
Stream Computing of Lattice - Boltzmann Method on Intel ...
26
Takaaki Miyajima , Tomohiro Ueno and Kentaro Sano Processor Research Team, RIKEN Center for Computational Science, Kobe, Hyogo, 650-0047, Japan Stream Computing of Lattice- Boltzmann Method on Intel Programmable Accelerator Card
Transcript of Stream Computing of Lattice - Boltzmann Method on Intel ...

Takaaki Miyajima, Tomohiro Ueno and Kentaro Sano
Processor Research Team,RIKEN Center for Computational Science,
Kobe, Hyogo, 650-0047, Japan
Stream Computing of Lattice-Boltzmann Method on Intel
Programmable Accelerator Card

2
Motivation and Goal: Provides a common platform for streaming computation with multiple FPGAs
Our platform Overview Intel PAC (Programmable Accelerator Card)Hardware: Arria10 FPGA + I/O + PCIe Software: Open Programmable Acceleration Engine
AFU Shell: DMA transfer API Application: Lattice Boltzmann Method
Summary
Agenda
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

3
Motivation Although FPGA gathers increasing attention in HPC area,
is still low. Especially for multiple FPGAs cluster.We don’t want to reinvent the wheel (Device driver, DMAC, Bad for collaborative research :(
Goal: Provides a common platform for streaming computation with multiple FPGAs. Common software interface Common hardware modules Portable bitstream Good for collaborative research :)
Motivation and goal of our research
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
Presenter
Presentation Notes
Concept, objective and goal are important.

44th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
Our platform
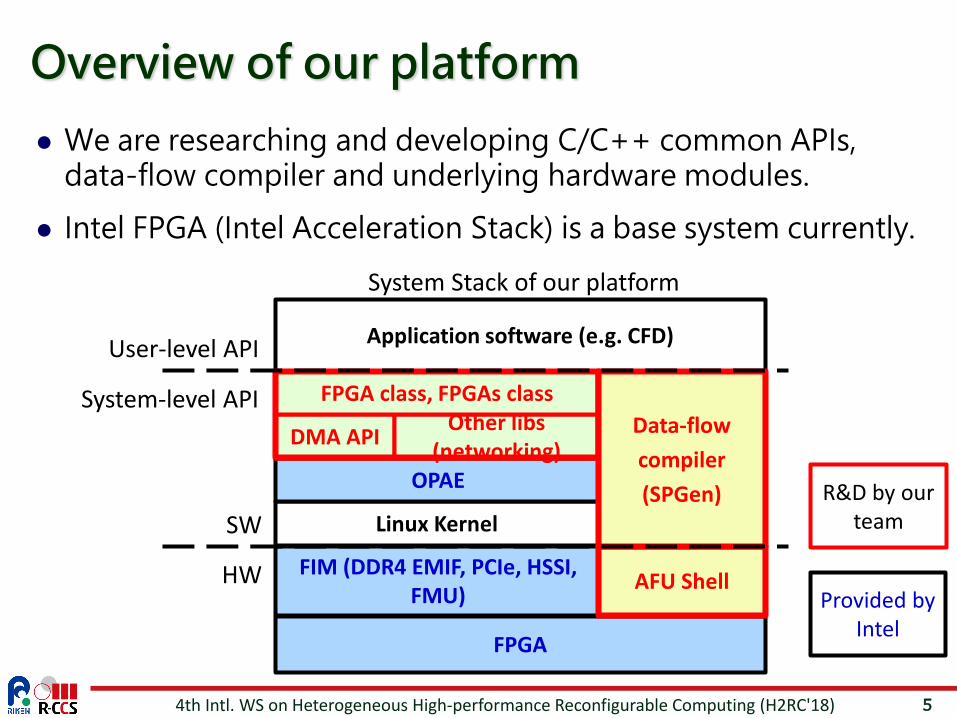
5
We are researching and developing C/C++ common APIs, data-flow compiler and underlying hardware modules.
Intel FPGA (Intel Acceleration Stack) is a base system currently.
Overview of our platform
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
Application software (e.g. CFD)
FPGA
Linux Kernel
FIM (DDR4 EMIF, PCIe, HSSI, FMU) AFU Shell
OPAE
DMA API Other libs (networking)
FPGA class, FPGAs classData-flow compiler(SPGen)
System Stack of our platform
HW
SWR&D by our
team
Provided by Intel
User-level API
System-level API

