
Nothing in ( computational ) biology makes sense except in the light of evolution
43
Nothing in ( computational ) biology makes sense except in the light of evolution after Theodosius Dobzhansky (1970) ing (and abusing) sequence analysis to ke biological discoveries
-
Upload
ainsley-velez -
Category
Documents
-
view
24 -
download
0
description
Using (and abusing) sequence analysis to make biological discoveries. Nothing in ( computational ) biology makes sense except in the light of evolution. after Theodosius Dobzhansky (1970). Significant sequence similarity is evidence of homology. - PowerPoint PPT Presentation
Transcript of Nothing in ( computational ) biology makes sense except in the light of evolution

Nothing in (computational) biology makessense except in the light of evolution
after Theodosius Dobzhansky (1970)
Using (and abusing) sequence analysis to make biological discoveries

Only a small fraction of amino acid residues is directlyinvolved in protein function (including enzymatic);the rest of the protein serves largely as structuralscaffold
Significant sequence similarity is evidence of homology
Conserved sequence motifs are determinants ofconserved ancestral functions

The evolving roles of computational analysis in biology
Pre-sequencing era (before 1978-80)
Study biological function
Study biological function Clone/sequence gene
Analyze/interpret sequence
Pre-genomic era (1980-1996)
Sequence genomeAnalyze/interpret sequences
of all genes
Prioritize targetsStudy biological function
Post-genomic era (1996-


Sequence complexity
Measure of the randomness of a sequence
Random sequence - highest complexity (entropy) -globular protein domains
Homopolymer - lowest complexity (entropy) -non-globular structures
Algorithmic complexity
QQQQQQQQQQQQQ = (Q)n
KRKRKRKRKRKR = (KR)n
ASDFGHKLCVNM - random sequence - no algorithm to derivefrom a simpler one

