
Moving object detection using spatio-temporal …ash/spatio-temporal multilayer compound...Multimed...
33
Multimed Tools Appl DOI 10.1007/s11042-016-3698-2 Moving object detection using spatio-temporal multilayer compound Markov Random Field and histogram thresholding based change detection Badri Narayan Subudhi 1 · Susmita Ghosh 2 · Pradipta Kumar Nanda 3 · Ashish Ghosh 4 Received: 29 October 2015 / Revised: 16 April 2016 / Accepted: 21 June 2016 © Springer Science+Business Media New York 2016 Abstract In this article, we propose a Multi Layer Compound Markov Random Field (MLCMRF) Model to spatially segment different image frames of a given video sequence. The segmented image frames are combined with the change between the frames to detect the moving objects from a video. The proposed MLCMRF uses five Markov models in a single framework, one in spatial direction using color feature, four in temporal direction (using two color features and two edges/line fields). Hence, the proposed MLCMRF is a combination of spatial distribution of color, temporal color coherence and edge maps in the temporal frames. The use of such an edge preserving model helps in enhancing the object boundary in spatial segmentation and hence can detect moving objects with less effect of sil- houette. A difference between the frames is used to generate the CDM and is subsequently updated with the previous frame video object plane (VOP) and the spatial segmentation of the consecutive frames, to detect the moving objects from the target image frames. Results Ashish Ghosh [email protected] Badri Narayan Subudhi [email protected] Susmita Ghosh [email protected] Pradipta Kumar Nanda pknanda [email protected] 1 Department of Electronics and Communication Engineering, National Institute of Technology Goa, Ponda, Goa 403401, India 2 Department of Computer Science and Engineering, Jadavpur University, Kolkata, 700032, India 3 Department of Electronics and Telecommunication Engineering ITER, Siksha ‘O’, Anusandhan University, Bhubaneswar 751030, India 4 Machine Intelligence Unit, Indian Statistical Institute, Kolkata, 700108, India
Transcript of Moving object detection using spatio-temporal …ash/spatio-temporal multilayer compound...Multimed...

Multimed Tools ApplDOI 10.1007/s11042-016-3698-2
Moving object detection using spatio-temporalmultilayer compound Markov Random Fieldand histogram thresholding based changedetection
Badri Narayan Subudhi1 ·Susmita Ghosh2 ·Pradipta Kumar Nanda3 ·Ashish Ghosh4
Received: 29 October 2015 / Revised: 16 April 2016 / Accepted: 21 June 2016© Springer Science+Business Media New York 2016
Abstract In this article, we propose a Multi Layer Compound Markov Random Field(MLCMRF) Model to spatially segment different image frames of a given video sequence.The segmented image frames are combined with the change between the frames to detectthe moving objects from a video. The proposed MLCMRF uses five Markov models in asingle framework, one in spatial direction using color feature, four in temporal direction(using two color features and two edges/line fields). Hence, the proposed MLCMRF is acombination of spatial distribution of color, temporal color coherence and edge maps in thetemporal frames. The use of such an edge preserving model helps in enhancing the objectboundary in spatial segmentation and hence can detect moving objects with less effect of sil-houette. A difference between the frames is used to generate the CDM and is subsequentlyupdated with the previous frame video object plane (VOP) and the spatial segmentation ofthe consecutive frames, to detect the moving objects from the target image frames. Results
� Ashish [email protected]
Badri Narayan [email protected]
Susmita [email protected]
Pradipta Kumar Nandapknanda [email protected]
1 Department of Electronics and Communication Engineering, National Institute of Technology Goa,Ponda, Goa 403401, India
2 Department of Computer Science and Engineering, Jadavpur University, Kolkata, 700032, India
3 Department of Electronics and Telecommunication Engineering ITER, Siksha ‘O’,Anusandhan University, Bhubaneswar 751030, India
4 Machine Intelligence Unit, Indian Statistical Institute, Kolkata, 700108, India

Multimed Tools Appl
of the proposed spatial segmentation approach are compared with those of the existingstate-of-the-art techniques and are found to be better.
Keywords Image segmentation · MAP estimation · Modeling · Simulated annealing ·Object detection · Tracking · Image motion analysis · Image edge analysis
List of notations(a, b) Pixel positiont t th time instantCDMt Change detection mask generated at time t
y Observed video sequenceyt Observed image frame at time t
T h Thresholdσ 2 Variance of each color planek Variance-covariance matrixs Spatial sitep A neighboring site of s
yst A site s of frame yt
x Segmentation of y
Xt Markov random field at time t
xt Realization of Xt , segmented version of yt
ηst Neighborhood of a site s in spatial direction of the t th frameq A neighboring site of s
r A site in (t − 1) or (t − 2) th frame termed as temporal sitee A site of the Laplacian edge image xt , xt−1 or xt−2 called as edge siteVc(xt ) Clique potential function in MRFVsc(xst , xqt ) Clique potential function in the spatial domainVtec(xst , xqr ) Clique potential function in the temporal domainVteec(xst , xer ) Clique potential function incorporating edge featuresα, β and γ MRF model bonding parametersxt Estimated label or MAP estimateθ Parameter vector associated with xt
U(xt ) Energy of realization xt
N Gaussian processZ Partition functionf Number of features (for RGB space it is 3)
1 Introduction
Moving object detection in a video is the process of identifying those objects in the videowhose movements create a dynamic variation in the scene [40]. It has wide applicationssuch as visual surveillance [30], face and gait-based human recognition [35, 43], activityrecognition [21], robotics [33] etc.
Moving object detection from a video scene can be achieved mainly by two ways: (i)motion detection/change detection and, (ii) motion estimation [40]. Change or motion detec-tion is the process of identifying the changed and the unchanged regions from the extracted

Multimed Tools Appl
video image frames when the camera is fixed and the objects are moving (i.e., staticbackground). Several algorithms on motion detection schemes are already developed andare popularly termed as local change detection. Among them, background subtraction(BGS) is popular and powerful. Different BGS techniques like frame differencing [6], Gaus-sian mixture model (GMM) [36], kernel based scheme [10], density based [2], Markovmodel based [38] hybrid approach [39], fuzzy modeling [5, 28], exist in the literature. Formotion estimation, we compute the motion vectors to estimate the positions of the movingobjects from frame to frame. In case of motion estimation, both the objects and the cameramay move [40].
Detection of moving objects from static background is always a crucial task. The processof motion/change detection is again restricted by the construction of the reference back-ground model. The moving object detection from videos captured by fixed camera where (i)the objects in the scene do not have a substantial amount of movement from frame to frame,(ii) the objects in a given scene move very slow and stop for some time and move further,(iii) the different objects in the scene have different velocity, or (iv) moving objects in thescene covers maximum area of the frame, identification of the moving objects becomes dif-ficult with temporal segmentation [6–13] alone. Spatio-temporal segmentation scheme [44]is very popular in this regard.
Spatio-temporal segmentation scheme is a way of performing moving object segmenta-tion by combining both spatial and temporal cues of the given video. It can be performedby combining both spatial and temporal features of a given image frame on a single seg-mentation framework [7, 24, 37] or by combining results of both spatial segmentationand temporal segmentation [9, 17]. In an image frame both stationary and non-stationaryobjects with background may be present, hence spatial segmentation scheme may providethe region boundary for both stationary and non-stationary objects. As our objective is tofind the non-stationary objects only, a combination of both spatial and temporal cues of agiven video may efficiently predict the locations of the moving objects.
The proposed object detection scheme is a combination of both spatio-temporal spa-tial and temporal segmentation. For spatial segmentation, we introduced a new MultilayerCompound Markov Random Field (MLCMRF) model that uses five Markov models ina single framework. The proposed MLCMRF is a combination of one MRF using spa-tial distribution of color, two MRFs using the temporal color coherence and two MRFsusing edge maps in the temporal directions. The use of such an edge preserving modelhelps in enhancing the object boundary in spatial segmentation and hence can detect mov-ing objects with less effects of silhouette. Since, the model uses multiple attributes fromspatial and temporal directions, it is refereed as a spatio-temporal spatial segmentation.Here the spatial segmentation task is considered as a pixel labeling problem and is solvedusing the maximum a posteriori probability (MAP) estimation principle. The MAP esti-mate of the considered MLCMRF is obtained by a combination of simulated annealing(SA) and iterative conditional mode (ICM) that converges fast. For temporal segmenta-tion, we initially obtained a change detection mask by taking pixel by pixel differenceof two consecutive image frames followed by Otsu’s thresholding [26]. The obtainedCDM is subsequently updated with the previous frame video object plane (VOP) and thespatial segmentation of the consecutive frames for detecting moving objects from the targetframes.
The results obtained by the proposed spatio-temporal spatial segmentation method arecompared with those of MRF-edgeless, JSEG [9], mean-shift [8], MRF and DDE [12],MRF-DGA [17] and supervoxel [25] methods of segmentation and is found to be better.Similarly, the results obtained for the VOPs by the proposed scheme are compared with

