
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights...
62
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 1 UNIX/Web Application Tutorial William R. Sullivan CTO WHAM Engineering & Software
-
Upload
lambert-wood -
Category
Documents
-
view
213 -
download
0
Transcript of Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights...

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 1
UNIX/Web Application Tutorial
William R. Sullivan
CTO
WHAM Engineering & Software

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 2
Three Important Components of Web Applications
• Threads
• Scheduling
• Memory Management

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 3
Three Important Components of Web Applications
• Threads– What they are– Where they are– What they do
• Thread Synchronization– Mutexes– Serialization and Concurrency

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 4
Three Important Components
• Memory Concepts– Address Space Management– Address Translation– Locality of Reference

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 5
Three Important Components
• Performance issues that can’t be solved with hardware– Scalability of Applications– Memory Management in C++ applications– Memory Management in Java applications

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 6
Thread Characteristics
• Schedulable entity
• Consumes CPU resource
• Contention Scope– Where it is scheduled

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 7
What is a Thread?
• A path of execution within a program• This can be a function that runs as an
infinite loop or that simply returns when it is done
• The name thread comes from the idea that a fabric is made up of many single threads. A program can considered as many different threads of execution.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 8
Thread Resources
• Has a stack even if it is local• Has a runtime context even if it is local
– Includes general purpose register set – Condition and floating point registers
• For a global scope thread there is a kernel level representation of the thread
• Uses process address space and I/O• Associated with some start-up function

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 9
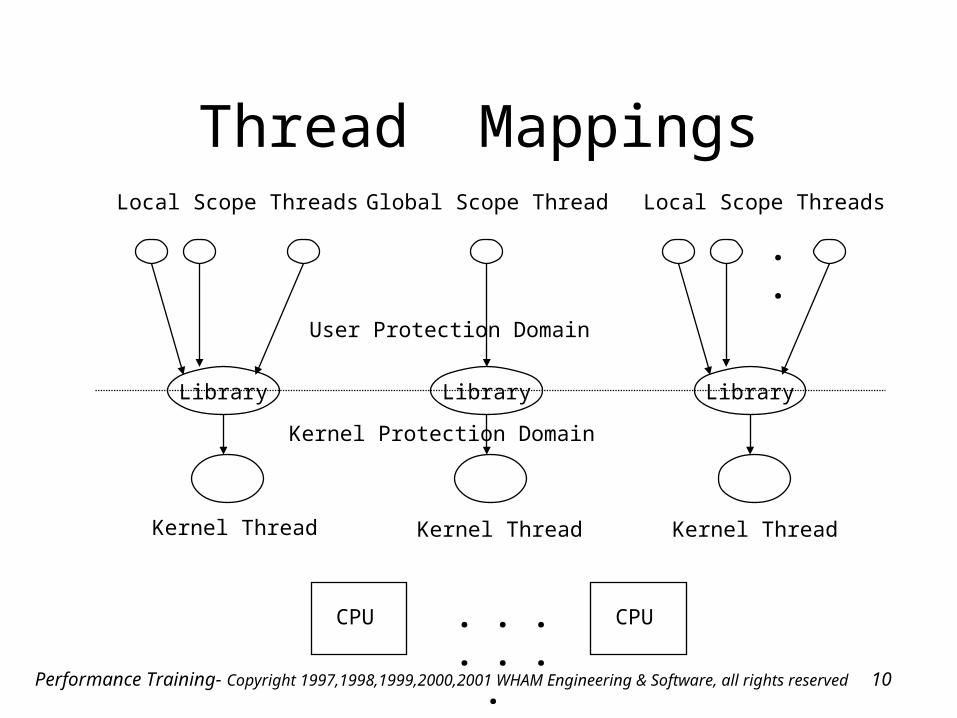
Thread Contention Scope
• Global (this is now default on Solaris 2.9)– contends with all threads– Context Switches occur in the kernel
• Local (default on AIX4.3+, Solaris 2.5-8)– contends with threads within process at library
level first – Context Switches are fast and efficient
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 10
Thread Mappings
. . . . . . .
Library
Local Scope Threads
Library
Global Scope Thread
. .
Library
Local Scope Threads
CPU CPU
Kernel Thread Kernel Thread Kernel Thread
User Protection Domain
Kernel Protection Domain

