
Prepared 5/24/2011 by T. O’Neil for 3460:677, Fall 2011, The University of Akron.
25
Prepared 5/24/2011 by T. O’Neil for 3460:677, Fall 2011, The University of Akron. CUDA Lecture 2 History of GPUs
-
Upload
linda-mackrell -
Category
Documents
-
view
215 -
download
0
Transcript of Prepared 5/24/2011 by T. O’Neil for 3460:677, Fall 2011, The University of Akron.

Prepared 5/24/2011 by T. O’Neil for 3460:677, Fall 2011, The University of Akron.
CUDA Lecture 2History of GPUs

Make great imagesIntricate shapesComplex optical effectsSeamless motion
Make them fastInvent clever techniquesUse every trick imaginableBuild monster hardware
Eugene d’Eon, David Luebke, Eric Enderton, In Proc. EGSR 2007 and GPU Gems 3
History of GPUs – Slide 2
Graphics in a Nutshell

History of GPUs – Slide 3
The Graphics PipelineVertex Transform & Lighting
Triangle Setup & Rasterization
Texturing & Pixel Shading
Depth Test & Blending
Framebuffer
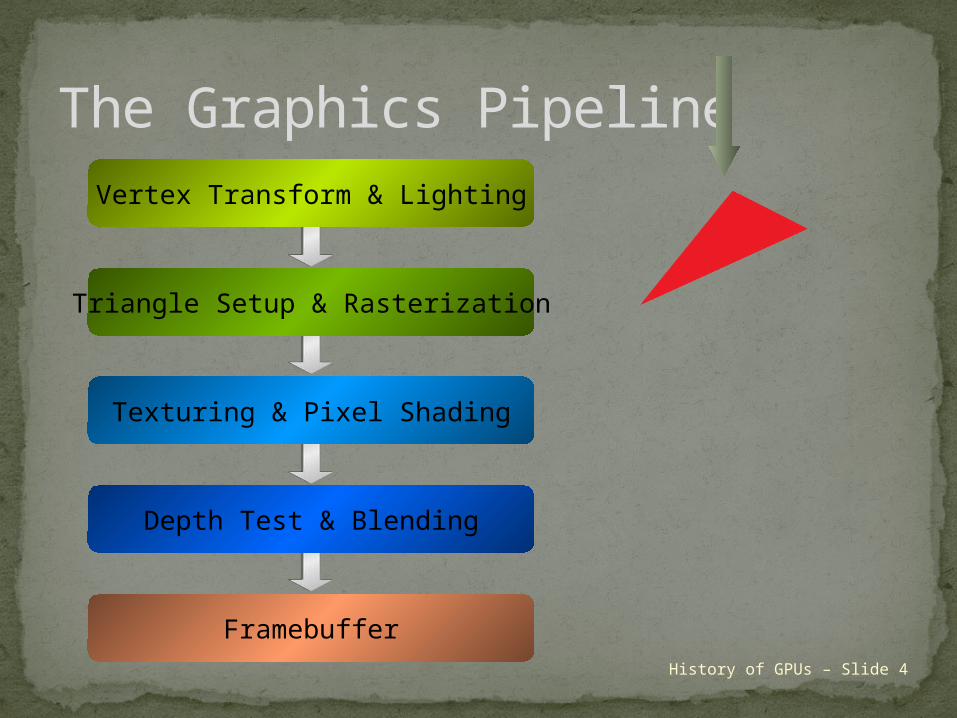
History of GPUs – Slide 4
The Graphics PipelineVertex Transform & Lighting
Triangle Setup & Rasterization
Texturing & Pixel Shading
Depth Test & Blending
Framebuffer
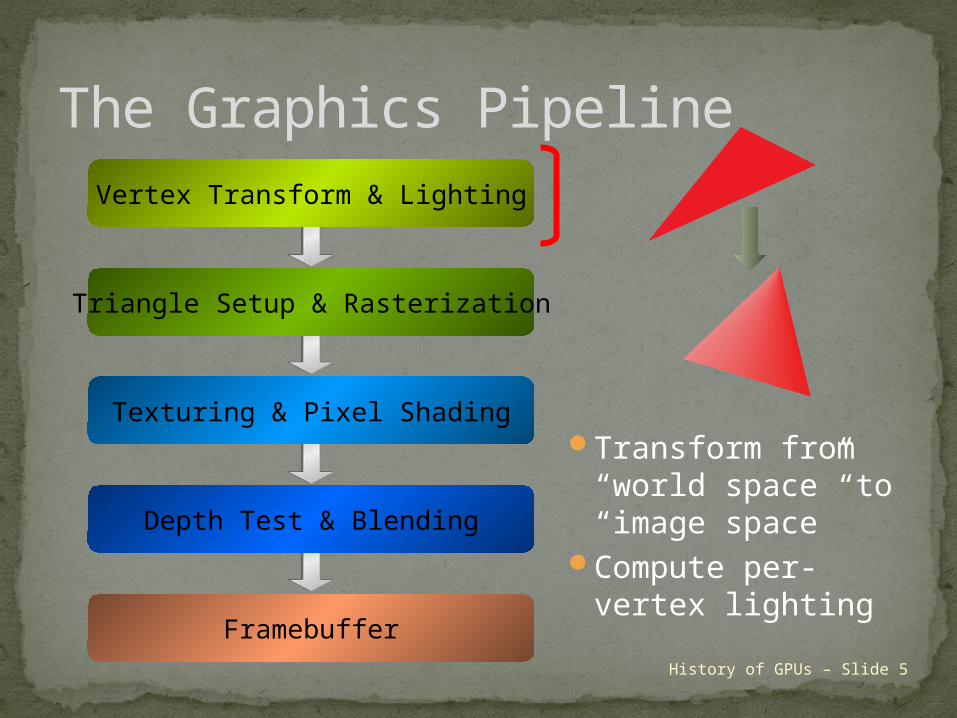
History of GPUs – Slide 5
The Graphics PipelineVertex Transform & Lighting
Triangle Setup & Rasterization
Texturing & Pixel Shading
