
VIII Jornadas Ibéricas de Infraestructuras de Datos Espaciales · VIII Jornadas Ibéricas de...
27
VIII Jornadas Ibéricas de Infraestructuras de Datos Espaciales Lisboa | 15-17 noviembre 2017 Cross-Nature, first steps
Transcript of VIII Jornadas Ibéricas de Infraestructuras de Datos Espaciales · VIII Jornadas Ibéricas de...

VIII Jornadas Ibéricas de
Infraestructuras de Datos Espaciales Lisboa | 15-17 noviembre 2017
Cross-Nature, first steps

SUMMARY 1. CROSS-NATURE GENERAL OVERVIEW
2. AN UPDATED STANDARD: PLINIAN CORE
3. PLINIAN CORE ONTOLOGY
4. LINKED OPEN DATA
5. FUTURE BENEFITS
6. GEOSPATIAL POINT OF VIEW; INSPIRE
7. PUBLISHING OPEN DATA OF SPECIES ADAPTED TO INSPIRE
8. SOME PRELIMINARY CONCLUSIONS

The Connecting Europe Facility (CEF) in Telecom is a key EU instrument to facilitate cross-border interaction between public administrations, businesses and citizens
The 2016 CEF Telecom Public Open Data call makes an indicative €3.5 million of funding available for proposals in this area
2016 CEF Telecom Call - Public Open Data (CEF-TC-2016-2)
Work programme 2016
eSubmission by Participant Portal INEA (sept 2016)
Project was accepted. Selected proposal code 2016-EU-IA-0071 (28.02.2017).
CROSS-NATURE MANAGEMENT ISSUES
3

Period: 01/05/2017 to 30/04/2019 (24 moths)
Only 3 partners:
1 from Portugal: DGT
2 from Spain: Tragsa Group and Carlos III University of Madrid
Main Spanish supporter: MAPAMA
Budget:
Total Bugdet accepted: 960,432,00 EUR
Total CEF contribution: 480,216,00 EUR (50 % eligible costs)
5 workpackages
2 Cross-cutting WPs
3 Technical WPs
CROSS-NATURE MANAGEMENT ISSUES
4

Portuguese datasets: ICNF - Database of the Birds and Habitats Directives and ad-hoc databases for species or groups of species (e.g. Atlas).
Spanish datasets: MAPAMA – EIDOS
The structure of those datasets and plinian core model (EIDOS) will be used as infrastructure for Cross-Nature Ontology
The main objective is publishing with linked open data (LOD) technology species distribution information
It is also necessary to follow the INSPIRE specifications for being geospatial information
TECHNICAL OVERVIEW
5
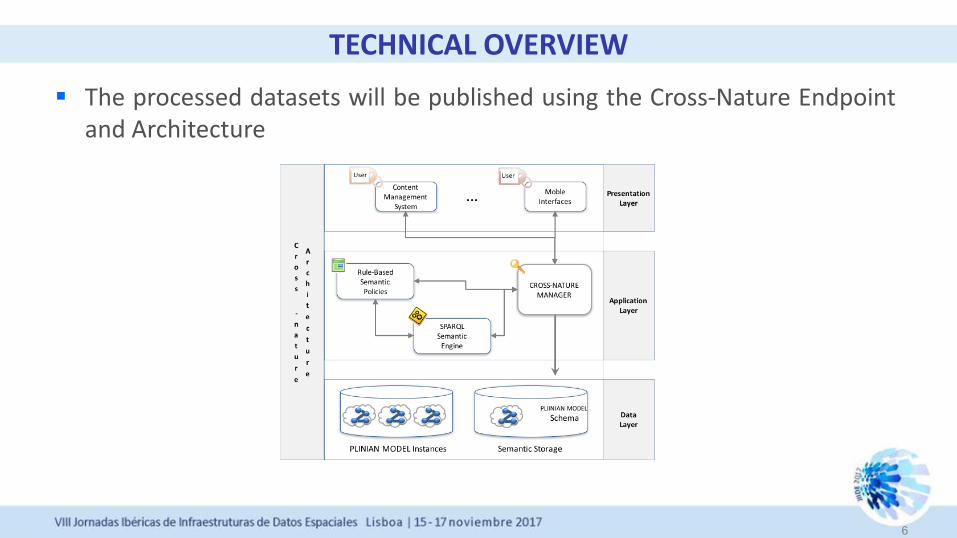
The processed datasets will be published using the Cross-Nature Endpoint and Architecture
TECHNICAL OVERVIEW
6