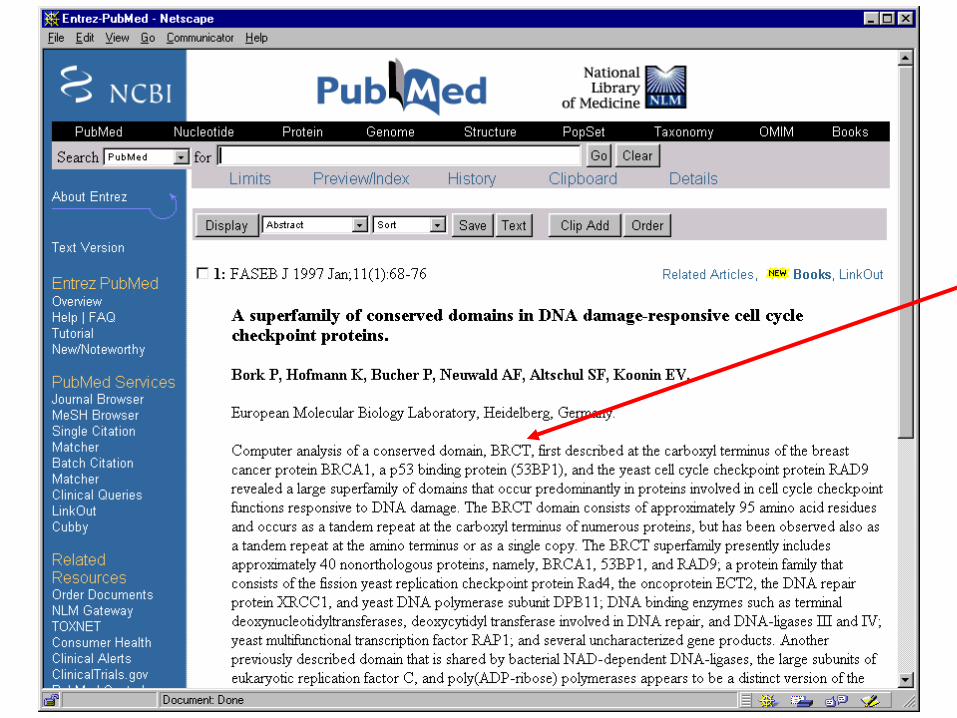
seg BRCA1 45 3.4 3.7 > BRCA1.seg>gi|728984|sp|P38398|BRC1_HUMAN Breast cancer type 1 susceptibility protein
1-388 MDLSALRVEEVQNVINAMQKILECPICLEL IKEPVSTKCDHIFCKFCMLKLLNQKKGPSQ CPLCKNDITKRSLQESTRFSQLVEELLKII CAFQLDTGLEYANSYNFAKKENNSPEHLKD EVSIIQSMGYRNRAKRLLQSEPENPSLQET SLSVQLSNLGTVRTLRTKQRIQPQKTSVYI ELGSDSSEDTVNKATYCSVGDQELLQITPQ GTRDEISLDSAKKAACEFSETDVTNTEHHQ PSNNDLNTTEKRAAERHPEKYQGSSVSNLH VEPCGTNTHASSLQHENSSLLLTKDRMNVE KAEFCNKSKQPGLARSQHNRWAGSKETCND RRTPSTEKKVDLNADPLCERKEWNKQKLPC SENPRDTEDVPWITLNSSIQKVNEWFSRsdellgsddshdgesesnakvadvldvlne 389-458vdeysgssekidllasdphealickservh sksvesnied 459-526 KIFGKTYRKKASLPNLSHVTENLIIGAFVT EPQIIQERPLTNKLKRKRRPTSGLHPEDFI KKADLAVQktpeminqgtnqteqngqvmnitnsghenk 527-635tkgdsiqneknpnpieslekesafktkaepisssisnmelelnihnskapkknrlrrkss trhihalelvvsrnlsppn 636-995 CTELQIDSCSSSEEIKKKKYNQMPVRHSRN LQLMEGKEPATGAKKSNKPNEQTSKRHDSD TFPELKLTNAPGSFTKCSNTSELKEFVNPS LPREEKEEKLETVKVSNNAEDPKDLMLSGE RVLQTERSVESSSISLVPGTDYGTQESISL LEVSTLGKAKTEPNKCVSQCAAFENPKGLI HGCSKDNRNDTEGFKYPLGHEVNHSRETSI EMEESELDAQYLQNTFKVSKRQSFAPFSNP GNAEEECATFSAHSGSLKKQSPKVTFECEQ KEENQGKNESNIKPVQTVNITAGFPVVGQK DKPVDNAKCSIKGGSRFCLSSQFRGNETGL ITPNKHGLLQNPYRIPPLFPIKSFVKTKCKknlleenfeehsmsperemgnenipstvst 996-1089isrnnirenvfkeasssninevgsstnevgssineigssdeniqaelgrnrgpklnamlr lgvl 1090-1238 QPEVYKQSLPGSNCKHPEIKKQEYEEVVQT VNTDFSPYLISDNLEQPMGSSHASQVCSET PDDLLDDGEIKEDTSFAENDIKESSAVFSK SVQKGELSRSPSPFTHTHLAQGYRRGAKKL ESSEENLSSEDEELPCFQHLLFGKVNNIPsqstrhstvateclsknteenllslknsln 1239-1312dcsnqvilakasqehhlseetkcsaslfss qcseledltantnt 1313-1316 QDPF
Non-globular regionsGlobular domains

1422-1513 GSQPSNSYPSIISDSSALEDLRNPEQSTSE KAVLTSQKSSEYPISQNPEGLSADKFEVSA DSSTSKNKEPGVERSSPSKCPSLDDRWYMH SCsgslqnrnypsqeelikvvdveeqqleesg 1514-1616phdltetsylprqdlegtpylesgislfsddpesdpsedrapesarvgnipsstsalkvp qlkvaesaqspaa 1617-1863 AHTTDTAGYNAMEESVSREKPELTASTERV NKRMSMVVSGLTPEEFMLVYKFARKHHITL TNLITEETTHVVMKTDAEFVCERTLKYFLG IAGGKWVVSYFWVTQSIKERKMLNEHDFEV RGDVVNGRNHQGPKRARESQDRKIFRGLEI CCYGPFTNMPTDQLEWMVQLCGASVVKELS SFTLGTGVHPIVVVQPDAWTEDNGFHAIGQ MCEAPVVTREWVLDSVALYQCQELDTYLIP QIPHSHY

