
Sociology 601, Class17: October 27, 2009
34
Sociology 601, Class17: October 27, 2009 • Linear relationships. A & F, chapter 9.1 • Least squares estimation. A & F 9.2 • The linear regression model (9.3) 1
-
Upload
blossom-benjamin -
Category
Documents
-
view
28 -
download
1
description
Sociology 601, Class17: October 27, 2009. Linear relationships. A & F, chapter 9.1 Least squares estimation. A & F 9.2 The linear regression model (9.3). Example of a linear Relationship. Equation for a linear relationship. - PowerPoint PPT Presentation
Transcript of Sociology 601, Class17: October 27, 2009

Sociology 601, Class17: October 27, 2009
• Linear relationships. A & F, chapter 9.1
• Least squares estimation. A & F 9.2
• The linear regression model (9.3)
1

Example of a linear Relationship
2

Equation for a linear relationship
A linear relationship is a relationship between two variables Y and X that can be defined by the equation:
Y = + X
•Y is the value for the response variable
•X is the value for the explanatory variable
is the Y-intercept
is the slope
3

Example of a linear relationship
Change over time in attitudes about gender
Y = α +βX
•Y (the response variable) = % disagree that men make better politicians than women
•X (the explanatory variable) = year of survey
•α(Y-intercept) = value of y when x=0
•β(the slope) = change in y per unit of x
4

Example of a linear relationship
Change over time in attitudes about gender
Yhat = a +bX = -25.62 + 0.013*year
year observed predicted1974 49.2% 47.6%
1975 48.3% 49.0%
1977 47.2% 51.6%
1978 54.5% 52.9%
1982 59.2% 58.2%
1983 61.1% 59.5%
1985 58.6% 62.2%
1986 60.5% 63.5%
1988 65.3% 66.1%
1989 64.7% 67.5%
1990 69.4% 68.8%
1991 71.1% 70.1%
1993 74.4% 72.7%
1994 74.6% 74.1%
1996 74.9% 76.7%5
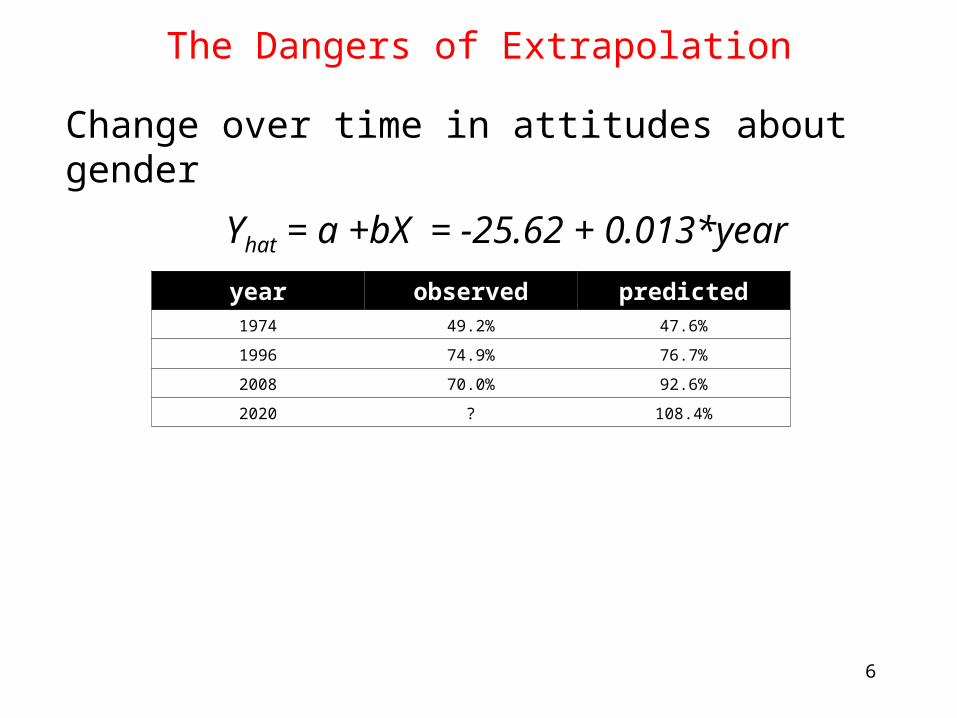
The Dangers of Extrapolation
Change over time in attitudes about gender
Yhat = a +bX = -25.62 + 0.013*year
year observed predicted1974 49.2% 47.6%
1996 74.9% 76.7%
2008 70.0% 92.6%
2020 ? 108.4%
6

