
Lattice Boltzmann sur architecture multicoeurs vectorielle - Une approche de haut niveau
26
Lattice Boltzmann sur architecture multicoeurs vectorielle une approche de haut niveau Antoine Tran Tan Joel Falcou Université de Paris Sud LRI - ParSys Inria - Postale Juin 2015 1 of 18
-
Upload
joel-falcou -
Category
Software
-
view
88 -
download
0
Transcript of Lattice Boltzmann sur architecture multicoeurs vectorielle - Une approche de haut niveau

Lattice Boltzmann sur architecture multicoeurs vectorielleune approche de haut niveau
Antoine Tran Tan Joel Falcou
Université de Paris SudLRI - ParSys
Inria - Postale
Juin 2015
1 of 18
Plan
Introduction
La bibliothèque NT2
L’algorithme Lattice Boltzmann
Conclusion
2 of 18

Plan
Introduction
La bibliothèque NT2
L’algorithme Lattice Boltzmann
Conclusion
2 of 18

Le compromis matériel/logiciel
Single Core Era
Performance
Expressiveness
C/Fort.
C++
Java
Multi-Core/SIMD Era
Performance
Expressiveness
Sequential
Threads
SIMD
Heterogenous Era
Performance
Expressiveness
Sequential
SIMD
Threads
GPUPhi
Distributed
3 of 18

Le compromis matériel/logiciel
Single Core Era
Performance
Expressiveness
C/Fort.
C++
Java
Multi-Core/SIMD Era
Performance
Expressiveness
Sequential
Threads
SIMD
Heterogenous Era
Performance
Expressiveness
Sequential
SIMD
Threads
GPUPhi
Distributed
?
Comment allier performance ET expressivité ?
4 of 18

Plan
Introduction
La bibliothèque NT2
L’algorithme Lattice Boltzmann
Conclusion
4 of 18

NT2 : The Numerical Template Toolbox
Une bibliothèque pour le calcul scientique
■ Interface semblable à M pour les utilisateurs■ Classes et primitives pour le calcul haute performance■ Souplesse vers les nouvelles architectures
Composantes
■ Boost.SIMD pour le parallélisme mono-processeur■ Utilisation de squelettes parallèles récursifs pour le parallélisme
multi-processeurs■ Un code portable multi-architectures et multi-runtimes
5 of 18

NT2 : The Numerical Template Toolbox
Une bibliothèque pour le calcul scientique
■ Interface semblable à M pour les utilisateurs■ Classes et primitives pour le calcul haute performance■ Souplesse vers les nouvelles architectures
Composantes
■ Boost.SIMD pour le parallélisme mono-processeur■ Utilisation de squelettes parallèles récursifs pour le parallélisme
multi-processeurs■ Un code portable multi-architectures et multi-runtimes
5 of 18

NT2 : Du code M au code C++
Code MatlabA1 = 1:1000;A2 = A1 + randn(size(A1));
X = lu( A1*A1’ );
rms = sqrt( sum(( A1(:) - A2(:) ).^2) / numel(A1) );
Code C++ avec bibliothèque NT2
..table <double > A1 = .._(1 ,1000..);
..table <double > A2 = A1 + randn(size(A1));
..table <double > X = lu( ..mtimes(A1 , ..trans(A1) ..) );
..table <double > rms = sqrt( sum(..sqr( A1(.._) - A2(.._) ..)) / numel(A1) );
6 of 18

Plan
Introduction
La bibliothèque NT2
L’algorithme Lattice Boltzmann
Conclusion
6 of 18

L’algorithme Lattice Boltzmann
Pourquoi cet algorithme ?
■ Simplicité du coeur de l’algorithme■ Fort parallélisme de données■ Degré de liberté sur la structure des données
La version D2Q9
■ Le schéma le plus simple■ Se généralise aux versions DnQm■ Des accès mémoire prenant le dessus sur le calcul
7 of 18

