
thesis_presentation_v1 shorter split
19
Identifying Single and Stacked News Triangles in Online News Articles - an Analysis of 31 Danish Online News Articles Annotated by 68 Journalists By Miklas Njor [email protected] Master Thesis Project, 15 ECTS, DA613A, Spring 2015 Supervisor: Daniel Spikol Examiner: Bengt Nilsson Link to data: http://figshare.com/account/projects/4414 and http://plot.ly (see thesis for direct links) Presentation Outline 1 Welcome to the presentation of the thesis “Identifying Single and Stacked News Triangles in Online News Articles”. My name is Miklas Njor. The supervisor of the thesis is Daniel Spikol and the Examiner is Bengt Nilsson. Sala will be the opponent.
-
Upload
miklas-njor -
Category
Documents
-
view
73 -
download
0
Transcript of thesis_presentation_v1 shorter split

Identifying Single and Stacked News Triangles in Online News Articles
- an Analysis of 31 Danish Online News Articles Annotated by 68 Journalists
By Miklas Njor [email protected]
Master Thesis Project, 15 ECTS, DA613A, Spring 2015
Supervisor: Daniel Spikol Examiner: Bengt Nilsson
Link to data: http://figshare.com/account/projects/4414 and http://plot.ly (see thesis for direct links)
Presentation Outline
1
Welcome to the presentation of the thesis “Identifying Single and Stacked News Triangles in Online News Articles”. My name is Miklas Njor. The supervisor of the thesis is Daniel Spikol and the Examiner is Bengt Nilsson. Sala will be the opponent.

• Introduction
• Research Questions
• Methodology (What was the set-up)
• Results
• Identifying the presence of Stacked News Triangles
• Named Entities influence on the presence of series of Stacked News Triangles
• Named Entities variance per Category
• Conclussion and Summary
Presentation Outline
2
I will start by talking about the background and also explaining what a News Triangle is. Based on the introduction, I will discuss the three Research Questions.The Methodology is in two parts - part one for collecting the data, and the next, part two, for processing the data. Results are divided into three parts based on the Research Questions: - Identifying the presence of Stacked News Triangles - How Named Entities - that is peoples names, the names of places and organizations - how these influence the presence of Stacked News Triangles. - and last, the variances between Named Entity TYPES within keywords in each category… This is followed by the Summary and Discussion. Regarding questions, unless something is very unclear, please wait until after the Discussion, where you will have opportunity to ask questions.

https://www.flickr.com/photos/boston_public_library/6801377949/
Intro: The Problem
Writing news has always been a messy activity, where you never knew what the day would look like. Here you see an image of what a news room used to look like.

https://www.flickr.com/photos/boston_public_library/6801377949/
Intro: The Problem
https://www.flickr.com/photos/greenwood100/7314522860/
And this is what a news room looks like today.The Internet forced the media to be more streamlined , but it also resulted in a huge decline in circulation and revenue for newspapers, which further led to layoff of staff …. The staff that are left are pressed for time, both when it comes to producing news and putting the articles online while adding metadata to the content…Each article undergoes an editorial process before publication. To make search retrieval and recommendations of related articles easier, each article is manually annotated with relevant keywords, taxonomies and category. This process is tedious and subjective, and over time , tags can become stale. Automatically annotating articles with relevant tags could help organize content better and ensure that keywords are always relevant.

Intro: The News Triangle
5
“News stories should flow logically from the first paragraph. […] One way of looking at it is through the News Triangle or inverted pyramid. Generations of journalists have been brought up on this.” - Sissons
The information in newspaper articles is presented in descending order of importance, where important information is relayed first. Within journalism this is known as the “News Triangle”, where the writer explains “What happened”, “How it happened”, “Amplify the point”, “Tie up loose ends” - also known as WHAT. The article is written using one large News Triangle, with a headpiece, an introduction followed by blocks of text, where the level of informations peters off the further you read. The process has worked well for more than a hundred years. However, the process of writing for online is different than writing for print. With the shift from reading news on paper to reading it on screens, there has also been a change in reading habits, where readers now skim text when reading news online.

Intro: Stacked New Triangles
News Triangle for print news
News Triangles for online news
Headline + Sub-headline Intro Body element 1…
For online news articles, the new notion is to use a series of stacked News Triangles, so that each section is a News Triangle, as this allows the reader to skim the text more easily. From a text-mining perspective this is interesting, because knowing how a piece of text is supposed to be structured, will make it more straightforward to teach a computer how to read and learn from the text , for instance to automatically add keywords and taxonomies.So instead of looking for one giant news triangle we are looking for a series of stacked news triangles.

