
Unanalysierte Einheiten und Sprachverarbeitung im ...diekmann/zfal/zfalarchiv/zfal37_1.pdf ·...
22
Manfred Pienemann Unanalysierte Einheiten und Sprachverarbeitung im Zweitspracherwerb The objective of this paper is to describe the status of unanalysed (morphological) forms in L2 production. To achieve this objective, I will give an overview of the de- velopment of the L2 production process which is characterised by a progression from unanalysed forms stored holistically in the mental lexicon to forms requiring grammatical information exchange between constituents. I will carry out a distri- butional analysis of one morphological system, subject-verb agreement marking, in a longitudinal corpus of a formal learner of German as L2 in order to identify the sys-tem that underlies L2 production at the various developmental points in the corpus. On the basis of this analysis I will demonstrate that formal learners may develop strategies of using unanalysed chunks to successfully mimic the use of morpho-logical systems and that the process of grammatical information transfer required for a fully productive use of the morphological system develops at the point predicted by the processability hierarchy - in formal as well as in informal learners. 1. Einführung Dieser Aufsatz befasst sich mit der Rolle von unanalysierten Einheiten in der Zweitsprachverarbeitung. Nach meiner Ansicht spielt der L2 Prozessor eine entscheidende Rolle in der Erklärung des sprachlichen L2 Entwicklungsver- laufs, weil der Lerner nur das produzieren kann, was er auch verarbeiten kann. Daher benötigt eine Theorie des Zweitspracherwerbs als einen notwen- digen Bestandteil die Beschreibung des L2 Prozessors und dessen Entwick- lung vom Anfangsstadium (Initial State) bis zu fortgeschrittenen Ebenen des Erwerbs. Die Verarbeitbarkeitstheorie (Processability Theory, Pienemann 1998) bietet eine solche Beschreibung. In diesem Beitrag werde ich einen Überblick über die Processability Theory (PT) geben und über deren Anwendung auf den Erwerb der L2-Morphologie geben. PT bietet einen Erklärungsrahmen für die Entwicklung der L2-Morphologie von unanalysierten lexikalischen
Transcript of Unanalysierte Einheiten und Sprachverarbeitung im ...diekmann/zfal/zfalarchiv/zfal37_1.pdf ·...

Manfred Pienemann
Unanalysierte Einheiten und Sprachverarbeitung imZweitspracherwerb
The objective of this paper is to describe the status of unanalysed (morphological)forms in L2 production. To achieve this objective, I will give an overview of the de-velopment of the L2 production process which is characterised by a progressionfrom unanalysed forms stored holistically in the mental lexicon to forms requiringgrammatical information exchange between constituents. I will carry out a distri-butional analysis of one morphological system, subject-verb agreement marking, ina longitudinal corpus of a formal learner of German as L2 in order to identify thesys-tem that underlies L2 production at the various developmental points in thecorpus. On the basis of this analysis I will demonstrate that formal learners maydevelop strategies of using unanalysed chunks to successfully mimic the use ofmorpho-logical systems and that the process of grammatical information transferrequired for a fully productive use of the morphological system develops at thepoint predicted by the processability hierarchy - in formal as well as in informallearners.
1. Einführung
Dieser Aufsatz befasst sich mit der Rolle von unanalysierten Einheiten in derZweitsprachverarbeitung. Nach meiner Ansicht spielt der L2 Prozessor eineentscheidende Rolle in der Erklärung des sprachlichen L2 Entwicklungsver-laufs, weil der Lerner nur das produzieren kann, was er auch verarbeitenkann. Daher benötigt eine Theorie des Zweitspracherwerbs als einen notwen-digen Bestandteil die Beschreibung des L2 Prozessors und dessen Entwick-lung vom Anfangsstadium (Initial State) bis zu fortgeschrittenen Ebenen desErwerbs.Die Verarbeitbarkeitstheorie (Processability Theory, Pienemann 1998) bieteteine solche Beschreibung. In diesem Beitrag werde ich einen Überblick überdie Processability Theory (PT) geben und über deren Anwendung auf denErwerb der L2-Morphologie geben. PT bietet einen Erklärungsrahmen fürdie Entwicklung der L2-Morphologie von unanalysierten lexikalischen

ZfAL 37, 2002. 3-26.4
Formen hin zu morphologischen Regularitäten, die den Austauschgrammatischer Informationen zwischen Konstituenten erfordern.Eine der grundlegenden empirischen Fragen bei der Überprüfung vonVorhersagen die auf Grund der PT gemacht werden können, ist die, wie manin einem gegebenen Korpus zwischen der Produktion von unanalysiertenFormen und regelgeleiteter Sprachproduktion unterscheiden kann. Ich werdezeigen, daß diese Frage nur auf der Basis einer Distributionsanalyse einesgenügend großen und linguistisch genügend variablen Korpus entschiedenwerden kann und nicht auf der Basis von Korrektheitsmaßen, denn letzterereflektieren nicht die Dynamik der Lernersprache. Mit anderen Worten,morphologische Formen, die auf den ersten Blick zielsprachlichen Normen zuähneln scheinen, erweisen sich bei genauerem systematischen Hinsehen alsunanalysierte Einheiten, die auf der Basis von Kommunikationsstrategien pro-duziert werden.In diesem Aufsatz werde ich ein Analyseverfahren vorschlagen, mit dem der-artige unanalysierte Einheiten identifiziert werden können. Ein solches Ver-fahren ist eine notwendige Vorraussetzung für eine valide Überprüfung destheoretischen Rahmens zur Erklärung der Entwicklung des L2-Prozessors.
2. Processability Theory: Ein kurzer Überblick
Zum besseren Verständnis der Rolle von unanalysierten Einheiten undsprachlichen Formeln in der L2 Verarbeitung dürfte es hilfreich sein,zunächst einen kurzen Überblick über die explizite Beschreibung der Ent-wicklung der L2 Verarbeitungskapazität im Rahmen der ProcessabilityTheory (Pienemann 1998) zu bieten.PT basiert auf einer universellen Hierarchie von Verarbeitungsprozeduren,die von der allgemeinen Architektur des Sprachprozessors abgeleitet ist. DieseHierarchie bezieht sich auf die prozeduralen Fertigkeiten, die für die Verar-beitung der Zielsprache notwendig sind. Auf diese Weise können Vorhersa-gen über Zweitsprachentwicklungsprozesse gemacht werden, die empirischgetestet werden können.PT folgt im wesentlichen Levelts (1989) Ansatz zur Erklärung der Sprachpro-duktion, der sich in gewissem Maße mit dem Verarbeitungsmodell von Kem-pen/ Hoenkamp (1987) überschneidet, welches seinerseits einen großen Teilder Arbeit von Merrill Garrit übernimmt (z.B. Gerrit 1976, 1980, 1982).
Die Grundannahmen dieses Ansatzes sind die folgenden:Annahme 1: Verarbeitungskomponenten wie die das Prozedere zum Aufbauvon NPs etc. sind relativ autonome Spezialisten, die im Wesentlichen auto-matisch ablaufen. Levelt (1989) beschreibt derartige grammatische Prozedereals „dumm“, weil ihre Fähigkeit streng auf die äußerst enge aber höchst effi-

