
Introduction to the Teradata RDBMS for UNIX
315
Introduction to the Teradata RDBMS for UNIX Version 2 Release 2.1.0 BD10-4955-B
Transcript of Introduction to the Teradata RDBMS for UNIX

Introduction to theTeradata RDBMS for UNIX
Version 2 Release 2.1.0BD10-4955-B

BD10-4955-B01.00.00May 29, 1998
Introduction to the Teradata® RDBMS for UNIX®Version 2 Release 2.1

The product described in this book is a licensed product of NCR Corporation.
BYNET is a registered trademark of Teradata CorporationCICS, CICS/ESA, CICS/VS, DATABASE2, DB2, IBM, MVS/ESA, MVS/XA, QMS, RACF, SQL/DS, VM/XA, and VTAM are trademarks or registered trademarks of International Business Machines Corporation in the U. S. and other countries. DBC/1012 is a registered trademark of Teradata Corporation.DEC, VAX, MicroVax, and VMS are registered trademarks of Digital Equipment Corporation.EXCELAN is a trademark of Excelan, Incorporated.HEWLETT-PACKARD is a registered trademark of Hewlett-Packard Company,INTELLECT and KBMS are trademarks of Trinzic Corporation.INTERTEST is a registered trademark of Computer Associates International, Inc.ISO is a trademark of International Standards Organization. MICROSOFT, MS-DOS, DOS/V, Windows, Windows 95, and Windows NT are registered trademarks of Microsoft Corporation.SABRE is a trademark of Seagate Technology, Inc.SAS and SAS/C are registered trademarks of SAS Institute Inc.SUN and SUN OS are trademarks of Sun Microsystems, Incorporated.TCP/IP protocol is a United States Department of Defense Standard ARPANET protocol. TERADATA is a registered trademark of Teradata Corporation.UNIX is a registered trademark of UNIX System Laboratories. YNET is a registered trademark of Teradata Corporation.X/Open and the X device are trademarks of X/Open Company Limited.XNS is a trademark of Xerox Corporation.
It is the policy of NCR Corporation (NCR) to improve products as new technology, components, software, and firmware become available. NCR, therefore, reserves the right to change specifications without prior notice.
All features, functions, and operations described herein may not be marketed by NCR in all parts of the world. In some instances, photographs are of equipment prototypes. Therefore, before using this document, consult with your NCR representative or NCR office for information that is applicable and current.
To maintain the quality of our information products, we need your comments on the accuracy, clarity, organization, and value of this book. Please complete the User Feedback Form and mail or e-mail the form to:
Information EngineeringNCR Corporation100 North Sepulveda BoulevardEl Segundo, CA 90245-4361U.S.A.
Copyright © 1998 By NCR CorporationDayton, Ohio U.S.A.All Rights ReservedPrinted in U.S.A.

i
Introduction to the Teradata RDBMS for UNIXAbout This BookPreface
About This Book
Note: The name of the Teradata Database System (DBS) has been changed to the Teradata Relational Database Management System (RDBMS) to more accurately reflect the true nature of the product. This change will take place over a period of time in documentation, product names, and screen displays. In the meantime, all occurrences of “Teradata Database System,” “Teradata DBS,” or “DBS” should be read as referring to the “Teradata Relational Database Management System.”
PurposeThis book provides an introduction to the Teradata RDBMS for UNIX.
AudienceThis book is intended for anybody who uses the Teradata RDBMS for UNIX.
How This Book Is Organized
This book contains thirteen chapters, one appendix and a glossary:
Chapter 1, “Overview,” introduces the Teradata RDBMS, including its design philosophy and goals, its shared information architecture, and its scalability.
Chapter 2, “Teradata RDBMS Architecture,” introduces the hardware and software architecture that supports the Teradata RDBMS, including both client and server software. System 3500, System 4500, and System 5100 (WorldMark) hardware is described.
Chapter 3, “The Relational Model,” presents an overview of the relational model for database management, including an introduction to normalization and a brief discussion of Teradata RDBMS macros.
Chapter 4, “Data Definition,” describes the data definition capabilities of Teradata SQL, the Structured Query Language, including how to create, change, and delete databases, tables, indexes, and macros.
Chapter 5, “Data Manipulation,” describes the data manipulation capabilities of Teradata SQL, including the SELECT, INSERT, UPDATE, and DELETE statements.
Chapter 6, “Views,” introduces the concept of the view, emphasizing that views are virtual, not base tables. The chapter also describes why views are the recommended means by which to present base table information to end users.

PrefaceAbout This Book
Chapter 7, “Data Dictionary,” describes the Data Dictionary (DD), the system catalog for the Teradata RDBMS. The DD includes definitions for the database objects, user characteristics, and much more.
Chapter 8, “Application Development,” introduces application development in the Teradata RDBMS environment, including the use of embedded SQL and CLI calls in client programming languages.
Chapter 9, “Fault Tolerance,” describes fault tolerance in the Teradata RDBMS, including both hardware and software elements.
Chapter 10, “Concurrency Control and Recovery,” introduces the topic of concurrency control and transactions. Object locking, serializability of transactions, and the two-phase commit protocol for distributed databases are among the subjects described.
Chapter 11, “Security and Integrity,” discusses security and integrity in the Teradata RDBMS environment.
Chapter 12, “System Administration,” introduces system administration of the Teradata RDBMS. Topics include user and space allocation, accounting, monitoring, and server-resident utilities.
Chapter 13, “Operating and Configuration Specifications,” describes the capacities of and requirements for the Teradata RDBMS.
Appendix A, “How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOS,” describes the differences between Version 1 and Version 2 Teradata database management systems.
The “Glossary” defines frequently used terms in the Teradata RDBMS environment.
PrerequisitesYou should be familiar with basic computer technology, NCR system hardware, the Teradata RDBMS, the system console environment, and X Windows.
It may be helpful to review the following books:
● Introduction to Teradata RDBMS for UNIX● Teradata RDBMS for UNIX Support Utilities Reference
ii Introduction to the Teradata RDBMS for UNIX

PrefaceChanges to This Book
Changes to This Book
Changes made to the Introduction to the Teradata RDBMS for UNIX are focused on DR maintenance and include:
Join Index
DR 37060
Join Index represents a new type of indexing structure. For introductory information on Join Index see page 4-10 and page 4-17.
For general information on Join Index, see the Teradata RDBMS for UNIX V2R2.1 Base System Release Definition and Transmittal Document. For usage information see the section on Join Index in the Teradata RDBMS for UNIX Database Design and Administration Manual.
RFC to provide ESCON mainframe channel connectivity
DCR 7030
This DR addresses changes to the mainframe physical connection to the Teradata server. Pages in this document that are impacted: page 2-3, page 2-4, page 2-5 and page 2-11.
Hash Join
DR 39131
Hash Join is an alternative join scheme and is introduced on page 5-13.
Decimal 18 Default is Regression Problem
DR 39789
The increase of the maximum Decimal value for TotalDigits from 15 to 18has caused regression problems some customer applications and third party vendor processes. This DR is addressed in page 4-2 and page 4-2.
Introduction to the Teradata RDBMS for UNIX iii

PrefaceChanges to This Book
Minor wording changes include:
DR 41272
Corrected on page 2-11.
Teradata RDBMS Year 2000 Qualification
DR 38139
Throughout this reference, there is frequent mention of the DATE parameter in a 2-digit year format ‘YY/MM/DD’.
Teradata RDBMS V2R2.1 introduces the use of a system-wide default called the CenturyBreak parameter which the RDBMS software will use to internally convert 2-digit dates (‘YY’) to the correct 4-digit date (‘XXYY’). This new parameter is a new general field in the DBS control record.
For more information on the CenturyBreak parameter see Chapter 14, “Setting Up, Creating, and Modifying the Database Structure,” of the Teradata RDBMS for UNIX Database Design and Administration Manual.
iv Introduction to the Teradata RDBMS for UNIX

PrefaceList of Acronyms
List of Acronyms
The following acronyms, listed in alphabetical order, are used in this book:
1NF First Normal Form
2NF Second Normal Form
2PC Two-Phase Commit
3NF Third Normal Form
4NF Fourth Normal Form
5NF Fifth Normal Form
AMP Access Module Process
ANSI American National Standards Institute
API Application Programming Interface
ASCII American Standard Code for Information Interchange
ASF2 Archive Storage Facility 2
AWS Administrative Workstation
BCNF Boyce-Codd Normal Form
BTEQ Basic Teradata Query Facility
CICS Customer Information Control System
CLIv2 Call-Level Interface, Version 2
CMS Conversational Monitor System
CNS Console Subsystem
DB2 DATABASE 2
DBC Database Computer
DBS Database System
DBW Database Window
DD Data Dictionary
DDL Data Definition Language
DML Data Manipulation Language
EBCDIC Extended Binary Coded Decimal Interchange Code
FIPS Federal Information Processing Standards
Introduction to the Teradata RDBMS for UNIX v
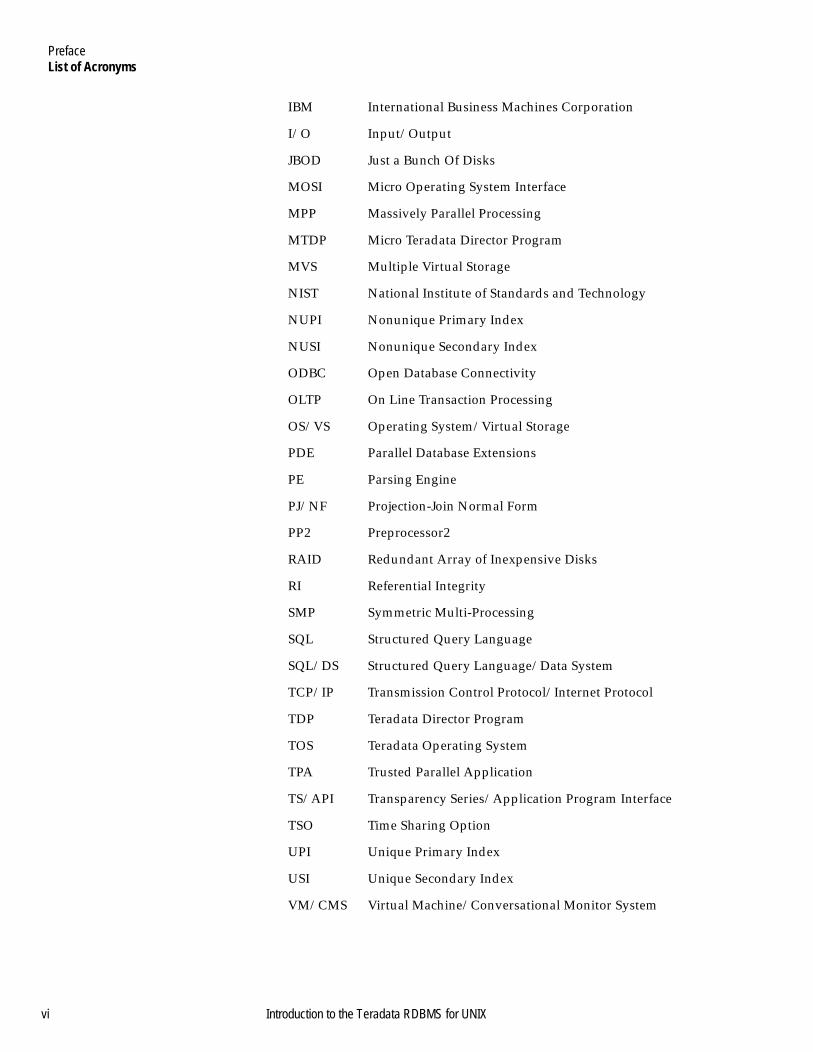
PrefaceList of Acronyms
IBM International Business Machines Corporation
I/O Input/Output
JBOD Just a Bunch Of Disks
MOSI Micro Operating System Interface
MPP Massively Parallel Processing
MTDP Micro Teradata Director Program
MVS Multiple Virtual Storage
NIST National Institute of Standards and Technology
NUPI Nonunique Primary Index
NUSI Nonunique Secondary Index
ODBC Open Database Connectivity
OLTP On Line Transaction Processing
OS/VS Operating System/Virtual Storage
PDE Parallel Database Extensions
PE Parsing Engine
PJ/NF Projection-Join Normal Form
PP2 Preprocessor2
RAID Redundant Array of Inexpensive Disks
RI Referential Integrity
SMP Symmetric Multi-Processing
SQL Structured Query Language
SQL/DS Structured Query Language/Data System
TCP/IP Transmission Control Protocol/Internet Protocol
TDP Teradata Director Program
TOS Teradata Operating System
TPA Trusted Parallel Application
TS/API Transparency Series/Application Program Interface
TSO Time Sharing Option
UPI Unique Primary Index
USI Unique Secondary Index
VM/CMS Virtual Machine/Conversational Monitor System
vi Introduction to the Teradata RDBMS for UNIX
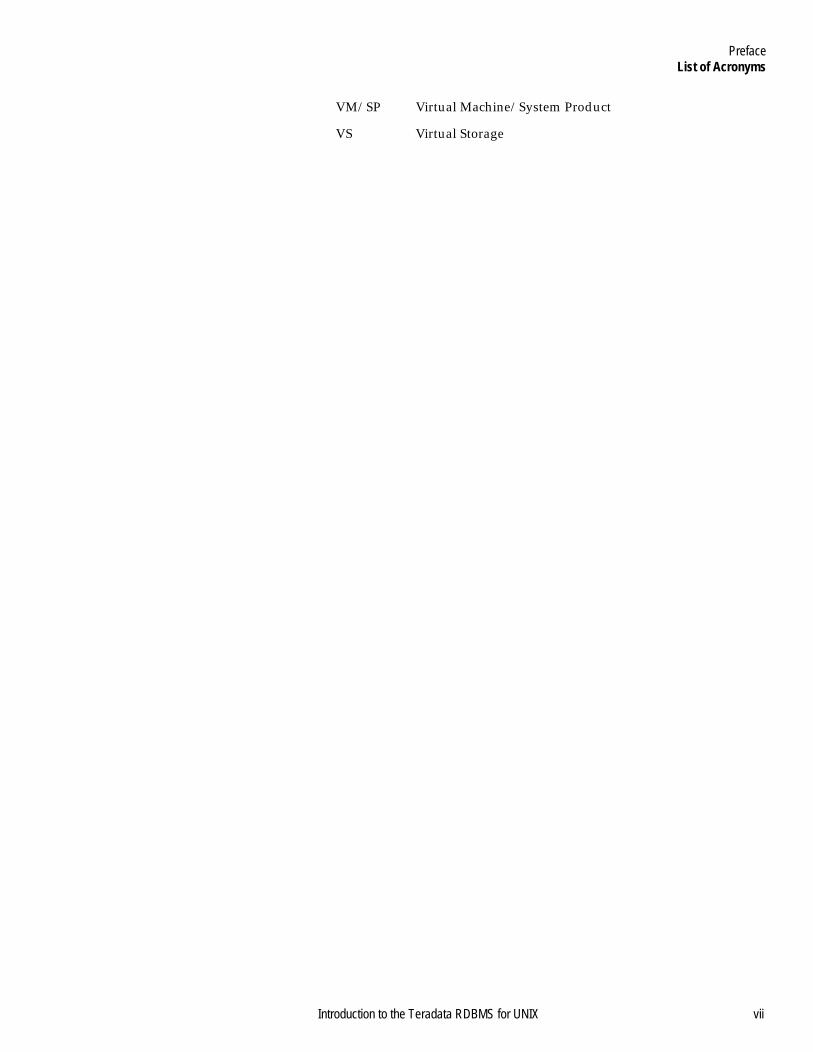
PrefaceList of Acronyms
VM/SP Virtual Machine/System Product
VS Virtual Storage
Introduction to the Teradata RDBMS for UNIX vii

PrefaceTeradata RDBMS for UNIX Library
Teradata RDBMS for UNIX Library
Titles of publications in the Teradata RDBMS for UNIX library begin with Teradata RDBMS for UNIX. The following publications, listed in alphabetical order, apply to Teradata RDBMS for UNIX, Version 2 Release 2.1, and will be available May 29, 1998:
Electronic Versions of Teradata Publications
To obtain the latest version of Teradata RDBMS for UNIX publications, please visit our Internet site at:
http://www.info.ncr.com
Product ID Publication Title
BD10-5059-B Data Dictionary Reference
BD10-4953-C Database Design and Administration
BD10-5060-B Database Window Reference
BD10-5061-E Field Support Guide
BD10-4955-B Introduction to the Teradata RDBMS for UNIX
BD10-4956-A Master Index, Bibliography, and Glossary
BD10-5062-D Messages Reference
B035-1005-048A Performance Maximization Guide for 5100M
BD10-5013-A Performance Monitor Reference
BD10-5063-A Publications Roadmap for Kanji Functions and Features
BD10-5064-C Resource Usage Macros and Tables
BD10-5052-B Security Administration Guide
B035-1507-048B SQL Quick Reference
BD10-4957-D SQL Reference
BD10-5065-D Support Utilities Reference
BD10-5066-C SystemFE Macros
B035-1504-048B Utilities Quick Reference
BD10-5067-D Utilities Reference
B035-1902-048D Teradata RDBMS for UNIX V2R2.1 and Client 9801 User Documentation CD-ROM
viii Introduction to the Teradata RDBMS for UNIX
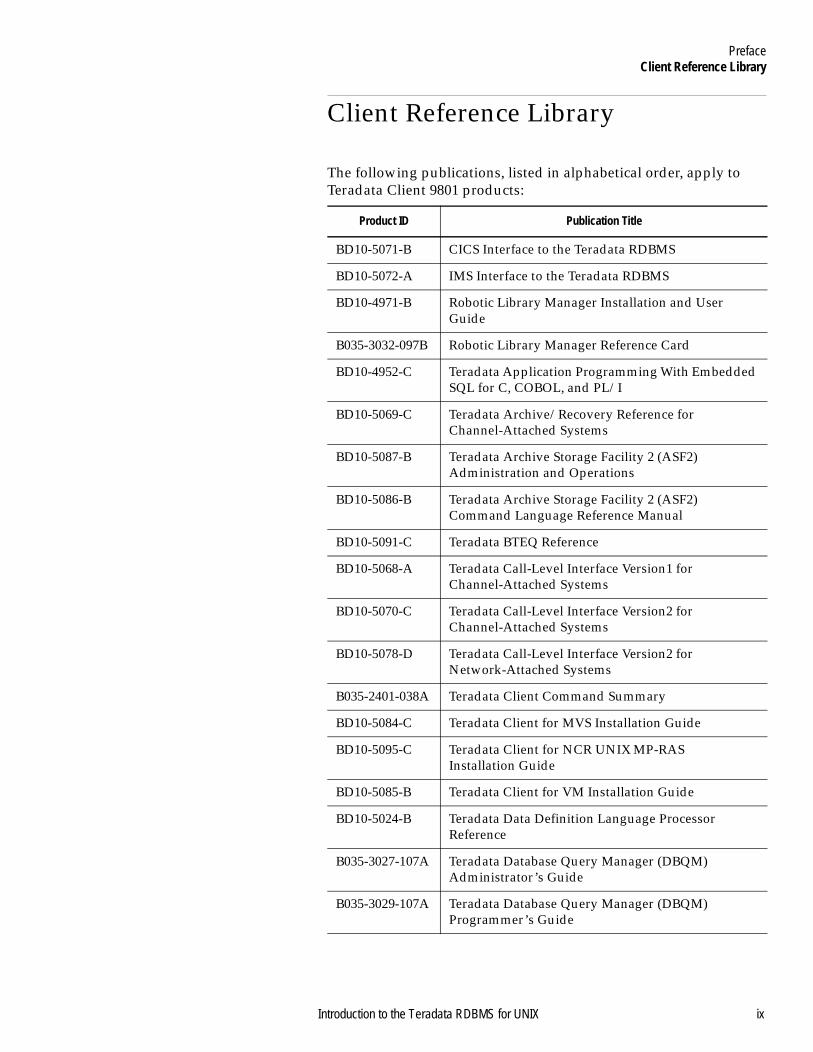
PrefaceClient Reference Library
Client Reference Library
The following publications, listed in alphabetical order, apply to Teradata Client 9801 products:
Product ID Publication Title
BD10-5071-B CICS Interface to the Teradata RDBMS
BD10-5072-A IMS Interface to the Teradata RDBMS
BD10-4971-B Robotic Library Manager Installation and User Guide
B035-3032-097B Robotic Library Manager Reference Card
BD10-4952-C Teradata Application Programming With Embedded SQL for C, COBOL, and PL/I
BD10-5069-C Teradata Archive/Recovery Reference for Channel-Attached Systems
BD10-5087-B Teradata Archive Storage Facility 2 (ASF2) Administration and Operations
BD10-5086-B Teradata Archive Storage Facility 2 (ASF2) Command Language Reference Manual
BD10-5091-C Teradata BTEQ Reference
BD10-5068-A Teradata Call-Level Interface Version1 for Channel-Attached Systems
BD10-5070-C Teradata Call-Level Interface Version2 for Channel-Attached Systems
BD10-5078-D Teradata Call-Level Interface Version2 for Network-Attached Systems
B035-2401-038A Teradata Client Command Summary
BD10-5084-C Teradata Client for MVS Installation Guide
BD10-5095-C Teradata Client for NCR UNIX MP-RAS Installation Guide
BD10-5085-B Teradata Client for VM Installation Guide
BD10-5024-B Teradata Data Definition Language Processor Reference
B035-3027-107A Teradata Database Query Manager (DBQM) Administrator’s Guide
B035-3029-107A Teradata Database Query Manager (DBQM) Programmer’s Guide
Introduction to the Teradata RDBMS for UNIX ix

PrefaceClient Reference Library
Electronic Versions of Teradata Publications
To obtain the latest version of Teradata Client publications, please visit our Internet site at:
http://www.info.ncr.com
B035-3028-107A Teradata Database Query Manager (DBQM) User’s Guide
BD10-5094-B Teradata Enhanced Call-Level Interface Reference
BD10-5079-C Teradata FastExport Reference
BD10-4954-D Teradata FastLoad Reference
BD10-5074-A Teradata ITEQ Reference Manual for Channel-Attached Systems
BD10-5075-A Teradata ITEQ User’s Guide for Channel-Attached Systems
BST0-2122-30 Teradata ITEQ Keypad Template
BST0-2122-34 Teradata ITEQ Keypad Template (3270 PC)
BST0-2126-20 Teradata ITEQ Reference
BD10-5076-C Teradata MultiLoad Reference
BST0-2141-00 Teradata ODBC Driver for WindowsInstallation and User’s Guide
B035-3021-018A Teradata Parallel Data Pump (TPump) Reference
BD10-5062-D Teradata RDBMS for UNIX Messages Reference
BD10-4966-C Teradata TDP Reference
BD10-5080-B Teradata TS/API Concepts and Facilities
BD10-5083-B Teradata TS/API Installation Guide
BD10-5082-B Teradata TS/API System & DatabaseAdministration Guide
BD10-5081-B Teradata TS/API User’s Guide
BD10-5090-A Teradata WinCLI Application Developer’s Guide
BD10-5093-A Teradata WinCLI Installation Guide
B035-1902-048D Teradata RDBMS for UNIX V2R2.1 and Client 9801 User Documentation CD-ROM
Product ID Publication Title
x Introduction to the Teradata RDBMS for UNIX

PrefaceHow to Order Teradata Publications
How to Order Teradata Publications
You may always order Teradata publications through your NCR Sales Representative, or you may use one of the methods listed below.
Order FormTo order Teradata publications, use the Information Products Order Form (form number IPP-WD02001).
Ordering AddressSend orders to the following address:
Electronic Versions of Teradata Publications
To obtain the latest version of Teradata publications, please visit our Internet site at:
http://www.info.ncr.com
U.S. Orders
NCR IPP-DAYTON1529 Brown StreetDayton, OH 45479USA
FAX: 937-445-6245PHONE: 1-800-543-2010 or VP 622-3727E-MAIL: [email protected]: Publishing, Information+Products
Non- U.S. Orders
NCR IPP-BRUSSELS-OTCRue de la Fusee 50B-1130 BrusselsBelgium
FAX: 32-2-727-95-50PHONE: 32-2-727-95-49 or 32-2-727-95-71E-MAIL: [email protected]
Introduction to the Teradata RDBMS for UNIX xi

PrefaceHow to Order Teradata Publications
xii Introduction to the Teradata RDBMS for UNIX

Contents
Table of Contents
xiii
Introduction to the Teradata RDBMS for UNIXPreface
About This Book ........................................................................................ iPurpose................................................................................................. iAudience .............................................................................................. iHow This Book Is Organized ............................................................ iPrerequisites ....................................................................................... ii
Changes to This Book .............................................................................iiiList of Acronyms ......................................................................................vTeradata RDBMS for UNIX Library .................................................. viiiClient Reference Library......................................................................... ixHow to Order Teradata Publications ................................................... xi
Chapter 1Overview
About This Chapter...............................................................................1-1Introduction .....................................................................................1-1Design Perspectives........................................................................1-1Teradata Database Software..........................................................1-1Client Software................................................................................1-1
Design Perspectives ..............................................................................1-2Introduction .....................................................................................1-2Charter for the Teradata Database System..................................1-2Research Ideas Leading to the Design of the
Teradata Database System ......................................................1-2Shared Information Architecture..................................................1-2
Teradata Database Software ................................................................1-4Introduction .....................................................................................1-4Structured Query Language (SQL) ..............................................1-4
For More Information ...........................................................................1-8

Table of Contents
Chapter 2Teradata RDBMS Architecture
About This Chapter...............................................................................2-1Introduction .....................................................................................2-1Hardware .........................................................................................2-1System Configuration.....................................................................2-3Client Software ................................................................................2-6Server Software ...............................................................................2-8
Virtual Processors..................................................................................2-9Introduction .....................................................................................2-9PEs .....................................................................................................2-9AMPs ..............................................................................................2-10
The Parsing Engine..............................................................................2-11Introduction ...................................................................................2-11Client Interface ..............................................................................2-11Session Control..............................................................................2-11Input Data Conversion.................................................................2-12SQL Parser......................................................................................2-13The Dispatcher...............................................................................2-14Dispatching the Steps ...................................................................2-15Processing the Steps......................................................................2-16
Structured Query Language ..............................................................2-18Introduction ...................................................................................2-18Why SQL? ......................................................................................2-18SQL Flagger ...................................................................................2-18SQL Lexicon...................................................................................2-19Character Sets ................................................................................2-22
Query Facilities ....................................................................................2-23Introduction ...................................................................................2-23BTEQ ...............................................................................................2-23
The BYNET ...........................................................................................2-24Introduction ...................................................................................2-24BYNET Functions..........................................................................2-24Virtual Processor Connectivity in Single Node Systems ........2-25
The Access Module Process ...............................................................2-26Introduction ...................................................................................2-26AMP Functions..............................................................................2-26Scalability and Performance........................................................2-26The Disk Subsystem......................................................................2-26AMP Clusters.................................................................................2-26
xiv Introduction to the Teradata RDBMS for UNIX

Table of Contents
Request Packaging and Unpackaging..............................................2-27Introduction ...................................................................................2-27Facilities for Packaging and Unpackaging
SQL Requests and Results.....................................................2-27Data Communications Management in the
Teradata RDBMS Environment......................................................2-28Introduction ...................................................................................2-28The TDP..........................................................................................2-28The Micro TDP ..............................................................................2-28
Application Programming Facilities.................................................2-29Introduction ...................................................................................2-29Embedded SQL .............................................................................2-29Call-Level Interface.......................................................................2-29ODBC..............................................................................................2-30
Archiving and Data Loading Utilities ..............................................2-31Introduction ...................................................................................2-31Archive and Restore Utility and ASF2.......................................2-31BulkLoad ........................................................................................2-31FastLoad .........................................................................................2-31MultiLoad ......................................................................................2-31FastExport ......................................................................................2-31
Administrative Workstation ..............................................................2-32Database Window ...............................................................................2-33
Introduction ...................................................................................2-33Workstation Types and Available Platforms............................2-33Database Window Communication ...........................................2-33Functions Provided by the Database Window.........................2-34Supervisor Subwindow................................................................2-34Utilities Available from the Supervisor Subwindow ..............2-34Supervisor Commands Available from the Database Window....
2-34RDBMS Gateway .................................................................................2-36Database Utility Software...................................................................2-37Teradata Manager ...............................................................................2-40
Introduction ...................................................................................2-40Performance Analysis ..................................................................2-40Session Information ......................................................................2-40Statistical Information ..................................................................2-40
For More Information .........................................................................2-41
Introduction to the Teradata RDBMS for UNIX xv

Table of Contents
Chapter 3The Relational Model
About This Chapter...............................................................................3-1Introduction .....................................................................................3-1What is a Relational Database? .....................................................3-1Some Other Definitions..................................................................3-2
Normalization ........................................................................................3-4Introduction .....................................................................................3-4
First, Second, and Third Normal Forms.............................................3-6Introduction .....................................................................................3-6First Normal Form ..........................................................................3-6Second Normal Form .....................................................................3-6Third Normal Form ........................................................................3-7
Boyce-Codd and Higher Normal Forms ............................................3-8Introduction .....................................................................................3-8Boyce-Codd Normal Form ............................................................3-8Fourth Normal Form ......................................................................3-8Fifth Normal Form..........................................................................3-8
Referential Integrity ..............................................................................3-9Introduction .....................................................................................3-9Enforcing RI in the Teradata RDBMS ..........................................3-9Primary and Foreign Keys.............................................................3-9Indexes..............................................................................................3-9How do Primary Keys and Primary Indexes Relate? ..............3-10What is Referential Integrity?......................................................3-10The Referential Constraint...........................................................3-11Referential Constraint Checks.....................................................3-12
Teradata Macros ..................................................................................3-13Introduction ...................................................................................3-13What is a Teradata Macro? ..........................................................3-13Creating a Macro...........................................................................3-13Using a Macro................................................................................3-13Modifying a Macro .......................................................................3-14Deleting a Macro ...........................................................................3-14
For More Information .........................................................................3-15
xvi Introduction to the Teradata RDBMS for UNIX

Table of Contents
Chapter 4Data Definition
About This Chapter...............................................................................4-1Introduction .....................................................................................4-1Basic Statements..............................................................................4-1
Teradata SQL Data Types ....................................................................4-2Introduction .....................................................................................4-2Teradata SQL Data Types..............................................................4-2Teradata SQL Column Attributes.................................................4-3
Creating New Tables.............................................................................4-6Introduction .....................................................................................4-6Example Database...........................................................................4-6Creating the Employee and Department Tables ........................4-7
Altering Tables.......................................................................................4-8Introduction .....................................................................................4-8Capabilities of the ALTER Statement ..........................................4-8Example: Adding a Column..........................................................4-8Example: Dropping a Column ......................................................4-8
Indexes ....................................................................................................4-9Introduction .....................................................................................4-9What Is An Index? ..........................................................................4-9Getting Ideas for Where and When to Index............................4-10Primary Indexes vs. Secondary Indexes ....................................4-11
Primary Indexes...................................................................................4-13Introduction ...................................................................................4-13Unique Primary Index..................................................................4-14Nonunique Primary Index ..........................................................4-14Guidelines for Selecting a Primary Index..................................4-14
Secondary Indexes...............................................................................4-15Introduction ...................................................................................4-15Subtables ........................................................................................4-15Journaling and Secondary Indexes.............................................4-15Advantages of Secondary Indexes .............................................4-16Unique Secondary Index..............................................................4-17Nonunique Secondary Index ......................................................4-17Guidelines for Selecting a Secondary Index .............................4-17
Creating an Index for a Table ............................................................4-18Introduction ...................................................................................4-18Creating a Primary Index ............................................................4-18Creating a Secondary Index ........................................................4-18
Introduction to the Teradata RDBMS for UNIX xvii

Table of Contents
Rule of Thumb for Creating Indexes..........................................4-18Dropping Tables and Indexes............................................................4-19
Introduction ...................................................................................4-19Dropping a Table ..........................................................................4-19Dropping an Index........................................................................4-19
For More Information .........................................................................4-20
Chapter 5Data Manipulation
About This Chapter...............................................................................5-1Introduction .....................................................................................5-1What is the Structured Query Language (SQL)?........................5-1SQL Data Manipulation .................................................................5-1
The SELECT Statement .........................................................................5-2Introduction .....................................................................................5-2Relational Algebra ..........................................................................5-2Teradata SQL Expressions.............................................................5-3Arithmetic Operators .....................................................................5-3Aggregate Operators ......................................................................5-4Comparison Operators...................................................................5-4Logical Operators............................................................................5-5Partial String Matching Operator .................................................5-5Set Operators ...................................................................................5-6Other Operators ..............................................................................5-6Arithmetic Functions......................................................................5-7
Using Fully Qualified Names to Reference Databases and Tables in Teradata SQL......................................................................5-8
Introduction .....................................................................................5-8Fully Qualified Names ...................................................................5-8
Simple SQL Queries: Using the SELECT Statement.........................5-9Introduction .....................................................................................5-9Selecting All Rows from a Table...................................................5-9Selecting Specific Columns from a Table ....................................5-9Selecting Specific Rows from a Table.........................................5-10Using Comparison and Logical Operators to
Select Specific Rows ...............................................................5-11Specifying Order in the Results Table........................................5-12Defining Groups............................................................................5-12Including Information from More Than
One Table in a Query .............................................................5-13Nesting Subqueries .......................................................................5-14
xviii Introduction to the Teradata RDBMS for UNIX

Table of Contents
Using the INSERT Statement.............................................................5-16Introduction ...................................................................................5-16INSERT: First Form.......................................................................5-16INSERT: Second Form..................................................................5-17INSERT: Third Form.....................................................................5-17
Using the UPDATE Statement...........................................................5-18Introduction ...................................................................................5-18How to Change Rows Using the UPDATE Statement ............5-18
Using the DELETE Statement to Delete Rows from a Table.........5-19Introduction ...................................................................................5-19How to Delete Rows from a Table .............................................5-19
Using Teradata SQL in Application Programs ...............................5-20Introduction ...................................................................................5-20Embedded SQL and Client Programming Languages............5-20Cursors ...........................................................................................5-21
For More Information .........................................................................5-22
Chapter 6Views
About This Chapter...............................................................................6-1Introduction .....................................................................................6-1Why Use Views? .............................................................................6-1
Creating and Altering Views ...............................................................6-2Introduction .....................................................................................6-2Creating a Teradata RDBMS View...............................................6-2Altering a Teradata RDBMS View ...............................................6-3
Why You Should Use Views................................................................6-4Introduction .....................................................................................6-4Simplified User Perception of the Database ...............................6-4Security for Restricting Table Access and Updates ...................6-4Well-Defined, High Performance Access to the Database........6-4Logical Data Independence ...........................................................6-5
Restrictions on DML Operations on Views .......................................6-6Introduction .....................................................................................6-6Views with Aggregates ..................................................................6-6Views with Joins..............................................................................6-6
For More Information ...........................................................................6-7
Introduction to the Teradata RDBMS for UNIX xix

Table of Contents
Chapter 7Data Dictionary
About This Chapter...............................................................................7-1Introduction .....................................................................................7-1DD Objects .......................................................................................7-1DD Users ..........................................................................................7-1
Structure of the Data Dictionary .........................................................7-2Introduction .....................................................................................7-2A Summary of the DD Views........................................................7-2End User Views...............................................................................7-3Supervisory User Views.................................................................7-3Administrator Views ......................................................................7-4Recovery Control User Views .......................................................7-5
Using the Data Dictionary....................................................................7-6Introduction .....................................................................................7-6Why Use the Data Dictionary?......................................................7-6How do you Access the Data Dictionary?...................................7-6
For More Information ...........................................................................7-8
Chapter 8Application Development
About This Chapter...............................................................................8-1Introduction .....................................................................................8-1Explicit SQL Development ............................................................8-1Implicit SQL Development............................................................8-1
Writing Embedded SQL Applications................................................8-2Introduction .....................................................................................8-2What is Embedded SQL? ...............................................................8-2How Does an Application Program Use Embedded SQL? ......8-2Supported Languages and Platforms...........................................8-3
Using Macros as SQL Applications ....................................................8-4Introduction .....................................................................................8-4Creating a Macro.............................................................................8-4Using a Macro..................................................................................8-5Modifying a Macro .........................................................................8-5Deleting a Macro .............................................................................8-5
Using the EXPLAIN Statement As a Tool To Optimize Your SQL Code..................................................................8-6
Introduction .....................................................................................8-6
xx Introduction to the Teradata RDBMS for UNIX

Table of Contents
Using EXPLAIN: First Example....................................................8-7Using EXPLAIN: Second Example...............................................8-8
Using the Call-Level Interface to Develop Applications .................8-9Introduction .....................................................................................8-9What is the CLI? ..............................................................................8-9What is ODBC?..............................................................................8-10
Using TS/API to Develop Applications for the Teradata RDBMS ..............................................................................8-11
Introduction ...................................................................................8-11TS/API Products...........................................................................8-11Compatible Third Party Software Products..............................8-11
For More Information .........................................................................8-12
Chapter 9Fault Tolerance
About This Chapter...............................................................................9-1Introduction .....................................................................................9-1Software Fault Tolerance ...............................................................9-1Hardware Fault Tolerance.............................................................9-1
Software Fault Tolerance......................................................................9-2Introduction .....................................................................................9-2vproc Migration ..............................................................................9-2Fallback Tables ................................................................................9-3AMP Clusters ..................................................................................9-4Journaling.........................................................................................9-6
Tape Archive and Restore/Recovery Utilities ..................................9-7Introduction .....................................................................................9-7Archiving Data ................................................................................9-7Restoring Data.................................................................................9-7Recovering Data ..............................................................................9-7
Table Rebuild Facility ...........................................................................9-8Introduction .....................................................................................9-8Table Rebuild Facility.....................................................................9-8Restrictions.......................................................................................9-8
Hardware Fault Tolerance ...................................................................9-9Introduction .....................................................................................9-9Dual BYNETs...................................................................................9-9RAID Disk Units .............................................................................9-9Multiple Channel and LAN Connections ...................................9-9Isolation From Client Hardware Defects.....................................9-9Battery Backup ................................................................................9-9
Introduction to the Teradata RDBMS for UNIX xxi

Table of Contents
Redundant Power Supplies and Fans........................................9-10Hot Swap Capability for Node Components............................9-10Cliques ............................................................................................9-10Single AWS System View ............................................................9-12
For More Information .........................................................................9-13
Chapter 10Concurrency Control and Recovery
About This Chapter.............................................................................10-1Introduction ...................................................................................10-1Concurrency Control ....................................................................10-1Recovery .........................................................................................10-1
The Concept of the Transaction.........................................................10-2Introduction ...................................................................................10-2Definition of a Transaction ..........................................................10-2Definition of Serializability..........................................................10-2Transaction Semantics..................................................................10-2ANSI Transactions ........................................................................10-2Rolling Back an ANSI Transaction .............................................10-3Teradata Transactions ..................................................................10-4How to Undo an Update..............................................................10-4
The Concept of the Lock.....................................................................10-5Introduction ...................................................................................10-5Overview of Teradata RDBMS Locking ....................................10-5Why is Locking Required for
Database Management Systems? .........................................10-6Teradata Lock Levels....................................................................10-6Teradata Lock Types ....................................................................10-7Teradata Automatic RDBMS Lock Levels .................................10-8Deadlocks .......................................................................................10-8
Host Utility Locks................................................................................10-9Introduction ...................................................................................10-9HUT Lock Types ...........................................................................10-9HUT Lock Characteristics............................................................10-9
System and Media Recovery............................................................10-10Introduction .................................................................................10-10System Restarts............................................................................10-10Transaction Recovery .................................................................10-10Down AMP Recovery.................................................................10-11
Two-Phase Commit...........................................................................10-12Introduction .................................................................................10-12
xxii Introduction to the Teradata RDBMS for UNIX

Table of Contents
Definitions....................................................................................10-12Two-Phase Commit ....................................................................10-12Limitations on Number of Sessions .........................................10-14Two-Phase Commit Processing ................................................10-15
For More Information .......................................................................10-16
Chapter 11Security and Integrity
About This Chapter.............................................................................11-1Introduction ...................................................................................11-1Definition of Security ...................................................................11-1Definition of Integrity ..................................................................11-1Tools for Enforcing System Security ..........................................11-1Tools for Enforcing System Integrity .........................................11-2
Resource Access Control ....................................................................11-3Introduction ...................................................................................11-3User Identifiers ..............................................................................11-3Client Identifiers ...........................................................................11-3Logon Policies................................................................................11-3TDP Security ..................................................................................11-5Password Security.........................................................................11-5DBC.SysSecDefaults .....................................................................11-6Password Encryption ...................................................................11-7Logon Control Using GRANT and REVOKE LOGON...........11-8Controlling Data Access by Granting or Revoking Access ....11-8
Establishing a Security Policy and Physical Access Control.......11-12Introduction .................................................................................11-12Key Ingredients of a Security Policy ........................................11-12Establishing a Security Policy ...................................................11-12Identifying Security Needs........................................................11-13Controlling Physical Access ......................................................11-13
Auditing and Accountability...........................................................11-14Introduction .................................................................................11-14System Views...............................................................................11-14
For More Information .......................................................................11-15
Introduction to the Teradata RDBMS for UNIX xxiii

Table of Contents
Chapter 12System Administration
About This Chapter.............................................................................12-1Introduction ...................................................................................12-1Space Allocation............................................................................12-1Accounting.....................................................................................12-1Monitoring .....................................................................................12-1
Space Allocation: Databases and Users............................................12-2Introduction ...................................................................................12-2Creating Databases and Users ....................................................12-2Scenario: Creating Finance and Administration Databases ...12-2Creating Databases .......................................................................12-4Creating Users ...............................................................................12-6
Accounting ...........................................................................................12-7Introduction ...................................................................................12-7
Session Management...........................................................................12-8Introduction ...................................................................................12-8Establishing a Session...................................................................12-8Logon Parameters .........................................................................12-8Session Requests............................................................................12-8
Account Usage .....................................................................................12-9Introduction ...................................................................................12-9Account String Expansion ...........................................................12-9Substitution Variables for ASE....................................................12-9Example ..........................................................................................12-9Account Performance Groups...................................................12-10
Monitoring..........................................................................................12-11Introduction .................................................................................12-11Teradata Manager .......................................................................12-11
System and Configuration Status....................................................12-12Resource Usage ..................................................................................12-13
Introduction .................................................................................12-13ResUsage Data.............................................................................12-13ResUsage Macros ........................................................................12-13ResUsage Data Categories .........................................................12-13ResUsage Data in Summarization Mode.................................12-14ResUsage Column Categories ...................................................12-15Controlling the Collection and Logging of ResUsage Data..12-17Rules for Sampling Intervals .....................................................12-18ResUsage Collection Modes ......................................................12-19
xxiv Introduction to the Teradata RDBMS for UNIX

Table of Contents
Performance Monitoring ..................................................................12-20Introduction .................................................................................12-20The TDPTMON ...........................................................................12-20System Management Facility ....................................................12-20The PM/API ................................................................................12-20Monitoring Performance............................................................12-21Gateway Control Utility.............................................................12-21
System Utility Software ....................................................................12-22For More Information .......................................................................12-24
Chapter 13Operating and Configuration Specifications
About This Chapter.............................................................................13-1Introduction ...................................................................................13-1
Performance .........................................................................................13-2Introduction ...................................................................................13-2Scalability .......................................................................................13-2
Database Capacities ............................................................................13-3Introduction ...................................................................................13-3Teradata RDBMS Capacities .......................................................13-3
IBM Channel-Attached Client Requirements..................................13-4Introduction ...................................................................................13-4Supported Environments.............................................................13-4
Network-Attached Client Requirements .........................................13-5Introduction ...................................................................................13-5Supported Software Environments............................................13-5
For More Information .........................................................................13-6
Appendix AHow the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOS
About This Appendix ..........................................................................A-1Teradata RDBMS for UNIX Differences............................................A-2
Open System with Less Dependence on Hardware .................A-2Additional Specific Improvements ....................................................A-3
Improved Performance and Added Features ............................A-3Increased Number of Hash Buckets............................................A-3Enhanced Row Evaluation ...........................................................A-4File System Improvements ...........................................................A-4Automatic Detection of Cylinder Fragmentation .....................A-5
Introduction to the Teradata RDBMS for UNIX xxv

Table of Contents
Uniqueness Code Carried in the Cylinder Index ......................A-5More Efficient Internal Format of Data Blocks ..........................A-5Larger Maximum Multi-Row Data Block Size...........................A-6Table-Level Attributes...................................................................A-6Optional Look-Ahead Reads........................................................A-7Optional Page Release ...................................................................A-7User-Tunable Cache Threshold for Data Block Caching .........A-7
Additional General Improvements....................................................A-8How the Teradata RDBMS for UNIX Differs
from the Teradata DBS for TOS.....................................................A-11
GlossaryGlossary .................................................................................... Glossary-1
IndexIndex................................................................................................Index-1
xxvi Introduction to the Teradata RDBMS for UNIX

List of Figures
List of Figures
vii
xxIntroduction to the Teradata RDBMS for UNIXChapter 1
Overview
Figure 1-1 Teradata RDBMS Shared Information Architecture..1-3Figure 1-2 Process Flow of a SQL Statement Through the Teradata
RDBMS.............................................................................1-5
Chapter 2
Teradata RDBMS Architecture
Figure 2-1 PE Software Components ...........................................2-10Figure 2-2 AMP Software Components .......................................2-10Figure 2-3 PE Routing of Teradata SQL Request Messages......2-15Figure 2-4 How the BYNET connects individual SMP nodes ..2-25
Chapter 3
The Relational Model
Figure 3-1 Layers of normalization. ...............................................3-4
Chapter 9
Fault Tolerance
Figure 9-1 vproc Migration..............................................................9-3Figure 9-2 Unclustered AMPs With Fallback................................9-4Figure 9-3 Clustered AMPs With Fallback ....................................9-5Figure 9-4 Four Node Clique.........................................................9-10Figure 9-5 How Vprocs Migrate After a Node Failure.............. 9-11

List of Figures
Chapter 10
Concurrency Control and Recovery
Figure 10-1 Lost Update Anomaly..................................................10-6Figure 10-2 Two-phase Commit Processing ................................10-13Figure 10-3 Two-phase Commit Processing as a
Function of Time.........................................................10-15
Chapter 12
System Administration
Figure 12-1 Hierarchy of Users, Databases, and Space Allocation ...................................................12-3
xxviii Introduction to the Teradata RDBMS for UNIX

Revision Record
xxix
Revision Record
Introduction to the Teradata RDBMS for UNIX
Date Description
November 1996 Initial printing.
Supports Teradata RDBMS for UNIX V2R2.0.
May 29, 1998 Supports Teradata RDBMS for UNIX V2R2.1.0

xxx

Overview
Introduction to the Teradata RDBMS for UNIX
Chapter 1
Overview

Overview
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 1
-1About This ChapterOverview1
About This Chapter 1
Introduction 1
This chapter presents an overview of the Teradata Relational Database Management System (RDBMS), including perspectives on its design and brief reviews of the hardware and software systems that comprise the Teradata RDBMS.
Design Perspectives 1
The topic on design perspectives for the Teradata RDBMS includes descriptions of the following:
● Research ideas leading to the eventual design● Design philosophy and goals● Scalability● Shared information architecture
Teradata Database Software 1
The topic on Teradata software includes descriptions of the following:
● The structured query language (SQL) and its uses for application programming and interactive database queries
● The Teradata database management system● The Teradata file system and disk handling system
Client Software 1
The topic on client software includes descriptions of the following:
● The request handler (Call Level Interface, or CLI)● The data communications component (Teradata Director
Program, or TDP)● Application development services, including:
● A SQL preprocessor● CLI● Third party query front ends, gateways, and fourth
generation languages● Data loading utilities● The archive/restore utility

OverviewDesign Perspectives
Design Perspectives 1
Introduction 1
This topic describes the considerations that went into the design of the original Teradata Database System. The topic also explains the overall perspectives behind the system.
Charter for the Teradata Database System 1
The original charter for development of the Teradata RDBMS included the following goals:
● Large capacity database system with thousands of MIPS capable of storing terabytes of data and billions of rows
● Fault tolerance to ensure data integrity● Network connectivity● Manageable growth● Relational database management system● Faster than other relational systems● Common access language● Single data store for multiple clients in a client/server
architecture
Research Ideas Leading to the Design of the Teradata Database System 1
The hardware component of the first generation Teradata RDBMS was a database machine. The current generation machine is a general purpose massively parallel machine running the Teradata RDBMS as a trusted parallel application (TPA). The earliest database machines were comprised of specialized hardware components. These machines were very expensive to implement and did not provide improved performance.
The concept behind the Teradata RDBMS was to build an inexpensive system using mostly off-the-shelf hardware components that would meet and exceed the performance of conventional database management systems using relational database management.
The architecture incorporates a parallel, distributed architecture in which the distributed functions communicate by means of a fast interconnect structure. This proprietary interconnect structure in the current architecture is known as the BYNET (for MPP systems) or the Vnet (for SMP systems).
Shared Information Architecture 1
One of the principal goals for the design of the Teradata RDBMS was to provide a single data store for any number of client architectures. This Shared Information Architecture (SIA) eliminates the need for maintaining duplicate databases on multiple platforms. With the SIA, most mainframe clients, workstations, and personal
1-2 Introduction to the Teradata RDBMS for UNIX

