
Teradata Platform Introduction
40
Teradata Platform Introduction Hardware and Software Components in Enterprise Data Warehouse Derek Jones March 2005
-
Upload
charlotte-keon -
Category
Documents
-
view
64 -
download
1
description
Teradata Platform Introduction. Hardware and Software Components in Enterprise Data Warehouse Derek Jones March 2005. Teradata in the Enterprise. Teradata is relational database management system Acts as central enterprise-wide database - PowerPoint PPT Presentation
Transcript of Teradata Platform Introduction

Teradata Platform Introduction
Hardware and Software Components in Enterprise Data Warehouse
Derek JonesMarch 2005

Teradata Confidential2 > 04/19/23
Teradata in the Enterprise
Teradata is relational database management system
• Acts as central enterprise-wide database> Contains information extracted from operational systems> Central placement minimizes data duplication and provides
single view of business

Teradata Confidential3 > 04/19/23
Key Teradata Differentiators
• Parallelism throughout platform• Shared Nothing Architecture• Proprietary intelligent system inter-connect

Teradata Confidential4 > 04/19/23
Teradata Scales Linearly
• Scaling achieved via ‘shared nothing’ architecture and unconditional parallelism
• Power is in linear scalability, where slope = 1• Scales with data• Scales with users• Scales with work
More nodes
More work
More users
More data
Node
Work
Users
Data
Teradata Confidential5 > 04/19/23
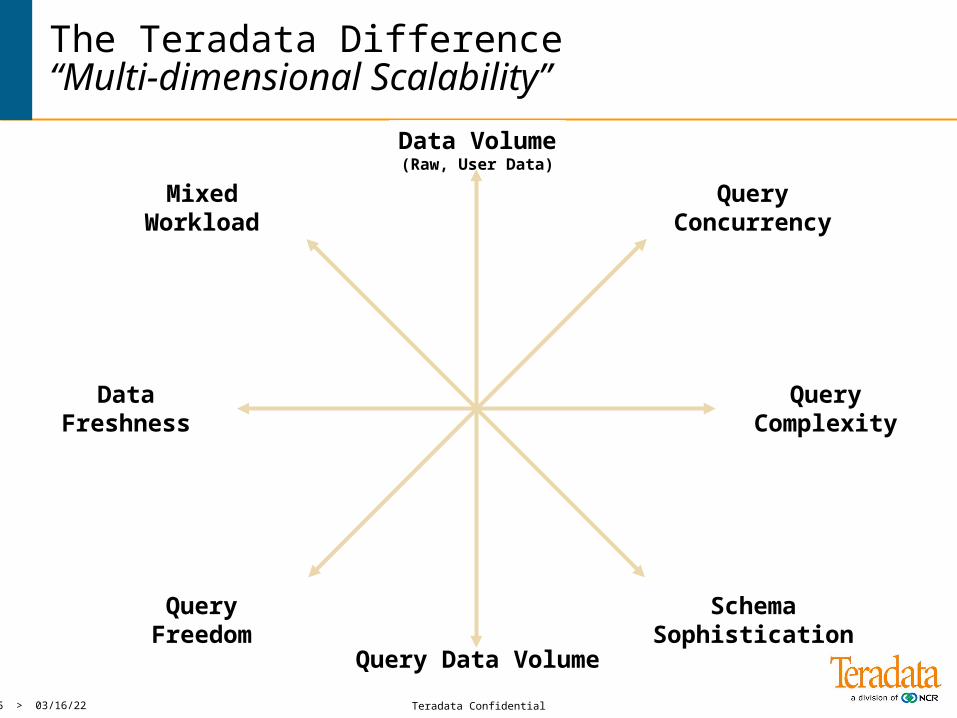
Data Volume(Raw, User Data)
SchemaSophistication
QueryFreedom
QueryComplexity
QueryConcurrency
MixedWorkload
Query Data Volume
DataFreshness
The Teradata Difference“Multi-dimensional Scalability”
Teradata Confidential6 > 04/19/23
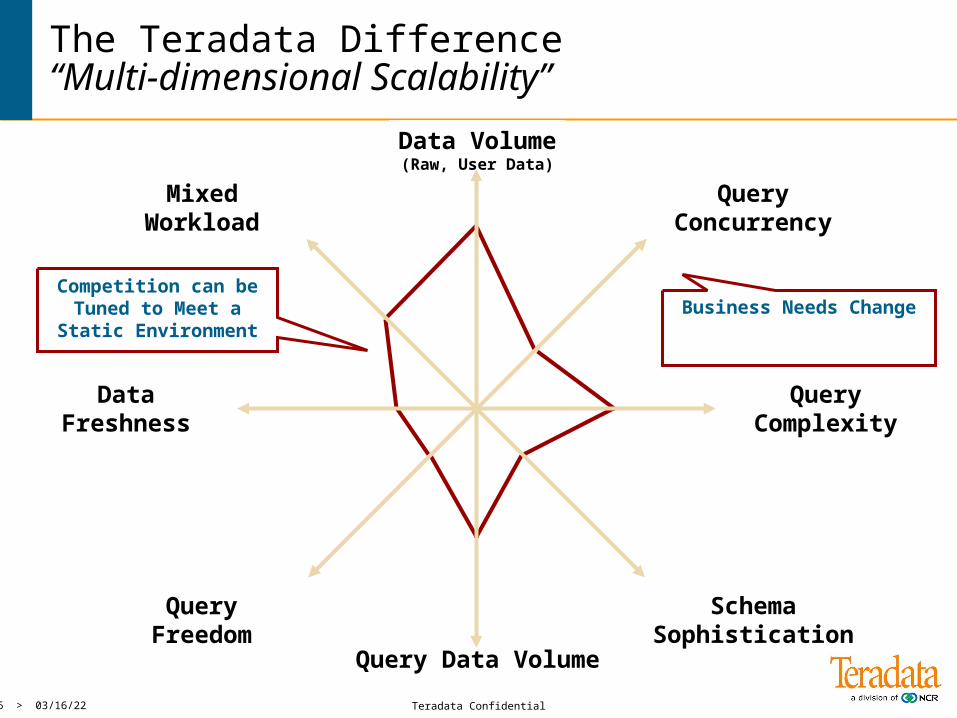
Data Volume(Raw, User Data)
Business Needs ChangeCompetition can be
Tuned to Meet a Static Environment
SchemaSophistication
QueryFreedom
QueryComplexity
DataFreshness
Query Data Volume
The Teradata Difference“Multi-dimensional Scalability”
QueryConcurrency
MixedWorkload

Teradata Confidential7 > 04/19/23
Data Volume(Raw, User Data)
Competition can be Tuned to Meet a
Static Environment
But At the Expense of Another Dimension
Competition Scales One Dimension at the
Expense of Others
Business Needs Change Desire to Increase User/
Query Concurrency
SchemaSophistication
QueryFreedom
QueryComplexity
DataFreshness
Query Data Volume
The Teradata Difference“Multi-dimensional Scalability”
QueryConcurrency
MixedWorkload

Teradata Confidential8 > 04/19/23
Data Volume(Raw, User Data)
Competition Scales One Dimension at the
Expense of Others
Limited by Technology!
SchemaSophistication
QueryFreedom
QueryComplexity
DataFreshness
Query Data Volume
The Teradata Difference“Multi-dimensional Scalability”
QueryConcurrency
MixedWorkload
Teradata can Scale Simultaneously Across Multiple Dimensions
Driven by Business!