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 5
ziente Bearbeitung von äußerst spezifischen Verarbeitungsprozeduren be-schränkt ist (z.B. NP-Prozeduren, VP-Prozeduren etc.). Die Automatizitätdieser Prozeduren impliziert, daß ihre Durchführung normalerweise nicht derbewußten Kontrolle unterliegt.Annahme 2: Verarbeitung ist inkrementell. Das bedeutet, daß oberflächlichelexikogrammatische Formen schrittweise konstruiert werden, während dieKonzeptualisierung noch nicht voll abgeschlossen ist. Eine wesentlicheImplikation der inkrementellen Sprachverarbeitung ist die Notwendigkeit ei-nes grammatischen Gedächtnisses. Damit das nächste Prozedere in der Lageist, den noch unfertigen Output des gegenwärtigen Prozederes zu verarbeiten,und damit all dies in eine kohärente oberflächliche Form führt, muß ein Teildes noch unfertigen unvollständigen Outputs im Gedächtnis behalten werden.Annahme 3: Der Output des Prozessors ist linear, obwohl dieser nicht unbe-dingt in linearer Weise auf die zu Grunde liegende Bedeutung abgebildetwerden kann. Dieser Umstand ist auch als das sogenannte Linearisierungs-problem (Levelt 1981) bekannt, das sich auf die Abbildung von konzeptuellenStrukturen auf sprachliche Formen ebenso bezieht wie auf die Generierungvon morphosyntaktischen Strukturen. Ein Beispiel dafür ist die Subjekt-VerbKongruenz wie etwa in dem Beispielsatz: Sie gibt ihm ein Buch. Die Affixie-rung der Kongruenzmarkierung am Verb hängt unter anderem von der Spei-cherung der Information über das grammatische Subjekt (nämlich Numerusund Person) ab, die generiert wurde, bevor das Verb vom Lexikon abgerufenwurde.Annahme 4: Der grammatische Prozessor hat Zugang zum grammatischenGedächtnis. Die Notwendigkeit, ein grammatisches Gedächtnis anzunehmen,leitet sich von Linearisierungsproblem ab sowie von der automatischen undinkrementellen Natur der Sprachgenerierung. Levelt (1989) nimmt an, daßgrammatische Information vorübergehend in einem grammatischen Gedächt-nis deponiert wird, das höchst aufgabenspezifisch ist, und in dem speziali-sierte grammatische Prozessoren Informationen spezifischer Art (z.B. denWert von diakritischen Merkmalen) speichern können. In Kempen und Hoen-kamps (1987) inkrementeller prozeduraler Grammatik ist das grammatischeGedächtnis in den spezialisierten Prozeduren angelegt, die NPs, VPs usw.verarbeiten. In Pienemann (1998) präsentiere ich Belege für diese Annahmenüber das Gedächtnis, die aus Online-Experimenten und Aphasiestudien stam-men (z.B. Cooper/ Zurif 1983; Paradis 1994; Zurif/ Swinney/ Prater/ Love1994).

ZfAL 37, 2002. 3-26.6
Conceptualiser
give (actor: Child) (beneficiary: mother) (object: cat)
EVENT
PAST CAUSE PERSON
THING CHILD GO
CAT FROM/TO
PATH
MOTHER
EVENT
PERSON PERSON
CHILD
Iteration 1
CHILD
NP
N DET
NPsubj
S
Iteration 2
a child ..........
Lexicon
lemma: A conceptual specs: "A" syntactic category: Det diacritic parameters: singular ...
Grammatical encoder
lemma: CHILD conceptual specs: "CHILD" syntactic category: N diacritic parameters: singular ...
Abb.1: Incremental language generation
Der Prozeß der inkrementellen Sprachgenerierung nach dem Ansatz von Le-velt (1989) und Kempen/ Hoenkamp (1987) wird in Abb. 1 exemplifiziert.Abb. 1 illustriert einige der wesentlichsten Prozesse, die bei der Generierungdes Beispielsatzes „A child gives a cat to the mother“ ablaufen. Die Konzepte,die diesem Satz zu Grunde liegen, werden im Konzeptualisierer produziert.Das konzeptuelle Material, das produziert wird, aktiviert zunächst das Lemmachild im Lexikon. Das Lemma enthält die kategorielle Information N, die daskategorielle Prozedere NP aufruft. Dieses Prozedere ist in der Lage, die phra-sale Kategorie aufzubauen, in der N head ist, nämlich die NP. Das kategorialeProzedere inspiziert das konzeptuelle Material der gegenwärtigen Iteration(dies ist das Material, das gegenwärtig verarbeitet wird) nach möglichenKomplementen und Spezifikatoren und stellt die Werte für die diakritischenMerkmale zur Verfügung. Bei bestimmten konzeptuellen Spezifikationen

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 7
wird das Lemma ‚A‘ (ein) aktiviert und das NP-Prozedere verknüpft denZweig DET mit NP.Während dieses Prozesses werden die diakritischen Merkmale von DET undN miteinander verglichen. Dies beinhaltet unter anderem, daß die grammati-sche Information „Singular“ von jedem der beiden Lemmata zum Zeitpunktderer Aktivierung extrahiert wird und dann in der NP gespeichert wird bisder head der Phrase produziert ist. Dieser Prozess des Austausches grammati-scher Information ist ein wesentliches Merkmal der Sprachproduktion. Weiterunten wird man sehen, daß die Lexikalisch Funktionale Grammatik (LFG)diesen Vorgang durch die Unifizierung (Vereinigung) von Merkmalenmodellieren kann.Der Produktionsprozeß ist jetzt fortgeschritten zu dem Punkt, an dem dieStruktur einer Phrase hergestellt wurde und die damit verbundenen Lemmataaktiviert sind. Was fehlt, um dies den Anfang einer zusammenhängenden undflüssigen Äußerung zu machen, ist die Herstellung einer Beziehung zwischender Phrase und dem Rest der intendierten Aussage. Dies wird erreicht, in demder neukreierten Phrase eine grammatische Funktion zugewiesen wird.Das Resultat all dieser Vorgänge wird in Abb. 1 durch ein Baumdiagrammdargestellt. Und während diese Struktur produziert wurde und die damit ver-bundenen Lemmata aktiviert wurden, wurde das nächste konzeptuelle Frag-ment parallel verarbeitet und der Output des Formulators an den Artikulatorweitergegeben. Dies bedeutet, daß der Sprecher neu konzeptualisiert, währenddie konzeptuelle Struktur der vorhergehenden Iteration noch produziert wird.Der ganze Prozeß bewegt sich dann von Iteration zu Iteration fort.Während der inkrementellen Sprachgenerierung werden die folgenden Verar-beitungsprozedere und Routinen in der folgenden Reihenfolge aktiviert:
1. Lemmazugriff,2. das Kategorieprozedere,3. das phrasale Prozedere (zuerst NP, dann VP),4. das S-Prozedere,5. das Nebensatz Prozedere – wenn vorhanden.
Die Grundhypothese in Pienemann (1998) besagt, daß die oben dargestelltenEnkodierungsprozedere im Spracherwerb in der Reihenfolge erworben wer-den, in der sie beim Sprachgenerierungsprozeß aktiviert werden. Und dieseSequenz folgt einem implikationellen Muster, in dem jedes Prozedere dieVoraussetzung für das nächste Prozedere bildet. Die grundlegende These derProcessabi l i ty Theory besagt , daß b e i m Erwerb derSprachverarbeitungsprozedere der Aufbau der Einzelbestandteile der obengenannten Implikationsreihenfolge folgt. Um nun Vorhersagen für verarbeit-bare Grammatiken machen zu können muß man bestimmen, welche Art vongrammatische Information zwischen welchen Konstituenten mit den jeweils