OverviewDesign Perspectives
computers can access and manipulate the same database simultaneously.
The following figure illustrates the principle of the SIA.
Figure 1-1 Teradata RDBMS Shared Information Architecture
Teradata RDBMSsingle data store
UnisysA-series
mainframe
BullGCOS
mainframe
UnisysOS/1100
mainframe
IBMVM
mainframe
DECVAXVMS
UNIXworkstation
PersonalComputer
IBMMVS
mainframe
FG01A001
Local Area Network
Introduction to the Teradata RDBMS for UNIX 1-3

OverviewTeradata Database Software
Teradata Database Software 1
Introduction 1
The Teradata Database Software is the foundation for the relational database server. Its purpose is to support SQL manipulations of the database.
The server software includes the following components:
● Channel communications support● LAN gateway communications support● SQL parser● Request dispatcher● Session control● Database manager● File manager
Structured Query Language (SQL) 1
The structured query language (SQL) is a data sublanguage designed specifically for manipulating data in relational databases. SQL is the only language the Teradata RDBMS understands, so all database manipulations, whether embedded in an application program or resulting from an interactive query, use SQL and SQL only.
The figure shows a process flow of a SQL statement through the Teradata RDBMS on a channel-attached system.
Process flow in a network-attached system is somewhat different (substituting the micro operating system (MOSI) and micro Teradata Director Program (MTDP) for the TDP), but the basic idea is very similar.
1-4 Introduction to the Teradata RDBMS for UNIX
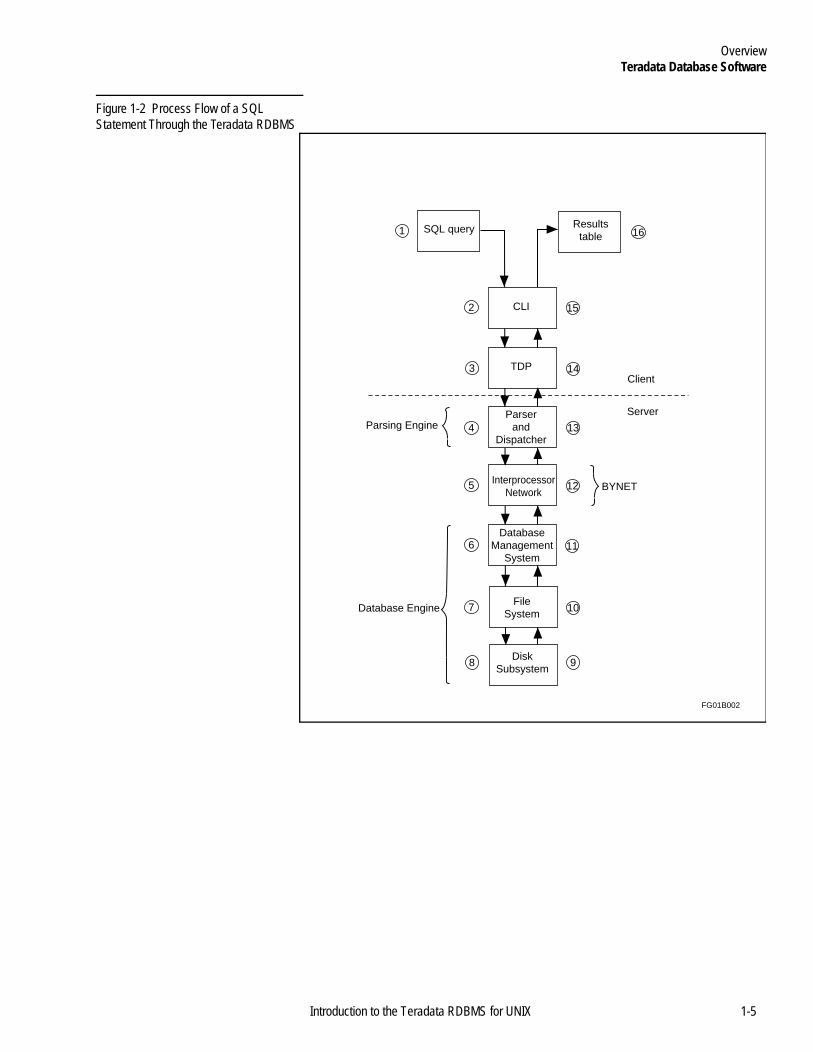
OverviewTeradata Database Software
Figure 1-2 Process Flow of a SQL Statement Through the Teradata RDBMS
SQL query Resultstable
FG01B002
FileSystem
CLI
TDP
Parserand
Dispatcher
DiskSubsystem
DatabaseManagement
System
InterprocessorNetwork
1
2
3
16
15
14
134
5 12
116
7 10
98
BYNET
Client
ServerParsing Engine
Database Engine
Introduction to the Teradata RDBMS for UNIX 1-5

OverviewTeradata Database Software
The following table describes the process flows illustrated by this picture.
Stage Process
1 A user generates an SQL query on the channel-attached client. The query can either be from a BTEQ session at an interactive terminal, from a compatible fourth generation language, or can originate from within an application program coded in a host language.
2 The request/results packaging component, CLI, packages the request and sends it to the TDP for routing to the server.
3 The TDP establishes a session, then routes the request across the communications channel to the parsing engine (PE).
4 The parser component of the PE opens the request package and parses the SQL code for processing, interprets it, checks its syntax, evaluates its semantics, and optimizes the access plan.
IF the SQL source code parses . . . THEN the . . .
without errors the parser decodes the request into a series of work steps and passes them to the dispatcher.
with errors the dispatcher receives the appropriate error message and returns it to the requester. Processing terminates.
The dispatcher sequences the steps and passes them on to the BYNET (or Vnet) with instructions about whether the steps are for one Access Module Process (AMP), an AMP group, or for all AMPs.
5 The BYNET (or Vnet on a single node system) distributes the execution steps to the appropriate AMP for processing.
6 The AMPs process the execution steps by performing select, insert, delete, and update operations on the database. The AMPs make these operations by making calls to the file system.
The AMPs also perform other functions such as journaling, space accounting, and index maintenance.
7 The file system performs primitive physical data block operations by locating the data blocks to be manipulated and then passing control to the disk subsystem.
1-6 Introduction to the Teradata RDBMS for UNIX

OverviewTeradata Database Software
8 The disk subsystem retrieves the requested blocks for the file system.
9 The disk manager returns the requested blocks to the file system.
10 The file system returns the requested data to the database manager.
11 The database manager sends a message back to the dispatcher stating that the data is ready to be returned to the requesting user, then sorts and transmits the data to the interface engine over the BYNET.
12 The BYNET (or Vnet on a single node system) merges the sorted response and returns it to the requesting interface engine for packaging.
13 The dispatcher builds the response message and routes it to the communications channel driver for return to the requesting client system.
14 The TDP receives and unpacks the response messages and makes them available to CLI.
15 CLI passes the received data back to the requesting application in blocks.
16 The requesting application receives the response data in the form of a relational table.
Stage Process
Introduction to the Teradata RDBMS for UNIX 1-7

OverviewFor More Information
For More Information 1
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Structured Query Language Teradata RDBMS for UNIX SQL Reference
Data flows through the Teradata RDBMS
Teradata RDBMS for UNIX Database Design and Administration
General aspects of the Teradata RDBMS
Teradata RDBMS for UNIX Database Design and Administration
1-8 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS Architecture
Introduction to the Teradata RDBMS for UNIX
Chapter 2
Teradata RDBMS Architecture

Teradata RDBMS Architecture
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 2
-1About This ChapterTeradata RDBMS Architecture2
About This Chapter 2
Introduction 2
The hardware that supports the Teradata software is based on off-the-shelf microprocessor technology combined with a proprietary communications network connecting the microprocessor elements.
The purpose of this chapter is to briefly mention and describe these hardware components and to describe the software architecture they support. Details are provided in the appropriate reference manuals.
Hardware 2
This manual documents the basic hardware configurations for both the SMP and MPP hardware platforms.
Unlike earlier database server technology supporting the Teradata database management system, these machines do not have specialized hardware processors.
Instead, they run virtual processors called vprocs (virtual processors). These vprocs provide the parallel environment that enables the Teradata RDBMS to run on SMP and MPP systems.
Teradata RDBMS ArchitectureAbout This Chapter
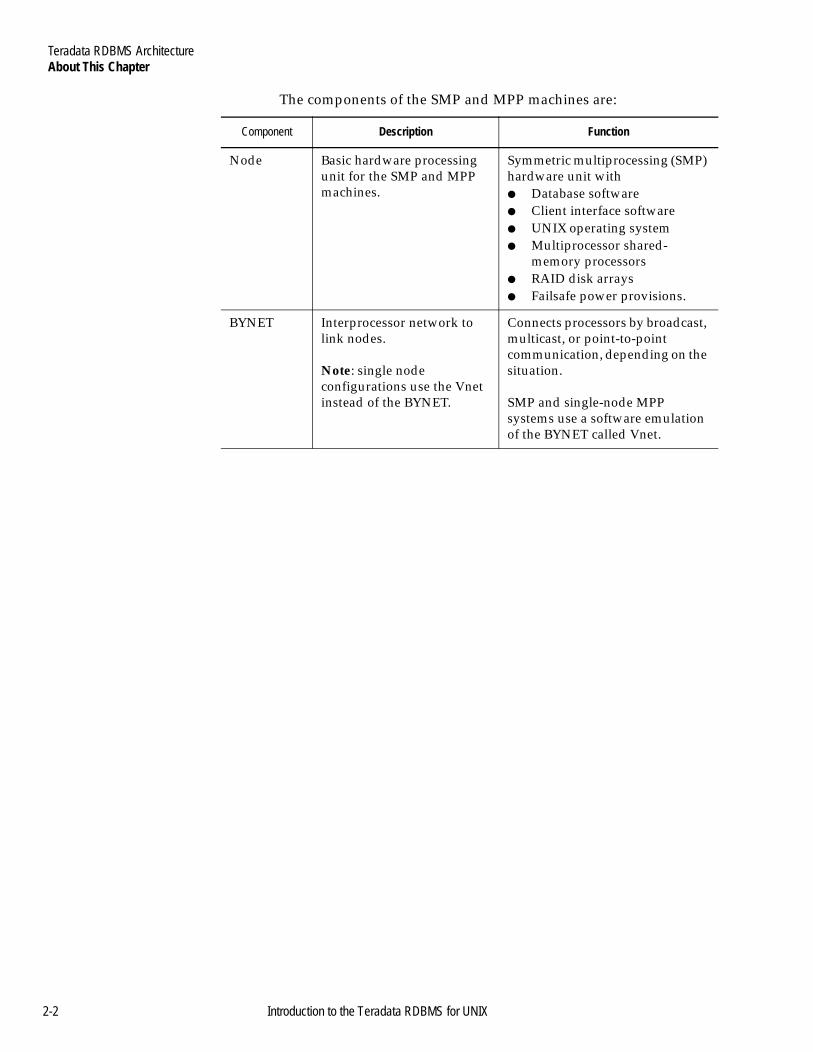
The components of the SMP and MPP machines are:
Component Description Function
Node Basic hardware processing unit for the SMP and MPP machines.
Symmetric multiprocessing (SMP) hardware unit with● Database software● Client interface software● UNIX operating system● Multiprocessor shared-
memory processors● RAID disk arrays● Failsafe power provisions.
BYNET Interprocessor network to link nodes.
Note: single node configurations use the Vnet instead of the BYNET.
Connects processors by broadcast, multicast, or point-to-point communication, depending on the situation.
SMP and single-node MPP systems use a software emulation of the BYNET called Vnet.
2-2 Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS ArchitectureAbout This Chapter
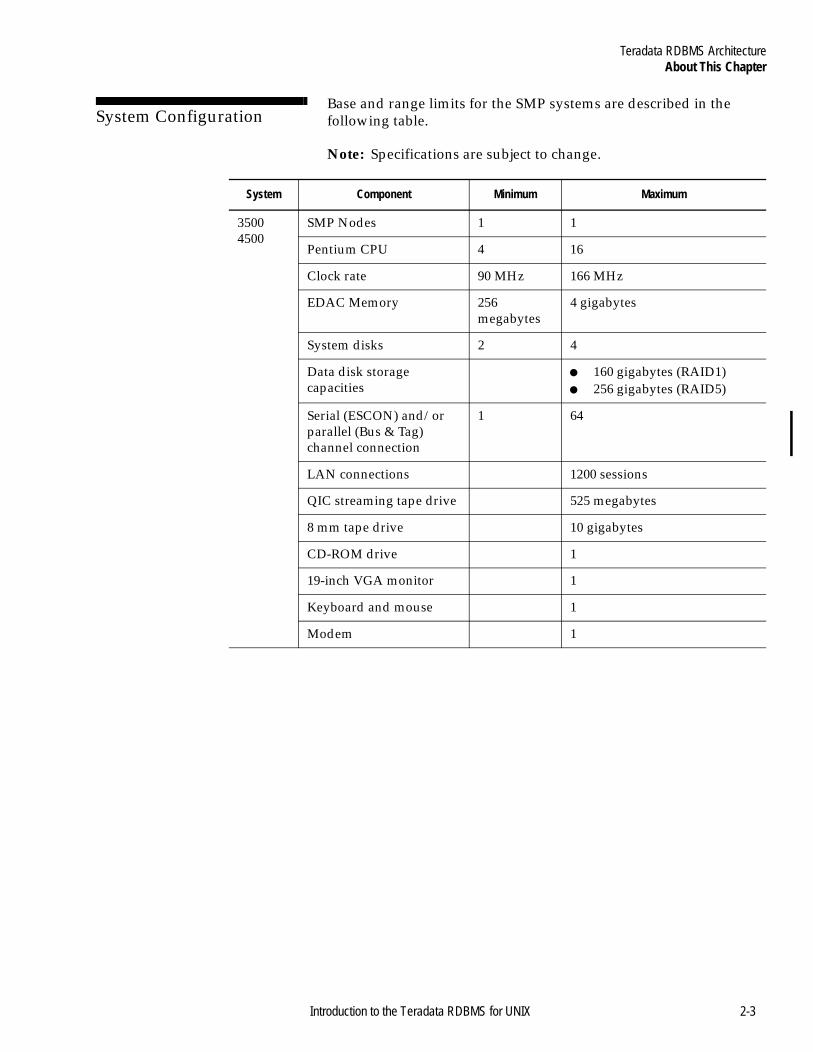
System Configuration 2
Base and range limits for the SMP systems are described in the following table.
Note: Specifications are subject to change.
System Component Minimum Maximum
35004500
SMP Nodes 1 1
Pentium CPU 4 16
Clock rate 90 MHz 166 MHz
EDAC Memory 256 megabytes
4 gigabytes
System disks 2 4
Data disk storage capacities
● 160 gigabytes (RAID1)● 256 gigabytes (RAID5)
Serial (ESCON) and/or parallel (Bus & Tag) channel connection
1 64
LAN connections 1200 sessions
QIC streaming tape drive 525 megabytes
8 mm tape drive 10 gigabytes
CD-ROM drive 1
19-inch VGA monitor 1
Keyboard and mouse 1
Modem 1
Introduction to the Teradata RDBMS for UNIX 2-3

Teradata RDBMS ArchitectureAbout This Chapter
5100S SMP Nodes 1 1
Pentium CPU 4 32
Clock rate 90 MHz 166 MHz
EDAC Memory 256 megabytes
4 gigabytes
System disks 2 4
Data disk storage capacities
● 160 gigabytes (RAID1)● 256 gigabytes (RAID5)
Serial (ESCON) and/or parallel (Bus & Tag) channel connection
1 64
LAN connections 1200 sessions
QIC streaming tape drive 525 megabytes
8 mm tape drive 10 gigabytes
CD-ROM drive 1
19-inch VGA monitor 1
Keyboard and mouse 1
Modem 1
System Component Minimum Maximum
2-4 Introduction to the Teradata RDBMS for UNIX
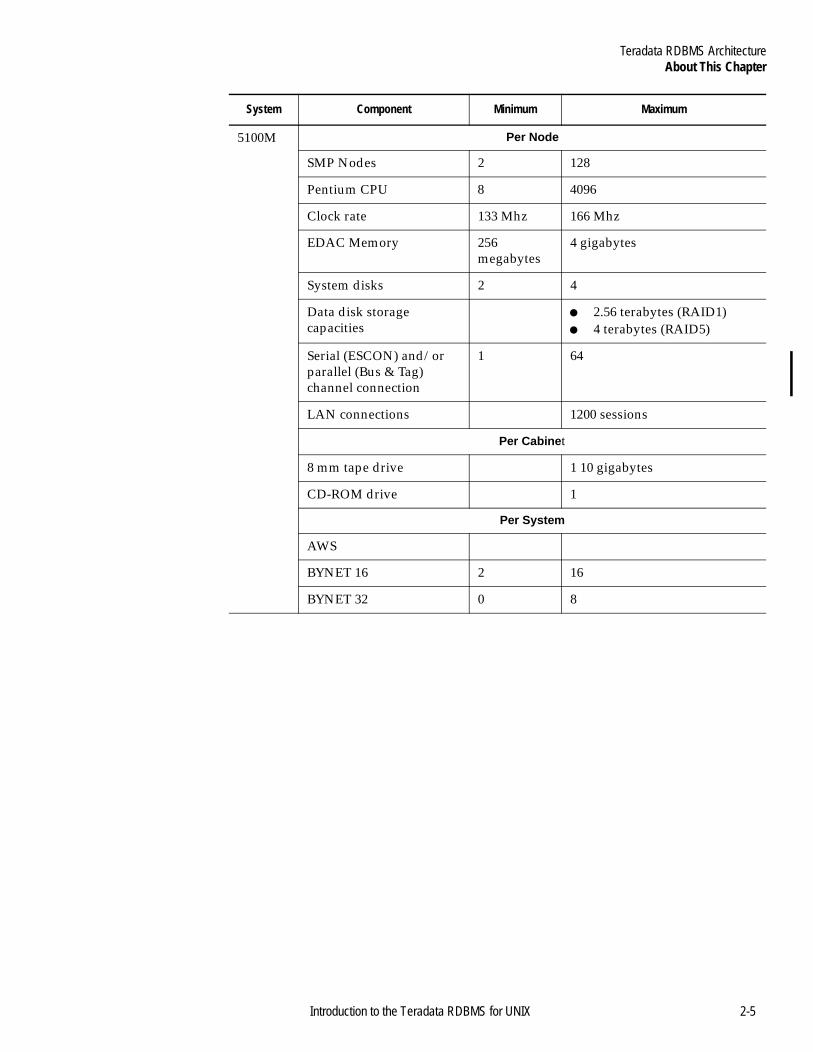
Teradata RDBMS ArchitectureAbout This Chapter
5100M Per Node
SMP Nodes 2 128
Pentium CPU 8 4096
Clock rate 133 Mhz 166 Mhz
EDAC Memory 256 megabytes
4 gigabytes
System disks 2 4
Data disk storage capacities
● 2.56 terabytes (RAID1)● 4 terabytes (RAID5)
Serial (ESCON) and/or parallel (Bus & Tag) channel connection
1 64
LAN connections 1200 sessions
Per Cabinet
8 mm tape drive 1 10 gigabytes
CD-ROM drive 1
Per System
AWS
BYNET 16 2 16
BYNET 32 0 8
System Component Minimum Maximum
Introduction to the Teradata RDBMS for UNIX 2-5
Teradata RDBMS ArchitectureAbout This Chapter
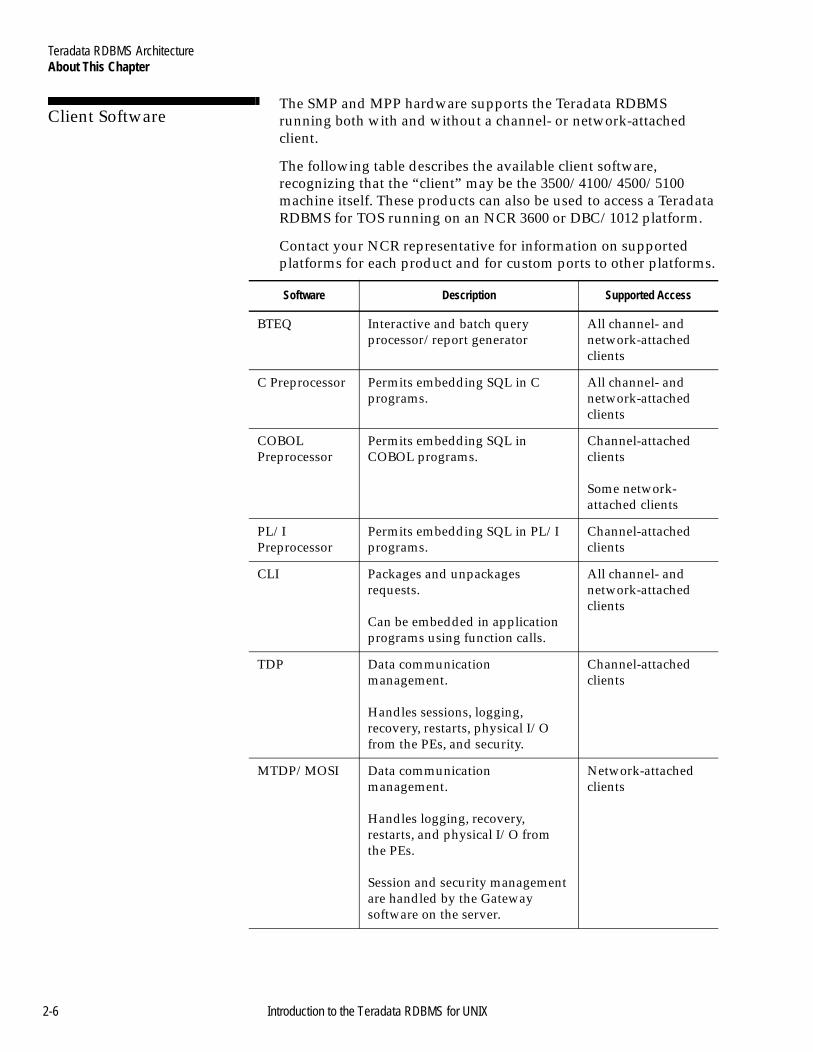
Client Software 2
The SMP and MPP hardware supports the Teradata RDBMS running both with and without a channel- or network-attached client.
The following table describes the available client software, recognizing that the “client” may be the 3500/4100/4500/5100 machine itself. These products can also be used to access a Teradata RDBMS for TOS running on an NCR 3600 or DBC/1012 platform.
Contact your NCR representative for information on supported platforms for each product and for custom ports to other platforms.
Software Description Supported Access
BTEQ Interactive and batch query processor/report generator
All channel- and network-attached clients
C Preprocessor Permits embedding SQL in C programs.
All channel- and network-attached clients
COBOL Preprocessor
Permits embedding SQL in COBOL programs.
Channel-attached clients
Some network-attached clients
PL/I Preprocessor
Permits embedding SQL in PL/I programs.
Channel-attached clients
CLI Packages and unpackages requests.
Can be embedded in application programs using function calls.
All channel- and network-attached clients
TDP Data communication management.
Handles sessions, logging, recovery, restarts, physical I/O from the PEs, and security.
Channel-attached clients
MTDP/MOSI Data communication management.
Handles logging, recovery, restarts, and physical I/O from the PEs.
Session and security management are handled by the Gateway software on the server.
Network-attached clients
2-6 Introduction to the Teradata RDBMS for UNIX
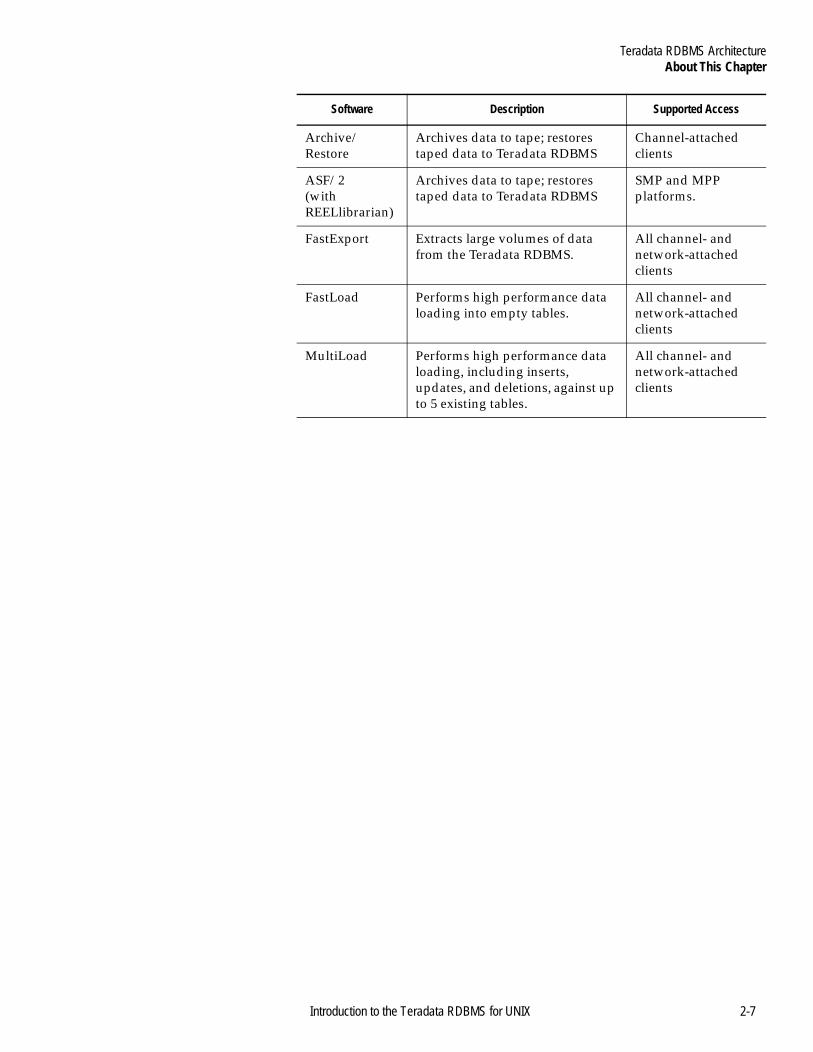
Teradata RDBMS ArchitectureAbout This Chapter
Archive/Restore
Archives data to tape; restores taped data to Teradata RDBMS
Channel-attached clients
ASF/2(with REELlibrarian)
Archives data to tape; restores taped data to Teradata RDBMS
SMP and MPP platforms.
FastExport Extracts large volumes of data from the Teradata RDBMS.
All channel- and network-attached clients
FastLoad Performs high performance data loading into empty tables.
All channel- and network-attached clients
MultiLoad Performs high performance data loading, including inserts, updates, and deletions, against up to 5 existing tables.
All channel- and network-attached clients
Software Description Supported Access
Introduction to the Teradata RDBMS for UNIX 2-7

Teradata RDBMS ArchitectureAbout This Chapter
Server Software 2
The server software includes all the following:
● The Database Window● The RDBMS Gateway● A SQL parser and syntaxer● A request dispatcher● A session controller● Facilities to control load balancing over the communications
network● The Teradata database management software● The Teradata file system● Teradata Parallel Database Extensions (PDE)● The UNIX operating system
A server may also contain data loading utilities such as MultiLoad and FastLoad, data export utilities like FastExport, and the SQL data access utility BTEQ.
2-8 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureVirtual Processors
Virtual Processors 2
Introduction 2
The versatility of the Teradata RDBMS is based on virtual processors (vprocs), which eliminate dependency on specialized physical processors.
This is made possible by the Parallel Database Extensions (PDE) for UNIX. The PDE is an interface layer between the Teradata RDBMS and the standard UNIX operating system that runs on the NCR server.
A vproc is a collection of tasks running under the multitasking environment of the UNIX operating system. The tasks in a vproc share resources with other tasks in the same vproc. Multiple vprocs can run on an SMP platform or a node.
The vprocs and the tasks running under them communicate using unique-address messaging, as if they were physically isolated from each other. This message communication is done using the Vnet software on single node platforms and using the BYNET and BYNET Driver Software on multinode platforms.
There are two types of vprocs:
Each type of vproc is described in the following passages.
PEs 2
Each Parsing Engine (PE) executes the database software that manages sessions and decomposes SQL into parallel steps.
The software, as shown in Figure 2-1, consists of the following elements:
● Parser (including the Optimizer)● Dispatcher● Session Control
The Parser decomposes the SQL into relational data management processing steps.
Type Description
PE Performs session control and dispatching tasks as well as parsing functions.
AMP Manages the distribution and retrieval of data on the virtual disks (vdisks), which are defined at system configuration time with the pdeconfig utility.
Introduction to the Teradata RDBMS for UNIX 2-9

Teradata RDBMS ArchitectureVirtual Processors
The steps are passed to the Dispatcher, which sends the steps to the appropriate AMPs.
Session Control provides user session management such as establishing and terminating sessions.
Figure 2-1 PE Software Components
AMPs 2
Each Access Module Process (AMP) executes the database software that performs relational functions and data management.
Each AMP, as shown in Figure 2-2, is assigned a portion of the database to control.
Each AMP provides the following functions:
● Data access● Concurrency control● Journaling● Cache management● Recovery functions.
Each AMP maintains its portion of the database tables stored on disks.
Figure 2-2 AMP Software Components
GG01A029
Parser(including Optimizer)
Dispatcher
PDE
UNIX
SessionControl
GG01A028
Relational Database Management
File System/Data Management
PDE
UNIX
2-10 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureThe Parsing Engine
The Parsing Engine 2
Introduction 2
The Parsing Engine is the processor that communicates with the client system on one side and with the AMPs (via the BYNET or Vnet) on the other.
Each PE executes the database software that manages sessions, decomposes SQL statements into parallel steps, and returns the answer rows to the requesting client.
The major components of the PE are
● Session Control● SQL Parser● Dispatcher.
Client Interface 2
The client interface provides handshaking across the communications channel between the server and its client or clients.
For a mainframe link, the connection is made by means of either:
● Serial (ESCON)● Parallel (Bus & Tag) Channel
implemented by means of the Teradata Channel Interface (TCI) protocol handler.
In the case of a network link, the connection is by means of a LAN connection using either:
● TCP/IP ● ISO/OSI protocols
implemented by means of the Teradata Gateway.
Session Control 2
Session numbers are assigned by the TDP and communicated to the server.
The PE establishes a session only if it can validate the username, password, and user type (application program, interactive BTEQ terminal, or third party software product). All subsequent traffic for the session are identified by their host id, session number, and request number.
Introduction to the Teradata RDBMS for UNIX 2-11

Teradata RDBMS ArchitectureThe Parsing Engine
Input Data Conversion 2
The Teradata RDBMS is an ASCII machine. The parsing engine converts EBCDIC (and other non-ASCII) input to ASCII before processing it.
2-12 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureThe Parsing Engine
SQL Parser 2
The SQL parser handles all incoming SQL requests. It processes these requests as follows.
Stage Process
1 The Parser looks in the Request cache to determine if the request is already there.
IF the request is . . . THEN the Parser . . .
in the Request cache generates AMP steps and passes them to the gncApply software.
not in the Request cache begins processing the request with the Syntaxer.
2 The Syntaxer checks the syntax of an incoming request.
IF there are . . . THEN the Syntaxer . . .
no errors converts the request to a parse tree and passes it to the Resolver.
errors passes an error message back to the requestor.
3 The Resolver adds information from the Data Dictionary cache to convert database, table, view, and macro names to numeric identifiers, then produces lists of objects and access rights. The output is a Resolver tree, which the Resolver passes to a security checking mechanism.
4 The security module checks access rights in the Data Dictionary.
IF the access rights are . . . THEN the Security module . . .
valid passes the request to the Optimizer.
not valid aborts the request.
5 The Optimizer determines the most effective way to access the data needed by the request.
6 The Optimizer scans the request to determine where locks should be placed, then passes the optimized parse tree to the Generator.
Introduction to the Teradata RDBMS for UNIX 2-13

Teradata RDBMS ArchitectureThe Parsing Engine
The Dispatcher 2
The Dispatcher controls the sequence in which steps are executed. It also passes the steps to the BYNET (or Vnet on single node systems) to be distributed to the AMP database management software.
Note that AMP steps can be sent in any one of the following ways:
● Between one PE and one AMP using the hashing algorithm● Among a selected group of AMPS (referred to as a dynamic
BYNET (or Vnet) group● Among all AMPs in the system.
7 The Generator transforms the optimized parse tree into plastic steps and passes them to the gncApply software.
Plastic steps are directives to the database management system that do not contain data values
8 gncApply takes the plastic steps produced by the Generator and transforms them into concrete steps.
Concrete steps are directives to the database management system that contain user- and session-specific information as well as data parcels.
9 gncApply passes the concrete steps to the Dispatcher.
Stage Process
1 The Dispatcher receives concrete steps from gncApply.
2 The Dispatcher places the first step on the BYNET (or Vnet)—the Dispatcher tells the BYNET whether the step is for one AMP, several AMPS, or all AMPS—and waits for a completion response.
Whenever possible, the Teradata RDBMS performs steps in parallel to enhance performance.
3 The Dispatcher receives a completion response from one or several AMPS and places the next step on the BYNET. It continues to do this until all the AMP steps associated with a request are done.
Stage Process
2-14 Introduction to the Teradata RDBMS for UNIX
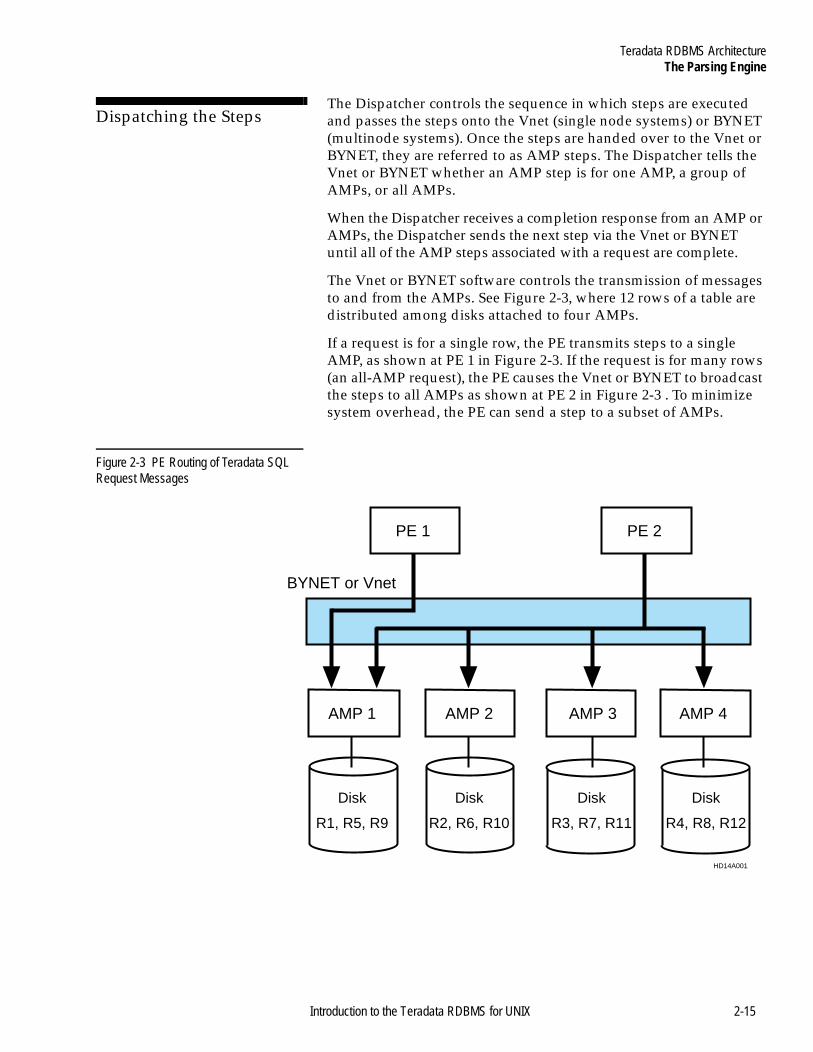
Teradata RDBMS ArchitectureThe Parsing Engine
Dispatching the Steps 2
The Dispatcher controls the sequence in which steps are executed and passes the steps onto the Vnet (single node systems) or BYNET (multinode systems). Once the steps are handed over to the Vnet or BYNET, they are referred to as AMP steps. The Dispatcher tells the Vnet or BYNET whether an AMP step is for one AMP, a group of AMPs, or all AMPs.
When the Dispatcher receives a completion response from an AMP or AMPs, the Dispatcher sends the next step via the Vnet or BYNET until all of the AMP steps associated with a request are complete.
The Vnet or BYNET software controls the transmission of messages to and from the AMPs. See Figure 2-3, where 12 rows of a table are distributed among disks attached to four AMPs.
If a request is for a single row, the PE transmits steps to a single AMP, as shown at PE 1 in Figure 2-3. If the request is for many rows (an all-AMP request), the PE causes the Vnet or BYNET to broadcast the steps to all AMPs as shown at PE 2 in Figure 2-3 . To minimize system overhead, the PE can send a step to a subset of AMPs.
Figure 2-3 PE Routing of Teradata SQL Request Messages
HD14A001
AMP 1 AMP 2 AMP 3 AMP 4
PE 2PE 1
Disk
R1, R5, R9
Disk
R2, R6, R10
Disk
R3, R7, R11
Disk
R4, R8, R12
BYNET or Vnet
Introduction to the Teradata RDBMS for UNIX 2-15

Teradata RDBMS ArchitectureThe Parsing Engine
As an example, consider the following two Teradata SQL statements from a table of checking account information:
1.SELECT * FROM Table_01 WHERE AcctNo = 129317 ; 2.SELECT * FROM Table_01 WHERE AcctBal > 1000 ;
In this example:
● PEs 1 and 2 receive requests 1 and 2.● The data for account 129317 is contained in table row R9 stored
on AMP 1● Information about all account balances is distributed evenly
among the disks of all four AMPs
The PE 1 Parser determines that its request is a primary-index retrieval, which calls for access and return of one specific row.
The Dispatcher in PE 1 then issues a message to the Vnet or BYNET containing an appropriate read step and R9/AMP 1 routing information. Once the desired record is received from AMP 1, PE 1 transmits the data back to the TDP.
The PE 2 Parser determines that this is an all-AMPs request, then issues a message to the Vnet or BYNET containing the appropriate read step to be broadcast to all four AMPs.
Once results are received from the AMPs, PE 2 transmits the data back to the TDP.
To enhance system performance, the RDBMS executes steps in parallel whenever possible.
Parallel steps can work with multi-statement requests, macros, and single statements and can provide a significant improvement in response time.
For example, the response time of a multi-statement request consisting of four statements that can be independently executed may be cut in half.
Processing the Steps 2
The AMPs are responsible for obtaining the rows required to process the request.
The software on the AMPs does the following:
● Processes AMP steps by performing select, insert, delete, and update operations on the data on the disks.
● Performs other functions associated with AMP steps such as journaling, space accounting, index maintenance, and output data conversion.
● Performs utilities to configure and reconfigure the RDBMS. (See Chapter 5, “Database Administration” for more information.)
2-16 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureThe Parsing Engine
● Uses the file system software to perform primitive physical data block operations.
An AMP step can be sent in one of the following ways:
● Between one PE and one AMP using hashing algorithm.● Among a selected set of AMPs, called a dynamic Vnet or BYNET
group.● Among all AMPs in the system.
An AMP step is broadcast to all AMPs when a full-table scan is requested or when the operation uses nonunique secondary indexes (NUSIs).
When an operation uses a unique primary index (UPI), nonunique primary index (NUPI), or unique secondary index (USI), the message includes the row hash value, which is used by the Vnet or BYNET to route the message to the correct vproc.
The sequence of AMP step processing is as follows:
Each AMP is associated with disks and uses its file system software to control the reading and writing of data on its disks.
The file system controls primitive physical data block reads, and translates AMP software row requests into physical data block requests.
Step Step Name Function
1 Lock Ensures that users who are concurrently trying to update the same rows do not violate the consistency of the data.
If the operation uses a UPI, NUPI, or USI, this step is incorporated into step 2.
2 Operation Performs the actual task required: select, delete, insert, update, sort.
There may be many operation steps.
3 End transaction
Required only for multiple AMP steps.
If the request is for a UPI, no end transaction step is necessary.
The end transaction step tells all AMPs that worked on the request that processing is complete.
Introduction to the Teradata RDBMS for UNIX 2-17

Teradata RDBMS ArchitectureStructured Query Language
Structured Query Language 2
Introduction 2
This topic describes SQL, the Structured Query Language.
SQL is the only language the Teradata RDBMS understands. It is the ANSI standard language for relational database management.
Why SQL? 2
SQL has the advantage of being the most commonly used language for relational database management systems.
Because of this, both the data structures in the database and the commands for manipulating those structures are controlled using SQL. Additionally, all applications, whether written in a client language with embedded SQL, a macro, or an ad hoc SQL query, are written and executed using the same set of instructions and syntax.
Other database management systems use different sublanguages for data definition and data manipulation and do not permit ad hoc queries of the database. This means that you must use one language to define your data and yet another to query and update it. And you are restricted to running applications written by programmers. You have very little flexibility with nonrelational database management systems.
SQL Flagger 2
The Teradata RDBMS has an optional feature that detects non-ANSI SQL extensions (for entry level ANSI SQL92 only) and reports them back to the user (either to an embedded SQL program or to BTEQ) without terminating execution of the query.
2-18 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureStructured Query Language
SQL Lexicon 2
Like any language, SQL has its rules for writing statements.
The following table describes the SQL lexicon.
Lexical Component Description
Word A character string of from 1 to 30 characters derived from the following character set:● Roman characters (both cases)● Digits● $● #● _Keywords are a special category of words that are reserved for use in SQL statements. You cannot use keywords as object names.
Introduction to the Teradata RDBMS for UNIX 2-19

Teradata RDBMS ArchitectureStructured Query Language
Delimiter Special characters whose meaning depends on context. The Teradata SQL delimiters and their functions are as follows.
Delimiter Function
() Groups expressions and defines the limits of various phrases
‘ Separates items in a listActs as a date separator
: Prefixes a referenced parameter or client system variableActs as a date separator
. Separates a database name from a table nameSeparates a table name from a column nameActs as the decimal pointActs as a date separator
; Separates statements in a requestTerminates a request (BTEQ)
‘ Defines boundaries of character string constantsActs as a data separator
“ Defines the boundaries of nonstandard names
/ Used as a date separator
B Blank. Used as a date separator
- Used as a date separator
Constant Numerics, strings, and characters embedded in a statement.
Lexical Component Description
2-20 Introduction to the Teradata RDBMS for UNIX
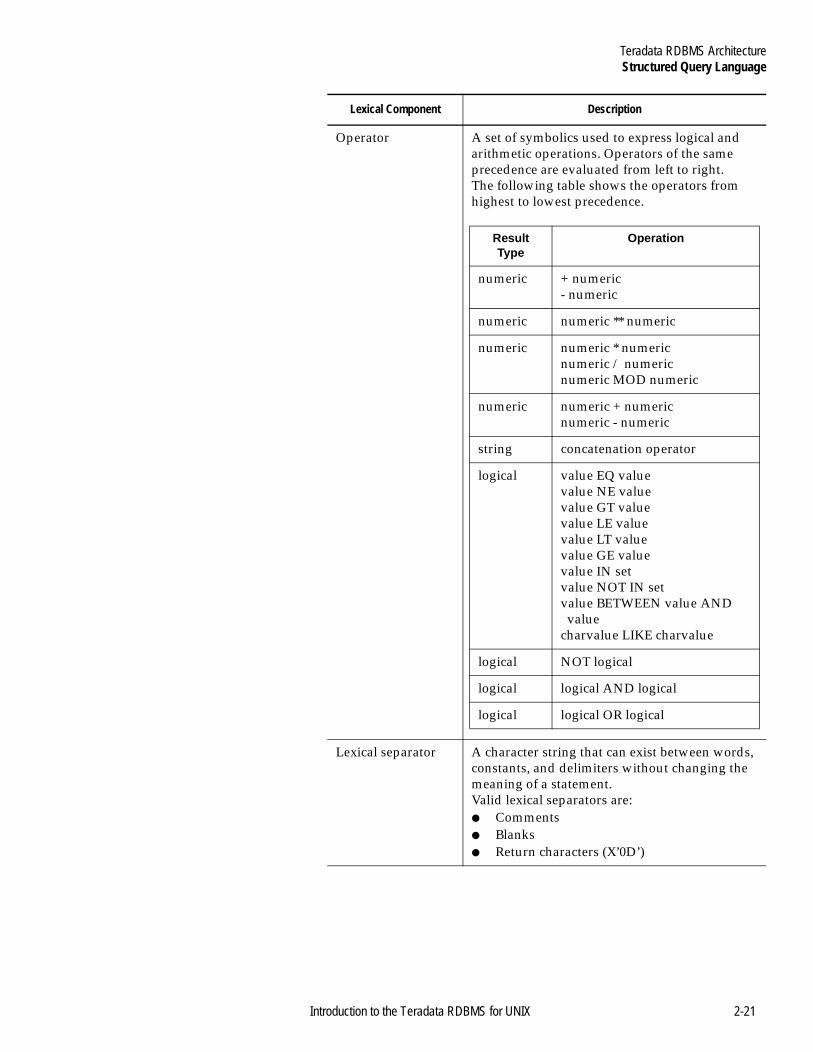
Teradata RDBMS ArchitectureStructured Query Language
Operator A set of symbolics used to express logical and arithmetic operations. Operators of the same precedence are evaluated from left to right.The following table shows the operators from highest to lowest precedence.
Result Type
Operation
numeric + numeric- numeric
numeric numeric ** numeric
numeric numeric * numericnumeric / numericnumeric MOD numeric
numeric numeric + numericnumeric - numeric
string concatenation operator
logical value EQ valuevalue NE valuevalue GT valuevalue LE valuevalue LT valuevalue GE valuevalue IN setvalue NOT IN setvalue BETWEEN value ANDvalue
charvalue LIKE charvalue
logical NOT logical
logical logical AND logical
logical logical OR logical
Lexical separator A character string that can exist between words, constants, and delimiters without changing the meaning of a statement.Valid lexical separators are:● Comments● Blanks● Return characters (X’0D’)
Lexical Component Description
Introduction to the Teradata RDBMS for UNIX 2-21

Teradata RDBMS ArchitectureStructured Query Language
Character Sets 2
The Teradata RDBMS supports multinational and multibyte character sets in several different environments.
Among the character sets supported are:
● Kanji● Katakana● Hiragana● European languages with characters using the umlaut, tilde, or
ring
The RDBMS provides multibyte support for the following operating systems:
● MVS● VM/CMS● UNIX● DOS/V
Multibyte support exists for the following Teradata software:
● Server-based utilities● Client-based utilities● BTEQ● Preprocessor2 (embedded SQL)● TDP● CLIv2
Users control the current character set and collation sequences using SQL statements.
Statement separator A character that separates each statement of a multistatement request.The Teradata SQL separator is the semicolon.
Request terminator A character that terminates a request in the body of a macro or that is entered from BTEQ.The Teradata SQL request terminator is the End of Text character for macros or the semicolon for BTEQ.
Lexical Component Description
2-22 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureQuery Facilities
Query Facilities 2
Introduction 2
The Teradata RDBMS supports several different facilities for making interactive or batch queries of the database from a terminal.
These include:
● Basic Teradata Query facility (BTEQ)● Fourth generation languages
Because SQL is the only language the Teradata RDBMS understands, all application programming facilities ultimately make their queries against the database using the SQL language.
BTEQ 2
The Basic Teradata Query facility is a SQL formatter/report generator that allows you to create and perform SQL queries interactively or in batch mode from an interactive terminal.
BTEQ supports the following facilities:
● Multiple Teradata SQL statements per request● Read from and write to client data files● Manage multiple sessions per job● Format output and write sophisticated reports
BTEQ is supported on the following platforms:
● Channel-attached client● Network-attached client● Teradata server
Introduction to the Teradata RDBMS for UNIX 2-23

