
Orchestrated Chaos: Applying Failure Testing Research at Scale.
120
PETER ALVARO Orchestrated Chaos With a prelude of vignettes and an appendix of fairy tales
-
Upload
reactivesummit -
Category
Technology
-
view
255 -
download
0
Transcript of Orchestrated Chaos: Applying Failure Testing Research at Scale.

PETER ALVARO
OrchestratedChaos
With a prelude of vignettes
and an appendix of fairy tales

Mythology

About me

About me

About me

Platitudes

“Managing complexity”

Easy: removing complexity

Much harder: moving complexity around

Much harder: moving complexity around

Much harder: moving complexity around

Much harder: moving complexity around

Much harder: moving complexity around

Nontrivial systems problems always require tradeoffs
Productivity /Convenience
Purity / Correctness

Vignettes

Vignette 1: teaching myself docker

Vignette 2: a DBA tale

Vignette 3: selling lovely languages

Vignette 4: Microservices
The UNIX philosophy:
Do one thing and do it well.

> man ls





Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

Ease of release wins

The profound solipsism of the microservice

The profound solipsism of the microservice

The profound solipsism of the microservice

The profound solipsism of the microservice

Every microservice is a piece of the continent

Every microservice is a piece of the continent

What could possibly go wrong?
Consider computation involving 100 services
Search Space:2100 executions

“Depth” of bugs
Single Faults Search Space:100 executions

“Depth” of bugs
Combination of 4 faults Search Space:3M executions

“Depth” of bugs
Combination of 7 faults Search Space:16B executions

Reflections
1. Managing complexity can be a zero-sum game2. Productivity trumps purity3. Chaos results…. and gives rise to a new order

Opportunity

What the hell is going on? (Observability)
Call graph tracing(e.g. Zipkin)

What could possibly go wrong? (Fault injection)
A fault injectionframework(e.g. FIT)

Random search
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

Random Search
Search Space:2100 executions

Engineer-guided search
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

Engineer-guided Search
Search Space:???

…?
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

A cunning malevolent sentience?
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

A cunning malevolent sentience?
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

Lineage-driven Fault Injection
A fault injectionframework(e.g. FIT)
LDFICall graph tracing(e.g. Zipkin)

Fault-tolerance “is just” redundancy

But how do we know redundancy when we see it?
Hard question: “Could a bad thing ever happen?”
Easier: “Exactly why did a good thing happen?”
“What could have gone wrong?”

Lineage-driven fault injection
Why did a good thing happen?
Consider its lineage.
The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client

Lineage-driven fault injection
Why did a good thing happen?
Consider its lineage.
What could have gone wrong?
Faults are cuts in the lineage graph.
Is there a cut that breaks all supports?
The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client

Lineage-driven fault injection
Why did a good thing happen?
Consider its lineage.
What could have gone wrong?
Faults are cuts in the lineage graph.
Is there a cut that breaks all supports?
The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client

What would have to go wrong?
(RepA OR Bcast1)
The write is stable
Stored on RepA
Stored on RepB
Bcast2
Client Client
Bcast1
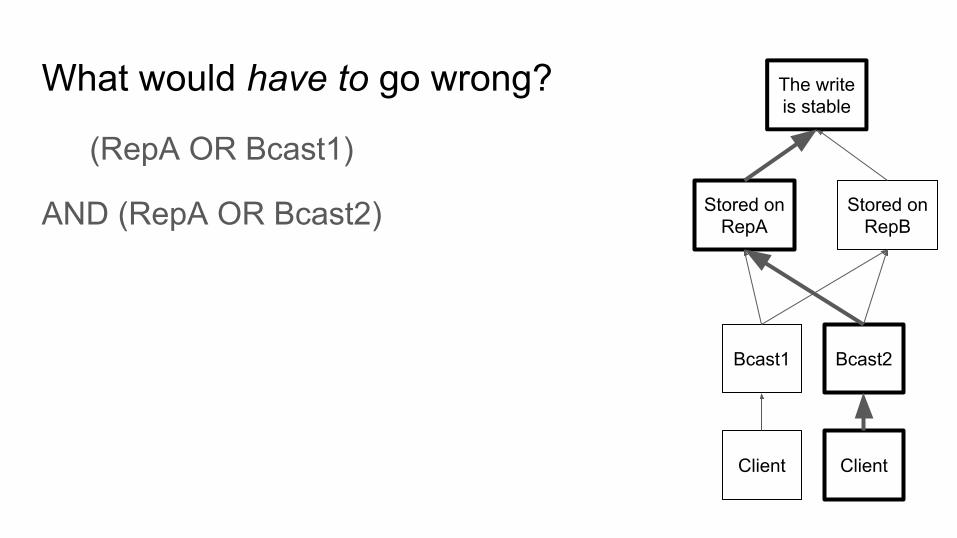
What would have to go wrong?
(RepA OR Bcast1)
AND (RepA OR Bcast2)
The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client

