
LOCAL FEATURE SELECTION FOR EFFICIENT BINARY DESCRIPTOR...
5
LOCAL FEATURE SELECTION FOR EFFICIENT BINARY DESCRIPTOR CODING Pedro Monteiro, João Ascenso, Fernando Pereira Instituto Superior Técnico – Instituto de Telecomunicações, Lisbon, Portugal ABSTRACT 1 In a visual sensor network, a large number of camera nodes are able to acquire and process image data locally, collaborate with other camera nodes and provide a description about the captured events. Typically, camera nodes have severe constraints in terms of energy, bandwidth resources and processing capabilities. Considering these unique characteristics, coding and transmission of the pixel-level representation of the visual scene must be avoided, due to the energy resources required. A promising approach is to extract at the camera nodes, compact visual features that are coded to meet the bandwidth and power requirements of the underlying network and devices. Since the total number of features extracted from an image may be rather significant, this paper proposes a novel method to select the most relevant features before the actual coding process. The solution relies on a score that estimates the accuracy of each local feature. Then, local features are ranked and only the most relevant features are coded and transmitted. The selected features must maximize the efficiency of the image analysis task but also minimize the required computational and transmission resources. Experimental results show that higher efficiency is achieved when compared to the previous state-of-the-art. Index Terms — visual sensor networks, local features, binary descriptors, descriptors selection, binary descriptor coding 1. INTRODUCTION Visual sensor networks (VSN) can be characterized by a large number of wireless low power sensing nodes that are empowered with sight and are capable of complex visual processing tasks [1]. Traditionally, sensing nodes must acquire visual data, and compress and transmit the pixel-level representation in bandwidth limited networks to a central location where further processing occurs. However, this many-to-one scenario demands significant computational and bandwidth resources at the sensing nodes, such as powerful video encoders and energy demanding communication techniques to cope with the huge amount of data that is necessary to transmit. Since VSN camera nodes have limited lifetime due to the battery powered operation, it is imperative to optimize the processing and transmission of visual data. Thus, camera nodes can acquire visual data and perform local processing to obtain local image features, that are delivered to other network nodes, thus enabling higher level image analysis by means of either centralized or distributed processing. In such scenario, image analysis tasks are performed over a succinct representation of the image without having access to the traditional pixel-level representation [2]. Thus, methods to extract/acquire and code local features are needed, which consider the scarce VSN resources, namely the limited energy, memory and bitrate. In this paper, low complexity binary descriptors [3-5] involving simple intensity tests performed over a smoothed image patch, are adopted to address these limitations. To achieve a more compact representation, this paper proposes an efficient method to select which binary descriptors should be coded and transmitted over the VSN thus further saving energy and bitrate. The proposed algorithm consists of two main steps: first, the discriminability of each binary descriptor, i.e. the descriptor accuracy when a visual scene is captured from a different viewpoint, illumination or scale, is assessed The project GreenEyes acknowledges the financial support of the Future Emerging Technologies (FET) program within the Seventh Framework Program for Research of the European Commission, under FET-Open grant number: 296676. using a novel descriptor evaluator; and second all descriptors are ranked according to their estimated score, thus coding and transmitting only the descriptors that contribute more to the matching accuracy and retrieval performance. This descriptor selection framework allows the definition of a rate-efficiency tradeoff that is critical to appropriately allocate the available bitrate budget to the extracted local descriptor. The key part of the proposed solution is how the proposed descriptor evaluator is able to accurately predict the accuracy of each descriptor without performing any matching. Thus, it is proposed to use an offline training phase that includes a quantization, matching and classification procedure to assess the discriminative power of each possible binary descriptor, thus improving the efficiency when bandwidth and computation resources are severely limited. The experimental results demonstrate the added efficiency of the proposed method for a traditional image retrieval scenario, when compared to the previous state-of-the-art solution. This paper is organized as follows: in the next section, related work is reviewed. After, Section 3 proposes the novel descriptor selection framework and Section 4 presents and discusses the experimental results. Finally, Section 5 presents the main conclusions and ideas for future work. 2. RELATED WORK Nowadays, local image features are a rather powerful representation paradigm to perform image analysis tasks, usually requiring the following steps: i) feature detection, where salient regions of the image are identified and associated to a keypoint and other patch information; and ii) feature extraction, where a descriptor is generated using the data in the keypoint neighborhood. Among all the local features proposed in the past, the Scale-Invariant Feature Transform (SIFT) [6] is widely used since it has top-level efficiency