
Scientific Computing on Graphical Processors: …ramani/pubs/SIAM_CSE_2009.pdfScientific Computing...
35
Scientific Computing on Graphical Processors: FMM, Flagon, Signal Processing, Plasma and Astrophysics Ramani Duraiswami Computer Science & UMIACS University of Maryland, College Park Joint work with Nail Gumerov, Yuancheng Luo, Adam O’Donovan, Bill Dorland, Kate Despain Partially supported by NASA, DOE, NSF, UMD, NVIDIA
Transcript of Scientific Computing on Graphical Processors: …ramani/pubs/SIAM_CSE_2009.pdfScientific Computing...

Scientific Computing on Graphical Processors: FMM, Flagon, Signal Processing, Plasma and Astrophysics
Ramani Duraiswami Computer Science & UMIACS
University of Maryland, College Park
Joint work with Nail Gumerov, Yuancheng Luo, Adam O’Donovan, Bill Dorland, Kate Despain
Partially supported by NASA, DOE, NSF, UMD, NVIDIA

Problem sizes in simulation/assimilation are increasing Change in paradigm in science
Simulate then test Fidelity demands larger simulations Problems being simulated are also much more
Sensors are getting varied and cheaper; and storage is getting cheaper Cameras, microphones
Other Large data Text (all the newspapers, books, technical papers) Genome data Medical/biological data (X-Ray, PET, MRI, Ultrasound, Electron
microscopy …) Climate (Temperature, Salinity, Pressure, Wind, Oxygen content, …)

Need fast algorithms, parallel processing, better software
Fast algorithms that improve asymptotic complexity of operations FFT, FMM, NUFFT, preconditioned Krylov iterations
Parallel processing can divide the time needed by the number of processors GPUs, multicore CPUs Partitioning problems across heterogeneous computing
environments Cloud computing
Architecture aware programming Data structures for parallel architectures and cache
optimization

Fast Multipole Methods Follows from seminal work of Rokhlin and Greengard (1987) General method for accelerating large classes of dense matrix
vector products Solve systems, compute eigenvalues etc. in combination with
iterative algorithms Allow reduction of O(N2) and O(N3) operations to linear order Dr. Gumerov and I are applying it to many areas
Acoustics, Synthetic beamforming Fluid mechanics (vortex methods, potential flow, Stokes flow) Electromagnetic scattering and Maxwell’s equations Fast statistics, similarity measures, image processing,
segmentation, tracking, learning Non uniform fast Fourier transforms and reconstruction Elastic registration, fitting thin-plate splines

Decompose matrix vector product into a sparse part taking care of local interactions
FMM replaces pairwise evaluations in dense part with an upward and downward pass via a hierarchy
Spatial data structures (octrees), associated lists of particles
MLFMM Source Data Hierarchy
N M
Evaluation Data Hierarchy
Level 2 Level 3
Level 4 Level 5 Level 2
Level 3 Level 4 Level 5
S S|S S|S S|R
R|R R|R

RBF/FMM interpolation to regular spatial grid

Helmholtz equation
© Gumerov & Duraiswami, 2006
Performance tests
Mesh: 249856 vertices/497664 elements
kD=29, Neumann problem kD=144, Robin problem (impedance, sigma=1)
(some other scattering problems were solved)

FMM on GPU N.A. Gumerov and R. Duraiswami, Fast multipole methods
on graphics processors. Journal of Computational Physics, 227, 8290-8313, 2008.
N-body problems --- several papers implement on GPU ( but restricted to O(10^5))
To go to O(106) and beyond we need the FMM Challenges Effect of GPU architecture on FMM complexity
and optimization Accuracy Performance

Basic FMM flow chart
© Gumerov & Duraiswami, 2006

Direct summation on GPU (final step in the FMM)
Computations of potential, optimal settings for CPU
Time=CNs, s=8-lmaxN
CPU:
GPU:
Time=A1 N+B1 N/s+C1 Ns
read/write
access to box data
float computations
b/c=16
These parameters depend on the hardware

Direct summation on GPU
Cost =A1 N+B1 N/s+C1 Ns.
Compare GPU final summation complexity:
and total FMM complexity:
Cost = AN+BN/s+CNs.
sopt = (B1 /C1 )1/2,
Optimal cluster size for direct summation step of the FMM
This leads to
Cost =(A+A1 )N+(B+B1 )N/s+C1 Ns,
and sopt = ((B+B1 )/C1 )1/2 .
FMM requires a balance between direct summation and the rest of the algorithm

Direct summation on GPU (final step in the FMM)
Computations of potential, optimal settings for GPU
b/c=300

Other steps of the FMM on GPU Accelerations in range 5-60; Effective accelerations for N=1,048,576 (taking into
account max level reduction): 30-60.

