
Linguistic and Logical Tools for an Advanced Interactive Speech System in Spanish J. Álvarez, V....
25
Linguistic and Logical Tools for an Advanced Interactive Speech System in Spanish J. Álvarez, V. Arranz, N. Castell & M. Civit TALP Research Centre UPC, Barcelona
-
Upload
lincoln-hinkley -
Category
Documents
-
view
215 -
download
0
Transcript of Linguistic and Logical Tools for an Advanced Interactive Speech System in Spanish J. Álvarez, V....

Linguistic and Logical Tools for an Advanced Interactive Speech
System in Spanish
J. Álvarez, V. Arranz, N. Castell & M. Civit
TALP Research Centre
UPC, Barcelona

Contents• Introduction
• Corpora Construction
• System Architecture
• Understanding Module:– Input Problems & Solutions Adopted
– Language Processing:• Morphology• Syntax• Semantic Extraction
• Dialogue Manager
• Conclusions

Introduction
• Increasing need for more natural HMI
• Development of a dialogue system:– spontaneous speech– restricted-domain: railway information– rather user-friendly communication exchange– language of application: Spanish
• Other related systems:ATIS, TRAINS, LIMSI ARISE, TRINDI, ...

Corpora Construction
• Project objective: none available in Spanish
• Two different corpora developed:– human-human– human-machine (Wizard of Oz technique):
• 150 different situations
• + an open scenario
• total of 227 dialogues

System Architecture

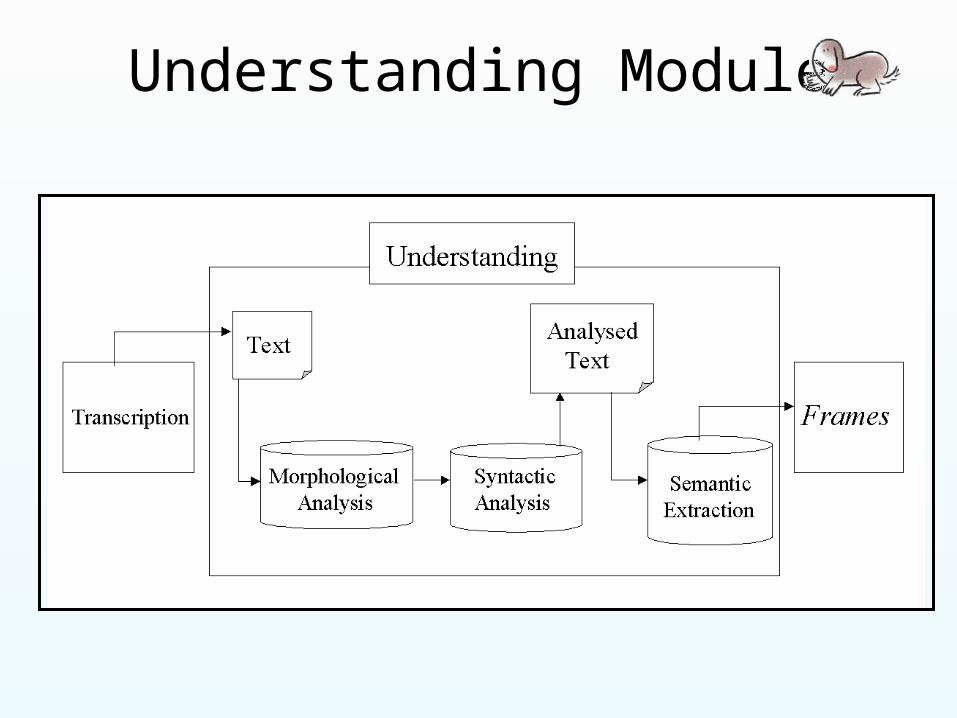
Understanding Module

Input Problems (1)
• Recognition Errors:
– Excess of information:• U: “sábado treinta de octubre” (“Saturday, October 30”)
• R: “un tren que o sábado treinta de octubre”
(“a train that or...”)
– Erroneous recognition:• U: “gracias” (“thank you”)
• R: “sí pero ellos” (“yes but they”)

Input Problems (2)
– Grammar errors:
• Lack of prep+det contractions: “de el” “del”
• Wrong use of indefinite determiner: “un de octubre”
“uno de octubre” (“1 October”)
• Wrong orthographical transcriptions: “qué/que, a/ha”,...
(“what/that, to/has,...”)

Input Problems (3)
• Problems caused by spontaneous speech:
– Syntactic disfluencies:
U: “a ver los horarios de los trenes que van de Teruel a Barcelona el este próximo viernes y que vayan de Barcelona a Teruel el próximo que vuelvan de Barcelona a Teruel el próximo domingo”
– Lexical disfluencies, pauses, noises, ...

