







Languages
Pages
Legal


CPS216: Advanced Database Systems
Notes 07:Query Execution
Shivnath Babu

parse
Query rewriting
Physical plan generation
execute
result
SQL query
parse tree
logical query planstatistics
physical query plan
Query Processing - In class order
2; 16.1
3; 16.2,16.3
1; 13, 15
4; 16.4—16.7
Roadmap• Path of a SQL query• Plans
– Operator trees– Physical Vs Logical plans– Plumbing: Materialization Vs pipelining
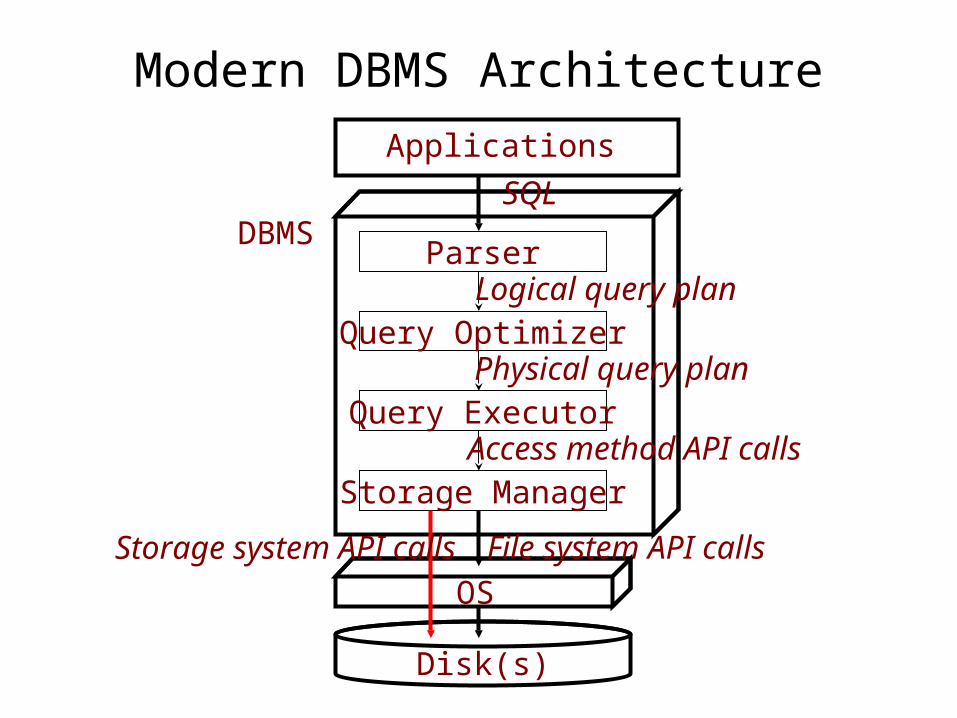
Modern DBMS Architecture
Disk(s)
Applications
OS
Parser
Query Optimizer
Query Executor
Storage Manager
Logical query plan
Physical query plan
Access method API calls
SQL
File system API callsStorage system API calls
DBMS
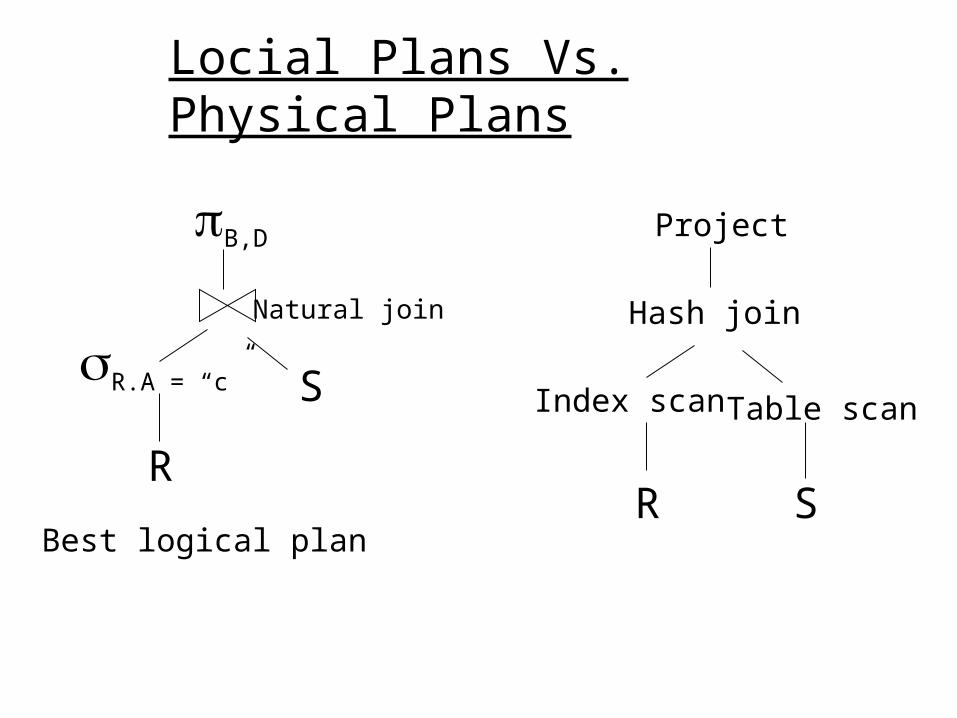
Locial Plans Vs. Physical Plans
B,D
R.A = “c”
R
S
Natural join
Best logical planR S
Index scan Table scan
Hash join
Project
B,D
R.A = “c”
R
S
