
MapReduce-BasedDynamicPartitionJoinwithShannon ...
15
Research Article MapReduce-Based Dynamic Partition Join with Shannon Entropy for Data Skewness Donghua Chen 1 and Runtong Zhang 2 1 School of Information Technology and Management, University of International Business and Economics, Beijing 100029, China 2 School of Economics and Management, Beijing Jiaotong University, Beijing 100044, China Correspondence should be addressed to Runtong Zhang; [email protected] Received 3 May 2021; Revised 4 September 2021; Accepted 18 October 2021; Published 24 November 2021 Academic Editor: Michele Risi Copyright © 2021 Donghua Chen and Runtong Zhang. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Join operations of data sets play a crucial role in obtaining the relations of massive data in real life. Joining two data sets with MapReduce requires a proper design of the Map and Reduce stages for different scenarios. e factors affecting MapReduce join efficiency include the density of the data sets and data transmission over clusters like Hadoop. is study aims to improve the efficiency of MapReduce join algorithms on Hadoop by leveraging Shannon entropy to measure the information changes of data sets being joined in different MapReduce stages. To reduce the uncertainty of data sets in joins through the network, a novel MapReduce join algorithm with dynamic partition strategies called dynamic partition join (DPJ) is proposed. Leveraging the changes of entropy in the partitions of data sets during the Map and Reduce stages revises the logical partitions by changing the original input of the reduce tasks in the MapReduce jobs. Experimental results indicate that the entropy-based measures can measure entropy changes of join operations. Moreover, the DPJ variant methods achieved lower entropy compared with the existing joins, thereby increasing the feasibility of MapReduce join operations for different scenarios on Hadoop. 1. Introduction Join algorithms between two data sets in stand-alone rela- tional databases have been optimized for years; meanwhile, the increasing needs of big data analysis result in the emergence of various types of parallel join algorithms [1]. In the era of big data, such join operations on large data sets should be performed in existing distributed computing architectures, such as Apache Hadoop; that is, efficient joins must follow the scheme of programming models and require the extended revision of conventional joins for architectures [2]. At present, the Hadoop system is able to process big data in a rapid way [3]. Joining two data sets with MapReduce requires a proper design of the Map and Reduce stages for different scenarios. e factors affecting MapReduce join efficiency include the density of the data sets and data transmission over clusters like Hadoop. Join algorithms should be revised to utilize the ability of parallel computing in Hadoop and data set sizes being joined in performing joins for large data sets in Hadoop. However, only a few of these algorithms have considered the data skewness of scientific data sets to optimize join operations. ere exists difficulty in estimating the amount of information within heterogeneous data sets for each join. e skewness causes the occurrences of uneven distributions and a severe problem of load imbalance; the use of join operations on big data even makes the skewness occur exponentially [4]. Since Shannon’s theory indicates that information is a measurable commodity, it is possible that MapReduce stages and the transmission of data sets over Hadoop clusters can be treated as a message channel between senders (mappers) and re- ceivers (reducers). A data set to be joined is considered as a memoryless message source that contains a set of messages with its own probabilities to send to receivers. is study aims to improve the efficiency of MapReduce join algorithms on Hadoop by leveraging Shannon entropy to measure the information changes of data sets being joined in different MapReduce stages. Our study highlights that leveraging the changes of entropy in the partitions of data sets during the Map and Reduce stages revises the logical Hindawi Scientific Programming Volume 2021, Article ID 1602767, 15 pages https://doi.org/10.1155/2021/1602767
Transcript of MapReduce-BasedDynamicPartitionJoinwithShannon ...

Research ArticleMapReduce-Based Dynamic Partition Join with ShannonEntropy for Data Skewness
Donghua Chen 1 and Runtong Zhang 2
1School of Information Technology andManagement University of International Business and Economics Beijing 100029 China2School of Economics and Management Beijing Jiaotong University Beijing 100044 China
Correspondence should be addressed to Runtong Zhang rtzhangbjtueducn
Received 3 May 2021 Revised 4 September 2021 Accepted 18 October 2021 Published 24 November 2021
Academic Editor Michele Risi
Copyright copy 2021 Donghua Chen and Runtong Zhang is is an open access article distributed under the Creative CommonsAttribution License which permits unrestricted use distribution and reproduction in anymedium provided the original work isproperly cited
Join operations of data sets play a crucial role in obtaining the relations of massive data in real life Joining two data sets withMapReduce requires a proper design of the Map and Reduce stages for different scenarios e factors affecting MapReduce joinefficiency include the density of the data sets and data transmission over clusters like Hadoop is study aims to improve theefficiency of MapReduce join algorithms on Hadoop by leveraging Shannon entropy to measure the information changes of datasets being joined in different MapReduce stages To reduce the uncertainty of data sets in joins through the network a novelMapReduce join algorithm with dynamic partition strategies called dynamic partition join (DPJ) is proposed Leveraging thechanges of entropy in the partitions of data sets during the Map and Reduce stages revises the logical partitions by changing theoriginal input of the reduce tasks in the MapReduce jobs Experimental results indicate that the entropy-based measures canmeasure entropy changes of join operations Moreover the DPJ variant methods achieved lower entropy compared with theexisting joins thereby increasing the feasibility of MapReduce join operations for different scenarios on Hadoop
1 Introduction
Join algorithms between two data sets in stand-alone rela-tional databases have been optimized for years meanwhilethe increasing needs of big data analysis result in theemergence of various types of parallel join algorithms [1] Inthe era of big data such join operations on large data setsshould be performed in existing distributed computingarchitectures such as Apache Hadoop that is efficient joinsmust follow the scheme of programmingmodels and requirethe extended revision of conventional joins for architectures[2] At present the Hadoop system is able to process big datain a rapid way [3] Joining two data sets with MapReducerequires a proper design of the Map and Reduce stages fordifferent scenarios e factors affecting MapReduce joinefficiency include the density of the data sets and datatransmission over clusters like Hadoop Join algorithmsshould be revised to utilize the ability of parallel computingin Hadoop and data set sizes being joined in performingjoins for large data sets in Hadoop However only a few of
these algorithms have considered the data skewness ofscientific data sets to optimize join operations ere existsdifficulty in estimating the amount of information withinheterogeneous data sets for each join e skewness causesthe occurrences of uneven distributions and a severeproblem of load imbalance the use of join operations on bigdata even makes the skewness occur exponentially [4] SinceShannonrsquos theory indicates that information is a measurablecommodity it is possible that MapReduce stages and thetransmission of data sets over Hadoop clusters can be treatedas a message channel between senders (mappers) and re-ceivers (reducers) A data set to be joined is considered as amemoryless message source that contains a set of messageswith its own probabilities to send to receivers
is study aims to improve the efficiency of MapReducejoin algorithms on Hadoop by leveraging Shannon entropyto measure the information changes of data sets being joinedin different MapReduce stages Our study highlights thatleveraging the changes of entropy in the partitions of datasets during the Map and Reduce stages revises the logical
HindawiScientific ProgrammingVolume 2021 Article ID 1602767 15 pageshttpsdoiorg10115520211602767
partitions by changing the original input of the reduce tasksin Hadoop MapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the samekey on Hadoop
e remainder of this paper is organized as follows enext section summarizes the related work in this researchfield Section 3 firstly leverages Shannon entropy to modelthe data intensity of data sets in aMapReduce join operationand then it proposes a novel join algorithm with dynamicpartition strategies for two-way joins by optimizing thepartitions of data sets with skewed data intensity for reducetasks Section 4 conducts a series of experiments on differentsettings of data set sizes to compare the proposed methodwith the methods in literature en Section 5 discusses ourwork in practice Finally the work is concluded in Section 6
2 Related Work
MapReduce is the most widely used programming model inHadoop and uses the Map Combine Shuffle and Reducestages to divide numerous data sets into small partitions andreduces the merged and sorted partitions on a cluster ofcomputer nodes [5] e Hadoop MapReduce architecturehas contributed immensely to the existing big-data-relatedanalyses Joining large data sets which is complex and timeconsuming is one of the most important uses in Hadoop [6]Applications of join operations include privacy preservingsimilarity [7] parallel set-similarity [8] and fuzzy joins [9]which focus on similarity estimation
Join operations in MapReduce are time consuming andcumbersome During a join operation in a Hadoop cluster amapper reads a partition from data sets and writes pairs ofjoin keys and their corresponding values to intermediate filesereafter the intermediate results are merged and sorted tobe fed into numerous reducers Eventually each reducer thatperforms multiple Reduce tasks joins two sets of records withthe same key Join optimization has encountered considerablebottlenecks in reducing time cost and increasing the feasibilityof dynamic partitioning data for different purposes e mainreason is that the shuffle stage on Hadoop is performed with acluster network With hardware upgrade GPU is also verypromising to improve the performance of join operations in ahybrid framework [10] Existing join processing using theMapReduce programming model includes k-NN [11] Equi-[12] eta- [13] Similarity [14] Top-K [15] and filter-basedjoins [16] To handle the problem that existing MapReduce-based filtering methods require multiple MapReduce jobs toimprove the join performance the adaptive filter-based joinalgorithm is proposed [17]eMapReduce framework is alsosuitable to handle large-scale high-dimensional data similarityjoins [18] For example spatial join is able to perform dataanalysis in geospatial applications which contain massivegeographical information in a high-dimensional form [19]
e various types of join algorithms in accordance withthe actual sides of performing MapReduce join operationsonHadoop include themap-side and reduce-side joins Suchalgorithms are also known for repartition broadcast andreplicated join in accordance with their features [20] Join
algorithms utilize the ability of parallel computing inHadoop and data set sizes being joined in performing joinsfor large data sets in Hadoop In general Bloom filter is ableto reduce workload such as minimizing nonjoining data andreducing the costs of communication [21] However only afew of these algorithms have considered the data skewness ofscientific data sets to optimize join operations e reason isthe difficulty in estimating the amount of information withinheterogeneous data sets for each join Chen et al [22]promoted metric similarity joins by using two sampling-based partition methods to enable equal-sized partitions Ingeneral a data set contains different amounts of relationsamong data fields thereby causing difference in workloadsof Reduce tasks fed into a reducer which differs fromtraditional joins To reduce the complexity of constructingthe index structure by using the see-based dynamic parti-tioning a MapReduce-based kNN-join algorithm for queryprocessing is proposed [23] e partition phrase is alsofocused on in existing research to produce filter balancedand meaning subdivisions of the data sets [24] Withouteffectively estimating such a difference of workload in twodata sets with proper measures joining data sets with skeweddata intensity affects join performance and its feasibility
