Methoden van Wetenschappelijk...
48
Introduction Collecting Data and Statistical Inference Logical Fallacies Methoden van Wetenschappelijk Onderzoek Clinicsessie 1 Katrien Beuls & Joris Bleys Artificial Intelligence Laboratory Vrije Universiteit Brussel katrien|[email protected] October 12, 2010 Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
Transcript of Methoden van Wetenschappelijk...

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Methoden van Wetenschappelijk OnderzoekClinicsessie 1
Katrien Beuls & Joris Bleys
Artificial Intelligence LaboratoryVrije Universiteit Brussel
katrien|[email protected]
October 12, 2010
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Welcome to MWO!
I Basic methods of scientific research: data collection, dataanalysis, scientific discourse (argumentation, references,abstract writing), patents, setting up experiments, etc.
I Contact person: Katrien Beuls
I Evaluation: 4 clinic sessions and 4 assignments
I All course information (slides, assignments, deadlines,resources, etc.) is available on the course website:http://arti.vub.ac.be/cursus/2010-2011/mwo/avond/
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Schedule
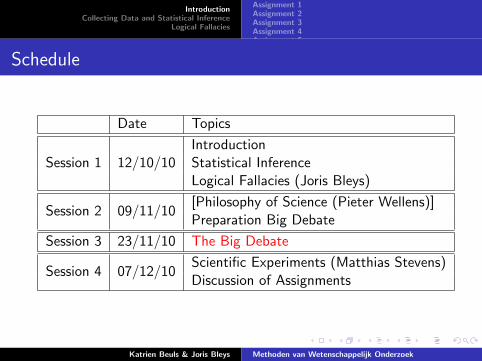
Date Topics
Session 1 12/10/10IntroductionStatistical InferenceLogical Fallacies (Joris Bleys)
Session 2 09/11/10[Philosophy of Science (Pieter Wellens)]Preparation Big Debate
Session 3 23/11/10 The Big Debate
Session 4 07/12/10Scientific Experiments (Matthias Stevens)Discussion of Assignments
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Assignments
1. Statistical Inference(deadline October 26th 2010, 6pm) (15%)
2. The Big Debate(Session 3; preparation during Session 2) (30%)
3. Philosophy of Science(deadline December 24th, 4pm) (10%)
4. Writing a Comment(deadline December 2nd 2010, 6pm) (15%)
5. Designing and Analysing an Experiment(deadline will be announced on website) (30%)
The written assignments (1, 2, 4, 5) should be sent to Katrien([email protected]) in PDF format. Handing in too late willhave effects on your marks !!
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Statistical Inference
Task: Running and reporting some significance tests using R:I You can download it from http://www.r-project.org/I A manual can be found here: http://www.gardenersown.
co.uk/Education/Lectures/R/basics.htmI .data files and full description are available from
http://arti.vub.ac.be/cursus/2010-2011/mwo/avond/assignment-1
I Easily loadable into R via scan() and read.csv()I Identify appropriate tests and run them
Format: Report the reasons for your choice of tests, thecommands you ran and the results in a report (max. 1 page)Resources:
I Common sense: Statistics for DummiesI Scientific approaches: see course website
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
The Big Debate
dust storms
agriculture
forest fires
Aërosolen hebben de opwarming door broeikasgassen gemaskeerd
CO2 molecule has an average lifetime of 100 yearsAërosols have an average lifetime of 10 days! Emission sources play a much larger role: see smog episodes in Brussels
16
Climate change will have many kinds of impacts. Climate change will affect ecosystems and human systems—such as agricultural, trans-portation, and health infrastructure—in ways we are only beginning to understand (see Figure 13). There will be positive and nega-tive impacts of climate change, even within a single region. For example, warmer tem-peratures may bring longer growing seasons in some regions, benefiting those farmers who can adapt to the new condi-tions but potentially harming native plant and animal species. In general, the larger and faster the changes in climate are, the more difficult it will be for human and natu-ral systems to adapt.
Unfortunately, the regions that will be most severely affected are often the regions that are the least able to adapt. Bangladesh, one of the poorest nations in the world, is projected to lose 17.5 percent of its land if sea level rises about 1 meter (39 inches), displacing millions of people. Several
The Chinstrap penguin: a regional winner.Even within a single regional ecosystem, there will be winners
and losers. For example, the population of Adélie penguins has decreased 22 percent during the past 25 years, while the Chinstrap
penguin population increased by 400 percent. The two species depend on different habitats for survival: Adélies inhabit the winter
ice pack, whereas Chinstraps remain in close association with open water. A 7-9° F rise in midwinter temperatures on the western Antarctic Peninsula during the past 50 years and associated reced-
ing sea-ice pack is reflected in their changing populations.