L’algorithme Lattice Boltzmann
Pourquoi cet algorithme ?
■ Simplicité du coeur de l’algorithme■ Fort parallélisme de données■ Degré de liberté sur la structure des données
La version D2Q9
■ Le schéma le plus simple■ Se généralise aux versions DnQm■ Des accès mémoire prenant le dessus sur le calcul
7 of 18
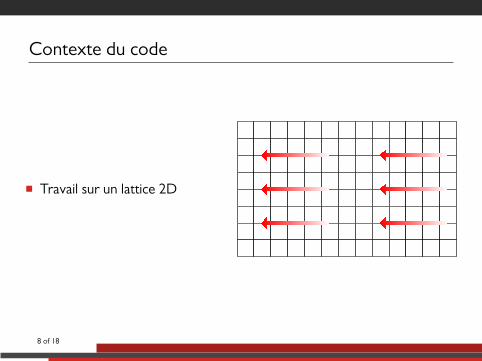
Contexte du code
■ Travail sur un lattice 2D
8 of 18

Contexte du code
■ Travail sur un lattice 2D■ Rebonds sur bords et
obstacle (en gris), etconditions de Neumann enentrée (en bleu)
8 of 18

Contexte du code
■ Travail sur un lattice 2D■ Rebonds sur bords et
obstacle (en gris), etconditions de Neumann enentrée (en bleu)
■ Mise à jour des 9composantes de vitesse pourchaque point
8 of 18

Coeur de l’algorithme - Version Pull
■ Propagation ■ Collision
Légendes. : élément à lire
. : position du point à mettre à jour9 of 18

Vers une version NT2
1. Obtenir un code simple similaire à Matlab
2. Utiliser tout le potentiel d’une machine multi-coeur
3. Tendre vers l’efficacité d’une version GPU écrite en CUDA
10 of 18

Aperçu du code
void get_f( table <float > const & f, table <float > & fcopy, int nx, int ny)
{..fcopy(_ ,_ , ..1) = ..f(_ ,_ , ..1);..fcopy(_(2,nx) ,_ , ..2) = ..f(_(1,nx -1) ,_ , ..2);..fcopy(_ ,_(2,ny) , ..3) = ..f(_ ,_(1,ny -1), ..3);..fcopy(_(1,nx -1) ,_ , ..4) = ..f(_(2,nx) ,_ , ..4);..fcopy(_ ,_(1,ny -1), ..5) = ..f(_ ,_(2,ny) , ..5);..fcopy(_(2,nx) ,_(2,ny) , ..6) = ..f(_(1,nx -1) ,_(1,ny -1), ..6);..fcopy(_(1,nx -1) ,_(2,ny) , ..7) = ..f( _(2,nx) ,_(1,ny -1), ..7);..fcopy(_(1,nx -1) ,_(1,ny -1), ..8) = ..f( _(2,nx) ,_(2,ny) , ..8);..fcopy(_(2,nx) ,_(1,ny -1), ..9) = ..f(_(1,nx -1) ,_(2,ny) , ..9);}
11 of 18

Aperçu du codevoid bouzidi ( table <float > & f, table <float > & fcopy
, table <int > & bc , table <int > & alpha, int k, int nx , int ny)
{table <int ,of_size_ <9> > invalpha = (cons <int >(1, 4, 5, 2, 3, 8, 9, 6, 7));const float q = .5f;
..fcopy(_,_,invalpha(k)) =if_else( (alpha >> (k-2) &1) // composante impliquée?
,..if_else( (bc == 1) // condition de rebond,if_else(q*ones(of_size(nx ,ny),meta::as_ <float >()) <=.5f
,(1.f-2.f*q)*..fcopy(_,_,k)+2.f*q*..f(_,_,k)+..fcopy(_,_,invalpha(k)),(1.f-.5f/q)*..f(_,_,invalpha(k)) +.5f/q*..f(_,_,k)+..fcopy(_,_,invalpha(k)))
, ..if_else( (bc == 2) // condition d’anti -rebond,if_else(q*ones(of_size(bound),meta::as_ <float >()) <.5f
,-(1.f-2.f*q)*..fcopy(_,_,k) -2.f*q*..f(_,_,k)+..fcopy(_,_,invalpha(k)),-(1.f-.5f/q)*..f(_,_,invalpha(k)) -.5f/q*..f(_,_,k)+..fcopy(_,_,invalpha(k)))
,..if_else( (bc == 3) // condition de Neumann, ..f(_,_,invalpha(k)), ..fcopy(_,_,invalpha(k)))
))
,..fcopy(_,_,invalpha(k)));
}
12 of 18

