
project--2 nd review_2
38
Deploying and Researching Hadoop in Virtual Machines
-
Upload
aswini-pilli -
Category
Documents
-
view
109 -
download
0
Transcript of project--2 nd review_2

Deploying and Researching Hadoop in Virtual Machines

Hadoop:
• Hadoop is an open source software platform. • It is derived from Google’s MapReduce and GFS(Google file
system).• Hadoop is an open source implementation of MapReduce.• It develops open source software for reliable and scalable distributed
computing. Definition:• Basically, it's a way of storing enormous data sets across clusters of
computers . • It is designed to be Robust and Efficient.• The Apache Hadoop software library is a framework .• It is designed to scale up from single servers to thousands of
machines.

Who uses Hadoop?

Abstract:
• Hadoop's emerging and the maturity of virtualization make it feasible.
• It introduces some technologies used such as CloudStack, MapReduce and Hadoop.
• How to deploy Hadoop in virtual machines which can be obtained from Cloud Stack .
• we run some Hadoop programs under the virtual cluster.

Introduction:
• Now a days, the most frequently used programs are those Internet based services.
• MapReduce can process 20 PB of data per day.• Ability to read and write data.• A reliable shared storage and analysis system (HDFS and
MapReduce)• Enables applications to work .

Literature survey:
• Ignoring the data locality issue in different types of environments can easily reduce the MapReduce performance.
• Experimental results on two real data-intensive applications show that their data placement strategy.
• The first generation of Hadoop had two single points of failure: the NameNode and JobTracker processes.
• Hadoop MapReduce has two main services: the jobtracker and the tasktracker.

Existing System:
• Need to process terabytes of data in efficient manner on daily bases.
• In the existing system we are using single virtual machine.• The disadvantage is that the potential for poor performance
and heavy load undoubtedly, which is what to be solved .

Proposed System:
• In the proposed system we are using cloud stack infrastructure. • MapReduce is designed under cluster, management of thousands
commodity PCs is a big job. • Deploying the Hadoop Applications on virtual machines .• Maybe the biggest problem is the power consumption.

Modules:
• Module 1: User has to start namenode, datanode, jobtracker and task tracker nodes based on the virtual machine.
• Module2: User observes the virtual machines running on cluster infrastructure.
• Module3: User can connect to any virtual machine running on cluster by providing required details.
• Module4: In this module user can deploy the files on connected virtual machine and do research on any virtual machine.

Hardware Requirements
• Pentium 4 Processor • 8GB RAM• 64 bit OS(Ubuntu)• 200 GB HDD

Software Requirements
• Java 6• Eclipse Indigo (With Hadoop Configuration)• Hadoop Appliance• Cygwin• CloudStack

ARCHITECTURE

3-Tier Architecture
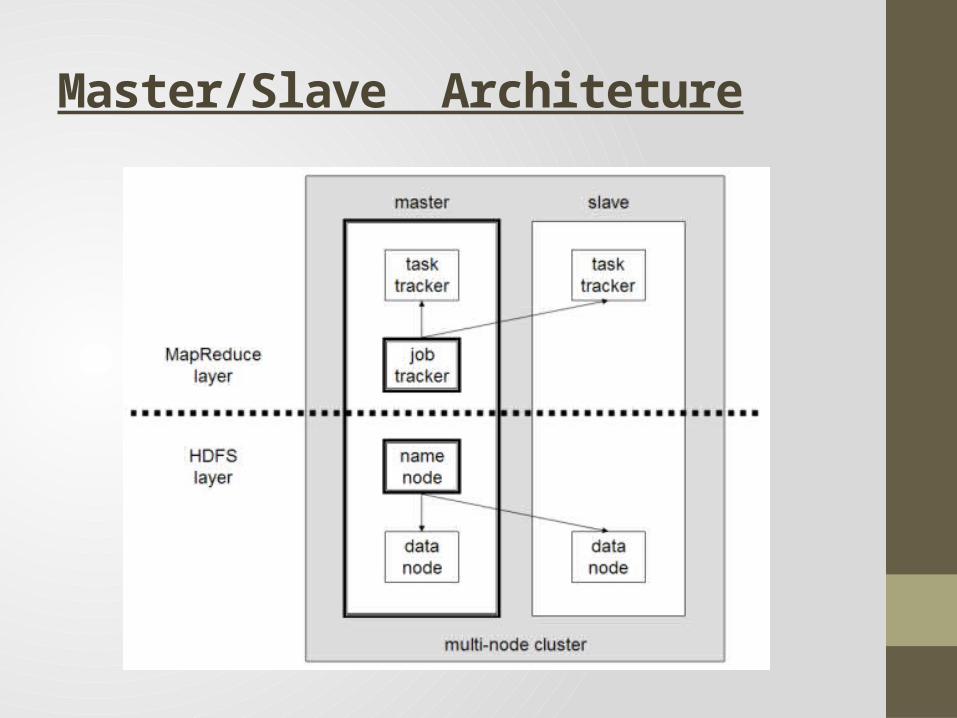
Master/Slave Architeture

