
Status report from the LCFI collaboration Konstantin Stefanov RAL Overview of the LCFI programme

Overview and Status Report
Bo Kagstrom and the NLAFET Consortium Team
Dept. of Computing Science and HPC2N, Umea University, [email protected], [email protected], www.nlafet.eu
B-R-RP BLAS Workshop, GATech, Atlanta, Feb 24–25, 2017

Towards Exascale High Performance ComputingAim of the Horizon 2020 FETHPC call:
Attract projects that can achieve world-class extreme scale computingcapabilities in platforms, technologies and applications
19 Research and Innovation Actions (RIA); 2 Coordination andSupport Actions (CSA)

FETHPC — Selected Projects

Members of the NLAFET ConsortiumUmea University, Sweden (UMU; Coordinator Bo Kagstrom;Lennart Edblom)
The University of Manchester, UK (UNIMAN; Jack Dongarra; NickHigham)
Institute National de Recherche en Informatique et enAutomatique, France (INRIA; Laura Grigori)
Science and Technology Facilities Council, UK (STFC; Iain Duff)
Key European players with recognized leadership, proven expertise,experience, and skills across the scientific areas of NLAFET!
Vast experience contributing to open source projects!

NLAFET—Aim and Main Research Objectives
Aim: Enable a radical improvement in the performance and scalabilityof a wide range of real-world applications relying on linear algebra
software for future extreme-scale systems.
Development of novel architecture-aware algorithms that exposeas much parallelism as possible, exploit heterogeneity, avoidcommunication bottlenecks, respond to escalating fault rates, andhelp meet emerging power constraintsExploration of advanced scheduling strategies and runtimesystems focusing on the extreme scale and strong scalability inmulti/many-core and hybrid environmentsDesign and evaluation of novel strategies and software support forboth offline and online auto-tuningResults will appear in the open source NLAFET software library
NLAFET Work Package Overview
WP1
WP2 WP3 WP4
WP5
WP6
WP7
WP1: Management and coordination (start M1)WP5: Challenging applications—a selection (start M13)Materials science, power systems, study of energy solutions, anddata analysis in astrophysicsWP7: Dissemination and community outreach (start M1)Research and validation results; stakeholder communities

Research focus—Critical set of NLA operations
WP1
WP2 WP3 WP4
WP5
WP6
WP7
WP2: Dense linear systems and eigenvalue problem solversWP3: Direct solution of sparse linear systemsWP4: Communication-optimal algorithms for iterative methodsWP6: Cross-cutting issues (All four start M1)
WP2, WP3 and WP4: research into extreme-scale parallel algorithmsWP6: research into methods for solving common cross-cutting issues

WP2, WP3 and WP4 at a glance!
Linear Systems SolversHybrid (Batched) BLASEigenvalue Problem SolversSingular Value Decomposition Algorithms
Lower Bounds on Communication for Sparse MatricesDirect Methods for (Near–)Symmetric SystemsDirect Methods for Highly Unsymmetric SystemsHybrid Direct–Iterative Methods
Computational Kernels for Preconditioned Iterative MethodsIterative Methods: use p vectors per it, nearest-neighbor commPreconditioners: multi-level, comm. reducing

WP2: Dense linear systems and eigenvalue solversOne-sided matrix factorizations
Tiled and new experimental algorithms for LU, Cholesky, symmetric indefinite and QR.Reporting on and documentation of task-based prototype code developed.
Batched (hybrid) BLAS
Task-based implementation and evaluation of the draft specification for a common setof high performance linear algebra kernels on hybrid systems.
EVP solvers (Ax = λx and Ax = λBx , unsymmetric)
Computation of eigenvectors and reordering of eigenvalues in Schur and generalizedSchur forms. Evaluation of the scalability and tunability of the prototype softwaredeveloped. Distributed and task-based QR and QZ algorithms (ongoing).
SVD Algorithms
Prototypes for two-sided bidiagonal factorization using a 2-stage approach (dense →banded → bidiagonal). In development.

