
Pmit 6102-14-lec1-intro
50
PMIT-6103 Advanced Database Systems By- Jesmin Akhter Assistant Professor, IIT, Jahangirnagar University
-
Upload
jesmin-rahaman -
Category
Documents
-
view
176 -
download
5
Transcript of Pmit 6102-14-lec1-intro

PMIT-6103Advanced Database Systems
By-
Jesmin Akhter
Assistant Professor, IIT, Jahangirnagar University

Slide 2
Continue from 16.01.2015-……
Every week
Friday
• From 2:30 PM-4:30 PM
NB: Schedule may change
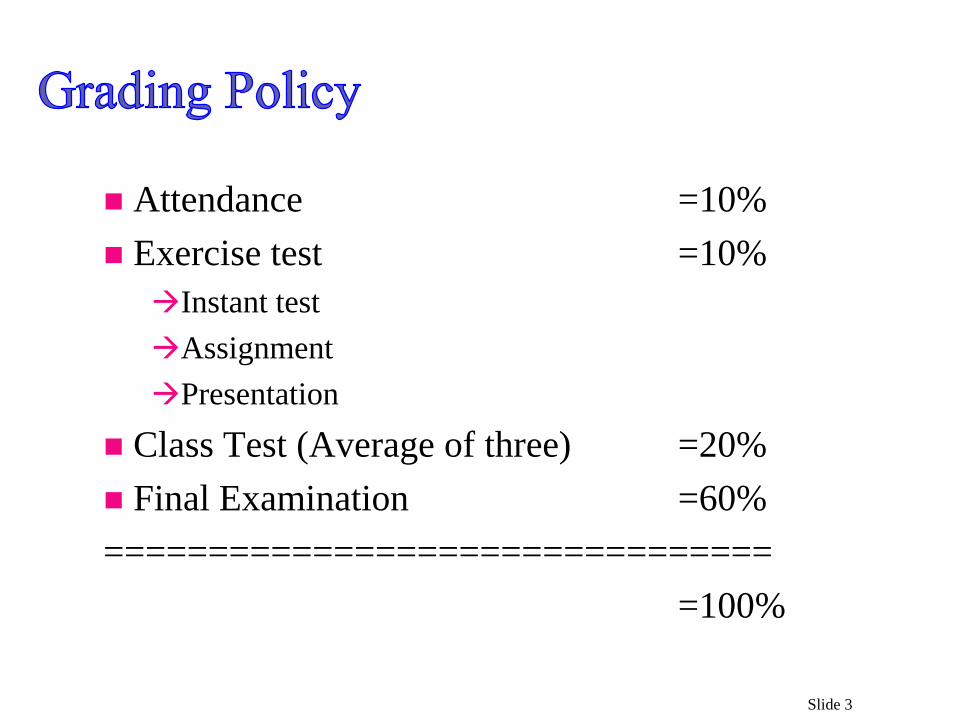
Slide 3
Attendance =10%
Exercise test =10%
Instant test
Assignment
Presentation
Class Test (Average of three) =20%
Final Examination =60%
================================
=100%
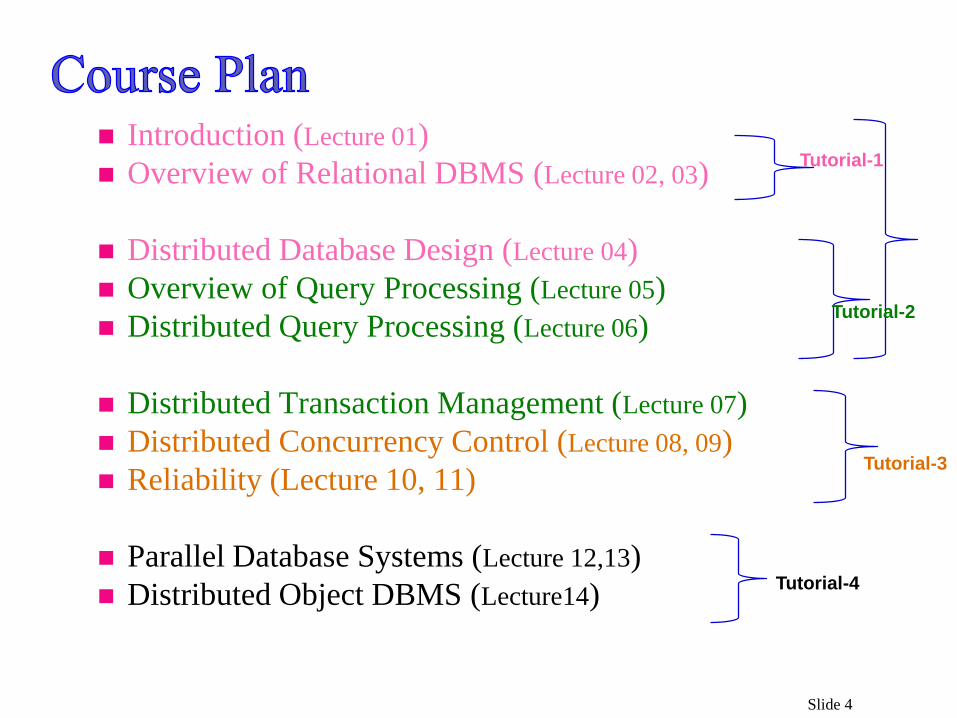
Slide 4
Introduction (Lecture 01)
Overview of Relational DBMS (Lecture 02, 03)
Distributed Database Design (Lecture 04)
Overview of Query Processing (Lecture 05)
Distributed Query Processing (Lecture 06)
Distributed Transaction Management (Lecture 07)
Distributed Concurrency Control (Lecture 08, 09)
Reliability (Lecture 10, 11)
Parallel Database Systems (Lecture 12,13)
Distributed Object DBMS (Lecture14)
Tutorial-1
Tutorial-2
Tutorial-3
Tutorial-4