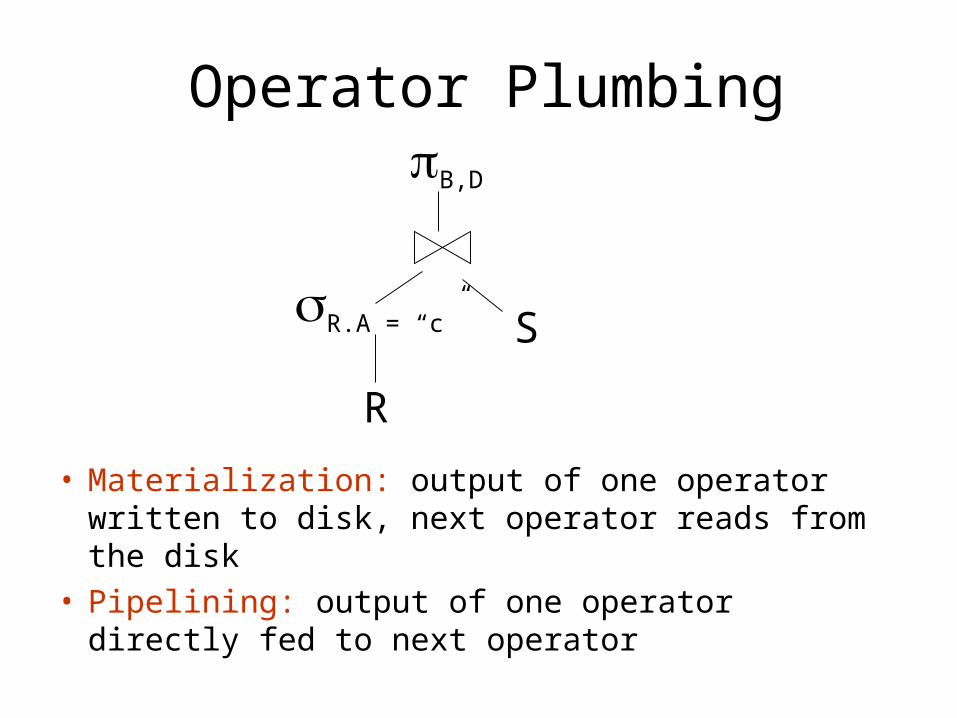
Operator Plumbing
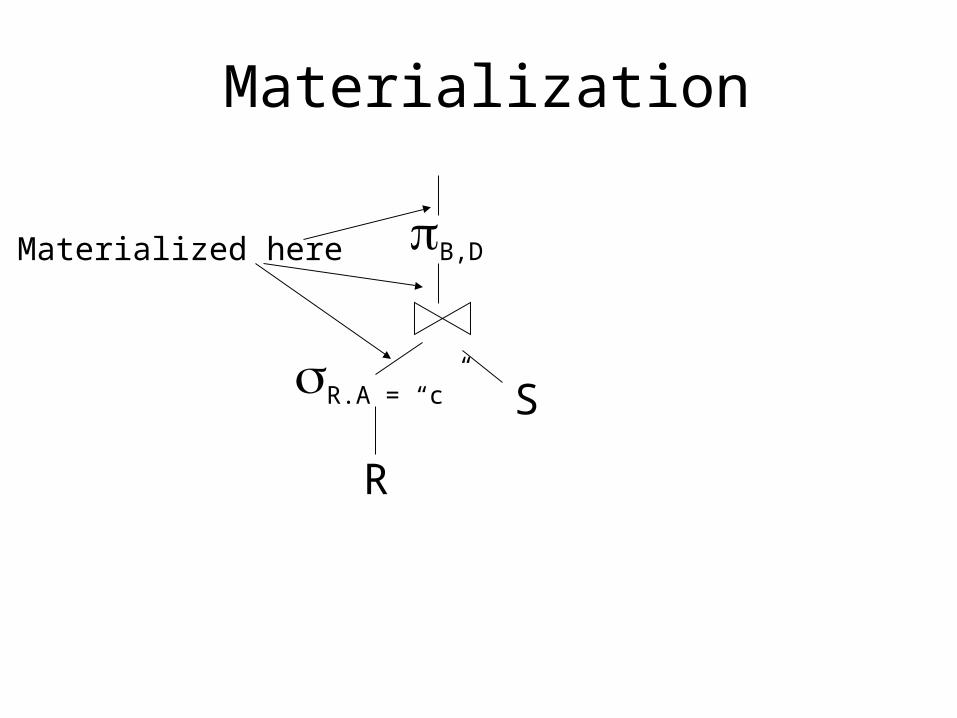
• Materialization: output of one operator written to disk, next operator reads from the disk
• Pipelining: output of one operator directly fed to next operator
B,D
R.A = “c”
R
S
Materialization
Materialized here
B,D
R.A = “c”
R
S
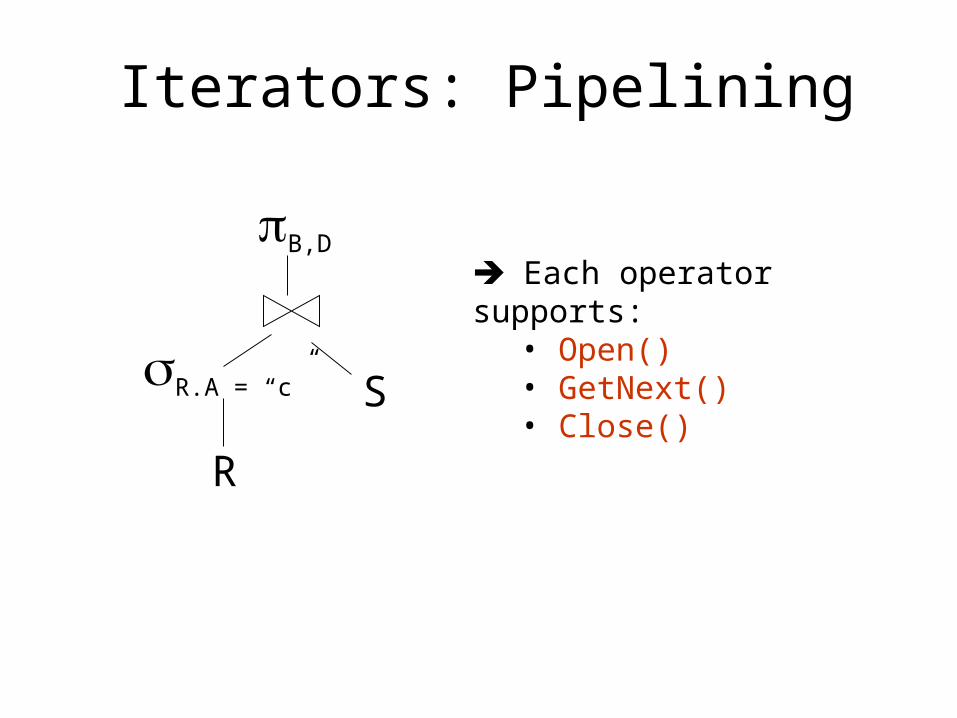
Iterators: Pipelining
Each operator supports:• Open()• GetNext()• Close()