Multimed Tools Appl
the VOPs obtained by the Kim’s MRF-DGA scheme [17], and it is observed that the VOPsobtained with the proposed scheme gives better result.
The organization of this article is as follows. Section 2 represents the background onliterature of Spatio-temporal Segmentation for object detection. In Section 3, the motivationbehind the work with detailed block diagram of the proposed scheme is discussed. Section 4gives a brief introduction to MRF model. In Section 5, spatial segmentation method usingthe proposed MLCMRF is presented. In Section 6, temporal segmentation based on CDMis elaborated. Section 7, provides simulation results and analysis. Conclusion is presentedin Section 8.
2 Background on spatio-temporal segmentation
There has been a growing research interest in video image segmentation over the pastdecade and towards this end, a wide variety of spatio-temporal segmentation based movingobject detection methodologies have been developed. However before spatial segmentation;many literature covers spatio-temporal segmentation for performing BGS. Elgammal et al.[10] proposed a kernelized Gaussian mixture model (GMM) to model the background ofthe scene, and have efficiently detected moving objects in the target frames with less mis-classification error. A computationally efficient visual surveillance tool, namely ViBe [2],is designed based on the non-parametric pixel based classification strategy, where a ran-dom sampling strategy is used and the neighborhood pixel statistics is considered to buildthe background model. The approach is found to be efficient in several complex scenarios.Background modeling and Markov Random Fields classification technique [38] is also usedfor BGS in literature, where affinity propagation clustering algorithm is initially applied toproduce the over-segmentation of a reference image by taking into account color differenceand spatial relation of pixel in the frame are used for object detection. A modified GMMbased BGS scheme is also proposed by Teixeira et al. [39], where the both the mixture ofGaussians and the kernel density estimation are used to detect structural changes and themoving objects in the scene. The flux tensor motion flow algorithm [27] and it modifiedfrom called as Flux Tensor with Split Gaussian models [41] are also explored for movingobject detection in from cluttered scenes. A foreground detection scheme that uses the localsaliency measures extracted from the spatio-temporal video cube [29]. This involves anoptimization process incorporating inter and intra feature competition at the spatio-temporalvideo cube level. Sheikh and Shah [34] proposed a BGS scheme where each pixel from thebackground frames are modeled by using a single probability density function. The authorshave considered the background and the foreground models competitively in a MAP-MRFdecision framework, to find the actual moving objects regions in the video frames. The con-cepts of outlier detection is also explored by Zhou et al. [45]. The authors have assumedthat the underlying background images are linearly correlated. The underlying backgroundframes are approximated by a low-rank matrix, and the moving objects are picked as out-liers in this low-rank representation. Liu et al. [23] also proposed a low-rank matrix andsparse decomposition technique for moving object detection which is found to be providinggood results. Recently, Liu and Qi [22] have proposed a BGS scheme where an effectivelearning strategy is proposed to provide better regularization of background adaptation formixture of Gaussian. The approach is found to be effective and producing good results.
From the above discussion it may be concluded that many spatio-temporal BGS schemesexist to achieve the task of moving object detection. However, all the techniques mentionedhere, are useful when the given sequence have enough background frames to model the

Multimed Tools Appl
background completely. In real life scenario, it may be observed that a video may not haveenough number of frames or no frame at all for background construction where the abovesaid approaches fail to provide good results and always found to produce ghosts in thescene. Again in a video the said techniques will not be able to provide good results, if themoving objects present in the scene i) are moving slowly ii) having “stop and go” motionor iii) different objects in the scene have different speeds, or (iv) moving objects in thescene cover maximum area of the frame. In this regard, object detection by spatio-temporalsegmentation is found to be efficient.
An efficient watershed based spatio-temporal moving object detection approach was pro-posed by Salember et al. [31]. The authors have used spatial segmentation and temporal seg-mentation to detect object boundaries. However, this method produced over-segmentationand hence could not detect the moving object satisfactorily. To enhance the accuracy ofmoving object detection, Deng and Manjunath [9] proposed a robust scheme where spatialsegmentation of an image frame is obtained by color quantization followed by region grow-ing. This method is popularly known as joint segmentation (JSEG) scheme. For temporalsegmentation, regions corresponding to the objects are matched in the temporal directionby computing the motion vectors of the object regions in the target frame. It has been foundthat the use of region based segmentation scheme fails to take care of the spatial ambiguitiesof image gray values; hence produces an over segmentation result that gives rise to a largereffect of object background misclassification in moving object detection. Recently, a super-voxel method, that performs a hierarchical clustering of superpixels in a graph with spatialand temporal connections, is proposed by Oneata et al. [25]. An optical flow based motionestimation scheme is combined with supervoxel based segmentation results to get the finaloutput of object detection.
The video segmentation methodologies have extensively used probabilistic image mod-els, particularly Markov Random Field (MRF) model, to model the video images for objectdetection [14, 17]. MRF model is proved to be an effective stochastic model for imagesegmentation [4, 6, 20] because of its attribute to model context dependent entities suchas image pixels and correlated features. In conventional MRF based image segmentationscheme mostly the spatial constraints are used. It is to be noted that the features in the spatialdirection are modeled with Gibb’s MRF and the method is referred as spatial segmentation.Whereas in Video segmentation, besides spatial modeling and constraints, temporal con-straints are also considered and the concerned process is referred as spatio-temporal imagesegmentation or spatio-temporal spatial segmentation. Here, Gibb’s MRF is used to modelthe features from a particular frame both in spatial and temporal direction. Such models arealso referred to as multilayer MRF and in the literature, spatial segmentation with multilayerMRF is found to be providing better results [1, 3, 17, 19] in video segmentation. An adaptivemultilayer MRF clustering has been reported [14] where temporal constraints and tempo-ral local intensity have been adopted for smooth transition of segmentation from frame toframe. Spatio-temporal segmentation has also been applied to image sequences [42] withdifferent filtering techniques. Hwang et al. [16] had proposed a method of video objectdetection where each frame was modeled with MRF, and the MAP estimate was obtainedusing distributed genetic algorithms (DGA). The temporal segmentation was obtained bydirect combination of VOP of the previous frame with the current frame CDM. A modi-fied version of DGA has been proposed in [17] to obtain segmentation of video sequencesin spatio-temporal framework. The authors had extended the video segmentation schemeof [16] and used a probability measure to update the crossover and mutation rate throughevolution in DGA. Thereafter for temporal segmentation of current frame, the CDM wasupdated with the label information of the current and the previous frames. Combination of

Multimed Tools Appl
both spatial segmentation and temporal segmentation was performed to obtain the VOP, thatgives an accurate shape of the moving objects. An automatic moving object segmentationscheme has been proposed in [15]. In this approach, first region based motion segmentationalgorithm is proposed and thereafter the labels of the pixels are determined.
Ghosh et al. [12] also have proposed a spatio-temporal object detection scheme wherethe spatial segmentation is achieved by modeling with MRF model and MAP estimationby distributed differential evolution (DDE) scheme. The authors have considered a changeinformation based initialization scheme to get the results of spatial segmentation schemefaster. However, it may be observed that due to the use of change information in segmenta-tion; spatial segmentation becomes more dependent to heuristic initialization and may getstuck to local minima during the evolution through DDE.
3 Proposed algorithm for moving object detection
This section includes the motivation behind the proposed work and a brief description ofthe proposed object detection technique with block diagram.
3.1 Motivation
It is known that detection of moving objects with temporal segmentation alone does notalways produce good results in complex situations. Background subtraction technique, atemporal segmentation procedure, relies on the availability of the reference frame. With-out the availability of reference frame, object detection using simple frame differencingis difficult. Again the case will be more critical when the objects in the scene have veryslow movement or the objects in the scene stop for sometime and move further or it coversmaximum part of the scene.
In this regard, spatio-temporal segmentation based object detection and tracking tech-niques are sometimes found to be efficient. However, a spatio-temporal segmentationtechnique relies on the accuracy of spatial segmentation. Generally, a video scene con-tains illumination variation, noise and motion blurring. Use of conventional segmentationtechniques is likely to be affected by these effects and hence will give rise to inaccurate seg-mentation maps. Inaccurate spatial segmentation may cause effects of silhouette in objectdetection and tracking [12]. Generally, effects of silhouette arise in the scene, when someparts of the objects are identified as background or some parts of background are identifiedas objects. It is caused due to noise or variation of gray level at the boundary of an imageframe.
Most of the literature [12, 16, 17] concentrate on the direction of development of accu-rate spatial segmentation scheme. In the literature of object detection by spatio-temporalsegmentation MRF based segmentation is quite popular for spatial segmentation. Howeverthe accuracy of spatial segmentation get degraded due to motion blurring, noise and illu-mination variate scene. In [16, 17], the authors tried to model the information from thetemporal frames using MRF model. It is quite common that in a video there exist a largecorrelation between two consecutive frames. Hence the inclusion of temporal frame infor-mation in MRF model add an advantage of improving the accuracy of spatial segmentation.However for a video scene blurred edge and loss of boundary information is quite common.Hence an inclusion of edges and temporal information with MRF will suppose to strengthenthe accuracy of segmentation. The object movement information can be captured by find-ing the changes between the frames. However, it produces many false alarms due to noise,

Multimed Tools Appl
illumination variation and other scene complexity. Hence, a combination spatial segmen-tation and frame subtraction based change information is expected to detect the objectmovements accurately in the scene.
3.2 Block diagram for proposed technique
A block diagrammatic representation of the proposed scheme is given in Fig. 1. Asmentioned earlier, here we have used two types of segmentation schemes: one is aspatio-temporal spatial segmentation and the other is a temporal segmentation. Spatial seg-mentation helps in determining the boundary of the regions in the scene accurately, whiletemporal segmentation facilitates the determination of the foreground and the backgroundparts.
The spatial segmentation task is considered in spatio-temporal framework. Here, theattributes, like color or gray value in the spatial direction, color or gray value in the tem-poral direction and edge map/ line fields both in spatial as well as temporal directions aremodeled with MRFs and is termed as MLCMRF. The RGB color model is used. The edgemap considered is obtained by using a 3 × 3 Laplacian window. In order to make the algo-rithm faster, initial image frame is segmented with edge based spatio-temporal modelingand MAP estimation by a combination of SA [18] and ICM [4] methods.
For temporal segmentation, a CDM is obtained by taking the difference between twoconsecutive frames followed by thresholding. The information from the previous frame isfed back and the label of the current spatial segmentation result is used to modify the CDM.
Fig. 1 Block diagram of the proposed object detection scheme

