
Spring XD for Real-Time Hadoop Workload Analysis
35
© 2014 SpringOne 2GX. All rights reserved. Do not distribute without permission. Spring XD for Real-Time Hadoop Workload Analysis Vineet Goel Girish Lingappa Rodrigo Meneses
Transcript of Spring XD for Real-Time Hadoop Workload Analysis

© 2014 SpringOne 2GX. All rights reserved. Do not distribute without permission.
Spring XD for Real-Time Hadoop Workload Analysis Vineet Goel
Girish Lingappa Rodrigo Meneses

Project Experience
• The Problem Statement • The Environment • Architectural Components • Putting it All Together • Application & Use Cases • Demo
2

3

Problem Statement
• Allow real-time logs collection & analysis of jobs at a user or application level esp. in a multi-tenant Hadoop environment.
• Easier way to do real-time or near-real-time workload analysis for troubleshooting & better cluster utilization.
• Build a SQL-based system for interactive queries and analyzing trends.
• Build a reference architecture (not a commercial product) for any application log analysis.
4

5

Analytics Workbench (AWB)
• 1000-node cluster • Collaborative project with industry
leaders (Mellanox, Intel, Seagate) • Contains entire Apache Hadoop
based stack (Pivotal HD) • (HDFS, HBASE, PIG, HIVE)
• Mixed mode environment • Server config: Two 6-core CPUs, 48
GB RAM, 2 TB Drives
PIVOTAL

Analytics Workbench (AWB) Mission
• Provide a collaborative platform that is • Agile: Support platform for proving mixed mode
enterprise readiness at scale.
• Innovative : Showcase ground breaking data science.
• Accessible : Create a shared environment for rapid innovation of big data and cloud computing technologies.
• Educational : Provide a resource for educating developers, partners and customers on big data and cloud technologies
• www.analyticsworkbench.com

8

Real-Time Hadoop Log Analysis
• Real-Time: The time between the occurrence of an event and the use of the processed data
• Hadoop is a complex, multi-framework data platform • Applications & Workloads are complex in the cluster • Hadoop admin & operational management is complex • Admins require more than just cluster health monitoring • Multiple logs & locations to sift through • Hard to troubleshoot resource consumption of applications • Typically Reactive (after the fact) • Take action on FRESH data
9

About Hadoop Logs • Log collection for Hadoop YARN /
MapReduce applications
§ YARN daemons logs § Hadoop job history logs § Hadoop M/R task logs
10

11
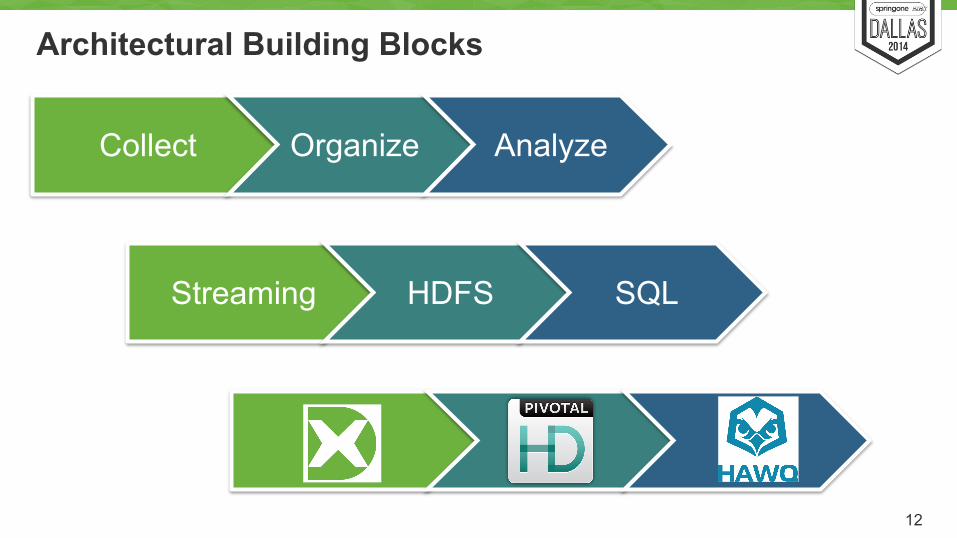
Architectural Building Blocks
12
Collect Organize Analyze
Streaming HDFS SQL