Teradata Confidential9 > 04/19/23
Key Teradata Differentiators
• Parallelism throughout platform• Shared Nothing Architecture• Proprietary intelligent system inter-connect

Teradata Confidential10 > 04/19/23
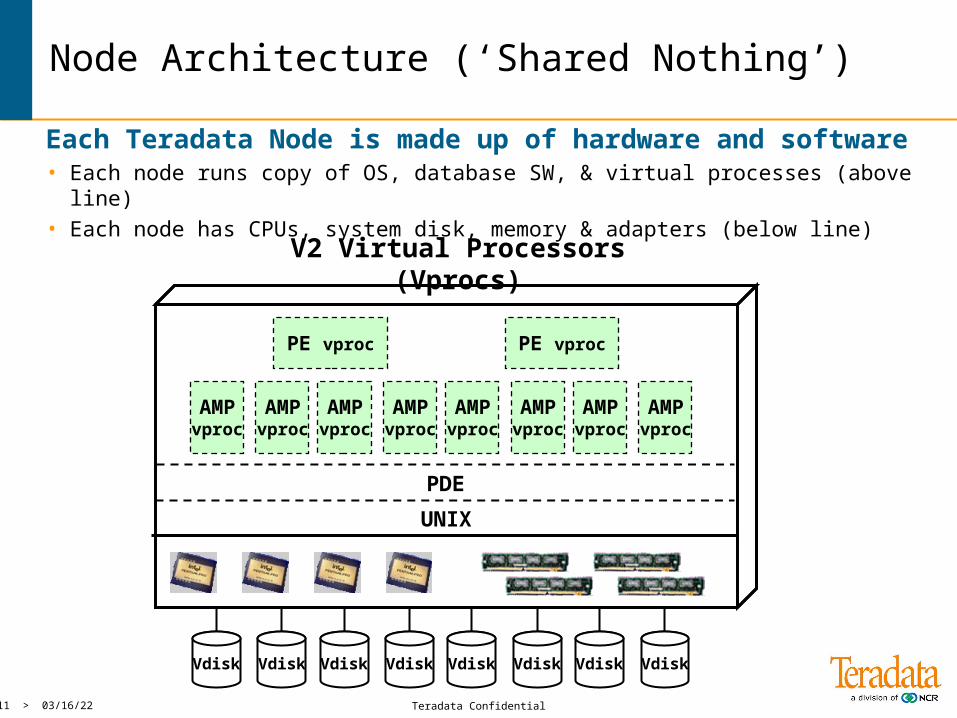
Node Architecture (‘Shared Nothing’)
Each Teradata Node is made up of hardware and software
• Each node has CPUs, system disk, memory and adapters• Each node runs copy of OS and database SW
Teradata Confidential11 > 04/19/23
Node Architecture (‘Shared Nothing’)
Each Teradata Node is made up of hardware and software
• Each node runs copy of OS, database SW, & virtual processes (above line)• Each node has CPUs, system disk, memory & adapters (below line)
PE vproc
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
AMPvproc
Vdisk
PE vproc
UNIX
PDE
V2 Virtual Processors (Vprocs)

Teradata Confidential12 > 04/19/23
NCR 5400 Server Value Prop
1. Better Price/Performance> 20% Performance Improvement> 12% Price/Performance
Improvement
2. Advanced Cabinet Design> Up to 10 Nodes Per Cabinet> Up to a 40% Reduction in Floor
Space
3. Investment Protection> Multi Generation (5) Coexistence> 32-bit/64-bit Transition Platform

Teradata Confidential13 > 04/19/23
NCR 5400 Server Key Messages#2 – Advanced Cabinet Design
• Revolutionary cabinet increases reliability and provides greater configuration flexibility.
> up to 10 nodes per cabinet enable a 20% - 40% smaller footprint than the 5380
> 30% increase in system storage reliability with new advanced cooling mechanisms
> Extend supported distance for large systems (65+ nodes) between cabinets to 300 – 600 meters with new BYNET V3.
> Doubles the number of configurable nodes to 1,024
1
3
1
3
1
3
1
3
1
3
1
3
1
3
1
3
1
3
1
3
1
3
BYNET V3 Switches
Five UPS Modules
Ethernet Switches
Up to 10 nodes within each cabinet
Server Management
Module (3GSM)
FC Switches

