
Pitch Perfect: Predicting Startup Funding Success Based on ...
8
Pitch Perfect: Predicting Startup Funding Success Based on Shark Tank Audio Shubha Raghvendra [email protected] Jeremy Wood [email protected] Minna Xiao [email protected] Abstract In this paper we describe the design and evaluation of a neural network trained to distinguish between funded and unfunded venture capital pitches, particularly within the context of the television show Shark Tank. This work represents a novel ap- plication of existing research in the realm of emotion and persuasion detection and broader speech processing. After attempt- ing various architectures, including a sup- port vector machine-based model, a recur- rent neural net (RNN), and a convolutional neural net (CNN), we settled on on a hy- brid CNN-LSTM. Utilizing this optimal model, we were able to obtain validation accuracy of up to 68%. Given prior work in the field and the challenges associated with this problem, the test accuracy pro- duced by our optimal model exceeded our expectation. This work demonstrates the feasibility of applying speech features to gauge startup pitch quality, as well as the utility of hybrid neural networks in rep- resenting the persuasiveness of small seg- ments of speech data. 1 Introduction 1.1 Motivation Venture capital as a field has long struggled with issues of diversity (Cutler, 2015). Because success in securing funding is largely a function of presen- tation quality, we were interested in understand- ing which specific aspects of a pitch predispose an entrepreneur to securing funding. Equipped with such knowledge, minority founders could inch closer to equal footing in securing venture capital. Figure 1: The Kang sisters, founders of Cof- fee Meets Bagel, pitching on Shark Tank in 2015. The Emmy-award winning television show Shark Tank, which has been on the air since 2009, embodies made-for-TV venture capitalism. In any given episode, several entrepreneurs pitch their ideas for a company to sharks (a panel of potential investors) who decide whether or not to fund the enterprise, and on what terms. While we initially hoped to evaluate actual venture capital pitches, perhaps from the records of a Silicon Valley firm, given barriers to access to confidential early-stage information, we opted to evaluate publicly avail- able Shark Tank pitches. To do so, we found sev- eral playlists on YouTube of each episode, and, for some seasons of the show, segmented by in- dividual pitch and scraped the audio files asso- ciated with each video. (For those seasons for which nicely segmented playlists did not exist, we manually segmented them; our methodology is de- scribed below). We labeled this raw data with in- formation about whether or not the venture was funded, and to what extent, with information tab- ulated about the show available online. Our ap- proach is described in greater detail below.
Transcript of Pitch Perfect: Predicting Startup Funding Success Based on ...

Pitch Perfect: Predicting Startup Funding Success Based on Shark TankAudio
Shubha [email protected]
Jeremy [email protected]
Minna [email protected]
Abstract
In this paper we describe the design andevaluation of a neural network trained todistinguish between funded and unfundedventure capital pitches, particularly withinthe context of the television show SharkTank. This work represents a novel ap-plication of existing research in the realmof emotion and persuasion detection andbroader speech processing. After attempt-ing various architectures, including a sup-port vector machine-based model, a recur-rent neural net (RNN), and a convolutionalneural net (CNN), we settled on on a hy-brid CNN-LSTM. Utilizing this optimalmodel, we were able to obtain validationaccuracy of up to 68%. Given prior workin the field and the challenges associatedwith this problem, the test accuracy pro-duced by our optimal model exceeded ourexpectation. This work demonstrates thefeasibility of applying speech features togauge startup pitch quality, as well as theutility of hybrid neural networks in rep-resenting the persuasiveness of small seg-ments of speech data.
1 Introduction
1.1 Motivation
Venture capital as a field has long struggled withissues of diversity (Cutler, 2015). Because successin securing funding is largely a function of presen-tation quality, we were interested in understand-ing which specific aspects of a pitch predisposean entrepreneur to securing funding. Equippedwith such knowledge, minority founders couldinch closer to equal footing in securing venturecapital.
Figure 1: The Kang sisters, founders of Cof-fee Meets Bagel, pitching on Shark Tank in2015.