Teradata RDBMS ArchitectureThe BYNET
The BYNET 2
Introduction 2
This topic explains the concepts behind the interprocessor network technology used by the Teradata RDBMS: the BYNET.
BYNET Functions 2
At the most elementary level, you can look at the BYNET as a bus that loosely couples all the SMP nodes in a multinode system. This view does an injustice to the BYNET, however, because the capabilities of the network range far beyond those of a simple system bus.
The BYNET also possesses high speed logic arrays that provide bidirectional broadcast, multicast, and point-to-point communication and merge functions.
A multinode system has two BYNETs. This both creates a fault tolerant environment and provides for enhanced interprocessor communication. When BYNET traffic becomes particularly heavy, the two BYNETs can handle separate (rather than redundant) traffic. The machine provides load balancing software to optimize this process.
The total bandwidth for each network link to a processor node is 10 megabytes. Because there are two network links per node and because the bandwidth is linearly scalable, the total throughput available for each node is 20 megabytes.
For example, a 16-node 5100M system has 320 megabytes of bandwidth for point-to-point connections.
Total available broadcast bandwidth for any size 5100M system is 20 megabytes.
The BYNET software provides a standard TCP/IP interface for communication among the SMP nodes.
Figure 2-4 illustrates how the BYNET connects individual SMP nodes to create an MPP system in the 5100M configuration.
2-24 Introduction to the Teradata RDBMS for UNIX
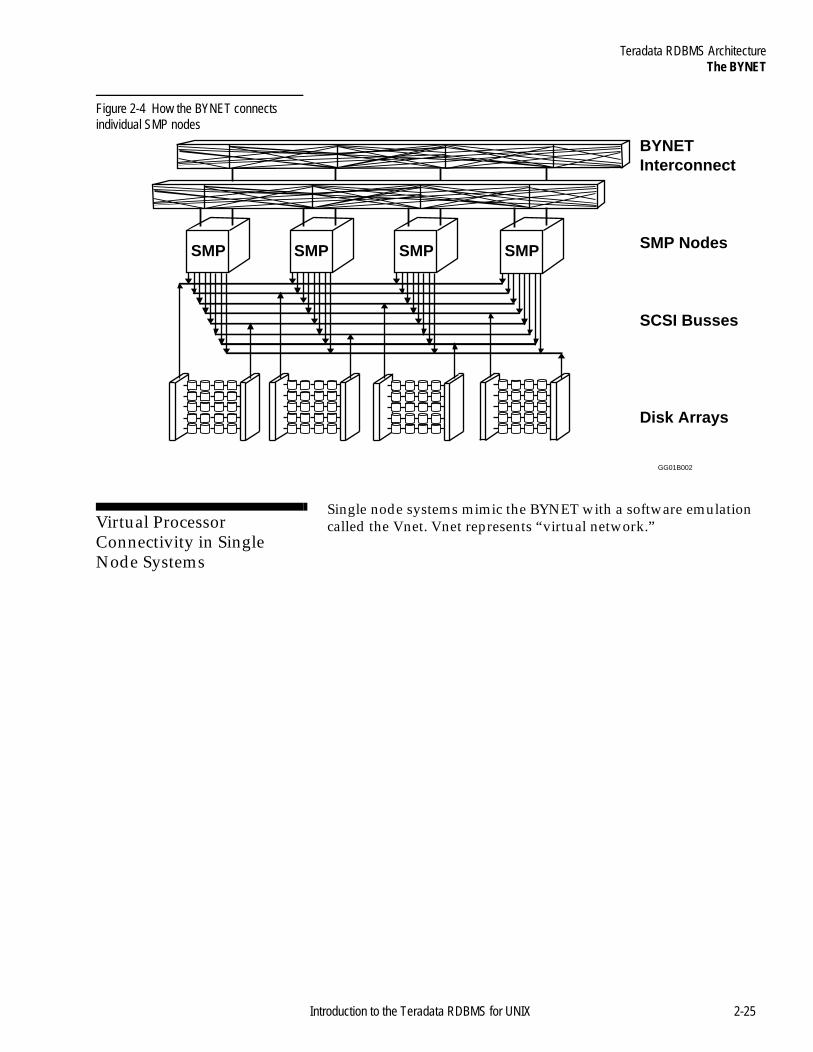
Teradata RDBMS ArchitectureThe BYNET
Figure 2-4 How the BYNET connects individual SMP nodes
Virtual Processor Connectivity in Single Node Systems 2
Single node systems mimic the BYNET with a software emulation called the Vnet. Vnet represents “virtual network.”
GG01B002
BYNETInterconnect
SMP Nodes
SCSI Busses
Disk Arrays
SMP SMP SMP SMP
Introduction to the Teradata RDBMS for UNIX 2-25

Teradata RDBMS ArchitectureThe Access Module Process
The Access Module Process 2
Introduction 2
The Access Module Process (AMP) is the heart of the Teradata RDBMS. The Access Module Process is a virtual processor (vproc) that provides a BYNET interface and performs many database and file management tasks.
AMPs control the management of the Teradata RDBMS and also provide control over the disk subsystem, with each virtual AMP being assigned to a virtual disk.
AMP Functions 2
Each AMP controls the following set of functions:
● BYNET (or Vnet) interface● Database manager
● Locking● Joins● Sorting● Aggregation● Output data conversion● Disk space management● Accounting● Journaling
● File system and disk management
Scalability and Performance 2
You can increase the performance of a Teradata RDBMS by adding SMP nodes to your system. Performance increases at a nearly linear rate with the addition of SMP nodes to a 5100M configuration.
The Disk Subsystem 2
Each AMP supports one virtual disk unit, using either RAID1 (mirroring) or RAID5 (parity striping) technology.
AMP Clusters 2
AMPs are grouped into logical clusters to enhance the fault tolerant capabilities of the Teradata RDBMS. This method of creating additional fault tolerance in your system is discussed further in Chapter 9, “Fault Tolerance.”
2-26 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureRequest Packaging and Unpackaging
Request Packaging and Unpackaging 2
Introduction 2
Any SQL statement must be packaged before being transmitted to the server-based database where it is executed. The returned response must then be unpackaged and presented to the requesting terminal or application program.
This topic discusses the mechanism for request handling used by the Teradata RDBMS.
Facilities for Packaging and Unpackaging SQL Requests and Results 2
The Call-Level Interface (CLI) is the primary mechanism the Teradata RDBMS uses to package and unpackage SQL requests and results. It is the principal API for the Teradata RDBMS.
The CLI packages queries into uniform blocks that are routed to the server by the Teradata Director Program (TDP) in IBM mainframe configurations or by the MTDP in other configurations.
Result tables returned to the requesting terminal or application are similarly routed by the TDP to the appropriate requester where they are unpackaged and presented as a results table.
Personal computers running Microsoft Windows® can use the Windows CLI (WinCLI) package to access the Teradata RDBMS. WinCLI uses the Dynamic Data Exchange (DDE) protocol to communicate with application programs.
The industry-standard ODBC driver to the Teradata RDBMS is another API for packaging and unpackaging SQL requests.
Introduction to the Teradata RDBMS for UNIX 2-27

Teradata RDBMS ArchitectureData Communications Management in the Teradata RDBMS Environment
Data Communications Management in the Teradata RDBMS Environment 2
Introduction 2
This topic discusses the Teradata RDBMS component that handles all data communications management: the Teradata Director Program (TDP).
The TDP 2
SQL requests from a client-based user, whether made as an interactive query or from an application program, are transmitted in the form of CLI packet messages, as are the responses to the query.
These transmissions are managed by a data communications manager.
In the Teradata RDBMS, the data communications manager is called the Teradata Director Program, or TDP.
The TDP does all of the following:
● Establishes and manages session control● Routes requests● Routes logons● Verifies users● Initiates recovery and restart processing● Monitors and controls security
The Teradata RDBMS also provides facilities to enable the TDP to communicate with client application services.
The Micro TDP 2
Workstation clients run a version of the TDP called the Micro TDP (MTDP) and an additional component called the Micro Operating System Interface (MOSI), which contains libraries of procedures to handle operating system-dependent and communications protocol-dependent services.
The MTDP calls MOSI routines for system services like:
● Interrupt processing● I/O processing● Network connection and processing
2-28 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureApplication Programming Facilities
Application Programming Facilities 2
Introduction 2
This topic discusses the application programming facilities provided by the Teradata RDBMS software.
This software falls into several broad categories:
● Embedded SQL● Call Level Interface● ODBC
Because SQL is the only language the Teradata RDBMS understands, all application programming facilities ultimately make their queries against the database using the SQL language.
Embedded SQL 2
The Teradata RDBMS provides a preprocessing facility that enables you to include ANSI-compliant SQL statements in your application programs.
The SQL preprocessor parses your application code for SQL statements, converts them to CLI calls, and then comments out the SQL statements. After the application code has been preprocessed by the Teradata RDBMS Preprocessor2, you can submit it to your client application language compiler.
Preprocessor2 supports the following client programming languages.
Call-Level Interface 2
The Call-Level Interface (CLI) is an application programming interface that provides facilities that enable any client application programming language that supports a CALL statement to query the Teradata RDBMS.
The CLI is also supported directly on NCR servers running the Teradata RDBMS.
A Windows®-based version of CLI, called WinCLI, is also available.
This programming language . . . Is supported on this platform . . .
PL/I IBM mainframe clients
COBOL ● IBM mainframe clients● Selected workstation clients
C ● IBM mainframe clients● UNIX clients
Introduction to the Teradata RDBMS for UNIX 2-29

Teradata RDBMS ArchitectureApplication Programming Facilities
ODBC 2
Open Database Connectivity (ODBC) is an industry standard application programming interface you can use with Microsoft Windows®, Windows® NT, and Windows 95 to make SQL queries against a Teradata RDBMS database.
The ODBC Driver for Teradata RDBMS provides Core-level SQL and Extension-level 1 (with some Extension-level 2) function call capability using the Windows® Sockets (WinSock) TCP/IP communications software interface.
An additional software package, the Database Query Manager, permits the Teradata RDBMS to manage requests from applications running under Windows®, Windows® NT, and Windows® 95 using ODBC.
ODBC operates independently of CLI and WinCLI.
2-30 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureArchiving and Data Loading Utilities
Archiving and Data Loading Utilities 2
Introduction 2
The Teradata RDBMS provides several utilities for archiving and restoring the database and for data loading. Data loading utilities are typically used in a decision support environment where the client machine gathers data during the day and dumps it to the server over night. This topic briefly describes these utilities.
Archive and Restore Utility and ASF2 2
The Archive and Restore utility and the Archive Storage Facility (ASF2) support archiving of databases, individual tables, or permanent journals to any of the following media:
● 3500/4500/5100 tape (ASF2 only)● Client tape● Client file
The utility also restores databases from those archival media to the Teradata RDBMS.
Archive and Restore is supported in the MVS and VM environments only.
BulkLoad 2
The BulkLoad utility permits batch insert, update, and delete operations on an existing database. The program moves large quantities of data from a client to the Teradata RDBMS on the server.
BulkLoad is supported in the MVS and VM environments only.
FastLoad 2
The FastLoad utility permits you to load unpopulated tables only. The program is similar to BulkLoad except that it runs much faster and does not support update and delete operations.
FastLoad is supported in both the client and server environments.
MultiLoad 2
The MultiLoad utility loads large quantities of data into unpopulated tables. MultiLoad also supports bulk inserts, updates, and deletions against populated tables.
MultiLoad is supported in both the client and server environments.
FastExport 2
The FastExport utility exports large quantities of data from the Teradata RDBMS to a client and is the functional complement of the FastLoad and MultiLoad utilities.
Introduction to the Teradata RDBMS for UNIX 2-31

Teradata RDBMS ArchitectureAdministrative Workstation
Administrative Workstation 2
The Administrative Workstation (AWS) performs many of the functions of a system console for multinode Teradata RDBMS systems.
Single node systems do not have an AWS.
It is an intelligent workstation attached to an SMP node and its primary roles are to:
● Monitor system performance● Provide an input mechanism for the system administrator.
2-32 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureDatabase Window
Database Window 2
Introduction 2
The console software for the Teradata RDBMS for UNIX is called the Database Window (DBW). It runs in the following X windows environments:
● System console● Administrative workstation (AWS)● Remote workstation or PC
The Database Window provides an interface to all the following windows:
● Supervisor● Database Message● Application Windows (including any currently active support
utilities)
Workstation Types and Available Platforms 2
Some of the workstation types are available only on specific platforms.
The following table shows which workstations are appropriate for the different platforms and how they are connected to the node.
Database Window Communication 2
The DBW communicates with the Teradata RDBMS through the console subsystem (CNS), which is part of the PDE. Because the DBW is managed by the CNS, you will occasionally see CNS messages in the DBW.
Type of Workstation Platform Description
System console SMP Connected directly to the SMP node
Administrative workstation MPP LAN-connected through an Ethernet card on the node. The AWS provides a single operational view of the multiple-node system.
Remote connection through LAN:● UNIX workstation● PC with X Windows server
Both LAN-connected through an Ethernet card on the node.
Introduction to the Teradata RDBMS for UNIX 2-33

Teradata RDBMS ArchitectureDatabase Window
Functions Provided by the Database Window 2
The system console provides all of the following functions:
● Displays system status● Displays the current system configuration● Displays performance statistics● Controls various AMP utilities
Supervisor Subwindow 2
The DBW has a main window and several subwindows. The principal subwindow, called the Supervisor Subwindow, permits an operator to run utilities and enter various commands.
Utilities Available from the Supervisor Subwindow 2
Many utilities used to control, monitor, and configure the RDBMS are available from the Supervisor subwindow. A partial list of the utilities invoked from the DBW is provided in Chapter 12, “System Administration,” in the section “System Utility Software.”
Supervisor Commands Available from the Database Window 2
The following table lists the commands available from the Supervisor Subwindow of the Database Window.
Command Function
CNSGET Displays the setting for the CNS variables.
CNSSET DBWTIMEOUT
Sets how often the CNS checks the connection between the CNS and the DBW.
CNSSET LINES Sets the number of lines that are saved and available to you in the output display area after a reconnect to the CNS.
CNSSET STATEPOLL
Sets how often the CNS checks the RDBMS state and substate.
CNSSET TIMEOUT Sets the interval between the time you type a request and the time the DBW rejects it because a program did not solicit the input.
DISABLE LOGONS Prevents new sessions from logging on.
ENABLE LOGONS Restores the ability of new sessions to log on.
GET CONFIG Displays the current system configuration.
GET LOGTABLE Displays the status of logging to the specified resource usage tables.
GET RESOURCE Displays the resource collection and logging rates, and the memory clearing rate of a vproc or node.
GET TIME Displays the current date and time.
GET VERSION Displays the PDE and RDBMS version numbers.
2-34 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureDatabase Window
LOG Logs the specified text into the errorlog.
QUERY STATE Displays the current state of the RDBMS.
RESTART TPA Restarts the RDBMS.
SET LOGTABLE Enables or disables logging to the specified resource usage tables.
SET RESOURCE Sets the resource collection and logging rates, and the memory buffer clearing rate of a vproc or node.
START Starts a RDBMS utility in a DBW application subwindow.
STOP Stops a RDBMS utility in a DBW application subwindow.
Command Function
Introduction to the Teradata RDBMS for UNIX 2-35

Teradata RDBMS ArchitectureRDBMS Gateway
RDBMS Gateway 2
The RDBMS Gateway maps the external network protocols onto the internal database message protocols. It is a server program that provides a pathway for applications running on a network-connected client to access the Teradata server.
The RDBMS Gateway also permits clients running locally to communicate with the Teradata RDBMS.
There is one RDBMS Gateway per machine, controlling up to 600 sessions per node.
2-36 Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS ArchitectureDatabase Utility Software
Database Utility Software 2
Database utilities are used to perform maintenance functions on the Teradata RDBMS.
They are invoked from the Database Window with the following exceptions:
The system utilities include:
Utility Name Runs under . . .
xmppconfig UNIX as an application.
pdeconfig UNIX as an application.
DIP control of BTEQ as well as the Database Window.
XPT UNIX as an application.
xperfstate UNIX as an application.
Utility Name Function
AbortHost Aborts outstanding transactions.
Checktable Checks for table inconsistencies.
Config Specifies logical database configuration (AMPs and PEs).
XCTL Displays and modifies the fields of the Control Parameters Globally Distributed Objects (GDO) of the Parallel Database Extension (PDE) software.
Accessed from an xterm window.
DBSControl Specifies global runtime flags for database software.
VprocManager Provides status for vprocs and permits manipulation of their attributes.
GtwGlobal Manages LAN connections.
Introduction to the Teradata RDBMS for UNIX 2-37
Teradata RDBMS ArchitectureDatabase Utility Software
Ferret Displays and sets various disk space utilization attributes without destroying the data for which the File System is responsible.
For new attributes, Ferret reconfigures the stored data dynamically to match them.
Utilities running under Ferret include the following:
● Scandisk● Showspace● Packdisk
Filer Displays information used to correct problems within the File System.
pdeconfig Allocates PE and AMP vproces to physical resources, including all of the following:● Configuring disk arrays● Assigning logical units (LUNS) to the disks● Allocating disks to AMPs● Allocating LANs and channels to PEsAlways run xmppconfig before running pdeconfig.
QryConfig Displays the current database software logical configuration.
QrySessn Displays session status information.
RcvManager Displays recovery status.
Rebuild Reconstructs tables from fallback copies (only works when fallback is used).
Reconfig Redistributes disk data automatically whenever AMP vprocs are added or removed.
Showlocks Displays host utility (HUT) locks on databases and tables.
SysInit Initializes the Teradata system tables and all user tables.
xmppconfig Sets up and updates configurations.
Use this utility to specify the physical configuration before running pdeconfig. Must be run prior to pdeconfig for MPP systems.
DIP Executes one or more of the standard DIP (Database Initialization Program) SQL scripts packaged with the RDBMS
Utility Name Function
2-38 Introduction to the Teradata RDBMS for UNIX

Teradata RDBMS ArchitectureDatabase Utility Software
XPT Installs multiple copies of the same software across all nodes of an MPP system.
xperfstate Provides real time display of PDE system performance, including system-wide CPU utilization and disk utilization.
Utility Name Function
Introduction to the Teradata RDBMS for UNIX 2-39

Teradata RDBMS ArchitectureTeradata Manager
Teradata Manager 2
Introduction 2
Teradata Manager is a PC-based package that provides easy access to resource usage information in the Teradata Data Dictionary. The PC supporting Teradata Manager must be running the Windows NT operating system.
Performance Analysis 2
The Teradata Manager Performance Monitor uses two commands to monitor the performance of the Teradata RDBMS.
The commands are:
● MONITOR CONFIG● MONITOR SUMMARY
You can specify date sampling rates and durations and the Teradata Manager collects and analyzes the data for you. Results of data analyses can be displayed in a text window.
The Locking Logger feature permits you to determine whether an application mix is causing delays because of database lock contention.
Session Information 2
Teradata Manager provides facilities for:
● Setting session rates● Monitoring sessions● Identifying sessions● Aborting sessions
Statistical Information 2
Teradata Manager provides facilities for:
● Detecting which tables have statistics● Create statistics for columns and indexes● Drop statistics by table or column/index● Refresh statistics for:
● Entire Teradata RDBMS● Database● Table● Column/Index
2-40 Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS ArchitectureFor More Information
For More Information 2
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
System process flows Teradata RDBMS for UNIX Database Design and Administration
Teradata SQL Teradata RDBMS for UNIX SQL Reference
General Teradata software architecture
Teradata RDBMS for UNIX Database Design and Administration
The TDP Teradata TDP Reference
Preprocessor2 Teradata Application Programming Using Embedded SQL
Embedded SQL Teradata RDBMS for UNIX SQL ReferenceTeradata Application Programming Using Embedded SQL for C, COBOL, and PL/I
Teradata Manager Teradata Manager Reference Guide
ODBC Teradata ODBC Driver for Windows Installation and User’s Guide
Introduction to the Teradata RDBMS for UNIX 2-41

Teradata RDBMS ArchitectureFor More Information
2-42 Introduction to the Teradata RDBMS for UNIX

The Relational Model
Introduction to the Teradata RDBMS for UNIX
Chapter 3
The Relational Model

The Relational Model
Introduction to the Teradata RDBMS for UNIX
Introduction to the Teradata RDBMS for UNIX 3
-1About This ChapterThe Relational Model3
About This Chapter 3
Introduction 3
This chapter reviews the relational model for database management. The chapter also describes issues like normalization, referential integrity, and macros.
The relational model for database management is based on concepts derived from the mathematical theory of sets. This chapter touches on the relational model from that viewpoint to establish its solid foundation in mathematics. By way of comparison, database management products based on the hierarchical, network, and object-oriented architectures are not based on rigorous theoretical foundations and so their behavior is not as predictable as are relational products.
Database management systems based on the hierarchical, network, and object-oriented models use different languages to define and manipulate the database, and none provides the capability for making ad hoc queries.
The chapter describes the process of further normalization of a database, then describes macros in the Teradata environment.
What is a Relational Database? 3
A relational database is a database that is perceived by its users as a collection of tables and nothing but tables. This deceptively simple concept permits information to be created and maintained without any kind of anomalies as well as providing users with a simple presentation of data which can, in turn, be manipulated with ease.
The freedom from anomalies is based on the fact that relational databases are based on the mathematics of set theory. Roughly speaking, set theory defines a table as a relation. Each entity in a relation is called a tuple and each column is an attribute. The number of tuples is the cardinality of the relation and the number of attributes its degree.
The following table presents these correspondences. Note that relational databases are a generalization of the mathematics of set theory relations and the correspondences between set theory and relational databases are not always direct.
Set theory term Relational database term
Relation Table
Tuple Row (or record)
Attribute Column

The Relational ModelAbout This Chapter
Because the mathematical operations on relations are well-defined, any manipulation of a table in a relational database has a consistent, predictable outcome. This contrasts with all other database management systems, none of which is based on mathematical theory and none of which treats its data formally. Because the operations on relational databases are so well defined, users can perform ad hoc, interactive queries of the database-—unlike other database management systems that require a system programmer to predefine all links between files and all possible queries of the database.
Under the covers, the SQL optimizer uses relational algebra to build the most optimal access to the requested data. Because the definition of the database can change from time to time, the optimizer can readily adapt to any such changes and reoptimize access paths without programmer intervention.
Some Other Definitions 3
The following terms are defined now to make the discussion that follows easier to understand.
Term Definition
Primary key A unique identifier for a relation.
In set theory (and in relational database theory), duplicate rows are not allowed. However, commercially available relational databases often allow duplicate rows in relations. In those cases, the relation does not have a primary key.
Relations with a primary (or candidate) key do not permit duplicate rows.
The Teradata RDBMS permits enforcement of the no duplicates rule even when no primary key is specified.
Candidate key Any relation might have multiple unique identifiers. Each such unique identifier is called a candidate key.
A candidate key must satisfy the properties of uniqueness and minimality. That is, for any attribute, no two rows of the table have the same value for that attribute and if it is composite, no component can be eliminated without destroying the uniqueness property.
Alternate key Any candidate key not chosen as the primary key.
3-2 Introduction to the Teradata RDBMS for UNIX
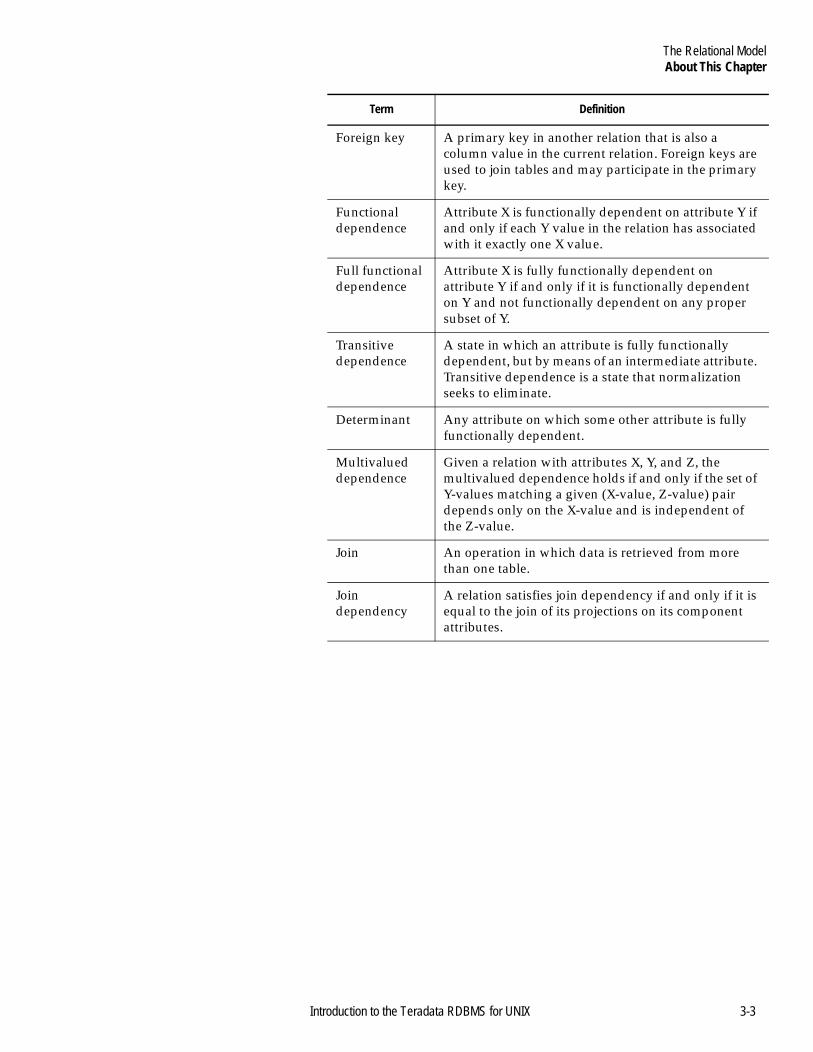
The Relational ModelAbout This Chapter
Foreign key A primary key in another relation that is also a column value in the current relation. Foreign keys are used to join tables and may participate in the primary key.
Functional dependence
Attribute X is functionally dependent on attribute Y if and only if each Y value in the relation has associated with it exactly one X value.
Full functional dependence
Attribute X is fully functionally dependent on attribute Y if and only if it is functionally dependent on Y and not functionally dependent on any proper subset of Y.
Transitive dependence
A state in which an attribute is fully functionally dependent, but by means of an intermediate attribute. Transitive dependence is a state that normalization seeks to eliminate.
Determinant Any attribute on which some other attribute is fully functionally dependent.
Multivalued dependence
Given a relation with attributes X, Y, and Z, the multivalued dependence holds if and only if the set of Y-values matching a given (X-value, Z-value) pair depends only on the X-value and is independent of the Z-value.
Join An operation in which data is retrieved from more than one table.
Join dependency
A relation satisfies join dependency if and only if it is equal to the join of its projections on its component attributes.
Term Definition
Introduction to the Teradata RDBMS for UNIX 3-3

The Relational ModelNormalization
Normalization 3
Introduction 3
The theory of normalization is at the root of the relational model of database management. Normalization theory is constructed around the concept of normal forms. These normal forms define a system of constraints. If a relation meets the constraints of a particular normal form, then it is said to be in that form.
You can think of the normal forms as an onion, with the outermost layer being the set of all relations, including unnormalized relations. The figure that follows illustrates this. As you work your way to the core of the onion, you must pass through each lower normal form. As a result, a relation that has achieved fifth normal form has also achieved first, second, third, and fourth normal forms.
Figure 3-1 Layers of normalization.
5NFrelations
BCNF relations
3NF relations
2NF relations
1NF relations
All relations
FG04A001
4NF relations
3-4 Introduction to the Teradata RDBMS for UNIX

The Relational ModelNormalization
By definition, a relational database is always normalized because its field values are always atomic. But to simply leave it at that invites a number of problems with redundancy and potential update anomalies, and that is why the higher normal forms were developed. The next topics describe normal forms and how to achieve them.
Introduction to the Teradata RDBMS for UNIX 3-5

The Relational ModelFirst, Second, and Third Normal Forms
First, Second, and Third Normal Forms 3
Introduction 3
This topic describes the first three normal forms: what they are, why they are needed, and how to achieve them.
The first three normal forms are stepping stones to Boyce-Codd normal form and, when appropriate, the higher normal forms.
The next topic describes Boyce-Codd (BCNF) and higher normal forms.
First Normal Form 3
First normal form (abbreviated 1NF) is definitive for a relational database. All relations in a relational database must be in first normal form by definition.
A relation is said to be in first normal form if all its fields (simple domains in mathematics) are atomic. This means that a field can contain one value and one value only. No hierarchies of data values are allowed. This concept is sometimes referred to as the elimination of repeating groups from a relation.
The formal definition is as follows: For a relation to be in first normal form, the relationship between the primary key of the relation and each of the other attributes must be one-to-one (in that direction). In other words, all underlying simple domains of the relation contain atomic values only.
The nonkey attributes are said to be functionally dependent on the key.
Note: a nonkey attribute is any attribute that is not part of the primary key for the relation.
Second Normal Form 3
Second normal form (abbreviated 2NF) deals with the elimination of circular dependencies from a relation.
A relation is said to be in second normal form if it is in 1NF and every nonkey attribute is fully dependent on the entire primary key.
The formal definition is as follows: For a relation to be in second normal form, the relationship between any portion of the primary key of a relation and each of the other columns must not be one-to-one (in that direction). In other words, the nonkey columns are fully functionally dependent on the key.
3-6 Introduction to the Teradata RDBMS for UNIX

The Relational ModelFirst, Second, and Third Normal Forms
Third Normal Form 3
Third normal form (abbreviated 3NF) deals with the elimination of nonkey attributes that do not describe the primary key.
The formal definition is as follows: For a relation to be in third normal form, the relationship between any two nonprimary key columns or groups of columns in a relation must not be one-to-one in either direction. In other words, the nonkey columns are nontransitively dependent upon each other and the key. No transitive dependencies implies no mutual dependencies.
Attributes are said to be mutually independent if none of them is functionally dependent on any combination of the others. This mutual independence ensures that individual attributes can be updated without any danger of affecting any other attribute in a row.
Introduction to the Teradata RDBMS for UNIX 3-7

The Relational ModelBoyce-Codd and Higher Normal Forms
Boyce-Codd and Higher Normal Forms 3
Introduction 3
When the relational model of database management was originally proposed, it only addressed the first three normal forms. Later work with the model showed that 3NF required further refinement to ensure that update anomalies would never occur.
This topic describes Boyce-Codd normal form and briefly mentions fourth and fifth normal forms for completeness.
Boyce-Codd Normal Form 3
Third normal form does not handle situations in which a relation has multiple composite candidate keys with overlapping attributes. To eliminate these problems, Codd developed the so-called Boyce-Codd normal form (BCNF), which reduces to 3NF whenever the special situation that defines this problem does not apply.
A relation is in BCNF if and only if every determinant is a candidate key. This means that only determinants are candidate keys.
Fourth Normal Form 3
A relation is said to be in fourth normal form (4NF) if and only if whenever there is a multivalued dependency in the relation (for example, say X multiply determines Y) then all attributes of the relation are also functionally dependent on X.
In practice, the need for 4NF is rarely seen.
Fifth Normal Form 3
So far it has been possible to normalize relations by decomposing them into two of its projections. In rare occasions, simple projections are not sufficient to decompose a nonnormal relation into two relations. In these rare instances, Fifth Normal Form (5NF) is used to decompose the unnormalized relation into three or more projections of the original relation.
A relation is said to be in fifth normal form (5NF - sometimes called projection-join normal form, or PJ/NF) if and only if every join dependency in the relation is a consequence of the candidate keys of the relation.
This makes 5NF the final possible normal form to be achieved by taking projections and using joins. It is guaranteed to be free of all anomalies that can be removed by taking projections, but not necessarily of all possible anomalies.
3-8 Introduction to the Teradata RDBMS for UNIX

The Relational ModelReferential Integrity
Referential Integrity 3
Introduction 3
Referential integrity (RI) is a key concept for the relational model.
RI is defined by the Referential Integrity Rule, which states that a relational database cannot contain any unmatched foreign key values.
Enforcing RI in the Teradata RDBMS 3
To implement RI in the Teradata RDBMS, you have three choices:
● Use the referential constraint checks supplied by the database software
● Write your own, site-specific macros.● Enforce constraints through application code.
Primary and Foreign Keys 3
For review, a primary (parent) key is the candidate key selected to identify each tuple in a relation uniquely.
A foreign key is a (possibly composite) attribute of one relation whose values are required to match those of the primary key of some other relation.
Indexes 3
An index is a special file used to speed retrieval. The typical index contains two fields: a value and a pointer to instances of that value in a data table. Because the Teradata RDBMS uses hashing to distribute rows across the AMPs, the value is condensed into an entity called a row hash, which is used as the pointer. The row hash is not the value, but a mathematically transformed address. The Teradata RDBMS uses this transformed address as a retrieval index.
The Teradata RDBMS uses indexes to define row uniqueness. This means that each row in a table must be identified uniquely, either by a unique primary index or by a unique secondary index.
The value or values chosen to be the unique index for a table are frequently the same values identified as the primary key during the data modeling process, but there is not any hard and fast rule that makes this so. In fact, physical database design considerations often lead to values other than the primary key being chosen as the unique index for a table
Introduction to the Teradata RDBMS for UNIX 3-9

The Relational ModelReferential Integrity
How do Primary Keys and Primary Indexes Relate? 3
The following table demonstrates some of the conceptual differences between primary indexes and primary keys.
What is Referential Integrity? 3
Referential integrity is a mechanism to keep you from accidentally corrupting your database. Suppose you have a table like the following:
ORDER PART
Part number and order number, each a foreign key in this relation, also form the composite primary key.
Primary key Primary index
Naming convention used to ensure referential integrity
Physical access mechanism
Required by the Teradata RDBMS only if referential integrity checks are to be performed
Required by Teradata RDBMS
16-column limitIF the Teradata RDBMS performs . . .
THEN the column limit is . . .
referential integrity checks
16.
no referential integrity checks
Unlimited.
Defined by CREATE TABLE statement Defined by CREATE TABLE statement
Must be unique May be unique or nonunique
Identifies a row uniquely Distributes rows
Values cannot be changed Values can be changed
May not be null May be null
Does not imply access path Defines most common access path
Order Number Part Number Quantity
PKNot Null
FK FK
1 1 110
1 2 275
2 1 152
3-10 Introduction to the Teradata RDBMS for UNIX

The Relational ModelReferential Integrity
Suppose you were to go the PART NUMBER table and delete the row defined by the primary key value 1. The key for the first and third rows in the ORDER PART table are now corrupted because there is no row in the PART NUMBER table with a primary key of 1 to support them. Such a situation exhibits a loss of referential integrity.
Now, suppose you had a mechanism to prevent this from happening? If you tried to delete the row with a primary key value of 1 from the PART NUMBER table, the database management system does not allow you to remove the row. This is the way the Teradata RDBMS maintains referential integrity.
If a row is selected for deletion, insertion, or updating that is in any way related to rows in another table, those related rows are also updated or deleted.
The Referential Constraint 3
The table containing the referencing rows is the child table, while the table containing the referenced rows is the parent table. References between tables are made by means of foreign keys. Each foreign key in a child table is a primary key in the parent table. The combination of the foreign key, the parent key, and the relationship between them is called the referential constraint.
Referential constraints must meet the following criteria:
● The parent key must exist when the referential constraint is defined.
● The parent key columns must be either a unique primary index (UPI) or a unique secondary index (USI).
● The foreign and parent keys must have the same number of columns and their data types must match.
● The foreign and parent keys cannot exceed 16 columns.● Duplicate referential constraints are not allowed.● You cannot drop or alter either foreign or parent keys using an
ALTER TABLE statement after a referential constraint has been defined.
To drop a foreign or parent key after a referential constraint has been defined you must first drop the constraint and then alter the table.
Introduction to the Teradata RDBMS for UNIX 3-11

The Relational ModelReferential Integrity
● The foreign key must be equal to the parent key or it must be null.
● Self-reference is allowed, but the foreign and parent keys cannot consist of identical columns.
● You can define no more than 64 referential constraints per table.
A maximum of 64 tables can reference a single table.
Create referential constraints using the CREATE TABLE statement with the REFERENCES option.
Add or drop referential constraints using the ALTER TABLE statement with the FOREIGN KEY and REFERENCES options.
Rollforwards and rollbacks on either a parent or child table result in both tables becoming not valid. To resolve these inconsistent references, use the ALTER TABLE statement with the DROP FOREIGN KEY and REFERENCES options.
To resolve inconsistent references that occur because of a Restore or Copy operation on either the parent or the child table, use the ALTER TABLE statement with the DROP INCONSISTENT REFERENCES option.
Referential Constraint Checks 3
The Teradata RDBMS performs referential constraint checks whenever any of the following things occur:
● A referential constraint is added to a populated table● A row is inserted, deleted, or updated● A parent or foreign key is modified
The following table summarizes these actions.
Action on RDBMS Constraint check performed
INSERT into parent table None.
INSERT into child table Must have matching parent key value if the foreign key is not null.
DELETE from parent table Abort the request if the deleted parent key is referenced by any foreign key.
DELETE from child table None.
UPDATE parent table Abort the request if the parent key is referenced by any foreign key.
UPDATE child table New value must match the parent key when the foreign key is updated.
3-12 Introduction to the Teradata RDBMS for UNIX

The Relational ModelTeradata Macros
Teradata Macros 3
Introduction 3
This topic describes Teradata SQL macros: what they are and how advantageous it is to use them in many situations.
What is a Teradata Macro? 3
Teradata macros are SQL code that is stored on the server. Macros act as a single transaction to perform complex tasks. They are typically used to reduce the number of characters that must be entered to specify an operation, saving the user time and decreasing the chance of making errors. Teradata macros are something of a cross between an interactive query and an application program using embedded SQL.
Creating a Macro 3
You create macros much the same way you create views, using the CREATE MACRO statement.
The following example statement defines a macro for adding new employees to the Employee table and incrementing the EmpCount field in the Department table.
CREATE MACRO NewEmp (name (VARCHAR(12)),number (INTEGER, NOT NULL),dept (INTEGER, DEFAULT 100))
AS (INSERT INTO Employee (Name, EmpNo, DeptNo)VALUES (:name, :number, :dept);UPDATE Department SET EmpCount=EmpCount + 1WHERE DeptNo=:dept;);
Note the host variable-like parameters that begin with a colon character. The macro fills in the values for these with data you provide each time you execute it.
Using a Macro 3
This example shows how you might use the NewEmp macro to add employee Goldsmith to the Manufacturing department.
EXECUTE NewEmp (‘Goldsmith H’, 10015, 600);
Introduction to the Teradata RDBMS for UNIX 3-13

The Relational ModelTeradata Macros
Modifying a Macro 3
Use the REPLACE MACRO statement to modify a macro. The following statement replaces NewEmp with a macro that changes the default department number from 100 to 300.
REPLACE MACRO NewEmp (name (VARCHAR (12)),number (INTEGER, NOT NULL),dept (INTEGER, DEFAULT 300))
AS (INSERT INTO Employee (Name, EmpNo, DeptNo)VALUES (:name, :number, :dept);UPDATE Department SET EmpCount=EmpCount+1WHERE DeptNo=:dept;);
Deleting a Macro 3
Use the DROP MACRO statement to delete a macro. The following statement removes the NewEmp macro from the database.
DROP MACRO NewEmp;
3-14 Introduction to the Teradata RDBMS for UNIX

The Relational ModelFor More Information
For More Information 3
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
The relational model of database management
Teradata RDBMS for UNIX Database Design and Administration
Normalization Teradata RDBMS for UNIX Database Design and Administration
Teradata macros Teradata RDBMS for UNIX SQL Reference
Introduction to the Teradata RDBMS for UNIX 3-15

The Relational ModelFor More Information
3-16 Introduction to the Teradata RDBMS for UNIX

Data Definition
Introduction to the Teradata RDBMS for UNIX
Chapter 4
Data Definition

Data Definition
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 4
-1About This ChapterData Definition4
About This Chapter 4
Introduction 4
This chapter describes the data definition capabilities of Teradata Structured Query Language (SQL), emphasizing the basic elements it operates on, the types of data supported, and the statements and operators SQL uses for its Data Definition Language (DDL) functions. Other topics described are base tables, null handling, and indexes.
The first part of the chapter deals with SQL data definition statements and the basic objects and operators, data types, and other operations SQL supports.
The second part of the chapter describes how to define base tables, while the final topic is indexes.
Basic Statements 4
The following table illustrates the basic statements of SQL data definition.
Statement Action performed
CREATE Defines a new table, index, macro, or view, depending on the object of the CREATE statement.
DROP Removes a table, index, macro, or view definition, depending on the object of the DROP statement.
ALTER Changes a table or protection definition. For example, you can add or remove columns from a table using this statement.

Data DefinitionTeradata SQL Data Types
Teradata SQL Data Types 4
Introduction 4
This topic introduces the data types supported by Teradata SQL.
While data is stored in ASCII format in the Teradata RDBMS, results are returned to a client in its native format, which could be any of the following:
● ASCII● EBCDIC● KatakanaEBCDIC● KanjiEUC● KanjiShift-JIS.
Teradata SQL Data Types 4
The following table lists each data type supported by the Teradata RDBMS and a brief description.
Data Type Description
INTEGER 32-bit, signed binary whole number.
Range: -2,147,483,648 to 2,147,483,647
SMALLINT 16-bit, signed binary whole number.
Range: -32,768 to 32,767
BYTEINT 8-bit, signed binary whole number.
Range: -128 to 127
DECIMAL[(n[,m])] Packed decimal of n digits, m to the right of the decimal.
Precision (n) range: 1 to 18 A system flag, DecimalMax, allows the maximum range value to be set to 0, 15 or 18. See the discussion of data types in the Teradata RDBMS SQL Reference.
Scale (m) range: 0 to n
FLOAT 64-bit floating point number in sign-and-magnitude form.
Range: 2.226 x 10-308 to 1.797 x 10308
CHAR(n) Fixed length character string of n characters.
Range: 32,000 is the maximum for n
4-2 Introduction to the Teradata RDBMS for UNIX

Data DefinitionTeradata SQL Data Types
Teradata SQL Column Attributes 4
The following table lists each column attribute type supported by the Teradata RDBMS and a brief description.
VARCHAR(n) Variable length character string of maximum length n.
Range: 32,000 is the maximum for n
LONG VARCHAR Longest variable length character string.
Equivalent to VARCHAR(32000)
BYTE(n) Fixed length binary string of n bytes.
Range: 32,000 is the maximum for n
VARBYTE(n) Variable length binary string of maximum value n.
Range: 32,000 is the maximum for n
DATE 32-bit integer that represents the date in YY/MM/DD format.
NUMERIC See description for DECIMAL.
REAL See description for FLOAT.
DOUBLE PRECISION
See description for FLOAT.
Column Attribute Description
NULL Field can be null.
NOT NULL Field can not be null.
COMPRESS Space occupied by one or more columns can be compressed to zero space for a given value.
BETWEEN n AND n Range constraint.
Available for the following data types:● INTEGER● SMALLINT● BYTEINT● DECIMAL● FLOAT● DATE
Data Type Description
Introduction to the Teradata RDBMS for UNIX 4-3

Data DefinitionTeradata SQL Data Types
You should avoid using NULLs if possible because they can complicate the meaning of a result table.
Because NULLs have no value, their meaning is ambiguous and easily misinterpreted by users—especially when you are dealing with an outer join problem, which naturally generates many nulls of its own.
CONSTRAINT Type or range constraint.
CONSTRAINTs can be named at either the column or table level. Naming makes it easier to drop or alter a CONSTRAINT.
Valid CONSTRAINTs are:● PRIMARY KEY● UNIQUE● CHECK● FOREIGN KEY
CASESPECIFIC Data stored as it is entered and not converted to uppercase for comparison operations.
This is the default in ANSI mode.
NOT CASESPECIFIC Data is converted to uppercase for comparison operations.
This is the default in Teradata mode.
UPPERCASE Data stored in all capital letters irrespective of how it is entered.
FORMAT Specifies the display format for column data.Available for the following data types:● Character● Numeric● DATE
TITLE Specifies a title for displayed or printed results that differs from the default column name
DEFAULT Supplies a default value for a field when an INSERT statement does not specify a value.
Column Attribute Description
4-4 Introduction to the Teradata RDBMS for UNIX

Data DefinitionTeradata SQL Data Types
When you “define” a piece of data as a null, the null can be interpreted at least two different ways:
● the information is missing because its value is not known, but that value is applicable (missing but applicable)
● the information is missing because its value is inapplicable in the current row (missing and inapplicable)
Introduction to the Teradata RDBMS for UNIX 4-5

Data DefinitionCreating New Tables
Creating New Tables 4
Introduction 4
This topic describes how to create new tables using the SQL data definition language (DDL) capabilities.
Example Database 4
The examples in this chapter use a Personnel database consisting of two tables named Employee and Department.
Employee Table
Department Table
EmpNo Name DeptNo JobTitle Salary YrsExp
10001 Peterson J 100 Payroll Clerk 25,000.00 5
10002 Moffit H 100 Recruiter 35,000.00 3
10003 Leidner P 300 Secretary 23,000.00 13
10004 Smith T 500 Engineer 42,000.00 10
10005 Omura H 500 Programmer 40,000.00 8
10006 Kemper R 600 Assembler 29,000.00 7
10007 Aguilan J 600 Manager 45,000.00 11
10008 Phan A 300 Vice President 55,000.00 12
10009 Marston A 500 Secretary 22,000.00 12
10010 Reed C 500 Technician 30,000.00 4
10011 Chin M 100 Controller 38,000.00 11
10012 Watson L 500 Vice President 56,000.00 8
10013 Regan R 600 Purchaser 44,000.00 10
DeptNo DeptName EmpCount Loc MgrNo
100 Administration 3 NYC 10004
300 Exec Office 2 NYC 10012
500 Engineering 5 ATL 10008
600 Manufacturing 3 CHI 10009
4-6 Introduction to the Teradata RDBMS for UNIX

Data DefinitionCreating New Tables
Creating the Employee and Department Tables 4
The following CREATE TABLE statement creates the Employee table illustrated above.
CREATE TABLE Employee, FALLBACK(EmpNo INTEGER,Name VARCHAR(12),DeptNo SMALLINT,JobTitle VARCHAR(12),Salary DECIMAL (8,2),YrsExp BYTEINT
)UNIQUE PRIMARY INDEX (EmpNo)INDEX (Name);
The unique primary index for this table is the EmpNo column, with Name being a nonunique secondary index. The table has fallback enabled.
The following CREATE TABLE statement creates the Department table illustrated above.
CREATE TABLE Department, FALLBACK(DeptNo SMALLINT,DeptName VARCHAR(14),EmpCount INTEGER,Loc CHAR(3),MgrNo INTEGER
)UNIQUE PRIMARY INDEX (DeptNo);
The unique primary index for this table is the DeptNo column. There is no secondary index on the table. The table has fallback enabled.
Note that column definitions follow the table name. Each column defined is characterized by one or more attributes, including a mandatory data type.
Introduction to the Teradata RDBMS for UNIX 4-7

Data DefinitionAltering Tables
Altering Tables 4
Introduction 4
This topic describes the SQL statement used to change the characteristics of an existing table.
Capabilities of the ALTER Statement 4
The ALTER statement supports changes to the following table entities:
● Columns (add or drop)● Column attributes (add or drop; FORMAT, TITLE, and
DEFAULT)● Fallback (add or drop)
Named CONSTRAINTs can be dropped using their name.
Example: Adding a Column 4
This example alters the Department table to add a column called Budget.
ALTER TABLE DepartmentADD Budget DECIMAL(9,2)
;
After you perform this statement, the Department table looks like this:
Department Table
Note that the rows all contain nulls for the Budget column.
Example: Dropping a Column 4
This example alters the Department table to drop the Budget column.
ALTER TABLE DepartmentDROP Budget
;
DeptNo DeptName EmpCount Loc MgrNo Budget
100 Administration 3 NYC 10004
300 Exec Office 2 NYC 10012
500 Engineering 5 ATL 10008
600 Manufacturing 3 CHI 10009
4-8 Introduction to the Teradata RDBMS for UNIX

