![Deep Image Retrieval: arXiv:1604.01325v1 [cs.CV] 5 Apr 2016 › pdf › 1604.01325v1.pdf · Deep Image Retrieval: Learning global representations for image search Albert Gordo, Jon](https://static.fdocuments.us/doc/165x107/5f034af47e708231d4087ef9/deep-image-retrieval-arxiv160401325v1-cscv-5-apr-2016-a-pdf-a-1604-.jpg)







Languages
Pages
Legal


@graphificRoelof Pieters
Guest Lecture: Deep Learning for Informa8on Retrieval28 April 2015
www.csc.kth.se/~roelof/ [email protected]
Gve Systems Graph Technologies R&D
DD2476 Search Engines and Information Retrieval Systemshttps://www.kth.se/social/course/DD2476/
slides online at h4p://www.slideshare.net/roelofp/deep-‐learning-‐for-‐informa=on-‐retrieval

2
About Me • (-10y) CS dropout (Amsterdam Technical Univ.)• (2y) Msc Social Anthropology, Stockholm
University• Current: PhD candidate at KTH/CSC with focus
on:• Deep Learning for Natural Language
Processing (Distributed Semantics) • Graph-based approaches for Knowledge
Representation• Multi-modal models
• Current: Data Science Consultant at Graph Technologies RD & Gve-Systems• Recommender Systems• Deep Learning• Realtime Graph-based Search Engines

3
Information Retrieval (IR)
- Hedvig Kjellström, lecture 1

4
Data landscape is changing
1. Amount of digital data is growing at increasing rate (IOT, digitalization, wearables, phones/tablets)
2. Data types are shifting as well:
1. from text to audio-visual
2. from professional to personal/social (social media)
3. from semi-structured to unstructured

[Jussi Karlgren, NLP Sthlm Meetup 2014]