Teradata Confidential14 > 04/19/23
Key Teradata Differentiators
• Parallelism throughout platform• Shared Nothing Architecture• Proprietary intelligent system inter-connect
Teradata Confidential15 > 04/19/23
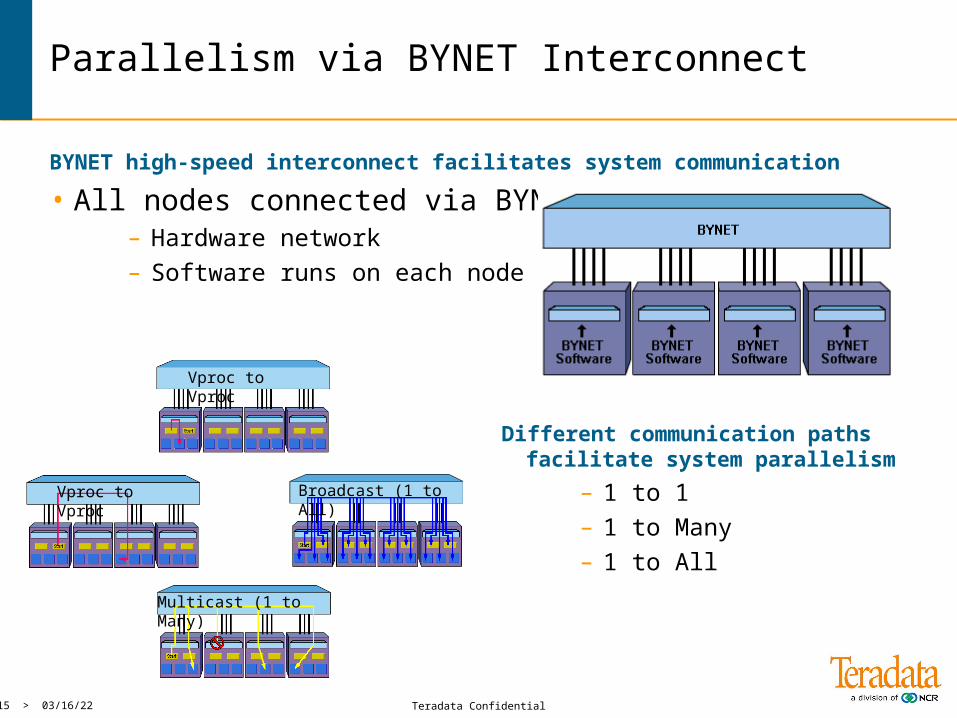
Parallelism via BYNET Interconnect
BYNET high-speed interconnect facilitates system communication
• All nodes connected via BYNET– Hardware network– Software runs on each node
Vproc to Vproc
Vproc to Vproc
Multicast (1 to Many)
Broadcast (1 to All)
Different communication paths facilitate system parallelism
– 1 to 1– 1 to Many– 1 to All
Teradata Confidential16 > 04/19/23
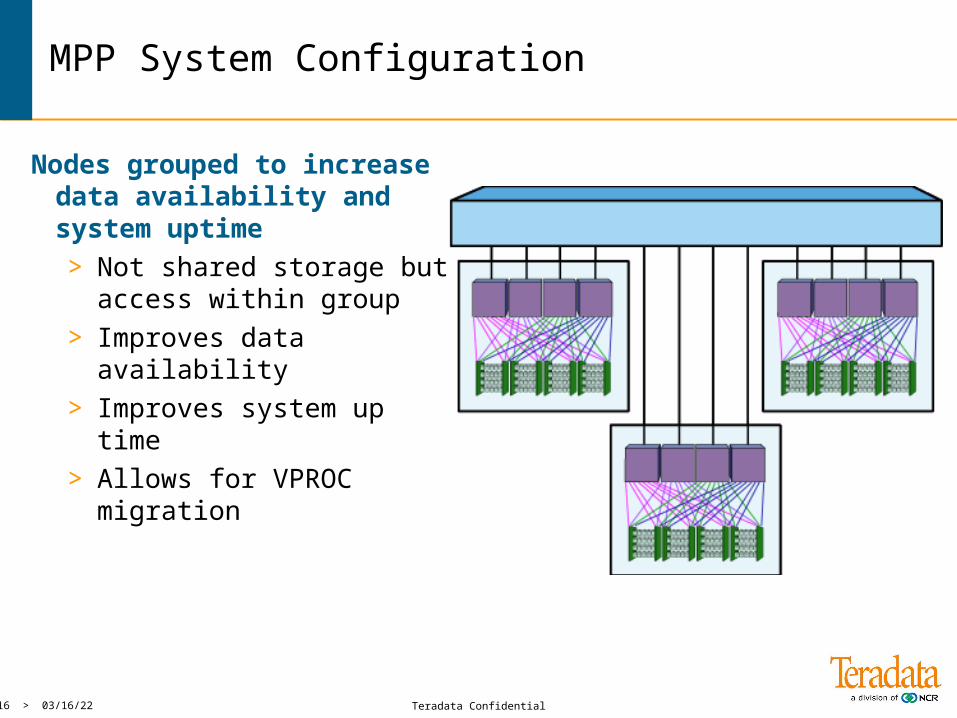
MPP System Configuration
Nodes grouped to increase data availability and system uptime > Not shared storage but
access within group> Improves data availability> Improves system up time> Allows for VPROC
migration
Teradata Confidential17 > 04/19/23
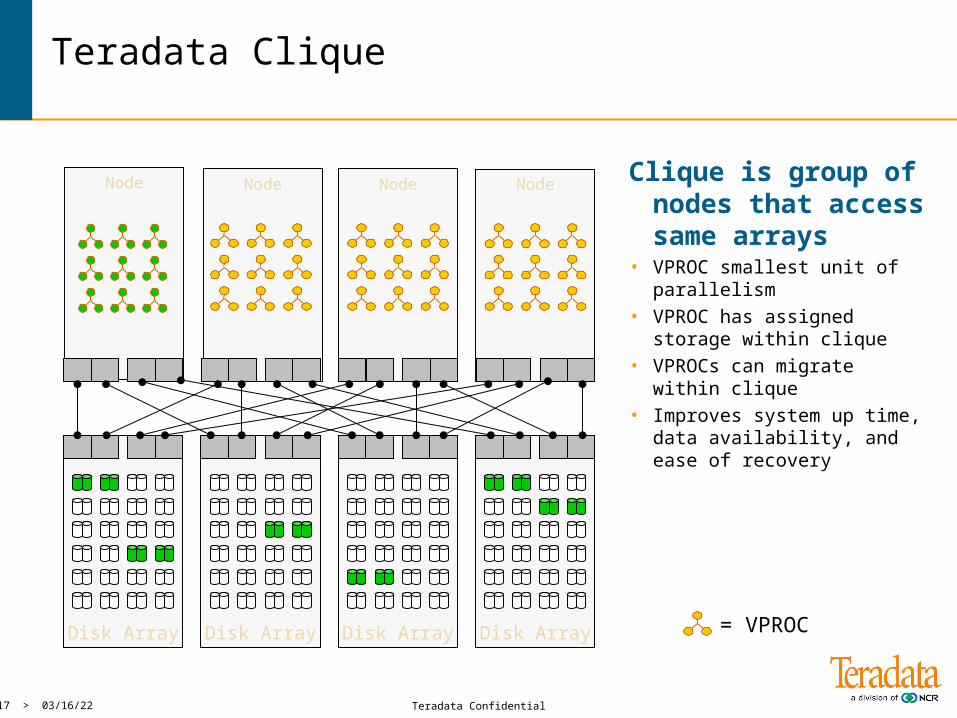
Teradata Clique
NodeNode Node Node
Disk Array Disk Array Disk Array Disk Array
Clique is group of nodes that access same arrays
• VPROC smallest unit of parallelism
• VPROC has assigned storage within clique
• VPROCs can migrate within clique
• Improves system up time, data availability, and ease of recovery
= VPROC

Teradata Confidential18 > 04/19/23
Teradata Clique and VPROC
NodeNode Node Node
Disk Array Disk Array Disk Array Disk Array
VPROC smallest unit of parallelism
• VPROC smallest unit of parallelism or work
• Data distributed by hash to all VPROCs
• VPROC has assigned storage within clique
• VPROCs can migrate within clique
• Improves system up time, data availability, and ease of recovery
• Data fully available at degraded performance until node returns.
= VPROC
X