Data DefinitionIndexes
Indexes 4
Introduction 4
The Teradata RDBMS supports five types of indexes:
● Unique Primary Index (UPI)● Unique Secondary Index (USI)● Nonunique Primary Index (NUPI)● Nonunique Secondary Index (NUSI)● Join Index
This section defines these different index types and explains how to use them.
What Is An Index? 4
Indexes on tables in a relational database function much like book indexes—they speed up information retrieval.
In general, an index is used to perform the following:
● Distribute data rows (primary index only)● Locate data rows● Improve performance (indexed access is often more efficient
than searching all rows of a table)● Ensure uniqueness of the index values (only one row of a table
can have a particular value in the column (s) defined as a unique index)
A table must have one primary index and none, one or several secondary indexes.
You cannot force the optimizer to use any index—it selects whichever index or indexes will return the query result most quickly. In some cases, the optimizer will process the query without using any index.
Selection of indexes:
● can have a direct impact on overall Teradata performance● is not always a straight forward process● is based partly on usage information
Logically, an index consists of two values: a data value and a pointer to a data row. In the case of non-unique indexes, a data value can point to one or more data rows.
Introduction to the Teradata RDBMS for UNIX 4-9

Data DefinitionIndexes
Primary Index 4
The primary index is defined at the time the table is created. The primary index affects system performance in the following ways:
● The hash value of the primary index values determine the distribution of rows on disk.
● When the value of a primary index column is specified in an equality constraint, the hash value is used to directly access the applicable row.
When a new row is inserted into a table, a hashing algorithm is applied to the primary index value. The hash result determines on which disk the row will be stored.
Secondary Index 4
Secondary indexes allow access to information in a table by alternate, less frequently used paths.
Secondary indexes require the maintenance of a subtable and the associated overhead (additional storage space and maintenance.)
Join Index 4
A join index is an indexing structure containing columns from multiple tables, specifically the resulting columns from one or more tables.
Join Index was developed so that frequently executed join queries could be processed more efficiently. Rather than having to join individual tables each time the join operation is needed, the query can be resolved via a join index subtable and, in most cases dramatically improve performance.
For more details on join index see Chapter 16, “Indexing Tables,” in the Teradata RDBMS for UNIX Database Design and Administration Manual. For information on the join index syntax structure, see the Teradata RDBMS for UNIX SQL Reference.
Getting Ideas for Where and When to Index 4
There are several things you can do to help determine what columns to index.
● Run EXPLAINs on typical queries with and without indexes defined on various columns to determine which performs best.
● Run HELP INDEX tablename statements to produce information helpful for interpreting the EXPLAIN statements you run.
● Run COLLECT STATISTICS on the tables to be indexed to provide data for assessing the cost/benefit balance afforded by indexes.
4-10 Introduction to the Teradata RDBMS for UNIX

Data DefinitionIndexes
Primary Indexes vs. Secondary Indexes 4
The following table details facts comparing primary and secondary indexes for the Teradata RDBMS.
The following table summarizes the number of AMPs and results rows used by each index access method.
IF there . . . THEN make . . .
is only one frequently used set selection
it the primary index if it is unique or nearly unique.
are two frequently used set selections, one of which is unique and the other of which is very selective
the unique set selection a Unique Secondary Index (USI) and make the highly selective set selection a Non-Unique Primary Index (NUPI).
Index Primary Secondary
Required Yes No
Number per table 1 0–32
Affects row distribution Yes No
Affects performance Yes Yes
Number of columns 1–16 1–16
Multiple data types Yes Yes
Unique UPI USI
Nonunique NUPI NUSI
Unique vs. nonunique Function similarly
Function differently
Subtable required No Yes
Extra processing overhead No Yes
Define in CREATE TABLE Yes Yes
Define in CREATE INDEX No Yes
Drop index No Yes
Access Method Number of AMPs Used Number of Results Rows Returned
UPI 1 1
NUPI 1 1 - many
USI 2 1
Introduction to the Teradata RDBMS for UNIX 4-11

Data DefinitionIndexes
It is difficult to provide concrete recommendations for using indexes or combinations of indexes because their usefulness depends so highly on individual tables and their application.
The following table explains the strengths and weaknesses of the various access methods.
NUSI all 1 - many
Full table scan all 1 - all
Access Method Comments
UPI ● Very efficient● One AMP, one row● No spool file
NUPI ● Efficient when the number of rows per value is fewer than 100
● One AMP, multiple rows● May require spool file
USI ● Very efficient● Two AMPs, one row● No spool file
NUSI ● Efficient only when the number of rows accessed is fewer than the number of data blocks in the table.
● All AMPS, multiple rows● May require spool file
Full table scan ● Efficient because each row is touched only once
● All AMPS, all rows● Spool file might be as large as the base table
Access Method Number of AMPs Used Number of Results Rows Returned
4-12 Introduction to the Teradata RDBMS for UNIX

Data DefinitionPrimary Indexes
Primary Indexes 4
Introduction 4
In the Teradata RDBMS, at least one primary index is required for each table, while no secondary indexes are required.
Primary indexes:
● Affect the distribution of rows across AMPs.● Do not have subtables● Can be unique and nonunique
The primary index for a table should represent the data values most used by the SQL to access the data for the table.
In the following example, DeptNo would be a suitable primary key.
When a row of information is inserted into the table, the primary index value for that row is processed using a hashing algorithm which determines a specific location within the system for the row of information.
At a later time, in order to retrieve the information, the primary index value provided is used in the hashing algorithm to “compute” the location of the row.
Since the primary index value is supplied when the row is initially stored, it can be used to locate the row without the additional overhead involved in maintaining a separate index subtable.
DeptNo DeptName EmpCount Loc MgrNo Budget
100 Administration 3 NYC 10004
300 Exec Office 2 NYC 10012
500 Engineering 5 ATL 10008
600 Manufacturing 3 CHI 10009
Introduction to the Teradata RDBMS for UNIX 4-13

Data DefinitionPrimary Indexes
Unique Primary Index 4
A unique primary index (UPI) corresponds to one and only one data row in the table. Use a UPI when you want to ensure even distribution of data for a table across all AMPs. Even distribution optimizes both retrieval and disk storage.
The UPI is typically assigned to the column (or columns) that comprise the primary key in the logical design.
If you choose not to have a UPI for a table, you should assign a USI to the “primary key” column set.
Nonunique Primary Index 4
A non-unique primary index (NUPI) corresponds to one or more data rows in the table. Distribution of rows depends on the value of the primary index for a table, to obtain the most even distribution of rows possible across AMPs, you should select as “nearly unique” a nonunique primary index as possible.
All rows with the same primary index value are stored on the same AMP, so if you choose a frequently duplicated column as a nonunique primary index, row distribution could be very uneven.
Guidelines for Selecting a Primary Index 4
Keep these guidelines in mind when you select a primary index for your tables.
● The column (or column set) chosen should be the set selection most frequently used to select rows from the table and should be unique (UPI) or close to unique (NUPI)
● Selection should be based on an equality search● The data values for the index should not be subject to change● Distinct index values hash evenly across all AMPs, while
duplicate index values hash to the same AMP● A nonunique primary index should have no more than 100
duplicate values
4-14 Introduction to the Teradata RDBMS for UNIX

Data DefinitionSecondary Indexes
Secondary Indexes 4
Introduction 4
Use a secondary index as an alternative access path to enhance retrieval performance.
Secondary indexes come in two forms: unique and nonunique.
Secondary indexes always have an associated subtable. Because of this, table updates, inserts, and deletes are slower than they would be without a secondary index because each updated row in the base table is accompanied by an updated row for the subtable.
For this reason, secondary indexes may not be appropriate in situations like a heavily used OLTP application.
On the other hand, multiple secondary indexes are useful in a decision support environment.
Subtables 4
A subtable is a table of indexes comprised of two fields: a data value (which may be composite) and a pointer to one (in the case of a USI) or several (in the case of a NUSI) data rows.
The optimizer uses secondary index subtables for aggregate processing whenever it can because queries can frequently be answered based on the data in the subtable alone without having to refer to the base table.
The overall usefulness of a NUSI is heavily dependent on the
If a secondary index is weakly selective, then the optimizer does not use it.
Journaling and Secondary Indexes 4
Changes to USI rows are kept in the Transient Journal.
Changes to NUSI rows are not journaled.
Introduction to the Teradata RDBMS for UNIX 4-15
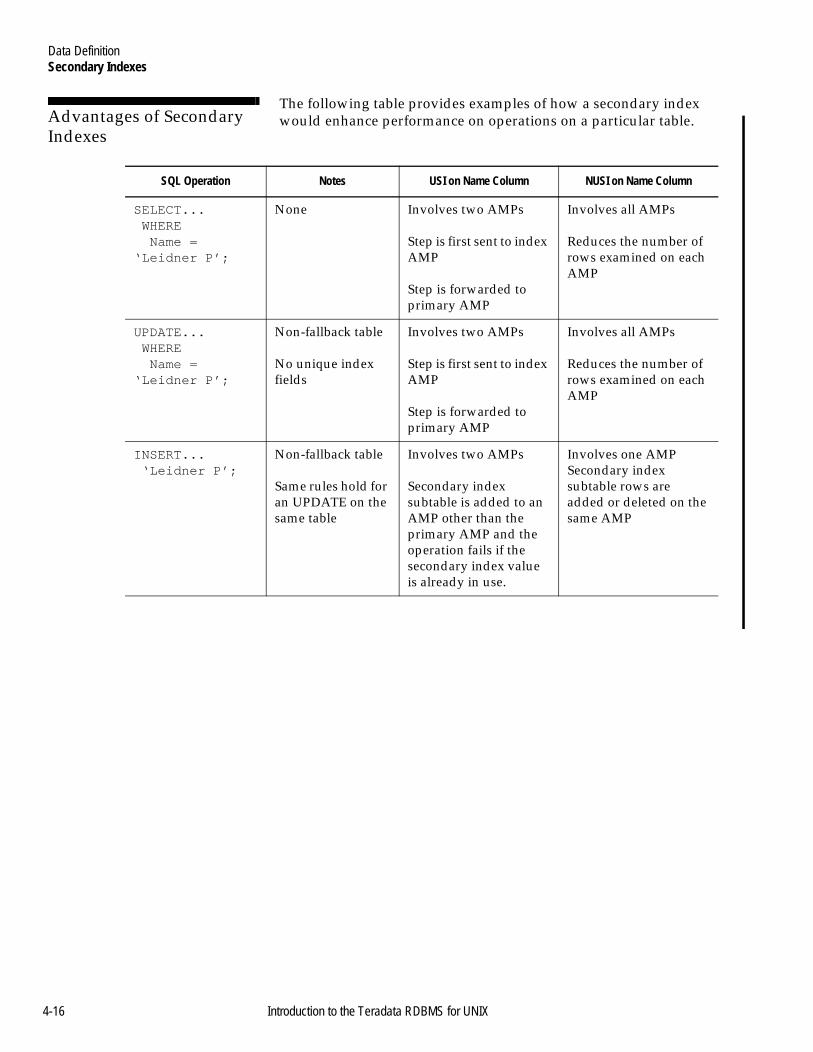
Data DefinitionSecondary Indexes
Advantages of Secondary Indexes 4
The following table provides examples of how a secondary index would enhance performance on operations on a particular table.
SQL Operation Notes USI on Name Column NUSI on Name Column
SELECT...WHERE Name =
‘Leidner P’;
None Involves two AMPs
Step is first sent to index AMP
Step is forwarded to primary AMP
Involves all AMPs
Reduces the number of rows examined on each AMP
UPDATE...WHERE
Name = ‘Leidner P’;
Non-fallback table
No unique index fields
Involves two AMPs
Step is first sent to index AMP
Step is forwarded to primary AMP
Involves all AMPs
Reduces the number of rows examined on each AMP
INSERT...‘Leidner P’;
Non-fallback table
Same rules hold for an UPDATE on the same table
Involves two AMPs
Secondary index subtable is added to an AMP other than the primary AMP and the operation fails if the secondary index value is already in use.
Involves one AMPSecondary index subtable rows are added or deleted on the same AMP
4-16 Introduction to the Teradata RDBMS for UNIX

Data DefinitionSecondary Indexes
Unique Secondary Index 4
A unique secondary index (USI) associates one subtable row with each base table data row.
In general, use a USI on the primary key column whenever your primary index is nonunique. This makes row updates and deletions more efficient.
USIs are also useful for enhancing the performance of nested joins.
The subtable for a USI is usually stored on a different AMP from the base table it indexes.
Nonunique Secondary Index 4
Non-unique secondary indexes (NUSIs) are maintained as separate subtables on each AMP. The index subtable entries point to base table rows that reside on the same AMP as the index subtable.
NUSIs are useful for situations in which a full table scan would otherwise occur, for example when you need to locate rows with a particular value or set of values. Though such an operation still involves all AMPs, a properly selected NUSI limits the number of rows that need to be processed.
Teradata RDBMS has been enhanced in two important ways:
● Support for the user-specified option of sorting the index rows by data value rather than by the corresponding hash code. This is particularly useful for range queries where only a portion of the index subtable will be accessed.
● Improvements have been made to use NUSIs to “cover” queries, that is, to avoid accessing the data rows altogether for those queries that reference only indexed columns.
Guidelines for Selecting a Secondary Index 4
Keep these guidelines in mind when you select a secondary index for your tables.
● The column (or column set) chosen should be a frequently used set selection.
● Selection should be based on an equality search.● The data values for the index should not be subject to frequent
changes because of the overhead involved in updating subtables.
Introduction to the Teradata RDBMS for UNIX 4-17

Data DefinitionCreating an Index for a Table
Creating an Index for a Table 4
Introduction 4
Database systems use indexes to facilitate quick selection of rows. Unlike other database management systems, relational systems typically do not permit explicit use of indexes in application programs or queries. Instead, the optimizer decides at the moment of SQL compilation which index or indexes (if any) to use to optimize the query.
This topic describes how to use SQL to create an index on a table.
Creating a Primary Index 4
All tables require a primary index. If you do not specify a column or group of columns to act as a primary index for a table when you create it, the system defaults to the first column you define. Because this could lead to uneven distribution of data, you should choose the primary index for your table carefully.
You create a unique primary index for a table using the UNIQUE PRIMARY INDEX clause of the CREATE TABLE statement. You cannot change the primary index for a table.
To create a nonunique primary index, drop the keyword UNIQUE or use the PRIMARY INDEX clause in the CREATE TABLE statement.
Creating a Secondary Index 4
Secondary indexes are always optional.
To create a unique secondary index, use the CREATE UNIQUE INDEX statement.
For example,
CREATE UNIQUE INDEX (cust)ON CUSTOMER
;
To create a nonunique secondary index, drop the keyword UNIQUE or use the INDEX clause of the CREATE TABLE statement.
Rule of Thumb for Creating Indexes 4
A general rule of thumb to observe when creating indexes is this: if the primary key for your table is not the unique primary index, then make it a unique secondary index.
4-18 Introduction to the Teradata RDBMS for UNIX

Data DefinitionDropping Tables and Indexes
Dropping Tables and Indexes 4
Introduction 4
This topic describes how to use Teradata SQL to drop indexes and tables from a database.
Dropping a Table 4
The following example drops a table named Employee from the database.
DROP TABLE Employee;
Dropping an Index 4
The following example drops an index on the Name column from the Employee table. Note that this action does not remove the Name column, only its use as an index for the table.
DROP INDEX (Name) ON Employee;
Introduction to the Teradata RDBMS for UNIX 4-19

Data DefinitionFor More Information
For More Information 4
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
If you want to learn more about . . . THEN see this manual . . .
Teradata SQL Teradata RDBMS for UNIX Database Design and AdministrationTeradata RDBMS for UNIX SQL
Indexes Teradata RDBMS for UNIX Database Design and Administration
4-20 Introduction to the Teradata RDBMS for UNIX

Data Manipulation
Introduction to the Teradata RDBMS for UNIX
Chapter 5
Data Manipulation

Data Manipulation
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 5
-1About This ChapterData Manipulation5
About This Chapter 5
Introduction 5
This chapter describes the data definition and manipulation capabilities of the Teradata Structured Query Language (SQL), emphasizing the basic statements and expressions used to manipulate data.
What is the Structured Query Language (SQL)? 5
SQL (the official pronunciation is “ess-cue-ell”) is a database sublanguage; that is, it’s a subset of the total language that is concerned specifically with relational database entities and operations.
In principle, the SQL language is a combination of at least two subordinate languages and the SELECT statement:
● A data definition language (DDL), which provides statements for the definition and description of entities (CREATE, ALTER, DROP)
● A data manipulation language (DML), which supports statements for manipulating and processing database values (INSERT, UPDATE, DELETE, ROLLBACK). With DML statements, you can insert new rows into a table, update one or more values in stored rows, or delete a row.
● the Select statement, which is used for data retrieval.
SQL Data Manipulation 5
The SELECT statement is the basic SQL data manipulation statement in a decision support environment because all information retrieval from a relational database is done using the SQL SELECT statement.
The following table lists and describes the four SQL data manipulation statements.
Statement Description
SELECT Performs query functions. Though SQL does not use them explicitly, the relational algebra functions of Select, Project, Join, Union, Intersect, and Minus are all performed using SELECT.
INSERT Inserts new rows into a table.
UPDATE Modifies values in an existing row (or rows) of a table.
DELETE Removes a row (or rows) from a table.

Data ManipulationThe SELECT Statement
The SELECT Statement 5
Introduction 5
The SELECT statement is used to extract data from relational tables using Teradata SQL.
This topic describes the SELECT statement in some detail.
Relational Algebra 5
The SELECT statement and its clauses performs some or all of the following relational algebra statements. You cannot execute these operators directly—the SELECT statement itself performs them for you. The purpose of this section is to illustrate the formal algebraic capabilities of the SELECT statement.
Note that the first four operations are from traditional set theory while the second four are special relational operations.
The SQL SELECT builds on these primitive operations to perform all its work.
Operator Description
UNION Select all rows belonging to either or both of two named tables A and B.
INTERSECT Select all rows belonging to both of two named tables A and B.
DIFFERENCE Select all rows belonging to table A but not to table B.
PRODUCT Select the concatenation of all rows t such that t is the concatenation of row a belonging to table A and row b belonging to table B.
Formally speaking, this operation is called an extended Cartesian product.
SELECT Select a horizontal subset of rows of a table.This operation is not the same as the SQL select, but does provide the WHERE clause function.
PROJECT Select a vertical subset of rows of a table. In other words, select a subset of nonredundant attributes of a table (all unique instances of an attribute or attributes).
JOIN Select rows from two (or more) tables that meet some criterion (equal, not equal, greater than, less than) on primary/foreign keys shared among the tables.
DIVISION Select the result of dividing table A by table B on some common attribute or attributes.
5-2 Introduction to the Teradata RDBMS for UNIX

Data ManipulationThe SELECT Statement
Teradata SQL Expressions 5
Teradata SQL expressions permit you to perform arithmetic and logical operations, to generate new values or Boolean results from constants and stored values, and to select results that meet specific criteria.
An expression can consist of a column name, a constant, or a combination of column names and constants connected by operators.
The Teradata SQL expressions can be grouped as follows:
● Arithmetic operators● Aggregate operators● Comparison operators● Logical operators● Partial string matching operators● Set operators● Other operators
Arithmetic Operators 5
Arithmetic operators support the standard operations of addition, subtraction, multiplication, and division. The following table lists and describes the Teradata SQL arithmetic operators.
The data type of the result of an arithmetic expression is a function of the data types of the two operands. Appropriate conversions are made before the operations are carried out. For example, before an INTEGER value is added to a DECIMAL(5,2) value, the INTEGER value is converted to DECIMAL(5,2), and that is the data type of the result.
Operator Definition
+ Addition
- Subtraction
* Multiplication
/ Division
MOD Modulus
** Exponentiation
() Evaluated first
Introduction to the Teradata RDBMS for UNIX 5-3

Data ManipulationThe SELECT Statement
Aggregate Operators 5
Aggregate operators are used to group data to define a query result. The following table lists and describes the Teradata SQL aggregate operators.
The set on which the aggregate operator functions can consist either of all values in a particular column or a subset of column values.
Comparison Operators 5
Comparison operators compare numeric or character values to produce a logical (TRUE or FALSE) result. The following table lists and describes the Teradata SQL comparison operators.
Operator Definition
AVERAGE Computes the average of a set of values.
COUNT Returns the number of members in a set of values.
MAXIMUM Returns the maximum value in a set of values.
MINIMUM Returns the minimum value in a set of values.
SUM Computes the sum of a set of values.
Operator Definition
= EQ
Equal
> GT
Greater than
< LT
Less than
<= LE
Less than or equal
>= GE
Greater than or equal
BETWEEN...AND Range
5-4 Introduction to the Teradata RDBMS for UNIX

Data ManipulationThe SELECT Statement
Logical Operators 5
Logical operators combine logical expressions and generate compound conditions. They can be used in the WHERE clause of a SELECT statement. The following table lists and describes the Teradata SQL logical operators.
Partial String Matching Operator 5
Partial string matching operators locate character strings that match portions or complete strings of characters. The following table lists and describes the Teradata SQL partial string matching LIKE operator.
Operator Definition
AND Specifies that both conditions must be true for the condition to evaluate true.
OR Specifies that either (or both) conditions must be true for the condition to evaluate true.
NOT ^
Specifies logical exclusion. The condition evaluates true if and only if the value is not true.
( ) Delimits precedence
Operator Definition
[NOT] LIKE charstring% String begins with partial string charstring, but can contain any other characters trailing charstring.
[NOT] LIKE %charstring String ends with partial string charstring, but can contain any other characters leading charstring.
[NOT] LIKE %charstring% String has partial string charstring embedded within it, but can lead or trail with any other characters.
Introduction to the Teradata RDBMS for UNIX 5-5

Data ManipulationThe SELECT Statement
Set Operators 5
Teradata RDBMS SQL set operators are used in conditional expressions. The operators test whether one or more values are within a defined set of values. You can express a set as a list of constants or as a single column table. The following table lists and describes the Teradata SQL set operators.
Suppose we have a parts database where table Suppliers defines suppliers, table Parts defines parts, and table SupplierParts relates the two. You want to find part numbers for parts that either weigh more than 50 pounds or are supplied by supplier Western Widgets. Use the UNION set operator in a conditional expression like one of the following:
SELECT PartNumberFROM PartsWHERE Weight > 50
UNIONSELECT PartNumber
FROM SupplierPartsWHERE SupplierNumber = ‘Western Widgets’
;
The result of this query is a list of all parts that weigh more than 50 pounds or are supplied by Western Widgets.
Other Operators 5
Teradata RDBMS SQL also provides a concatenation operator and string functions for working with character data.
Operator Definition
INTERSECT Find the set of all results rows in tables A and B that belong to both A and B.
MINUS Find the set of all results rows in tables A and B that are not in both.
UNION Find the set of all results rows in tables A and B that appear in either or both A and B.
5-6 Introduction to the Teradata RDBMS for UNIX
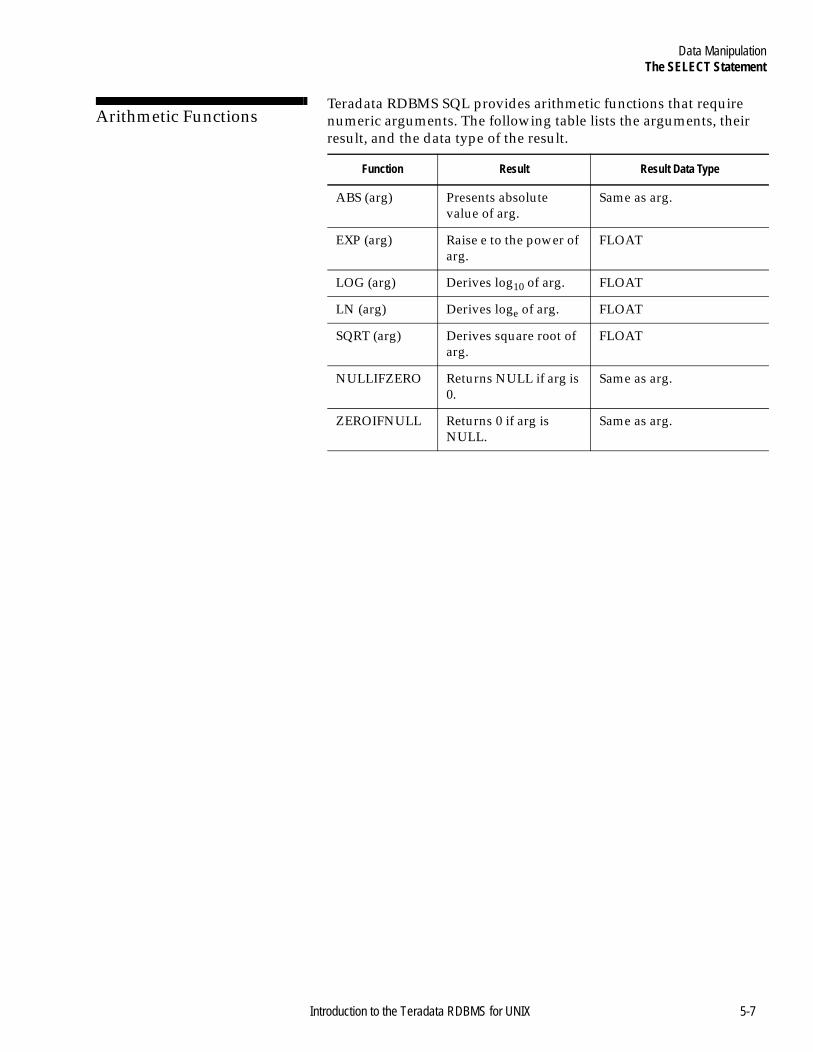
Data ManipulationThe SELECT Statement
Arithmetic Functions 5
Teradata RDBMS SQL provides arithmetic functions that require numeric arguments. The following table lists the arguments, their result, and the data type of the result.
Function Result Result Data Type
ABS (arg) Presents absolute value of arg.
Same as arg.
EXP (arg) Raise e to the power of arg.
FLOAT
LOG (arg) Derives log10 of arg. FLOAT
LN (arg) Derives loge of arg. FLOAT
SQRT (arg) Derives square root of arg.
FLOAT
NULLIFZERO Returns NULL if arg is 0.
Same as arg.
ZEROIFNULL Returns 0 if arg is NULL.
Same as arg.
Introduction to the Teradata RDBMS for UNIX 5-7

Data ManipulationUsing Fully Qualified Names to Reference Databases and Tables in Teradata SQL
Using Fully Qualified Names to Reference Databases and Tables in Teradata SQL 5
Introduction 5
Successful query operations in a Teradata database require unique names for each element of the query object: the database, the table, and the column (or columns) queried. Because several tables within a given database might have columns with the same name, it is necessary to develop a mechanism for ensuring uniqueness. This mechanism is the fully qualified name.
Fully Qualified Names 5
A fully qualified name in a Teradata base consists of the database name, the table name, and the column name concatenated together.
This is done using the following format:
databasename.tablename.columnname
Such a column reference is considered to be a fully qualified name.
For example, to fully qualify column JobTitle in table Employee in database Personnel, you would type
Personnel.Employee.JobTitle
You do not need to specify a fully qualified name if the reference is otherwise unambiguous. You need not specify a database name (or table name) if they occur elsewhere in the statement and no ambiguity results from the omission.
5-8 Introduction to the Teradata RDBMS for UNIX

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Simple SQL Queries: Using the SELECT Statement 5
Introduction 5
This topic describes simple SQL queries of a Teradata database using the SELECT statement.
Selecting All Rows from a Table 5
The most simple Teradata SQL query is one that selects all rows from a table.
If the table is named Employee, the query looks like this:
SELECT * FROM Employee;
Note that the asterisk character denotes all columns.
Selecting Specific Columns from a Table 5
The PROJECT operator of the relational algebra permits you to select data from individual columns using the SELECT statement.
For example, to select only the names, salaries, and positions of employees, the query looks like this:
SELECT Name, Salary, JobTitle
FROM Employee;
This query produces the following results table. Note there is no ordering to the rows. Columns are ordered by their precedence in the SELECT statement. Facilities for ordering rows in the results table are described later in this topic.
Introduction to the Teradata RDBMS for UNIX 5-9

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Selecting Specific Rows from a Table 5
The SELECT operator of the relational algebra permits you to select data from individual rows using the SELECT statement.
For example, to report the name, salary, and job title for only employees in department 100, the query looks like this:
SELECT Name, Salary, JobTitle
FROM EmployeeWHERE DeptNo = 100;
This query produces the following results table.
Name Salary JobTitle
Peterson J 25,000.00 Payroll Ck
Moffit H 35,000.00 Recruiter
Leidner P 23,000.00 Secretary
Smith T 42,000.00 Engineer
Omura H 40,000.00 Programmer
Kemper R 29,000.00 Assembler
Aguilan J 45,000.00 Manager
Phan A 55,000.00 Vice Pres
Marston A 22,000.00 Secretary
Reed C 30,000.00 Technician
Chin M 38,000.00 Controller
Watson L 56,000.00 Vice Pres
Regan R 44,000.00 Purchaser
Name Salary JobTitle
Peterson J 25,000.00 Payroll Ck
Moffit H 35,000.00 Recruiter
Chin M 38,000.00 Controller
5-10 Introduction to the Teradata RDBMS for UNIX

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Using Comparison and Logical Operators to Select Specific Rows 5
You can use various comparison and logical operators with the WHERE clause in a Teradata SQL statement to further refine your selection of rows from a table.
You can use any column name and specify any compound selection criteria.
For example, suppose you wanted to report the names and salaries of employees in departments 100 and 600 who earn more than $35,000.00 per year. The query looks like this:
SELECT Name,Salary
FROM EmployeeWHERE DeptNo IN (100, 600)
ANDSalary > 35000
;
In this query, the IN set operator is used in the WHERE clause in place of the = comparison operator to specify the condition:
WHERE DeptNo = 100ORDeptNo = 600
The first part of the WHERE clause in the query could have been written in this form to produce the same result.
This query produces the following results table.
Name Salary
Aguilan J 45,000.00
Chin M 38,000.00
Regan R 44,000.00
Introduction to the Teradata RDBMS for UNIX 5-11

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Specifying Order in the Results Table 5
The ORDER BY clause determines the sequence of returned data in the results table.
Suppose you wanted to report the name and years of experience for each employee in department 600 and you wanted to list them in ascending order of seniority. The query looks like this:
SELECT Name,YrsExp
FROM EmployeeWHERE DeptNo = 600ORDER BY YrsExp;
This query produces the following results table.
Defining Groups 5
You can group table data according to the values in one or more of the columns in the table. You can then use the Teradata SQL aggregate operators to provide summary information about the group in a results table.
The GROUP BY clause defines a group. When you use a GROUP BY clause in a SELECT statement, each item in the statement must be a unique property of the group.
Teradata SQL provides a HAVING clause, which has a similar function to the WHERE clause, to restrict the groups that appear in the results table.
Suppose you wanted to know the minimum and maximum salary for every department with a salary totaling more than $170,000.00. The query looks like this:
SELECT DeptNo,MIN(Salary),MAX(Salary)
FROM EmployeeGROUP BY DeptNoHAVING SUM(Salary) > 170000;
Name YrsExp
Kemper R 7
Regan R 10
Aguilan J 11
5-12 Introduction to the Teradata RDBMS for UNIX

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Including Information from More Than One Table in a Query 5
The JOIN algebraic relational operator permits you to select data from more than one table using the Teradata SQL SELECT statement.
The WHERE clause specifies the join criteria. Suppose you wanted to report the names and locations of all employees. This requires a join of the Employee and Department tables on DeptNo. The query looks like this:
SELECT Name,Loc
FROM Employee,Department
WHERE Employee.DeptNo = Department.DeptNo;
A join operator can be one of the following types:
Product Join A product join compares every qualifying row from one table to every qualifying row from the other table; those that match the WHERE condition are saved.
Merge Join A merge join retrieves rows from two tables, then puts them onto a common AMP, based on the row hash of the columns involved in the join.
Nested Join, local and remote
A local nested join is more typical than a remote nested join. It implies that no messages are sent during the execution of the nested join.A remote nested join implies the message will be sent to another AMP to get the rows from the right table.
Exclusion Join, merge and product
An exclusion join is a product or merge join where only the rows that do not satisfy (are NOT IN) any condition specified in the request are joined.
RowID Join A rowID join requires the following conditions:● The condition must match another column of the first table to a NUSI or
USI of the second table.● Only a subset of the NUSI or USI values from the second table are
qualified via the join condition, and a nested join is done between the two tables to retrieve the row IDs from the second table.
Self-Join A normal join establishes a relationship between the rows in different tables or views. You may also want to establish a relationship between different rows in the same table or view. To do this, you treat the table or view as two separate tables or views and join it to itself.
Hash Join Hash Join is an alternative join scheme that performs better than Merge Join under certain conditions. The performance gain comes mainly from eliminating the need for sorting the join tables before performing the actual join.
Introduction to the Teradata RDBMS for UNIX 5-13

Data ManipulationSimple SQL Queries: Using the SELECT Statement
Nesting Subqueries 5
Suppose you wanted to know who the manager of employee Marston is. To determine this information, you could perform the following three SQL statements in order, taking the answer to the first query (500) and inserting it into the WHERE clause of the second, then taking the answer of that query (10008) and inserting it into the WHERE clause of the third. The SQL statements are:
SELECT DeptNoFROM EmployeeWHERE Name = ‘Marston A’;SELECT MgrNoFROM DepartmentWHERE DeptNo = 500;SELECT NameFROM EmployeeWHERE EmpNo = 10008;
Teradata SQL provides facilities that allow you to determine this result with one query by using nested subqueries.
5-14 Introduction to the Teradata RDBMS for UNIX

Data ManipulationSimple SQL Queries: Using the SELECT Statement
For example, the following query references the result of the first subquery in the WHERE clause of the second, then references the result of the second in the WHERE clause of the third.
SELECT NameFROM EmployeeWHERE EmpNo IN
(SELECT Mgr NoFROM DepartmentWHERE DeptNo IN
(SELECT DeptNoFROM EmployeeWHERE Name = ‘Marston A’
))
;
You can obtain the same result by nesting only one level deep, for example:
SELECT NameFROM Employee
WHERE EmpNo IN (SELECT MgrNo
FROM Department,Employee
WHERE Employee.Name = ‘Marston A’ANDDepartment.DeptNo = Employee.DeptNo
);
Introduction to the Teradata RDBMS for UNIX 5-15

Data ManipulationUsing the INSERT Statement
Using the INSERT Statement 5
Introduction 5
Before you can query a database, you must first populate its tables with data. The INSERT statement is the means for populating tables with data from within an application program. The bulk data loading programs such as Fastload and Multiload can be used to perform bulk insertions of data into tables.
There are three different forms of the INSERT statement.
INSERT: First Form 5
In the first form on the INSERT statement, the columns to receive the values are listed separately, enclosed by parentheses.
The values to be added to those columns are also listed separately, enclosed by parentheses, and presented in the same left-to-right order as the columns for which they are intended, preceded by the keyword VALUES.
For example:
INSERT INTO Employee(Name,EmpNo,DeptNo,YrsExp
)VALUES
(‘Clarkson B’,10014,600,3
);
Note that the salary and position for Clarkson, presumably unknown, were not added to the table. Those fields in the table are null.
After this INSERT operation, the row for Clarkson in the table looks like this:
EmpNo Name DeptNo JobTitle Salary YrsExp
10014 Clarkson B 600 3
5-16 Introduction to the Teradata RDBMS for UNIX

Data ManipulationUsing the INSERT Statement
INSERT: Second Form 5
In the second form of the INSERT statement, you need only list the field values, but you must present them in the same left-to-right order the columns were defined in the CREATE TABLE statement. The list must account for the position of a column whether data is entered or not. To achieve this, the syntax requires you to indicate the position of a column with a comma.
Suppose you wanted to add an employee to the Employee table whose position and salary are not known. The INSERT statement looks like this:
INSERT INTO EmployeeVALUES (10015,
‘Goldsmith H’,600,,,,5
);
INSERT: Third Form 5
In the third form of the INSERT statement, you use an embedded SELECT statement to insert values from one table into another.
Suppose you need to insert employee information into a new table you have created called PROMOTION. In the example provided below, you want information for all employees having more than 10 years experience with the organization.
Note that column values must be provided in the order in which columns are defined in the CREATE TABLE statement for the Promotion table.
The INSERT statement looks like this:
INSERT INTO PromotionSELECT Name,
DeptNo,YrsExp
FROM EmployeeWHERE YrsExp > 10;
Introduction to the Teradata RDBMS for UNIX 5-17

Data ManipulationUsing the UPDATE Statement
Using the UPDATE Statement 5
Introduction 5
Most databases require frequent updating in order to remain current. The UPDATE statement provides the capability of changing the information in existing rows.
How to Change Rows Using the UPDATE Statement 5
The UPDATE statement allows you to modify existing columns in one or more rows of a table. You can use the UPDATE statement both in interactive queries and in embedded SQL applications.
Suppose you want to add position and salary data for the employees named Clarkson and Goldsmith whom you inserted into the Employee table in earlier examples.
The UPDATE statements look like these:
UPDATE EmployeeSET JobTitle = ‘Inspector’,
Salary = 32000WHERE EmpNo = 10014;
UPDATE EmployeeSET JobTitle = ‘Assembler’,
Salary = 25000WHERE EmpNo = 10015;
Having made these updates, you must now update the Department table to increment the employee count.
The UPDATE statement looks like this:
UPDATE DepartmentSET EmpCount = EmpCount +2WHERE DeptName = ‘Manufacturing’;
The following UPDATE statement gives all employees a ten percent raise:
UPDATE EMPLOYEESET Salary = Salary * 1.1ALL;
5-18 Introduction to the Teradata RDBMS for UNIX

Data ManipulationUsing the DELETE Statement to Delete Rows from a Table
Using the DELETE Statement to Delete Rows from a Table 5
Introduction 5
You will need to remove rows from your database from time to time. The DELETE statement provides this capability. The DELETE statement deletes one or more rows from a table. You can use the DELETE statement both in interactive queries and in embedded SQL applications.
How to Delete Rows from a Table 5
As in the UPDATE statement, you use a WHERE clause to determine which rows are affected by a DELETE statement.
Suppose Employee T Smith has left the company and you want to delete his information from the database. This requires two updates:
The statements to achieve these actions look like these:
DELETE FROM EmployeeWHERE Name = ‘Smith T’;
UPDATE DepartmentSET EmpCount = EmpCount - 1WHERE DeptNo = 500;
Step Action
1 Delete the employee from the Employee table
2 Decrement the count in the Department table for the department of T Smith by one
Introduction to the Teradata RDBMS for UNIX 5-19

Data ManipulationUsing Teradata SQL in Application Programs
Using Teradata SQL in Application Programs 5
Introduction 5
So far, the discussion of Teradata SQL has concerned how to use it in interactive queries from a user terminal. In fact, SQL statements are more frequently used in application programs, particularly in an OLTP environment. This topic introduces the subject of embedded SQL and describes some of the additional statements you must include to use SQL in your applications.
Embedded SQL and Client Programming Languages 5
The Teradata RDBMS supports embedded SQL programming for several different client platforms.
When you develop an application using one of these languages, you embed the SQL code within the client programming language. You use slightly different mechanisms for doing this depending on the language, but the beginning of a SQL code set usually begins with a prefix something like
EXEC SQL
and ends with some terminating symbol, depending on the language. Note: unlike interactive SQL, embedded SQL contains several nonexecutable, declarative statements.
After you have coded the application, you can test it. To do this, you must first process it through a program that translates the SQL into native code. It does this by commenting out all the SQL code and substituting executable statements using CLI calls. The program that performs this translation is called a precompiler, and the Teradata SQL precompiler is called Preprocessor2. In the final step, you compile the native code with its compiler and test it.
Language Platform
COBOL ● IBM mainframe clients● Some workstation clients
PL/I IBM mainframe clients
C ● IBM mainframe clients● UNIX clients
5-20 Introduction to the Teradata RDBMS for UNIX

Data ManipulationUsing Teradata SQL in Application Programs
Cursors 5
Because SQL is a set-oriented language, traditional application development languages cannot deal with results tables without some kind of intermediary mechanism. That mechanism is the cursor.
A cursor is a pointer that the application program uses to move through a results table one row (record in programming language terminology) at a time. You declare a cursor for a SELECT statement and then open the named cursor. The act of opening the cursor causes the SQL statement to be executed. The rows are individually fetched and written into host variables using a FETCH ... INTO ... statement. The application can then use the host variables to do computations.
Because there are typically multiple records in the results table, the FETCH is normally embedded within a loop so the results can be processed until the last record has been processed. You can also use cursors with the UPDATE and DELETE statements.
Introduction to the Teradata RDBMS for UNIX 5-21

Data ManipulationFor More Information
For More Information 5
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Teradata SQL data manipulation statements
Teradata RDBMS for UNIX SQL Reference
Embedded SQL Teradata RDBMS for UNIX SQL Reference ManualTeradata Application Programming With Embedded SQL for C, COBOL, and PL/I
Teradata SQL join capabilities Teradata RDBMS for UNIX Database Design and Administration
5-22 Introduction to the Teradata RDBMS for UNIX

Views
Introduction to the Teradata RDBMS for UNIX
Chapter 6
Views

Views
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 6
-1About This ChapterViews6
About This Chapter 6
Introduction 6
This chapter discusses relational database views.
A view is a virtual table that appears to the user as a base table. You can think of a view as a dynamic window on the underlying database.
Views are constructed from one or more base tables (or views) but usually present only a subset of the columns in the base table or tables that comprise them.
Some view columns do not exist in the underlying base tables. For example, it is possible to present data summaries in a view (for example, an average), which you cannot maintain in a base table.
You can create hierarchies of views in which views can be created on views. This can be useful, but you should be aware that deleting any of the lower level views invalidates dependencies of higher level views in the hierarchy.
Why Use Views? 6
There are at least four reasons to use views. Views provide all of the following:
● A simplified user perception of the database.● Security for restricting table access and updates.● Well-defined, well-tested, high performance access to data.● Logical data independence, which minimizes application
modification if base tables need to be restructured.
The remainder of this chapter discusses the following topics:
● How to create and alter a view.● Expanded discussion of why database administrators should
use views.● Restrictions on the updatability of some views.

ViewsCreating and Altering Views
Creating and Altering Views 6
Introduction 6
This topic discusses the SQL statements used to create and alter views.
Creating a Teradata RDBMS View 6
Use the CREATE VIEW statement to create views for the Teradata RDBMS. The view definitions are stored in the Data Dictionary.
Suppose you wanted to create a view called Employee_Info for a personnel clerk who needs access to the Personnel database, but whose access needs to be restricted. The clerk needs to know the following information for employees:
● Employee name● Job title● Department
The SQL to create the view looks like this:
CREATE VIEW Employee_Info(Employee,JobTitle,Department
)AS SELECT Name,
JobTitle,DeptName
FROM Employee,Department
WHERE Employee.DeptNo = Department.DeptNo;
The SQL to perform a simple query of this view looks like this:
SELECT *FROM Employee_Info;
This query produces the following results table.
6-2 Introduction to the Teradata RDBMS for UNIX

ViewsCreating and Altering Views
Altering a Teradata RDBMS View 6
Use the REPLACE VIEW statement to alter the characteristics of an existing view.
For example, suppose you want to replace the Employee_Info view with one that includes an employee number column. The SQL to alter the view looks like this:
REPLACE VIEW Employee_Info(Number,Employee,Department
)AS SELECT EmpNo,
Name,DeptName
FROM Employee,Department
WHERE Employee.DeptNo = Department.DeptNo;
If the view named Employee_Info had not existed previously, this SQL statement would create it.
Employee JobTitle Department
Peterson J Payroll Ck Administration
Moffit H Recruiter Administration
Leidner P Secretary Exec Office
Smith T Engineer Engineering
Omura H Programmer Engineering
Kemper R Assembler Manufacturing
Aguilan J Manager Manufacturing
Phan A Vice Pres Exec Office
Marston A Secretary Engineering
Reed C Technician Engineering
Chin M Controller Administration
Watson L Vice Pres Engineering
Regan R Purchaser Manufacturing
Introduction to the Teradata RDBMS for UNIX 6-3

ViewsWhy You Should Use Views
Why You Should Use Views 6
Introduction 6
This topic discusses the reasons you should use views with your Teradata RDBMS.
Among the topics discussed are:
● Simplified user perception of the database.● Security for restricting table access and updates.● Well-defined, well-tested, high performance access to data.● Logical data independence, which minimizes application
modification if base tables need to be restructured.
Simplified User Perception of the Database 6
Views simplify user perception of the database in two ways:
● They allow users to focus on the part of the database that is of interest to them and only on that part.
● They simplify retrieval by eliminating the need to formulate complex queries.
Security for Restricting Table Access and Updates 6
Views can be constructed in such a way that target users can see only the data columns that they need to see and no others. For example, a clerk might need to know the department number and years of service for an employee, but should not know the salary for that employee. You can construct a view that permits the clerk to see the information required and no other columns in the table. The unviewable data is sometimes called hidden data.
Forcing users to access the database through views is an effective means of securing hidden data and, effectively, of maintaining authorization control.
Well-Defined, High Performance Access to the Database 6
Users sometimes have difficulty formulating SQL queries that report the information they need efficiently.
Views provide a means for application programmers to develop and test SQL statements that are highly optimized. These views can then be provided to users who can use them without worrying about tying up system resources needlessly.
Well written macros provide the same facility.
6-4 Introduction to the Teradata RDBMS for UNIX

ViewsWhy You Should Use Views
Logical Data Independence 6
Logical data independence is one of the hallmarks of relational database management systems, and views are one of the easier ways to provide logical data independence in the face of restructuring the database.
Sometimes it becomes necessary to reorganize the database in such a way that columns previously belonging to one table are now allocated to a different table. This sort of reorganization is not generally encouraged, but one example of when it might become necessary is a vertical split of a table for performance reasons.
Using views to present these columns to end users greatly lessens, if not removes, the need to change user applications that use those views.
Introduction to the Teradata RDBMS for UNIX 6-5

ViewsRestrictions on DML Operations on Views
Restrictions on DML Operations on Views 6
Introduction 6
Not every view can be updated (update here means insert, update, and delete), though all views can be queried. Some views cannot be updated for technological reasons, but most that cannot be updated are so restricted by theoretical constraints.
The sets of updatable views are ranked as follows:
● All possible views● Theoretically updatable views● A gray area in which views might be theoretically possible, but
technology limits the implementation● Views updatable in SQL
This topic discusses which types of views cannot be updated in the Teradata RDBMS and explains why they cannot be updated.
Views with Aggregates 6
You cannot update view columns that are aggregates. This means that any column in any view that is defined using any of the following aggregate and logical functions cannot be updated:
● AVG● SUM● COUNT● MAX● MIN● DISTINCT● GROUP BY● UNION● JOIN
Views with Joins 6
Views with joins are the classic category of theoretically nonupdatable view. The Teradata RDBMS cannot update a view created with a join.
You can sometimes work around this limitation by using nested subqueries instead of joins.
6-6 Introduction to the Teradata RDBMS for UNIX

ViewsFor More Information
For More Information 6
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Views Teradata RDBMS for UNIX Database Design and AdministrationTeradata RDBMS for UNIX SQL Reference
Teradata SQL Teradata RDBMS for UNIX SQL Reference
Introduction to the Teradata RDBMS for UNIX 6-7

ViewsFor More Information
6-8 Introduction to the Teradata RDBMS for UNIX

Data Dictionary
Introduction to the Teradata RDBMS for UNIX
Chapter 7
Data Dictionary

Data Dictionary
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 7
-1About This ChapterData Dictionary7
About This Chapter 7
Introduction 7
The Data Dictionary (DD) is the system catalog for the Teradata RDBMS. It contains metadata: table and index definitions, view and macro definitions, resource usage statistics, and much more.
The DD is a system database—a repository containing data about user databases and properties of those databases. The DD also contains a good deal of administrative information about the Teradata RDBMS.
Unlike the system catalogs of nonrelational systems, the Teradata Data Dictionary is a fully relational database that uses SQL as its data sublanguage just like the user databases.
DD Objects 7
Among the objects defined or administered by the DD are:
● Database and user profiles● System journals● Security audit and logon information● Error and message logs● Archive information● Lock journals● Session status information● Space allocation information● Accounting information● Database, table, view, index, and macro definitions
DD Users 7
The DD is useful to all of the following categories of user:
● System administrator● Database administrator● Supervisory users● Operations control personnel● End users
This chapter touches briefly on the properties and capabilities of the Data Dictionary (DD).

