
Stories About Spark, HPC and Barcelona by Jordi Torres
63
STORIES ABOUT SPARK, HPC & BARCELONA Jordi Torres Barcelona Supercomputing Center UPC Barcelona Tech www.JordiTorres.eu - @JordiTorresBCN
-
Upload
spark-summit -
Category
Data & Analytics
-
view
1.360 -
download
1
Transcript of Stories About Spark, HPC and Barcelona by Jordi Torres

STORIES ABOUT SPARK, HPC & BARCELONAJordi TorresBarcelona Supercomputing CenterUPC Barcelona Techwww.JordiTorres.eu - @JordiTorresBCN

Why HPC?

Scientists always needed the best instruments which technology of the time allowed to build
Microscope (Santiago Ramon y Cajal) Large Hadron Collider (CERN)

And supercomputers today can be considered as the ultimate scientific
instrument that enables progress in science

The Evolution of The Research Paradigm
High Performance Computing means Numerical Simulation and Big Data Analysis that allows
Reduce expense Avoid dangerous experiments Help to build knowledge where experiments are impossible or not affordable

HPC is an enabler for all scientific fields
Life Sciences & Medicine
Earth Sciences
Astro, High Energy & Plasma Physics
Materials, Chemistry & Nanoscience
Engineering Neuroscience

Emergent focus on big data requires a transition of computing facilities into a data-centric paradigm too
However, traditional HPC systems are designed according to the compute-centric paradigm

We have experimented with this in our HPC facility in Barcelona.
And this is what I’m going to talk about today!
How can traditional HPC existing infrastructure evolve to meet the new demands?

What is HPC in Barcelona like?

In Barcelona HPC is without doubt …A team of 425 people(from 40 countries)

BSC scientific departmentsEARTH SCIENCES
LIFE SCIENCES
ENGINEERING SCIENCE
COMPUTER SCIENCES

Joint Research Centres with IT Companies
BSC-Microsoft Research Centre
BSC-IBM Technology Center for Supercomputing
Intel-BSC Exascale Lab
BSC-NVIDIA CUDA Center of Excellence

Our Supercomputer in BarcelonaMarenostrum
Supercomputer

Born inside a deconsecrated chapel

The Marenostrum 3 SupercomputerOver 1015 Floating Points Operations per second (Petaflop)
– Nearly 50,000 cores
– 100.8 TB of memory
– 2000 TB disk storage

The third of three brothers• 2004: MareNostrum 1
– Nearly 5x1013 Floating Points per second
– Nearly 5.000 cores– 236 TB disk storage
• 2006: MareNostrum 2– Nearly 1014 Floating
Points per second– Over 10.000 cores– 460 disk storage
• 2012: MareNostrum 3

Marenostrum ancestors in the chapelA parallel system inside the same chapel:
Grandparent:Processing capacity: Over 1000 operations-beats per minuteParallel system with 8 parallel typewriter units.
Grandmother:Storage capacity: over 100MbParallel Storage System with 14 drawer devices.

How could BSC meet new Big Data demands?

Until now, the habitual MN3 workloads have been numerical applications
• MN3 Basic software Stack:– OpenMP– MPI– Threads– …

How can MN3 evolve to meet new Big Data Analytics demand?
New module developed at BSC
MarenostrumSupercomputer+

SPARK4MN module• framework to enable Spark workloads over
IBM LSF Platform workload manager on MN3

Spark4MN in action
Lets go!

Spark4MN in action• We performed a System level Performance
Evaluation & Tuning to MN3• Example of some results:
– Speed-up– Scale-up– Parallelism