6
IAS is a robust collection of software, firmware, and tools to make it easier to develop and deploy Intel FPGAs.
SW: Open Program-mable AccelerationEngine(OPAE)
HW: Intel Programma-ble FPGA Card. (Accelerator Function unitincluding CCI-P, partialreconfiguration regionand so on.)
Intel Acceleration Stack (IAS)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

7
Intel Programmable Accelerator Card
PAC = PCIe-base FPGA board
FPGA: Intel Arria 10 GX 10AX115N2F40E2LG SERDES transceiver
(15 Gbps per port at maximum) 1150K Logic elements
(Speed grade: -2L) 53 Mb Embedded Memory
Memory 8 GB DDR4, 2 channels
External Port PCIe Gen3 x8 1X QSFP (4X 10GbE or 40GbE)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
Appearance of PAC
Substrate of PAC
Block diagram
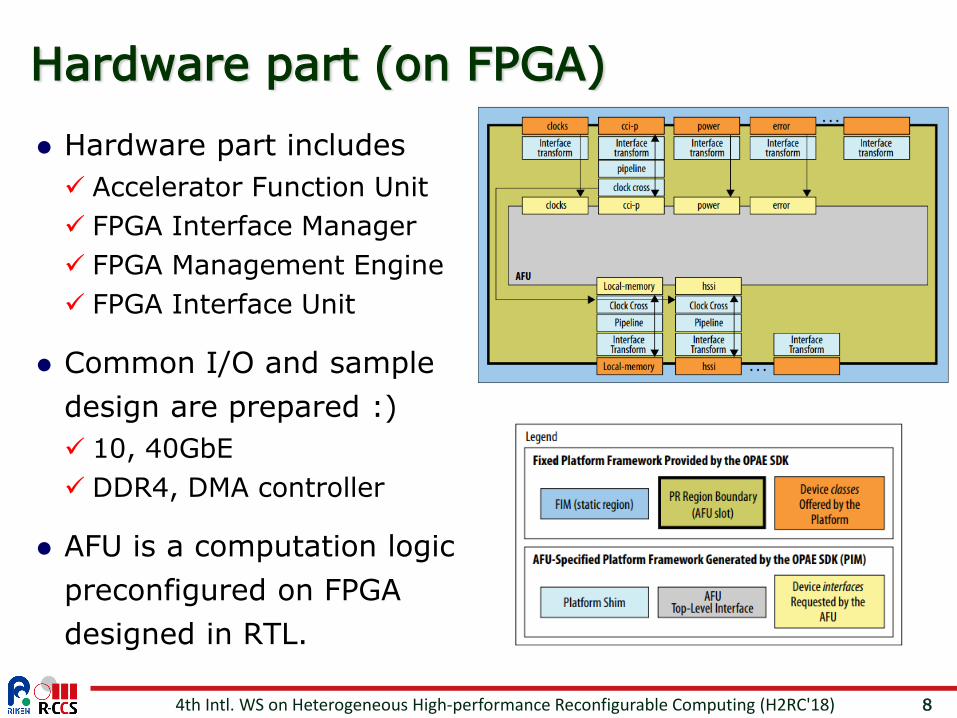
8
Hardware part (on FPGA)
Hardware part includes Accelerator Function Unit FPGA Interface Manager FPGA Management Engine FPGA Interface Unit
Common I/O and sample design are prepared :) 10, 40GbE DDR4, DMA controller
AFU is a computation logic preconfigured on FPGA designed in RTL.
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