Data DictionaryStructure of the Data Dictionary
Structure of the Data Dictionary 7
Introduction 7
This topic introduces the components of the DD. In particular, the topic addresses the various supplied views for the DD.
There are roughly 50 different views of DD tables, grouped by user audience in the following table:
A Summary of the DD Views 7
The following topics list the more important DD views. Note that views with an [x] suffixed to them exist in two forms:
● Without an x, they provide information about the entire group of objects controlled by the view.
● With an x, they provide information only about those objects the user executing the view:● Owns● Created● Has privileges on
User audience Description
End Responsible for personal databases.
Needs to know what information is available, what form it is in, how to get it, and what access rights have been granted to others.
Supervisory Responsible for databases and users.
Creates and organizes databases, monitors space usage, defines new users, allocates control privileges, creates index, performs archives.
Administrative Responsible for operation and administration of the system.
Needs to know about system performance, status and statistics, errors, and accounting.
7-2 Introduction to the Teradata RDBMS for UNIX
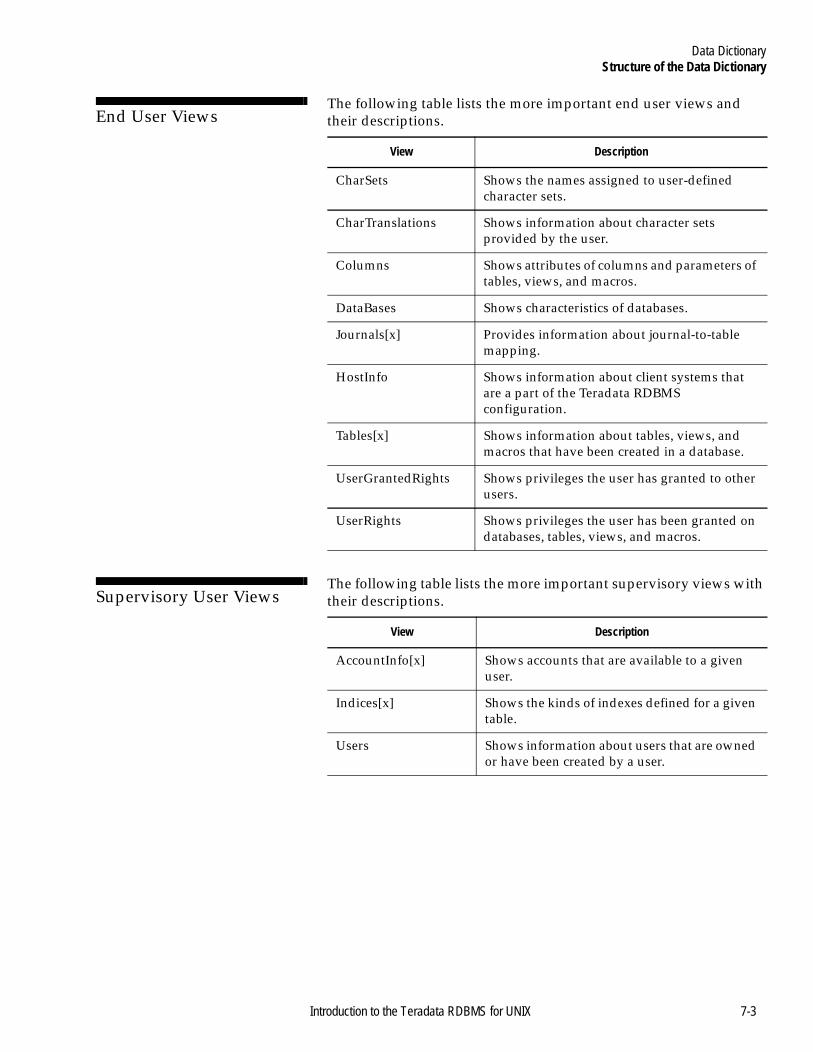
Data DictionaryStructure of the Data Dictionary
End User Views 7
The following table lists the more important end user views and their descriptions.
Supervisory User Views 7
The following table lists the more important supervisory views with their descriptions.
View Description
CharSets Shows the names assigned to user-defined character sets.
CharTranslations Shows information about character sets provided by the user.
Columns Shows attributes of columns and parameters of tables, views, and macros.
DataBases Shows characteristics of databases.
Journals[x] Provides information about journal-to-table mapping.
HostInfo Shows information about client systems that are a part of the Teradata RDBMS configuration.
Tables[x] Shows information about tables, views, and macros that have been created in a database.
UserGrantedRights Shows privileges the user has granted to other users.
UserRights Shows privileges the user has been granted on databases, tables, views, and macros.
View Description
AccountInfo[x] Shows accounts that are available to a given user.
Indices[x] Shows the kinds of indexes defined for a given table.
Users Shows information about users that are owned or have been created by a user.
Introduction to the Teradata RDBMS for UNIX 7-3
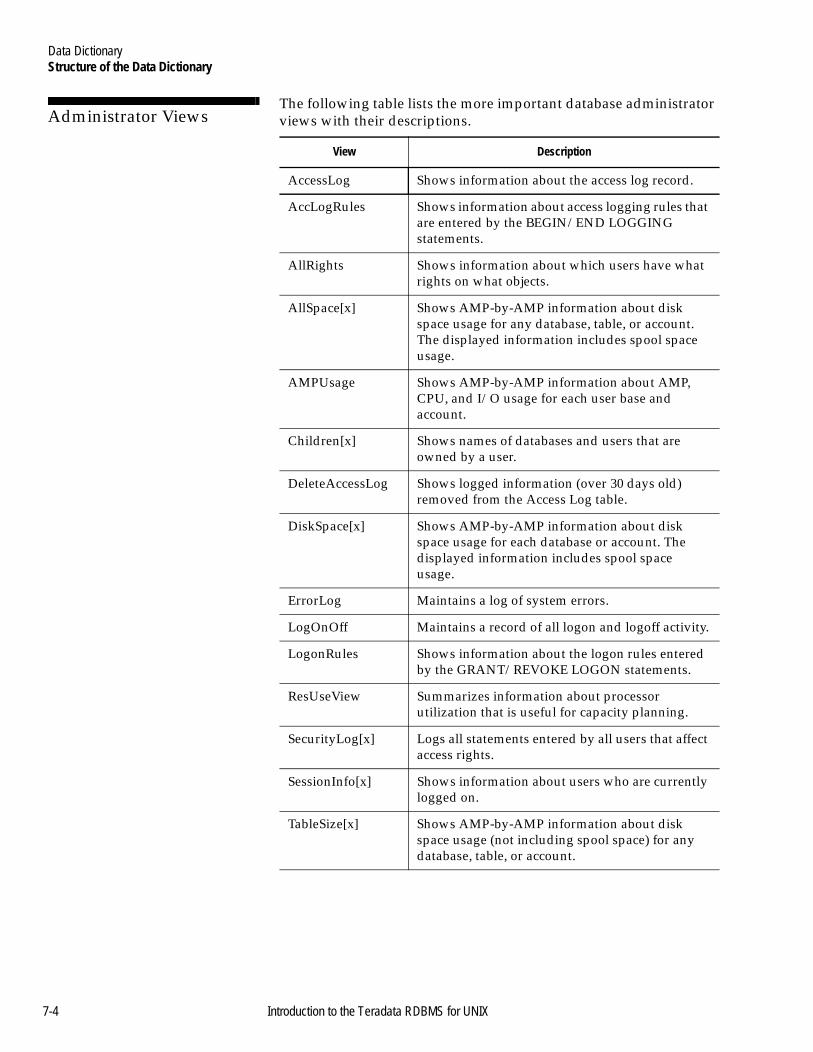
Data DictionaryStructure of the Data Dictionary
Administrator Views 7
The following table lists the more important database administrator views with their descriptions.
View Description
AccessLog Shows information about the access log record.
AccLogRules Shows information about access logging rules that are entered by the BEGIN/END LOGGING statements.
AllRights Shows information about which users have what rights on what objects.
AllSpace[x] Shows AMP-by-AMP information about disk space usage for any database, table, or account. The displayed information includes spool space usage.
AMPUsage Shows AMP-by-AMP information about AMP, CPU, and I/O usage for each user base and account.
Children[x] Shows names of databases and users that are owned by a user.
DeleteAccessLog Shows logged information (over 30 days old) removed from the Access Log table.
DiskSpace[x] Shows AMP-by-AMP information about disk space usage for each database or account. The displayed information includes spool space usage.
ErrorLog Maintains a log of system errors.
LogOnOff Maintains a record of all logon and logoff activity.
LogonRules Shows information about the logon rules entered by the GRANT/REVOKE LOGON statements.
ResUseView Summarizes information about processor utilization that is useful for capacity planning.
SecurityLog[x] Logs all statements entered by all users that affect access rights.
SessionInfo[x] Shows information about users who are currently logged on.
TableSize[x] Shows AMP-by-AMP information about disk space usage (not including spool space) for any database, table, or account.
7-4 Introduction to the Teradata RDBMS for UNIX
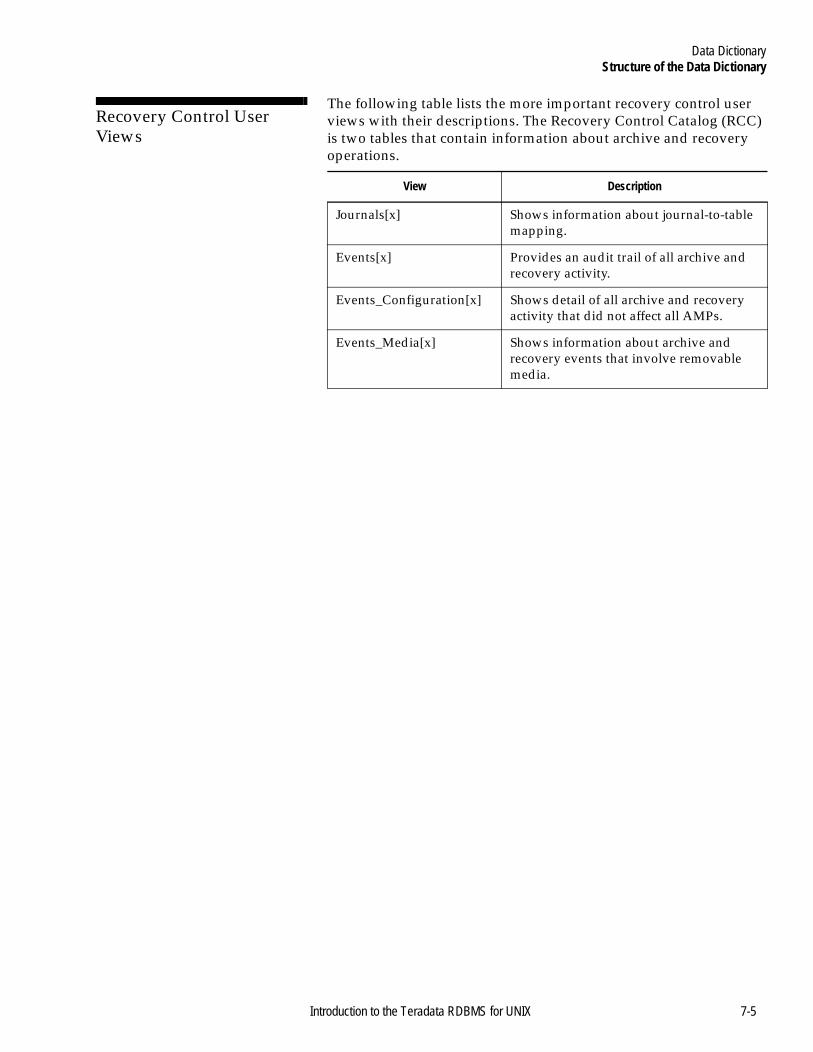
Data DictionaryStructure of the Data Dictionary
Recovery Control User Views 7
The following table lists the more important recovery control user views with their descriptions. The Recovery Control Catalog (RCC) is two tables that contain information about archive and recovery operations.
View Description
Journals[x] Shows information about journal-to-table mapping.
Events[x] Provides an audit trail of all archive and recovery activity.
Events_Configuration[x] Shows detail of all archive and recovery activity that did not affect all AMPs.
Events_Media[x] Shows information about archive and recovery events that involve removable media.
Introduction to the Teradata RDBMS for UNIX 7-5

Data DictionaryUsing the Data Dictionary
Using the Data Dictionary 7
Introduction 7
This topic describes why you might want to use the DD and then briefly touches on how you can use it.
Why Use the Data Dictionary? 7
You use the DD whether you think you do or not. Every time you log onto the system, every time you perform a SQL query, every time you type your password, you are using the DD.
The real question is, why should you make queries against the DD tables using the supplied DD views?
All these users can use the DD to answer their questions.
How do you Access the Data Dictionary? 7
The most important thing to know is that you cannot use any of the following SQL commands to alter the DD in any way:
● INSERT● UPDATE● DELETE
For security and data integrity reasons, the only SQL DML command you can use on the DD is the SELECT statement. Note: to update the DD database, you must use SQL DDL statements. You can use SELECT to examine any view in the DD to which your administrator has granted access.
IF you are this type of user. . . THEN you might . . .
end want to query the DD to discover the underlying structure of the database and to find what access rights you have granted to others on your databases. A few simple queries of the DD can supply you with all the information you need to formulate complex queries against any table
supervisory need to know how much database space is being used, what sorts of archiving of the database is occurring, and what databases are in the database system.
database administrator
need to know about system performance, status and statistics, errors, and accounting
7-6 Introduction to the Teradata RDBMS for UNIX

Data DictionaryUsing the Data Dictionary
For example, suppose you needed to know some things about the Personnel database. You could query the DBC.DataBases view like this:
SELECT Databasename,Creatorname,Ownername,Permspace
FROM DBC.DataBasesWHERE Databasename=’Personnel’;
The report produced by this query looks like this.
Databasename Creatorname Ownername Permspace
Personnel Jones Jones 1,000,000
Introduction to the Teradata RDBMS for UNIX 7-7

Data DictionaryFor More Information
For More Information 7
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
the Data Dictionary Teradata RDBMS for UNIX Data Dictionary Reference Teradata RDBMS for UNIX Database Design and Administration
7-8 Introduction to the Teradata RDBMS for UNIX

Application Development
Introduction to the Teradata RDBMS for UNIX
Chapter 8
Application Development

Application Development
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 8
-1About This ChapterApplication Development8
About This Chapter 8
Introduction 8
Teradata SQL is the only language the Teradata RDBMS understands. You can think of application development for the Teradata RDBMS as falling into one of two categories: explicit SQL or implicit SQL.
Explicit SQL Development 8
Under explicit SQL application development you have the following tools:
● Embedded SQL● BTEQ● Teradata and third party products that package and submit SQL● CLI calls● ODBC calls
Macros are also a means of submitting SQL queries to the Teradata RDBMS.
Implicit SQL Development 8
Under implicit SQL application development you have tools such as Teradata and third party products that permit various fourth generation languages and application generators to be translated into SQL.
This chapter describes the various facilities and tools used to develop applications for the Teradata RDBMS in these environments.

Application DevelopmentWriting Embedded SQL Applications
Writing Embedded SQL Applications 8
Introduction 8
This topic introduces writing applications using embedded SQL.
What is Embedded SQL? 8
When you write applications using embedded SQL, you insert SQL statements into your native language application program.
Because third generation application development languages do not have facilities for dealing with results sets, embedded SQL contains extensions to executable SQL that permit declarations.
Embedded SQL declarations include:
● Code to encapsulate the SQL from the native application language
● Cursor definition and manipulation.
A cursor is a pointer device you use to read through a results table one record (row) at a time.
How Does an Application Program Use Embedded SQL? 8
The client application languages that support embedded SQL are all compiled languages. SQL is not defined for any of them. For this reason, you must precompile your embedded SQL code to translate the SQL into native code before you can compile the source using a native compiler. This precompiler tool is called Preprocessor2.
The precompiler reads your application source code looking for the defined SQL code fragments.
After it isolates all the SQL code in the application, it interprets the intent of the code and translates it into CLI calls.
The precompiler then comments out all the SQL source.
The output of the precompiler is native language source code with CLI calls substituting for the SQL source.
You can then process this converted source code with the native language compiler.
8-2 Introduction to the Teradata RDBMS for UNIX

Application DevelopmentWriting Embedded SQL Applications
Supported Languages and Platforms 8
Preprocessor2 supports the following application development languages on the specified platforms.
Application development language Platform
C ● IBM mainframe clients● UNIX clients
COBOL ● IBM mainframe clients● Some workstation clients
PL/I IBM mainframes
Introduction to the Teradata RDBMS for UNIX 8-3

Application DevelopmentUsing Macros as SQL Applications
Using Macros as SQL Applications 8
Introduction 8
Teradata macros are SQL statements that are stored on the server and executed there. The advantage is less channel traffic and easy execution of frequently used SQL operations. Macros are particularly useful for enforcing data integrity rules, for providing data security and improving performance.
Creating a Macro 8
You use the CREATE MACRO statement to create Teradata macros. The format of CREATE MACRO is similar to CREATE VIEW.
For example, suppose you wanted to define a macro for adding new employees to the Employee table and incrementing the EmpCount field in the Department table. The CREATE MACRO statement looks like this:
CREATE MACRO NewEmp (name (VARCHAR(12)),number (INTEGER, NOT NULL),dept (INTEGER, DEFAULT 100)
)AS (INSERT INTO Employee (Name,
EmpNo,DeptNo
)VALUES (:name,
:number,:dept
)UPDATE DepartmentSET EmpCount=EmpCount+1WHERE DeptNo=:dept;
);
This macro defines parameters that must be filled in each time it is executed. These are indicated with a leading : character.
8-4 Introduction to the Teradata RDBMS for UNIX

Application DevelopmentUsing Macros as SQL Applications
Using a Macro 8
This example illustrates how to use the NewEmp macro to insert data into the Employee and Department tables.
The information to be inserted is the name, employee number, and department number for employee H Goldsmith. The EXECUTE macro statement looks like this:
EXECUTE NewEmp (‘Goldsmith H’, 10015, 600);
Modifying a Macro 8
This example illustrates how to modify a macro. Suppose you wanted to change the NewEmp macro so the default department number is 300 instead of 100. The REPLACE MACRO statement looks like this:
REPLACE MACRO NewEmp (name (VARCHAR(12)),number (INTEGER, NOT NULL),dept (INTEGER, DEFAULT 300)
)AS (INSERT INTO Employee (Name,
EmpNo,DeptNo
)VALUES (:name,
:number,:dept
)UPDATE DepartmentSET EmpCount=EmpCount+1WHERE DeptNo=:dept;
);
Deleting a Macro 8
This example illustrates how to delete a macro. Suppose you wanted to drop the NewEmp macro from the database. The DROP MACRO statement looks like this:
DROP MACRO NewEmp;
Introduction to the Teradata RDBMS for UNIX 8-5

Application DevelopmentUsing the EXPLAIN Statement As a Tool To Optimize Your SQL Code
Using the EXPLAIN Statement As a Tool To Optimize Your SQL Code 8
Introduction 8
Teradata SQL supplies a very powerful EXPLAIN statement that allows you to try out various approaches to the same answer. The EXPLAIN statement not only explains how it would go about executing your SQL query, it provides information about the relative time the query would take to execute.
While it is true that the optimizer uses indexes to maximize query performance, it does not reformulate a query it is presented with to make it more efficient; it only performs that particular query in the most efficient way it knows how. The power of EXPLAIN is that it allows you to experiment with different approaches to an answer, then select the one that performs best.
EXPLAIN details what indexes (if any) the optimizer would use to process the request, identifies any temporary files that would be generated, shows whether the transactions for the statement would be dispatched in parallel, and so on.
You should always make the results of EXPLAINs an integral part of your code review process; they might indicate inefficiencies or errors in the structure of your queries.
8-6 Introduction to the Teradata RDBMS for UNIX

Application DevelopmentUsing the EXPLAIN Statement As a Tool To Optimize Your SQL Code
Using EXPLAIN: First Example 8
The Personnel.Employee table has a unique primary index defined on the EmpNo column and a nonunique secondary index defined on the Name column. The EXPLAIN statement to examine this query looks like this:
EXPLAIN SELECT Name,DeptNo
FROM EmployeeWHERE EmpNo = 10009
;
The output of the query looks like this:
Explanation----------------------------------------------------1) First, we do a single-AMP RETRIEVE step from Personnel.Employee by way of the unique primary index “PERSONNEL.Employee.EmpNo = 10009” with no residual conditions. The input table will not be cached in memory. The result pool will not be cached in memory. The estimated time for this step is 0.03 seconds-> The row is sent directly back to the user as the result of statement 1. The total estimated time is 0.03 seconds.
Introduction to the Teradata RDBMS for UNIX 8-7

Application DevelopmentUsing the EXPLAIN Statement As a Tool To Optimize Your SQL Code
Using EXPLAIN: Second Example 8
The Personnel.Employee table request EXPLAINed below has a WHERE condition that is based on a column defined as a nonunique index. The Teradata RDBMS places a READ lock on the table. The EXPLAIN statement to examine the query looks like this:
EXPLAIN SELECT EmpNo,DeptNo
FROM EmployeeWHERE Name = ‘Smith T’
;
The output of the query looks like this:
Explanation----------------------------------------------------1) First, we lock PERSONNEL.Employee for read.2) Next, we do an all-AMPS RETRIEVE step from PERSONNEL.Employee by way of an all-rows scan with a condition of (“PERSONNEL.Employee.Name = ‘Smith T’”) into Spool 1, which is built locally on the AMPs. The size of Spool 1 is estimated to be 2rows. The estimated time for this step is 0.03 seconds.3) Finally, we send out an END TRANSACTION step to all AMPs involved in processing the request.-> The contents of Spool 1 are sent back to the user as the result of statement 1. The total estimated time is 0 hours and 0.03 seconds.
8-8 Introduction to the Teradata RDBMS for UNIX

Application DevelopmentUsing the Call-Level Interface to Develop Applications
Using the Call-Level Interface to Develop Applications 8
Introduction 8
The Teradata RDBMS uses CLI or ODBC for all communication between a user terminal and the Teradata RDBMS. Whether used explicitly or under the covers, the CLI and ODBC are the basis for all communication between users and the Teradata RDBMS.
This topic describes using the CLI explicitly to develop applications.
What is the CLI? 8
The CLI packages SQL requests on a client for routing to the Teradata server. When a results set is returned to the client, the CLI unpackages the results for the system to display to the user or write in a report.
The CLI can be used directly in application programs written in any language that supports a CALL statement.
The exact implementation of the CLI differs slightly between channel-attached and network-attached clients, but the basic functions of the CLI are the following:
● To block and unblock messages● To log sessions on and off the server● To provide an interface between users and the TDP (or MTDP).
Like all other messages sent to the Teradata RDBMS, the CLI messages are ultimately processed as SQL by the parser on the server. The CLI packages and unpackages this SQL by means of calls to system subroutines.
Because any client language that supports a call statement can use the CLI to communicate with a Teradata RDBMS, the CLI is a very flexible tool for developing applications.
On the other hand, it is rather difficult to master, and most users will probably find that their time is better spent developing applications using explicit SQL, either embedded in a native client language supported by Preprocessor2 or in macros.
Introduction to the Teradata RDBMS for UNIX 8-9

Application DevelopmentUsing the Call-Level Interface to Develop Applications
CLI routines are provided as object modules that have been compiled or assembled according to standard linkage conventions. CLI routines are available for many client operating environments including the following:
● MVS● CICS● IMS● VM/SP● UNIX● DOS
Custom ports to other platforms are also available.
What is ODBC? 8
The OBDC Driver for Teradata Database System provides an alternate, CLI-independent interface to Teradata databases using the industry standard OBDC application programming interface. OBDC is support in the Windows, Windows NT, and Windows 95 environments.
8-10 Introduction to the Teradata RDBMS for UNIX

Application DevelopmentUsing TS/API to Develop Applications for the Teradata RDBMS
Using TS/API to Develop Applications for the Teradata RDBMS 8
Introduction 8
The Teradata RDBMS supports many third party software products. There are two general components of supported products: those of the transparency series and the native interface products.
TS/API Products 8
The Transparency Series/Application Program Interface (TS/API) product provides a gateway between the IBM mainframe relational database products DB2 (MVS/TSO) and SQL/DS (VM/CMS) and the Teradata RDBMS.
TS/API permits a SQL statement formulated for either DB2 or SQL/DS to be translated into Teradata SQL so DB2 or SQL/DS applications can access data stored in a Teradata RDBMS.
Compatible Third Party Software Products 8
Many third party interactive query products operate in conjunction with the Teradata RDBMS, permitting queries formulated in a native query language to access a Teradata RDBMS.
The list of supported third party products changes continuously.
For a current list, contact your NCR sales office.
Introduction to the Teradata RDBMS for UNIX 8-11

Application DevelopmentFor More Information
For More Information 8
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Teradata SQL data manipulation statements
Teradata RDBMS for UNIX SQL Reference Manual
Embedded SQL Teradata RDBMS for UNIX SQL ReferenceTeradata Application Programming With Embedded SQL for C, COBOL, and PL/I
Using the Teradata SQL preprocessor
Teradata Application Programming With Embedded SQL for C, COBOL, and PL/I
Call Level Interface programming Teradata Call-Level Interface Version2 for Channel-Attached SystemsTeradata Call-Level Interface Version2 for Network-Attached Systems
TS/API products Teradata RDBMS TS/API Concepts and Facilities Teradata RDBMS TS/API User’s GuideTeradata RDBMS TS/API System and Database Administration GuideTeradata RDBMS TS/API Installation Guide
8-12 Introduction to the Teradata RDBMS for UNIX

Fault Tolerance
Introduction to the Teradata RDBMS for UNIX
Chapter 9
Fault Tolerance

Fault Tolerance
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 9
-1About This ChapterFault Tolerance9
About This Chapter 9
Introduction 9
This topic provides an overview of the fault tolerance capabilities of the Teradata RDBMS.
The Teradata RDBMS addresses the critical requirements of reliability, availability, serviceability, usability, and installability (RASUI) by combining multiple microprocessors (in so-called symmetric multiprocessing, or SMP), parity or mirrored disk storage, and protection of the database from operating anomalies of the client platform.
Some fault tolerance is provided by hardware and some by software. Some is mandatory and some is optional. The high availability of the Teradata RDBMS is one of its more remarkable features.
Software Fault Tolerance 9
The Teradata RDBMS provides the following software fault tolerance capabilities:
● vproc migration● Fallback tables and AMP clusters● Journaling● Archive and Restore utility● System maintenance facilities
Hardware Fault Tolerance 9
The Teradata RDBMS provides the following hardware fault tolerance capabilities:
● Dual BYNETs (5100M systems only)● RAID disk units● Multiple channel and LAN connections● Isolation from client hardware defects● Battery backup for all cabinets● Redundant power supplies and fans● Hot swap capability for RAID disks, fans, and power supplies● Cliques● Separate diagnostic processor● A single system view provided by the AWS controlling all
cabinets in a multinode system.

Fault ToleranceSoftware Fault Tolerance
Software Fault Tolerance 9
Introduction 9
The Teradata RDBMS provides many facilities for software fault tolerance. These are:
● vproc migration● Fallback tables and AMP clusters● Journaling● Archive and restore utility● System maintenance facilities
vproc Migration 9
Parsing Engine (PE) and Access Module Process (AMP) software replaces the hardware devices that existed on the old Teradata DBC/1012 and System 3600 configurations.
Because these “processors” are now software, they can migrate from their home node to another node within the same hardware clique if the home node fails for any reason.
Preferred migratory destinations are user-configurable, but in general, you should allow the system to determine which vprocs migrate to which nodes.
vproc migration permits complete operation of the affected “processors” during any node failure. vproc migration is illustrated in Figure 9-1, where a failed node is indicated by a large X and migration is indicated by arrows pointing to nodes that are still running.
9-2 Introduction to the Teradata RDBMS for UNIX
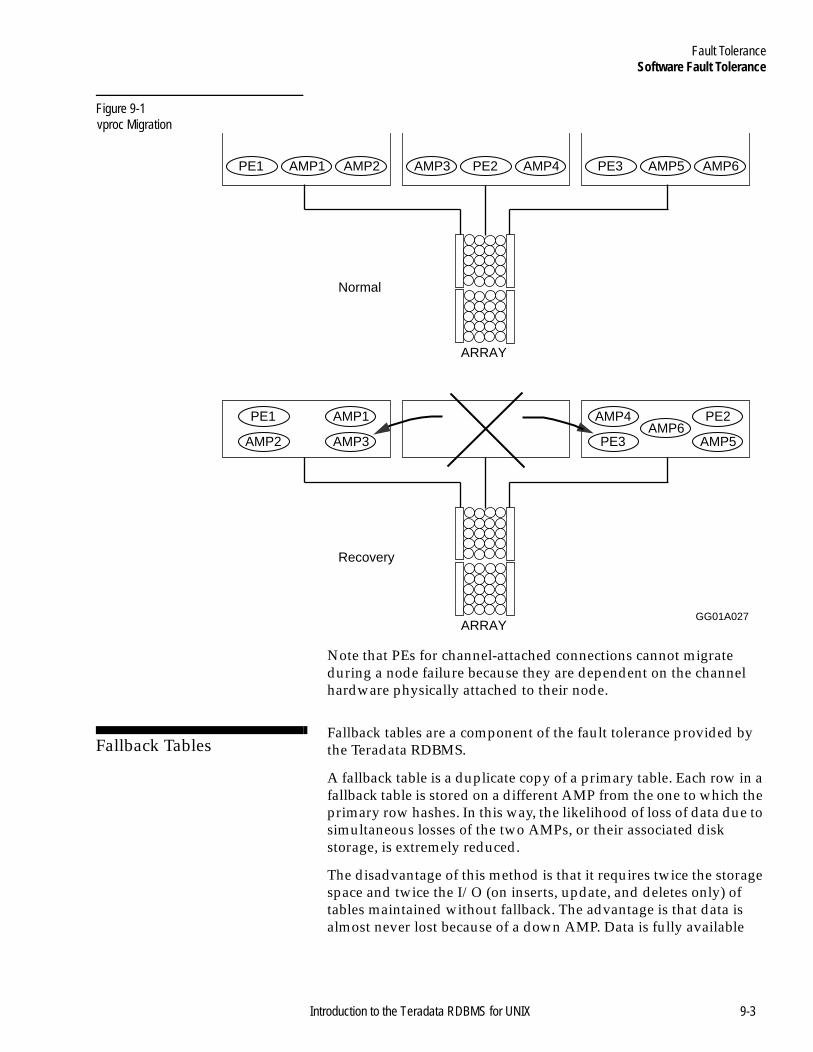
Fault ToleranceSoftware Fault Tolerance
Figure 9-1 9vproc Migration
Note that PEs for channel-attached connections cannot migrate during a node failure because they are dependent on the channel hardware physically attached to their node.
Fallback Tables 9
Fallback tables are a component of the fault tolerance provided by the Teradata RDBMS.
A fallback table is a duplicate copy of a primary table. Each row in a fallback table is stored on a different AMP from the one to which the primary row hashes. In this way, the likelihood of loss of data due to simultaneous losses of the two AMPs, or their associated disk storage, is extremely reduced.
The disadvantage of this method is that it requires twice the storage space and twice the I/O (on inserts, update, and deletes only) of tables maintained without fallback. The advantage is that data is almost never lost because of a down AMP. Data is fully available
GG01A027
PE1 AMP1 AMP2 AMP3 PE2 AMP4 PE3 AMP5 AMP6
ARRAY
AMP2 AMP3 PE3AMP6
AMP5
ARRAY
Normal
Recovery
PE1 AMP1 AMP4 PE2
Introduction to the Teradata RDBMS for UNIX 9-3

Fault ToleranceSoftware Fault Tolerance
during an AMP or disk outage, and recovery is automatic after repairs have been made.
The Teradata RDBMS for UNIX permits the definition of fallback for individual tables. As a general rule, it is wise to run all tables critical to your enterprise in fallback mode. Other tables can be run in non-fallback mode in order to maximize resource usage.
The vproc migration feature offered by systems using disk array technology can safely recover this storage capacity by running without fallback. Running in this mode does not provide availability of data during an AMP outage, however.
You specify whether a table is fallback or not using the CREATE TABLE (or ALTER TABLE) statement. The default is not to create tables with fallback.
AMP Clusters 9
Clustering is a means of logically grouping AMPs to minimize (or eliminate) data loss that might occur from losing an AMP. Note that AMP clusters are used only for fallback data.
AMP clustering is best explained with pictures. The first picture illustrates a situation in which there is fallback but no AMP clustering.
Figure 9-2 9Unclustered AMPs With Fallback
.
Note that the fallback copy of any row is always located on a different AMP from the primary copy. This is an entry level fault tolerance strategy. The data on AMP3 is fallback-protected on AMPs 4, 5, and 6. If AMP 3 were to fail, the data would still be available on the other AMPS. If AMPs 3 and 6 were to fail at the same time, however, the system would become unavailable.
AMP1
1,9,17
21,22,15
AMP2
2,10,18
1,23,8
AMP3
3,11,19
9,2,16
AMP4
4,12,20
17,10,3
AMP5
5,13,21
18,11,4
AMP6
6,14,22
19,12,24
AMP7
7,15,23
20,5,6
AMP8
8,16,24
13,14,7
Primary copy area
Fallback copy area
Primary copy area
Fallback copy area
FG10A001
9-4 Introduction to the Teradata RDBMS for UNIX

Fault ToleranceSoftware Fault Tolerance
The next picture illustrates a way around this problem—clustering.
Figure 9-3 9Clustered AMPs With Fallback
The illustration shows the same eight AMP configuration which has been partitioned into two AMP clusters of four AMPs each.
A cluster is a group of from two to sixteen AMPs in which each primary row in the cluster is fallback-protected on another AMP in the same cluster.
Compare this clustered configuration with the earlier illustration of an unclustered AMP configuration. In the example, the (primary) data on AMP 3 is backed up on AMPs 0, 1, and 2 and the data on AMP 6 is backed up on AMPs 4, 5, and 7.
If AMPs 3 and 6 were to fail at the same time, the system would continue to function normally. Only if two failures occurred within the same cluster would the system halt.
The primary issue determining cluster size is performance. While two-AMP clusters provide maximum protection against system loss (because the likelihood of both AMPs in a cluster going down simultaneously is vanishingly small), this configuration also suffers from a higher workload per AMP in the event of a failure.
A rule of thumb to follow is to create AMP clusters of 4 AMPs each. This configuration maximizes the tradeoff between the probability of a failure and performance degradation.
AMP1
1,9,17
2,3,4
AMP2
2,10,18
1,11,12
AMP3
3,11,19
9,10,20
AMP4
4,12,20
17,18,19
AMP5
5,13,21
6,7,8
AMP6
6,14,22
5,15,16
AMP7
7,15,23
13,14,24
AMP8
8,16,24
21,22,23
Primary copy area
Fallback copy area
Primary copy area
Fallback copy area
FG10A002
Cluster A
Cluster B
Introduction to the Teradata RDBMS for UNIX 9-5

Fault ToleranceSoftware Fault Tolerance
Journaling 9
The Teradata RDBMS permits several different kinds of journaling. Some are done by the system and others are user-specified.
The following table explains the different journaling capabilities of the Teradata RDBMS.
Journal Type Description Maintained By
Down AMP recovery journal
● Active during an AMP failure only.● Journals fallback tables only.● Discarded after the down AMP
recovers.
System (automatic)
Transient journal
● Logs BEFORE images for all transactions.
● Used by system to roll back failed transactions aborted either by the user or by the system.
● Captures:● BT/ET images for all transactions.● Before images for updates and deletes.● Row IDs for inserts.● Control records for creates and drops.● Each image is kept on the same AMP
as the row it describes.● Images are discarded when the
transaction or rollback completes.
System (automatic)
Permanent journal
● Active continuously.● Available for tables or databases.● Provides rollforward for hardware
failure recovery.● Provides rollback for software failure
recovery.● Provides full recovery of nonfallback
tables.● Reduces need for frequent full table
archives.
User (optional)
9-6 Introduction to the Teradata RDBMS for UNIX

Fault ToleranceTape Archive and Restore/Recovery Utilities
Tape Archive and Restore/Recovery Utilities 9
Introduction 9
This topic describes using the Archive and Restore/Recovery and ASF2 utilities to copy and restore or recover a table or database.
The Archive and Restore/Recovery utility backs up data to an IBM channel-attached client, while the ASF2 utility performs a local backup or a backup to a network-attached client.
Archiving Data 9
An archive operation is one in which you use the utility to copy selected or all tables or databases from your Teradata RDBMS.
You should archive your Data Dictionary immediately after you archive your data.
If your system is used only for decision support and is updated regularly with data loads, you might not want to archive the data. Consult your DBA or system programmer about the advisability of not making regular archives of your databases.
Restoring Data 9
Restoring is distinct from recovering.
In a restore operation, you are copying an archive from the client or server back to the database.
You can restore data to all AMPs, to clusters of AMPs, or to a specific AMP as long as the data dictionary contains the definitions of the table or database you want to restore.
If the table does not have a definition in the data dictionary because of a DROP or RENAME statement, you can still restore data using the COPY statement.
Recovering Data 9
Recovering is distinct from restoring.
In a recovery operation, you are applying before or after journal images using a ROLLBACK or ROLLFORWARD statement.
Introduction to the Teradata RDBMS for UNIX 9-7

Fault ToleranceTable Rebuild Facility
Table Rebuild Facility 9
Introduction 9
This topic introduces the table rebuild facility available for the Teradata RDBMS.
Table Rebuild Facility 9
The table rebuild utility is used to recreate a table, database, or entire disk on a single AMP under the following conditions:
● Table structure or data is damaged because of a software problem, head crash, power failure, or other malfunction.
● Affected tables were enabled for fallback protection.
Table rebuild can create all of the following on an AMP-by-AMP basis:
● Primary or fallback portions of a table● Entire table (both primary and fallback portions)● All tables in a database● All tables on an individual AMP
Restrictions 9
This utility is usually run by a System Engineer, Field Engineer, or System Support Representative.
The facility rebuilds a table only if fallback protection is enabled for that table.
9-8 Introduction to the Teradata RDBMS for UNIX

Fault ToleranceHardware Fault Tolerance
Hardware Fault Tolerance 9
Introduction 9
The Teradata RDBMS provides several facilities for hardware fault tolerance. These are:
● Dual BYNETs● RAID disk units● Multiple channel and LAN connections● Isolation from client hardware defects● Battery backup● Redundant power supplies and fans● Hot swap capability for node components● Cliques
Dual BYNETs 9
Multinode Teradata RDBMS servers are equipped with two BYNETs.
Interprocessor traffic is never stopped unless both BYNETs fail. Within a BYNET, traffic can often be rerouted around failures.
RAID Disk Units 9
Teradata RDBMS servers use Redundant Array of Independent Disk (RAID) units configured for use as either RAID1 or RAID5 arrays.
JBOD is not a supported option.
RAID1 arrays offer mirroring (identical copies of data are maintained).
RAID5 arrays protect data from single disk failures with a 25 percent increase in disk storage to provide parity.
Multiple Channel and LAN Connections 9
In a client-server environment, multiple channel connections between mainframe and network-based clients ensures that most processing will continue even with one or several connections between the clients and server not working.
The migrating vproc feature is a software feature supporting this hardware issue.
Isolation From Client Hardware Defects 9
In a client-server environment, a server is isolated from many client hardware defects and can continue processing in spite of client defects.
Battery Backup 9
All cabinets have battery backup in case of building power failures.
Introduction to the Teradata RDBMS for UNIX 9-9

Fault ToleranceHardware Fault Tolerance
Redundant Power Supplies and Fans 9
Each cabinet in a configuration has redundant power supplies and fans to ensure failsafe operation.
Hot Swap Capability for Node Components 9
The following components are all offered with hot swap capability:
● RAID disks● Fans● Power supplies
Cliques 9
The clique is a feature of multinode systems that physically groups nodes together by multiported access to common disk array units. Internode disk array connections are made by way of SCSI buses. Shared SCSI-II paths enable redundancy to ensure that loss of a processor node or loss of a disk controller does not decrease data availability.
The nodes do not share data, only access to the disk arrays. Figure 9-4 illustrates a four node system.
Figure 9-4 Four node clique
Cliques are the physical medium that supports the migration of vprocs during times of node failure. If a node in a clique fails, then its vprocs migrate to another node in the clique and continue to operate while recovery occurs on their home node.
GG01A003
MCA
Node 4
Q 720
MCAMCA
Node 3
Q 720
MCAMCA
Node 2
Q 720
MCAMCA
Node 1
Q 720
MCA
DAC
SCSI
9-10 Introduction to the Teradata RDBMS for UNIX
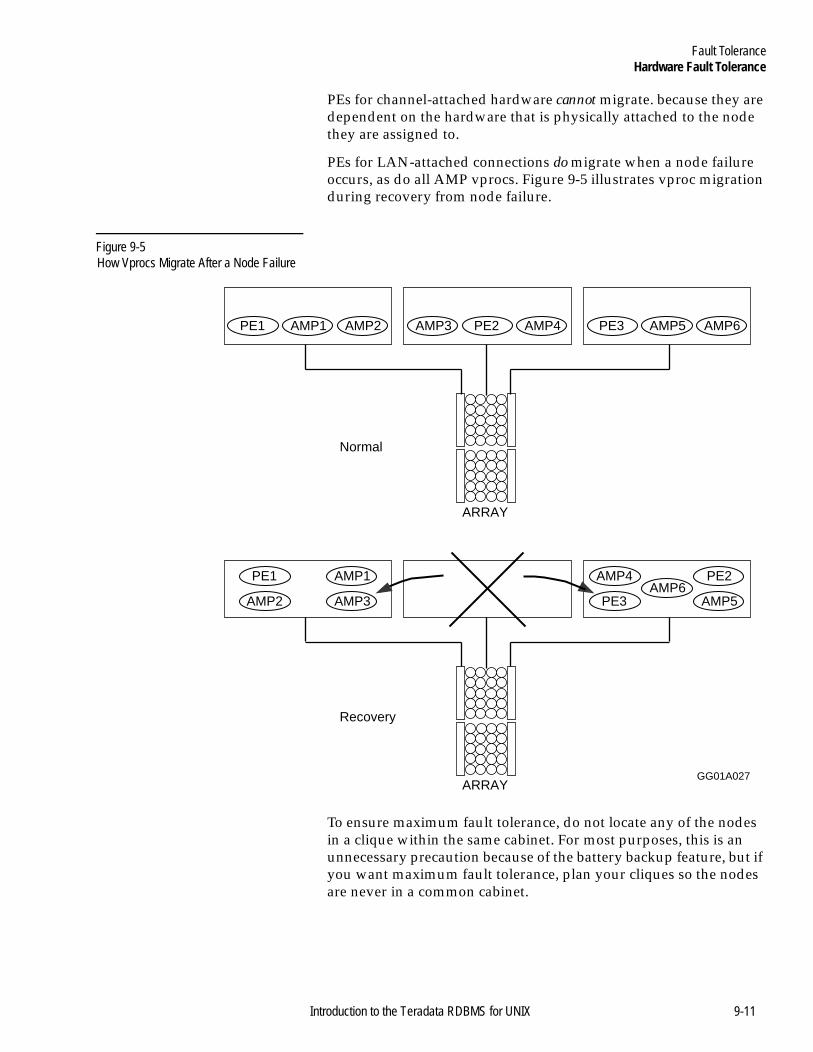
Fault ToleranceHardware Fault Tolerance
PEs for channel-attached hardware cannot migrate. because they are dependent on the hardware that is physically attached to the node they are assigned to.
PEs for LAN-attached connections do migrate when a node failure occurs, as do all AMP vprocs. Figure 9-5 illustrates vproc migration during recovery from node failure.
Figure 9-5 9How Vprocs Migrate After a Node Failure
To ensure maximum fault tolerance, do not locate any of the nodes in a clique within the same cabinet. For most purposes, this is an unnecessary precaution because of the battery backup feature, but if you want maximum fault tolerance, plan your cliques so the nodes are never in a common cabinet.
GG01A027
PE1 AMP1 AMP2 AMP3 PE2 AMP4 PE3 AMP5 AMP6
ARRAY
AMP2 AMP3 PE3AMP6
AMP5
ARRAY
Normal
Recovery
PE1 AMP1 AMP4 PE2
Introduction to the Teradata RDBMS for UNIX 9-11

Fault ToleranceHardware Fault Tolerance
Single AWS System View 9
The Administrative Workstation AWS provides a single system view for 5100M (multinode) environments.
9-12 Introduction to the Teradata RDBMS for UNIX

Fault ToleranceFor More Information
For More Information 9
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Physical database design Teradata RDBMS for UNIX Database Design and Administration
Introduction to the Teradata RDBMS for UNIX 9-13

Fault ToleranceFor More Information
9-14 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and Recovery
Introduction to the Teradata RDBMS for UNIX
Chapter 10
Concurrency Control and Recovery

Concurrency Control and Recovery
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 10
-1About This ChapterConcurrency Control and Recovery10
About This Chapter 10
Introduction 10
This chapter describes the topic of concurrency control in relational database management systems and how transaction journaling can be used to recover lost data or restore an inconsistent database to a consistent state.
The first part of this chapter deals with the concepts of transactions and locks.
This chapter also describes the closely related topics of concurrency control and recovery.
Concurrency Control 10
Concurrency control deals with preventing concurrently running processes from improperly inserting, deleting, or updating the same data. Concurrency control is maintained through two mechanisms:
● Transactions● Locks
The second part of this chapter deals with recovery.
Recovery 10
Recovery is a process by which an inconsistent database is brought back to a consistent state. Transactions play the critical role in this process as well because they are used to “play back” a series of updates (using the term in its most general sense) to the database, either taking it back to some earlier state or bringing it forward to a current state.