6
Data landscape is changing
Triple V’s of Big Data:1. Volume2. Velocity3. Variety
7
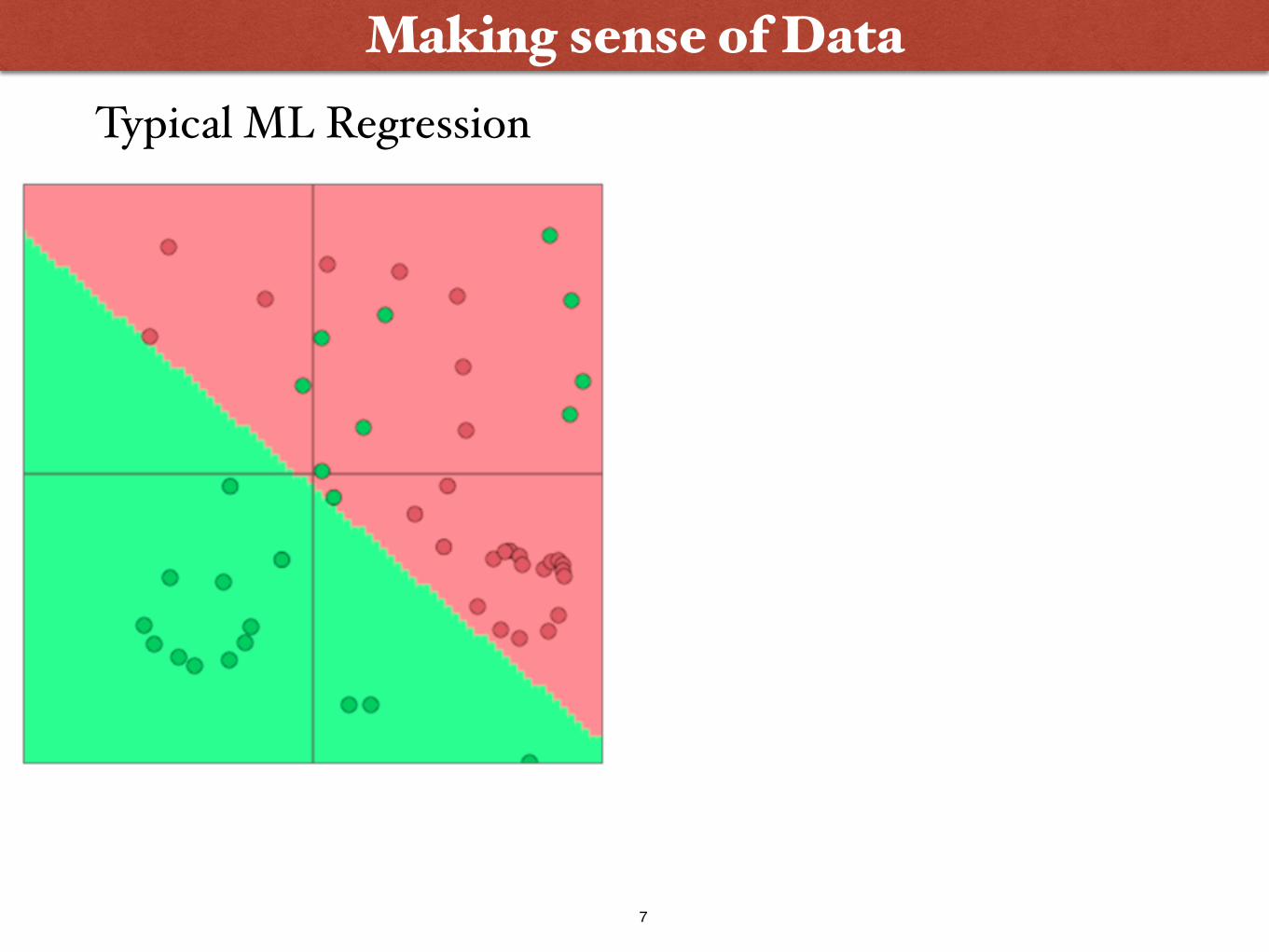
Making sense of DataTypical ML Regression
8
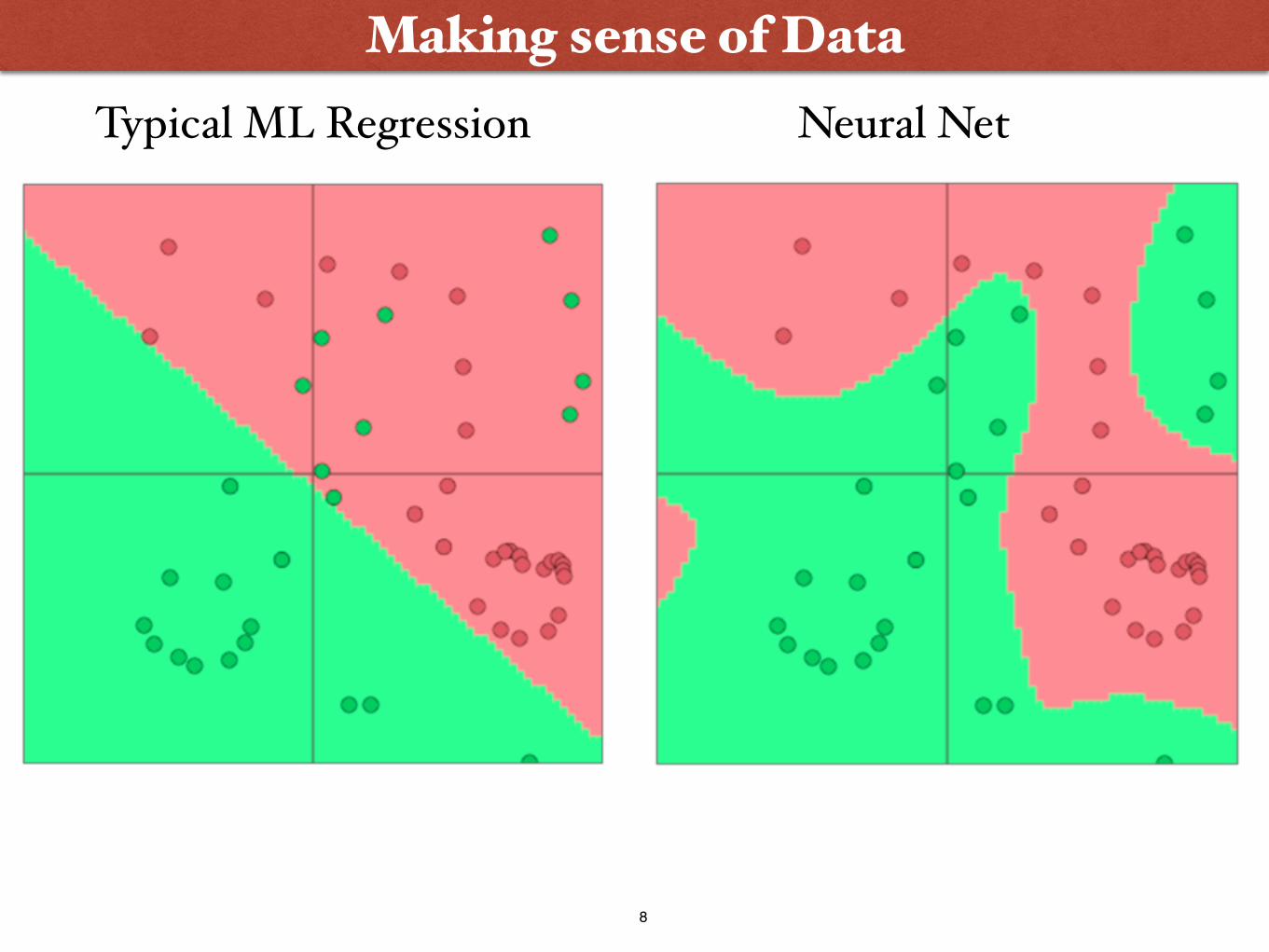
Making sense of DataNeural NetTypical ML Regression
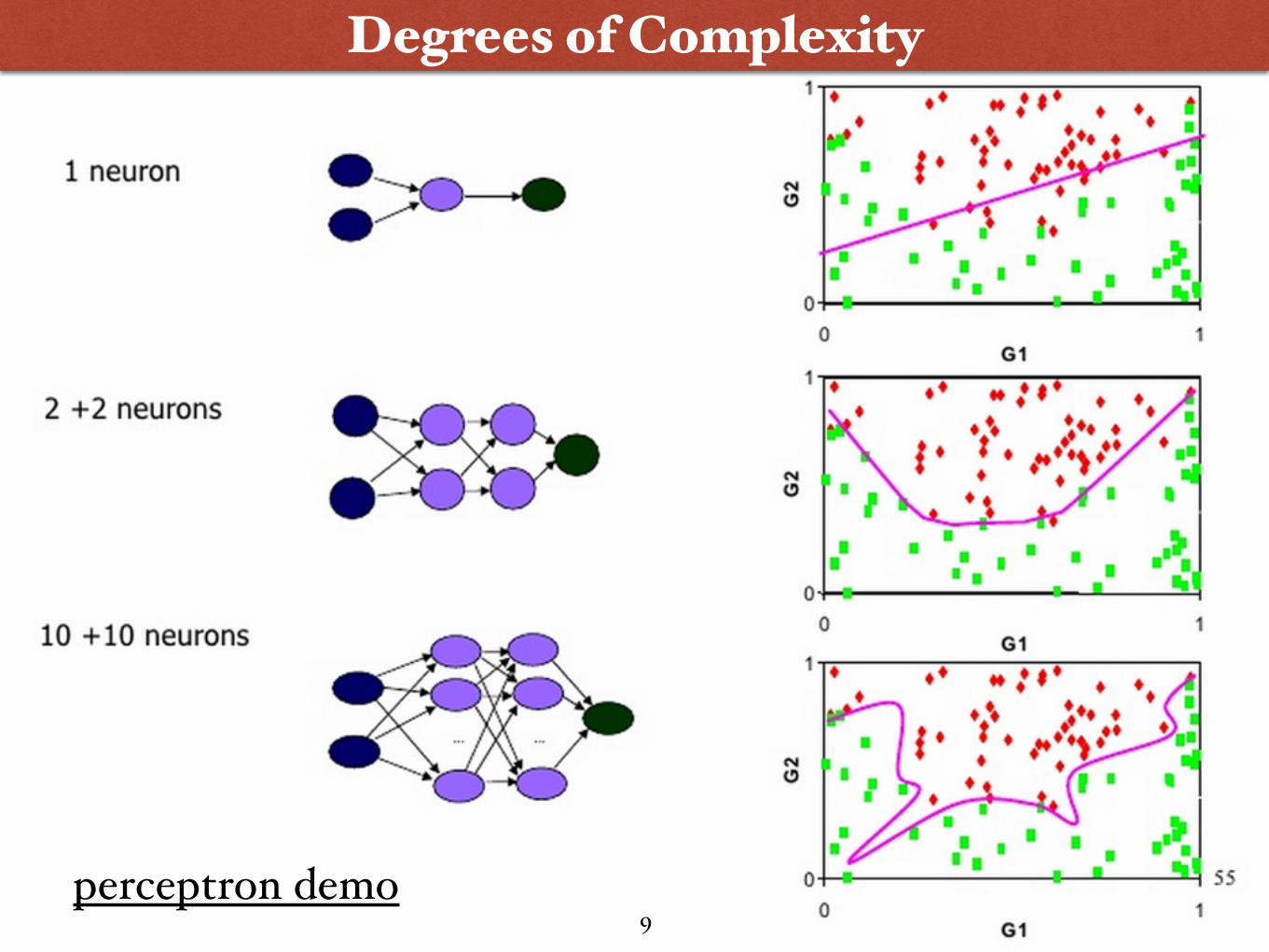
Degrees of Complexity
9perceptron demo
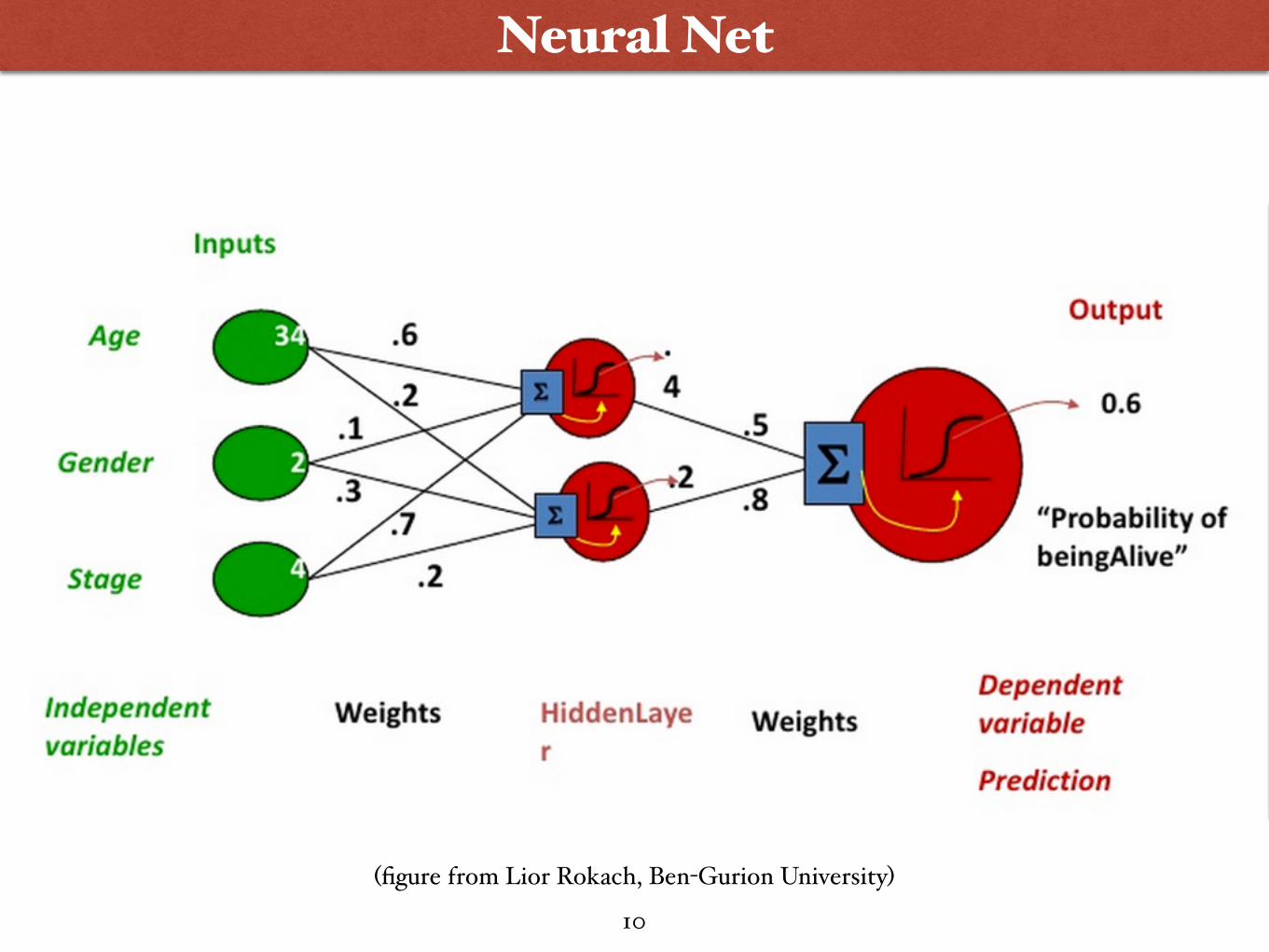
Neural Net
10
(figure from Lior Rokach, Ben-Gurion University)
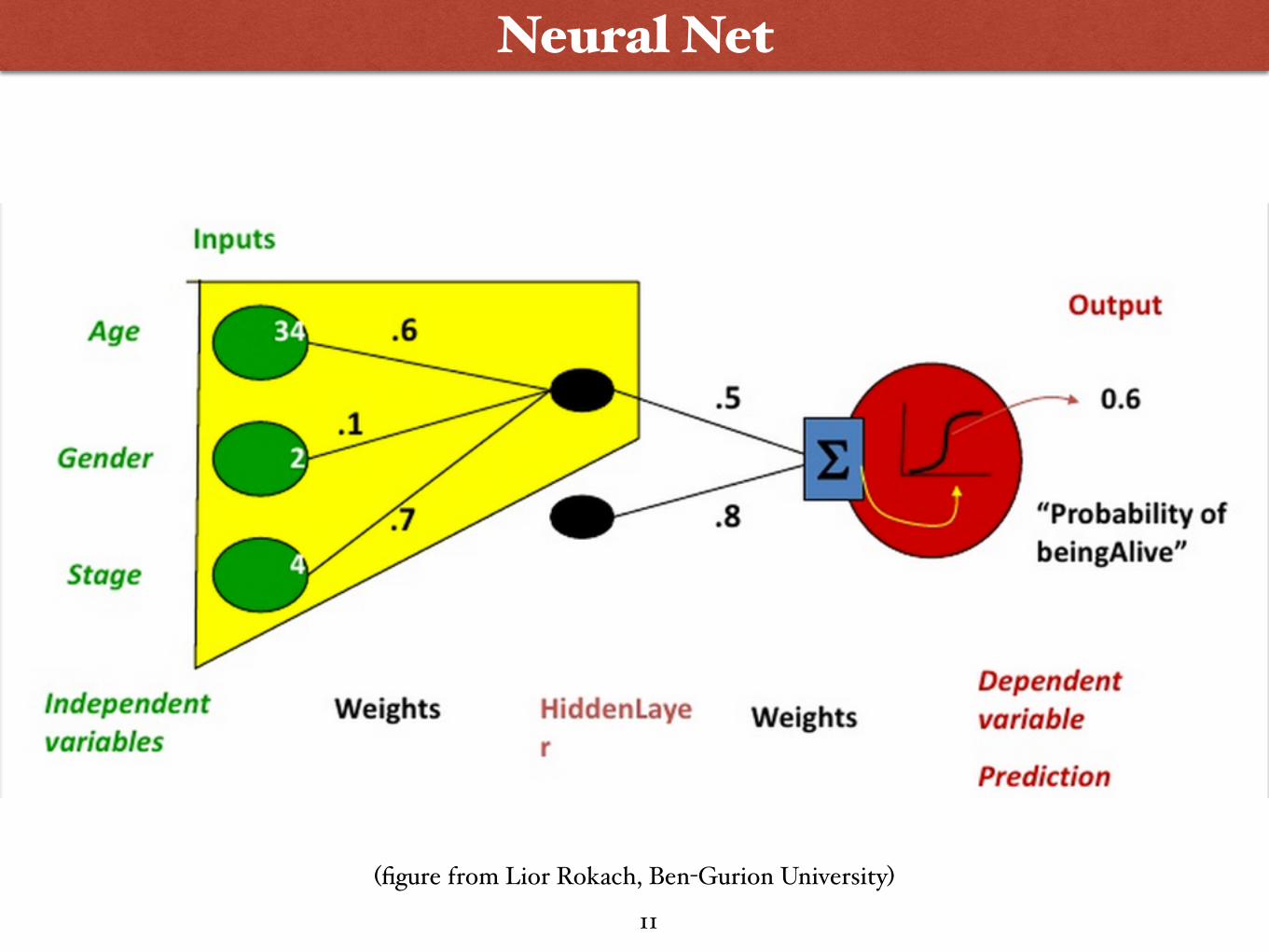
Neural Net
11
(figure from Lior Rokach, Ben-Gurion University)
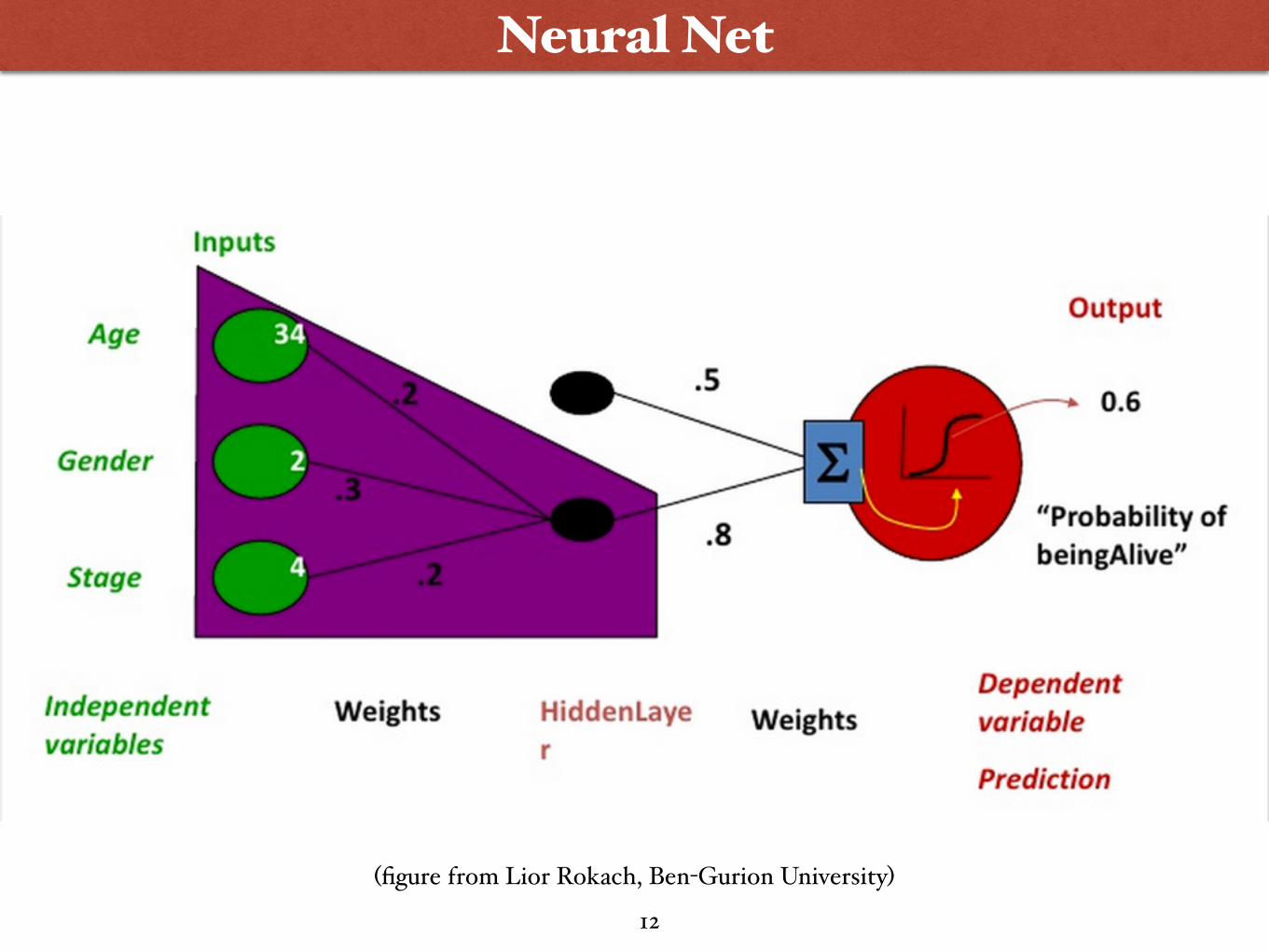
Neural Net
12
(figure from Lior Rokach, Ben-Gurion University)

