
M.Tech - Dissertation Presentation
28
Scaling Up Machine Learning Verification and Validation of MapReduce Program Model for Parallel Support Vector Machine Algorithm on Hadoop Cluster 09 th April 2013 Presented by, KIRAN M. IV Sem, M.Tech - CSE Reg. No. 1127108 Under the guidance of Dr. Ravi Prakash G. Co – Guide: Mr. Saikat Mukherjee (Senior Software Engineer, HP)
description
Keywords: Machine Learning, SVM, LIBSVM, WEKA Tool, MultiFileWordCount, PiEstimator, Parallel SVM, Hadoop, MapReduce.Co-Authors: Amresh Kumar, Saikat Mukherjee and Dr. Ravi Prakash G.
Transcript of M.Tech - Dissertation Presentation

Scaling Up Machine LearningScaling Up Machine Learning
Verification and Validation of MapReduce Program Model for Parallel Support Vector Machine Algorithm on Hadoop Cluster
09th April 2013
Presented by,
KIRAN M. IV Sem, M.Tech - CSE
Reg. No. 1127108
Under the guidance of Dr. Ravi Prakash G.Under the guidance of
Dr. Ravi Prakash G.
Co – Guide: Mr. Saikat Mukherjee (Senior Software Engineer, HP)

Outline
► Presentation Plan: Stages & Main Outcomes
► Conclusion & Future Work
► References

Presentation Plan: Stages & Main Outcomes

Presentation Plan: Stages and Main Outcomes

Research Clarification
Machine Learning
Support Vector Machine
Hadoop
Cloudera

Machine Learning A major focus of machine learning research is the design of algorithms that recognize complex
patterns and make predictions/intelligent decisions based on input data.
Two forms of machine learning settings are: Supervised Learning – Example: Classification. Unsupervised Learning – Example: Data Clustering. Additional: Semi-supervised Learning – Example: Speech Analysis.
Application of machine learning methods to large databases is called data mining.

Support Vector Machine
A classification is defined as finding a separating hyperplane between 2 set of points , X+ & X- .
An SVM classifier [Supervised Learning & Binary Classification] is defined as the maximum margin classifier between X+ & X- sets.
The term support vectors refers to the vectors of both classes that touch or near to the margin lines.

Hadoop
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers.
- Grace Hopper
Hadoop provides a distributed file system and a framework for the analysis and transformation of very large data sets using the MapReduce Concept.Hadoop is an Apache project; all components are available via the Apache open source license.Standalone, Pseudo-distributed & Fully-distributed.
Hadoop Sub-Projects
Core: A set of components and interfaces for distributed file systems.
Avro: A data serialization system for efficient and persistent data storage.
MapReduce: A distributed data processing model. HDFS: A distributed file system.
ZooKeeper: Used for building distributed applications.HBase: A distributed, column-oriented database. Hive: A distributed data warehouse. Pig: A data flow language.Chukwa: A distributed data collection and analysis
system.
Doug Cutting

Cloudera
Cloudera Inc. is a software company that provides Apache Hadoop-based software, support and services called CDH.
CDH has version of Apache Hadoop packages and updates.
CDH4 (Cloudera's Distribution Including Apache Hadoop: Version 4)
CDH4 supports the following operating systems:
•For Red Hat-compatible systems, Cloudera provides:
o64-bit packages for Red Hat Enterprise Linux 5.7, CentOS 5.7, and Oracle Linux 5.6 with Unbreakable Enterprise Kernel.
o32-bit and 64-bit packages for Red Hat Enterprise Linux 6.2 and CentOS 6.2
•For Ubuntu systems, Cloudera provides 64-bit packages for the Long-Term Support (LTS) releases Lucid (10.04) and Precise (12.04).