Example of a linear Relationship
7

Key terms for linear relationships
• Explanatory variable: a variable that we think of as explaining or “causing” the value of another variable. (also called the independent variable)• We reserve X to denote the explanatory variable
• Response variable: a variable that we think of as being explained or “caused” by the value of another variable.
(also called the dependent variable)• We reserve Y to denote the response variable
(Q: what happens if both variables explain each other?)
8

More key terms for linear relationships
: the slope of a linear relationship : the increment in y per one unit of x
o If > 0, the relationship between the explanatory and response variables is positive.
o If < 0, the relationship between the explanatory and response variables is negative.
o If = 0, the explanatory and response variables are said to be independent.
• if x is multiplied by 12 (e.g., months rather than years), then ’ = ?• if x is divided by 10 (e.g., decades rather than years), then ’ = ?• if y is multiplied by 100 (e.g., percentage points rather than
proportion), then ’ = ? • if you subtract 1974 from x, then ’ = ?
9

More key terms for linear relationships
: the y-intercept of a linear relationship
is the value of y when x = 0.
o this is sometimes a meaningless value of x way beyond its observed range.
• : determines the height of the line up or down on the y-axis
• if x is multiplied by 12 (e.g., months rather than years), then ’ = ?• if x is divided by 10 (e.g., decades rather than years), then ’ = ?• if y is multiplied by 100 (e.g., percentage points rather than proportion),
then ’ = ? • if you subtract 1974 from x, then ’ = ?
(note: and are both population parameters like )10

More key terms for linear relationships
• model: a formula that provides a simple approximation for the relationship between variables.• The linear function is the simplest model for a
relationship between two interval scale variables.
• Regression analysis: using linear models to study…o the form of a relationship between variables
o the strength of a relationship between variables
o whether a statistically significant relationship exists between variables
11

Another Example of a linear Relationship
12

9.2 Predicting Y-scores using least squares regression
• Next, we study relationships between two variables where• there are multiple cases of X, and • Y scores do not always line up on a straight line.• There is some scatter to the data points.
• The objective is still to predict a value of Y, given a value of X.
13

Linear prediction: an example.
• Chaves, M. and D.E. Cann. 1992. “Regulation, Pluralism, and Religious Market Structure.” Rationality and Society 4(3): 272-290.
• observations for 18 countries• outcome var: weekly percent attending religious services
• variable name – “attend”• explanatory var: level of state regulation of religion
• variable name – “regul”• (not really interval scale), ordinal ranking 0-6
14
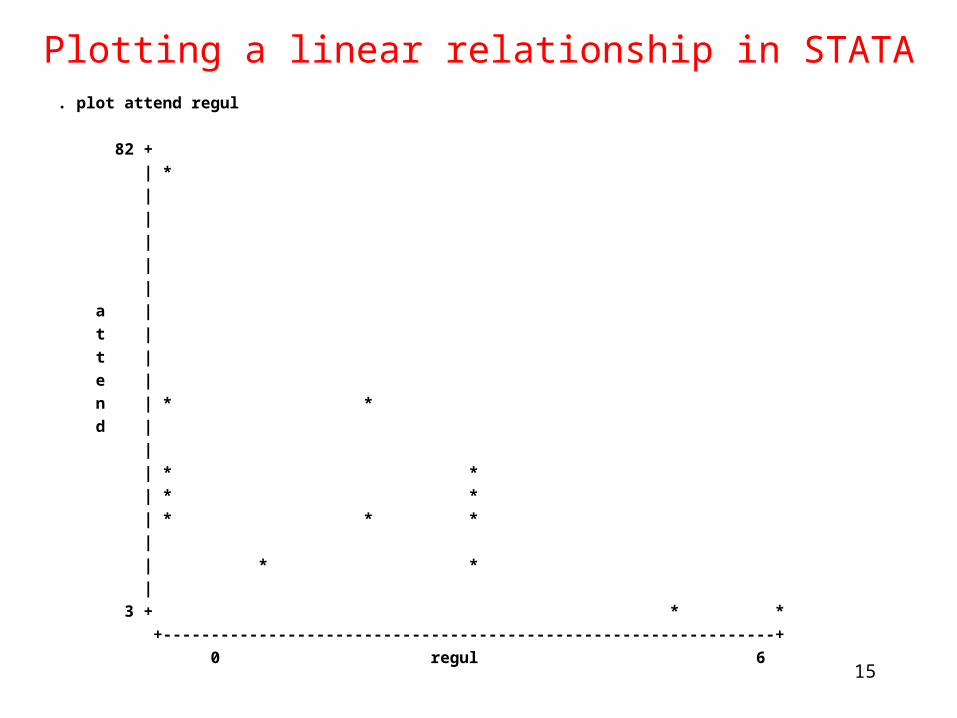
Plotting a linear relationship in STATA. plot attend regul
82 +
| *
|
|
|
|
|
a |
t |
t |
e |
n | * *
d |
|
| * *
| * *
| * * *
|
| * *
|
3 + * *
+----------------------------------------------------------------+
0 regul 615