Accuracy
Relative L2 –norm error measure:
CPU single precision direct summation was taken as “exact”; 100 sampling points were used.

What is more accurate for solution of large problems on GPU: direct summation or FMM?
Error computed over a grid of 729 sampling points, relative to “exact” solution, which is direct summation with double precision.
Possible reason why the GPU error in direct summation grows: systematic roundoff error in computation of function 1/sqrt(x). (still a question).

Performance
66 1.761 s 116.1 s p=12 72 1.227 s 88.09 s p=8 29 0.979 s 28.37 s p=4
Ratio GPU serial CPU
(potential only) N=1,048,576
48 1.395 s 66.56 s p=12 56 0.908 s 51.17 s p=8 33 0.683 s 22.25 s p=4
Ratio GPU serial CPU
(potential+forces (gradient)) N=1,048,576

Performance
p=4 p=8 p=12

Performance
Computations of the potential and forces:
Peak performance of GPU for direct summation 290 Gigaflops, while for the FMM on GPU effective rates in range 25-50 Teraflops are observed (following the citation below).
M.S. Warren, J.K. Salmon, D.J. Becker, M.P. Goda, T. Sterling & G.S. Winckelmans. “Pentium Pro inside: I. a treecode at 430 Gigaflops on ASCI Red,” Bell price winning paper at SC’97, 1997.
CPU
GPU
direct
dir
FMM
FMM

Introduction GPUs are great as all the previous talks have said But require you to program in extended version of C Need NVIDIA toolchain What if you have an application that is
In Fortran 9x/2003, Matlab, C/C++ Too large to fit on the GPU and needs to use the CPU cores, MPI,
etc. as part of a larger application, but take advantage of GPU Offload computations which have good speedups on the GPU to
it using library calls in your programming environment
Enter the FLAGON An extensible open source library and a middleware
framework that allows use of GPU Implemented currently for Fortran-9X, and preliminarily for C++
and MATLAB

Programming on the GPU GPU organized as 2-30 groups of multiprocessors
(8 relatively slow processors) with small amount of own memory and access to common shared memory
Factor of 100s difference in speed as one goes up the memory hierarchy
To achieve gains problems must fit the SPMD paradigm and manage memory
Fortunately many practically important tasks do map well and we are working on converting others Image and Audio Processing Some types of linear algebra cores Many machine learning algorithms
Research issues: Identifying important tasks and mapping them to the
architecture Making it convenient for programmers to call GPU code from
host code
Local memory ~50kB
GPU shared memory
~1GB
Host memory ~2-32 GB

Approach to use GPU: Flagon Middleware
Programming from higher language on CPU (Fortran /C++/Matlab)
Defines Module/Class that provides pointers on CPU to Device Variables on the GPU
Execute small, well written, CU functions to perform primitive operations on device avoid data transfer overhead
Provide wrappers to BLAS, FFT, and other software (random number, sort, screen dump, etc.)
Allow incorporation of existing mechanisms for doing distributed programming (OpenMP, MPI, etc.) to handle clusters
Allow relatively easy conversion of existing code

Sample scientific computing applications Radial basis function fitting Plasma turbulence computations Fast Multipole Force calculation in particle systems Numerical Relativity Signal Processing Integral Equations

FLAGON Framework Fortran Layer
Device Variables (devVar) communicates with lower levels
Fortran interfaces and wrappers pass parameters to C/C++ level
May directly call CUBLAS/CUFFT library functions
C/C++ Layer Communicates with CUDA
kernels Setup function calls,
parameter passing to kernels Module management of
external functions CUDA Layer
Performs operations on the device
FLAGON
Fortran - C Wrappers/Interfaces
C/CUDA
Fortran Level
CUBLAS/CUFFT Functionality
Device Kernels

