
A. Shtertser* , О. Stoyanovskii, B. Zlobin, Yu. Meshcheryakov, Yu. Skornyakov
Upload
londonmet-pgr-studentsCategory
view
212download
0
An Agent-based Adaptive Join Algorithm for Distributed Data Warehousing
1ST ANNUAL POSTGRADUATE RESEARCH STUDENT CONFERENCE
Qicheng Yu FoC of London Metropolitan University
Dr. Fang Fang Cai FoC of London Metropolitan UniversityDr. Julie A McCann DoC of Imperial College
Supervisors:

Introduction
� Data warehousing continues to play an important role in global information systems for businesses.Applications of data warehousing have evolved � Applications of data warehousing have evolved from reporting and decision support systems to mission critical decision making systems.
� This requires data warehouses to combine both historical and current data from operational systems.

Introduction (cont’d)
The primary objective of this research is to seeking effective and efficient join techniques for distributed data warehousing. This is because:
� Joins are a frequently occurring operation in DW queries. queries.
� Joins are one of the most expensive operations that a DW performs.
� Joining two large tables could consume a significant amount of the system’s CPU cycles, disk or network bandwidth, and buffer memory.
� Traditional join algorithms caused significant performance issues in a distributed and dynamic network environment .

Theories and Techniques
Software Agents software entities that have an internal goal and acts on behalf of a user.
� Autonomy� Adaptiveness� Adaptiveness� Collaboration� Mobility
They are well suited to applications which involve distributed computation or communication between components, sensing or monitoring of their environment, or autonomous operation.

Theories and Techniques
� Adaptive Join Algorithms focus on using runtime feedback to modify query processing in a way that provides better response time or more efficient CPU utilization. Good examples are:
� Nested Loop Ripple Join� Nested Loop Ripple Join� Hash Ripple Join � XJoin.
� Distributed Query Technique Semi-join was introduced for reducing data transmission in processing distributed queries. It has been traditionally used to great advantage in distributed systems.

The Main Idea of AJoin
The main idea of AJoin is based on software agents and extend the ripple join and semi-join techniques into a multi-agent system where a join task is decomposed into smaller independent units which will be assigned to software agents. software agents.
� It takes data warehousing features into account � It utilises intelligent software agents for the dynamic optimisation and coordination of join processing.
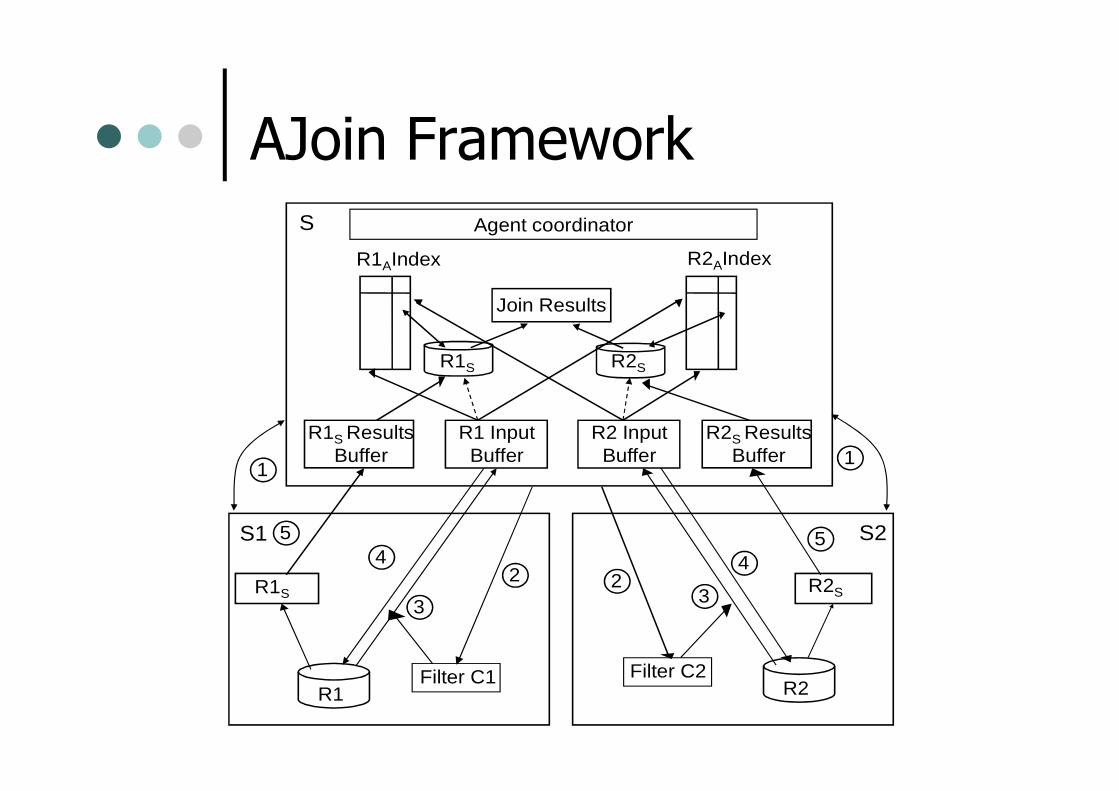
AJoin FrameworkS
R1AIndex R2AIndex
R1S R2S
Join Results
Agent coordinator
R1 R2Filter C1 Filter C2
S1 S2
R1 InputBuffer
R1S R2S
R1S ResultsBuffer
2 23 3
4 4
5 5
11
R2S ResultsBuffer
R2 InputBuffer

