
Pengantar Deep Learning - Information Retrieval Lab -...
108
Pengantar Deep Learning untuk NLP 9 October 2017 1 Information Retrieval Lab. Fakultas Ilmu Komputer Universitas Indonesia 2017 Alfan Farizki Wicaksono ([email protected]) Alfan F. Wicaksono, FASILKOM UI
Transcript of Pengantar Deep Learning - Information Retrieval Lab -...

Pengantar Deep Learning untuk NLP 9
Oct
ob
er 2
01
7
1
Information Retrieval Lab.
Fakultas Ilmu Komputer
Universitas Indonesia
2017
Alfan Farizki Wicaksono ([email protected])
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Deep Learning Tsunami
“Deep Learning waves have lapped at the shores ofcomputational linguistics for several years now, but 2015seems like the year when the full force of the tsunami hit themajor Natural Language Processing (NLP) conferences.”
-Dr. Christopher D. Manning, Dec 2015
9 O
cto
ber
20
17
2
Christopher D. Manning. (2015). Computational Linguistics and Deep Learning Computational Linguistics, 41(4), 701–707.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Tips
Sebelum mempelajari RNNs dan arsitektur Deep Learningyang lainnya, disarankan untuk kita mempelajari beberapatopik berikut:
• Gradient Descent/Ascent
• Linear Regression
• Logistic Regression
• Konsep Backpropagation dan Computational Graph
• Multilayer Neural Networks
9 O
cto
ber
20
17
3
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Referensi/Bacaan
• Andrej Karpathy’ Blog
• http://karpathy.github.io/2015/05/21/rnn-effectiveness/
• Colah’s Blog
• http://karpathy.github.io/2015/05/21/rnn-effectiveness/
• Buku Deep Learning Yoshua Bengio
• Y. Bengio, Deep Learning, MLSS 2015
9 O
cto
ber
20
17
4
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Deep Learning vs Machine Learning
• Deep Learning adalah bagian dari isu Machine Learning
• Machine Learning adalah bagian dari isu Artificial Intelligence
9 O
cto
ber
20
17
5
Artificial Intelligence
Machine Learning
Deep Learning
• Searching• Knowledge
Representation and reasoning
• Planning
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Machine Learning(rule-based)
9 O
cto
ber
20
17
6
“Buku ini sangat menarik dan penuh manfaat”
Hand-crafted rules:
if contains(‘menarik’):return positive
...
Predicted label: positive
: Dirancang manusia
: Di-infer otomatis
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Machine Learning(classical ML)Fungsi klasifikasi dioptimasi berdasarkan input (fitur) &ouput.
9 O
cto
ber
20
17
7
“Buku ini sangat menarik dan penuh manfaat”
Hand-designed Feature Extractor:Contoh: Menggunakan TF-IDF, informasi syntax dengan POS Tagger, dsb.
Predicted label: positive
Learn mapping from features to label
: Dirancang manusia
: Di-infer otomatis
Feature Engineering!
Representation
Classifier
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Machine Learning(Representation Learning)Fitur dan fungsi klasifikasi di-optimasi secara bersama-sama.
9 O
cto
ber
20
17
8
“Buku ini sangat menarik dan penuh manfaat”
Learn Feature ExtractorContoh: Restricted Boltzman Machine,Autoencoder, dsb.
Predicted label: positive
Learn mapping from features to label
: Dirancang manusia
: Di-infer otomatis
Representation
Classifier
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Machine Learning(Deep Learning)Deep Learning learns Features!
9 O
cto
ber
20
17
9
“Buku ini sangat menarik dan penuh manfaat”
Fitur Sederhana
Predicted label: positive
Learn mapping from features to label
: Dirancang manusia
: Di-infer otomatis
Representation
Classifier
Fitur Kompleks/High-Level
Fitur yang Lebih High Level
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Sejarah
9 O
cto
ber
20
17
10
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Perceptron (Rosenblatt, 1958)
• Sejarah dimulai dimulai dengan Perceptron di akhir tahun 1950.
• Perceptron terdiri dari 3 layer: Sensory, Association, danResponse.
9 O
cto
ber
20
17
11
Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Perceptron (Rosenblatt, 1958)
9 O
cto
ber
20
17
12
http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
Activation function adalah fungsi non-linier. Dalam kasus perceptronRosenblatt, activation function adalah operasi thresholding biasa (stepfunction).
Learning perceptron menggunakan metode Donald Hebb.
Saat itu, mampu melakukan klasifikasi untuk input Pixel 20x20!
The organization of behavior: A neuropsychological theory. D. O. Hebb. John Wiley And Sons, Inc., New York, 1949
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Fathers of Deep Learning(?)
9 O
cto
ber
20
17
13
https://www.datarobot.com/blog/a-primer-on-deep-learning/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Fathers of Deep Learning(?)
• Di tahun 2006, ketiga orang tersebut mengembangkan carauntuk memanfaatkan dan mengatasi masalah trainingterhadap deep neural networks.
• Sebelumnya, banyak orang yang sudah menyerah terkaitmanfaat dari neural network, dan cara training-nya.
• Mereka mengatasi masalah terkait Neural Network belummampu belajar untuk menemukan representasi yangberguna.
• Geoff Hinton has been snatched up by Google;
• Yann LeCun is Director of AI Research at Facebook;
• Yoshua Bengio holds a position as research chair forArtificial Intelligence at University of Montreal
9 O
cto
ber
20
17
14
https://www.datarobot.com/blog/a-primer-on-deep-learning/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Fathers of Deep Learning(?)
• Automated learning of data representations and features is what the hype is all about!
