
Hadoop and MapReduce - Courses · Hadoop and MapReduce Guest Lecturer: Jiaheng Lu ... Simple...
78
www.helsinki.fi Hadoop and MapReduce Guest Lecturer: Jiaheng Lu Homepage: https://www.cs.helsinki.fi/u/jilu / Autumn 2017 17.9.2017 1 Big Data Framework “Introduction to Data Science”
Transcript of Hadoop and MapReduce - Courses · Hadoop and MapReduce Guest Lecturer: Jiaheng Lu ... Simple...

www.helsinki.fi
Hadoop and MapReduce
Guest Lecturer: Jiaheng Lu
Homepage: https://www.cs.helsinki.fi/u/jilu/
Autumn 2017
17.9.2017 1
Big Data Framework
“Introduction to Data Science”

www.helsinki.fi
Outline
• Big data and Google File System (GFS)
• Hadoop and HDFS
• MapReduce and examples
• Hands-on exercise on table join
• Questions and answers for quiz

www.helsinki.fi
• One Big challenge in the era of Big Data:
• How to efficiently handle big data?
• Make big data divided
• Hadoop, GFS, MapReduce
• Make big data small
• FM Sketch, Count Sketch, Count Min Sketch
17.9.2017 3
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Two ways to handle big data

www.helsinki.fi
• One Big challenge in the era of Big Data:
• How to efficiently handle big data?
• Make big data divided
• Hadoop, GFS, MapReduce
• Make big data small
• FM Sketch, Count Sketch, Count Min Sketch
17.9.2017 4
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Two ways to handle big data
this lecture
To appear in
“Introduction to Big
´Data Management”

www.helsinki.fi
The Google File System(GFS)
A scalable distributed file system for large
distributed data intensive applications
MapReduce Bigtable
Google File System

www.helsinki.fi
GFS: Introduction
Shares many same goals as previous
distributed file systems
performance, scalability, reliability, etc
GFS design has been driven by four key
observations of Google application
workloads and technological environment

www.helsinki.fi
Intro: Observations
•1. Component failures are the norm
constant monitoring, error detection, fault tolerance
and automatic recovery are integral to the system
•2. Huge files (by traditional standards)
Multi GB files are common
I/O operations and blocks sizes must be revisited

www.helsinki.fi
Intro: Observations (Contd)
• 3. Most files are mutated by appending new data
This is the focus of performance optimization and atomicity
guarantees
• 4. Co-designing the applications and APIs
benefits overall system by increasing flexibility

www.helsinki.fi
The Design
Cluster consists of a single master and multiple
chunkservers and is accessed by multiple clients

www.helsinki.fi
The Master
Maintains all file system metadata.
names space, access control info, file to chunk mappings, chunk
(including replicas) location, etc.
Periodically communicates with chunkservers in HeartBeat
messages to give instructions and check state

www.helsinki.fi
Chunkservers
Files are broken into chunks. Each chunk has
a globally unique 64-bit chunk-handle.
handle is assigned by the master at chunk creation
Chunk size is 64 MB
Each chunk is replicated on 3 (default)
servers

www.helsinki.fi
GFS paper
• More information on data update and performance of
GFS, read the original paper:
• http://static.googleusercontent.com/media/research.g
oogle.com/en//archive/bigtable-osdi06.pdf
2017/9/17 12

www.helsinki.fi
Outline
• Google File System (GFS)
• Hadoop and HDFS
• MapReduce and examples
• Hands-on exercise on table join
• Questions and answers for quiz

www.helsinki.fi
What is Hadoop?
• Apache top level project, open-source
implementation of frameworks for reliable, scalable,
distributed computing and data storage.

www.helsinki.fi
Hadoop’s Developers
2005: Doug Cutting and Michael J. Cafarella developed
Hadoop to support distribution for the Nutch search
engine project.
The project was funded by Yahoo.
2006: Yahoo gave the project to Apache Software
Foundation.

