
1 03 - tensor calculus 03 - tensor calculus - tensor analysis.

Photos placed in horizontal position with even amount of white space
between photos and header
Sandia National Laboratories is a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC, a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA0003525.
PortabilityandScalabilityofSparseTensorDecompositionsonCPU/MIC/GPUArchitectures
ChristopherForster,KeitaTeranishi,GregMackey,DanielDunlavy andTamaraKolda
SAND2017-6575C

SparseTensorDecomposition
§ DevelopproductionqualitylibrarysoftwaretoperformCPfactorizationwithAlternatingPoissonRegression onHPCplatforms§ SparTen
§ SupportseveralHPCplatforms§ Nodeparallelism(Multicore,Manycore andGPUs)
§ MajorQuestions§ SoftwareDesign§ PerformanceTuning
§ Thistalk§ Weareinterestedintwomajorvariants
§ MultiplicativeUpdates§ ProjectedDampedNewtonforRow-subproblems
2

CPTensorDecomposition
3
§ Expresstheimportantfeatureofdatausingasmallnumberofvectorouterproducts
Key references: Hitchcock (1927), Harshman (1970), Carroll and Chang (1970)
CANDECOMP/PARAFAC (CP) Model
Model:

PoissonforSparseCountData
4
Gaussian (typical) PoissonThe random variable x is a
continuous real-valued number.The random variable x is a
discrete nonnegative integer.

Model: Poisson distribution (nonnegative factorization)
SparsePoissonTensorFactorization
5
§ Nonconvexproblem!§ AssumeRisgiven
§ Minimizationproblemwithconstraint§ Thedecomposedvectorsmustbenon-negative
§ AlternatingPoissonRegression(ChiandKolda,2011)§ Assume(d-1)factormatricesareknownandsolvefortheremainingone

NewMethod:AlternatingPoissonRegression(CP-APR)
6
Repeat until converged…
Fix B,C;solveforA
Fix A,C;solvefor B
Fix A,B;solvefor C
Theorem: The CP-APR algorithm will converge to a constrained stationary point if the subproblems are strictly convex and solved exactly at each iteration. (Chi and Kolda, 2011)
Convergence Theory

CP-APR
7
Minimization problem is expressed as:

CP-APR
8
Minimization problem is expressed as:
• 2 major approaches• Multiplicative Updates like Lee & Seung
(2000) for matrices, but extended by Chi and Kolda (2011) for tensors
• Newton and Quasi-Newton method for Row-subpblems by Hansen, Plantenga and Kolda(2014)

KeyElementsofMUandPDNRmethods
§ Keycomputations§ Khatri-RaoProduct§ Modifier(10+iterations)
§ Keyfeatures§ Factormatrixisupdatedallatonce
§ Exploitstheconvexityofrowsubproblems forglobalconvergence
§ Keycomputations§ Khatri-RaoProduct§ ConstrainedNon-linearNewton-basedoptimizationforeachrow
§ Keyfeatures§ Factormatrixcanbe
updatedbyrows§ Exploitstheconvexityof
row-subproblems
9
Multiplicative Update (MU) Projected Damped Newton for Row-subproblems (PDNR)

CP-APR-MU
10
Key Computations

CP-APR-PDNR
11
Key Computations
Algorithm 1: CPAPR-PDNR algorithm
1 CPAPR PDNR (X ,M);
Input : Sparse N -mode Tensor X of size I
1
⇥ I
2
⇥ . . . IN and the
number of components R
Output: Kruskal Tensor M = [�;A
(1)
. . . A
(N)
]
2 Initialize3 repeat4 for n = 1, . . . , N do5 Let ⇧
(n)= (A
(N) � · · ·�A
(n+1) �A
(n�1) � . . . A
(1)
)
T
6 for i = 1, . . . , In do
7 Find b
(n)i s.t. min
b(n)i �0
f
row
(b
(n)i , x
(n)i ,⇧
(n))
8 end
9 � = e
TB
(n)where B
(n)= [b
(n)1
. . . b
(n)In
]
T
10 A
(n) B
(n)⇤
�1
, where ⇤ = diag(�)
11 end
12 until all mode subproblems converged ;