9
Accelerator Functional Unit (AFU)
AFU is a computation logic preconfigured on FPGA. The logic is designed in RTL and synthesized into a bitstream.
It contains AF and control and status registers. It represents a resource discoverable and usable by your applications. fpgaconfis provided to reconfigure an FPGA using a bitstream. 4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
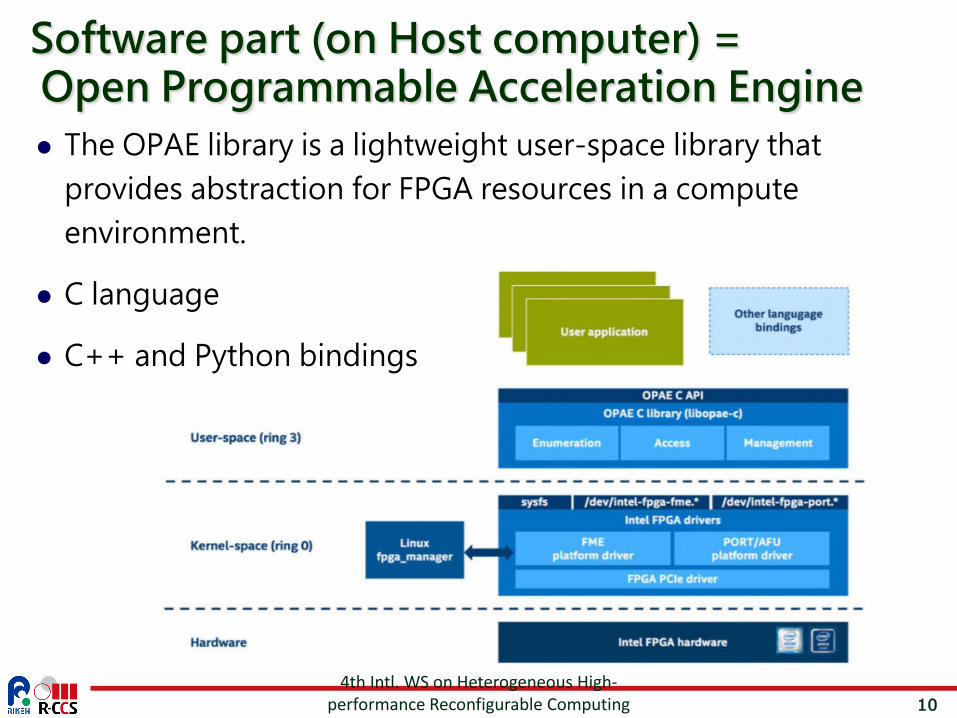
10
The OPAE library is a lightweight user-space library that provides abstraction for FPGA resources in a compute environment.
C language
C++ and Python bindings
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing
Software part (on Host computer) =Open Programmable Acceleration Engine
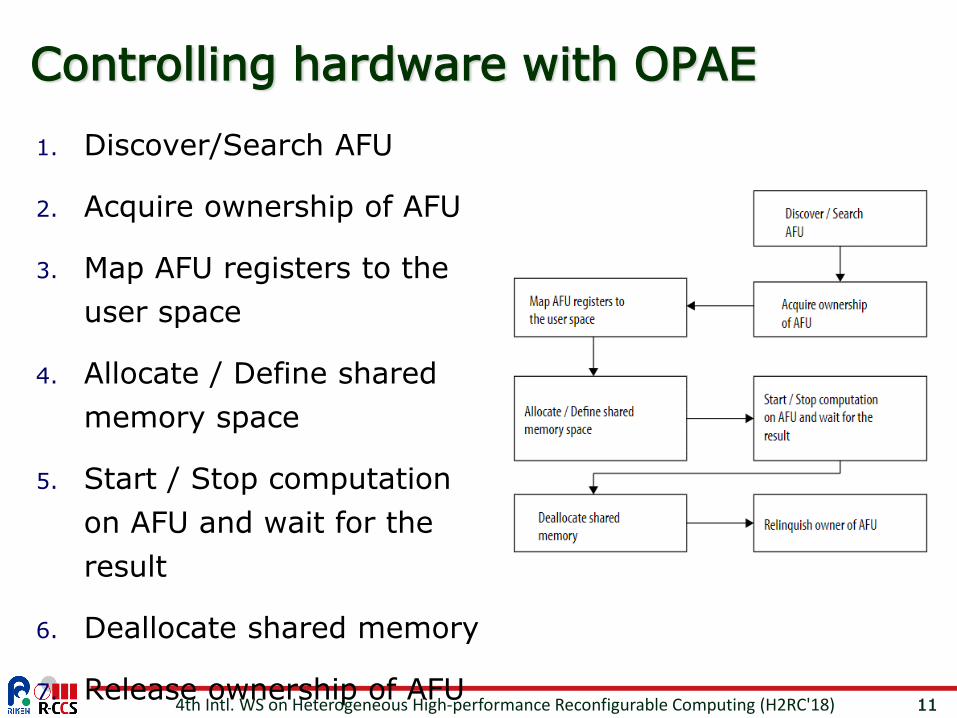
11
Controlling hardware with OPAE
1. Discover/Search AFU
2. Acquire ownership of AFU
3. Map AFU registers to the user space
4. Allocate / Define shared memory space
5. Start / Stop computation on AFU and wait for the result
6. Deallocate shared memory
7. Release ownership of AFU4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