Neural Net
13
(figure from Lior Rokach, Ben-Gurion University)

Neural Net
14
(figure from Lior Rokach, Ben-Gurion University)

Neural Net
15
multilayer nn demo

Deep Learning ??
16

Deep Learning ??
17
• Learning multiple layers• “Back propagation”• Can “theoretically” learn any function!
Prior to 2006:• Very slow and inefficient• SVMs, random forests, etc. SOTA

18
2006+: the 3 Deep Learning Conspirators

19

20

— Andrew Ng
“I’ve worked all my life in Machine Learning, and I’ve
never seen one algorithm knock over benchmarks like Deep
Learning”
Deep Learning: Why?
21

Different Levels of Abstraction
22

Hierarchical Learning• Natural progression
from low level to high level structure as seen in natural complexity
Different Levels of AbstractionFeature Representation
23
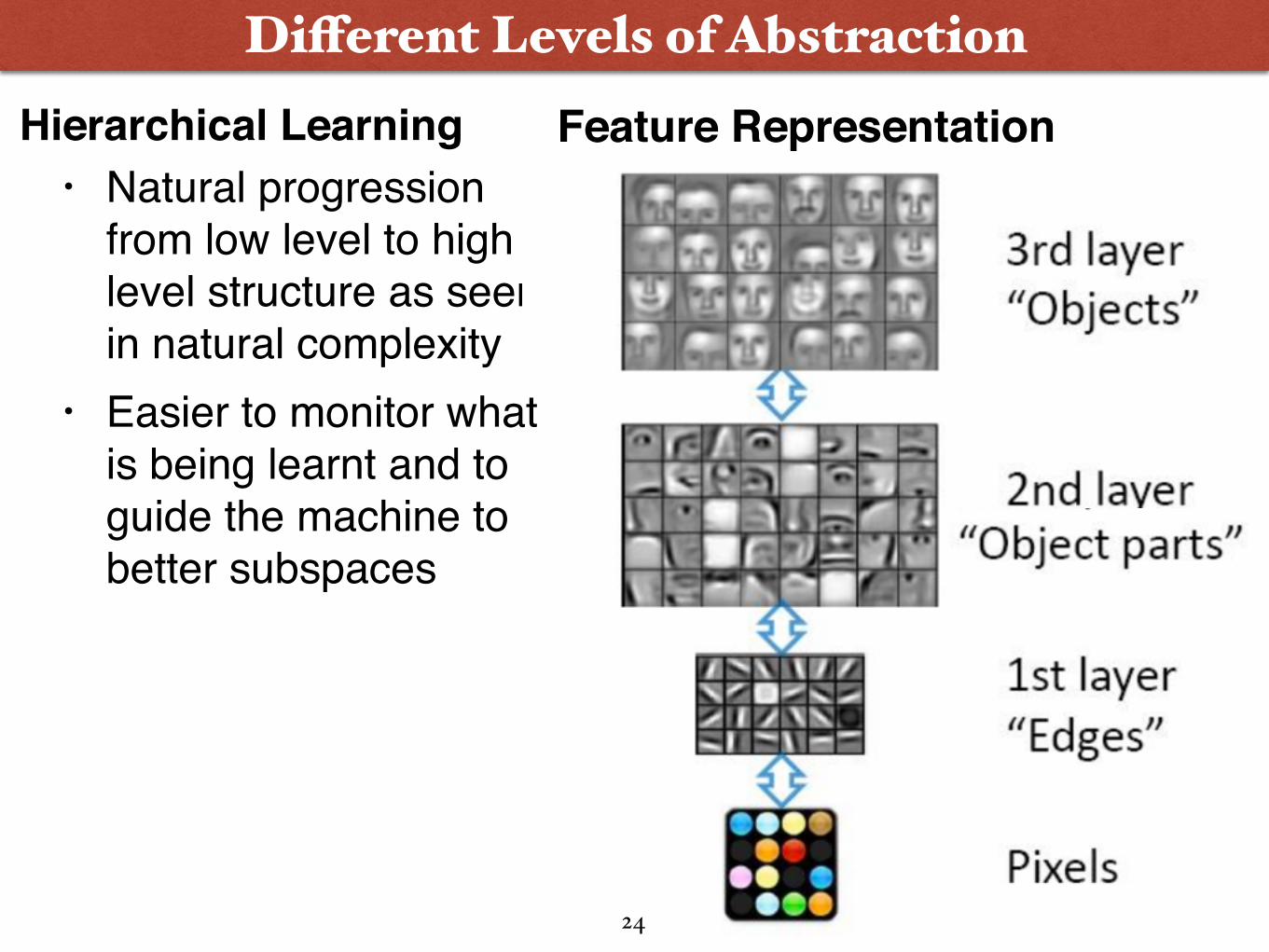
Hierarchical Learning• Natural progression
from low level to high level structure as seen in natural complexity
• Easier to monitor what is being learnt and to guide the machine to better subspaces
Different Levels of AbstractionFeature Representation
24

Hierarchical Learning• Natural progression
from low level to high level structure as seen in natural complexity
• Easier to monitor what is being learnt and to guide the machine to better subspaces
• A good lower level representation can be used for many distinct tasks
Different Levels of AbstractionFeature Representation
25

