
Twitter: listening to a kitchen table conversation involving 17 million people
25
Twitter: Listening to a Kitchen Table Conversation Involving 17 Million People Erik Tjong Kim Sang (Netherlands eScience Center, Amsterdam)
Transcript of Twitter: listening to a kitchen table conversation involving 17 million people

Twitter: Listening to a Kitchen Table
Conversation Involving 17 Million People
Erik Tjong Kim Sang (Netherlands eScience Center, Amsterdam)

28 February 1942: De Ruyter sinks
Ship: HNLMS De Ruyter
Commander: Karel Doorman
Date: 28 February 1942
Location: Java Sea
Lives lost: 345

Social Media

How do we deal with the data volumes?
Twitter:
• Maximum of 140 characters per message
But:
• 200 million users (1-2 million NL)
• 300 million tweets per day (3-4 million NL)

Netherlands eScience Center (NLeSC)
Supporting data-intensive research
Distributing project calls offering both
money and expertise
Involved in 21 projects dealing with
various areas in science
by SURF and NWO
See: http://esciencecenter.nl/

Engineers/Scientists @ NLeSC
In every NLeSC project, one eScience engineer is
involved: a scientist (often with PhD) with strong
computational skills

The project TwiNL
With about 4 million messages in Dutch per day covering different
topics, this is an interesting data source for researchers
Project task: collect Dutch tweets, offer a search facility for the data and
provide different views on search results
Twitter: a social network on which
participants communicate by exchanging
messages of up to 140 characters
with Radboud University Nijmegen
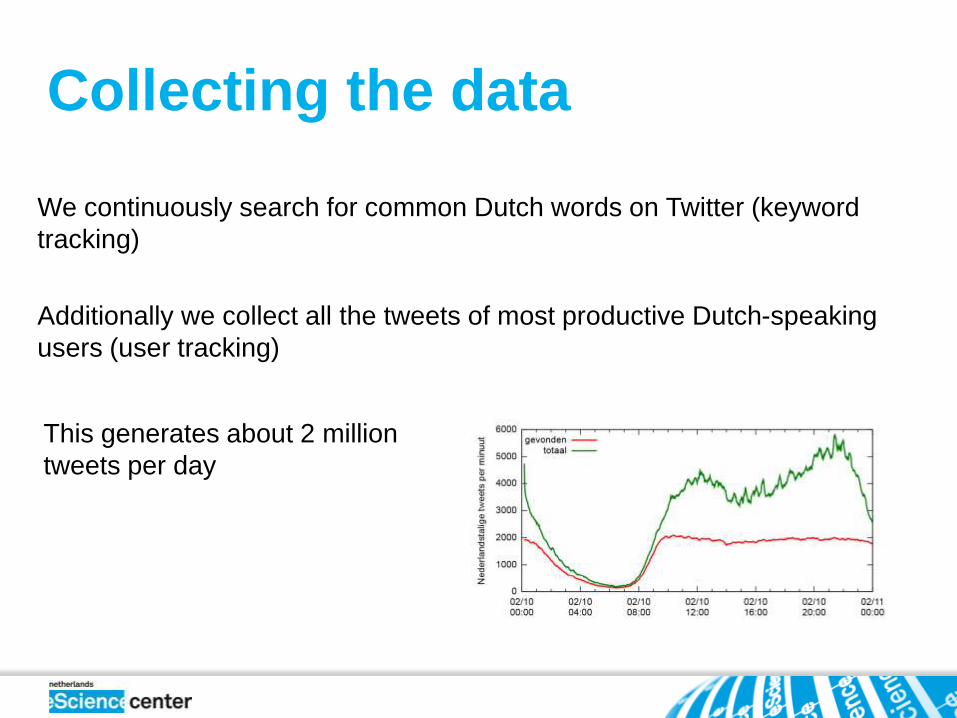
Collecting the data
We continuously search for common Dutch words on Twitter (keyword
tracking)
Additionally we collect all the tweets of most productive Dutch-speaking
users (user tracking)
This generates about 2 million
tweets per day
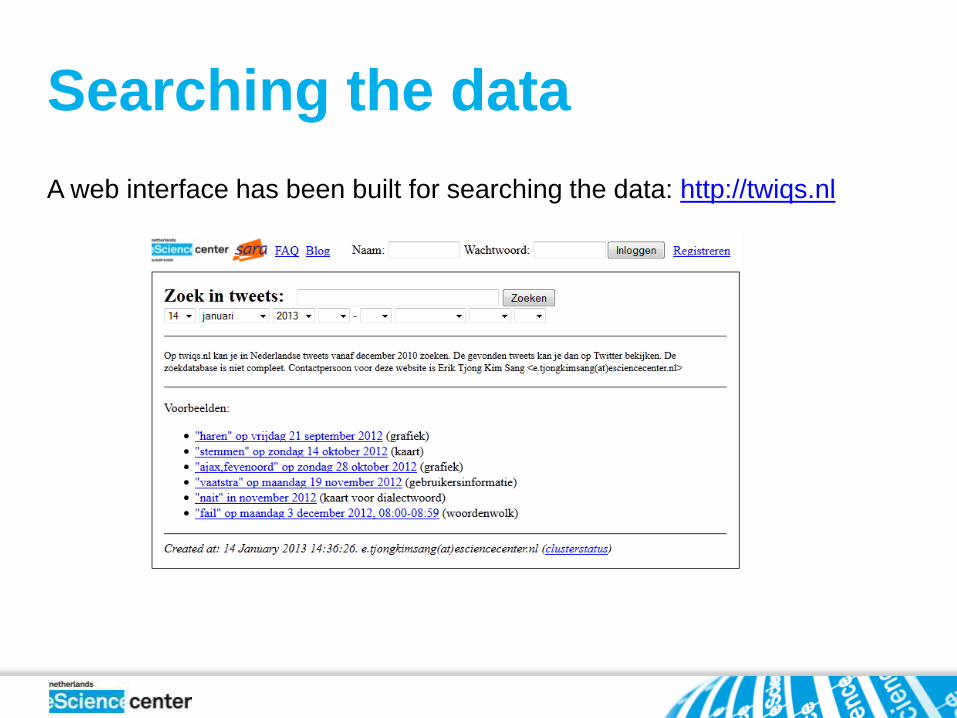
Searching the data
A web interface has been built for searching the data: http://twiqs.nl