Spring XD • Unified Platform
• Ingestion and stream processing • Workflow and data export
• Developer Productivity • Modular Extensibility • Distributed Architecture • Portable Runtime • Proven Foundation
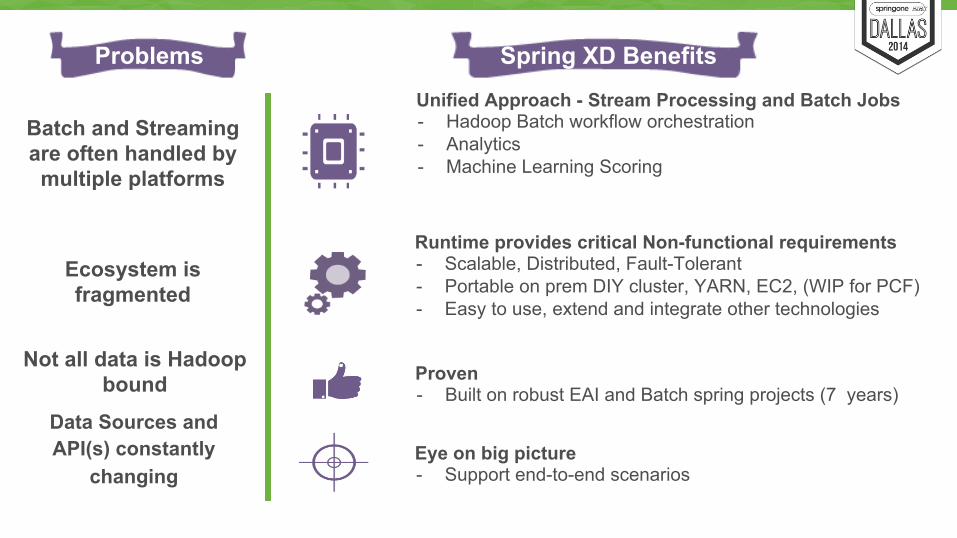
Problems
Batch and Streaming are often handled by multiple platforms
Unified Approach - Stream Processing and Batch Jobs - Hadoop Batch workflow orchestration - Analytics - Machine Learning Scoring
Ecosystem is fragmented
Runtime provides critical Non-functional requirements - Scalable, Distributed, Fault-Tolerant - Portable on prem DIY cluster, YARN, EC2, (WIP for PCF) - Easy to use, extend and integrate other technologies
Proven - Built on robust EAI and Batch spring projects (7 years)
Eye on big picture - Support end-to-end scenarios
Data Sources and API(s) constantly
changing
Spring XD Benefits
Not all data is Hadoop bound
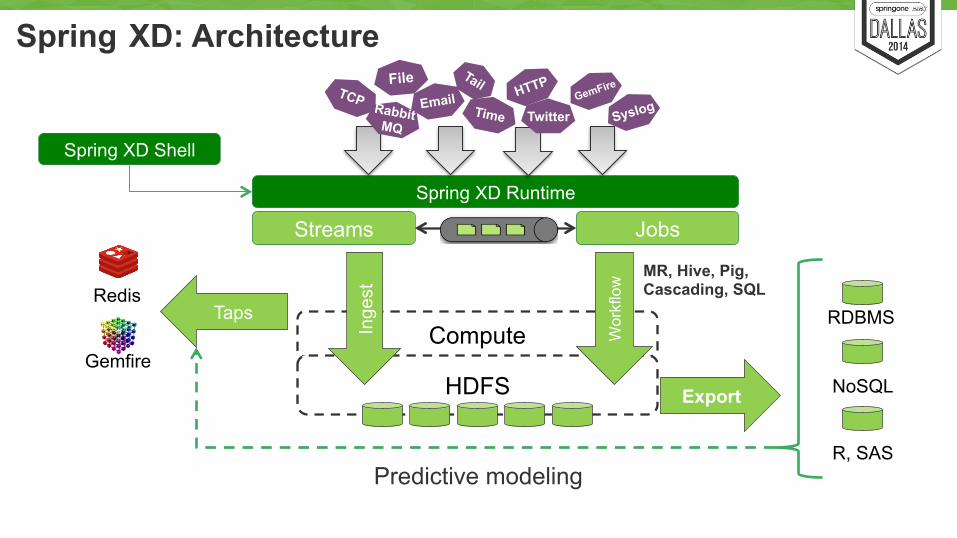
Taps Compute
HDFS
Wor
kflo
w
Export
Spring XD Runtime
Inge
st
Jobs
Export
RDBMS
NoSQL
R, SAS
Spring XD Shell
Streams
Redis
Gemfire
Predictive modeling
MR, Hive, Pig, Cascading, SQL
File GemFire
Email Rabbit MQ
Syslog Time Twitter
Spring XD: Architecture
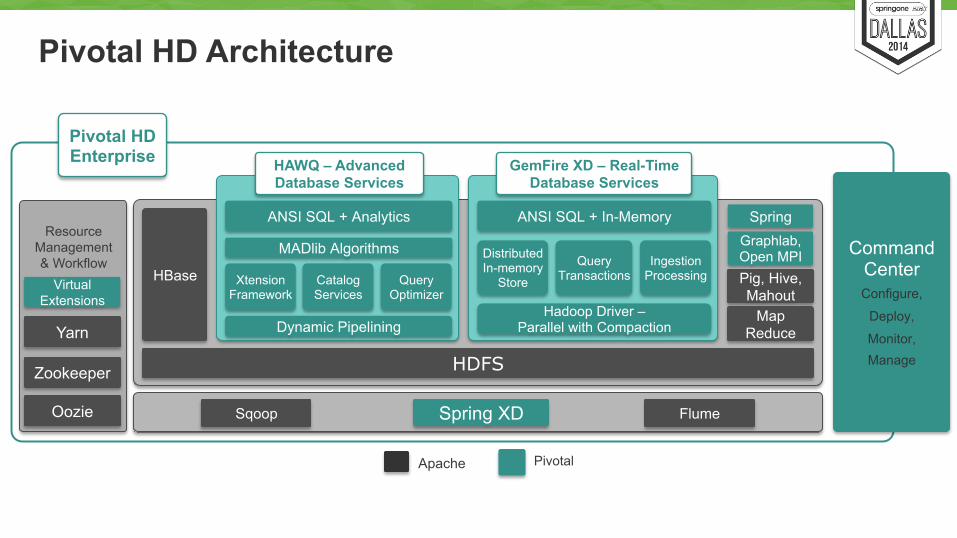
Pivotal HD Architecture
HDFS
HBase Pig, Hive, Mahout
Map Reduce
Sqoop Flume
Resource
Management & Workflow
Yarn
Zookeeper
Apache Pivotal
Command Center Configure,
Deploy,
Monitor, Manage
Spring XD
Pivotal HD Enterprise
Spring
Xtension Framework
Catalog Services
Query Optimizer
Dynamic Pipelining
ANSI SQL + Analytics
HAWQ – Advanced Database Services
Distributed In-memory
Store
Query Transactions
Ingestion Processing
Hadoop Driver – Parallel with Compaction
ANSI SQL + In-Memory
GemFire XD – Real-Time Database Services
MADlib Algorithms
Oozie
Virtual Extensions
Graphlab, Open MPI