WP3: Direct solution of sparse linear systems
Theoretical bounds for communication in sparse operations
Theoretical lower bounds for key sparse matrix operations such as matrix-matrixmultiplication and factorization.
Algorithm design for highly unsymmetric factorizations
Experimental algorithms for parallel Markowitz ordering, analyzing variousapproaches and highlighting issues arising. Reporting on prototype code testingpossible algorithms and solutions.

Direct methods for sparse matrices
Developed a sparse task-based Cholesky code, SpLLT-STF, usingOpenMP (Version4) and StarPU runtime systems.
Two versions are using a pruning strategy aiming at:Enhancing data locality of operations at the bottom of the tree
Reducing runtime overhead
All four variants are competitive with the hand-coded OpenMP codeHSL MA87, using an integrated ad-hoc scheduler:
Performance on a 28-cores Haswell machine approaches half peak performance
A task-based code, SSIDS, that includes numerical pivoting forindefinite problems also gets close to half-peak performance.

Runs on large three-dimensional problems
0
100
200
300
400
500
600
20 40 60 80 100 120 140 160 180
GFlop/s
Mesh size
Poisson 3D - Factor. GFlop/s - 28 cores
MA87SpLLT-STF (OpenMP)
SpLLT-STF w/ pruning (OpenMP)SpLLT-STF (StarPU)
SpLLT-STF w/ pruning (StarPU)
Problem size = (meshsize + 1)3

Runs on symmetric indefinite matrices
Problems from Tim Davis collection (ordered by size).

WP4: Communication-optimal algorithms for iterativemethods
Prototype software, phase 1
Prototype for sparse matrix-matrix multiplication and sparse low-rank matrixapproximation.
Analysis and algorithm design
Enlarged Krylov methods and multilevel preconditioners, focusing on numericalefficiency and theoretical properties.
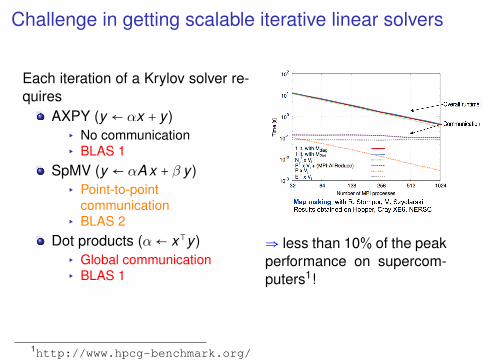
Challenge in getting scalable iterative linear solvers
Each iteration of a Krylov solver re-quires
AXPY (y ← αx + y )▸ No communication▸ BLAS 1
SpMV (y ← αA x + β y )▸ Point-to-point
communication▸ BLAS 2
Dot products (α ← x⊺y )▸ Global communication▸ BLAS 1
⇒ less than 10% of the peakperformance on supercom-puters1!
1http://www.hpcg-benchmark.org/

Ways to improve performance
Improve the performance of sparse matrix-vector productImprove the performance of collective communicationAvoid communication, e.g., by increasing the task granularity
Change numerics – enlarged Krylov methods▸ Decrease the number of iterations to decrease the number of global
communications▸ Increase arithmetic intensity compute sparse matrix-set of vectors
product
Use preconditioners to decrease the number of iterations untilconvergence

Enlarged Krylov methods (L. Grigori et al’2016)
Partition the matrix into t domainsSplit the residual rk into t vectors corresponding to the t domains,
r0 → T (r0) =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
∗ 0 0⋮ ⋮ ⋮
∗ 0 00 ∗ 0⋮ ⋮ ⋮
0 ∗ 0⋱
0 0 ∗
⋮ ⋮ ⋮
0 0 ∗
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦
Generate t new basis vectors, obtain an enlarged Krylov subspace
Kt ,k+1(A, r0) = span{T (r0),AT (r0),A2T (r0), ...,AkT (r0)}
Search for the solution of the system Ax = b in Kt ,k+1(A, r0)

