
MIL Speech Seminar TRACHEOESOPHAGEAL SPEECH REPAIR Arantza del Pozo CUED Machine Intelligence...
25
MIL Speech Seminar TRACHEOESOPHAGEAL SPEECH REPAIR Arantza del Pozo CUED Machine Intelligence Laboratory November 20th 2006
-
Upload
noah-nathaniel-kelley -
Category
Documents
-
view
218 -
download
1
Transcript of MIL Speech Seminar TRACHEOESOPHAGEAL SPEECH REPAIR Arantza del Pozo CUED Machine Intelligence...

MIL Speech Seminar
TRACHEOESOPHAGEAL SPEECH REPAIR
Arantza del PozoCUED Machine Intelligence Laboratory
November 20th 2006

Arantza del Pozo @ CUED Machine Intelligence Laboratory 2
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work

Arantza del Pozo @ CUED Machine Intelligence Laboratory 3
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work

Arantza del Pozo @ CUED Machine Intelligence Laboratory 4
SPEECH REPAIR
SPEECH REPAIR SYSTEM
Speech Model Deviant features Correction algorithms

Arantza del Pozo @ CUED Machine Intelligence Laboratory 5
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work
Arantza del Pozo @ CUED Machine Intelligence Laboratory 6
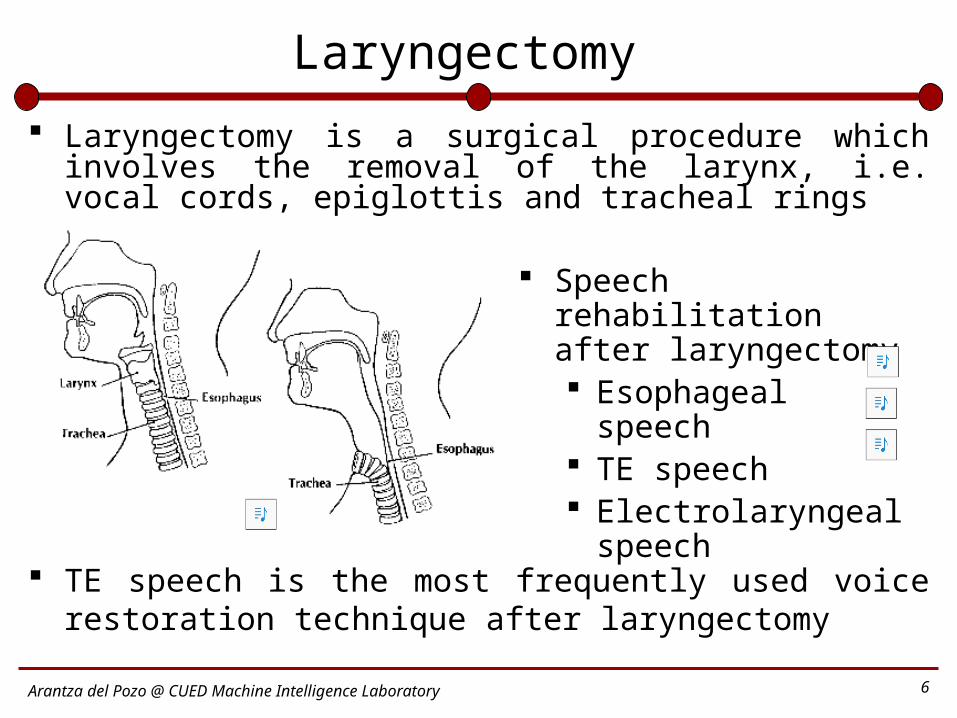
Laryngectomy
Laryngectomy is a surgical procedure which involves the removal of the larynx, i.e. vocal cords, epiglottis and tracheal rings
Speech rehabilitation after laryngectomy Esophageal speech TE speech Electrolaryngeal
speech
TE speech is the most frequently used voice restoration technique after laryngectomy

Arantza del Pozo @ CUED Machine Intelligence Laboratory 7
Acoustic properties of TE speech
Voicing source highly variable and deviant Lower F0 (female) and higher jitter and shimmer Higher high-frequency noise and lower
harmonic-to-noise-ratio (HNR), glottal-to-noise excitation ratio (GNE), band-energy difference (BED)
Some evidence of higher formant values in Spanish and Dutch TE speech
Shorter maximum phonation time, longer vowel duration and slower speaking rates

Arantza del Pozo @ CUED Machine Intelligence Laboratory 8
Main limitations of TE speech
Inability to properly control the EXCITATION deviant glottal waveforms irregular pitch and amplitude contours higher turbulence noise spectral envelope deviations caused by coupling
DURATION deviations caused by the disconnection between the lungs and the vocal tract more pauses longer vowels slower rates rushes before breaks