and robustness to many image transformations. However, binary descriptors are becoming widely popular since they provide an alternative to real value descriptors such as SIFT and SURF [7] while offering similar performance with lower computational cost. Binary descriptors rely on the computation of simple (0/1) intensity difference tests over a smoothed patch and are very fast to extract and match, thus suited for devices with resource constrained resources (e.g. energy, computation) such as VSN nodes. The output of the intensity tests made correspond to descriptor elements, which when aggregated form a single descriptor representing an image patch. A key aspect in the binary descriptors design is the definition of the sampling pattern: the number and pairwise locations of the intensity tests. In the BRIEF descriptor [3], a pre-defined sampling pattern following a bi-dimensional Gaussian distribution is used. However, BRIEF is not invariant to rotation and scale changes, which motivated the development of other descriptors such as BRISK [4] and FREAK [5]. The scale invariant BRISK descriptor [4] adopts a sampling pattern with scaled concentric circles and uses the long-distance intensity tests to estimate the orientation of each keypoint. The FREAK descriptor [5] is inspired by the Human Visual System characteristics using a retinal sampling pattern and a training procedure to find the best intensity tests. In addition, several contributions of visual feature compression have been made in the past, mostly for mobile visual search and especially for real-valued descriptors. In [8], a framework for computing low bitrate descriptors is proposed, where gradient histograms are calculated over spatial bins, quantized and entropy coded. In [9], several lossy coding schemes are proposed for the SURF descriptor by 978-1-4799-5751-4/14/$31.00 ©2014 IEEE ICIP 2014 4027
Transcript of LOCAL FEATURE SELECTION FOR EFFICIENT BINARY DESCRIPTOR...

LOCAL FEATURE SELECTION FOR EFFICIENT BINARY DESCRIPTOR CODING
Pedro Monteiro, João Ascenso, Fernando Pereira
Instituto Superior Técnico – Instituto de Telecomunicações, Lisbon, Portugal
ABSTRACT1
In a visual sensor network, a large number of camera nodes are able to acquire and process image data locally, collaborate with other camera nodes and provide a description about the captured events. Typically, camera nodes have severe constraints in terms of energy, bandwidth resources and processing capabilities. Considering these unique characteristics, coding and transmission of the pixel-level representation of the visual scene must be avoided, due to the energy resources required. A promising approach is to extract at the camera nodes, compact visual features that are coded to meet the bandwidth and power requirements of the underlying network and devices. Since the total number of features extracted from an image may be rather significant, this paper proposes a novel method to select the most relevant features before the actual coding process. The solution relies on a score that estimates the accuracy of each local feature. Then, local features are ranked and only the most relevant features are coded and transmitted. The selected features must maximize the efficiency of the image analysis task but also minimize the required computational and transmission resources. Experimental results show that higher efficiency is achieved when compared to the previous state-of-the-art.
Index Terms — visual sensor networks, local features, binary descriptors, descriptors selection, binary descriptor coding
1. INTRODUCTION
Visual sensor networks (VSN) can be characterized by a large number of wireless low power sensing nodes that are empowered with sight and are capable of complex visual processing tasks [1]. Traditionally, sensing nodes must acquire visual data, and compress and transmit the pixel-level representation in bandwidth limited networks to a central location where further processing occurs. However, this many-to-one scenario demands significant computational and bandwidth resources at the sensing nodes, such as powerful video encoders and energy demanding communication techniques to cope with the huge amount of data that is necessary to transmit. Since VSN camera nodes have limited lifetime due to the battery powered operation, it is imperative to optimize the processing and transmission of visual data. Thus, camera nodes can acquire visual data and perform local processing to obtain local image features, that are delivered to other network nodes, thus enabling higher level image analysis by means of either centralized or distributed processing. In such scenario, image analysis tasks are performed over a succinct representation of the image without having access to the traditional pixel-level representation [2]. Thus, methods to extract/acquire and code local features are needed, which consider the scarce VSN resources, namely the limited energy, memory and bitrate. In this paper, low complexity binary descriptors [3-5] involving simple intensity tests performed over a smoothed image patch, are adopted to address these limitations. To achieve a more compact representation, this paper proposes an efficient method to select which binary descriptors should be coded and transmitted over the VSN thus further saving energy and bitrate. The proposed algorithm consists of two main steps: first, the discriminability of each binary descriptor, i.e. the descriptor accuracy when a visual scene is captured from a different viewpoint, illumination or scale, is assessed The project GreenEyes acknowledges the financial support of the Future Emerging Technologies (FET) program within the Seventh Framework Program for Research of the European Commission, under FET-Open grant number: 296676.