Enlarged CG: sample parallel performanceRun on MeSU (UPMC cluster) → 28 nodes, 24 cores per node
Comparison with Petsc 3.7.4
PETSc ECG(4) ECG(8) ECG(12) ECG(16) ECG(20) ECG(24)0
1
2
3
4
5
6
7
8
Tim
e (
s)
Ela400, nproc = 48
24 48 96 192nproc
0
2
4
6
8
10
12
14
Tim
e (
s)
Ela400
ECG(12)PETSc
Method iter time (s) time/iterECG(12) 318 1.3 4.1 × 10−3
PETSc 5198 3.3 6.3 × 10−4

WP6: Cross-cutting issues and challenges!
Extreme-scale systems are hierarchical and heterogeneous in nature!
Scheduling and Runtime Systems:▸ Task-graph-based multi-level scheduler for multi-level parallelism▸ Investigate user-guided schedulers: application-dependent balance
between locality, concurrency, and scheduling overhead▸ Run-time system based on parallelizing critical tasks (Ax = λBx)▸ Address the thread-to-core mapping problem
Auto-Tuning:▸ Off-line: tuning of critical numerical kernels across hybrid systems▸ On-line: use feedback during and/or between executions on similar
problems to tune in later stages of the algorithmAlgorithm-Based Fault Tolerance:
▸ Explore new NLA methods of resilence and develop algorithms withthese capabilities.

WP5: Challenging applications—a selectionDense solvers/eigensolvers in materials science and chemistry
▸ Thomas Schulthess, ETH Zurich, Switzerland▸ Ax = λBx , A Hermitian dense, B Hermitian positive definite
Load flow based calculations in large-scale power systems▸ Bernd Kloss, DIgSILENT GmbH, Germany▸ Extreme scale, highly sparse, unsymmetrical and very ill-conditioned
Ax = b; also eigenvalue computations (xis to a selection of λis).
Energy solutions and Code Saturne▸ Yvan Fournier, EDF, France▸ Communication-avoiding (CA) methods for sparse linear systems
Data analysis in astrophysics and the Midapack library▸ Radoslaw Stompor, University Paris 7, France; Carlo Baccigalupi, SISSA
Italy▸ CA methods adapted to generalized least-squares problem
Requirement analysis: NLA problem characteristics, sizes (X kL),sparsity, application parameters etc.

Case study: Eigenvalue reordering in Schur forms
QT SQ = T Q = [Q1,Q2] span(Q1) inv. subspace (1)

The swap kernel
Solve tiny Sylvester equation AX −XB = −CCompute a QR fact. of [X T I]T to generate orthogonal QPerform swap - orth. similarity transformation with Q

Scalar swapping
Swap each eigenvalue up the diagonal as in bubble-sortLow arithmetic intensityPoor cache utilization

Blocked swapping
Move eigenvalues within a small windowApply accumulated transformation to block row/columnSlide window upward and repeat

Parallel blocked swapping using multiple windows
What updates can be done when?Swapping inside diagonal blocks still a bottleneck!

Task based approach — Small example
symbol operation exampleS Swap adjacent blocks S(3,4)R Right update of block column R(i < 3,3 ∶ 4)L Left update of block row L(3 ∶ 4,3 < j)

Compressed DAG
S(4,5)
S(3,4)
S(2,3)
S(1,2)
R(i < 4,4 ∶ 5)
R(i < 3,3 ∶ 4)
R(i < 2,2 ∶ 3)
L(3 ∶ 4,4 < j)
L(2 ∶ 3,3 < j)
L(1 ∶ 2,2 < j)
start
end
SIAM CSE MS101 for more details!