Multimed Tools Appl
The modified CDM itself represents a binary mask of foreground and background regionswhere VOP is extracted by superimposing the original pixels of the current frame on theforeground part of the temporal segmentation.
Here we assume the frame instants to be the same as the time instants. We model a frameat t th time with its 2nd order neighbors both in spatial and temporal directions. For tem-poral direction modeling, we have considered two temporal frames at the (t − 1)th and the(t −2)th instants. Similarly, edge map/ line fields of t th frame is modeled with its neighborsin temporal direction at the (t − 1)th and the (t − 2)th frames. The estimated MAP of theMRF represents the spatial segmentation of the t th frame. The whole process is performedin spatio-temporal framework, and hence is called spatio-temporal spatial segmentation.
For temporal segmentation, we have used a motion detection scheme. We obtain a dif-ference image of the t th and the (t − d)th frame and is thresholded by a suitable thresholdvalue. The thresholded image itself represents the amount of movement performed by theobjects in the scene from the (t − d)th instant to the t th instant of time. The spatial segmen-tation result of the t th frame, the (t−d)th frame, along with VOP of the (t−d)th frame werefed back to perform a temporal segmentation of the t th frame. The pixels corresponding tothe object regions of the temporal segmented output are replaced by the original pixels ofthe t th frame to obtain the VOP of the same.
4 Introduction to Markov Random Field (MRF) model
The MRF is a spatio-contextual statistical model mainly used for partitioning an image intoa number of regions with the constraint of Gibb’s distribution as prior probability distri-bution [11]. In MRF, the spatial property of the image can be modeled through differentaspects, among which, the contextual constraint is a general and powerful one [20]. MRFtheory provides a convenient and consistent way to model context-dependent entities suchas image pixels or some specific features of an image. Segmentation is achieved by charac-terizing mutual influences among such entities in conditional probability framework. Oneof the MRF models favors the class of patterns encoded by itself by associating them withlarger probabilities than those of other pattern classes. MRF theory is often used in con-junction with statistical decision and estimation theories, so as to formulate the objectivefunctions in terms of some optimality principles. MAP is one of the most popular statisticalcriterion for optimality and in fact it is the most popular choice in MRF modeling. MRFsand the MAP criterion together give rise to the MRF-MAP framework. This framework,advocated by Geman and Geman [11] and others, enables us to develop algorithms for avariety of vision problems systematically using rational principles rather than relying onadhoc heuristics. MRF is used for image segmentation from early eighties. Segmentation ofan input image is obtained by estimating some spatially varying quantity from noisy mea-surement. This can be obtained by MAP estimate of the underlying quantity formulated inBayesian framework [20].
It is assumed that the observed video sequence y is a 3-D volume consisting of spatio-temporal image frames. yt represents the video image frame at time t .
The different terminologies associated with MRF e.g.,: sites, labels, neighborhood,cliques and line fields are described below in brief.
Sites and Labels: A site may be defined as a point or a region in the Euclidean space. Inan image, pixel or a feature such as a corner point, a line segment or a surface patch maybe considered as a site. We may define a site as s, and S as the set of sites. Similarly, a

Multimed Tools Appl
Fig. 2 Spatial neighborhood
label is an event that may be given to a site. It is to be noted that, MRF based segmentationscheme may be considered as a pixel labeling scheme.Neighborhood System and Cliques: The sites in S are related to one another via aneighborhood system [20]. A neighborhood system for site s can be defined as (shownin Fig. 2),
η = {ηs | ∀ s ∈ S}, (1)
where ηs is the set of sites neighboring s. The neighboring relationship obeys thefollowing properties:
(i) A site is not a neighbor to itself: s /∈ ηs .(ii) The neighboring relationship is mutual: s ∈ ηs′ ⇔ s′ ∈ ηs .
A clique C for (s, η) is defined as a subset of sites C = {s, s′}, or a triple of neigh-boring sites C = {s, s′ s′′}, and so on (as shown in Fig. 3). The collections of single-site,pair-site and triple-site cliques will be denoted by C1, C2, C3, respectively [20], where
C1 = {s | s ∈ S}C2 = {{s, s′} | s′ ∈ ηs, s ∈ S}C3 = {{s, s′, s′′} | s, s′, s′′ ∈ S}.
The same concept can be extended for multiple-site cliques.Line fields: Lie fields or edge field is mainly used to model the discontinuity of imagein MRFs. The conventional MRF consider the bonding among the pixels by consideringsmoothness constraints, where all the pixels are equally weighted during the Gibb’s MRFmodeling. Again the model will try to provide an equal penalization of all the boundarypixels results in a greater penalty to weak edge pixels and a lesser penalty to the strongedge pixels. In the proposed scheme we have considered two ways of line field modeling:one for spatial direction and other is spatial line field is modeled in temporal direction.
4.1 MAP framework for MRF model
Let the observed video sequence y be a 3-D volume consisting of spatio-temporal imageframes. yt represents a video image frame at time t and hence is a spatial entity. Each pixelin yt is a site s denoted by yst . Let Yt represent a random field and yt be a realization ofit at time t . Thus, yst denotes a spatio-temporal co-ordinate of the grid (s, t). Let x denotethe segmentation of video sequence y and xt denote the segmented version of yt . Similarly,

Multimed Tools Appl
Fig. 3 Neighborhood systems with the associated cliques
xst represents label of a site in t th frame. Let us assume that Xt represents the MRF fromwhich xt is a realization.
For any segmentation problem, the label field can be estimated by maximizing thefollowing posterior probability distribution.
xt = argmaxxt
P (Xt = xt |Yt = yt ). (2)
Using Bayes’ framework we can derive
xt = arg maxxt
P (Yt = yt |Xt = xt )P (Xt = xt )
P (Yt = yt ), (3)
where xt denotes the estimated labels. The prior probability P(Yt = yt ) is constant andhence (3) reduces to
xt = arg maxxt
P (Yt = yt |Xt = xt , θ)P (Xt = xt , θ); (4)
where θ is the parameter vector associated with the clique potential function of xt . Here, xt
is the MAP estimate. Equation (4) contains two parts P(Xt = xt ), the prior probability andP(Yt = yt |Xt = xt , θ) as the likelihood function.
The prior probability P(Xt = xt ) can be expressed as
P(Xt = xt , θ) = 1
ze
−U(xt )T = 1
ze
−{∑c∈C Vc(xt )}T , (5)
where z is the partition function expressed as z = ∑xt
e−U(xt )
T , U(Xt ) is the energy function(a function of clique potentials). In (5), Vc(xt ) represents the clique potential function inspatial domain. It can be defined in terms of MRF model bonding parameter as
Vc(xt ) ={ +α if xst = xqt
−α if xst �= xqt ,(6)
where α is the MRF model bonding parameter and q is a neighboring site of s.

Multimed Tools Appl
5 Multilayer compound MRF based spatial segmentation
In a video, there is a large coherence in position and movement of objects from one frameto another. Use of such coherence can improve the quality of the object segmentation task.In this work, we have incorporated the intensive coherence of each frame with two of itsprevious frames via edges. The proposed MLCMRF uses five Markov models in a singleframework, one in spatial direction using color feature, four in temporal direction (using twocolor coherence features and two edges/line fields). The considered MLCMRF is associatedwith five layer and each layer has the same size as the image lattice. Hence the proposedMLCMRF is a combination of spatial distribution of color, temporal color coherence andedge maps in the temporal frames. Since, the model uses multiple attributes from spatialand temporal directions, it is refereed as a spatio-temporal spatial segmentation.
5.1 Multi-layer Compound Markov Random Field model based MAPframework for segmentation
In spatio-temporal spatial segmentation, we adhere to use of MLCMRF model. InMLCMRF, an MRF model is considered in spatial direction. Similarly, pixels in the tem-poral direction are also modeled as MRFs. We have considered the second order MRFmodeling both in spatial as well as in temporal directions. In order to preserve the edgefeatures, another MRF model is considered with the line fields of xt and those of xt−1 andxt−2. It is known that if Xt is an MRF then it satisfies the Markovianity property [20] inspatial direction; i.e.,
P(Xst = xst | Xqt = xqt , ∀qεS, s �= q) = P(Xst = xst | Xqt = xqt , (q, t)εηst );where ηst denotes the neighborhood of (s, t) and S denotes the spatial lattice of Xt . Fortemporal MRF, the following Markovianity property is also satisfied:
p(Xst = xst | Xqr = xqr , s �= q, t �= r, ∀(s, t), (q, r)εV )
= p(Xst = xst | Xqr = xqr , s �= q, t �= r, (q, r)εηsr ).
Here, V denotes the 3-D volume of the video sequence and ηsr denotes the neighborhoodof (s, t) in temporal direction.We have considered s as a spatial site, q as a temporal site ande as an edge site. The set of all the sites is represented by S. Therefore, S = {s} ∪ {q} ∪ {e}.
The novelty of MRF model lies in the fact that it takes into account the spatial andtemporal intrinsic characteristics of a region and is well known in the literature [20]. Theregions are assumed to have uniform intensities. The considered image frame is assumed tocome from an imperfect imaging modality. It is assumed that noise has corrupted the actualimage to produce the observed image yt . Given this observed image yt , we seek the imagext , which maximizes the posterior probability. We denote the estimate of xt by xt . Hence,it is assumed here that due to the presence of noise we are not able to observe xt . But wecan observe a noisy version of xt as yt . Noise is assumed to be white (additive i.i.d., i.e.,independent and identically distributed). Hence Yt can be expressed as [20]
yt = xt + N(0, σ 2), (7)
where N(0, σ 2) is the i.i.d. noise with zero mean and σ 2 variance.We describe the mathematical formulation of the proposed MRF modeling as follows.
Here Xt represents the MRF model of xt and hence the prior probability can be expressed
as Gibb’s distribution with P(Xt ) = 1ze
−U(Xt )T , where z is the partition function expressed