PARALLELCP-APRALGORITHMS
12
ParallelizingCP-APR§ Focusonon-nodeparallelismformultiplearchitectures
§ Multiplechoicesforprogramming§ OpenMP,OpenACC, CUDA,Pthread …§ Managedifferentlow-levelhardwarefeatures(cache,devicememory,NUMA…)
§ OurSolution:UseKokkos forproductivityandperformanceportability§ Abstractionofparallelloops§ AbstractionDatalayout(row-major,columnmajor,programmablememory)§ Samecodetosupportmultiplearchitectures
13
Kokkos
Intel Multicore Intel Manycore NVIDIA GPU IBM PowerAMD Multicore/APU ARM
Support multiple Architectures

WhatisKokkos?
§ TemplatedC++LibrarybySandiaNationalLabs(Edwards,etal)§ Serveassubstratelayerofsparsematrixandvectorkernels§ Supportanymachineprecisions
§ Float§ Double§ QuadandHalffloatifneeded.
§ Kokkos::View()accommodatesperformance-awaremultidimensionalarraydataobjects§ Light-weightC++classto
§ ParallelizingloopsusingC++languagestandard§ Lambda§ Functors
§ Extensivesupportofatomics
14

ParallelProgramingwithKokkos
§ ProvideparallelloopoperationsusingC++languagefeatures§ Conceptually,theusageisnomoredifficultthanOpenMP.
Theannotationsjustgoindifferentplaces. 15
for (size_t i = 0; i < N; ++i) {
/* loop body */}
#pragma omp parallel forfor (size_t i = 0; i < N; ++i) {
/* loop body */}
parallel_for (( N, [=], (const size_t i) {
/* loop body */});
Seria
lO
penM
PKo
kkos
Kokkos information courtesy of Carter Edwards

WhyKokkos?
§ ComplyC++languagestandard!§ Supportmultipleback-ends
§ Pthread,OpenMP,CUDA,IntelTBBandQthread
§ Supportmultipledatalayoutoptions§ ColumnvsRowMajor§ Device/CPUmemory
§ Supportdifferentparallelism§ Nestingsupport§ Vector,threads,Warp,etc.§ Taskparallelism(underdevelopment)
16
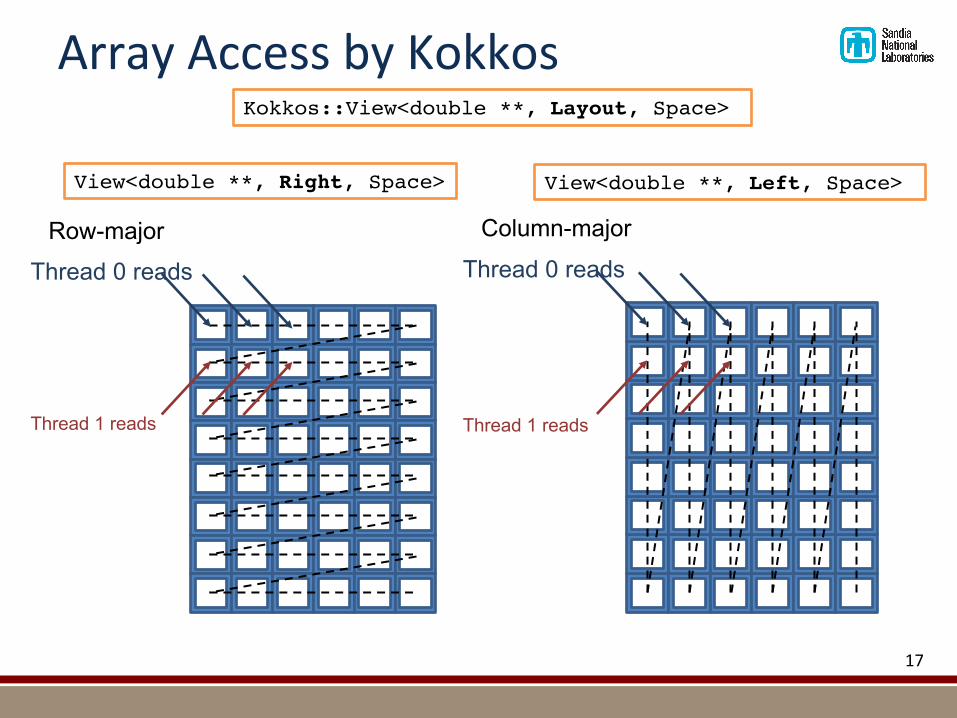
ArrayAccessbyKokkos
17
Row-majorThread 0 reads
Thread 1 reads
Column-major
Thread 0 reads
Thread 1 reads
Kokkos::View<double **, Layout, Space>
View<double **, Right, Space> View<double **, Left, Space>