AJoin Algorithm
Join coordinate at local site S: 1.Initialization.
Perform cost-benefit analysis; Allocate initial memory and buffer.
2. Activate RIA at sites S1 and S2 (see table 4)Start Remote Adapting
3. Activate MTA and OA at site S (see table 2)4. Coordinate and monitor join process5. Iterate from step 4 until join completed6. Deactivate MTA, RIA, and OA 7. End AJoin
Table1 - Join Coordinator Agent (JCA)

AJoin Algorithm (cont’d)
MTA for R1 at local site S: 1. Receive a tuple from IB (see table 3)2. If a tuple is received from R13. If full-join method is selected4. Save R1S at local site S and add its LAP and R1AS A
to index table for R1A5. Else // semi-join is selected6. Add negative RAP and R1A to index table for R1A7. Using R1A to probe R2A in index table for R2A8. If a match is found9. For each matched R1A and R2A
TABLE 2-1. TUPLE MATCHING AGENT (MTA)

AJoin Algorithm (cont’d)
MTA for R1 at local site S:
10. If the access pointer of RS is RAP11. Call RIA at S1 and/or S2 (see table 5)
to retrieve R1S and/or R2S respectively S S 12. Else // RS accessible from the local storage13. Retrieve R1S and/or R2S locally14. Output the matched R1S and R2S15. Iterate from step 1 until no more tuples from R116.Notify JCA to end the process
TABLE 2-2. TUPLE MATCHING AGENT (MTA)

AJoin Algorithm (cont’d)
Receive tuple procedure at local site S: 1. If all tuples from both relation R1 and R2 are received2. Join completed3. If both R1 and R2 buffer are not empty 4. Retrieve a tuple from R1 and R2 IB in turn5. Else 5. Else 6. If both R1 and R2 IB are empty7. Waiting tuples to arrive8. Else // one of R1 orR2 IB is not empty9. If R1 IB is not empty10. Retrieve a tuple from R1 IB11. Else // R2 IB is not empty12. Retrieve a tuple from R2 IB13. Return
TABLE 3. RECEIVE A TUPLE PROCEDURE

AJoin Algorithm (cont’d)
Tuple filter and join adapting at remote site S1:1. Receive join parameter (C and join selection threshold)2. Retrieve a tuple from R13. If the tuple is not meet the condition C14. Repeat step 25. Evaluate join cost-benefit6. If semi-join is selected 7. Send R1A and its remote access pointer to R1 IB at site S8. Else // full-join is selected9. Send R1A and R1s to R1 IB at site S10. Iterate from step 2 until no more tuples from R1
TABLE 4. REMOTE INFORMATION AGENT (RIA)