9 O
cto
ber
20
17
15
https://www.datarobot.com/blog/a-primer-on-deep-learning/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Mengapa sebelumnya “deep learning” tidak sukses?
• Sebenarnya, neural network kompleks sudah banyakditemukan sebelumnya.
• Bahkan Long-Short Term Memory (LSTM) network, yangsaat ini ramai digunakan di bidang NLP, ditemukan tahun1997 oleh Hochreiter & Schmidhuber.
• Ditambah lagi, orang dahulu percaya bahwa neuralnetwork “can solve everything!”. Tetapi, mengapa merekatidak bisa melakukannya dahulu?
9 O
cto
ber
20
17
16
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Mengapa sebelumnya “deep learning” tidak sukses?
• Beberapa alasan, oleh Ilya Sutskever:• http://yyue.blogspot.co.id/2015/01/a-brief-overview-of-deep-
learning.html
• Computers were slow. So the neural networks of past were tiny.And tiny neural networks cannot achieve very high performance onanything. In other words, small neural networks are not powerful.
• Datasets were small. So even if it was somehow magicallypossible to train LDNNs, there were no large datasets that hadenough information to constrain their numerous parameters. Sofailure was inevitable.
• Nobody knew how to train deep nets. The current best objectrecognition networks have between 20 and 25 successive layers ofconvolutions. A 2 layer neural network cannot do anything good onobject recognition. Yet back in the day everyone was very sure thatdeep nets cannot be trained with SGD, since that would’ve beentoo good to be true
9 O
cto
ber
20
17
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

The Success of Deep Learning
Salah satu faktor-nya adalah karena saat ini ditemukan caralearning yang bekerja secara praktikal.
9 O
cto
ber
20
17
18
The success of Deep Learning hinges on a very fortunate fact: that well-tuned and carefully-initialized stochastic gradient descent (SGD) can train LDNNs on problems that occur in practice. It is not a trivial fact since the training error of a neural network as a function of its weights is highly non-convex. And when it comes to non-convex optimization, we were taught that all bets are off...
And yet, somehow, SGD seems to be very good at training those large deep neural networks on the tasks that we care about. The problem of training neural networks is NP-hard, and in fact there exists a family of datasets such that the problem of finding the best neural network with three hidden units is NP-hard. And yet, SGD just solves it in practice.
Ilya Sutskever, http://yyue.blogspot.co.at/2015/01/a-brief-overview-of-deep-learning.html
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Apa Itu Deep Learning?
9 O
cto
ber
20
17
19
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Apa itu Deep Learning?
• Kenyataannya, Deep Learning = (Deep) Artificial NeuralNetworks (ANNs)
• Dan Neural Networks sebenarnya adalah sebuahTumpukan Fungsi Matematika 9
Oct
ob
er 2
01
7
20
Image Courtesy: Google
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Apa itu Deep Learning?
Secara praktis, (supervised) Machine Learning itu adalah:Ekspresikan permasalahan ke dalam sebuah fungsi F (yangmempunyai parameter θ), lalu secara otomatis cariparameter θ sehingga fungsi F tepat mengeluarkan outputyang diinginkan.
9 O
cto
ber
20
17
21
X: “Buku ini sangat menarik dan penuh manfaat”
Y = F(X; θ)
Predicted label: Y = positive
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Apa itu Deep Learning?
Untuk Deep Learning, fungsi tersebut biasanya terdiri daritumpukan banyak fungsi yang biasanya serupa.
9 O
cto
ber
20
17
22
“Buku ini sangat menarik dan penuh manfaat”
F(X; θ1)
Y = positive
F(X; θ2)
F(X; θ3)
)););;((( 123 XFFFY
Tumpukan Fungsi ini sering disebut dengan Tumpukan Layer
Gambar ini sering disebut dengan istilah Computational Graph
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Apa itu Deep Learning?
• Layer yang paling terkenal/umum adalah Fully-ConnectedLayer.
• “weighted sum of its inputs, followed by a non-linear function”
• Fungsi non-linier yang umum digunakan: Tanh (tangenthyperbolic), Sigmoid, ReLU (Rectified Linear Unit)
9 O
cto
ber
20
17
23
).()( bXWfXFY
NRX
NMRW
MRb
X
).( bXWf
f
Non-linearity
i
ii bxw
i
ii bxwf
N unitM unit
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Mengapa perlu “Deep”?
• Humans organize their ideas and concepts hierarchically
• Humans first learn simpler concepts and then composethem to represent more abstract ones
• Engineers break-up solutions into multiple levels ofabstraction and processing
• It would be good to automatically learn / discover theseconcepts
9 O
cto
ber
20
17
24Y. Bengio, Deep Learning, MLSS 2015, Austin, Texas, Jan 2014
(Bengio & Delalleau 2011)
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Neural Networks
9 O
cto
ber
20
17
25
).( 11 bXWfY
X ).( 11 bXWfY Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Neural Networks
9 O
cto
ber
20
17
26
))).(.(( 1211 bbXWfWfY
X ).( 111 bXWfH
).( 212 bHWfY
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Neural Networks
9 O
cto
ber
20
17
27
))))).(.((.(( 123321 bbbXWfWfWfY
X
).( 111 bXWfH ).( 2122 bHWfH
).( 323 bHWfY
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Alasan matematis mengapa harus “deep”?
• A neural network with a single hidden layer of enoughunits can approximate any continuous function arbitrarilywell.
• In other words, it can solve whatever problem you’reinterested in!
(Cybenko 1998, Hornik 1991)
9 O
cto
ber
20
17
28
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Alasan matematis mengapa harus “deep”?
Akan tetapi ...
• “Enough units” can be a very large number. There are functionsrepresentable with a small, but deep network that wouldrequire exponentially many units with a single layer.