Challenges and solutions
Challenge 1: we have a lot of data (five terabytes)
Challenge 2: the collection is growing every second
Challenge 3: we want to search both text and metadata
Solution: parallel processing with Hadoop, make possible by :

Views on search results
We offer five different views on search results:
• Tweets (restricted)
• Keyword frequency graph
• Keyword usage map
• Vocabulary overview, including sentiment analysis
• User analysis
All numbers used for creating the views are available for download

Examples of search results
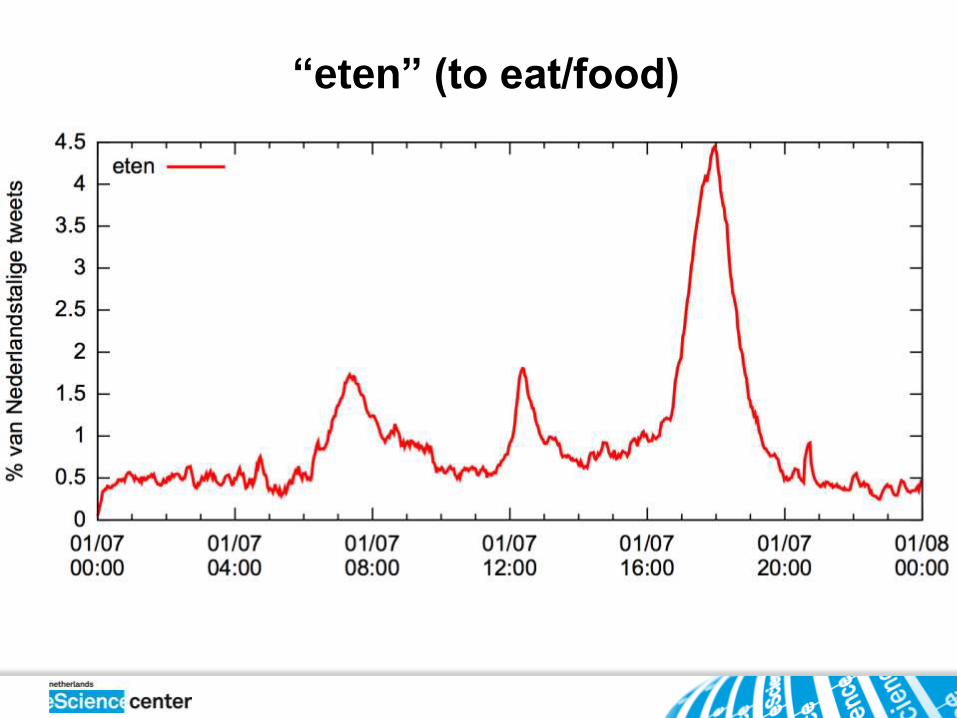
“eten” (to eat/food)