Teradata Confidential19 > 04/19/23
Node Node Node Node Node NodeNode Hot Standby
X
Disk Array Disk Array Disk Array Disk Array Disk Array Disk Array
Fibre Channel Switches
Teradata Clique with Hot Standby

Teradata Confidential20 > 04/19/23
Teradata Optimizer
• The Teradata Optimizer is the most robust in the industry• Optimizer is parallel-aware, understands available system
components• Handles mixed work loads
> Multiple complex queries > Joins per query > Unlimited ad-hoc processing
• Output is least expensive plan (resources) to answer request

Teradata Confidential21 > 04/19/23
Teradata Request Cycle
DBaseAccessRightsTVMTVFieldsIndexes
DATA parcel
AMPSTEPS
STATISTICS
GENERATOR
OPTIMIZER
RESOLVER
SYNTAXER
DD
REQUEST Parcel
CACHED?
No
GNCAPPLY
SECURITY
Yes
Request flow diagram• Each request parcel contains at least
one SQL statement• Six main component steps
> Syntaxer> Resolver> Security> Optimizer> Generator> gncApply
• AMP steps are instructions sent to AMP VPROCs to complete the request
• Following completion each request generates a success/fail parcel with any necessary records.

Teradata Confidential22 > 04/19/23
Data Protection (Object Locks)
Locks protect data from simultaneous access• Vary by type
– Exclusive, Write, Read, & Access
• Vary by object locked – Database, Table, & Row Hash
• Locks enforced by hierarchy
Teradata Confidential23 > 04/19/23
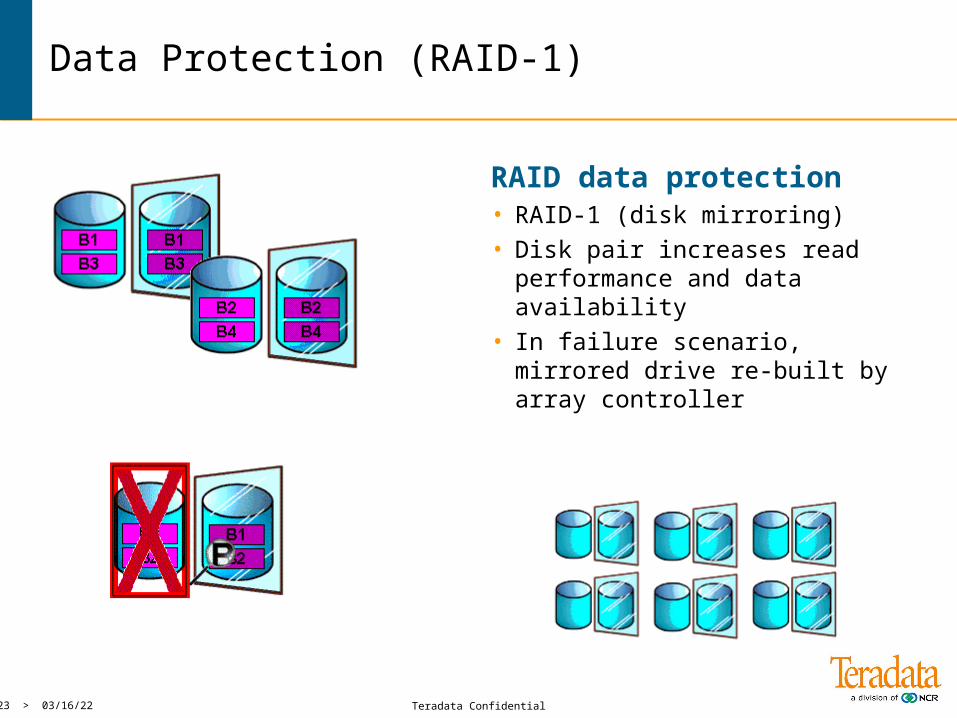
Data Protection (RAID-1)
RAID data protection• RAID-1 (disk mirroring)• Disk pair increases read
performance and data availability• In failure scenario, mirrored drive
re-built by array controller

Teradata Confidential24 > 04/19/23
Data Protection (Fallback)
• Fallback table data• Copy of table rows maintained by database on
second AMP VPROC
• Fallback copies grouped logically in CLUSTERS so data fully available when physical CLIQUE is
off-line.• Fallback + RAID increase data availability

Teradata Confidential25 > 04/19/23
Data Storage and Access
Bucket #
Row Hash
Parsing Engine
Primary Index value = 25
Message Passing Layer
AMP AMP AMP AMP
Hash Map
Hashing Algorithm
25
Data stored by hash• Primary Index is chosen for
data distribution, not same as primary key
• Primary Index value hashed• Hash value creates bucket
assignment• Hash Map assigns buckets to
AMP VPROCs• AMP VPROCs reside on
specific node• AMP VPROC writes row to
disk• Data and algorithm
exceptions require Uniqueness value for guaranteed unique Row ID

Teradata Confidential26 > 04/19/23
Data Access by Primary Index
Data accessed by row hash valueNeed 3 pieces of information
to find a row• Table ID• Row Hash of PI value
> Output of hash algorithm on PI Value
• PI Value• Operation involves only
one AMP VPROC
Table-idRow-hash
Cyl 1Index
Cyl 2Index
Cyl 3Index
Cyl 4Index
Cyl 5Index
Cyl 6Index
Cyl 7Index
Master
Index
Data RowData Row
DATA BLOCK
AMP #3
Cylinder #PI Value

Teradata Confidential27 > 04/19/23
Base Table Base Table Base Table Base Table
RowID Cust Name Phone
USI NUPI471, 1 45 Adams 444-6666555, 6 98 Brown 333-9999717, 2 72 Adams 666-7777884, 1 74 Smith 555-6666
RowID Cust Name Phone
USI NUPI147, 1 49 Smith 111-6666147, 2 12 Young 777-4444388, 1 27 Jones 222-8888822, 1 62 Black 444-5555
RowID Cust Name Phone
USI NUPI107, 1 37 White 555-4444536, 5 84 Rice 666-5555638, 1 31 Adams 111-2222640, 1 40 Smith 222-3333
AMP 1 AMP 2 AMP 3 AMP 4
Message Passing Layer
Data Access by Unique Secondary Index (USI)
USI Data access• Index is created on table• SQL uses USI by value• PE VPROC managing
session uses same information as primary index access (Table ID, Row Hash, Index Value)
• This process involves two AMP VPROC operations
• After USI subtable lookup, process similar to primary index access
RowID Cust Name Phone
USI NUPI639, 1 77 Jones 777-6666778, 3 95 Peters 555-7777778, 7 56 Smith 555-7777915, 9 51 Marsh 888-2222
Table ID
100
Row Hash
778
Unique Val
7
USI Subtable USI Subtable USI Subtable USI Subtable
RowID Cust RowID244, 1 74 884, 1505, 1 77 639, 1744, 4 51 915, 9757, 1 27 388, 1
RowID Cust RowID135, 1 98 555, 6296, 1 84 536, 5602, 1 56 778, 7969, 1 49 147, 1
RowID Cust RowID288, 1 31 638, 1339, 1 40 640, 1372, 2 45 471, 1588, 1 95 778, 3
RowID Cust RowID175, 1 37 107, 1489, 1 72 717, 2838, 4 12 147, 2919, 1 62 822, 1
Message Passing Layer
AMP 1 AMP 2 AMP 3 AMP 4
CREATE UNIQUE INDEX (cust) on customer;
SELECT *FROM customerWHERE cust = 56;
Create USI
Access via USI
Table ID
100
Row Hash
602
Index Value
56
Customer Table ID = 100
USI Value = 56
Hashing Algorithm
PE