HAWQ: Interactive Analytics
� SQL on Hadoop
� World-class query optimizer
� Interactive query
� Horizontal scalability
� Robust data management
� Common Hadoop formats
� Deep analytics
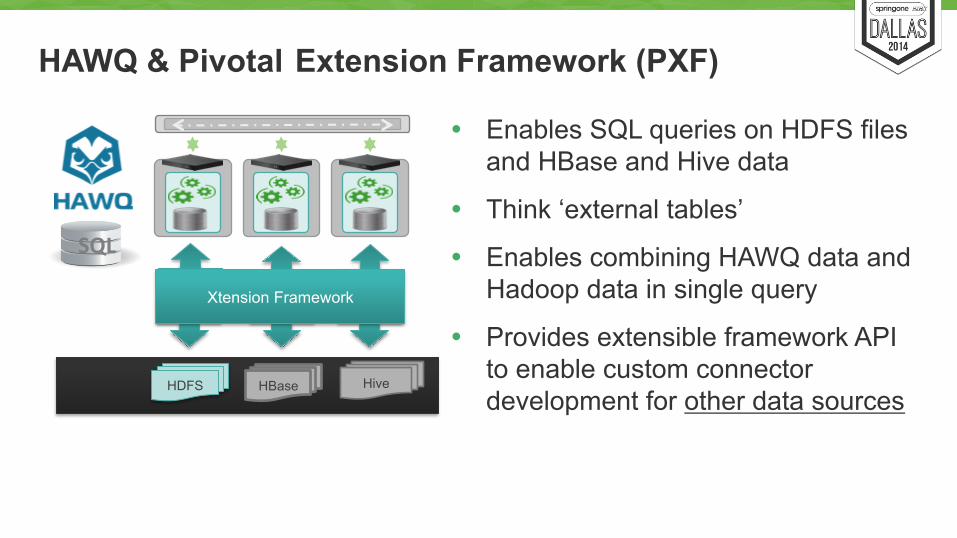
HAWQ & Pivotal Extension Framework (PXF)
� Enables SQL queries on HDFS files and HBase and Hive data
� Think ‘external tables’
� Enables combining HAWQ data and Hadoop data in single query
� Provides extensible framework API to enable custom connector development for other data sources
HDFS HBase Hive
Xtension Framework
SQL