Example 1: Kmeans Speed-upMore dimensions smaller speed-up because of increased shuffling (same number of centroids to shuffle but bigger)
• Times for running k-means for 10 iterations.
• Problem size constant = 100GBs (10M1000D = 10M vectors of 1000 dimensions)
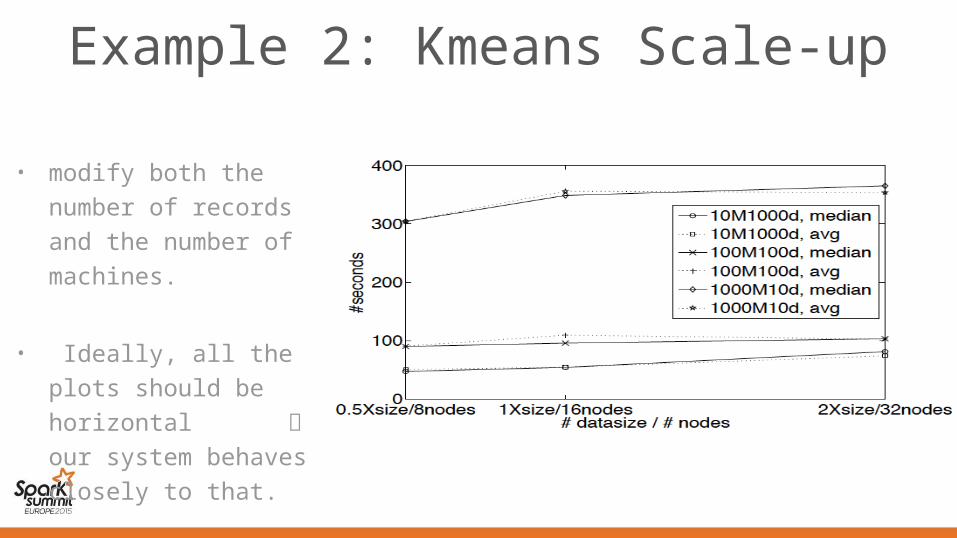
Example 2: Kmeans Scale-up
• modify both the number of records and the number of machines.
• Ideally, all the plots should be horizontal
our system behaves closely to that.

Example 3: Configuring task parallelismVarying the number of tasks over the same amount of cores
for k-means, the best-performing configuration is to have as many partitions as cores = 1 task per core is better!
• Median times for running k-means for 10 iterations with different number of partitions
• In our benchmarks the number of tasks is equal to the number of RDD partitions.

Example 3: Configuring task parallelism• Using Sort-by-key: a more intensive shuffling-intensive scenario
– We sort 1 billion records using 64 nodes & different partition sizes
– Contrary to the previous case, we observe speed-ups when there are 2 partitions per core

Exemple 4: sort-by-key• How many concurrent tasks an executor
can supervise?Having 2 8-core executors instead of 8 2-core ones, improves on the running time by a factor of 2.79 leaving all the other parameters the same.

More results on Friday at the Santa Clara conference!
2015 IEEE International Conference on Big Data October 29-November 1, Santa Clara, CA, USA

Spark and node level performance?

New Architecture Support for Big Data Analytics
Exponential increase in core countNever promising technologies (Hybrid Memory Cubes, NVRAM, etc)

Our Research Goal
Improve the node level performance of
state-of-the-art scale-out data
processing framework
+

Speed-up vs Executor threads
(*) Processor Intel Xeon E5-2697 (24 cores) & Spark 1.3

Data Processing Capacity scaling at large input dataset
The performance of Spark workloads degrades with large volumes of data due to substantial increase in garbage collection and file I/O time.
Spark workloads do not saturate the available bandwidth and hence their performance is bound on DRAM latency

More results on
• A. J. Awan, M. Brorsson, V. Vlassov and E. Ayguade, "Performance Characterization of In-Memory Data Analytics on a Modern Cloud Server", in 5th IEEE International Conference on Big Data and Cloud Computing (BDCloud), Aug 2015, Dalina, China (Best Paper Award)
• A. J. Awan, M. Brorsson, V. Vlassov and E. Ayguade, "How Data Volume Affects Spark Based Data Analytics on a Scale-up Server", in 6th International Workshop on Big Data Benchmarks, Performance Optimization and Emerging Hardware (BpoE), held in conjunction with 41st International Conference on Very Large Data Bases, Sep 2015, Hawaii, USA.

Next generation of HPC programming models and Spark?