Slide 5
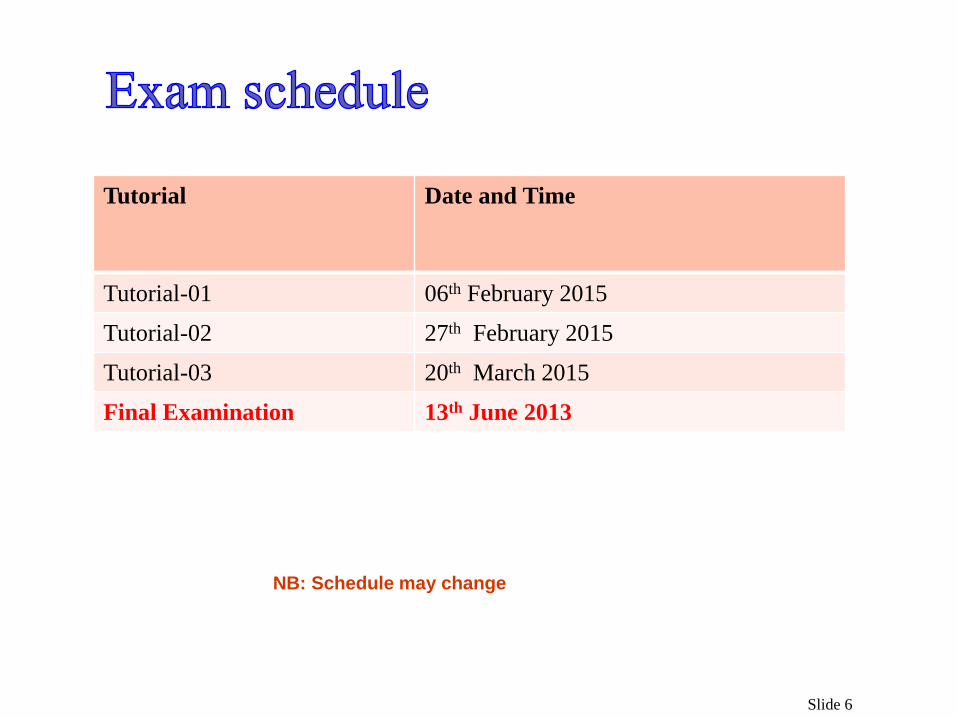
Slide 6
Tutorial Date and Time
Tutorial-01 06th February 2015
Tutorial-02 27th February 2015
Tutorial-03 20th March 2015
Final Examination 13th June 2013
NB: Schedule may change