19
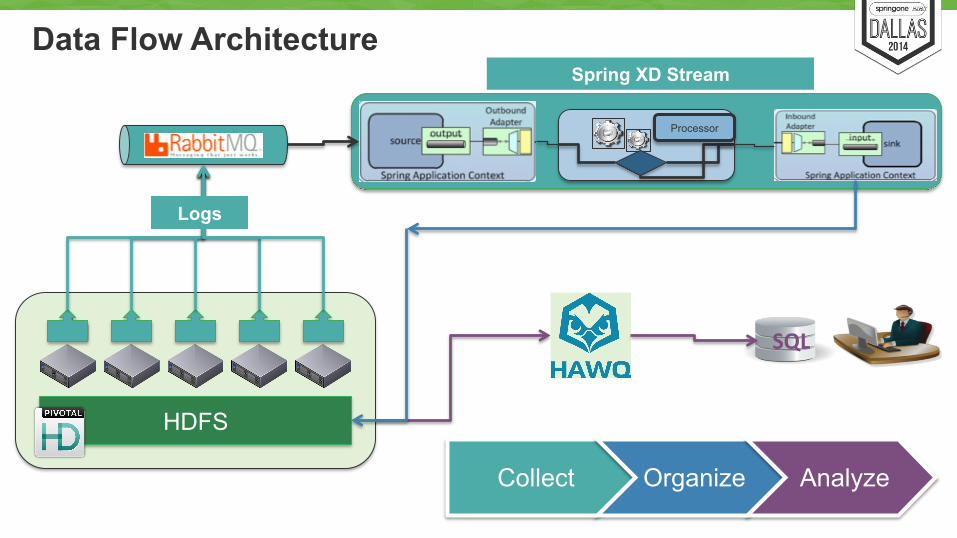
Data Flow Architecture
Processor
HDFS
SQL
Collect Organize Analyze
Logs
Spring XD Stream

HTTP Tail File Mail
Twi,er Gemfire Syslog TCP UDP JMS
RabbitMQ MQTT Trigger
Reactor TCP/UDP
Filter Transformer
Object-‐to-‐JSON JSON-‐to-‐Tuple
Spli,er Aggregator HTTP Client
Groovy Scripts Java Code
JPMML Evaluator
File HDFS JDBC TCP Log Mail
RabbitMQ Gemfire Splunk MQTT
Dynamic Router Counters
Spring XD - Streams
Based on Unix Pipes and Filters, Uses DSL