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 11
Managing Thread Mappings
• Thread Library manages local to global scope thread mappings normally
• AIXTHREAD_MNRATIO overrides whatever ratio the library defaults to
• pthread_create accepts a thread attribute and scope can be set to process or system (local or global)

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 12
Thread Synchronization
• Mutexes– Mutex - Mutual Exclusion– Acts as a gate where threads wait
• The wait isn’t fair and the next thread enabled is random
• At the lowest level they are a spin-lock which is based on a test and set instruction implemented in hardware

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 13
Thread Synchronization
• Condition Variables– Consist of a Mutex and a Predicate which is
usually a variable used for counting– Used for implementing master-slave thread
communication and thread-thread communication
– Can be used to implement a fair FIFO access scheme for variables protected by a mutex

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 14
Mutex Contention - How it occurs
• Mutex contention occurs when multiple threads attempt to acquire the same mutex and resolve the conflict in the kernel
• When two threads attempt to obtain a mutex one wins and the other spins in a loop testing the status of the mutex until either – a maximum spin count is reached (and then the thread
blocks)– the mutex is released and the waiting thread gets it
• When more than two threads attempt to obtain a single mutex, more than two will spin, this is wasteful since only one will ever get the mutex next

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 15
Mutex Contention - Where it occurs
• In your application due to a single locking point that is entered frequently by all or many threads in your application (malloc/free)
• In the operating system where there is conflict on a single point of high use by many programs (the dispatch queue)

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 16
Mutex Contention - What it CostsThread HoldingLock in func()
Thread Spin Waitingto enter func()
Thread Spin Waitingto enter func()
Thread Spin Waitingto enter func()
Thread Spin Waitingto enter func()
Thread 1 Executes func() in time tsThread 2 spins for t and executes func() in ts for a total 2ts Thread n spins for (n-1)ts and executes func() in ts for a total ntsThe average execution time for func() across n threads is expressed as
k=1
n
k =t
n
t
n
n(n+1)
2=
t(n+1)
2

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 17
Mutex Contention - What it Costs
• The generalized magnification factor for a critical section when n threads collide is given by (n+1)/2
• If the contention persists and causes queuing on the critical section, the magnification factor for the execution time of the critical section is given by q where q is the average queue depth.
• Mutex Contention can rapidly degrade the performance of programs as concurrency is increased

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 18
Pathology of Mutex Contention
• What can you look for to detect mutex contention?– CPU time not scaling linearly with workload
– High system to user CPU ratio on Solaris
– Increased cost per transaction as workload increases
– Reduced throughput with higher concurrency
– More threads active with less work being done
• We will be looking at an example of how Mutex Contention causes the same work being done to cost 20x in CPU with our scheduling example.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 19
Scheduling Policies• FIFO
– Runs until yields, blocked, or interrupted by higher priority thread
– Fixed priority
• Round Robin– Fixed priority
• Other– Implementation defined

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 20
Scheduling Concepts Solaris
• Priority -- A number associated with a run queue from which the dispatcher selects threads to run. The highest number queue is searched first.
• Quantum -- An amount of time the thread is allowed to run without losing the CPU.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 21
Scheduling Concepts Solaris
• Preemption -- The process of bumping a running thread from the CPU in favor of an interrupt or a real-time thread requesting a kernel preemption.
• Tick -- The timing interval at which synchronous scheduling decisions are made. On Solaris this is every 10ms.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 22
Scheduling Concepts Solaris
• Priority Queues -- Per CPU dispatch queues for threads needing service. There is a dispatch queue for each priority level.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 23
Scheduling Classes Solaris
• Time Share (TS)– The idea is to give small jobs the best response.
Long running jobs get less favored priority at the expense of short jobs. Scheduling policy is priority RR.
• Real Time (RT)– Fixed Priority for life or until manually
changed by super-user. Scheduling policy is priority RR.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 24
Scheduling Classes (cont.)
• Interactive (IA)– A special case of TS created for GUI based
threads. A boost in priority is always given to the thread in the focus window
• System (SYS)– These threads run in kernel mode under the
FIFO scheduling policy

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 25
Dispatch Algorithm - Per CPU
• Check global kernel preempt queue for interrupt threads or system threads
• Look for highest priority thread on RT, TS or IA queues (per CPU queues)– CPU structure includes a bit mask representing
each priority queue
• Look on other CPU queues for work if none on it’s own