Lecture 01Introduction to DDBMS

Slide 8
Introduction
Distributed Database System
Applications
Distributed DBMS Promises
Problem Areas
Architectural Models for Distributed DBMSs
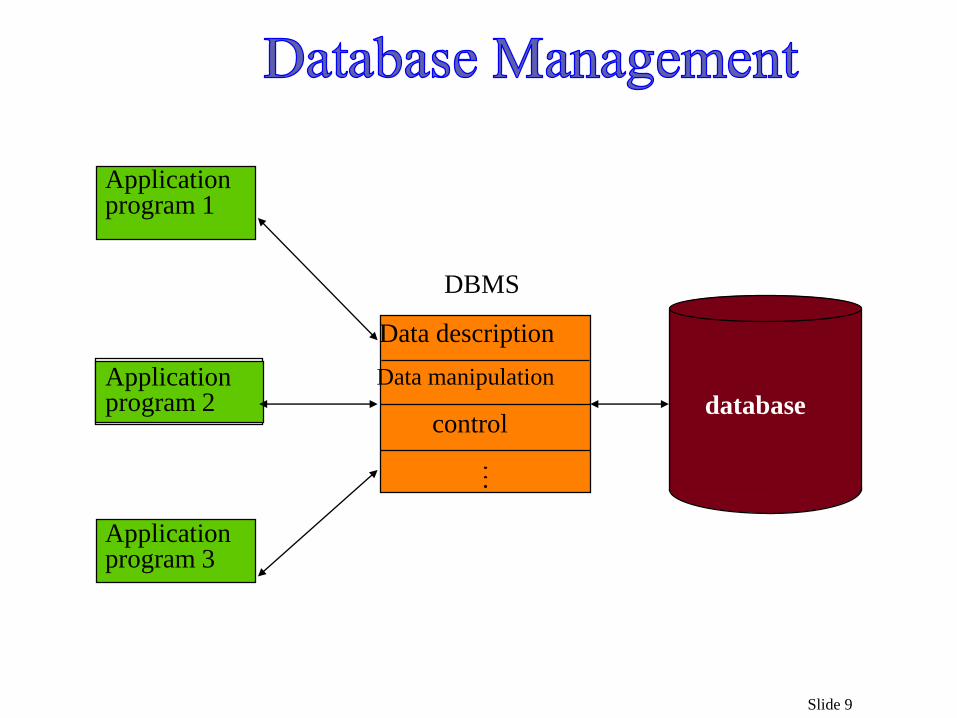
Slide 9
database
DBMS
Applicationprogram 1
Applicationprogram 2
Applicationprogram 3
Data description
Data manipulation
control
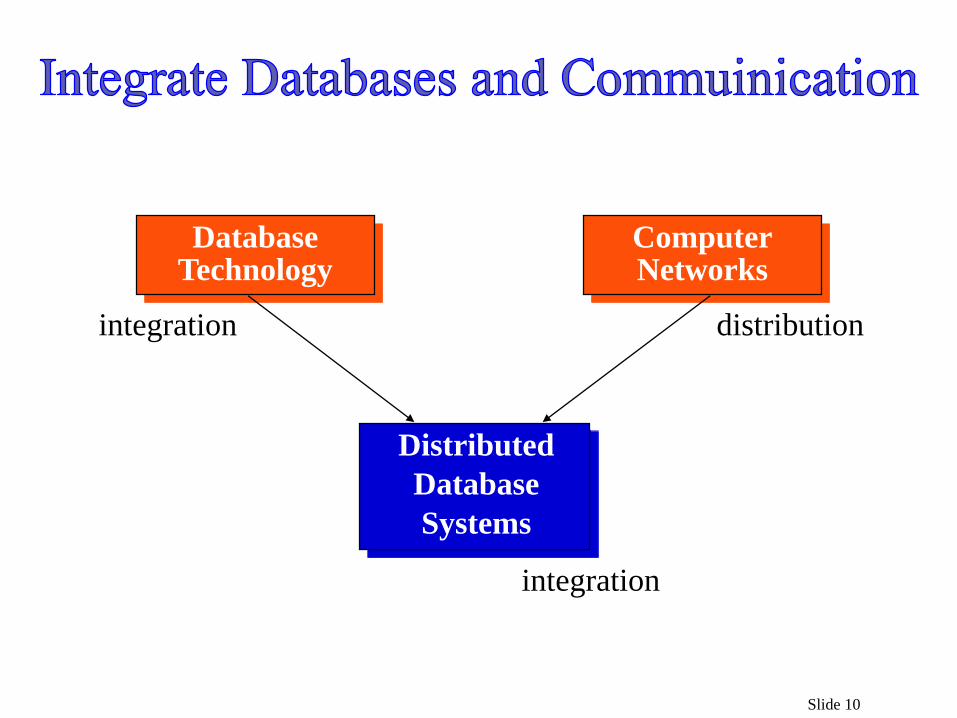
Slide 10
DatabaseTechnology
ComputerNetworks
integration distribution
integration
Distributed
Database
Systems

Slide 11
A number of autonomous processing elements
that are interconnected by a computer network and
that cooperate in performing their assigned tasks.
The “processing element” referred to a computing device that can execute a program on its own.

Slide 12
Processing logic: processing logic or processing elements are
distributed
Functions: Various functions of a computer system could be delegated to various pieces of hardware or software
Data: Data used by a number of applications may be distributed to a number of processing sites
Control: The control of the execution of various tasks might be distributed instead of being performed by one computer system.

Slide 13
“Distributed database system” (DDBS) is used to refer
jointly distributed database and the distributed DBMS.
A distributed database (DDB) is a collection of multiple, logically interrelated databases distributed over a
computer network.
A distributed database management system (D–DBMS) is the software
manages the DDB and
provides an access mechanism
makes this distribution transparent to the users.

Slide 14
Physical distribution does not necessarily imply that the computer systems be geographically far apart;
May be in the same room.
The communication between them is done over a network instead of
through shared memory or shared disk (multiprocessor systems) with the network as the only shared resource.

Slide 15
A timesharing computer system
A loosely or tightly coupled multiprocessor system
Not DDBS, Because in DDBS communication between computer systems is done over a network instead of through shared memory or shared disk with the network as the only shared resource.
A database system
which resides at one of the nodes of a network of computers - this is
a centralized database on a network node