Cross-Nature Endpoint, among others datasources, will be used by NATURE AND LANDSCAPE INTERPRETATION Apps
TECHNICAL OVERVIEW
7
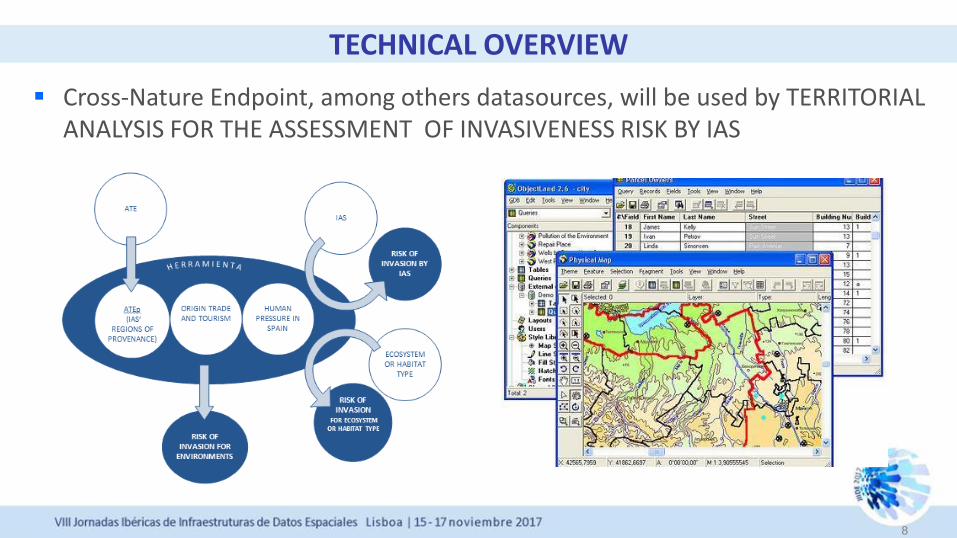
Cross-Nature Endpoint, among others datasources, will be used by TERRITORIAL ANALYSIS FOR THE ASSESSMENT OF INVASIVENESS RISK BY IAS
TECHNICAL OVERVIEW
8
EIDOS MAPAMA
9
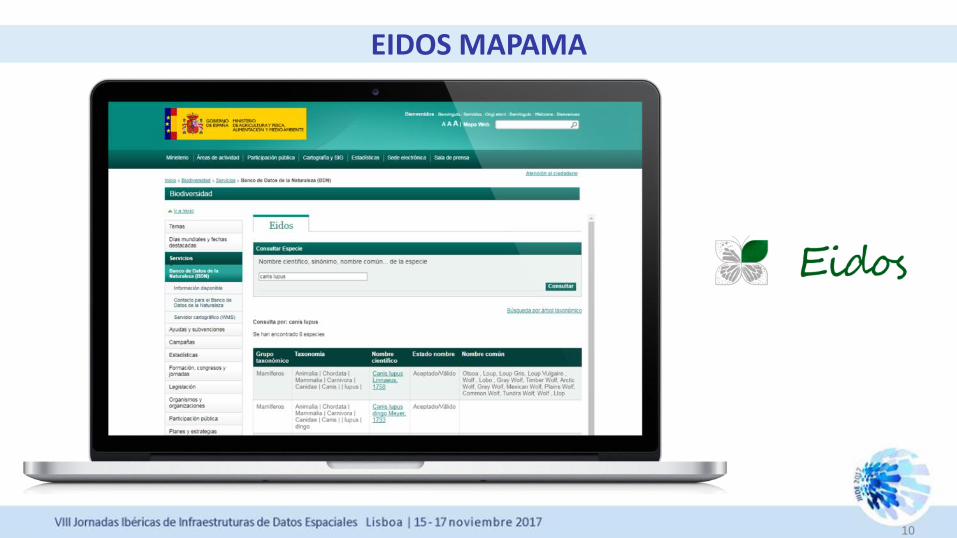
EIDOS MAPAMA
10