Re moving spurious database hits for the low se que nce comple xity prote in BRCA1 by modifying SEG parame te rs a
Number of residues E-value s of the BLAST hits Parame te r se t of SEGa Maske
d Unmaske d Dentin Plant
BRCA1
Opossum BRCA1
No filtering 0 1,863 3e-11 4e-15 1e-28
12 2.1 2.4 35 1,828 4e-9 4e-15 1e-28 12 2.2 2.5 (default)
117 1,746 5e-4 5e-12 7e-22
12 2.3 2.6 172 1,691 - 5e-11 3e-21 12 2.4 2.7 279 1,584 - 5e-11 1e-14 12 2.5 2.8 487 1,376 - 6e-11 8e-10 12 2.6 2.9 616 1,247 - 2e-10 5e-9 12 2.7 3.0 908 955 - 4e-06 2e-8 12 2.8 3.1 1,164 699 - 0.003 6e-7
Composition-based filtering
0 1,863 - 3e-12 1e-20
aSEG parameters are trigger window length, trigger complexity, and extension




1422-1513 GSQPSNSYPSIISDSSALEDLRNPEQSTSE KAVLTSQKSSEYPISQNPEGLSADKFEVSA DSSTSKNKEPGVERSSPSKCPSLDDRWYMH SCsgslqnrnypsqeelikvvdveeqqleesg 1514-1616phdltetsylprqdlegtpylesgislfsddpesdpsedrapesarvgnipsstsalkvp qlkvaesaqspaa 1617-1863 AHTTDTAGYNAMEESVSREKPELTASTERV NKRMSMVVSGLTPEEFMLVYKFARKHHITL TNLITEETTHVVMKTDAEFVCERTLKYFLG IAGGKWVVSYFWVTQSIKERKMLNEHDFEV RGDVVNGRNHQGPKRARESQDRKIFRGLEI CCYGPFTNMPTDQLEWMVQLCGASVVKELS SFTLGTGVHPIVVVQPDAWTEDNGFHAIGQ MCEAPVVTREWVLDSVALYQCQELDTYLIP QIPHSHY




Paradigm shift in database searching
Querysequence
Sequence database
Set of homologs
PSSM
Querysequence
PSSM databaseDomainarchitecture
Traditional
New
PSI-BLAST
RPS-BLAST









BRCA1RING
BARD1
DOMAIN ARCHITECTURE OF SELECTED BRCT PROTEINS
BRCTBRCT
CMP-trans REV1 yeast
DPB11 yeast
ATP-dep ligase DNA ligase IIIhuman
AZFPARP
PARPvertebrates
HhHpolX TdT eukaryotes
ATP and PCNA-binding RFC1
NAD-dep ligase DNA ligasebacteria
eukaryotes
PHD-lBRCA1/BARDhomolog plant