Slide 16
The CPU time is shared by different processes
Time slice is defined by the OS, for sharing CPU time between processes.
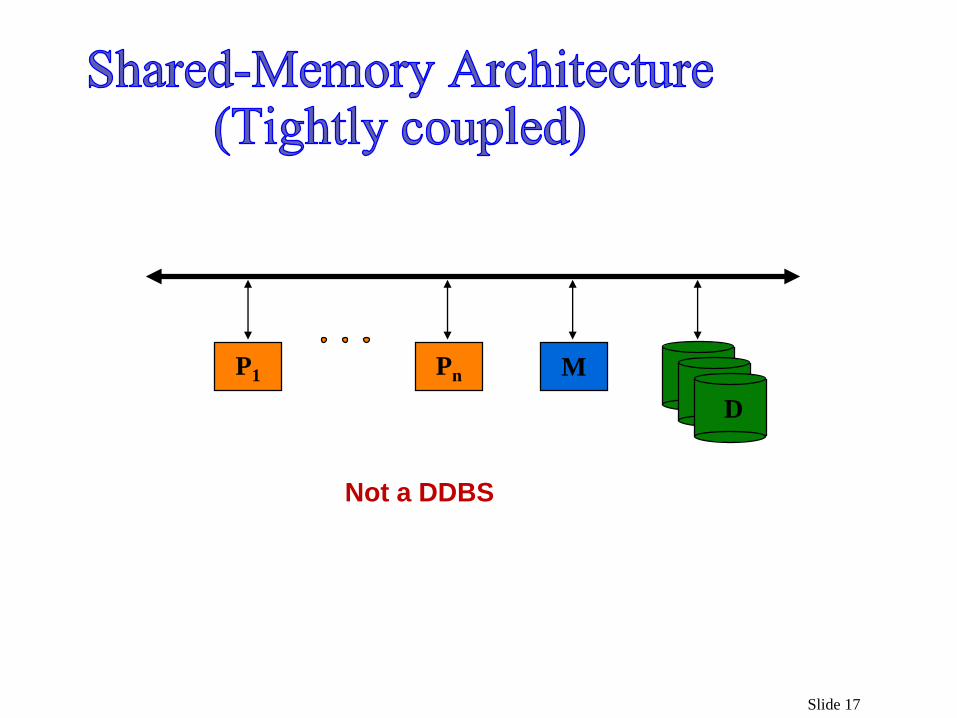
Slide 17
P1 Pn M
D
Not a DDBS
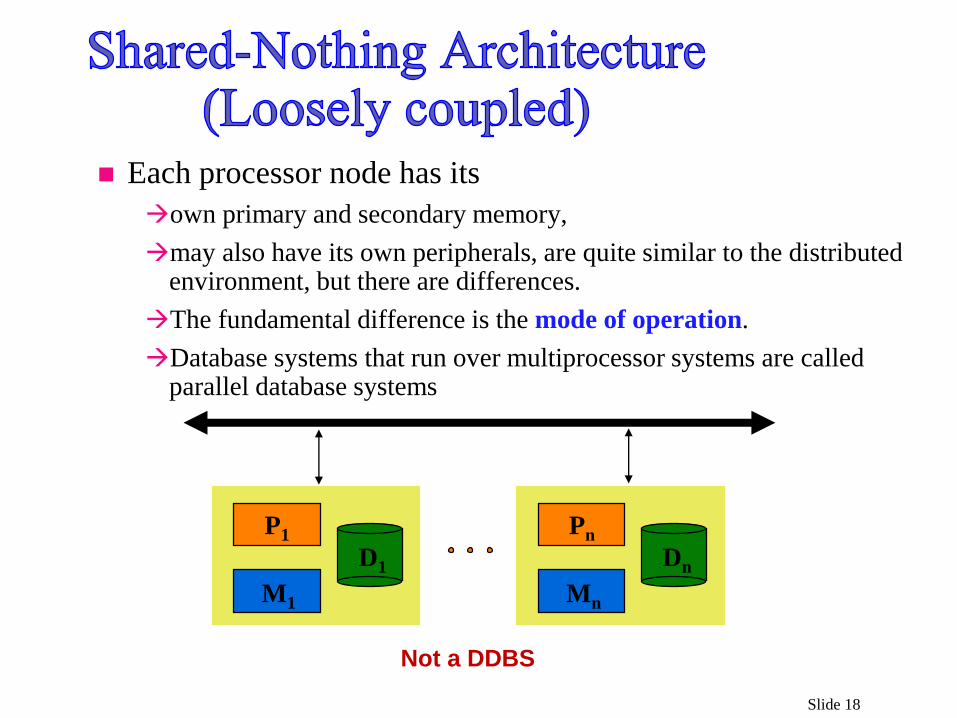
Slide 18
P1
M1
D1
Pn
Mn
Dn
Each processor node has its
own primary and secondary memory,
may also have its own peripherals, are quite similar to the distributed environment, but there are differences.
The fundamental difference is the mode of operation.