Multimed Tools Appl
as z = ∑xt
e−U(xt )
T , U(Xt ) is the energy function (a function of clique potentials). We haveconsidered the following clique potential functions for the present work.
Vsc(xst , xqt ) ={ +α if xst �= xqt and (s, t), (q, t)εS
−α if xst = xqt and (s, t), (q, t)εS.
Analogously, in temporal direction
Vtec(xst , xqr ) ={ +β if xst �= xqr , (s, t), (q, r)εS, t �= r, and rε{(t − 1), (t − 2)}
−β if xst = xqr , (s, t), (q, r)εS, t �= r, and rε{(t − 1), (t − 2)};and for the edge map in the temporal direction
Vteec(xst , xer ) ={ +γ if xst �= xer , (s, t), (e, r)εS, t �= r, and rε{(t − 1), (t − 2)}
−γ if xst = xer , (s, t), (e, r)εS, t �= r, and rε{(t − 1), (t − 2)}.Vsc(xst , xqt ), Vtec(xst , xqr ) and Vteec(xst , xer ) denote spatial, temporal and edge clique
potential functions, respectively. Here, α, β, and γ are the parameters associated with theclique potential functions. These are positive constants and are determined on trial and errorbasis. In an image modeling, the clique potential function is the combination of the abovethree terms. Hence, the energy function is of the following form:
U(Xt ) =∑
c∈C
Vsc(xst , xqt ) +∑
c∈C
Vtec(xst , xqr ) +∑
c∈C
Vteec(xst , xer ). (8)
5.2 Framework for MLCMRF-MAP estimation
Here image segmentation problem is considered to be a process of determining a realizationxt that has given rise to the actual image frame yt . The realization xt can not be obtaineddeterministically from yt . Hence, it requires to estimate xt from yt . One way to estimatext is based on the statistical MAP criterion. The objective of statistical MAP estimationscheme is to have a rule, which yields xt that maximizes the a posteriori probability, i.e.,
xt = arg maxxt
P (Xt = xt |Yt = yt ), (9)
where xt denotes the estimated labels. Since xt is unknown, it is difficult to evaluate (9).Using Bayes’ theorem, (9) can be written as
xt = arg maxxt
P (Yt = yt |Xt = xt )P (Xt = xt )
P (Yt = yt ). (10)
Since yt is known, the prior probability P(Yt = yt ) is constant. Hence (10) reduces to
xt = arg maxxt
P (Yt = yt |Xt = xt , θ)P (Xt = xt , θ); (11)
where θ is the parameter vector associated with the clique potential function of xt . Accord-ing to Hammerseley Clifford theorem [20], the prior probability P(Xt = xt , θ) followsGibb’s distribution and is of the following form,
P(Xt = xt ) = e−U(xt ,θ)
= e[− ∑
s,t {Vsc(xst ,xqt )+Vtec(xst ,xqr )+Vteec(xst ,xer )}]
. (12)
In (12), Vsc(xt ) is the clique potential function in spatial domain at time t , Vtec(xt )
denotes the clique potential in temporal domain, and Vteec(xt ) denotes the clique potentialin temporal domain with edge features. We have used this additional feature in the temporal

Multimed Tools Appl
direction and the whole model is referred to as edgebased model. The correspondingedgeless model is expressed as
P(Xt = xt ) = e−U(xt ,θ)
= e[−∑
cεC[Vsc(xst ,xqt )+Vtec(xst ,xqr )]]. (13)
The likelihood function P(Yt = yt |Xt = xt ) of (11) can be expressed as
P(Yt = yt |Xt = xt ) = P(yt = xt + n|Xt = xt , θ)
= P(N = yt − xt |Xt = xt , θ); (14)
here n is a realization of the Gaussian degradation process N(μ, σ). Thus, P(Yt = yt |Xt =xt ) can be expressed as
P(N = yt − xt |Xt, θ)
= 1√
(2π)f det [k]e− 1
2 (yt−xt )T k−1(yt−xt ) (15)
where k is the variance-covariance matrix, det[k] represents the determinant of matrix k
and f is the number of features. The variance-covariance matrix k can be expressed as
k = [kij ]f ×f ,
where kij is the covariance between ith and j th components of yt and 1 < i < f , 1 < j <
f . Since here we have considered color image frames with three features (components) asR, G and B, the matrix k will reduce to the form
k =⎛
⎝kRR kRG kRB
kGR kGG kGB
kBR kBG kBB
⎞
⎠ .
Assuming decorrelation between the R, G and B planes, and the variance in each planei.e., kRR = kGG = kBB = σ 2, the matrix k will look like
k =⎛
⎝σ 2 0 00 σ 2 00 0 σ 2
⎞
⎠ .
Now we may obtain the determinant det[k] as
det[k] =⎡
⎣σ 2 0 00 σ 2 00 0 σ 2
⎤
⎦ = σ 2[σ 4 − 0] = σ 6.
Assuming decorrelation among the three R, G and B planes and the variance to be thesame among all the planes, (15) can be expressed as
P(N = yt − xt |Xt, θ)
= 1√
(2π)3σ 3e− 1
2 (yt−xt )T k−1(yt−xt ). (16)
In (16), variance σ 2 corresponds to the Gaussian degradation. Hence (11) can beexpressed as:
xt = argmaxxt
1√
(2π)3σ 3
[e(yt−xt )
T k−1(yt−xt )−
∑
s,t
{Vsc(xst , xqt ) + Vtec(xst , xqr ) + Vteec(xst , xer )
}](17)

Multimed Tools Appl
Maximization of (17) is equivalent to minimization of
xt = argminxt
[(yt − xt )
T k−1(yt − xt )+∑
s,t
{Vsc(xst , xqt ) + Vtec(xst , xqr ) + Vteec(xst , xer )
}](18)
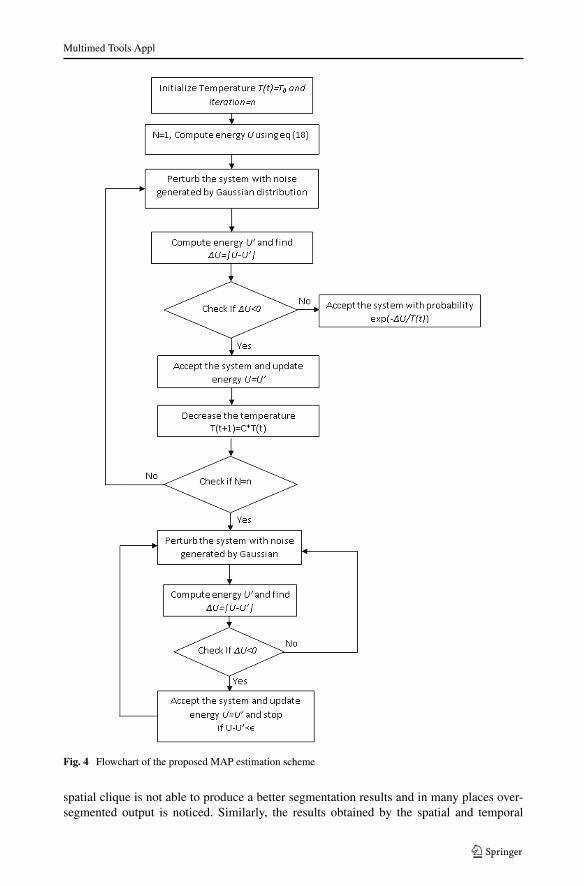
xt in (18) is the MAP estimate. Maximization of (18) requires 2q×M×N possible imageconfigurations to be searched, where q represents the number of bits required to representthe segmented image and M × N is the size of the image. A combination of SA and ICMis used for MAP estimation. The salient steps of the MAP estimation are enumerated belowand corresponding flowchart is given in Fig. 4.
Simulated Annealing is a meta-heuristic search algorithm [18]. The algorithm is basedon an acceptance criterion with probability. In theory, if SA can run for an infinite amountof time, the global optimum could be found [18]. It is also reported that for any givenfinite problem, SA terminates with the global optimal solution as the annealing scheduleis extended. ICM uses a deterministic strategy to find the local minimum. It starts withan estimate of the labeling, and for each pixel, the label that gives a decrease in energyvalue is chosen for next iteration of processing. With a degenerate version (with constanttemperature) we conjecture that the average time will grow as a polynomial with the increasein the number of pixels. In other words the time will grow as a polynomial with increasein the size of the image. The Sasaki and Hajek’s [32] time complexity analysis revealsthat a degenerate form of the algorithm can find the optimum by computing the maximumcardinality matching in a graph.
Results obtained using the layers of the MRFs are shown in Fig. 5. The original 27thimage frame of Deadline video sequence is shown in Fig. 5a. While, Fig. 5b–d depict thesegmented outputs using spatial clique, spatial and temporal clique and spatial, temporaland edge cliques. From Fig. 5b it is found that the conventional MRF scheme, using only
Multimed Tools Appl
Fig. 4 Flowchart of the proposed MAP estimation scheme
spatial clique is not able to produce a better segmentation results and in many places over-segmented output is noticed. Similarly, the results obtained by the spatial and temporal