• The proof only says that a shallow network exists, it does not sayhow to find it.
• Evidence indicates that it is easier to train a deep network toperform well than a shallow one.
• A more recent result brings an example of a very large class offunctions that cannot be efficiently represented with a small-depth network.
(e.g., Hastad et al. 1986, Bengio & Delalleau 2011)(Braverman, 2011)
9 O
cto
ber
20
17
29
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Mengapa perlu non-linearity?
9 O
cto
ber
20
17
30
f
Non-linearity
i
ii bxw
i
ii bxwf
323
2122
111
.
.
.
bHWY
bHWH
bXWH
Mengapa perlu fungsi non-linier f?
Kalau tanpa f, rangkaian fungsi ini adalahtetap fungsi linier.
Data bisa sangat kompleks, dan terkadanghubungan yang ada pada data tidak hanyalinier, tetapi bisa non-linier. Perlurepresentasi yang bisa menangkap hal ini.?
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Secara random, kita inisialisasi semua parameter W1, b1,W2, b2, W3, b3
• Definisikan sebuah cost function/loss function yangmengukur seberapa baik fungsi neural network Anda.
• Seberapa jauh nilai yang diprediksi dengan nilai sesungguhnya
• Secara iteratif/berulang-ulang, sesuaikan nilai parametersehingga nilai loss function menjadi minimal.
9 O
cto
ber
20
17
31
))))).(.((.(( 123321 bbbXWfWfWfY
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Initialize trainable parametersrandomly
9 O
cto
ber
20
17
32Buku ini sangat baik dan mendidik
W(1)
W(2)
W(3)
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example 9 O
cto
ber
20
17
33Buku ini sangat baik dan mendidik
W(1)
W(2)
W(3)
x
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
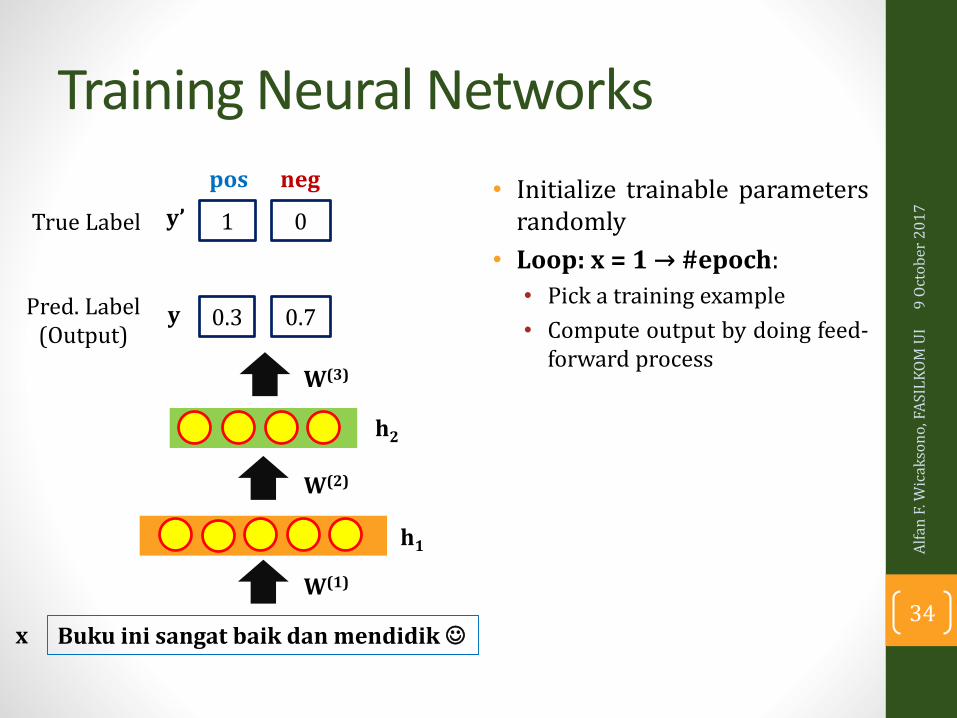
Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example
• Compute output by doing feed-forward process
9 O
cto
ber
20
17
34Buku ini sangat baik dan mendidik
1 0True Label
0.3 0.7Pred. Label(Output)
W(1)
W(2)
W(3)
h1
h2
y
y’
x
pos neg
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
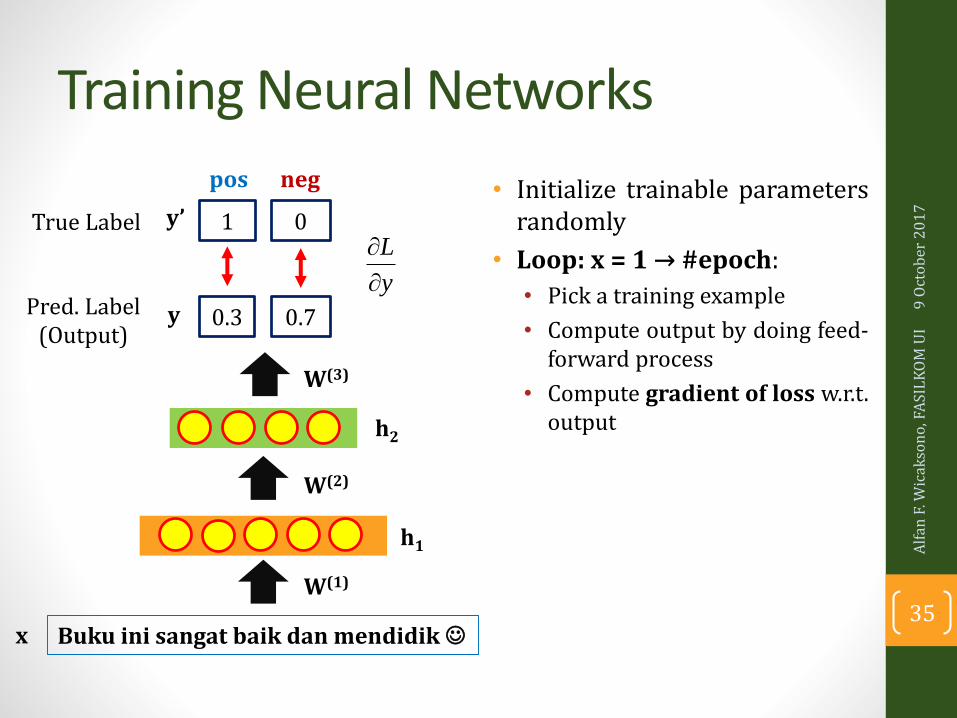
Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example
• Compute output by doing feed-forward process
• Compute gradient of loss w.r.t.output
9 O
cto
ber
20
17
35Buku ini sangat baik dan mendidik
1 0True Label
0.3 0.7Pred. Label(Output)
W(1)
W(2)
W(3)
h1
h2
y
y’
x
pos neg
y
L
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example
• Compute output by doing feed-forward process
• Compute gradient of loss w.r.t.output
• Backpropagate loss, computinggradients w.r.t trainableparameters. It’s likecomputing contribution oferror to the output of eachparameter
9 O
cto
ber
20
17
36Buku ini sangat baik dan mendidik
1 0True Label
0.3 0.7Pred. Label(Output)
W(1)
W(2)
h1
y
y’
x
pos neg
y
L
)3(W
L
2h
L
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example
• Compute output by doing feed-forward process
• Compute gradient of loss w.r.t.output
• Backpropagate loss, computinggradients w.r.t trainableparameters. It’s likecomputing contribution oferror to the output of eachparameter
9 O
cto
ber
20
17
37Buku ini sangat baik dan mendidik
1 0True Label
