M45 Ceva Reprint
5
NOVEMBER 2010 CEVA TRAINS DSP GUNS ON TI Ceva Coaxes Designers to Move to Its Ceva-X and Ceva-XC DSP IP By Joseph Byrne {11/8/10-01} ................................................................................................................... Although Texas Instruments (TI) has long been the leading supplier of DSP-based ASICs and discrete DSP chips, Ceva has been operating in TI’s shadow, licensing DSP intellectual-property (IP) cores to companies develop- ing their own chips. Although Ceva is much smaller than TI, its opportunities are expanding, thanks to changes in the ASIC market, a broadening of TI’s product focus, and other market dynamics. Ceva was formed in 2002 when DSP Group spun out its DSP-licensing business and merged it with Parthus, a purveyor of analog IP and design services. DSP Group was founded in 1979 and went public in 1994. The company used its internally developed DSPs—Oak, Pine, and Teak—to create chips for answering machines (remember those?) and other speech-related systems. It also licensed these DSP designs to other companies, such as LSI, NEC, and Siemens. Most importantly, DSP Group landed early wins in cellular-baseband chips. Unfortunately, the Ceva-Parthus merger was disas- trous. The combined entity then restructured to focus on licensing DSPs for cellular basebands, mobile multimedia, and consumer electronics. It narrowed its technology offer- ing to DSPs and DSP-based subsystems and developed a stronger ecosystem of complementary software such as standard codecs, development tools, and operating systems. Ceva is now by far the largest licensor of DSP IP. In 2009, its licensees shipped 334 million chips based on its IP. In just the first nine months of 2010, the company topped this figure as its licensees shipped 389 million units. To keep the momentum rolling, the company has re- cently released two updates to its DSP line. The first is Ceva-X1643, which upgrades its predecessor, Ceva-X1641. A general-purpose architecture, Ceva-X serves in diverse applications including cellular basebands from ST-Ericsson and media processors from Rockchip. The second update is Ceva-XC323. Ceva-XC adds single-instruction, multiple- data (SIMD) vector units to the Ceva-X architecture. Ceva targets the XC323 at cellular base stations, whereas the ear- lier XC321 targets cellular user equipment, such as handsets and data cards, and has been designed into chips such as an LTE baseband from Beceem. Opportunity Knocks for DSP IP Meanwhile, several factors are rocking the DSP market. Foremost among these, Nokia—the world’s leading cell- phone vendor—has turned from developing ASICs with TI to sourcing application-specific standard products (ASSPs) for its handsets. Nokia’s ASSP suppliers, such as Broadcom and Infineon, use Ceva DSPs, causing Ceva’s DSP shipments to soar. The trend away from ASICs is not limited to Nokia. In general, the ASIC industry has slowed, and ASIC-design starts have plateaued over the past decade as ASIC-design costs have risen. Thus, OEMs have turned increasingly to ASSPs and FPGAs. The need for DSP technology has not slowed, however, creating an opportunity for Ceva to sup- ply the technology in place of ASIC companies such as TI that provide both IP and chip-making services. Trends in cellular base-station design have differed. Commonly, base stations use several off-the-shelf DSP chips (which are usually classified as general-purpose de- vices, not ASSPs), ASICs, and FPGAs on each baseband card. Here, too, TI has been a leader, providing both stan- dard DSPs and ASICs. Freescale has recently made inroads because of the greater capabilities of its DSP chips. Running counter to the overall trend away from ASICs, however, some base-station OEMs have explored using their own DSP-based ASICs. Ceva seeks to capitalize
-
Upload
ninjaskinja -
Category
Documents
-
view
61 -
download
6
Transcript of M45 Ceva Reprint

NOVEMBER 2010
CEVA TRAINS DSP GUNS ON TI Ceva Coaxes Designers to Move to Its Ceva-X and Ceva-XC DSP IP
By Joseph Byrne {11/8/10-01}
...................................................................................................................
Although Texas Instruments (TI) has long been the leading supplier of DSP-based ASICs and discrete DSP chips, Ceva has been operating in TI’s shadow, licensing DSP intellectual-property (IP) cores to companies develop-ing their own chips. Although Ceva is much smaller than TI, its opportunities are expanding, thanks to changes in the ASIC market, a broadening of TI’s product focus, and other market dynamics.