Iterator for Table Scan (R)
Open() { /** initialize variables */ b = first block of R; t = first tuple in block b;}
GetNext() { IF (t is past last tuple in block b) { set b to next block; IF (there is no next block) /** no more tuples */ RETURN EOT; ELSE t = first tuple in b; } /** return current tuple */ oldt = t; set t to next tuple in block b; RETURN oldt;}
Close() { /** nothing to be done */}

Iterator for Select
Open() { /** initialize child */ Child.Open();}
GetNext() { LOOP: t = Child.GetNext(); IF (t == EOT) { /** no more tuples */ RETURN EOT; } ELSE IF (t.A == “c”) RETURN t; ENDLOOP:}
Close() { /** inform child */ Child.Close();}
R.A = “c”
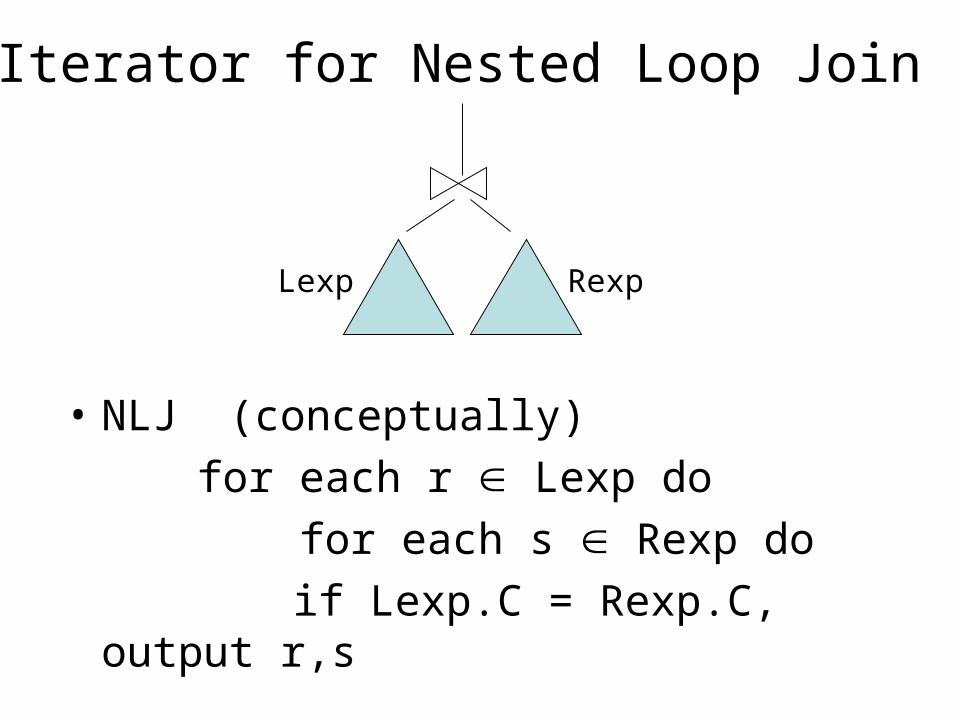
• NLJ (conceptually)
for each r Lexp do
for each s Rexp do
if Lexp.C = Rexp.C, output r,s
Iterator for Nested Loop Join
Lexp Rexp

Iterator for Sort
Open() { /** Bulk of the work is here */ Child.Open(); Read all tuples from Child and sort them}
GetNext() { IF (more tuples) RETURN next tuple in order; ELSE RETURN EOT;}
Close() { /** inform child */ Child.Close();}
R.A
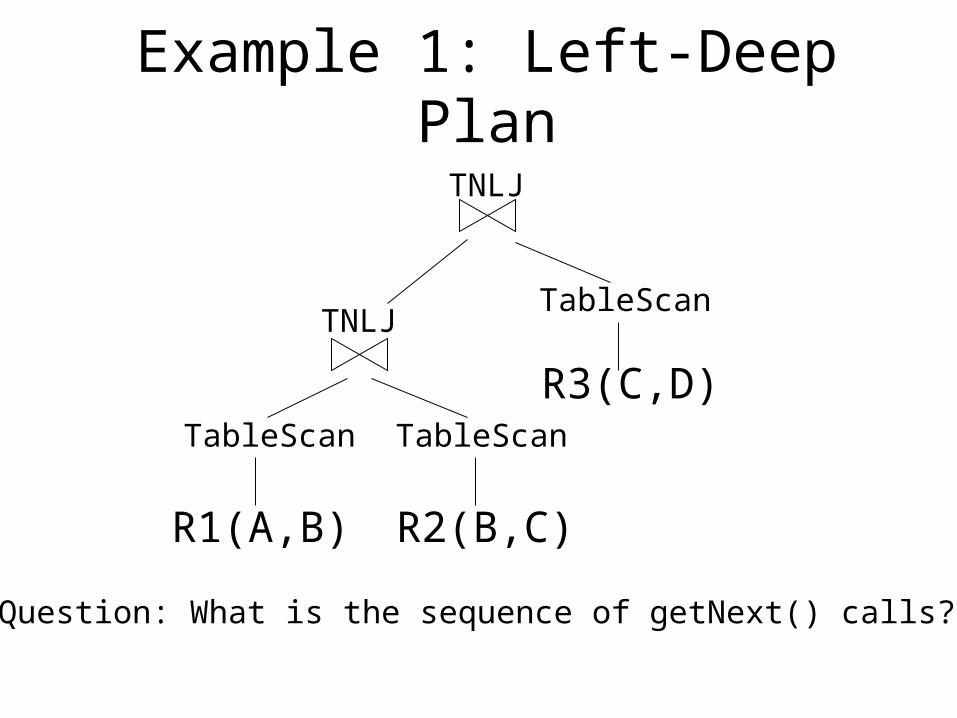
Example 1: Left-Deep Plan
R1(A,B)
TableScan
R2(B,C)
TableScan
R3(C,D)
TableScan
TNLJ
TNLJ
Question: What is the sequence of getNext() calls?