12
Board Support Package (BSP) is provided by FPGA vendor to use OpenCL on their boards.
IAS is more flexible than BSP and gives the users more responsibility. No limitations of BSP. No need to write OpenCL runtime. Need to write almost everything...
Requires more comprehensive system-wide knowledge e.g. DMA controller and drivers.
Difference between BSP
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

134th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
AFU Shell and DMA Transfer API

14
AFU Shell is a base hardware of our platform. includes two DMA controller and computing core. Semi-automated design flow for FIM & OPAE 1.1beta "make (for spgen); make embed generate makegbs (for
AFU Shell for Intel PAC w/ Arria10
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
FPGA Board (PAC)PCIe (Host CPU's memory)
FIMDDR4A EMIF DDR4B EMIF
Fabric
PCIe Gen3 x8 EP
FME
PR
HSSI PHY Mode CtrlPlatform
Management
HSSI PHY
HSSI PLL
HSSI Reset
HSSI Reconf
HSSI Controller
FIU
HSSI
Local Memory
DDR4 mems
QSF
P+
Arria10 FPGA
PCIe host
M2S DMA
Mem
ory
inte
rcon
nect
DDR4 EMIF
S2M DMA
Switch 1
Switch 2
StreamComputing
Coregenerated by
SPGen
AFU Shell
AFU SlotAvailable to AFU
ALMs 391,213 (92%)M20K 510,04 (94%)DSPs 1,518 (100%) H
SSI I
nter
face
Local Memory Interface
CCI-P Interface, Clocks, Power, Error

15
DMA Controller is based on mSGDMA TX DMAC and RX DMAC are separated for flexibility
DMA Transfer API (Synchronous) fpga_result afuShellDMATransfer(
void* dst, const void* src, size_t count, dma_transfer_type_t type )
Four types of data transfer are supported HOST→FPGA, FPGA→HOST, FPGA→FPGA, HOST→HOST
DMA hardware and API for AFU Shell
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
FPGA/module ALMs Registers BRAM Kbits DSPsafuShell (2 DMACs) 2905 3055 135040 27

16
mQsys_Core8
src
snk
mAvlsT_widthConverter_16to8snk
src
mAvlsT_widthConverter_8to16
snk
src
M2S DMABBB
m
msrc
s
EMIF Clock CrossingBridge A sm
S2M DMABBB
m
msnk
s
Host ReadPipelineBridge
sm
EMIF Clock CrossingBridge B sm
Host WriteResponse
Bridgesm
CsRPipelineBridge
s
m
streaming DMA AFU
DFH
m mAvlsT_switch_1to2to1
s
afuShellDMATransfer( 0x0, 0x100, 100, FPGA_TO_FPGA)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