ZfAL 37, 2002. 3-26.8
verfügbaren Prozedere und deren Speicherkapazität ausgetauscht werdenkönnen.Es ist wichtig, sich zu vergegenwärtigen, daß die oben beschriebenen Verar-beitungsprozeduren nur von erwachsenen Benutzern einer Sprache und nichtvon Sprachlernern operationalisiert werden. Wenn auch schon frühe Zweit-sprachlerner Zugriff auf dieselben allgemeinen kognitiven Resourcen habenwie vollentwickelte Muttersprachler, so müssen sie dennoch die sprachspezi-fischen Sprachverarbeitungsroutinen erwerben. In diesem Zusammenhang istes wichtig sicherzustellen, daß Levelts Modell im Prinzip auch auf Sprach-verarbeitung von Bilingualen anwendtbar ist, denn Zweitspracherwerb führtzur Entwicklung eines bilingualen Sprachprozessors.De Bot (1992) adaptierte Levelts Modell für die Sprachproduktion von Bilin-gualen. Auf der Basis der Arbeit von Paradis (1987) zeigt er, daß Kenntnisüber die spezifische Sprache, die zu benutzen ist, in dem jeweiligen Teil derpräverbalen Nachricht enthalten ist und daß dies anschließend die Auswahlder sprachspezifischen lexikalischen Einheiten sowie der sprachspezifischenRoutinen im Formulator bestimmt. De Bots Grundannahme über die zweit-sprachliche Verarbeitung ist die, daß in allen Fällen, in denen die L2 nichteng mit der L1 verwandt ist, andersartige und sprachspezifische Prozedereangenommen werden müssen. Daher müssen die Mehrheit der oben bespro-chenen Verarbeitungsprozeduren vom L2-Lerner erworben werden. Unter-schiede in den lexikalischen Voraussetzungen für die Sprachverarbeitung sindganz offensichtlich bei den diakritischen Merkmalen, wie zum Beispiel Tem-pus, Numerus, Genus und Kasus, die zwischen Sprachen variieren.Man mag sich nun fragen, was passiert, wenn ein Element dieser implikatio-nellen Hierarchie fehlt. Meine Hypothese (Pienemann 1998) ist, daß die Hie-rarchie in der Lernergrammatik an dem Punkt abgebrochen wird, an dem einVerarbeitungsprozedere fehlt, und der Rest der Hierarchie wird durch einedirekte Abbildung der konzeptuellen Strukturen auf die Oberflächenform er-setzt solange wie es Lemmata gibt, die mit den konzeptuell betriebenen Such-prozeduren im Lexikon übereinstimmen. Mit anderen Worten bedeutet dies,daß die Verarbeitungsprozeduren und die Fähigkeit für den Austausch gram-matischer Informationen in der Reihenfolge entwickelt werden, die in Tabelle1 dargestellt ist.
t1 t2 t3 t4 t5
S'-procedure- - - - -

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 9
S-procedure - simplified simplified simplified inter-phrasalinformationexchange
Phrasal pro-cedureVP
- - phrasal in-formationexchange
in VP
phrasal in-formationexchange
in VP
phrasal in-formationexchange
in VP
Phrasal pro-cedureNP
- - phrasal in-formationexchange
in NP
phrasal in-formationexchange
in NP
phrasal in-formationexchange
in NPcategoryprocedure(lex. categ.)
- category +affix
category +affix
category +affix
category +affix
word/lemma
noinformationexchange,
lemma access
lemma access lemma access lemma access Lemma ac-cess
Tabelle 1: Hypothetical hierarchy of processing procedures
Wenn die oben diskutierte Hierarchie universell für den Spracherwerb gültigsein soll, dann muß sie für die grammatischen Strukturen aller Einzelspracheninterpretierbar sein. Dies wird erreicht, indem die Verarbeitungshierarchievon einer Grammatiktheorie interpretiert wird, die typologisch und psycholo-gisch plausibel ist. Die hierfür gewählte Theorie ist die Lexikalisch Funktio-nale Grammatik (LFG). Der Grund für diese Wahl besteht darin, dasß jedeEbene der Hierarchie von Verarbeitungprozeduren in der LFG durch die Uni-fikation von Merkmalen dargestellt werden kann. Die LFG hat außerdem dreiHaupteigenschaften mit Kempen/ Hoenkamps prozeduralem Ansatz zurSprachgenerierung gemeinsam, nämlich erstens die Annahme, dass Gramma-tiken lexikalisch angetrieben werden, zweitens die funktionale Annotierungvon Phrasen (zum Beispiel Subjekt von) und drittens die Unifizierung vonlexikalischen Merkmalen als wesentlicher Prozeß der Satzgenerierung. Mitanderen Worten bietet eine LFG basierte Beschreibung der zu lernendenStrukturen eine Analyse der psycholinguistischen Prozesse des grammatischenInformationsaustausches, und dieser ist die Schlüsselkomponente derVerarbeitungshierarchie.
3. Morphologie und Verarbeitbarkeit
Durch die Implementierung der Verarbeitungshierarchie in eine LFG basierteBeschreibung der Zielsprache ermöglicht eine Vorhersage der Stufen, in de-

ZfAL 37, 2002. 3-26.10
nen die Sprache sich in Zweitsprachlernern entwickeln kann. Der wesentlicheAspekt bei dieser Implementierung besteht darin, den Fluß grammatischerInformationen bei der Produktion von linguistischen Strukturen darzustellen.Ich werde dies anhand von drei morphologischen Regularitäten exemplifizie-ren.In der LFG operiert die morphologische Komponente auf der Basis einerfunktionellen Beschreibung des Satzes. Der folgende Satz mag als Beispieldienen.
A man owns many dogs.
Hier sind zunächst einmal die in den lexikalischen Einträgen enthaltenenSchemata relevant, die in Tabelle zwei aufgeführt sind.
Tabelle 2:
a: DET, SPEC = 'A'NUM = SG
man: N, PRED = 'MAN'NUM = SGPERS = 3
owns: V, PRED = 'OWN' (SUBJ) (OBJ)SUBJ NUM = SGSUBJ PERS = 3TENSE = PRESENT
many: DET, SPEC = 'MANY'NUM = PL
dogs: N, PRED = 'DOG'NUM = PL
Die Wohlgeformtheit wird unter anderem durch gewährleistet, daß die funk-tionale Beschreibung des Satzes und die lexikalischen Einheiten überein-stimmen. Zum Beispiel die Phrase „a man“ ist funktional wohlgeformt, weilunter anderen der Wert für NUM sowohl in der Unterfunktion SUBJ als auchim lexikalischen Eintrag für „man“ Singular (SG) ist. In derselben Weise istdie Phrase „many dogs“ wohlgeformt, weil auch hier die Werte des MerkmalsNUM in DET und N identisch sind, also unifiziert werden können.Die eigentliche Struktur der morphologischen Komponente ist für die hierdargestellte Argumentation nicht wesentlich. Die Hauptaussage für den ge-genwärtigen Kontext ist die, daß morphologische Prozesse durch Merkmals-unifizierung informiert werden. Man kann nun leicht erkennen, daß die Uni-fizierung des Merkamls in NUM in Normalphrasen eine Operation ist, dieausschließlich auf die NP beschränkt ist. In der Processability Theory wirddiese Art von Affixierung phrasal genannt weil sie innerhalb der phrasalenGrenzen stattfindet (vgl. Pienemann 1998).