www.helsinki.fi
Some Hadoop Milestones
• 2008 - Hadoop Wins Terabyte Sort Benchmark (sorted 1 terabyte of
data in 209 seconds, compared to previous record of 297 seconds)
• 2010 - Hadoop's Hbase, Hive and Pig subprojects completed,
adding more computational power to Hadoop framework
• 2013 - Hadoop 1.1.2 and Hadoop 2.0.3 alpha.
- Ambari, Cassandra, Mahout have been added
• 2016 - Hadoop 3.0.0 Alpha-1

www.helsinki.fi
Google Origins
2003
2004
2006

www.helsinki.fi 17.9.2017 18
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu

www.helsinki.fi
• Hadoop Common - libraries and utilities
• Hadoop Distributed File System (HDFS) – a distributed
file-system
• Hadoop YARN – a resource-management platform,
scheduling
• Hadoop MapReduce – a programming model for large
scale data processing
17.9.2017 19
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
The Basic Hadoop Components

www.helsinki.fi
• Single NameNode - a master server that manages the file
system namespace and regulates access to files by clients.
•
• Multiple DataNodes – typically one per node in the cluster.
Functions: Manage storage, serving read/write requests from
clients
17.9.2017 20
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Original HDFS Design

www.helsinki.fi
Unique features of HDFS
• Failure tolerant - data is duplicated across multiple
DataNodes to protect against machine failures.
• Scalability - data transfers happen directly with the
DataNodes so your read/write capacity scales fairly well
with the number of DataNodes
21

www.helsinki.fi
HDFS Architecture
22

www.helsinki.fi
• Watch two videos on Hadoop
• https://www.youtube.com/watch?v=9s-vSeWej1U
• https://www.youtube.com/watch?v=4DgTLaFNQq0
17.9.2017 23
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu

www.helsinki.fi
Outline
• Google File System (GFS)
• Hadoop and HDFS
• MapReduce and examples
• Hands-on exercise on table join
• Questions and answers for quiz

MapReduce: Insight
Consider the problem of counting the number of frequency of each word in a large collection of documents
( Trump)
( Donald Trump)
(Trump Clinton)
(USA President)
(Donald Trump)
(President election)
( Donald, 2)
(election, 1)
(Clinton, 1)
( Trump, 4)
( USA, 1)

www.helsinki.fi
Simple example: Word count
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
Each mapper
receives some
of documents
as input
1
( Trump)
( Donald Trump)
(Trump Clinton)
(USA President)
(Donald Trump)
(President election)

www.helsinki.fi
Simple example: Word count
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
( Trump)
( Donald Trump)
(Trump Clinton)
(President election)
(USA President)
(Donald Trump)
Each mapper
receives some
of documents
as input
Mappers
process the
KV-pairs.
1 2
( Trump, 1)
( Donald, 1), (Trump, 1)
( President,1),(election, 1)
( Trump, 1), (Clinton, 1)
( Donald,1),(Trump, 1)
( USA, 1), (President, 1)

www.helsinki.fi
Simple example: Word count
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
( Trump)
( Donald Trump)
(Trump Clinton)
(President election)
(USA President)
(Donald Trump)
Each mapper
receives some
of documents
as input
Mappers
process the
KV-pairs.
1 2
( Trump, 1)
( Donald, 1)
(election, 1)
(Clinton, 1)
(Trump, 1)
(President, 1)
Each KV-pair output
by the mapper is sent
to the reducer
3
( Trump, 1)
( Trump, 1)
( President,1)
( USA, 1)
( Donald,1)

www.helsinki.fi
Simple example: Word count
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
( Trump)
( Donald Trump)
(Trump Clinton)
(President election)
(USA President)
(Donald Trump)
Each mapper
receives some
of documents
as input
Mappers
process the
KV-pairs.
1 2
( Trump, 1)
( Donald, 1)
(election, 1)
(Clinton, 1)
(Trump, 1)
(President, 1)
Each KV-pair output
by the mapper is sent
to the reducer
3
( Trump, 1) ( Trump, 1)
( President,1)
( USA, 1)
( Donald,1)
The reducers
sort their input
by key
4

www.helsinki.fi
Simple example: Word count
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
( Trump)
( Donald Trump)
(Trump Clinton)
(President election)
(USA President)
(Donald Trump)
Each mapper
receives some
of documents
as input
Mappers
process the
KV-pairs.
1 2
( Donald, 2)
(election, 1)
(Clinton, 1)
(President, 2)
Each KV-pair output
by the mapper is sent
to the reducer
3
( Trump, 4)
( USA, 1)
The reducers
sort their input
by key
4 The reducers
process their
input
5

www.helsinki.fi
MapReduce dataflow
31
Mapper
Mapper
Mapper
Mapper
Reducer
Reducer
Reducer
Reducer
Input data
Outp
ut
data
"The Shuffle"
Intermediate
(key,value) pairs