Arantza del Pozo @ CUED Machine Intelligence Laboratory 9
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work

Arantza del Pozo @ CUED Machine Intelligence Laboratory 10
Previous excitation repair attempts
Qi et al. Resynthesis of female TE words with a synthetic
glottal waveform and with smoothed and raised F0 Replacement of voice source and conversion of
spectral envelopes
Limitations of previous repair attempts Only most obvious deviant features have been
tackled Evaluation limited to sustained vowels and words Only a small number of TE speakers and qualities
have been tested Degree of perceptual enhancement has not been
quantified

Arantza del Pozo @ CUED Machine Intelligence Laboratory 11
Adopted approach
DATA 13 TE speakers (11 male, 2 female)
Patients of the Speech and Language Therapy Department of Addenbrookes Hospital, Cambridge
Control group of 11 normal speakers (8 male, 3 female)
BASELINE SYSTEM Glottal resynthesis Jitter and shimmer reduction
ENHANCED SYSTEM Spectral envelope smoothing and
Tilt reduction
Feature correction
Perceptual evaluation
DEVIANT FEATURES:-voice source-jitter & shimmer-spectral envelope

Arantza del Pozo @ CUED Machine Intelligence Laboratory 12
Baseline system
Glottal resynthesisbreathiness reduction
Jitter and shimmer reductionroughness reduction
Lip radiation VT

Arantza del Pozo @ CUED Machine Intelligence Laboratory 13
Enhanced system (1/2)
Resynthesised speech still has a harsh quality caused by deviations in TE spectral envelopes (SE)
Spectral envelope analysis Higher std of formant gains, frequencies and
bandwidths and spectral distortion Lower relative gain difference between 1st and 3rd
formants and spectral tilt
Arantza del Pozo @ CUED Machine Intelligence Laboratory 14
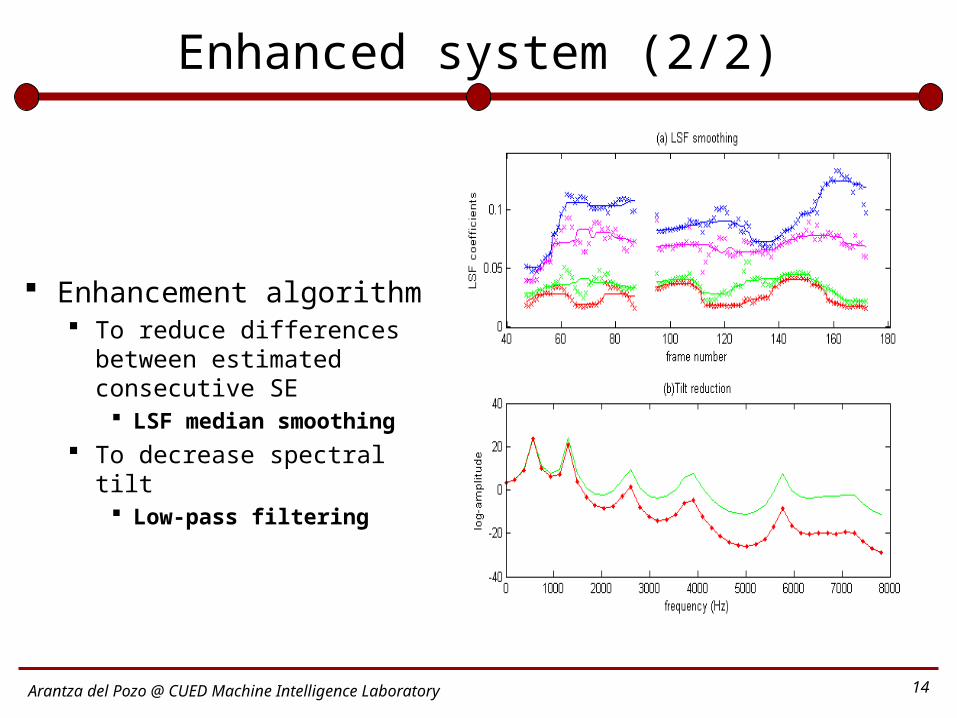
Enhanced system (2/2)
Enhancement algorithm To reduce differences
between estimated consecutive SE
LSF median smoothing To decrease spectral tilt
Low-pass filtering

Arantza del Pozo @ CUED Machine Intelligence Laboratory 15
Results
Perceptual tests
original baseline enhanced
“more breathy”
82.69% 17.31%
“harsher” 73.72% 26.28%
“more normal speaker”
58.33% 41.67%
38.78% 61.22%

Arantza del Pozo @ CUED Machine Intelligence Laboratory 16
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work