The Emmy-award winning television showShark Tank, which has been on the air since 2009,embodies made-for-TV venture capitalism. In anygiven episode, several entrepreneurs pitch theirideas for a company to sharks (a panel of potentialinvestors) who decide whether or not to fund theenterprise, and on what terms. While we initiallyhoped to evaluate actual venture capital pitches,perhaps from the records of a Silicon Valley firm,given barriers to access to confidential early-stageinformation, we opted to evaluate publicly avail-able Shark Tank pitches. To do so, we found sev-eral playlists on YouTube of each episode, and,for some seasons of the show, segmented by in-dividual pitch and scraped the audio files asso-ciated with each video. (For those seasons forwhich nicely segmented playlists did not exist, wemanually segmented them; our methodology is de-scribed below). We labeled this raw data with in-formation about whether or not the venture wasfunded, and to what extent, with information tab-ulated about the show available online. Our ap-proach is described in greater detail below.

1.2 Problem Statement
Our goal was to understand which features of astartup pitch correspond to whether or not it wasfunded in the context of Shark Tank. While we ini-tially planned to segment based on precisely whichshark elected to fund an entrepreneur, in our sur-vey of relevant literature we found that even two-class problems in this realm were sufficiently chal-lenging. Thus we focused on refining our tech-niques in the realm of binary classification for thepurposes of this project (Chernykh et al., 2017).We planned to extract both raw audio and MFCCfeatures (Han et al., 2006), as well as other emer-gent speech features such as prosodic features.(Agarwal et al., 2011; Schuller et al., 2016).
1.3 Challenges
From the outset, we knew this would be a chal-lenging problem to tackle, and hence wanted toadjust our expectations accordingly. First, SharkTank is a network television show whose ability toengage its audience is predicated on building sus-pense and injecting drama into the process of se-lecting pitches to fund. Therefore, we expect theaudio of the television show to attempt to obfus-cate the sharks’ ultimate decision on a pitch, mak-ing predicting outcomes a challenging undertak-ing.
Second, because not all seasons were availableas segmented individual pitches, we had to manu-ally segment over one hundred episodes into indi-vidual pitches. This process was somewhat imper-fect given that occasionally a shark would unex-pectedly interject or ask a question, and that somepitches involved gimmicks such as demos or per-formances.
Finally, technical problems in this realm havebeen shown to be quite pernicious. For instance,Chernykh et al. studied the efficacy of labelingutterances in the IEMO-CAP database (discussedbelow), and achieved a modest 54% accuracy on afour-class classification problem (Chernykh et al.,2017). Given that the utterances in IEMO-CAPare both much shorter in length than the pitches wetrained our model on, and that they were recordedin a much more controlled environment (withoutany background noise) with a set number of ac-tors, we expected achieving a very high valida-tion accuracy to be fairly challenging (Busso et al.,2008).
2 Background/Related Work
Existing research in the realm of classifying au-dio utterances has been conducted on the tasksof emotion recognition, personality identification,and deception detection in speech. Prior to 2014,most research for classifying emotion in speechinvolved extracting prosodic (pitch, energy) andcepstral features (LPCC, MFCC) from the audioand running them through a support vector ma-chine (SVM). Pan et al. achieved a best recog-nition rate of 90% on a small dataset consistingof 212 utterances of the Berlin Database of Emo-tional Speech (Emo-DB) for a three-class clas-sification task for the emotions of sad, happy,and neutral (Pan et al., 2012). Experiments in-volving the Big-Five personality traits (Extrover-sion, Agreeableness, Conscientiousness, Neuroti-cism, Openness) have also been performed usingMFCC and prosodic features with SVM classifiers(Polzehl et al., 2010; Mohammadi and Vinciarelli,2012).
Recent work has begun introducing the appli-cation of neural network architectures toward theaforementioned problems. In 2014, Lee et al.trained a bi-directional long short-term memory(BLSTM) recurrent neural network on the Inter-active Emotional Dyadic Motion Capture (IEMO-CAP) database for four emotion classes (Lee andTashev, 2015), including F0, zero-crossing rate,and MFCCs, which were then used as input forthe two-hidden-layer BLSTM. Lee et al. achievedup to a 63% accuracy on the IEMO-CAP database.In 2017, Chernykh et al. also performed utterance-level classification on the IEMO-CAP database us-ing an LSTM architecture (Chernykh et al., 2017).They tried two approaches to training their net-work: 1) one-label approach and 2) ConnectionistTemporal Classification (CTC) approach. In theone-label approach, each utterance has only oneemotional label regardless of the utterance length;in the CTC approach, the probability of a partic-ular labeling is added up from the probabilities ofevery alignment. The authors found the best re-sults with the CTC approach, achieving up to 54%accuracy on their four-class task.