I M P A C T S O F C L I M AT E C H A N G E
Many of the world’s poorest
people, who lack the resources
to respond to the impacts of
climate change,are likely
to suffer the most.
—Joint science academies’ statement on sustainability,
energy efficiency, and climate protection (May 2007)
This brochure highlights findings and recommendations from National Academies’ reports on climate change. These reports are the products of the National Academies’ consensus study process, which brings together leading scientists, engineers, public health officials, and other experts to address specific scien-tific and technical questions. Such reports have evaluated climate change science, identified new avenues of inquiry and critical needs in the research infrastructure, and explored opportunities to use scientific knowledge to more effectively respond to climate change.
3
Figure 1. The greenhouse effect is a natural phenomenon that is essential to keeping the Earth’s surface warm. Like a greenhouse window, greenhouse gases allow sunlight to enter and then prevent heat from leaving the atmosphere. Water vapor (H2O) is the most important greenhouse gas, followed by carbon dioxide (CO2), methane (CH4), nitrous oxide (N2O), halocarbons, and ozone (O3). Human activities—primarily burning fossil fuels—are increasing the con-centrations of these gases, amplifying the natural greenhouse effect. Image courtesy of the Marion Koshland Science Museum of the National Academy of Sciences.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
The Big Debate
Task: Discuss the arguments you want to use during the debatewithin your group. You can divide the preparation of eachargument among the group members.
Format: The Big Debate will take place during the third MWOsession (November 23, 2010).
Resources:I Starters’ Kit: http://www.realclimate.org/index.php/
archives/2007/05/start-here/I Met Office:
I http://www.metoffice.gov.uk/climatechange/science/explained/
I http://www.metoffice.gov.uk/climatechange/guide/I http://climateprediction.net/content/
climate-science-explainedKatrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Philosophy of Science
Task: Pick one philosopher of your choice and discuss his mostimportant contribution(s) to science. It is important to also situatethese in the scientific debate that was going on at the time.Conclude with a brief personal reflection. Examples are:
I Philosophers of science: Kuhn, Popper, . . .
I General philosophers that also had an effect on science:Aristoteles, Descartes, Leibniz, Wittgenstein, Russell, . . .
Format: A written text with a length of max. 1500 words
Resources:
I http://plato.stanford.edu
I Okasha S. (2002) Philosophy of Science: A Very ShortIntroduction. Oxford University Press, Oxford, UK.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Patents vs. Open Source
There are two main perspectives in the debate on software patents:big companies trying to protect their own software products andopen-source believers fighting for more freedom in softwaredevelopment. In the USA, software patents have become rathercommon, which can sometimes lead to rather weird situations (e.g.the famous hyperlink patent). In Europe, the debate is still goingon.
A recent talk on the topic can be found here: http://itia.ntua.gr/antonis/political/software-patents-in-europe/
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
Patents vs. Open Source
Task: Write a comment on the Patent Debate. The mostimportant thing here it becomes clear why you choose for aspecific point of view. You do not necessarily have to be in favouror against software patents but you can opt for an intermediateposition where only a few types of software can be patented.
Format: A written text, max. 1000 words
Resources: http://www.softwarepatenten.be/
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Assignment 1Assignment 2Assignment 3Assignment 4Assignment 5
NoiseTube
Noise pollution is a serious problem in many cities. NoiseTube is aresearch project, started in 2008 at the Sony Computer ScienceLab in Paris, which aims to develop a new participative approachfor monitoring noise pollution by involving the general public1.
AboutCitiesPeopleTagsDownloadAPIJoin!Login
HelpPublicationsTeam
To view the maps in KML format you need to install Google Earth (v5 or higher).
Each KML file is with contains a map consisting of several layers:
Dynamic Legend layer: different distributions (levels of exposure , social tagging) changingaccording to the area viewedMeasurements Layer (separated by range of exposure to noise)Semantics Layer (Annotations)Contribution LayerTemporal aspect: Use the history panel to play with the temporal dimension
131 Cities
Map Satellite Hybrid Terrain
Task: the task will be explained by Matthias during the last clinicsession.