Hierarchical Learning• Natural progression
from low level to high level structure as seen in natural complexity
Different Levels of AbstractionFeature Representation
2626
• Easier to monitor what is being learnt and to guide the machine to better subspaces
• A good lower level representation can be used for many distinct tasks
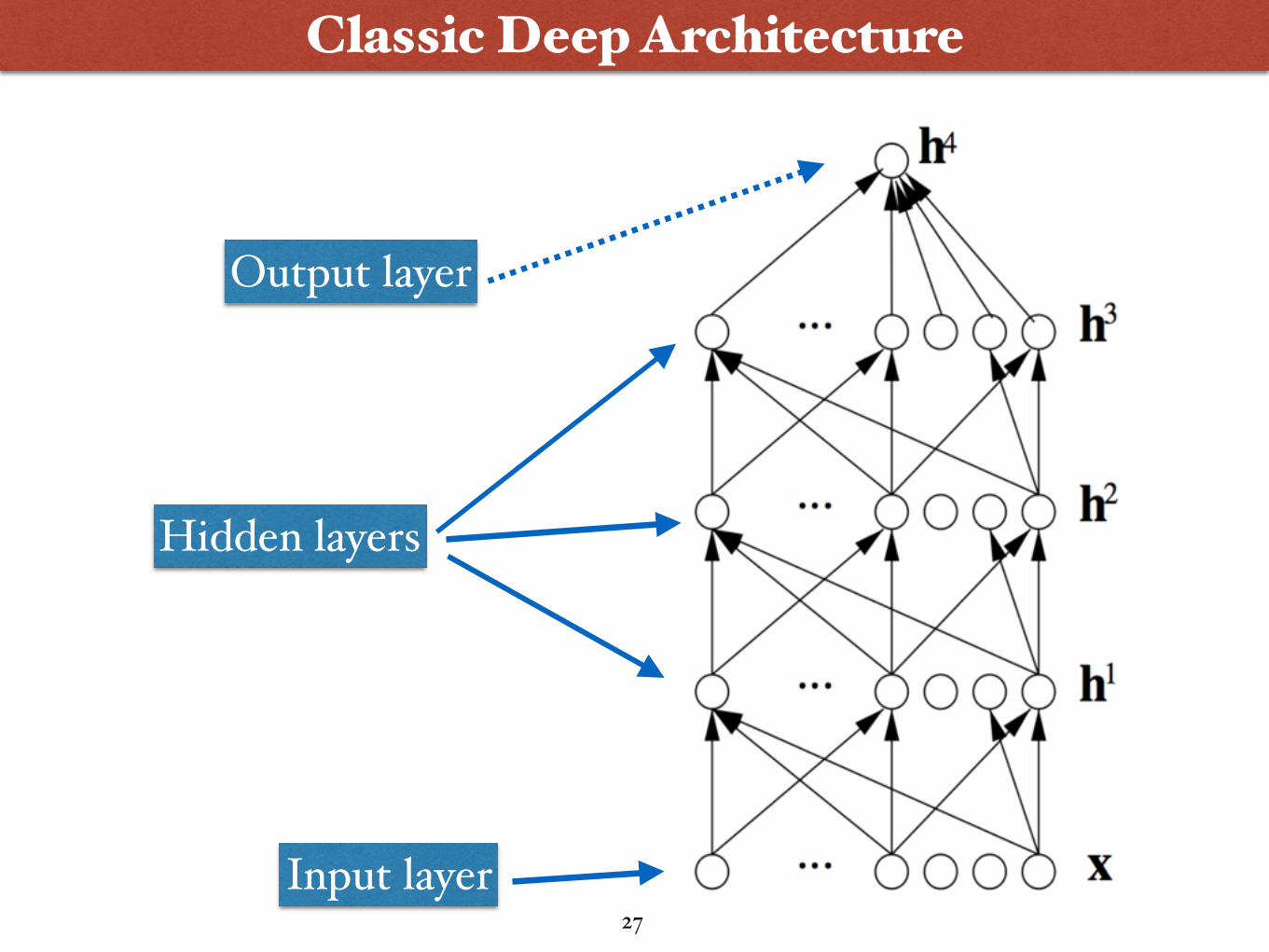
Classic Deep Architecture
Input layer
Hidden layers
Output layer
27
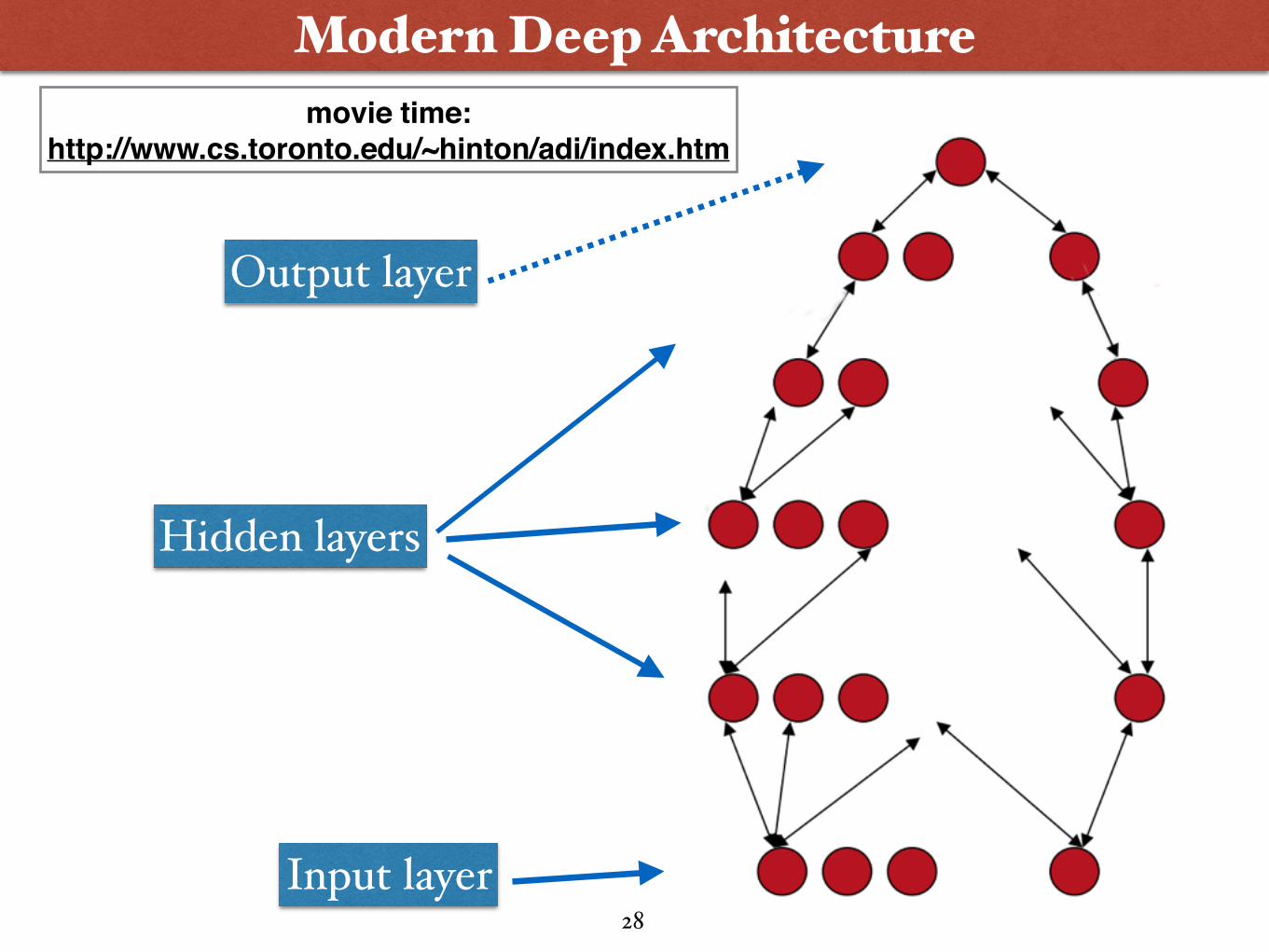
Modern Deep Architecture
Input layer
Hidden layers
Output layer
movie time:http://www.cs.toronto.edu/~hinton/adi/index.htm
28

[Kudos to Richard Socher, for this eloquent summary :) ]
• Manually designed features are often over-specified, incomplete and take a long time to design and validate
• Learned Features are easy to adapt, fast to learn
• Deep learning provides a very flexible, (almost?) universal, learnable framework for representing world, visual and linguistic information.
• Deep learning can learn unsupervised (from raw text/audio/images/whatever content) and supervised (with specific labels like positive/negative)
Why Deep Learning ?
29

Word Embeddings
30

31
What about NLP ?
1. Language is ambiguous:Every sentence has many possible interpretations.
2. Language is productive:We will always encounter new words or new constructions
3. Language is culturally specific
Some of the challenges in Language Understanding:

• NLP treats words mainly (rule-based/statistical approaches at least) as atomic symbols:
• or in vector space:
• also known as “one hot” representation.
• Its problem ?
Language Representation
Love Candy Store
[0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 …]
Candy [0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 …] ANDStore [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 …] = 0 !
32
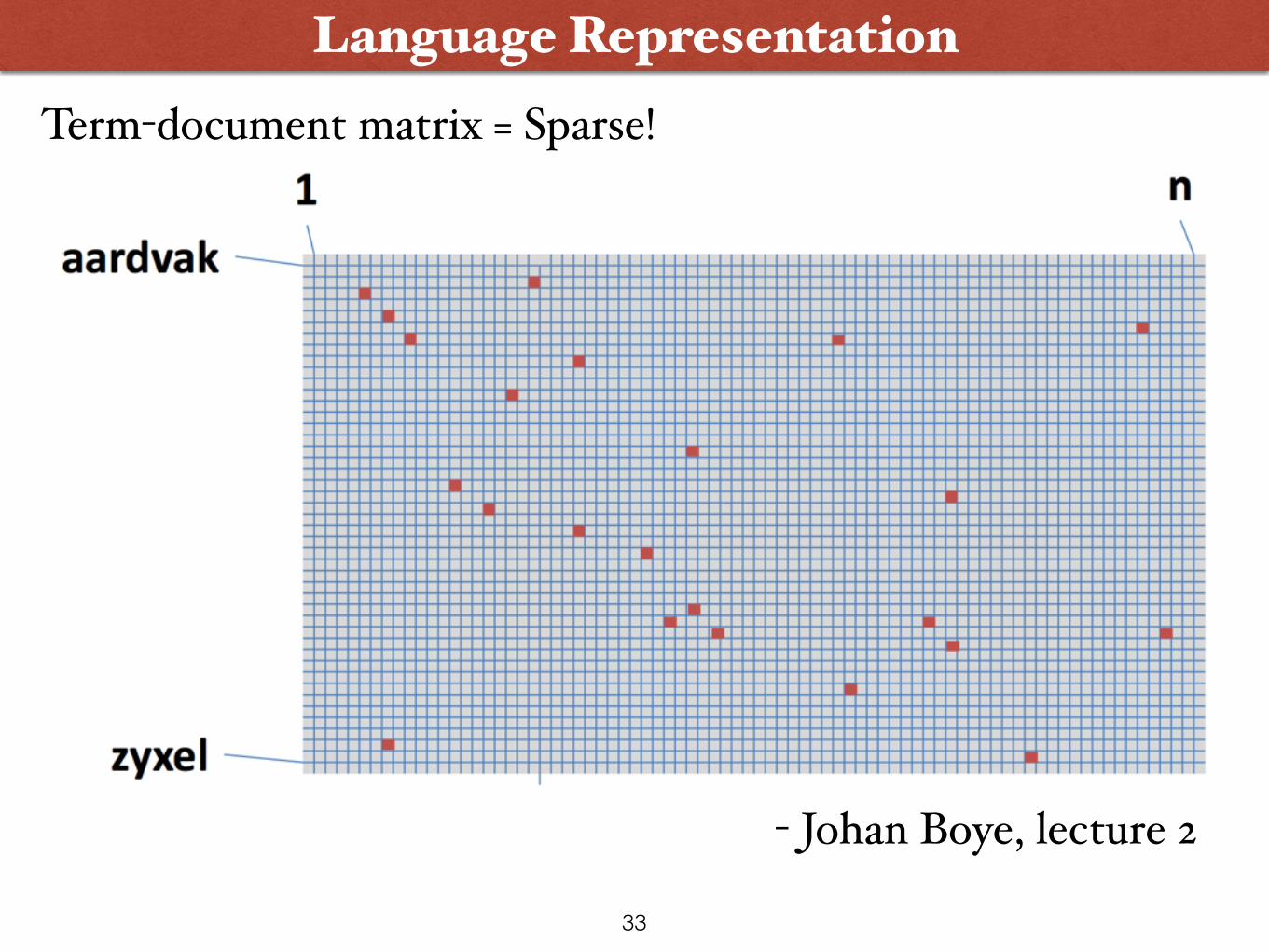
Language Representation
33
- Johan Boye, lecture 2
Term-document matrix = Sparse!