3 Approach
3.1 Dataset
Our dataset consists of audio scraped fromYouTube uploads of Shark Tank episodes, seg-

mented by pitch.To collect the data we need for labeling the
pitches, we referenced a database cultivated byHalle Tecco, an angel investor, the founder ofRock Health, and a self-proclaimed “Shark Tankfanatic. The database contains investment datafrom every season of Shark Tank, including the on-going 8th season. For the purposes of our project,we actually reached out to Ms. Tecco for guid-ance, and were able to access the entirety of herdatabase as a result. For each company that haspitched on the show, the database contains infor-mation on the final deal terms for the product,including amount, equity and valuation. Addi-tionally, we have some supplementary informationon the industry, entrepreneur gender, and whichsharks agreed to fund the company.
3.1.1 Data Collection and PreprocessingIn order to collect the raw labeled audio, we wrotea scraper in Python using the youtube-dl pack-age to pull audio from pre-assembled playlists ofShark Tank pitches. We extracted audio clips fromthese videos in the .wav format, which is widelysupported by several Python packages, includingTensorFlow. We then ran Mel-Frequency Cep-stral Coefficient (MFCC) feature extraction on ourraw audio files in order to prepare them for ourmodel (Han et al., 2006), which was necessary be-cause our inputs differed in elapsed time. These.wav files were then mapped to labels (funded ver-sus not funded) obtained from the aforementioneddatabase of Shark Tank outcomes compiled byHalle Tecco. We ultimately collected 509 pitchesin .wav form, each approximately two minutes inlength. We segmented each pitch into five-secondsegments and generated MFCC features (totaling7,895 data points) for each segment to be fed intoour models.
3.1.2 Dataset DistributionOne reason why this dataset was ideal for a classi-fication problem was the near-even split amongstfunded and unfunded pitches. Most Shark Tankepisodes featured two funded pitches and two un-funded pitches, which prevented oversampling ofany one particular label type in model training.
However, agreement amongst sharks (where wedefine “agreement” as either more than one sharkexpressing positive interest in a pitch or no sharkexpressing a desire to fund a pitch) averaged just52.3%, per the Tecco database. This is a relatively
low rate of agreement amongst sharks, renderingthis an even more exacting problem.
3.2 Baseline Approach
Motivated by existing research in emotion recog-nition and personality detection (Pan et al., 2012;Polzehl et al., 2010; Mohammadi and Vinciarelli,2012), which use low-level feature extraction forhigh-level classification tasks, we implemented abaseline binary support vector machine.
3.2.1 Mel-Frequency Cepstral CoefficientsWe extracted the first 13-order mel-frequency cep-stral coefficients for each frame of an input audiodata segment. MFCC-based features are widelyused in automatic speech recognition (ASR) tasks.Due to the limitations of the size of our dataset, weconsciously attempted to reduce the dimensional-ity of our feature vectors. Thus, instead of con-catenating all the MFCCs over an audio segmentto create one large feature vector, we computedthe statistics of mean, standard deviation, median,maximum, and minimum over the MFCC numbersof all the frames in an audio segment.
3.2.2 Prosodic FeaturesWe also experimented with accounting for theprosodic features in our audio segments. Prosody,which refers to the aspect of speech not specificto the individual phoneme, but rather the tune andrhythm of speech, is characterized by such factorsas vocal pitch (fundamental frequency), loudness(acoustic intensity), and rhythm. We surmised thatintonation of a founder’s speech and the supraseg-mental aspects of her startup pitch delivery couldhave some influence over the sharks’ perceptionsof the the company. Thus, we extracted valuesfor the fundamental frequency (F0) and intensityof each syllable of the audio using Praat, a pieceof software for linguistic and phonetic analysis ofspeech. For each data point, we once again com-puted statistics (mean, standard deviation, median,maximum, and minimum) over the F0 and inten-sity figures.