Multimed Tools Appl
Fig. 5 Deadline video sequence (a) original frame no. 27, segmentation using (b) spatial cliques (b) spatialand temporal cliques and (d) spatial, temporal and edge cliques
cliques based MRF scheme (Fig. 5c) though produced better results than earlier method, yetmany parts of the image frame are over-segmented (e.g; hand region, shirt and coat, booksand shelves in the back and coat regions). Such limitation is handled by inclusion of edgein temporal direction of the MLCMRF model (Fig. 5d).
6 Temporal segmentation
The temporal segmentation is performed to classifying the foreground and the backgroundof the video image frame. In temporal segmentation, initially a CDM is obtained and thisCDM serves as a precursor for detection of the foreground as well as the background.The CDM is obtained by taking pixel by pixel difference of two consecutive image framesfollowed by Otsu’s histogram thresholding.
To get the object location of the considered frame, the obtained CDM is subsequentlyupdated with some information from the previous frame. The CDM thus obtained is verifiedand compensated by considering the information of the pixels belonging to the objects inthe previous frame. This is represented as
R = {ri,j |0 ≤ i ≤ (M − 1), 0 ≤ j ≤ (N − 1)
}, (19)
whereR is a matrix having the same size of the frame. ri,j is the value of the VOP at location(i, j), where (i, j) location represents the ith row and the j th column. If a pixel is found tohave ri,j = 1, then it belongs to a moving object in the previous frame; otherwise it belongsto the background in the previous frame. Based on this information, CDM is modified asfollows: if it belongs to a moving object in the previous frame and its label obtained byspatio-temporal spatial segmentation is the same as that of one of the corresponding pixelsin the previous frame, then it is marked as a foreground area in the current frame else as thebackground. The modified CDM thus represents the final temporal segmentation.
After obtaining a temporal segmentation of a frame at time t , we get a binary outputwith objects as one class (denoted by FMt ) and the background as other class (denoted asBMt ). The regions forming the foreground part in the temporal segmentation is identified asmoving object regions, and the pixels corresponding to the FMt part of the original frameyt form the VOP.
7 Experimental result and analysis
We have implemented this algorithm in a Pentium4(D), 3GHz, L2 cache 4MB,1GBRAM desktop. We have considered seven different video sequences: six benchmark

Multimed Tools Appl
and one real life video sequence. The considered video sequences are namely ‘Grandma’,‘Container’, ‘Suzie’, ‘Rahul’, Deadline, Karlsruhe taxi-I, and Claire, as shown in Figs. 6, 7,8, 9, 10, 11 and 12. To test the effectiveness of the proposed scheme, the results obtained byit are evaluated against some manually constructed ground truth image frames.
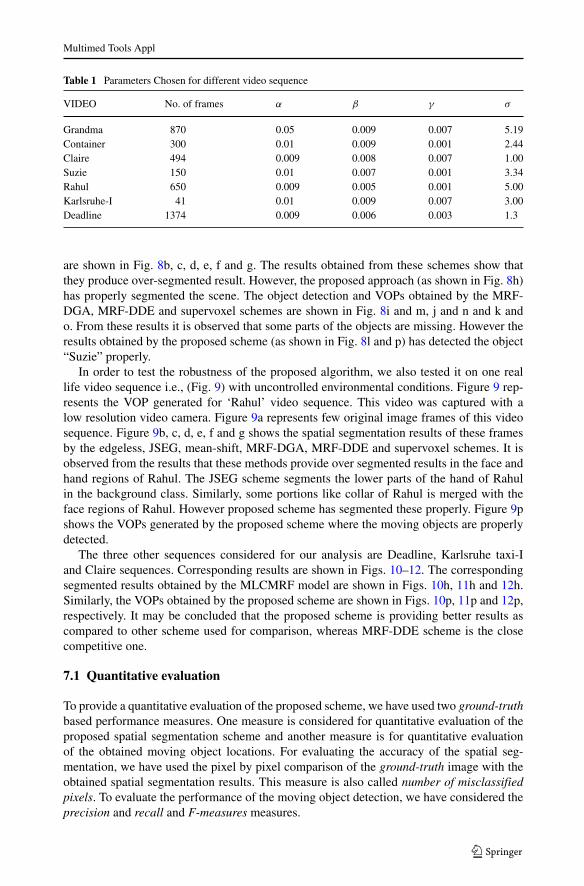
The first video sequence considered for our analysis is ‘Granmda’ sequence. Figure 6ashows the considered original image frames of ‘Grandma’ sequence. It is observed fromthese frames that there are slow movements of Grandma from one frame to another. Thebody of the Grandma is having less movement whereas the head/face region of the ladyis having more movement from frame to frame. Hence, this is an example of object withstop and go motion and its motion is very slow and unpredictable. The segmentation resultusing MRF modeling with edgeless approach (as discussed in Section 5.2) is shown inFig. 6b. It is observed from Fig. 6b that different parts of Grandma like face, nose, eyes, andbackground region are not properly segmented. The results obtained by JSEG [9] method isshown in Fig. 6c and that of mean-shift method is shown in Fig. 6d. It is found from thesesegmentation results that different regions of Grandma like face, nose and eyes of grand maare over segmented. Similarly the results obtained by MRF-DGA scheme [17] are shownin Fig. 6e, where the segmentation results are found to be over segmented, specifically theface region. An improved result is obtained by using MRF and DDE scheme (Fig. 6f).The results obtained by supervoxel scheme is shown in Fig. 6g and they found to be over-segmented too. Figure 6h shows the MLCMRF based spatio-temporal segmentation resultof considered frames of Grandma sequence, where the results are found to be better thanthat of MRF edgeless, JSEG, mean-shift and MRF-DGA schemes. The parameters used forthe considered results are reported in Table 1.
The temporal segmentation results obtained using Kim’s MRF-DGA scheme [17] isshown in Fig. 6i and corresponding VOPs are shown in Fig. 6m. The temporal segmen-tation and corresponding VOPs obtained by MRF & DDE and those using supervoxelschemes are respectively, shown in Fig. 6j, n and k, o. The results show that many parts ofgrandma are unable to be detected as a part of the moving object. Hence there is an object-background misclassification error. The moving object detection results and correspondingVOPs obtained by the proposed scheme are shown in Fig. 6l and p. Thus, we notice thatthe object detection results obtained by the proposed scheme yields better VOPs than thoseusing Kim’s MRF-DGA scheme [17].
The second example considered is ‘Container’ video sequence. Figure 7a represents fewconsidered original image frames of this video sequence. This is an example with multipleobjects with each object having different speed and motion of each individual is unpre-dictable. The moving objects in the scene are a ship, a trawler and a flying flag. Thesegmentation result of these frames using edgeless, JSEG, mean-shift, MRF-DGA, MRF-DDE and supervoxel based schemes are shown in Fig. 7b, c, d, e, f and g. The resultsobtained from edgeless and MRF-DGA scheme show that they produce over-segmentedresult. Similarly, the segmentation results obtained by mean-shift and JSEG schemes areunable to segment different parts of the scene properly like the trawler, the flag, etc. How-ever, the proposed approach (as shown in Fig. 7h) has properly segmented the scene. Theobject detection and VOPs obtained by the MRF-DGA, MRF-DDE and supervoxel schemesare shown in Fig. 7i and m, j and n and k and o. From these results it is observed that someparts of the objects are missing. However the results by the proposed scheme (as shown inFig. 7l and p) has detected three different objects properly.
The third example considered is ‘Suzie’ video sequence. Figure 8a represents few consid-ered original image frames of this video sequence. The segmentation result of these framesusing edgeless, JSEG, mean-shift, MRF-DGA, MRF-DDE and supervoxel based schemes

Multimed Tools Appl
Fig. 6 VOP generated for Grandma video sequence for frame numbers 37 and 62

Multimed Tools Appl
Fig. 7 VOP generated for Container video sequence for frame numbers 12 and 20

Multimed Tools Appl
Fig. 8 VOP generated for Suzie video sequence for frame numbers 8 and 11

Multimed Tools Appl
Fig. 9 VOP generated for Rahul video sequence for frame numbers 21, and 26

Multimed Tools Appl
Fig. 10 VOP generated for Deadline video sequence for frame numbers 27 and 75
Multimed Tools Appl
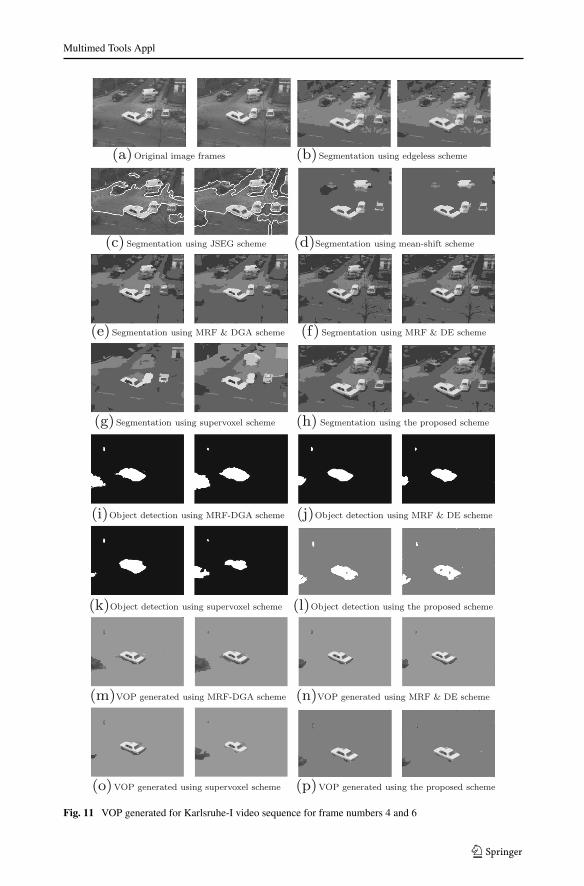
Fig. 11 VOP generated for Karlsruhe-I video sequence for frame numbers 4 and 6