0.3 0.7Pred. Label(Output)
W(1)
y
y’
x
pos neg
y
L
)3(W
L
2h
L
)2(W
L
1h
L
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Training Neural Networks
• Initialize trainable parametersrandomly
• Loop: x = 1 → #epoch:
• Pick a training example
• Compute output by doing feed-forward process
• Compute gradient of loss w.r.t.output
• Backpropagate loss, computinggradients w.r.t trainableparameters. It’s likecomputing contribution oferror to the output of eachparameter
9 O
cto
ber
20
17
38Buku ini sangat baik dan mendidik
1 0True Label
0.3 0.7Pred. Label(Output)
y
y’
x
pos neg
y
L
)3(W
L
2h
L
)2(W
L
1h
L
)1(W
L
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Take small step in direction of negative gradient!
9 O
cto
ber
20
17
39https://github.com/joshdk/pygradesc
)( )(
)(
)()1( t
t
n
t
t
n
t
n f
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Lebih Detail dalam Hal Teknis …
9 O
cto
ber
20
17
40
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Salah satu framework paling sederhana untuk permasalahanoptimasi (multivariate optimization).
Digunakan untuk mencari konfigurasi parameter-parametersehingga cost function menjadi optimal, dalam hal inimencapai local minimum.
GD menggunakan metode iteratif, yang dimulai dari sebuahtitik acak, dan secara perlahan-lahan mengikuti arah negatifdari gradient sehingga pada akhirnya akan berpindah kesuatu titik kritikal, yang diharapkan merupakan localminimum.
Tidak dijamin mencapai global minimum !
9 O
cto
ber
20
17
41
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Problem: carilah nilai x sehingga fungsi f(x) = 2x4 + x3 – 3x2
mencapai titik local minimum.
Misal, kita pilih x dimulai dari x=2.0:
9 O
cto
ber
20
17
42
Local minimum
Algoritma GD konvergenpada titik x = 0.699, yang merupakan local minimum.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Algorithm:
9 O
cto
ber
20
17
43
"")()(
""
int"")('
)('
:...,,2,1
1
1
1
1
max
divergingreturnthenxfxfIf
valuexonconvergedreturnthenxxIf
pocriticalonconvergedreturnthenxfIf
xfxx
NtFor
tt
tt
t
tttt
αt : learning rate atau step size pada iterasi ke-tϵ: sebuah bilangan yang sangat kecilNmax: batas banyaknya iterasi, atau disebut epoch jika iterasi selalu sampai akhir
Algoritma dimulai dengan menebak nilai x1 !
Tips: pilih αt yang tidak terlalu kecil, juga tidak terlalu besar.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Kalau parameter-nya ada banyak ?
Carilah θ = θ1, θ2, …, θn sehingga f(θ1, θ2, …, θn) mencapailocal minimum !
9 O
cto
ber
20
17
44)(
)(
)(
:
)(
)(
)()1(
)(
)(
2
)(
2
)1(
2
)(
)(
1
)(
1
)1(
1
t
t
n
t
t
n
t
n
t
tt
tt
t
tt
tt
f
f
f
convergednotwhile
Dimulai dengan menebaknilai awal θ = θ1, θ2, …, θn
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Gradient Descent (GD)
Take small step in direction of negative gradient!
9 O
cto
ber
20
17
45
)( )(
)(
)()1( t
t
n
t
t
n
t
n f
https://github.com/joshdk/pygradesc
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Berbeda dengan Linear Regression, Logistic Regressiondigunakan untuk permasalahan Binary Classification. Jadioutput yang dihasilkan adalah diskrit ! (1 atau 0), (ya atautidak).