1http://noisetube.net
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
1. Collecting Data andStatistical Inference
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Outline
Introduction
Collecting Data and Statistical InferenceEmpirical Data
Data SamplingGenerating HypothesesVariablesDistributions
Descriptive StatisticsCentral TendencyDispersionSymmetry
Statistical InferenceUsing statistics to test hypothesesSignificance testing
Examples
Logical Fallacies
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Data gathering
I Already a source of many mistakes (conscious or unconscious)I Examples
I A railway company investigating the temporal accuracy of thetrains
I The government investigating the happiness of the peopleI A questionnaire about hygiene
I In all of these cases, the results are likely to be biased
I Be aware of possible biases, and report them together withyour statistics!
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Methods of data gathering
I Random sampling: Each case has an equal chance tobecome part of the sample.
I Needed: a well-defined population, a list of all cases and arandom number generator.
I Systematic sampling: The first case is picked randomly, therest according to a specific procedure (e.g. Start at randomrole number, increment with 10 after that.).
I Possibly introduces a bias. (Example?)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
How much data is required?
I The more, the better!I In practice, research is of course limited by money, time and
space.
I The amount of data sometimes depends on the distribution ofdata points (e.g. some may be very rare but still have a majorinfluence).
I This could require iterated sampling.
I Always report the number of samples and how they wereobtained.
I If not, you could just as well be showing that the probability ofthrowing a 6 when rolling a dice is 100%.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
!"#$%"&'(' &
)*+",-./-0-1$/1+"20"3+4+$%1*
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Importance of Hypotheses
I Science and engineering proceed byI the formulation of hypothesesI and the provision of supporting (or refuting) evidence for them.
I Computer Science (CS) should be no exception.I But the provision of explicit hypotheses in CS is rare! This
causes lots of problems:I Usually many possible hypothesesI Ambiguity is a major cause of referee/reader
misunderstandingI Vagueness is a major cause of poor methodology
(inconclusive evidence, unfocussed research direction)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Evaluation begins with claims
Hypotheses in CS can be:I Claims about a task, system, technique or parameter, e.g.:
I System X performs better than System Y on dimension ZI Technique X has property YI X is the optimal setting of parameter Y
I Properties and relations along scientific, engineering orcognitive science dimensions.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Scientific Hypotheses
For the first claim, relevant hypotheses would be:
I Experimental Hypothesis (H1): The mean of the ratings forthe new system is higher than the mean of the ratings for thebaseline system.
I Null Hypothesis (H0): There is no difference in the mean ofthe ratings for the new system and the mean of the ratings ofthe baseline system.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Variables
The data of an experiment is a set of observations that ischaracterised by one or more properties that are extracted asvariables:
I Independent variable: A variable that indicates somethingyou manipulate in an experiment, or some supposedly causalfactor that you can’t manipulate such as Corpus and Systemin the sentence compression experiment.
I Dependent variable: A variable that indicates to greater orlesser degree the causal effects of the factors represented bythe independent variables. Examples for sentence compressionare compression rate (percentage of words removed) andsentence ratings (1-5).
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Levels of Measurement
Variables can be split into categorical and continuous, and withinthese types there are different levels of measurement:
I Categorical (entities that are divided into distinct categories)I Binary variable: There are only two categoriesI Nominal variable: There are more than two categoriesI Ordinal variable: The same as a nominal variable but the
categories have a logical order
I Continuous (entities get a distinct score)I Interval variable: Equal intervals on the variable represent
equal differences in the property being measuredI Ratio variable: The same as an interval variable, but the
ratios of scores on the scale must also make sense
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
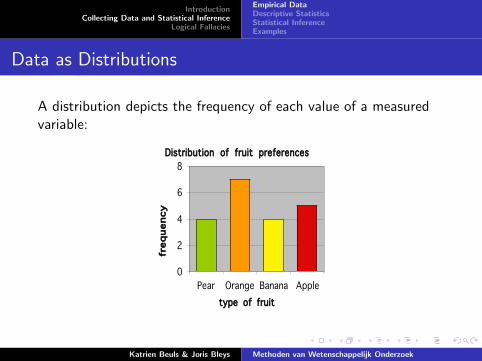
Data as Distributions
A distribution depicts the frequency of each value of a measuredvariable:
Favourite fruit - Answer at a glance. ..\
Fruit values
Tally FREQUENCY
Apple //// 5
Banana //// 4
Orange //// // 7
Pear //// 4
B. Single snapshot: DISTRIBUTION = pictures of frequency x value
Distribution of fruit preferences
0
2
4
6
8
Pear Orange Banana Apple
type of fruit
frequency
Distribution of fruit preferences
0 2 4 6 8
Pear
Orange
Banana
Apple
type
of f
ruit
numbers of choosers = frequency
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Outline
Introduction
Collecting Data and Statistical InferenceEmpirical Data
Data SamplingGenerating HypothesesVariablesDistributions
Descriptive StatisticsCentral TendencyDispersionSymmetry
Statistical InferenceUsing statistics to test hypothesesSignificance testing
Examples
Logical Fallacies
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Descriptive Statistics
What do we need to describe about a distribution?