What would have to go wrong?
(RepA OR Bcast1)
AND (RepA OR Bcast2)
AND (RepB OR Bcast2)
The write is stable
Stored on RepA
Stored on RepB
Bcast1
Client Client
Bcast2

What would have to go wrong?
(RepA OR Bcast1)
AND (RepA OR Bcast2)
AND (RepB OR Bcast2)
AND (RepB OR Bcast1)
The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client

Lineage-driven fault injection The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client
Hypothesis: {Bcast1, Bcast2}

Lineage-driven fault injection The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client
Bcast3
Client
(RepA OR Bcast1)
AND (RepA OR Bcast2)
AND (RepB OR Bcast2)
AND (RepB OR Bcast1)

Lineage-driven fault injection The write is stable
Stored on RepA
Stored on RepB
Bcast1 Bcast2
Client Client
Bcast3
Client
(RepA OR Bcast1)
AND (RepA OR Bcast2)
AND (RepB OR Bcast2)
AND (RepB OR Bcast1)
AND (RepA OR Bcast3)
AND (RepB OR Bcast3)

Search Space Reduction
Each Experiment finds a bug, OR
Reduces the Search space

Lineage-driven Fault InjectionRecipe:
1. Start with a successful outcome. Work backwards.
2. Ask why it happened: Lineage3. Convert lineage to a boolean
formula and solve4. Lather, rinse, repeat
2. Lineage 3. CNF
Fail1. Success
Why?
Encode
Solve
4. REPEAT

Minimal requirements
1. Fault injection infrastructure2. Mechanism for collecting lineage3. Ability to replay interactions

Lineage

Request Tracing
Request Tracing

Alternate Execution

Redundancy through History
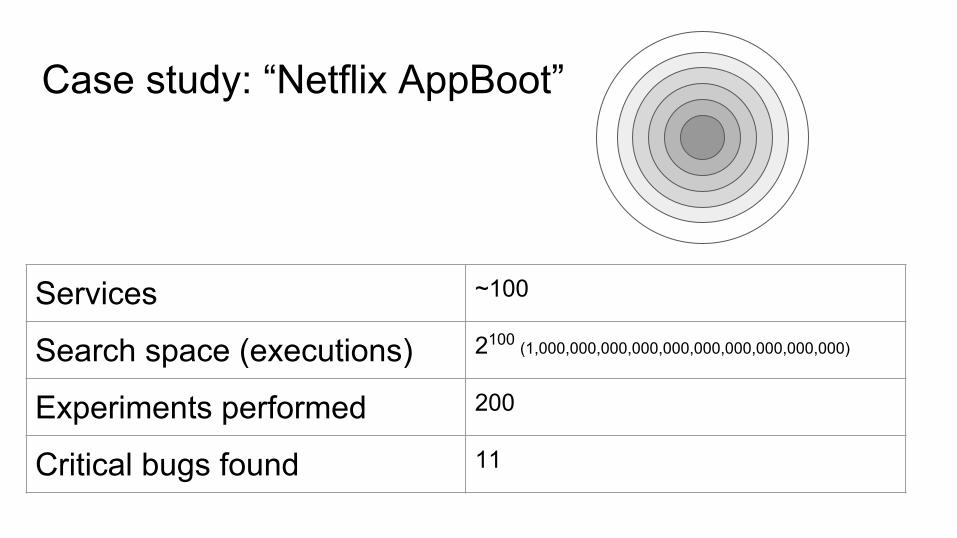
Case study: “Netflix AppBoot”
Services ~100
Search space (executions) 2100 (1,000,000,000,000,000,000,000,000,000,000)
Experiments performed 200
Critical bugs found 11