Concurrency Control and RecoveryThe Concept of the Transaction
The Concept of the Transaction 10
Introduction 10
This topic describes the concept of a transaction. Transactions are a mandatory facility for maintaining the integrity of a database while running multiple concurrent operations.
Definition of a Transaction 10
A transaction is a logical unit of work. It is both the unit of work and the unit of recovery. The statements nested within a transaction must either all happen or none happen. Transactions are atomic: there is no such thing as a partial transaction.
Definition of Serializability 10
A set of transactions is said to be serializable if and only if it produces the same result as some arbitrary serial execution of those same transactions for arbitrary input.
A set of transactions can be correct only if it is serializable.
Serializability is achieved through the use of the Two-Phase Locking (2PL) protocol. The two phases are the growing phase and the shrinking phase.
In the growing phase, for any object, a transaction must first acquire a lock on that object before operating on it.
In the shrinking phase, a transaction must never acquire any more locks once it has released a lock. Lock release is an all-or-none operation.
Transaction Semantics 10
The Teradata RDBMS supports both ANSI transaction semantics and its own transaction semantics.
Default transaction mode for a site is a system default parameter.
The default can be overridden for a session.
The Teradata RDBMS returns an error when a COMMIT statement is issued by a transaction operating in Teradata semantics mode.
The ANSI COMMIT WORK statement is supported in ANSI transaction mode.
ANSI Transactions 10
All ANSI transactions are implicit.
Either of the following events opens an ANSI transaction:
● First SQL statement executed in a session
10-2 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryThe Concept of the Transaction
● First statement executed following the close of a previous transaction.
Transactions close when the application performs a COMMIT, ROLLBACK, or ABORT statement.
The last statement in a transaction must be a data definition statement (including DATABASE and SET SESSION, which are considered to be DDL statements in this context).
The statements BEGIN TRANSACTION and END TRANSACTION, along with the two-phase commit protocol, are not allowed for a session executing under ANSI transaction semantics.
When an application submits these statements in an ANSI situation, the database software generates an error.
Rolling Back an ANSI Transaction 10
ANSI rolls back the entire transaction under the following conditions when the current request:
● Results in a deadlock● Performs a DDL statement that aborts● Executes an explicit ROLLBACK or ABORT statement.
The ABORT and ROLLBACK statements are accepted in ANSI mode, including conditional forms of those statements.
When an errors for either a single or multistatement request, only that request is rolled back and the transaction remains open except in the following special circumstances:
When these statements are executed and are either unconditional or the specified condition is true, then the entire transaction is rolled back. This action does not result in a request-level rollback.
Application-initiated asynchronous aborts also cause full transaction rollback in the ANSI environment.
Introduction to the Teradata RDBMS for UNIX 10-3

Concurrency Control and RecoveryThe Concept of the Transaction
Teradata Transactions 10
Teradata transactions can be either implicit or explicit.
Multistatement requests and macros are examples of implicit transactions.
The sorts of transactions undertaken by embedded SQL applications are examples of explicit transactions. Consider the following COBOL program with embedded SQL and transactions (no COBOL code is shown, but the embedded SQL code is of the type required by COBOL SQL programs).
EXEC SQLBEGIN TRANSACTIONEND-EXECEXEC SQLDELETE FROM EmployeeWHERE Name = ‘Smith T’END-EXECEXEC SQLUPDATE DepartmentSET EmpCount=EmpCount-1WHERE DeptNo=500END-EXECEXEC SQLEND TRANSACTIONEND-EXEC
If an error were to occur during the processing of either the DELETE or UPDATE statement within the BEGIN TRANSACTION and END TRANSACTION statements, both Employee and Department tables would be restored to their states before the transaction began.
When an error occurs during a Teradata transaction, the entire transaction is rolled back.
How to Undo an Update 10
An obvious question to ask is this: how do you undo an update once it has been made?
The answer is by applying a transaction log (or journal) to the database to write it back to its state before the transaction began. The journal contains before images of the database, which you can use to undo a transaction.
A transaction log of after images of the database can be used to redo a transaction.
Transactions begin and end at a checkpoint or synchronization point. The transaction recovery system uses these checkpoints to apply its data to exactly the right time to recover the database to an earlier (or later) state.
10-4 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryThe Concept of the Lock
The Concept of the Lock 10
Introduction 10
A lock is a means of claiming usage rights on some resource.
There can be several different types of resources that can be locked and several different ways of locking those resources.
Overview of Teradata RDBMS Locking 10
Most locks exerted on Teradata resources are locked automatically by default. Users can override some locks by making specific lock specifications, but the overrides are allowed only when the integrity of the data can be assured.
The type of lock exerted depends on the data integrity requirement of the request.
A request for a locked resource by another user is queued until the process using the resource releases its lock on that resource.
The Teradata lock manager implicitly locks the following objects.
Object Locked Description
Database Locks rows of all tables in the database
Table Locks all rows in the table and any index and fallback subtables
View Locks all underlying tables in the view
Row hash Locks the primary copy of a row (all rows that share the same hash code)
Introduction to the Teradata RDBMS for UNIX 10-5

Concurrency Control and RecoveryThe Concept of the Lock
Why is Locking Required for Database Management Systems? 10
The best example of why locks are required for database management systems in which multiple processes are accessing the same database is the well known lost update anomaly.
Consider the following picture.
Figure 10-1 10Lost Update Anomaly.
This is a classic example of a nonserializable set of transactions. If locking had been in effect, there is no way that the database could add $3,000.00 to $500.00 and get two different (wrong) results. This is only the most common problem encountered in a transaction processing system without locks. There are several other classic problems, but the lost update problem is sufficient to illustrate the necessity of locking.
Teradata Lock Levels 10
A user can lock three resource types in a Teradata database:
● Database● Table● Row Hash
$500.00
$1,500.00
$2,500.00
$500.00
$2,500.00
$500.00
$1,500.00
READ Balance READ Balance
Add $1,000.00
Database
WRITE result todatabase
Add $2,000.00
WRITE result todatabase
Execution oftransaction T1
Execution oftransaction T2
FG11A001
10-6 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryThe Concept of the Lock
Teradata Lock Types 10
Users can exert four different levels of locking on Teradata resources. The following table explains the lock types.
Lock Type Description
Exclusive The requester has exclusive rights to the locked resource. No other process can read from, write to, or access the locked resource in any way.
Exclusive locks are generally only necessary when structural changes are being made to the database.
Write The requester has exclusive rights to the locked resource except for readers not concerned with data consistency.
Read The requester has exclusive rights to the locked resource while it is reading that resource.
Read locks ensure consistency during read operations such as those that occur during a SELECT statement.Several users can hold Read locks on a resource, during which no modification of that resource is permitted.
Access The requester does not care about the consistency of the data while it is accessing the database.
An access lock permits modifications on the underlying data while the SELECT operation is in progress.
Introduction to the Teradata RDBMS for UNIX 10-7
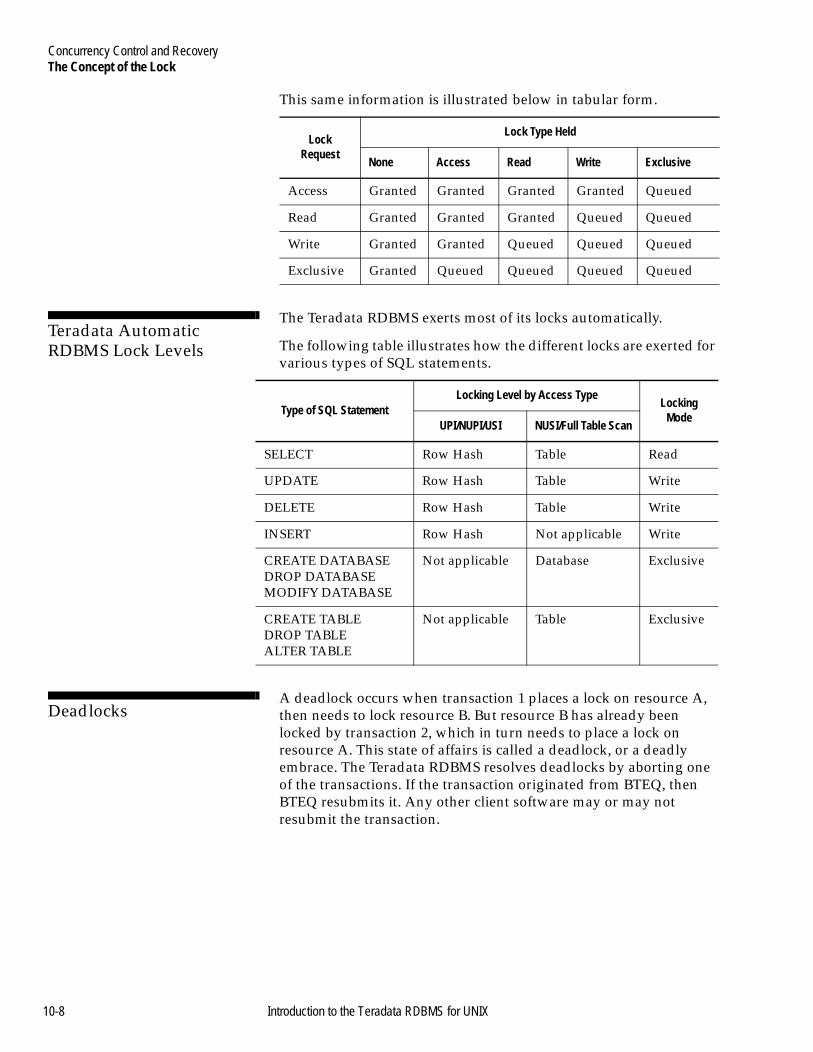
Concurrency Control and RecoveryThe Concept of the Lock
This same information is illustrated below in tabular form.
Teradata Automatic RDBMS Lock Levels 10
The Teradata RDBMS exerts most of its locks automatically.
The following table illustrates how the different locks are exerted for various types of SQL statements.
Deadlocks 10
A deadlock occurs when transaction 1 places a lock on resource A, then needs to lock resource B. But resource B has already been locked by transaction 2, which in turn needs to place a lock on resource A. This state of affairs is called a deadlock, or a deadly embrace. The Teradata RDBMS resolves deadlocks by aborting one of the transactions. If the transaction originated from BTEQ, then BTEQ resubmits it. Any other client software may or may not resubmit the transaction.
LockRequest
Lock Type Held
None Access Read Write Exclusive
Access Granted Granted Granted Granted Queued
Read Granted Granted Granted Queued Queued
Write Granted Granted Queued Queued Queued
Exclusive Granted Queued Queued Queued Queued
Type of SQL StatementLocking Level by Access Type
Locking Mode
UPI/NUPI/USI NUSI/Full Table Scan
SELECT Row Hash Table Read
UPDATE Row Hash Table Write
DELETE Row Hash Table Write
INSERT Row Hash Not applicable Write
CREATE DATABASEDROP DATABASEMODIFY DATABASE
Not applicable Database Exclusive
CREATE TABLEDROP TABLEALTER TABLE
Not applicable Table Exclusive
10-8 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryHost Utility Locks
Host Utility Locks 10
Introduction 10
The locking operation used by the Archive/Storage Facility (ASF2) and client-resident Archive/Recovery facilities are very different from those performed by the Teradata RDBMS. The locks are frequently referred to as HUT (for Host UTility) locks in the Teradata RDBMS manuals.
HUT Lock Types 10
HUT locks are placed as follows.
HUT Lock Characteristics 10
HUT locks have the following characteristics.
● Associated with the currently logged-on user who entered the statement rather than with a job or transaction.
● Placed only on objects on the AMPs that are participating in a utility operation.
● Placed at the cluster level during a CLUSTER dump.● Never conflict with a utility lock at another level that was placed
on the same object for the same user.● Remain active until they are released either by the RELEASE
LOCK option of the utility command or by the execution of a Teradata SQL RELEASE LOCk statement after a utility operation completes.
● Automatically reinstated following a Teradata RDBMS restart if they had not been released.
Lock Type Object Locked
Read Any object being dumped.
Group Read Rows of a table being dumped if and only if the table is defined for an after-image permanent journal and you selected the appropriate option on the DUMP command.
Write Permanent journal table being restored.
Write All tables in a ROLLFORWARD or ROLLBACKWARD during recovery operations.
Write Journal table being deleted.
Exclusive Any object being restored.
Introduction to the Teradata RDBMS for UNIX 10-9

Concurrency Control and RecoverySystem and Media Recovery
System and Media Recovery 10
Introduction 10
This topic describes how the Teradata RDBMS restarts itself after a system or media failure.
System Restarts 10
Unscheduled restarts occur for one of the following reasons:
● AMP or disk failure● Software failure● Parity error
All software recovery is effected in the same way. Hardware failures put the affected component offline and it remains so until repaired or replaced.
Transaction Recovery 10
Two types of automatic recovery of transactions can occur when an unscheduled restart occurs:
● Single transaction recovery● RDBMS recovery
The following table details when these two automatic recovery mechanisms take place.
This recovery type . . . Happens when . . .
single transaction the RDBMS aborted a single transaction because of:● Transaction deadlock timeout● User error● User-initiated abort command● An inconsistent data table● Unavailable resources for parsingSingle transaction recovery uses the transient journal to effect its data restoration.
RDBMS a RDBMS restart is caused by:● Hardware failure● Software failure● User command
10-10 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoverySystem and Media Recovery
Down AMP Recovery 10
When an AMP fails to come online during system recovery, the RDBMS continues to process transactions using fallback data. When the down AMP comes back online, down AMP recovery procedures begin to bring the data for the AMP up to date.
If there are a large number of rows to be processed, the AMP recovers offline. The RDBMS sends updates to the offline AMP in background mode.
If the AMP needs to process only a few rows, then the recovery is done online.
Once all updates are made, the AMP is considered to be fully online.
Introduction to the Teradata RDBMS for UNIX 10-11

Concurrency Control and RecoveryTwo-Phase Commit
Two-Phase Commit 10
Introduction 10
Two-phase commit (2PC) is a protocol for ensuring transaction commitment in a distributed database environment. Two-phase commit for the Teradata RDBMS is supported by default only in MVS environments running either IMS or CICS databases. ANSI transaction semantics do not permit use of the two-phase commit protocol.
The Teradata RDBMS implements the participant side, while IMS and CICS implement a coordinator. Any user can write custom coordinator software and implement 2PC with the Teradata RDBMS and any other DBMS that also supports the participant side.
The protocol ensures that all participants in a distributed transaction agree on whether to commit a transaction or not before proceeding.
Definitions 10
A participant is a database manager that performs some work on behalf of the transaction and that commits or aborts database transactions in a distributed environment.
Any number of participants can engage in a two-phase commit operation.
A participant is defined as being in doubt from the time it votes to commit or abort until the time it receives a commit or abort instruction from the coordinator.
A coordinator is a controlling database manager with respect to the distributed situation.
The coordinator is never in doubt. Selection of the coordinator is arbitrary, but with respect to the Teradata RDBMS it is always either IMS or CICS.
There can be only one coordinator per transaction at one time.
Two-Phase Commit 10
The two-phase commit protocol was developed to ensure that multiple transaction postings in distributed environments are always either committed or aborted.
In the Teradata environment, the Teradata database manager is always a participant, while the IMS or CICS database manager is always the coordinator.
In phase 1 of 2PC, the coordinator requests all participants to vote to commit or abort or go into a state where they can either commit or rollback.
10-12 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryTwo-Phase Commit
When a participant reaches this state, it sends an OK message to the coordinator.
If the coordinator does not receive such a message (or if it times out), then it assumes failure.
After all participants in the transaction send an OK message back to the coordinator, phase 2 begins when the coordinator broadcasts a commit command to all participants.
If all participants do not send an OK, then the coordinator broadcasts a rollback command.
The following diagram illustrates the major components and interfaces of 2PC in the Teradata environment.
Figure 10-2 10Two-phase Commit Processing
IMS or CICSapplication
Application-participant interface
Application-coordinator interface
FG11A002
CoordinatorParticipant
Participant-coordinator interface
Coordinator-participant interface
Introduction to the Teradata RDBMS for UNIX 10-13

Concurrency Control and RecoveryTwo-Phase Commit
The following table explains the functions of the various interfaces illustrated by the diagram.
Limitations on Number of Sessions 10
The number of sessions supported with 2PC varies by application development tool as detailed in the following table.
Interface Function
Application-participant Requests 2PC sessions.
Coordinator-participant 2PC protocol. Handles vote requests and abort and commit messages.
Participant-coordinator Manages communications from participant to coordinator including responses to requests for session information.
Application-coordinator Initiates commit requests.
Application Development Tool Number of Sessions Supported
CLI Version 2 Multiple
Preprocessor2 One
10-14 Introduction to the Teradata RDBMS for UNIX

Concurrency Control and RecoveryTwo-Phase Commit
Two-Phase Commit Processing 10
The following picture illustrates 2PC processing as a function of time.
Figure 10-3 10Two-phase Commit Processing as a Function of Time
Participant
Coordinator
Transaction in doubt
Participant possiblyin doubt
FG11A003
{{
Phase1 Phase 2
time
Vot
e R
eque
st
Vot
e
Com
mit
Con
firm
End
Introduction to the Teradata RDBMS for UNIX 10-15

Concurrency Control and RecoveryFor More Information
For More Information 10
For more information on the topics presented in this chapter, see the following Teradata manuals.
IF you want to learn more about . . . THEN see this manual . . .
Specifying transactions in an embedded SQL program
Teradata RDBMS for UNIX SQL ReferenceTeradata Application Programming With Embedded SQL for C, COBOL, and PL/I
Two-phase commit Teradata RDBMS for UNIX Database Design and AdministrationTeradata TDP ReferenceTeradata Client for MVS Installation Guide
Transaction processing in general Teradata RDBMS for UNIX Database Design and Administration
10-16 Introduction to the Teradata RDBMS for UNIX

Security and Integrity
Introduction to the Teradata RDBMS for UNIX
Chapter 11
Security and Integrity

Security and Integrity
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 11
-1About This ChapterSecurity and Integrity11
About This Chapter 11
Introduction 11
This chapter describes security and integrity for the Teradata RDBMS.
Among the topics described are:
● Establishing a security policy● Client password security● Server password security● Teradata SQL Data Control Language commands for granting
and revoking privileges
The descriptions include both client and server security and Teradata RDBMS user privileges
The Teradata RDBMS provides DoD C2 level security.
Definition of Security 11
Security is a mechanism that protects the database against unauthorized users.
Definition of Integrity 11
Integrity ensure that the things that users do are correct. In other words, integrity protects the database against authorized users doing the wrong things.
Tools for Enforcing System Security 11
There are four categories of solutions for system security.
These are:
Category Description
Resource access control software-enforced access restrictions
Physical access control physical access restrictions
Auditing and accountability system auditing of security-related user actions
Policy a sound, well-enforced data center security policy

Security and IntegrityAbout This Chapter
Tools for Enforcing System Integrity 11
Release 2.0 of the Teradata RDBMS for UNIX provides support for referential integrity. Users may also provide their own facilities for policing referential integrity in the Teradata RDBMS.
To do this, write macros that enforce the referential integrity of each table in your system that contains fields that act as foreign keys.
Read Chapter 3, “The Relational Model,” for more information about referential integrity.
11-2 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityResource Access Control
Resource Access Control 11
Introduction 11
This topic introduces the Teradata software tools you can use to enforce access restrictions.
These include:
● User identifiers (user names)● Channel or LAN identifiers (host, or client identifiers)● Logon policies● TDP user security interface● Client security
User Identifiers 11
Teradata access control is based on a user identifier. The security administrator can optionally enforce a channel- or LAN-client identifier as well.
A user name is the name defined in a CREATE USER statement. The security administrator must perform one CREATE USER statement for each authorized user in order to establish the user name, define its password, and allocate user disk space.
User names and database names are stored in the DBase table, which resides in the space allocated to a system user named DBC. You can retrieve information about user names from the DBC.DBase table by querying the system view named DBC.Users.
Client Identifiers 11
Any number of different client types can connect to the Teradata RDBMS server. Each connection must have its own unique client identifier.
Each connection is assigned a unique value that is defined to the Teradata RDBMS using the Config utility. Each defined value is used as a client identifier, or hostid.
Logon Policies 11
Users must issue a logon request so the Teradata RDBMS can identify the user and establish a session. The logon string must include a user name that has already been established in the system in DBase.
The logon string may also include any combination of the following operands:
● tdpid● password● acctid
Introduction to the Teradata RDBMS for UNIX 11-3

Security and IntegrityResource Access Control
The following table outlines the meanings of these terms.
These items are described in more detail in the following pages.
Operand Definition
tdpid Each copy of the TDP on a given client is assigned a unique tdpid to identify it. The tdpid is a client-based operand and is not transmitted to the Teradata RDBMS.
password A password authenticates a user request to initiate a Teradata session under the supplied user name.
Use the CREATE USER statement to establish a password for a user. The default is that the password must appear in the user logon string.
The security administrator can establish the ability to log on without a password by setting up the following conditions:● There must be a current GRANT LOGON statement
containing the WITH NULL PASSWORD option for the user.
● The TDP security user exit TDPLGUX must acknowledge that the logon string is valid without a password (IBM mainframe clients only)
The security user exit is expected to authenticate the identify of a user.
Because the null password applies only to logging onto the Teradata RDBMS, all other system security measures continue to be enforced.
acctid The account id can be used for resource accounting.
Each user name may have one or more acctids.
The logon processor assigns a default value for the acctid if it detects none in the logon string for a user.
The acctid can also contain a priority-level prefix that can be used when interactive users are competing for system resources with long-running batch jobs.
11-4 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityResource Access Control
TDP Security 11
IBM mainframe clients running either MVS or VM have the option of enforcing security at the TDP level using tdpids.
The TDP provides a user logon exit called TDPLGUX which you can embed in a user-written routine to process logon requests. Using TDPLGUX, you can reject, accept, provide, or modify any logon request to the Teradata RDBMS.
TDPLGUX also permits users to set any of the following options:
● No logon string (implicit logon)● A user id that the user routine provides a password for● A user id that can be validated as not requiring a password.
TDPGLUX can be used by itself or in conjunction with any security package such as:
● RACF● CA-ACF2● CA-TOP SECRET
Password Security 11
Besides the existence of passwords, you can also use a number of add on features to enhance Teradata RDBMS security.
The following table lists and describes these features.
Password features for the Teradata RDBMS are stored in the DBC.SysSecDefaults table in the Data Dictionary.
Password Feature Description
Expiration Defines a time span during which the password is valid. After that duration, the user must change passwords.
Number of characters/digits/special characters
Restricts the number of characters, digits, or special characters permitted in a password.
Maximum logon attempts Defines the sequential number of erroneous logon attempts permitted before locking the user from further attempts.
Lockout time Sets the time duration of the user lock after the user has exceeded the maximum number of erroneous logon attempts.
Reuse Defines the time span that must elapse before a previously used password can be reassigned to the same user.
Introduction to the Teradata RDBMS for UNIX 11-5

Security and IntegrityResource Access Control
DBC.SysSecDefaults 11
The DBC.SysSecDefaults table stores password information for the Teradata RDBMS.
Any of the following cause errors if you attempt to perform them:
● Specify a negative value in:● ExpirePassword● MaxLogonAttempts● LockedUserExpire● PasswordReuse
● Specify a value for PasswordMaxChar that is less than the value for PasswordMinChar.
● Type a character other than Y or N in one of these columns:● PasswordDigits● PasswordSpecChar
Any of these events causes the Teradata RDBMS to generate an error message for the event log during startup and replace the value with the system default for the corresponding column.
11-6 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityResource Access Control
The following table lists and describes the columns in DBC.SysSecDefaults.
Password Encryption 11
Teradata passwords are encrypted.
The encrypted information is stored in the PasswordString field of the DBC.DBase table.
Column Name Description
ExpirePassword Number of days to elapse before the password expires.
0 indicates no expiration.
PasswordMinChar Minimum number of characters in a valid password.
PasswordMaxChar Maximum number of characters in a valid password.
PasswordMaxChar must be equal to or greater than PasswordMinChar.
PasswordDigits Indicates if digits are allowed in a password.
Y = allow digits (except as first character)N = do not allow digits
PasswordSpecChar Indicates if special characters are allowed in a password.
Y = allow special charactersN = do not allow special characters
MaxLogonAttempts Number of erroneous logons allowed before locking the user.
0 indicates no locks.
LockedUserExpire Number of minutes to elapse before unlocking a locked user.
0 indicates immediate unlock.
PasswordReuse Number of days to elapse before a user can reuse a password.
0 indicates immediate reuse.
Introduction to the Teradata RDBMS for UNIX 11-7

Security and IntegrityResource Access Control
Logon Control Using GRANT and REVOKE LOGON 11
Because of the Teradata Shared Information Architecture, the RDBMS can be connected to multiple clients simultaneously.
The system default is to grant logon permission to all users from all connections. The RDBMS provides tools for restricting logons from specific clients. The statements GRANT LOGON and REVOKE LOGON provide the capability of associating specific user names with specific client (host) ids.
You can only grant logons using GRANT LOGON if the user is already created in the Teradata RDBMS and if the client (host) id corresponds to a value assigned to a LAN or channel connection by the Teradata RDBMS.
The following table shows the four possible permissions you can allot using GRANT LOGON.
You can retract the privileges awarded by a GRANT LOGON statement by using the REVOKE LOGON statement.
Controlling Data Access by Granting or Revoking Access 11
The first level of access to the Teradata RDBMS is at the level of the user and the database. The concepts of user and database are described in Chapter 12, “System Administration,”and are not reviewed here.
This topic discusses explicit access rights as controlled by the GRANT and REVOKE statements. These statements award or remove from a user or group of users one or more privileges on a database, user, table, view, or macro.
You must be an owner of the object being controlled or must have GRANT/REVOKE privileges on it before you can submit GRANT or REVOKE statements.
If the object is a view or macro, then the owner must also have the GRANT privilege and any other applicable privileges on the object or objects referenced by the view or macro.
GRANT LOGON Statement Clause Description
ON ALL AS DEFAULT Most general form. Grants LOGON for all clients to all users.
ON clientid AS DEFAULT Grants LOGON for a particular client to all users.
ON ALL TO username Grants LOGON for all clients to a particular user.
ON clientid TO username Most specific form. Grants LOGON to a particular user on a particular client.
11-8 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityResource Access Control
You cannot grant more privileges on an object than you have yourself on that object.
Privileges are any of the following:
When a user explicitly grants privileges to another user or database, certain rules determine whether, how, and on what object the requested privilege is implemented.
The following table lists these restrictions.
CHECKPOINT DROP DATABASE INSERT
CREATE DATABASE DROP MACRO MACRO
CREATE MACRO DROP TABLE REFERENCES
CREATE TABLE DROP USER RESTORE
CREATE USER DROP VIEW SELECT
CREATE VIEW DUMP TABLE
DATABASE EXECUTE UPDATE
DELETE INDEX USER
VIEW
Privilege Database or User Table, View, Macro
CREATE DATABASECREATE USER
CREATE granted for the specified space. Not applicable.
CREATE MACROCREATE TABLECREATE VIEW
CREATE granted for the object type for the specified space.
Not applicable.
DROP DATABASEDROP USER
DROP granted for the specified space. Not applicable
● DROP MACRO● DROP TABLE● DROP VIEW
DROP granted for the object type for the specified space.
DROP granted for the specified macro, table, or view.
● DATABASE● USER
CREATE and DROP granted for the specified space.
Not applicable.
● MACRO● VIEW● TABLE
CREATE and DROP granted for the object type for the specified space.
Not applicable.
Introduction to the Teradata RDBMS for UNIX 11-9

Security and IntegrityResource Access Control
● DELETE● INSERT● SELECT● UPDATE
Privilege applies to all tables or views in the specified database.
For the grantee to use the granted rights on a view, the owner of the view must have appropriate privileges on the underlying table or tables or view or views of the view.
Privilege applies only to the specified table or view.
The owner of the view must have appropriate privileges on the underlying table or tables or view or views of the view.
● EXECUTE Privilege applies to all macros in the specified database.
For the grantee to use the privilege on a macro, the owner of the macro must also have appropriate privileges on the objects referenced by that macro.
Privilege applies to the specified macro only.
The owner of the macro must have the appropriate privileges on the objects referenced by the macro.
ALL All privileges granted except:● GRANT and MONITOR privileges● ABORT SESSION MONITOR
RESOURCE● MONITOR SESSION● SET SESSION RATE● SET RESOURCE RATE
Grants EXECUTE and DROP on a macro.
Grants:● DROP● DELETE● INSERT● SELECT● UPDATE● RESTORE● DUMP on a data table.
Grants:● DROP● DELETE,● INSERT● SELECT● UPDATE on a view.
Grants:● INSERT● DUMP● RESTORE● CHECKPOINTon a journal table.
Privilege Database or User Table, View, Macro
11-10 Introduction to the Teradata RDBMS for UNIX
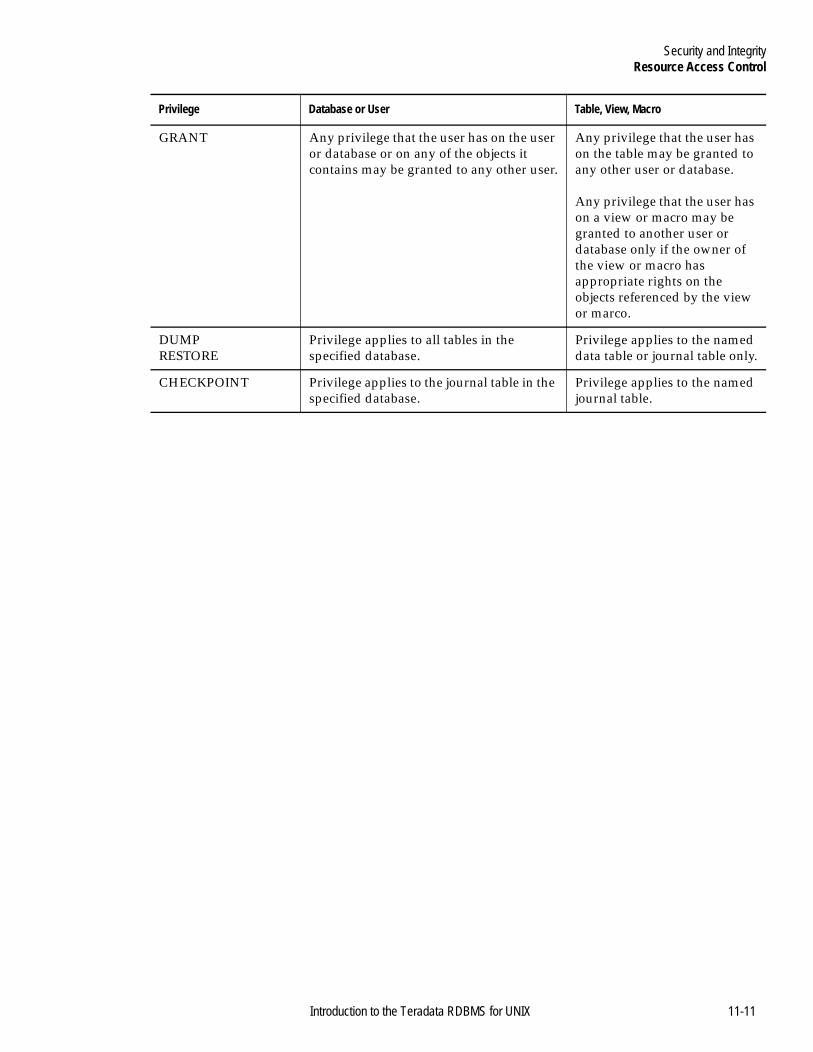
Security and IntegrityResource Access Control
GRANT Any privilege that the user has on the user or database or on any of the objects it contains may be granted to any other user.
Any privilege that the user has on the table may be granted to any other user or database.
Any privilege that the user has on a view or macro may be granted to another user or database only if the owner of the view or macro has appropriate rights on the objects referenced by the view or marco.
DUMPRESTORE
Privilege applies to all tables in the specified database.
Privilege applies to the named data table or journal table only.
CHECKPOINT Privilege applies to the journal table in the specified database.
Privilege applies to the named journal table.
Privilege Database or User Table, View, Macro
Introduction to the Teradata RDBMS for UNIX 11-11

Security and IntegrityEstablishing a Security Policy and Physical Access Control
Establishing a Security Policy and Physical Access Control 11
Introduction 11
This topic introduces the methods you can use to ensure physical access to your Teradata RDBMS and the hardware on which it runs.
Key Ingredients of a Security Policy 11
The security policy for your Teradata RDBMS should include two essential implementation elements:
● System-enforced security features● Personnel-enforced security features
You should write a set of security policies and procedures to be distributed to all users of the system. Among the topics you should cover in this document are:
● Why security is needed● Benefits of the security policy for the users and for the company● Suggested security actions for users to follow● Required security actions for users to follow
Establishing a Security Policy 11
The primary consideration for physical access control is establishing a security policy.
The security policy is based on two principal elements:
● Identification of security needs● Identification of policies and procedures to meet those needs.
11-12 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityEstablishing a Security Policy and Physical Access Control
Identifying Security Needs11
The following table illustrates a process flow for identifying security needs.
The Teradata RDBMS Security Administration Guide contains a wealth of suggestions for establishing a security policy for your Teradata RDBMS.
Controlling Physical Access 11
Physical access includes issues such as protecting the system and its components against deliberate damage and protecting the system console or Administration Workstation (multinode systems only) from unauthorized access.
The simplest way to accomplish this is to restrict access to your data center machine room. This means:
● Restricting machine room access to authorized personnel only or to escorted guests
● Maintaining a log of all escorted visitors● In the case of unescorted visitors,
● Logging off any administrative users● Turning off the entire system
● Screening non-operations personnel who require long term access to the machine room as if they were prospective operations staff employees.
● Reviewing the list of authorized personnel and updating it regularly
● Instructing the operations staff to challenge any unauthorized personnel they encounter in the machine room
● Storing any media containing sensitive data in a secure area
The Teradata RDBMS Security Administration Guide contains many other guidelines for controlling physical access to your Teradata RDBMS.
Stage Process
1 Identify the business importance of the data and its associated processing system.
2 Assign a security priority to the data based on the business case evaluation.
3 Identify the class of users who require access to the Teradata RDBMS and the date under its control.
4 Identify the system resources that require protection to ensure continued availability to all Teradata RDBMS users.
Introduction to the Teradata RDBMS for UNIX 11-13

Security and IntegrityAuditing and Accountability
Auditing and Accountability 11
Introduction 11
This topic introduces the tools you can use to audit and account for activity on your Teradata RDBMS.
System Views 11
The Teradata RDBMS supplies numerous system views for accessing information in the Data Dictionary/Directory. Logs are initiated and terminated with the BEGIN LOGGING and END LOGGING Teradata SQL statements.
The following table illustrates system views that provide information about users and access rights and grant, logon, and access activities.
View Name Description
DBC.AccessLog Records privilege checks performed against a Teradata SQL request based on the criterion defined in a BEGIN LOGGING statement.
DBC.AccLogRules Logs entries as the result of executing BEGIN LOGGING and END LOGGING statements.Used by the system to determine which privilege checks should result in entries being generated in the DBC.AccLogTbl table.
DBC.AllRights Provides information about all users who have been automatically or explicitly granted privileges and the objects on which those privileges were granted.
DBC.DeleteAccessLog Used as the parameter of a Teradata SQL DELETE statement to remove access log row entries older than 30 days.
DBC.LogOnOff Records logon and logoff activity, the associated session number, and attempted logon events. Event data indicates why a logon attempt was unsuccessful.
DBC.LogonRules Stores entries as a result of GRANT LOGON and REVOKE LOGON statements. Used by the system to determine whether to allow or prevent system access.
DBC.Users Extracts information about the user submitting the request and all users owned by that user.
11-14 Introduction to the Teradata RDBMS for UNIX

Security and IntegrityFor More Information
For More Information 11
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
System administration in general Teradata RDBMS for UNIX Database Design and Administration
Security and security administration
Teradata RDBMS for UNIX Security Administration Guide
Client (TDP) security Teradata TDP Reference
Introduction to the Teradata RDBMS for UNIX 11-15

Security and IntegrityFor More Information
11-16 Introduction to the Teradata RDBMS for UNIX

System Administration
Introduction to the Teradata RDBMS for UNIX
Chapter 12
System Administration

System Administration
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 12
-1About This ChapterSystem Administration12
About This Chapter 12
Introduction 12
This chapter covers topics relating to space allocation, accounting, diagnostics and maintenance, and monitoring.
The topics of security and the Data Dictionary are far ranging enough to justify their own chapters. For that reason, those system administration topics are discussed elsewhere in this manual (see Chapter 7, “Data Dictionary,” and Chapter 11, “Security and Integrity”).
Space Allocation 12
Space allocation for the Teradata RDBMS relates not only to the disk space required for databases, but to the space required to define users as well.
Accounting 12
The broad topic of accounting for the Teradata RDBMS includes all of the following subtopics:
● Users and accounts● Client accounting● Server accounting
Monitoring 12
This topic discusses various aspects of monitoring the Teradata RDBMS, including the facilities for performance monitoring.

System AdministrationSpace Allocation: Databases and Users
Space Allocation: Databases and Users 12
Introduction 12
In a Teradata RDBMS, a database is a collection of related tables, views, and macros.
A database also contains an allotment of space from which users can create and maintain their own tables, views, macros, or other users or databases.
A database and a user are almost the same thing in the Teradata RDBMS, the only difference being that a user can log on to the system while a database cannot. A user identifies both someone who can log onto the system and a database.
Creating Databases and Users 12
When the Teradata RDBMS is first installed on a server, there is only one user on the system. Its name is DBC.
This user typically is managed by a database administrator who assigns space from DBC to all other organizations. DBC owns all other databases and users in the system.
To protect the security of system tables within the Teradata RDBMS, the database administrator typically creates a RDBMS administrator user from DBC. The usual procedure is to assign all RDBMS disk space not needed for system tables to the new administrator database.
The database administrator then uses this database as a resource from which to allocate space to the databases and users of the system.
Scenario: Creating Finance and Administration Databases 12
Consider the following scenario: the database administrator needs to create a Finance and Administration (F&A) department database with user Jones as a supervisory user, or database administrator (DBA) within the F&A department.
The Teradata RDBMS database administrator first creates the F&A database, then allocates space from it to Jones to act as the F&A DBA. The Teradata RDBMS DBA also allocates space from F&A to Jones for his personal use and to create a Personnel database and other databases and user space allocations.
Note that when you create a new database or allot space to a user, the system assigns disk space from the space belonging to an existing database or user. The creating database (or user) is the owner of the new database (or user space).
12-2 Introduction to the Teradata RDBMS for UNIX
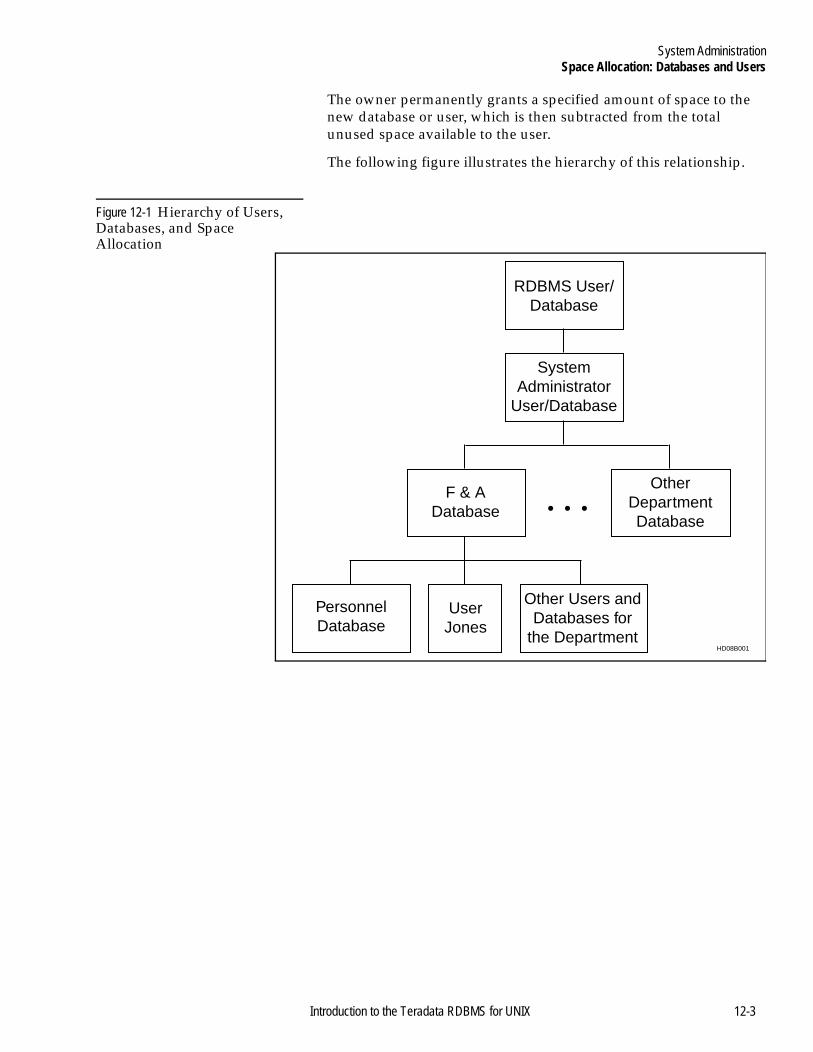
System AdministrationSpace Allocation: Databases and Users
The owner permanently grants a specified amount of space to the new database or user, which is then subtracted from the total unused space available to the user.
The following figure illustrates the hierarchy of this relationship.
Figure 12-1 Hierarchy of Users, Databases, and Space Allocation
HD08B001
RDBMS User/Database
SystemAdministrator
User/Database
OtherDepartmentDatabase
F & ADatabase
Other Users andDatabases for
the Department
UserJones
PersonnelDatabase
• • •
Introduction to the Teradata RDBMS for UNIX 12-3

System AdministrationSpace Allocation: Databases and Users
The F&A Database owns Personnel and all the other department databases. F&A also owns user Jones and all other users within the department. Because the user DBC ultimately owns all other databases and users, it is the final owner of all the databases and user space belonging to the organization.
This hierarchical ownership structure provides the owner of a database or user space with complete control over the security of owned data. The owner can archive the database or can control access to it by granting or revoking privileges on it. For more information on granting and revoking access privileges, see Chapter 11, “Security and Integrity.”
Creating Databases 12
The previous section explained the concept of databases and users in the Teradata RDBMS environment. This section explains how to create a database from DBC. Before you can create tables, views, users, or macros, you must first create a database. The SQL statement for creating a database is CREATE DATABASE.
Suppose you wanted to create the Personnel database for the Employee and Department tables. The SQL to create the Personnel database looks like this:
CREATE DATABASE PersonnelFROM F&AAS PERMANENT = 10000000 BYTES,
SPOOL = 100000000 BYTESFALLBACK,ACCOUNT = ‘Administration’;
12-4 Introduction to the Teradata RDBMS for UNIX

System AdministrationSpace Allocation: Databases and Users
The explanation for the components of this statement are as follows.
Component Description
AS Introduces a clause that specifies one or more database parameters.
FROM Introduces an owner database whose disk space is allocated to create the new database.
IF . . . THEN . . .
you do not specify an owner database
disk space allocation comes from the database of the user entering the statement.
you specify an owner database
you must either have the CREATE DATABASE privilege on that database or be its owner.
PERMANENT Specifies the allocation of disk space to the new database.
SPOOL Specifies a space limit for spool files, which are temporary files used to store the interim results of a Teradata SQL statement until they can be examined by a user or application program.
IF . . . THEN . . .
you do not specify the SPOOL parameter
the system allocates spool space from the owner database.
FALLBACK Specifies that, in addition to the primary copy of the rows of all database tables, a secondary (fallback) copy is to be distributed among the disks of all AMPs in the RDBMS.FALLBACK is the default value.
ACCOUNT Identifies the department or budget responsible for accumulated disk space used by the new database. This information is used for accounting purposes only.
IF . . . THEN . . .
you do not specify an account name
the system uses the account name of the owner database.
Introduction to the Teradata RDBMS for UNIX 12-5

System AdministrationSpace Allocation: Databases and Users
Creating Users 12
This section explains how to create a user.
The SQL statement for creating a user is CREATE USER. The statement authorizes a new user identification (user name) for the RDBMS and specifies a password for user authentication. Because the system creates a database for each user, the CREATE USER statement is very similar to the CREATE DATABASE statement.
The SQL to create user Jones in the F&A database looks like this:
CREATE USER JonesFROM F&AAS PERMANENT = 1000000 BYTES,
SPOOL = 1000000 BYTESPASSWORD = Jan,FALLBACK,ACCOUNT = ‘Administration’STARTUP = ‘DATABASE F&A;’;
The optional STARTUP clause specifies one or more Teradata SQL statements that the system can execute automatically when the user establishes a session. Any user who performs this statement must have a CREATE USER privilege on the owner database or be its owner.
The system automatically grants the new user all privileges on tables, views, and macros created in this space.
12-6 Introduction to the Teradata RDBMS for UNIX

System AdministrationAccounting
Accounting 12
Introduction 12
This topic introduces the accounting options available for the Teradata RDBMS.
Among the areas covered are:
● Session management● Account usage and security violation logging
Introduction to the Teradata RDBMS for UNIX 12-7

System AdministrationSession Management
Session Management 12
Introduction 12
Before any accounting can occur, a user must be logged onto the Teradata RDBMS.
To do this, a user must establish a session.
Establishing a Session 12
To establish a session, the user logs on to the RDBMS.
The procedure varies depending on the client system, the operating system, and whether the user is an application programmer or a user in an interactive terminal session using BTEQ or a third party query processing product.
Logon Parameters 12
Logon parameters can include any of the following:
● Optional identifier for the RDBMS, called a tdpid● User name● Password● Optional account number.
Session Requests 12
A session is established once the RDBMS accepts the user name, password, and account number and returns a session number to the process.
Subsequent Teradata SQL requests generated by the user and responses returned from the RDBMS are identified by:
● Host id● Session number● Request number.
The context for the session also includes a default database name which is the same as the user name.
When the session ends, the system discards the context and accepts no further Teradata SQL statements from the user.
12-8 Introduction to the Teradata RDBMS for UNIX

System AdministrationAccount Usage
Account Usage 12
Introduction 12
Most account usage information is best gathered by the client system.
You can use client-provided facilities to gather information about RDBMS use by accounts by recording logon/logoff activity.
You can also use client-provided solutions to capture attempted security violations.
The principal Teradata RDBMS feature for accounting is the optional Account String Expansion (ASE) capability.
Account String Expansion 12
ASE permits you to use substitution variables to include date and time information in the account ID portion of a user logon string. The system inserts actual values for the variables at Teradata SQL execution time.
ASE permits more accurate measurement of individual Teradata SQL statement execution, more precise statistics, more accurate capacity planning, and more information for chargeback and accounting software.
Substitution Variables for ASE 12
The following table describes the substitution variables for ASE.
Example 12
An example of how to use the ASE substitution variables might be the following, where the ASE variables are appended to a typical BTEQ logon string:
&D&TacctXYZ
At Teradata SQL execution time, the system replaces &D with the current date and replaces &T with the current time.
For each account string in effect, the system collects and stores a set of statistics as a row in the Data Dictionary in a table called DBC.AMPUsage.
Substitution Variable Description Format
&D Date YYMMDD
&T Time HHMMSS
&H Hour HH
&L Logon timestamp YYMMDDHHMMSS.hh
Introduction to the Teradata RDBMS for UNIX 12-9

System AdministrationAccount Usage
ASE can generate a summary row for each of the following:
● Teradata SQL request● User● Session● Aggregation of daily activity for a user
You can specify collection rates for statistics based on the date and time of the request or by the time the user logs on.
Account Performance Groups 12
Performance groups are a mechanism to allow system resources to be distributed among sessions predictably.
When an account id prefixed with a group code is provided in a LOGON string, the session is assigned to the associated performance group when the logon is successful.
If this form of account id is not present, the session is assigned a default value corresponding to the group specified by $M.
Each session is assigned, either explicitly or implicitly, to a performance group, and each performance group is assigned a proportional resource weight.
The Fair Share Scheduler manages the workload based on the relative priority of each group’s resource weight.
This weight does not guarantee system responsiveness in a corresponding proportion because responsiveness is a function of overall system activity.
Codes and their associated group names are listed in the following table.
CodePerformance
GroupDescription of Resources Allocated
$L Low Half the computed resource allocated to a $M session.
$M Medium Default.
$H High Twice the computed resource allocated to a $M session.
$R Rush Four times the computed resource allocated to a $M session.
Should be used only for administrative and supervisory users.
12-10 Introduction to the Teradata RDBMS for UNIX

System AdministrationMonitoring
Monitoring 12
Introduction 12
This topic discusses how the Teradata RDBMS monitors aspects of the system such as:
● System states● Resource usage● Performance
Teradata Manager 12
The Teradata Manager is a production and performance monitoring system used to monitor, control, and administer one of more Teradata servers.
The Teradata Manager provides a variety of tools and applications to gather, manipulate, and analyze information about the RDBMS on which you are working.
From a single platform, you can query, manipulate, and analyze the information your need.
Introduction to the Teradata RDBMS for UNIX 12-11
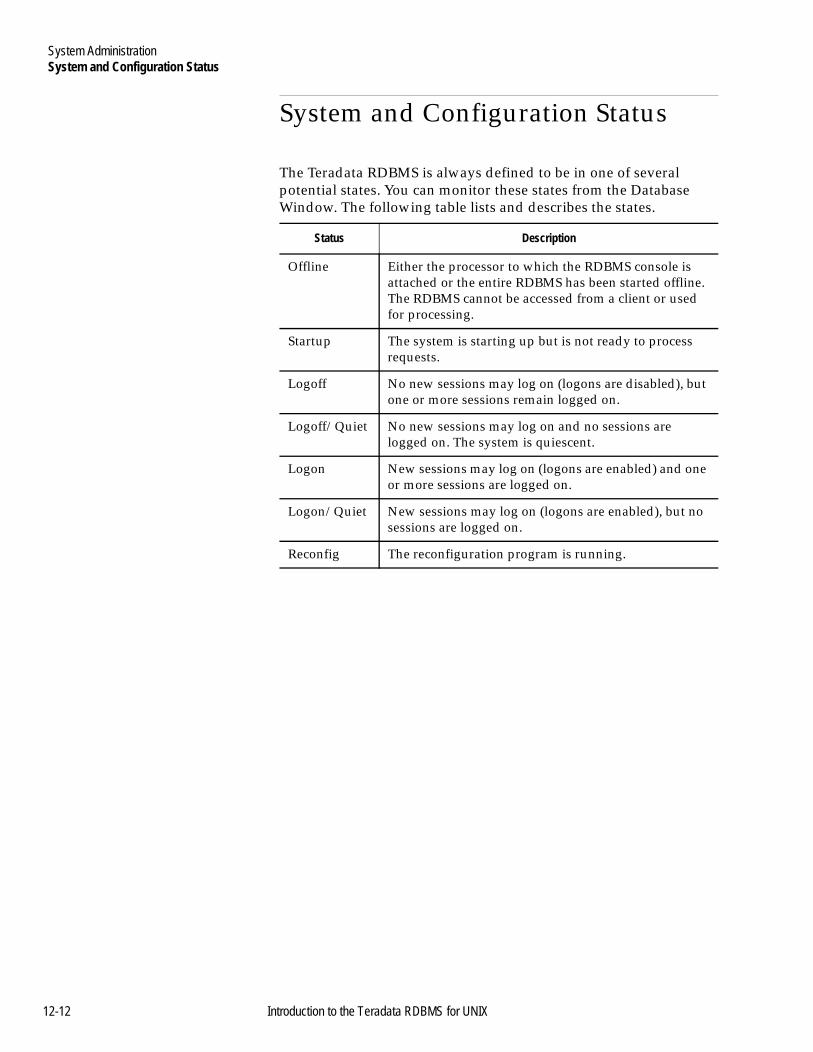
System AdministrationSystem and Configuration Status
System and Configuration Status 12
The Teradata RDBMS is always defined to be in one of several potential states. You can monitor these states from the Database Window. The following table lists and describes the states.
Status Description
Offline Either the processor to which the RDBMS console is attached or the entire RDBMS has been started offline.The RDBMS cannot be accessed from a client or used for processing.
Startup The system is starting up but is not ready to process requests.
Logoff No new sessions may log on (logons are disabled), but one or more sessions remain logged on.
Logoff/Quiet No new sessions may log on and no sessions are logged on. The system is quiescent.
Logon New sessions may log on (logons are enabled) and one or more sessions are logged on.
Logon/Quiet New sessions may log on (logons are enabled), but no sessions are logged on.
Reconfig The reconfiguration program is running.
12-12 Introduction to the Teradata RDBMS for UNIX

