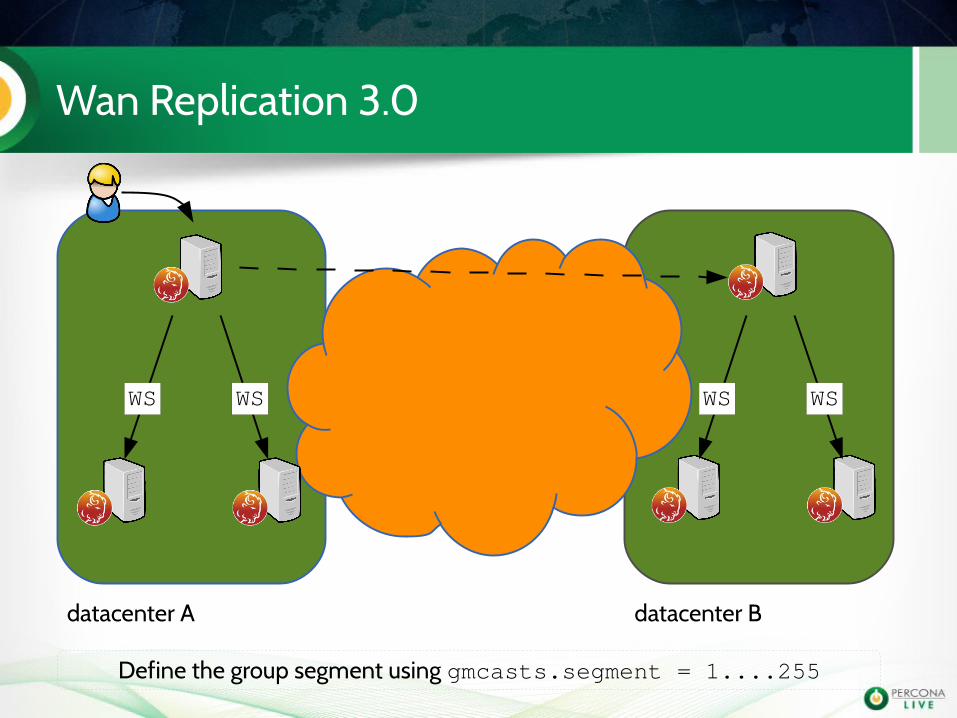
Wan Replication 3.0
datacenter A datacenter B
WSWS WSWS
Define the group segment using gmcasts.segment = 1....255

Lab 10: WAN Handso
n!
Run the application
Check the traffic and the connections using iftop N P i eth1 f "port 4567"
Put node3 on a second segment
Run again the application
What do you see when you check the traffic this time ?

Credits
WSREP patches and Galera library is developed by Codership Oy
Percona & Codership present tomorrow http://www.percona.com/live/london-2013/

Resources
Percona XtraDB Cluster website: http://www.percona.com/software/percona-xtradb-cluster/
Codership website: http://www.codership.com/wiki/doku.php
PXC articles on percona's blog: http://www.percona.com/blog/category/percona-xtradb-cluster/
devops animations: http://devopsreactions.tumblr.com/

Thank you !
tutorial is OVER !

Percona provides
24 x 7 Support Services Quick and Easy Access to Consultants Same Day Emergency Data Recovery Remote DBA Services [email protected] or 00442081330309


