Depth Test & Blending
Framebuffer
Transform from “world space” to “image space”
Compute per-vertex lighting
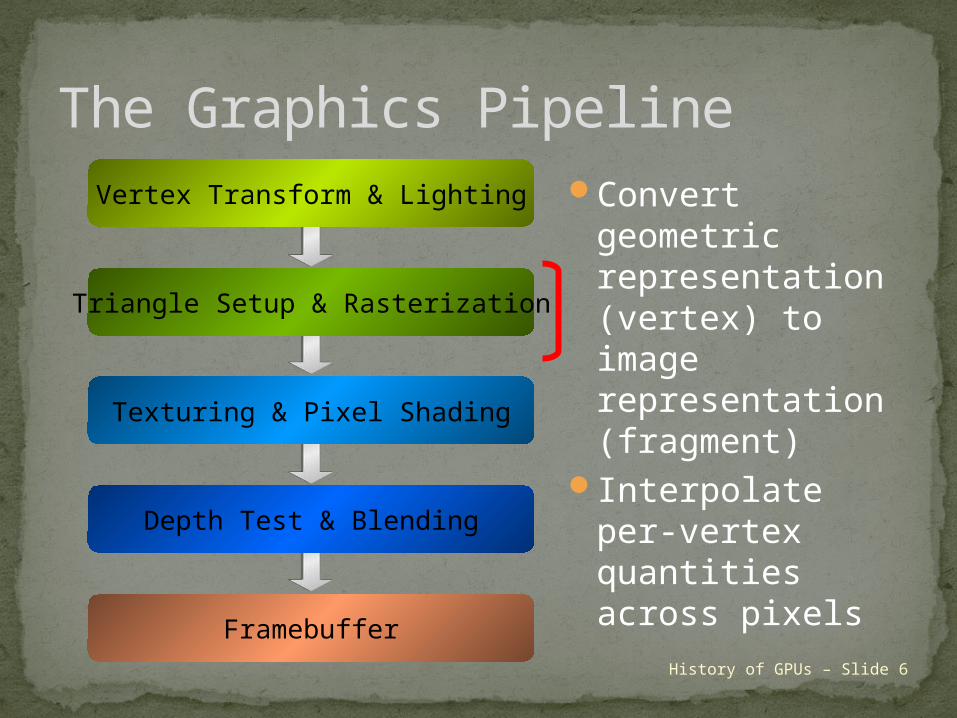
History of GPUs – Slide 6
The Graphics PipelineVertex Transform & Lighting
Triangle Setup & Rasterization
Texturing & Pixel Shading
Depth Test & Blending
Framebuffer
Convert geometric representation (vertex) to image representation (fragment)
Interpolate per-vertex quantities across pixels
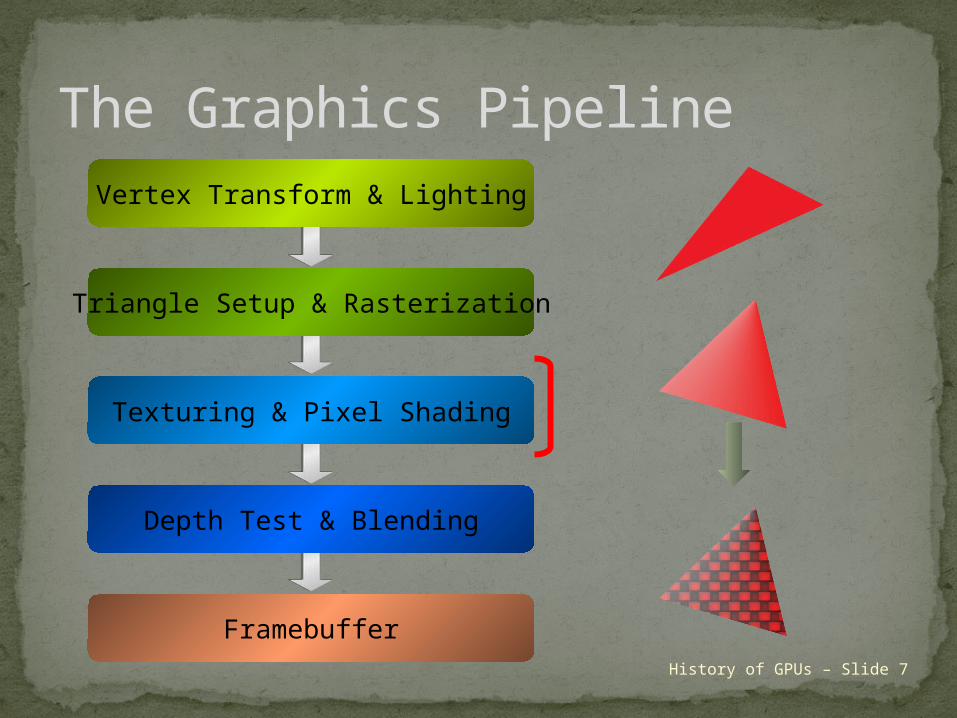
History of GPUs – Slide 7
The Graphics PipelineVertex Transform & Lighting
Triangle Setup & Rasterization
Texturing & Pixel Shading
Depth Test & Blending
Framebuffer