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 11
Daneben gibt es auch lexikalische Morpheme, für die die notwendige Infor-mation direkt vom lexikalischen Eintrag abgelesen werden kann. Ein Beispieldafür ist die Tempusmarkierung mit dem Morphem -ed im Englischen oder -te im Deutschen. Im Gegensatz zur lexikalischen und phrasalen Affixierungbasiert die Subjekt-Verb-Kongruenz darauf, daß lexikalische Merkmale inzwei unterschiedlichen Konstituenten unifiziert werden, nämlich in derNPsubj und der VP. Die Einfügung des -s Affixes für englische Subjekt-Verb-Kongruenz erfordert folgende grammatische Informationen:
S -V affix TENSE = presentSUBJ NUMBER = sgSUBJ PERSON = 3
Während der Wert der ersten zwei Gleichungen von der funktionalen Be-schreibung des Satzes abgelesen werden kann, wie oben dargestellt wurde,müssen die Werte für Numerus und Person in der F-Struktur von SUBJ unddem lexikalischen Eintrag von V identisch sein. Daher muß diese grammati-sche Information über Konstituentengrenzen hinweg unifizert werden. DieserProzeß kann informell folgendermaßen beschrieben werden:
[A man]NPsubj [ {holds} ...]VP (Present, imperfective)
PERSON = 3 PERSON = 3NUM = sg NUM = sg
Aus der Perspektive der Satzverarbeitung haben die beiden morphologischenProzesse, Pluralkongruenz in der Nominalphrase und Subjekt-Verb-Kon-gruenz, einen unterschiedlichen Status. Während die Pluralkongruenz aus-schließlich innerhalb einer größeren Konstituente bleibt, erfordert die Sub-jekt-Verb-Kongruenz den Austausch von grammatischer Information überKonstituentengrenzen hinweg. Daher wird innerhalb der PT dieser morpholo-gische Prozeß als interphrasale Affixierung bezeichnet.Wir können jetzt drei morphologische Phänomene innerhalb der Verarbei-tungsbarkeits-hierarchie positionieren. Die oben diskutierten Strukturen wer-den in Tabelle 4 der Hierarchie von Verarbeitungsprozedere zugeordnet.
Tabelle 4Processing procedures applied to morphology
Processing procedure L2 process morphology
6 • subord. cl. procedure main and sub clause

ZfAL 37, 2002. 3-26.12
5 • S-procedure inter-phrasal information inter-phrasalexchange morpheme
4 • phrasal procedure information phrasal morpheme VP exchange in VP
3 • phrasal procedure information phrasal morpheme NP exchange in NP
2 • category procedure no information exchange lexical morpheme
1 • word/ lemma 'words' invariant forms
Diese vorhergesagte Hierarchie wird durch mehrere empirische Studien ge-stützt. Pienemann/ Håkansson (1999) zeigen in einem Überblick über einegroße Anzahl von Studien zum Schwedischen als Zweitsprache, daß die obengenannte Hierarchie mit dem Erwerb von schwedischen Morphemen überein-stimmt, und zwar in folgender Weise:
Erstens in varianten Formen, zweitens Pluralmarkierung
1. invariant forms2. plural marking (hund-ar, 'dogs')3. agreement marking in NPs (den stor-a hund-en, 'the big dogs')4. agreement marking in predicative adjectives (hus-et är stor-t, 'the houses are big').
A very similar sequence can be found in the acquisition of German as a second language:1. invariant forms2. plural marking (hund-e, 'dogs')3. agreement marking in NPs (zwei Hunde, 'two dogs')4. subject-verb agreement marking (die Hunde rennen ständig , 'the dogs are running all thetime').
[FORMAT von Seite 8 übernehmen und jeweils in Klammernschreiben, was dort in Englisch und Schwedisch steht ]

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 13
Drittens Kongruenz in der NP [Schwedische und Englische Beispiele]Viertens Kongruenz in prädikativen Adjektiven (Schwedisch und Englisch)Eine sehr ähnliche Erwerbsequenz findet sich im Erwerb des Deutschen alsZweitsprache: Erstens in varianten Formen, zweitens Pluralmarkierung (-e,wie im Originaltext)Drittens Kongruenz in der NP [Originaltext übernehmen]Viertens Subjekt-Verb Kongruenz [Originaltext übernehmen]
In Pienemann (1998) belege ich, daß die Verarbeitungsbarkeitshierarchie ineiner Reihe von Zweitsprachen deutlich erkennbar ist. Insbesondere zeige ichdies für das Deutsche, Englische und Japanische als Zweitsprache auf der Ba-sis von extensiven empirischen Studien. Diese Ergebnisse belegen die psy-chologische Plausibilität der Verarbeitungsbarkeitshierarchie.Eine entscheidende Implikation dieser Hierarchie ist es, dass sie mit morpho-logisch invarianten Formen beginnt. Dies ist dadurch bedingt, daß derartigeFormen keinen Austausch grammatischer Information noch eine Zuordnungvon lexikalischen Material zu einer lexikalischen Kategorie erfordern. In em-pirischen Studien zeigt sich, daß von der Zielspracheperspektive betrachtet,solche Invariantenformen tatsächlich aus lexikalischen und grammatischenMorphemen bestehen wie etwa in dem Wort ‚dog‘, das sowohl in dem Kon-text ‚*he has a dogs‘ als auch in dem Kontekt ‚two dogs‘ vorkommen mag.Mit anderen Wortern derartige invarianten Formen sind in Wirklichkeit un-analysierte Einheiten.Der folgende Abschnitt beschäftigt sich mit Verfahren zur Identifizierung vonunanalysierten Einheiten in großen lernersprachlichen Korpora, da derartigeVerfahren entscheidend sind für die empirische Überprüfung des theoreti-schen Ansatzes. Man kann nur dann die Vorhersagen von Theorien wie PTvalide empirisch überprüfen, wenn man sicher sein kann, daß eine gegebenegrammatische Form, die in einem Korpus vorkommt in der Tat von den pro-duktiven Mechanismen wie sie in der Zielsprache vorkommen, generiertwurde und nicht durch eine ‚Chunking‘-Strategie.
4. Eine Fallstudie: Aspekte der Morphologie in GuysLernersprache
Grundlage dieser Studie ist eine einjährige Beobachtung des Erwerbs desDeutschen als Zweitsprache in einem formalen Kontext. In dieser Studiewerde ich mich auf die Lernersprache eines Lerners, nämlich Guy, eines Stu-denten an der Universität Sydney konzentrieren. Der Informant begann denErwerb des Deutschen ohne jegliche Vorkenntnisse. Er wurde in vierzehntäg-lichen Abständen interviewt. Der Sprachkurs bestand aus sechs Unterrichts-einheiten pro Woche, in denen das Lehrbuch Sprachkurs Deutsch und ergän-