Shannon entropy in information theory which initiallymeasures the information of communication systemscharacterizes the impurity of arbitrary collections of ex-amples [25] e entropy of a variable is used to estimate thedegree of information or uncertainty inherent in the scope ofthe variable outcomes It is originally used to estimate theinformation value of a message between different entitiesHowever the entropy is also useful to measure diversity Atpresent this theory has shaped virtually all systems thatstore process or transmit information in digital forms (egperforming knowledge reduction on the basis of informationentropy using MapReduce) [26] Chaos of data is thecomplete unpredictability of all records in a data set and canbe quantified using Shannon entropy [27] erefore aMapReduce-based join is naturally regarded as an entropy-based system for storing processing and transmitting datasets With the use of hyperparameter optimization withautomated tools MapReduce-based joins can be easily ap-plied in big data production environments [28] In the fu-ture automated join optimizer systems will be able toperform optimization of the hyperparameters of join op-erations and obtain the most efficient join strategy forvarious big data applications [29]
3 Materials and Methods
We first illustrate the concept of Shannon entropy of datasets to be joined using MapReduce and then present aframework to evaluate the entropy of data sets for existingjoin algorithms using MapReduce A novel join algorithmwith dynamic partition strategies is also proposed
31 Shannon Entropy of Data Sets Shannonrsquos theory indicatesthat information is a measurable commodity ConsideringentropyH of a discrete random variableX x1 xn and the
2 Scientific Programming
probability mass function is defined as P (X) we obtainH (X)
E [I (X)] E [minuslog (P (X)] according to Shannonrsquos theoryerefore MapReduce stages and the transmission of data setsover Hadoop clusters can be treated as a message channelbetween senders (mappers) and receivers (reducers) A data setto be joined is a memoryless message source that contains a setof messages with its own probabilities to send to receivers
Figure 1 illustrates a toy example of two data sets to bejoined in MapReduce-based joins A message in a data set isassumed as a record (a row) with data fields For examplegiven two data sets (ie left data set (L) and right data set(R)) in data fields D (T isin L) and C (T isinR) T is a join keybetween L and R A two-way join operation discussed in thisstudy is to join two data sets into a new data set containingdata fields D C and T where T isin L and T isinR
DS is a data set with two data fields (D and T) similar tothe left data set in Figure 1 where each record stands for aninstance of relations between D and T e amount of in-formation of a record (r) is regarded as self-information (I)of a record in entropyus I (r) minuslog (pr) where pr standsfor the probability of r within DS erefore the total in-formation of DS is obtained as follows
H(DS) 1113944
N
i1I ri( 1113857 (1)
where ri represents the ith of the unique records from DSand N is the number of unique records H (DS) is called thefirst order of entropy of DS which is also regarded as thedegree of uncertainty within DS
Equation (1) is ideally an extreme case without skeweddata intensity In general supposing that pi is the probabilityof a relation i in DS we have the following equation
H(DS) minus 1113944N
i1pilog2pi (2)
where pi is the number of occurrences of the records dividedby N e maximum entropy of DS is H (DS) logN if allrecords have equivalent pi e difference between logN andH (DS) in (2) is called the redundancy of data set Equations(1) and (2) leverage Shannon entropy to estimate the un-certainty of data sets or the partitions using MapReduce onHadoop clusters
Figure 2 illustrates the information changes of datasets in the different stages of MapReduce Four dataaccessing points namely mapper input (MI) mapperoutput (MO) reducer input (RI) and reducer output(RO) are evaluated using Shannon entropy Two data setsare input into separate mappers and output to an in-termediate file MI and MO are the input and outputrespectively of a mapper After the shuffle stage themerged and sorted outputs of a mapper are fed intonumerous reducers RI and RO are the input and outputrespectively of a reducer
Supposing that a data set is divided into m partitionsafter MI the entropy of a partition (Partitioni) can be de-fined as follows
H Partitioni( 1113857 minus 1113944
|Relations|
j1pijlog2pij (3)
where pij m (i j)m (i) is the probability that a record of apartition i belongs to partition j m (i j) is the number ofrecords in partition i with relation j andmi is the number ofrecords in partition i e total entropy of all partitions afterMI is defined as follows
H(Partition) 1113944K
1
mi
mH Partitioni( 1113857 (4)
wheremi is the number of records in partition i andm is thetotal number of records in a data set Equations (3) and (4)represent how the total entropy of a group of partitions iscalculated after MO
To measure the impurity of a group of partitions from adata set information gain (G) is used to estimate the gain ofentropy when a join algorithm divides the data set into agroup of partitions (PS) following a pipeline of MI MO RIand RO For example if the gain of entropy from MI to MOincreases then the aggregated output of mappers containshigh uncertainty of data sets Accordingly reducers needcapability to complete further join operations If PS is agroup of partitions then we have the following equation
G(DS PS) H(DS) minus 1113944visinvalues(PS)
DSv
11138681113868111386811138681113868111386811138681113868
|DS|H DSv( 1113857 (5)
where DSy is a partition of DS and |DS| represents thenumber of records in DS erefore the information changebetween the input and output of mappers is denoted as G
(mapper)H (MO)minusH (MI) Similarly the informationchange of the reducers is denoted as G (reducer)H (RO)minus
H (RI) whereas the information gain between MO and RI isdenoted as G (shuffle)H (RI)minusH (MO) Equations (1) to(5) present a systematic modelingmethod based on Shannonentropy to estimate the uncertainty of the data sets in joinalgorithms during the different MapReduce stages onclusters
32 MapReduce-Based Evaluation for Join AlgorithmsEvaluating information changes of data sets duringMapReduce join operations are difficult when handlingdata sets with massive contents erefore a five-stage
D T
D1 T1
D2 T2
D3 T2
D3 T1
C T
C1 T1
C2 T2
C3 T2
C4 T2
Left data set Right data set
Figure 1 Toy example of two data sets to be joined
Scientific Programming 3
MapReduce-based evaluation framework for MapReducejoin algorithms is proposed (see Figure 3) e frameworkwith Stages 1 to 5 is designed by using the MapReduceprogramming model to overcome the difficulty of thedata set sizes
In Stage 1 the entropy of two data sets is calculated fromthe Left Mapper for the left data set and RightMapper for theright data set ereafter the merged and sorted results arefed into the reducers Eventually H (left data set) and H(right data set) are obtained ereafterH (MI) is defined asin equation (6) In Stage 2 the entropy of the intermediateoutput of the mappers for the left and right data sets in a joinalgorithm is obtained in H (MO of left data set) and H (MOof right data set) ereafter the total entropyH (MO) is thesame as in equation (7) In Stage 3 the intermediate resultsafter the shuffle stage in the join algorithm are evaluated inH(RI) In Stage 4 the entropy of RO in the join algorithm isobtained Lastly all entropy values of Stages 1 to 4 aresummarized in Stage 5
H(MI) H(L) + H(R) (6)
H(MO) H(L MO) + H(R MO) (7)
e entropy-based metrics representing the informationchanges of the data sets in join operation are defined as H(MI)H (MO)H (RI) andH (RO) Comparing themeasuresillustrates the performance of different MapReduce joinalgorithms in terms of change of entropy and accordinglyreflects their efficiency of join operations
33 MapReduce Join Algorithms e existing join algo-rithms have advantages in different application senecios[30] e entropy-based framework in Figure 3 can integrateinto these algorithms to quantify the uncertainty of theintermediate results produced in the Map and Reduce stagesin Hadoop To simplify the descriptions of these algorithmsFigure 4 illustrates the toy examples of two data sets to bejoined in different MapReduce join algorithms In the figureT1 and T2 are two toy data sets where the values of the joinkey are denoted as V1 V2 Vn
A reduce-side join which is also called sort-merge joinin Figure 4(a) preprocess T1 and T2 to organize them interms of join keys ereafter all tuples are sorted andmerged before being fed into the reducers on the basis of thejoin keys such that all tuples with the same key go to onereducere join works only for equi-joins A reducer in thisjoin eventually receives a key and its values from both datasets e number of reducers is the same as that of the keysgenerated from the mappers ereafter the HadoopMapReduce framework sorts all keys and passes them to thereducers Tuples from a data set come before another data setbecause the sorting is done on composite keys Lastly areducer performs cross-product between records to obtainjoining results
A map-side join in Figure 4(b) occurs when a data set isrelatively smaller than the other data set assuming that asmaller data set can fit into memory easily [31] e map-side join is also called memory-backed join [32] In this casethis algorithm initially replicates the small data set to thedistributed cache of Hadoop to all the mapper sides wherethe data from the smaller data set is loaded into the memoryof the mapper hosts before implementing the tasks of themapper When a record from a large data set is input into amapper each mapper looks up join keys from the cacheddata sets and fetches values from the cache accordinglyereafter the mapper performs join operation using datasets in the mapper for direct output to HDFS without usingreducers
When the small data set cannot fit into memory thecached table in the framework is replaced by a hash table orthe Bloom filter [33] to store join keys from the afore-mentioned data set Eventually join performance is im-proved by reducing the unnecessary transmission of datathrough the network which is called semireduce side join(see Figure 4(c)) is join often occurs when the join keysof the small data set can fit into the memory ereafter areducer is responsible for the cross-product of recordssimilar to the reduce-side join e Bloom filter is used tosolve the problem in which Hadoop is inefficient to per-form the join operation because the reduce-side joinconstantly processes all records in the data sets even in the
Ledata set
Rightdata set
Mapper
Mapper
Shuffle
Partition 1
Partition 2
Partition n
Reducer 1
Reducer 2
Reducer n
MI Mapper Input
RI Reducer Input
RO ReducerOutput
MO MapperOutput
Results
Figure 2 Information changes of data in MapReduce join algorithms
4 Scientific Programming
case when only a small fraction of the data sets are relevante probability of a false positive (p) after inserting n el-ements in the Bloom filter can be calculated in [34] asfollows
p 1 minus 1 minus1m
1113874 1113875kn
1113888 1113889
k
asymp 1 minus eknm
1113872 1113873k (8)
where n is the number of elements k is the number ofindependent hash functions and m is the number of bitse size of the Bloom filter is fixed regardless of the numberof the elements n When using the Bloom filter as shown inFigure 4(d) the parameters of the filter should be predefinedto ensure that all keys from the small data set have sufficientspaces for indexing the join keys by the Bloom filter
LeMapper
RightMapper
Reducer
LeMapper
RightMapper
Reducer
RI Mapper RIReducer
MapperInput
MapperOutput
ReducerInput
ROMapper
ROReducer
ReducerOutput
H(Le dataset)H(right dataset)
H(le MO )H(right MO)
H(RI)
H(RO)
Summaryof Reducer
Summary of Mapper
Entropychanges
Stage 1 Evaluate entropy of datasets
Stage 2 Evaluate entropy of mapper output
Stage 3 Evaluate entropy of reducer input
Stage 4 Evaluate entropy of reducer output
Stage 4Summary offour stages
Figure 3 Entropy evaluation for join algorithms based on the five MapReduce jobs on Hadoop
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V4)(D5 V3)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V4 (T2 D4))(V3 (T2 D5))
T1
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))(V3 (T2 D5))
(V4 (T1 C4))(V4 (T2 D5))
Reduce
Reduce
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
(D5 C3)
(D5 C4)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(a)
Setup
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V5)(D4 V6)(D5 V2)(D6 V3)
(V1 C1)(V2 C2)(V3 C3)(V4 C4)
(D1 V1 C1)(D2 V2 C2)(D5 V2 C2)(D6 V3 C3)
T1 (Small)
T2
K in memeory
Load
In K
Yes
Dischard
NoCompare
(D1 C1)(D2 C2)(D5 C2)(D6 C3)
Output
(b)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))