17
mQsys_Core8
src
snk
mAvlsT_widthConverter_16to8snk
src
mAvlsT_widthConverter_8to16
snk
src
M2S DMABBB
m
msrc
s
EMIF Clock CrossingBridge A sm
S2M DMABBB
m
msnk
s
Host ReadPipelineBridge
sm
EMIF Clock CrossingBridge B sm
Host WriteResponse
Bridgesm
CsRPipelineBridge
s
m
streaming DMA AFU
DFH
m mAvlsT_switch_1to2to1
s
afuShellDMATransfer( 0x0, host_dst, 100, FPGA_TO_HOST)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
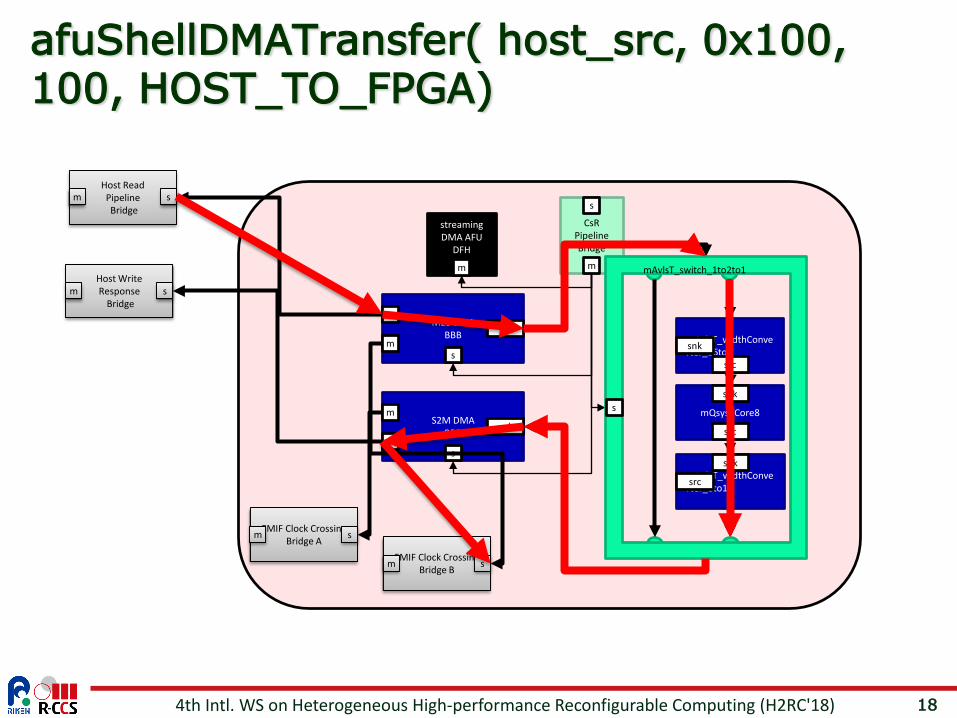
18
mQsys_Core8
src
snk
mAvlsT_widthConverter_16to8snk
src
mAvlsT_widthConverter_8to16
snk
src
M2S DMABBB
m
msrc
s
EMIF Clock CrossingBridge A sm
S2M DMABBB
m
msnk
s
Host ReadPipelineBridge
sm
EMIF Clock CrossingBridge B sm
Host WriteResponse
Bridgesm
CsRPipelineBridge
s
m
streaming DMA AFU
DFH
m mAvlsT_switch_1to2to1
s
afuShellDMATransfer( host_src, 0x100, 100, HOST_TO_FPGA)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
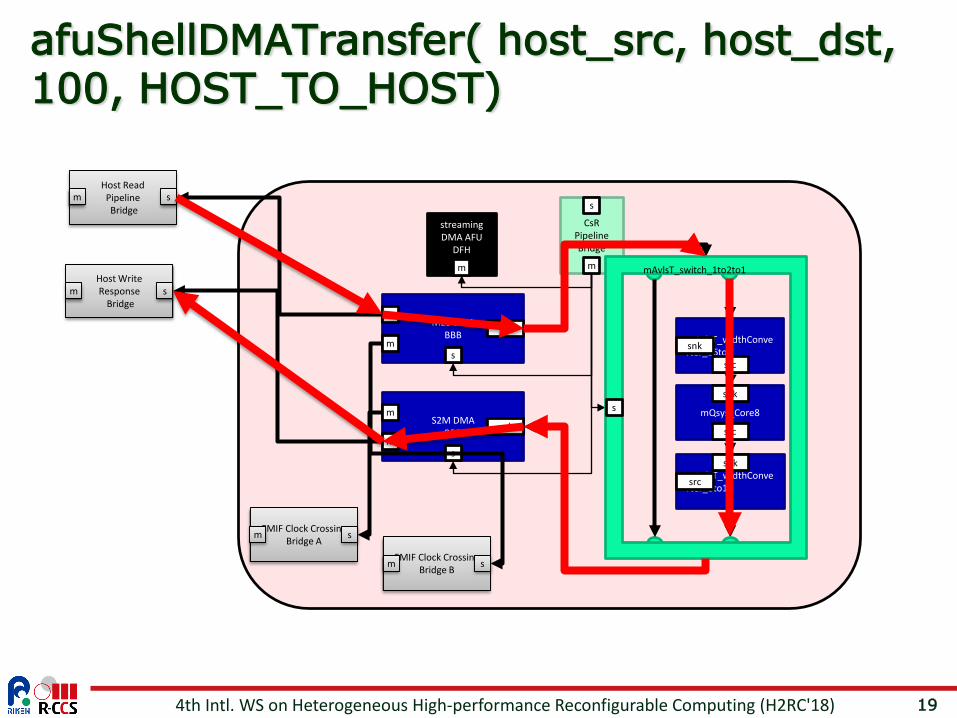
19
mQsys_Core8
src
snk
mAvlsT_widthConverter_16to8snk
src