EIDOS MAPAMA
11
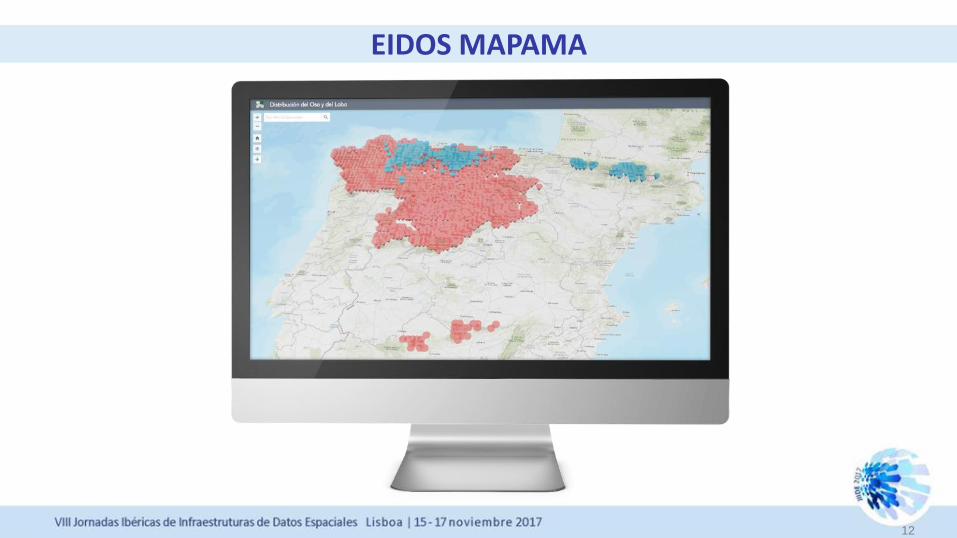
EIDOS MAPAMA
12

EIDOS MAPAMA
13
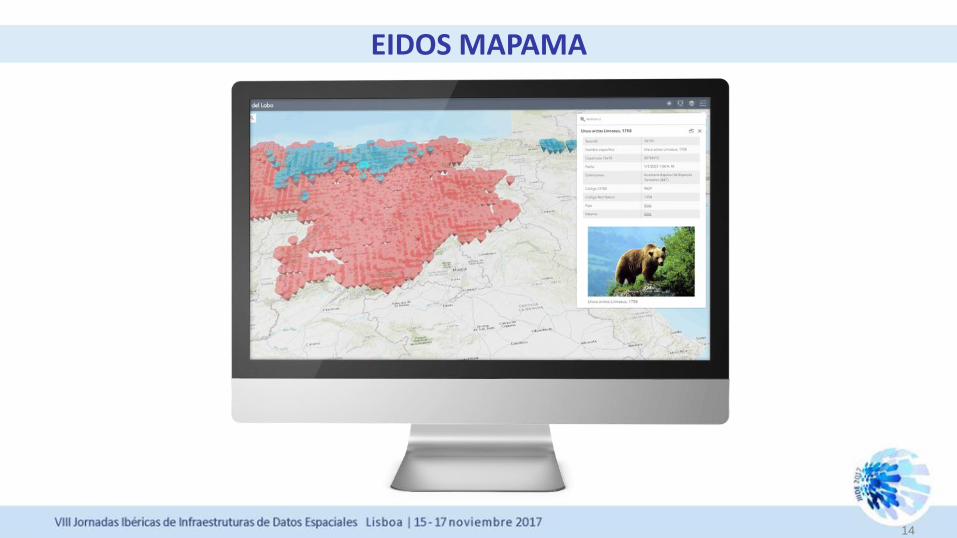
EIDOS MAPAMA
14

Traditional models for the biological description of species did not include aspects such as the incorporation of information concerning terms, descriptions, legal aspects, conservation, management, demography, nomenclature or related resources with the described species.
In 2004, following the collaboration for the creation of a "species information management" system between GBIF.ES and INBio (Costa Rica), the need arises to have a standard for species data adapted to the current needs.
From that moment a series of initiatives are promoted for the creation of a new standard that will crystallize with the creation of the standard Plinian Core in 2006.
In 2015 the IEPNB (Spanish Inventory of Natural Heritage and Biodiversity) approved the adoption of the Plinian Core standard as a structure for the storage, distribution and management of all species information.
AN UPDATED STANDARD: PLINIAN CORE
15

The general principles of the standard are as follows:
Accessible
Autonomous
Able to represent the information that is handled in ongoing projects
Extensible
Integrable
Not owner
Reuse elements of other existing standards as much as possible
Currently Plinian Core is expressed as XML Schema Definition (XSD); To describe a species and ensure its validation with the model, it will be necessary to translate it into an XML that must conform to the schema (XSD).
This format has the advantage of ensuring compliance with certain rules and restrictions contained in the XSD schema relating to the formal grammar of the XML document but can not express complex relationships between elements and their meanings.
AN UPDATED STANDARD: PLINIAN CORE
16

To carry out the evolution of the Plinian Core standard to a semantic model will be necessary to create an ontology: a system of representation of knowledge that provides a formal and logical description understandable both by machines and humans.