T1 (Small)
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
Cartesian Product
V1V2V3V4
V1V2V3V4
Join Key Hash Table
Join Key Hash Table
(V5 (T2 None))(V6 (T2 None))
Discard
(c)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V5 (T2 D4))(V6 (T2 D5))
T1 (Small)
T2
Shuffle
(V1 (T1 C1))(V1 (T2 D2))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))
(V4 (T1 C4))
Reduce
Reduce
Reduce
Reduce
(D2 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(V5 (T2 None))(V6 (T2 None))
Discard
0 0 1 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0Bloom Filter
HashFunctions
Check if exists
Exists if all byes are zero
Setup
Generate
(V5 (T2 D4)) Reduce T1timesT2
(V6 (T2 D5)) Reduce T1timesT2
(d)
Figure 4 Example data flows of typical join algorithms in MapReduce Input data sets are T1 and T2 (a) Reduce-side join (b) Map-sidejoin (c) semi-reduce-side join (d) Semi-reduce-side join with Bloom filter
Scientific Programming 5
34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

partitions by changing the original input of the reduce tasksin Hadoop MapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the samekey on Hadoop
e remainder of this paper is organized as follows enext section summarizes the related work in this researchfield Section 3 firstly leverages Shannon entropy to modelthe data intensity of data sets in aMapReduce join operationand then it proposes a novel join algorithm with dynamicpartition strategies for two-way joins by optimizing thepartitions of data sets with skewed data intensity for reducetasks Section 4 conducts a series of experiments on differentsettings of data set sizes to compare the proposed methodwith the methods in literature en Section 5 discusses ourwork in practice Finally the work is concluded in Section 6
2 Related Work
MapReduce is the most widely used programming model inHadoop and uses the Map Combine Shuffle and Reducestages to divide numerous data sets into small partitions andreduces the merged and sorted partitions on a cluster ofcomputer nodes [5] e Hadoop MapReduce architecturehas contributed immensely to the existing big-data-relatedanalyses Joining large data sets which is complex and timeconsuming is one of the most important uses in Hadoop [6]Applications of join operations include privacy preservingsimilarity [7] parallel set-similarity [8] and fuzzy joins [9]which focus on similarity estimation
Join operations in MapReduce are time consuming andcumbersome During a join operation in a Hadoop cluster amapper reads a partition from data sets and writes pairs ofjoin keys and their corresponding values to intermediate filesereafter the intermediate results are merged and sorted tobe fed into numerous reducers Eventually each reducer thatperforms multiple Reduce tasks joins two sets of records withthe same key Join optimization has encountered considerablebottlenecks in reducing time cost and increasing the feasibilityof dynamic partitioning data for different purposes e mainreason is that the shuffle stage on Hadoop is performed with acluster network With hardware upgrade GPU is also verypromising to improve the performance of join operations in ahybrid framework [10] Existing join processing using theMapReduce programming model includes k-NN [11] Equi-[12] eta- [13] Similarity [14] Top-K [15] and filter-basedjoins [16] To handle the problem that existing MapReduce-based filtering methods require multiple MapReduce jobs toimprove the join performance the adaptive filter-based joinalgorithm is proposed [17]eMapReduce framework is alsosuitable to handle large-scale high-dimensional data similarityjoins [18] For example spatial join is able to perform dataanalysis in geospatial applications which contain massivegeographical information in a high-dimensional form [19]
e various types of join algorithms in accordance withthe actual sides of performing MapReduce join operationsonHadoop include themap-side and reduce-side joins Suchalgorithms are also known for repartition broadcast andreplicated join in accordance with their features [20] Join
algorithms utilize the ability of parallel computing inHadoop and data set sizes being joined in performing joinsfor large data sets in Hadoop In general Bloom filter is ableto reduce workload such as minimizing nonjoining data andreducing the costs of communication [21] However only afew of these algorithms have considered the data skewness ofscientific data sets to optimize join operations e reason isthe difficulty in estimating the amount of information withinheterogeneous data sets for each join Chen et al [22]promoted metric similarity joins by using two sampling-based partition methods to enable equal-sized partitions Ingeneral a data set contains different amounts of relationsamong data fields thereby causing difference in workloadsof Reduce tasks fed into a reducer which differs fromtraditional joins To reduce the complexity of constructingthe index structure by using the see-based dynamic parti-tioning a MapReduce-based kNN-join algorithm for queryprocessing is proposed [23] e partition phrase is alsofocused on in existing research to produce filter balancedand meaning subdivisions of the data sets [24] Withouteffectively estimating such a difference of workload in twodata sets with proper measures joining data sets with skeweddata intensity affects join performance and its feasibility
Shannon entropy in information theory which initiallymeasures the information of communication systemscharacterizes the impurity of arbitrary collections of ex-amples [25] e entropy of a variable is used to estimate thedegree of information or uncertainty inherent in the scope ofthe variable outcomes It is originally used to estimate theinformation value of a message between different entitiesHowever the entropy is also useful to measure diversity Atpresent this theory has shaped virtually all systems thatstore process or transmit information in digital forms (egperforming knowledge reduction on the basis of informationentropy using MapReduce) [26] Chaos of data is thecomplete unpredictability of all records in a data set and canbe quantified using Shannon entropy [27] erefore aMapReduce-based join is naturally regarded as an entropy-based system for storing processing and transmitting datasets With the use of hyperparameter optimization withautomated tools MapReduce-based joins can be easily ap-plied in big data production environments [28] In the fu-ture automated join optimizer systems will be able toperform optimization of the hyperparameters of join op-erations and obtain the most efficient join strategy forvarious big data applications [29]
3 Materials and Methods
We first illustrate the concept of Shannon entropy of datasets to be joined using MapReduce and then present aframework to evaluate the entropy of data sets for existingjoin algorithms using MapReduce A novel join algorithmwith dynamic partition strategies is also proposed
31 Shannon Entropy of Data Sets Shannonrsquos theory indicatesthat information is a measurable commodity ConsideringentropyH of a discrete random variableX x1 xn and the
2 Scientific Programming
probability mass function is defined as P (X) we obtainH (X)
E [I (X)] E [minuslog (P (X)] according to Shannonrsquos theoryerefore MapReduce stages and the transmission of data setsover Hadoop clusters can be treated as a message channelbetween senders (mappers) and receivers (reducers) A data setto be joined is a memoryless message source that contains a setof messages with its own probabilities to send to receivers
Figure 1 illustrates a toy example of two data sets to bejoined in MapReduce-based joins A message in a data set isassumed as a record (a row) with data fields For examplegiven two data sets (ie left data set (L) and right data set(R)) in data fields D (T isin L) and C (T isinR) T is a join keybetween L and R A two-way join operation discussed in thisstudy is to join two data sets into a new data set containingdata fields D C and T where T isin L and T isinR
DS is a data set with two data fields (D and T) similar tothe left data set in Figure 1 where each record stands for aninstance of relations between D and T e amount of in-formation of a record (r) is regarded as self-information (I)of a record in entropyus I (r) minuslog (pr) where pr standsfor the probability of r within DS erefore the total in-formation of DS is obtained as follows
H(DS) 1113944
N
i1I ri( 1113857 (1)
where ri represents the ith of the unique records from DSand N is the number of unique records H (DS) is called thefirst order of entropy of DS which is also regarded as thedegree of uncertainty within DS
Equation (1) is ideally an extreme case without skeweddata intensity In general supposing that pi is the probabilityof a relation i in DS we have the following equation
H(DS) minus 1113944N
i1pilog2pi (2)
where pi is the number of occurrences of the records dividedby N e maximum entropy of DS is H (DS) logN if allrecords have equivalent pi e difference between logN andH (DS) in (2) is called the redundancy of data set Equations(1) and (2) leverage Shannon entropy to estimate the un-certainty of data sets or the partitions using MapReduce onHadoop clusters
Figure 2 illustrates the information changes of datasets in the different stages of MapReduce Four dataaccessing points namely mapper input (MI) mapperoutput (MO) reducer input (RI) and reducer output(RO) are evaluated using Shannon entropy Two data setsare input into separate mappers and output to an in-termediate file MI and MO are the input and outputrespectively of a mapper After the shuffle stage themerged and sorted outputs of a mapper are fed intonumerous reducers RI and RO are the input and outputrespectively of a reducer
Supposing that a data set is divided into m partitionsafter MI the entropy of a partition (Partitioni) can be de-fined as follows
H Partitioni( 1113857 minus 1113944
|Relations|
j1pijlog2pij (3)
where pij m (i j)m (i) is the probability that a record of apartition i belongs to partition j m (i j) is the number ofrecords in partition i with relation j andmi is the number ofrecords in partition i e total entropy of all partitions afterMI is defined as follows
H(Partition) 1113944K
1
mi
mH Partitioni( 1113857 (4)
wheremi is the number of records in partition i andm is thetotal number of records in a data set Equations (3) and (4)represent how the total entropy of a group of partitions iscalculated after MO
To measure the impurity of a group of partitions from adata set information gain (G) is used to estimate the gain ofentropy when a join algorithm divides the data set into agroup of partitions (PS) following a pipeline of MI MO RIand RO For example if the gain of entropy from MI to MOincreases then the aggregated output of mappers containshigh uncertainty of data sets Accordingly reducers needcapability to complete further join operations If PS is agroup of partitions then we have the following equation
G(DS PS) H(DS) minus 1113944visinvalues(PS)
DSv
11138681113868111386811138681113868111386811138681113868
|DS|H DSv( 1113857 (5)
where DSy is a partition of DS and |DS| represents thenumber of records in DS erefore the information changebetween the input and output of mappers is denoted as G
(mapper)H (MO)minusH (MI) Similarly the informationchange of the reducers is denoted as G (reducer)H (RO)minus
H (RI) whereas the information gain between MO and RI isdenoted as G (shuffle)H (RI)minusH (MO) Equations (1) to(5) present a systematic modelingmethod based on Shannonentropy to estimate the uncertainty of the data sets in joinalgorithms during the different MapReduce stages onclusters
32 MapReduce-Based Evaluation for Join AlgorithmsEvaluating information changes of data sets duringMapReduce join operations are difficult when handlingdata sets with massive contents erefore a five-stage
D T
D1 T1
D2 T2
D3 T2
D3 T1
C T
C1 T1
C2 T2
C3 T2
C4 T2
Left data set Right data set
Figure 1 Toy example of two data sets to be joined
Scientific Programming 3
MapReduce-based evaluation framework for MapReducejoin algorithms is proposed (see Figure 3) e frameworkwith Stages 1 to 5 is designed by using the MapReduceprogramming model to overcome the difficulty of thedata set sizes
In Stage 1 the entropy of two data sets is calculated fromthe Left Mapper for the left data set and RightMapper for theright data set ereafter the merged and sorted results arefed into the reducers Eventually H (left data set) and H(right data set) are obtained ereafterH (MI) is defined asin equation (6) In Stage 2 the entropy of the intermediateoutput of the mappers for the left and right data sets in a joinalgorithm is obtained in H (MO of left data set) and H (MOof right data set) ereafter the total entropyH (MO) is thesame as in equation (7) In Stage 3 the intermediate resultsafter the shuffle stage in the join algorithm are evaluated inH(RI) In Stage 4 the entropy of RO in the join algorithm isobtained Lastly all entropy values of Stages 1 to 4 aresummarized in Stage 5