Pseudo-code
map(String input_key, String input_value):
// input_key: document name
// input_value: document contents
for each word w in input_value:
EmitIntermediate(w, "1");
reduce(String output_key, Iterator intermediate_values):
// output_key: a word
// output_values: a list of counts
int result = 0;
for each v in intermediate_values:
result += ParseInt(v);
Emit(AsString(result));
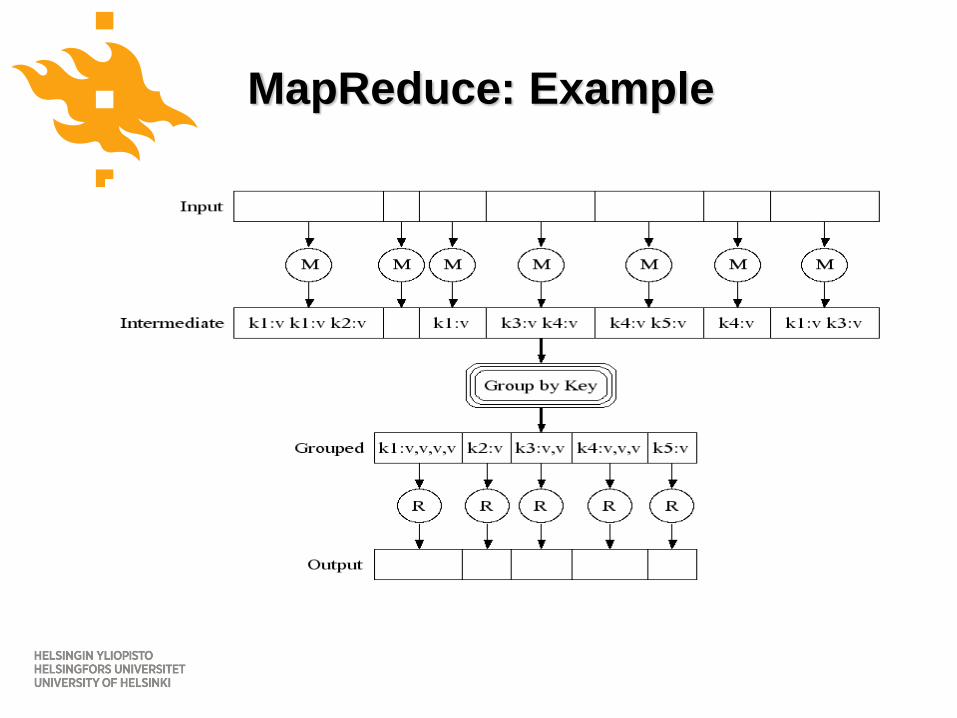
MapReduce: Example
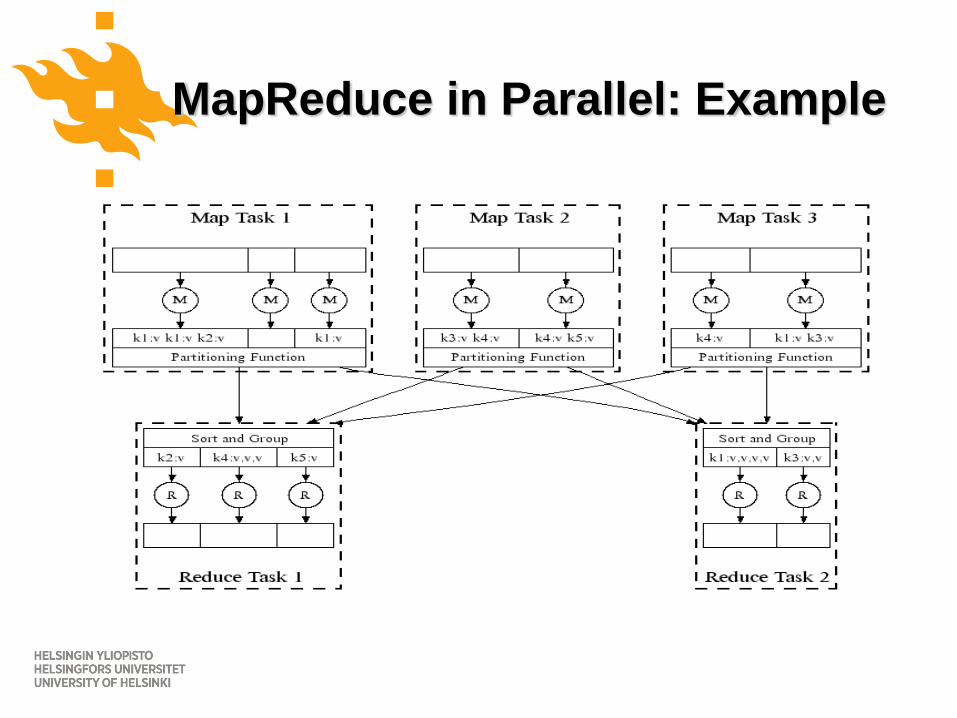
MapReduce in Parallel: Example