Ceva was formed in 2002 when DSP Group spun out its DSP-licensing business and merged it with Parthus, a purveyor of analog IP and design services. DSP Group was founded in 1979 and went public in 1994. The company used its internally developed DSPs—Oak, Pine, and Teak—to create chips for answering machines (remember those?) and other speech-related systems. It also licensed these DSP designs to other companies, such as LSI, NEC, and Siemens. Most importantly, DSP Group landed early wins in cellular-baseband chips.
Unfortunately, the Ceva-Parthus merger was disas-trous. The combined entity then restructured to focus on licensing DSPs for cellular basebands, mobile multimedia, and consumer electronics. It narrowed its technology offer-ing to DSPs and DSP-based subsystems and developed a stronger ecosystem of complementary software such as standard codecs, development tools, and operating systems.
Ceva is now by far the largest licensor of DSP IP. In 2009, its licensees shipped 334 million chips based on its IP. In just the first nine months of 2010, the company topped this figure as its licensees shipped 389 million units.
To keep the momentum rolling, the company has re-cently released two updates to its DSP line. The first is Ceva-X1643, which upgrades its predecessor, Ceva-X1641. A general-purpose architecture, Ceva-X serves in diverse applications including cellular basebands from ST-Ericsson
and media processors from Rockchip. The second update is Ceva-XC323. Ceva-XC adds single-instruction, multiple-data (SIMD) vector units to the Ceva-X architecture. Ceva targets the XC323 at cellular base stations, whereas the ear-lier XC321 targets cellular user equipment, such as handsets and data cards, and has been designed into chips such as an LTE baseband from Beceem.
Opportunity Knocks for DSP IP Meanwhile, several factors are rocking the DSP market. Foremost among these, Nokia—the world’s leading cell-phone vendor—has turned from developing ASICs with TI to sourcing application-specific standard products (ASSPs) for its handsets. Nokia’s ASSP suppliers, such as Broadcom and Infineon, use Ceva DSPs, causing Ceva’s DSP shipments to soar.
The trend away from ASICs is not limited to Nokia. In general, the ASIC industry has slowed, and ASIC-design starts have plateaued over the past decade as ASIC-design costs have risen. Thus, OEMs have turned increasingly to ASSPs and FPGAs. The need for DSP technology has not slowed, however, creating an opportunity for Ceva to sup-ply the technology in place of ASIC companies such as TI that provide both IP and chip-making services.
Trends in cellular base-station design have differed. Commonly, base stations use several off-the-shelf DSP chips (which are usually classified as general-purpose de-vices, not ASSPs), ASICs, and FPGAs on each baseband card. Here, too, TI has been a leader, providing both stan-dard DSPs and ASICs. Freescale has recently made inroads because of the greater capabilities of its DSP chips.
Running counter to the overall trend away from ASICs, however, some base-station OEMs have explored using their own DSP-based ASICs. Ceva seeks to capitalize

2 Ceva Trains DSP Guns on TI
NOVEMBER 2010
on this interest as well by supplying the core DSP building block and by differentiating its features from those of the C6x and StarCore DSPs used by TI and Freescale, respec-tively.
Meanwhile, TI’s strategic gaze has turned toward ana-log technologies and microcontrollers. Although DSPs re-main an important technology for the company, they no longer have the prominence they once did, resulting in longer product-introduction cycles in some markets and thereby creating opportunities for other DSP-technology suppliers—particularly Ceva.
Enter Ceva With Two New DSPs The newest member of the Ceva-X family, Ceva-X1643 is comparable to TI’s C64x DSP core. Ceva-X uses a very long instruction word (VLIW) design that issues up to eight instructions per cycle. The 4 in X1643 indicates that the DSP has four multiply-accumulate (MAC) units, like the earlier X1641. New features in the X1643 include a data cache and memory-control unit, improved power manage-ment, and support for the widely used AXI bus standard, which is freely licensed by ARM. The X1643 thus provides an upgrade path for existing users of quad- and dual-MAC Ceva-X DSPs.
Equipped with two (as indicated by the 2 in XC323) 256-bit SIMD units, Ceva-XC323 is unlike the TI and Freescale DSP cores. An extension of the Ceva-X VLIW architecture, Ceva-XC can dispatch up to four independent vector instructions at a time, consuming half of the available VLIW slots.
Ceva also provides a library of intrinsic functions (compiler extensions) that are compatible with those from Texas Instruments, easing customers’ transistion from TI’s DSPs. The X1643 is thus an excellent choice for a variety of DSP-based designs, and porting of base-station code to the XC323 is simplified.