Misal, diberikan 2 hal:
1. Unseen data x yang ingin diprediksi labelnya, yaitu y.
2. Model logistic regression dengan parameter θ0, θ1, …, θn
yang sudah ditentukan.
9 O
cto
ber
20
17
46
z
n
i
iinn
ez
xyPxyP
xxxxyP
1
1)(
);|1(1);|0(
)()...();|1(1
0110
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Bisa digambarkan dalam bentuk “single neuron”.
9 O
cto
ber
20
17
47
z
n
i
iinn
ez
xyPxyP
xxxxyP
1
1)(
);|1(1);|0(
)()...();|1(1
0110
x1
x2
x3
+1
θ1
θ2
θ3
θ0
Dengan fungsi sigmoid sebagai activation function
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Slide sebelumnya mengasumsikan bahwa parameter θ sudahditentukan.
Bagaimana bila belum ditentukan ?
Kita bisa estimasi parameter θ dengan memanfaatkantraining data {(x(1), y(1)), (x(2), y(2)), …, (y(n), y(n))} yangdiberikan (learning).
9 O
cto
ber
20
17
48
x1
x2
x3
+1
θ1
θ2
θ3
θ0
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Misal,
Probabilitas masing-masing kelas dapat dituliskan secara singkat(persamaan di slide-slide sebelumnya) dengan:
Diberikan m buah training examples, likelihood:
9 O
cto
ber
20
17
49
)()...()(1
0110
n
i
iinn xxxxh
}1,0{))(1.())(();|( 1 yxhxhxyP yy
m
i
yiyi
m
i
ii
ii
xhxh
xyPL
1
1)()(
1
)()(
)()(
))(1.())((
);|()(
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Dengan MLE, kita akan mencari konfigurasi parameter yangmemberikan nilai likelihood maksimal (= nilai log-likelihoodmaksimal).
Atau, kita cari parameter yang meminimalkan fungsi negativelog-likelihood (cross-entropy loss). Inilah cost function kita !
9 O
cto
ber
20
17
50
))(1(log)1()(log
)(log)(
)()()(
1
)( iiim
i
i xhyxhy
Ll
))(1(log)1()(log)( )()()(
1
)( iiim
i
i xhyxhyJ
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Agar bisa menggunakan Gradient Descent untuk mencariparameter yang meminimalkan cost function, kita perlumenurunkan:
Dapat ditunjukkan bahwa untuk sebuah training example (x,y):
Jadi, untuk update nilai parameter di tiap iterasi untuk semuaexample:
9 O
cto
ber
20
17
51
)(
Ji
j
j
xyxhJ ))(()(
m
i
i
j
ii
jj xyxh1
)()( ))((:
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Batch Gradient Descent untuk learning model
inisialisasi θ1, θ2, …, θnwhile not converged :
9 O
cto
ber
20
17
52
m
i
i
n
ii
nn
m
i
iii
m
i
iii
xyxh
xyxh
xyxh
1
)()(
1
2
)()(
22
1
1
)()(
11
))((:
))((:
))((:
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Stochastic Gradient Descent: kita bisa membuat progress danupdate parameter ketika kita melihat sebuah training example.
inisialisasi θ1, θ2, …, θnwhile not converged :
for i := 1 to m do :
9 O
cto
ber
20
17
53
i
n
ii
nn
iii
iii
xxhy
xxhy
xxhy
))((:
))((:
))((:
)()(
2
)()(
22
1
)()(
11
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Logistic Regression
Learning
Mini-Batch Gradient Descent untuk learning model: Daripada kitagunakan sebuah sample untuk update (seperti online learning),gradient dihitung dengan cara rata-rata/sum dari sebuah mini-batch sample (misal, 32 atau 64 sample).
Batch Gradient Descent: gradient dihitung untuk semua sample!
• Untuk sekali step, terlalu besar komputasinya
Online Learning: gradient dihitung untuk sebuah sample!
• Terkadang noisy
• Update step sangat kecil
9 O
cto
ber
20
17
54
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Logistic Regression sebenarnya bisa dianggap sebagai NeuralNetwork dengan beberapa unit di layer input, satu unit dilayer output, dan tanpa hidden layer.
9 O
cto
ber
20
17
55
x1
x2
x3
+1
θ1
θ2
θ3
θ0
Dengan fungsi sigmoid sebagai activation function
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Misal, ada 3-layer NN, dengan 3 input unit, 2 hidden unit, dan2 output unit.
9 O
cto
ber
20
17
56
x1
x2
x3
+1
+1
𝑊11(1)
𝑊21(1)
𝑊12(1)
𝑊22(1)
𝑊13(1)
𝑊23(1)
𝑏1(1) 𝑏2
(1)
𝑊11(2)
𝑊12(2)
𝑊21(2)
𝑊22(2)
𝑏1(2) 𝑏2
(2)
W(1), W(2), b(1), b(2) adalah parameter !
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Seandainya parameter sudah diketahui, bagaimana caranyamemprediksi label dari input (klasifikasi) ?
Dari contoh sebelumnya, ada 2 unit di output layer. Kondisiini biasanya digunakan untuk binary classification. Unitpertama menghasilkan probabilitas untuk pertama, dan unitkedua menghasilkan probabilitas untuk kelas kedua.
Kita perlu melakukan proses feed-forward untukmenghitung nilai yang dihasilkan di output layer.
9 O
cto
ber
20
17
57
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Misal, untuk activation function, kita gunakan fungsihyperbolic tangent.
Untuk menghitung output di hidden layer:
9 O
cto
ber
20
17
58
)tanh()( xxf
)1(
23
)1(
232
)1(
221
)1(
21
)2(
2
)1(
13
)1(
132
)1(
121
)1(
11
)2(
1
bxWxWxWz
bxWxWxWz
)(
)(
)2(
2
)2(
2
)2(
1
)2(
1
zfa
zfa
Ini hanyalah perkalian matrix !