using a novel descriptor evaluator; and second all descriptors are ranked according to their estimated score, thus coding and transmitting only the descriptors that contribute more to the matching accuracy and retrieval performance. This descriptor selection framework allows the definition of a rate-efficiency tradeoff that is critical to appropriately allocate the available bitrate budget to the extracted local descriptor. The key part of the proposed solution is how the proposed descriptor evaluator is able to accurately predict the accuracy of each descriptor without performing any matching. Thus, it is proposed to use an offline training phase that includes a quantization, matching and classification procedure to assess the discriminative power of each possible binary descriptor, thus improving the efficiency when bandwidth and computation resources are severely limited. The experimental results demonstrate the added efficiency of the proposed method for a traditional image retrieval scenario, when compared to the previous state-of-the-art solution. This paper is organized as follows: in the next section, related work is reviewed. After, Section 3 proposes the novel descriptor selection framework and Section 4 presents and discusses the experimental results. Finally, Section 5 presents the main conclusions and ideas for future work.
2. RELATED WORK
Nowadays, local image features are a rather powerful representation paradigm to perform image analysis tasks, usually requiring the following steps: i) feature detection, where salient regions of the image are identified and associated to a keypoint and other patch information; and ii) feature extraction, where a descriptor is generated using the data in the keypoint neighborhood. Among all the local features proposed in the past, the Scale-Invariant Feature Transform (SIFT) [6] is widely used since it has top-level efficiency and robustness to many image transformations. However, binary descriptors are becoming widely popular since they provide an alternative to real value descriptors such as SIFT and SURF [7] while offering similar performance with lower computational cost. Binary descriptors rely on the computation of simple (0/1) intensity difference tests over a smoothed patch and are very fast to extract and match, thus suited for devices with resource constrained resources (e.g. energy, computation) such as VSN nodes. The output of the intensity tests made correspond to descriptor elements, which when aggregated form a single descriptor representing an image patch. A key aspect in the binary descriptors design is the definition of the sampling pattern: the number and pairwise locations of the intensity tests. In the BRIEF descriptor [3], a pre-defined sampling pattern following a bi-dimensional Gaussian distribution is used. However, BRIEF is not invariant to rotation and scale changes, which motivated the development of other descriptors such as BRISK [4] and FREAK [5]. The scale invariant BRISK descriptor [4] adopts a sampling pattern with scaled concentric circles and uses the long-distance intensity tests to estimate the orientation of each keypoint. The FREAK descriptor [5] is inspired by the Human Visual System characteristics using a retinal sampling pattern and a training procedure to find the best intensity tests. In addition, several contributions of visual feature compression have been made in the past, mostly for mobile visual search and especially for real-valued descriptors. In [8], a framework for computing low bitrate descriptors is proposed, where gradient histograms are calculated over spatial bins, quantized and entropy coded. In [9], several lossy coding schemes are proposed for the SURF descriptor by
978-1-4799-5751-4/14/$31.00 ©2014 IEEE ICIP 20144027

exploiting Intra-descriptor (between the elements of the descriptor) and inter-descriptor (between descriptors) redundancy. However, the proposed methods demand significant computation effort for feature detection, extraction and coding. Thus, methods to code binary descriptors exploiting the inter-descriptor [10] and Intra-descriptor redundancy [11] have been proposed. Typically, inter-descriptor redundancy is eliminated by selecting the descriptors used as coding references and Intra-descriptor redundancy is eliminated by selecting the order to predict and entropy code the descriptor elements.
3. LOCAL BINARY DESCRIPTOR SELECTION ALGORITHM
The goal of the proposed algorithm is to obtain a compact image representation by selecting the local features to transmit while still achieving high efficiency in a content-based image search system. The total number of local features extracted from an image depends on its visual content and spatial resolution. However, considering an image with a 640×480 resolution, the average number of features extracted with a binary feature detector/extractor framework can go up to 1500. Considering that a typical binary descriptor has 512 bits, significant bandwidth resources (and energy for transmission) is required, e.g. around 23 Mbit/s for video sequences at 30Hz. Thus, it is crucial to select the most relevant descriptors without decreasing the overall image representation power. Usually, the binary feature detector computes a response value that represents the relevance of each keypoint and only the descriptors associated to the most important keypoints are extracted. However, this approach does not evaluate the relevance of each individual descriptor created, since it assumes that the descriptor is relevant due to an early classification of the keypoint. In this context, this paper proposes a local binary descriptor selection algorithm where the key part is the accuracy evaluation of the extracted binary descriptors; by ranking the binary descriptors according to their accuracy a better selection of the descriptor to code and transmit can be made, thus improving the image analysis task performance. 3.1. Binary Descriptor Offline Evaluation At the camera node, a feature detector and extractor should output a set of local descriptors which are coded and sent to a sink node where the entire description is decoded and matched to an image database. With this classic solution, it is only possible to evaluate the descriptor at the sink node with the help of a known dataset with ground-truth information, which is rather impractical. Thus, it is proposed to evaluate each possible binary descriptor with an offline training phase that creates an accuracy table (AT) with an accuracy score estimate, i.e. how many times correct matches were found. Typically, binary descriptors perform 512 binary intensity tests, which means that there are around possible descriptors. Therefore, it is impractical to evaluate each possible binary descriptor individually. To overcome this obstacle, a clustering approach is proposed, where each cluster represents a group of similar value descriptors. The usage of clusters allows the effective evaluation of small groups of descriptors by assigning a representative accuracy score for each group using a large number of query and corresponding database images. 3.1.1. Clusters Creation algorithm The main objective of the clusters creation algorithm is to compute centroids that represent small groups of descriptors, i.e. clusters. The architecture of the proposed clusters creation algorithm is presented in Figure 1.