Multimed Tools Appl
Fig. 12 VOP generated for Claire video sequence for frame numbers 7 and 15
Multimed Tools Appl
Table 1 Parameters Chosen for different video sequence
VIDEO No. of frames α β γ σ
Grandma 870 0.05 0.009 0.007 5.19Container 300 0.01 0.009 0.001 2.44Claire 494 0.009 0.008 0.007 1.00Suzie 150 0.01 0.007 0.001 3.34Rahul 650 0.009 0.005 0.001 5.00Karlsruhe-I 41 0.01 0.009 0.007 3.00Deadline 1374 0.009 0.006 0.003 1.3
are shown in Fig. 8b, c, d, e, f and g. The results obtained from these schemes show thatthey produce over-segmented result. However, the proposed approach (as shown in Fig. 8h)has properly segmented the scene. The object detection and VOPs obtained by the MRF-DGA, MRF-DDE and supervoxel schemes are shown in Fig. 8i and m, j and n and k ando. From these results it is observed that some parts of the objects are missing. However theresults obtained by the proposed scheme (as shown in Fig. 8l and p) has detected the object“Suzie” properly.
In order to test the robustness of the proposed algorithm, we also tested it on one reallife video sequence i.e., (Fig. 9) with uncontrolled environmental conditions. Figure 9 rep-resents the VOP generated for ‘Rahul’ video sequence. This video was captured with alow resolution video camera. Figure 9a represents few original image frames of this videosequence. Figure 9b, c, d, e, f and g shows the spatial segmentation results of these framesby the edgeless, JSEG, mean-shift, MRF-DGA, MRF-DDE and supervoxel schemes. It isobserved from the results that these methods provide over segmented results in the face andhand regions of Rahul. The JSEG scheme segments the lower parts of the hand of Rahulin the background class. Similarly, some portions like collar of Rahul is merged with theface regions of Rahul. However proposed scheme has segmented these properly. Figure 9pshows the VOPs generated by the proposed scheme where the moving objects are properlydetected.
The three other sequences considered for our analysis are Deadline, Karlsruhe taxi-Iand Claire sequences. Corresponding results are shown in Figs. 10–12. The correspondingsegmented results obtained by the MLCMRF model are shown in Figs. 10h, 11h and 12h.Similarly, the VOPs obtained by the proposed scheme are shown in Figs. 10p, 11p and 12p,respectively. It may be concluded that the proposed scheme is providing better results ascompared to other scheme used for comparison, whereas MRF-DDE scheme is the closecompetitive one.
7.1 Quantitative evaluation
To provide a quantitative evaluation of the proposed scheme, we have used two ground-truthbased performance measures. One measure is considered for quantitative evaluation of theproposed spatial segmentation scheme and another measure is for quantitative evaluationof the obtained moving object locations. For evaluating the accuracy of the spatial seg-mentation, we have used the pixel by pixel comparison of the ground-truth image with theobtained spatial segmentation results. This measure is also called number of misclassifiedpixels. To evaluate the performance of the moving object detection, we have considered theprecision and recall and F-measures measures.

Multimed Tools Appl
For calculating precision, recall and F-measure, we have used the pixel by pixel com-parison of the ground-truth images with the obtained results. The considered measures arecomputed as follows:
precision = T rue positive
T rue positive + False positive, (20)
recall = T rue positive
T rue positive + False negative, (21)
and
F-measure = 2 × Precision × recall
P recision + recall. (22)
Here true positive is the number of pixels correctly labeled as belonging to the positive class(i.e., the object class). The false positive is the number of pixels that are incorrectly labeledas object class. Similarly, false negative is the number of pixels which were not labeled asobject class but should have been. Precision is the fraction of retrieved instances that arerelevant, while recall is the fraction of relevant instances that are retrieved. F-measure com-bines precision and recall and is the harmonic mean of precision and recall. To validate theproposed scheme we have reported here the average of these measures obtained by takingthe mean value over all the image frames of the considered video sequences. Hence, themeasures are called as average number of misclassified pixels, average precision, averagerecall and average F-measure. It may be noted that for better object detection, the mea-sures average precision, average recall and average F-measure should be high. The averagenumber of misclassified pixels should be low.
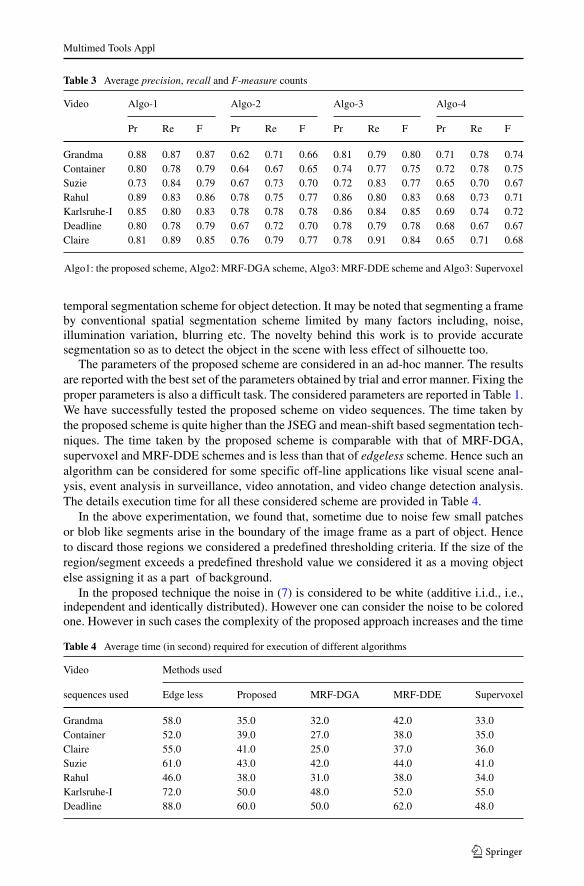
By comparing the spatial segmentation results with a set of manually constructed ground-truth images, it is observed that the average number of misclassified pixels is quite lessin case of proposed spatial segmentation approach than that of MRF-edgeless, mean-shift,MRF-DGA, MRF-DDE and JSEG approaches of segmentation as shown in Table 2. Sim-ilarly, the average precision, average recall and average F-measure obtained for differentframes of the Grandma, Container, Suzie, Rahul, Deadline, Karlsruhe taxi-I and Clairevideo sequences are provided in Table 3. It is concluded from this table that a higher pre-cision, recall and F-measure are obtained for the proposed technique as compared to theMRF-DGA and MRF-DDE techniques. Hence, the results obtained by the proposed schemehas a higher accuracy.
7.2 Discussion and analysis
Use of spatio-temporal segmentation scheme for object detection is quite popular in lastten years, where conventional background subtraction and spatial segmentation schemes areunable to provide acceptable results. The proposed work is a combination of both spatial and
Table 2 Average number of misclassified pixels for spatial segmentation
Video Edge less Proposed Mean-shift MRF-DGA JSEG MRF-DDE
Grandma 420 150 731 434 1973 311Container 412 133 522 203 1066 189Suzie 217 177 1601 192 1418 188Rahul 207 108 262 152 417 138Karlsruhe-I 910 518 2340 864 1723 687Claire 512 417 517 499 1418 476
Multimed Tools Appl
Table 3 Average precision, recall and F-measure counts
Video Algo-1 Algo-2 Algo-3 Algo-4
Pr Re F Pr Re F Pr Re F Pr Re F
Grandma 0.88 0.87 0.87 0.62 0.71 0.66 0.81 0.79 0.80 0.71 0.78 0.74Container 0.80 0.78 0.79 0.64 0.67 0.65 0.74 0.77 0.75 0.72 0.78 0.75Suzie 0.73 0.84 0.79 0.67 0.73 0.70 0.72 0.83 0.77 0.65 0.70 0.67Rahul 0.89 0.83 0.86 0.78 0.75 0.77 0.86 0.80 0.83 0.68 0.73 0.71Karlsruhe-I 0.85 0.80 0.83 0.78 0.78 0.78 0.86 0.84 0.85 0.69 0.74 0.72Deadline 0.80 0.78 0.79 0.67 0.72 0.70 0.78 0.79 0.78 0.68 0.67 0.67Claire 0.81 0.89 0.85 0.76 0.79 0.77 0.78 0.91 0.84 0.65 0.71 0.68
Algo1: the proposed scheme, Algo2: MRF-DGA scheme, Algo3: MRF-DDE scheme and Algo3: Supervoxel
temporal segmentation scheme for object detection. It may be noted that segmenting a frameby conventional spatial segmentation scheme limited by many factors including, noise,illumination variation, blurring etc. The novelty behind this work is to provide accuratesegmentation so as to detect the object in the scene with less effect of silhouette too.
The parameters of the proposed scheme are considered in an ad-hoc manner. The resultsare reported with the best set of the parameters obtained by trial and error manner. Fixing theproper parameters is also a difficult task. The considered parameters are reported in Table 1.We have successfully tested the proposed scheme on video sequences. The time taken bythe proposed scheme is quite higher than the JSEG and mean-shift based segmentation tech-niques. The time taken by the proposed scheme is comparable with that of MRF-DGA,supervoxel and MRF-DDE schemes and is less than that of edgeless scheme. Hence such analgorithm can be considered for some specific off-line applications like visual scene anal-ysis, event analysis in surveillance, video annotation, and video change detection analysis.The details execution time for all these considered scheme are provided in Table 4.
In the above experimentation, we found that, sometime due to noise few small patchesor blob like segments arise in the boundary of the image frame as a part of object. Henceto discard those regions we considered a predefined thresholding criteria. If the size of theregion/segment exceeds a predefined threshold value we considered it as a moving objectelse assigning it as a part of background.
In the proposed technique the noise in (7) is considered to be white (additive i.i.d., i.e.,independent and identically distributed). However one can consider the noise to be coloredone. However in such cases the complexity of the proposed approach increases and the time
Table 4 Average time (in second) required for execution of different algorithms
Video Methods used
sequences used Edge less Proposed MRF-DGA MRF-DDE Supervoxel
Grandma 58.0 35.0 32.0 42.0 33.0Container 52.0 39.0 27.0 38.0 35.0Claire 55.0 41.0 25.0 37.0 36.0Suzie 61.0 43.0 42.0 44.0 41.0Rahul 46.0 38.0 31.0 38.0 34.0Karlsruhe-I 72.0 50.0 48.0 52.0 55.0Deadline 88.0 60.0 50.0 62.0 48.0