www.helsinki.fi
Common mistakes:
Use static variables
• Don't use static shared variables for mappers
• After map + reduce return, they should remember nothing about
the processed data!
35University of Pennsylvania
HashMap h = new HashMap();
map(key, value) {
if (h.contains(key)) {
h.add(key,value);
emit(key, "X");
}
}
Wrong!

www.helsinki.fi
Common mistakes:
Do your own I/O
• Don't try to do your own I/O!
• Don't try to read from, or write to, files in the file system
• The MapReduce framework does all the I/O for you:
‒ All the incoming data will be fed as arguments to map and reduce
‒ Any data your functions produce should be output via emit
36University of Pennsylvania
map(key, value) {
File foo =
new File("xyz.txt");
while (true) {
s = foo.readLine();
...
}
} Wrong!

www.helsinki.fi
Common mistakes:
Too much data on the same key
• Mapper must not map too much data to the same key
• In particular, don't map everything to the same key!!
• Otherwise the reduce worker will be overwhelmed!
• It's okay if some reduce workers have more work than others
37University of Pennsylvania
map(key, value) {
emit("FOO", key + " " + value);
}
Wrong!

www.helsinki.fi
Designing MapReduce
algorithms
• Key decision: What should be done by map, and what by
reduce?
• map can do something to each individual key-value pair, but
it can't look at other key-value pairs
• reduce can aggregate data; it can look at multiple values, as long
as map has mapped them to the same (intermediate) key
‒ Example: Count the number of words, add up the total cost, ...
38University of Pennsylvania

www.helsinki.fi
More details on the MapReduce
data flow
39
Data partitions
by key
Map computation
partitions
Reduce
computation
partitions
Redistribution
by output’s key("shuffle")
Coordinator

www.helsinki.fi
Some additional details
• To make this work, we need a few more parts in Hadoop
HDFS system
• The file system (distributed across all nodes):
• Stores the inputs, outputs, and temporary results
• The driver program (executes on one node):
• Specifies where to find the inputs, the outputs
• Specifies what mapper and reducer to use
• Can customize behavior of the execution
• The runtime system (controls nodes):
• Supervises the execution of tasks
40

Java MapReduce code
on Apache Hadoop 2.7.2

www.helsinki.fi
MapReduce Program
• A MapReduce program consists of the following 3
parts :
• Driver → main (would trigger the map and reduce
methods)
• Mapper
• Reducer
• It is better to include the map reduce and main
methods in 3 different classes
2017/9/17 42

www.helsinki.fi
Mapper
• public static class TokenizerMapper
• extends Mapper<Object, Text, Text, IntWritable>{
• private final static IntWritable one = new IntWritable(1);
• private Text word = new Text();
• public void map(Object key, Text value, Context context
• ) throws IOException, InterruptedException {
• StringTokenizer itr = new StringTokenizer(value.toString());
• while (itr.hasMoreTokens()) {
• word.set(itr.nextToken());
• context.write(word, one);
• }
• }
• }
2017/9/17 43

www.helsinki.fi
Mapper
• public static class TokenizerMapper
• extends Mapper<Object, Text, Text, IntWritable>{
• private final static IntWritable one = new IntWritable(1);
• private Text word = new Text();
• public void map(Object key, Text value, Context context
• ) throws IOException, InterruptedException {
• StringTokenizer itr = new StringTokenizer(value.toString());
• while (itr.hasMoreTokens()) {
• word.set(itr.nextToken());
• context.write(word, one);
• }
• }
• }
2017/9/17 44
Interface
Mapper<K1,V1,K2,V2> , the
first pair is the input key/value
pair, the second is the output
key/value pair