Figure 1. Architecture of the clusters creation algorithm.
As shown, the popular k-means clustering algorithm is used, which can be understood as a way to perform vector quantization (i.e. to reduce the dimensionality of the descriptor values). Since it is here necessary to perform clustering of binary data, the Euclidean distance cannot be used and thus, the more suitable median distance, which is reliable for discrete and binary data sets, is adopted instead. The proposed clusters creation algorithm proceeds as follows: 1. Binary Feature Detection and Extraction: Binary descriptors are
extracted from a large set of representative images and stored in a big matrix . For feature detection, it is used the SURF detector which provides good accuracy and precision despite its higher computational cost when compared to binary feature detectors, e.g. FAST or BRISK. However, as this procedure is performed only once (offline), its complexity is not critical and thus a high complexity feature detector may be used. For feature extraction, any binary descriptor can be used, but here k-centroids are obtained for the popular BRIEF, BRISK and FREAK binary descriptors.
2. K-means++ Initialization: Then, a k-means++ initialization algorithm is used to select the initial centroids [12]. This well-known algorithm allows k-means to converge faster and avoids the poor clustering solutions and sensitivity to initialization typical of the standard k-means initialization algorithm.
3. K-means Clustering: At last, the k-means clustering algorithm starts grouping all the descriptors from until reaching clusters. The clusters are formed by assigning to each centroid the descriptors closer to that centroid than to any other centroids. Then, new centroids are computed as the median of the binary descriptors included in the cluster and this process is repeated until the algorithm converges, i.e. no descriptor changes its associated centroid.
After obtaining the centroids, each representing a cluster, the accuracy for all clusters must be computed. 3.1.2 Cluster Accuracy Evaluation The main objective of the cluster accuracy evaluation is to offline evaluate the accuracy of each descriptor that is represented through the newly found centroids. To assess each descriptor accuracy, it is necessary to perform feature matching with a well-known dataset of query and database images that provides information about the pairs of matching and non-matching images (ground truth). Figure 2 shows the architecture of the proposed cluster accuracy evaluation algorithm.
Accuracy Table
k centroidsDatabase Images
Query Images
Ground-truth data
Figure 2. Architecture of the cluster accuracy evaluation algorithm.
The proposed algorithm proceeds as follows: 1. Binary Feature Detection and Extraction: First, the keypoint
locations and the corresponding descriptors from the database and query images are extracted and stored. Again, the top-performing SURF detector and the BRIEF, BRISK and FREAK extractors are used. Naturally, since each binary descriptor has different sampling patterns, a suitable accuracy table is built for each one.
2. Feature Matching and Classification: Then, pair-wise matching between the descriptors of each query image and the descriptors of each database image is performed. The correspondences between descriptors are found by assigning each query image descriptor to its nearest neighbor database image descriptor (using the Hamming distance metric). After, each query image descriptor is classified according to:
ICIP 20144028

a. Ratio-test evaluation: A ratio test [13] is used to compare the ratio of distances between the correspondence found and the 2nd best correspondence for every keypoint of the query image; the top correspondence is removed if the ratio is above a threshold of 0.7. If the query descriptor has no longer any correspondence, the descriptor is classified as no matching descriptor (NMD) since it does not provide useful matching information.
b. Ground-truth evaluation: Then, the correspondences left are evaluated to assess if each correspondence was made between matching images according to the ground truth or not. If correspondences were made between non-matching images, an error in the ratio test was done and all query descriptors associated are classified as false matching descriptors (FMD). This procedure is applied since all 'good' descriptors should be removed with the ratio test for the non-matching images identified by the ground truth.
c. Random Sample Consensus (RANSAC) evaluation: In the case the ground truth identifies the correspondences as valid, the RANSAC algorithm [14] is used to force a geometric constraint in the remaining correspondences. Each correspondence is classified according to a robustly estimated geometric model (more precisely, a perspective model). Thus, correspondences that follow the estimated model are considered inliers and the associated query descriptors classified as true matching descriptors (TMD); the other remaining query descriptors associated to correspondences considered as outliers by the model are classified as FMD.