3.2.3 Support Vector Machine ModelFor our baseline approach, we combined MFCCand prosodic features, explained above, in a sup-port vector machine model. We tested both MFCCand prosodic features individually, and evaluatedthe performance of the model when both werecombined additively, for which there is precedent

Figure 2: CNN-LSTM architecture
in the literature. As explained in the Results sec-tion below, the SVMs performed poorly, which webelieve is a result of the fact that they do not ade-quately model temporal information, which is crit-ical in applications such as this. Thus we weremotivated to attempt a more complex architecturegrounded in deep learning, explained below.
3.3 Intermediate Experimental Architectures
We took a variety of approaches to modeling ourdata in an effort to improve results before achiev-ing our best-performing model, the hybrid CNN-LSTM described in the subsequent subsection. Wecan split our attempts into two categories: datahandling and model architecture.
3.3.1 Data Handling Experiments
Our initial pipeline involved the full 1-2 minutepitches. However we quickly came to the conclu-sion that this length (over 10,000 frames, even af-ter MFCC extraction reduced the raw signal) wasuntenable for either RNNs or one-dimensionalCNNs, so we initially split each pitch into 10-second (minimum six-second) segments. We sawfurther improvement from splitting them into five-second segments. These proved much more man-ageable for our temporal networks and yieldedbetter results, but it is possible that we discardedsome information about the overall structure ofeach pitch in the process. We also tried usingboth prosodic features and MFCC features (usingraw features was difficult because of the length ofthe raw signal); however, while prosodic featuresworked better for the SVM than MFCC it proved
too great of a reduction of data for our hybrid neu-ral models. We saw very poor performance onall of our neural models when we ran them onMFCC features. Ultimately we settled on usingthe MFCC features on five-second segments of au-dio from the pitches.
3.3.2 Neural Network Architectures
Given the time-based nature of our data, we werelimited to architectures that operated on series ofdata points. Two networks are currently avail-able as options: RNNs and 1-D CNNs. Knowingthis, we wanted to try out different combinationsthereof.
While first developing, our default model was avanilla RNN with a final affine layer on top of thefinal output state. However, we also attempted torun the affine layer on all of the RNN’s hidden-state outputs across the time series. This producedpoor results, perhaps due to the larger size of thefinal layer (we were always limited in the amountof data and therefore could not fit too large of amodel). Thus, we ultimately only ran the post-RNN layer on the final hidden state output of theRNN. We also switched to using LSTM cells andthen tanh activation functions within the RNN,as ReLU units caused the gradient to explode tooquickly.
Eventually, we branched out into experiment-ing with other network architectures. We tried us-ing just one-dimensional convolutional neural netsinitially. 1-D CNNs stride across a single dimen-sion (i.e. the time) instead of across two dimen-sions (such as in an image). Similar to the motiva-

tion for their usage in image systems, we wantedto try to use CNNs because they can, at least intheory, model higher-level abstract concepts fromthe amalgamation of smaller signals. In imagesthis amounts to understanding higher level visualconcepts. In audio analysis, we were hoping to usethem to understand semantic content. However, ascan be seen in Table 2, pure CNN models did notperform well. This led to us combining them withLSTMs as seen in our final model. Together, theirresults were superior to either model operating inisolation.
Finally, we also tried concatenating meta-features to the input of the final hidden layer, feed-ing them in at the end to increase their importance.However, as we hypothesized from the fact thatpredicting off only meta-features did not producea model that was better than random, this modelshowed no improvement to previous architectures.
3.4 CNN-LSTM Model
Our optimal model configuration was a hybridCNN-LSTM model consisting of a temporal con-volutional neural net feeding into a recurrent neu-ral net, as shown in 1.
Our CNN performs a one-dimensional convolu-tion over the time of an audio segment, in whichwe shape the input to the CNN by concatenatingthe first 13-order MFCC features for each timeframe together to create one long 1-D feature vec-tor.
Figure 3: Layers of the CNN-LSTM model
3.4.1 Convolutional LayerOur optimal architecture uses three convolutionallayers (see Figure 3). The first convolutional layer,for example, consists of 64 filters with a ker-nel width of six. These layers convolve nearbyMFCC features, thereby capturing abstract repre-sentations of discrete segments of speech. Theo-retically, this allows the recurrent layer on top ofthe CNN to operate over emergent semantic repre-sentations instead of low level feature sets.