Descriptive Study I
Base Paper: Synthesis Matrix
List of Problems
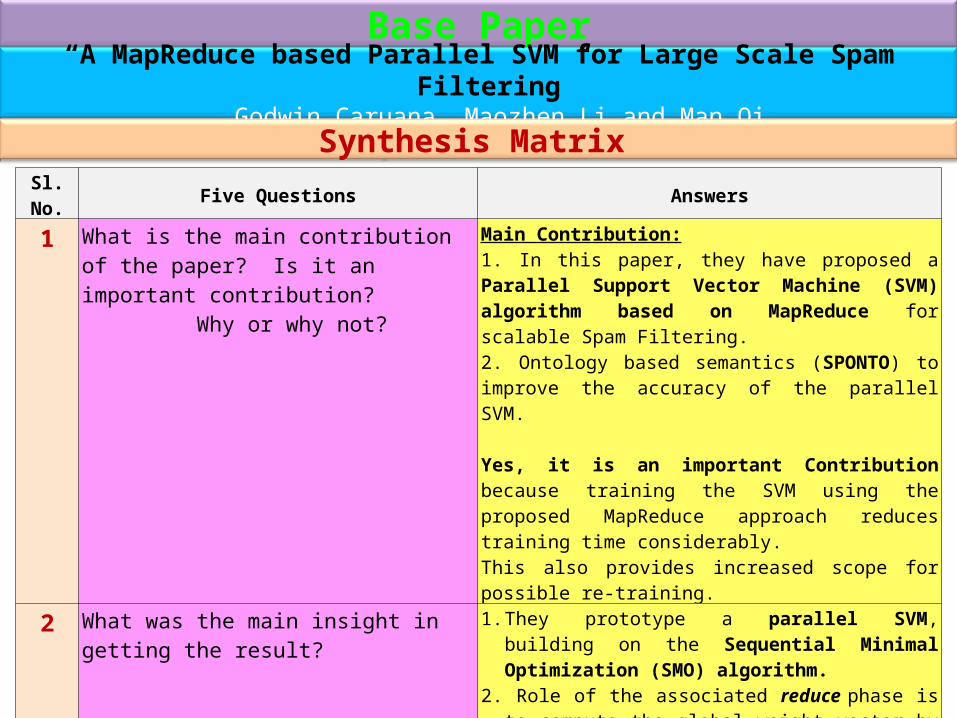
Base Paper“A MapReduce based Parallel SVM for Large Scale Spam Filtering”
Godwin Caruana, Maozhen Li and Man Qi
Synthesis Matrix
Sl. No. Five Questions Answers
1 What is the main contribution of the paper? Is it an important contribution? Why or why not?
Main Contribution:1. In this paper, they have proposed a Parallel Support Vector Machine (SVM) algorithm based on MapReduce for scalable Spam Filtering.2. Ontology based semantics (SPONTO) to improve the accuracy of the parallel SVM.
Yes, it is an important Contribution because training the SVM using the proposed MapReduce approach reduces training time considerably. This also provides increased scope for possible re-training.
2 What was the main insight in getting the result?
1. They prototype a parallel SVM, building on the Sequential Minimal Optimization (SMO) algorithm.
2. Role of the associated reduce phase is to compute the global weight vector by summing the individual maps weight vectors. The bias thresholds from each map output are averaged by the respective reduce phase.

Synthesis Matrix
Sl. No. Five Questions Answers
3 Propose an extension to the paper which would be interesting to consider. 1. Experimentation on the same approach i.e., using Parallel
SVM based on MapReduce with different Datasets.2. Ontology based approach can be used on other Datasets
for accuracy.3. Accuracy can be also further improved via automated
annotation.
4 Suggest a question arising from the paper.1. What are the other approaches for spam filtering?
2. How exactly MapReduce Works?
5 What are the applications of this work? Are the underlying assumptions appropriate for the applications?
Application of this Work:
1.By taking large number of instances, this approach reduces training time.

List of Problems
SVMs suffer from a widely recognized scalability problem in both memory use and computational time.
PSVM cannot achieve linear speedup when the number of machines continues to increase beyond a data-size-dependent threshold.
To improve scalability, a parallel SVM Algorithm is developed, which reduces memory use through parallel computation
This is expected because of Communication & Synchronization Overheads.Communication Time is incurred when message passing takes place between machines.Synchronization Overhead is incurred when the Master node waits for the task completion on the slowest machine.
By using Hadoop Cluster with the same versions of Software (CentOS 6.2) and same hardware configurations, linear speedup can be achieved.

Prescriptive Study
Hadoop Architecture
Overview of MapReduce
Parallel SVM using MapReduce

Hadoop Cluster Architecture

Overview of MapReduce
Input
Mapping Function
Output
Input
Reducing Function
Final Result

MapReduce Example – Vehicle Count
Car Bike BusCar Car BusBike Bus Car
Car Bike Bus
Car Car Bus
Bike Bus Car
Car,1Bike,1Bus,1
Car,1Car,1Bus,1
Bike,1Bus,1Car,1
Bus,1Bus,1Bus,1
Car,1Car,1Car,1Car,1
Bike,1Bike,1 Bike,2
Bus,3
Car,4
Bike,2Bus,3Car,4
Input Mapping Shuffling Reducing Final Result
Splitting