mAvlsT_widthConverter_8to16
snk
src
M2S DMABBB
m
msrc
s
EMIF Clock CrossingBridge A sm
S2M DMABBB
m
msnk
s
Host ReadPipelineBridge
sm
EMIF Clock CrossingBridge B sm
Host WriteResponse
Bridgesm
CsRPipelineBridge
s
m
streaming DMA AFU
DFH
m mAvlsT_switch_1to2to1
s
afuShellDMATransfer( host_src, host_dst, 100, HOST_TO_HOST)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
20
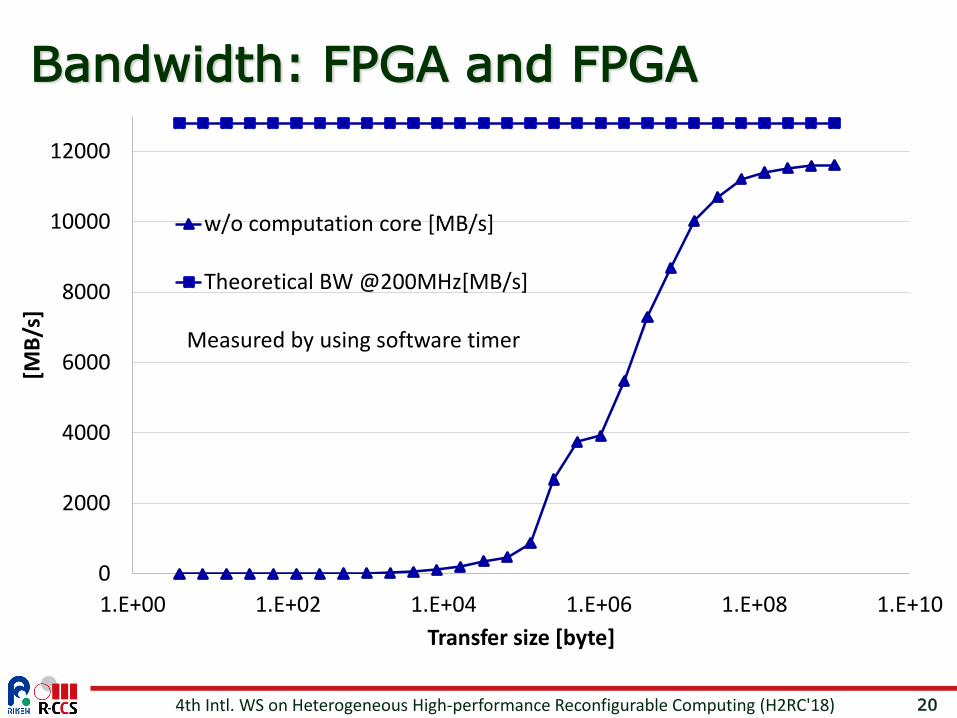
Bandwidth: FPGA and FPGA
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
0
2000
4000
6000
8000
10000
12000
1.E+00 1.E+02 1.E+04 1.E+06 1.E+08 1.E+10
[MB/
s]
Transfer size [byte]
w/o computation core [MB/s]
Theoretical BW @200MHz[MB/s]
Measured by using software timer
21
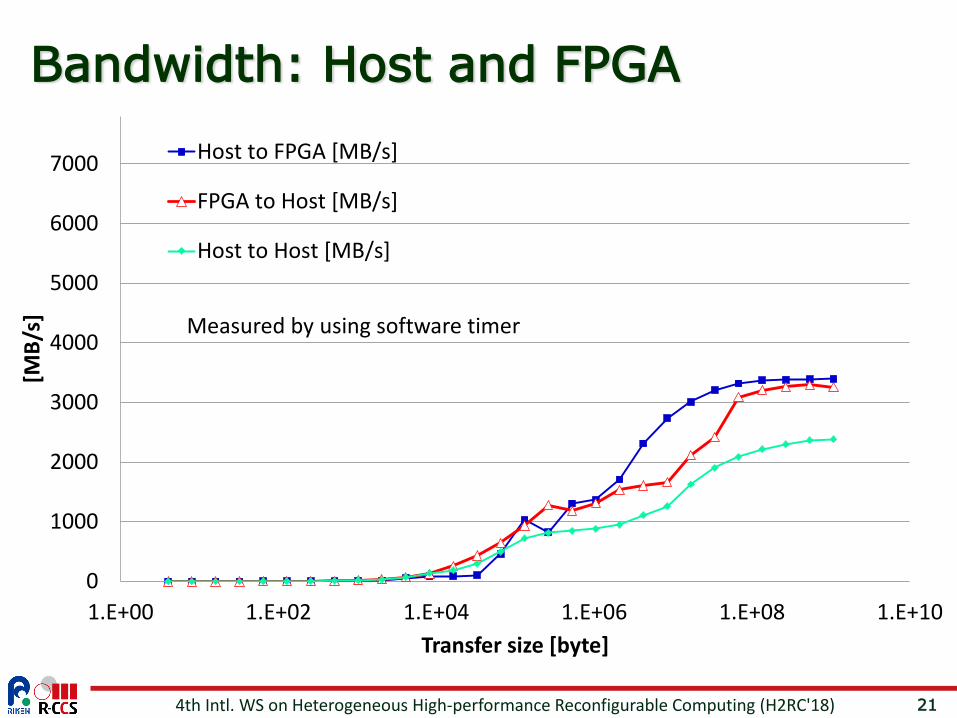
Bandwidth: Host and FPGA
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
0
1000
2000
3000
4000
5000
6000
7000
1.E+00 1.E+02 1.E+04 1.E+06 1.E+08 1.E+10
[MB/
s]
Transfer size [byte]
Host to FPGA [MB/s]
FPGA to Host [MB/s]
Host to Host [MB/s]
Measured by using software timer