H(MI) H(L) + H(R) (6)
H(MO) H(L MO) + H(R MO) (7)
e entropy-based metrics representing the informationchanges of the data sets in join operation are defined as H(MI)H (MO)H (RI) andH (RO) Comparing themeasuresillustrates the performance of different MapReduce joinalgorithms in terms of change of entropy and accordinglyreflects their efficiency of join operations
33 MapReduce Join Algorithms e existing join algo-rithms have advantages in different application senecios[30] e entropy-based framework in Figure 3 can integrateinto these algorithms to quantify the uncertainty of theintermediate results produced in the Map and Reduce stagesin Hadoop To simplify the descriptions of these algorithmsFigure 4 illustrates the toy examples of two data sets to bejoined in different MapReduce join algorithms In the figureT1 and T2 are two toy data sets where the values of the joinkey are denoted as V1 V2 Vn
A reduce-side join which is also called sort-merge joinin Figure 4(a) preprocess T1 and T2 to organize them interms of join keys ereafter all tuples are sorted andmerged before being fed into the reducers on the basis of thejoin keys such that all tuples with the same key go to onereducere join works only for equi-joins A reducer in thisjoin eventually receives a key and its values from both datasets e number of reducers is the same as that of the keysgenerated from the mappers ereafter the HadoopMapReduce framework sorts all keys and passes them to thereducers Tuples from a data set come before another data setbecause the sorting is done on composite keys Lastly areducer performs cross-product between records to obtainjoining results
A map-side join in Figure 4(b) occurs when a data set isrelatively smaller than the other data set assuming that asmaller data set can fit into memory easily [31] e map-side join is also called memory-backed join [32] In this casethis algorithm initially replicates the small data set to thedistributed cache of Hadoop to all the mapper sides wherethe data from the smaller data set is loaded into the memoryof the mapper hosts before implementing the tasks of themapper When a record from a large data set is input into amapper each mapper looks up join keys from the cacheddata sets and fetches values from the cache accordinglyereafter the mapper performs join operation using datasets in the mapper for direct output to HDFS without usingreducers
When the small data set cannot fit into memory thecached table in the framework is replaced by a hash table orthe Bloom filter [33] to store join keys from the afore-mentioned data set Eventually join performance is im-proved by reducing the unnecessary transmission of datathrough the network which is called semireduce side join(see Figure 4(c)) is join often occurs when the join keysof the small data set can fit into the memory ereafter areducer is responsible for the cross-product of recordssimilar to the reduce-side join e Bloom filter is used tosolve the problem in which Hadoop is inefficient to per-form the join operation because the reduce-side joinconstantly processes all records in the data sets even in the
Ledata set
Rightdata set
Mapper
Mapper
Shuffle
Partition 1
Partition 2
Partition n
Reducer 1
Reducer 2
Reducer n
MI Mapper Input
RI Reducer Input
RO ReducerOutput
MO MapperOutput
Results
Figure 2 Information changes of data in MapReduce join algorithms
4 Scientific Programming
case when only a small fraction of the data sets are relevante probability of a false positive (p) after inserting n el-ements in the Bloom filter can be calculated in [34] asfollows
p 1 minus 1 minus1m
1113874 1113875kn
1113888 1113889
k
asymp 1 minus eknm
1113872 1113873k (8)
where n is the number of elements k is the number ofindependent hash functions and m is the number of bitse size of the Bloom filter is fixed regardless of the numberof the elements n When using the Bloom filter as shown inFigure 4(d) the parameters of the filter should be predefinedto ensure that all keys from the small data set have sufficientspaces for indexing the join keys by the Bloom filter
LeMapper
RightMapper
Reducer
LeMapper
RightMapper
Reducer
RI Mapper RIReducer
MapperInput
MapperOutput
ReducerInput
ROMapper
ROReducer
ReducerOutput
H(Le dataset)H(right dataset)
H(le MO )H(right MO)
H(RI)
H(RO)
Summaryof Reducer
Summary of Mapper
Entropychanges
Stage 1 Evaluate entropy of datasets
Stage 2 Evaluate entropy of mapper output
Stage 3 Evaluate entropy of reducer input
Stage 4 Evaluate entropy of reducer output
Stage 4Summary offour stages
Figure 3 Entropy evaluation for join algorithms based on the five MapReduce jobs on Hadoop
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V4)(D5 V3)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V4 (T2 D4))(V3 (T2 D5))
T1
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))(V3 (T2 D5))
(V4 (T1 C4))(V4 (T2 D5))
Reduce
Reduce
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
(D5 C3)
(D5 C4)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(a)
Setup
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V5)(D4 V6)(D5 V2)(D6 V3)
(V1 C1)(V2 C2)(V3 C3)(V4 C4)
(D1 V1 C1)(D2 V2 C2)(D5 V2 C2)(D6 V3 C3)
T1 (Small)
T2
K in memeory
Load
In K
Yes
Dischard
NoCompare
(D1 C1)(D2 C2)(D5 C2)(D6 C3)
Output
(b)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))
T1 (Small)
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
Cartesian Product
V1V2V3V4
V1V2V3V4
Join Key Hash Table
Join Key Hash Table
(V5 (T2 None))(V6 (T2 None))
Discard
(c)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V5 (T2 D4))(V6 (T2 D5))
T1 (Small)
T2
Shuffle
(V1 (T1 C1))(V1 (T2 D2))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))
(V4 (T1 C4))
Reduce
Reduce
Reduce
Reduce
(D2 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(V5 (T2 None))(V6 (T2 None))
Discard
0 0 1 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0Bloom Filter
HashFunctions
Check if exists
Exists if all byes are zero
Setup
Generate
(V5 (T2 D4)) Reduce T1timesT2
(V6 (T2 D5)) Reduce T1timesT2
(d)
Figure 4 Example data flows of typical join algorithms in MapReduce Input data sets are T1 and T2 (a) Reduce-side join (b) Map-sidejoin (c) semi-reduce-side join (d) Semi-reduce-side join with Bloom filter
Scientific Programming 5
34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

probability mass function is defined as P (X) we obtainH (X)
E [I (X)] E [minuslog (P (X)] according to Shannonrsquos theoryerefore MapReduce stages and the transmission of data setsover Hadoop clusters can be treated as a message channelbetween senders (mappers) and receivers (reducers) A data setto be joined is a memoryless message source that contains a setof messages with its own probabilities to send to receivers
Figure 1 illustrates a toy example of two data sets to bejoined in MapReduce-based joins A message in a data set isassumed as a record (a row) with data fields For examplegiven two data sets (ie left data set (L) and right data set(R)) in data fields D (T isin L) and C (T isinR) T is a join keybetween L and R A two-way join operation discussed in thisstudy is to join two data sets into a new data set containingdata fields D C and T where T isin L and T isinR
DS is a data set with two data fields (D and T) similar tothe left data set in Figure 1 where each record stands for aninstance of relations between D and T e amount of in-formation of a record (r) is regarded as self-information (I)of a record in entropyus I (r) minuslog (pr) where pr standsfor the probability of r within DS erefore the total in-formation of DS is obtained as follows
H(DS) 1113944
N
i1I ri( 1113857 (1)
where ri represents the ith of the unique records from DSand N is the number of unique records H (DS) is called thefirst order of entropy of DS which is also regarded as thedegree of uncertainty within DS
Equation (1) is ideally an extreme case without skeweddata intensity In general supposing that pi is the probabilityof a relation i in DS we have the following equation
H(DS) minus 1113944N
i1pilog2pi (2)
where pi is the number of occurrences of the records dividedby N e maximum entropy of DS is H (DS) logN if allrecords have equivalent pi e difference between logN andH (DS) in (2) is called the redundancy of data set Equations(1) and (2) leverage Shannon entropy to estimate the un-certainty of data sets or the partitions using MapReduce onHadoop clusters
Figure 2 illustrates the information changes of datasets in the different stages of MapReduce Four dataaccessing points namely mapper input (MI) mapperoutput (MO) reducer input (RI) and reducer output(RO) are evaluated using Shannon entropy Two data setsare input into separate mappers and output to an in-termediate file MI and MO are the input and outputrespectively of a mapper After the shuffle stage themerged and sorted outputs of a mapper are fed intonumerous reducers RI and RO are the input and outputrespectively of a reducer
Supposing that a data set is divided into m partitionsafter MI the entropy of a partition (Partitioni) can be de-fined as follows
H Partitioni( 1113857 minus 1113944
|Relations|
j1pijlog2pij (3)
where pij m (i j)m (i) is the probability that a record of apartition i belongs to partition j m (i j) is the number ofrecords in partition i with relation j andmi is the number ofrecords in partition i e total entropy of all partitions afterMI is defined as follows
H(Partition) 1113944K
1
mi
mH Partitioni( 1113857 (4)
wheremi is the number of records in partition i andm is thetotal number of records in a data set Equations (3) and (4)represent how the total entropy of a group of partitions iscalculated after MO
To measure the impurity of a group of partitions from adata set information gain (G) is used to estimate the gain ofentropy when a join algorithm divides the data set into agroup of partitions (PS) following a pipeline of MI MO RIand RO For example if the gain of entropy from MI to MOincreases then the aggregated output of mappers containshigh uncertainty of data sets Accordingly reducers needcapability to complete further join operations If PS is agroup of partitions then we have the following equation
G(DS PS) H(DS) minus 1113944visinvalues(PS)
DSv
11138681113868111386811138681113868111386811138681113868
|DS|H DSv( 1113857 (5)
where DSy is a partition of DS and |DS| represents thenumber of records in DS erefore the information changebetween the input and output of mappers is denoted as G
(mapper)H (MO)minusH (MI) Similarly the informationchange of the reducers is denoted as G (reducer)H (RO)minus
H (RI) whereas the information gain between MO and RI isdenoted as G (shuffle)H (RI)minusH (MO) Equations (1) to(5) present a systematic modelingmethod based on Shannonentropy to estimate the uncertainty of the data sets in joinalgorithms during the different MapReduce stages onclusters
32 MapReduce-Based Evaluation for Join AlgorithmsEvaluating information changes of data sets duringMapReduce join operations are difficult when handlingdata sets with massive contents erefore a five-stage
D T
D1 T1
D2 T2
D3 T2
D3 T1
C T
C1 T1
C2 T2
C3 T2
C4 T2
Left data set Right data set
Figure 1 Toy example of two data sets to be joined
Scientific Programming 3
MapReduce-based evaluation framework for MapReducejoin algorithms is proposed (see Figure 3) e frameworkwith Stages 1 to 5 is designed by using the MapReduceprogramming model to overcome the difficulty of thedata set sizes
In Stage 1 the entropy of two data sets is calculated fromthe Left Mapper for the left data set and RightMapper for theright data set ereafter the merged and sorted results arefed into the reducers Eventually H (left data set) and H(right data set) are obtained ereafterH (MI) is defined asin equation (6) In Stage 2 the entropy of the intermediateoutput of the mappers for the left and right data sets in a joinalgorithm is obtained in H (MO of left data set) and H (MOof right data set) ereafter the total entropyH (MO) is thesame as in equation (7) In Stage 3 the intermediate resultsafter the shuffle stage in the join algorithm are evaluated inH(RI) In Stage 4 the entropy of RO in the join algorithm isobtained Lastly all entropy values of Stages 1 to 4 aresummarized in Stage 5
H(MI) H(L) + H(R) (6)
H(MO) H(L MO) + H(R MO) (7)
e entropy-based metrics representing the informationchanges of the data sets in join operation are defined as H(MI)H (MO)H (RI) andH (RO) Comparing themeasuresillustrates the performance of different MapReduce joinalgorithms in terms of change of entropy and accordinglyreflects their efficiency of join operations
33 MapReduce Join Algorithms e existing join algo-rithms have advantages in different application senecios[30] e entropy-based framework in Figure 3 can integrateinto these algorithms to quantify the uncertainty of theintermediate results produced in the Map and Reduce stagesin Hadoop To simplify the descriptions of these algorithmsFigure 4 illustrates the toy examples of two data sets to bejoined in different MapReduce join algorithms In the figureT1 and T2 are two toy data sets where the values of the joinkey are denoted as V1 V2 Vn