Example 1 (contd.)• Assume Statistics:
– B(R1) = 1000 blocks, T(R1) = 10,000 tuples – B(R2) = 500 blocks, T(R2) = 5000 tuples– B(R3) = 1000 blocks, T(R3) = 10,000 tuples– Let X = R1 Join (R1.B = R2.B) R2 – T(X) = 1,000,000 tuples, B(X) = 200,000 blocks– Let Output = 1000 tuples
• Questions:– Number of getNext() calls?– Number of disk I/Os?– Assume we have 1000 blocks of memory, how can
we improve the plan?
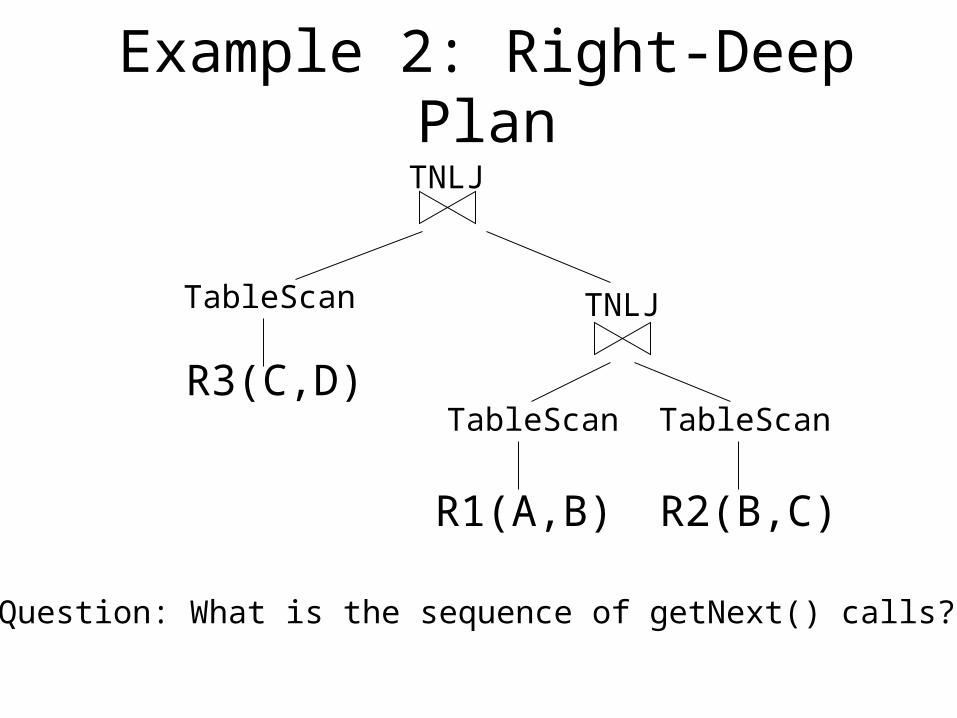
Example 2: Right-Deep Plan
R3(C,D)
TableScan
TNLJ
R1(A,B)
TableScan
R2(B,C)
TableScan
TNLJ
Question: What is the sequence of getNext() calls?