The Graphics PipelineKey abstraction of real-time
graphics
Hardware used to look like this
One chip/board per stage
Fixed data flow through pipeline
Vertex
Rasterize
Pixel
Test & Blend
FramebufferHistory of GPUs – Slide 8

The Graphics PipelineEverything fixed function with
a certain number of modes
Number of modes for each stage grew over time
Hard to optimize hardware
Developers always wanted more flexibility
Vertex
Rasterize
Pixel
Test & Blend
FramebufferHistory of GPUs – Slide 9

The Graphics PipelineRemains a key abstraction
Hardware used to look like this
Vertex and pixel processing became programmable, new stages added
GPU architecture increasingly centers around shader execution
Vertex
Rasterize
Pixel
Test & Blend
FramebufferHistory of GPUs – Slide 10

The Graphics PipelineExposing an (at first limited)
instruction set for some stages
Limited instructions and instruction types and no control flow at first
Expanded to full ISA
Vertex
Rasterize
Pixel
Test & Blend
FramebufferHistory of GPUs – Slide 11

Workload and programming model provide lots of parallelism
Applications provide large groups of vertices at onceVertices can be processed in parallelApply same transform to all vertices
Triangles contain many pixelsPixels from a triangle can be processed in
parallelApply same shader to all pixels
Very efficient hardware to hide serialization bottlenecks History of GPUs – Slide 12
Why GPUs Scale So Nicely
History of GPUs – Slide 13
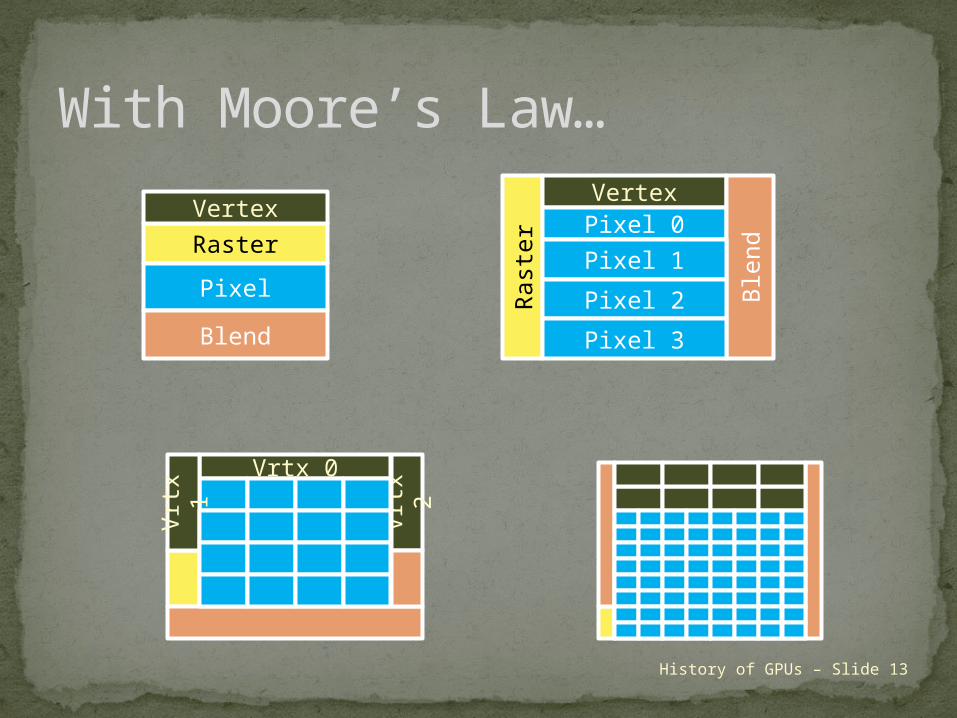
With Moore’s Law…
Raster
Vertex
Pixel
Blend
Rast
er
VertexPixel 0
Ble
nd
Pixel 1
Pixel 2
Pixel 3
Vrtx 0
Vrt
x 2
Vrt
x 1
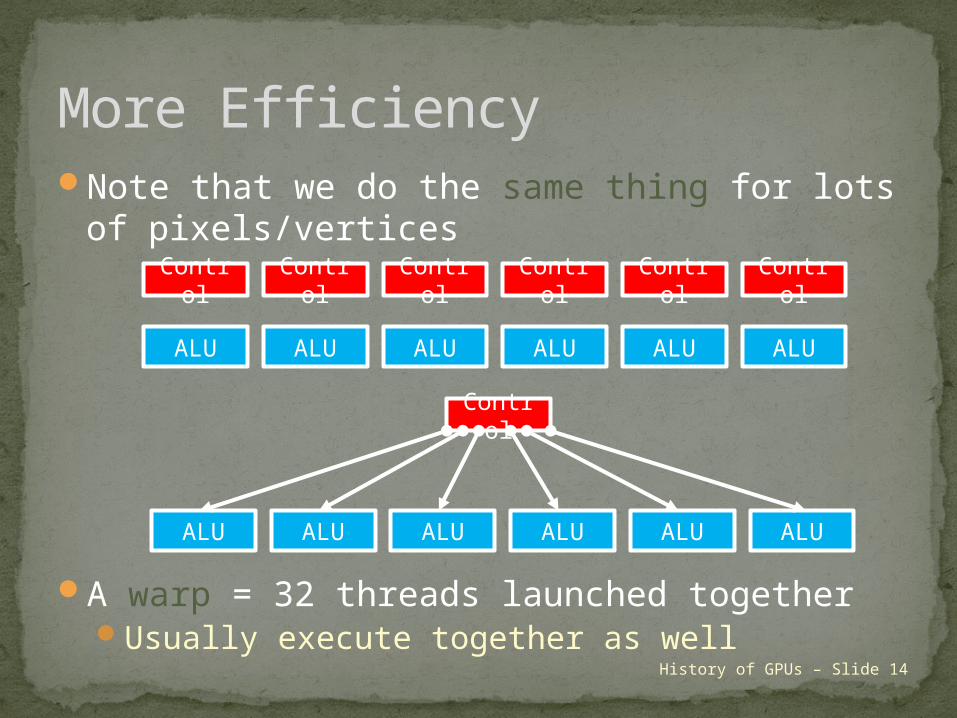
Note that we do the same thing for lots of pixels/vertices
A warp = 32 threads launched togetherUsually execute together as well
History of GPUs – Slide 14
More Efficiency
ALU
Control
ALU
Control
ALU
Control
ALU
Control
ALU
Control
ALU
Control
ALU ALU ALU
Control
ALU ALU ALU