It is a crucial process in which experts in different disciplines have to intervene and define all kinds of logical relationships between the elements and meanings related to species. They will also have to select the part of the knowledge already published in this format that can enrich the ontology.
This ontology will be expressed in standard formats defined by the World Wide Web Consortium (W3C).
PLINIAN CORE ONTOLOGY
18

Linked Data allows building the Web of data, a large database interconnected and distributed on the Web. This is expressed in RDF format with expressions of the subject-predicate-object type, called triplets. The concepts or things described are identified by unique URIs to avoid ambiguities.
With this format it will be possible to publish the data about the species with reference to the previously defined ontology. This will create the processes to transform the current data to RDF and will be stored in a platform that stores the triplets. This RDF server will have a point (Endpoint) accessible from the web for any person or machine in which the information will be consulted.
These queries will be performed using the SPARQL (Protocol and RDF Query Language).
LINKED OPEN DATA
19
GeoSPARQL

Plinian Core is already accessible, autonomous, extensible and integrable, but can be much more enriched thanks to semantic web technologies. The application of these technologies to the existing model will enhance their possibilities and will put in value the great effort made to create this standard.
Based on the axioms of the ontology model it will be possible to validate and augment information through automatic inference systems.
It will allow to have data of heterogenous sources that will be bound to enrich the information. Other areas of knowledge that may provide greater rigor to the consultations and their conclusions may be incorporated.
A broadcast without limits as it will allow you to consult and share on the internet all the information. It will imply the possibility of a retrieval of accurate information through semantic search engines that will work with meanings.
FUTURE BENEFITS
20