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 26
Priority Calculation Solaris
• Determined by a table for the scheduling class associated with an LWP– Value between 0 and 59 for TS and IA– Value between 60 and 99 for SYS– Fixed Value between 100 and 159 for RT– Value between 160 and 169 for interrupts

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 27
Time Share Table Time Sharing Dispatcher Configuration
RES=1000 ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL
200 0 50 0 50 # 0
160 0 51 0 51 # 10
120 10 52 0 52 # 20
80 20 53 0 53 # 30
80 29 54 0 54 # 39 40 30 55 0 55 # 40 40 39 58 0 59 # 49 40 40 58 0 59 # 50 40 41 58 0 59 # 51 40 42 58 0 59 # 52 40 43 58 0 59 # 53 40 44 58 0 59 # 54 40 45 58 0 59 # 55 40 46 58 0 59 # 56 40 47 58 0 59 # 57 40 48 58 0 59 # 58 20 49 59 32000 59 # 59

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 28
TS Column Meanings• ts_quantam – time to run on CPU• ts_qexp - next priority after quantum used• ts_slpret – next priority after wakeup • ts_maxwait – how many second to wait
without getting a priority boost or a quantum
• ts_lwait – priority after ts_maxwait exceeded

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 29
Priority Calculation Example
• Two threads in the TS class with different work loads – fast thread only has 25ms to spend every 100ms– busy thread has 500ms work to do each second
• Many fast threads take precedence and the busy thread provides poor response

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 30
Priority Calculation Example
0
1
2
3
4
5
6
7
8
9
10
59 58 49 39
bt,ft
bt,ft
bt,ft
bt,ft
ft
ft
bt
bt
bt,ft
bt,ft
11
bt
bt
ft
ft
ft bt
bt

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 31
Scheduling Matters on Solaris
• We have a case here of two processes that are doing the same work but with different RPC implementations. The two RPCs are different architectures to implement the same solution.
• The server processes are the same but the client calls them using two different RPC protocols
• Work done is the same in each case but one is efficient the other isn’t. One is plagued by mutex contention in a critical code location used by all threads in the application.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 32
Scheduling Matters on Solaris
• Point of the exercise was to show how an inefficient process could impact an efficient process (will second hand smoke hurt me?)
• Many business areas “that have no time for optimization” will use the excuse that they bought X cpus on this system and they can use them however they see fit.
• This scenario was developed to determine if that argument was specious, it was, as we will see.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 33
Scheduling Matters on Solaris
• Servers (rpc_test) implement the same operations using a tcp rpc or a udp rpc
• Several clients were started up to access servers in each mode.
• One server was accessed in tcp mode then udp mode while two others were tcp only
• One server was accessed in udp mode only
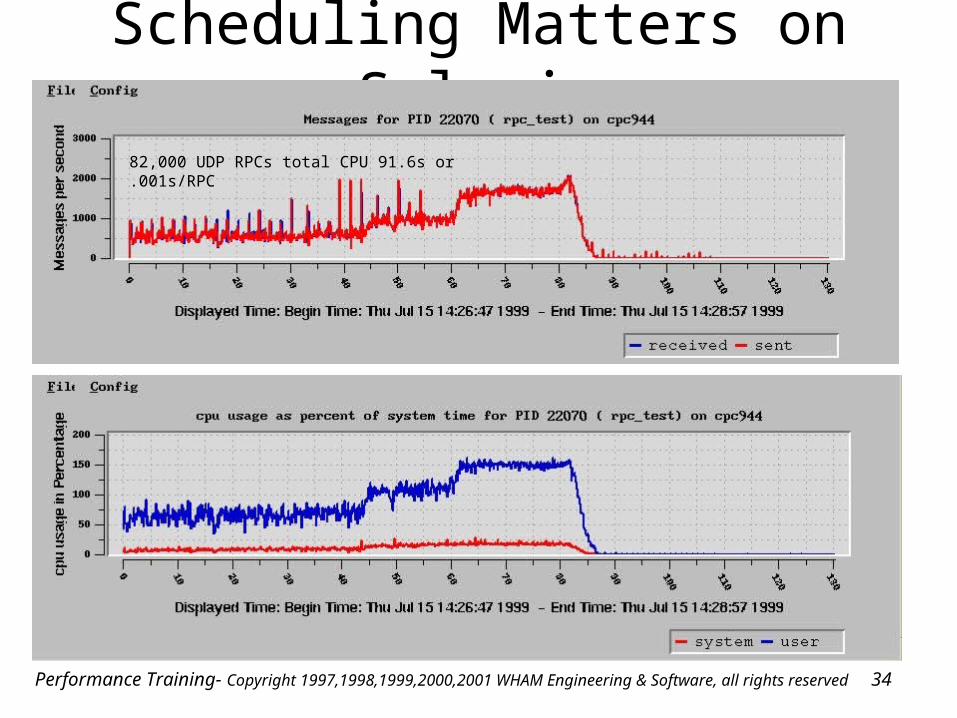
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 34
Scheduling Matters on Solaris
82,000 UDP RPCs total CPU 91.6s or .001s/RPC