RQ 1: To what extent do online news articles follow the idiom of many News Triangles, instead of only one News Triangle, where information is distributed at the beginning of the text. I.e. do the keyword candidates appear less frequently the further we move away from the start of each element block?
RQ 2: Given that much news concerns something that happened to someone somewhere, what influence does Named Entity keywords have on the
presence of News Triangles?
RQ 3: Is there a distinct variance of Named Entity Type keywords (Persons, Place or Organisations) within the categories Culture, Domestic, Economy, and Sports?
RQ 1: To what extent do online news articles follow the idiom of many News Triangles, instead of only one News Triangle, where information is distributed at the beginning of the text. I.e. do the keyword candidates appear less frequently the further we move away from the start of each element block?
RQ 2: Given that much news concerns something that happened to someone somewhere, what influence does Named Entity keywords have on the
presence of News Triangles?
RQ 3: Is there a distinct variance of Named Entity Type keywords (Persons, Place or Organisations) within the categories Culture, Domestic, Economy, and Sports?
RQ 1: To what extent do online news articles follow the idiom of many News Triangles, instead of only one News Triangle, where information is distributed at the beginning of the text. I.e. do the keyword candidates appear less frequently the further we move away from the start of each element block?
RQ 2: Given that much news concerns something that happened to someone somewhere, what influence does Named Entity keywords have on the
presence of News Triangles?
RQ 3: Is there a distinct variance of Named Entity Type keywords (Persons, Place or Organisations) within the categories Culture, Domestic, Economy, and Sports?
Research Questions
7
Research Question 1 is about identifying if there is a CLICK series of stacked news triangles.Research Question 2 deals with looking for traces of whether Named Entities influence the presence of Stacked News Triangles.Research Question 3 looks at the variance of Named Entity TYPES among the keywords in each category.Next we will look at how keywords we collected and how the data is processed.