Solutions
• Adapting the recogniser to the domain
• Adapting the recogniser to spontaneous speech
• Adapting the understanding module
• Closing the entry channel

Tools
• MACO+: Morphological Analyzer Corpus Oriented [Carmona et al., 98]
• RELAX: Relaxation Labelling Based Tagger [Padró, 97]
• TACAT: Tagged Corpus Analyzer Tool [Castellón et al., 98]
• PRE+: Production Rule Environment [Turmo, 99]

Example
User turn:
“Me gustaría información sobre trenes de Guadalajara a Cáceres para la primera semana de agosto”
(“I would like some information about trains from Guadalajara to Caceres for the first week of August”)

Language Processing
Transcription
Text
Morphological Analysis
Syntactic Analysis
Analysed Text
Semantic Extraction
Frames
Understanding

Morphology (1)
• MACO+:– contains knowledge organised into classes and
inflection paradigms– uses a task/domain lexicon: less ambiguity and
better execution time– provides all possible labels per word
• RELAX:– disambiguates obtained labels– is constraint based with relaxation labelling

Morphology (2)me yo PP1CSO00gustaría gustar VMCP1S0información información NCFS000sobre sobre SPS00trenes tren NCMP000de de SPS00Guadalajara guadalajara NP000C0a a SPS00Cáceres cáceres NP000C0para para SPS00la la TDFS0primera primero MOFS00semana semana NCFS000de de SPS00agosto agosto NCMS000. . Fp

Syntax (1)
• TACAT:
– shallow parser
– context-free grammar adapted for the domain:• rules re-written for dates, timetables and proper names
– bottom-up strategy
– this adaptation helps semantic searches

Syntax (2)[ { pos=>S } [ { pos=>patons } [ { pos=>pp1cso00 , forma=>"Me" , lema=>"yo" } ] ] [ { pos=>grup-verb }
[ { pos=>vmcp3s0 , forma=>"gustaría" , lema=>"gustar" } ] ] [ { pos=>sn }
[ { pos=>ncfs000 , forma=>"información" , lema=>"información" } ] ] [ { pos=>grup-sp }
[ { pos=>sps00 , forma=>"sobre" , lema=>"sobre" } ] [ { pos=>sn } [ { pos=>ncmp000 , forma=>"trenes" , lema=>"tren" } ] ] ]
[ { pos=>grup-sp } [ { pos=>sps00 , forma=>"de" , lema=>"de" } ] [ { pos=>sn } [ { pos=>np000c0 , forma=> "Guadalajara" , lema=> " Guadalajara" } ] ] ]
[ { pos=>grup-sp } [ { pos=>sps00 , forma=>"a" , lema=>"a" } ]
[ { pos=>sn } [ { pos=>np000c0 , forma=>"Cáceres" , lema=> " Cáceres" } ] ] ]
[ { pos=>grup-sp } .........

Semantic Extraction (1)
(HORA-SALIDA)
CIUDAD-ORIGEN: GuadalajaraCIUDAD-DESTINO: CáceresINTERVALO-FECHA-SALIDA: 31-7-2000/6-8-2000
Aim: generation of semantic frames

Semantic Extraction (2)
• System implemented in PRE+
• PRE+:– production rule environment– very flexible and robust:
• rule conditions contain syntactic patterns and lexical items to search for
• priority, score and control: allow to specify rule application, location of concept to extract,...

Semantic Extraction (3)(rule CiudadOrigen3 ruleset CiudadOrigen priority 10 score [0,_,1,0] control forever ending Postrule (InputSentence ^tree <+a>tree_matching( [{pos=>grup-sp} [{lema=> de|desde}] [{pos=> np000c0, forma=>?forma}] ])) -> (?_ := Print(CiudadOrigen,?forma)) (?_ := REM(CiudadOrigen,X,+a)))
Understanding Module

Dialogue Manager (1)
• Implemented using YAYA [Alvarez, 00]
• Reasoning engine combines:– frames from the understanding module, with– facts from the dialogue history, and with– axioms
• in order to generate:– reaction facts from the system
• Output based on frames:– for the natural language generator (content)– for the recogniser (Speech Act prediction)

Dialogue Manager (2)
Sentence to generate:
“De Guadalajara a Cáceres ¿qué día desea viajar?”(“From Guadalajara to Caceres, when do you wish to travel?”)
Output Frame:
(CONFIRMACIÓN)TIPO: implícitaCIUDAD-ORIGEN: GuadalajaraCIUDAD-DESTINO: Cáceres
(SOLICITUD)CONCEPTO: FECHA-SALIDA

Conclusions
• Corpus development: valuable resource
• Adaptation of general NLP tools for:– domain– spontaneous speech dialogue
• Development of new tools:– semantic extraction (use of PRE+): flexible & robust– dialogue manager (use of YAYA): fast to develop &
easy to modify
• Challenge: processing in real time

Linguistic and Logical Tools for an Advanced Interactive Speech
System in Spanish
J. Álvarez, V. Arranz, N. Castell & M. Civit
TALP Research Centre
UPC, Barcelona


