www.helsinki.fi
Mapper
• public static class TokenizerMapper
• extends Mapper<Object, Text, Text, IntWritable>{
• private final static IntWritable one = new IntWritable(1);
• private Text word = new Text();
• public void map (Object key, Text value, Context context) throws IOException, InterruptedException {
• StringTokenizer itr = new StringTokenizer(value.toString());
• while (itr.hasMoreTokens()) {
• word.set(itr.nextToken());
• context.write(word, one);
• }
• }
• }
2017/9/17 45
Keys are the position in the file,
and values are the line of text.
Context emits the output.

www.helsinki.fi
Reducer
• public static class IntSumReducer
• extends Reducer<Text,IntWritable,Text,IntWritable> {
• private IntWritable result = new IntWritable();
• public void reduce(Text key, Iterable<IntWritable> values,
• Context context
• ) throws IOException, InterruptedException {
• int sum = 0;
• for (IntWritable val : values) {
• sum += val.get();
• }
• result.set(sum);
• context.write(key, result);
• }
• }
2017/9/17 46

www.helsinki.fi
Main function
• public static void main(String[] args) throws Exception {
• Configuration conf = new Configuration();
• Job job = Job.getInstance(conf, "word count");
• job.setJarByClass(WordCount.class);
• job.setMapperClass(TokenizerMapper.class);
• job.setCombinerClass(IntSumReducer.class);
• job.setReducerClass(IntSumReducer.class);
• job.setOutputKeyClass(Text.class);
• job.setOutputValueClass(IntWritable.class);
• FileInputFormat.addInputPath(job, new Path(args[0]));
• FileOutputFormat.setOutputPath(job, new Path(args[1]));
• System.exit(job.waitForCompletion(true) ? 0 : 1);
• }
2017/9/17 47
Given the Mapper and Reducer
code, the main() starts the
MapReduce running.

www.helsinki.fi
Main function
• public static void main(String[] args) throws Exception {
• Configuration conf = new Configuration();
• Job job = Job.getInstance(conf, "word count");
• job.setJarByClass(WordCount.class);
• job.setMapperClass(TokenizerMapper.class);
• job.setCombinerClass(IntSumReducer.class);
• job.setReducerClass(IntSumReducer.class);
• job.setOutputKeyClass(Text.class);
• job.setOutputValueClass(IntWritable.class);
• FileInputFormat.addInputPath(job, new Path(args[0]));
• FileOutputFormat.setOutputPath(job, new Path(args[1]));
• System.exit(job.waitForCompletion(true) ? 0 : 1);
• }
2017/9/17 48
Configurations are specified by
resources. A resource contains
a set of name/value pairs as
XML data.

www.helsinki.fi
Main function
• public static void main(String[] args) throws Exception {
• Configuration conf = new Configuration();
• Job job = Job.getInstance(conf, "word count");
• job.setJarByClass(WordCount.class);
• job.setMapperClass(TokenizerMapper.class);
• job.setCombinerClass(IntSumReducer.class);
• job.setReducerClass(IntSumReducer.class);
• job.setOutputKeyClass(Text.class);
• job.setOutputValueClass(IntWritable.class);
• FileInputFormat.addInputPath(job, new Path(args[0]));
• FileOutputFormat.setOutputPath(job, new Path(args[1]));
• System.exit(job.waitForCompletion(true) ? 0 : 1);
• }
2017/9/17 49
Normally the user creates the
application, describes various
facets of the job via Job and
then submits the job and
monitor its progress.

www.helsinki.fi
Main function
• public static void main(String[] args) throws Exception {
• Configuration conf = new Configuration();
• Job job = Job.getInstance(conf, "word count");
• job.setJarByClass(WordCount.class);
• job.setMapperClass(TokenizerMapper.class);
• job.setCombinerClass(IntSumReducer.class);
• job.setReducerClass(IntSumReducer.class);
• job.setOutputKeyClass(Text.class);
• job.setOutputValueClass(IntWritable.class);
• FileInputFormat.addInputPath(job, new Path(args[0]));
• FileOutputFormat.setOutputPath(job, new Path(args[1]));
• System.exit(job.waitForCompletion(true) ? 0 : 1);
• }
2017/9/17 50
CombinerClass is a
mini reducer running in
a single Mapper node.