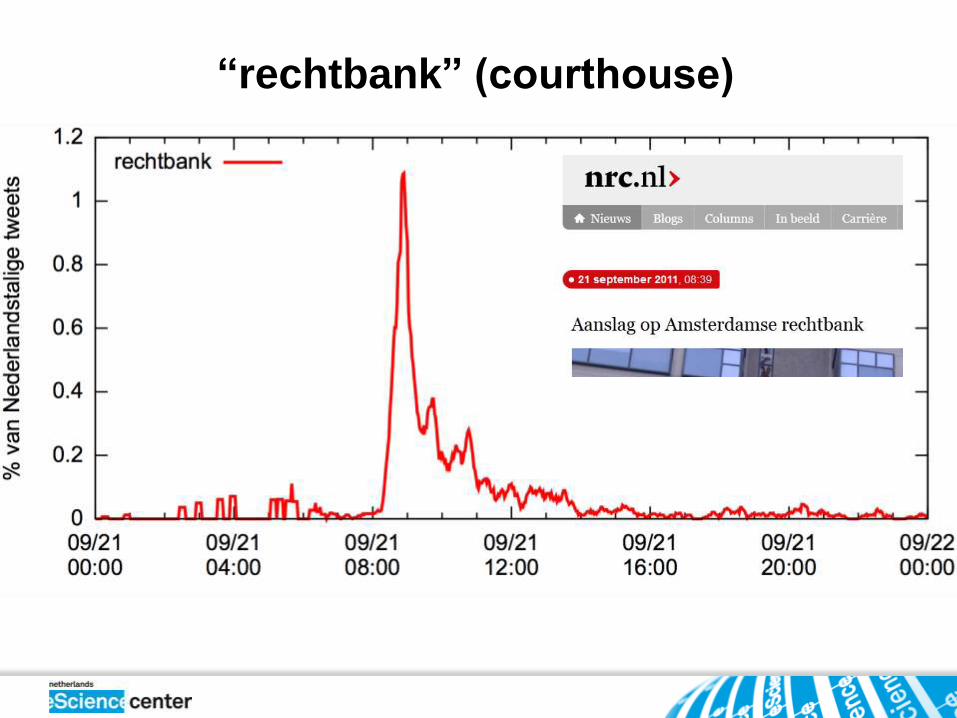
“rechtbank” (courthouse)
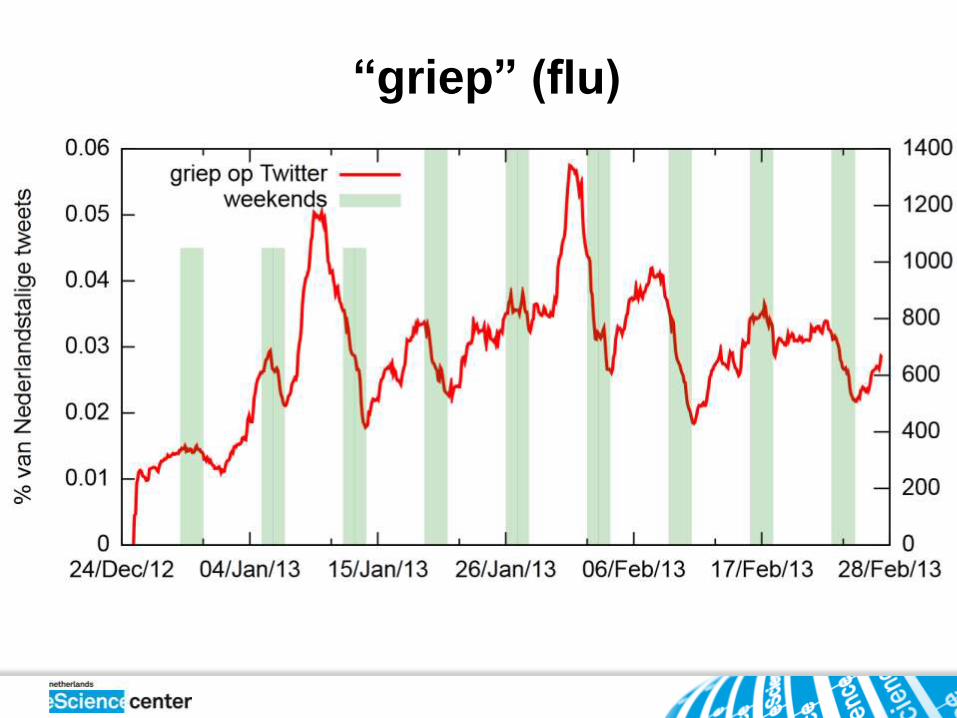
“griep” (flu)
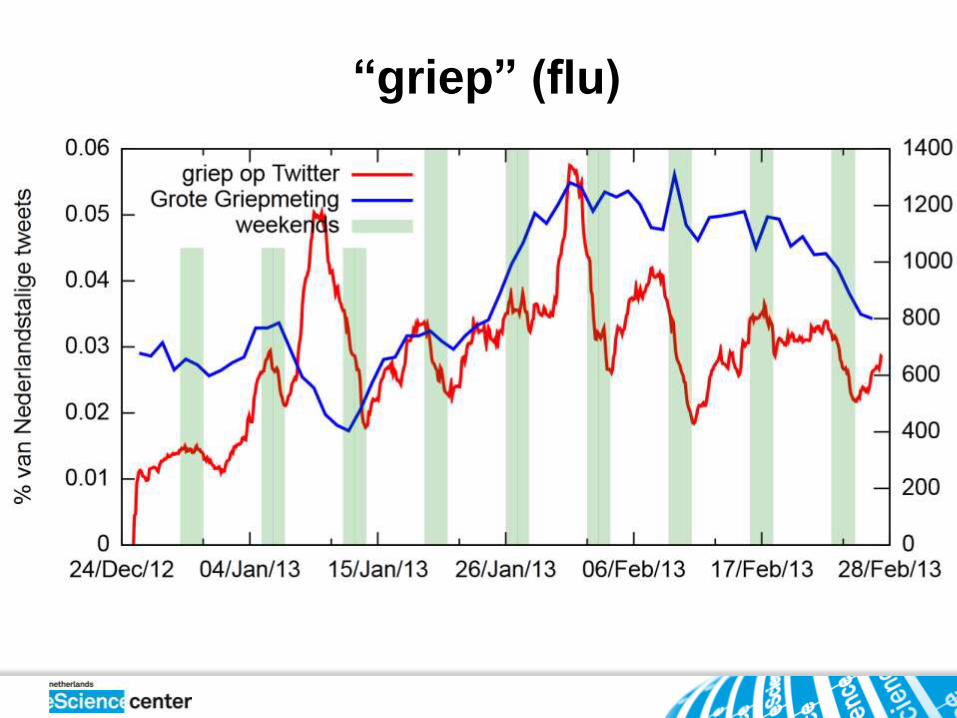
“griep” (flu)
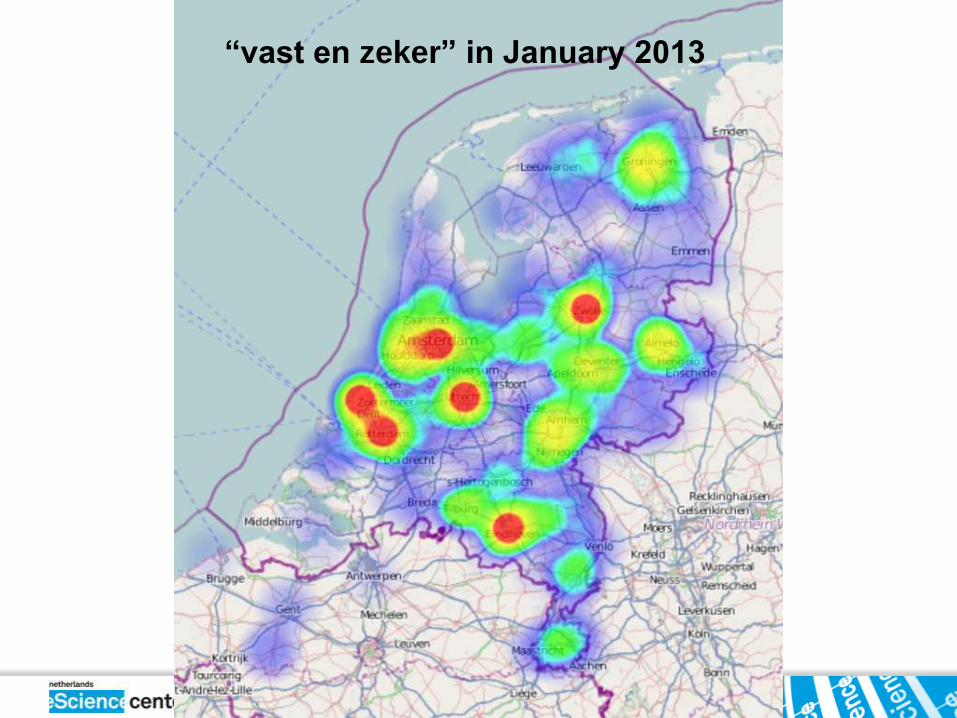
“vast en zeker” in January 2013
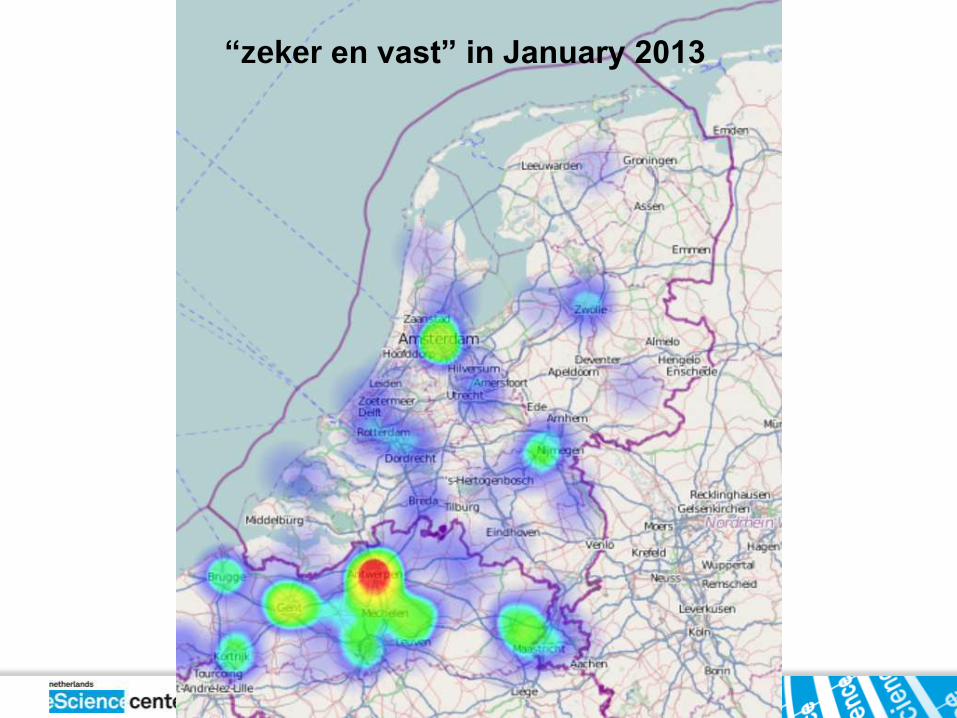
“zeker en vast” in January 2013