ArrayAccessbyKokkos
18
Row-major
Thread 0 reads
Thread 1 reads
Contiguous reads per thread
Column-major
Thread 0 reads
Thread 1 reads
Coalesced reads w
ithin warp
View<double **, Right, Host> View<double **, Left, CUDA>
Kokkos::View<double **, Layout, Space>

ParallelCP-APR-MU
19
Data Parallel

ParallelCP-APR-PDNR
20
Data Parallel
Task Parallel

NotesonDataStructure
§ UseKokkos::View§ SparseTensor
§ SimilartotheCoordinate(COO)FormatinSparseMatrixrepresentation
§ Kruskal Tensor&KhatriRaoProduct§ Providesoptionsforroworcolumnmajor
§ Kokkos::Viewprovidesanoptiontodefinetheleadingdimension.§ Determinedduringcompileorruntime
§ AvoidAtomics§ ExpensiveinCPUsandManycore§ Useextraindexingdatastructure
§ CP-APR-PDNR§ Createsapooloftasks§ Adedicatedbufferspace(Kokkos::View)isassignedtoindividualtask
21

PERFORMANCE
22

PerformanceTest§ StrongScalability
§ Problemsizeisfixed§ RandomTensor
§ 3Kx4Kx5K,10Mnonzeroentries§ 100outeriterations
§ RealisticProblems§ CountData(Non-negative)§ Availableathttp://frostt.io/§ 10outeriterations
§ DoublePrecision
23
Data Dimensions Nonzeros RankLBNL 2K x 4K x 2K x 4K x 866K 1.7M 10NELL-2 12K x 9K x 29K 77M 10NELL-1 3M x 2M x 25M 144M 10Delicious 500K x 17M x 3M x 1K 140M 10

CPAPR-MUonCPU(Random)
24
0
200
400
600
800
1000
1200
1400
1600
1800
1 2 4 6 8 10 12 14 16 18 20 22 24 26 28
Exec
utio
n Ti
me
(s)
Core Count
CP-APR-MU method, 100 outer-iterations, (3000 x 4000 x 5000, 10M nonzero entries), R=10, PC cluster, 2 Haswell (14 core) CPUs
per node, MKL-11.3.3, HyperThreading disabled
Pi Phi+ Update

Results:CPAPR-MUScalability
25
DataHaswell CPU
1-core
2 Haswell CPUs
14-cores
2 Haswell CPUs
28-coresKNL
68-core CPUNVIDIA
P100 GPUTime(s) Speedup Time(s) Speedup Time(s) Speedup Time(s) Speedup Time(s) Speedup
Random 1715* 1 279 6.14 165 10.39 20 85.74 10 171.5LBNL 131 1 32 4.09 32 4.09 103 1.27NELL-2 1226 1 159 7.77 92 13.32 873 1.40NELL-1 5410 1 569 9.51 349 15.50 1690 3.20Delicious 5761 1 2542 2.26 2524 2.28
100 outer iterations for the random problem10 outer iterations for realistic problems* Pre-Kokkos C++ code on 2 Haswell CPUs:
1-core, 2136 sec14-cores, 762 sec28-cores, 538 sec

CPAPR-PDNRonCPU(Random)
26
0100200300400500600700800900
1 2 4 6 8 10 12 14 16 18 20 22 24 26 28
Exec
utio
n Ti
me
(s)
Core Count
CPAPR-PDNR method, 100 outer-iterations, 1831221 inner iterations total, (3000 x 4000 x 5000, 10M nonzero entries), R=10,
PC cluster, 2 Haswell (14 core) CPUs per node, MKL-11.3.3, HyperThreading disabled
Pi RowSub

Results:CPAPR-PDNRScalability
27
DataHaswell CPU
1 core2 Haswell CPUs
14 cores2 Haswell CPUs
28 coresTime(s) Speedup Time(s) Speedup Time(s) Speedup
Random 817* 1 73 11.19 44 18.58
LBNL 441 1 187 2.35 191 2.30
NELL-2 2162 1 326 6.63 319 6.77
NELL-1 17212 1 4241 4.05 3974 4.33
Delicious 18992 1 3684 5.15 3138 6.05
100 outer iterations for the random problem10 outer iterations for realistic problems* Pre-Kokkos C++ code spends 3270 sec on 1 core