Stream
Spring XD – Stream Definition
Ø rabbit --queues=logIngestion --addresses=sjc-w9:5672 | script --location=linemerge.groovy | hdfs --rollover=10M --idleTimeout=10000 --fileUuid=true --directory=/data/loganalysis --partitionPath=path(payload.split(’\u0001')[1],dateFormat('yyyy/MM/dd/HH',payload.split(’\u0001')[0],'yyyyMMddHHmmss'))
Source (rabbitMQ)
Processor (Groovy)
Sink (HDFS)

23

log4j.appender.amqp=org.springframework.amqp.rabbit.log4j.AmqpAppender #------------------------------- ## Connection settings #------------------------------- log4j.appender.amqp.host=<RabbitMQ broker host url> log4j.appender.amqp.port=5672 log4j.appender.amqp.username=guest log4j.appender.amqp.password=guest log4j.appender.amqp.virtualHost=/ #------------------------------- ## Exchange name and type #------------------------------- log4j.appender.amqp.exchangeName=<RabbitMQ exchange name> log4j.appender.amqp.exchangeType=direct #------------------------------- log4j.appender.amqp.routingKeyPattern=<Routing Key> #-------------------------------#------------------------------- ## Message properties #------------------------------- log4j.appender.amqp.contentType=text/plain #------------------------------- log4j.appender.amqp.layout=org.apache.log4j.PatternLayout log4j.appender.amqp.layout.ConversionPattern=%d{yyyyMMddHHmmss}\u0001%X{applicationId}\u0001<SOURCE_HOST_NAME>\u0001%p\u0001[%c]\u0001-<%m>
24
Setting up AMQP log4j Appender