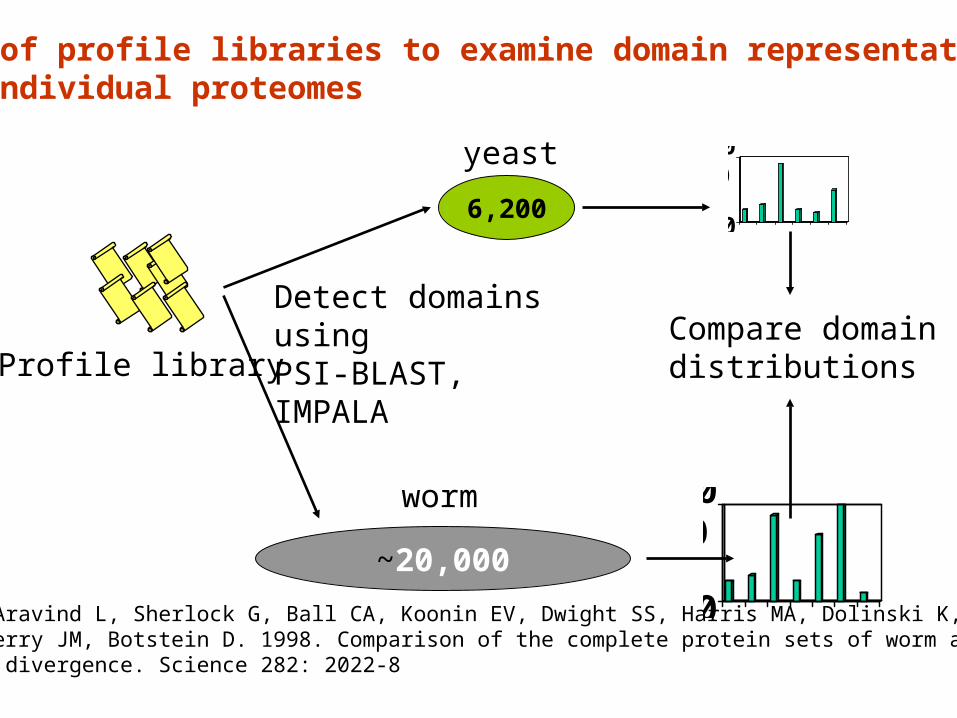
Use of profile libraries to examine domain representation in individual proteomes
Profile library
6,200
~20,000
yeast
worm
0
100
0
100
Detect domainsusingPSI-BLAST,IMPALA
Compare domaindistributions
Chervitz SA, Aravind L, Sherlock G, Ball CA, Koonin EV, Dwight SS, Harris MA, Dolinski K, Mohr S, SmithT, Weng S, Cherry JM, Botstein D. 1998. Comparison of the complete protein sets of worm and yeast: orthology and divergence. Science 282: 2022-8
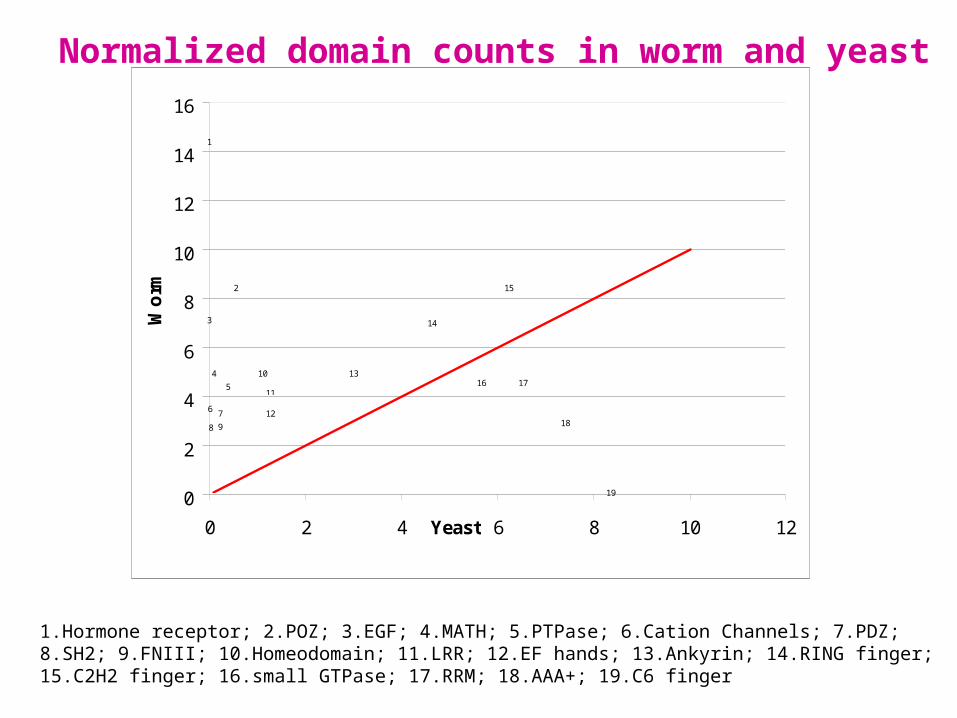
Normalized domain counts in worm and yeast
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12Yeast
Wo
rm1
2
3
4
5
6 7
98
10
11
12
13
14
15
16 17
18
19
1.Hormone receptor; 2.POZ; 3.EGF; 4.MATH; 5.PTPase; 6.Cation Channels; 7.PDZ; 8.SH2; 9.FNIII; 10.Homeodomain; 11.LRR; 12.EF hands; 13.Ankyrin; 14.RING finger; 15.C2H2 finger; 16.small GTPase; 17.RRM; 18.AAA+; 19.C6 finger

•Searching a domain library is often easier and more informative than searching the entire sequence database. However, the latter yields complementary information and should not be skipped if details are of interest.•Varying the search parameters, e.g. switching composition-based statistics on and off, can make a difference.•Using subsequences, preferably chosen according to objective criteria, e.g. separation from the rest of the protein by a low-complexity linker, may improve search performance. •Trying different queries is a must when analyzing protein (super)families.Even hits below the threshold of statistical significance often are worth analyzing, albeit with extreme care. Transferring functional information between homologs on the basis of a database description alone is dangerous.• Conservation of domain architectures, active sites and other features needs to be analyzed (hence automated identification of protein families is difficult and automated prediction of functions is extremely error-prone). •Always do a reality check!


















