
SNIA SDC 2016 final
38
-
Upload
dan-lambright -
Category
Software
-
view
21 -
download
1
Transcript of SNIA SDC 2016 final



● Technologies○ Persistent memory, aka storage class memory (SCM)○ Distributed storage
● Case studies○ GlusterFS, Ceph
● Challenges○ Network latency○ Accelerating parts of the system with SCM○ CPU latency

● Near DRAM speeds● Wearability better than SSDs (claims Intel) ● API available
○ Crash-proof transactions○ Byte or block addressable
● Likely to be at least as expensive as SSDs● Fast random access● Has support in Linux
What do we know / expect?

● Single server scales poorly○ Horizontal scaling expensive
● Multiple servers in distributed storage scale well ○ Maintain single namespace
● Commodity nodes○ Easy expansion by adding nodes○ Good fit for low cost hardware○ Minimal impact on node failure
How to scale performance and capacity?

●●●
○

●●
○○


●
○
○
●
○
○
○
○


● “Primary copy” : update replicas in parallel, ○ processes reads and writes○ Ceph’s choice, also Gluster’s “journal based replication” (under development)
● Other design options○ Read at “tail” - the data there is always committed
Latency cost to replicate across nodes
client
Primary server
Replica 1
Replica 2

●
●
●
client
Replica 1
Replica 1
Replica 2

●○○
●○○○
○
○

●
●
○
○
●
○
○
○
○
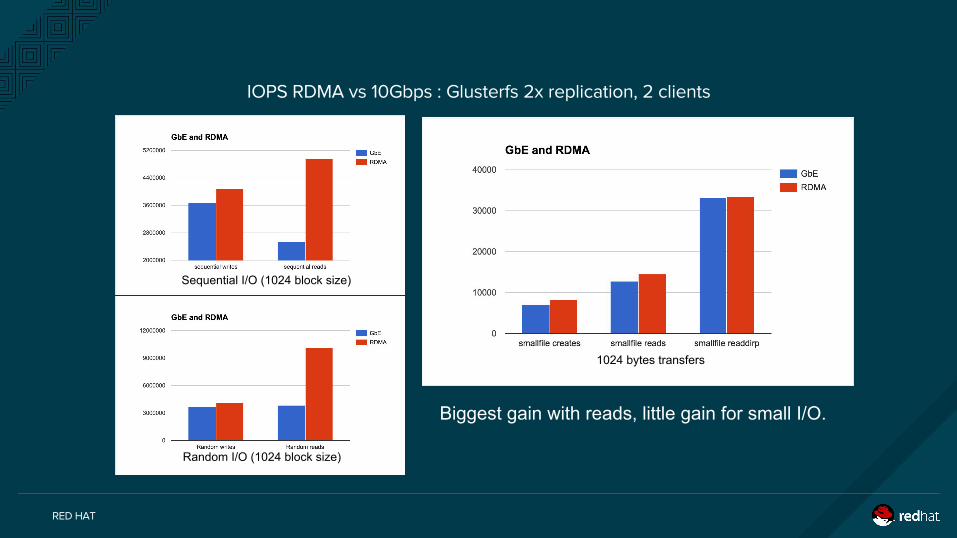
Biggest gain with reads, little gain for small I/O.
Sequential I/O (1024 block size)
Random I/O (1024 block size)
1024 bytes transfers

●
●
○
●
○


DM-cache Ceph tiering

●
●
●OSD
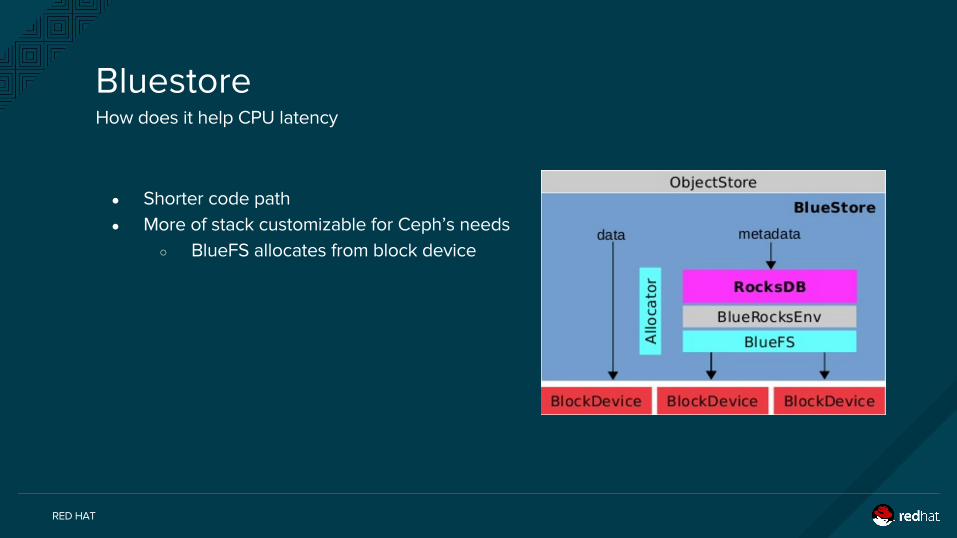
bluestore
RocksDBWAL
OSD
filestore
XFS
Journal
Journal

●
○
○
○
○
●
○
○


●
●
○
○
●
●
○

●○○○○
d1
d2
d3
f1

●
○
○
○
○
●
○
●

d2 d3 f1
S1 S2 S3 S4
d1/d2/d3/f1Four LOOKUPsFour servers16 LOOKUPs total in worse case
d2 VFS layer
Gluster client
Gluster server
Client

●
○
●
○
○
Red is cached


●
○
○
○
○

●
●
●
●
●
session_dispatch _lock
PG::map_lock
pg_map_lock
OpWQ lock

●
○
○
○
○
●
○
○
○

●
●
○
○
○
●
○
○
●
●
○



●
○
○
○
○
○
●
B


●○○○
●○○
●○○












![What I Did on My Holiday - ubiqx.netubiqx.net/presentations/SNIA/SNIA_SDC_2011.pdfSNIA SDC 2011 3. Me Your Friendly Neighborhood CIFS Geek Tainted! Lead author of the Microsoft [MSCIFS]](https://static.fdocuments.us/doc/165x107/5d2b17f888c993140a8d4e8b/what-i-did-on-my-holiday-ubiqx-sdc-2011-3-me-your-friendly-neighborhood-cifs.jpg)