I Where is it on the scale axis = central tendencyI What kind of shape does it have?
I Does it spread out or bunch up? = dispersionI Is it symmetrical? = symmetry
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Representative values
I Mean: The average value. x̄ = 1N
∑xi
I Median: The value which splits a sorted distribution in half.The 50th quantile of the distribution.
I Quantile: A ”cut point” q that divides the distribution intopieces of size q/100 and 1− (q/100). Examples: 50th quantilecuts the distribution in half. 25th quantile cuts off the lowerquartile. 75th quantile cuts off the upper quartile.
Useful TermsMedian: The value which splits a sorted distribution in half. The 50th quantileof the distribution.
1 2 3 7 7 8 14 15 17 21 22Mean: 10.6
Median: 8
1 2 3 7 7 8 14 15 17 21 22 1000Mean: 93.1
Median: 11Quantile: A "cut point" q that divides the distribution into pieces of size q/100 and 1-(q/100). Examples: 50thquantile cuts the distribution in half. 25th quantile cuts off the lower quartile. 75thquantile cuts off the upper quartile.
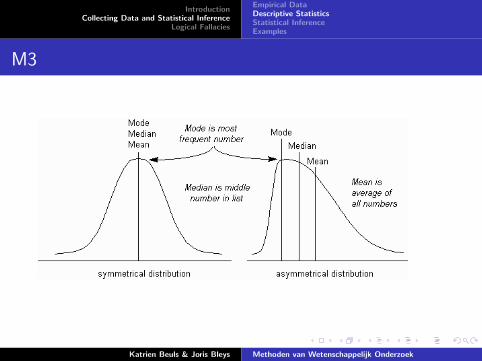
I Mode: Most frequent value.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
M3
Reporting a statistic
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
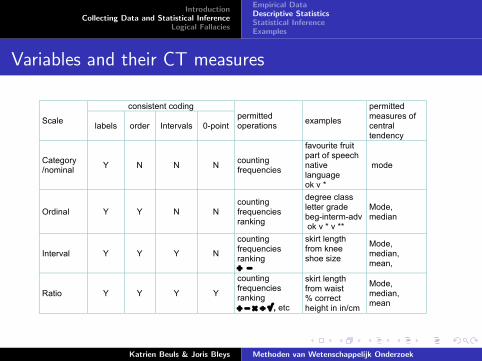
Variables and their CT measures
MATISYAHU:TEACHING:SED:08-09:sed5-08.docLast printed 7/10/08 3:02P age 3 of 13
consistent coding
Scale labels order Intervals 0-point
permitted operations
examples
permitted measures of central tendency
Category /nominal
Y N N N counting frequencies
favourite fruit part of speech native language ok v *
mode
Ordinal Y Y N N counting frequencies ranking
degree class letter grade beg-interm-adv ok v * v **
Mode, median
Interval Y Y Y N
counting frequencies ranking + !
skirt length from knee shoe size
Mode, median, mean,
Ratio Y Y Y Y
counting frequencies ranking + ! " ÷ # , etc
skirt length from waist % correct height in in/cm
Mode, median, mean
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Measures of Dispersion
I Some measures of dispersion should always accompanyrepresentative values.
I A good measure of dispersion should:I take into account all data points;I describe the average deviation of data points with respect to
the mean;I increase when data heterogeneity increases.
I Examples:I Range = max(x)−min(x)I Deviation = difference of a score from the sample mean:
(xi − x̄)I Variance = average of squared deviations from the mean:
V = 1N
∑(xi − x̄)2 (used when scale is no issue)
I Standard Deviation: S =√
V =√
1N
∑(xi − x̄)2
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek
IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
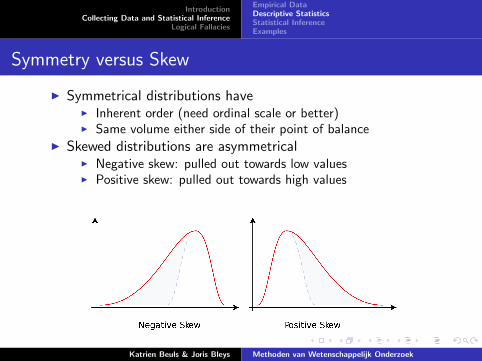
Symmetry versus Skew
I Symmetrical distributions haveI Inherent order (need ordinal scale or better)I Same volume either side of their point of balance
I Skewed distributions are asymmetricalI Negative skew: pulled out towards low valuesI Positive skew: pulled out towards high values
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Symptoms of bad methodology
I Where there is a minimum or maximum score and distributionis pushed up against it.