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 35
Scheduling Matters on Solaris
PID 22063 - 42,275 TCP RPCs, 317 CPUs or .0075s/RPC ||42,700 UDP RPCs, 31.9 CPUs or .00075s/RPC
PID 22066 – 28,600 TCP RPCs, 227 CPUs or .0079s/RPC PID 22068 - 16,200 TCP RPCs, 123 CPUs or .0075s/RPC

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 36
Scheduling Matters on Solaris

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 37
Scheduling Matters on Solaris

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 38
Process Addressing Hierarchy
• Program Address– Address between 0 and 0xffffffff that is
produced by your program– All programs produce the same range of
addresses
• Virtual Address– Program Address as seen by the Address
Translation Hardware (MMU)

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 39
Address Hierarchy (cont)
• Physical Address– Address emitted by the MMU after translation
takes place– This interfaces with the system memory bus to
actually reference RAM data

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 40
Memory Management Terms
• Addressing Fault– A failure of the addressing hardware to be able
to translate a virtual address to a physical address
• Protection Fault– A failure of the segment driver to allow access
to a program address that produced an addressing fault

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 41
Memory Management Terms
• Process Context– The collection of registers both machine level
and general purpose used by a kernel thread as it runs on a CPU
– This context is used when addressing faults occur to resolve them. The context is saved when a thread is switched out by the dispatcher.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 42
Memory Management Elements• Virtual Memory (VM) system manages all virtual
memory objects in the system• Virtual Memory mappings are contained in
Segments of up to 4Gb on Solaris and 256Mb on AIX
• Segments are the level at which memory is protected and shared by processes in the system
• Segments are contained in Address Spaces

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 43
Pages
• Physical memory is divided into pages– The size of a page is dependent on the hardware
but VM doesn’t care how big they are
• Segments are divided into pages
• Segment pages are mapped to physical memory pages by the VM system

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 44
Hardware Address TranslationProgram A
0x25900
Program B
0x25900
Program C
0x25900
Memory Management Unit
Virtual Address Input
Physical Address Output

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 45
Hardware Address Translation
• In the previous slide we have three programs applying the same virtual address to the MMU
• What real address gets emitted?• It puts out the last one it was programmed
for• The others will produce addressing faults
(They don’t have correct context)

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 46
Hardware Address TranslationProgram Address + Process Context
Tag RAM
Virtual Address Generator
PN RAM
Virtual Page Address/Number
Comparator
Tag RAM
PN RAM
Comparator
Hardware Address BusTLB

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 47
Locality of Reference
• This simply refers to the fact that the next location fetched from memory is close to the first
• As long as it is in the same page, no new virtual mapping needs to be created
• Programs with poor locality of reference rarely get extra performance with faster CPUs

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 48
Address Space Management in C++ Applications
• The operator new is used to create instances of C++ class objects which invokes the class constructor
• delete invokes the class destructor• If no class specific constructor or destructor are
provided, malloc and free are used• This leads to poorly performing applications
where lots of construction and destruction occur for a specific class