AJoin Algorithm (cont’d)
Retrieve RS at remote site S1 (or S2): 1. Get the remote access pointer 2. Retrieve the tuple according to its access pointer3. Return R to R buffer at site S3. Return RS to RS buffer at site S
TABLE 5. RIA RETRIEVE RS SERVICE

Cost and Benefit Analysiscost of full ripple join:
Cost F (R1⋈AR2) = (1)
where T0 is the cost to start-up a new network connection and V is the network speed. |R1| and |R2| to indicate the cardinality of R1 and R2 respectively,
⋈
0| 1| ( 1) | 2| ( 2)R Size R R Size R
T V× + ×+
cost of semi ripple join: CostS (R1⋈AR2) =
(2)
where Size(P) is the size in byte of the RAP.
0| 1| ( 1 ) ( 1) ( ( 1 ) ( ))
| 1| ( 2 ) ( 2) ( ( 2 ) ( ))
A S
A S
R Size R JC R Size R Size PT V
R Size R JC R Size R Size PV
× + × +
× + × +
+
+

Cost and Benefit AnalysisCost and Benefit :
Cost F (R1⋈AR2) - CostS (R1⋈AR2) =
(3)
| 1| ( 1) | 1| ( 1 ) ( 1) ( ( 1 ) ( ))
| 2| ( 2) | 1| ( 2 ) ( 2) ( ( 2 ) ( ))
A S
A S
R Size R R Size R JC R Size R Size PV
R Size R R Size R JC R Size R Size PV
× − × − × +
× − × − × ++
In AJoin, full-join or semi-join can be applied independently to each relation. The semi-join method will be chosen only when:
(4) or CR(R) × SR(R) < 1 (5)
where CR(R) = denotes as join cardinality ratio as %;
SR(R) = denotes as attribute selection ratio as %
V+
| | ( ) | | ( ) ( ) ( ( ) ( ))0
A SR Size R R Size R JC R Size R Size PV
× − × − × +>
( )| |
JC RR
( ) ( )( ) ( )
S
A
Size R Size PSize R Size R
+−

AJoin for Data Warehousing
� Multiple one-to-many joins between the fact table andthe dimensional tables.
� referential integrity constraints are applied e.g. all joinattributes in fact table must have a matching joinattributes in fact table must have a matching joinattributes in the dimensional tables. Therefore,CR(R1) =100% full-join method will be used forR1 unless SR(R1) is low.
� run-time data of the fact table only represents a smallportion of the fact table. Therefore, CR(R2) << 100%
the semi-join method should be chosen for R2.