It will allow the creation of a solid distributed publication system where each institution adhering to the standard can publish its RDFs in its own Endpoint and link its data with other triplet servers.
A complete interoperability between applications thanks to the various APIs that are currently capable of processing and extracting conclusions about information published in semantic technologies.
This will lay the foundation of a service system that will be able to obtain and process information in a completely autonomous way. This possibility is especially useful in the interpretation of natural phenomena, cycles and their impact on species as they will lay the foundations of a system capable of publishing accurate and interpretable information by applications that can analyze and draw conclusions autonomously.
FUTURE BENEFITS
21

class Species Distribution ov erv iew
ISO 19136 GML
GCM - Document Reference
«dataType»
PopulationSizeType
+ countingMethod: CountingMethodValue
+ countingUnit: CountingUnitValue
+ populationSize: RangeType
«featureType»
SpeciesDistributionUnit
+ geometry: GM_Object [0..1]
+ inspireId: Identifier [0..1]
+ speciesName: SpeciesNameType
«voidable, l ifeCycleInfo»
+ beginLifespanVersion: DateTime
+ endLifespanVersion: DateTime [0..1]
«voidable»
+ distributionInfo: DistributionInfoType [0..*]
constraints
{noGeometry}
«featureType»
SpeciesDistributionDataSet
+ inspireId: Identifier [0..1]
«voidable»
+ beginLifespanVersion: DateTime
+ domainExtent: GM_MultiSurface
+ endLifespanVersion: DateTime [0..1]
+ name: CharacterString
«dataType»
DistributionInfoType
+ occurrenceCategory: OccurrenceCategoryValue
«voidable»
+ collectedFrom: Date
+ collectedTo: Date
+ populationSize: PopulationSizeType [0..1]
+ populationType: PopulationTypeValue [0..1]
+ residencyStatus: ResidencyStatusValue [0..1]
+ sensitiveInfo: Boolean [0..1]
«dataType»
RangeType
+ lowerBound: Integer [0..1]
+ upperBound: Integer [0..1]
«dataType»
SpeciesNameType
+ referenceSpeciesId: ReferenceSpeciesCodeValue