Methodology - Collecting Annotations
8
68 journalist 8 articles each Set of 31 articles
Categories: Culture (7) Domestic (14) Economy (6) Sports (4)
68 journalist annotate 8 articles from a set of 31 articles. The articles are from the Culture, Domestic, Economy and Sports sections from the danish newspaper Politiken. The keywords from each article are collected using the box on the right, where they are asked to type keywords, taxonomies and section (which is the journalistic name for category). The plan was to also dig into taxonomies and categories, but the number of keywords collected proved to be more than I expected, so I decided to concentrate on those.
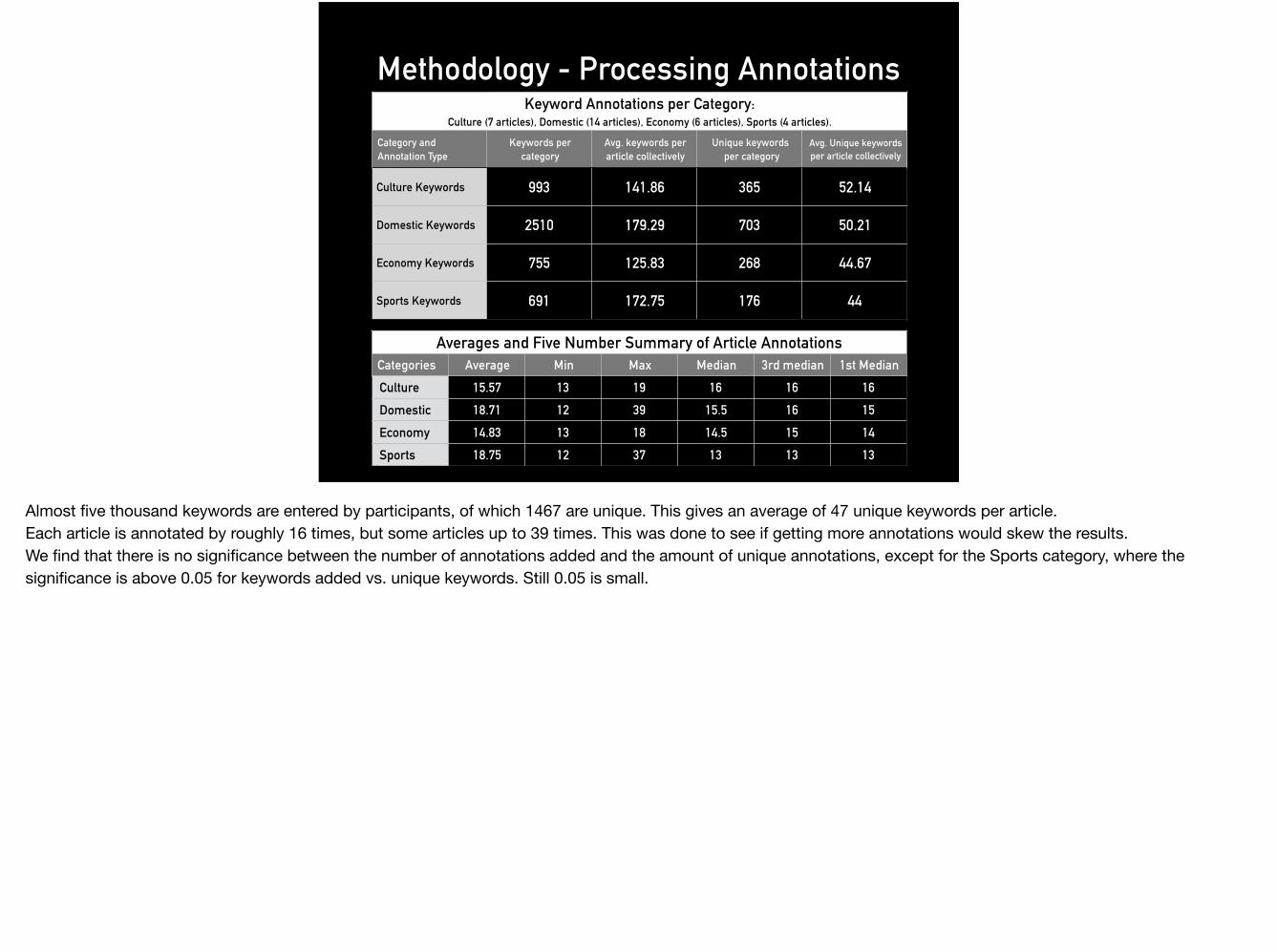
Methodology - Processing AnnotationsKeyword Annotations per Category:
Culture (7 articles), Domestic (14 articles), Economy (6 articles), Sports (4 articles).
Category and Annotation Type
Keywords per category
Avg. keywords per article collectively
Unique keywords per category
Avg. Unique keywords per article collectively
Culture Keywords 993 141.86 365 52.14
Domestic Keywords 2510 179.29 703 50.21
Economy Keywords 755 125.83 268 44.67
Sports Keywords 691 172.75 176 44
Averages and Five Number Summary of Article AnnotationsCategories Average Min Max Median 3rd median 1st Median Culture 15.57 13 19 16 16 16 Domestic 18.71 12 39 15.5 16 15 Economy 14.83 13 18 14.5 15 14 Sports 18.75 12 37 13 13 13
Almost five thousand keywords are entered by participants, of which 1467 are unique. This gives an average of 47 unique keywords per article.Each article is annotated by roughly 16 times, but some articles up to 39 times. This was done to see if getting more annotations would skew the results. We find that there is no significance between the number of annotations added and the amount of unique annotations, except for the Sports category, where the significance is above 0.05 for keywords added vs. unique keywords. Still 0.05 is small.

Methodology - Processing AnnotationsArticle 22 - Keywords - 3RD QUARTILE
KEYWORD COUNTdansk svømmeunion 13svømning 9trygfonden 9drukneulykker 6svømmeundervisning 6svømme 4børn 4tobias marling 4rené højer 3druknestatistik 2statistik 2folkeskolen 2drukneulykke 2skoler 2yougov 2skole 2yougov-undersøgelse 2
Article 4 - Keywords - 3RD QUARTILEKEYWORD COUNT KEYWORD COUNTodsherred 25 forældre 9tutoring 21 birgitte henriksen 9nordskolen 17 niveaudeling 9cooperative learning 15 elever 8manu sareen 14 kommuner 8undervisningsmetoder 12 lektier 8folkeskole 11 makkerlæsning 7undervisningsministeriet 11 trelærerordning 6folkeskolen 11 matematik 6specialundervisning 10 nordvestsjælland 6undervisning 10 undervisningsdifferentiering 6ppr 10 lektiehjælp 6peter holm 9
In order to prune the data and reduce noise, we only consider the most popular keywords, i.e. keywords that are in the 3rd quartile. And even doing so, we still have a lot of data to work with. These are the keywords from article 22 and article 4, where the count is how many times a participant entered the keyword.

