







Languages
Pages
Legal


1Internet search engines:
Fluctuations in document accessibility
• Wouter Mettrop
CWI, Amsterdam, The Netherlands
• Paul Nieuwenhuysen
Vrije Universiteit Brussel, and Universitaire Instelling Antwerpen, Belgium
http://www.cwi.nl/cwi/projects/IRT
Presented at NOM 2000 New York Hilton May 16-18, 2000

3
WWW
WWW: growing number of WWW servers
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
1993 1994 1995 1996 1997 1998 1999 2000

4
Internet based information sources: how many? how much?
In 2000:
• about 1 billion = 1000 million unique URLs in the total Internet
• about 10 terabyte (= 10 000 gigabyte) of text data

5
Internet information retrieval systems in 2000
• Several types of systems exist to retrieve information:
»Directories of selected sources categorised by subject, made by humans, mainly for browsing.
»Search systems, based on databases with machine made indexes, for word-based searching!
»“Meta-search” or “multi-threaded” search systems.
• We have studied and compared several well-known international (and a few national) word-based Internet search engines.

6
Internet information retrieval systems: evaluation criteria
• Many aspects/criteria can be considered in the evaluation of an Internet search engine, including
»coverage of documents present on WWW (studies exist);
»number of elements of a document, that are indexed to make them usable for retrieval = “depth of indexing”;…
• We started to study the depth of indexing and we were soon confronted with the fluctuations in the performance that do exist.
• We think that these fluctations are another important aspect of performance.

7
Internet information retrieval systems: our research group
The following persons have been involved in the research: • Louise Beijer (Hogeschool van Amsterdam, The Netherlands)
• Hans de Bruin (Unilever Research Laboratorium, Vlaardingen, The Netherlands)
• Hans de Man (JdM Documentaire Informatie, Vlaardingen, The Netherlands)
• Rudy Dokter (PNO Consultants, Hengelo, The Netherlands)
• Marten Hofstede ( Rijksuniversiteit Leiden, The Netherlands)
• Wouter Mettrop (CWI, Amsterdam, The Netherlands)
• Paul Nieuwenhuysen (Vrije Universiteit Brussel, Belgium)
• Eric Sieverts (Hogeschool van Amsterdam, and RUU, The Netherlands)
• Hanneke Smulders (Infomare, Terneuzen, The Netherlands)
• Hans van der Laan (Consultant, Leiderdorp, The Netherlands)
• Ditmer Weertman (ADLIB, Utrecht, The Netherlands)

8
Internet search engines: research on indexing functionality
• Our method to assess the indexing functionality of search engines:
»A “rich” test document with many element types has been created
»Identical test documents were placed at 8 sites in 2 countries
»A procedure was set up to assess retrieval
—in an automatic way
—with regular intervals

9
0 8 16
Number of our test documents thatwere retrieved at least once during theinvestigation period
Number of our test documents that were retrieved

10
Internet search engines : reachability
• 14 528 queries were sent to 13 search engines.
• Search engines were 721 times unreachable.
• The percentage of unreachability varies from nearly 0% to nearly 15%.
• The studied search engines were reachable for 95% of the queries.

11
Internet search engines: elements of test document studied
• title tag
• META-tags: keywords, description and author
• comment tag
• ALT tag
• text/URL of a link to a document
• H3 tag
• table header
• text of: an internal link, a reference anchor, a link to a sound file
• name of a sound file (au/wav/aiff/ra)
• text of a link to an image
• name of an image file (gif or jpg; inline or linked to)
• name of a Java applet (with or without extension class)
• terms after the first 100 lines in a document (200/…/700)
• the URL of a document

12
0 5 10 15 20 25
Number of studieddocument elementsthat were indexedat least once duringthe observationperiod
Number of the studied document elements that were indexed

13
Search engine indexing functionality: conclusions
• Considerable differences among search engines exist in their depth of indexing!
• Not “all of the static web” is indexed.
»Not each of our test documents/pages.
»Not all HTML elements of our test document/page.
• Some of the studied search engines showed changes in the indexing policy during the experiment fluctuations…

14
Internet search engines: fluctuations - definition
• A fluctuation appears when the result set of an observation
- i.e.
» one query or
» set of queries
misses documents with respect to a frame of reference
- i.e.
» other observations and
» knowledge about Web reality

15
Internet search engines: detecting fluctuations
• Through time: comparing result sets of 1 observation repeatedly performed
» Observation = one query or set of queries
» Frame of reference = other observations & web-knowledge
• One moment: consistency of result sets
» Observation = one query in set of queries
» Frame of reference = other observations

16
Internet search engines: types of fluctuations
• Through time: comparing result sets of 1 observation repeatedly performed
» “Document fluctuations”
» “Indexing fluctuations”
• One moment: consistency of result sets
» “Element fluctuations”