ZfAL 37, 2002. 3-26.14
zendes Grammatikmaterial benutzt wurden. Das Lehrbuch folgt einem kom-munikativen Ansatz, von dem der Lektor abwich, wenn er oder sie dies fürnotwendig befand (besonders beim Grammatikunterricht).Da einige der Vorhersagen der PT sich auf die Interaktion zwischen der syn-taktischen und morphologischen Entwicklung beziehen, mag es nützlich seindie Entwicklung des Lerners im Bereich des Syntaxes zu beschreiben. Da-durch wird es möglich, seine morphologische Entwicklung auf syntaktischeBezugspunkte zu beziehen. Zu diesem Zweck wird im folgenden kurz dieAnwendung der Verarbeitungshierarchie auf einige typische Wortstellungsre-geln des Deutschen angewendet. Dadurch wird eine übergreifende Matrix vonmorphosyntaktische Entwicklung dargestellt. Die Beschreibung des Erwerbsdieser syntaktischen Regeln mit Guy bietet dann einen Bezugspunkt der syn-taktischen Entwicklung, demgegenüber die Entwicklung morphologischerRegeln bewertet werden kann.Man muß jedoch bedenken, daß aus Platzgründen die syntaktische Matrix undGuys Entwicklung innerhalb dieser Matrix nur ein sehr knapper Überblicksein kann. Einzelheiten zum psycholinguistischen Hintergrund, zur formalenAnwendung der PT auf deutsche Wortstellung und die ausführliche Analyseder Entwicklung von Guys Wortstellungsregeln ist in Pienemann (1998) zufinden.
Tabelle 5
Processing procedures applied to German morphosyntax
Processing procedure L2 process morphology syntax
6 • subord. cl. procedure main and sub clause V-final
5 • S-procedure inter-phrasal information inter-phrasal subject-verbexchange morpheme: inversion
SV-agreement (=INV)
4 • phrasal procedure information phrasal split verb VP exchange in VP morpheme: (SEP)
Aux+V tense
3 • phrasal procedure information phrasal adverb fronting NP exchange in NP morpheme: (=ADV)
NP agreement
2 • category procedure no information exchange lexical canonical ordermorpheme: SVOpast -te

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 15
1 • word/ lemma 'words' invariant forms single constituent
Die detaillierte Analyse der lernersprachlichen Samples dieses Sprechers(Pienemann 1998) belegte folgendes Entwicklungsschema für den Bereichder Syntax:
week 1 7 15 19 --rule SVO ADV SEP INV (V-END)
Mit anderen Worten, es stellte sich heraus, daß die obengenannten deutschenWortstellungsregeln sich in der Tat in der vorhergesagten Reihenfolge entwi-ckelten. Gleichzeitig bieten diese Ergebnisse einen zeitlichen Bezugspunkt,mit dem vorhergesagt werden kann, wann das Auftreten welcher morphologi-schen Regeln in der Entwicklung von Guys Lernersprache zu erwarten ist.Diese Erwartung basiert auf der Tatsache, daß die PT Prozeduren nicht nurfür die Syntax- sondern auch für die Morphologieverarbeitungs-Prozedurendefinieren. Daher kann man von der allgemeinen Struktur der PT ableiten,daß das Auftreten von INV belegt, daß das S-Prozedere sich entwickelt hat,und dass daher Subjekt-Verb-Kongruenz im Prinzip zu diesem Zeitpunkt ver-arbeitbar ist oder zumindest wenig später. Im folgenden wird es darum gehen,dieses zeitliche Zusammenspiel in dem lernersprachlichen Korpus von Guy zubelegen.Die Datenanalyse konzentriert sich hier auf interphrasale Morpheme insbe-sondere auf die morphologische Markierung von Person und Numerus imVerb. Um die Analyse einfach zu halten, beschränkt sie sich auf grammati-sche Subjekte, die als Singular markiert sind. Weiterhin steht für dieses Ka-pitel die Analyse der Subjekt-Verb-Kongruenz mit lexikalischen Verben imGegenwartstempus im Mittelpunkt.Die für die Analyse relevante Affixierung am Verb kann schematisch folgen-dermaßen dargestellt werden:
Person marking in German lexical verb (singular)1st person ich V-e or V-Ø I V2nd person du V-st or V-s I V3rd person er, sie, es he, she, it
singular-NP V-t Singular NP V-s(Note: V signifies „verb stem“)

ZfAL 37, 2002. 3-26.16
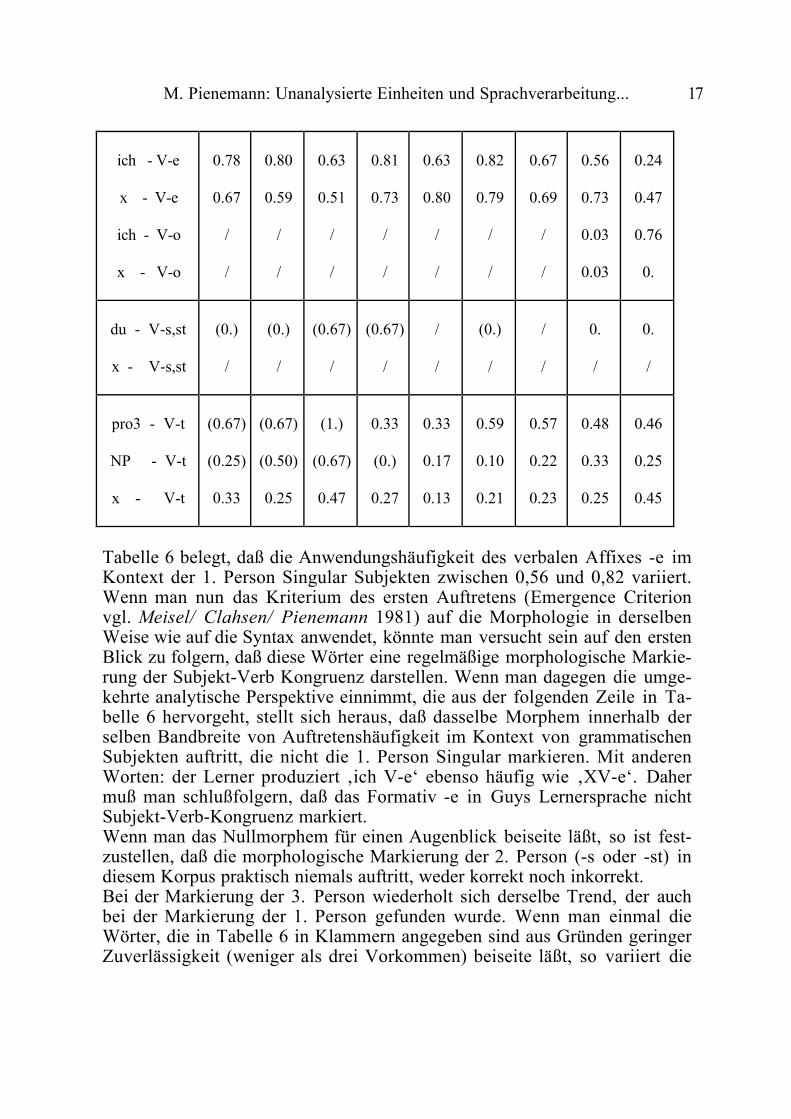
Wie bereits gesagt, kann man nicht davon ausgehen, daß lexikalische Formen,die in der Lernersprache auftreten, notwendigerweise zielsprachliche Regula-ritäten reflektieren. Zum Beispiel kann das Wort ‚geht‘ in dem Kontext ‚ergeht‘ verwendet werden und ebenso in dem Kontext ‚es geht‘. Um sicher zugehen, daß Wortformen in der Tat zielsprachlichen Regularitäten folgen, mußeine Distributionsanalyse entworfen werden, in der Wortformen innerhalb deslernsprachlichen Korpus dahingehend überprüft werden, ob sie in verschiede-nen sprachlichen Kontexten variieren. Im Falle der Markierung von Numerusund Person am Verb muß daher geprüft werden, ob das verbale Affix nur indem Kontext von grammatischen Subjekten auftritt, die mit den gleichenWerten für Numerus und Person markiert sind. Dies kann erreicht werden, indem das jeweilige verbale Affix in seiner zielsprachlichen Umgebung (z.B.Subjekt gleich Singular und 3. Person, und Verb markiert für Singular und 3.Person) wie auch in nicht Kontexten (z.B. Subjekt nicht gleich Singular und3. Person und Verb markiert für Singular dritte Person) ausgezählt wird.Das Ergebnis der Distributionsanalyse für die Markierung von Personen inGuys Lernersprache ist in Tabelle 6 dargestellt, die nach den oben diskutier-ten analytischen Prinzipien entworfen worden ist. Auf der linken Seiten vonTabelle 6 werden die verschiedenen linguistischen Kontexte aufgeführt, dieanalysiert wurden. In der Zeile ‚ich‘–V-e‘ wird die relative Häufigkeit aufge-führt, mit der Verben markiert mit -e im Kontext von grammatischen Subjek-ten mit erster Person Singular auftreten. Die Zeile ‚X-V-e‘ kehrt die Analyseder vorherigen Zeile um. Hier wird das Auftreten von Verben mit dem Affix–e aufgeführt, die im Kontext von grammatischen Subjekten auftreten, dienicht für 1. Person Singular markiert sind.Diese Distributionsanalyse wird auch für das Nullmorphem wiederholt, das indeutscher Umgangssprache auch zur Markierung der 1. Person Singular dient.Für die 2. und 3. Person wird die Analyse in ähnlicher Weise wiederholt. DasKürzel – pro3 – steht für Pronomen der 3. Person Singular und -NP-V-T- be-zieht sich auf Subjekt NPs mit lexikalischem Head.
Tabelle 6
Guy: SV-agreement with lexical verbs13 5 7 9 11 13 15 17 19
1 This table is based on a minor re-analysis of the data presented in Pienemann (1998)
where some calculations were carried out in a manner different to the present analysis.Nevertheless the overall trend remains the same.
M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 17
ich - V-e
x - V-e
ich - V-o
x - V-o
0.78
0.67
/
/
0.80
0.59
/
/
0.63
0.51
/
/
0.81
0.73
/
/
0.63
0.80
/
/
0.82
0.79
/
/
0.67
0.69
/
/
0.56
0.73
0.03
0.03
0.24
0.47
0.76
0.
du - V-s,st
x - V-s,st
(0.)
/
(0.)
/
(0.67)
/
(0.67)
/
/
/
(0.)
/
/
/
0.
/
0.
/
pro3 - V-t
NP - V-t
x - V-t
(0.67)
(0.25)
0.33
(0.67)
(0.50)
0.25
(1.)
(0.67)
0.47
0.33
(0.)
0.27
0.33
0.17
0.13
0.59
0.10
0.21
0.57
0.22
0.23
0.48
0.33
0.25
0.46
0.25
0.45
Tabelle 6 belegt, daß die Anwendungshäufigkeit des verbalen Affixes -e imKontext der 1. Person Singular Subjekten zwischen 0,56 und 0,82 variiert.Wenn man nun das Kriterium des ersten Auftretens (Emergence Criterionvgl. Meisel/ Clahsen/ Pienemann 1981) auf die Morphologie in derselbenWeise wie auf die Syntax anwendet, könnte man versucht sein auf den erstenBlick zu folgern, daß diese Wörter eine regelmäßige morphologische Markie-rung der Subjekt-Verb Kongruenz darstellen. Wenn man dagegen die umge-kehrte analytische Perspektive einnimmt, die aus der folgenden Zeile in Ta-belle 6 hervorgeht, stellt sich heraus, daß dasselbe Morphem innerhalb derselben Bandbreite von Auftretenshäufigkeit im Kontext von grammatischenSubjekten auftritt, die nicht die 1. Person Singular markieren. Mit anderenWorten: der Lerner produziert ‚ich V-e‘ ebenso häufig wie ‚XV-e‘. Dahermuß man schlußfolgern, daß das Formativ -e in Guys Lernersprache nichtSubjekt-Verb-Kongruenz markiert.Wenn man das Nullmorphem für einen Augenblick beiseite läßt, so ist fest-zustellen, daß die morphologische Markierung der 2. Person (-s oder -st) indiesem Korpus praktisch niemals auftritt, weder korrekt noch inkorrekt.Bei der Markierung der 3. Person wiederholt sich derselbe Trend, der auchbei der Markierung der 1. Person gefunden wurde. Wenn man einmal dieWörter, die in Tabelle 6 in Klammern angegeben sind aus Gründen geringerZuverlässigkeit (weniger als drei Vorkommen) beiseite läßt, so variiert die