Methodology - Processing AnnotationsArticle 22 - Keywords
KEYWORD COUNT
dansk svømmeunion 13
svømning 9
trygfonden 9
drukneulykker 6
svømmeundervisning 6
svømme 4
børn 4
tobias marling 4
rené højer 3
druknestatistik 2
statistik 2
folkeskolen 2
drukneulykke 2
skoler 2
yougov 2
skole 2
yougov-undersøgelse 2
Article 4 - Keyowrds
KEYWORD COUNT KEYWORD COUNT
odsherred 25 forældre 9
tutoring 21 birgitte henriksen 9
nordskolen 17 niveaudeling 9
cooperative learning 15 elever 8
manu sareen 14 kommuner 8
undervisningsmetoder 12 lektier 8
folkeskole 11 makkerlæsning 7
undervisningsministeriet 11 trelærerordning 6
folkeskolen 11 matematik 6
specialundervisning 10 nordvestsjælland 6
undervisning 10 undervisningsdifferentiering 6
ppr 10 lektiehjælp 6
peter holm 9
Notice that keyword count’s have a fairly evenly decline, where Named Entity count’s , drop off more quickly.Armed with the annotations, we can now concentrate on the distribution of keywords across the articles.

Results - Keyword Distribution - 1
12
News Triangles for online news
Headline + Sub-headline Intro Body element 1…
Each article is divided into partitions (Headpiece, Intro and subsequent Section blocks according to the original HTML markup) The popular keywords for each article are searched for in the article, and their position, if found, is mapped for each partition block.
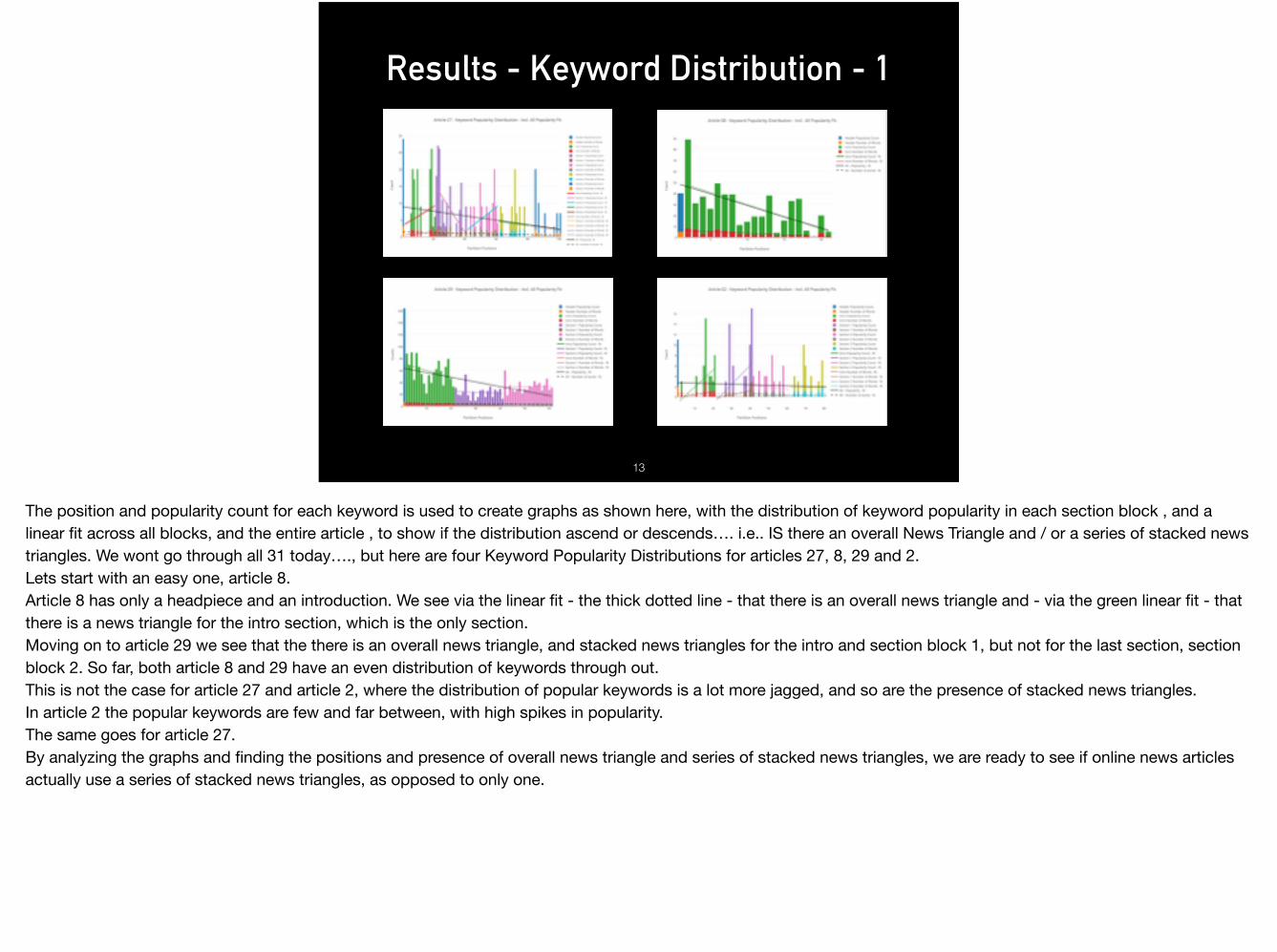
Results - Keyword Distribution - 1
13
The position and popularity count for each keyword is used to create graphs as shown here, with the distribution of keyword popularity in each section block , and a linear fit across all blocks, and the entire article , to show if the distribution ascend or descends…. i.e.. IS there an overall News Triangle and / or a series of stacked news triangles. We wont go through all 31 today…., but here are four Keyword Popularity Distributions for articles 27, 8, 29 and 2.Lets start with an easy one, article 8.Article 8 has only a headpiece and an introduction. We see via the linear fit - the thick dotted line - that there is an overall news triangle and - via the green linear fit - that there is a news triangle for the intro section, which is the only section. Moving on to article 29 we see that the there is an overall news triangle, and stacked news triangles for the intro and section block 1, but not for the last section, section block 2. So far, both article 8 and 29 have an even distribution of keywords through out.This is not the case for article 27 and article 2, where the distribution of popular keywords is a lot more jagged, and so are the presence of stacked news triangles.In article 2 the popular keywords are few and far between, with high spikes in popularity.The same goes for article 27.By analyzing the graphs and finding the positions and presence of overall news triangle and series of stacked news triangles, we are ready to see if online news articles actually use a series of stacked news triangles, as opposed to only one.

