
Model Selection with Many More Variables than Observationsvcs/talks/MicrosoftMay082008.pdf · Model...
35
Victoria Stodden Stanford University Model Selection with Many More Variables than Observations Microsoft Research Asia May 8, 2008
-
Upload
nguyendung -
Category
Documents
-
view
215 -
download
0
Transcript of Model Selection with Many More Variables than Observationsvcs/talks/MicrosoftMay082008.pdf · Model...

Victoria Stodden
Stanford University
Model Selection with Many MoreVariables than Observations
Microsoft Research Asia
May 8, 2008

Victoria Stodden Department of Statistics, Stanford University
Classical Linear Regression Problem
> Given predictors and response ,
> Linear model , with
> Estimate with
> Widely used in a huge amount of empirical
statistical research.
n pX
1ny
y X= + 0, )N2
(
1( ' ) 'X X X y

Victoria Stodden Department of Statistics, Stanford University
Developing Trend
> Classical model requires , but recent
developments have pushed people beyond the
classical model, to .
p n<
p n

Victoria Stodden Department of Statistics, Stanford University
New Data Types
> MicroArray Data: is number of genes, is
number of patients
> Financial Data: is number of stocks, prices,
etc, is number of time points
> Data Mining: automated data collection can
imply large numbers of variables
> Texture Classification in Images (eg. satellite):
is number of pixels, is number of imagesp
p
p
n
n
n

Victoria Stodden Department of Statistics, Stanford University
Estimating the model
> Can we find an estimate for when ?
> George Box (1986) Effect-Sparsity: the vast
majority of factors have zero effect, only a small
fraction actually affect the reponse.
> can still be modeled but now
must be sparse, containing a few nonzero
elements, the remaining elements zero.
p n
y X= +

Victoria Stodden Department of Statistics, Stanford University
Commonly Used Strategies for Sparse Modeling
1. All Subsets Regression• Fit all possible linear models for all levels of sparsity.
2. Forward Stepwise Regression• Greedy approach that chooses each variable in the model
sequentially by significance level.
3. LASSO (Tibshirani 1994), LARS (Efron, Hastie,
Johnstone, Tibshirani 2002)
• ‘shrinks’ some coefficient estimates to zero.

Victoria Stodden Department of Statistics, Stanford University
LASSO and LARS: a quick tour
> LASSO solves:
for a choice of .
> LARS: a stepwise approximation to LASSO• Advantage: guaranteed to stop in n steps
2
2 1min s.t. y X t
t

Victoria Stodden Department of Statistics, Stanford University
A New Perspective
> Up until now we’ve described the statistical view
of the problem when .
> Now we introduce ideas from Signal Processing
and a new tool for understanding regression
when , in the case of large.
> Claim: This will allow us to see that, for certain
problems, statistical solutions such as LASSO,
LARS, are just as good as all subsets
regression.
p n
p n> n

Victoria Stodden Department of Statistics, Stanford University
Background from Signal Processing
> There exists a signal , and several ortho-bases(eg. sinusoids, wavelets, gabor).
> Concatenation of several ortho-bases is adictionary.
> Postulate that the signal is sparselyrepresentable, i.e. made up from fewcomponents of the dictionary.
> Motivation:• Image = Texture + Cartoon
• Signal = Sinusoids + Spikes
• Signal = CDMA + TDMA + FM + …
y