ZfAL 37, 2002. 3-26.18
Häufigkeit der T-Affixierung zwischen 0,33 und 0,59 bei pronominalenSubjekten und zwischen 0,10 und 0,33 bei nicht pronominalen Subjekten,während die Häufigkeit der zufälligen T-Affixierung zwischen 0,23 und 0,47variiert. Also variiert das zufällige Auftreten des T-Morphems im selbenBereich wie das Auftreten des Morphems in Kontexten, in denen es Subjekt-Verb Kongruenz zu markieren scheint. Man kann also nicht ausschließen, daßdie Fälle in denen das Subjekt und das Verb in Person und Numerus überein-zustimmen scheinen, lediglich zufällige „Treffer“ sind. In diesem Kontext ist es wichtig, den Grad der morphologischen Variation indem von Guy produzierten lexikalischen Material zu betrachten. Wenn maneinmal das Prefix ge- ausnimmt (eine morphologische Markierung für Ver-gangenheit in der Deutschen Umgangssprache), dann alternieren lediglich18% aller Verben in ihrer morphologischen Form. Das heißt, völlig unabhän-gig vom Subjekt bleibt die Form des Verbs immer
helf-eleb-eles-eschlaf-efähr-tgib-t*lauf-tusw.
Diese überwiegend eingefrorenen lexikalischen Formen und der geringe Gradder morphologischen Variation ist verantwortlich für die oben diskutiertenAuftretenshäufigkeiten und die scheinbare Subjekt-Verb Kongruenz, die aberin Wirklichkeit nicht durch eine morphologische Affixierungsregel hervorge-rufen wird.Die einzige Ausnahme von dieser Beobachtung erscheint in der 18. Wochebei der Benutzung des ∅-Morphems zur Markierung der 1. Person. Tabelle 6zeigt recht deutlich, daß ∅-Morpheme sehr selten vor Woche 19 auftretenund daß sie in Woche 19 ausschließlich die 1. Person markieren und inkeinem anderen Kontext auftreten. Daher wird es nicht überraschen, daß 75%der Verben, die mit einem ∅-Mrphem markiert sind, zu diesem Zeitpunkt zurkleinen Gruppe von Verben gehört, die in Guys Lernersprache überhauptmorphologisch variieren.Daher ist die ∅-Markierung der 1. Person Singular die einzige produktiveRegel für Subjekt-Verb-Kongruenz in Guys Lernersprache. Diese Regel trittvier Wochen später auf als die morphologische Markierung für Vergangenheit(ge-) und in derselben Woche wie Subjekt-Verb Inversion (INV) (vergleichePienemann 1998). Dies belegt meine Hypothese über die Reihenfolge, in derphrasale und nicht phrasale Morpheme erworben werden.