Aperçu du codevoid relaxation( nt2::table <float > & m
, nt2::table <float > const s_)
{const float la = 1.f; const float rho = 1.f; const float dummy_ = 1.f/(la*la*rho);
..m(_,_,4) = ..m(_,_,4) *(1.f-s_(1))+ s_(1)*(-2.f*..m(_,_,1)
+ 3.f*( dummy_*..m(_,_,2)*..m(_,_,2) + dummy_*..m(_,_,3)*..m(_,_,3)));
..m(_,_,5) = ..m(_,_,5)*( 1.f-s_(2))+ s_(2)*( ..m(_,_,1)
+ 1.5f*( dummy_*..m(_,_,2)*..m(_,_,2) + dummy_*..m(_,_,3)*..m(_,_,3)));
..m(_,_,6) = ..m(_,_,6) *(1.f-s_(3))- s_(3)*..m(_,_,2)/la;
..m(_,_,7) = ..m(_,_,7) *(1.f-s_(4))- s_(4)*..m(_,_,3)/la;
..m(_,_,8) = ..m(_,_,8) *(1.f-s_(5))+ s_(5)*( dummy_*..m(_,_,2)*..m(_,_,2) - dummy_*..m(_,_,3)*..m(_,_,3));
..m(_,_,9) = ..m(_,_,9) *(1.f-s_(6))+ s_(6)*dummy_*..m(_,_,2)*..m(_,_,3);
}13 of 18

Mesures de performance - Architecture
■ 2 processeurs Intel Westmere (6 coeurs chacun)■ Cache L3 : 12 MB■ RAM : 2 x 24 GB
14 of 18
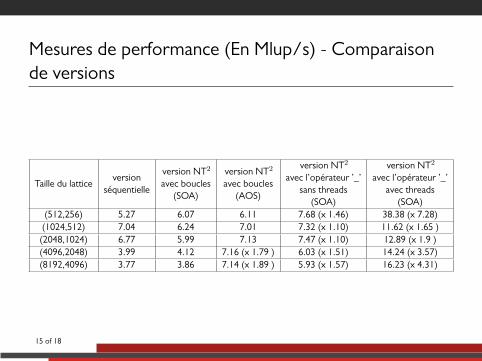
Mesures de performance (En Mlup/s) - Comparaisonde versions
Taille du latticeversion
séquentielle
version NT2
avec boucles(SOA)
version NT2
avec boucles(AOS)
version NT2
avec l’opérateur ’_’sans threads
(SOA)
version NT2
avec l’opérateur ’_’avec threads
(SOA)(512,256) 5.27 6.07 6.11 7.68 (x 1.46) 38.38 (x 7.28)(1024,512) 7.04 6.24 7.01 7.32 (x 1.10) 11.62 (x 1.65 )(2048,1024) 6.77 5.99 7.13 7.47 (x 1.10) 12.89 (x 1.9 )(4096,2048) 3.99 4.12 7.16 (x 1.79 ) 6.03 (x 1.51) 14.24 (x 3.57)(8192,4096) 3.77 3.86 7.14 (x 1.89 ) 5.93 (x 1.57) 16.23 (x 4.31)
15 of 18
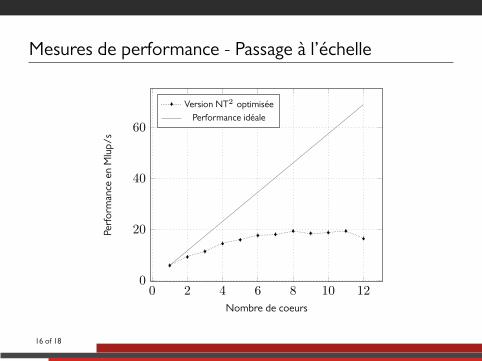
Mesures de performance - Passage à l’échelle
.....
0
.
2
.
4
.
6
.
8
.
10
.
12
.
0
.
20
.
40
.
60
.
Nombre de coeurs
.
Perfor
man
ceen
Mlu
p/s
.
. ..Version NT2 optimisée
. ..Performance idéale
16 of 18

Plan
Introduction
La bibliothèque NT2
L’algorithme Lattice Boltzmann
Conclusion
16 of 18

Conclusion
■ Des performances attendues pour un problème limité par la bandepassante mémoire
■ Extension sur GPU disponible (Ian Masliah, Doctorant au LRI)■ Suivez-nous sur https://github.com/NumScale/nt2
17 of 18

Merci pour votre attention
18 of 18


