Victoria Stodden Department of Statistics, Stanford University
Overcomplete Dictionaries
Canonical Basis• orthogonal columns
Standard Fourier Basis• where
• indicates cosine, sine
• orthogonal columns
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
1( ,0) ( , )
n 2 , 0, , / 2k
k k n= = …
0,1
n
is an overcomplete dictionary2[ | ]C F n n
A B B=
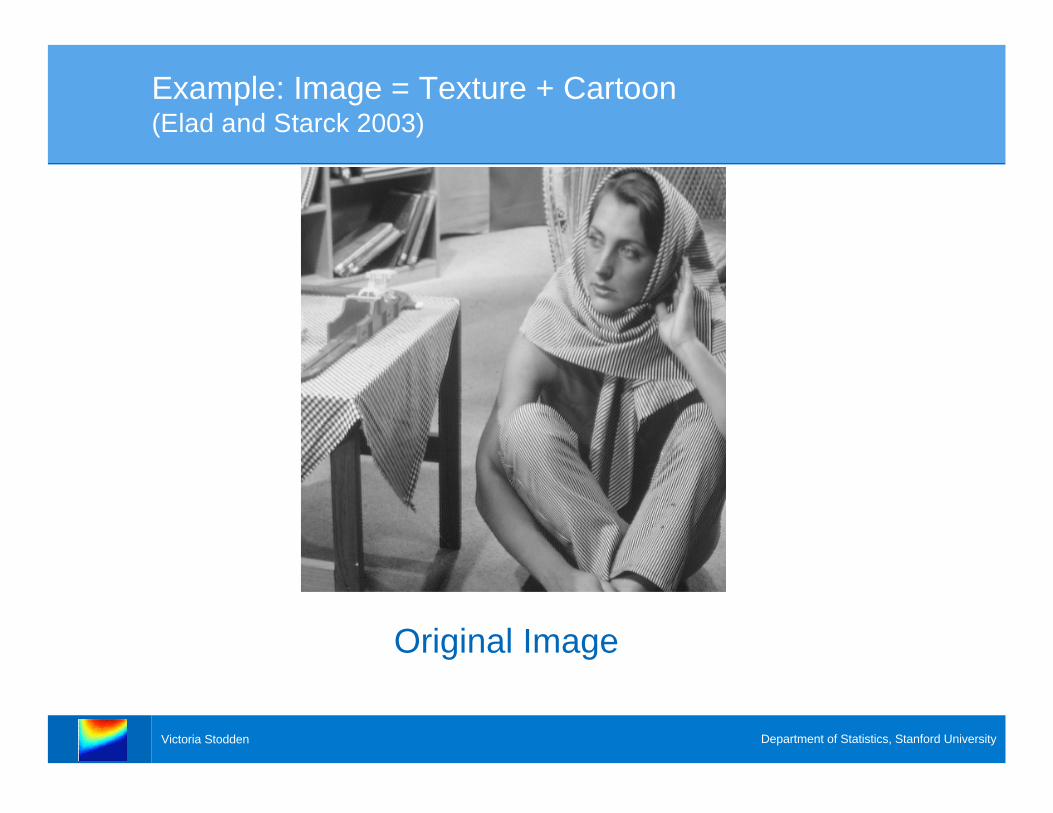
Victoria Stodden Department of Statistics, Stanford University
Original Image
Example: Image = Texture + Cartoon(Elad and Starck 2003)

Victoria Stodden Department of Statistics, Stanford University
Example: Image = Texture + Cartoon(Elad and Starck 2003)
Cartoon (Curvelets) Texture (local sinusoids)

Victoria Stodden Department of Statistics, Stanford University
Formal Signal Processing Problem Description
Signal decomposition:
With a noise term:
If #bases > 1, .
Signal
Matrix
Coefficients
Noise
n
p
signal length
= #bases
observations
predictors
DecompositionRegression
y
X
y
A
z
x
y Ax=
, (0, )y Ax z z N2
= +
/p n
p > n

Victoria Stodden Department of Statistics, Stanford University
Signal Processing Solutions
1. .Matching Pursuit (Mallat, Zhang 1993)• Forward Stepwise Regression
2. .Basis Pursuit (Chen, Donoho 1994)• Simple global optimization criteria:
3. Maximally Sparse Solution:• Intuitively most compelling but not feasible!
0 0( ) min x s.t. xP y Ax=
1 1( ) min x s.t. xP y Ax=

Victoria Stodden Department of Statistics, Stanford University
> We can’t hope to do an all subsets search, but
we are lucky!
is a convex problem, and it can sometimes
solve .
Problem Impossible!0l
1( )P
0( )P

Victoria Stodden Department of Statistics, Stanford University
Equivalence
> Signal processing results show solves
for certain problems.
> Donoho, Huo (IEEE IT, 2001)
> Donoho, Elad (PNAS, 2003)
> Tropp (IEEE IT, 2004)
> Gribonval (IEEE IT, 2004)
> Candès, Romberg, Tao (IEEE IT, to appear)
0( )P1( )P
1, 0( )l l