Teradata Confidential28 > 04/19/23
Data Access via Non-uniqueSecondary Index (NUSI)
CREATE INDEX (name) on customer;
SELECT *FROM customerWHERE name = ‘Adams’;
Create NUSI
Access via NUSI
Table ID
100
Row Hash
567
Index Value
‘Adams’
Hashing Algorithm
PE
NUSI Subtable NUSI Subtable NUSI Subtable NUSI Subtable
RowID Name RowID432, 8 Smith 640, 1448, 1 White 107, 1567, 3 Adams 638, 1656, 1 Rice 536, 5
Message Passing Layer
AMP 1 AMP 2 AMP 3 AMP 4
RowID Name RowID432, 1 Smith 147, 1448, 4 Black 822, 1567, 6 Jones 338, 1770, 1 Young 147, 2
RowID Name RowID155, 1 Marsh 915, 9396, 1 Peters 778, 3432, 5 Smith 778, 7567, 1 Jones 639, 1
RowID Name RowID432, 3 Smith 884,1567, 2 Adams 471,1 717,2852, 1 Brown 555,6
Base Table Base Table Base Table Base Table
RowID Cust Name Phone
NUSI NUPI147, 1 49 Smith 111-6666147, 2 12 Young 777-4444388, 1 27 Jones 222-8888822, 1 62 Black 444-5555
RowID Cust Name Phone
NUSI NUPI107, 1 37 White 555-4444536, 5 84 Rice 666-5555638, 1 31 Adams 111-2222640, 1 40 Smith 222-3333
AMP 1 AMP 2 AMP 3 AMP 4
RowID Cust Name Phone
NUSI NUPI639, 1 77 Jones 777-6666778, 3 95 Peters 555-7777778, 7 56 Smith 555-7777915, 9 51 Marsh 888-2222
RowID Cust Name Phone
NUSI NUPI471, 1 45 Adams 444-6666555, 6 98 Brown 333-9999717, 2 72 Adams 666-7777884, 1 74 Smith 555-6666
NUSI Value = ‘Adams’Customer Table ID = 100
•Index is created on table
•SQL uses NUSI by value
•PE VPROC managing session uses same information as primary index access (Table ID, Row Hash, Index Value)
•This process involves all-AMP VPROC operations

Teradata Confidential29 > 04/19/23
Teradata Structures
Database structures
• Users• Databases
> Tables> Views> Macros> Triggers> Stored
Procedures> User Defined
Functions