Results - Keyword Distribution - 2Category Article ID Overall News
Triangle Intro Section 1 Section 2 Section 3 Section 4 Section 5 How Many Have Stacked News Triangles?
Culture Article 16 1 0
3 of 7Article 17 1 1 0 1Article 18 1 1Article 22 1 0Article 23 1 1Article 27 1 0 1 0 1 1Article 28 1 1 1
Domestic Article 03 1 1 1
7 of 14
Article 04 1 1 1 1 1Article 05 1 1 1Article 07 1 0 1 1Article 08 1 1Article 13 1 1 1 1 1 1Article 19 1 1 1Article 20 1 1 1 0Article 21 1 1 0 0 1 0 0Article 24 1 0 1 1 1 0Article 25 1 0 1 0 1Article 26 1 1Article 29 1 1 1 0Article 30 1 0
Economy Article 01 1 1 0 1 1
2 of 5Article 02 1 0 0 1 1Article 06 1 1 0 1 0Article 09 1 1 1Article 10 1 1 1 1 1Article 11 1 1 1 0 1
Sport Article 12 1 1
2 of 4Article 14 1 0Article 15 1 1 1 1Article 31 0 1 0 1 1
In culture we find that all articles have an overall news triangle, and three of seven have a series of stacked news triangles. For Domestic, we find that all articles have an overall news triangle, and seven out of fourteen articles have a series of stacked news triangles.For economy, two out of five articles have a series of stacked news triangles, and all articles have an overall news triangle.For sports, two of four articles have a series of stacked news triangles, however, we find that one article of the four, doesn’t have an overall news triangle. Looking at the illustration of article 31 , we can see that the overall news triangle linear fit is almost horizontal.SO to quickly summarize, 30 of 31 articles have an overall news triangle, and just below half of the articles in each category feature a series of Stacked News Triangles.
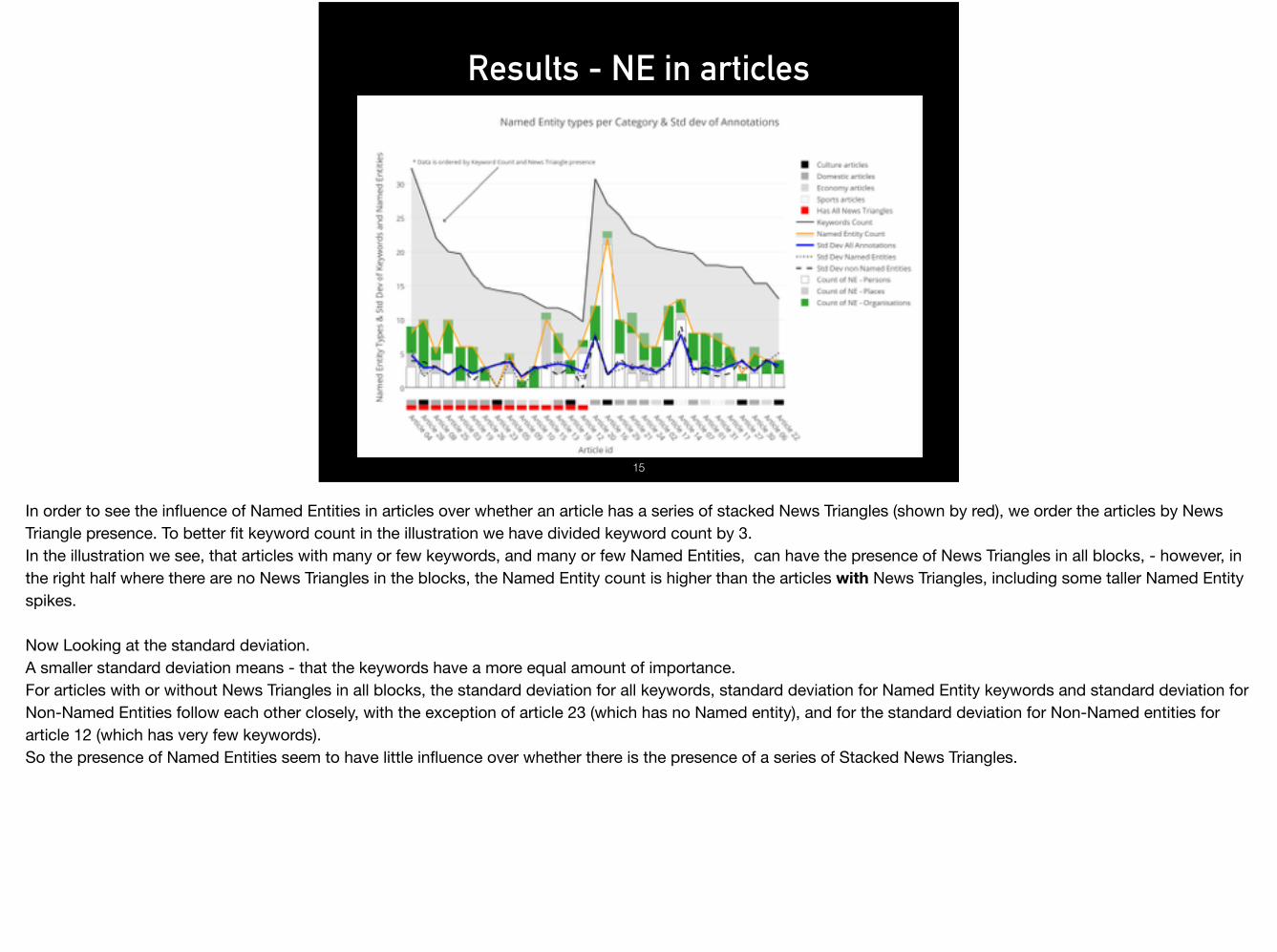
Results - NE in articles
15
In order to see the influence of Named Entities in articles over whether an article has a series of stacked News Triangles (shown by red), we order the articles by News Triangle presence. To better fit keyword count in the illustration we have divided keyword count by 3.In the illustration we see, that articles with many or few keywords, and many or few Named Entities, can have the presence of News Triangles in all blocks, - however, in the right half where there are no News Triangles in the blocks, the Named Entity count is higher than the articles with News Triangles, including some taller Named Entity spikes.