Victoria Stodden Department of Statistics, Stanford University
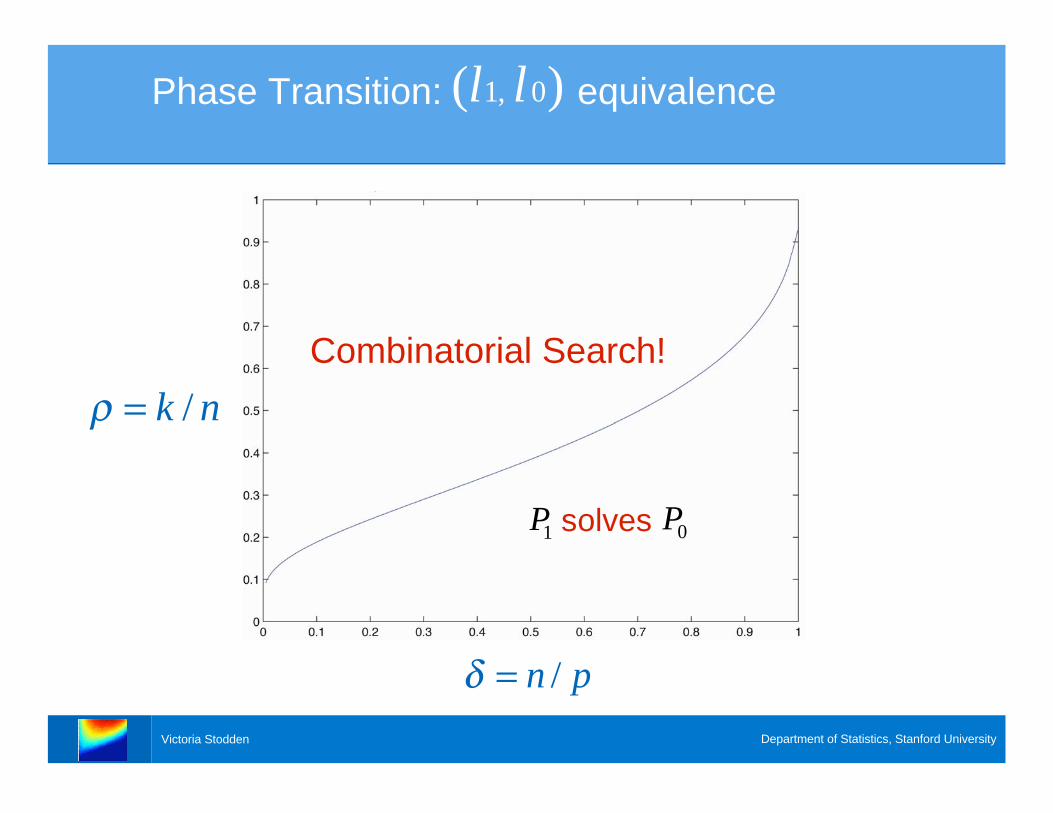
Phase Transition in Random Matrix Model
>
> , where has random nonzeros,positions random.
> Phase Plane• : degree of sparsity
• : degree of underdetermination
Theorem (DLD 2005) There exists a criticalsuch that, for every , for theoverwhelming majority of pairs, if , solves .
, , (0,1)n p i jA A N
/k n=
/n p=
1( )P 0( )P
(w )w<
x k
( , )
w<( , )y A
y Ax=
Victoria Stodden Department of Statistics, Stanford University
Phase Transition: equivalence1, 0( )l l
/k n=
/n p=
Combinatorial Search!
solves1
P0
P
Combinatorial Search!

Victoria Stodden Department of Statistics, Stanford University
Paradigm for study
> is a property of an algorithm,
> is a random ensemble,
> Find the Phase Transitions for property .
Approach pioneered by Donoho, Drori, and Tsaig:
1. Generate , where sparse.
2. Run full solution path to find solution ,
3. Property
P
( , )y X
P
2
2
ˆ
: P
y X=
ˆ

Victoria Stodden Department of Statistics, Stanford University
This implies a statistics question!
> Could this paradigm be used for linear
regression with noisy data?
> For example, when are LASSO, LARS, Forward
Stepwise just as good as all subsets regression?
> Reformulate problems with Noise:
20, 2 0( ) minP y X +
21, 2 1( ) minP y X +