BSC programming model COMPSs
– Sequential programming model
– Abstracts the application from the underlying distributed infrastructure
– Exploit the inherent parallelism at runtime

We are studying the comparison and interaction between these two programming
models in platforms like marenostrum 3
MarenostrumSupercomputer
MarenostrumSupercomputer

Profiling Spark with BSC’s HPC tools
• Relying on over 20 years HPC experience & tools for profiling
• Preliminary work: Developed the Hadoop Instrumentation Toolkit
CPU
Memory
Page Faults
processes and communication

Project ALOJA: Benchmarking Spark
• Open initiative to Explore and produce a systematic study of Hadoop/Spark efficiency on different SW and HW
• Online repository that allows compare, side by side all execution parameters ( 50,000+ runs over 100+ HW config.)

Big Data Analytics workloads at BSC?
(with Spark)

Preliminary work• Multimedia Big Data Computing: Work with three kinds of data at the same time
social network
relationships
audiovisualcontent metadata

Preliminary case study Multimodal Data Analytics systems
E.g. Latent User Attribute Inference to Predicting Desigual Followers

44
Example of tools created: VectorizationNecessary for visual similarity search, visual clustering, classification, etc.

45
Available in our github: bsc.spark.image scala> import bsc.spark.image.ImageUtils…scala> images = ImageUtils.seqFile("hdfs://...", sc);
scala> dictionary = ImageUtils.BoWDictionary(images);
scala> vectors = dictionary.getBags(images); … scala> val splits = vectors.randomSplit(Array(0.6, 0.4), seed = 11L)
scala> training = splits(0)
scala> test = splits(1)
scala> model = NaiveBayes.train(training, lambda = 1.0)…

Applications: Locality Sensitive Hashinge.g. near-replica detection (visual spam detection, copyright infringement)
PATCH 1
PATCH 2
PATCH 3
PATCH 4
KP1
KP2
KP3
KP4
feature detection
feature description
0000 0100 1100
0010 0110 1110
0011 0111 1111
features are sketched, embedded into a Hamming space
Similar features are hashed into similar buckets in a hash table
SIFT, SURF, ORB, etc.
0 1 1 0

Current work: Computer Vision
• Makes very productive use of (convolutional) neural networks • SIFT features became unnecessary (used for decades)

What next at BSC?

BSC vision:Giving computers a greater
ability to understand information, and to learn, to
reason, and act upon it

Old wine in a new bottle?
• the term itself dates from the 1950s. • periods of hype and high
expectations alternating with periods of setback and disappointment.
Artificial Intelligence
plays an important
role

Why Now?1. Along the explosion of
data …
now algorithms can be “trained” by exposing them to
large data sets that were previously unavailable.
2. And the computing power necessary to
implement these algorithms are now available

Evolution of computing powerFLOP/second
1988Cray Y-MP (8 processadors)
1998Cray T3E (1024 processadors)
2008Cray XT5 (15000 processadors)
~2019? (1x107 processadors

This new type of computing requires
DATA
SupercomputersResearch
Big DataTechnologies
Advanced Analytic
Algorithms
1. the continuous development of supercomputing systems
2. enabling the convergence of advanced analytic algorithms
3. and big data technologies

Today technologies & focus at BSC
COMPUTERVISION
Advanced Analytics
Algorithms

Cognitive Computing requires a transition of computing facilities into a new paradigm too
Name? … We use Cognitive Computing
Yesterday Today Tomorrow

And to finish… Welcome to Barcelona!

Welcome to our wonderful city
57

Welcome to our university
22 schools - 4K employees - 35K students

Welcome to our research center

Welcome to our everyday life
60

Welcome to our academic activities• Teaching Spark @ Master courses• Using Spark @ Final Master Thesis• Using Spark @ Research activity
• NEW Spark Book in Spanish• Editorial UOC • Presentation November 3, 2015
61
Foreword by Matei Zaharia

1000+ members
62
Welcome to our Spark Community

1000+ members
63
Thank you for your attention!Jordi Torres @JordiTorresBCN www.JordiTorres.eu
Welcome to our Spark Community


