)1(
2
)1(
1
3
2
1
)1(
23
)1(
22
)1(
21
)1(
13
)1(
12
)1(
11)1()1()2(
b
b
x
x
x
WWW
WWWbxWz
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Jadi, Proses feed-forward secara keseluruhan hinggamenghasilkan output di kedua output unit adalah:
9 O
cto
ber
20
17
59
)(ax )(
)(
)3()3(
,
)2()2()2()3(
)2()2(
)1()1()2(
zsoftmaxh
baWz
zfa
bxWz
bW
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Ada Cost function yang berupa cross-entropy loss:
m adalah banyaknya training examples.
9 O
cto
ber
20
17
60
Regularization terms
1
1 1 1
2)(
,
1
,
1
)(2
)(log1
),(l l ln
l
s
i
s
j
l
jiji
m
i j
ji Wpym
bWJ
Berarti, cost function untuk satu sample (x,y) adalah:
j
jj
j
jbWj pyxhyyxbWJ log)(log),;,( ,
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Namun, kali ini, Cost function kita adalah squared-error:
m adalah banyaknya training examples.
9 O
cto
ber
20
17
61
Regularization terms
1
1 1 1
2)(
1
2)()(
,
1
)(2
)(2
11),(
l l ln
l
s
i
s
j
l
ji
m
i
ii
bW Wyxhm
bWJ
Berarti, cost function untuk satu sample (x,y) adalah:
2)()(
,
2)()(
, )(2
1)(
2
1),;,(
j
i
j
i
jbW
ii
bW yxhyxhyxbWJ
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Batch Gradient Descent
inisialisasi W, b
while not converged : 9 O
cto
ber
20
17
62
),(
),(
)(
)()(
)(
)()(
bWJb
bb
bWJW
WW
l
i
l
i
l
i
l
ij
l
ij
l
ij
Bagaimana cara menghitung gradient ??
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Misal, (x, y) adalah sebuah training sample, dan dJ(W,b;x,y)adalah turunan parsial terkait sebuah sample (x,y).
dJ(W,b;x,y) menentukan overall partial derivative dJ(W,b): 9 O
cto
ber
20
17
63
)(
1
)()(
)()(),;,(
1),( l
ij
m
i
ii
l
ij
l
ij
WyxbWJWm
bWJW
m
i
ii
l
i
l
i
yxbWJbm
bWJb 1
)()(
)()(),;,(
1),(
Dihitung dengan teknik BackPropagation
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Back-Propagation
1. Jalankan proses feed-forward
2. Untuk setiap output unit i pada layer nl (output layer)
3. l = nl - 1, nl - 2, ... 2
Untuk setiap node i di layer l
4. Finally..
9 O
cto
ber
20
17
64
)(')(),;,()()(
)(
)( ll
l
l n
ii
n
in
i
n
i zfyayxbWJz
)(')( )()1(
1
)()(1
l
i
l
j
s
j
l
ji
l
i zfWl
)1()(
)(),;,(
l
i
l
jl
ij
ayxbWJW
)1(
)(),;,(
l
il
i
yxbWJb
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Multilayer Neural Network (Multilayer Perceptron)
Learning
Back-Propagation
Contoh hitung gradient di output ...
9 O
cto
ber
20
17
65
)2(
2
)3(
11
)3(
1
)2(
12
)3(
1
)3(
1
)3(
1
)3(
1
)2(
12
)('
),;,(
azfya
W
z
z
a
a
JyxbWJ
W
+1
𝑊11(2)
𝑊12(2)
𝑊21(2)
𝑊22(2)
𝑏1(2) 𝑏2
(2)
𝑎1(3)
𝑧1(3)
𝑧2(3)
𝑎2(3)
22
)3(
2
2
1
)3(
12
1
2
1),;,( yayayxbWJ
1
)3(
1)3(
1
yaa
J
)3(
1)3(
1
)3(
1
)3(
1
)3(
1 ' zfz
zf
z
a
)2(
1
)2(
2
)2(
12
)2(
1
)2(
11
)3(
1 baWaWz
)2(
2)2(
12
)3(
1 aW
z
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Sensitivity – Jacobian Matrix
The Jacobian J is the matrix of partial derivatives of thenetwork output vector y with respect to the input vector x.
These derivatives measure the relative sensitivity of theoutputs to small changes in the inputs, and can thereforebe used, for example, to detect irrelevant inputs.
9 O
cto
ber
20
17
66
....
....
....
....
Ji
kik
x
yJ
,
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

More Complex Neural Networks(Neural Network Architectures)
9 O
cto
ber
20
17
67
Recurrent Neural Networks (Vanilla RNN, LSTM, GRU)Attention MechanismsRecursive Neural Networks A
lfan
F. W
icak
son
o, F
ASI
LK
OM
UI

Recurrent Neural Networks
9 O
cto
ber
20
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
68X1 X2 X3 X4 X5
h1 h2 h3 h4 h5
O1 O2 O3 O4 O5
One of the famous Deep Learning Architectures in the NLP community

Recurrent Neural Networks (RNNs)
Kita biasanya menggunakan RNNs untuk:
• Memproses Sequences
• Menghasilkan Sequences
• …
• Intinya … ada Sequences
Sequences biasanya:
• Urutan kata-kata
• Urutan kalimat-kalimat
• Signal
• Suara
• Video (Sequence of Images)
• …
9 O
cto
ber
20
17
69
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
70
Not RNNs (Vanilla Feed-Forward NNs)
Sequence Output(e.g. Image Captioning)
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Sequence Input(e.g. Sentence Classification)
Sequence Input/Output(e.g. Machine Translation)
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
RNNs combine the input vector with their state vector with a fixed(but learned) function to produce a new state vector.