Cost and Benefit in High Bandwidth Network
The join cost of local processing cannot be ignored any more. But, sincethe cost of joins at a local site using full or semi-join method is at anequivalent level.The semi-join method will be chosen only when:
| | ( ) | | ( ) ( ) ( ( ) ( ))R Size R R Size R JC R Size R Size P× − × − × +
(6)
V< (7)
where V’ is the desk data access speed and V is the join switch threshold.
| | ( ) | | ( ) ( ) ( ( ) ( ))
( ) ( )'
A S
S
R Size R R Size R JC R Size R Size PV
JC R Size RV
× − × − × +
×>
| | ( ) | | ( ) ( ) ( ( ) ( ))' ( ) ( )
A S
S
R Size R R Size R JC R Size R Size PV JC R Size R
× − × − × +× ×
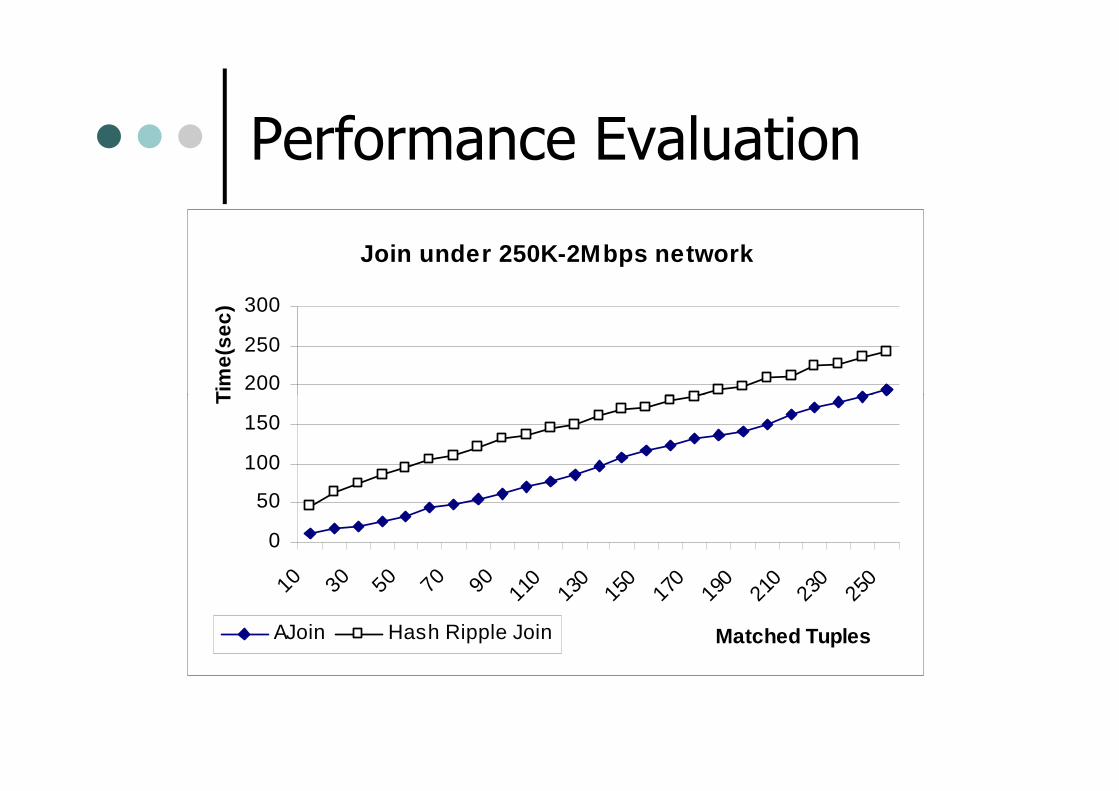
Performance Evaluation
Join under 250K-2Mbps network