After each convolutional layer, we apply anactivation layer using the Rectified Linear Unit(ReLU) operation (1) in order to introduce non-linearity to our network. We also tried usingParametrized ReLUs (PReLUs), wherein the rec-tified unit is similar to leaky ReLU except that theleakiness-factor (a) is a learned variable instead ofa set constant (2). Ultimately we found better per-formance using the ReLU activation.
ReLU(x) =
{x x > 0
0 x ≤ 0(1)
PReLU(x) =
{x x > 0
ax x ≤ 0(2)
3.4.2 Max-pooling LayerFor our pooling layers, we use a 2x2 max poolwith a stride of 3, 2, and finally 1 (in the respectivelayers) on our rectified feature maps in order todownsample the spatial size of our representationand reduce the number of parameters in the net-work. Such an operation helped to control overfit-ting and accommodate for the size of our dataset.
3.4.3 Batch Normalization LayerWe found a 3% gain in accuracy when we incor-porated batch normalization layers after our pool-ing layers into our network. Using the techniqueintroduced by Ioffe and Szegedy (2015), whichinvolves normalizing activations using mini-batchstatistics, we were able to achieve a faster conver-gence and higher accuracy. Since batch normal-ization reduces the internal covariance shift due tothe changing network parameters during training,the network became more robust to badly initial-ized weights, and we were able to utilize a higherlearning rate during training.
During training, for the x activations in a mini-batch B of size m, we perform the Batch Normal-izing Transform to obtain the normalized values,
using the mini-batch estimates of mean and vari-ance, µB and σ2B:
BNγ,β : x1...m → y1...m
xi ←xi − µB√σ2B + ε
(3)
yi ← γxi + β ≡ BNγ,β(xi) (4)
The output y values are then passed as input to thenext convolutional layer.
3.4.4 LSTMFor the second part of our hybrid model, we de-cided to use an LSTM instead of a vanilla RNNbecause of the difficulties vanilla RNNs have inlearning long-range dependencies due to the ob-served vanishing gradient problem. LSTMs use agating mechanism to combat this vanishing gradi-ent problem - for each LSTM unit, the input, for-get, and output (i, f , o) gates squash their corre-sponding values between 0 and 1 using the sig-moid function. The “candidate” hidden state g iscomputed using the current input xt and the previ-ous hidden state ht−1. Equation 6 corresponds tothe internal memory of the unit, the cell state ct,while the output hidden state ht is computed bythe elementwise multiplication of the output gatewith the tanh activation of the cell state (eq. 7).
ifog
=
σσσtanh
W
(ht−1xt
)(5)
ct = f � ct−1 + i� g (6)
ht = o� tanh(ct) (7)
Our final two-layer portion uses one hiddenLSTM layer followed by a fully-connected (affine)layer that reduces the final hidden state of theLSTM to a single output (the prediction). Foreach time step t of the LSTM, we used as inputxt where xt was the output of the final 1-D con-volutional layer; i.e. each xt had a dimension of16 features from the 16 filters applied in the finalconvolutional layer.
Finally, one additional component that yieldedmodest improvements was using meta-features tocondition the LSTM. We took two meta-features
available to us from the Tecco database: a sparserepresentation of the gender of the team (all fe-male, all male, or mixed team) and a sparse rep-resentation of the industry the pitch was in. Theseare both reasonable meta-features that do not inand of themselves solve the problem: we triedrunning an SVM on just the meta-features andthe accuracy achieved barely surpassed random-assignment strategies. Thus on their own thesefeatures were not valuable. However we concate-nated sparse representations of gender and indus-try and used an affine layer to transform them intothe hidden and internal state fed as the initial stateto the LSTM.