Now Looking at the standard deviation.A smaller standard deviation means - that the keywords have a more equal amount of importance. For articles with or without News Triangles in all blocks, the standard deviation for all keywords, standard deviation for Named Entity keywords and standard deviation for Non-Named Entities follow each other closely, with the exception of article 23 (which has no Named entity), and for the standard deviation for Non-Named entities for article 12 (which has very few keywords). So the presence of Named Entities seem to have little influence over whether there is the presence of a series of Stacked News Triangles.
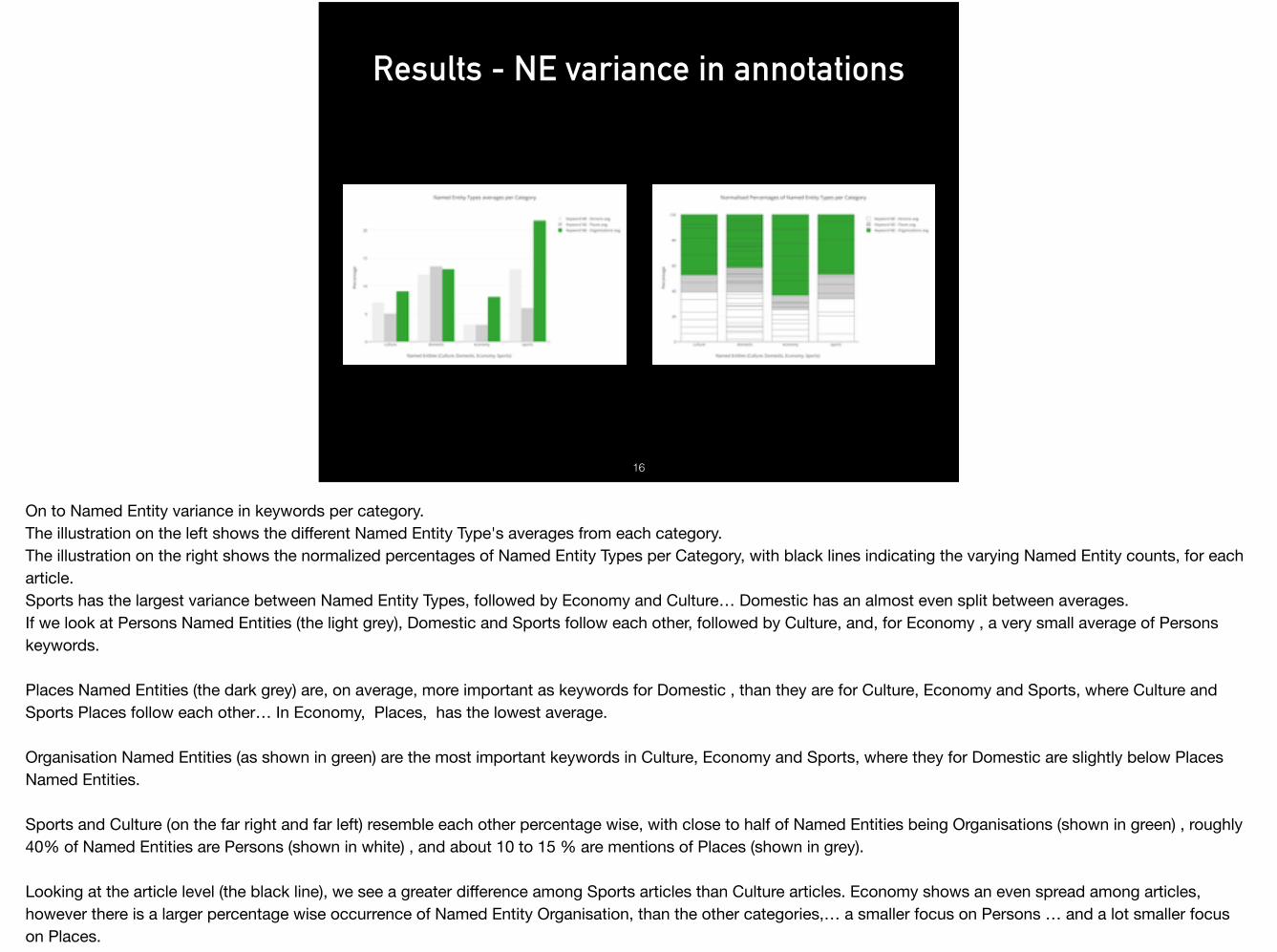
Results - NE variance in annotations
16
On to Named Entity variance in keywords per category.The illustration on the left shows the different Named Entity Type's averages from each category. The illustration on the right shows the normalized percentages of Named Entity Types per Category, with black lines indicating the varying Named Entity counts, for each article.Sports has the largest variance between Named Entity Types, followed by Economy and Culture… Domestic has an almost even split between averages. If we look at Persons Named Entities (the light grey), Domestic and Sports follow each other, followed by Culture, and, for Economy , a very small average of Persons keywords.
Places Named Entities (the dark grey) are, on average, more important as keywords for Domestic , than they are for Culture, Economy and Sports, where Culture and Sports Places follow each other… In Economy, Places, has the lowest average.
Organisation Named Entities (as shown in green) are the most important keywords in Culture, Economy and Sports, where they for Domestic are slightly below Places Named Entities.
Sports and Culture (on the far right and far left) resemble each other percentage wise, with close to half of Named Entities being Organisations (shown in green) , roughly 40% of Named Entities are Persons (shown in white) , and about 10 to 15 % are mentions of Places (shown in grey). Looking at the article level (the black line), we see a greater difference among Sports articles than Culture articles. Economy shows an even spread among articles, however there is a larger percentage wise occurrence of Named Entity Organisation, than the other categories,… a smaller focus on Persons … and a lot smaller focus on Places.