Fairy tale





Growing Research
Don’t:
“Throw it over the wall”
Do:
Deep embeddings
Trading shoes

Growing Research

Work with us
Search prioritization
Input generation
Richer lineage collection

Search prioritization: minimal hitting sets
(A ∨ B ∨ C ) ∧ (C ∨ D ∨ E ∨ F) ∧ (D ∨ E ∨ F ∨ G) ∧ (H ∨ I)
(A, B, C), (C, D, E, F), (D, E, F, G), (H, I)
⇩

Search prioritization: minimal hitting sets
(A ∨ B ∨ C ) ∧ (C ∨ D ∨ E ∨ F) ∧ (D ∨ E ∨ F ∨ G) ∧ (H ∨ I)
(A, B, C), (C, D, E, F), (D, E, F, G), (H, I)
⇩
e.g. (C, E, H) ✔
X X X X X
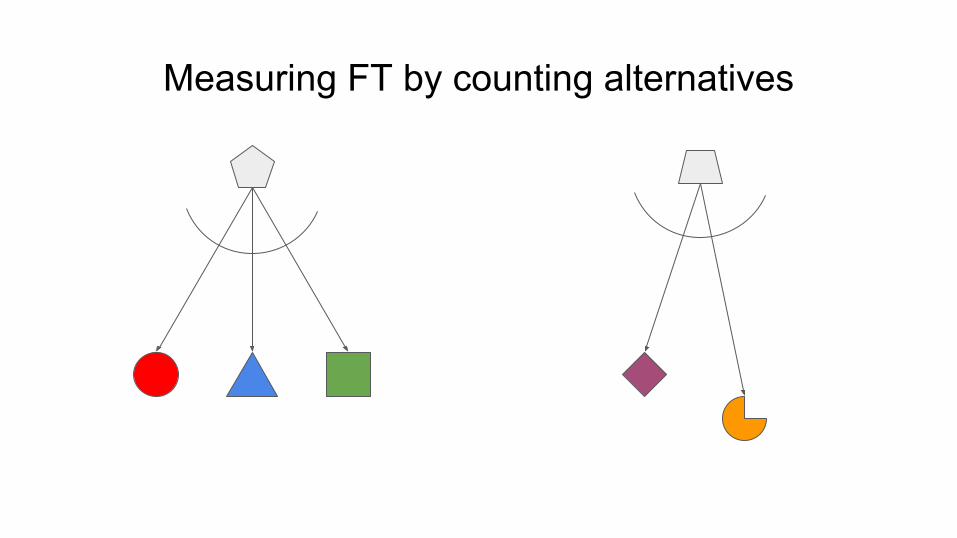
Measuring FT by counting alternatives