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 19
Die Entwicklung von morphologischen und Wortstellungsregeln in Guys Ler-nersprache kann daher folgendermaßen zusammengefaßt werden.
week 1 7 15 19 word order SVO ADV SEP INVmorphology -- -- ge-V SV agreement
Wie dieser Überblick zeigt belegt die oben zusammengefaßte Analyse derEntwicklung von Guys Lernersprache meine Hypothese über die Reihenfolgedes Erwerbs von phrasalen und inter-phrasalen Morphemen. Dabei ist zu be-denken, daß diese Lernprozesse in einem formalen Kontext auftraten, in demdie Progression der Lerngegenstände und der linguistische Input im scharfenGegensatz zu diesem linguistischen Output stehen. Damit wird klar, daß derhier beobachtete Lernprozeß nicht einfach ein Produkt einer formalen Lern-umgebung ist. In der Tat zeigte sich in einer Untersuchung des natürlichenErwerbs des Deutschen als Zweitsprache ein strukturell sehr ähnliches Lern-muster (Pienemann 1981).Man könnte nun vermuten, daß Guy den muttersprachlichen Gesprächspartner„getäuscht“ hat und in der Lage war, den Eindruck zu vermitteln, daß seineLernersprache ein hochkomplexes morphologisches Muster aufweist, obwohlsie in Wirklichkeit morphologisch kaum variierte. In der Tat sind die mor-phologischen Formen die Guy produzierte, höchst unterschiedlich von denendie man typischerweise bei Arbeitsmigranten findet, die Deutsch als Zweit-sprache erwerben (vgl. Clahsen/ Meisel/ Pienemann 1983). Die letztereGruppe generalisiert in typischer Weise die Infinitivform (gehen) auf alleKontexte. Dadurch wird diese Art von Lernersprache automatisch als simpli-fiziert markiert. Dagegen lernte Guy Deutsch in einem universitären Kontextund wurde ständig auf grammatische Richtigkeit hin überprüft. Guy wandtezwei simple Strategien an, um diesen markanten Unterschied im Output zuerreichen. Erstens speicherte er flektierte Verbformen statt der infitivenForm, und zweitens benutzte er spezifische Verben vorwiegend in Bezug aufsich selbst und andere vorwiegend in Bezug auf eine dritte Person. In derfreien Konversation des Interviews mit dem muttersprachlichenwissenschaftlichen Mitarbeiter war es nicht schwierig, diese Strategieerfolgreich anzuwenden, vor allem weil die Gesprächsthemen relativ repetetivblieben.Es läßt sich also feststellen, daß sowohl der australische Student als auch Ar-beitsmigranten dieselben psycholinguistischen Prozedere für Subjekt-Verb-Kongruenz zu dem selben Entwicklungszeitpunkt erwerben. Dabei entwickeltaber der normale Lerner eine Chunking-Strategie, die komplexe morphologi-sche Regularitäten erfolgreich nachahmt.

ZfAL 37, 2002. 3-26.20
Diese Schlussfolgerung steht auch im Einklang mit der Analyse von Kon-gruenzmarkierungen in Guys Äquationalsätzen, in denen man naturgemäßsehr viel weniger lexikalische Variation findet als in Sätzen mit lexikalischenVerben.Die deutsche Kopula weist folgendes morphologisches Muster auf
The German copula (singular)1st person ich bin I am2nd person du bist or bis you are3rd person er,sie, es he, she, it
singular-NPist or is singular-NPis
Diese einfache Liste macht deutlich, daß in Äquationalsätzen überhaupt keinelexikalische Variation auftritt, weder im pronominalen Subjekt noch im Verb.Dies ist völlig anders als bei lexikalischen Verben und Subjekt-NPs mit lexi-kalischen heads. Lexikalisches Material, das weder lexikalisch noch mor-phologisch variiert, muß also nicht analysiert werden und kann direkt vomLexikon ohne intervenierende Prozeduren abgerufen werden, die möglicher-weise den Transfer von grammatischer Information zwischen Konstituentenbeinhalten. Man kann daher vorhersagen, daß die morphologischen Formen,die für Äquationalsätze erforderlich sind (also PRO und Kopula) auf Ebene 2der Processability Hierarchie verarbeitet werden können, da diese keinenTransfer von grammatischer Information erfordert. In der Tat könnten Lernerzunächst Formen wie „ ich bin“, „du bist“ usw. als einzelne Einträge in dasLexikon speichern.Das Ergebnis der Distributionsanalyse der von Guy produzierten Äquational-sätze ist in Tabelle 7 zu finden, die demselben Aufbau folgt wie Tabelle 6.
Tabelle 7:Guy: SV-agreement with copula
3 5 7 9 11 13 15 17 19
ich - copl
x - cop l
omission ofsubj or cop
(0.33)
(0.)
(0.67)
0.83
0.
0.17
(1.)
(0.)
(0.)
1.
0.
0.
(0.)
(0.)
(1.)
(1.)
(0.)
(0.)
(1.)
0.
(0.)
0.67
0.
0.17
0.88
0.
0.12
du - cop2
x - cop2
omission ofsubj or cop
(0.)
(0.)
(1.)
/
/
(1.)
/
/
/
(1.)
(0.)
(0.)
/
(1.)
/
(0.)
(1.)
0.
/
/
/
(1.)
(0.)
(0.)
/
/
/

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 21
pro3 - cop3
NP - cop3
x - cop3
omission ofsubj or cop
0.75
(1.)
(0.)
(0.25)
1.
(1.)
(0.)
0.
(1.)
1.
0.
0.
1.
(1.)
0.
0.
0.75
1.
0.
0.25
1.
(0.67)
0.
0.
0.80
(1.)
0.
0.2
1.
0.67
0.
0.
1.
(1.)
0.
0.
type/token -ratio: NP
0.55 0.53 1.
Eine Beobachtung in Tabelle 7 fällt sofort auf: Es gibt kaum Fälle in deneneine Form der Kopula in einem Nichtkontext benutzt wurde. Das heißt, For-meln wie „*ich geht“ kamen praktisch niemals vor. Diese Beobachtung stehtin scharfem Gegensatz zu der Situation, die wir bei den lexikalischen Verbengefunden haben. Schon in Woche fünf ist die Verteilung zwischen Kontextund Nichtkontext bei den Äquationalsätzen kategorial. Das heißt, die Kopula,die die 1. Person Singular markiert, wird fast ausschließlich im Kontext vongrammatischen Subjekten gebraucht, die für 1. Person Singular markiert sindund kaum an anderer Stelle. Dieser Trend wird von Interview zu Interviewstärker.Überraschenderweise gilt dies auch für NPs mit lexikalischen heads. Manhätte vielleicht in diesem Bereich ein anderes Verhalten erwartet, da lexikali-sche heads sowohl lexikalisch als auch morphologisch variieren. Um diesesPhänomen zu klären, wurde eine Type-Token-Relation für all die Interviewsberechnet, die drei oder mehr „volle NPs“ enthielten. Das Ergebnis dieser Be-rechnung ist in der letzten Zeile von Tabelle 7 aufgeführt. Hier zeigt sich,daß diese NPs in der Tat lexikalisch sehr wenig variieren. Das heißt, daß auchhier eine Chunking-Strategie für den Lerner möglich war.Zusammenfassend lässt sich also feststellen, daß Guys Verwendung vonÄquationalsätzen völlig mit der Hypothese übereinstimmt, daß er lexikalischund morphologisch invariante Formen als einzelne unanalysierte lexikalischeEinträge gespeichert hat und so in der Lage ist, bestimmte Aspekte der deut-schen Verbmorphologie nachzuahmen, ohne dabei die für die Subjekt-Verb-Kongruenz notwendigen Verarbeitungsvoraussetzungen zu erwerben.
5. Zusammenfassende Bewertung
Die späte Entwicklung von Subjekt-Verb-Kongruenzenmarkierung ist in denvorliegenden Daten nicht sofort augenscheinlich, da das vorliegende Korpuseinen hohen Anteil von flektierten Verbformen enthält. Es wurde gezeigt, daßin Äquationalsätzen mit pronominalen Subjekten Subjekt-Verb-Kongruenz