Multimed Tools Appl
Fig. 13 Moving object detection for different sequences: (a) original frame, object detection results by, (b)KDE based BGS, (c) ViBe based BGS, (d) MRF based BGS, (e) Cascaded based BGS, and (f) the proposed BGS
required for expectation per each frame is increased by almost double. As per experimentalverification it is observed that the accuracy of object detection improved by only 5–7 %.
It may be noted that we also tested different BGS scheme for testing the effectivenessover the above said considered techniques: Grandma, Suzie, Claire, Karlsruhe taxi-I, Rahul,Container, and Deadline sequences. However since these sequences does not have enoughframes to model the background properly the output results are fund to be providing onlyghosts in the scene. For checking the effectiveness of the proposed scheme we also testedit on different change detection data set and compared its results with that of KDE [10],ViBe [2], hierarchical MRF [38] and cascaded GMM [39] based BGS schemes. The resultsobtained by different schemes are shown in Fig. 13. The quantitative evaluation of them areobtained by checking against some ground-truth images. The performance evaluation mea-sures obtained for these images in terms of precession, recall and F-measures are providedin Table 5. It may be obtained from the table that the proposed scheme is providing betterresults as compared to other considered techniques.
We have provided the results of the proposed scheme on some dynamic backgroundbased sequences. However, by experimental evaluation it is observed that the proposedscheme is not able to provide better object detection results in a scene with large dynamicbackground and camera jitter. Hence in future we would like to concentrate on this. In thepresent work MRF model parameters are set manually. Our future work will focus on esti-
Table 5 Average precision, recall and F-measure for different video Sequence
Approaches Water surface MSA PETS2006 Snowfall
Pr Re FM Pr Re FM Pr Re FM Pr Re FM
KDE 0.40 0.79 0.52 0.67 0.79 0.73 0.83 0.79 0.81 0.90 0.68 0.78ViBe 0.71 0.85 0.77 0.86 0.90 0.88 0.86 0.70 0.78 0.71 0.76 0.73Cascaded GMM 0.68 0.79 0.73 0.84 0.89 0.87 0.73 0.69 0.71 0.67 0.74 0.71MRF 0.83 0.86 0.85 0.84 0.90 0.88 0.81 0.91 0.85 0.77 0.84 0.81Proposed 0.85 0.87 0.86 0.86 0.89 0.88 0.90 0.95 0.93 0.86 0.89 0.88
Pr:precision, Re:recall and FM:F-measure

Multimed Tools Appl
mation of MRF model parameters using some sort of parameter estimation scheme. Weare also looking at related problems with moving camera where existing approach does notyield good results.
8 Conclusion and discussion
In this article, we have proposed a moving object detection technique using the advantagesof multilayer compound Markov Random Field (MLCMRF) based spatial segmenta-tion technique and histogram thresholding based temporal segmentation. The proposedMLCMRF uses five Markov models in a single framework, one in spatial direction usingcolor features, four in temporal direction (using two color features and two edges/linefields). Hence, the proposed MLCMRF is a combination of spatial distribution of color,temporal color coherence and edge maps in the temporal frames. The use of such an edgepreserving model helps in enhancing the object boundary in spatial segmentation and hencecan detect moving objects with less effects of silhouette. The MAP estimate of the con-sidered MLCMRF is obtained by a combination of simulated annealing (SA) and iterativeconditional mode (ICM) that converges fast. For temporal segmentation, a gray level dif-ference based change detection mask (CDM) is constructed. The CDM is subsequentlyupdated with the previous frame video object plane (VOP) and the spatial segmentationof the consecutive frames for detecting the moving objects from the target frames. Resultsof the proposed spatial segmentation approach is compared with those of MRF-edgeless,JSEG, mean-shift, and MRF-DGA approaches of segmentation. It is noticed that the pro-posed approach provides a better spatial segmentation results compared to other consideredmethods. Similarly, the VOPs obtained by the proposed scheme are compared with those ofthe MRF-DGA based object detection scheme and found to be better.
References
1. Babacan SD, Pappas TN (2007) Spatiotemporal algorithm for background subtraction. In: Proceedingof IEEE international conference on acoustics, speech, and signal processing, pp 1065–1068
2. Barnich O, Van Droogenbroeck M (2011) ViBe: a universal background subtraction algorithm for videosequences. IEEE Trans Image Process 20(6):1709–1724
3. Benedek C, Sziranyi T, Kato Z, Zerubia J (2009) Detection of object motion regions in aerial image pairswith a multilayer Markovian model. IEEE Trans Image Process 18(10):2303–2315
4. Besag J (1986) On the statistical analysis of dirty pictures. J R Stat Soc Ser B Methodol 48(3):259–3025. Bouwmans T (2012) Background subtraction for visual surveillance: a fuzzy approach. In: Pal S,
Petrosino A, Maddalena L (eds) Handbook on soft computing for video surveillance, vol 5. Taylor andFrancis Group, New York, pp 103–138
6. Bovic AL (2000) Handbook of image and video processing. Academic Press, New York7. Cho JH, Kim SD (2004) Object detection using spatio-temporal thresholding in image sequences.
Electron Lett 40(18):1109–11108. Comaniciu D, Meer P (2002) Mean shift: a robust approach toward feature space analysis. IEEE Trans
Pattern Anal Mach Intell 24(5):603–6199. Deng Y, Manjunath BS (2001) Unsupervised segmentation of color-texture regions in images and video.
IEEE Trans Pattern Anal Mach Intell 23(8):800–81010. Elgammal A, Duraiswami R, Harwood D, Davis LS (2002) Background and foreground modeling using
nonparametric kernel density estimation for visual surveillance. Proc IEEE 90(7):1151–116311. Geman S, Geman D (1984) Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of
images. IEEE Trans Pattern Anal Mach Intell 6(6):721–74112. Ghosh A, Mondal A, Ghosh S (2014) Moving object detection using markov random field and
distributeddifferential evolution. Appl Soft Comput 15:121–13513. Gonzalez RC, Woods RE (2001) Digital image processing. Pearson Education, Singapore

Multimed Tools Appl
14. Hinds RO, Pappas TN (1995) An adaptive clustering algorithm for segmentation of video sequences. In:Proceedings of international conference on acoustics, speech and signal processing, vol 4, pp 2427–2430
15. Huang SS, Fu LC, Hsiao PY (2007) Region-level motion-based background modeling and subtractionusing MRFs. IEEE Trans Image Process 16(5):1446–1456
16. Hwang SW, Kim EY, Park SH, Kim HJ (2001) Object extraction and tracking using genetic algorithms.In: Proceedings of international conference on image processing, vol 2, pp 383–386
17. Kim EY, Park SH (2006) Automatic video segmentation using genetic algorithms. Pattern Recogn Lett27(11):1252–1265
18. Kirkpatrick SC, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Science220(4598):671–680
19. Lee DS, Yeom S, Son JY, Kim SH (2010) Automatic image segmentation for concealed object detectionusing the expectation-maximization algorithm. Opt Express 18(10):10659–10667
20. Li SZ (2001) Markov random field modeling in image analysis. Springer, Japan21. Lin W, Sun MT, Poovendran R, Zhang Z (2008) Activity recognition using a combination of cate-
gory components and local models for video surveillance. IEEE Trans Circuits Syst Video Technol18(8):1128–1139
22. Liu X, Qi C (2013) Future-data driven modeling of complex backgrounds using mixture of gaussians.Neurocomputing 119:439–453
23. Liu X, Zhao G, Yao J, Qi C (2015) Background subtraction based on low-rank and structured sparsedecomposition. IEEE Trans Image Process 24(8):2502–2514
24. Luthon F, Caplier A, Lievin M (1999) Spatiotemporal MRF approach to video segmentation: applicationto motion detection and lip segmentation. Signal Process 76(1):61–80
25. Oneata D, Revaud J, Verbeek J, Schmid C (2014) Spatio-temporal object detection proposals. In:European conference on computer vision, pp 737–752
26. Otsu N (1979) A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern9(1):62–66
27. Palaniappan K, Ersoy I, Seetharaman G, Davis S, Kumar P, Rao RM, Linderman R (2011) Parallel fluxtensor analysis for efficient moving object detection. In: Proceedings of the 14th international conferenceon information fusion, pp 535–546
28. Qiao Y-L, Yuan K-L, Song C-Y, Xiang X-Z (2014) Detection of moving objects with fuzzy colorcoherence vector. Math Probl Eng 2014, Article ID 138065:8
29. Rapantzikos K, Tsapatsoulis N, Avrithis Y, Kollias S (2009) Spatiotemporal saliency for videoclassification. Signal Process Image Commun 24(7):557–571
30. Rougier C, Meunier J, St-Arnaud A, Rousseau J (2011) Robust video surveillance for fall detection basedon human shape deformation. IEEE Trans Circuits Syst Video Technol 21(5):611–622
31. Salember P, Marques F (1999) Region based representation of image and video segmentation tools formultimedia services. IEEE Trans Circuits Syst Video Technol 9(8):1147–1169
32. Sasaki GH, Hajek B (1988) The time complexity of maximum matching by simulated annealing. J ACM35(2):387–403
33. Satake J, Miura J (2009) Robust stereo-based person detection and tracking for a person following robot.In: Proceedings of IEEE international conference on robotics and automation, pp 1–6
34. Sheikh Y, Shah M (2005) Bayesian modeling of dynamic scenes for object detection. IEEE Trans PatternAnal Mach Intell 27(11):1778–1792
35. Shi Q, Wang L, Cheng L, Smola A (2008) Discriminative human segmentation and recognition usingsemi-Markov model. In: Proceedings of IEEE conference on computer vision and pattern recognition,pp 1–8
36. Stauffer C, Grimson WEL (2000) Learning patterns of activity using real-time tracking. IEEE TransPattern Anal Mach Intell 22(8):747–757
37. Stolkin R, Greig A, Hodgetts M, Gilby J (2008) An EM/E-MRF algorithm for adaptive model basedtracking in extremely poor visibility. Image Vis Comput 26(4):480–495
38. Su TF, Chen YL, Lai SH (2010) Over-segmentation based background modeling and foregrounddetection with shadow removal by using hierarchical MRFs. In: Proceedings of ACCV, pp 535–546
39. Teixeira LF, Cardoso JS, Corte-Real L (2007) Object segmentation using background modelling andcascaded change detection. J Multimed 2(5):55–65
40. Tekalp AM (1995) Digital video processing. Prentice Hall, New Jersey41. Wang R, Bunyak F, Seetharaman G, Palaniappan K (2014) Static and moving object detection using flux
tensor with split gaussian models. In: 2014 IEEE conference on computer vision and pattern recognitionworkshops (CVPRW), pp 420–424
42. Wu GK, Reed TR (1999) Image sequence processing using spatio temporal segmentation. IEEE TransCircuits Syst Video Technol 9(5):798–807
43. Xu D, Yan S, Tao D, Zhang L, Li X, Zhang HJ (2006) Human gait recognition with matrix representation.IEEE Trans Circuits Syst Video Technol 16(7):896–903