Distributional representations
“You shall know a word by the company it keeps” (J. R. Firth 1957)
One of the most successful ideas of modern statistical NLP!
these words represent banking
• Hard (class based) clustering models
• Soft clustering models34

Distributional hypothesis
He filled the wampimuk, passed it around and we all drunk some
We found a little, hairy wampimuk sleeping behind the tree
(McDonald & Ramscar 2001)35

Distributional semantics
Landauer and Dumais (1997), Turney and Pantel (2010), …36
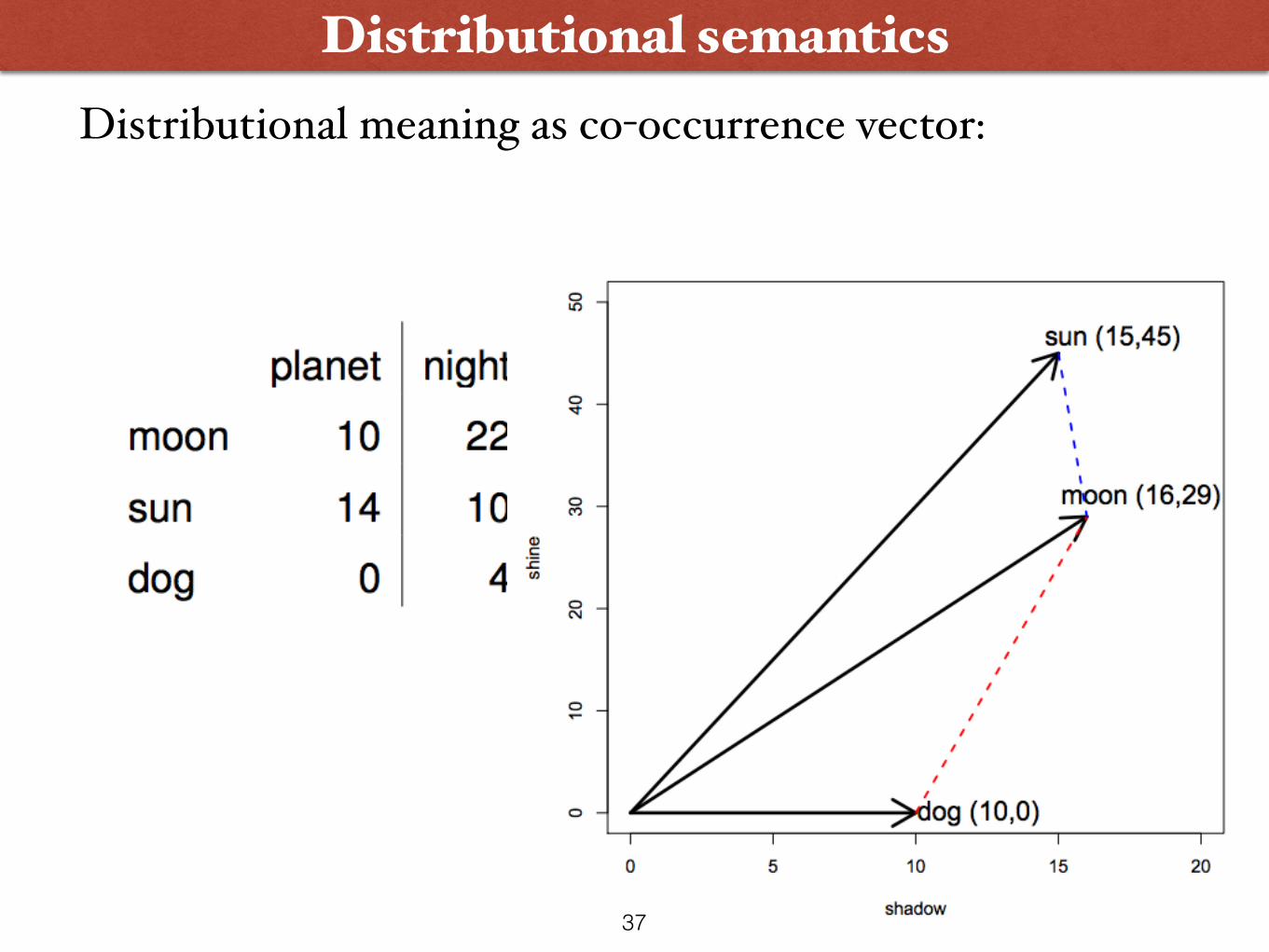
Distributional semanticsDistributional meaning as co-occurrence vector:
37

Distributional representations
• Taking it further:
• Continuous word embeddings
• Combine vector space semantics with the prediction of probabilistic models
• Words are represented as a dense vector:
Candy =
38

Word Embeddings: SocherVector Space Model
adapted rom Bengio, “Representation Learning and Deep Learning”, July, 2012, UCLA
In a perfect world:
39

Word Embeddings: SocherVector Space Model
adapted rom Bengio, “Representation Learning and Deep Learning”, July, 2012, UCLA
In a perfect world:
the country of my birththe place where I was born
40

• Can theoretically (given enough units) approximate “any” function
• and fit to “any” kind of data
• Efficient for NLP: hidden layers can be used as word lookup tables
• Dense distributed word vectors + efficient NN training algorithms:
• Can scale to billions of words !
Why Neural Networks for NLP?
41

Word Embeddings: SocherVector Space Model
Figure (edited) from Bengio, “Representation Learning and Deep Learning”, July, 2012, UCLA
In a perfect world:
the country of my birththe place where I was born ?
…
42

Compositionality
Principle of compositionality:
the “meaning (vector) of a complex expression (sentence) is determined by:
— Gottlob Frege (1848 - 1925)
- the meanings of its constituent expressions (words) and
- the rules (grammar) used to combine them”
43

• How do we handle the compositionality of language in our models?
44
Compositionality

• How do we handle the compositionality of language in our models?
• Recursion :the same operator (same parameters) is applied repeatedly on different components
45
Compositionality

• How do we handle the compositionality of language in our models?
• Option 1: Recurrent Neural Networks (RNN)
46
RNN 1: Recurrent Neural Networks
(we ignore recurrent NN’s for this talk)

• How do we handle the compositionality of language in our models?
• Option 2: Recursive Neural Networks (also sometimes called RNN)
47
RNN 2: Recursive Neural Networks

Recursive Neural Tensor Network
48
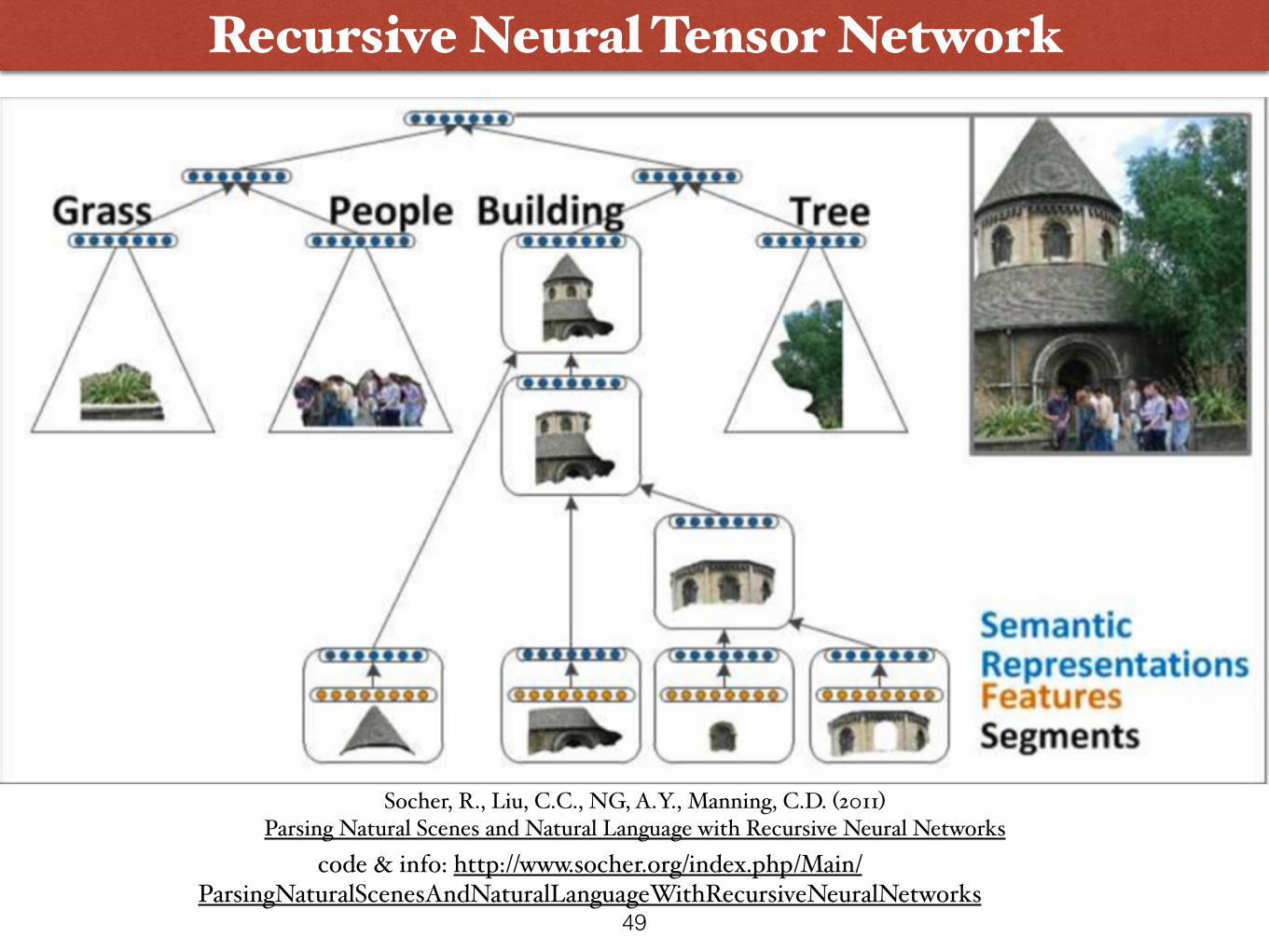
Recursive Neural Tensor Network
49
code & info: http://www.socher.org/index.php/Main/ParsingNaturalScenesAndNaturalLanguageWithRecursiveNeuralNetworks
Socher, R., Liu, C.C., NG, A.Y., Manning, C.D. (2011) Parsing Natural Scenes and Natural Language with Recursive Neural Networks