Teradata Confidential30 > 04/19/23
Teradata is an Open System
Virtually any application or middleware framework can be integrated with Teradata.
Teradata
CORBA
ODBC
.NET
OLE-DB
TeradataUtilities
Adapter(s)
Mess
age B
us
Publis
h &
Subsc
ribe
JAVA
JDBC
EJB
JDBC
Adapter(s)TeradataUtilities
Web
Messages
IIOP ASPJSPJSM
Queues
Teradata Confidential31 > 04/19/23
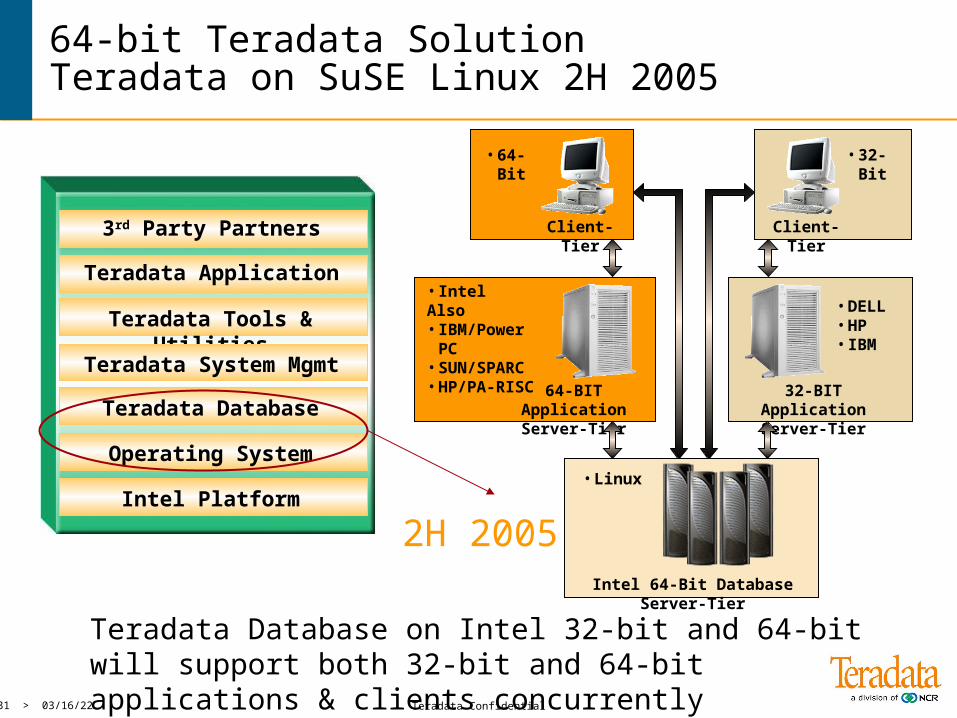
64-bit Teradata SolutionTeradata on SuSE Linux 2H 2005
64-BIT ApplicationServer-Tier
Client-Tier Client-Tier
• 64-Bit
32-BIT ApplicationServer-Tier
• IntelAlso• IBM/Power PC• SUN/SPARC• HP/PA-RISC
• 32-Bit
• DELL• HP• IBM
Teradata Tools & Utilities
Teradata System Mgmt
Intel Platform
Teradata Application
3rd Party Partners
• Linux
Intel 64-Bit Database Server-Tier
Teradata Database on Intel 32-bit and 64-bit will support both 32-bit and 64-bit applications & clients concurrently
Teradata Database
Operating System
2H 2005
Teradata Confidential32 > 04/19/23
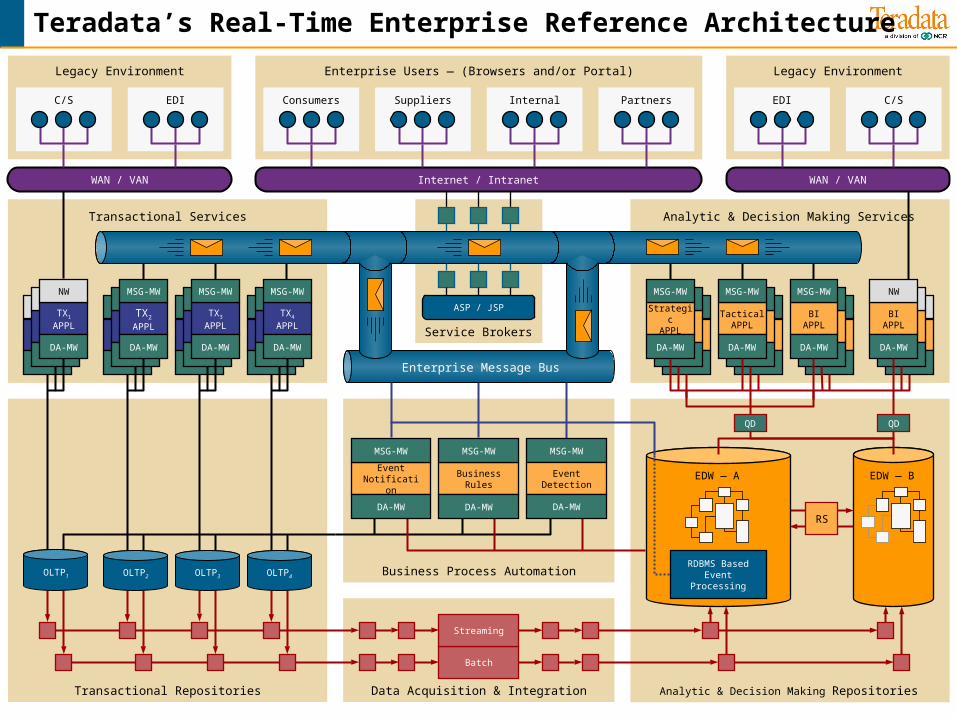
Enterprise Message Bus
TX1
APPL
NW
DA-MW
TX2
APPL
MSG-MW
DA-MW
TX3
APPL
MSG-MW
DA-MW
TX4
APPL
MSG-MW
DA-MW
BIAPPL
MSG-MW
DA-MW
TacticalAPPL
MSG-MW
DA-MW
StrategicAPPL
MSG-MW
DA-MW
Business Process Automation
Analytic & Decision Making Repositories
Analytic & Decision Making Services
Transactional Repositories
Batch
Streaming
Data Acquisition & Integration
Transactional Services
Enterprise Users — (Browsers and/or Portal) Legacy EnvironmentLegacy Environment
Service Brokers
Business Rules
MSG-MW
Event Notification
MSG-MW MSG-MW
Event Detection
WAN / VAN
RS
EDW — BEDW — A
Internet / Intranet WAN / VAN
OLTP1 OLTP2 OLTP3 OLTP4
DA-MWDA-MWDA-MW
RDBMS BasedEvent
Processing
BIAPPL
NW
DA-MW
QDQD
C/S EDI Consumers Suppliers Internal Partners EDI C/S
ASP / JSP
Teradata’s Real-Time Enterprise Reference Architecture
Teradata Confidential33 > 04/19/23
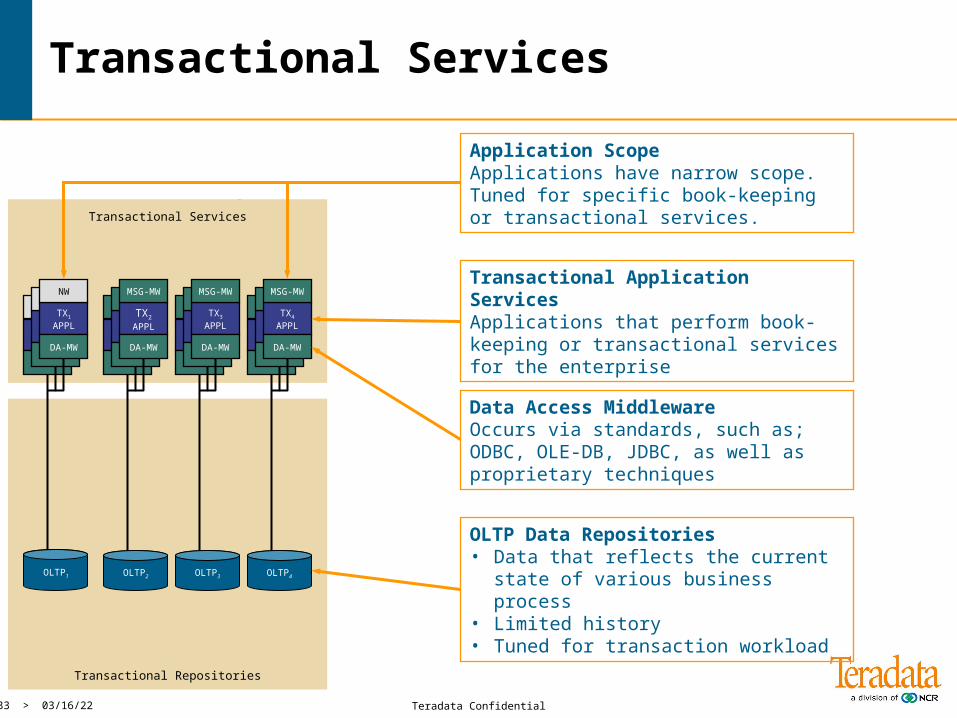
Transactional Services
TX1
APPL
NW
DA-MW
TX2
APPL
MSG-MW
DA-MW
TX3
APPL
MSG-MW
DA-MW
TX4
APPL
MSG-MW
DA-MW
Transactional Repositories
Transactional Services
OLTP1 OLTP2 OLTP3 OLTP4
Data Access Middleware Occurs via standards, such as; ODBC, OLE-DB, JDBC, as well as proprietary techniques
Transactional Application ServicesApplications that perform book-keeping or transactional services for the enterprise
OLTP Data Repositories• Data that reflects the current state
of various business process• Limited history • Tuned for transaction workload
Application Scope Applications have narrow scope. Tuned for specific book-keeping or transactional services.
Teradata Confidential34 > 04/19/23
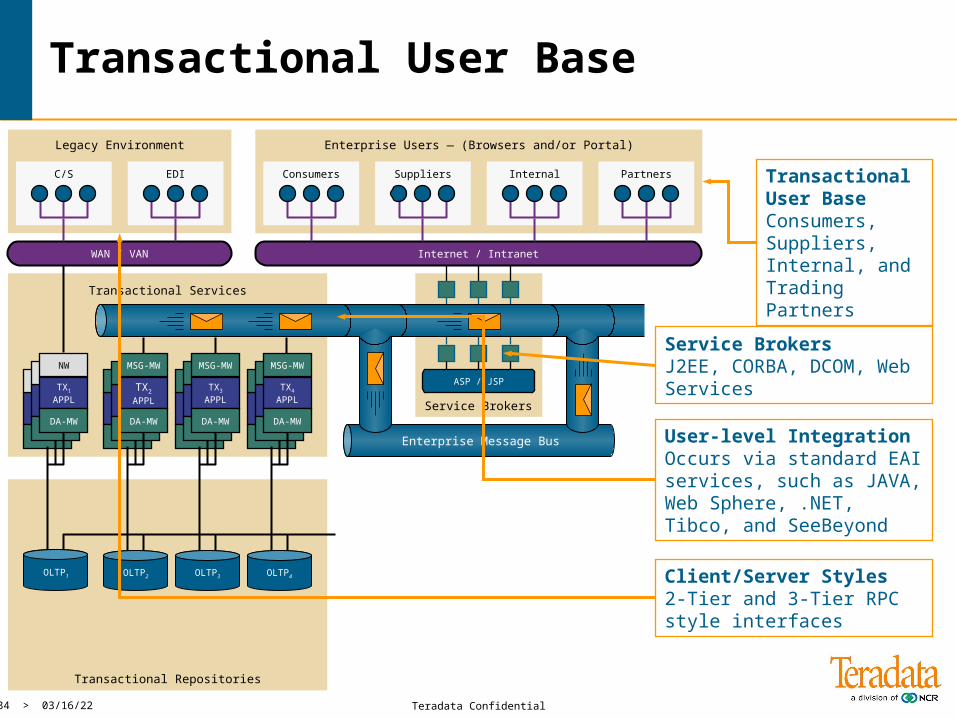
Transactional User Base
Enterprise Message Bus
TX1
APPL
NW
DA-MW
TX2
APPL
MSG-MW
DA-MW
TX3
APPL
MSG-MW
DA-MW
TX4
APPL
MSG-MW
DA-MW
Transactional Repositories
Transactional Services
Enterprise Users — (Browsers and/or Portal)Legacy Environment
Service Brokers
WAN / VAN Internet / Intranet
OLTP1 OLTP2 OLTP3 OLTP4
C/S EDI Consumers Suppliers Internal Partners
ASP / JSP
Client/Server Styles 2-Tier and 3-Tier RPC style interfaces
User-level IntegrationOccurs via standard EAI services, such as JAVA, Web Sphere, .NET, Tibco, and SeeBeyond
Transactional User Base Consumers, Suppliers, Internal, and Trading Partners
Service Brokers J2EE, CORBA, DCOM, Web Services