Victoria Stodden Department of Statistics, Stanford University
Experiment Setup
> , with random entries generated from
, and normalized columns.
> is a -vector with the first entries drawn
from remaining entries .
> ~ -vector.
> Create
> We find the solution using an algorithm
(LASSO, LARS, Forward Stepwise) with and
as inputs.
n pX(0,1)N
p k
(0,100)U 0
(0,16) N n
y X= +
ˆ
X
y

Victoria Stodden Department of Statistics, Stanford University
Questions
> Will there be any phase transition?
> Can we learn something about the properties of
these algorithms from the Phase Diagram?
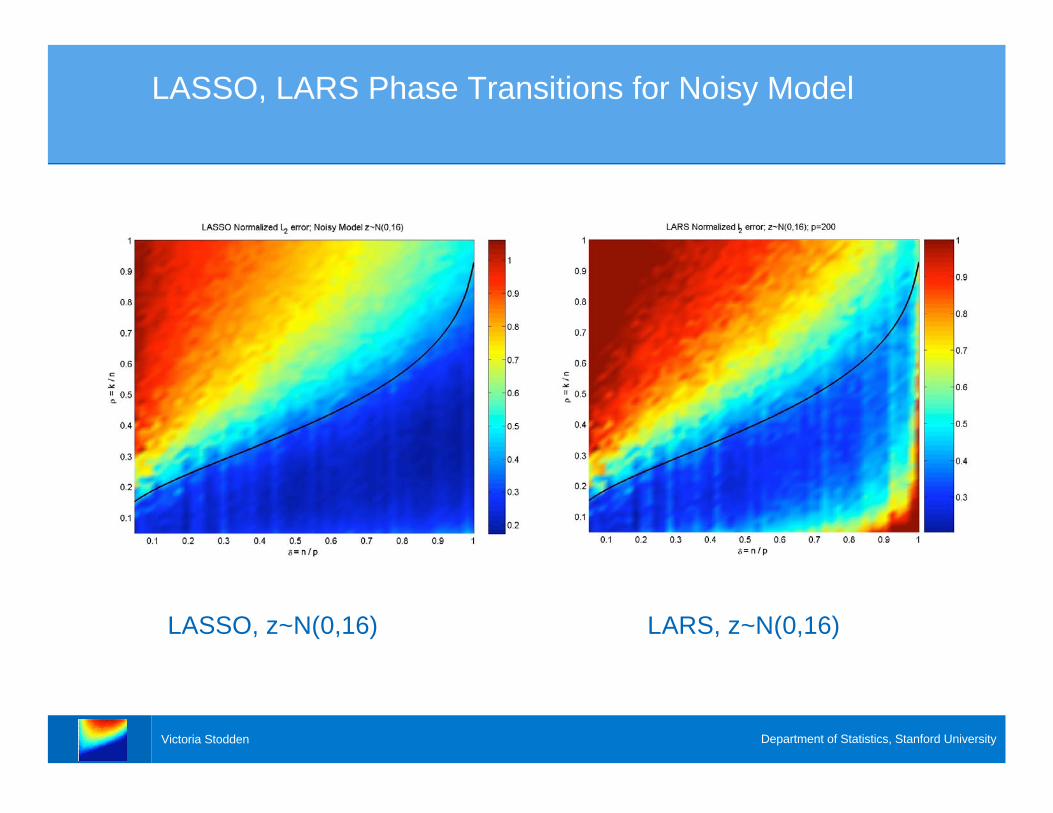
Victoria Stodden Department of Statistics, Stanford University
LASSO, LARS Phase Transitions for Noisy Model
LASSO, z~N(0,16) LARS, z~N(0,16)