Kebnekaise @ HPC2N, Umea University
Standard compute nodeIntel Xeon E5-2690v4(Broadwell)
2 NUMA islands per node
14 cores per NUMA island
Each core has its own FPU
Cores drawn from list 0:1:27
128 GB
Kebnekaise also has large memory nodes (3TB), NVIDIA GPUs K80, and Intel KNLs(just installed).
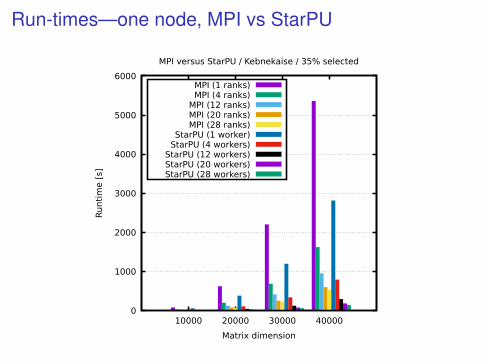
Run-times—one node, MPI vs StarPU
0
1000
2000
3000
4000
5000
6000
10000 20000 30000 40000
Runti
me [
s]
Matrix dimension
MPI versus StarPU / Kebnekaise / 35% selected
MPI (1 ranks)MPI (4 ranks)
MPI (12 ranks)MPI (20 ranks)MPI (28 ranks)
StarPU (1 worker)StarPU (4 workers)
StarPU (12 workers)StarPU (20 workers)StarPU (28 workers)

Strong scalability—one node, MPI vs. StarPU
(w.r.t. fastest performance on one core)
0
0.2
0.4
0.6
0.8
1
4 8 12 16 20 24 28
Effi
ciency
CPU cores / MPI ranks
Strong scalability / MPI / Kebnekaise / 35% selected
N = 10000N = 20000N = 30000N = 40000
0
0.2
0.4
0.6
0.8
1
4 8 12 16 20 24 28
Effi
ciency
CPU cores / StarPU workers
Strong scalability / StarPU / Kebnekaise / 35% selected
N = 10000N = 20000N = 30000N = 40000
In progress: StarPU – MPI distributed algorithm and software

SIAM CSE - MS101 Parallel Numerical Linear Algebrafor Extreme Scale Systems
The Design and Implementation of a Dense Linear AlgebraLibrary for Extreme Parallel Computers Linear Systems SolversJack Dongarra,ICL, UNIMAN; Sven Hammarling, Nicholas Higham, ZounonMawussi, Samuel Relton, UNIMAN
Computing the Low Rank Approximation of a Sparse MatrixLaura Grigori and Sebastien Cayrols, INRIA; James Demmel, UCB; Alan Ayala,INRIA
Sparse Direct Solvers for Extreme Scale ComputingIain Duff, STFC and CERFACS; Jonathan Hogg, Florent Lopez, and StojceNakov, RAL
Extreme-Scale Eigenvalue Reordering in the Real Schur Form:Lars Karlsson, Carl Christian Kjelgaard Mikkelsen, Mirko Myllykoski, BjornAdlerborn, and Bo Kagstrom, UMU
Organizers: Nick and Bo Tue., Feb. 27, 9:10–10:50 AM

SIAM CSE - MS64 Batched Linear Algebra onMulti/Many-Core Architectures
Recent Advances in Batched Linear Algebra ComputationSamuel Relton, Mawussi Zounon, and Pedro Valero-Lara, UNIMAN
Optimizing Batched Linear Algebra on Intel(R) Xeon Phi(TM)ProcessorsSarah Knepper, Murat E. Guney, Kazushige Goto, Shane Story, Arthur AraujoMitrano, Timothy B. Costa, and Louise Huot, Intel Corporation, USA
Extending Batched GEMM for Tensor Contractions on GPUCris Cecka, NVIDIA, USA
Batch Linear Algebra for GPU-Accelerated High PerformanceComputing Environments:Ahmad Abdelfattah, ICL-UTK
Organizers: Mawussi and Pedro Mon., Feb. 27, 4:35–6.15 PM

NLAFET SummaryDeliver a new generation of computational tools and software forproblems in numerical linear algebra with a focus onextreme-scale systemsLinear algebra is both fundamental and ubiquitous incomputational science and its vast application areasCo-design effort for designing, prototyping, and deploying newNLA software libraries:
▸ Exploration of new algorithms▸ Investigation of advanced scheduling strategies▸ Investigation of advanced auto-tuning strategies▸ Open source
Stakeholder collaborations (users, academia, HW and SWvendors)


