Setting up mapred-site.xml <property> <name>yarn.app.mapreduce.am.command-opts</name> <value>-Xmx1024m -Dhadoop.root.logger=INFO,amqp,CLA -Dcustom.type=jobhistory -Dcustom.id=$APPLICATION_ID -Dlog4j.configuration=log4j-amqp.properties -Dorg.apache.ha\ doop.mapreduce.jobhistory.JobHistoryEventHandler$JobHistoryEventLogger=INFO,amqp,CLA</value> </property> <property> <name>mapreduce.map.log.level</name> <value>INFO,amqp,CLA -Dcustom.type=task -Dcustom.id=$TASK_ATTEMPT_ID -Dlog4j.configuration=log4j-amqp.properties -Dhadoop.root.logger=INFO,amqp</value> </property> <property> <name>mapreduce.reduce.log.level</name> <value>INFO,amqp,CLA -Dcustom.type=task -Dcustom.id=$TASK_ATTEMPT_ID -Dlog4j.configuration=log4j-amqp.properties -Dhadoop.root.logger=INFO,amqp</value> </property> <property> <name>logs.streaming.enabled</name> <value>true</value> 25
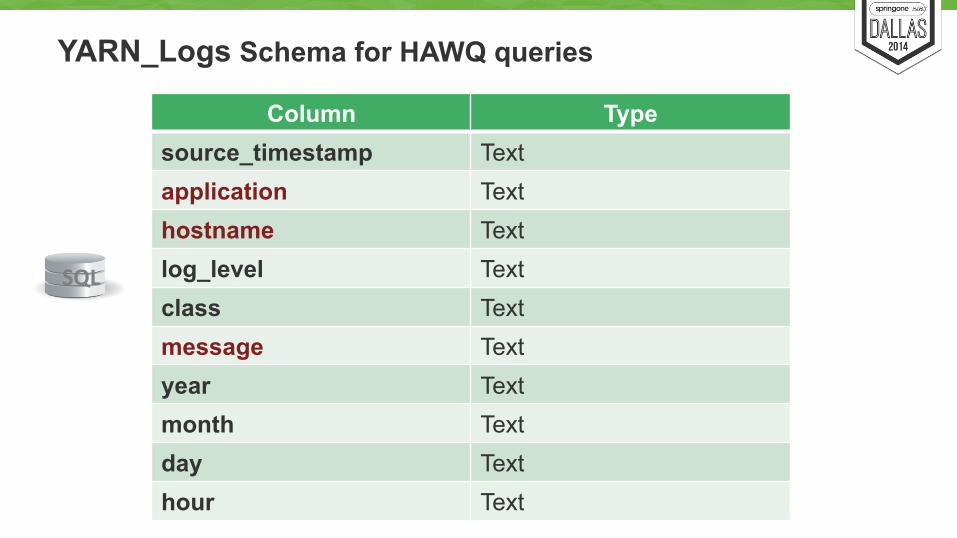
YARN_Logs Schema for HAWQ queries
Column Type source_timestamp Text application Text hostname Text log_level Text class Text message Text year Text month Text day Text hour Text
SQL
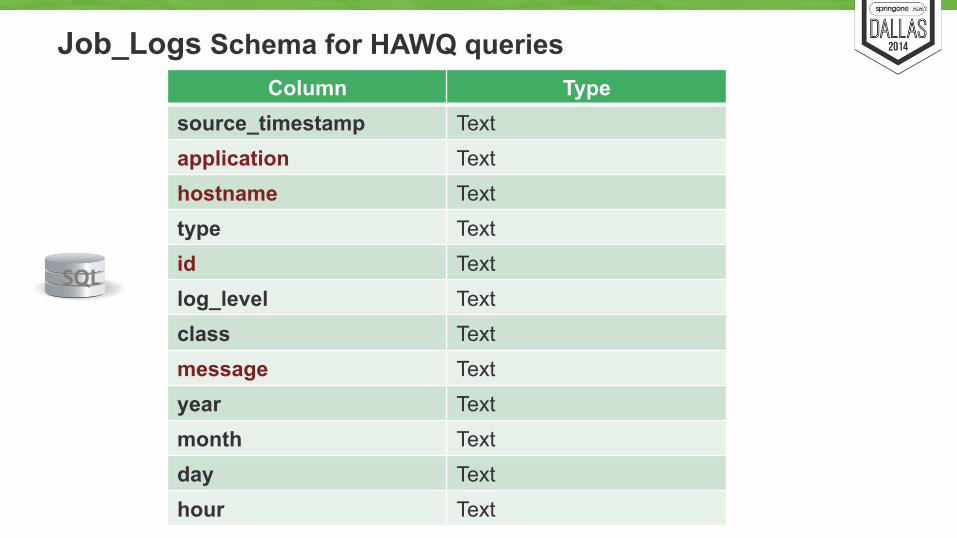
Job_Logs Schema for HAWQ queries Column Type
source_timestamp Text application Text hostname Text type Text id Text log_level Text class Text message Text year Text month Text day Text hour Text
SQL

Use Cases for querying logs
● Failed / Succeeded jobs, corresponding runtime and wait-time over a given time period
● Query task logs to identify the cause of a MR job failure ● Identify long running jobs that have multiple failed attempts ● Identify jobs that fail too often ● Total map and reduce slot seconds used over a given time period
across applications ● Average input, shuffle & output data size for failure and successful
cases ● Average physical memory, virtual memory, cpu time for map tasks
and reduce tasks over a given time period across applications ● Node vs number of task failures histogram ● Number of errors / fatal messages per NM over a given time period