Teradata Confidential35 > 04/19/23
Data Warehouse Services
Data Access Middleware Occurs via standards, such as ODBC, OLE-DB, JDBC, as well as proprietary techniques
Application Services Applications that provide predictive analysis and assisted decision making
Enterprise Data Warehouse• Consolidated enterprise data• Crosses multiple business
domains• Integrated data model
BIAPPL
MSG-MW
DA-MW
TacticalAPPL
MSG-MW
DA-MW
StrategicAPPL
MSG-MW
DA-MW
Analytic & Decision Making Repositories
Analytic & Decision Making Services
RS
EDW — BEDW — A
RDBMS BasedEvent
Processing
BIAPPL
NW
DA-MW
QDQD
Application ScopeStrategic and Tactical decision making applications.Though BI tools or custom applications.

Teradata Confidential36 > 04/19/23
Decision Support User Base
BIAPPL
MSG-MW
DA-MW
TacticalAPPL
MSG-MW
DA-MW
StrategicAPPL
MSG-MW
DA-MW
Analytic & Decision Making Repositories
Analytic & Decision Making Services
RS
EDW — BEDW — A
RDBMS BasedEvent
Processing
BIAPPL
NW
DA-MW
QDQD
Enterprise Message Bus
Enterprise Users — (Browsers and/or Portal)
Service Brokers
Internet / Intranet
Consumers Suppliers Internal Partners
ASP / JSP
Service Broker Styles J2EE, CORBA, DCOM, Web Services
Client/Server Styles 2-Tier and 3-Tier RPC style interfaces
User-level Integrationoccurs via standard EAI services, such as Web Services, JAVA, .NET, Tibco, and SeeBeyond
Legacy Environment
WAN / VAN
EDI C/S
DW User Base Consumers, Suppliers, Internal, and Trading Partners