This can, in programming terms, be interpreted as running a fixedprogram with certain inputs and some internal variables.
In fact, it is known that RNNs are Turing-Complete in the sense thatthey can simulate arbitrary programs (with proper weights).
9 O
cto
ber
20
17
71
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
http://binds.cs.umass.edu/papers/1995_Siegelmann_Science.pdf
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
72X1 X2
s1 s2
Y1 Y2
)(xhW
)(hhW
)(hyW
1
)()(
t
hh
t
xh
t sWxWh
t
hy
t sWy )(
00 h
1 H
t Rh1 I
t Rx1 K
t Ry
IHxh RW )( HHhh RW )(
HKhy RW )(
tt hs tanh
Misal, ada I input unit, K output unit, dan H hidden unit (state).
Komputasi RNNs untuk satu sample:
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
73X1 X2
s1 s2
Y1 Y2
ti
H
n
h
tn
hh
ni
K
j
y
tj
hy
ji
h
ti hfWW ,
1
)(
1,
)(
,
1
)(
,
)(
,
)(
, '
Back Propagation Through Time (BPTT)
The loss function depends on the activationof the hidden layer not only through itsinfluence on the output layer.
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
ti
ty
tiy
L
,
)(
,
ti
th
tih
L
,
)(
,
Di output:
Di setiap step, kecualipaling kanan:
0)(
1,
h
Ti
)(h
)( y
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
74X1 X2
s1 s2
Y1 Y2
T
t
ti
h
tjhh
ji
sW
L
1
1,
)(
,)(
,
Back Propagation Through Time (BPTT)
The same weights are reused at everytimestep, we sum over the whole sequence toget the derivatives with respect to thenetwork weights.
)(xhW
)(hhW
)(hyW
T
t
ti
y
tjhy
ji
sW
L
1
,
)(
,)(
,
T
t
ti
h
tjxh
ji
xW
L
1
,
)(
,)(
,
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
75
Back Propagation Through Time (BPTT)
Pascanu et al., On the difficulty of training Recurrent Neural Networks, 2013
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
76
Back Propagation Through Time (BPTT)
t
khh
k
k
t
t
t
hh
t
W
h
h
h
h
L
W
L
1)()(
Misal, untuk parameter antar state:
k
k
k
k
t
t
t
t
k
t
h
h
h
h
h
h
h
h
h
h
1
1
2
2
1
1
1 k t
Diputus sampai k step ke belakang.Di sini artinya “immediate derivative”,yaitu hk-1 dianggap konstan terhadapW(hh).
1)(
1
)()(
)(
thh
t
hh
t
xh
hh
k sW
sWxW
W
h
Term-term ini disebut temporalcontribution: bagaimana W(hh)
pada step k mempengaruhi costpada step-step setelahnya (t > k)
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
77
Vanishing & Exploding Gradient Problems
Bengio et al., (1994) said that “the exploding gradients problem refers to thelarge increase in the norm of the gradient during training. Such events arecaused by the explosion of the long term components, which can growexponentially more then short term ones.”
And “The vanishing gradients problem refers to the opposite behaviour, whenlong term components go exponentially fast to norm 0, making it impossible forthe model to learn correlation between temporally distant events.”
Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks
k
k
k
k
t
t
t
t
k
t
h
h
h
h
h
h
h
h
h
h
1
1
2
2
1
1
Kok bisa terjadi? Coba lihat salah satu temporal component dari sebelumnya:
In the same way a product of t - k real numbers can shrink to zero or explode to infinity, so does this product of Matrices. (Pascanu et al.,)
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
78
Vanishing & Exploding Gradient Problems
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Sequential Jacobian biasadigunakan untuk analisispenggunaan konteks padaRNNs.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
9 O
cto
ber
20
17
79
Solusi untuk Vanishing Gradient Problem
1) Penggunaan non-gradient based training algorithms (SimulatedAnnealing, Discrete Error Propagation, etc.) (Bengio et al., 1994)
2) Definisikan arsitektur baru di dalam RNN Cell!, seperti Long-Short TermMemory (LSTM) (Hochreiter & Schmidhuber, 1997).
3) Untuk metode yang lain, silakan merujuk (Pascanu et al., 2013).
Y. Bengio, P. Simard, and P. Frasconi. Learning Long-Term Dependencies with Gradient Descent is Difficult. IEEE Transactions on Neural Networks, 1994
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Pascanu et al., On the difficulty of training Recurrent Neural Networks, 2013
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
Variant: Bi-Directional RNNs
9 O
cto
ber
20
17
80
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recurrent Neural Networks (RNNs)
Sequential Jacobian (Sensitivity) untuk Bi-Directional RNNs
9 O
cto
ber
20
17
81
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
1. The LSTM architecture consists of a set of recurrentlyconnected subnets, known as memory blocks.
2. These blocks can be thought of as a differentiable versionof the memory chips in a digital computer.
3. Each block contains:
1. Self-connected memory cells
2. Three multiplicative units (gates)
1. Input gates (analogue of write operation)
2. Output gates (analogue of read operation)
3. Forget gates ((analogue of reset operation))
9 O
cto
ber
20
17
82
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
9 O
cto
ber
20
17
83
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
9 O
cto
ber
20
17
84
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
The multiplicative gates allow LSTMmemory cells to store and accessinformation over long periods of time,thereby mitigating the vanishinggradient problem.