I Ceiling effect (negative skew) (e.g. topmost score)I Floor effect (positive skew) (e.g. fastest possible reading
time)
I Where there are a few outliers = cases separated from bulkof cases and from central tendency.
I If you don’t examine the distribution of results in such studies,you may be drawing incorrect conclusions from your results.E.g.
I An outlier affects the mean disproportionally, for example, thecollege with the highest mean salary for its graduates.(Use standard deviation!)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Outline
Introduction
Collecting Data and Statistical InferenceEmpirical Data
Data SamplingGenerating HypothesesVariablesDistributions
Descriptive StatisticsCentral TendencyDispersionSymmetry
Statistical InferenceUsing statistics to test hypothesesSignificance testing
Examples
Logical Fallacies
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Using statistics to test hypotheses
I Hypothesis: A dice is crookedI I roll it twice, 6 shows up both times
I Hypothesis: Using Microsoft Windows makes people angryI A friend of mine is using Windows and he’s always complaining
to me about how unstable his computer is
I Hypothesis: Using Microsoft Windows makes people angryI I ask 312 VUB students to fill out a questionnaire after using
the computer lab, stating which operation system they usedand whether they felt happy or angry when leaving the lab.Operating system usage is roughly the same, but while only12% of Linux and MacOS users felt angry, 37% of Windowsusers did.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Using statistics to test hypotheses
I Hypothesis: Using Microsoft Windows makes people angryI I run a large scale evaluation with 21.492 participants who
have to perform standardised tasks on different operatingsystems. The participants are evenly distributed across all ages,half of them are male and half of them female. Right beforeand right after working at the computer for 30 minutes theyundergo a standardised psychological test to evaluate theiraggressiveness before and after the task. I end up with ordinalresults for each participant stating whether they became less(<) or more aggressive (>), or whether their aggressivenesslevel stayed approximately the same (=). The percentage ofWindows users with a > result seems disproportionately higherthan in the other operating system groups.
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
The plural of anecdote isn’t data
I The more data, the better
I Hypothesis: A coin is biased towards heads
N Heads Tails
5 3 210 6 4
100 60 401000 600 400
1.000.000 600.000 400.000
I Higher N is closer in size to an infinite populationI Remember: we want to make a general claim
I But: We want to have a measure on how much data we need
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Significance testing
I We cannot simply compare descriptive parameters, but entiredistributions of data
I Null Hypothesis Significance TestingI H0 comes from the sampling distribution: we are seeing only
variations we would expect to find by chance when samplingthe population
I H1 is defined against that distribution: ‘the result is veryunlikely to belong to the distribution of chance outcomesaccording to H0’
I In order to have a ‘standard case’ to compare against (H0),we need a model of the data
I For the coin: p(Heads) = p(Tails) = 0.5I For the dice: p(1) = p(2) = p(3) = p(4) = p(5) = p(6) = 1
6I To test the effectiveness of a medical treatment: the mortality
rate of untreated patients
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Significance level
I Statistical significance tests give a probability p
I p = the probability that the given data set is simply sampledfrom the ‘normal’ H0 distribution and that any variation fromit can be accounted for by the deviation which we wouldexpect for the sample size N
I If we want to support our H1, we want this p to be low
I Typical significance levels α = .05, .01, .001, .0001 (* ** ***)
I A low p does not mean that H1 is proven, only that H0
doesn’t account well for the observed data
I Say we run and publish 20 experiments where the result isp < .05. What does this mean?
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Types of error in statistical hypothesis testing
I Type I error (false positive): reject the null hypothesis when itis actually true
I Type II error (false negative): accept the null hypothesis whenit is actually false
I Since we want to be conservative with the claims we makebased on our experiments, we want to keep the Type I errorrate α low.
I The lower we set our mandatory significance level α, thehigher our Type II error rate β gets - we increase the chancethat we reject our H1 when it is actually true
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
The simplest case with two outcomes: Binomial test
I The math is easy so we can use the Binomial distribution toget an exact result
I For the coin example, use B(N, 12 ) to run a one-tailed test
I How likely is it that we got H or even more Heads assumingthe coin is not biased?