Teradata Confidential37 > 04/19/23
Data Acquisition Services
Analytic & Decision Making RepositoriesTransactional Repositories
Batch
Streaming
Data Acquisition & Integration
RS
EDW — BEDW — A
OLTP1 OLTP2 OLTP3 OLTP4
RDBMS BasedEvent
Processing
QDQD
Data Transformation Services• Data cleansing• Data transformation (normalization)• Streaming data for frequent updates• Batch data moves for bulk operations• Partner ETL tools are typically used to
perform these services
Data Extraction• Data is extracted
from OLTP systems• Partner ETL tools are
frequently used here
Data Load• Data is loaded into
EDW system using Teradata Load tools
• FastLoad• MultiLoad• TPump
Data Acquisition Options• Traditional load utilities
(bulk or continuous loads)• Loads through – “in-flight”
Message Passing• Replication – Table level
replication from source to target
Teradata Confidential38 > 04/19/23
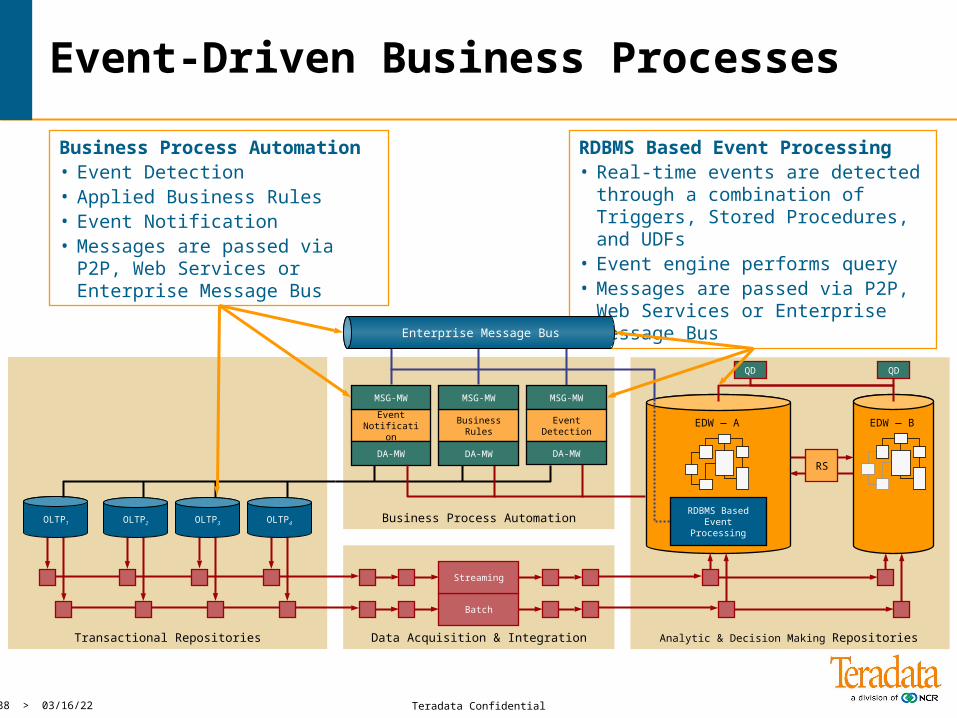
RDBMS Based Event Processing• Real-time events are detected
through a combination of Triggers, Stored Procedures, and UDFs
• Event engine performs query• Messages are passed via P2P, Web
Services or Enterprise Message Bus
Business Process Automation• Event Detection• Applied Business Rules• Event Notification• Messages are passed via P2P,
Web Services or Enterprise Message Bus
Event-Driven Business Processes
Analytic & Decision Making RepositoriesTransactional Repositories
Batch
Streaming
Data Acquisition & Integration
RS
EDW — BEDW — A
OLTP1 OLTP2 OLTP3 OLTP4
RDBMS BasedEvent
Processing
QDQD
Business Process Automation
Business Rules
MSG-MW
Event Notification
MSG-MW MSG-MW
Event Detection
DA-MWDA-MWDA-MW
Enterprise Message Bus

Teradata Confidential39 > 04/19/23
Application Integration
Enterprise Message Bus
TX1
APPL
NW
DA-MW
TX2
APPL
MSG-MW
DA-MW
TX3
APPL
MSG-MW
DA-MW
TX4
APPL
MSG-MW
DA-MW
BIAPPL
MSG-MW
DA-MW
TacticalAPPL
MSG-MW
DA-MW
StrategicAPPL
MSG-MW
DA-MW
Business Process Automation
Analytic & Decision Making Repositories
Analytic & Decision Making Services
Transactional Repositories
Batch
Streaming
Data Acquisition & Integration
Transactional Services
Service Brokers
Business Rules
MSG-MW
Event Notification
MSG-MW MSG-MW
Event Detection
RS
EDW — BEDW — A
OLTP1 OLTP2 OLTP3 OLTP4
DA-MWDA-MWDA-MW
RDBMS BasedEvent
Processing
BIAPPL
NW
DA-MW
QDQD
ASP / JSP
Decision Making Applications interact with bookkeeping applications via standard Enterprise services, such as Web Services, JAVA, .NET, -or- through the use of traditional client/server technology.
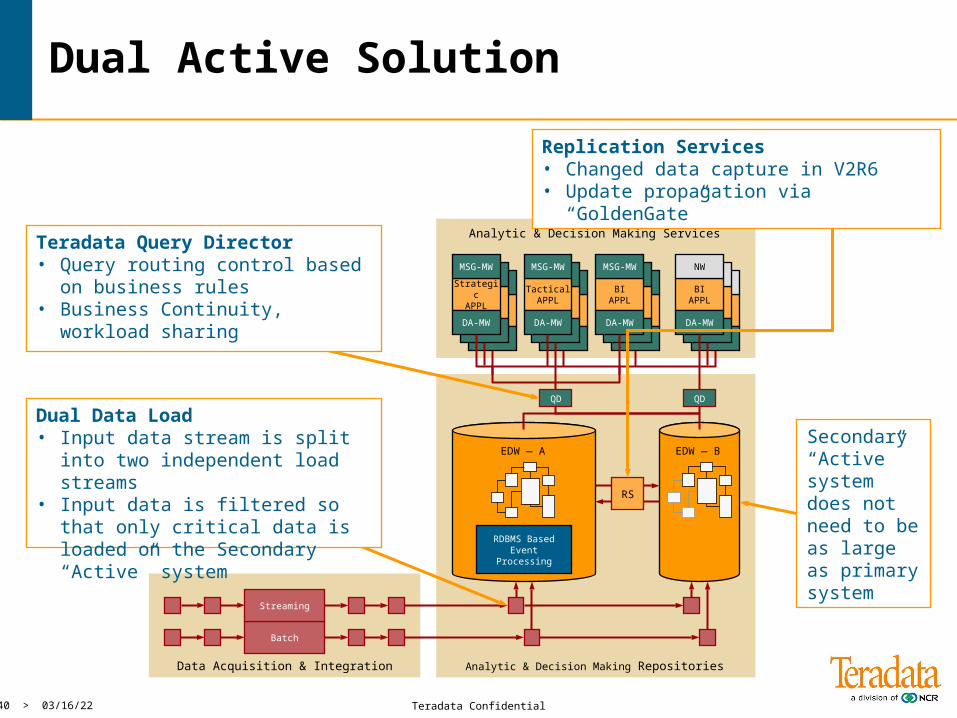
Teradata Confidential40 > 04/19/23
Dual Active Solution
BIAPPL
MSG-MW
DA-MW
TacticalAPPL
MSG-MW
DA-MW
StrategicAPPL
MSG-MW
DA-MW
Analytic & Decision Making Repositories
Analytic & Decision Making Services
Batch
Streaming
Data Acquisition & Integration
RS
EDW — BEDW — A
RDBMS BasedEvent
Processing
BIAPPL
NW
DA-MW
QDQD
Secondary “Active” system does not need to be as large as primary system
Replication Services• Changed data capture in V2R6• Update propagation via “GoldenGate”
Dual Data Load• Input data stream is split into
two independent load streams• Input data is filtered so that only
critical data is loaded on the Secondary “Active” system
Teradata Query Director• Query routing control based on
business rules• Business Continuity, workload
sharing


