Ceva-X1643 Targets 1GHz Ceva rates the X1643 at 1GHz in a 40nm G process (worst case)—the same clock rate as the X1641 in the same process. The 90nm TI C6455 is available in 1.2GHz, but compari-sons are difficult. On the one hand, the X1643 requires a process advantage of two generations to top 1GHz. On the other hand, this 1GHz rating is for a synthesized design assuming worst-case process conditions rather than for a fast speed bin of a customized design.
Excluding memories, the X1643’s area is 0.3mm2, as Table 1 shows. Dynamic power usage is 0.18mW/MHz for the most demanding DSP code. Power consumption improves for lighter loads because a power-management unit (PMU) can turn off unused function units.
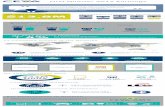
Ceva-X1643 has seven main function units. Figure 1 shows the computation, data-addressing, program-control, and two memory-control units. Not shown are the emula-tion unit, which supports debugging, and the system unit, which includes the PMU and a peripheral-bus port.
The computation unit includes four function blocks. All four handle multiply-accumulate and ALU operations, such as addition, subtraction, and minimum. One also handles bit manipulation, shift, and exponent detection (determination of the number of shifts to normalize a num-ber). Another also handles logical operations.
The Ceva-X architecture natively supports data types 8, 16, 32, and 40 bits wide, packing together multiple 8-bit and 16-bit words to support SIMD execution. The multi-pliers, however, support only 8-bit and 16-bit data. Soft-ware emulates 32-bit multiplication.
Data gets into and out of the register file through load and store instructions. Computation instructions are not interlocked as they would be in a CPU; data dependencies must be avoided in software—a task handled by Ceva’s compiler. A load-store buffer ensures that loads obtain the correct information if a store is pending.
Typical of a DSP, a dedicated data-addressing unit with its own registers and a pair of address-generation blocks handles loads and stores. It also manages address pointers. A scalar ALU assists with generating addresses, which are 32 bits long. Modes include modulo (circular), bit-reversed, and auto-increment addressing. The load-use penalty is one cycle for the computation unit. Ceva-X can issue two loads or stores per cycle, moving 128 bits in a single cycle.
VLIW Combines With SIMD The program control unit handles branches and exceptions, as well as routine fetching, decoding, and dispatching of
Ceva-X1643 Ceva-XC323 Target Applications General-purpose DSP Cellular infrastructure Maximum Clock Rate* 1.0GHz 1.0GHz Instruction Issue 8 per cycle 8 per cycle MACs/Cycle 4× 16×16-bit 32× 16×16-bit Complex FFT (1,024-point 16-bit)
7,575 cycles 960 cycles
8-Tap FIR (1,024-point 16-bit)
2,315 cycles 256 cycles
Tightly Coupled Memory
0–1MB I-TCM, 0–512KB D-TCM
0–512KB I-TCM, 0–1MB D-TCM
Cache Memory 0–32KB I$, 0–32KB D$
0–32KB I$
Interfaces 3×64/128-bit AXI + 1×32-bit APB
3×128-bit AXI + 1×32-bit APB
Die Area (no memory)* 0.3mm2 1.7mm2 Maximum Power* 180mW @ 1.0GHz 360mW @ 1.0GHz RTL Release 3Q10 4Q10 First Commercial SoC Shipments
4Q11 (est) 1Q12 (est)
Table 1. Key attributes of the Ceva-X1643 and Ceva-XC323 DSPs. Sporting four MAC units, the X1643 is a high-end general-purpose DSP. The XC323 adds even more number-crunching power by way of its two vector units, making it well suited to handling 4G-cellular signal processing. *40nm G process, SVT library, postlayout, worst-case process. (Source: Ceva)

Ceva Trains DSP Guns on TI 3
NOVEMBER 2010
instructions. Four of the eight basic instructions in the Ceva-X family map to the four blocks in the computation unit, three map to the three blocks in the addressing unit, and one maps to the program-control unit. The four basic computation-unit instructions can be SIMD operations for added parallelism.
The degree of parallelism afforded by the VLIW design enables quick execution of the BDTImark benchmark and common DSP algorithms. For example, an FFT butterfly involving two data loads, two multiplies, one add, one sub-tract, one pointer update, and one branch can be dispatched in a single cycle.
In addition to branching, the Ceva-X architecture sup-ports conditional execution, in which each basic instruction within a VLIW bundle executes according to the value of a predicate register, which, for example, may be set by a com-parison instruction. Predicates can be combined logically to create complex conditions. Conditional execution can be more efficient than branching, particularly for short if-then-else sequences. It also streamlines VLIW code; thus, basic instructions that are dependent on different conditions can be packed together instead of being put in separate VLIW words.