Example 2 (contd.)• Assume Statistics:
– B(R1) = 1000 blocks, T(R1) = 10,000 tuples – B(R2) = 500 blocks, T(R2) = 5000 tuples– B(R3) = 1000 blocks, T(R3) = 10,000 tuples– Let X = R1 Join (R1.B = R2.B) R2 – T(X) = 1,000,000 tuples, B(X) = 200,000 blocks– Let Output = 1000 tuples
• Questions:– Number of getNext() calls?– Number of disk I/Os?– Assume we have 1000 blocks of memory, how can
we improve the plan?

Questions to think about• What "shape" of plan works best for nested loop
joins: 'Left deep' (Example 1) or 'right deep' (Example 2)?
• Will sorting help for nested loop join? (Hint: think about clustered vs. unclustered indexes)
• Can materialization help for nested loop join?• Generalize Example 1 (and 2) to 'n' relations:
What is the optimal use of M blocks of memory? (I don't know the answer :-) )
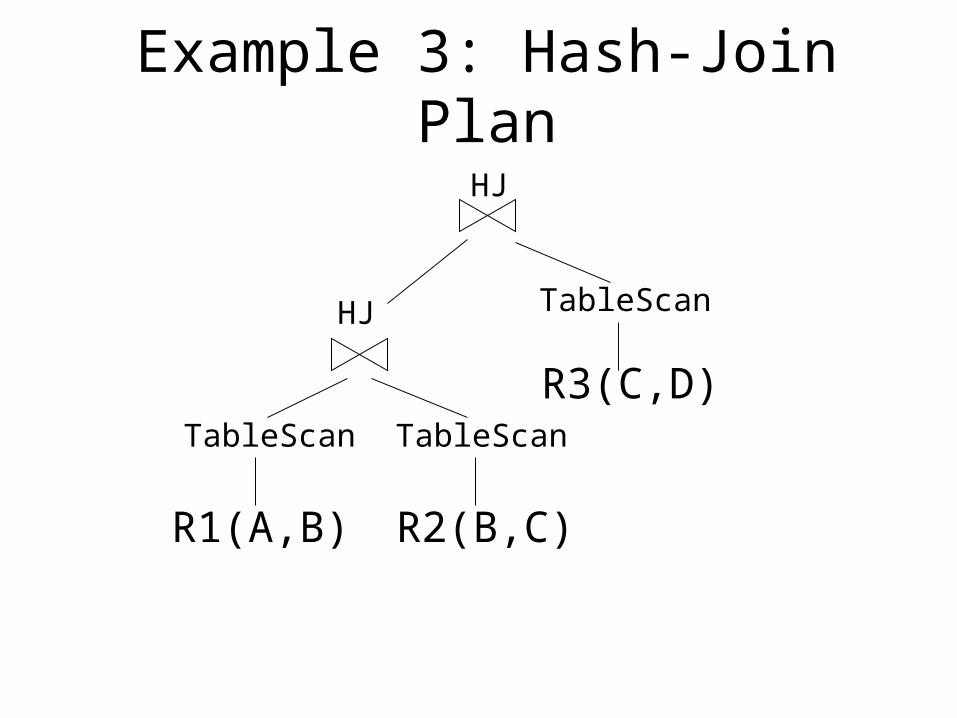
Example 3: Hash-Join Plan
R1(A,B)
TableScan
R2(B,C)
TableScan
R3(C,D)
TableScan
HJ
HJ

Example 3 (contd.)
• Naive materialization:– Compute hash join of R1, R2 (called X)– Write output X to disk– The (outer) hash join reads X (table scan) and
reads R3 and performs hash join
• What is the cost of naive materialization?
• Suggest an improved processing strategy that shaves 2 B(X) from the above cost

Example 3 (contd.)
• Can this be completely pipelined if you have limited memory?
• How much memory do you need to be able to pipeline this plan?

Questions to think about• If you are designing/building the basic set of
physical operators for your database system, would you implement the hash-join as a single operator or as two operators -- one that partitions and the second that joins?
• If you are designing physical operators for your database system, would you implement sort-merge join as a single operator or as two operators -- one that sorts and one that merges?
• Think about pipelining vs. materialization issues in plans involving sort-merge joins
Top Related