Since for each query image, this procedure is performed for all database images, the number of times , and that each query descriptor is classified in each of the three classes, NMD, FMD and TMD, respectively, can be obtained.
3. Centroids Rating: Next, the cluster of each descriptor is found by searching for the closest centroid (using Hamming distance) to the query descriptor. Since each centroid uniquely identifies one cluster, all query descriptors are assigned to their respective clusters. Then, all , and values associated to the descriptors belonging to the same cluster are summed together to obtain a single , and value for each cluster. These values are used to compute the cluster accuracy score , with a statistical f-measure type metric, that corresponds to a weighted harmonic mean of precision (P) and recall (R), widely used efficiency metrics. Thus, the success in the matching procedure, is expressed by:
where is a scaling factor representing the number of correspondences that should be true for matching images assuming a perfect descriptor. Notice also, that was found that including does not provide any valuable information about the descriptor accuracy score.
Then, the accuracy table (AT) is created with an identifier for each cluster, the corresponding centroid and the computed accuracy. 3.2. Accuracy-based Binary Descriptor Selection and Coding The architecture of the proposed binary descriptor encoder (BDE) is presented in Figure 3.
Figure 3. Architecture of the proposed binary descriptor encoder. The encoder exploits the AT already created to evaluate online the accuracy of the extracted descriptors, selecting for transmission the
descriptors that maximize the efficiency with a rather simple table lookup operation, thus suitable for resource constrained VSN nodes. The proposed BDE assigns an accuracy score to the extracted descriptors without performing any matching between images; after, they are ranked, selected and Intra coded, thus prioritizing some descriptors over others and selecting the descriptors more likely to provide true matches, thus, maximizing the efficiency for a given bitrate budget. This process proceeds as follows: 1. Binary Feature Detection and Extraction: In this module,
keypoints are detected using any feature detector available and the descriptor of each keypoint is extracted with any state-of-the-art binary descriptor. Thus, the proposed pairs of detectors and extractors used are AGAST[15]-BRIEF, BRISK-BRISK and SURF-FREAK. In the last case, the SURF detector was used as recommended by the authors of the FREAK descriptor.
2. Descriptors Rating: Then, the accuracy of each extracted descriptor is evaluated without performing any matching, by using the AT table. Simply, the cluster of each descriptor is found by first calculating the distance between the descriptor and all centroids. Then, using the closest centroid to the descriptor (with minimum Hamming distance), it is possible to retrieve the associated cluster identifier and corresponding cluster accuracy from the AT table.
3. Descriptors Selection: After obtaining the accuracy value and a cluster identifier for each descriptor, the descriptors to transmit are selected according to a fixed bitrate budget. Two proposed selection techniques are described in Section 3.2.1.
4. Intra Coding: Finally, the selected descriptors are Intra coded, i.e. exploiting the redundancy between descriptor elements, according to the algorithm described in Section 3.2.2.
3.2.1 Descriptors Selection The selection of the descriptors to transmit is a very important task that can significantly affect the retrieval results. In this paper, two descriptors selection techniques are proposed: • Accuracy-only Selection: The accuracy selection technique focus
only on the accuracy of the descriptors extracted. This technique ranks the descriptors by the highest accuracy and selects the number of descriptors to transmit from the highest to the lowest accuracy according to the bitrate budget.
• Accuracy-Diversity Selection: The diversity selection technique also ranks the descriptors according to their accuracy but it adds one limitation: only one descriptor per cluster can be selected. Since the clusters represent small groups of descriptors, this technique aims to achieve a more diverse selection of the descriptors, i.e. it does not allow similar descriptors to be coded and transmitted. Thus, the top rank descriptors are selected as for the Accuracy Selection technique but whenever a descriptor is coded and transmitted its cluster identifier is marked as visited and no more descriptors of that cluster can be sent independently of their accuracy.