www.helsinki.fi
Combiner class
• Combiner class "mini-reduce"
• machine A emits <the, 1>, <the, 1>
• machine B emits <the, 1>.
• a Combiner on machine A emits <the, 2>. This value,
along with the <the, 1> from machine B will both go
to the Reducer node
• We have now saved bandwidth, but preserved the
computation.
2017/9/17 51

www.helsinki.fi
• Watch a video
• https://www.youtube.com/watch?v=bcjSe0xCHbE
•
2017/9/17 52

www.helsinki.fi
Outline
• Google File System (GFS)
• Hadoop Eco-system
• MapReduce and examples (with a video)
• Hands-on exercise on table join
• Questions and answers for quiz

www.helsinki.fi
Hands-on exercise on
MapReduce
• Write one executable MapReduce programs to perform
the table inner-join in the exercise
A B
1 ab
1 cd
4 ef
A C
1 b
2 d
4 c
Table x Table y
A B C
1 ab b
1 cd b
4 ef c
Output

www.helsinki.fi
Hands-on exercise on
MapReduce
• Download the instructions of the exercise at
• https://www.cs.helsinki.fi/u/jilu/dataset/HadoopExerci
ses.pdf
• Read the instruction to install Hadoop on Ukko
• Download the dataset

www.helsinki.fi
Reduce-side join
• Map
• output <key, value>
• key>>join key, value>>tagged with data source
• Reduce
• do a full cross-product of values
• output the combination results

www.helsinki.fi
Example
A B
1 ab
1 cd
4 ef
A C
1 b
2 d
4 c
table x
table y
map()
map()
1
4
key
x ab
x cd
x ef
value
1
2
4
key
y b
y d
y c
valuetag
join key
shuffle()1
key
x ab
x cd
y b
valuelist
2 y d
4x ef
y c
reduce()
A B C
1 ab b
1 cd b
4 ef c
output
1

www.helsinki.fi
Outline
• Google File System (GFS)
• Hadoop Eco-system
• MapReduce and examples (with a video)
• Hands-on exercise on table join
• Questions and answers for quiz

www.helsinki.fi
Google File System is scalable, distributed file system
on inexpensive commodity hardware that provides:
A. Fault Tolerance
B. High Aggregate Performance
C. ACID transaction model
D. Failure detection on replicas
17.9.2017 59
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 1

www.helsinki.fi
Google File System is scalable, distributed file system
on inexpensive commodity hardware that provides:
A. Fault Tolerance
B. High Aggregate Performance
C. ACID transaction model
D. Failure detection on replicas
17.9.2017 60
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 1

www.helsinki.fi
What are the assumptions in designing Google File Systems?
A. The system is built from many inexpensive commodity
components.
B. The workloads have very frequent updating operations.
C. The stringent response time requirements for an individual
read or write are not the primary designing goal.
D. The workload consists of both large streaming reads and
small random reads.
17.9.2017 61
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 2

www.helsinki.fi
What are the assumptions in designing Google File Systems?
A. The system is built from many inexpensive commodity
components.
B. The workloads have very frequent updating operations.
C. The stringent response time requirements for an individual
read or write are not the primary designing goal.
D. The workload consists of both large streaming reads and
small random reads.
17.9.2017 62
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 2

www.helsinki.fi
3. What is the chunk size in GFS ?
A. 16MB
B. 32MB
C. 64 MB
D. 128MB
17.9.2017 63
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 3

www.helsinki.fi
3. What is the chunk size in GFS ?
A. 16MB
B. 32MB
C. 64 MB
D. 128MB
17.9.2017 64
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 3

www.helsinki.fi
4. Which are the mistakes on MapReduce programs?
A. Using the static shared variables for mappers
B. Map too much data to the same key
C. Write the own I/O codes
D. Always map all data to the same key
17.9.2017 65
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 4

www.helsinki.fi
Which are the mistakes on MapReduce programs?
A. Using the static shared variables for mappers
B. Map too much data to the same key
C. Write the own I/O codes
D. Always map all data to the same key
17.9.2017 66
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 4

www.helsinki.fi
Which are the typical application scenarios for a
MapReduce program?
A. Perform the matrix multiplication and other
complicated computing operations
B. Run machine learning algorithms with many
iterations
C. Compute the inverted indices
D. Summarize the number of pages crawled per host
on Internet
17.9.2017 67
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 5