NP
PP/IN
NP
DT NN PRP$ NN
Parse TreeRecurrent NN for Vector Space
50

NP
PP/IN
NP
DT NN PRP$ NN
Parse Tree
INDT NN PRP NN
Compositionality
51
Recurrent NN: CompositionalityRecurrent NN for Vector Space

NP
IN
NP
PRP NN
Parse Tree
DT NN
Compositionality
52
Recurrent NN: CompositionalityRecurrent NN for Vector Space

NP
IN
NP
DT NN PRP NN
PP
NP (S / ROOT)
“rules” “meanings”
Compositionality
53
Recurrent NN: CompositionalityRecurrent NN for Vector Space

Vector Space + Word Embeddings: Socher
54
Recurrent NN: CompositionalityRecurrent NN for Vector Space

Vector Space + Word Embeddings: Socher
55
Recurrent NN for Vector Space

Word Embeddings: Turian (2010)
Turian, J., Ratinov, L., Bengio, Y. (2010). Word representations: A simple and general method for semi-supervised learning
code & info: http://metaoptimize.com/projects/wordreprs/ 56

Word Embeddings: Turian (2010)
Turian, J., Ratinov, L., Bengio, Y. (2010). Word representations: A simple and general method for semi-supervised learning
code & info: http://metaoptimize.com/projects/wordreprs/ 57

Word Embeddings: Demo
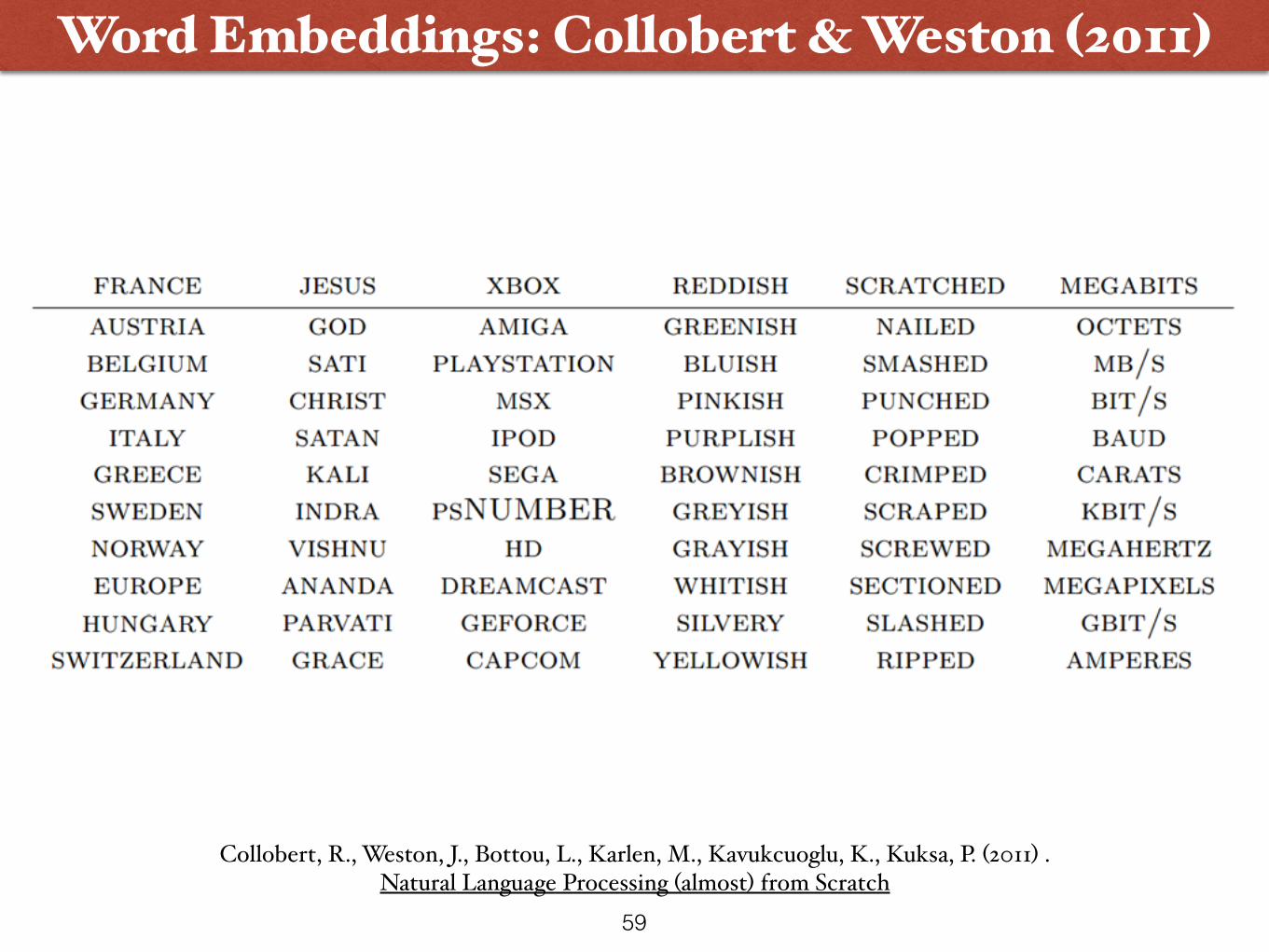
Word Embeddings: Collobert & Weston (2011)
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., Kuksa, P. (2011) . Natural Language Processing (almost) from Scratch
59

Polysemous-embeddings: Stanford (2012)
Eric H. Huang, Richard Socher, Christopher D. Manning, Andrew Y. Ng (2012)Improving Word Representations via Global Context and Multiple Word Prototypes
60

Linguistic Regularities: Mikolov (2013)
code & info: https://code.google.com/p/word2vec/ Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations
61

Word Embeddings for MT: Mikolov (2013)
Mikolov, T., Le, V. L., Sutskever, I. (2013) . Exploiting Similarities among Languages for Machine Translation
62

Word Embeddings for MT: Kiros (2014)
Kiros, R., Zemel, R. S., Salakhutdinov, R. (2014) . A Multiplicative Model for Learning Distributed Text-Based Attribute Representations
63

Recursive Deep Models & Sentiment: Socher (2013)
Socher, R., Perelygin, A., Wu, J., Chuang, J.,Manning, C., Ng, A., Potts, C. (2013) Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank.
code & demo: http://nlp.stanford.edu/sentiment/index.html64

Paragraph Vectors: Le & Mikolov (2014)
Le, Q., Mikolov,. T. (2014) Distributed Representations of Sentences and Documents65
• add context (sentence, paragraph, document) to word vectors during training
!
Results on Stanford Sentiment Treebank dataset:

Paragraph Vectors: Dai et al. (2014)
Dai, A., Olah,. C., Le, Q., Corrado, G. (2014) Document Embedding with Paragraph Vectors66
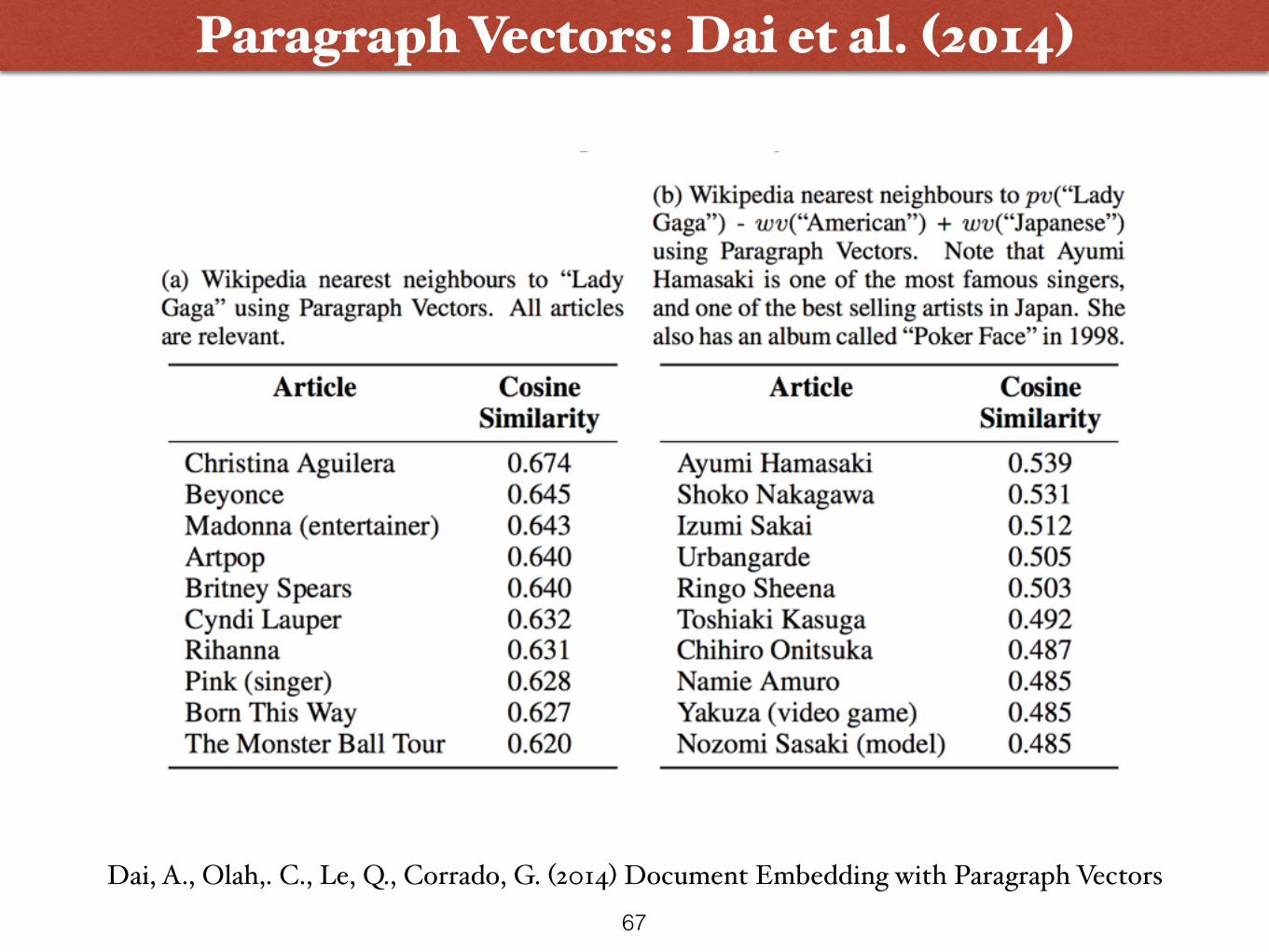
Paragraph Vectors: Dai et al. (2014)
Dai, A., Olah,. C., Le, Q., Corrado, G. (2014) Document Embedding with Paragraph Vectors67

Paragraph Vectors: Dai et al. (2014)
Dai, A., Olah,. C., Le, Q., Corrado, G. (2014) Document Embedding with Paragraph Vectors68
Nearest neighbours to the machine learning paper “Distributed Representations of Sentences and Documents” in arXiv.