3.2.2 Binary descriptors Intra coding The Intra coding module aims to exploit the correlation between the descriptor elements and is based on the work of [11]. First, the descriptor elements are sorted to maximize the correlation between neighboring descriptor elements. Then, the descriptor elements of the extracted descriptors are differentially coded and a binary arithmetic encoder is used to obtain the final bitstream. The best ordering among descriptor elements is computed offline, where binary descriptors for a large number of images are extracted and their descriptor elements analyzed for similarity.
4. PERFORMANCE EVALUATION
This section evaluates the performance of the proposed binary descriptor encoder in the context of an image retrieval task. For this
ICIP 20144029
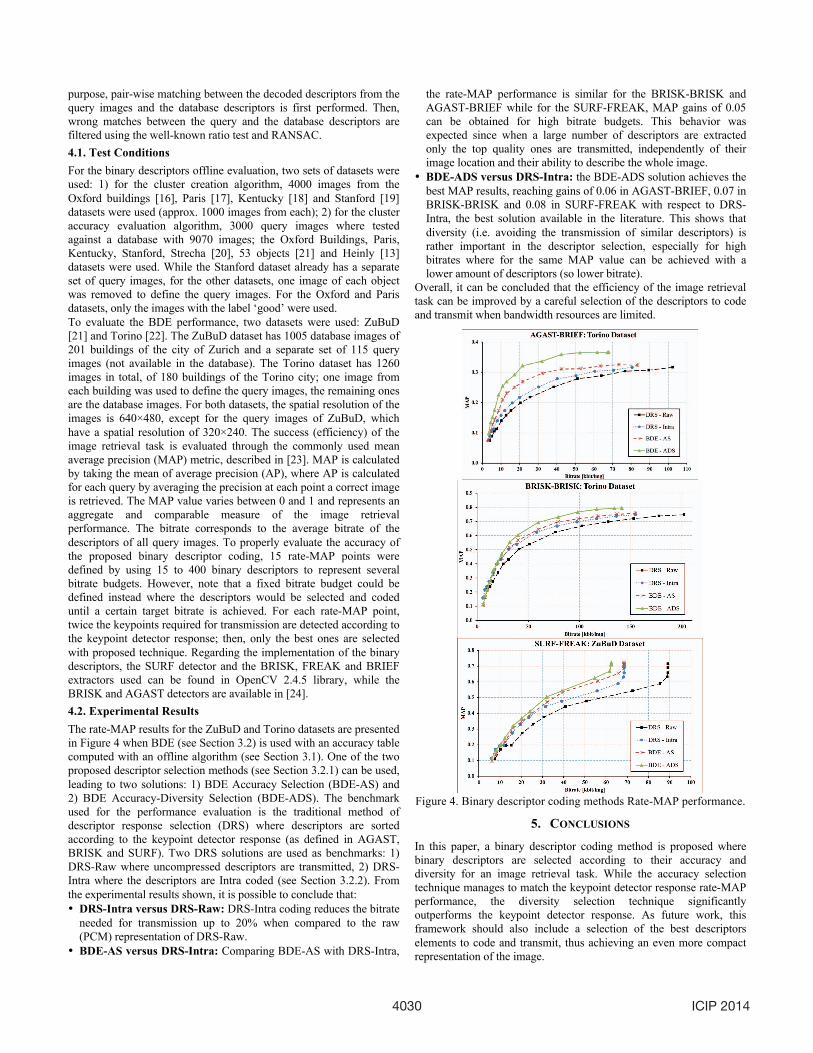
purpose, pair-wise matching between the decoded descriptors from the query images and the database descriptors is first performed. Then, wrong matches between the query and the database descriptors are filtered using the well-known ratio test and RANSAC. 4.1. Test Conditions For the binary descriptors offline evaluation, two sets of datasets were used: 1) for the cluster creation algorithm, 4000 images from the Oxford buildings [16], Paris [17], Kentucky [18] and Stanford [19] datasets were used (approx. 1000 images from each); 2) for the cluster accuracy evaluation algorithm, 3000 query images where tested against a database with 9070 images; the Oxford Buildings, Paris, Kentucky, Stanford, Strecha [20], 53 objects [21] and Heinly [13] datasets were used. While the Stanford dataset already has a separate set of query images, for the other datasets, one image of each object was removed to define the query images. For the Oxford and Paris datasets, only the images with the label ‘good’ were used. To evaluate the BDE performance, two datasets were used: ZuBuD [21] and Torino [22]. The ZuBuD dataset has 1005 database images of 201 buildings of the city of Zurich and a separate set of 115 query images (not available in the database). The Torino dataset has 1260 images in total, of 180 buildings of the Torino city; one image from each building was used to define the query images, the remaining ones are the database images. For both datasets, the spatial resolution of the images is 640×480, except for the query images of ZuBuD, which have a spatial resolution of 320×240. The success (efficiency) of the image retrieval task is evaluated through the commonly used mean average precision (MAP) metric, described in [23]. MAP is calculated by taking the mean of average precision (AP), where AP is calculated for each query by averaging the precision at each point a correct image is retrieved. The MAP value varies between 0 and 1 and represents an aggregate and comparable measure of the image retrievalperformance. The bitrate corresponds to the average bitrate of the descriptors of all query images. To properly evaluate the accuracy of the proposed binary descriptor coding, 15 rate-MAP points were defined by using 15 to 400 binary descriptors to represent several bitrate budgets. However, note that a fixed bitrate budget could be defined instead where the descriptors would be selected and coded until a certain target bitrate is achieved. For each rate-MAP point, twice the keypoints required for transmission are detected according to the keypoint detector response; then, only the best ones are selected with proposed technique. Regarding the implementation of the binary descriptors, the SURF detector and the BRISK, FREAK and BRIEF extractors used can be found in OpenCV 2.4.5 library, while the BRISK and AGAST detectors are available in [24]. 