29
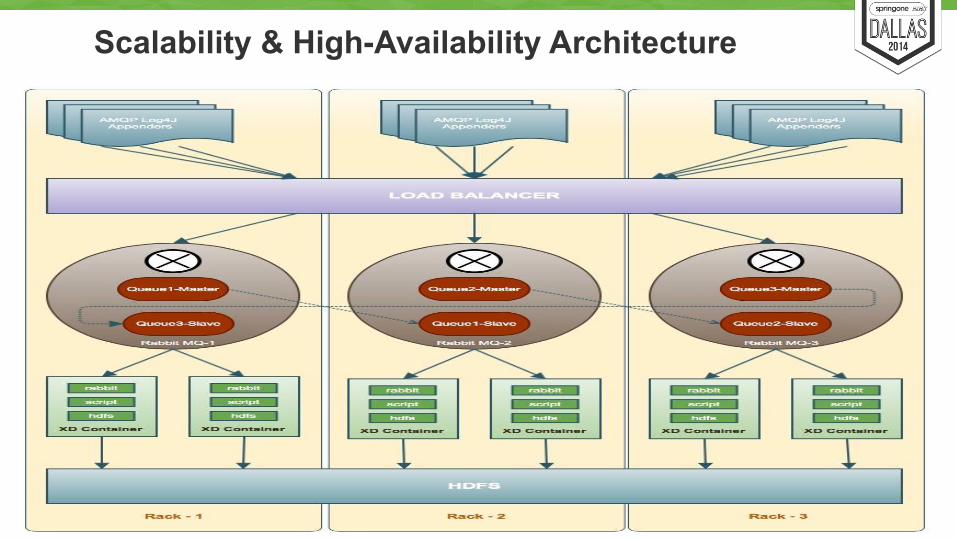
Scalability & High-Availability Architecture

31

Future Considerations
● Possibility to leverage GemXD (in-memory data grid) with HDFS persistence using a Spring XD JDBC sink. ● Lower latency, real-time applications ● Fully SQL-compatible ● Recent data in memory ● Historical data in HDFS
● Visual UI & dashboard for cluster utilization ● Out-of-the-box standard queries ● Text Search & Indexing ● Time-series Analysis
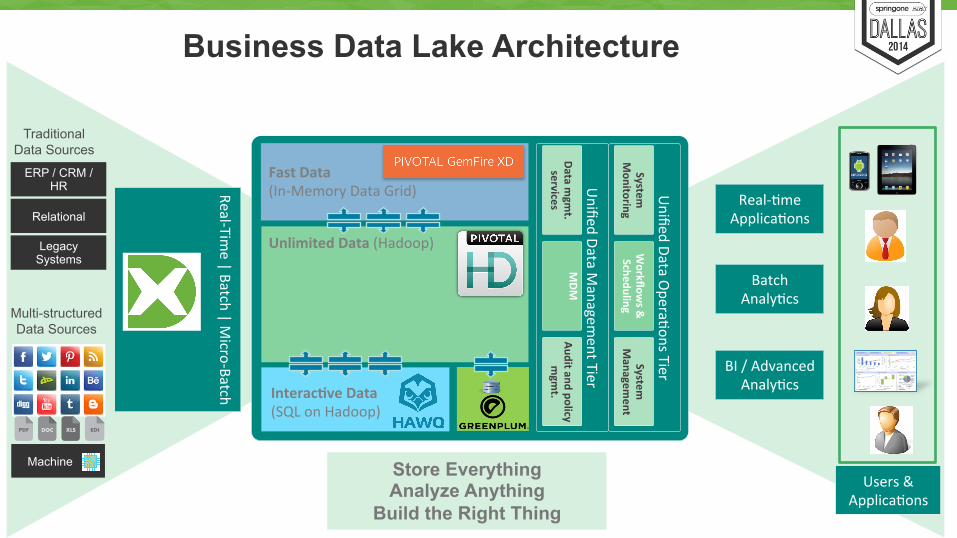
Real-‐Time | Batch | M
icro-‐Batch
ERP / CRM / HR
Relational
Legacy Systems
Multi-structured Data Sources
Machine
Traditional Data Sources
Users & ApplicaRons
Unlimited Data (Hadoop)
Fast Data (In-‐Memory Data Grid)
Interac=ve Data (SQL on Hadoop)
Unified Data M
anagement Tier
Data mgm
t. services
MDM
Audit and policy
mgm
t.
Unified Data O
peraRons Tier System
Monitoring
Workflow
s &
Scheduling System
Managem
ent
Batch AnalyRcs
BI / Advanced AnalyRcs
Real-‐Rme ApplicaRons
Business Data Lake Architecture
Store Everything Analyze Anything
Build the Right Thing

34
Thank You !
Check out:
Spring XD: http://projects.spring.io/spring-xd/
Pivotal Big Data Suite : http://www.pivotal.io/big-data
35


