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
For example, as long as the input gateremains closed (i.e. has an activation near0), the activation of the cell will not beoverwritten by the new inputs arriving inthe network, and can therefore be madeavailable to the net much later in thesequence, by opening the output gate.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
Visualisasi lain dari satu cell di LSTM
9 O
cto
ber
20
17
85
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
Komputasi di LSTM
9 O
cto
ber
20
17
86
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Long-Short Term Memory (LSTM)
Preservation of Gradient Information pada LSTM
9 O
cto
ber
20
17
87
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory. Neural Computation,9(8):1735 1780, 1997
Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Example: RNNs for POS Tagger
9 O
cto
ber
20
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
88
I went to west java
h1 h2 h3 h4 h5
PRP VBD TO JJ NN
(Zennaki, 2015)

LSTM + CRF for Semantic Role Labeling
(Zhou and Xu, ACL 2015)
9 O
cto
ber
20
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
89

Attention Mechanism
A potential issue with this encoder–decoder approach is that a neuralnetwork needs to be able to compress all the necessary information ofa source sentence into a fixed-length vector. This may make it difficultfor the neural network to cope with long sentences, especially thosethat are longer than the sentences in the training corpus.
Dzmitry Bahdanau, et al., Neural machine translation by jointlylearning to align and translate, 2015
9 O
cto
ber
20
17
90
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Neural Translation Model TANPA Attention Mechanism
9 O
cto
ber
20
17
91
Sutkever, Ilya et al., Sequence to Sequence Learning with Neural Networks, NIPS 2014.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Neural Translation Model TANPA Attention Mechanism
9 O
cto
ber
20
17
92
Sutkever, Ilya et al., Sequence to Sequence Learning with Neural Networks, NIPS 2014.
https://blog.heuritech.com/2016/01/20/attention-mechanism/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Mengapa Perlu Attention Mechanism?
• Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
• … it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector.
Dzmitry Bahdanau, et al., Neural machine translation by jointlylearning to align and translate, 2015
9 O
cto
ber
20
17
93
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Neural Translation Model – dengan Attention Mechanism
9 O
cto
ber
20
17
94
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio, Neural Machine Translation by Jointly Learning to Align and Translate, arXiv:1409.0473, 2016
https://blog.heuritech.com/2016/01/20/attention-mechanism/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Neural Translation Model – dengan Attention Mechanism
9 O
cto
ber
20
17
95
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio, Neural Machine Translation by Jointly Learning to Align and Translate, arXiv:1409.0473, 2016
Cell merepresentasikan bobot attention, terkait translation.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Simple Attention Networks untuk Sentence Classification
9 O
cto
ber
20
17
96
Colin Raffel, Daniel P. W. Ellis, F EED -F ORWARD NETWORKS WITH ATTENTION CANS OLVE S OME L ONG-T ERM MEMORY P ROBLEMS, Workshop track - ICLR 2016
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Hierarchical Attention Networks untuk Sentence Classification
9 O
cto
ber
20
17
97
Yang, Zichao, et al., Hierarchical Attention Networks for Document Classification, NAACL 2016
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Hierarchical Attention Networks untuk Sentence Classification
9 O
cto
ber
20
17
98
Yang, Zichao, et al., Hierarchical Attention Networks for Document Classification, NAACL 2016
Task: Prediksi Rating Dokumen
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
9 O
cto
ber
20
17
99
https://blog.heuritech.com/2016/01/20/attention-mechanism/
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
9 O
cto
ber
20
17
100https://blog.heuritech.com/2016/01/20/attention-mechanism/
Xu, Kelvin, et al. « Show, Attend and Tell: Neural Image CaptionGeneration with Visual Attention (2016).
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
9 O
cto
ber
20
17
101https://blog.heuritech.com/2016/01/20/attention-mechanism/
Xu, Kelvin, et al. « Show, Attend and Tell: Neural Image CaptionGeneration with Visual Attention (2016).
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Attention Mechanism untuk Textual Entailment
Diberikan pasangan premis-hipotesis, tentukan apakah 2 tersebutkontradiksi, tidak berhubungan, atau logically entail.
Sebagai contoh:
• Premis: “A wedding party taking pictures“
• Hipotesis: “Someone got married“
9 O
cto
ber
20
17
102
Tim Rocktaschel et al., REASONING ABOUT ENTAILMENT WITH NEURAL ATTENTION, ICLR 2016
Attention Model digunkanuntuk menghubungkankata-kata di premis danhipotesis.
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Attention Mechanism
Attention Mechanism untuk Textual Entailment
Diberikan pasangan premis-hipotesis, tentukan apakah 2 tersebutkontradiksi, tidak berhubungan, atau logically entail.
9 O
cto
ber
20
17
103
Tim Rocktaschel et al., REASONING ABOUT ENTAILMENT WITH NEURAL ATTENTION, ICLR 2016
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recursive Neural Networks
9 O
cto
ber
20
17
104
R. Socher, C. Lin, A. Y. Ng, and C.D. Manning. 2011a. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. In ICML
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recursive Neural Networks
9 O
cto
ber
20
17
105
Socher et al., Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank, EMNLP 2013
biascbWgp ;.1
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Recursive Neural Networks
9 O
cto
ber
20
17
106
Socher et al., Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank, EMNLP 2013
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I

Convolutional Neural Networks (CNNs) for Sentence Classification
(Kim, EMNLP 2014)
9 O
cto
ber
20
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
107

Recursive Neural Network for SMT Decoding.
(Liu et al., EMNLP 2014)
9 O
cto
ber
20
17
Alf
an F
. Wic
akso
no
, FA
SIL
KO
M U
I
108


