Database systems that run over multiprocessor systems are called parallel database systems
Not a DDBS
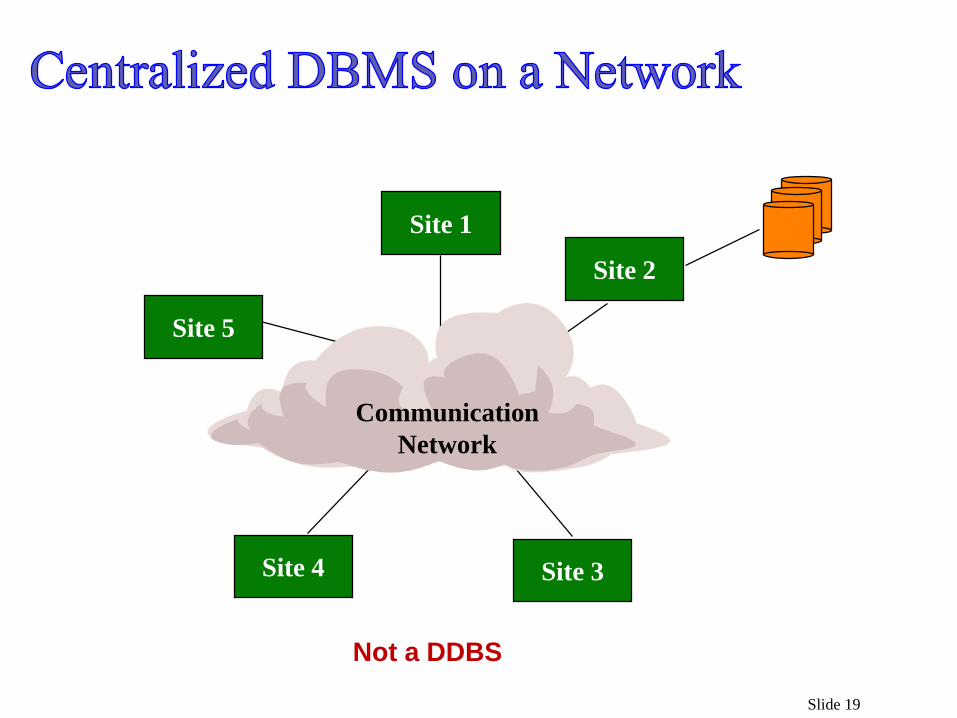
Slide 19
Site 5
Site 1
Site 2
Site 3Site 4
Communication
Network
Not a DDBS
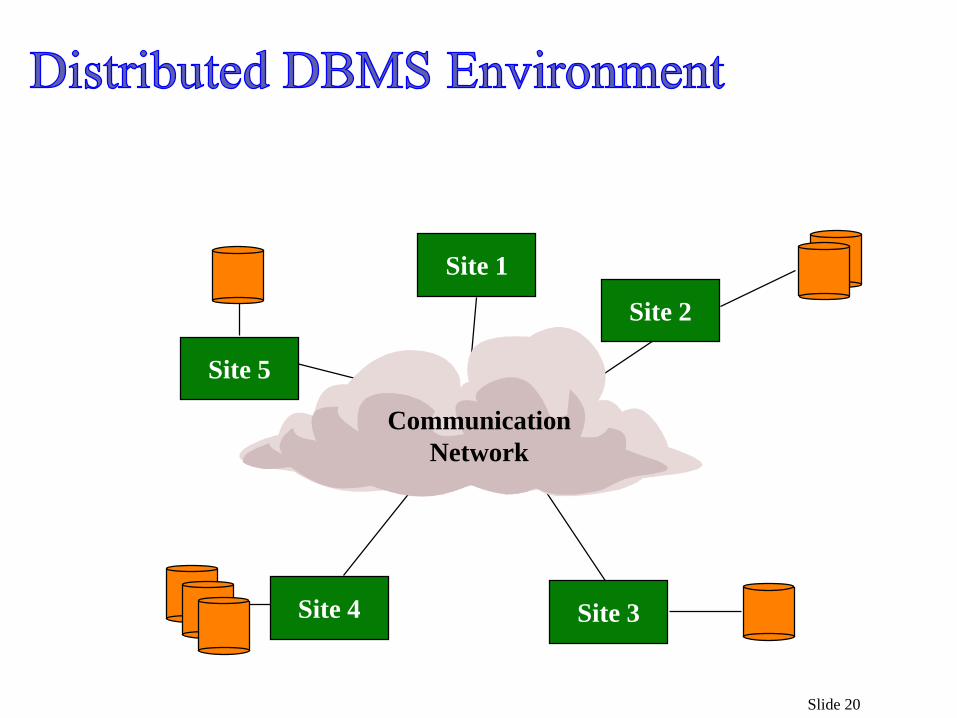
Slide 20
Site 5
Site 1
Site 2
Site 3Site 4
Communication
Network
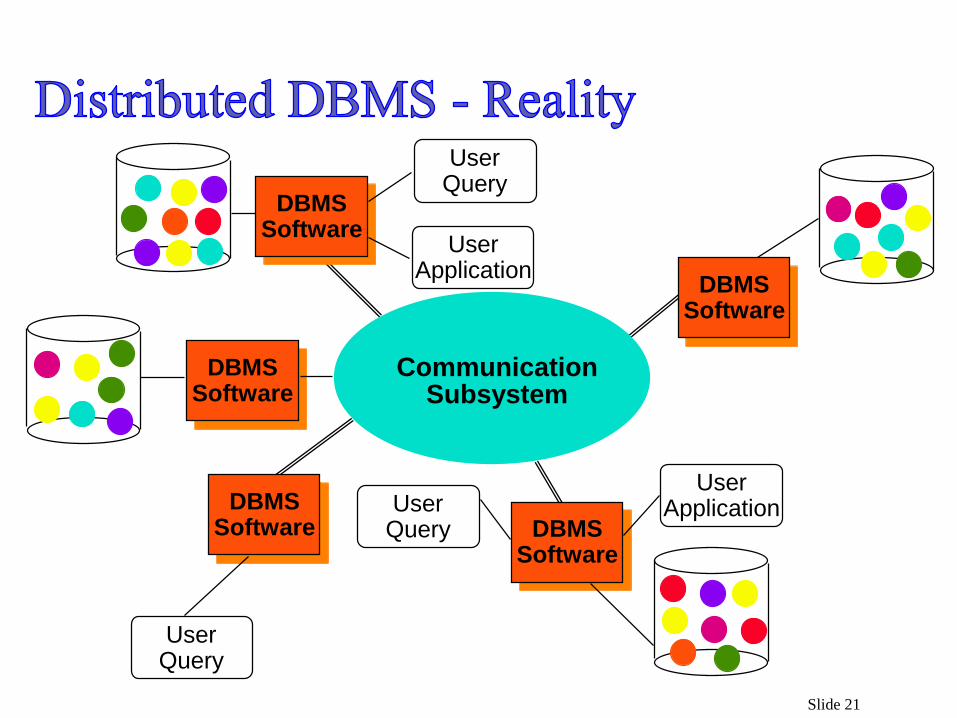
Slide 21
CommunicationSubsystem
UserQuery
DBMSSoftware
DBMSSoftware
UserApplication
DBMSSoftware
UserApplicationUser
QueryDBMS
Software
UserQuery
DBMSSoftware