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 49
A Poisonous Mix
• Amonia and Bleach combined, produce a toxic gas, Chloramine. If you combine these in your home, you better get out fast.
• Threads and C++ applications are a poisonous mix as well, which can be seen in the following case example.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 50
Webc Performance on ES6000 20way for 1000 requests Elapsed time 850 seconds and 3500 CPU seconds
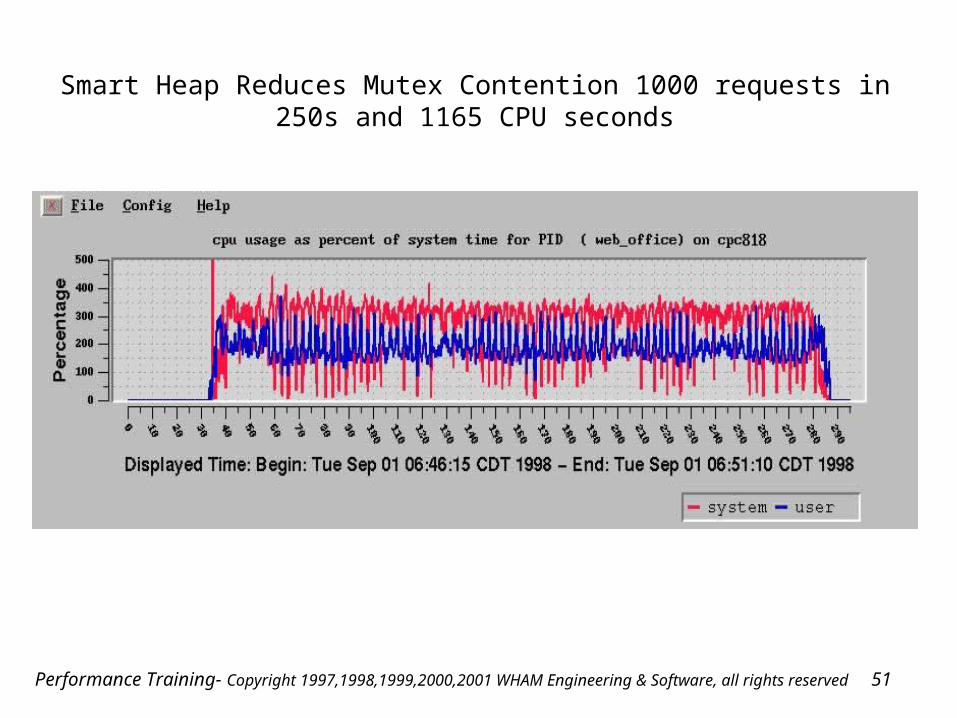
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 51
Smart Heap Reduces Mutex Contention 1000 requests in 250s and 1165 CPU seconds

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 52
No Contention After Adding RWT Mutex Pool Modification1000 requests in 110s using 350 CPU seconds

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 53
Java Address Space Management
• The Java language has a new but no delete
• This is nice because programmers do not have to match the pairs
• The difficulty for the JVM is in reclaiming unused memory
• This is done by a process called garbage collection

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 54
Java Address Space Management
• The heap is where all dynamic storage for classes is allocated
• The JVM has a garbage collection thread that operates either synchronously or asynchronously
• When the garbage collection thread runs, it finds unused memory and collects it as well as de-fragmenting the heap
• De-fragmentation involves copying data from one location to another. This necessitates all other threads wait until garbage collection is complete

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 55
Java Address Space Management
• Two significant impacts on program operation– Locality of reference is not controllable except
by using a very small heap which is not practical
– If the program uses many objects, garbage collection can take too long and cause excessive CPU use

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 56
A JVM with a GC Limitation