Solving a least squares regression, using STATA. regress attend regul
Source | SS df MS Number of obs = 18
-------------+------------------------------ F( 1, 16) = 9.65
Model | 2240.05128 1 2240.05128 Prob > F = 0.0068
Residual | 3715.94872 16 232.246795 R-squared = 0.3761
-------------+------------------------------ Adj R-squared = 0.3371
Total | 5956 17 350.352941 Root MSE = 15.24
------------------------------------------------------------------------------
attend | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
regul | -5.358974 1.72555 -3.11 0.007 -9.016977 -1.700972
_cons | 36.83761 5.395698 6.83 0.000 25.39924 48.27598
------------------------------------------------------------------------------
• b is the coefficient for “regul”.• a is the coefficient for “_cons”.
(ignore all the other output for now)
%attend = 36.8 - 5.4 * regul16

Finding the predicted values of religious attendance (yhat) for each observed level of regulation (x)
regul calculation yhat = predicted attendance
0 36.8 – 5.4*0 36.8%
1 36.8 – 5.4*1 31.5%
2 36.8 – 5.4*2 26.1%
3 36.8 – 5.4*3 20.8%
4 36.8 – 5.4*4 15.4%
5 36.8 – 5.4*5 10.0%
6 36.8 – 5.4*6 4.7%
%attend = 36.8 - 5.4 * regul
17

Finding the predicted values for each observed level of X, using STATA
. predict pattend
(option xb assumed; fitted values)
. tabulate pattend regul
Fitted | regul
values | 0 1 2 3 5 6| Total
-----------+-----------------------------------------------------+--------
4.683761 | 0 0 0 0 0 2| 2
10.04274 | 0 0 0 0 2 0| 2
20.76068 | 0 0 0 5 0 0| 5
26.11966 | 0 0 2 0 0 0| 2
31.47863 | 0 1 0 0 0 0| 1
36.83761 | 6 0 0 0 0 0| 6
-----------+-----------------------------------------------------+--------
Total | 6 1 2 5 2 | 18
you can use the predict command only after you have used regress to estimate the regression function.
18

Plotting the predicted values for each observed level of X - in STATA
. plot pattend regul
36.8376 +
| *
|
|
F |
i | *
t |
t |
e | *
d |
|
v | *
a |
l |
u |
e |
s |
| *
|
|
4.68376 + *
+----------------------------------------------------------------+
0 regul 6
19

Interpreting a regression
• When the data are scattered, we need to ask two questions:o Is the data suitable for a linear model?o If so, how do we draw a line through it?
• Checking suitability (i.e,. assumptions)• scattergrams• crosstabs (including means and sd’s by x-levels)
• The assumptions of a linear regression are violated ifo the plot / crosstab suggests a nonlinear relationshipo there are severe outliers (extreme x or y scores)o there is evidence of heteroskedasticity
(the amount of “scatter” of the dots depends on the x-score)
20

Possible prediction methods
Once you have decided that a linear model is appropriate, how do you choose a linear equation with a scattered mess of dots?
A.) Calculate a slope from any two points?
B.) Calculate the average slope of all the points (with the least error)?
C.) Calculate the slope with the least squared error)?
All these solutions may be technically unbiased, but C. is generally accepted as the most efficient. (C gives a slope that is, on average, closest to the slope of the population.)
21

Least squares prediction: formal terms
• population equation for a linear model: Y = + X + ε
• equation for a given observation: Yi = a + bXi + ei
where Yi and Xi are observed values of Y and X, and ei is the error in observation Yi .
• prediction for a given value of X, based on a sample:
• Yhat = a + bX, where Yhat is the predicted value of Y
• Note that Yi – Yhat = ei = residual for observation i
22

Least squares prediction: equation for b
• goal for a given sample: estimate b and a such that
(Yi – Yhat )2 is as small as possible.
(To derive the solution: start with Q = (Yi – a - bXi )2 , take partial differentials of Q with respect to a and b, and solve for relative minima. This will not be tested in class!)
• solution:
XbYaXX
YYXXb
,)(
))((2
23