Slide 22
Data stored at a number of sites each site logicallyconsists of a single processor.
Processors at different sites are interconnected by a computer network no multiprocessors
parallel database systems
Distributed database is a database, not a collection of files data logically related as exhibited in the users’ access patterns
relational data model
D-DBMS is a full-fledged DBMS
not remote file system.

Slide 23
Manufacturing - especially multi-plant manufacturing
Military command and control
Electronic fund transfers and electronic trading
Corporate MIS
Airline restrictions
Hotel chains
Any organization which has a decentralized organization structure

Slide 24
Transparent management of distributed, fragmented, and replicated data
Improved reliability/availability through distributed transactions
Improved performance
Easier and more economical system expansion

Slide 25
Example: Four relations:
EMP(ENO, ENAME, TITLE)
PROJ(PNO,PNAME, BUDGET)
SAL(TITLE, AMT)
ASG(ENO, PNO, RESP, DUR).
For a centralized DBMS, find out the names of employees with salary who worked on a project for more than 12 months
SELECT ENAME, AMT
FROM EMP, ASG, SAL
WHERE ASG.DUR > 12
AND EMP.ENO = ASG.ENO
AND SAL.TITLE = EMP.TITLE
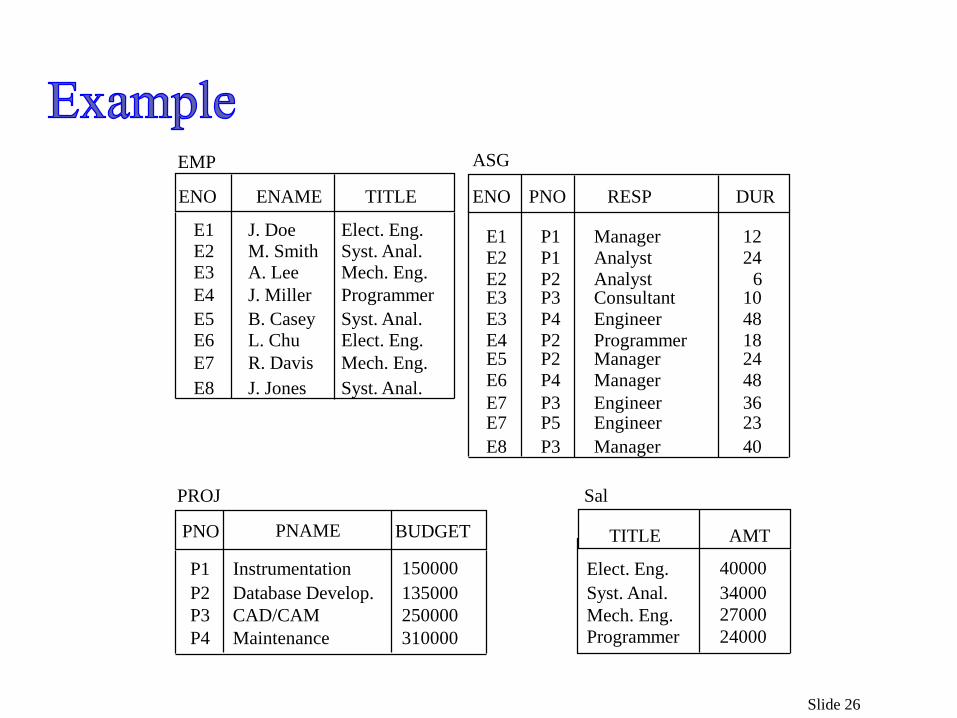
Slide 26
TITLE AMT
Sal
Elect. Eng. 40000
Syst. Anal. 34000
Mech. Eng. 27000
Programmer 24000
PROJ
PNO PNAME BUDGET
ENO ENAME TITLE
E1 J. Doe Elect. Eng.
E2 M. Smith Syst. Anal.
E3 A. Lee Mech. Eng.
E4 J. Miller Programmer
E5 B. Casey Syst. Anal.
E6 L. Chu Elect. Eng.
E7 R. Davis Mech. Eng.
E8 J. Jones Syst. Anal.
EMP
ENO PNO RESP
E1 P1 Manager 12
DUR
E2 P1 Analyst 24
E2 P2 Analyst 6E3 P3 Consultant 10
E3 P4 Engineer 48
E4 P2 Programmer 18E5 P2 Manager 24
E6 P4 Manager 48
E7 P3 Engineer 36
E8 P3 Manager 40
ASG
P1 Instrumentation 150000
P3 CAD/CAM 250000
P2 Database Develop. 135000
P4 Maintenance 310000
E7 P5 Engineer 23