RQ 1: To what extent do online news articles follow the idiom of many News Triangles, instead of only one News Triangle, where information is distributed at the beginning of the text. I.e. do the keyword candidates appear less frequently the further we move away from the start of each element block?
Summary/DiscussionSummary/Discussion
RQ 2: Given that much news concerns something that happened to someone somewhere, what influence does Named Entity keywords have on the presence of News Triangles?
RQ 3: Is there a distinct variance of Named Entity Type keywords (Persons, Place or Organisations) within the categories Culture, Domestic, Economy, and Sports?
Category How Many Articles Have Stacked News Triangles?
Culture 3 of 7 have Stacked News Triangles
Domestic 7 of 14 have Stacked News Triangles
Economy 2 of 5 have Stacked News Triangles
Sports 2 of 4 have Stacked News Triangles
SUMMARYWe have conducted an experiment, where 68 participants tagged 8 articles from a set of 31 articles ranging across four categories. The keywords the participants entered where collected for each article and analyzed.For the articles, we divided the text into sections. For the collected keywords we use those in the 3rd quartile to cut down on noisy data. The keywords where mapped to their position across the article, along with their popularity count. The popularity count was used to measure if there was an ascending or descending linear fit across the entire article and for each section. We found that 30 of 31 articles have and overall News Triangle, and 14 of 31 article feature a series of stacked News Triangles. As to research question 2, We have difficulty finding a pattern of what influences News Triangle presence,BUT We do find a variation in types of Named Entities present per annotations in each category.