+ referenceSpeciesScheme: ReferenceSpeciesSchemeValue
«voidable»
+ localSpeciesId: LocalSpeciesNameCodeValue [0..1]
+ localSpeciesName: CharacterString [0..1]
+ localSpeciesScheme: CharacterString [0..1]
+ qualifier: QualifierValue [0..1]
+ referenceSpeciesName: CharacterString
Base Types 2::DocumentCitation
+ name: CharacterString
«voidable»
+ date: CI_Date
+ link: URL [1..*]
+ shortName: CharacterString [0..1]
+ specificReference: CharacterString [0..*]
AbstractGML
«FeatureType»
feature::AbstractFeature
+ boundedBy: GM_Envelope [0..1]
+member 1..*
+documentBasis
«voidable»
0..*
GEOSPATIAL POINT OF VIEW; INSPIRE
22
Natura 2000
CDE –Capa especies
Especie
(poligono multiparte – 1
polígono = 1 especie)
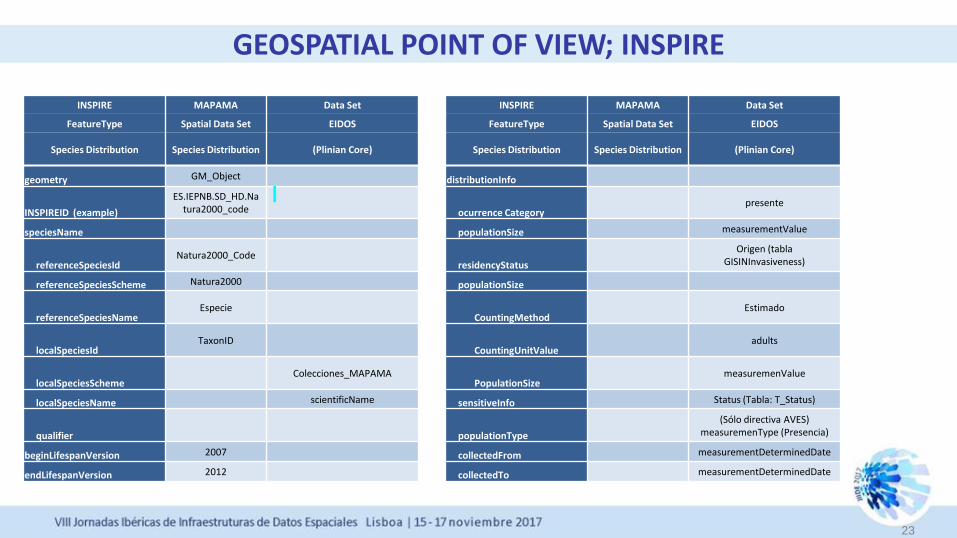
GEOSPATIAL POINT OF VIEW; INSPIRE
23
INSPIRE MAPAMA Data Set INSPIRE MAPAMA Data Set
FeatureType Spatial Data Set EIDOS FeatureType Spatial Data Set EIDOS
Species Distribution Species Distribution (Plinian Core) Species Distribution Species Distribution (Plinian Core)
geometry GM_Object distributionInfo
INSPIREID (example)
ES.IEPNB.SD_HD.Natura2000_code
ocurrence Category presente
speciesName populationSize measurementValue
referenceSpeciesId Natura2000_Code
residencyStatus
Origen (tabla GISINInvasiveness)
referenceSpeciesScheme Natura2000 populationSize
referenceSpeciesName Especie
CountingMethod Estimado
localSpeciesId TaxonID
CountingUnitValue adults
localSpeciesScheme Colecciones_MAPAMA
PopulationSize measuremenValue
localSpeciesName scientificName sensitiveInfo Status (Tabla: T_Status)
qualifier
populationType
(Sólo directiva AVES) measuremenType (Presencia)
beginLifespanVersion 2007 collectedFrom measurementDeterminedDate
endLifespanVersion 2012 collectedTo measurementDeterminedDate
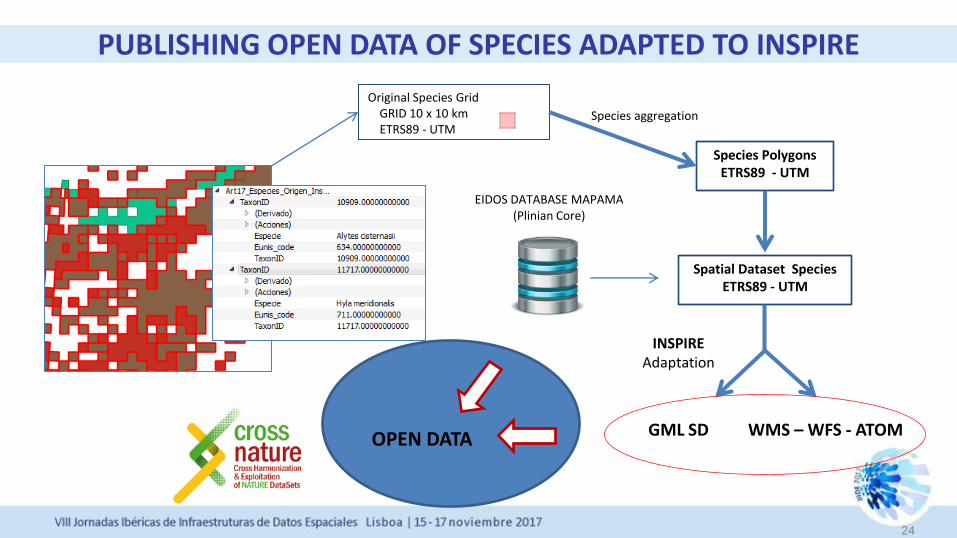
PUBLISHING OPEN DATA OF SPECIES ADAPTED TO INSPIRE
24
Original Species Grid
GRID 10 x 10 km
ETRS89 - UTM
Species Polygons
ETRS89 - UTM
Species aggregation
EIDOS DATABASE MAPAMA (Plinian Core)
Spatial Dataset Species
ETRS89 - UTM
GML SD
INSPIRE Adaptation
WMS – WFS - ATOM OPEN DATA