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 57
Impact on Response Times
Transactions that are pending prior to GC cause an increase in average service time from 2s to 8 or 10s
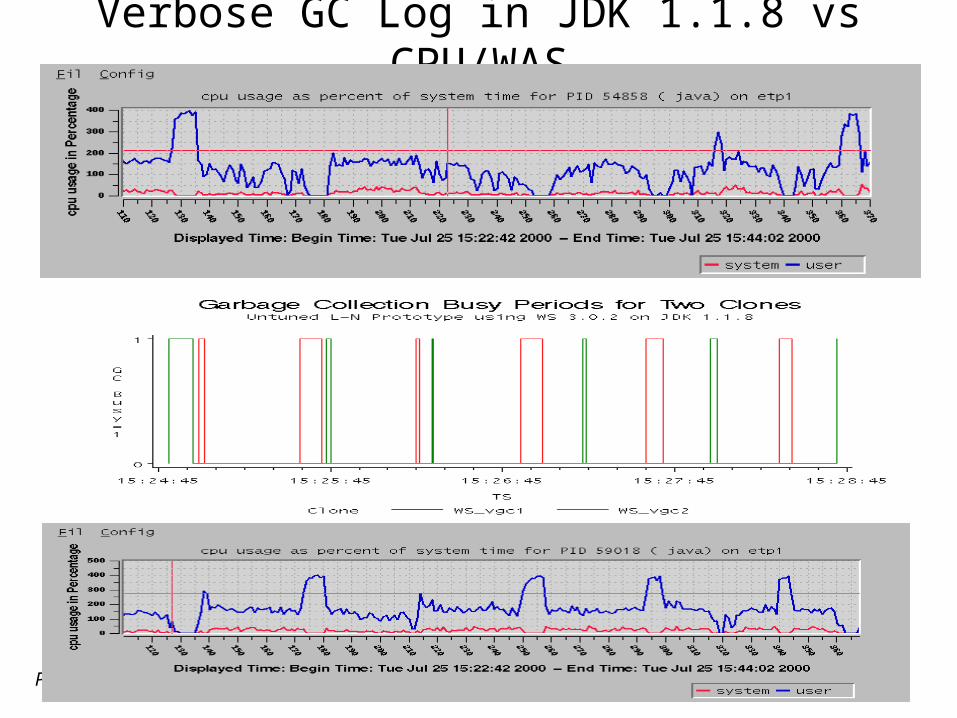
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 58
Verbose GC Log in JDK 1.1.8 vs CPU/WAS
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 59
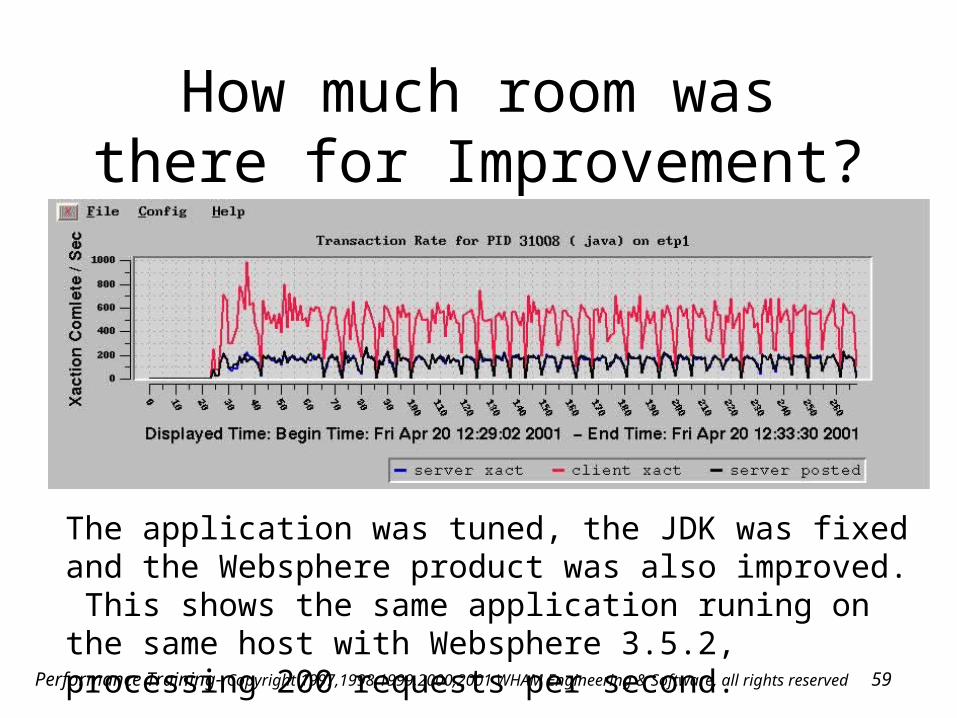
How much room was there for Improvement?
The application was tuned, the JDK was fixed and the Websphere product was also improved. This shows the same application runing on the same host with Websphere 3.5.2, processing 200 requests per second.
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 60
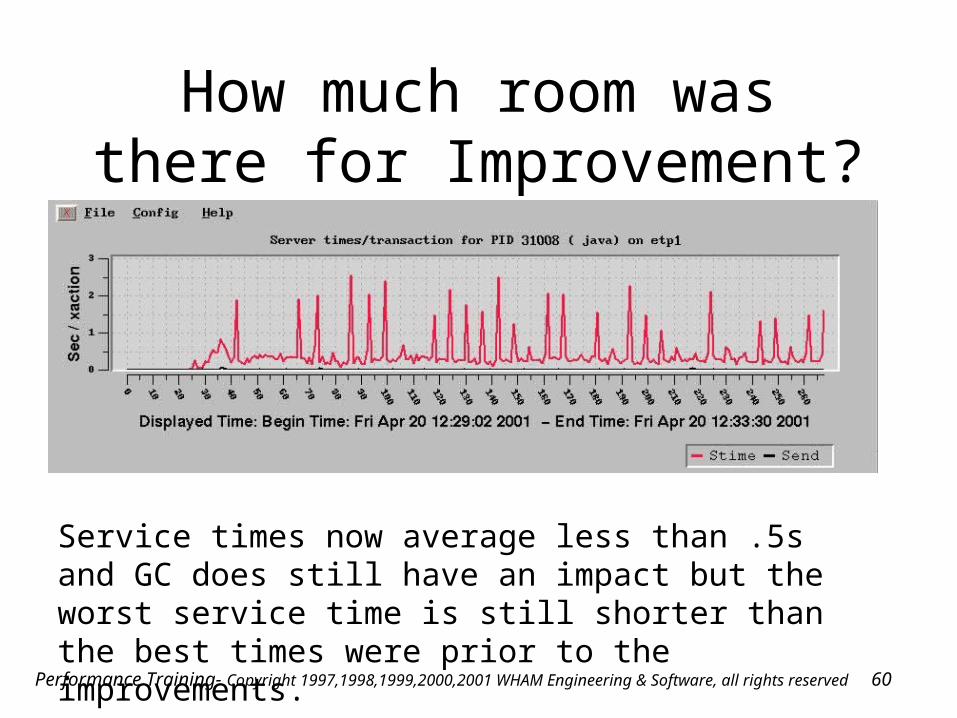