Victoria Stodden Department of Statistics, Stanford University
Aside: Stepwise Thresholding
> Stepwise Algorithm – typical implementation:• Add the variable with the highest t-statistic to the model, if
that t-statistic is greater than , (Bonferroni).
> Stepwise Algorithm: False Discovery Rate
(FDR) Threshold:• Add the variable with the highest t-statistic to the model, if
that t-statistic’s p-value is less than the FDR statistic.
• , where is (the FDR
• parameter), is the number of variables in the current
model, and is the potential number of variables.
2log( )p
*stat
q kFDR
pq
kp
{#falseDiscoveries}
{#totalDiscoveries}E
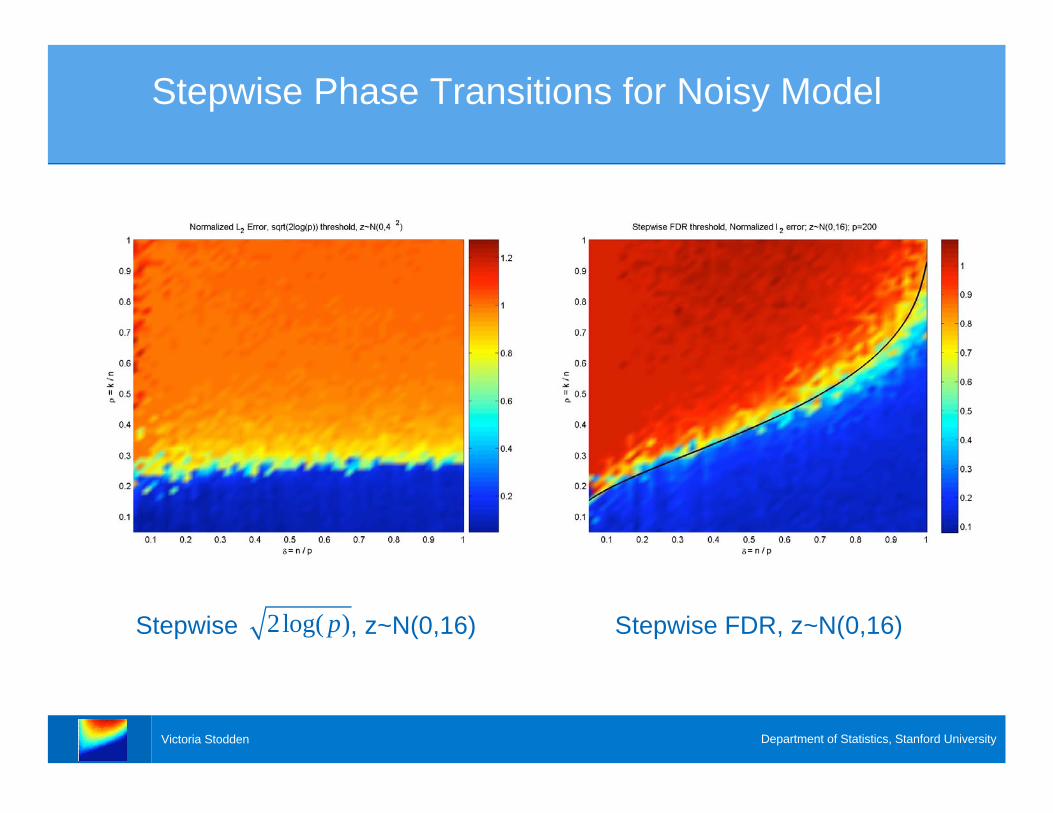
Victoria Stodden Department of Statistics, Stanford University
Stepwise Phase Transitions for Noisy Model
Stepwise , z~N(0,16) Stepwise FDR, z~N(0,16)2log( )p

Victoria Stodden Department of Statistics, Stanford University
Phase Transition Surprises
> Surprise: LASSO finds underlying model, for
> Hoped for: LARS finds underlying model, for
. .
> Surprise: Stepwise only successful for
. .
LASSO<
LARS<
LASSOc