HDFS Architecture

DESIGNING
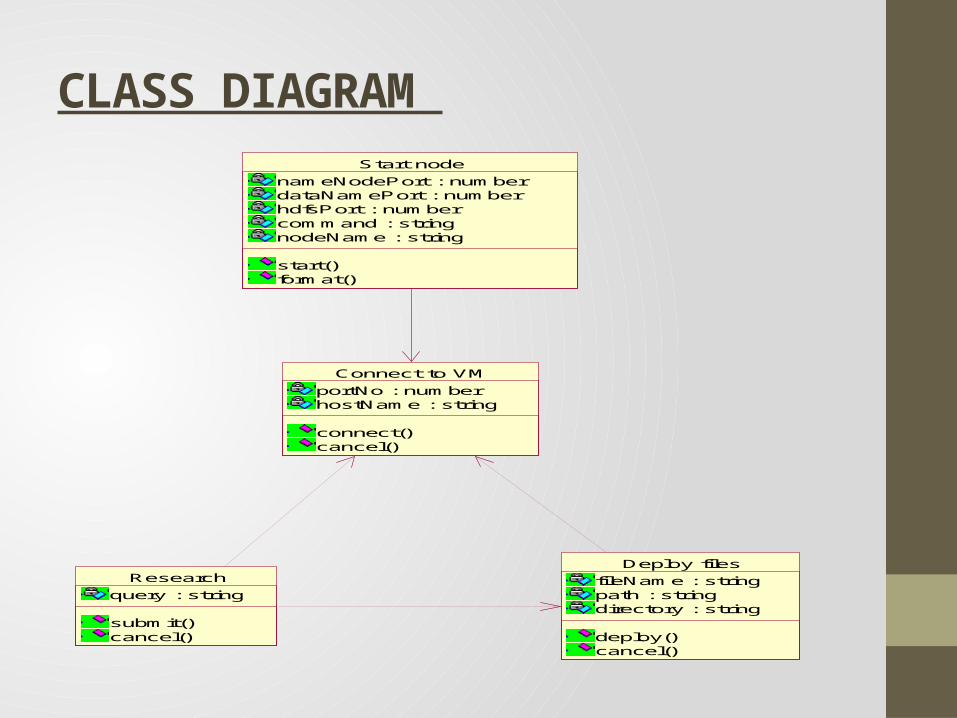
CLASS DIAGRAM Start node
nameNodePort : numberdataNamePort : numberhdfsPort : numbercommand : stringnodeName : string
start()format()
Researchquery : string
submit()cancel()
Deploy filesfileName : stringpath : stringdirectory : string
deploy()cancel()
Connect to VMportNo : numberhostName : string
connect()cancel()

USECASE DIAGRAM
name node
data node
start job tracker
connect to VM
logout
deploy files
research on files
user