A reduce-side join which is also called sort-merge joinin Figure 4(a) preprocess T1 and T2 to organize them interms of join keys ereafter all tuples are sorted andmerged before being fed into the reducers on the basis of thejoin keys such that all tuples with the same key go to onereducere join works only for equi-joins A reducer in thisjoin eventually receives a key and its values from both datasets e number of reducers is the same as that of the keysgenerated from the mappers ereafter the HadoopMapReduce framework sorts all keys and passes them to thereducers Tuples from a data set come before another data setbecause the sorting is done on composite keys Lastly areducer performs cross-product between records to obtainjoining results
A map-side join in Figure 4(b) occurs when a data set isrelatively smaller than the other data set assuming that asmaller data set can fit into memory easily [31] e map-side join is also called memory-backed join [32] In this casethis algorithm initially replicates the small data set to thedistributed cache of Hadoop to all the mapper sides wherethe data from the smaller data set is loaded into the memoryof the mapper hosts before implementing the tasks of themapper When a record from a large data set is input into amapper each mapper looks up join keys from the cacheddata sets and fetches values from the cache accordinglyereafter the mapper performs join operation using datasets in the mapper for direct output to HDFS without usingreducers
When the small data set cannot fit into memory thecached table in the framework is replaced by a hash table orthe Bloom filter [33] to store join keys from the afore-mentioned data set Eventually join performance is im-proved by reducing the unnecessary transmission of datathrough the network which is called semireduce side join(see Figure 4(c)) is join often occurs when the join keysof the small data set can fit into the memory ereafter areducer is responsible for the cross-product of recordssimilar to the reduce-side join e Bloom filter is used tosolve the problem in which Hadoop is inefficient to per-form the join operation because the reduce-side joinconstantly processes all records in the data sets even in the
Ledata set
Rightdata set
Mapper
Mapper
Shuffle
Partition 1
Partition 2
Partition n
Reducer 1
Reducer 2
Reducer n
MI Mapper Input
RI Reducer Input
RO ReducerOutput
MO MapperOutput
Results
Figure 2 Information changes of data in MapReduce join algorithms
4 Scientific Programming
case when only a small fraction of the data sets are relevante probability of a false positive (p) after inserting n el-ements in the Bloom filter can be calculated in [34] asfollows
p 1 minus 1 minus1m
1113874 1113875kn
1113888 1113889
k
asymp 1 minus eknm
1113872 1113873k (8)
where n is the number of elements k is the number ofindependent hash functions and m is the number of bitse size of the Bloom filter is fixed regardless of the numberof the elements n When using the Bloom filter as shown inFigure 4(d) the parameters of the filter should be predefinedto ensure that all keys from the small data set have sufficientspaces for indexing the join keys by the Bloom filter
LeMapper
RightMapper
Reducer
LeMapper
RightMapper
Reducer
RI Mapper RIReducer
MapperInput
MapperOutput
ReducerInput
ROMapper
ROReducer
ReducerOutput
H(Le dataset)H(right dataset)
H(le MO )H(right MO)
H(RI)
H(RO)
Summaryof Reducer
Summary of Mapper
Entropychanges
Stage 1 Evaluate entropy of datasets
Stage 2 Evaluate entropy of mapper output
Stage 3 Evaluate entropy of reducer input
Stage 4 Evaluate entropy of reducer output
Stage 4Summary offour stages
Figure 3 Entropy evaluation for join algorithms based on the five MapReduce jobs on Hadoop
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V4)(D5 V3)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V4 (T2 D4))(V3 (T2 D5))
T1
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))(V3 (T2 D5))
(V4 (T1 C4))(V4 (T2 D5))
Reduce
Reduce
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
(D5 C3)
(D5 C4)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(a)
Setup
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V5)(D4 V6)(D5 V2)(D6 V3)
(V1 C1)(V2 C2)(V3 C3)(V4 C4)
(D1 V1 C1)(D2 V2 C2)(D5 V2 C2)(D6 V3 C3)
T1 (Small)
T2
K in memeory
Load
In K
Yes
Dischard
NoCompare
(D1 C1)(D2 C2)(D5 C2)(D6 C3)
Output
(b)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))
T1 (Small)
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
Cartesian Product
V1V2V3V4
V1V2V3V4
Join Key Hash Table
Join Key Hash Table
(V5 (T2 None))(V6 (T2 None))
Discard
(c)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V5 (T2 D4))(V6 (T2 D5))
T1 (Small)
T2
Shuffle
(V1 (T1 C1))(V1 (T2 D2))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))
(V4 (T1 C4))
Reduce
Reduce
Reduce
Reduce
(D2 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(V5 (T2 None))(V6 (T2 None))
Discard
0 0 1 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0Bloom Filter
HashFunctions
Check if exists
Exists if all byes are zero
Setup
Generate
(V5 (T2 D4)) Reduce T1timesT2
(V6 (T2 D5)) Reduce T1timesT2
(d)
Figure 4 Example data flows of typical join algorithms in MapReduce Input data sets are T1 and T2 (a) Reduce-side join (b) Map-sidejoin (c) semi-reduce-side join (d) Semi-reduce-side join with Bloom filter
Scientific Programming 5
34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

MapReduce-based evaluation framework for MapReducejoin algorithms is proposed (see Figure 3) e frameworkwith Stages 1 to 5 is designed by using the MapReduceprogramming model to overcome the difficulty of thedata set sizes
In Stage 1 the entropy of two data sets is calculated fromthe Left Mapper for the left data set and RightMapper for theright data set ereafter the merged and sorted results arefed into the reducers Eventually H (left data set) and H(right data set) are obtained ereafterH (MI) is defined asin equation (6) In Stage 2 the entropy of the intermediateoutput of the mappers for the left and right data sets in a joinalgorithm is obtained in H (MO of left data set) and H (MOof right data set) ereafter the total entropyH (MO) is thesame as in equation (7) In Stage 3 the intermediate resultsafter the shuffle stage in the join algorithm are evaluated inH(RI) In Stage 4 the entropy of RO in the join algorithm isobtained Lastly all entropy values of Stages 1 to 4 aresummarized in Stage 5
H(MI) H(L) + H(R) (6)
H(MO) H(L MO) + H(R MO) (7)
e entropy-based metrics representing the informationchanges of the data sets in join operation are defined as H(MI)H (MO)H (RI) andH (RO) Comparing themeasuresillustrates the performance of different MapReduce joinalgorithms in terms of change of entropy and accordinglyreflects their efficiency of join operations
33 MapReduce Join Algorithms e existing join algo-rithms have advantages in different application senecios[30] e entropy-based framework in Figure 3 can integrateinto these algorithms to quantify the uncertainty of theintermediate results produced in the Map and Reduce stagesin Hadoop To simplify the descriptions of these algorithmsFigure 4 illustrates the toy examples of two data sets to bejoined in different MapReduce join algorithms In the figureT1 and T2 are two toy data sets where the values of the joinkey are denoted as V1 V2 Vn
A reduce-side join which is also called sort-merge joinin Figure 4(a) preprocess T1 and T2 to organize them interms of join keys ereafter all tuples are sorted andmerged before being fed into the reducers on the basis of thejoin keys such that all tuples with the same key go to onereducere join works only for equi-joins A reducer in thisjoin eventually receives a key and its values from both datasets e number of reducers is the same as that of the keysgenerated from the mappers ereafter the HadoopMapReduce framework sorts all keys and passes them to thereducers Tuples from a data set come before another data setbecause the sorting is done on composite keys Lastly areducer performs cross-product between records to obtainjoining results
A map-side join in Figure 4(b) occurs when a data set isrelatively smaller than the other data set assuming that asmaller data set can fit into memory easily [31] e map-side join is also called memory-backed join [32] In this casethis algorithm initially replicates the small data set to thedistributed cache of Hadoop to all the mapper sides wherethe data from the smaller data set is loaded into the memoryof the mapper hosts before implementing the tasks of themapper When a record from a large data set is input into amapper each mapper looks up join keys from the cacheddata sets and fetches values from the cache accordinglyereafter the mapper performs join operation using datasets in the mapper for direct output to HDFS without usingreducers
When the small data set cannot fit into memory thecached table in the framework is replaced by a hash table orthe Bloom filter [33] to store join keys from the afore-mentioned data set Eventually join performance is im-proved by reducing the unnecessary transmission of datathrough the network which is called semireduce side join(see Figure 4(c)) is join often occurs when the join keysof the small data set can fit into the memory ereafter areducer is responsible for the cross-product of recordssimilar to the reduce-side join e Bloom filter is used tosolve the problem in which Hadoop is inefficient to per-form the join operation because the reduce-side joinconstantly processes all records in the data sets even in the
Ledata set
Rightdata set
Mapper
Mapper
Shuffle
Partition 1
Partition 2
Partition n
Reducer 1
Reducer 2
Reducer n
MI Mapper Input
RI Reducer Input
RO ReducerOutput
MO MapperOutput
Results
Figure 2 Information changes of data in MapReduce join algorithms
4 Scientific Programming
case when only a small fraction of the data sets are relevante probability of a false positive (p) after inserting n el-ements in the Bloom filter can be calculated in [34] asfollows
p 1 minus 1 minus1m
1113874 1113875kn
1113888 1113889
k
asymp 1 minus eknm
1113872 1113873k (8)
where n is the number of elements k is the number ofindependent hash functions and m is the number of bitse size of the Bloom filter is fixed regardless of the numberof the elements n When using the Bloom filter as shown inFigure 4(d) the parameters of the filter should be predefinedto ensure that all keys from the small data set have sufficientspaces for indexing the join keys by the Bloom filter
LeMapper
RightMapper
Reducer
LeMapper
RightMapper
Reducer
RI Mapper RIReducer
MapperInput
MapperOutput
ReducerInput
ROMapper
ROReducer
ReducerOutput
H(Le dataset)H(right dataset)
H(le MO )H(right MO)
H(RI)
H(RO)
Summaryof Reducer
Summary of Mapper
Entropychanges
Stage 1 Evaluate entropy of datasets
Stage 2 Evaluate entropy of mapper output
Stage 3 Evaluate entropy of reducer input
Stage 4 Evaluate entropy of reducer output
Stage 4Summary offour stages
Figure 3 Entropy evaluation for join algorithms based on the five MapReduce jobs on Hadoop
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V4)(D5 V3)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V4 (T2 D4))(V3 (T2 D5))
T1
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))(V3 (T2 D5))
(V4 (T1 C4))(V4 (T2 D5))
Reduce
Reduce
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
(D5 C3)
(D5 C4)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(a)
Setup
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V5)(D4 V6)(D5 V2)(D6 V3)
(V1 C1)(V2 C2)(V3 C3)(V4 C4)
(D1 V1 C1)(D2 V2 C2)(D5 V2 C2)(D6 V3 C3)
T1 (Small)
T2
K in memeory
Load
In K
Yes
Dischard
NoCompare
(D1 C1)(D2 C2)(D5 C2)(D6 C3)
Output
(b)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))
T1 (Small)
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
Cartesian Product
V1V2V3V4
V1V2V3V4
Join Key Hash Table
Join Key Hash Table
(V5 (T2 None))(V6 (T2 None))
Discard
(c)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V5 (T2 D4))(V6 (T2 D5))
T1 (Small)
T2
Shuffle
(V1 (T1 C1))(V1 (T2 D2))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))
(V4 (T1 C4))
Reduce
Reduce
Reduce
Reduce
(D2 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(V5 (T2 None))(V6 (T2 None))
Discard
0 0 1 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0Bloom Filter
HashFunctions
Check if exists
Exists if all byes are zero
Setup
Generate
(V5 (T2 D4)) Reduce T1timesT2
(V6 (T2 D5)) Reduce T1timesT2
(d)
Figure 4 Example data flows of typical join algorithms in MapReduce Input data sets are T1 and T2 (a) Reduce-side join (b) Map-sidejoin (c) semi-reduce-side join (d) Semi-reduce-side join with Bloom filter
Scientific Programming 5
34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

case when only a small fraction of the data sets are relevante probability of a false positive (p) after inserting n el-ements in the Bloom filter can be calculated in [34] asfollows