ZfAL 37, 2002. 3-26.22
allein auf der Basis von Subjekt-Verb-Blocks als unanalysierte einzelne lexi-kalische Einheiten produziert werden können. Da diese Blöcke lexikalischund morphologisch invariant bleiben, muß keine grammatische Informationzwischen Konstituenten ausgetauscht werden, um diese Strukturen zu produ-zieren.Im Fall von lexikalischen Verben wurde gezeigt, daß das scheinbar hohe Maßan korrekter Regelverwendung bei der Benutzung der Formative -e und -t zu-rückzuführen ist auf eine äußerst geringe morphologische Variation der ver-wendeten Verben. Dies ermöglicht dem Lerner, Zufallstreffer zu landen. Eswurde gezeigt, daß die zufällige Verwendung der oben genannten Formativein demselben Bereich variierte wie die scheinbare Markierung der Subjekt-Verb-Kongruenz.Daher zeigt sich, daß die scheinbare Verwendung von Subjekt-Verb-Kon-gruenz vor Woche 17 lediglich durch lexikalisch und morphologisch invari-ables Material hervorgehoben wurde. Der erste wirkliche Fall von Subjekt-Verb-Kongruenz trat mit denjenigen Verben auf, die lexikalisch und mor-phologisch variierten. Daher scheint Variabilität in diesen beiden Dimensio-nen ein entscheidender Faktor bei der Entwicklung von Formativen zu sein.Man kann also bei der Entwicklung von Formativen in Guys Lernersprachedrei Stufen unterscheiden, die wie folgt skizziert werden können:
variability_____lexical morphological1 - -2 + -3 + +
Stufe 1 entspricht Fällen wie Äquationalsätzen mit pronominalen Subjektenoder invariablen lexikalischen Subjekten. Wegen ihrer fehlenden Variabilitätkönnen die zwei Konstituenten als eine Einheit memoriert werden. Stufe 2bezieht sich auf morphologisch invariable Verben, die mit verschieden gram-matikalischen Subjekten benutzt werden.Aus der Perspektive der Zielsprache enthalten diese Verben Formative, dieaber in der Lernersprache bei den einzelnen Verben nicht variieren, daher be-handelt der Lerner diese Form des Verbs als eine unanalysierte Einheit. AufStufe 3 werden morphologisch variable Verben in verschiedenen Kontextenbenutzt.Ziel dieses Aufsatzes war es, den Status von unanalysierten morphologischenFormen in der Zweitsprachproduktion zu beschreiben. Der L2-Produktions-prozeß wurde als eine Progression von unanalysierten Formen, die holistischim mentalen Lexikon gespeichert sind, zu Formen mit grammatischen Infor-mationsaustausch dargestellt. Die Distributionsanalyse von Subjekt VerbKongruenz in einem longitudinalen Korpus belegt, daß formale Lerner Stra-

M. Pienemann: Unanalysierte Einheiten und Sprachverarbeitung... 23
tegien entwickeln können, mit deren Hilfe sie unanalysierte Chunks benutzen,um erfolgreich den Gebrauch von morphologischen Systemen vorzuspiegeln,und daß der Prozeß des grammatischen Informationstransfers, der für einenproduktiven Gebrauch des morphologischen Systems notwendig ist sich erstin dem Punkt entwickelt, der von der Processability Hierarchie vorhergesagtwird. Mit anderen Worten erlaubte uns diese Analyse, diejenigen Prozesse zukennzeichnen, die bei dem Übergang des Lerners von unanalysierten zu voll-analysierten morphologischen Formen beteiligt sind.Dieser Ansatz läßt dennoch absichtlich eine ganze Reihe von Fragen offen.Insbesondere bleibt der Bereich des inferenziellen Lernens außerhalb derZielperspektive dieses Aufsatzes. Letztendlich wird einer Theorie des Zweit-spracherwerbs diejenigen Prozesse identifizieren müssen, die es dem Lernererlauben, Formative als morphologische Einheiten zu erkennen und die esihm oder ihr erlauben, den Wortstamm zu erkennen. Obwohl diese Ent-deckungsprozeduren nicht garantieren, daß die Kongruenz zielsprachenkor-rekt markiert wird, sind sie eine notwendige Vorraussetzung für morphologi-sche Affixierung.Formkorrektheit hängt vermutlich auch zum Teil von der Entdeckung vonzielsprachlichen Form-Funktions-Relationen ab, und dies stellt eine weitereKernkomponente einer Theorie des Zweitspracherwerbs dar. Irgendwann inder Zukunft werden all diese Fragestellungen in einem übergreifenden Ansatzzum Zweitspracherwerb behandelt und integriert werden müssen.
Literatur
Clahsen, H., J./ Meisel/ Pienemann, M. (1983): Deutsch als Zweitsprache. Der Spracher-
werb ausländischer Arbeiter. Tübingen: Narr.
Cooper, W. E./ Zurif, E.B.V . (1983): Aphasia: Information-processing in language produc-
tion and reception“. In: Butterworth, B.: Language Production. Vol. 2.
de Bot, K.(1992): „A Bilingual Production Model: Levelt's 'Speaking' Model Adapted“.
Applied Linguistics 13 (1): 1-24.
Garrett, M. F. (1975): „The analysis of sentence production“. In: Bower, G. (ed.): The
psychology of learning and motivation, Vol. 9. New York: Academic Press, 133-177.
Garrett, M. F. (1976): „Syntactic processes in sentence production“. In: Wales, V./
Walker, E. (eds.): New approaches to language mechanisms. Amsterdam: North
Holland, 231-256.
Garrett, M. F. (1980): „Levels of processing in language production“. In: Butterworth, B.
(ed.): Language production, Vol 1. Speech and Talk. London: Academic Press, 170-220.

ZfAL 37, 2002. 3-26.24
Garrett, M. F. (1982): „Production of speech: Observations from normal and pathological
language use“. In: Ellis, A. W. (ed.): Normality and pathology in cognitive functions.
London: Academic Press.
Kempen, G./ Hoenkamp, E. (1987): „An incremental procedural grammar for sentence for-
mulation“. Cognitive Science 11: 201-258.
Levelt, W. J. M. (1981): „The speaker's linearisation problem“. Philosophical transactions.
Royal Society London. B295, 305-315.
Levelt, W. J. M. (1989): Speaking. From intention to articulation. Cambridge, Mass.: MIT
Press.
Meisel, J. M./ Clahsen, H./ Pienemann, M. (1981): „On determining developmental stages
in natural second language acquisition“. Studies in Second Language Acquisition 3: 109-
135.
Paradis, M. (1987): The assessment of bilingual aphasia. Hillsdale: Earlbaum.
Paradis, M. (1994): „Neurolinguistic Aspects of Implicit and Explicit Memory: Implica-
tions for Bilingualism and SLA“. In: Ellis, N. (ed.): Implicit and Explicit Learning of
Languages London, San Diego: Academic Press 1994, 393-419.
Pienemann, M. (1981): Der Zweitspracherwerb ausländischer Arbeiterkinder. Bonn: Bou-
vier.
Pienemann, M. (1998): Language Processing and Second Language Development.
Processability Theory. Benjamins: Amsterdam.
Pienemann, M./ Håkansson, G. (1999): A unified approach towards a theory of the de-
velopment of Swedish as L2. A processability account. Studies in Second Language Ac-
quisition. 21,383-420. Cambridge University Press.
Zurif, E./ Swinney, D./ Prather, P./ Love, T. (1994): „Functional Localisation in the Brain
with respect to Syntactic Processing“. Journal of Psycholinguistic Research, Vol. 23,
No. 6, 487-497.
Adresse des Verfassers:???