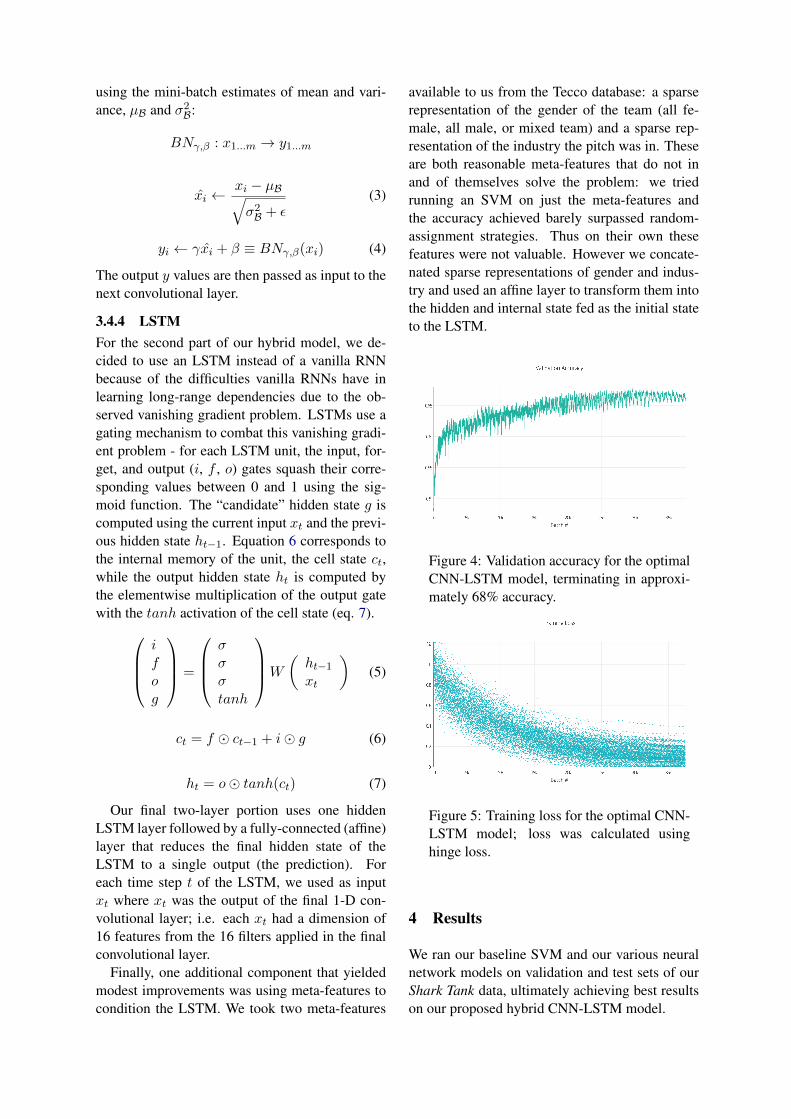
Figure 4: Validation accuracy for the optimalCNN-LSTM model, terminating in approxi-mately 68% accuracy.
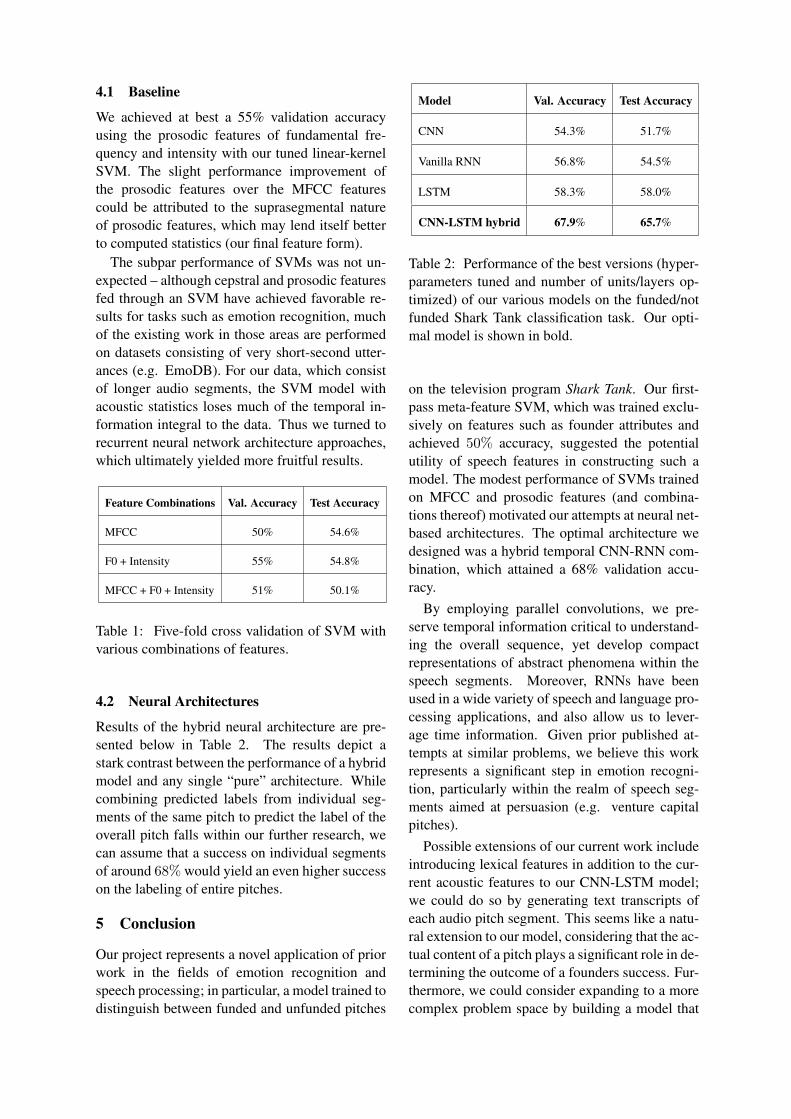
Figure 5: Training loss for the optimal CNN-LSTM model; loss was calculated usinghinge loss.
4 Results
We ran our baseline SVM and our various neuralnetwork models on validation and test sets of ourShark Tank data, ultimately achieving best resultson our proposed hybrid CNN-LSTM model.
4.1 Baseline
We achieved at best a 55% validation accuracyusing the prosodic features of fundamental fre-quency and intensity with our tuned linear-kernelSVM. The slight performance improvement ofthe prosodic features over the MFCC featurescould be attributed to the suprasegmental natureof prosodic features, which may lend itself betterto computed statistics (our final feature form).
The subpar performance of SVMs was not un-expected – although cepstral and prosodic featuresfed through an SVM have achieved favorable re-sults for tasks such as emotion recognition, muchof the existing work in those areas are performedon datasets consisting of very short-second utter-ances (e.g. EmoDB). For our data, which consistof longer audio segments, the SVM model withacoustic statistics loses much of the temporal in-formation integral to the data. Thus we turned torecurrent neural network architecture approaches,which ultimately yielded more fruitful results.
Feature Combinations Val. Accuracy Test Accuracy
MFCC 50% 54.6%
F0 + Intensity 55% 54.8%
MFCC + F0 + Intensity 51% 50.1%
Table 1: Five-fold cross validation of SVM withvarious combinations of features.