Words co-occurring with “hedde’’ (Brabant dialect)
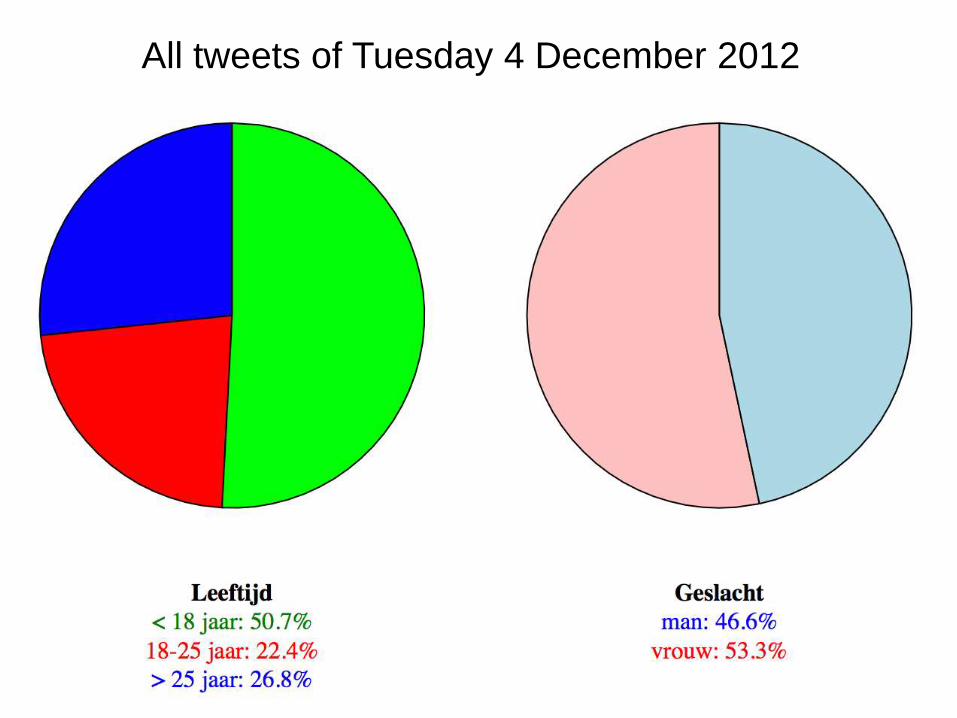
All tweets of Tuesday 4 December 2012
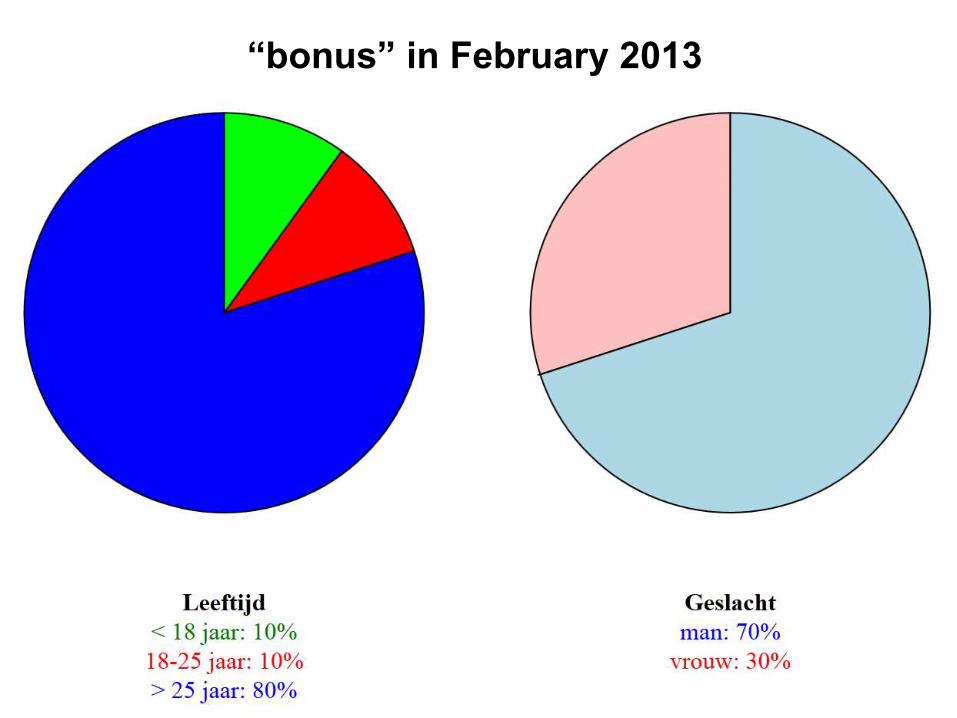
“bonus” in February 2013


Concluding remarks
Social media conversations make up interesting research data
The website http://twiqs.nl can be used for accessing this data
The interface can be used by university staff and students for exploring
Twitter conversations
Examples of applications are early news detection, tracking disease
spread, studying dialects and obtaining local weather information

THE END

SRIE13 on Twitter (February 2013)











![LISTENING AUDIOSCRIPT · LISTENING AUDIOSCRIPT . LISTENING DIAGNOSTIC PRE-TEST . Page 143 [mp3 001-002] Questions 1 through 5. Listen to a conversation between an advisor and a .](https://static.fdocuments.us/doc/165x107/5ea642f4ee28a8761017d514/listening-audioscript-listening-audioscript-listening-diagnostic-pre-test-page.jpg)