Victoria Stodden Department of Statistics, Stanford University
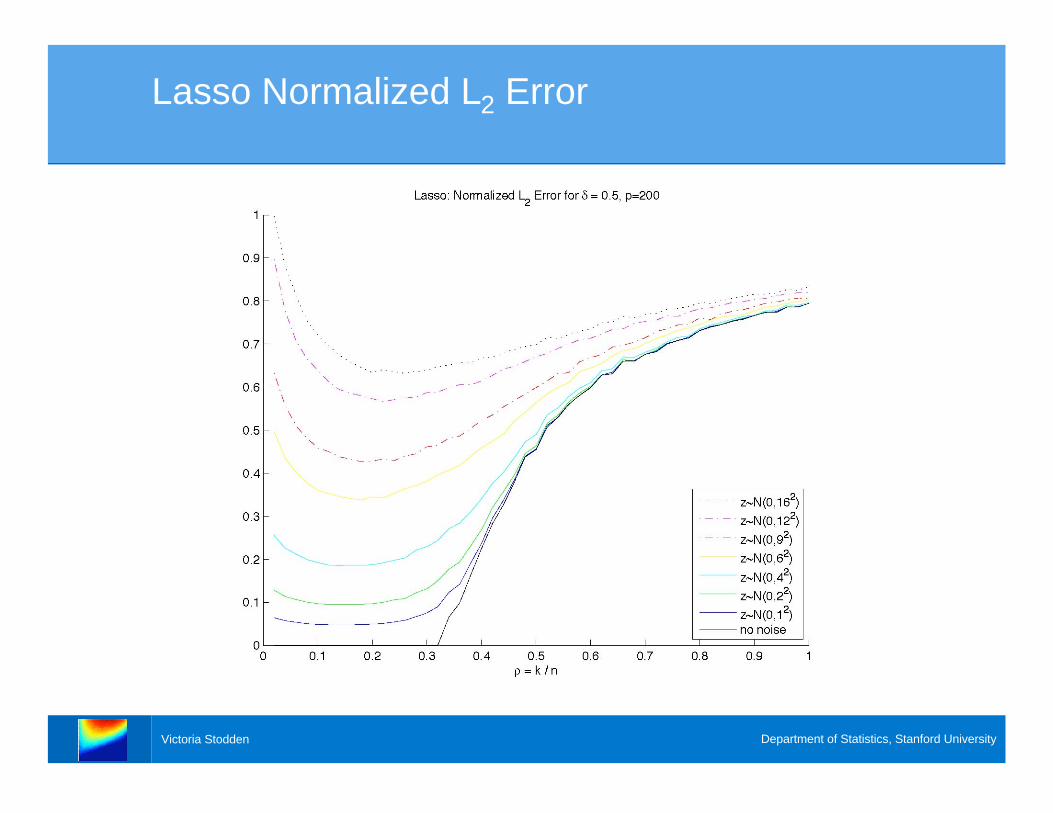
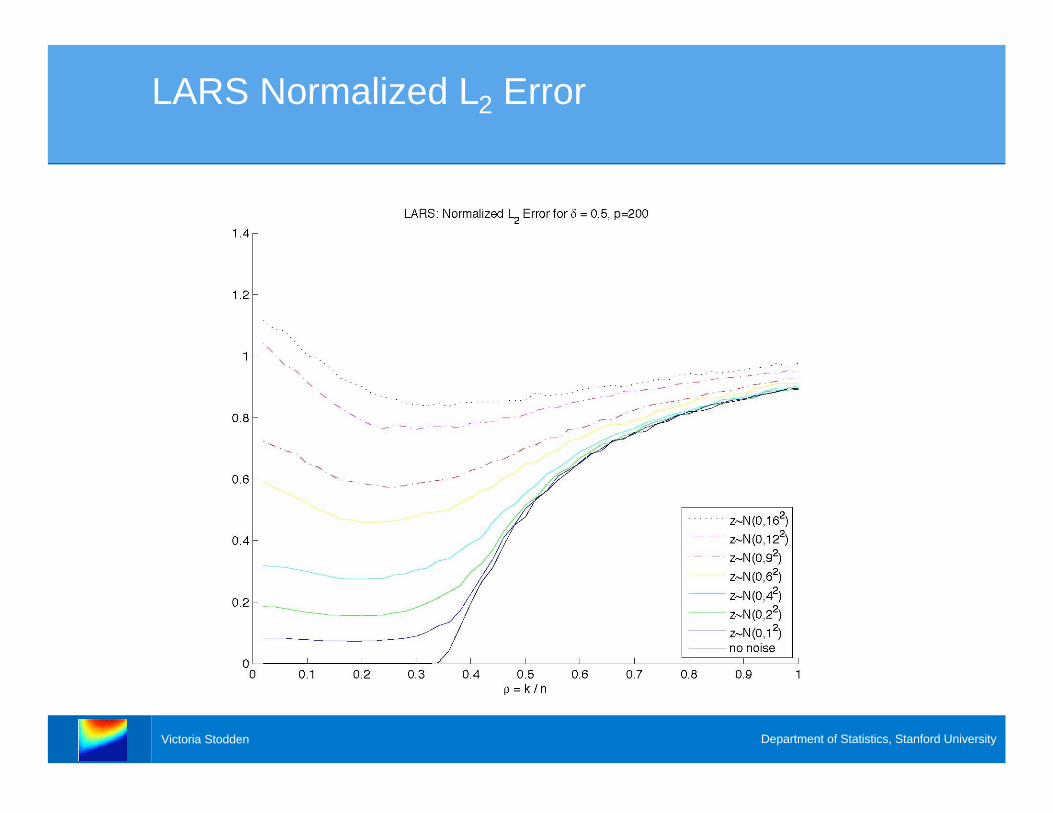
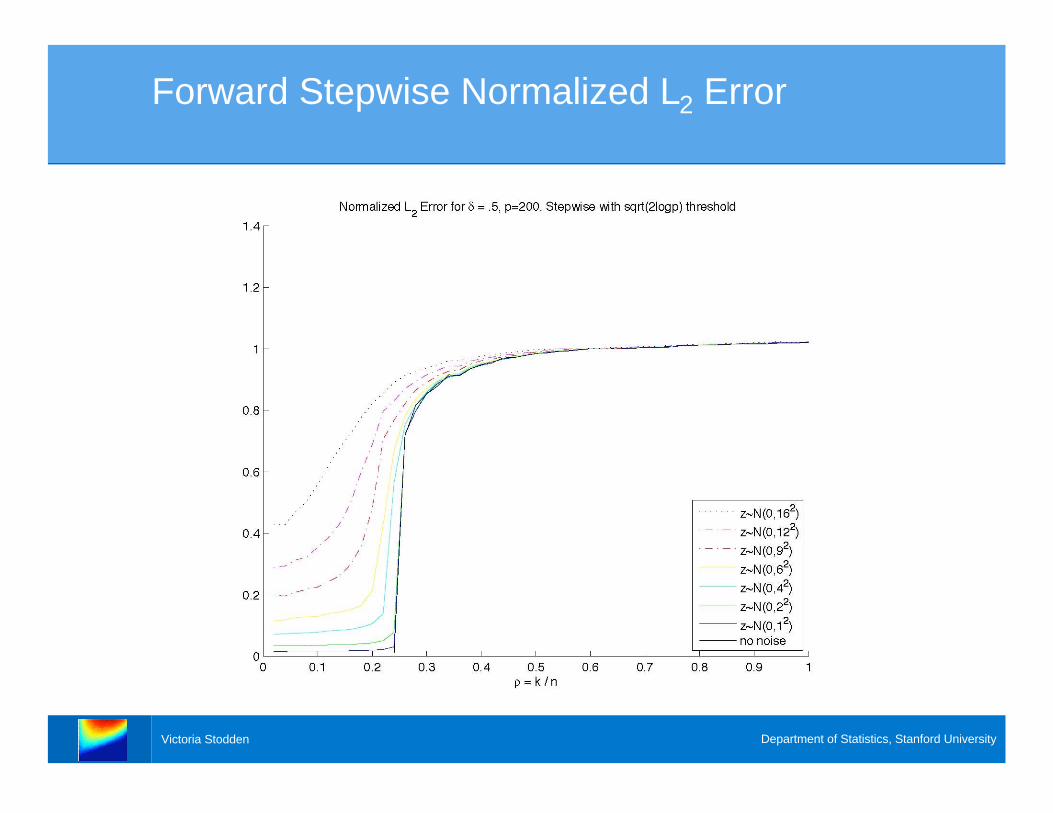
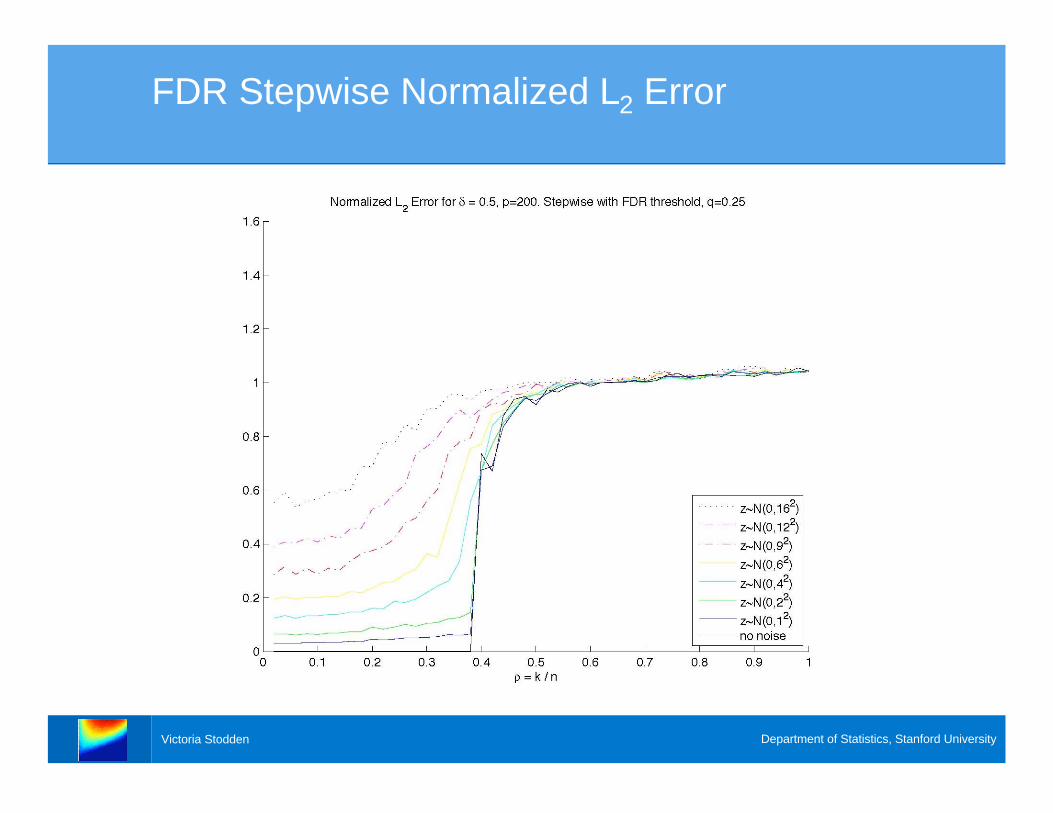
Error Analysis
> With increased noise levels, at what sparsity
levels does these algorithms continue to recover
the correct underlying model, if at all?
> We fix and examine a “slice” of the phase
transition diagram..5=
Victoria Stodden Department of Statistics, Stanford University
Lasso Normalized L2 Error
Victoria Stodden Department of Statistics, Stanford University
LARS Normalized L2 Error
Victoria Stodden Department of Statistics, Stanford University
Forward Stepwise Normalized L2 Error
Victoria Stodden Department of Statistics, Stanford University
FDR Stepwise Normalized L2 Error