Slide 27
To localize data such that data about the employees in
Waterloo office are stored in Waterloo,
those in the Boston office are stored in Boston, and so forth.
The same applies to the project and salary information.
That is data is distributed.
We partition each of the relations and store each partition at a
different site. This is known as fragmentation.
Data that are commonly accessed by one user
can be placed on that user’s local machine
as well as on the machine of another user with the same access requirements.
That is data is replicated
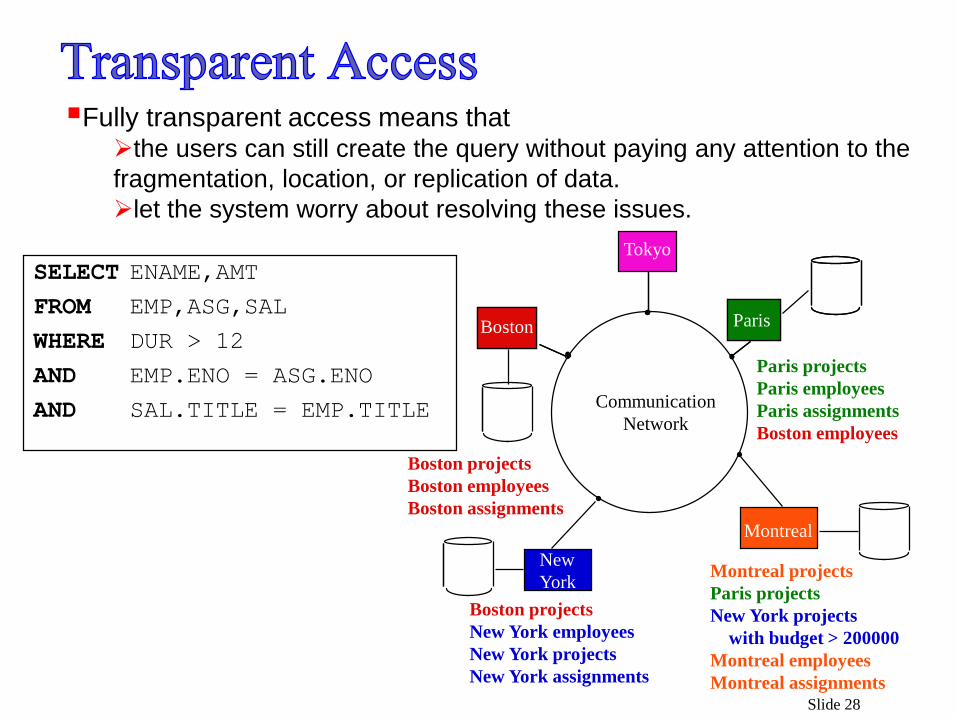
Slide 28
SELECT ENAME,AMT
FROM EMP,ASG,SAL
WHERE DUR > 12
AND EMP.ENO = ASG.ENO
AND SAL.TITLE = EMP.TITLE
Paris projects
Paris employees
Paris assignments
Boston employees
Montreal projects
Paris projects
New York projects
with budget > 200000
Montreal employees
Montreal assignments
Boston
Communication
Network
Montreal
Paris
New
York
Boston projects
Boston employees
Boston assignments
Boston projects
New York employees
New York projects
New York assignments
Tokyo
Fully transparent access means that the users can still create the query without paying any attention to the
fragmentation, location, or replication of data.
let the system worry about resolving these issues.

Slide 29
A transparent system “hides” the implementation details from users.
Fundamental issue is to provide Data independence in the distributed environment
Network (distribution) transparency
Replication transparency
Fragmentation transparency
horizontal fragmentation: selection
vertical fragmentation: projection
hybrid

Slide 30
It refers to the immunity of user applications to changes in the definition and organization of data.
Logical data independence
Logical data independence refers to the immunity of user applications to changes in the logical structure (i.e., schema) of the database.
Physical data independence
Deals with hiding the details of the storage structure from
user applications.

Slide 31
In centralized database systems, the only available resource that needs to be shielded from the user is the data.
In a distributed database environment
a second resource that needs to be managed in much the same
manner: the network.
The user should be protected from the operational details of the network; possibly even hiding the existence of the network.
Then there would be no difference between database applications that would run on a centralized database and those that would run on a distributed database.
This type of transparency is referred to as network transparency or distribution transparency.

Slide 32
From a DBMS perspective, distribution transparency requires that users do not have to specify where data are located.
Sometimes two types of distribution transparency are identified:
location transparency
Naming transparency.

Slide 33
Location transparency refers to the fact that the command used to perform a task is independent of
both the location of the data and the system on which an operation
is carried out.
Naming transparency means that a unique name is provided for each object in the database.
In the absence of naming transparency, users are required to embed the location name as part of the object name.

Slide 34
Distribute data in a replicated fashion across the machines on a network.
If one of the machines fails, a copy of the data are still available on another machine on the network
Increase reliability, and availability of data.
Increases the locality of reference.

Slide 35
Data are replicated, the transparency issue is:
The users should not be aware of the existence of copies and the system should handle the management of copies.
The users not to be involved with handling copies and having to specify the fact that a certain action can
and/or should be taken on multiple copies.

Slide 36
Increase performance, availability and reliability.
fragmentation can reduce the negative effects of replication.
Each replica is not the full relation but only a subset of it;
thus less space is required and fewer data items need be managed.

Slide 37
Horizontal fragmentation: A relation is partitioned into a set of sub-relations each of which have a subset of the tuples (rows) of the original relation.
Vertical fragmentation: Where each sub-relation is defined on a subset of the attributes (columns) of the original relation.

Slide 38
Improve reliability since they have replicated components and, thereby eliminate single points of failure.
The failure of a single site, or the failure of a communication link which makes one or more sites unreachable, is not sufficient to bring down the entire system.