4.2 Neural Architectures
Results of the hybrid neural architecture are pre-sented below in Table 2. The results depict astark contrast between the performance of a hybridmodel and any single “pure” architecture. Whilecombining predicted labels from individual seg-ments of the same pitch to predict the label of theoverall pitch falls within our further research, wecan assume that a success on individual segmentsof around 68% would yield an even higher successon the labeling of entire pitches.
5 Conclusion
Our project represents a novel application of priorwork in the fields of emotion recognition andspeech processing; in particular, a model trained todistinguish between funded and unfunded pitches
Model Val. Accuracy Test Accuracy
CNN 54.3% 51.7%
Vanilla RNN 56.8% 54.5%
LSTM 58.3% 58.0%
CNN-LSTM hybrid 67.9% 65.7%
Table 2: Performance of the best versions (hyper-parameters tuned and number of units/layers op-timized) of our various models on the funded/notfunded Shark Tank classification task. Our opti-mal model is shown in bold.
on the television program Shark Tank. Our first-pass meta-feature SVM, which was trained exclu-sively on features such as founder attributes andachieved 50% accuracy, suggested the potentialutility of speech features in constructing such amodel. The modest performance of SVMs trainedon MFCC and prosodic features (and combina-tions thereof) motivated our attempts at neural net-based architectures. The optimal architecture wedesigned was a hybrid temporal CNN-RNN com-bination, which attained a 68% validation accu-racy.