FLAGON Principles Build a module/class that
defines device variables, and host pointers to them, allows their manipulation via functions and overloaded FORTRAN
95 operators Extensible via CUDA kernels that work with module
Use external CUDA kernel loaders and generic kernel callers
Efficient memory management Data is stored on the device and managed by the host Asynchronous operations continuously performed on the device Minimizes data transfers between host and device
Integrated Libraries CUBLAS/CUFFT CUDPP Some new linear algebra cores, small FFT code, random numbers

FLAGON Device Variables User instantiates device
variables in Fortran Encapsulates parameters
and attributes of the data structure transferred between host and device
Tracks (via pointers) allocated memory on the device
Stores data attributes (type and dimensions) on the host and device
FLAGON Structure
devVar Device Pointer
Device Dimensions Device Leading
Dimensions
Device Status Device Data Type
Pointer to device memory address Data type stored on device Allocation status on device X, Y, Z dimensions of vector or matrix on host X L , XY L leading dimensions of vector or matrix on device

FLAGON Work-Cycle Compiling and link
library to user Fortran code
Load library into memory Allocate device variables
and copy host data to device
Work-cycle allows subsequent computations to be performed solely on the device
Data transfer from device to host when done
Discard/free data on the device
FLAGON Work Cycle
Load FLAGON Library
Allocate Device Variable(s )
Memory Transfer Host to Device
Work
Memory Transfer Device to Host
Allocates and pads memory on GPU Device
Transfer host data from Fortran to CUDA global
memory Call CUBLAS, CUFFT,
CUDPP, CUDA functions and perform all
calculations on the GPU Transfer data back from
device to host
Specify GPU device, load CUBLAS library

FLAGON Functions Initialization functions
open_devObjects, close_devObjects Memory functions
Allocation/deallocation allocate_dv(chartype, nx, ny, nz) deallocate_dv(devVar)
Memory transfer transfer_[i, r, c]4(hostVar, devVar, c2g) transfer_[i, r, c] (hostVar, devVar, c2g)
Memory copy copy(devVar1,devVar2) function cloneDeepWData(devVarA) function cloneDeepWOData(devVarA)
Misc. swap(devVar1, devVar2) part(deviceVariable,i1,i2,j1,j2,k1,k2) get_[i, s, c] set_[I, s, c]
Point-wise Functions Arithmetic
devf_[hadamardf, divide, addition, subtraction] (devVar3, devVar1, devVar2, option)
Scaling devf_[i,s,c]scal(deviceVariable, a, b),
devf_cscalconj(deviceVariable, a, b) Misc.
devf_zeros(deviceVariable), devf_conjugate(deviceVariable), devf_partofcmplx(whichpart,deviceVariable)
CUBLAS Functions: BLAS 1, BLAS 2, BLAS 3 (with
shorter call strings) CUFFT Functions:
FFT Plans devf_fftplan(devVariable, fft_type,
batch) devf_destroyfftplan(plan)
FFT Functions devf_fft(input, plan, output) devf_bfft(input, plan, output) devf_ifft(input, plan, output) devf_fftR2C(input, plan, output) devf_fftC2R(input, plan, output)
CUDPP Functions: devf_ancCUDPPSortScan(devVarIn,
devVarOut, operation, dataType, algorithm, option)
devf_ancCUDPPSortSimple(devVarIn, devVarOut)
Ancillary Functions: devf_ancMatrixTranspose(devVarIn,
devVarOut) devf_ancBitonicSort(devVar1)