The VLIW approach requires less control logic than a superscalar implementation. Ceva-X designs are upwardly binary compatible: object code for the X1622 will run on the X1641 and object code for the X1641 will run on the X1643, but the reverse is not true.
Ceva-X allows for customer-defined instructions and logic. Certain instruction encodings, data, and control paths are reserved, and licensees can use these to implement their own instructions.
Data Cache Simplifies Programming The X1643 is the first Ceva-X DSP with a data cache. The main benefit of the data cache is that it simplifies program-ming compared with using a tightly coupled memory (TCM) for local data storage. Software need not explicitly move data between local and external memory, making code more portable and easier to develop. The cache also saves power compared with going off chip for frequently used data.
The drawback of a cache is that performance is no longer deterministic but instead depends on whether data is in cache. The X1643 thus retains the option for TCM so that programmers can explicitly stash data for sections of code where determinism is critical. The X1643 supports data TCM up to 512KB and data caches up to 32KB.
For off-chip accesses, the X1643 supports 64-bit and 128-bit AXI buses, compared with the X1641’s lower-performance AHB-Lite buses. The data-memory control unit has separate AXI read and write ports for added performance.
Ceva-X provides a separate memory hierarchy for instructions. First-level instruction memory can be up to
1,056KB configured as a mixture of TCM and cache. Instructions are fetched 256 bits at a time and are queued pending decoding. Basic instructions are either 16 or 32 bits wide, and a VLIW packet can have from one to eight basic instructions. Instruction words therefore range from 16 bits to 256 bits. A dedicated 64-bit or 128-bit AXI master retrieves instructions from main memory. All AXI con-trollers support AXI’s low-power mode. In addition to the AXI ports, the X1643 has an APB port for accessing low-speed peripherals built around the DSP.
The X1643 provides a basic memory-control unit. Although virtual memory is not supported, as would be required for a general-purpose processor running a high-level operating system (OS), this unit provides protection among different processes to assist memory management by a real-time OS (RTOS). RTOSs supporting Ceva-X include Nucleus from Mentor Graphics, OSEck from Enea, and ThreadX from Express Logic. The memory-control unit is flexible, allowing the programmer to apply policies to par-ticular address ranges and to change these policies on the fly. Policies include whether to cache the range and whether to enable hardware prefetching of data in the range.
Ceva-XC Adds Vector Units Ceva-XC extends the Ceva-X architecture by adding vector units. Much like ARM’s Neon or Intel’s SSE, the XC vector units have their own register file and execution units. The XC323 has two such units, each 256 bits wide, compared with the 128-bit architectures of Neon (implemented in Cortex-A9 by a 64-bit physical data path) and SSE. Each 256-bit value is a SIMD vector of 8-bit, 16-bit, or 32-bit data. Support for 32-bit data, which is not available in the XC321 targeted at user equipment, alleviates underflow—
Figure 1. Block diagram of Ceva-X1643 DSP. A VLIW design, the X1643 can dispatch eight instructions per cycle: one to each of the four computation unit blocks, three to each of the data-address generation blocks, and one to the program-control unit. The X1643 features both caches and tightly coupled memories.

4 Ceva Trains DSP Guns on TI
NOVEMBER 2010
a more significant risk on the base-station side of a 4G wire-less link owing to the additional processing and precision required.
Ceva also added new instructions to the vector unit. For example, these include instructions to accelerate Viterbi coding, which is handled by a hardware accelerator in XC321 designs. The company moved this function to software for the infrastructure-targeted XC323 because it expects designers to use multiple DSP cores allocated to a changing set of functions depending on the task at hand. Providing dedicated hardware would consume die area for a function not consistently used. The DSP also has instruc-tions to improve performance on algorithms for channel estimation, MIMO detection, interleaving, and other 3G- and 4G-cellular functions. Ceva does not publicly release the instruction set for its advanced DSPs, so it is unclear what changes have been made.
Each vector unit in the XC323 has four function blocks: one each for arithmetic, logic, MAC, and division. The division block is optional and also supports instruc-tions for maximum-likelihood decoding, square root, and inverse square root. The XC323’s two vector units can com-plete thirty-two 16×16-bit MACs or sixty-four 16×8-bit MACs per cycle. The units can operate in lockstep as a double-wide SIMD unit, or they can operate independently. They can collectively issue four instructions per cycle, using four of the eight VLIW slots in the XC323 architecture.