By employing parallel convolutions, we pre-serve temporal information critical to understand-ing the overall sequence, yet develop compactrepresentations of abstract phenomena within thespeech segments. Moreover, RNNs have beenused in a wide variety of speech and language pro-cessing applications, and also allow us to lever-age time information. Given prior published at-tempts at similar problems, we believe this workrepresents a significant step in emotion recogni-tion, particularly within the realm of speech seg-ments aimed at persuasion (e.g. venture capitalpitches).
Possible extensions of our current work includeintroducing lexical features in addition to the cur-rent acoustic features to our CNN-LSTM model;we could do so by generating text transcripts ofeach audio pitch segment. This seems like a natu-ral extension to our model, considering that the ac-tual content of a pitch plays a significant role in de-termining the outcome of a founders success. Fur-thermore, we could consider expanding to a morecomplex problem space by building a model that

both buckets pitches into funded and not-fundedand regresses against equity and valuation for amore granular prediction.
We also wish to train our model on largerdatasets and with real VC pitches without the the-atrical elements of Shark Tank (which contributeunwanted noise to the pitch audio). We would alsolike to try combining the results of the segmentedpitch prediction in order to predict the results of aunified pitch. While all the above are viable ex-tensions, they lay outside the scope of our origi-nal novel problem. Given how noisy our data was,the fact that not all VCs agree on which venturesto fund, the relatively small size of our dataset,and the higher-level considerations (e.g. a com-pany’s sales to date) needed to decide which ven-tures to fund: 68% accuracy was a strong step to-wards proving that neural models can capture thecogency of complex persuasive speeches.
Acknowledgments
We would like to give special thanks to our in-structor Andrew Maas and our teaching assistantJiwei Li for their support and guidance.
ReferencesApoorv Agarwal, Boyi Xie, Ilia Vovsha, Owen Ram-
bow, and Rebecca Passonneau. 2011. Sentimentanalysis of twitter data. In Proceedings of the work-shop on languages in social media. Association forComputational Linguistics, pages 30–38.
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, AbeKazemzadeh, Emily Mower, Samuel Kim, Jean-nette N Chang, Sungbok Lee, and Shrikanth SNarayanan. 2008. Iemocap: Interactive emotionaldyadic motion capture database. Language re-sources and evaluation 42(4):335.
Vladimir Chernykh, Grigoriy Sterling, and Pavel Pri-hodko. 2017. Emotion recognition from speechwith recurrent neural networks. arXiv preprintarXiv:1701.08071 .
Kim-Mai Cutler. 2015. Here’s a detailedbreakdown of racial and gender diver-sity data across u.s. venture capital firms.https://techcrunch.com/2015/10/06/s23p-racial-gender-diversity-venture/.
Wei Han, Cheong-Fat Chan, Chiu-Sing Choy, andKong-Pang Pun. 2006. An efficient mfcc extractionmethod in speech recognition. In Circuits and Sys-tems, 2006. ISCAS 2006. Proceedings. 2006 IEEEInternational Symposium on. IEEE, pages 4–pp.
Sergey Ioffe and Christian Szegedy. 2015. Batch nor-malization: Accelerating deep network training byreducing internal covariate shift. arXiv:1502.03167.
Jinkyu Lee and Ivan Tashev. 2015. High-level fea-ture representation using recurrent neural networkfor speech emotion recognition. In INTERSPEECH.pages 1537–1540.
Gelareh Mohammadi and Alessandro Vinciarelli. 2012.Automatic personality perception: Prediction of traitattribution based on prosodic features. IEEE Trans-actions on Affective Computing 3(3):273–284.
Yixiong Pan, Peipei Shen, and Liping Shen. 2012.Speech emotion recognition using support vectormachine. International Journal of Smart Home6(2):101–108.
Tim Polzehl, Sebastian Moller, and Florian Metze.2010. Automatically assessing personality fromspeech. In Semantic Computing (ICSC), 2010 IEEEFourth International Conference on. IEEE, pages134–140.
Bjorn Schuller, Stefan Steidl, Anton Batliner, JuliaHirschberg, Judee K Burgoon, Alice Baird, AaronElkins, Yue Zhang, Eduardo Coutinho, and KeelanEvanini. 2016. The interspeech 2016 computationalparalinguistics challenge: Deception, sincerity &native language. In Proceedings of Interspeech.


