www.helsinki.fi
Which are the typical application scenarios for a
MapReduce program?
A. Perform the matrix multiplication and other
complicated computing operations
B. Run machine learning algorithms with many
iterations
C. Compute the inverted indices
D. Summarize the number of pages crawled per host
on Internet
17.9.2017 68
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 5

www.helsinki.fi
MapReduce is an abstraction to hide the following
messy details of parallelization, including:
A. fault-tolerance
B. data distribution
C. high performance
D. load balancing
17.9.2017 69
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 6

www.helsinki.fi
MapReduce is an abstraction to hide the following
messy details of parallelization, including:
A. fault-tolerance
B. data distribution
C. high performance
D. load balancing
17.9.2017 70
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 6

www.helsinki.fi
Which are the correct statements on the workflow of MapReduce program?
A. The intermediate key/value pairs produced by the Map function are buffered in memory and periodically, these buffered pairs are written to local disk.
B. Master node is responsible for forwarding the location of the buffered pairs on local disk to the reduce works.
C. A reduce worker uses remote procedure calls to read the buffered data from the local disks of map workers.
D. When a reduce worker read partial of intermediate data, it start to sort it by the intermediate keys so that the same keys are grouped together.
17.9.2017 71
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 7

www.helsinki.fi
Which are the correct statements on the workflow of MapReduce program?
A. The intermediate key/value pairs produced by the Map function are buffered in memory and periodically, these buffered pairs are written to local disk.
B. Master is responsible for forwarding the location of the buffered pairs on local disk to the reduce workers.
C. A reduce worker uses remote procedure calls to read the buffered data from the local disks of map workers.
D. When a reduce worker read partial of intermediate data, it start to sort it by the intermediate keys so that the same keys are grouped together.
17.9.2017 72
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 7

www.helsinki.fi
Which are the correct statements on the functions of
Mapper and Reducer?
A. Each Mapper can do something to each individual
key-value pair.
B. Each Mapper can look at key-value pairs of other
mappers.
C. Each Reducer can aggregate data.
D. Each Reduce can look at multiple values from other
reducers.
17.9.2017 73
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 8

www.helsinki.fi
Which are the correct statements on the functions of
Mapper and Reducer?
A. Each Mapper can do something to each individual
key-value pair.
B. Each Mapper can look at key-value pairs of other
mappers.
C. Each Reducer can aggregate data.
D. Each Reduce can look at multiple values from other
reducers.
17.9.2017 74
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 8

www.helsinki.fi
What are the purposes of Combine Function?
A. The Combine function is executed on each
machine that performs a reduce task.
B. Typically the same code is used to implement both
the combine and the reduce functions.
C. The output of a combiner function is written to an
intermediate file that will be sent to a reduce task.
D. Partial combining can significantly speed up certain
of MapReduce operations.
17.9.2017 75
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 9

www.helsinki.fi
What are the purposes of Combine Function?
A. The Combine function is executed on each
machine that performs a reduce task.
B. Typically the same code is used to implement both
the combine and the reduce functions.
C. The output of a combiner function is written to an
intermediate file that will be sent to a reduce task.
D. Partial combining can significantly speed up certain
of MapReduce operations.
17.9.2017 76
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Question 9

www.helsinki.fi
Limitations of Hadoop
• Latency, slow processing speed
• No Real-time Data Processing
• Not fit for small files
2017/9/17 77

www.helsinki.fi
• Hadoop is an open-source platform for big data processing
• MapReduce is a programming framework to process big
data
• More information on big data management, join the course
“Introduction to big data management”:
• https://courses.helsinki.fi/DATA14002/119122647
17.9.2017 78
Matemaattis-luonnontieteellinen tiedekunta /
Iso tiedonhallinta/
Jiaheng Lu
Summary

















![ApproxHadoop: Bringing Approximations to MapReduce Frameworkssantosh.nagarakatte/... · Hadoop. Hadoop is the best-known, publicly available im-plementation of MapReduce [1]. Hadoop](https://static.fdocuments.us/doc/165x107/5f0f6abb7e708231d4440e6d/approxhadoop-bringing-approximations-to-mapreduce-frameworks-santoshnagarakatte.jpg)