Like the X1643, the XC323 has a general-purpose computation unit with four function blocks. All four can perform arithmetic operations and multiply-accumulate operations on 16-bit operands and 40-bit accumulators. One also handles shifts and the other arithmetic and logic opera-tions, as in the X1643.
Ceva developed the computation unit with an eye toward supporting C-based general-purpose processing and 2G/3G baseband processing, deriving the unit from that in the X1643. The XC321, in contrast, had a simpler general computation unit. The XC323 also supports accelerated context switching. The quad-MAC capability provides horsepower for legacy baseband protocols. Owing to these features, the XC323 may appeal to designers of mobile basebands in addition to designers of base stations, as they may be able to consolidate in a single XC323 some functions performed by legacy 2G/3G modems and control CPUs.
To keep the wide vector units fed with data, the XC323 has wide paths to memory. Two 1,024-bit paths connect to the data TCM. The AXI ports connected to the data-addressing unit are 128 bits wide. Like the X1643, the XC323 fetches instructions 256 bits at a time.
Because a baseband processor for a base station is likely to have multiple DSPs, the XC323 incorporates fea-tures for multicore designs. The bus interface controllers snoop the AXI bus to provide a degree of coherence among the DSP cores’ local memories. One DSP can also request
exclusive access to a particular external memory address to enable atomic transactions—for example, to set a semaphore before transferring data to a shared memory region. The XC323 also provides a system for sharing messages among multiple DSP cores.
Both the X1643 and XC323 incorporate a PMU to autonomously manage entry to and exit from sleep states for the whole DSP and to control power-related attributes of major function units. For example, the PMU can turn off clocks to unused units to conserve dynamic power, and it can power off the DSP (except for memories) when idle to reduce static power. A similar PMU is found in the earlier XC321, but the X1643 is the first Ceva-X design to incor-porate it.
Software and Tools Accelerate Development Like many other processor suppliers, Ceva offers a complete set of development tools. Per the strategy developed in the wake of the post-Parthus restructuring, Ceva also offers software to complete its ecosystem. The company provides various audio, voice, and video codecs for its Ceva-X DSPs as well as cellular-modem code. For Ceva-XC, the company offers low-level software for customers to build their 4G-cellular stacks, and it also collaborates with ArrayComm and MimoOn for complete LTE stacks.
A longstanding goal of DSP suppliers has been to en-able their customers to program in C. This goal has been met with mixed success in that performance-critical rou-tines are still commonly written in assembly code. In a push to use C for all code, Ceva released a tool chain in late 2009 that it calls the Application Optimizer. This tool chain has multiple modules and seeks to improve the code size and execution performance of code written in C.
For DSPs, C code is peppered with calls to intrinsic operators, which are similar to calls to C functions. Intri-niscs can efficiently implement operations, such as saturat-ing arithmetic, that are not found in C but are directly sup-ported by a DSP. Because one of Ceva’s strategic goals is to attract designers that have used TI DSPs, the IP company has developed a library of intrinsics compatible with those from TI. Besides these tools, Ceva offers a set of code translators to aid developers in porting code among Ceva’s DSPs and from TI’s processors to Ceva’s.
Few Companies License DSPs Ceva has a few competitors with licensable quad-MAC DSPs, including Tensilica, VeriSilicon, and NXP. Tensilica offers the Vectra LX DSP extensions to its base Xtensa CPU architecture (see MPR 11/30/09-01, “Tensilica Tweaks Xtensa”). By default, it does not include caches, but design-ers add them and other features using Xtensa’s customiza-tion support. Vectra issues up to three instructions per cycle and supports SIMD operation; the latter is required to perform four MACs per cycle. The eight-way X1643 is thus likely to be faster at a given clock rate and provides

Ceva Trains DSP Guns on TI 5
NOVEMBER 2010
programmers more flexibility. The X1643 is also likely to clock faster. (Tensilica rates the simpler dual-MAC Xtensa-based ConnX D2 at a maximum frequency of 605MHz in 65nm G. A shrink to 40nm could increase performance by 30% to 50%.)
VeriSilicon’s ZSP800 DSP is a four-issue superscalar design, and the ZSP840 adds caches. Programmers can gang together the ZSP’s four 16×16-bit MACs to achieve 32×32-bit operation with 72-bit accumulation, which is useful in applications such as high-definition audio. We estimate that the ZSP800, which has been available since 2007, is larger and slower than the X1643. VeriSilicon rates 65nm ZSP800 implementations at about 0.7mm2 and 450MHz (worst case). A shrink to 40nm would halve its area and increase performance, as noted above.