PerformanceIssues
§ Ourimplementationexhibitsverygoodscalabilitywiththerandomtensor.§ Similarmodesizes§ Regulardistributionofnonzeroentries
§ Somecacheeffects§ Kokkos isNUMA-awareforcontiguousmemoryaccess(first-touch)
§ Somescalabilityissueswiththerealistictensorproblems.§ Irregularnonzerodistributionanddisparityinmodesizes§ Task-parallelcodemayhavesomememorylocalityissuestoaccess
sparsetensor,Kruskal Tensor,andKhatori-Raoproduct§ Preprocessingcouldimprovethelocality
§ ExplicitDatapartitioning(SmithandKarypis)§ PossibletoimplementusingKokkos
28
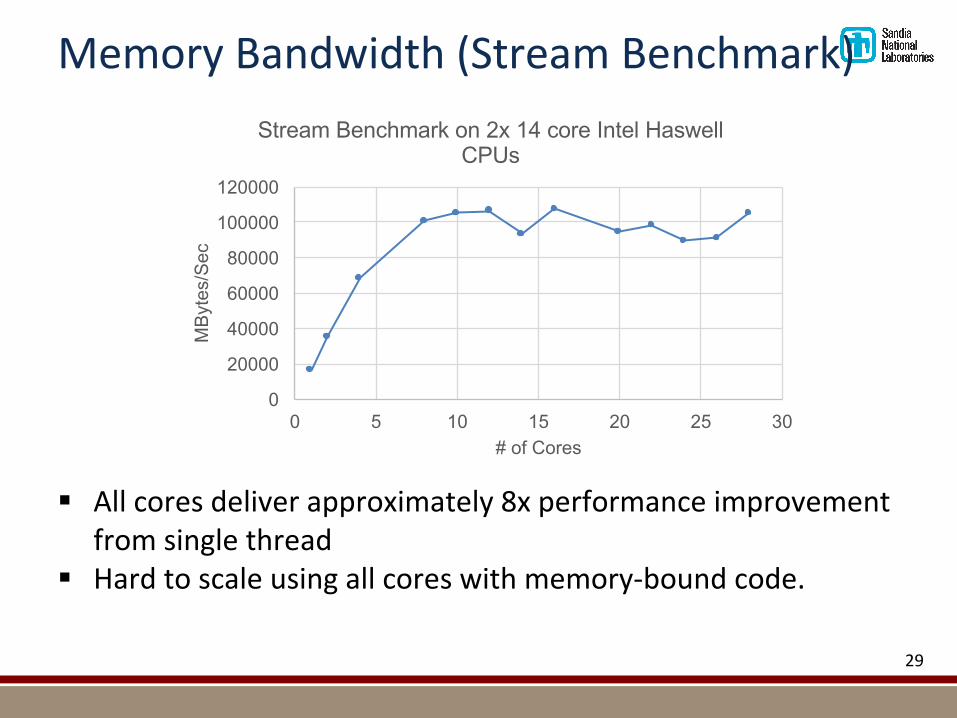
MemoryBandwidth(StreamBenchmark)
§ Allcoresdeliverapproximately8xperformanceimprovementfromsinglethread
§ Hardtoscaleusingallcoreswithmemory-boundcode.
29
0
20000
40000
60000
80000
100000
120000
0 5 10 15 20 25 30
MBy
tes/
Sec
# of Cores
Stream Benchmark on 2x 14 core Intel Haswell CPUs

Conclusion
§ DevelopmentofPortableon-nodeParallelCP-APRSolvers§ DataparallelismforMUmethod§ MixedData/TaskparallelismforPDNRmethod§ MultipleArchitectureSupportusingKokkos
§ ScalablePerformanceforrandomsparsetensor
§ FutureWork§ ProjectedQuasi-NewtonforRow-subproblems (PQNR)§ GPUandManycore supportforPDNRandPQNR§ Performancetuningtohandleirregularnonzerodistributionsand
disparityinmodesizes
30














![Sparse tensor discretization of elliptic sPDEs...accordingly “sparse tensor product stochastic Galerkin FEM”. In [7] we presented an efficient numerical sGFEM algorithm to solve](https://static.fdocuments.us/doc/165x107/5f77ae6cf8131406cd2a74b8/sparse-tensor-discretization-of-elliptic-spdes-accordingly-aoesparse-tensor.jpg)