22
We put LBM computing core [1] into the AFU Shell 131 Single precision floating-point / LBM coreWorking frequency: 200MHz Input width: 40byte Required bandwidth: 200MHz * 40byte = 8000 MB/s Theoretical perf. : 200MHz * 131 FP = 26.2 GFlops / LBM
Our LBM core can improveperformance by cascadingthe core withoutincreasing input bandwidth.
Sample app: Lattice Boltzmann Method
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
Example result of our LBM
[1] K. Sano and S. Yamamoto, “Fpga-based scalable and powerefficient fluid simulation sing floating-point dsp blocks,” IEEE Transactions on Parallel and Distributed Systems, vol. 28, no. 10, pp. 2823–2837, Oct 2017.

23
Eight LBM can be cascaded, currently
Sustained performance Initial data on a FPGA DRAM channel go through LBM core,
back to the other FPGA DRAM channel. Ratio of stall cycles to total cycles is measured by HW counter
it is 1.04 e-05 when the input data size is 1.92MB Thus, sustained performance for each implementation is the
as theoretical peak.
Performance of LBM
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
# of cascaded core 1 2 4 8ALMs 2.85 1.94 1.06 5.53Registers 5.62 3.85 2.3 11.06BRAM Kbits 11.1 7.66 4.78 22.13DSPs 22.1 15.28 9.74 44.26
Theoretical performance [Gflops] 26.2 52.4 104.8 209.6

24
LBM core bandwidth (FPGA and FPGA)
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)
0
2000
4000
6000
8000
10000
12000
1.E+00 1.E+02 1.E+04 1.E+06 1.E+08 1.E+10
[MB/
s]
Transfer size [byte]
w/o computation core [MB/s]Theoretical BW @200MHz[MB/s]w/ computation core [MB/s]Theoretical BW[MB/s]

25
We are researching and developing a common platform for streaming computation with multiple FPGAs based on Intel PAC
Intel PAC consist of Arria10 FPGA (HW) and OPAE (SW)
AFU Shell is a base hardware of our platform including DMA Controller and API. afuShellDMATransfer ()
Sample application: Lattice Bolztmann Method Sustained performance is equal to theoretical performance.
Need collaboration :)
Summary
4th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)

264th Intl. WS on Heterogeneous High-performance Reconfigurable Computing (H2RC'18)











![Improving computational efficiency of lattice Boltzmann ... · 1.1 The lattice Boltzmann method The lattice Boltzmann method [7] [20] is a relative new technique to CFD. Classical](https://static.fdocuments.us/doc/165x107/5f03952b7e708231d409c3df/improving-computational-efficiency-of-lattice-boltzmann-11-the-lattice-boltzmann.jpg)