FUTURE WORK • Looking much closer at what causes of the ascent or descent of the linear fit. • If a smaller or larger set of keywords is better • A larger set of articles • Named Entities in taxonomies
Summary/DiscussionSummary/Discussion• Including more keywords?
• Removing Stop words?
• De- or increasing partitions of the text?
Discussion. We cannot see why some article have or have no stacked News Triangle presence, since we cannot see what influence the ascent or descent. Although including keywords from the first and second quartile, obviously would change what we see, but since we cannot see a distinct common pattern for all the articles, we suspect that we would be none the wiser adding or subtracting keywords.A common preprocessing step is to remove stop words, which we did not do. However, we do not regard this as problematic, since we partition each section block into equal sizes.As to dividing the sections into more or less than 20 partitions, this could also influence what we see, since some keywords might change their order and push more or less to the popularity score. Again, we suspect de- or increasing partitions would only produce slightly different results, but no answer as to what influences the presence of News Triangles.For Future Work we think that- looking much closer at what causes the ascent and descent of the linear fit which we use to measure the presence of News Triangles would be a logical first step.- Seeing if a smaller set of keywords is better, or if colocations, synonyms and TF-IDF are useful to culling the lists of keywords would be next.- The data set of 31 articles might be too small and/or the article's subjects to wide, and a more specific look at one type of article would reveal a better picture, however, this would also make it more difficult to generalise.- we believe that the aspect of Named Entities in taxonomies should be looked at closer. While the idea of taxonomies is to be a very general description of what an item
is about, and as such Named Entities might be too specific, it is an area that should be investigated. - Seeing that keyword density across articles and article sections varies, this should also be highlighted as another subject for future work.Thank you for your time. I will now try to answer your questions.

Summary/DiscussionSummary/Discussion
QUESTIONS?
Thank you for your time. I will now try to answer your questions. [email protected]


