Victoria Stodden Department of Statistics, Stanford University
Experiences with Noisy Case
> Phase Diagrams revealing, stimulating.
> Stepwise Regression falls apart at a critical
sparsity level (why?)
> LARS in same cases works very well!
> Suggests other interesting properties to study.
> Other algorithms: Forward Stagewise, Backward
Elimination, Stochastic Search Variable
Selection, ...

Victoria Stodden Department of Statistics, Stanford University
Introducing SparseLab!
http://sparselab.stanford.edu
> Matlab toolbox that makes software solutions for
sparse systems available.
> Growing research on sparsity, variable selection
issues – could advance the research community
if they have standard tools.
> SparseLab is a system to do this.

Victoria Stodden Department of Statistics, Stanford University
SparseLab in Depth
> Reproducible Research: SparseLab makes
available the code to reproduce figures in
published papers.
> Some papers currently included:• “Model Selection When the Number of Variables Exceeds
the Number of Observations” (Donoho, Stodden 2006)
• “Extensions of Compressed Sensing” (Tsaig, Donoho 2005)
• “Neighborliness of Randomly-Projected Simplices in High
Dimensions” (Donoho, Tanner 2005)
• “High-Dimensional Centrally-Symmetric Polytopes With
Neighborliness Proportional to Dimension” (Donoho 2005)
> All open source!

Victoria Stodden Department of Statistics, Stanford University
Acknowledgments
David Donoho
Iddo Drori
Joshua Sweetkind-Singer
Yaakov Tsaig


