p 1 minus 1 minus1m
1113874 1113875kn
1113888 1113889
k
asymp 1 minus eknm
1113872 1113873k (8)
where n is the number of elements k is the number ofindependent hash functions and m is the number of bitse size of the Bloom filter is fixed regardless of the numberof the elements n When using the Bloom filter as shown inFigure 4(d) the parameters of the filter should be predefinedto ensure that all keys from the small data set have sufficientspaces for indexing the join keys by the Bloom filter
LeMapper
RightMapper
Reducer
LeMapper
RightMapper
Reducer
RI Mapper RIReducer
MapperInput
MapperOutput
ReducerInput
ROMapper
ROReducer
ReducerOutput
H(Le dataset)H(right dataset)
H(le MO )H(right MO)
H(RI)
H(RO)
Summaryof Reducer
Summary of Mapper
Entropychanges
Stage 1 Evaluate entropy of datasets
Stage 2 Evaluate entropy of mapper output
Stage 3 Evaluate entropy of reducer input
Stage 4 Evaluate entropy of reducer output
Stage 4Summary offour stages
Figure 3 Entropy evaluation for join algorithms based on the five MapReduce jobs on Hadoop
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V4)(D5 V3)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V4 (T2 D4))(V3 (T2 D5))
T1
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))(V3 (T2 D5))
(V4 (T1 C4))(V4 (T2 D5))
Reduce
Reduce
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
(D5 C3)
(D5 C4)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(a)
Setup
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V5)(D4 V6)(D5 V2)(D6 V3)
(V1 C1)(V2 C2)(V3 C3)(V4 C4)
(D1 V1 C1)(D2 V2 C2)(D5 V2 C2)(D6 V3 C3)
T1 (Small)
T2
K in memeory
Load
In K
Yes
Dischard
NoCompare
(D1 C1)(D2 C2)(D5 C2)(D6 C3)
Output
(b)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))
T1 (Small)
T2Shuffle
(V1 (T1 C1))(V1 (T2 D1))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
Reduce
Reduce
(D1 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
Cartesian Product
V1V2V3V4
V1V2V3V4
Join Key Hash Table
Join Key Hash Table
(V5 (T2 None))(V6 (T2 None))
Discard
(c)
Map
Map
(C1 V1)(C2 V2)(C3 V3)(C4 V4)
(D1 V1)(D2 V2)(D3 V2)(D4 V5)(D5 V6)
(V1 (T1 C1))(V2 (T1 C2))(V3 (T1 C3))(V4 (T1 C4))
(V1 (T2 D1))(V2 (T2 D2))(V2 (T2 D3))(V5 (T2 D4))(V6 (T2 D5))
T1 (Small)
T2
Shuffle
(V1 (T1 C1))(V1 (T2 D2))
(V2 (T1 C2))(V2 (T2 D2))(V2 (T2 D3))
(V3 (T1 C3))
(V4 (T1 C4))
Reduce
Reduce
Reduce
Reduce
(D2 C1)
(D2 C2)(D3 C2)
T1timesT2
T1timesT2
T1timesT2
T1timesT2
Cartesian Product
(V5 (T2 None))(V6 (T2 None))
Discard
0 0 1 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0Bloom Filter
HashFunctions
Check if exists
Exists if all byes are zero
Setup
Generate
(V5 (T2 D4)) Reduce T1timesT2
(V6 (T2 D5)) Reduce T1timesT2
(d)
Figure 4 Example data flows of typical join algorithms in MapReduce Input data sets are T1 and T2 (a) Reduce-side join (b) Map-sidejoin (c) semi-reduce-side join (d) Semi-reduce-side join with Bloom filter
Scientific Programming 5
34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

34 Join with Dynamic Partition Strategies Although theHadoop framework internally divides the data sets intopartitions for different mappers to process the existing joinalgorithms such as reduce-side join cannot perform dy-namic partitions on the basis of the data intensity of the datasets to be joined In existing algorithms an output key of amapper is consistently the join key of reducers therebyforcing all values belonging to one key to be fed into a singlereducer is scenario causes heavy workloads to a reducerwhen the reducer receives numerous values whereas otherreducers receive considerably less values
To address the aforementioned problem a novel joinalgorithm with dynamic partition strategies which is calleddynamic partition join (DPJ) over the number of records ofdata sets is proposed DPJ aims to dynamically revise thenumber of Reduce tasks after a mapperrsquos output by intro-ducing a parameter that determines the number of partitionsthat the data set should be divided intoe join enables usersto specify the number of partitions over the data sets tochange the number of reducers A two-phraseMapReduce jobon Hadoop is required to perform this join A toy examplebased on the data sets in Figure 1 is demonstrated as follows
In the first stage a counter job to calculate the number ofrecords within the two data sets is performed After the job iscompleted the total numbers of records within the data setsare determined and fed into the second job as a parameter toperform job operations e counter job uses Hadoopcounters to obtain numbers of records us its time costcan be ignored
In the second stage a join job is performed to generatethe joined results is job requires three parametersnamely number of partitions (N) total record number of theleft data set (RNL) and total record number of the right dataset (RNR) e steps are as follows
Step 1 Calculate the number of partitions of the left (PL)and right (PR) data sets
AfterN is determined the PL and PR parameters by usingequations (9) and (10) are determined to mappers and re-ducers of the job during the job configuration
PL
RNL
N + 1 RNLNgt 0
RNL
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(9)
PR
RNR
N + 1 RNRNgt 0
RNR
N otherwise
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
(10)
Step 2 Set up mappers for the left and right data setse left data set is input into the Left Mapper defined in
Algorithm 1 and the right data set is input into the RightMapper defined in Algorithm 2 In the algorithms [keyvalue] stands for a record consisting of a specified join keyand its values in a data set L (i) stands for the ith partitions
of a key from the left data set R (i) stands for the ithpartitions of a key from the right data set LN is a Hadoopcounter to count the number of records in the left data setand RN is another counter to count the number of records inthe right data set
Step 3 Set up reducers for the output of the combinerse reducer defined in Algorithm 3 joins the partitioned
records with the same key Meanwhile the job reduces theworkload of each reducer because the number of Reduce taskincreases In the algorithm L stands for the left data set Rstands for the right data set and k is the original join keylocated in the third part within the partition key
e proposed DPJ on Hadoop is defined in Steps 1 to 3Table 1 illustrates a split data analysis based on the toy datasets Table 2 shows its inputs of reducers
Various variant methods based on DPJ include DPJwith combiner DPJ with Bloom filter and DPJ withcombiner and Bloom filter e combiner is used to reducethe time cost of shuffle stage e Bloom filter is used toutilize the join keys of the small data set in reducing thenumber of unnecessary join operations between the twodata sets e experimental results are examined in thedifferent settings of the data set sizes for existing join al-gorithms and variant methods
4 Experimentation and Results
To empirically evaluate the aforementioned join algorithmsseveral experiments are conducted in a Hadoop cluster tojoin two data sets with different settings of sizes is sectionfirstly introduces the detailed environment settings and thedata set configurations in our experiments en eight typesof join algorithms on Hadoop have been defined and used inperformance evaluation Finally a comparison of runningtime cost information changes of data sets and performancechange over hyperparameters respectively is conducted
41 Environment Settings Our experiments are performedin the distributed Hadoop architecture e cluster consistsof one master node and 14 data nodes to support parallelcomputing Its total configured capacity is 2496 TB whereeach data node has 178 TB capacity of distributed storageand 800GB random-access memory e performancemetrics from MapReduce job history files are collected foranalysis
e process of evaluating the proposed method is asfollows First several data sets needed in performingMapReduce join operations are uploaded to Hadoop Dis-tributed File Systems (HDFS) e data sets have differentdata sizes according to simulating different workloads of joinoperations in big data analysis en the proposed joinalgorithms have been revised following the MapReducescheme in order to run on the Hadoop Reduce environmentHyperparameters such as the input and output directories ofdata sets and partition number are supported flexibly toconfigure within the join algorithms so we do not need torevise the same join algorithm in different cases of join
6 Scientific Programming
(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

(1) class Mapper(2) method Map ([key value])(3) set LN LN+ 1(4) set LPN (LNminus 1)PL(5) for each i in [1 2 N](6) write ((L (LPN) R (i) key) (L value))
ALGORITHM 1 Left Mapper for the left data set
(1) class Mapper(2) method Map ([key value])(3) set RNRN+1(4) set RPN (RNminus 1)PR(5) for each i in [1 2 N](6) write ((L (i) R (RPN) key) (R value))
ALGORITHM 2 Right Mapper for the right data set
(1) class Reducer(2) method Reduce (key [value])(3) k keymiddotget (2)(4) List (L) [value] from left data set(5) List (R) [value] from right data set(6) for each l in List (L)(7) for each r in List (R)(8) write (k (l r))
ALGORITHM 3 Reducing for both data sets
Table 1 Mapper outputs of the dynamic partition join using toy data sets
Partitions of left data set Partitions of right data setL1 R1(L1 R1 T1) D1 (L1 R1 T1) C1(L1 R2 T1) D1 (L2 R1 T1) C1(L1 R1 T2) D2 (L1 R1 T2) C2(L1 R2 T2) D2 (L2 R1 T2) C2L2 R2(L2 R1 T2) D3 (L1 R2 T2) C3(L2 R2 T2) D3 (L2 R2 T2) C3(L2 R1 T1) D4 (L2 R2 T2) C4(L2 R2 T1) D4 (L2 R2 T2) C4
Table 2 Reducer inputs of dynamic partition join using toy data sets
Reducer Input key Input valuesReducer 1 (L1 R1 T1) (D1 C1)Reducer 2 (L1 R1 T2) (D2 C2)Reducer 3 (L1 R2 T2) (D2 C3 C4)Reducer 4 (L2 R1 T2) (D3 C2)Reducer 5 (L2 R2 T2) (D3 C3 C4)
Scientific Programming 7
operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

operations After the join algorithm finishes running therunning time cost from its job history file is collected andanalysed Other measures related to CPU virtual memoryphysical memory and heap use can be collected from the logfile of running MapReduce jobs Finally a performancecomparison from the perspectives of running time costinformation changes and tuning performance is conducted
42 Data Sets e data sets used in the experiments aresynthetic from real-world data sets Different settings ofusing the data sets include three types of combinations ofdata set sizes namely Setting 1 (S1) in which both arerelatively small data sets Setting 2 (S2) in which one is arelatively large data set and another is a relatively small dataset and Setting 3 (S3) in which both are relatively large datasetse small and large data sets referred to here are relativeconcepts For example a small data set may contain severalhundred records while the larger one may contain over onemillion records e data sets have the same width innumber of fields for proper comparison
In S1 one data set with 15490 records and another dataset with 205083 records are used In S2 one data set with205083 records and another data set with 2570810 recordsare used In S3 one data set with 1299729 records andanother data set with 2570810 records are used e sameinput of data sets and joined results in the experimentsensure that the measures are comparable
43Useof JoinAlgorithms in theExperiments To simplify thereferences of the algorithms in the following experimentsthe abbreviations of join are used in Table 3 e join al-gorithms include map-side join (MSJ) reduce-side join(RSJ) semi-reduce-side join (S-RSJ) semi-reduce-side joinwith Bloom filter (BS-RSJ) dynamic partition join (DSJ)dynamic partition join with combiner (C-DPJ) dynamicpartition join with Bloom filter (B-DPJ) and dynamicpartition join with combiner and Bloomer filter (BC-DPJ)Here the C-DPJ B-DPJ and BC-DPJ are variant methods ofDPJ
Each join algorithm is able to configure its hyper-parameters in a flexible manner so we can evaluate the samejoin algorithm in different settings of hyperparameters Ourobjective to is use multiple existing join algorithms and theproposed variant methods to examine the performancechange of join operations in different cases
44 Comparison of Time Cost between Join Algorithmsis section presents the result of comparison of time costbetween the used algorithms in different cases in Table 3Figure 5 illustrates the comparison of the time cost of joins inS1 S2 and S3 With increasing data set sizes all time costs ofjoins increase In S1 the difference of time cost is relativelysmall but the existing joins perform slightly better than thevariant methods of DPJ With increasing data set sizes timecost varies In S2 MSJ BS-RSJ RSJ and S-RSJ performbetter than all DPJ-related variant methods but B-DPJ is thebest among the variant methods In S3 the performances of