Multimed Tools Appl
44. Zhang YJ (2006) Advances in image and video segmentation. IRM Press, New York45. Zhou X, Yang C, Yu W (2013) Moving object detection by detecting contiguous outliers in the low-rank
representation. IEEE Trans Pattern Anal Mach Intell 35(3):597–610
Badri Narayan Subudhi received B. E degree in Electronics and Telecommunication from Biju PatnaikUniversity of Technology, Orissa, India, in 2004, and the M.Tech. in Electronics and System Communica-tion from National Institute of Technology, Rourkela, India, in 2009. He obtained his PhD from JadavpurUniversity in year 2014. He was a Research Scholar at the Machine Intelligence Unit, Indian Statistical Insti-tute, Kolkata, India with financial support from Council of Scientific and Industrial Research (CSIR) schemefrom 2011–2014. Currently he is serving as an Assistant Professor at National Institute of Technology Goa,India. He was nominated for Indian Science Congress Association Young Scientist Award for the year 2012–2013. He received CSIR senior research fellowship for the year 2011–2015. He was awarded with YoungScientist Travel grant award from DST, Government of India and CSIR in 2011. He is the receiptant ofBose-Ramagnosi Award for the year 2010 from DST, Government of India under India-Trento Programmefor Advanced Research (ITPAR). Under this scheme, he was a visitingscientist at University of Trento, Italyduring Aug. 2010 to Feb 2011. His research interests include Video Processing, Image Processing, MachineLearning, Pattern Recognition, and Remote Sensing Image Analysis.
Susmita Ghosh received the B.Sc. (with honors) in Physics and the B.Tech. in Computer Science and Engi-neering from the University of Calcutta, India, in 1988 and 1991, respectively, the M.Tech. in ComputerScience and Engineering from the Indian Institute of Technology, Bombay, in 1993, and the Ph.D. (Engineer-ing) from Jadavpur University, Kolkata, in 2004. She has visited various universities/ academic institutes forcollaborative research/ international projects and delivered lectures in different countries including Australia,China, Italy, Japan and the USA. She has published many research papers in internationally reputed journalsand referred conferences and has edited 3 books. She was a Lecturer and then a Reader with the Depart-ment of Computer Science and Engineering, Jadavpur University since 1997. She is currently an AssociateProfessor at the same department. Her research interests include genetic algorithms, neural networks, imageprocessing, pattern recognition, soft computing, and remotely sensed image analysis.

Multimed Tools Appl
Pradipta Kumar Nanda obtained his B.Sc(Engg) in Electrical Engineering with First Class Hons fromVSSUT, Odisha in 1984 and MSc(Engg.) in Electronic Systems and Communication from NIT Rourkelain the year 1989. He obtained his PhD from IIT Bombay in 1996 in the area of computer Vision. He hasserved more than 21 years at NIT Rourkela with the last position as professor and Head of the Department.During his career at NIT Rourkela, He has contributed to the growth of the department and Institute as well.Currently, he is the Dean(Res) of Siksha O Anusandhan University, Bhubaneswar, Odisha.
He has supervised three PhD students at NIT as sole guide. He has guided 34 M.Tech and oneM.Tech(Res) student. He has supervised several B.Tech. Projects in different areas. Currently, He is supervis-ing 8 PhD 2 M.Tech and 20 B. Tech students. He has completed several AICTE/MHRD sponsored projectsand running a collaborative project with Center for soft Computing, ISI Kolkata. He has published 74 papersin various Journals and Conference proceedings and has authored 3 research books and two book chapters. He has visited UK, USA, Malayasia in connection with academic programs. He was a academic visitor toSchool of Computing, University of Leeds, UK in March 2006 and delivered lectures to their faculties andstudents. He has delivered several invited lectures in different workshops/summer and winter schools. He hasbeen program chair of three International Conferences and General chair of an International Conferences.He has organized several National and International Conferences. He has been serving as a expert memberof NBA, Govt. of India. He is an expert in DRDO, NITS and many National Level Institutions.
On 14th Feb, he has received the Bharat Jyoti award in a function at New Delhi from Indian InternationalFriendship Society. Received Odisha Technocrat award on 15th Sept 2013 form Ever green forum of Odishaon the Engineers day.
He has chaired sessions in many International and national Conferences. He is a reviewer of IEEE trans-action on SMC, IET Computer Vision and Image Processing, International Journals on Pattern recognitionLetters, Digital Signal Processing, Journal of Electronics Imaging (SPIE) and many IEEE conferences. Hehas organized many National and International Conferences. He has served as program committee membersof many reputed International Conferences. He is a Fellow of IETE, India and senior member IEEE, USA,member IET and life member of ISTE, India. His research interests are Image Processing and Analysis, Bio-medical Image Analysis, Video-tracking, Computer Vision, Soft computing and their applications, and inAd-hoc wireless sensor networks.

Multimed Tools Appl
Ashish Ghosh is Head and Professor of the Machine Intelligence Unit at Indian Statistical Institute, Kolkata,India. He received the B.E. degree in Electronics and Telecommunication from the Jadavpur University,Kolkata, in 1987, and the M.Tech. and Ph.D. degrees in Computer Science from the Indian Statistical Insti-tute, Kolkata, in 1989 and 1993, respectively. He received the prestigious and most coveted Young Scientistsaward in Engineering Sciences from the Indian National Science Academy in 1995; and in Computer Sciencefrom the Indian Science Congress Association in 1992.
He has been selected as an Associate of the Indian Academy of Sciences, Bangalore, in 1997. He vis-ited the Osaka Prefecture University, Japan, with a Post-doctoral fellowship during October 1995 to March1997, and Hannan University, Japan as a Visiting Faculty during September to October, 1997 and Septem-ber to October, 2004. He has also visited Hannan University, Japan, as Visiting Professor with a fellowshipfrom Japan Society for Promotion of Sciences (JSPS) during February to April, 2005. During May 1999he was at the Institute of Automation, Chinese Academy of Sciences, Beijing, with CIMPA (France) fel-lowship. He was at the German National Research Center for Information Technology, Germany, with aGerman Government (DFG) Fellowship during January to April, 2000, and at Aachen University, Germanyin September 2010 with an European Commission Fellowship. During October to December, 2003 he wasa Visiting Professor at the University of California, Los Angeles, and during December 2006 to January2007 he was at the Computer Science Department of Yonsei University, South Korea. His visits to Univer-sity of Trento and University of Palermo (Italy) during May to June 2004, March to April 2006, May to June2007, 2008, 2009 and 2010 were in connection with collaborative international projects. He also visited var-ious Universities/Academic Institutes and delivered lectures in different countries including Poland and TheNetherlands.
His research interests include Pattern Recognition and Machine Learning, Data Mining, Image Analysis,Remotely Sensed Image Analysis, Video Image Analysis, Soft Computing, Fuzzy Sets and Uncertainty Anal-ysis, Neural Networks, Evolutionary Computation and Bioinformatics. He has already published more than120 research papers in internationally reputed journals and referred conferences, has edited 8 books and isacting as a member of the editorial board of various international journals. He is a member of the found-ing team that established a National Center for Soft Computing Research at the Indian Statistical Institute,Kolkata, in 2004, with funding from the Department of Science and Technology (DST), Government of India,and at present is the In-Charge of the Center.


