All this performance attracted developersTo use GPUs, re-expressed their algorithms
as general purpose computations using GPUs and graphics API in applications other than 3-D graphicsPretend to be graphics; disguise data as
textures or geometry, disguise algorithm as render passes
Fool graphics pipeline to do computation to take advantage of massive parallelism of GPU
GPU accelerates critical path of application
History of GPUs – Slide 15
What Is (Historical) GPGPU?

Data parallel algorithms leverage GPU attributesLarge data arrays, streaming throughputFine-grain SIMD parallelismLow-latency floating point (FP) computation
Applications – see http://GPGPU.orgGame effects (FX) physics, image processingPhysical modeling, computational engineering,
matrix algebra, convolution, correlation, sorting
History of GPUs – Slide 16
General Purpose GPUs (GPGPUs)

Previous GPGPU ConstraintsDealing with graphics API
Working with the corner cases of the graphics API
Addressing modes Limited texture size/dimension
Shader capabilities Limited outputs
Instruction sets Lack of integer & bit ops
Communication limited Between pixels Scatter a[i] = p
History of GPUs – Slide 17
Input Registers
Fragment Program
Output Registers
Constants
Texture
Temp Registers
per threadper Shaderper Context
FB Memory

To use GPUs, re-expressed algorithms as graphics computations
Very tedious, limited usabilityStill had some very nice results
This was the lead up to CUDA
History of GPUs – Slide 18
Summary: Early GPGPUs

General purpose programming modelUser kicks off batches of threads on the GPUGPU = dedicated super-threaded, massively
data parallel co-processorTargeted software stack
Compute oriented drivers, language, and tools
History of GPUs – Slide 19
Compute Unified Device Architecture (CUDA)