Slide 39
Proximity to its points of use (also called data localization).
Requires some support for fragmentation and replication.
This has two potential advantages:
Since each site handles only a portion of the database, contention for CPU and I/O services is not as severe as for centralized databases.
Localization reduces remote access delays that are usually involved in wide area networks.

Slide 40
Issue is database scaling
One aspect of easier system expansion is economics.
It normally costs much less to put together a system of “smaller” computers with the equivalent power of a single big machine.

Slide 41
First, data may be replicated in a distributed environment.
A distributed data base can be designed so that the entire database, or portions of it, reside at different sites of a computer network.
Second, if some sites fail (e.g., by either hardware or software malfunction), or if some communication links fail (making some of the sites unreachable)
While an update is being executed, the effects will not be reflected on the data residing at the failing or unreachable.
The third point is that since each site cannot have instantaneous information on the actions currently being carried out at the other sites,
The synchronization of transactions on multiple sites is considerably harder than for a centralized system.
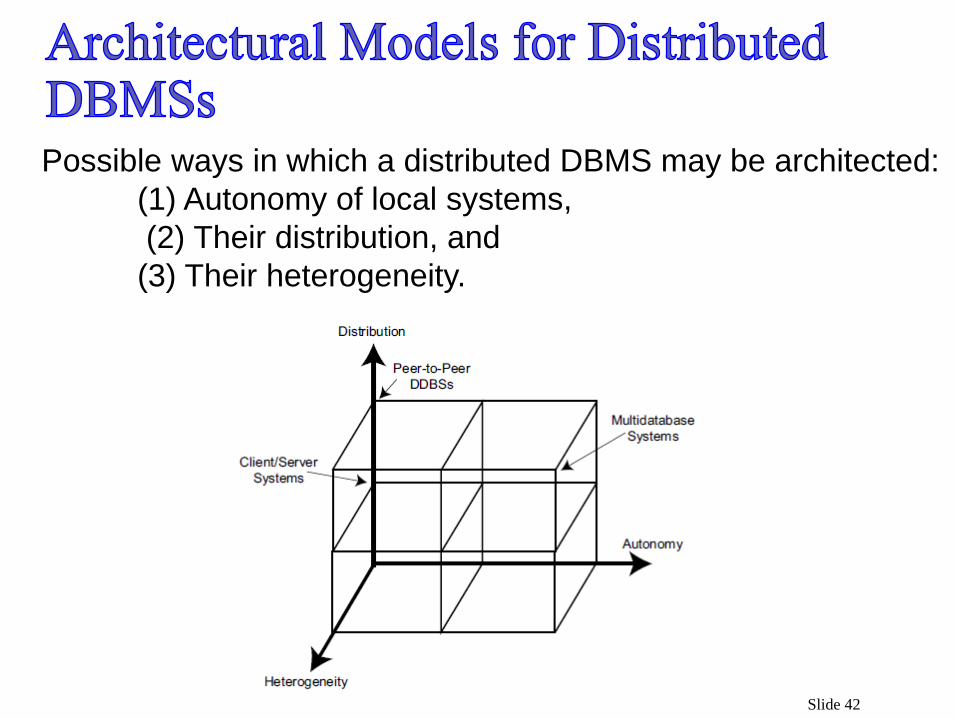
Slide 42
Possible ways in which a distributed DBMS may be architected:
(1) Autonomy of local systems,
(2) Their distribution, and
(3) Their heterogeneity.

Slide 43
Autonomy
Autonomy, refers to the distribution (or decentralization) of control, not of data.
It indicates the degree to which individual DBMSs can operate independently.
Autonomy is a function of a number of factors such as
whether the component systems (i.e., individual DBMSs)
exchange information,
whether they can independently execute transactions, and whether one is allowed to modify them.

Slide 44
Dimensions of Autonomy
Design autonomy
Individual DBMSs are free to use the data models and transaction management techniques that they prefer.
Communication autonomy
Each of the individual DBMSs is free to make its own decision as to what type of information it wants to provide to the other DBMSs or to the software that controls their global execution.
Execution autonomy
Each DBMS can execute the transactions that are submitted to it in any way that it wants to.

Slide 45
Distribution
The distribution dimension of the taxonomy deals with data.
Physical distribution of data over multiple sites;
The user sees the data as one logical pool.
There are a number of ways DBMSs have been distributed. Two classes:
client/server distribution
peer-to-peer distribution (or full distribution).

Slide 46
Client/server distribution
The client/server distribution concentrates data management duties at servers
while the clients focus on providing the application environment including the user interface.
The communication duties are shared between the client machines and servers.

Slide 47
Peer-to-peer distribution (or full distribution).
In peer-to-peer systems, there is no distinction of client machines versus servers.
Each machine has full DBMS functionality and can communicate with other machines to execute queries and transactions.

Slide 48
Heterogeneity
Hardware heterogeneity
Differences in networking protocols to variations in data managers.
Heterogeneity in query languages
not only involves the use of completely different data access paradigms in different data models.
but also covers differences in languages even when the individual systems use the same data model.

Slide 49

Slide 50
What is the basic difference between Database systems and distributed Database Systems?
What is being distributed?
Define a loosely or tightly coupled multiprocessor system
Draw Distributed Database System –Reality
What do you mean by replicated data?
What are the Promises Distributed DBMS


