System AdministrationResource Usage
Resource Usage 12
Introduction 12
The Teradata RDBMS has facilities that permit you to monitor the use of resources such as:
● CPUs● AMPs● Disk activity● BYNET/Vnet activity
ResUsage Data 12
Resource usage (ResUsage) data handling for the Teradata RDBMS is divided into two phases:
The logged ResUsage data is then available for analysis by the various ResUsage macros.
ResUsage Macros 12
The facilities for analyzing resource usage data are provided by means of a set of ResUsage macros tailored to retrieving information from a set of system views designed to collect and present resource usage information.
These views use a base table called DBC.ResUsage for their information source.
ResUsage Data Categories 12
Each row of ResUsage data contains two broad categories of information:
● Housekeeping, containing identifying information● Statistical
Step Action
1 Various subsystems gather ResUsage data and the Resource Sampling Subsystem (RSS) collects the data into collect buffers.
2 The collected data is logged to ResUsage tables periodically (as determined by user-defined logging intervals).
Introduction to the Teradata RDBMS for UNIX 12-13

System AdministrationResource Usage
Each item of statistical data falls into a defined kind and class. Each kind corresponds to one (or several) different things that may be measured about a resource.
Classes correspond to the different statistical attributes of a piece of data. Defined classes are:
ResUsage Data in Summarization Mode 12
You can activate summarization mode for many ResUsage tables independently.
Summarization mode reduces database I/O by summarizing data from multiple vprocs and other objects on each node in one representative row.
This kind of measured data . . . Is defined as . . .
track a logical metric that provides the current value of some measurement.
tmon how much time was recorded in some specific state or for some specific activity during the measured logging period.
count a tally of occurrences of some event or a measurement of some resource usage during the logging period.
countshft a special case of count data in which the data is gathered in a specific bit size and then is shifted to a larger grain by some conversion program.
Class name Definition
cnt A simple measure of kind:● tmon● count● countshft
cur A current value of kind track
max A maximum value of kind:● track● tmon
min A minimum value of kind:● track● tmon
avg An average value of kind:● count● tmon
12-14 Introduction to the Teradata RDBMS for UNIX

System AdministrationResource Usage
This summarization reduces detail, but is very useful for exploratory data analysis of performance problems and general resource usage issues.
When summary mode is active, the different data classes are summarized as represented by the following table:
ResUsage Column Categories 12
While it is true that some ResUsage data is for internal use only, all columns found in the ResUsage tables can be categorized as one of the following column types.
This data class . . . Contains this measure of the summarized values represented . . .
● cnt● cur● avg
Sum.
max Maximum.
min Minimum.
Column Type Description
Housekeeping Contain the following data:● Timestamp● Collection element and its characteristics● Current logging characteristics
Exclude configuration details.
Process scheduling
Contain snapshot data of work started (with current characteristics and states).
Memory Contain memory-related events, subdivided into memory types, for these categories:● Allocation and deallocation● Logical memory reads and writes● Physical disk reads and writes● Access and deaccess● Memory control● Memory management events leading up to— Paging— Swapping— Aging● Detailed memory snapshot
Introduction to the Teradata RDBMS for UNIX 12-15

System AdministrationResource Usage
Net Contain network traffic events for these categories:● Number of messages (by transmission type)● Direction of messages (by transmission type)● Physical utilization of net lines (BYNET only)● Controller overhead● Channel utilization● Net contention (BYNET only)Logical messages and direction are identified through subdivisions of the message class.
General concurrency control
Contain concurrency control activity information for the following categories:● Control performed for user-level processing● System overhead processing● Database locksDoes not include information specific to these controls, which are contained in the disk, memory, or net columns:● Disk concurrency● Memory concurrency● Net concurrency
File system Contain information for the following:● Logical memory reads and writes● Physical disk reads and writes● Locking control activitiesOther columns identify the purpose of operations performed on disk segments, such as cylinder migration and data updates.
Transient journal management
Contain information identifying the background management overhead associated with transient journal purging.
SCSI logical device driver
Contain information identifying the following for external storage components connected through the SCSI buses (statistics are minimal):● Controller activities● Channel activities● Overhead activities
SCSI logical device
Contain information identifying individual logical device activities for external storage components connected through the SCSI buses. Statistics are minimal.
Secondary cache
Contain columns identifying the secondary cache miss rate.
Column Type Description
12-16 Introduction to the Teradata RDBMS for UNIX

System AdministrationResource Usage
Controlling the Collection and Logging of ResUsage Data 12
Several mechanisms exist within the Teradata RDBMS for setting the collection and logging rates of ResUsage data. These control parameters can be set by the following means:
● xctl program● Operator console● Performance Monitor window
The control sets allow users to do any of the following:
● Enable or disable ResUsage table on a table by table basis● Specify collection and logging periods● Summarize the data or not.
You can use the statistics collected in DBC.ResUsage to analyze system bottlenecks, determining excessive swapping, and detecting system load imbalances
Collection rates control the frequency that ResUsage data is made available to applications.
Logging rates control the frequency that ResUsage data is logged to the ResUsage tables.
Blocking cross reference
Contain summary cross reference information derived from other columns. Includes data for all concurrency control and resource blocking occurring on the system.
Host controller Contain information identifying:● Traffic on host-to-node channels● Traffic on LANs● Overhead and management of the host channel
and LANs
User controller Contain information identifying commands issued by users to the RDBMS and their progress.
Database object locking
Contain information identifying both explicit and implicit lock requests held and waiting by a user on a database object.
Database object operations
Contain information identifying mode (indexed or mass access) and kind (insert, update, etc.) of access to data rows.
Column Type Description
Introduction to the Teradata RDBMS for UNIX 12-17
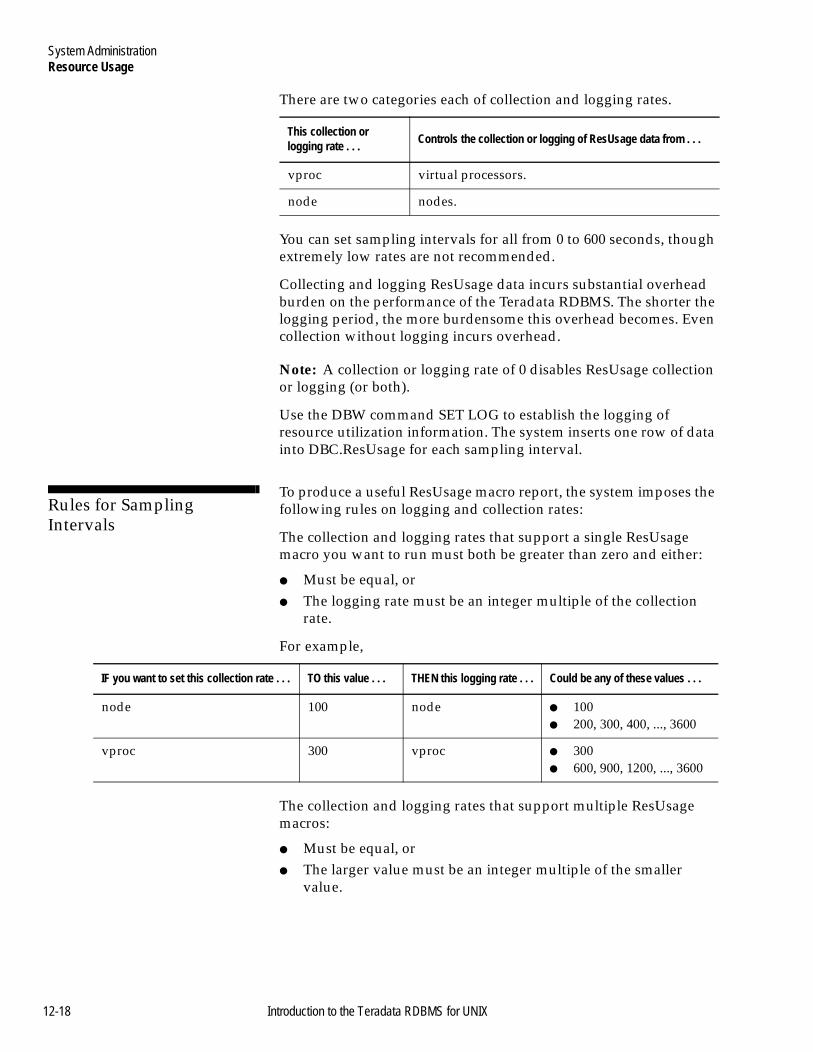
System AdministrationResource Usage
There are two categories each of collection and logging rates.
You can set sampling intervals for all from 0 to 600 seconds, though extremely low rates are not recommended.
Collecting and logging ResUsage data incurs substantial overhead burden on the performance of the Teradata RDBMS. The shorter the logging period, the more burdensome this overhead becomes. Even collection without logging incurs overhead.
Note: A collection or logging rate of 0 disables ResUsage collection or logging (or both).
Use the DBW command SET LOG to establish the logging of resource utilization information. The system inserts one row of data into DBC.ResUsage for each sampling interval.
Rules for Sampling Intervals 12
To produce a useful ResUsage macro report, the system imposes the following rules on logging and collection rates:
The collection and logging rates that support a single ResUsage macro you want to run must both be greater than zero and either:
● Must be equal, or● The logging rate must be an integer multiple of the collection
rate.
For example,
The collection and logging rates that support multiple ResUsage macros:
● Must be equal, or● The larger value must be an integer multiple of the smaller
value.
This collection or logging rate . . .
Controls the collection or logging of ResUsage data from . . .
vproc virtual processors.
node nodes.
IF you want to set this collection rate . . . TO this value . . . THEN this logging rate . . . Could be any of these values . . .
node 100 node ● 100● 200, 300, 400, ..., 3600
vproc 300 vproc ● 300● 600, 900, 1200, ..., 3600
12-18 Introduction to the Teradata RDBMS for UNIX

System AdministrationResource Usage
For example,
If you enter collection or logging rates that do not comply with these rules, the system displays a diagnostic error message but does not update the rates to valid values.
ResUsage Collection Modes 12
You can specify either normal or summary modes for inserting information into ResUsage tables.
IF you want to set this collection rate . . . TO this value . . . THEN this logging rate . . . Could be any of these values . . .
node 100 vproc ● 100● 200, 300, 400, ..., 3600● 1, 2, 4, 5, 10, ..., 50
vproc 300 node ● 300● 600, 900, 1200, ..., 3600● 1, 3, 5, 10, 12, ..., 150
In this mode . . . This many rows are inserted per log period . . . Into this table . . .
Normal 1 row/node Spma
1 row/node-SCSI combination Sctl
1 row/vproc plus 1 row/node Svpr
1 row/vproc-client combination Shst
Summary 1 row/node Spma
0 or 1 row/node Sctl
1-3 rows/node Svpr
0-2 rows/node Shst
Introduction to the Teradata RDBMS for UNIX 12-19

System AdministrationPerformance Monitoring
Performance Monitoring 12
Introduction 12
Several facilities exist for monitoring and controlling system performance. This section briefly discusses many of these facilities.
The TDPTMON 12
The TDP User Transaction Monitor (TDPTMON) is a client routine that enables a system programmer to write code to track TDP elapsed time statistics.
System Management Facility 12
The System Management Facility (SMF) is available in the MVS environment only.
This facility collects data about Teradata performance, accounting, and usage.
Data is grouped into the following categories:
● Session information● Security violations● PE stops
The PM/API 12
The Performance Monitor/Application Programming Interface (PM/API) provides hooks into server performance monitoring routines. You initiate data collection using the SET COLLECT DBW command.
12-20 Introduction to the Teradata RDBMS for UNIX

System AdministrationPerformance Monitoring
Monitoring Performance 12
The Performance Monitor (PM) utility provides support for user-developed and NCR-developed applications to monitor Teradata activity within production environments.
Access to the RDBMS from the PM is provided by a session partition named the MONITOR partition. To use the monitoring and control facilities, you log on to the RDBMS and then gain access to a MONITOR partition.
PM commands permit you to do the following:
● Examine:● Current system configuration● Global summary of system status● Activity and current status on a session-by-session basis● Resource usage on a processor-by-processor basis
● Set the system-wide rate for updating:● Session level statistics● Resource usage statistics
● Obtain the name corresponding to a given session id, user/database id, or table id
● Abort session activity and (optionally) log the specified session or sessions off
Gateway Control Utility 12
The Gateway Control Utility is a package that supports management of Teradata servers connected to a local area network. The utility provides controls for ensuring that network-attached clients do not damage or in any way modify the operating parameters of other network-attached clients.
Services offered by the utility include:
● Displaying configuration information● Displaying session status information● Displaying session debugging information● Enabling/disabling logons● Enabling/disabling session event tracing
Introduction to the Teradata RDBMS for UNIX 12-21
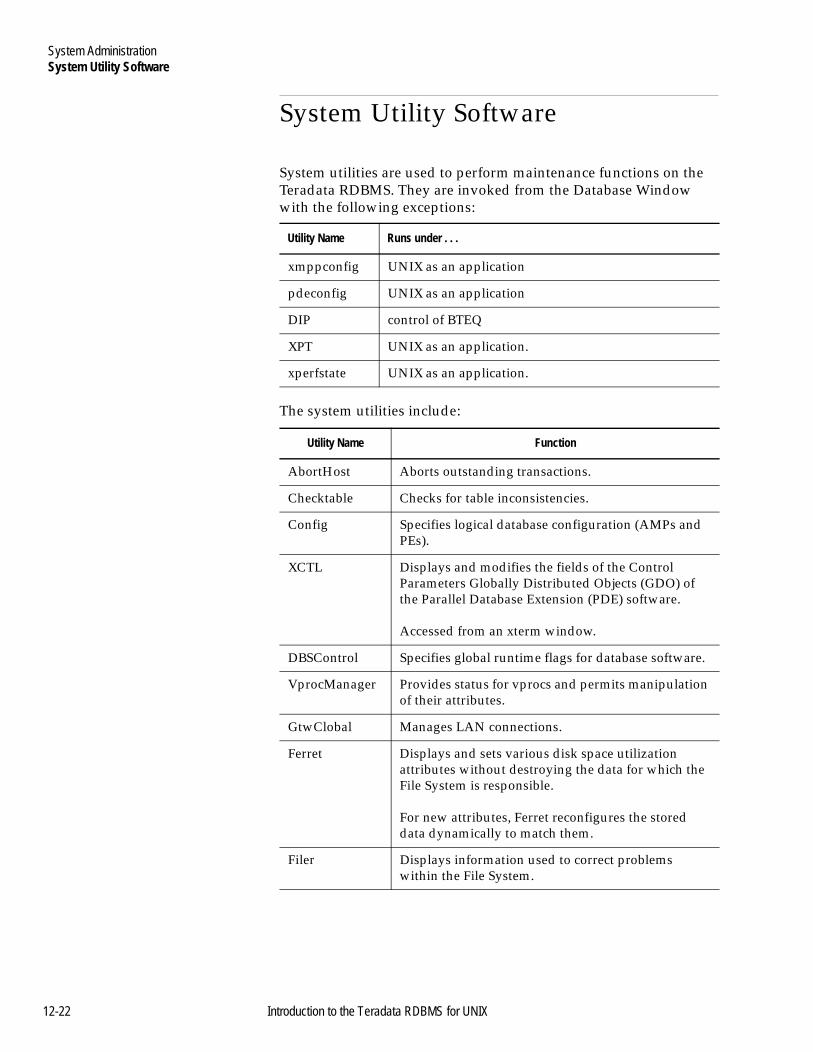
System AdministrationSystem Utility Software
System Utility Software 12
System utilities are used to perform maintenance functions on the Teradata RDBMS. They are invoked from the Database Window with the following exceptions:
The system utilities include:
Utility Name Runs under . . .
xmppconfig UNIX as an application
pdeconfig UNIX as an application
DIP control of BTEQ
XPT UNIX as an application.
xperfstate UNIX as an application.
Utility Name Function
AbortHost Aborts outstanding transactions.
Checktable Checks for table inconsistencies.
Config Specifies logical database configuration (AMPs and PEs).
XCTL Displays and modifies the fields of the Control Parameters Globally Distributed Objects (GDO) of the Parallel Database Extension (PDE) software.
Accessed from an xterm window.
DBSControl Specifies global runtime flags for database software.
VprocManager Provides status for vprocs and permits manipulation of their attributes.
GtwClobal Manages LAN connections.
Ferret Displays and sets various disk space utilization attributes without destroying the data for which the File System is responsible.
For new attributes, Ferret reconfigures the stored data dynamically to match them.
Filer Displays information used to correct problems within the File System.
12-22 Introduction to the Teradata RDBMS for UNIX
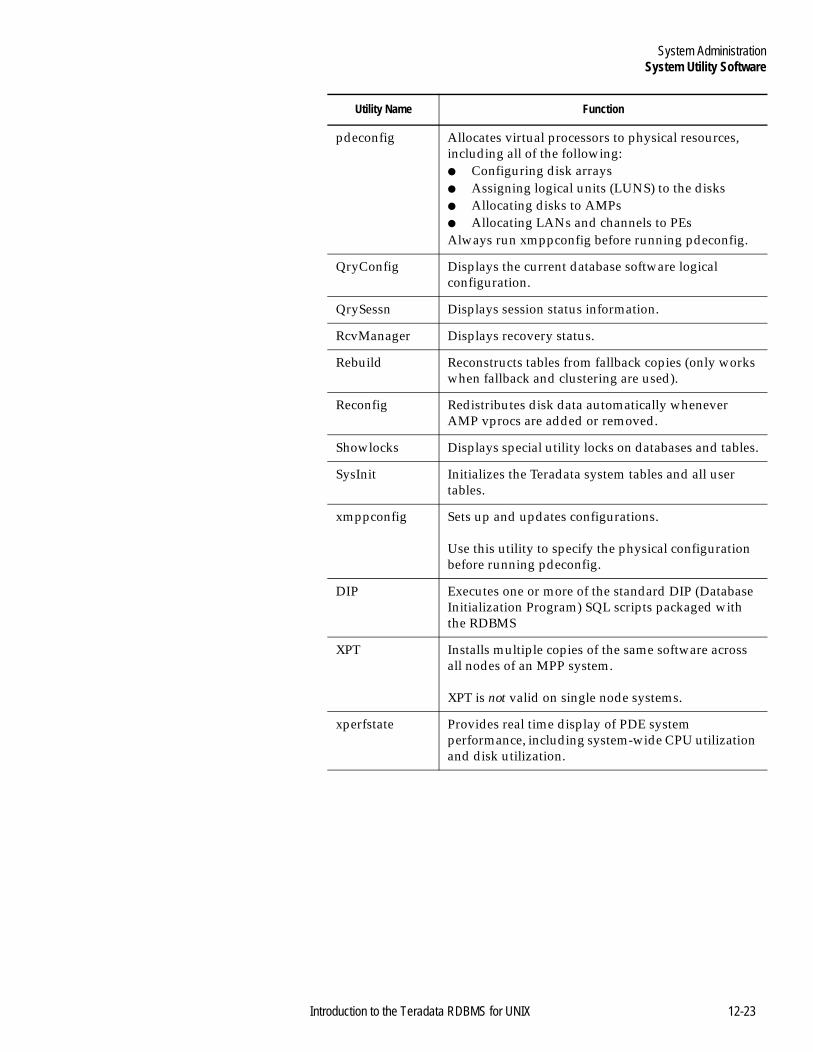
System AdministrationSystem Utility Software
pdeconfig Allocates virtual processors to physical resources, including all of the following:● Configuring disk arrays● Assigning logical units (LUNS) to the disks● Allocating disks to AMPs● Allocating LANs and channels to PEsAlways run xmppconfig before running pdeconfig.
QryConfig Displays the current database software logical configuration.
QrySessn Displays session status information.
RcvManager Displays recovery status.
Rebuild Reconstructs tables from fallback copies (only works when fallback and clustering are used).
Reconfig Redistributes disk data automatically whenever AMP vprocs are added or removed.
Showlocks Displays special utility locks on databases and tables.
SysInit Initializes the Teradata system tables and all user tables.
xmppconfig Sets up and updates configurations.
Use this utility to specify the physical configuration before running pdeconfig.
DIP Executes one or more of the standard DIP (Database Initialization Program) SQL scripts packaged with the RDBMS
XPT Installs multiple copies of the same software across all nodes of an MPP system.
XPT is not valid on single node systems.
xperfstate Provides real time display of PDE system performance, including system-wide CPU utilization and disk utilization.
Utility Name Function
Introduction to the Teradata RDBMS for UNIX 12-23

System AdministrationFor More Information
For More Information 12
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
System administration in general Teradata RDBMS for UNIX Database Design and Administration
Performance monitoring Teradata RDBMS for UNIX Resource Usage Macros and TablesTeradata RDBMS for UNIX Performance Monitor Reference
The Teradata Manager Teradata Manager for the Teradata RDBMS on UNIX User’s Guide
12-24 Introduction to the Teradata RDBMS for UNIX

Operating and Configuration Specifications
Introduction to the Teradata RDBMS for UNIX
Chapter 13
Operating and Configuration Specifications

Operating and Configuration Specifications
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX 13
-1About This ChapterOperating and Configuration Specifications13
About This Chapter 13
Introduction 13
This chapter is a compendium of operation and configuration issues you need to consider when installing and using a server that runs the Teradata RDBMS.
Topics described include:
● Performance● Database capacities● Storage capacity● Channel-attached client requirements● Network-attached client requirements

Operating and Configuration SpecificationsPerformance
Performance 13
Introduction 13
This topic describes very broad guidelines for increasing performance on your NCR System systems.
Each MPP system is certified to support as many as 32 nodes. More nodes can be added on a custom basis.
The general rule is to consult your NCR Global Information Solutions representative.
Scalability 13
The word to remember is scalability. The NCR massively parallel systems are designed to scale performance nearly linearly with increased nodes.
13-2 Introduction to the Teradata RDBMS for UNIX
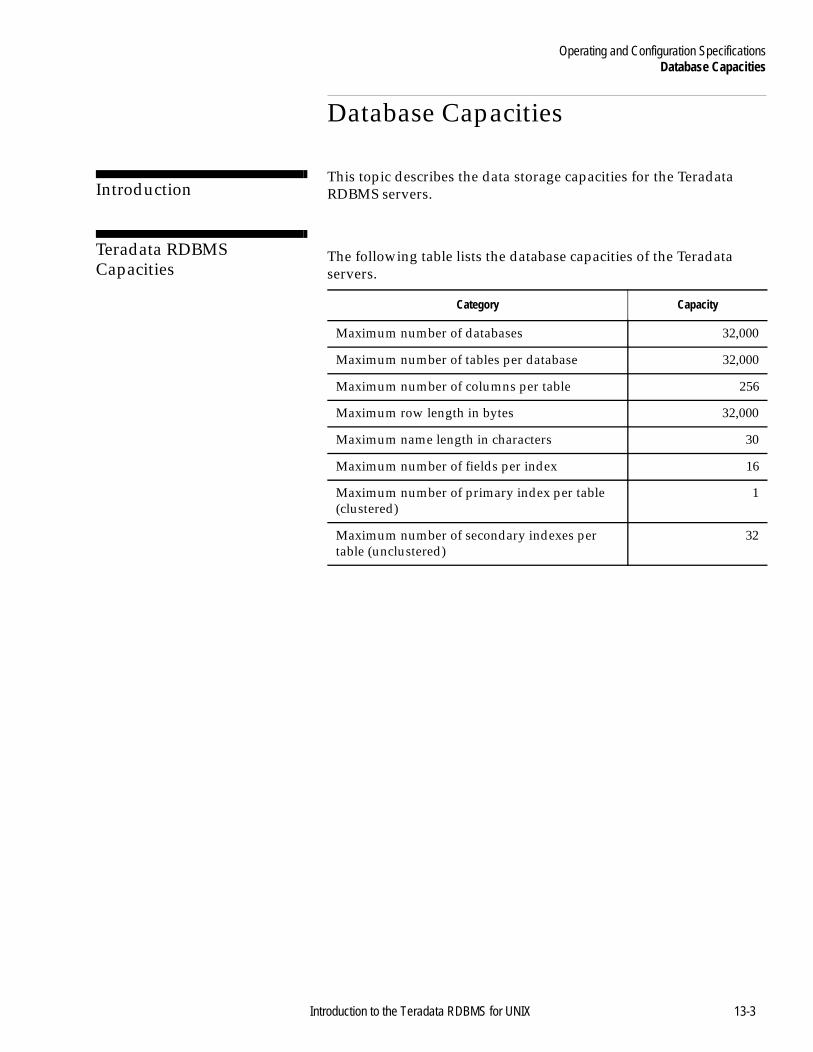
Operating and Configuration SpecificationsDatabase Capacities
Database Capacities 13
Introduction 13
This topic describes the data storage capacities for the Teradata RDBMS servers.
Teradata RDBMS Capacities 13
The following table lists the database capacities of the Teradata servers.
Category Capacity
Maximum number of databases 32,000
Maximum number of tables per database 32,000
Maximum number of columns per table 256
Maximum row length in bytes 32,000
Maximum name length in characters 30
Maximum number of fields per index 16
Maximum number of primary index per table (clustered)
1
Maximum number of secondary indexes per table (unclustered)
32
Introduction to the Teradata RDBMS for UNIX 13-3

Operating and Configuration SpecificationsIBM Channel-Attached Client Requirements
IBM Channel-Attached Client Requirements 13
Introduction 13
This topic supplies information about supported IBM mainframe clients. For information about hardware requirements for other mainframe clients, see the appropriate platform-specific documentation.
Supported Environments 13
The following table lists the hardware and software requirements for IBM and plug compatible clients to support the Teradata environment.
Mainframe Client Hardware Operating SystemsTransaction
Processing MonitorsApplication Languages
● 370/148 with DAT● 370/155 with DAT● 370/158● 370/168● 370/303X● 370/308X● 370/309X● 370/43XX● Plug compatibles
● OS/VS-MVS, Release 3.8 and above, including MVS/SP Release 1 or 2.SP Release 1.3 is required for CICS support
● MVS/XP● VM/SP Release 3
and above
● CICS 1.6 and above
● TSO● CMS
● Preprocessor2:● ANSI COBOL,
X3.23-1974● PL/I● CLI:● COBOL● FORTRAN● Pascal● PL/I● C● Assembler● any language with a
CALL statement
13-4 Introduction to the Teradata RDBMS for UNIX

Operating and Configuration SpecificationsNetwork-Attached Client Requirements
Network-Attached Client Requirements 13
Introduction 13
You can access the Teradata RDBMS through a network-attached client interface. Both hardware and software are required to make an interface from the network-attached client to the Teradata RDBMS. The interface software consists of one portion residing on the Teradata server and another portion residing on each network-attached client that is communicating with the Teradata RDBMS.
Supported Software Environments 13
The following table lists software environments supported for the Teradata RDBMS in a network-attached client environment.
NCR makes available custom ports of the Teradata client system to other platforms.
NCR Interface Software Environment
CLIent for DOS MS-DOS 3.2 or higher
Teradata Omni Access Module for Teradata RDBMS
This interface supports Sybase access to the Teradata RDBMS
UNIX SunOS 4.2xAT&T 3000 UNIX and COP interface software, Release 4.1 or higher.
NCR System 3000 CLIent interface UNIX V, Release 4
CLIent for OS/2 OS/2
CLIent for Macintosh Macintosh operating systems
WinCLI ● MS-DOS● Microsoft Windows
ODBC Driver for Teradata Database System
● Windows● Windows NT
Introduction to the Teradata RDBMS for UNIX 13-5

Operating and Configuration SpecificationsFor More Information
For More Information 13
For more information on the topics presented in this chapter, see the following Teradata RDBMS manuals.
IF you want to learn more about . . . THEN see this manual . . .
Configuration specifications Teradata RDBMS for UNIX Field Support Guide
Gateway configuration Teradata RDBMS Gateway Control Utility Reference Manual
13-6 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Introduction to the Teradata RDBMS for UNIX
Appendix A
How the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS

How the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Introduction to the Teradata RDBMS for UNIX

Introduction to the Teradata RDBMS for UNIX A
-1About This AppendixHow the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSA
About This Appendix A
The first section of this appendix discusses the major feature differences between the Teradata DBS for TOS and the Teradata RDBMS for UNIX).
A table summarizes the feature differences and references the Teradata RDBMS customer documents in which technical information for each Teradata RDBMS for UNIX feature can be found. (For the publication number of each document, please see the “Teradata RDBMS for UNIX Library” in the Preface.)

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSTeradata RDBMS for UNIX Differences
Teradata RDBMS for UNIX Differences A
The Teradata Relational Database Management System for UNIX is significantly different from previous releases of the Teradata DBS for TOS.
Open System with Less Dependence on Hardware A
The two most significant differences between the two Teradata RDBMS versions include the following:
● The Teradata DBS for TOS requires the proprietary Teradata operating system (TOS) installed on a massively parallel processing (MPP) NCR System 3600 or DBC/1012 computing platform.
With the Parallel Database Extensions (PDE) for UNIX, the Teradata RDBMS for UNIX runs on the standard UNIX operating system that comes pre-installed on the general purpose NCR server computers.
● The Teradata DBS for TOS takes advantage of a large number of special purpose hardware processors to provide unmatched parallel performance.
The Teradata RDBMS for UNIX provides this same parallel performance using virtual processors (vprocs) on both Symmetric Multiprocessing (System 3500 and 5100S) and Massively Parallel Processing (System 5100M) systems. Vprocs are described in more detail in Chapter 2.
These differences mean that the Teradata RDBMS, the world’s most powerful parallel relational database system, provides entry-level, medium-size, and the world’s largest decision enabling solutions using databases ranging from several gigabytes to terabytes. The Teradata RDBMS for UNIX system also provides a low-price replacement for small to moderate scale Teradata users with Model 2 or Model 3 DBC/1012s.
A-2 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional Specific Improvements
Additional Specific Improvements A
Improved Performance and Added Features A
In addition to the major differences described above, The Teradata RDBMS for UNIX includes many differences that enhance Teradata RDBMS performance and functionality, including the following:
● An increased number of hash buckets● Executable versus interpretive row evaluation● File System improvements● General improvements and added features
These differences are described in more detail in the following passages.
Increased Number of Hash Buckets A
The number of hash buckets has increased from 3643 in the Teradata DBS for TOS to 65,536 in the Teradata RDBMS for UNIX. The larger number of hash buckets provides the following improvements:
● A decrease in the possibility of two rows of data with different index values hashing to the same hash-id, making much less likely the possibility of a query having to read multiple blocks of data to find a specified row.
● An improvement in lock granularity, since fewer rows are locked when a single row is accessed.
● The allowance of data to be distributed more evenly across the AMPs, taking even more advantage of the power and performance of parallel processing.
With 3643 hash buckets, there is always an uneven number of buckets assigned across the AMPs, because 3643 is a prime number.
For example, if your system has 332 AMPs, the data imbalance between processors is ten percent; 323 AMPs will have 11 buckets, and nine AMPs will have 10 buckets.
If you have 608 AMPs, the data imbalance reaches 20%; 603 AMPs will have 6 buckets, and five AMPs will have five buckets.
Introduction to the Teradata RDBMS for UNIX A-3

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional Specific Improvements
Enhanced Row Evaluation A
During a full file scan (a query for which the WHERE clause does not fully specify the value of an index), a large number of rows are read.
After each row is accessed, the RDBMS reinterprets the WHERE clause to determine if the row matches the conditions of the WHERE clause.
The Teradata RDBMS for UNIX provides the following enhancements to the row evaluation process:
● Executable vs. interpretive row evaluation.
If the number of rows to be accessed and interpreted is large enough, it becomes more efficient to compile the interpretive code into executable code, which can run up to 50 times faster. The Teradata RDBMS for UNIX always compiles this code during the parsing phase.
● Compile time (versus run time) operand typing and field offset calculation.
The Teradata RDBMS for UNIX evaluates data types and positions only once, at compile time, rather than repetitively, at run time.
● Common subexpression elimination.
Enhances the row evaluation process by eliminating the repetitive evaluation of the same subexpressions.
● NULL and compressed field access optimization.
Streamlined processes provide optimal evaluation of NULL values and compressed fields.
File System Improvements A
Many improvements have been made to the RDBMS file system, including the following:
● Automatic detection of cylinder fragmentation● Uniqueness code carried in the cylinder index● More efficient internal format of data blocks● Larger maximum multi-row data block size (32 KB)● Table-level attributes● Optional look-ahead reads● Optional page release● User-tunable cache size for spool files
A-4 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional Specific Improvements
Automatic Detection of Cylinder Fragmentation A
In the Teradata DBS for TOS, disk fragmentation is not realized until a data block or cylinder is not available for allocation.
Once realized for a data block allocation request, an attempt is made to migrate data blocks to an adjacent cylinder or a new cylinder altogether to make room available for the request.
For a cylinder allocation request, a mini-cylpack operation is done.
These operations can cause a significant delay to the query that is inserting the data.
The Teradata RDBMS for UNIX automatically performs a check for disk fragmentation.
Upon detection of fragmentation within a cylinder, a defragmentation task is scheduled to defragment the cylinder in the background.
In the case of fragmentation where the number of cylinders available for allocation is below a certain threshold, a background mini-cylpack task is scheduled to free up cylinders.
These operations as part of the automatic disk fragmentation detection significantly reduce the number of times that customer queries against databases are delayed due to disk fragmentation.
Uniqueness Code Carried in the Cylinder Index A
In the Teradata DBS for TOS, the cylinder index identifies the hash value associated with data blocks.
Because multiple data blocks can have the same hash value, a secondary lookup is required to read multiple data blocks until the block containing the desired row is found.
By indicating the uniqueness value associated with the first row in a data block, the cylinder index of the Teradata RDBMS for UNIX file system can be used to directly find the correct data block on a secondary index lookup (where the hash-id and uniqueness have already been determined), thereby reducing the number of blocks that have to be read to just one.
More Efficient Internal Format of Data Blocks A
The internal format of data blocks includes two improvements:
● Search of block based on pointer array, allowing fast access within larger blocks
● Faster non-unique primary index access with large numbers of duplicates
Introduction to the Teradata RDBMS for UNIX A-5

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional Specific Improvements
Larger Maximum Multi-Row Data Block Size A
In the Teradata DBS for TOS, data blocks with multiple rows are limited to 16KB in an NCR System 3600 and 8KB in an NCR DBC/1012 Model 4.
With the Teradata RDBMS for UNIX, the maximum size can be set at the system or table level to as much as 32K (less one sector).
The ability to adjust the size of the data blocks allows system administrators to fine tune the system for the type of workload desired.
As a general rule, systems used for heavy decision enabling support will benefit from using larger data block sizes.
Systems used for decision enabling support and some online transaction processing will have better performance with smaller data block sizes (the more OLTP performed, the smaller the data block size).
If a row is larger than the maximum multi-row data block size, it will be in a data block by itself; a single row data block can always be up to 32KB.
Table-Level Attributes A
The Table Level Attribute feature allows you to set certain attributes at the table level.
Currently, this feature allows you to specify the maximum default size of the data blocks used to store the primary rows of a table, and the percentage of space to be left free on the cylinders consumed by a table during bulk data load operations.
You can use each attribute to improve performance and lower the consumption of resources, as follows:
● Data Block Size. This feature allows you to achieve optimum performance of the type of application that will most frequently access the table.
Decision support queries operate most efficiently on tables with large data block sizes because large blocks minimize the number of I/O operations involved.
Online transaction processing (OLTP) is most efficient on tables with a small data block size.
● Cylinder Percent of Free Space. This feature allows you to make the most efficient use of available disk space for decision support applications, and also improve the throughput of large DML applications.
A-6 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional Specific Improvements
If the table is normally static and used for decision support applications, then little or no free space (for example, 0%) is most efficient.
A table that will experience many inserts and thus grow rapidly should have a high percentage of free space. This will improve overall performance by reducing the need for cylinder splits and migrations.
Optional Look-Ahead Reads A
The Teradata RDBMS for UNIX reads one block ahead during scans. By reading ahead, processing can be overlapped with I/O, improving performance for some workloads.
Note however that for other workloads it may be desirable to turn this feature off, as the aging of the data block may cause the block to be released from memory before it is accessed, thereby causing a waste of I/O.
Optional Page Release A
In the Teradata DBS for TOS, a data block that has been accessed stays in memory until it ages out. The Teradata RDBMS for UNIX has an option which, when turned on, allows the system to immediately release data blocks once they have been accessed when it is unlikely that the data block will be accessed again in the near-term, thereby releasing memory for other use.
Note that it is possible (but unlikely) that some workloads will perform better with this option turned off.
User-Tunable Cache Threshold for Data Block Caching A
This Teradata RDBMS for UNIX feature allows the System Administrator to make tradeoffs between memory usage and I/O so that the workload for a system can be tuned for best performance.
Introduction to the Teradata RDBMS for UNIX A-7

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional General Improvements
Additional General Improvements A
A number of general improvements have also been made to the Teradata RDBMS for UNIX. These improvements include the following:
● The aggregate cache has been increased to 96 KB, making it three times as large as the Teradata DBS for TOS aggregate cache (the V1 aggregate cache is 32 KB). This reduces row redistribution overhead when large aggregations are performed.
In addition, the performance of aggregations with a large number of groups has been significantly improved.
● The Teradata RDBMS for UNIX Optimizer has adjusted bit map sizes, reducing bit map collisions.
In the Teradata DBS for TOS, the Optimizer (which is used to minimize the I/O for certain types of table joins) is limited to 32KB.
The Teradata RDBMS for UNIX Optimizer has an adjustable bit map size (based on table statistics) that provides an effective use of the bit map without unnecessarily wasting memory.
● The Teradata RDBMS for UNIX has expanded parsing capabilities for complex queries.
● The Teradata RDBMS for UNIX has increased the information obtained by the Resource Usage (ResUsage) macros. ResUsage improvements include:● A breakdown of I/O information by spool, transient journal,
and data block● More flexible logging intervals (Teradata DBS for TOS is
limited to logging intervals of 6, 60, or 600 seconds)● The information obtained can be specific to vprocs, nodes, or
the entire system● An improved hash function that eliminates the additive effect of
multi-column indexes.● New Teradata SQL features, including the following:
● Functions for investigating data row distribution, which allow the user to more effectively select a table’s primary index. These functions are as follows:● Hashrow● Hashbucket● Hashamp● Hashbakamp
A-8 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional General Improvements
● The CASE expression, which enables the user to convert a code into a word or a null into a concrete value, or to generate a null value based on information derived from the database.
● The NOWAIT option to the LOCKING modifier, which can be used to abort a transaction that should not wait in a locking queue.
● Improved Optimizer formulas.● Improvements in path length and addressability.● Optimization of journal append, resulting in a reduction of the
number of data block writes when permanent journals are used.
In the Teradata DBS for TOS, whenever a permanent journal data block is written, the cylinder index is also written.
In the Teradata RDBMS for UNIX, if an existing data block is being appended to, the cylinder index is not written, nearly halving the number of writes for permanent journals.
This significantly reduces the overhead of using permanent journaling.
● Message broadcasts have been changed to point-to-point in many cases. By making messages point-to-point, only the vprocs needing the message are interrupted.
● The sizes of the transactions in progress (TIP) table and lock table have been increased, reducing the likelihood that the system will run out of these internal resources.
● The dictionary cache has been increased, and is user tunable.● Parsing memory has been increased, with a corresponding
increase in size for both plastic steps and concrete steps.
The increase in parsing memory size allows for the execution of larger and more complex queries.
Additionally, parsing memory size is user-tunable; the size can be limited to control system workload as needed.
● User-defined collation.
In the Teradata DBS for TOS, a limited number of collations are supported.
In the Teradata RDBMS for UNIX, the system administrator can define and install custom-defined collation sequences that can be requested at the session level.
● The PDE controls scheduler class groupings and functions for Teradata RDBMS processes via the Fair Share scheduler.
Introduction to the Teradata RDBMS for UNIX A-9

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSAdditional General Improvements
The ACCOUNT clause of the CREATE/MODIFY USER statement can be used to assign a user’s sessions to a particular performance group.
If no performance group is specified for the acctid under which a session is invoked, that session is assigned to the Medium performance group.
● The client software and interfaces for the Teradata RDBMS for UNIX are the same as those for the Teradata DBS for TOS.
A-10 Introduction to the Teradata RDBMS for UNIX
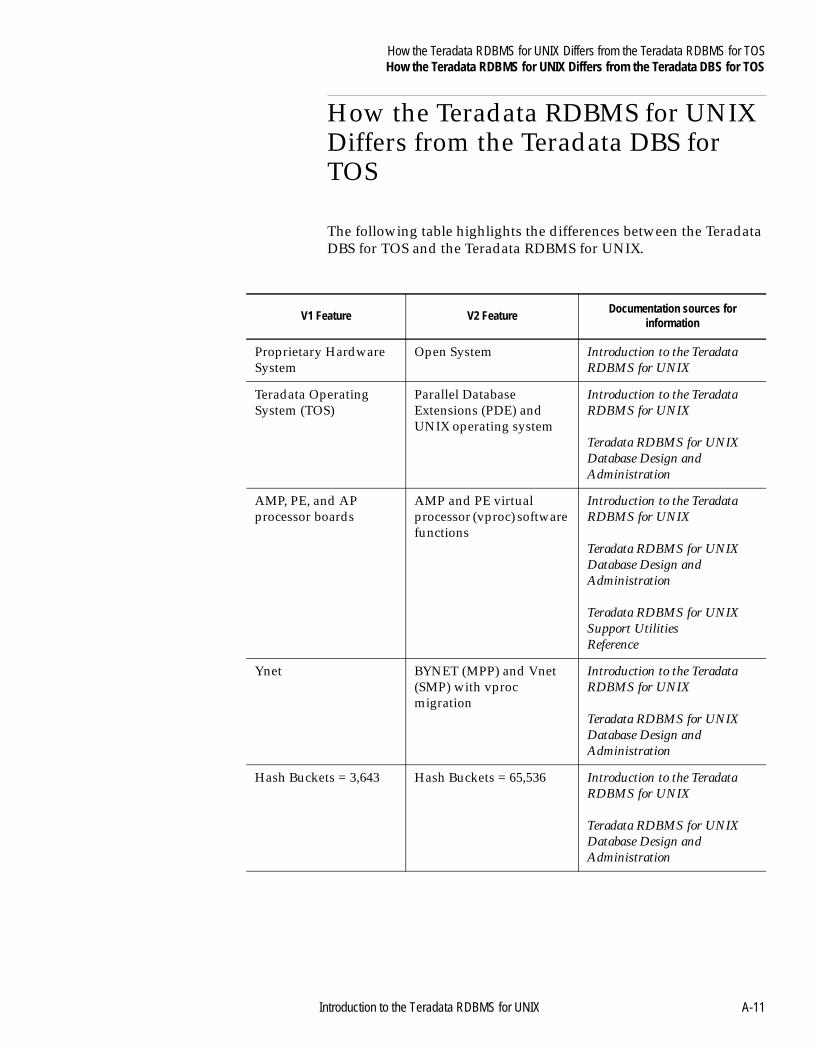
How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
How the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS A
The following table highlights the differences between the Teradata DBS for TOS and the Teradata RDBMS for UNIX.
V1 Feature V2 FeatureDocumentation sources for
information
Proprietary Hardware System
Open System Introduction to the Teradata RDBMS for UNIX
Teradata Operating System (TOS)
Parallel Database Extensions (PDE) and UNIX operating system
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
AMP, PE, and AP processor boards
AMP and PE virtual processor (vproc) software functions
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Teradata RDBMS for UNIX Support UtilitiesReference
Ynet BYNET (MPP) and Vnet (SMP) with vproc migration
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Hash Buckets = 3,643 Hash Buckets = 65,536 Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Introduction to the Teradata RDBMS for UNIX A-11
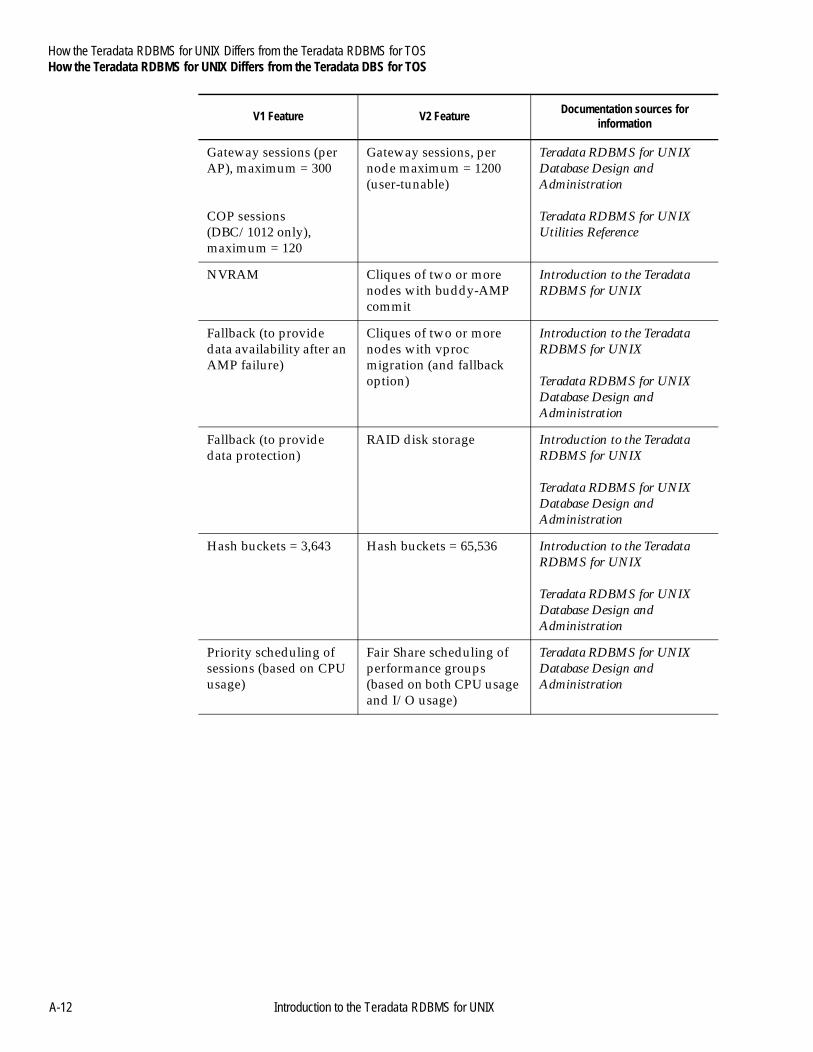
How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Gateway sessions (per AP), maximum = 300
COP sessions (DBC/1012 only),maximum = 120
Gateway sessions, per node maximum = 1200 (user-tunable)
Teradata RDBMS for UNIX Database Design and Administration
Teradata RDBMS for UNIX Utilities Reference
NVRAM Cliques of two or more nodes with buddy-AMP commit
Introduction to the Teradata RDBMS for UNIX
Fallback (to provide data availability after an AMP failure)
Cliques of two or more nodes with vproc migration (and fallback option)
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Fallback (to provide data protection)
RAID disk storage Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Hash buckets = 3,643 Hash buckets = 65,536 Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Priority scheduling of sessions (based on CPU usage)
Fair Share scheduling of performance groups (based on both CPU usage and I/O usage)
Teradata RDBMS for UNIX Database Design and Administration
V1 Feature V2 FeatureDocumentation sources for
information
A-12 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Teradata File System Teradata File System improvements
Automatic detection of cylinder fragmentation
Uniqueness code carried in the cylinder index
More efficient internal format of data blocks
Larger maximum multi-row data block size (32 KB)
Table-level attributes (data block size and free space percent)
Optional look-ahead reads
Optional page release
User-tunable cache size for spool files
User-tunable dictionary cache size
User-tunable global default size of permanent and journal data blocks
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Support Utilities
Teradata RDBMS for UNIX Utilities Reference
Teradata RDBMS for UNIX Database Design and Administration
V1 Feature V2 FeatureDocumentation sources for
information
Introduction to the Teradata RDBMS for UNIX A-13
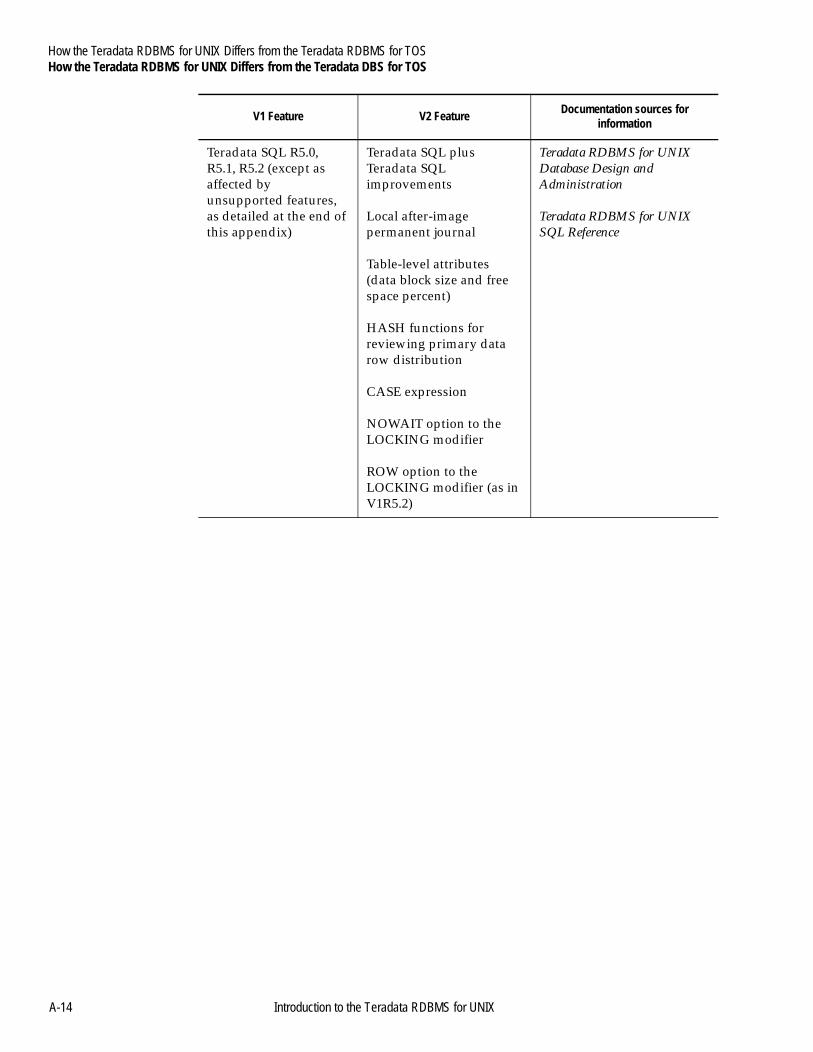
How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Teradata SQL R5.0, R5.1, R5.2 (except as affected by unsupported features, as detailed at the end of this appendix)
Teradata SQL plus Teradata SQL improvements
Local after-image permanent journal
Table-level attributes(data block size and free space percent)
HASH functions for reviewing primary data row distribution
CASE expression
NOWAIT option to the LOCKING modifier
ROW option to the LOCKING modifier (as in V1R5.2)
Teradata RDBMS for UNIX Database Design and Administration
Teradata RDBMS for UNIX SQL Reference
V1 Feature V2 FeatureDocumentation sources for
information
A-14 Introduction to the Teradata RDBMS for UNIX
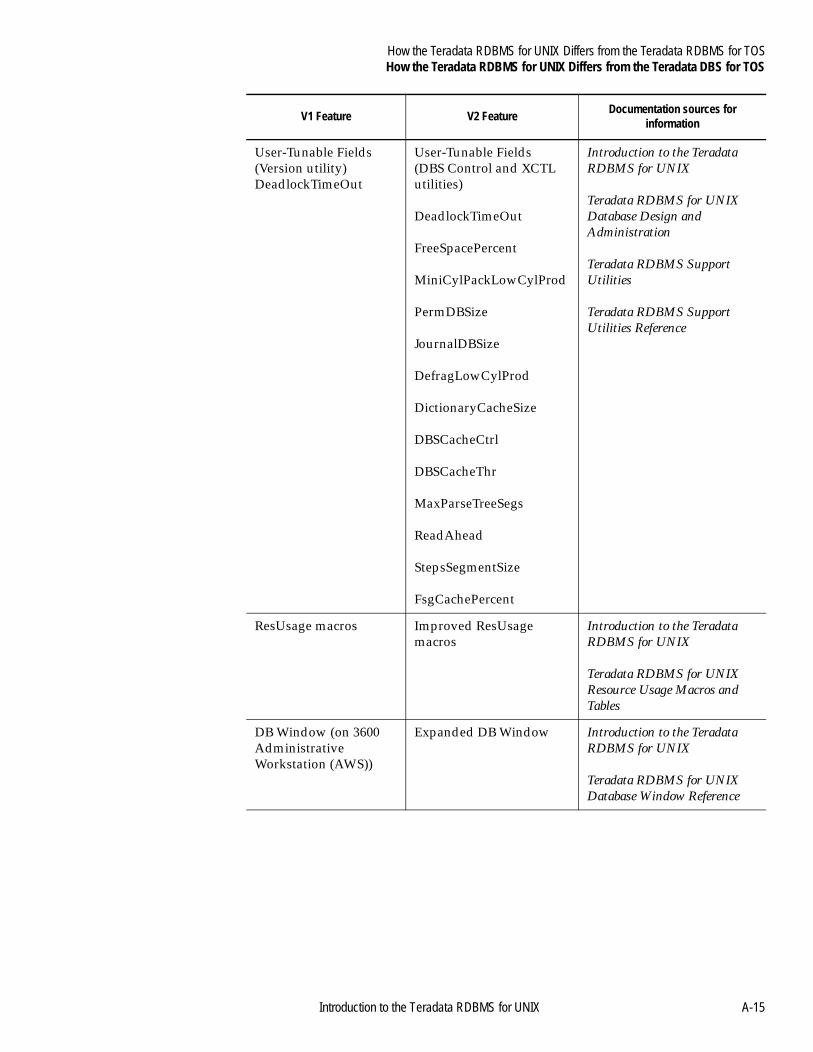
How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
User-Tunable Fields(Version utility)DeadlockTimeOut
User-Tunable Fields(DBS Control and XCTL utilities)
DeadlockTimeOut
FreeSpacePercent
MiniCylPackLowCylProd
PermDBSize
JournalDBSize
DefragLowCylProd
DictionaryCacheSize
DBSCacheCtrl
DBSCacheThr
MaxParseTreeSegs
ReadAhead
StepsSegmentSize
FsgCachePercent
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Design and Administration
Teradata RDBMS Support Utilities
Teradata RDBMS Support Utilities Reference
ResUsage macros Improved ResUsage macros
Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Resource Usage Macros and Tables
DB Window (on 3600 Administrative Workstation (AWS))
Expanded DB Window Introduction to the Teradata RDBMS for UNIX
Teradata RDBMS for UNIX Database Window Reference
V1 Feature V2 FeatureDocumentation sources for
information
Introduction to the Teradata RDBMS for UNIX A-15