Measuring fault tolerance by counting alternatives

Most likely combination of faults
X
X
X
XX

Most likely combination of faults
X
X
X
XX

Most likely combination of faults
X
X
X
XX

Input generation
Using lightweight modeling to understand ChordPamela Zave
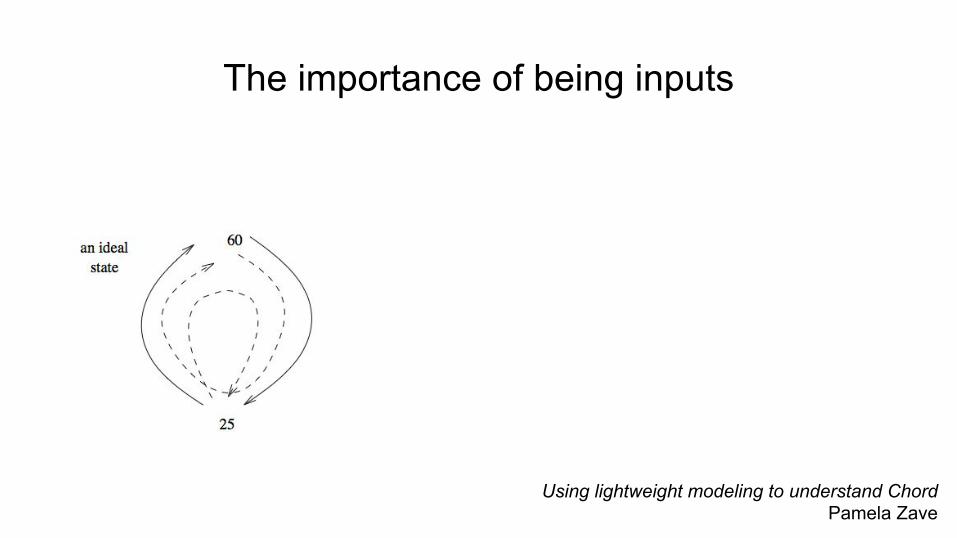
The importance of being inputs
Using lightweight modeling to understand ChordPamela Zave

The importance of being inputs
Using lightweight modeling to understand ChordPamela Zave
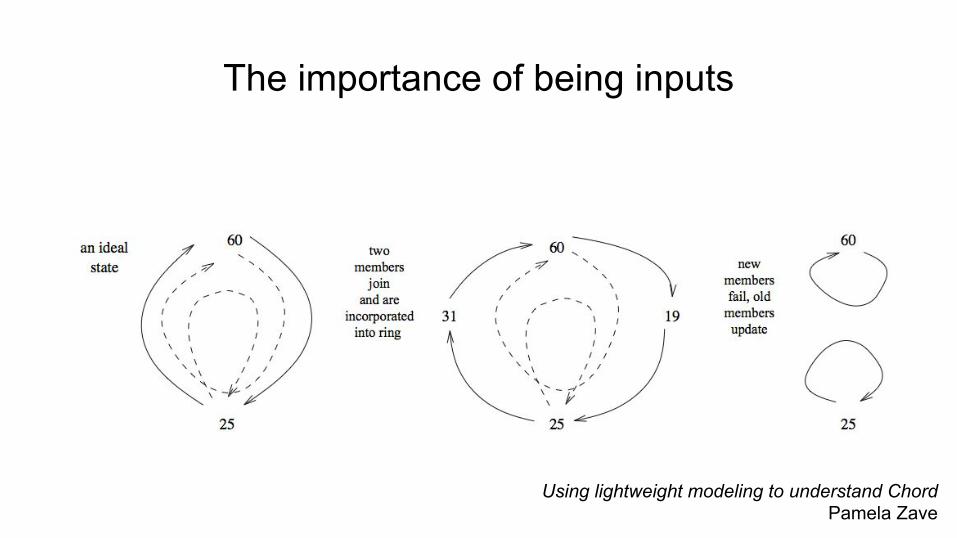
The importance of being inputs
Using lightweight modeling to understand ChordPamela Zave

Richer lineage collection

Where we are
A fault injectionframework(e.g. FIT)
Call graph tracing(e.g. Zipkin)

Where we’re headed
A fault injectionframework(e.g. FIT)
Lineage-driven faultinjection
Call graph tracing(e.g. Zipkin)

Thanks to our hosts, benefactors and collaborators!