Arantza del Pozo @ CUED Machine Intelligence Laboratory 17
Preliminary experiments
Duration deviations more pauses longer vowels slower rates rushes before breaks
Possible duration repair approaches Rule-based
Reduce pauses, reduce vowels, increase speech rate, increase duration of phones before breaks, etc.
Difficult to obtain adequate reduction/increase rates Break sentence rhythm
Transplantation of average normal phone durations Phone durations obtained with Forced Alignment (FA) Overall improvement which increased naturalness of TE
sentences Sentence rhythm was preserved
Duration repair algorithm is an automatization of the transplantation experiment

Arantza del Pozo @ CUED Machine Intelligence Laboratory 18
Regression tree modelling (1/2)
Classification and regression trees (CART) are widely used for duration modelling in TTS systems
Employed features are extracted from text Phone identity Identities of previous and next phones Position of syllable in word Position of word in sentence Number of syllables before/after a break Type of lexical stress Lexical stress type of previous and next syllables ...
A speech repair framework constrains the possible feature space to recognisable features For TE speech repair, assumed that only phone recognition is
viable Features relying on word, syllable or lexical stress information
cannot be used

Arantza del Pozo @ CUED Machine Intelligence Laboratory 19
Regression tree modelling (2/2)
Several CART trees were built with different features Explored features
Phone identity Identities of previous and next phones Positions of phones in the sentence Pitch and energy (as an attempt to incorporate some stress info) Short pauses (SP) not regarded as phones, modelled independently
Trees T1 F1: phone identity T2 F2: F1 + previous & next phone identities (broad class) T3 F3: F2+ position of phone in sentence T4 F4: F3+ pitch (positive/negative/no slope) T5 F5: F4+ energy (positive/negative/no slope) TSP number of phones since previous sp & until next sp
Performance measured as Mean Squared Error (MSE) between normal mean durations used for transplantation and predicted values T3>T2>T1>T5>T4 Substitution of T3+TSP predicted durations of TE sentences with FA
phone segmentation almost indistinguishable from transplantation

Arantza del Pozo @ CUED Machine Intelligence Laboratory 20
Improving TE recognition (1/2)
Little work on automatic TE speech recognition Haderlein et al. (2004) adapted a speech recogniser
trained on normal speech to single TE speakers by unsupervised HMM interpolation and obtained an average word accuracy of 36.4%
Focus on improving TE phone recognition Novel performance measures which take recognition (r),
segmentation (s) and duration prediction (p) errors into account
NP
isirSPC
NP
i
1
)()(
NP
ipsP
SPE
ES
s
ESP
i
1 1
)()(FA
REC

Arantza del Pozo @ CUED Machine Intelligence Laboratory 21
Improving TE recognition (2/2)
Explored systems Baseline (BL): monophone HMM trained on WSJCAM0 R1: BL + CMN + CMLLR R2: R1 + MAP R3: R1 + bigram LM R4: R1 + trigram LM R5: CUHTK 2003 BN LVCSR + CMLLR phone level output
Results R5>R4>R3>R1>R2
BL R1 R2 R3 R4 R5
SPC [%] 0.1634 0.3129 0.3044 0.3249 0.3340 0.5148
SPE [ms]
39.444 29.713 30.926 27.329 26.682 14.257

Arantza del Pozo @ CUED Machine Intelligence Laboratory 22
Fixing recognition artifacts
Use of best recognised labels for duration repair still produced artifacts
Method for robust duration modification (RM) Take recognition confidence into account
computed from TE phone duration probability distributions recogniser confidence scores takes phone confusions into account in R4
OPN ddd )1(
Pd

Arantza del Pozo @ CUED Machine Intelligence Laboratory 23
Results
Objective evaluation: MSE between repaired sentences and target transplanted durations R5+RM>R5>R4+RM>R4>original TE durations
Subjective evaluation: perceptual test
RANK (1-5) O T R
PREFERENCETEST
R448%
R552% - > = <
T - M 0.54 0.22 0.24
M - O 0.52 0.31 0.17
T - O 0.66 0.20 0.14

Arantza del Pozo @ CUED Machine Intelligence Laboratory 24
OUTLINE
Speech repair Tracheoesophageal (TE) speech
Laryngectomy Acoustic properties Main limitations
Excitation repair Previous attempts Adopted approach Baseline system Enhanced system Results
Duration repair Preliminary experiments Regression tree modelling Improving TE recognition Fixing recognition artifacts Results
Conclusions and future work

Arantza del Pozo @ CUED Machine Intelligence Laboratory 25
CONCLUSIONS AND FUTURE WORK
Deviant TE excitation and duration features have been identified and repaired
Synthetic quality of excitation repaired speech nullifies results in some cases
Future work Improve excitation resynthesis quality Improve TE speech recognition step Attempt text-based features for duration modelling


