4.2. Experimental Results The rate-MAP results for the ZuBuD and Torino datasets are presented in Figure 4 when BDE (see Section 3.2) is used with an accuracy table computed with an offline algorithm (see Section 3.1). One of the two proposed descriptor selection methods (see Section 3.2.1) can be used, leading to two solutions: 1) BDE Accuracy Selection (BDE-AS) and 2) BDE Accuracy-Diversity Selection (BDE-ADS). The benchmark used for the performance evaluation is the traditional method of descriptor response selection (DRS) where descriptors are sorted according to the keypoint detector response (as defined in AGAST, BRISK and SURF). Two DRS solutions are used as benchmarks: 1) DRS-Raw where uncompressed descriptors are transmitted, 2) DRS-Intra where the descriptors are Intra coded (see Section 3.2.2). From the experimental results shown, it is possible to conclude that: • DRS-Intra versus DRS-Raw: DRS-Intra coding reduces the bitrate
needed for transmission up to 20% when compared to the raw (PCM) representation of DRS-Raw.
• BDE-AS versus DRS-Intra: Comparing BDE-AS with DRS-Intra,
the rate-MAP performance is similar for the BRISK-BRISK and AGAST-BRIEF while for the SURF-FREAK, MAP gains of 0.05 can be obtained for high bitrate budgets. This behavior was expected since when a large number of descriptors are extracted only the top quality ones are transmitted, independently of their image location and their ability to describe the whole image.
• BDE-ADS versus DRS-Intra: the BDE-ADS solution achieves the best MAP results, reaching gains of 0.06 in AGAST-BRIEF, 0.07 in BRISK-BRISK and 0.08 in SURF-FREAK with respect to DRS-Intra, the best solution available in the literature. This shows that diversity (i.e. avoiding the transmission of similar descriptors) is rather important in the descriptor selection, especially for high bitrates where for the same MAP value can be achieved with a lower amount of descriptors (so lower bitrate).
Overall, it can be concluded that the efficiency of the image retrieval task can be improved by a careful selection of the descriptors to code and transmit when bandwidth resources are limited.
Figure 4. Binary descriptor coding methods Rate-MAP performance.
5. CONCLUSIONS
In this paper, a binary descriptor coding method is proposed where binary descriptors are selected according to their accuracy and diversity for an image retrieval task. While the accuracy selection technique manages to match the keypoint detector response rate-MAP performance, the diversity selection technique significantly outperforms the keypoint detector response. As future work, this framework should also include a selection of the best descriptors elements to code and transmit, thus achieving an even more compact representation of the image.
ICIP 20144030

6. REFERENCES
[1] S. Soro and W. Heinzelman, “A Survey of Visual Sensor Networks,” Advances in Multimedia, vol. 2009, Article ID 640386, 2009.
[2] A. Redondi, L. Baroffio, M. Cesana, M. Tagliasacchi, “Compress-then-Analyze vs. Analyse-then-Compress: Two Paradigms for Image Analysis in Visual Sensor Networks“, IEEE International Workshop on Multimedia Signal Processing, Pula, Italy, September 2013.
[3] M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “BRIEF: Binary Robust Independent Elementary Features,” European Conference on Computer Vision, Crete, Greece, September 2010.
[4] S. Leutenegger, M. Chli, and R. Siegwart, “BRISK: Binary Robust Invariant Scalable Keypoints,” IEEE International Conference on Computer Vision, Barcelona, Spain, November 2011.