Joint Image-Word Embeddings
69

1. Multimodal representation learning
2. Generating descriptions of images
3. Ranking images and captions (“image-sentence ranking”)
Some Current Approaches
70

Bags of Visual Words
71
Source credit : K. Grauman, B. Leibe

Bags of Visual Words (Sivic & Zisserman 2003)
standard BoW issues however
What we get:
But we want:• visual word order/relations• location• scale/viewpoint invariance• …
72

Zero-shot Learning
• skip-gram text model on wikipedia corpus of 5.7 million documents (5.4 billion words) - approach from (Mikolov et al. ICLR 2013)
73
Frome, A., Corrado, G.S., Shlens, J., Bengio, S., Dean, J., Mikolov, T., Ranzato, M.A. (2013) Devise: A deep visual-semantic embedding model
DeViSE model

Encoder: A deep convolutional network (CNN) and long short-term memory recurrent network (LSTM) for learning a joint image-sentence embedding. Decoder: A new neural language model that combines structure and content vectors for generating words one at a time in sequence.
Encoder-Decoder pipeline
74
Kiros, R., Salakhutdinov, R., Zemerl, R. S. (2014) Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
(Kiros et al 2014)

• captures Multimodal linguistic regularities
Encoder-Decoder pipeline
75
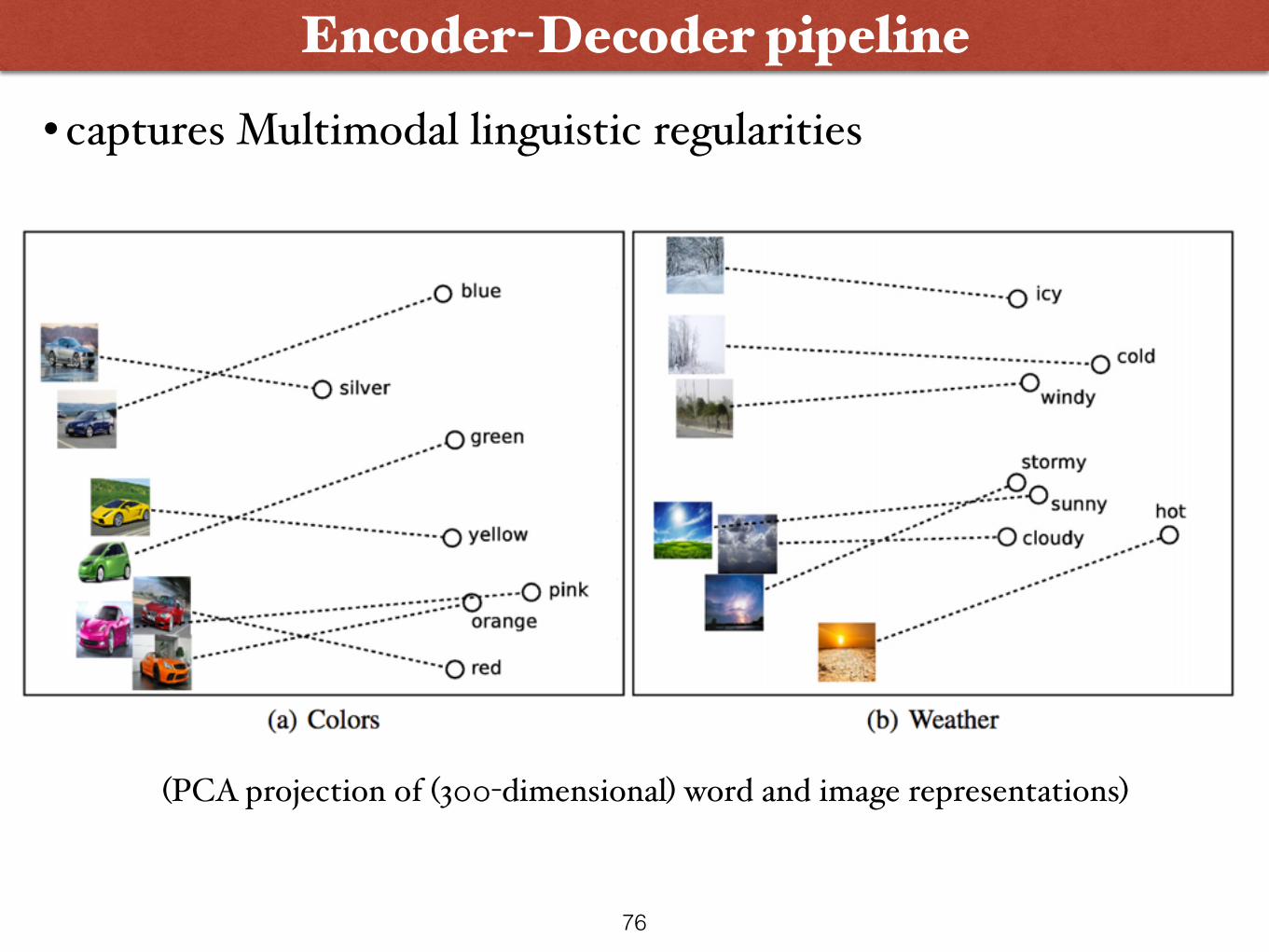
• captures Multimodal linguistic regularities
Encoder-Decoder pipeline
76
(PCA projection of (300-dimensional) word and image representations)

77
Vinyals, O., Toshev, A., Bengio, S., Erhan. D. (2015) Show and Tell: A Neural Image Caption Generator
Joint Visual-Semantic embedding
Karpathy, A., Fei Fei, L. (2015) Deep Visual-Semantic Alignments for Generating Image Descriptions
CNN+LSTM
CNN+RNN

78
Karpathy, A., Fei Fei, L. (2015) Deep Visual-Semantic Alignments for Generating Image Descriptions
Joint Visual-Semantic embedding

79
Joint Visual-Semantic embedding
Karpathy, A., Fei Fei, L. (2015) Deep Visual-Semantic Alignments for Generating Image Descriptions

80
Joint Visual-Semantic embedding
Karpathy, A., Fei Fei, L. (2015) Deep Visual-Semantic Alignments for Generating Image Descriptions

Joint Visual-Semantic embedding
81
Karpathy, A., Fei Fei, L. (2015) Deep Visual-Semantic Alignments for Generating Image Descriptions
demo

Any Questions?

Download example code samples fromhttps://github.com/graphific/DL-Meetup-intro
83
git clone --recursive https://github.com/graphific/DL-Meetup-intro.git
Wanna Play ? Code!
(more at http://deeplearning.net/ )

• Theano - CPU/GPU symbolic expression compiler in python (from LISA lab at University of Montreal). http://deeplearning.net/software/theano/
• Pylearn2 - library designed to make machine learning research easy. http://deeplearning.net/software/pylearn2/
• Torch - Matlab-like environment for state-of-the-art machine learning algorithms in lua (from Ronan Collobert, Clement Farabet and Koray Kavukcuoglu) http://torch.ch/
• more info: http://deeplearning.net/software links/
Wanna Play ?
Wanna Play ? General Deep Learning
84

• RNNLM (Mikolov) http://rnnlm.org
• NB-SVM https://github.com/mesnilgr/nbsvm
• Word2Vec (skipgrams/cbow)https://code.google.com/p/word2vec/ (original) http://radimrehurek.com/gensim/models/word2vec.html (python)
• GloVehttp://nlp.stanford.edu/projects/glove/ (original) https://github.com/maciejkula/glove-python (python)
• Socher et al / Stanford RNN Sentiment code:http://nlp.stanford.edu/sentiment/code.html
• Deep Learning without Magic Tutorial: http://nlp.stanford.edu/courses/NAACL2013/
Wanna Play ? NLP
85

• cuda-convnet2 (Alex Krizhevsky, Toronto) (c++/CUDA, optimized for GTX 580) https://code.google.com/p/cuda-convnet2/
• Caffe (Berkeley) (Cuda/OpenCL, Theano, Python)http://caffe.berkeleyvision.org/
• OverFeat (NYU) http://cilvr.nyu.edu/doku.php?id=code:start
Wanna Play ? Computer Vision
86