Structure and Flow of PSVM Algorithm using MapReduce
SVSV
REDUCE1Compute: Wglobal Sum (w1…wn)
REDUCE1Compute: Wglobal Sum (w1…wn)
Global w and SVGlobal w and SV
Data Chunkn
Data Chunkn
SVSV
Data Chunk1
Data Chunk1
Data Chunk2
Data Chunk2
Data Chunk3
Data Chunk3
MAP1 (w1)
MAP2 (w2)
MAP3 (w3)
MAPn (wn)
SVSV
SVSV
Training Dataset
Training Time

Descriptive Study II
Analysis of Sequential SVM
Analysis of MapReduce
Programs

Experiment: Sequential SVM using LIBSVM in WEKA
No. of Instances No. of Classes Training Time (sec)150 3 57846 4 265.75
2310 7 3024.354601 2 5256.29
10992 10 12556.3520000 26 22846.34
LIBSVM – Is a library for Support Vector Machines. SVC: Support Vector Classification (binary-class and multi-class).Implementation of MSVM - Three Methods based on binary classification: One-Against-All, One-Against-One and DAGSVM.Kernel Function: to map the data into a different space where a hyperplane can be used to do the separation. WEKA Tool LIBSVM Datasets used for the experiment are:Iris : Instances – 150 Attributes – 4 Classes - 3Vehicle : Instances – 846 Attributes – 18 Classes - 4Segment : Instances – 2310 Attributes – 19 Classes - 7SpamBase : Instances – 4601 Attributes – 57 Classes - 2Pendigits : Instances – 10992 Attributes – 16 Classes - 10Letter : Instances – 20000 Attributes – 16 Classes - 26

Analysis of Sequential SVM using LIBSVM in WEKA
Sequential SVM : No. of Instances versus Training Time
Result

Analysis of MapReduce Programs on Hadoop Cluster
Performance has been shown with respect to execution time/training time, number of files/maps/data size and number of nodes, using Hadoop cluster of four nodes.
One Master (NameNode) and Three Slaves (DataNodes)
NameNode – node4.christ.com
DataNodes – node1.christ.com, node2.christ.com, node3.christ.com
Experiment 01: MultiFileWordCount - A job that counts words from several files. Experiment 02: PiEstimator - A map/reduce program that estimates Pi using
Monte-Carlo method. Monte-Carlo method: are a broad class of computational algorithms that rely
on random sampling to obtain numerical results. Experiment 03: Parallel SVM – A map/reduce program that train the input data and results with
the Model.Graphical Analysis of Various Cases using Dataset
Sr. No. No. of Files / Maps No. of Nodes
1 Increasing Constant
2 Constant Increasing
3 Increasing Increasing

Analysis of MapReduce Programs on Hadoop Cluster
Experiment 01: MultiFileWordCount No. of Files: 2 (512MB), 3 (768MB), 4 (1GB)
Result

Analysis of MapReduce Programs on Hadoop Cluster
Experiment 02: PiEstimator When No. of Maps is constant and No. of Nodes is increasing.
Result
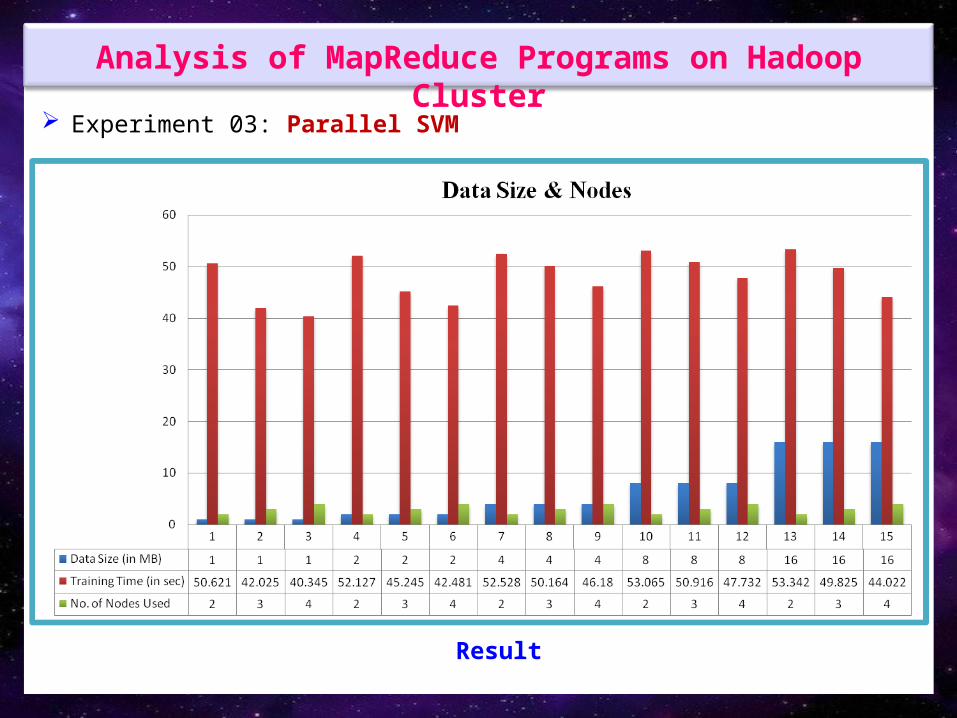
Analysis of MapReduce Programs on Hadoop Cluster
Experiment 03: Parallel SVM
Result