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
Additional reserved words (keywords):
HASHAMPHASHBAKAMPHASHBUCKETHASHROW
Additional reserved words:
CASEDATABLOCKSIZEELSEFREESPACEKILOBYTESNOWAITTHENWHEN
New utilities:
FerretFair Share Scheduler MonitorXCTLDBS ControlFilerVproc ManagerDatabase Initialization Program (DIP)XPTxperfstate
Teradata RDBMS for UNIX SQL Reference
Teradata RDBMS for UNIX Support Utilities Reference
Teradata RDBMS for UNIX Support Utilities
Teradata RDBMS for UNIX Database Design and Administration
V1 Feature V2 FeatureDocumentation sources for
information
A-16 Introduction to the Teradata RDBMS for UNIX

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
New Features:● CASE expressions● Correlated subqueries● EXISTS predicate● CHECK constraints● Various ANSI
compliances, including:
— Transaction semantics— SQL flagger— Duplicate rows
permitted— Entry-level access
rights— New, compliant data
types— Column-level rights— Support for duplicate
rows— Referential integrity— Kanji support— Updatable cursors— WITH CHECK clause
in views— DISTINCT qualifier in
views— Aggregates in views— CREATE SCHEMA
statement— Case Specific
character data— New syntax for these
statements:— GRANT— REVOKE— CREATE TABLE
● New functions and expressions
● Expanded HELP statements
● UPPER● TRIM● CASE
V1 Feature V2 FeatureDocumentation sources for
information
Introduction to the Teradata RDBMS for UNIX A-17

How the Teradata RDBMS for UNIX Differs from the Teradata RDBMS for TOSHow the Teradata RDBMS for UNIX Differs from the Teradata DBS for TOS
A-18 Introduction to the Teradata RDBMS for UNIX

Glossary
Introduction to the Teradata RDBMS for UNIX G
-1lossaryGlossary 0
This glossary defines terms specific to the Teradata RDBMS for UNIX. It also defines some general-use computer terms critical to an understanding of the Teradata RDBMS, as well as some general-use terms whose definition has been enhanced for the Teradata RDBMS.
Words that are italicized in the explanations are themselves defined in the glossary. For your convenience, frequently misunderstood terms are flagged with “cf” (compare) citations to alert you to similar terms for comparison; parenthetical notes to similar or contrasting terms. All command or statement keywords, modifiers, and other reserved words are fully capitalized.
In alphabetizing entries in this glossary, a blank character sorts before any letter, and a dash character sorts after any letter.
AABORT In Teradata SQL, a statement that aborts a transaction in progress and backs out changes to the database only if the conditional expression associated with the abort statement is true.
Access Module Process (AMP) An instance (virtual processor) of database management data (tables, rows, indices) with their associated data manipulation processes and their data context (Transaction In Progress table, lock information, disk access information).
administrator A special user responsible for allocating resources to a community of users.
Administration Workstation The system console of an NCR System 5100M.
AMP See Access Module Process.
application program A host program that performs a particular function or set of functions that the user desires to perform.
AWS See Administration Workstation
Bbackout The process by which database changes are reversed after an aborted transaction so that the database is restored the state prior to the transaction. Cf: ABORT, transaction.
batch Host application programs that run in a background mode where their execution is not under the direct moment-to-moment control of a user are said to run in batch. Batch programs or jobs are often run for an extensive period of time and may be part of a data

Glossary
processing operation that is routinely run every day, week, month, or year.
Basic Teradata Query (BTEQ) A host-resident application program that enables a user to execute a series of Teradata SQL requests in either batch or interactive mode. BTEQ can read from or write to host data sets and use more than one Teradata session.
block A collection of records, rows, or packets that is manipulated as a unit, typically for efficiency of execution.
BTEQ See Basic Teradata Query.
buffer A software area in main memory used for constructing and processing messages.
BYNET The dual interconnection network that allows high-speed communications between the nodes of an NCR System 5100M. Provides greater bandwidth than the Ynet, and point-to-point as well broadcast communications.
byte In Teradata SQL, a data type in which information is stored as a string of zero or more 8-bit elements without translation. Also, one such 8-bit element.
CC Preprocessor A program that facilitates productive design, coding, and testing of user application programs written in C that interact with the Teradata RDBMS.
cache A high-speed buffer storage area that contains frequently accessed instructions and data. It is used to reduce access time.
Call-Level Interface (CLI) A set of entry points provided by Teradata to facilitate low-level communication between programs running on the host and the Teradata RDBMS. CLI is used by Teradata programs such as BTEQ, the COBOL Preprocessor (runtime environment), FastLoad, and host utility programs. CLI is available to customer-written application programs coded in any language that supports a call statement and separate compilation of source modules.
channel The hardware means by which a central processor is attached to peripheral units. The path by which data is transferred between a mainframe host and the Teradata RDBMS.
channel connection software A program on the server that provides a pathway for applications running on a channel-connected mainframe (host) to access the Teradata RDBMS. Cf: Gateway.
CICS The Customer Information Control System, an IBM program product that acts as a supervisory or “monitor” program for application programs that are optimized for real-time interaction with users to perform relatively constrained information processing
Glossary-2 Introduction to the Teradata RDBMS for UNIX

Glossary
tasks. CICS runs under control of the MVS operating system (there is also a DOS version of CICS) and communicates with a network of terminals. Application programs written for CICS must use only CICS system services and must obey a number of other constraints imposed by the CICS environment.
CLI See Call-Level Interface.
Clique A logical group of nodes on the NCR System 5100M that shares access to disk storage. The vprocs on a failed node of a clique can migrate to other nodes within the clique during the recovery process, allowing uninterrupted use of the Teradata RDBMS.
cluster A collection of AMPs that handles the fallback data for a given AMP.
CNS See Console Subsystem.
COBOL Preprocessor A program that facilitates productive design, coding, and testing of user application programs written in COBOL that interact with the Teradata RDBMS.
column In the relational model of Teradata SQL, databases consist of one or more tables. In turn, each table consists of fields, organized into one or more columns by zero or more rows. All of the fields of a given column share the same attributes.
Console Subsystem (CNS) Software that is responsible for the I/O between the system console and the Teradata RDBMS. It acts as the interface between the Database Window (DBW) and the Teradata RDBMS and between the DBW and the DBW Startable Programs (it reads the RDBMS commands entered on the DBW).
Ddatabase. In Teradata SQL, a related set of tables that share a common space allocation and owner.
Database Management System (DBMS) Computer procedures that permit the database to be maintained independently of application programs. A database management system provides services for data definition, data manipulation, and data integrity.
Database System See Teradata Database System.
Database Window (DBW) An application that is a high-level graphical user interface that acts as an interface between operator commands and the Teradata RDBMS.
data block See block.
data definition In Teradata SQL, the statements and facilities that manipulate (create, modify, and delete) database structures and the Data Dictionary information kept about these structures. Cf: data manipulation.
Introduction to the Teradata RDBMS for UNIX Glossary-3

Glossary
Data Dictionary In the Teradata RDBMS, the information automatically maintained about all tables, views, macros, databases, and users known to the Teradata RDBMS system, including information about ownership, space allocation, accounting, and access right relationships between those objects. Data Dictionary information is updated automatically during the processing of Teradata SQL data definition statements, and is used by the Parser to obtain information needed to process all Teradata SQL statements.
data integrity The condition where accidental or intentional destruction, alteration, or loss of data does not occur.
data manipulation In Teradata SQL, the statements and facilities that change the information content of the database. These statements include SELECT, INSERT, UPDATE, and DELETE.
DBMS See Database Management System.
DBS See Teradata Database System.
DBS/SQL See Teradata SQL.
DBW See Database Window.
DBW startable program A database utility that can be started through a command entered on the Database Window. These commands are a subgroup of the Teradata RDBMS utility set.
deadlock In Teradata SQL, a condition in which two or more transactions are competing for locks on the same resources in such a way that none of the deadlocked transactions can make any progress without access to resources held by another transaction. The Teradata RDBMS detects deadlocks and resolves them by automatically aborting one or more of the transactions that is causing the deadlock condition.
delimiter In Teradata SQL, a punctuation mark or other special symbol that separates one clause in a Teradata SQL statement from another, or that separates one Teradata SQL statement from another.
diagnostic A program that exercises a hardware subsystem to verify that it is operating correctly, and if not, to provide information to assist the field engineer in isolating the failure to a field-replaceable unit.
disk Primary form of data storage. Multiple disks can be connected to a system.
Dispatcher A program that executes in the PE to coordinate the flow of processing by the Teradata RDBMS.
dump An operational function provided to create an archival copy, typically on tape, of a data base, part of a data base, or a collection of databases stored by the Teradata RDBMS. Cf: restore.
Glossary-4 Introduction to the Teradata RDBMS for UNIX

Glossary
dynamic A form of buffer or memory management that acquires buffers of varying sizes from the free space within the address space of a partition.
EECC See error correction.
end user An ordinary user of the Teradata RDBMS, as opposed to a supervisory user or an administrator. An end user cannot create a subordinate user or database, except within the end user’s space.
error correction Logic that uses additional memory bits to correct errors when one or more bits of main or secondary storage become unreliable. Error correction logic improves the reliability of the system and the integrity of stored data.
Ffailure Any condition that precludes complete processing of a Teradata SQL statement. Any failure will abort the current transaction.
fallback The ability of the Teradata RDBMS to maintain an extra copy of every row of a table in different AMPs. During normal processing, reads are performed using only the primary copy, while updates are performed on both copies. If a failure renders the primary copy inaccessible, the fallback copy is used for reads and updates. The database maintains a log of changes missed by inaccessible copies and automatically applies the missed changes to synchronize the table copy when it becomes accessible.
field The basic unit of information stored in the Teradata RDBMS. A field is either null, or has a single numeric or string value. See also column, database, row, table.
firmware Programming that is permanently fixed into a subsystem, as opposed to a software system, which is replaced without altering a hardware configuration.
foreign key An attribute of one table whose values are required to match those of the primary key of some other table.
GGateway A program on the server that provides a pathway for applications running on a network-connected client to access the Teradata RDBMS. Cf: channel connection software.
Hhashing A way of mapping data records to various physical storage areas. In the Teradata RDBMS, hashing is used to determine at which AMP a given row will be stored.
hierarchical An organization of entities, such as data records, in which some “superior” or “parent” entities are related to one or more “subordinate” or “child” entities. Also pertains to any
Introduction to the Teradata RDBMS for UNIX Glossary-5

Glossary
database management system that uses or describes information in a hierarchical form, such as IMS/VS. Cf: inverted, network, relational.
host A general-purpose computer that can execute application programs that access and manipulate information within the Teradata RDBMS.
host-resident Pertaining to a system or application program that executes on a host computer.
Host System Communication Interface. See HSCI.
host utility program One of several programs that executes on the mainframe host computer to archive data from the Teradata RDBMS to tape and/or to restore archived data to the Teradata RDBMS, and to load data to the Teradata RDBMS from a host input file.
HSCI The Host System Communication Interface, which consists of the Teradata Director Program, Call-Level Interface, and user-to-TDP communication techniques. These HSCI components enable communication between the user-written and Teradata application programs and the Teradata RDBMS.
Iindex In Teradata SQL, a means of ordering and locating rows on disk for efficient access and processing. Cf: primary index, secondary index, unique.
inverted A form or organization of records in a Database Management System in which extensive use is made of secondary index capability to access alternative paths to records. Each secondary index is also known as an “inversion.” Cf: hierarchical, network, relational.
Jjoin In Teradata SQL, a select operation that combines information from two or more tables to produce a result.
Kkey The value(s) of the index field(s) that locates a row within a user database running under the Teradata RDBMS.
keyword A string of characters that has a special meaning in the Teradata SQL. A keyword cannot be used as a name.
LLAN See Local Area Network.
Local Area Network (LAN) A means of connecting workstations that allows them to communicate with one another. The LAN is usually confined to a limited area, such as a building.
lock In Teradata SQL, the right to use a database, table, or row for a particular purpose (such as to read or write) with the assurance that other activities in the system cannot alter the object in a way that
Glossary-6 Introduction to the Teradata RDBMS for UNIX

Glossary
could affect the outcome of the activity that holds the lock. Users who do not require data consistency may use a lock specifically for access.
logical Pertaining to an entity, record, or grouping of data that is treated as a unit by a software program, as opposed to an entity that is treated as a unit by hardware.
Mmacro A set of Teradata SQL statements stored by the Teradata RDBMS and executed by a single EXECUTE statement. Each macro execution is implicitly treated as a transaction.
mainframe A large computer with extensive capabilities and resources to which other computers can be connected so they can share facilities.
message The basic unit of information interchange between an application program and the Teradata RDBMS. An application program sends messages via a session to the Teradata RDBMS in half-duplex fashion and must wait for a response message from the Teradata RDBMS before sending another message on the same session. Messages consist of one or more parcels, which are logical subdivisions of a message.
module A unit of software that typically performs one function or a set of closely related functions and is the smallest unit of software that can be replaced.
multitasking The ability to share the resources of a computer, operating system, or address space among several tasks, or “threads” of execution, where the state of each task is, in general, independent of the state of other tasks.
MVS See Multiple Virtual Storage.
Multiple Virtual Storage (MVS) One of the primary operating systems (or system control programs) for medium and large IBM computers. MVS offers multiprogramming for multiple users.
Nname In Teradata SQL, a word supplied by the user that refers to an object, such as a column, database, macro, table, user, or view.
network A method of organizing records in a Database Management System in which relationships between one record and another are represented by pointers. A pointer is a part of a record that gives the address, typically on disk, where the next related record resides. The database thus consists of a network of records and pointers. This organizational form is also known as a “plex” structure, a “navigational” database, or a CODASYL model database. Cf: hierarchical, inverted, relational.
Introduction to the Teradata RDBMS for UNIX Glossary-7

Glossary
node A processor node consisting of one or more processors that share memory. Peripheral devices such as disk storage may be connected to a node. An interconnect between the nodes facilitates message communication between nodes. Network and channel connections provide for communication to clients and those between interconnected nodes.
null In Teradata SQL, the absence of a value for a field.
Ooffline A state of a system or component in which it is logically disconnected from its normal operating environment so that special functions such as service, maintenance, and/or diagnostics can be performed on the component or system in isolation from the rest of the environment.
online Any state in which a system is available for users to enter ordinary requests, and in which all normal functions are provided.
operand Values, given by constants or variables, that an operator acts upon to produce a result.
operator In Teradata SQL, a symbol or keyword that specifies an operation performed on the values of the operands (if any).
owner In Teradata SQL, the user who has the ability to grant or revoke all access rights on a database to and from other users. By default, the creator of the database is the owner, but ownership can be transferred from one user to another by the GIVE statement.
Ppacket In host software, the smallest unit of data sent on the channel between the TDP and the channel connection software. A message consists of one or more packets. A packet is a purely physical division of a message. Packets are distinct from parcels, which are logical subdivisions of a message.
Parallel Database Extensions (PDE) Message-based kernel service extensions to UNIX System V, Release 4, suitable for a parallel distributed-memory machine.The extensions include network services and message services, memory management services, and file system access services. These services provide parallelism and are available only to a TPA, that is, the Teradata RDBMS.
parallel processing Simultaneous or concurrent execution of two or more processes in a single functional unit.
parameter In Teradata SQL, a variable name in a macro for which an argument value is substituted when the macro is executed.
parcel In host software, a logical part of a message. A parcel contains the message information (Teradata SQL statements, result rows, failure codes, etc.).
Glossary-8 Introduction to the Teradata RDBMS for UNIX

Glossary
Parser A program executing in a PE that translates Teradata SQL statements entered by a user into the steps that accomplish the user’s intentions.
Parsing Engine (PE) An instance (virtual processor) of the database management Session Control, Parsing, and Dispatching processes and their data context (caches).
partition A logical connection of tasks and associated resources within a virtual processor that performs a related function.
PDE See Parallel Database Extensions.
PE See Parsing Engine.
PL/I Preprocessor A program that facilitates productive design, coding, and testing of user application programs written in PL/I that interact with the Teradata RDBMS.
Preprocessor See COBOL Preprocessor, C Preprocessor, PL/I Preprocessor.
primary index In Teradata SQL, an index that determines in which AMP (and the location in that AMP where) a row is stored. Access through the primary index is generally the most efficient means of locating a row.
primary key A unique identifier for a row.
privilege The right of a specified user to enter a specified RDBMS/SQL statement (such as CREATE, SELECT, GRANT, etc.) against a specified database, macro, table, user, or view.
program A unit of software that performs a set of operations to satisfy the needs of users or other programs. A program consists of one or more modules.
protocol A set of rules that govern the communication between two or more entities, such as processors, programs, or systems, including the formats of messages that flow among the entities.
Qquery A Teradata SQL statement, particularly a SELECT statement.
queue A list of requests to use system resources, such as processor time, memory, access to a peripheral device, or lock.
RRAID Redundant Array of Inexpensive Disks. A technology using specialized disk controllers and software to distribute data across a set of multiple disk drives (arrays). The data is segmented across the different disks in the array, a method known as striping.
Introduction to the Teradata RDBMS for UNIX Glossary-9

Glossary
RAID1 An implementation of RAID technology in which striped data is stored as identical (mirrored) copies on separate disk media, so the data is both striped and mirrored.
RAID5 An implementation of RAID technology in which data and parity segments are stored by means of striping across multiple disks. Failures in any one component can be compensated for by reconstructing the data from the parity information and the surviving data. RAID5 data is not mirrored and uses approximately 60 percent less disk storage than does RAID1 for the same amount of data.
RAM See random access memory.
random access memory A quality of a memory device that writes or reads data from the memory through direct locating, rather than locating through references to other data in the memory.
recovery See backout.
redundancy group A group of disks protected by the same parity scheme. The groups are tolerant of any single point disk failure.
relational A database management system in which complex data structures are represented as simple, two-dimensional tables consisting of columns and rows. Cf: hierarchical, inverted, network.
request In host software, a message sent from an application program to the Teradata RDBMS.
resource monitoring Performance monitoring features to help users gather performance data in real time that may help tune the system.
Resource Usage (ResUsage) data Resource usage and performance data that is stored in database tables for subsequent analysis, which may help to identify trends and help tune the system.
Resource Sampling Subsystem A PDE software component that provides the ability to gather resource statistics which may be presented to real-time resource monitoring or saved as ResUsage data or both.
response The result (success or failure) generated when the Teradata RDBMS processes a Teradata SQL statement.
restart The process by which online operation of the Teradata RDBMS resumes after a system error, such as a hardware failure, a software protocol failure, or loss and restoration of AC power.
restore A function provided by a host utility program that re-creates a database from archived dump tapes. Cf: dump.
result The information returned to the user to satisfy a request made of the Teradata RDBMS. Results may include a return code,
Glossary-10 Introduction to the Teradata RDBMS for UNIX

Glossary
activity count, error message, warning message, title information, and/or rows from a spool file.
ResUsage data See Resource Usage.
row In Teradata SQL, the fields, whether null or not, that represent one entry under each column in a table. The row is the smallest unit of information operated on by data manipulation statements. Cf: column, database, field, table.
SSCSI See Small Computer Systems Interface.
secondary index In Teradata SQL, an index on a column or group of columns other than those used for the primary index. A secondary index stores of extra information ordered on the secondary index columns, which more rapidly locates information in the Teradata RDBMS.
separator A character or group of characters that separates words and special symbols in Teradata SQL. Blanks and comments are the most common separators.
session In client software, a logical connection between an application program on a host and the Teradata RDBMS that permits the application program to send one request to and receive one response from the Teradata RDBMS at a time.
Session Control A program that executes in a PE to manage user sessions with the Teradata RDBMS.
SLAN See System LAN.
Small Computer Systems Interface (SCSI) An input and output bus that provides a standard interface for peripheral devices.
spool file A file that holds the results of the processing of Teradata SQL statements until they can be examined by the user or application program.
SQLflagger The feature of the SQL parser that detects syntax legal for Teradata SQL but illegal for ANSI SQL and reports the discrepancy.
startup string One or more Teradata SQL statements that are executed automatically when a user performs a LOGON.
statement A Preprocessor statement, Teradata SQL statement, COBOL statement, C statement, or PL/I statement.
statement A request for processing by the Teradata RDBMS that consists of a keyword verb, optional phrases, operands and is processed as a single entity.
Introduction to the Teradata RDBMS for UNIX Glossary-11

Glossary
step A unit of work that does some or all of the processing of a single Teradata SQL statement. A step is created by the Parser and sent to the AMPs by the Dispatcher. Steps for a given statement are parallel processed. As many as 20 steps from a request can be executed at the same time.
success A parcel that is returned from every Teradata SQL statement that executes to normal completion.
Supervisor Window A window that runs under the Database Window on a system console that allows the user to control Teradata RDBMS applications.
supervisory user In Data Dictionary, a user who has been delegated authority by the administrator to further allocate Teradata RDBMS resources such as space and the ability to create, drop, and modify users within the overall user community. Cf: end user, administrator.
system console A workstation that offers a user interface to system management functions. These include administration, operation, installation, and maintenance of the system. See also: backup system console, master system console.
System Management Window A system console window that allows invocation of any system console application, such as the Database Window.
system view In Data Dictionary, a view that permits end users, supervisory users, and administrators to get appropriate information about databases, macros, tables, users, views, and their relationships.
Ttable In Teradata SQL, a set of one or more columns with zero or more rows that consist of fields of related information. See also database.
TDP See Teradata Director Program.
Tera A prefix that means “trillion” (1,000,000,000,000).
Teradata Database System (DBS) Teradata RDBMS software that manages database functions. It provides the Teradata parallel SQL implementation made available with virtual processors The RDBMS is a Trusted Parallel Application.
Teradata Structured Query Language (Teradata SQL) A multipurpose database language used for defining, manipulating, controlling, loading, and archiving data.
Teradata RDBMS See Teradata Relational Database Management System.
Teradata Director Program (TDP) A program that manages communication between application programs and the Teradata RDBMS. It is a part of the Host System Communication Interface.
Glossary-12 Introduction to the Teradata RDBMS for UNIX

Glossary
Teradata SQL See Teradata Structured Query Language.
Teradata SQL statement A statement in the Teradata SQL language that is processed by the Teradata RDBMS.
title. In Teradata SQL, a string used as a column heading in a report. By default it is the column name, but a title can also be explicitly declared by a TITLE phrase.
transaction A set of Teradata SQL statements that is performed as a unit. Either all of the statements are executed normally or else any changes made during the transaction are backed out and the remainder of the statements in the transaction are not executed.The Teradata RDBMS supports both ANSI and Teradata transaction semantics.
Trusted Parallel Application (TPA) An application system, such as the Teradata RDBMS, that uses the parallelism made available with virtual processors and UNIX. The TPA has access to the Parallel Database Extensions (PDE) that provide parallel processing capability. A TPA can consist of more than one program if the various programs are coordinated in their use of operating system facilities.
type An attribute of a column that specifies the representation of data values for fields in that column. Teradata SQL data types include numerics and strings.
Uunique In Teradata SQL, a property of an index that specifies that two rows of a table are not allowed the same key value for that index. The default is non-unique, which permits duplicate keys.
UNIX An open operating system developed by Bell Laboratories that features multiprogramming in a multi-user environment. Teradata release 2 systems use UNIX System V, Release 4 MP-RAS.
update operation In Teradata SQL, an operation that alters the contents of a database, such as an INSERT, DELETE, or UPDATE data manipulation statement.
user In Teradata SQL, a database associated with a person who uses the Teradata RDBMS. The database stores the person’s private information and accesses other Teradata databases.
user-to-TDP communication technique One of the ways in which application software communicates with the Teradata Director Program. Techniques include: SVC and commonly addressable utility routines (under MVS); IBM Cross Memory Services routines and routines that reside in common storage (under MVS); Inter-User Communication Vehicle (under VM).
utility See host utility program.
Introduction to the Teradata RDBMS for UNIX Glossary-13

Glossary
Vview In Teradata SQL, an alternate way of organizing and presenting information in the Teradata RDBMS. A view, like a table, has rows and columns. However, the rows and columns of a view are not directly stored by the Teradata RDBMS, but are derived from the rows and columns of tables (or other views) whenever the view is referenced.
virtual A system resource that can be used by programs but that is not an actual hardware device in the system. A “virtual” resource is simulated by software and “real” hardware resources.
virtual disk (vdisk) One or more physical disk regions that are grouped together to be associated with a virtual processors.
Virtual Machine (VM) One of the primary operating systems (or system control programs) for medium and large IBM computers.
virtual processor (vproc) A collection of processes (tasks) working together that has addressable attributes. The concept of the virtual processor provides the basic unit of parallelism to a Trusted Parallel Application. The parallelism is independent of actual hardware parallelism. The virtual processor allows multiple instances of database functions.
In the Teradata RDBMS, virtual processors assume the identity of AMP and PE. The standard virtual processor type available, independent of the presence of a TPA, is the node.
VM See Virtual Machine.
vproc See virtual processor.
Wword In Teradata SQL, a string of one to 30 contiguous, nonblank, alphabetic, numeric characters ( $, _, # ).
YYnet The interconnection network that allowed high-speed communications between the processor nodes of an NCR System 3600 and DBC/1012.
Glossary-14 Introduction to the Teradata RDBMS for UNIX

Index
Introduction to the Teradata RDBMS for UNIX
-1IndexIndex 0
Numerics
2PC 10-12coordinator 10-12interfaces 10-14participant 10-12processing 10-15sessions supported 10-14
2PL 10-2
A
Access control 11-3acctid 11-4client identifiers 11-3GRANT LOGON statement 11-8logon policies 11-3password 11-4password encryption 11-7password security 11-5REVOKE LOGON statement 11-8TDP security 11-5tdpid 11-4user identifiers 11-3
Access Module Processor. See AMPAccount String Expansion. See ASEAccount usage 12-9
string expansion 12-9Accounting 12-7Administrative Workstation. See AWSAggregate operators 5-4
AVERAGE 5-4COUNT 5-4MAXIMUM 5-4MINIMUM 5-4SUM 5-4
ALTER statement 4-8ALTER TABLE statement 9-4AMP 2-11, 2-14, 2-25
clusters 2-25, 9-4multiple requests 2-17receiving steps 2-15
step processing 2-16, 2-17steps 2-13
Application development 8-1application generators 8-1CLI 8-9embedded SQL 8-2fourth generation languages 8-1implicit 8-1macros 8-4Preprocessor2 8-3third party software 8-11
Application programming facilities 2-28
Archive and Restore utility 2-30, 9-1, 9-7
Archive Storage Facility 2. See ASF2Archive/Recovery utility. See Archive
and Restore utilityArithmetic functions 5-7
ABS(arg) 5-7EXP(arg) 5-7LN(arg) 5-7LOG(arg) 5-7NULLIFZERO 5-7SQRT(arg) 5-7
Arithmetic operators 5-3ASE 12-9
DBC.AMPUsage table 12-10ASF2 2-30Attribute 3-1AWS 2-31
B
Basic Teradata Query. See BTEQBoyce-Codd normal form. See BCNFBTEQ 1-6, 2-11, 2-22
logon string 12-9BulkLoad utility 2-30BYNET 1-6, 2-11, 2-14, 2-23, 2-25

Index
Index-2
C
CA-ACF2 11-5Call Level Interface. See CLICandidate key 3-2, 3-9CA-TOP SECRET 11-5Circular dependencies, elimination
of 3-6CLI 1-1, 1-6, 2-26, 2-28
what is CLI? 8-9Client
interface 2-11software 1-1, 2-6
Column 3-1adding 4-8attributes 4-3
CASESPECIFIC 4-4CONSTRAINT 4-4DEFAULT 4-4FORMAT 4-4NOT CASESPECIFIC 4-4NOT NULL 4-3TITLE 4-4UPPERCASE 4-4
Communications management 2-27Concrete steps 2-14Concurrency control 10-1Configuration status 12-12CREATE MACRO statement 3-13, 8-4CREATE TABLE statement 9-4CREATE VIEW statement 6-2Creating databases 12-2Creating users 12-2
D
Dataarchiving 9-7controlling access 11-8conversion 2-12restoring 9-7
Data Definition Language. See DDL
Introduction to the Teradata RDBMS for UNIX
Data Dictionary. See DDData Manipulation Language. See
DMLData types 4-2
BYTE 4-3BYTEINT 4-2DECIMAL 4-2INTEGER 4-2SMALLINT 4-2VARBYTE 4-3
Databasecreating 12-2names 11-3
Database managementhierarchical model 3-1network model 3-1object-oriented model 3-1relational model 3-1
Database management system. See Teradata DBS
DBC 12-2DBC database 12-2DBC.SysSec table defaults 11-6DBS
database engine 2-25database manager 2-25recovery 10-10views 6-1
DBS. See Teradata DBSDD 7-1, 9-7, 11-5, 12-9
accessing 7-6administrator views 7-4end user views 7-3objects 7-1RCC views 7-5structure 7-2supervisory views 7-3users 7-1views 7-2why use? 7-6x views 7-2
DDE 2-26DDL 4-1

Index
DecimalMax flag 4-3DELETE statement 5-19Design philosophy and goals 1-1Determinant 3-3Directory cache 2-13Disk Subsystem 2-25Dispatcher 2-14, 2-15DML
restrictions 6-6DROP INDEX statement 4-19DROP MACRO statement 3-14, 8-5DROP TABLE statement 4-19Dual BYNETs 9-1, 9-9Dynamic Data Exchange. See DDE
E
Embedded SQL 5-20Encryption 11-7ESCON channel connectivity 2-3, 2-4,
2-5, 2-11Exclusion join
described 5-13EXECUTE statement 3-13, 8-5EXPLAIN statement 8-6
F
Fallback tables 9-1, 9-3FastExport utility 2-30FastLoad utility 2-30Fault tolerance 9-1
hardware 9-1, 9-9software 9-1, 9-2
FETCH CURSOR 5-21Fifth normal form. See Normal form,
5NFFile system 2-16, 2-25First normal form
See Normal form, 1NF
Introduction to the Teradata RDBMS for UNIX
Foreign key 3-3, 3-9Fourth generation languages 2-22,
2-23Fourth normal form. See Normal form,
4NFFull functional dependence 3-3Functional dependence 3-3
G
Gateway Control utility 12-21gncApply 2-13, 2-14GRANT LOGON statement 11-8
restrictions 11-9Groups
defining 5-12guidelines for selecting, 4-17
H
Hardware requirementsIBM channel-attached clients 13-4network-attached clients 13-5
Hash Join 5-13Hash value
processing 2-17Host Utility. See HUT
I
Index 4-9AMP usage 2-17creating 4-18creating primary 4-18creating secondary 4-18dropping 4-19processing 2-17
INSERT statement 5-16
Index-3

Index
Index-4
populating tables 5-16ISO/OSI 2-11
J
Join 3-3dependency 3-3
Join index 4-10Joins
types of 5-13Journaling 9-1, 9-6
down AMP recovery 9-6permanent 9-6transaction 10-1transient 9-6
L
Lock manager 10-5Locking Logger 2-39Locks
concept 10-5deadlocks 10-8HUT 10-9
characteristics 10-9types 10-9
levels 10-6automatic 10-8
lost updates 10-6types 10-7
access 10-7exclusive 10-7read 10-7write 10-7
Why required? 10-6Logical data independence 6-5Logical operators 5-5
AND 5-5NOT 5-5OR 5-5
Logon policies 11-3
Introduction to the Teradata RDBMS for UNIX
Lost update anomaly 10-6
M
Macros 3-1, 3-13application development 8-4creating 3-13, 8-4deleting 3-14, 8-5executing 8-5modifying 3-14, 8-5SQL 3-13using 3-13
Micro Operating System Interface. See MOSI
Micro TDP. See MTDPMicro Teradata Director Program. See
MTDPMonitoring 12-11MOSI 2-27
functions 2-27MultiLoad utility 2-30Multivalued dependence 3-3
N
Namesfully qualified 5-8
Nesting subqueries 5-14Nonunique Primary Index 4-14Nonunique secondary index 4-17Non-unique Secondary Index. See
NUSINormal form 3-6
1NF 3-62NF 3-63NF 3-74NF 3-85NF 3-8BCNF 3-8fifth 3-8

Index
first 3-6fourth 3-8PJ/NF 3-8projection-join 3-8second 3-6third 3-7
Normalization 3-4NUSI 4-11
O
ODBC 2-28, 2-29, 13-5Open Database Connectivity. See
ODBCOperators
partial string matching 5-5relational algebra 5-2
Optimizing SQLEXPLAIN statement 8-6
P
Parallelstep execution 2-16
Parent key 3-9Parse tree 2-13Parser
processing example 2-15Passwords 11-5Performance 2-25
improvements 13-2scalability 2-25
Performance Monitor 2-39Performance Monitor utility. See PMPerformance Monitor/Application
Programming Interface. See PM/API
Physical accesscontrolling 11-13
Plastic steps 2-14
Introduction to the Teradata RDBMS for UNIX
PM 12-21PM/API 12-20Preprocessor2 2-28, 5-20Primary index 4-10
attributes 4-13creating 4-18guidelines for selection 4-14nonunique 4-14unique 4-14
Primary key 3-2, 3-9
R
RACF 11-5RAID 9-9
disk units 9-1, 9-9RAID5 2-25
RCC views 7-5RDBMS
concurrency control 10-1RDBMS. See Teradata DBSRecovering data 9-7Recovery 10-1
DBS 10-10down AMP 10-11single transaction 10-10system and media 10-10transaction 10-10
Recovery Control Catalog. See RCCRedundant Array of Inexpensive Disks
- Level 5. See RAID5Redundant Array of Inexpensive
Disks. See RAIDReferential integrity 3-1, 3-9Relation 3-1
cardinality 3-1degree 3-1
Relational algebra 3-2Relational algebra operators
DIVISION 5-2INTERSECT 5-2JOIN 5-2
Index-5

Index
Index-6
PRODUCT 5-2PROJECT 5-2SELECT 5-2UNION 5-2
Relational Database Management System. See RDBMS
REPLACE MACRO statement 3-14, 8-5
REPLACE VIEW statement 6-3Request
cache 2-13dispatcher 2-8handler 1-1multiple 2-17packaging 2-26
Resolver tree 2-13Restarts
system 10-10Results table
order 5-12REVOKE LOGON statement 11-8ROLLBACK statement 9-7ROLLFORWARD statement 9-7Row 3-1RowID join, described 5-13
S
Scalability 2-25, 13-2Second normal form. See Normal form,
2NFSecondary index 4-10, 4-15, 4-17
advantages of, 4-16creating 4-18journaling 4-15subtables 4-15
Securityaccess 11-12C2 11-7identifying needs 11-13policy 11-1, 11-12TDP 11-5
Introduction to the Teradata RDBMS for UNIX
tools 11-1SELECT statement 5-2, 5-9
comparison operators 5-11defining groups 5-12GROUP BY clause 5-12HAVING clause 5-12JOIN operator 5-13logical operators 5-11nesting subqueries 5-14ORDER BY clause 5-12relational algebra operators 5-2selecting all rows 5-9selecting columns 5-9selecting specific rows 5-10specifying results order 5-12WHERE clause 5-13
Self-join, described 5-13Server
software 2-8Session
control 2-11, 2-27controller 2-8management 12-8
account numbers 12-8passwords 12-8tdpid 12-8user names 12-8
Set operators 5-6INTERSECT 5-6MINUS 5-6UNION 5-6
Set theory 3-1Shared information architecture. See
SIASIA 1-2, 1-3Space allocation 12-2SQL 1-4, 1-6, 2-18
aggregate operators 5-4ANSI standard language 2-18application development 5-20arithmetic functions 5-7arithmetic operators 5-3comparison operators 5-4concatenation operator 5-6

Index
cursor 5-21data definition statements 4-1data manipulation statements 5-1data types 4-2DELETE statement 5-19dispatcher 1-6, 2-14embedded 5-20embedded SQL 2-28expressions 5-3FETCH INTO statement 5-21generator 2-14INSERT statement 5-1, 5-16lexicon 2-19logical operators 5-5optimizer 3-2parser 1-6, 2-8, 2-13preprocessor 2-28request packaging 2-26rules for writing statements 2-19SELECT statement 5-1, 5-2set operators 5-6string functions 5-6string matching operators 5-5syntaxer 2-8, 2-13UPDATE statement 5-1, 5-18
Stepdispatching 2-15parallel execution 2-16placing on BYNET 2-15processing 2-16receiving 2-15sending to AMPs 2-17
Storage capacitiesDBS 13-3servers 13-3
Structured Query Language. See SQLSubqueries
nesting 5-14System
integritytools 11-2
maintenance facilities 9-1System Management Facility. See SMFSystem status 12-12
Introduction to the Teradata RDBMS for UNIX
T
Table 3-1adding column 4-8altering 4-8creating 4-6creating index 4-18dropping 4-19dropping column 4-8rebuild facility 9-8rebuilding 9-8
TCP/IP 2-11TDP 1-1, 1-6, 2-26, 2-27, 12-20
functions 2-27MTDP 2-27
TDP User Transaction Monitor. See TDPTMON
TDPLGUX logon exit 11-5TDPTMON 12-20Teradata DBS
archiving and restoring 2-30database software 1-1design 1-2design philosophy and goals 1-1disk handling system 1-1file system 1-1scalability 1-1security 11-1shared architecture 1-1shared information architecture 1-1
Teradata Director Program. See TDPTeradata Manager 2-39, 12-11Teradata Operating System. See TOSTeradata SQL. See SQLThird normal form. See Normal form,
3NFTOS 2-8Transactions
concept 10-2explicit 10-4implicit 10-4serializability 10-2
Transitive dependence 3-3
Index-7

Index
Index-8
Transmission Control Protocol/Internet Protocol. See TCP/IP
Transparency Series/Application Program Interface. See TS/API
TS/API 8-11Tuple 3-1Two Phase Commit protocol. See 2PCTwo-Phase Locking Protocol. See 2PL
U
Unique primary index 4-14Unique Primary Index. See UPIUnique secondary index 4-17UPDATE statement 5-18Updates
undo 10-4UPI 4-11User
creating 12-2names 11-3
V
Views 6-1access to database 6-4administrator
AccessLog 7-4AccLogRules 7-4AllRights 7-4AllSpace 7-4AMPUsage 7-4Children 7-4DeleteAccessLog 7-4DiskSpace 7-4ErrorLog 7-4LogOnOff 7-4LogonRules 7-4ResUseView 7-4SecurityLog 7-4
Introduction to the Teradata RDBMS for UNIX
SessionInfo 7-4TableSize 7-4
altering 6-3creating 6-2data independence 6-5RCC
Events 7-5Events_Configuration 7-5Events_Media 7-5Journals 7-5
restrictions on DML operations 6-6security 6-4why use them? 6-4
Virtual processor. See vprocVproc
AMP 2-10PE 2-9
W
WinCLI 2-26, 2-28, 2-29Windows Call Level Interface. See
WinCLI

Number:
Title:
Cut
User Feedback Form
NCR welimprove
Circle the
Ease of u
Accuracy
Clarity
Complete
Organiza
Appearan
Examples
Illustratio
Job perfo
Question
Overall sa
Indicate t
❑
❑
❑
❑
❑
❑
Impr
Impr
Impr
Impr
Mak
Mak
Introduction to the Teradata RDBMS for UNIX
sue: ate:
IsBD10-4955-Bcomes your feedback on this publication. Yoour information products.
numbers below that best represent your op
se
ness
tion
ce
ns
rmance
resolution
tisfaction
5
5
5
5
5
5
5
5
5
5
5
4
4
4
4
4
4
4
4
4
4
4
3
3
3
3
3
3
3
3
3
3
3
2
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
he ways you feel we could improve this pub
ove the table of contents
ove the overall / introduction
ove the organization
ove the index
e it less technical
e it more concise / brief
❑
❑
❑
❑
❑
❑
D01.00.00
ur comments can be of great v
inion of this publication.
5 = Excellen4 = Good3 = Adequa2 = Fair1 = Poor
0 = Not Ap
lication.
Add more /better quick r
Add more examples
Add more illustrations
Add more step-by-step pr
Add more troubleshooting
Add more detail
May 29, 1998
alue in helping us
t
te
plicable
eference aids
ocedures
information

Fold
Fold
Cut
NO POSTAGENECESSARY
IF MAILEDIN THE
UNITED STATES
BUSINESS REPLY MAILPOSTAGE WILL BE PAID BY ADDRESSEE
Write any additional comments you may have below and on additional sheets, if necessary. Include page numbers where applicable.
If we may contact you concerning your comments, please fill in the information below.
Name:
Organization:
Company:
Address:
Phone: Fax:
Thank you for your evaluation of this publication. Fold the form where indicated, tape (please do not staple), and drop in the mail.
F8763-0695
FIRST CLASS PERMIT NO. 3 DAYTON, OHIO
NCR CORPORATIONINFORMATION ENGINEERING, DEPT 7012100 NORTH SEPULVEDA BOULEVARDEL SEGUNDO, CA 90245-4361U.S.A.

















![SINGLE REPOSITORY FOR SOFTWARE COMPONENT SELECTION … · FastExport data is exported from Teradata RDBMS to Flat Files or Tables etc [18]. 2. LITERATURE SURVEY Component Based Software](https://static.fdocuments.us/doc/165x107/5fb14fd612abe26af27dd85d/single-repository-for-software-component-selection-fastexport-data-is-exported-from.jpg)