N Heads Tails p(B(N, 12 ) ≥ H)
5 3 2 0.510 6 4 0.337
100 60 40 0.028441000 600 400 0.0000000001364
1.000.000 600.000 400.000 0.00000000000000022
Remember: None of this means that H1 is proven!
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Multiple nominal outcomes: χ2-test
For more than two possible outcomes and large sample sizes wecan’t afford to run an exact test but have to use an approximation(e.g. Pearson’s χ2-test)
χ2 =n∑
i=1
(Oi − Ei )2
Ei
Oi = observed frequencyEi = expected frequencyn = number of possible outcomes (bins)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Pearson’s χ2-test
χ2 =n∑
i=1
(Oi − Ei )2
Ei
I Additional conditions for Pearson’s χ2-test:I unrelated design: different individuals in different bins -
otherwise you would have to use a multinomial test - why?I bins mutually exclusiveI if the sample size or the expected frequencies for each bin are
too low, the approximation of Pearson’s χ2-test to a realχ2 distribution is not reliable. In these cases Fisher’s exact testcan be used instead.
I Can also be used to check whether 2 observed sample sets arelikely to come from the same distribution!
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Directionality of hypotheses
I A hypothesis can beI directed/one-tailed: there is a bias in one specific direction -
we are only interested in the probability of that one tail ofpossible outcomes
I undirected/two-tailed: there is some bias - unlikely high as wellas unlikely low outcomes confirm our hypothesis
I Some tests (like χ2) can only be used for two-tailed tests.Why? (Hint: only when n = 2 can you inquire about thedirectionality of the bias)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Other univariate significance tests
I For ordinal data: Wilcoxon, Mann-Whitney, Friedman,Kruskal-Wallis, Cohen’s Kappa,. . .
I For normally distributed interval data: z-test (simply thecontinuous version of the Binomial distribution/test)
I For normally distributed interval data of which the underlyingdistribution of H0 is not known: t-test
I For experimental designs involving more than 2 conditions:ANOVA (Analysis of Variance)
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Multivariate statistics
I So far we have only looked at univariate statistics: only asingle dependent variable
I What about correlations between multiple dependent variablesmeasured in the same experiment?
I Non-parametric (ordinal): Spearman Rank Order CorrelationI Parametric (interval/ratio): Pearson Product-Moment
Correlation
I Joint probability distributions - covariance
I Correlation will not tell you the direction of a potential causalrelationship
I Correlation 6= causation!I There is a strong negative correlation between the number of
mules and number of PhDs among American states
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Linear regression
I Simple linear regression: treating Y as a function of X
I Multiple linear regression: treating Y as a function of anynumber of Xs
I Different from multivariate statistics:I We are investigating the conditional rather than the joint
probability distributions
I OutcomeI Linear model: Y = β1X1 + β2X2 + · · ·+ βnXn + εI Quantitative measure of the strength (significance) of the
relationship between Y and every Xi
I Just like with correlation coefficients only linear relationshipscan be detected
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Statistical significance tests in practice
I Wide-spread in psychology and medicineI Controlled experiment setups (often geared towards suiting a
particular test. . . )
I Software: SPSS, MatLab, R,. . .I Sometimes tests are run on data that they aren’t actually
made for. . .I Interval+ratio data can be binned to run ordinal+nominal
tests on (e.g. χ2). . .I The conditions for many tests aren’t strictly adhered to and
there are a number of established “corrections” that have beenproven to “work in practice” (e.g. Yates Correction for χ2 withlow expected frequencies,. . . )
I Many experimental setups (e.g. complex interactions inmulti-agent systems) are hard to capture with statistical tests
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
Empirical DataDescriptive StatisticsStatistical InferenceExamples
Final thoughts on statistical significance tests
I Not all correlations are interesting, relevant or importantI You shouldn’t run random or exhaustive tests
I Testing should be motivated by your theory and hypothesesI Results should be analysed and interpreted in terms of your
theory (and beyond - keep thinking!)
I Statistical parameters don’t capture everythingI Eyeball your data closely before running tests, it can give you
important clues on what you actually want to look forI A picture is worth a thousand words
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek

IntroductionCollecting Data and Statistical Inference
Logical Fallacies
2. Logical Fallacies
Katrien Beuls & Joris Bleys Methoden van Wetenschappelijk Onderzoek