Guidelines Inspire for the RDF encoding of spatial data
http://inspire-eu-rdf.github.io/inspire-rdf-guidelines/#ogc_geosparql
The methodology for adapting data to INSPIRE schemes and generating GMLs is well defined, but a methodology for the publication of INSPIRE data as Linked Data must still be defined.
INSPIRE INTEROPERABILITY IN THE WORLD LINKED DATA
The methodology should cover:
Creation of RDF vocabularies representing the INSPIRE data models
Transformation of INSPIRE data into RDF
(RDF language is based on URIs to describe concepts and avoid ambiguities)

Create an OWL ontology SD schemas INSPIRE
Match SD dataset attributes against
INSPIRE RDF vocabularies.
ETL process translating from INSPIRE SD datasets to INSPIRE RDF
Publish RDF produced data
LINKED DATA Networked and distributed
Web database
class Species Distribution ov erv iew
ISO 19136 GML
GCM - Document Reference
«dataType»
PopulationSizeType
+ countingMethod: CountingMethodValue
+ countingUnit: CountingUnitValue
+ populationSize: RangeType
«featureType»
SpeciesDistributionUnit
+ geometry: GM_Object [0..1]
+ inspireId: Identifier [0..1]
+ speciesName: SpeciesNameType
«voidable, l ifeCycleInfo»
+ beginLifespanVersion: DateTime
+ endLifespanVersion: DateTime [0..1]
«voidable»
+ distributionInfo: DistributionInfoType [0..*]
constraints
{noGeometry}
«featureType»
SpeciesDistributionDataSet
+ inspireId: Identifier [0..1]
«voidable»
+ beginLifespanVersion: DateTime
+ domainExtent: GM_MultiSurface
+ endLifespanVersion: DateTime [0..1]
+ name: CharacterString
«dataType»
DistributionInfoType
+ occurrenceCategory: OccurrenceCategoryValue
«voidable»
+ collectedFrom: Date
+ collectedTo: Date
+ populationSize: PopulationSizeType [0..1]
+ populationType: PopulationTypeValue [0..1]
+ residencyStatus: ResidencyStatusValue [0..1]
+ sensitiveInfo: Boolean [0..1]
«dataType»
RangeType
+ lowerBound: Integer [0..1]
+ upperBound: Integer [0..1]
«dataType»
SpeciesNameType
+ referenceSpeciesId: ReferenceSpeciesCodeValue
+ referenceSpeciesScheme: ReferenceSpeciesSchemeValue
«voidable»
+ localSpeciesId: LocalSpeciesNameCodeValue [0..1]
+ localSpeciesName: CharacterString [0..1]
+ localSpeciesScheme: CharacterString [0..1]
+ qualifier: QualifierValue [0..1]
+ referenceSpeciesName: CharacterString
Base Types 2::DocumentCitation
+ name: CharacterString
«voidable»
+ date: CI_Date
+ link: URL [1..*]
+ shortName: CharacterString [0..1]
+ specificReference: CharacterString [0..*]
AbstractGML
«FeatureType»
feature::AbstractFeature
+ boundedBy: GM_Envelope [0..1]
+member 1..*
+documentBasis
«voidable»
0..*
GeoSPARQL A Geographic Query
Language for RDF Data
LINKED DATA SPECIES DISTRIBUTION (SD)

The starting point of these works has the advantage of having an updated standard as Plinian Core in the case of MAPAMA species information.
This project should include specialists in information on species, geographic information and ontology creation working together to carry out the publication.
We must search collections of data in Portugal that can be integrated for a joint publication and check the benefits of the Linked Open Data technology.
In the Tragsa Group we are going to implement a development environment with this technology available to the project that should culminate with a query endpoint.
The project should consider the initiatives currently being carried out in the European Commission for the definition of INSPIRE data transformation guidelines in RDF.
SOME PRELIMINARY CONCLUSIONS
30

VII Jornadas Ibéricas de
Infraestructuras de Datos Espaciales Lisboa | 15-17 noviembre 2017
Thank you for your attention
Ramon Baiget | [email protected]


