17
A
B
C

18
Document fluctuations: example 1
TIME

19
Document fluctuations: example 2
TIME

20
0 10 20 30 40 50 60 70 80 90 100
AltaVistaEuroferret
Excite
HotBot
Ilse
Infoseek Lycos
MSNNorthernLight
Search.nl
Snap
VindexWebcrawler
Average percentage offorgotten documents perround
Percentage of roundswith one or moreforgotten documents
Document fluctuations: experimental results

21

22
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
Average percentageof missed documentsper result set =Percentage of resultsets with missingdocuments
Indexing fluctuations:experimental results

23
A1 A1 A1A2 A2 A2
A3 A4 A3 A4 A3 A4

24
Element fluctuations: example
0
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
Number of documents retrieved by HotBot in every query in observation set 23
25
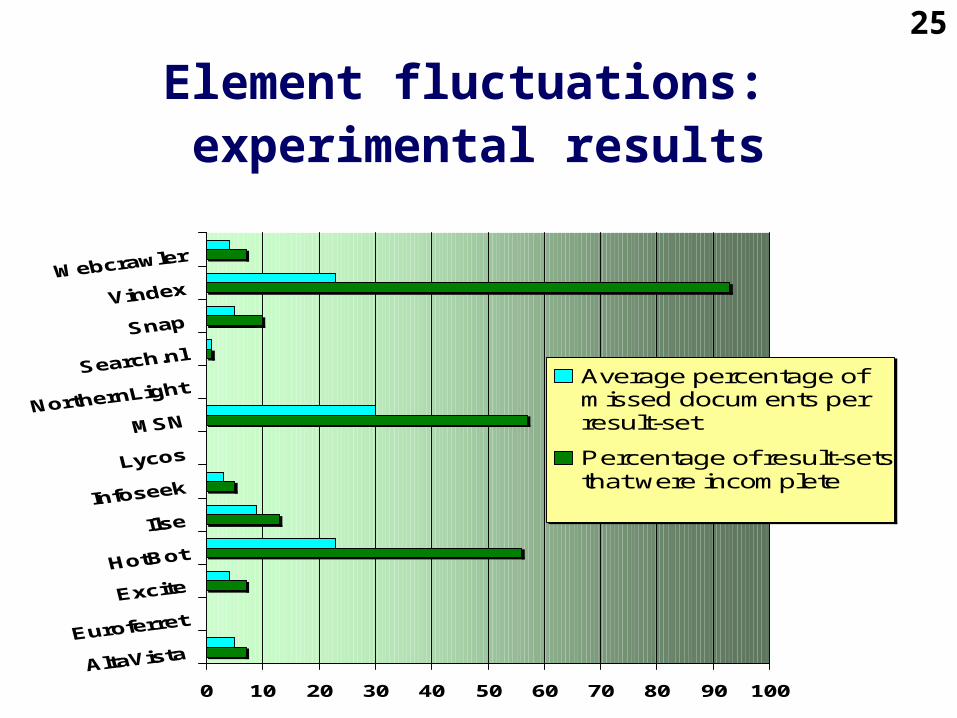
0 10 20 30 40 50 60 70 80 90 100
Average percentage ofmissed documents perresult-set
Percentage of result-setsthat were incomplete
Element fluctuations: experimental results

26
0 10 20 30 40 50
Lost by elementfluctuations
Lost by documentfluctuations
Lost by indexingfluctuations
Percentage of documents missed due to fluctuations

28
Fluctuations: remarks on “correctness”
• Fluctuations can be seen as “correct”, if they are reflections of alterations in:
»(web-) reality
— then document, indexing and element fluctuations are incorrect
»the indexed database of a search engine
— then only element fluctuations are incorrect
• Users do not care; they miss documents

29
Fluctuations:remarks on “size”
• No relation document / element fluctuations < ===== > “size”
• Percentage missed documents determines (with other reducing effects, such as depth of indexing) the effective size of an engine

30
Fluctuations:remarks on “importance”
• Users of information
»should be aware of the existence of fluctuations
»should observe them systematically
• Providers of information
»should be aware of the existence of fluctuations
• Quantitative analyses of the web are hindered by fluctuations
»scientometrics; citation analysis
»fluctuations lower the effective size of an index

31
Internet search engines: conclusions of our research
• Search engines differ in depth of indexing documents.
• Search engines make mistakes:
»They are subject to changes in indexing policy.(“indexing fluctuations”)
»They forget documents completely (“document fluctuations”)
»They miss documents in their result sets (“element fluctuations”).
• Considerable differences exist among search engines regarding these fluctuations.

32
Internet search engines: recommendations related to fluctuations
• Fluctuations are “normal”; do not be surprised; do not worry.
• Do not try to find a simple explanation to fully understand what happens.
• Known item searchers should repeat the search
»when using an engine with many element fluctuations; use other search terms;
»when using an engine with many document fluctuations: repeat later.
Top Related