Least squares prediction: more terms
(Yi – Yhat )2
is also called the sum of squared errors or SSE.
(Also called the residual sum of squares, the squared errors in the response variable left over after you control for variation due to the explanatory variable.)
• The method that calculates b and a to produce the smallest possible SSE is the method of least squares.
• b and a are least squares estimates
• The prediction line Yhat = a + bX is the least squares line
24

Least squares prediction: still more terms
• For a given observation, the prediction error ei
(Yi – Yhat ) is called the residual.
• An atypical X or Y score or a large residual can be called an outlier. o outliers can bias an estimate of a slopeo outliers can increase the possibility of a type I error of
inference.o outlier Y scores are especially troublesome when they
are associated with extreme values of X.o outliers sometimes belong in the data, sometimes not.o Q: DC homicide rates?
25

Calculating the residuals for each observation, using STATA
. predict rattend, residuals
. summarize attend pattend rattend if country=="Ireland"
Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- attend | 1 82 . 82 82 pattend | 1 36.83761 . 36.83761 36.83761 rattend | 1 45.16239 . 45.16239 45.16239
• reminder: you can only use the predict command after you have used regress to estimate the regression function.
26

Plotting the residuals for each observed level of X, using STATA
. plot rattend regul
45.1624 + | | * | | | R | e | s | i | d | * u | * a | * l | * s | * | * * | * * | * * * | * | *-19.4786 + * * +----------------------------------------------------------------+
0 regul
do you notice the residual that is an outlier? 27

More on Sums of Squares:
• Sum of Squares refers to the act of taking each ‘error’, squaring it, and adding it to all the other errors in the sample.This operation is analogous to calculating a variance, without dividing by n-
1.
• Sum of Squares Total (SST) refers to the difference between a score yi and the overall mean Ybar.
(Yi – Ybar )2
• Sum of Squares Error (SSE), also called Sum of Squares Residual (SSR), refers to the difference between a score yi and the corresponding prediction from the regression line Yhat.
(Yi – Yhat )2 28

9.3 the linear regression model
The conceptual problem:• The linear model Y = + X has limited use because it is
deterministic and cannot account for variability in Y-values for observations with the same X-value.
The conceptual solution:• The linear regression model E(Y) = + X is a probabilistic
model more suited to the variable data in social science research.
• A regression function describes how the mean of the response variable changes according to the value of an explanatory variable.
• For example, we don’t expect qll college graduates to earn more than all high school graduates, but we expect the mean earnings of college graduates to be greater than the mean earnings of high school graduates.
29

A standard deviation for the linear regression model
• A new problem:
How do we describe variation about the means of a regression line?
• A solution:
The conditional standard deviation refers to variability of Y values about the conditional population mean
E(Y) = + X
for subjects with the same value of X.
Q: why n-2?
2
)ˆ(
2ˆ
2
n
YY
n
SSE
30

The linear regression model: example of conditional standard deviation
• Church attendance and state control problem:
SSE (also called SSR) = 3715.9
n = 18, n-2 = 16
24.1516
9.3715
2ˆ
n
SSE
31

Solving a least squares regression, using STATA. regress attend regul
Source | SS df MS Number of obs = 18
-------------+------------------------------ F( 1, 16) = 9.65
Model | 2240.05128 1 2240.05128 Prob > F = 0.0068
Residual | 3715.94872 16 232.246795 R-squared = 0.3761
-------------+------------------------------ Adj R-squared = 0.3371
Total | 5956 17 350.352941 Root MSE = 15.24
------------------------------------------------------------------------------
attend | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
regul | -5.358974 1.72555 -3.11 0.007 -9.016977 -1.700972
_cons | 36.83761 5.395698 6.83 0.000 25.39924 48.27598
------------------------------------------------------------------------------
• b is the coefficient for “regul”.• a is the coefficient for “_cons”.
(ignore all the other output for now)
%attend = 36.8 - 5.4 * regul32

interpreting the conditional standard deviation
Church attendance and state control problem:
• For every level of state control of religion, the standard deviation for the predicted mean church attendance is 15.24 percentage points. (Draw chart on board)
• By assumptions of the regression model, this is true for every level of state control.
• (Is that assumption valid in this case?)
33

Conditional standard deviation and Marginal standard deviation
• Degrees of freedom are different
• E(Y) is different: Ybar versus Yhat
• Conditional s.d. is usually smaller than marginal.
2
)ˆ(ˆ
2
n
YY
1
)( 2
n
YYsY
34


