[5] A. Alahi, R. Ortiz, and P. Vandergheynst, “FREAK: Fast Retina Keypoint,” IEEE Conference on Computer Vision and Pattern Recognition, Providence, Rhode Island, USA, June 2012.
[6] D. G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints,” International Journal of Computer Vision, vol. 60, no. 2, November 2004.
[7] H. Bay, A. Ess, T. Tuytelaars, and L. V. Gool, “SURF: Speeded Up Robust Features,” Computer Vision and Image Understanding, vol. 110, no. 3, June 2008.
[8] V. Chandrasekhar, G. Takacs, D. Chen, S. Tsai, R. Grzeszczuk, and B. Girod, “CHoG: Compressed Histogram of Gradients A Low Bit-rate Feature Descriptor,” IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, June 2009.
[9] A. Redondi, M. Cesana, and M. Tagliasacchi, “Low Bitrate Coding Schemes for Local Image Descriptors,” IEEE International Workshop on Multimedia Signal Processing, Banff, Canada, September 2012.
[10] J. Ascenso, F. Pereira, “Lossless Compression of Binary Image Descriptors for Visual Sensor Networks”, IEEE/EURASIP Digital Signal Processing Conference, Santorini, Greece, July 2013.
[11] A. Redondi, L. Baroffio, J. Ascenso, M. Cesana, M. Tagliasacchi, “Rate-accuracy optimization of binary descriptors”, IEEE International Conference on Image Processing, Melbourne, Australia, September 2013.
[12] D. Arthur and S. Vassilvitskii, “k-means++: The Advantages of Careful Seeding”, Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Portland, OR, USA, January 2007.
[13] J. Heinly, E. Dunn, and J.-M. Frahm, “Comparative Evaluation of Binary Features,” European Conference on Computer Vision, Crete, Greece, September 2010.
[14] M. A. Fischler and R. C. Bolles, “Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography,” Communications of the ACM, vol. 24, no. 6, June 1981.
[15] E. Mair, G. D. Hager, D. Burschka, M. Suppa, and G. Hirzinger, “Adaptive and Generic Corner Detection Based on the Accelerated Segment Test,” European Conference on Computer Vision, Heraklion, Greece, September 2010.
[16] J. Philbin, R. Arandjelovic, A. Zisserman, The Oxford Buildings Dataset, http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/
[17] J. Philbin and A. Zisserman, The Paris Dataset, http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/
[18] D. Nistér and H. Stewénius, “Scalable Recognition with a Vocabulary Tree,” IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, June 2006.
[19] V. Chandrasekhar, D. Chen, S. Tsai, N.-M. Cheung, H. Chen, G. Takacs, Y. Reznik, R. Vedantham, R. Grzeszczuk, J. Bach, and B. Girod, “The Stanford Mobile Visual Search Dataset,” ACM Multimedia Systems Conference, San Jose, USA, February 2011.
[20] C. Strecha, W. von Hansen, L. Van Gool, P. Fua, and U. Thoennessen, “Benchmarking Camera Calibration and Multi-View Stereo for High Resolution Imagery,” IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, USA, June 2008.
[21] http://www.vision.ee.ethz.ch/datasets/index.en.html
[22] Requirements Subgroup, "Evaluation Framework for Compact Descriptors for Visual Search," ISO/IEC JTC1/SC29/WG11/N12202, July 2011.
[23] A. Canclini, R. Cilla, A. Redondi, J. Ascenso, M. Cesana, M. Tagliasacchi, “Evaluation of Visual Feature Detectors and Descriptors for Low-complexity Devices”, IEEE/EURASIP Digital Signal Processing Conference, Santorini, Greece, 2013
[24] http://www.asl.ethz.ch/people/lestefan/personal/BRISK
ICIP 20144031




![BRIEF: Computing a local binary descriptor very fast · The SIFT descriptor [3] is highly discriminant but, being a 128-vector, relatively slow to compute and match. This substantially](https://static.fdocuments.us/doc/165x107/6032e016e5b2cc54ee06c1eb/brief-computing-a-local-binary-descriptor-very-fast-the-sift-descriptor-3-is.jpg)






![ISSN: 1992-8645 LOCAL QUANTIZED EDGE BINARY PATTERNS … · retrieval.Muralaet.al[37] proposed a new texture feature descriptor called local extrema patterns, where it collects the](https://static.fdocuments.us/doc/165x107/5f24a11c4ca8f168f84d0e8c/issn-1992-8645-local-quantized-edge-binary-patterns-retrievalmuralaetal37-proposed.jpg)