References● ‘Automating Failure Testing at Internet Scale [ACM SoCC’16]
https://people.ucsc.edu/~palvaro/fit-ldfi.pdf
● ‘Lineage Driven Fault Injection’ [ACM SIGMOD’15]http://people.ucsc.edu/~palvaro/molly.pdf
● Netflix Tech Blog on ‘Automated Failure Testing’ http://techblog.netflix.com/2016/01/automated-failure-testing.html

FOLD


The profound solipsism of the microservice

UGLY

GOOD RAW

GOOD RAW

GOOD RAW

GOOD RAW

True Silicon Valley Stories
1. Crazy legwork2. The “what the hell does our site do” project3. Offsite => online

Replay
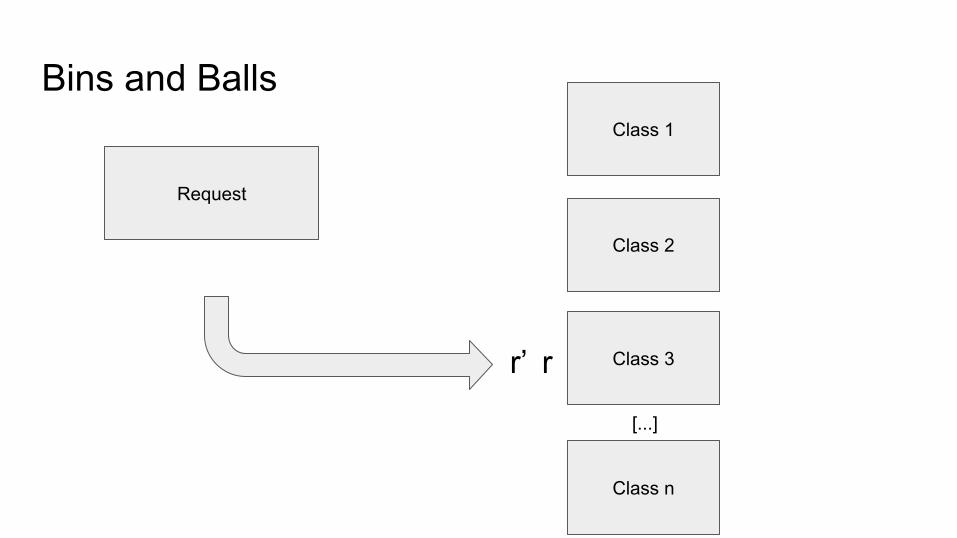
Bins and Balls
Request
Class 1
Class 2
Class 3
Class n
[...]
r’ r
Class n
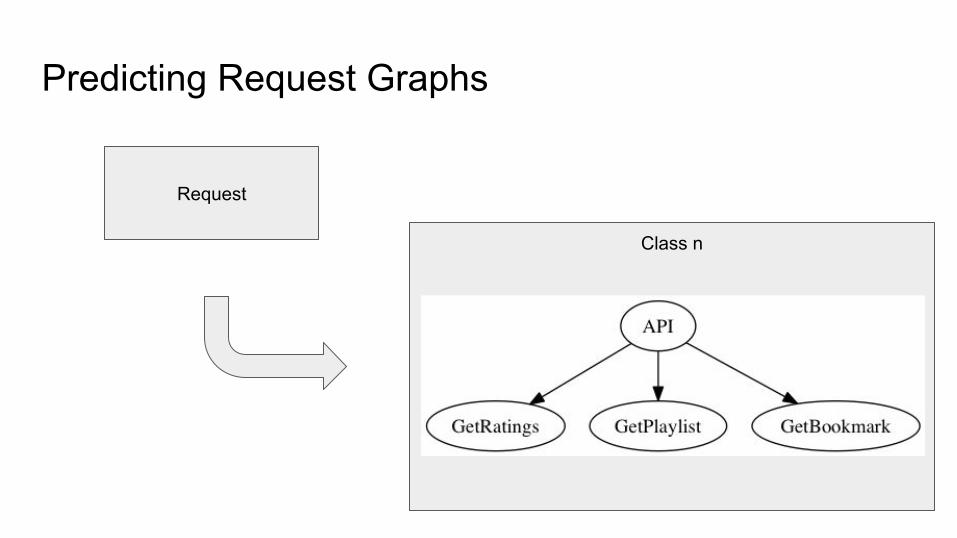
Predicting Request Graphs
Request

Class n
Predicting Request Graphs
Request
Some function f: Requests → Classes

F( ) = Class n
Request
Predicting Request Graphs

The profound solipsism of the microservice


