BS-RSJ and RSJ are better than those of the other joinsHowever the performance of C-DPJ is approximatelysimilar to that of S-RSJ MSJ performs well in S1 and S2 butfails to run in S3 BS-RSJ performs best in S2 and S3
Furthermore we examine the time cost in differentMapReduce stages over different settings of data sets Table 4summarizes the time costs in the differentMapReduce stagesin S1 S2 and S3 B-RSJ in S1 and S2 requires the largestsetup time cost before its launch although B-DPJ and BC-DPJ which also use the Bloom filter do not take substantialtime for setup However the DPJ-derived methods needadditional time during the cleanup In S1 all time costs ofthe Map tasks are larger than those of the Reduce tasks Bycontrast the difference between them varies in S2 and S3e time costs of the Map stage of B-DPJ and RSJ in S1 arelarger than those of the Reduce stage in S2 and S3 e timecost of the Shuffle andMerge stages in S3 is less than those inS1 and S2 e time cost of MSJ in S3 is substantially largerthan that in any other method owing to its failure to run inthe cluster
45 Comparison of Information Changes over Data Set SizesTo investigate the amount of information changes in dif-ferent data set sizes during performing join operations weused the proposed MapReduce-based entropy evaluationframework to estimate information changes and make acomparison of their entropy in different MapReducephrases e information changes of each stage in Map-Reduce join algorithms with entropy-based measures areestimated in S1 S2 and S3 (see Figure 6) e inputs andoutputs of the different joins are comparable because allMIs and ROs in S1 S2 and S3 are equivalent Figure 6shows that the entropy in MO and RI varies erefore thejoins change the amount of information during the Mapand Reduce stages owing to their different techniques emajority of the DPJ variant methods have less value ofentropy than those of the other existing joins Hence theuncertainty degree of the data sets and partitions haschanged thereby reducing the workload of the Reducetasks during MO and RI
46 Comparison of Performance in Different DPJ VariantsTo compare the performances of different DPJ variantmethods we conduct several experiments to examine DPJC-DPJ B-DPJ and BC-DPJ in terms of different perfor-mance measures such as cumulative CPU virtual memoryphysical memory and heap over data set settings e usageof cumulative CPU virtual memory physical memory andheap is summarized in Figure 7 To evaluate the performanceof the DPJ variant methods from the perspective of resourceusage in the cluster Figure 7 shows that B-DPJ using theBloom filter in Figure 7(b) uses less CPU resources than PDJin Figure 7(a) However the virtual memory of B-DPJ islarger than that of PDJ in Reduce tasks C-DPJ usingcombiners in Figure 7(c) uses larger CPU resources thanDPJ but other metrics remain similar BC-DPJ using theBloom filter and combiner in Figure 7(d) uses larger physicalmemory than PDJ B-DPJ and C-DPJ However the usage of
8 Scientific Programming
Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

Table 3 Abbreviation of names of the join algorithms used in this study
Name of join algorithm AbbreviationMap-side join MSJReduce-side join RSJSemi-reduce-side join S-RSJSemi-reduce-side join with Bloom filter BS-RSJDynamic partition join DPJDynamic partition join with combiner C-DPJDynamic partition join with Bloom filter B-DPJDynamic partition join with combiner and Bloom filter BC-DPJ
Settings
Joins
Tim
e cos
t (m
s)
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S3
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S1
C-D
PJM
SJB-
DPJ
BC-D
PJD
PJ RSJ
S-RS
J
BS-R
SJ
S2
0
20000
40000
60000
80000
100000
120000
140000
160000
Figure 5 Comparison of the time costs of the MapReduce join algorithms in three settings of data setsrsquo sizes
Table 4 Summary of the time cost of joins in different settings (unit seconds)
Setting Join Setup Map Reduce Shuffle Merge
S1
B-RSJ 030 355 179 1194 1197C-DPJ 003 871 397 0 0MSJ 004 184 178 5131 5135B-DPJ 003 489 391 0 0BC-DPJ 004 692 273 0 0DPJ 004 746 666 0 0RSJ 005 333 242 0 0S-RSJ 005 331 196 435 437
S2
B-RSJ 003 1087 676 0 0C-DPJ 004 9706 4805 0 0MSJ 005 1661 328 2039 2039B-DPJ 003 283 4079 1804 1804BC-DPJ 004 7173 4459 0 0DPJ 003 6734 5638 093 093RSJ 003 1000 1464 0 0S-RSJ 004 1146 856 0 0
S3
B-RSJ 015 2686 1418 0 0C-DPJ 004 6070 3733 0 0MSJ 003 46202 0 0 0B-DPJ 003 5562 12022 0 0BC-DPJ 004 10271 7460 924 924DPJ 007 5809 6307 0 0RSJ 003 1166 2187 0 0S-RSJ 004 8956 1767 0 0
Scientific Programming 9
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15
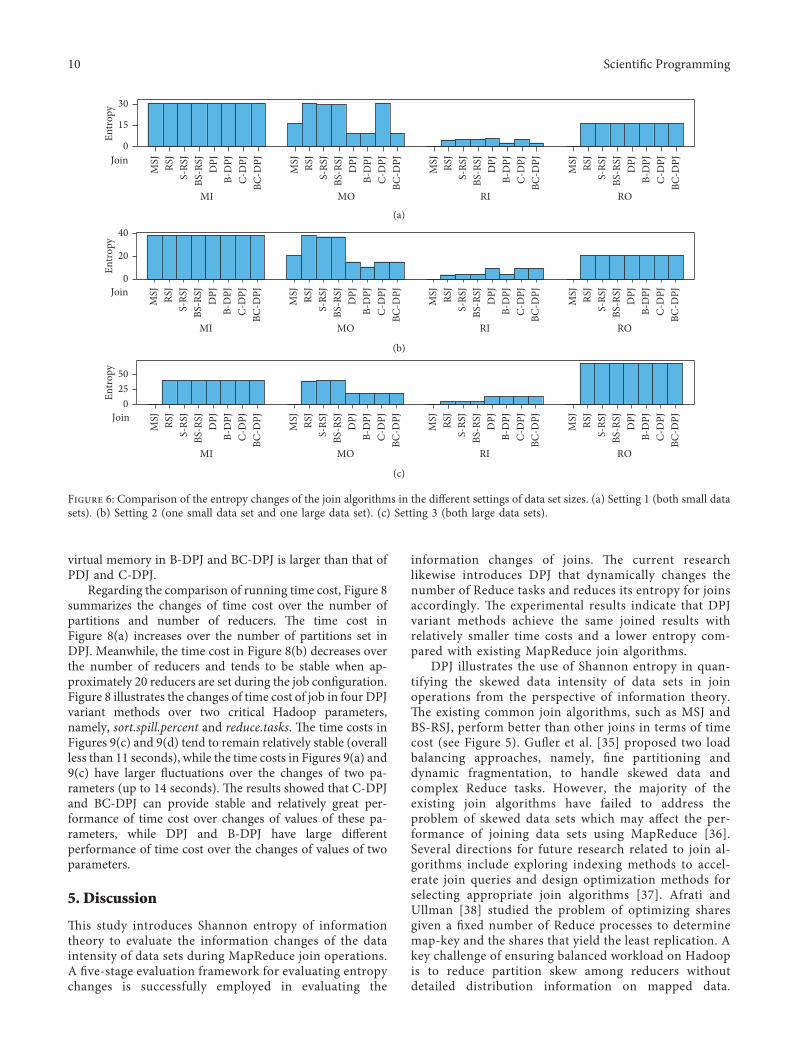
virtual memory in B-DPJ and BC-DPJ is larger than that ofPDJ and C-DPJ
Regarding the comparison of running time cost Figure 8summarizes the changes of time cost over the number ofpartitions and number of reducers e time cost inFigure 8(a) increases over the number of partitions set inDPJ Meanwhile the time cost in Figure 8(b) decreases overthe number of reducers and tends to be stable when ap-proximately 20 reducers are set during the job configurationFigure 8 illustrates the changes of time cost of job in four DPJvariant methods over two critical Hadoop parametersnamely sortspillpercent and reducetasks e time costs inFigures 9(c) and 9(d) tend to remain relatively stable (overallless than 11 seconds) while the time costs in Figures 9(a) and9(c) have larger fluctuations over the changes of two pa-rameters (up to 14 seconds) e results showed that C-DPJand BC-DPJ can provide stable and relatively great per-formance of time cost over changes of values of these pa-rameters while DPJ and B-DPJ have large differentperformance of time cost over the changes of values of twoparameters
5 Discussion
is study introduces Shannon entropy of informationtheory to evaluate the information changes of the dataintensity of data sets during MapReduce join operationsA five-stage evaluation framework for evaluating entropychanges is successfully employed in evaluating the
information changes of joins e current researchlikewise introduces DPJ that dynamically changes thenumber of Reduce tasks and reduces its entropy for joinsaccordingly e experimental results indicate that DPJvariant methods achieve the same joined results withrelatively smaller time costs and a lower entropy com-pared with existing MapReduce join algorithms
DPJ illustrates the use of Shannon entropy in quan-tifying the skewed data intensity of data sets in joinoperations from the perspective of information theorye existing common join algorithms such as MSJ andBS-RSJ perform better than other joins in terms of timecost (see Figure 5) Gufler et al [35] proposed two loadbalancing approaches namely fine partitioning anddynamic fragmentation to handle skewed data andcomplex Reduce tasks However the majority of theexisting join algorithms have failed to address theproblem of skewed data sets which may affect the per-formance of joining data sets using MapReduce [36]Several directions for future research related to join al-gorithms include exploring indexing methods to accel-erate join queries and design optimization methods forselecting appropriate join algorithms [37] Afrati andUllman [38] studied the problem of optimizing sharesgiven a fixed number of Reduce processes to determinemap-key and the shares that yield the least replication Akey challenge of ensuring balanced workload on Hadoopis to reduce partition skew among reducers withoutdetailed distribution information on mapped data
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
0
15
30
(a)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
0
20
40
(b)
Join
Entr
opy
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MI
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
MO
BC-D
PJC-
DPJ
B-D
PJD
PJBS
-RSJ
S-RS
JRS
JM
SJ
RI
02550
(c)
Figure 6 Comparison of the entropy changes of the join algorithms in the different settings of data set sizes (a) Setting 1 (both small datasets) (b) Setting 2 (one small data set and one large data set) (c) Setting 3 (both large data sets)
10 Scientific Programming
Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

Shannon entropy has been used in handling the het-erogeneity of nodes in virtualized clusters and new datasets [39] MapReduce stages (see Figure 2) are considereda channel between senders and receivers erefore in-formation change among the different stages reflects theefficiency of information processing tasks in mappers andreducers A large entropy of input produces a small
entropy of output that often stands for a low uncertaintydegree of generated output data which is confirmed inthe comparison in Figure 6
DPJ utilizes a parameter of the number of partitions toadjust the number of reduce tasks this process is not basedon join keys of a data set but a dynamic parameter Wanget al [40] used similar techniques to divide mapped data into
20
24
28
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(a)
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
10
15
20
Max
imum
Reso
urce
Usa
ge
193
194
195
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(b)
12
16
20
Max
imum
Reso
urce
Usa
ge
14
16
18
Max
imum
Reso
urce
Usa
ge
20
24
28
Max
imum
Reso
urce
Usa
ge
0
8
16
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(c)
10
15
20
Max
imum
Reso
urce
Usa
ge
1930
1935
1940
Max
imum
Reso
urce
Usa
ge
0
5
10
Max
imum
Reso
urce
Usa
ge
20
25
30
Max
imum
Reso
urce
Usa
ge
2 31Setting
2 31Setting
2 31Setting
2 31Setting
Cumulative Cpu Virtual Memory
Physical Memory Heap
taskMapReduce
taskMapReduce
taskMapReduce
taskMapReduce
(d)
Figure 7 Comparison of the maximum resource usage among PDJ B-DPJ C-DPJ and BC-DPJ with different settings of sizes S1 small-size data sets S2 middle-size data sets S3 large-size data sets (a) PDJ (b) B-DPJ (c) C-DPJ (d) BC-DPJ
Scientific Programming 11
manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

manymicropartitions and gradually gather statistics on theirsizes during mapping e parameter is not for physicalpartitions but logical partitions In particular this parameterpromotes the proper processing for skewed data sets to bejoined DPJ does not change the number of reducers setduring the job configuration because a Reduce task is just an
instance of reducers Figure 8 indicates that the DPJ variantmethods should be optimized by increasing the number ofreducers to reduce their time cost and achieve similar timecost using S-RSJ erefore the workload of each Reducetask using DPJ can be divided into several subtasks for onejoin key (see Tables 1 and 2) Such a division is particularly
Tim
e cos
t (se
cond
)
0
400
800
1200
1600
12 24 36 480Number of partitions
(a)
Tim
e cos
t (se
cond
s)
10 20 300Number of reducers
60
75
90
105
120
(b)
Figure 8 Trends of time cost over the partition numbers and reducer numbers in DPJ (a) Changes of time cost over partition numbers ofDPJ (b) Changes of time cost over reducer numbers of DPJ
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(a)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(b)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(c)
020045
070 0
10
20
14000
12000
10000
8000
time c
ost
reduce
tasks
sortspillpercent
(d)
Figure 9 Comparison of the time cost of job in four DPJ methods over two Hadoop parameters namely sortspillpercent and reducetaskse unit of time cost is millisecond (a) DPJ (b) C-DPJ (c) B-DPJ (d) BC-DPJ
12 Scientific Programming
beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

beneficial when different operations are required to handledifferent customized join operations for small partitionswith the same key
Our methods do not aim to replace the existingMapReduce join algorithms for various application sce-narios on Hadoop Common join algorithms namely MSJRSJ S-RSJ and BS-RSJ (see Figure 4) work in differenttypes of join operations for data sets without priorknowledge Evidently so does our method However if thescheme and knowledge of data set are known then theTrojan Join running on Hadoop++ has advantages forjoining data sets in this specific scenario [41]is join aimsto copartition the data sets at load time and group them onany attribute other than join attributes Otherwise if we areworking on two-relation joins then the most cost-effectivemethod is to perform broadcast join such as S-RSJ and BS-RSJ (see results in Figure 5) e hash table in S-RSJ andBloom filter in BS-RSJ are used to optimize the broadcastjoin but this optimization requires additional setup timecost in accordance with Table 4 e three variant methodsof DPJ are proposed by using the combiner Bloom filterand both of them separately Figure 5 shows that DPJperforms worse than C-DPJ and BC-DPJ erefore thecombiner and Bloom filter play a substantial role inMapReduce joins Overall the criteria for selecting theproper join algorithms rely on the prior knowledge ofschema and join conditions transmission over networkand number of tuples We introduce Shannon entropy inevaluating information changes between the input andoutput of mappers and reducers during join operationse entropy-based measures naturally fit into the existingjoin operations because the definitions of senders andreceivers in Shannonrsquos theory are similar In this mannerthe mapper output is the input of the Reduce tasks throughthe Shuffle stage across the network