Example of code conversion

Plasma turbulence computations spectral code, solved via a standard Runge-Kutta time advance, coupled with a
pseudo-spectral evaluation of NL terms. Derivatives are evaluated in k−space, while multiplications in Eq. (2) are carried
out in real space. standard 2/3 rule for dealiasing is applied, and small “hyperviscous” damping
terms are added to provide stability at the grid scale. results agree with analytic expectations and same on both CPU & GPU.
32x speedup!
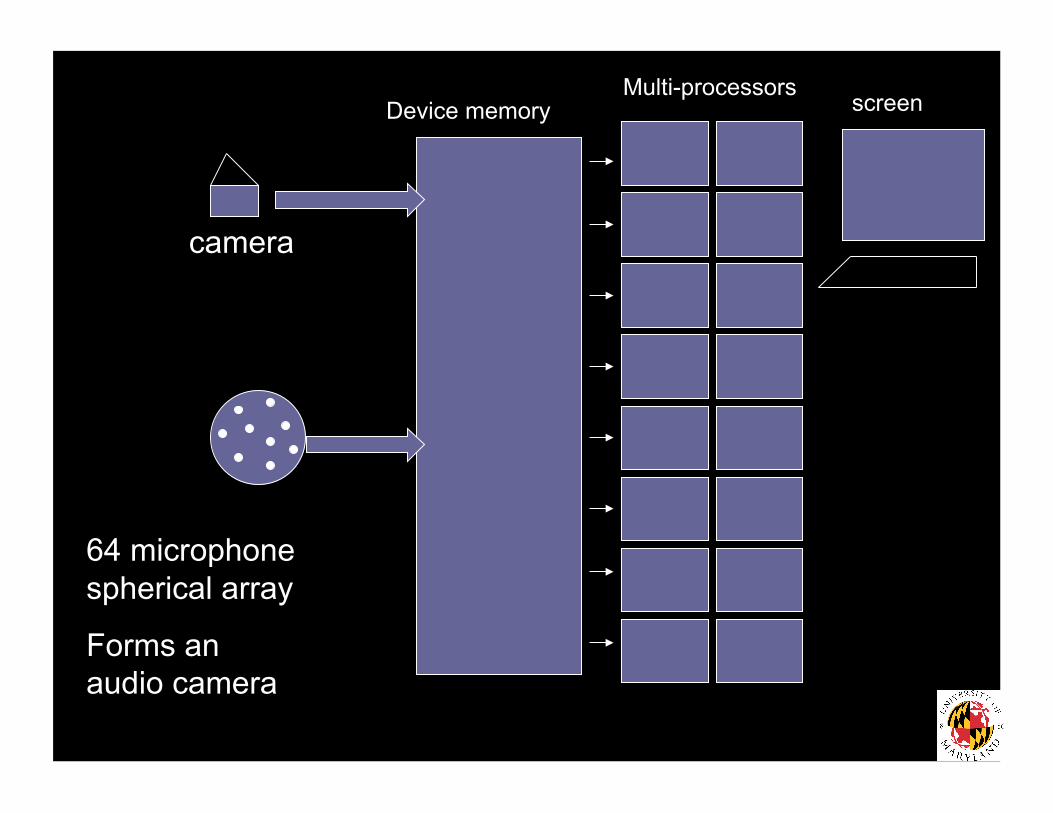
64 microphone spherical array
Forms an audio camera
Device memory Multi-processors
screen
camera

Audio Camera spherical array of microphones Use beamforming algorithms we developed can find sounds coming from
particular directions Run several beamformers, one “look
direction” and assign output to an “ Audio pixel”
Compose audio image. Transform the spherical array into
a camera for audio images Requires significant processing to
form pixels from all directions in a frame before the next frame is ready
Azimuth φ
Elevation θ
Azimuth

O’Donovan et al. : Several papers in IEEE CVPR, IEEE ICASSP, WASPAA (2007-2008)

Plasma Computations via PIC

Data structures for coalesced access Particles modeling a density or real particles Right hand side of evolution equation controlled by
a PDE for field solved on a regular grid Either spectrally or via finite differences Before/After time step require interpolation of field
quantities at grid nodes to/from particles
Organized particles in a box using octrees created via bit interleaving resulting in a Morton curve layout
Update procedures at the end of each time step
George Stantchev, William Dorland, Nail Gumerov “Fast parallel particle-to-grid interpolation for plasma PIC simulations on the GPU,” J. Parallel Distrib. Comput., 2008

Numerical relativity Beginning collaboration with Prof. Tiglio's group Hope to report more later


