How much room was there for Improvement?
Service times now average less than .5s and GC does still have an impact but the worst service time is still shorter than the best times were prior to the improvements.
Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 61
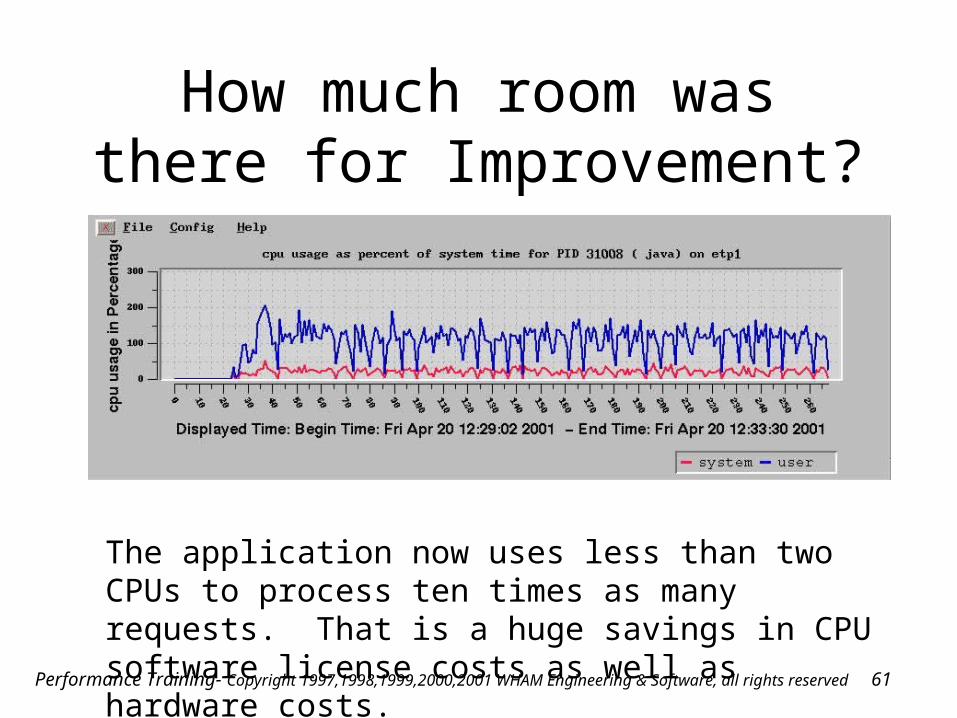
How much room was there for Improvement?
The application now uses less than two CPUs to process ten times as many requests. That is a huge savings in CPU software license costs as well as hardware costs.

Performance Training- Copyright 1997,1998,1999,2000,2001 WHAM Engineering & Software, all rights reserved 62
Conclusions
• What you don’t know can hurt you
• You don’t know what you can’t measure
• Only WHAM can provide all these measurements in one tool


