ere are threats that can result in different outcomes inour study We proposed the counter-attack methods toaddress the issues First since the distributed computingenvironments like Hadoop are dynamic and complex therunning time of the same join algorithm every time isslightly different Hadoop clusters with different data nodesettings can vary in running job performance ereforewe run the same experiment several times to obtain itsmean running time for robust analysis in our experimentalcluster Second the data set sizes used for evaluatingMapReduce join performance include three groups ofsetting namely small size middle size and large sizesettings We cannot examine the performance change ofevery combination of data sizeserefore the three groupsof setting are used to simulate different join scenariosird the different data sets we used have various dataskewness that may affect the performance of join opera-tions on Hadoop But we use entropy to evaluate the dataskewness for convenience of comparison in the experi-ments Finally several measures to evaluate the perfor-mance on MapReduce jobs are used to ensure thecomprehensive understanding of the job performanceWith all aforementioned methods the threats that exist inour experiments are addressed
e limitation of this study is as follows First dif-ferent data set sizes used to evaluate two-way join op-erations are only for case study Evidently these data setsare not sufficiently large to perform the optimization ofjoining large data sets in real life Big data applications invarious scenarios based on our methods should be furtherstudied Second multiway joins involving over two datasets such as Reduce-Side One-Shot join Reduce-SideCascade Join and eta-Join are not considered [42]Such multiway joins are increasingly important in bigdata analysis in the future ird although the entropy-based measures are appropriate in evaluating the infor-mation change of each MapReduce stage the time cost oftransmission which has considerable influence on thejoin performance over the network should be consideredin the future us the measures only reflect the infor-mation change of the data intensity during the stages ofMapReduce for two-way joins Multiway joins withedifferent entropy theories should be examined in thefuture Besides multiway join algorithms that considereddata skewness in different distributed computing archi-tectures such as Apache Spark [43] can be further studiedon the basis of our research Nonetheless this studyprovides a novel method using MapReduce to achievelogically flexible partitions for join algorithms onHadoop
6 Conclusions
is study aims to improve the efficiency and enhance theflexibility of MapReduce join algorithms on Hadoop byleveraging Shannon entropy to measure the informationchanges of data sets being joined in differentMapReduce stagesTo reduce the uncertainty of data sets in joins through thenetwork a novel MapReduce join algorithm with dynamicpartition strategies called DPJ is proposed e experimentalresults indicate that the DPJ variant methods on Hadoopachieve the same joined results with a lower entropy comparedwith the existing MapReduce join algorithms Our studyhighlights that leveraging the changes of entropy in the par-titions of data sets during theMap and Reduce stages revises thelogical partitions by changing the original input of the Reducetasks in HadoopMapReduce jobs Such an action is particularlybeneficial when different operations are required to handledifferent customized join operations for data with the same keyonHadoop In the future we are going to examine the use of theMapReduce-based multiway join algorithms with differententropy theories and their hyperparameter optimizationmethods with skewed data sets in distributed computingenvironments
Data Availability
No data were used to support this study
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this paper
Scientific Programming 13
Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

Acknowledgments
is work was supported in part by a project of the NationalNatural Science Foundation of China (62102087 and62173025) and the Fundamental Research Funds for theCentral Universities in UIBE (20QD22 and CXTD12-04)
References
[1] M M Barhoush A M AlSobeh and A A Rawashdeh ldquoAsurvey on parallel join algorithms using MapReduce onHadooprdquo in Proceedings of the IEEE Jordan Int Joint ConfElectrical Engineering and Information Technology (JEEIT)pp 381ndash388 Amman Jordan April 2019
[2] K Shim ldquoMapReduce algorithms for big data analysisrdquo inProceedings of the International Workshop on Databases inNetworked Information Systems (DNIS 2013) pp 44ndash48 Aizu-Wakamatsu Japan March 2013
[3] A O Hassan and A A Hassan ldquoSimplified data processingfor large cluster a MapReduce and Hadoop based studyrdquoAdvances in Applied Sciences vol 6 no 3 pp 43ndash48 2021
[4] K Meena D K Tayal O Castillo and A Jain ldquoHandlingdata-skewness in character based string similarity join usingHadooprdquo Applied Computing and Informatics 2020
[5] J Dean and S Ghemawat ldquoMapReduce simplified dataprocessing on large clustersrdquo in Proceedings of the Sixth ConfSymp Operating Systems Designamp Implementation (OSDIrsquo04)vol 6 pp 137ndash150 San Francisco CA USA December 2004
[6] D Dai X Li C Wang J Zhang and X Zhou ldquoDetectingassociations in large dataset onMapReducerdquo in Proceedings ofthe IEEE International Conference Trust Security and Privacyin Computing and Communication (TrustCom) pp 1788ndash1794 Melbourne Australia July 2013
[7] X Ding W Yang K K R Choo X Wang and H JinldquoPrivacy preserving similarity joins using MapReducerdquo In-formation Sciences vol 493 pp 20ndash33 2019
[8] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the 2010ACM Int Conf Management of Data (SIGMODrsquo10)pp 495ndash506 Indianapolis Indiana USA June 2010
[9] C Bellas and A Gounaris ldquoA hybrid framework for exact setsimilarity join using a GPUrdquo Parallel Computingvol 104ndash105 Article ID 102790 2021
[10] F N Afrati A D Sarma D Menestrina A Parameswaranand J D Ullman ldquoFuzzy joins using MapReducerdquo in Pro-ceedings of the IEEE 28th International Conference DataEngineering pp 498ndash509 Arlington VA USA April 2012
[11] X Zhao J Zhang and X Qin ldquokN N-D P Handling dataskewness in kNN joins using MapReducerdquo IEEE Transactionson Parallel and Distributed Systems vol 29 no 3 pp 600ndash613 2018
[12] H C Yang A Dasdan R L Hsiao and D S ParkerldquoMapreduce-merge simplified relational data processing onlarge clustersrdquo in Proceedings of the ACM InternationalConference Managerment of Data (SIGMOD) pp 1029ndash1040Beijing China June 2007
[13] A Okcan and M Riedewald ldquoProcessing theta-joins usingMapReducerdquo in Proceedings of the 2011 ACM InternationalConference Management of Data (SIGMODrsquo11) pp 949ndash960Athens Greece June 2011
[14] R Baraglia G D F Morales and C Lucchese ldquoDocumentsimilarity self-join with mapreducerdquo in Proceedings of theIEEE International Conference Data Mining (ICDM)pp 731ndash736 Sydney NSW Australia December 2010
[15] Y Kim and K Shim ldquoParallel top-k similarity join algorithmsusing MapReducerdquo in Proceedings of the IEEE InternationalConference Data Engineering (ICDE) pp 510ndash521 ArlingtonVA USA April 2012
[16] S M Mahajan and M V P Jadhav ldquoBloom join fine-tunesdistributed query in Hadoop environmentrdquo InternationalJournal of Advanced Engineering Technology vol 4 no 1pp 67ndash71 2013
[17] S Rababa and A Al-Badarneh ldquoOptimizations for filter-basedjoin algorithms in MapReducerdquo Journal of Intelligent andFuzzy Systems vol 40 no 5 pp 8963ndash8980 2021
[18] Y Ma R Zhang Z Cui and C Lin ldquoProjection based largescale high-dimensional data similarity join using MapReduceframeworkrdquo IEEE Access vol 8 Article ID 121677 July 2021
[19] A Belussi S Migliorini and A Eldawy ldquoCost estimation ofspatial join in spatialhadooprdquo GeoInformatica vol 24 no 4pp 1021ndash1059 2020
[20] S Blanas J M Patel V Ercegovac J Rao E J Shekita andY Tian ldquoA comparison of join algorithms for log processingin MapReducerdquo in Proceedings of the 2010 ACM Int ConfManagement of Data (SIGMODrsquo10) pp 975ndash986 Indian-apolis Indiana USA June 2010
[21] A C Phan T C Phan and T N Trieu ldquoA theoretical andexperimental comparison of large-scale join algorithms insparkrdquo SN Computer Science vol 2 no 5 2021
[22] G Chen K Yang L Chen Y Gao B Zheng and C ChenldquoMetric similarity joins usingMapReducerdquo IEEE Transactionson Knowledge and Data Engineering vol 29 no 3 pp 656ndash669 2016
[23] H Lee J W Chang and C Chae ldquokNN-join query processingalgorithm on mapreduce for large amounts of datardquo ldquo inProceedings of the 2021 International Symposium on ElectricalElectronics and Information Engineering pp 538ndash544 SeoulSouth Korea February 2021
[24] S Migliorini and A Belussi ldquoA balanced solution for thepartition-based spatial merge join in MapReducerdquo in Pro-ceedings of the EDBTICDT Workshops Copenhagen Den-mark April 2020
[25] C E Shannon ldquoA mathematical theory of communicationrdquoBell System Technical Journal vol 27 no 3 pp 379ndash423 1948
[26] W Cui and L Huang ldquoKnowledge reduction method basedon information entropy for port big data using MapReducerdquoin Proceedings of the 2015 International Conference on Lo-gistics Informatics and Service Sciences (LISS) BarcelonaSpain July 2015
[27] J Chen H Chen X Chen G Zheng and ZWu ldquoData chaosan entropy-based MapReduce framework for scalable learn-ingrdquo in Proceedings of the IEEE International Conference BigData pp 71ndash78 Silicon Valley CA USA October 2013
[28] D Chen R Zhang and R G Qiu ldquoNoninvasive MapReduceperformance tuning using multiple tuning methods onHadooprdquo IEEE Systems Journal vol 15 no 2 pp 2906ndash29172020
[29] A F Al-Badarneh and S A Rababa ldquoAn analysis of two-wayequi-join algorithms under MapReducerdquo Journal of KingSaud University - Computer and Information Sciences vol 33no 9 2020
[30] J Chandar Join Algorithms Using MapReduce Master ofScience School of Informatics Univ Edinburgh EdinburghUK 2010
[31] K Lee Y Lee H Choi Y D Chung and B Moon ldquoParalleldata processing with MapReducerdquo ACM SIGMOD Recordvol 40 no 4 pp 11ndash20
14 Scientific Programming
[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15

[32] J Lin and C Dyer ldquoData-intensive text processing withMapReducerdquo Synthesis Lectures on Human Language Tech-nologies vol 3 no 1 pp 1ndash177 2010
[33] T Lee K Kim and H J Kim ldquoJoin processing using Bloomfilter in MapReducerdquo in Proceedings of the 2012 ACM ResApplied Computation Symp pp 100ndash105 San Antonio TXUSA October 2012
[34] B H Bloom ldquoSpacetime trade-offs in hash coding withallowable errorsrdquo Communications of the ACM vol 13 no 7pp 422ndash426 1970
[35] B Gufler N Augsten A Reiser and A Kemper ldquoHandlingdata skew in MapReducerdquo ldquo in Proceedings of the 1st In-ternational Conference on Cloud Computing and ServicesScience pp 574ndash583 Noordwijkerhout Netherlands 2011
[36] E Gavagsaz A Rezaee and H Haj Seyyed Javadi ldquoLoadbalancing in join algorithms for skewed data in MapReducesystemsrdquo De Journal of Supercomputing vol 75 no 1pp 228ndash254 2019
[37] M H Khafagy ldquoIndexed map-reduce join algorithmrdquo In-ternational Journal of Scientific Engineering and Researchvol 6 no 5 pp 705ndash711 2015
[38] F N Afrati and J D Ullman ldquoOptimizing multiway joins in amap-reduce environmentrdquo IEEE Transactions on Knowledgeand Data Engineering vol 23 no 9 pp 1282ndash1298 2011
[39] K H K Reddy V Pandey and D S Roy ldquoA novel entropy-based dynamic data placement strategy for data intensiveapplications in Hadoop clustersrdquo International Journal of BigData Intelligence vol 6 no 1 pp 20ndash37 2019
[40] Z Wang Q Chen B Suo W Pan and Z Li ldquoReducingpartition skew on MapReduce an incremental allocationapproachrdquo Frontiers of Computer Science vol 13 no 5pp 960ndash975 2019
[41] J Dittrich J A R Quiane A Jindal Y Kargin V Setty andJ Schad ldquoHadoop++ making a yellow elephant run like acheetah (without it even noticing)rdquo in Proceedings of the 36thInt Conf Very Large Data Bases (VLDB) vol 3 no 1pp 518ndash529 Singapore September 2010
[42] X Zhang L Chen and M Wang ldquoEfficient multi-way theta-join processing using MapReducerdquo Proceedings of the VLDBEndowment vol 5 no 11 pp 1184ndash1195 2012
[43] A Phan T Phan and T Trieu ldquoA comparative study of joinalgorithms in sparkrdquo in Proceedings of the InternationalConference on Future Data and Security Engineeringpp 185ndash198 Springer Quy Nhon Vietnam November 2020
Scientific Programming 15


