Conclusion & Future Work
Conclusion: Observations and Result analysis show that in Sequential SVM - as the number of
instances increases, training time also increases.
Also, in the Hadoop Cluster – we have verified and validated that as the number of
nodes increases, with respect to large size of Input Data, execution time decreases.
From this, it is shown that Parallel SVM using MapReduce Model performs
efficiently.
An advantage of using HDFS & MapReduce is the data awareness between the
NameNode & DataNode and also between JobTracker & TaskTracker. Future Work:
1.Scaling up the Hadoop Cluster - having Client, Secondary NameNode.
2. Further study and research of various concepts related with hadoop. Ex:- hadoop – streaming.
3. Performance Evaluation of Parallel SVM Algorithm by introducing different Kernel Methods. Ex:- vector space kernel.

References[1] Gunnar Ratsch, “A Brief Introduction into Machine Learning”, Friedrich Miescher Laboratory of the Max Planck Society, 2004.
[2] Cortes and V. Vapnik. Support-vector network. Machine Learning, 20:273-297, 1995.
[3] Chih-Wei Hsu and Chih-Jen Lin. A Comparison of Methods for Multi-class Support Vector Machines,13 (2): 415-425, 2002.
[4] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, “The Hadoop Distributed File System”, IEEE, 2010.
[5] Mahesh Maurya and Sunita Mahajan. “Performance analysis of MapReduce Programs on Hadoop cluster”, World Congress on
Information and Communication Technologies 2012.
[6] http://www.csie.ntu.edu.tw/~cjlin/libsvm
[7] http://www.cs.waikato.ac.nz/~ml/weka/
[8] http://ieeexplore.ieee.org/
[9] http://hadoop.apache.org/
[10] http://books.dzone.com/books/hadoop-definitive-guide-Tom White
[11] http://www.cloudera.com/hadoop-support
[12] http://www.kernel-methods.net
References[1] Gunnar Ratsch, “A Brief Introduction into Machine Learning”, Friedrich Miescher Laboratory of the Max Planck Society, 2004.
[2] Cortes and V. Vapnik. Support-vector network. Machine Learning, 20:273-297, 1995.
[3] Chih-Wei Hsu and Chih-Jen Lin. A Comparison of Methods for Multi-class Support Vector Machines,13 (2): 415-425, 2002.
[4] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, “The Hadoop Distributed File System”, IEEE, 2010.
[5] Mahesh Maurya and Sunita Mahajan. “Performance analysis of MapReduce Programs on Hadoop cluster”, World Congress on
Information and Communication Technologies 2012.
[6] http://www.csie.ntu.edu.tw/~cjlin/libsvm
[7] http://www.cs.waikato.ac.nz/~ml/weka/
[8] http://ieeexplore.ieee.org/
[9] http://hadoop.apache.org/
[10] http://books.dzone.com/books/hadoop-definitive-guide-Tom White
[11] http://www.cloudera.com/hadoop-support
[12] http://www.kernel-methods.net

Thanks to:Dr. Ravi Prakash G. Mr. Saikat Mukherjee Guide Co-Guide
Special Thanks to:Mr. Amresh
KumarMr. IllayarajaMr. Linto










![ADIKAVI NANNAYA UNIVERSITY RAJAMAHENDRAVARAM · dissertation and presentation in all PG courses [except MBA/MCA/MA (SW) and M.Tech]. Thus the grand total for the science PG courses](https://static.fdocuments.us/doc/165x107/5fc0f282ab13a9516e3b5923/adikavi-nannaya-university-dissertation-and-presentation-in-all-pg-courses-except.jpg)