The NXP CoolFlux BSP is an exceptionally compact and low-power design, but at the expense of features and capabilities. Quad-MAC operation is possible provided that precision is limited to 12 bits. Caches are not available, and memory addressing is only 16Mwords for each address space (program, x data, and y data).
Several companies have DSPs with wide vector units targeting 4G cellular and competing with Ceva-XC. These companies include Blue Wonder, ARM spinoff Cognovo, Coresonic, and NXP with its CoolFlux, Tensilica with an Xtensa variant called the Baseband Engine (BBE), and Silicon Hive. Most address mobile instead of infrastructure applications. Owing to its built-in queues and stacks, Ten-silica’s BBE could also be adapted to a multicore base-station chip, and Silicon Hive provides a tool to configure a highly parallel DSP that is based on its technology. Unlike the XC323, none of these cores was designed specifically for mobile infrastructure. (See MPR 8/10/09-01, “Tensilica Plays Baseband,” for a comparison of Ceva-XC, CoolFlux BSP, and the ConnX BBE. Further information, including coverage of the other suppliers, is available in The Linley Group’s report A Guide to CPU Cores and Processor IP.)
Practically speaking, the XC323 targets chips designed to replace a set of standalone DSP-based processors, such as the TI TCI6488 and Freescale MSC8156. Neither of these chips uses a DSP with vector units, making the XC323 much better suited for algorithms (e.g., FFT) that operate on data in parallel.
Instead, the TI and Freescale DSPs have accelerators for important functions. Although TI currently positions the TCI6488 for both 3G and 4G base stations, the accelerators on the chip (which entered production in 2007) are for CDMA (3G). The MSC8156, on the other hand, has accel-erators applicable to both 3G and 4G.
Conventional wisdom is that dedicated hardware is more efficient than the software-based approach in terms of die area and power for a given performance level. For some algorithms, such as turbo codes, this is clearly the case. For others, the situation is less clear. The situation becomes muddier when one chip must support multiple protocols.
Ceva claims that 9 to 12 XC323s can handle a three-sector Category 5 transceiver card, compared with 12 triple-core TCI6488 or 6 hex-core MSC8156 chips (i.e., a total of 36 TI or Freescale DSP cores) and their associated accelerators.
TI, however, is preparing a counterstrike. In February 2010, the company announced that it is working on a multi-core architecture designed to deliver 256 gigaMACs per second (GMACS). Assuming this performance is divided among eight cores, the design would provide the same per-core performance (in terms of GMACS) as the XC323, sug-gesting TI is also adding vector capabilities. This new ar-chitecture has the added advantage of supporting both fixed- and floating-point operations—likely a better approach to providing enhanced precision for complex algorithms than merely extending precision from 16 to 32 bits.
Ceva-X1643 Meets Many Designers’ Needs Propelled by design wins at multiple suppliers of cellular-baseband processors, Ceva is the most successful DSP IP company. Designers of cellular chips combining a DSP with hard-wired functions will find the X1643 a strong choice because of its high performance and power management. The X1643 is also well suited to general-purpose DSP functions, audio coding, and even video coding. It can thus be used in chips for personal media players, and owing to its C programmability, it can obviate a CPU for control func-tions in a low-cost design.
The XC323, on the other hand, is tuned for a single application: cellular-baseband processing. Geared for mul-ticore software-defined radio (SDR) designs, it offers fea-tures not found in standalone DSP chips commonly used in base stations. ASIC designers, therefore, have the ability to create their own baseband processors that are more efficient than off-the-shelf DSPs.
Because of their capabilities and surrounding software support, both the X1643 and XC323 provide a transition path for designers that use other DSPs—either in ASICs or in standard products. Ceva has enabled ASSP suppliers to displace TI-based ASICs at Ericsson and Nokia, and it has enabled others to enter diverse markets that would other-wise be closed, had those suppliers no access to DSP tech-nology. OEMs can now pursue custom chips using a DSP with unusual features (e.g., SIMD units) instead of taking standard DSPs from a chip company or working with TI as an ASIC supplier. Ceva is thus a potent threat to DSP-chip suppliers such as TI and Freescale. ♦
For More Information
Ceva-X1643 and Ceva-XC323 are both available for licensing. For more information, point your browser to www.ceva-dsp.com/products/cores/ceva-x1643.php and www.ceva-dsp.com/products/cores/ceva-xc323.php.