87
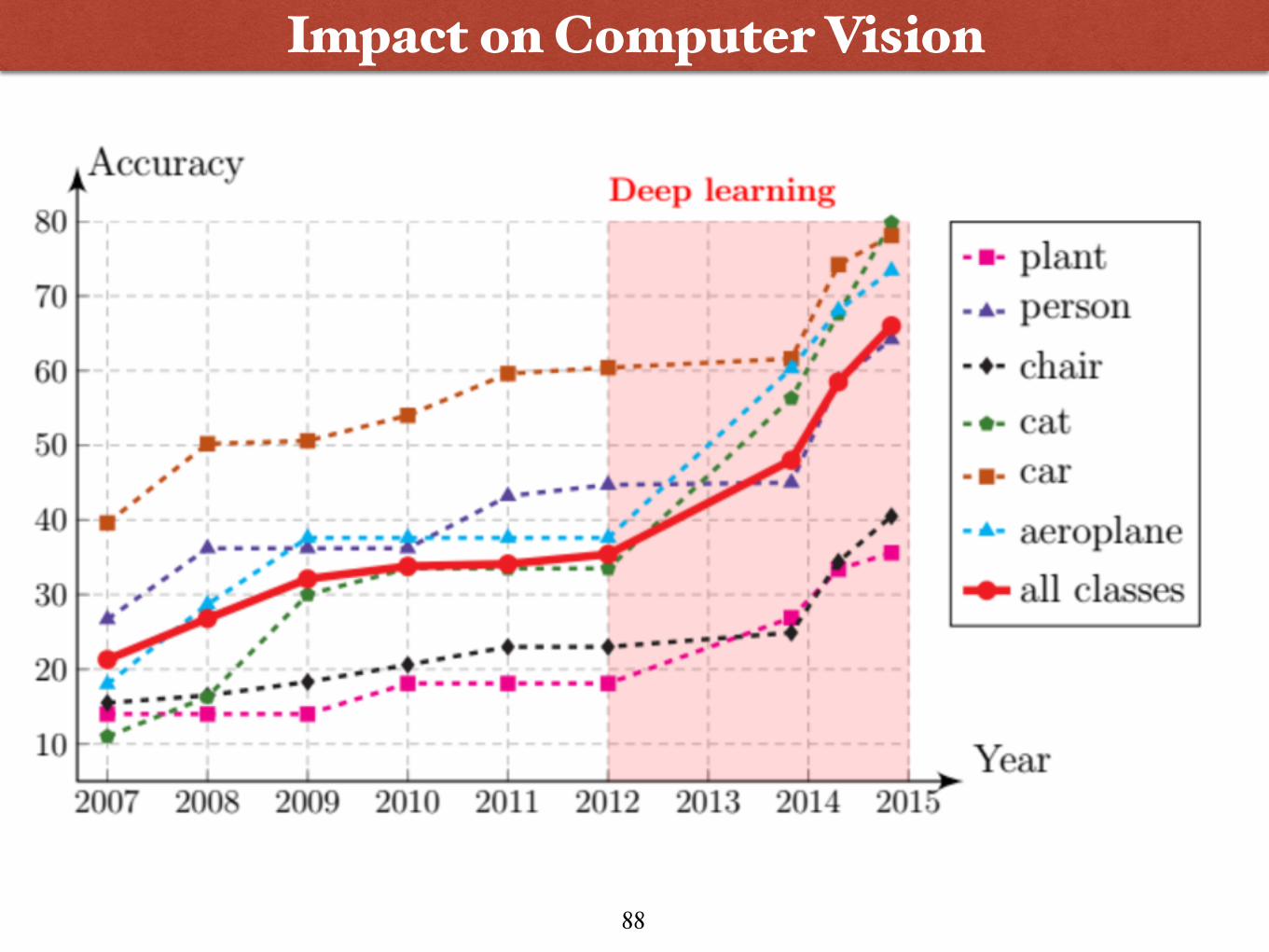
Impact on Computer Vision
88

Impact on Computer Vision
(from Clarifai)89
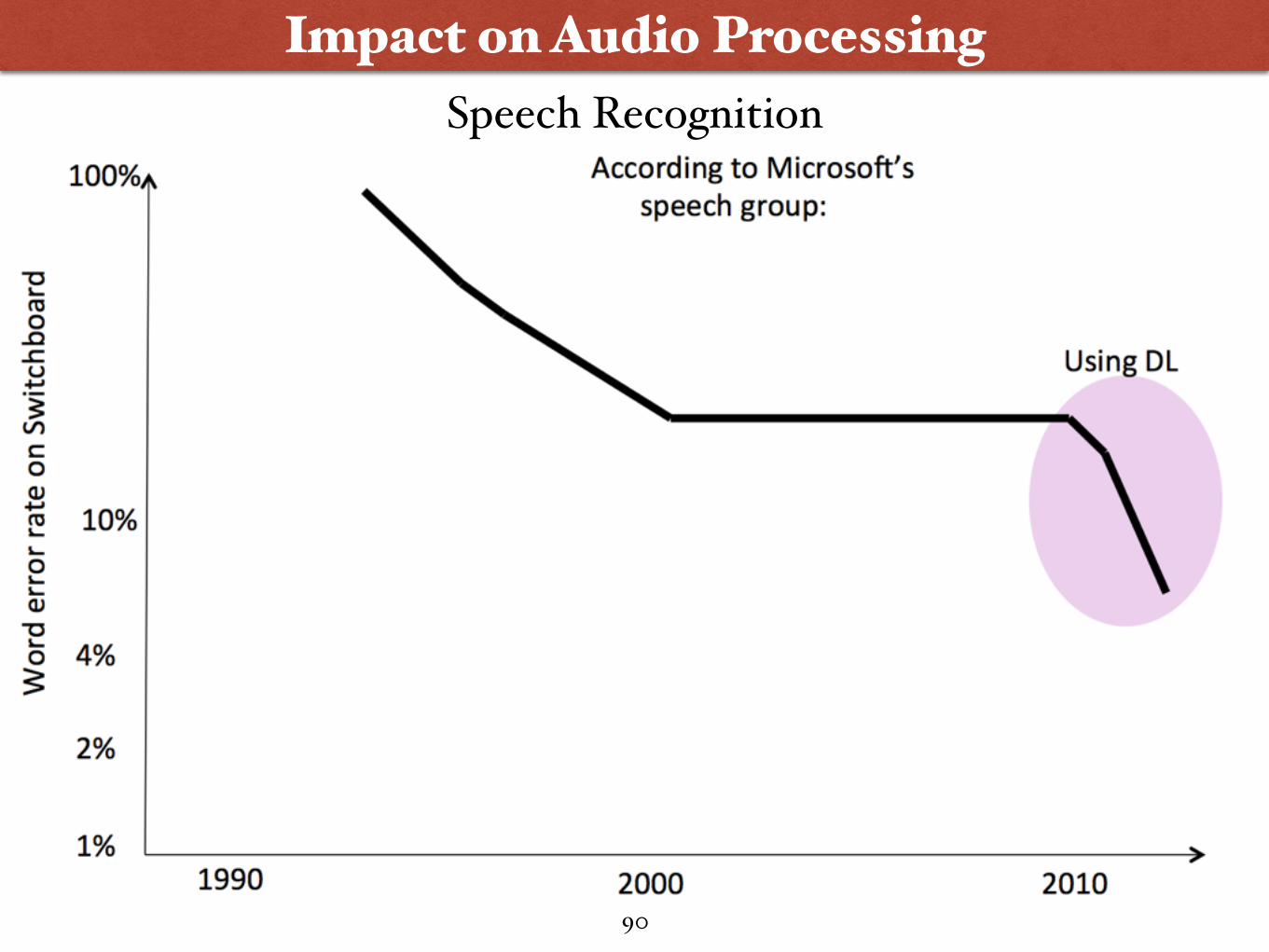
Impact on Audio ProcessingSpeech Recognition
90

Impact on Audio ProcessingTIMIT Speech Recognition
(from: Clarifai)91
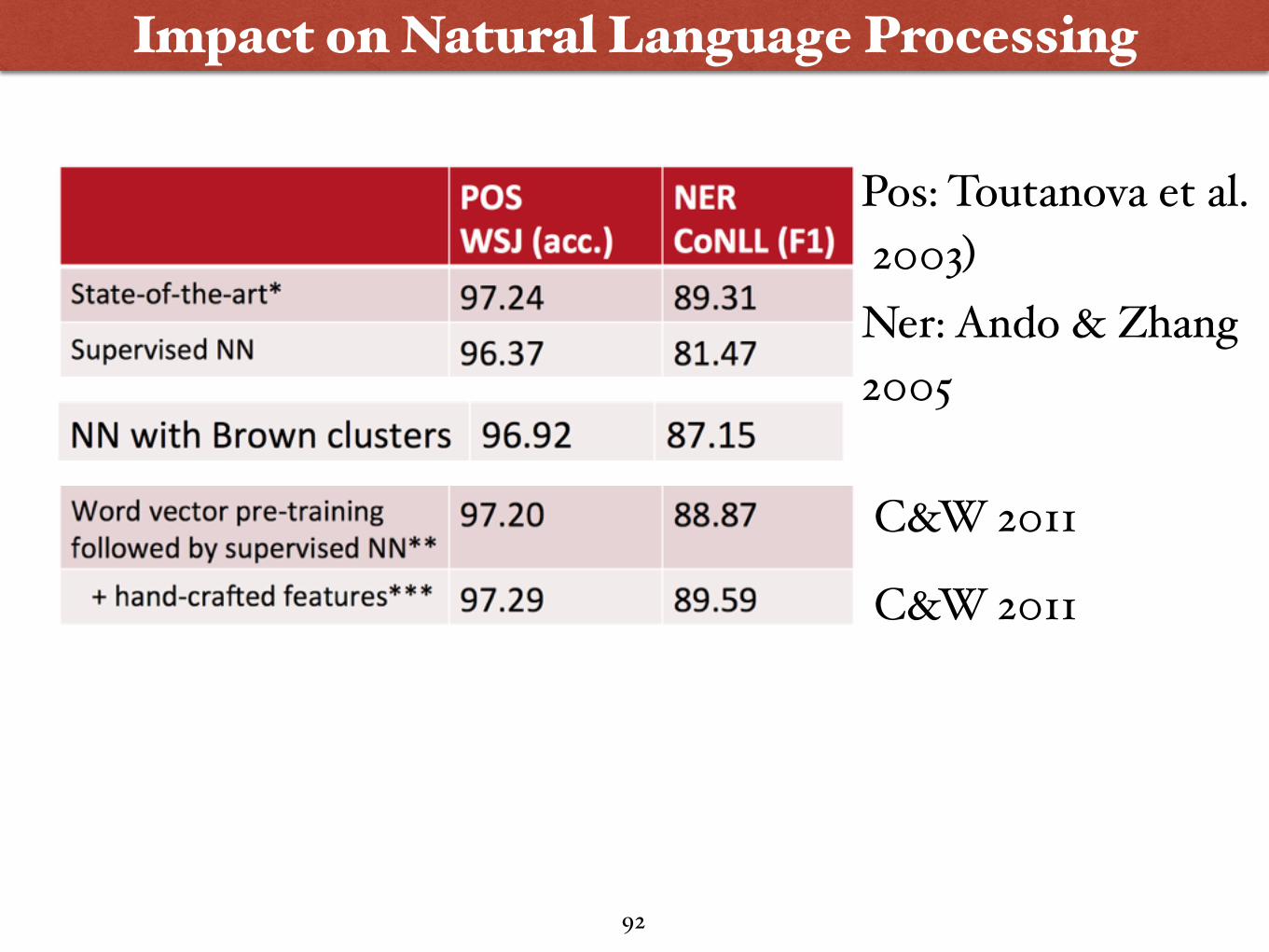
C&W 2011
Impact on Natural Language Processing
Pos: Toutanova et al. 2003)Ner: Ando & Zhang 2005
C&W 2011
92

Impact on Natural Language Processing
Named Entity Recognition:
93
Top Related