SEQUENCE DIAGRAM
user HDFS
start name node
response
data noderesponse
job tracker
response
deploy files
response
research on filesresponse
logout
response
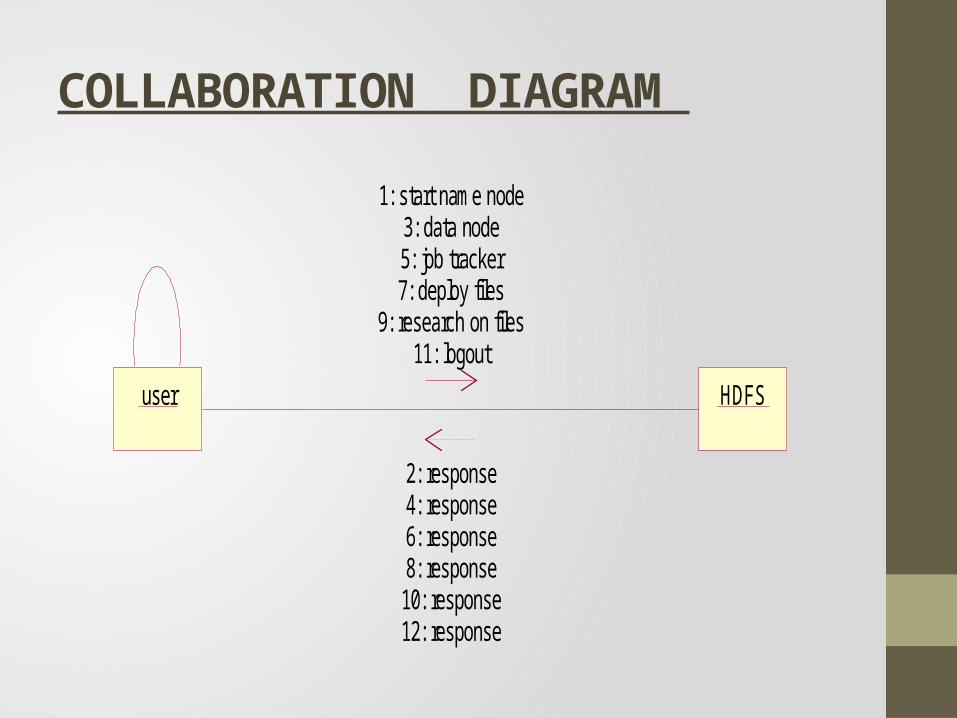
COLLABORATION DIAGRAM
user HDFS
1: start name node
2: response
3: data node
4: response
5: job tracker
6: response
7: deploy files
8: response
9: research on files
10: response
11: logout
12: response

TESTING Black Box Testing White Box Testing Grey Box Testing Regression Testing

Test CasesName Input Output
Activate Root Account Username and password Successfully Enabled
Starting management
Server
Management Server Details
Successfully started
Adding Pod Pod details
Successfully Added
Adding Zone Zone Details
Successfully Added
Adding Cluster Cluster Details
Successfully Added
Primary Storage Primary Storage Details
Successfully Added
Secondary Storage Secondary Storage Details
Successfully Added

OUTPUTSCREENS

Home Page

Dash Board

Instances
Network

Events

Accounts

Domains

Infrastructure

Projects

Global Settings
Service Settings

Conclusion:
• This Project CloudStack, MapReduce programming model and Hadoop, which allows distributed parallel running, which shows that it is feasible to deploying and research Hadoop in Virtual machines . The advantages are that it can ease the management, fully utilize the computing resources, make Hadoop more reliable and save power and so on. Then some methods to optimize Hadoop in virtual machines are discussed.

Future Enhancements
• Right Management:For example, we can arrange a test administrator to
be responsible for this experimental course, then the experimental teachers can only view and count related information of experimental course, other courses do not have permission. • Experimental Control and Report Submission:
The instructor can specify the actionable experimental project, and the system design experimental record, save the 1219 experimental project information that students have taken in pilot project, facilitate faculty management .

BIBLIOGRAPHY• List of Reference Documents:• Grady Brooch, “The Unified Modeling Language Users guide” • Roger S Pressman, “Software Engineering”, A practitioners
approach• Walker Royce, “Software Project Management”• Head First Series for Java
• Web References:• http://en.wikipedia.org/wiki/HDFS#Hadoop_distributed_file_sy
stem• http://hadoop.apache.org/• http://en.wikipedia.org/wiki/Mapreduce• http://en.wikipedia.org/wiki/Main_Page• http://cloudstack.apache.org/about.html

Thank you for
watching…!


