Driver for loading computation programs into GPUStandalone Driver - Optimized for computation Interface designed for compute – graphics-free
APIData sharing with OpenGL buffer objects Guaranteed maximum download & readback
speedsExplicit GPU memory management
History of GPUs – Slide 20
Compute Unified Device Architecture (CUDA)
History of GPUs – Slide 21
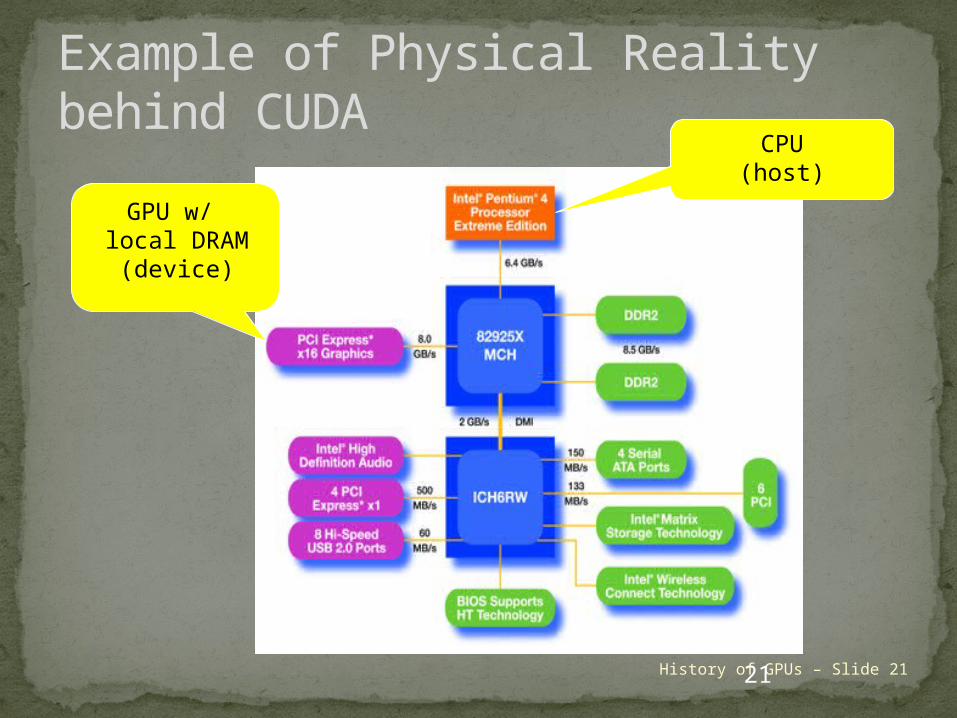
Example of Physical Reality behind CUDA
21
CPU(host)
GPU w/ local DRAM
(device)

8-series GPUs deliver 25 to 200+ GFLOPSon compiled parallel C applications Available in laptops,
desktops, and clusters
GPU parallelism is doubling every year
Programming model scales transparently
History of GPUs – Slide 22
Parallel Computing on a GPU
GeForce 8800
Tesla D870

Programmable in C with CUDA tools Multithreaded SPMD model uses application
data parallelism and thread parallelism
History of GPUs – Slide 23
Parallel Computing on a GPU
Tesla S870

GPUs evolve as hardware and software evolve
Five stage graphics pipelining
An example of GPGPU
Intro to CUDA
History of GPUs – Slide 24
Final Thoughts

Reading: Chapter 2, “Programming Massively Parallel Processors” by Kirk and Hwu.
Based on original material fromThe University of Illinois at Urbana-Champaign
David Kirk, Wen-mei W. HwuThe University of Minnesota: Weijun XiaoStanford University: Jared Hoberock, David
TarjanRevision history: last updated 5/24/2011.
History of GPUs – Slide 25
End Credits


