200
250
300
Tim
e(se
c)
0
50
100
150
10 30 50 70 90 110
130
150
170
190
210
230
250
Matched Tuples
Tim
e(se
c)
AJoin Hash Ripple Join
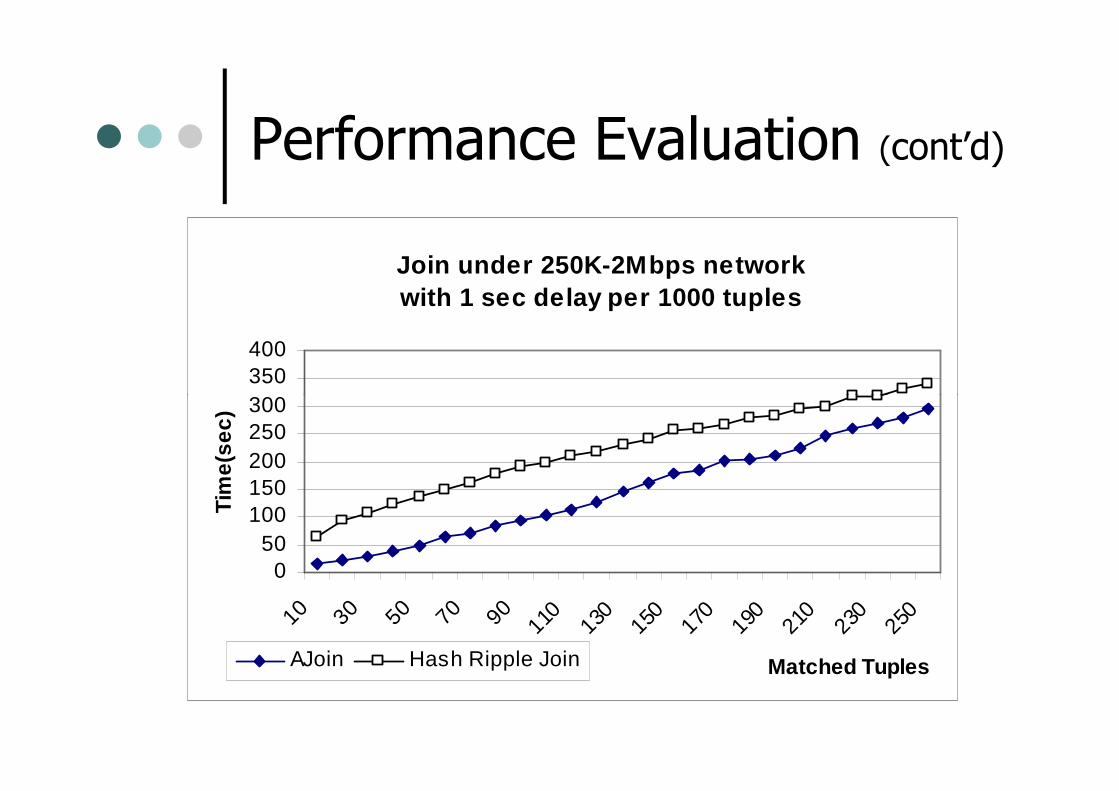
Performance Evaluation (cont’d)
Join under 250K-2Mbps network with 1 sec delay per 1000 tuples
300350400
050
100150200250300
10 30 50 70 90 110
130
150
170
190
210
230
250
Matched Tuples
Tim
e(se
c)
AJoin Hash Ripple Join
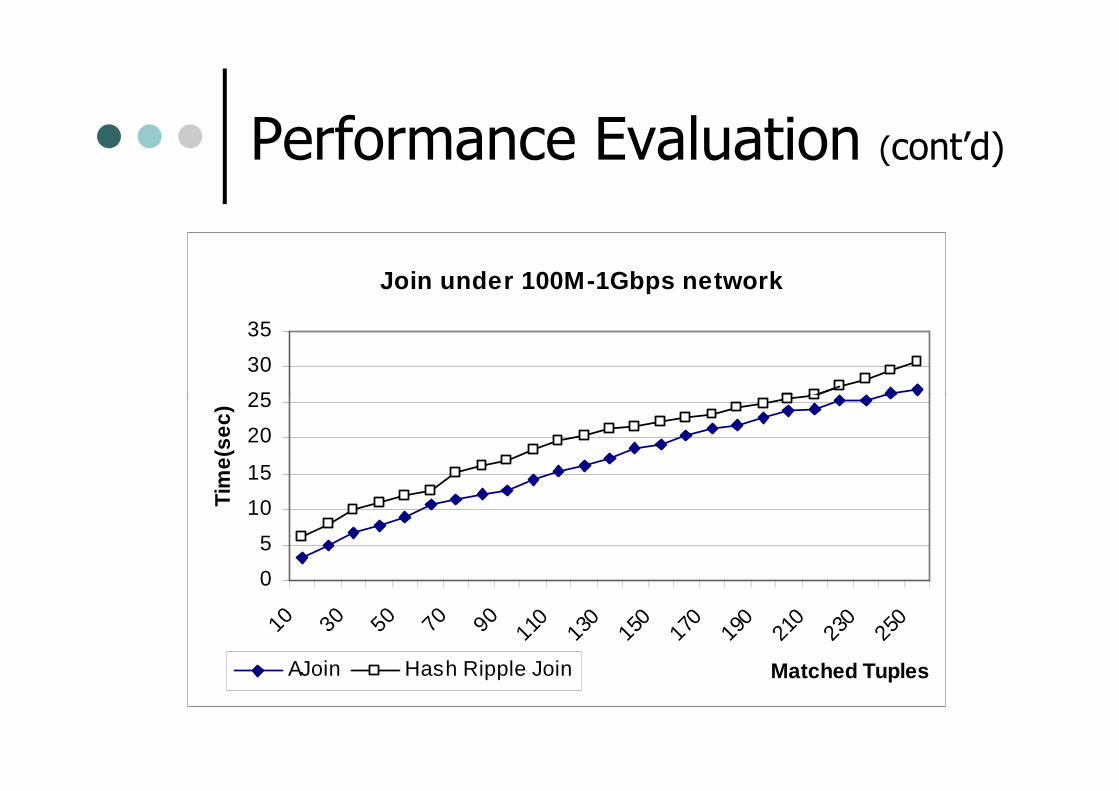
Performance Evaluation (cont’d)
Join under 100M-1Gbps network
25
30
35
0
5
10
15
20
25
10 30 50 70 90 110
130
150
170
190
210
230
250
Matched Tuples
Tim
e(se
c)
AJoin Hash Ripple Join
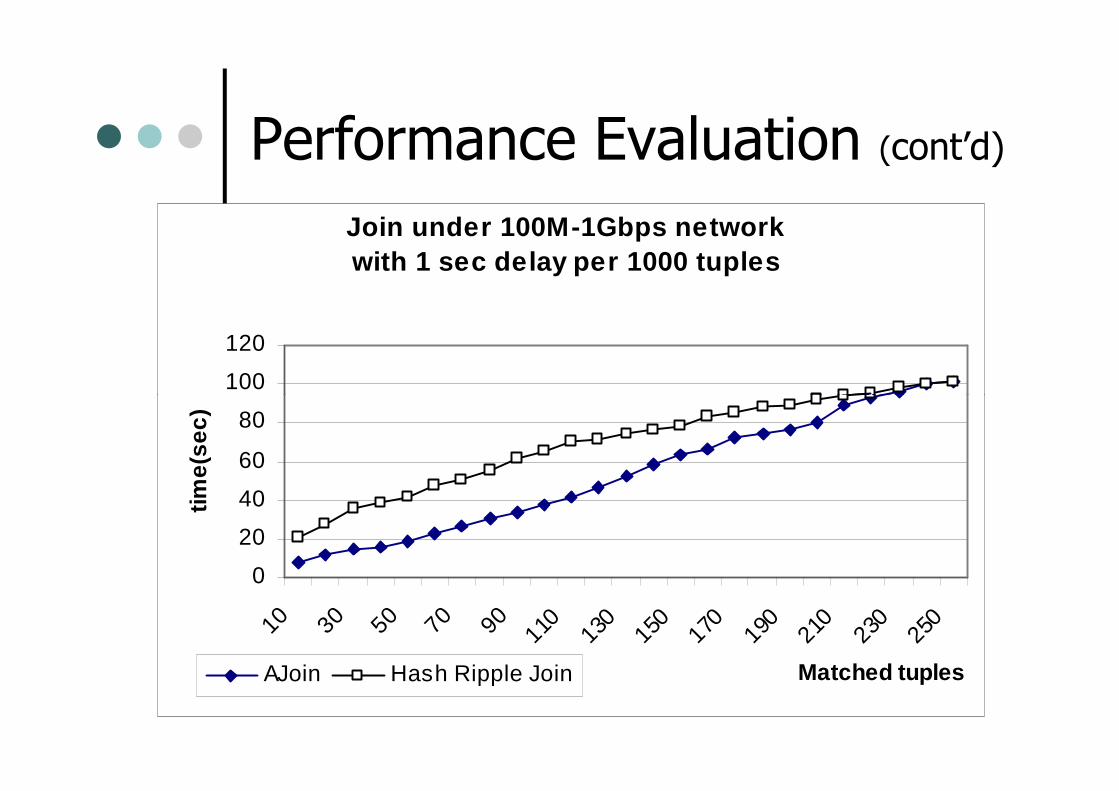
Performance Evaluation (cont’d)
Join under 100M-1Gbps network with 1 sec delay per 1000 tuples
100
120
0
20
40
60
80
10 30 50 70 90 110
130
150
170
190
210
230
250
Matched tuples
time(
sec)
AJoin Hash Ripple Join

Summary
The main work undertaken is summarized below:
� investigation the feasibility and effectiveness of utilising software agent technology to address some specific issues in data warehouses.
� conduction an experimental study on the performance of modern join algorithm for distributed environment.
� implement of a framework for an adaptive join algorithm using intelligent agents.
� evaluation the agent-based join approach against current approaches in distributed and dynamic data warehouse environments.
Questions & Comments


















